
Abstract
We analyze forest structure, diversity, and dominance in three large-scale Amazonian forest dynamics plots located in Northwestern (Yasuni and Amacayacu) and central (Manaus) Amazonia, to evaluate their consistency with prevailing wisdom regarding geographic variation and the shape of species abundance distributions, and to assess the robustness of among-site patterns to plot area, minimum tree size, and treatment of morphospecies. We utilized data for 441,088 trees (DBH ≥1 cm) in three 25-ha forest dynamics plots. Manaus had significantly higher biomass and mean wood density than Yasuni and Amacayacu. At the 1-ha scale, species richness averaged 649 for trees ≥1 cm DBH, and was lower in Amacayacu than in Manaus or Yasuni; however, at the 25-ha scale the rankings shifted, with Yasuni < Amacayacu < Manaus. Within each site, Fisher’s alpha initially increased with plot area to 1–10 ha, and then showed divergent patterns at larger areas depending on the site and minimum size. Abundance distributions were better fit by lognormal than by logseries distributions. Results were robust to the treatment of morphospecies. Overall, regional patterns in Amazonian tree species diversity vary with the spatial scale of analysis and the minimum tree size. The minimum area to capture local diversity is 2 ha for trees ≥1 cm DBH, or 10 ha for trees ≥10 cm DBH. The underlying species abundance distribution for Amazonian tree communities is lognormal, consistent with the idea that the rarest species have not yet been sampled. Enhanced sampling intensity is needed to fill the still large voids we have in plant diversity in Amazon forests.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The Amazon basin harbors the largest and most species-rich tropical forest on earth (Myers et al. 2000; Slik et al. 2015). An understanding of how forest structure and diversity vary across the whole Amazon region is critical for the development of effective regional conservation strategies. So far, these questions have been addressed mostly using census data for plots of ~1-ha in area that included only trees with diameter at breast height (DBH) ≥10 cm, henceforth referred to as large trees (Gentry 1988b; Phillips et al. 1998, 2004; ter Steege et al. 2003, 2006). However, previous studies in tropical forests out of the Amazon region showed that local samples of fewer than 3000 individuals tend to underestimate differences among species-rich sites (Condit et al. 1998), and these small plot data all fall within that sample size. Here, we take advantage of a new dataset of three intensively sampled large permanent plots (25-ha each; DBH ≥1 cm) located in central (CA) and northwestern Amazon (NWA) to test the validity of the prevailing wisdom (founded on small samples) about forest structure and diversity in Amazon forests. Assessments of the variation in forest structure and diversity based on intensively sampled tree communities may inform us about how to implement sound programs of forest management and conservation in this important ecosystem.
In the Amazon basin, rainfall seasonality, soil fertility, and forest turnover rates have been associated with local variation in forest productivity and patterns of tree density or number of individuals (ter Steege et al. 2003; Duivenvoorden et al. 2005) and aboveground biomass (AGB) (Malhi et al. 2006; Saatchi et al. 2007). At a regional scale, tree density has shown to be positively associated with the dry season length (ter Steege et al. 2003); on contrast, at a local scale, soil fertility seems to be inversely associated with it (Duivenvoorden et al. 2005). Variation in forest AGB within the Amazon is also strongly positively associated with variation in wood density (WD), which is higher in areas of more seasonal rainfall, lower soil fertility, and lower forest turnover, while basal area shows little regional variation (Baker et al. 2004). Forests with richer soils and more constant climates also show higher turnover (recruitment and mortality) and systematic differences in tree species functional composition, a pattern that reaches its apogee in the NWA region (Phillips et al. 1994, 1998; ter Steege et al. 2006). However, tree species richness and diversity from northwestern (NWA) to central (CA) Amazonian terra firme forests did not significantly vary along a geographical band around 5°S (ter Steege et al. 2003). Tree diversity around the regions of Urucu and Manus in CA has found to be as high as that reported in the richest plots of NWA (http://atdn.myspecies.info). Therefore, considering that our three study sites are located in the NWA (Yasuni and Amacayacu) and CA (Manaus), and assuming that these sites reflect the same general patterns in structure and diversity as the previously censused 1-ha plots, we expect a systematic decrease in tree density, a systematic increase in AGB, but similar values of species richness and diversity from west to east (Yasuni to Amacayacu to Manaus).
The design of effective conservation strategies also depends on knowledge of patterns of rarity and dominance (Pitman et al. 1999, 2001), and thus on species abundance distributions. Species abundance distributions are commonly modeled as either lognormal or logseries (McGill 2003). Both these distributions predict relatively few dominant species, but they differ in the expected number of rare species. Under the logseries distribution, most species are rare (Fisher et al. 1943); whereas under the lognormal distribution, most species have intermediate abundance, with few rare species (Preston 1948; McGill 2003; Connolly 2005; Connolly et al. 2014). If the logseries is the better model of species abundance distributions, this implies the existence of many rare species, which means that a much more radical conservation strategy is required to avoid considerable species extinction (Hubbell et al. 2008). Past analyses of tree species abundance distributions in Amazonia have been based on analyses of 1-ha, large-tree censuses, either individually or pooled, and have generally supported the use of the logseries distribution (Hubbell et al. 2008; ter Steege et al. 2013; Slik et al. 2015). However, we might expect that abundance distributions could take different shapes when smaller woody individuals are included, and at different spatial scales. Here, we evaluate the fit of the logseries relative to the lognormal for larger plots, and for all trees (≥1 cm dbh), thus testing the appropriateness of the logseries as the underlying species abundance distribution (SAD) model in tropical forests (Hubbell 2001, 2013; Hubbell et al. 2008; ter Steege et al. 2013; Slik et al. 2015).
