
Abstract
Single-trial analysis of human electroencephalography (EEG) has been recently proposed for better understanding the contribution of individual subjects to a group-analyis effect as well as for investigating single-subject mechanisms. Independent Component Analysis (ICA) has been repeatedly applied to concatenated single-trial responses and at a single-subject level in order to extract those components that resemble activities of interest. More recently we have proposed a single-trial method based on topographic maps that determines which voltage configurations are reliably observed at the event-related potential (ERP) level taking advantage of repetitions across trials. Here, we investigated the correspondence between the maps obtained by ICA versus the topographies that we obtained by the single-trial clustering algorithm that best explained the variance of the ERP. To do this, we used exemplar data provided from the EEGLAB website that are based on a dataset from a visual target detection task. We show there to be robust correpondence both at the level of the activation time courses and at the level of voltage configurations of a subset of relevant maps. We additionally show the estimated inverse solution (based on low-resolution electromagnetic tomography) of two corresponding maps occurring at approximately 300 ms post-stimulus onset, as estimated by the two aforementioned approaches. The spatial distribution of the estimated sources significantly correlated and had in common a right parietal activation within Brodmann’s Area (BA) 40. Despite their differences in terms of theoretical bases, the consistency between the results of these two approaches shows that their underlying assumptions are indeed compatible.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Classical analysis and interpretation of ERPs in human EEG is based on averaging peri-stimulus electrical responses to generate a single time series for each electrode within a given scalp montage. Although this has the advantage of increasing to a great extent the signal-to-noise ratio, it relies on the simplistic assumption that the signal related to the stimulus is stationary in time and that any activity that is not fixed in time is “noise”. On the other hand, single-trial methods are made problematic by the presence of many known and unknown sources of noise (physiological and instrumental) that can obfuscate the signal of interest. As a consequence a priori hypotheses about the brain processes underlying the measured signal are required. ICA is currently a typical single-trial analysis approach (Bell and Sejnowski 1995; Makeig et al. 1999, 2002). This technique relies on the hypothesis that brain activity is the result of a superimposition of a number of independent components in a number less than or equal to the total number of electrodes. Each of these components has an associated time course of the activity in every trial and a scalp map, representing the strength of the volume-conducted component activity at each scalp electrode. The applicability of ICA to ERP analyses has been shown repeatedly in a context in which it is possible to attribute a physiological meaning to one or more components (Makeig et al. 2002; Debener et al. 2004), for artifacts detection (Vigario 1997) and more generally for EEG pattern recognition and classification (Naeem et al. 2006; De Lucia et al. 2008). Numerous other approaches have been developed in the area of blind source separation (Belouchrani et al. 1997; Tang et al. 2005; Barbati et al. 2006), and several methods at the level of single waveforms either based on assuming stationary stereotypic wave shapes (Knuth et al. 2006) or on filtering and de-noising (Quiroga and Garcia 2003; Georgiadis et al. 2005).
More recently, a novel single-trial clustering algorithm based on topographic information has been proposed. This method stems from the hypothesis that event-related potentials at a single-trial level exhibit a semi-stationary temporal structure, characterized by a few representative topographic maps that appear over short time periods on the order of at least 10–20 ms duration. This hypothesis has been explored both at the single-subject (De Lucia et al. 2007a) and at a group level of analysis (De Lucia et al. 2007b) on a set of data from an auditory object discrimination experiment. The suitability of this model can be demonstrated by computing the amount of explained variance, as we will detail below, as well as by showing that it provides sufficient information so as to allow an above chance classification accuracy of independent datasets (Tzovara et al. 2010). The advantages of this approach are that it offers a flexible tool for estimating which voltage configurations appear reliably across trials, their latencies, and their differences across experimental conditions. Moreover, it takes full advantage of the reference-independent information conveyed by the spatial characteristics of the electric field measured at the scalp and does not make explicit a priori assumptions about the frequency or temporal features of the EEG signal.
Because these various single-trial analysis approaches stem from very different assumptions, it is an obvious question whether they detect/extract consistent information and to which extent they are comparable. Here, we compared the results of an ICA-based analysis and those obtained by the single-trial topographic clustering algorithm on a dataset derived from a visual target detection task. Despite their differences in terms of a priori assumptions and theoretical bases, one common goal is to estimate components that are consistent across trials so as to provide insights about the spatio-temporal profile of event-related brain activity (i.e. its time course and voltage distribution at the scalp), which ultimately reflects the activity of underlying sources.
