
Abstract
The task of Application Layer Multicast (ALM) routing is to establish a proper routing tree on application layer network, which transmits data packages from a source to multiple destinations. ALM routing tree is instable due to the end-hosts’ departure or failure. In view of this, we formulated the ALM routing as a multi-objective optimization problem, where the aim is to optimize the ALM routing tree’s topological structure for minimizing its transmission delay and instability simultaneously. A novel encoding-free non-dominated sorting genetic algorithm is proposed for solving our formulated optimization problem. For achieving encoding-free, genotypes are directly represented as tree-like phenotypes in our proposed algorithm. Accordingly, the genetic operators acting on genotypes, like crossover and mutation, need to be redesigned to adapt the tree-like genotypes. The worst-case time complexity of the proposed algorithm is theoretically analyzed and exhaustive simulation results manifest that our proposed algorithm is capable of obtaining high-quality Pareto front. Besides, several interesting issues, such as how to select the final solution out of the obtained Pareto front and the reason why GP is not used, are also discussed.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In the late 1980s, Deering proposed the concept of IP multicast [1, 2], which delivers multimedia data packages from a source to multiple destinations through a multicast routing tree. Comparing with separately delivering data packages to each destination by unicast, multicast helps to reduce the redundant data streams flowing in the network because data packages are duplicated and forwarded on switching nodes only. So far, multicast has been regarded as an efficient delivery mechanism for best-effort, large-scale, multi-point content delivery over the Internet. Increasingly more multimedia-oriented group communications, such as IPTV, remote video conference, etc., require the support of multicast. Although IP multicast has gained many attentions [3,4,5,6,7], its commercial deployment is still hysteretic [8,9,10]. Internet Service Providers (ISP) are reluctant to enable network infrastructure support in order to reduce router load and to protect against unwanted traffic [9].
To circumvent the hang-up on multicast’s deployment, more researchers paid their attentions to the Application Layer Multicast (ALM), an alternative multicasting technique that migrates the multicast transmission from the IP layer onto the application layer [9,10,11,12]. The ALM routing tree is no longer established on the routers, but on the end-hosts. Since the data distribution are accomplished by the end-hosts, ALM doesn’t require ISP to enable multicast support in their network domains and the communications between end-hosts still rely on the unicast of best-effort service. For this reason, ALM is easy to deploy and use economically. Chu et al. believe that ALM has the potential to address most problems associated with IP multicast [11].
However, migrating multicast transmission onto the application layer brings a new issue that the end-hosts’ abrupt departures or unexpected failures result in the tree-like ALM being instable. In a multicast session, a significant number of end-hosts stay on session for very short durations [13]. Once a certain number of end-host abruptly leaves or fails, all of its descendants become disconnected from the routing tree. Even if the disconnected descendants may connect back afterword, the continuity of the data transmission has been interrupted. A category of ALM solutions of using stable intermediate proxies to cooperatively construct a backbone overlay infrastructure and to establish routing trees among themselves [14,15,16,17], helps to reduce the instability of tree-like ALMs [18]. These solutions are in fact a trade-off between IP multicast and ALM. The cooperation from ISP and lots of funds for deploying and maintaining proxies are also required. As a result, their deployments are difficult as well [17], which is actually not in accordance with the original intention of the ALM proposal. Another category of ALM solutions can also reduce ALM routing trees’ instability to some extent [19,20,21]. They simultaneously construct multiple routing trees and split delivery data into blocks for multicasting each using a separate tree. Because a routing tree’s interior node may serve as a leaf node in other trees, its abrupt departure or failure can only interrupt the data traffic on few routing trees. Even the influenced descendants, can still receive data blocks from the other routing trees. Nevertheless, these benefits are achieved at the high overhead for maintaining multiple routing trees. The synchronization of multi-sources is a technical obstacle, too.