One of the main difficulties of working with species-rich communities like the Amazon is plant identification, and this raises the question of the degree to which observed diversity patterns depend on taxonomic resolution. Many if not most tree census datasets in this hyperdiverse region lack full species identifications for some subset of species, and it is thus important to know whether conclusions drawn from such incomplete datasets are robust. A previous analysis based on the three plots employed in this study showed that differences among research teams in morphotyping non-fully identified specimens could lead to biases in plant classification (Gomes et al. 2013). In contrast, Pos et al. (2014) argued that analysis that includes only fully botanically identified species (hereafter referred to as named species) should find patterns of species similarity between sites similar to those obtained when also including morpho-types (hereafter referred to as morphospecies), but not for assessments of species diversity. Here, we quantitatively assess whether the main pattern and trend of variation in species relative abundance distributions and diversity patterns, rather than the net values, are indeed robust to this difference in taxonomic resolution. For the species abundance models, we expect that the inclusion of morphospecies will result in relatively more rare species, and thus that the logseries will better fit the data including morphospecies than the data not including morphospecies, and similarly that the lognormal will better fit the data without the morphospecies than the data with morphospecies (Pos et al. 2014; Magurran and Henderson 2003); however, we expect these changes to be relatively small compared with the differences between the models, such that the same model will prove the best fit in both cases.
In this study, we analyze patterns of variation in forest structure, diversity, and dominance across CA and NWA, to evaluate their consistency with prevailing wisdom regarding geographic variation, species abundance distributions, and robustness to details of the census methods. We use a dataset composed of 441,088 individuals (DBH ≥1 cm) surveyed in the three most intensively sampled large permanent plots that currently exist in the Amazon basin, all associated with the Center for Tropical Forest Science-Forest Global Earth Observatory (CTFS-ForestGEO) global network. We address the following specific questions:
-
(i)
Is there systematic variation from central to northwestern Amazonia in tree density and aboveground biomass as reported from 1 ha plots?
-
(ii)
Are our data consistent with previous work suggesting the existence of a high tree species diversity band around 5° S in the Northwest and Central Amazon (NWA and CA)?
-
(iii)
How do the details of tree censuses, specifically differences in minimum tree size (DBH ≥1 cm vs. DBH ≥10 cm), plot size (1-ha vs. 25-ha), and taxonomic resolution (all morphospecies vs. only named species), affect among-site patterns in forest structure?
-
(iv)
Are species abundance distributions better fit by the logseries or the lognormal?
-
(v)
What insights into metacommunity diversity and abundance patterns can we obtain by combining data from multiple large plots?
Methods
Study sites
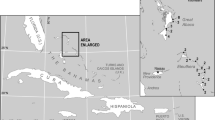
Data were collected in three permanent 25-ha plots established in terra-firme forests located in NWA and CA in Ecuador (Yasuni), Colombia (Amacayacu), and Brazil (Manaus), respectively. These plots are arrayed roughly on a straight line, with distances of 700 km between Yasuni and Amacayacu, 1100 km between Amacayacu and Manaus, and 1800 km between Yasuni and Manaus (Fig. 1). Yasuni National Park and Biosphere Reserve and the adjacent Huaorani Indian territory cover 1.6 million ha of forest and form the largest protected area in Amazonian Ecuador (Valencia et al. 2004). Amacayacu National Park covers around 220,000 ha of forest and is part of the protected system of national parks in the Colombian Amazon. The Manaus plot is located about 80 km north of the city of Manaus. The three plots are all located on terra-firme forests at elevations below 200 m asl. Precipitation at Yasuni and Amacayacu is aseasonal, with mean annual rainfall ~3000 mm and no months with less than 100 mm. Mean annual rainfall at Manaus is ~3500 mm, with a dry season of 1–2 months between June and October (Sombroek 2001).

Geographical location of the three 25 ha plots employed in this study (map adapted from ter Steege et al. 2013). CA central Amazon, EA eastern Amazon, GS Guyana shield, SA southern Amazon, WAN northwestern Amazon, WAS southwestern Amazon
Tree censuses
In each 25-ha plot (500 × 500 m), each individual free-standing woody plant with a DBH ≥1 cm was mapped, tagged and measured, including shrubs, trees, and palms (but not lianas). Multiple stems were separately recorded. Voucher collections were made for each unique species in each plot. We collected vouchers in all cases in which there was any doubt about a plant’s similarity with another individual that was already collected within the same plot. The taxonomic identifications were made by comparing the specimens with herbarium material and with the help of specialists. All of the samples are kept at the COAH, QCA, and INPA Herbaria. We assumed that all specimens with the same botanical name represented the same species, even though we did not standardize the taxonomy between plots. The plants that could not be identified as named species were separated into morphospecies that were treated as distinct species. Variation between sun-exposed and shaded leaves and between young and old leaves was documented in vouchers deposited in reference collections, to avoid splitting species with high plasticity and/or ontogenetic variation. Identifications were done by separate teams at each site, and thus there may be differences in the species concept between sites. For instance, the morphospecies classification in the Amacayacu and Yasuni plots was conservative with morphospecies including a relatively wide range of variation, while in Manaus, the classification allowed less variation within morphospecies.