Materials and Methods
Subjects, Stimuli and Task
Ten subjects participated in the experiment. ERPs were recorded while the subjects attended a sequence of visual stimuli appearing briefly in any of five squares arrayed horizontally above a central fixation cross. In each experimental block, one (target) box was differently colored from the rest. Whenever a square appeared in the target box, the subject was asked to respond quickly with a right thumb button press. The subject was asked to ignore circles presented either at the attended location or at an unattended one (for full details see Makeig et al. 1999). The dataset we consider here contains only target stimuli presented at the two attended locations in the left visual field for a single subject (downloadable from the EEGlab website, http://sccn.ucsd.edu/eeglab/).
EEG Acquisition and Preprocessing
EEG data were collected from 30 scalp electrodes mounted in a standard electrode cap at locations based on a modified International 10–20 system, and from two periocular electrodes placed below the right eye and the left outer canthus. Signals were referenced to the right mastoid and sampled at 512 Hz. Before the analysis, the dataset was down-sampled to a 128 Hz sampling rate and 40 Hz low-pass filtered. In total, we consider here 80 trials (including 1 s of baseline and 2 s of post-stimulus responses) baseline-corrected and common average re-referenced, concatenated one after the other.
ICA Analysis
The ICA analysis was performed using EEGLAB, version 6.01b, a freely available open source toolbox (http://sccn.ucsd.edu/eeglab/). We performed the independent component decomposition based on the ‘infomax’ ICA algorithm (Bell and Sejnowski 1995). The suitability of this ICA decomposition for ERP analysis is discussed in (Makeig et al. 1999).The output comprised a total of 32 components (i.e. equal to the number of electrodes) (for a complete methodological description of the ICA analysis on this dataset see Makeig et al. 1999). After visual inspection of the scalp maps and of the time-course of their activation, we selected the components accounting for artifacts. One of these components was clearly related to eyeblinks and therefore it was eliminated. The EEG data were back-projected to the subset of remaining 31 components. All the analyses we report in the following refer to this ‘clean’ dataset.
Single-Trial Topographic Analysis
Model Estimation
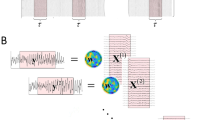
We consider each topography (or map) as an N-dimensional vector m = {m1(t),m2(t),…,mN(t)}, with N number of electrodes, for each trial and time-point (Fig. 1a). Each vector m is normalized by its global field power so as to not take into account instantaneous strength (Lehmann 1987; Michel et al. 2001, 2004; Murray et al. 2008). We would like to emphasize that at this point all the information about latencies and trial assignment is lost, as all the maps are treated as points in an N-dimensional space without any tracking of their original order in time. It is also worthwhile to remind the reader that analyses based on topographic information are inherently independent of the reference electrode (cf. Michel et al. 2004; Murray et al. 2008 for a treatment of this issue).

Flow-chart of the GMM modeling of the ERP dataset and statistical analysis. a Voltage maps are pooled together irrespective of time and trials in an N-dimensional space, where N is the total number of electrodes; (b) the ensemble of observations {m} are modeled as a GMM. In this panel we provide an example of three Gaussians in the mixture. Model’s parameters allows to assign to each map a vector of posterior probabilities as shown for one exemplar map belonging to the ‘blue’ Gaussian; (c) These set of posterior probabilities are re-ascribed with respect to time and trials; (d) Averaging across trials the posterior probabilities for each Gaussian and at each time-point, we can infer the presence of template maps during the post-stimulus period with respect to baseline, indicative of the degree of stimulus-related modulation of maps presence
In the attempt to represent our dataset in a number of representative maps, we propose to model the ensemble {m} as a mixture of Gaussians (GMM) (Fig. 1b):
where Gk is the kth Gaussian distribution with mean μk, covariance σ k, and pk prior probability. The mean of each of these Gaussians will be referred to as template map and considered as a prototypical voltage map for all those sets of maps that have been clustered together in one of the Gaussian. Q is the total number of Gaussians, which needs to be decided a priori before estimating the model’s parameters.