As a matter of fact, reducing the instability of an ALM routing tree by optimizing its topological structure is a more promising approach as compared to the above-mentioned solutions. However, it has not attracted wide attention yet. We noticed that an ALM routing tree’s instability is greatly dependent on its topological structure. To be specific, different end-hosts may leave from the multicast session in different probabilities. When constructing the routing tree, let an end-host with large departure probability serve as a leaf node is of course better in terms of reducing the tree’s instability than serve as an interior node in the tree. Furthermore, let the same end-host serve at different tree levels, or forward data duplications to different number of descendants, also result in distinct differences in terms of the instability. Since the instability of an ALM routing tree indeed depends on its topological structure to a large extent, it is thus feasible and effective to reduce the instability of an ALM routing tree by optimizing its topological structure. Cao et al. carried out a series of studies following this idea [22, 23]. They established a model for quantifying tree stability [22] and proposed a heuristic algorithm for constructing high-stability routing tree [23]. Apart from Cao’s studies, some other reported works reflect the same idea. Huo et al. proposed an algorithm based on the end-hosts’ stability and their contribution to the links, named as CL-S [24], to obtain stable ALM routing trees with low transmission delay. Suat Mercan et al. proposed an algorithm named as VDM through introducing the concept of virtual distance and pointed out that the VDM can construct stable ALM routing tree of low transmission delay so long as the virtual distance is delay- and stability-based [25]. These studies show that, it is a promising approach to reducing ALM routing tree’s instability in manner of topological structure optimization.
Motivated by the idea, we formulated the ALM routing as a multi-objective optimization problem, where the object is to optimize the ALM routing tree’s topological structure for minimizing its instability and transmission delay simultaneously. The minimization of instability and the minimization of transmission delay may be interdependent even conflicting. In this paper, we proposed a novel encoding-free multi-objective genetic algorithm based on the framework of the well-known elitist Non-dominated Sorting Genetic Algorithm (NSGA-II) [26] to solve our formulated problem. For convenience, our proposed algorithm is referred to as the encoding-free NSGA (EF-NSGA) here in after. Owing to the encoding-free characteristic, either the complicated encoding scheme or the frequent decoding operation is no longer required. The traditional genetic operators are redesigned to be fit for this encoding-free feature. We analyzed the benefits from encoding-free and demonstrated our proposed EF-NSGA’s performance via exhaustive simulations. The practical ALM system requires to establish a routing tree, while the multi-objective optimizer returns a set of Pareto optimal routing trees, we also discuss a method of choosing a trade-off solution out of the Pareto front.
The rest part of this paper is organized as follows. In Section 2, the multi-objective optimization problem is formulated. In Section 3, our motivation to propose the EF-NSGA is given. In Section 4, the detailed description to our proposed algorithm and theoretical analysis on the algorithm’s worst-case time complexity are given. In Section 5, exhaustive simulations are carried out and the related results are demonstrated. Discussions are given in Section 6. The conclusions are given in Section 7.
2 Optimization model
A practical application layer network can be treated as a graph G consisting of a vertex set V and an edge set E, in which each vertex v∈V stands for an end-host, while each edge e∈E represents the communication channel between two end-hosts. Since any two end-hosts can transmit data packages to each other via IP unicast, we suppose that the graph G is a complete graph. The transmission delay on an arbitrary edge e is denoted as d(e). Besides the transmission delay, the delay caused by processing messages within end-host v is also considered, and denoted as d(v). In order to imitate the event of end-host’s departure or failure, vertex v is allowed to disappear in probability p(v) from graph G. The out-degree of vertex v is denoted as Odv, and the number of its descendants is denoted as Ndv.
A routing tree for the multicast session on the practical application layer network can thus be treated as a Steiner tree that interconnects a specified set of vertices V′ including a source and multiple destinations, and the tree can be denoted as T = {VT, ET}. The total transmission delay of the routing tree T and the instability of it are respectively denoted as f1(T) and f2(T), which are two optimization objectives. Multi-objective optimization is to obtain a set of trade-off solutions between the conflicting objectives. These obtained trade-off solutions make up a Pareto front when they are shown graphically in the objective space. The solutions on the Pareto front are non-dominated to each other, thus being equally acceptable. The aim of our research is to find a set of Steiner trees connecting a number of specified vertices, such that their corresponding objectives can reach to the Pareto front.
Therefore, the optimization problem can be formulated as follows:
Two points to be explained here are:
- (1)
Transformation from network layer to application layer
An application layer network is treated as a complete graph in our formulated optimization problem. However, a specific network is usually given in the form of its topology on IP layer only, because application layer is merely an abstraction layer in the Open Systems Interconnection model (OSI model). Therefore, it is necessary to transform the given network into the form of application layer before further processing.