Structural variation
We analyzed the variation in the number of individuals (NI), basal area (BA in m2), aboveground biomass (AGB in Mg), and mean wood density (WD in g cm−3). The aboveground biomass (AGB) of each tree (in kg) was calculated using the general model without tree height developed for tropical forests by Chave et al. (2014), which employs DBH, wood specific gravity (referred to as wood density, WD), and a new site-specific environmental variable called E. The new parameter E is a coefficient derived from global databases on temperature seasonality (TS), the maximum climatological water deficit (CWD), and precipitation seasonality (PS) (Chave et al. 2014). The equation is
Wood density values of each species found in all plots were assigned following Chave et al. (2006), Zanne et al. (2009), and databases compiled by the CTFS-ForestGEO. In cases in which we could not assign a WD value at the species level, we used the average value at the genus or family level. For individuals without a botanical identification, we used the average WD value of all other individuals found in the same plot. E takes value −0.075 in Amacayacu, −0.111 in Manaus, and −0.023 in Yasuni. The total AGB in each quadrat, subplot, or plot was obtained by summing the AGB of all trees present including palms, but excluding lianas and tree ferns.
We used One Way Anova (ANOVA) to test for significant differences in the stand-level mean NI, BA, AGB, and WD at the 1-ha scale. That is, we divided each plot into 25 square 1-ha subplots (100 × 100 m) and treated these as replicate samples. When significant differences were found, a Tukey’s honest significant difference (TukeyHSD) test was used to compare the main trend of variation between sites. ANOVAs were done separately for two size categories: all individuals with DBH ≥1 cm (hereafter referred as to as all individuals) and only individuals with DBH ≥10 cm (hereafter referred as to as large individuals). For each site, we also characterized the distributions of these structural variables at the scale of 20 × 20 m (0.04 ha) quadrats using probability density functions.
Species diversity patterns
As above, we used ANOVAs and a subsequent TukeyHSD test to evaluate differences in species richness (SR) and species diversity (SD; assessed by the Fisher’s alpha index) among sites, based on 25 square 1-ha subplots (100 × 100 m) for each site. ANOVAs were performed for both size categories (all individuals and large individuals) and for both morphospecies and named species. The morphospecies dataset included all named and unnamed species that were compared with each other and classified as different within each site based on the morphology of vegetative characters, excluding individuals not collected and those for which no morphospecies assignment was possible. The named species dataset contained all individuals identified to species, and excluded non-fully identified species and uncollected individuals. We analyzed both morphospecies and named species in order to understand and compare results under these approaches, and thereby identify the uncertainty associated with the morphotyping of sterile specimens by different teams at different sites (Gomes et al. 2013). Overall, we are interested in evaluating whether the main pattern of variation within plots change with the use of either named species or morphospecies, rather than to compare the net values of diversity estimated by each one of them, which are expected to differ (Pos et al. 2014).
We used species–individual curves and graphs of Fisher’s alpha vs. area (henceforth Fisher’s alpha–area curves) to describe the overall patterns of species diversity at both plot and meta-community scales. We chose to use Fisher’s alpha over other commonly used diversity metrics both because of its conceptual roots (Fisher et al. 1943; Hubbell 2001) and because it is relatively less dependent on sample size than other metrics (e.g., Condit et al. 1996). At the plot scale, the development of the species–individual and Fisher’s alpha–area curves followed the approach of Condit et al. (1996). To build the species–individual curves at the plot scale, we employed 100 randomly chosen points as centers of progressively larger plots. The size of the square plots employed to build the curves increased from 0.01-ha (10 × 10 m) to 25-ha (500 × 500 m) (0.01, 0.04, 0.25, 1, 2, 3, 4, 5, 10, 15, 20, and 25-ha). At the plot scale, species–individual and Fisher’s alpha–area curves were analyzed for both morphospecies and named species datasets, for both all individuals and large individuals. To perform these analyses we used the CTFS R package (http://ctfs.arnarb.harvard.edu/Public/CTFSRPackage/). While the plot-level analysis sampled individuals within contiguous areas, the meta-community analyses were based on 500 random draws from the full merged dataset, with species–individuals curves based on random draws of individuals, and Fisher’s alpha–area curves based on random draws of complete 1-ha plots. The metacommunity analyses were performed only on named species because morphospecies could not be matched across plots. The metacommunity analyses of species–individuals and Fisher’s alpha–area curves were done using the vegan library for R (Oksanen et al. 2013).
Species abundance distributions
We analyzed species abundance distributions (SAD) at the plot and metacommunity scales. We characterized and fit the SAD for each plot, for named species and morphospecies as well as for all individuals and large individuals. At the metacommunity scale we characterized and fit the SAD only for named species in both size classes (as in ter Steege et al. 2013; Connolly et al. 2014; Slik et al. 2015). We used maximum likelihood methods to fit the lognormal (specifically the Poisson-lognormal) and logseries to each distribution (Prado and Miranda 2013), choosing these models because they have been found to be the most suitable SAD models for species rich communities(Wilson 1991; Hubbell 2001). We ranked models using the Akaike Information Criterion (AIC).