The GMM is estimated by an expectation–maximization algorithm, Baum-Welch algorithm (Dempster et al. 1977), which iterates the estimation of the model parameters in order to maximize the likelihood. This algorithm requires the parameters of the GMM to be initialized. Here we consider as initial means those obtained by a k-means clustering algorithm (Bishop 1995). The initial guess of the covariance (here restricted to be diagonal) is obtained by considering the topographies closer to each of the means as estimated by the k-means algorithm. The priors, {pk}, are obtained by the relative number of topographies for each cluster. In this GMM estimation, the value of the total number of Gaussians is fixed a priori. In order to find the optimum value of Q, we estimate a GMM model for a set of values of Q ranging from 4 to 28 and we choose the value of Q corresponding to a value of explained variance above a certain threshold.
ERP Analysis Based on the GMM
Once the optimal GMM model has been estimated, it is possible to assign to each map m, a posterior probability for each of the Gaussians. An example of posterior probability is provided in the inset of Fig. 1b for one of the maps. In this example, the cluster colored ‘blue’ is the one providing the highest posterior probability among the three; this map is therefore best represented by the template map corresponding to the blue Gaussian. By rearranging these posterior probabilities in the original order of trials and time (Fig. 1c), we can investigate which maps are best represented by one template map across trials and locked in time (Fig. 1d).
Specifically, we are interested in estimating at which point in time the average posterior probability exhibits a significant modulation with respect to pre-stimulus baseline. The presence of these modulations is indicative of the degree to which the model is representative of stimulus-related activity and of the presence of one specific template map across trials and at a certain latency. This statistical analysis was performed by means of a non-parametric test (Kruskall–Wallis) which contrasts—at each time-frame—the posterior probability values and corresponding median along the baseline across trials. For each of the estimated GMM, we consider therefore the total number of Gaussians Q and the subset of these Gaussians, Q’, whose posterior probability was significantly higher than baseline in some temporal intervals during the post-stimulus period. In general, not all the template maps will exhibit a posterior probability with a significant modulation with respect to baseline, and therefore Q’ will be lower than or equal to Q. We further constrain our analysis by considering as ‘active’ only those template maps with posterior probabilities significantly higher than baseline for at least 10 consecutive data-points, here corresponding to approximately 78 ms. This is a means of correcting for temporal auto-correlation in the data (e.g. Guthrie and Buchwald 1991).
In order to choose the best model, we compute for each total number of maps Q, the global explained variance (GEV) on the whole dataset and on those time periods where there was a significant modulation of the posterior probability. The GEV is based on the correlation between the template maps and the GFP-normalized voltage maps recorded at each time point and each trial and the instantaneous GFP. This notion of explained variance is an established measure in the context of microstate analysis, where the correlation is computed between template maps (estimated at average ERP level) and instantaneous voltage configuration of the average ERP (Murray et al. 2008; Pourtois et al. 2008). We choose the value of Q which provides a maximum or local maximum of the explained variance over these sub-periods (Fig. 2, red line).

Explained variance as a function of number of Gaussians in the mixture of Gaussians model. The blue line refers to the explained variance computed over the entire dataset. The red line refers to sub-periods where the posterior probabilities across trials were significantly higher than baseline. The tendency to obtain a higher explained variance when computed over those sub-periods shows how the model explains mostly those parts of the data which is event-related and locked across trials
Comparison Between Single-Trial and ICA Analyses
After selecting the mixture of Gaussians we considered within the set of template maps only those whose posterior probability was deemed ‘active’ according to the abovementioned criteria. As our aim is to compare the information conveyed by ICA and single-trial topographic clustering methods for ERP interpretation, we selected those ICA scalp maps that best correlated spatially with the Q’ template maps. In parallel, we computed the average activations of these scalp maps and compared the latencies of their maxima with those of the corresponding average posterior probabilities as obtained by the single-trial topographic analysis. It is worth emphasizing that a resemblance of the spatial maps obtained by the two analyses does not presuppose a similar temporal profile of the corresponding average activations.
Finally, we computed the EEG current source locations based on low-resolution electromagnetic tomography (LORETA) (Pascual-Marqui et al. 1994) of corresponding maps in the two approaches at latencies that were related to known ERP components. LORETA uses a three-shell spherical head model including scalp, skull, and brain compartments, registered to the digitized Montreal Neurological Institute (MNI) MRI template (Talairach and Tournoux 1988). The solution space corresponds to cortical gray matter sampled at 6-mm resolution, resulting in a total of 3005 voxels.
Results
The total explained variance of the GMM model increased with the total number of maps in the model when computed on the overall dataset (Fig. 2, blue line). The explained variance on those temporal intervals during which some of the posterior probabilities exhibited a significant modulation with respect to baseline (i.e. were ‘active’), peaked at two values of total number of maps Q (Fig. 2, red line). We therefore chose Q = 11 as this was providing the relative maximum contribution of explained variance (68%). The total number of active template maps Q’, was 5. We therefore refer to these five template maps in the analyses that follow. The average posterior probabilities across trials for these template maps are shown in Fig. 3a together with the intervals of significant modulation with respect to baseline for each of them (thicker lines). The corresponding template maps are shown in Fig. 4a.

Results obtained by applying the single-trial topographic clustering algorithm and ICA on the same datset from a visual target detection experiment. a Mean posterior probabilities of the five template maps obtained by the single-trial topographic clustering algorithm which were significantly higher than baseline in at least one sub-period of continuous ten data points (bold lines highlight these periods); text arrows show the post-stimulus latencies of the peaks for each posterior probability, when the peak was within periods of statistical significance; (b) Mean activation of the six independent components (in arbitrary units) whose scalp projection best correlated with the template maps obtained by the single-trial topographic algorithm (see Fig. 3 and Table 1); colors are assigned so as to emphasize the corresponding average posterior probability as in panel a; text arrows show the post-stimulus latencies of the peaks for each components, corresponding to the ones shown in panel a

a Template maps as obtained by the single-trial topographic clustering algorithm; frame colors correspond to the ones of the time courses of posterior probabilities in Fig. 2a; (b) scalp map projections (in arbitrary units) of the six independent components that best correlated with the template maps shown in a; frame colors correspond to the ones of the activation time courses as in b of Fig. 2
Among the 31 scalp projections identified by ICA, we selected those providing the highest spatial correlation with the abovementioned Q’ template maps (Fig. 4; Table 1). We discuss here only those scalp projections that were the most correlated with the Q’ template maps even if several others also produced an high and significant correlation. The mean activations of the selected scalp projections exhibited a temporal pattern closely resembling those of the posterior probabilities of corresponding template maps (Fig. 3a,b). In particular, the latencies of the peaks were matching when the maxima of the average posterior probabilities fell within periods of statistically significant modulation. The latencies of these peaks are indicated by arrows in Fig. 3. For example, the first template map peaked at 297 ms (39th data point) post-stimulus onset, and the ICA component whose scalp projection was most highly correlated with the first template map peaked at 305 ms (40th data point) post-stimulus onset. That is to say, their latency differed by only one data point. A full description of the periods of activity of the five template maps, their latencies and differences with the mean activation latencies of the ICA components is listed in Table 1.
It is worth noting that the peaks of activations in both panels of Fig. 3 occurred between 305 and 437 ms post-stimulus onset (here we focus only on the absolute peak of each activation, although other earlier peaks are also important and possibly accounting for early visual components). The appearance of the earliest of these components (component 1, blue trace in Fig. 3) at 297 and 305 ms, respectively, is consistent with the so-called P300 component, related to attending to novel stimuli. The later subset of components peaking between 391 and 437 ms, possibly comprised activities related to the motor response. This pattern of components has been extensively described in the original publication (Makeig et al. 1999).
In correspondence to the first of these components, we computed the inverse solution based on standard LORETA and we compared the results between the blue-framed maps obtained in the two approaches (Fig. 5). A quantitative comparison was possible only at the level of spatial correlation since, based on one single subject dataset, we are not in the position to assess statistically which sources were significantly active. The spatial (Pearson) correlation between the 3005 voxels within the inverse solution points was r = 0.57 (p < 10−15). To assess the existence of spatially overlapping sources, we looked at peaks of the inverse solution values as a percentage of the absolute maximum for each of the two solutions. At 80% of the maximum value for each of the two inverse solutions, we found the first overlapping voxels, whose peak was located at 34, 33, 57 mm using the Talairach and Tournoux (1988) coordinate system. This peak falls within Brodmann’s Area (BA) 40 of the right hemisphere (Fig. 4, coronal view).