All statistical analyses were performed using the Statistical Software R version 3.02 (R Development Core Team 2014).
Results
Structural variation
A total of 441,088 individuals with DBH ≥1 cm and 46,456 individuals ≥10 cm were recorded in the three 25-ha plots. When each plot was divided into 25 1-ha subplots, there were significant differences among sites in NI, BA, AGB, and WD for all individuals and large individuals (Table 1). Amacayacu had significantly lower values of NI and BA than Yasuni for all individuals (DBH ≥1 cm) and large individuals (DBH ≥10 cm). Manaus was similar to Yasuni in NI and BA of all individuals, similar to Amacayacu in the NI of large individuals, and indistinguishable from the other two sites in the BA of large individuals. The central Amazonian site of Manaus had significantly higher AGB and mean wood density than the two northwestern Amazonian sites for both all individuals and large individuals. Amacayacu also had significantly higher mean wood density than Yasuni. The distribution of structural parameters across 20 × 20 m quadrats illustrated the patterns found with 1-ha subplots in greater detail (Fig. 2). Overall, for all individuals, the distribution of NI differed noticeably among all three plots (Fig. 2a), while BA distributions were remarkably similar except for the longer tail due to the presence of larger trees in Manaus (Fig. 2b). WD varied strongly across sites with the highest values in Manaus (Fig. 2d), which then translates into the AGB distributions, where Manaus again stands out (Fig. 2c). For large individuals (DBH ≥10 cm), the basic patterns of variation remained almost the same for BA, GB, and WD, but NI was partially reversed, being higher in Yasuni than in Amacayacu and Manaus (Table 1; Fig. 2e).

Variation in forest structure within and among sites. Lines show empirical probability density functions for each site calculated from data for all individuals ≥1 cm DBH (a–d) and for large individuals ≥10 cm DBH (e–h)
Species diversity
A total of 2993 morphospecies, belonging to 419,576 individuals with DBH ≥1 cm (95% of total) were recorded in the three 25-ha plots, of which 70% were fully identified to species. The 2095 fully identified species (named species) accounted for 83% of the total number of individuals. When all individuals ≥1 cm were included, 1-ha subplots had average species richness of 649 ± 41 for morphospecies and 513 ± 32 for named species, with significantly lower richness in Amacayacu than in Yasuni and Manaus for both morphospecies and named species (Table 1). When only large individuals (≥10 cm) were included, species richness averaged 234 ± 19 for morphospecies and 204 ± 16 for named species, with Amacayacu again showing the lowest value and Manaus the highest (Table 1). The sites had a different ranking in species richness at the 25-ha scale, with Yasuni having the fewest morphospecies and named species for all individuals and large individuals, while Manaus had the most (Table 1). For all individuals the pattern of among-site variation in diversity, as measured by the mean Fisher´s alpha in 1-ha subplots, very much resembled the pattern of species richness. However, diversity pattern for large individuals in 1-ha subplots differed, with Manaus showing markedly higher Fisher’s alpha values than Yasuni and Amacayacu for both morphospecies and named species (Table 1). Among-site patterns in species richness and diversity in 1-ha subplots were qualitatively similar whether analyzing morphospecies or just named species.
Species–individuals patterns showed different patterns of variation between the size categories among plots. Overall, large individuals in Yasuni showed a higher number of species for a given number of individuals than Amacayacu and Manaus. In contrast, for all individuals, Yasuni showed a lower number of species for a given number of individuals than Amacayacu and Manaus, which followed exactly the same pattern of species accumulation with increasing sample size (Fig. 3). In Yasuni, a sample of a given number of large individuals had more species than an equivalently sized sample of all individuals, while Manaus showed the opposite pattern and Amacayacu had similar numbers of species in both size classes (Supplementary Fig. S1, Table 1). These patterns were qualitatively the same whether analyses were restricted to named species or not.

Species–individual curves for all sites and size categories. Comparisons for morphospecies are in the upper panel. Comparisons for named species are in the lower panel. Separate analyses per site are shown in Supplementary Fig. S1
Fisher’s alpha varied strongly with area in all analyses, with considerable variation in Fisher’s alpha–area between size categories and among sites. In the 25-ha plots, large individuals in Yasuni (DBH ≥10 cm) had the highest Fisher’s alpha, but all individuals (DBH ≥1 cm) the lowest (Fig. 4). All the curves showed a strong increase to 1 ha. Above 1 or 2 ha, the curves for all individuals tended to plateau (Amacayacu and Manaus) or even decrease (Yasuni). In contrast, the curves for large individuals continued to increase with area to larger areas, at best plateauing above 4–10 ha. Fisher’s alpha values for all individuals were larger than those for large individuals at areas <1 ha in all sites, with divergent patterns at larger areas. At Manaus and Amacayacu, the differences between the curves declined above 1 ha, and at Amacayacu the curves actually crossed above 10 ha and values remained quite similar beyond that. In contrast at Yasuni, the curves crossed between 1 and 2 ha, with Fisher’s alpha for large individuals becoming increasingly larger than that for all individuals at larger areas (Supplementary Fig. S2). The observed patterns were very similar for morphospecies compared with named species.

Fisher’s alpha–area curves for all sites and size categories. Comparisons for morphospecies are in the upper panel. Comparisons for named species are in the lower panel. Separate analyses per site are shown in Supplementary Fig. S2
Species abundance distributions
Species abundance distributions in all three 25-ha plots were better fit by the lognormal than by the logseries, for both morphospecies and named species as well as for all individuals and large individuals (Fig. 5; Supplementary Fig. S3 and Table S2). Although the lognormal model tended to systematically underestimate the number of the rarest species (those with just 1 individual in 25 ha), it performed better at fitting the number of species with the most common intermediate abundances than the logseries. In contrast, the log series tended to systematically overestimate rare species and to underestimate those with intermediate abundances for both all individuals (Fig. 5) and large individuals (Supplementary Fig. S3). The observed patterns were similar for morphospecies and for named species.

Species abundance distributions (bars) of all individuals (DBH ≥1 cm) for each 25-ha plot for all morphospecies (top) and just named species (bottom), along with best-fit lognormal (black) and logseries (grey) distributions. The parallel figure for large individuals only is shown in Supplementary Fig. S3
Metacommunity patterns
The metacommunity species–individual curves based on random draws of individuals of named species from across all three plots showed higher species richness in samples of all individuals than in equal-sized samples of just large individuals (Fig. 6a). These differences were statistically significant in samples of 2000 or more individuals (Supplementary Table S3). The Fisher’s alpha vs. area curves for all and large individuals crossed, with the all individuals curve showing higher diversity below 12 ha, and the large individuals higher diversity at larger areas (Fig. 6b; Supplementary Table S4). The SADs for both all individuals and large individuals showed the same shape, but with a considerable increase in the number of rare species in the latter (Fig. 6c). For both SADs (all individuals and large individuals), the lognormal provided a better fit than the logseries (Supplementary Fig. S4).

Metacommunity patterns for species–individuals curves (a), Fisher’s alpha versus area (b), and relative abundance distributions (c) based on pooling data for all three 25-ha plots. Small vertical lines in the species–individual curves (a) represent standard errors. The grey line indicates 1000 individuals and the red line indicates 3000 individuals
Discussion
Structural variation
The density of large trees (DBH ≥10 cm) was partially consistent with literature findings of a decrease from west to east (see Fig. 3 in ter Steege et al. 2003), with Yasuni showing the highest values and Amacayacu and Manaus substantially lower values. We expect soil fertility to be highest in Yasuni (Lips and Duivenvoorden 2001) and lowest in Manaus (Sombroek 2000), and thus our findings partially agree with the hypothesis that soil fertility drives large individual density in the Amazon terra firme forests (ter Steege et al. 2003). In contrast, the density of all individuals (DBH ≥1 cm) showed a different pattern, with Manaus having the highest values, Yasuni the next-highest, and Amacayacu a much lower value (Table 1). High densities of small individuals at Manaus can perhaps be explained by lower soil fertility, which is expected to promote increases in plant defenses and reduction in mortality of juveniles and shrubs (Duivenvoorden et al. 2005). In contrast, high densities at Yasuní might be explained by higher turnover and local disturbance rates (Phillips et al. 1994, 1998). Higher rates of disturbances in the more fertile soils of Yasuni than in the other two site may also in part explain why this site has the lowest mean wood density (ter Steege et al. 2006). We must acknowledge that a regional sampling of spread out small plots can represent better the structural variation than contiguous samples as those employed here. However, in the long-term the large permanent plots will surely help to identify the mechanisms acting on a fine-grain resolution that determines the structural variation of tropical forests at local scales.
In accordance with expectations, aboveground biomass was similar in the two northwest Amazon plots, and higher in the eastern central Amazon plot of Manaus. However, forest basal area was similar in Yasuni and Manaus, and considerably lower in Amacayacu. Thus, differences in wood density among plots appear as the main driver of the observed variation in aboveground biomass. Amacayacu had somewhat higher wood density than Yasuni, thus compensating for its lower basal area (Fig. 2). Likewise, Manaus’s much higher wood density clearly explains its higher aboveground biomass relative to Yasuni, which had the same basal area. Therefore, our results agree with previous findings from 1-ha plots that identified wood density as a major driver of regional variation in aboveground biomass in Amazonian terra firme forests (Baker et al. 2004). We obtained the same among-site pattern with the older moist forest biomass allometry equation of Chave et al. (2005), which yielded higher mean biomass values than the new model without height proposed by Chave et al. (2014: see Table 1): 298.5 Mg ha−1 for Amacayacu, 297.7 Mg ha−1 for Yasuni, and 380.6 Mg ha−1 for Manaus. This demonstrates that the among-site pattern is not merely a consequence of the new environmental factor (E) introduced in Chave et al. (2014).