Source estimations based on LORETA computed on the blue-framed voltage map in Fig. 3 estimated by the single-trial topographic approach (a) and ICA (b). These two maps share a common pattern of activation peaking at approximately the same latency in both analyses and around 300 ms post-stimulus onset. The spatial location of these estimated sources was highly correlated (R = 0.57, P < 10−15). A common set of sources (maximum located at 34 −33 57 mm, Talairach coordinates) appeared in the right parietal lobe, within BA 40 as shown in the coronal view of both panels
Discussion
The results reported here support the consistency between an ICA-based ERP analysis and a recently introduced single-trial topographic clustering algorithm. Several common lines of interpretation can be derived from these results. Both methods uncovered the presence of ERP components that matched each other both with respect to the latencies of their activation peaks and also their spatial configurations. In particular, three template maps estimated by the single-trial topographic clustering algorithm had their peak of activation that was nearly synchronous with the ICA-defined component scalp projection with which it also showed the highest spatial correlation. The first of these voltage configurations in the two approaches was identified as related to the classical P300 component, related to the appearance of infrequent or unexpected stimuli. The spatial distribution of the estimated inverse sources was significantly correlated and had in common one peak of activation within the right BA40. The significance of the estimated inverse solution is, however, severely limited by the low number of electrodes in the EEG montage (see Michel et al. 2004 for discussion on this point). Here, we show that even in an extreme case of poor spatial sampling of the voltage measurement we can expect a high correlation and partial spatial overlap in the estimated sources.
Other scalp maps obtained by ICA were highly correlated and with close peak latencies to those of the template maps estimated by the single-trial topographic algorithm. These results are compatible with what has been repeatedly shown in several experimental contexts; namely that several independent components can be clustered together as representing the same physiological process (Makeig et al. 2002; Debener et al. 2004). Several other secondary peaks of mean activation were closely matching those of the mean posterior probabilities (Fig. 2a,b), suggesting a large degree of overlap between the pattern of event-related components estimated by the two approaches. Here, we focused only on the most correlated voltage configurations and their corresponding global maxima in the mean activation profiles.
The analyses presented here do not support the conclusion that these two approaches allows to derive common ERP interpretation, but rather that there is a high degree of overlap between the pattern of estimated activation profiles and corresponding voltage configurations. Although this general agreement should be more extensively investigated in a larger dataset including several subjects, the consistency between these two approaches provides a good basis for validating to which extent ERP analyses can be conducted without making explicit a priori hypotheses on the statistical properties (i.e. independency) of the temporal activations of estimated voltage configurations. Indeed, the two approaches discussed in the present study aim at two different goals. The single-trial topographic analysis aims at estimating which event-related voltage configurations are active across trials and exhibit some form of stationarity or semi-stationarity (i.e. their activation lasts for some dozens of ms); ICA focuses on finding temporally independent source signals and corresponding scalp projections. As a consequence, the voltage configurations estimated by these two approaches will in general reflect different patterns of underlying activity. The template maps obtained using the single-trial topographic analysis based on a GMM model can result from the activation of largely overlapping source distributions, whereas the scalp projection resulting from ICA is likely to correspond to more spatially compact activity. However, the general agreement with the results obtained in terms of temporal patterns of the activation and correlation of estimated voltage configurations shows that the bases of these two approaches are compatible. Comparisons between different single-trial ERP analyses can help researchers evaluate the extent to which results are driven by a specific hypothesis or assumption or rather by the dataset itself. Reliability of ERP findings therefore benefit by cross-validating patterns of results inferred from different analysis models.
References
Barbati G, Sigismondi R, Zappasodi F, Porcaro C, Graziadio S, Valente G, Balsi M, Rossini PM, Tecchio F (2006) Functional source separation from magnetoencephalographic signals. Hum Brain Mapp 27:925–934
Bell AJ, Sejnowski TJ (1995) An information-maximization approach to blind source separation and blind deconvolution. Neural Comput 7(6):1129–1159
Belouchrani A, Abed-Merain K, Cardoso J-F, Moulines E (1997) A blind source separation technique using second-order statistics. IEEE Trans Signal Process 5:434–444
Bishop CM (1995) Neural networks for pattern recognition. Oxford University Press, Oxford
De Lucia M, Michel CM, Clarke S, Murray MM (2007a) Single subject EEG analysis based on topographic information. Int J Bioelectromagn 9(3):168–171
De Lucia M, Michel CM, Clarke S, Murray MM (2007b) Single-trial topographic analysis of human EEG: a new ‘image’ of event-related potentials. In: Proceedings of the IEEE/EMBS region 8 international conference on information technology applications in biomedicine, ITAB, art. no. 4407353, pp 95–98
De Lucia M, Fritschy J, Dayan P, Holder DS (2008) A novel method for automated classification of epileptiform activity in the human electroencephalogram-based on independent component analysis. Med Biol Eng Comput 46(3):263–272
Debener S, Makeig S, Delorme A, Engel AK (2004) What is novel in the novelty oddball paradigm? Functional significance of the novelty P3 event-related potential as revealed by independent component analysis. Cogn Brain Res 22(3):309–321
Dempster A, Laird N, Rubin D (1977) Maximum likelihood from incomplete data via the EM algorithm (with discussion). J R Stat Soc B 39:1–38
Georgiadis SD, Ranta-aho PO, Tarvainen MP, Karjalainen PA (2005) Single-trial dynamical estimantion of event-related potentials: a kalman filter-based approach. IEEE Trans Biomed Eng 52(8):1397–1406
Guthrie D, Buchwald JS (1991) Significance testing of difference potentials. Psychophysiology 28:240–244
Knuth KH, Shah AS, Truccolo WA, Ding M, Bressler SL, Schroeder CE (2006) Differentially variable component analysis: identifying multiple evoked components using trial-to-trial variability. J Neurophysiol 95:3257–3276
Lehmann D (1987) Principles of spatial analysis. In: Gevins AS, Remond A (eds) Handbook of electroencephalography and clinical neurophysiology, vol 1: methods of analysis of brain electrical and magnetic signals. Elsevier, Amsterdam, pp 309–354
Makeig S, Westerfield M, Jung TP, Covington J, Townsend J, Sejnowski TJ, Courchesne E (1999) Functionally independent components of the late positive event-related potential during visual spatial attention. J Neurosci 19(7):2665–2680
Makeig S, Westerfield M, Jung T-P, Enghoff S, Townsend J, Courchesne E, Sejnowski TJ (2002) Dynamic brain sources of visual evoked responses. Science 295:690–694
Michel CM, Thut G, Morand S, Khateb A, Pegna AJ, Grave de Peralta R, Gonzales S, Seeck M, Landis T (2001) Electric source imaging of human brain functions. Brain Res Rev 36:108–118
Michel CM, Murray MM, Lantz G, Gonzalez S, Grave de Peralta R (2004) EEG source imaging. Clin Neurophysiol 115:2195–2222
Murray MM, Brunet D, Michel CM (2008) Topographic ERP analyses: a step-by-step tutorial review. Brain Topogr 20:249–264
Naeem M, Brunner C, Leeb R, Graimann B, Pfurtscheller G (2006) Separability of four-class motor imagery data using independent components analysis. J Neural Eng 3:208–216
Pascual-Marqui RD, Michel CM, Lehmann D (1994) Low resolution electromagnetic tomography: a new method for localizing electrical activity in the brain. Int J Psychophysiol 18:49–65
Pourtois G, Delplanque S, Michel C, Vuilleumier P (2008) Beyond conventional event-related brain potential (ERP): exploring the time-course of visual emotion processing using topographic and principal component analyses. Brain Topogr 20(4):265–277
Quiroga RQ, Garcia H (2003) Single trial event-related potentials with wavelet denoising. Clin Neurophys 114:376–390
Talairach J, Tournoux P (1988) Co-planar stereotaxic atlas of the human brain. Thieme, New York
Tang AC, Sutherland MT, McKinney CJ (2005) Validation of SOBI components from high density EEG. Neuroimage 25:539–553
Vigario RN (1997) Extraction of ocular artefacts from EEG using independent component analysis. Electroencephal Clin Neurophysiol 103:395–404
Tzovara A, Murray MM, Plomp G, Herzog M, Michel CM, De Lucia M (2010) Event-related potential analyses via single-subject topographic classification. Neuroimage (in revision)
Acknowledgements
This work has been supported by the Swiss National Science Foundation (grant #K-33K1_122518/1). We thank Athina Tzovara for comments on previous versions of this manuscript.
Author information
Authors and Affiliations
Corresponding author
Additional information
This is one of several papers published together in Brain Topography on the ‘‘Special Topic: Cortical Network Analysis with EEG/MEG’’.
Rights and permissions
About this article
Cite this article
De Lucia, M., Michel, C.M. & Murray, M.M. Comparing ICA-based and Single-Trial Topographic ERP Analyses. Brain Topogr 23, 119–127 (2010). https://doi.org/10.1007/s10548-010-0145-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10548-010-0145-y