Species diversity
Our results are consistent with the existence of a high tree species diversity band around 5° S in the NWA and CA as proposed by ter Steege et al. (2003). A mean value of 649 ± 50 species (DBH ≥1 cm) per hectare is an unprecedented value of tree species richness that exceeds any previous report made in tropical forests. However, within this geographic band, we found differences in both tree species richness and diversity between plots, which also varied according to size. At the 1-ha subplot scale and for large individuals (DBH ≥10 cm), species richness and diversity patterns followed the not systematic west-east trend Yasuní > Manaus > Amacayacu. For all individuals (DBH ≥1 cm) and at the 1-ha scale, Manaus was as rich and diverse as Yasuni, with Amacayacu again having the lowest diversity. Therefore, for all individuals, this result is inconsistent with the hypothesis that species richness and diversity increase with soil fertility (after Gentry1988a, b). To some extent, it could be argued that our results are likely influenced by the different taxonomic treatment of species at each site. However, the relatively large differences found here, and their consistency in the named species dataset, suggest that such results reflect patterns that can be found even if we standardize the taxonomy across the three sites. Competing theories could explain the high species richness and diversity found in Manaus. First, the greater age of CA relative to the younger areas of NWA may have provided a longer time for species to arrive via dispersal. In contrast, the high species richness of Yasuni and NWA in general, may in part reflect higher speciation rates triggered by the uplift of the Andean mountains (Hoorn et al. 2010), which could partially balance the lower time and opportunity to accumulate species.
Among-site patterns in the species–individuals and Fisher’s alpha–area curves were dependent on both sampled area and size class. The species–individual curves assessed at 10,000 large individuals (DBH ≥10 cm) or more showed the Yasuni region as the most diverse and Manaus the least. In contrast, if all individuals (DBH ≥1 cm) are considered, the expected trend was basically reversed: Manaus and Amacayacu were more diverse than Yasuni at sample sizes larger than 20,000 individuals. At samples of less than 1000 individuals, it was difficult to differentiate the curves for all individuals among plots (Condit et al. 1996). For large individuals, at sample sizes of less than 1000 individuals, Yasuni appeared on top of the other two plots, thus confirming the high diversity of large trees reported for the Andean foothills (Gentry 1988a; ter Steege et al. 2003).
For Fisher’s alpha–area curves, the most striking pattern was the one found in Yasuni, where the accumulation trend in the Fisher’s alpha of all individuals and large individuals took different directions at sample sizes larger than 1-ha. In Yasuní, the Fisher’s alpha of all individuals showed a clear trend to systematically decrease with areas above 1 ha, whereas the value for large individuals continued to increase albeit at a progressively slower rate. The lack of an asymptote in the Fisher’s alpha for all individuals in Yasuní does not support the logseries expectation of a linear species accumulation with sample size (Hubbell 2001, 2013), which challenges the use of this function to extrapolate species richness to larger geographical areas (e.g., Hubbell et al. 2008). In the other two sites, Fisher’s alpha in samples of all individuals tended to level off around 1 ha or earlier, suggesting that samples incorporating all individuals should be considered more appropriate to extrapolate species richness at larger areas than samples based on only large individuals (DBH ≥10 cm). At sample sizes larger than or equal to 10 ha, diversity patterns for different minimum individual sizes in Amacayacu and Manaus tended to converge and asymptote, suggesting that 10 ha might be a minimum ideal sample size to assess Fisher’s alpha in local surveys based only on larger trees, particularly in cases in which the aim is to estimate species richness in large geographic regions (e.g., ter Steege et al. 2013).
Species abundance distribution models of independent communities
The results of this study are inconsistent with the hypothesis that the logseries is the “universal” SAD model that best fits the relative abundance distributions of tree communities in tropical forests (Hubbell 2001, 2013; Hubbell et al. 2008; ter Steege et al. 2013; Slik et al. 2015). All three sites assessed here were better fit by the lognormal than the logseries. Therefore, our results support the “veil effect” hypothesis (Preston 1948; Connolly 2005) as the most likely explanation of the observed SADs of tree communities in the Amazon basin. The “veil effect” hypothesis simply emphasizes that the underlying shape of the SAD is lognormal because the rarest species have not been sampled yet (Preston 1948). The lognormal distribution has many fewer rare species than the logseries, which has practical implications for the development of effective conservation strategies. For example, the recently estimated number of globally threatened Amazonian tree species (ter Steege et al. 2015), may be reduced. Overall, our results propose that in more intensive local samplings, such as those employed in this study, many rare species in 1-ha plots could be common elsewhere.
Metacommunity patterns
In recent years, a number of studies have sought insights into metacommunity diversity and abundance patterns by analyzing pooled datasets comprised of fully identified species (named species) censused in multiple spatially separate sampling units (ter Steege et al. 2013; Connolly et al. 2014; Slik et al. 2015). We take the same approach here, pooling data for our three large plots to investigate diversity and abundance patterns in the metacommunity, after first establishing that patterns observed within each site are qualitatively similar whether we use named species or morphospecies (see also Pos et al. 2014). Our analyses of metacommunity species–individual and Fishers alpha–area curves found that samples of large individuals show different patterns than samples of all individuals. In general, large individuals are a highly nonrandom subset of all individuals, demonstrating that the inclusion of all individuals will bring additional information in terms of diversity and species composition. Finally, our metacommunity species abundance distributions were better fit by the lognormal than by the logseries for both all individuals and just large individuals. This has consequences for the quantification of species rarity and dominance (Pitman et al. 1999, 2001), including estimates of the number of hyperdominant species (sensu ter Steege et al. 2013). The inclusion of all individuals and larger local samples should reduce the proportion of dominant species (Supplementary Fig. S5).
Conclusions and future directions
The use of plots larger than 1 ha that includes smaller sizes than the usually 10 cm DBH employed will surely shed new insights on forest structure and diversity of Amazon forests. The use of large permanent plots, although limited to describe structural patterns at the landscape and regional scales, will surely help to unravel the main mechanisms that maintain and regulate forests structural dynamics and the capability of these ecosystems to respond to climate change. However, based on our findings in these three large plots in Amazonia, we recommend that the minimum census area to adequately capture local tree diversity in the Amazon is 2 ha for the ≥1 cm size class, or 10 ha for the ≥10 cm size class. Below these areas, Fisher’s alpha continues to increase with increasing area. We emphasize that censuses of all individuals ≥1 cm capture more species and additional kinds of species relative to those of only individuals ≥10 cm, and that Fisher’s alpha values tend to be lower when only larger individuals are sampled. The sampling efficiency of large individuals tallied in 1-ha plots was approximately 40% relative to that observed for all individuals in the same plot, and roughly 30% relative to all species included in a 25-ha plot (Supplementary Fig. S6). It is clear that we still have much to learn about patterns of forest structure and tree species diversity in the Amazon. Enhanced sampling intensity, including more large plots, ≥2 ha each sampled to smaller size classes, is needed if we are to fill the still large voids in our knowledge of plant diversity in Amazon terra firme forests and tropical ecosystems more generally (Feeley 2015).
References
Baker T, Phillips O, Malhi Y et al (2004) Variation in wood density determines spatial patterns in Amazonian forest biomass. Glob Chang Biol 10:545–562. doi:10.1111/j.1529-8817.2003.00751.x
Chave J, Andalo C, Brown S et al (2005) Tree allometry and improved estimation of carbon stocks and balance in tropical forests. Oecologia 145:87–99. doi:10.1007/s00442-005-0100-x
Chave J, Muller-Landau HC, Baker TR et al (2006) Regional and phylogenetic variation of wood density across 2456 Neotropical tree species. Ecol Appl 16:2356–2367. http://www.ncbi.nlm.nih.gov/pubmed/17205910
Chave J, Réjou-Méchain M, Búrquez A et al (2014) Improved allometric models to estimate the aboveground biomass of tropical trees. Glob Chang Biol 20:3177–3190. doi:10.1111/gcb.12629
Condit R, Hubbell SP, Lafrankie JV et al (1996) Species-area and species–individual relationships for tropical trees: a comparison of three 50-ha plots. J Ecol 84:549–562. doi:10.2307/2261477
Condit R, Foster RB, Hubbell SP et al (1998) Assessing forest diversity on small plots: calibration using species–individual curves from 50 ha plots. In: Dallmeier F, Comiskey JA (eds) Forest biodiversity research, monitoring and modeling. UNESCO/Parthenon Publishing Group, Paris/New York, pp 247–268
Connolly SR (2005) Community structure of corals and reef fishes at multiple scales. Science 309:1363–1365. doi:10.1126/science.1113281
Connolly SR, MacNeil MA, Caley MJ et al (2014) Commonness and rarity in the marine biosphere. Proc Natl Acad Sci USA 111:8524–8529. doi:10.1073/pnas.1406664111
Duivenvoorden JF, Duque A, Cavelier J et al (2005) Density and diversity of plants in relation to soil nutrient reserves in well-drained upland forests in the north-western Amazon basin. K Danske Vidensk Selsk Biol Skr 55:25–35
Feeley K (2015) Are we filling the data void? An assessment of the amount and extent of plant collection records and census data available for Tropical South America. PLoS ONE 10:e0125629. doi:10.1371/journal.pone.0125629
Fisher RA, Steven Corbet A, Williams CB (1943) The relation between the number of species and the number of individuals in a random. J Anim Ecol 12:42–58
Gentry AH (1988a) Tree species richness of upper Amazonian forests. Proc Natl Acad Sci USA 85:156–159. doi:10.1073/pnas.85.1.156
Gentry AH (1988b) Changes in plant community diversity and floristic composition on environmental and geographical gradients. Ann Missouri Bot Gard 75:1–34
Gomes ACS, Andrade A, Barreto-Silva JS et al (2013) Local plant species delimitation in a highly diverse Amazonian forest: do we all see the same species? J Veg Sci 24:70–79. doi:10.1111/j.1654-1103.2012.01441.x
Hoorn C, Wesselingh FP, Steege H et al (2010) Amazonia through time: Andean uplift, climate change, landscape evolution, and biodiversity. Science 330:927–931. doi:10.1126/science.1194585
Hubbell SP (2001) The unified neutral theory of biodiversity and biography
Hubbell SP (2013) Tropical rain forest conservation and the twin challenges of diversity and rarity. Ecol Evol 3:3263–3274. doi:10.1002/ece3.705
Hubbell SP, He F, Condit R et al (2008) Colloquium paper: how many tree species are there in the Amazon and how many of them will go extinct? Proc Natl Acad Sci USA 105(Suppl):11498–11504. doi:10.1073/pnas.0801915105
Lips J, Duivenvoorden JF (2001) Caracterización ambiental. In: Duivenvoorden JF, Balslev H, Cavelier J et al (eds) Evaluación de recursos naturales no maderables en la Amzonía noroccidental. Universiteit van Amsterdam, Amsterdam, pp 19–46
Magurran AE, Henderson PA (2003) Explaining the excess of rare species in natural species abundance distributions. Nature 422:714–716
Malhi Y, Wood D, Baker TR et al (2006) The regional variation of aboveground live biomass in old-growth Amazonian forests. Glob Chang Biol 12:1107–1138. doi:10.1111/j.1365-2486.2006.01120.x
McGill B (2003) A test of the unified neutral theory of biodiversity. Nature 422:881–885. doi:10.1038/nature01569.1
Myers N, Mittermeier RA, Mittermeier CG et al (2000) Biodiversity hotspots for conservation priorities. Nature 403:853–858
Oksanen J, Blanchet F, Kindt R, et al (2013) vegan: Community Ecology Package. R package version 2.0-10. R package version 1. doi:10.4135/9781412971874.n145
Phillips O, Hall P, Gentry A et al (1994) Dynamics and species richness of tropical rain forests. Proc Natl Acad Sci USA 91:2805–2809
Phillips OL, Malhi Y, Higuchi N et al (1998) Changes in the carbon balance of tropical forests: evidence from long-term plots. Science 282:439–442. doi:10.1126/science.282.5388.439
Phillips OL, Baker TR, Arroyo L et al (2004) Pattern and process in Amazon tree turnover, 1976–2001. Philos Trans R Soc B Biol Sci 359:381–407. doi:10.1098/rstb.2003.1438
Pitman NCA, Terborgh J, Silman MR, Nuez P (1999) Tree species distributions in an upper Amazonian forest. Ecology 80:2651–2661
Pitman NCA, Terborgh JW, Silman MR et al (2001) Dominace and distribution of tree species in upper Amazonian terra firme forests. Ecology 82:2101–2117
Pos E, Guevara Andino JE, Sabatier D et al (2014) Are all species necessary to reveal ecologically important patterns? Ecol Evol 4:4626–4636. doi:10.1002/ece3.1246
Prado PI, Miranda MD (2013) Fitting species abundance model with maximum likelihood Quick reference for sads package. 1–20
Preston FW (1948) The commonness, and rarity, of species. Ecology 29:254–283. doi:10.2307/1930989
R Development Core Team (2014) R: a language and environment for statistical computing. R Foundation for Statistical Computing, Vienna. ISBN 3-900051-07-0
Saatchi SS, Houghton RA, Dos Santos Alvalá RC et al (2007) Distribution of aboveground live biomass in the Amazon basin. Glob Chang Biol 13:816–837. doi:10.1111/j.1365-2486.2007.01323.x
Slik JWF, Arroyo-Rodríguez V, Aiba S-I et al (2015) An estimate of the number of tropical tree species. Proc Natl Acad Sci USA 112:7472–7477. doi:10.1073/pnas.1423147112
Sombroek WG (2000) Amazon landforms and soils in relation to biological diversity. Acta Amaz 30:81–100
Sombroek W (2001) Spatial and temporal patterns of Amazon rainfall. Consequences for the planning of agricultural occupation and protection of primary forests. Ambio 30:388–396
ter Steege H, Pitman N, Sabatier D et al (2003) A spatial model of tree a—diversity and tree density for the Amazon. Biodivers Conserv 12:2255–2277
ter Steege H, Pitman NCA, Phillips OL et al (2006) Continental-scale patterns of canopy tree composition and function across Amazonia. Nature 443:444–447. doi:10.1038/nature05134
ter Steege H, Pitman NCA, Sabatier D et al (2013) Hyperdominance in the Amazonian tree flora. Science 342:1243092. doi:10.1126/science.1243092
ter Steege H, Pitman NCA, Killeen TJ et al (2015) Estimating the global conservation status of more than 15,000 Amazonian tree species. Science 1:e1500936. doi:10.1126/sciadv.1500936
Valencia R, Foster RB, Villa G et al (2004) Tree species distributions and local habitat variation in the Amazon: large forest plot in eastern Ecuador. J Ecol 92:214–229
Wilson JB (1991) Methods for fitting dominance/diversity curves. J Veg Sci 2:35–46. doi:10.2307/3235896
Zanne AE, López-González G, Coomes DA et al (2009) Global wood density database. Dryad Digit, Repos
Acknowledgements
We gratefully acknowledge the contributions of the many people who assisted in collecting the tree census data. In Colombia, this work was made possible by the Parques Nacionales de Colombia, and in particular to Eliana Martínez and staff members of the Amacayacu Natural National Park. The census of Yasuni plot was financed by Pontifical Catholic University of Ecuador (PUCE, research grants of Donaciones del Impuesto a la Renta from the government of Ecuador). The Yasuni plot census was endorsed by the Ministerio de Ambiente del Ecuador through several research permits. We also thank the Center for Tropical Forest Science-Forest Global Earth Observatory (CTFS-ForestGEO) of the Smithsonian Tropical Research Institute for partial support of plot census work. This manuscript was advanced at a working group meeting funded by a grant from the US National Science Foundation (DEB-1046113). Comments from Hans ter Steege and an anonymous reviewer helped to improve the contents of this manuscript.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Daniel Sanchez Mata.
This article belongs to the Topical Collection: Forest and plantation biodiversity.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Duque, A., Muller-Landau, H.C., Valencia, R. et al. Insights into regional patterns of Amazonian forest structure, diversity, and dominance from three large terra-firme forest dynamics plots. Biodivers Conserv 26, 669–686 (2017). https://doi.org/10.1007/s10531-016-1265-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10531-016-1265-9