Such a transformation is essentially to estimate the unicast delay between any two end-hosts according to the network topology. In other words, it is equivalent to estimate the delay on each edge in the complete graph G, i.e. d(e). Since the data traffic between any two end-hosts relies on the traditional unicast of best-effort service, the delay on each edge can thus be estimated by the commonly used Dijkstra’s algorithm [27].
- (2)
Departure or failure probability of vertex v
Usually, it is difficult to know the departure or failure probability of an end-host. Nevertheless, the end-hosts’ stay-on-session durations obey the heavy-tailed distribution [28, 29]. According to this phenomenon, Cao et al. gave a method for estimating the departure or failure probability of an end-host [23]. Since we only focus on the optimization of the ALM routing tree topological structure in this paper, the departure or failure probability of each vertex is directly given.
3 Why encoding-free?
The optimization model formulated in the preceding section is essentially a multi-objective optimization version of the Steiner Tree Problem (STP) in graph theory [30], while the STP is proven to be NP-complete [31]. No exact algorithm can solve NP-complete problem within polynomial-time unless P=NP, while heuristic algorithms can only return approximate solutions in most cases or even worse [32]. Whether P=NP is a mathematical problem. Some researchers believe P=NP but they cannot prove. More researchers still insist P ≠ NP. However, some problems which was originally considered as NP but finally solved by deterministic polynomial-time algorithm, thus being re-classifying into P category. For example, the shortest path problem is originally thought as an NP problem till it was well-solved by Dijkstra’s algorithm, which is deterministic polynomial-time. Minority thought that maybe the issue is independent of the currently accepted axioms and therefore is impossible to prove or disprove. In a word, whether P=NP is still not clear. Evolutionary algorithms thus become the best choice for solving the formulated problem because of their global search ability and acceptable running time. Especially, the population-based search mechanism of evolutionary algorithms is well suited for multi-objective optimization, which is beneficial to obtain the Pareto solution set [33, 46]. So far, although many multi-objective evolutionary algorithms have been proposed, in which NSGA-II is still considered as one of the best [33]. In the field of multi-objective optimization, the original literature on NSGA-II [26] has been cited as many as more than 27,000 times. Based on the above considerations, we used the NSGA-II as the optimization tool for solving the formulated problem.
Without loss of generality, the optimization fundamentals of evolutionary algorithm can be summarized as “operation + evaluation”. The NSGA-II also works in this way, to operate the candidate solutions’ genotypes and then evaluate their fitness according to their phenotypes. For our formulated problem, the phenotype refers to the Steiner tree. As for the genotype, it is encoded as the form of linear string via complicated encoding scheme as done in the reported works [4, 34, 35]. Linear string encoding is easy to operate, but the frequent decoding-operations need lots of computation resources. Figure 1 demonstrates the encoding and decoding schematics. Decoding procedure is always required to evaluate solution at each generation, which brings heavy computing burden and extra overhead to the NSGA-II.

Mapping relationship between the genotype in search space and the phenotype in solution space (“○” stands for the candidate solutions’ genotype; “×” stands for the candidate solutions’ phenotype)
In fact, the heavy computing burden resulted from frequent decoding-operations can be avoided if we directly use tree structure as the genotype rather than linear string-shaped genotype. Since tree-shaped genotype can be directly evaluated, decoding operation is no longer required. Based on this understanding, an idea of the encoding-free NSGA (EF-NSGA) forms naturally. However, to implement encoding-free is not a trivial task. The genetic operators need to be redesigned to be fit for the tree-shaped genotype. Section 4 gives the detailed description about this.
4 EF-NSGA for optimizing application layer multicast routing tree
4.1 Tree-shaped Genotype’s storage form and its generation
We illustrate the storage form of tree-shaped genotype with a simple example. Figure 2 demonstrates an ALM routing tree, which transmits data packages from the root vertex 1 to the vertices 10, 4, 5, 12, and 7. The tree-shaped ALM routing is treated as an intuitionistic genotype representation. We store the tree-shaped genotype as its several branches, e.g. {(1 → 2 → 3 → 10), (3 → 11 → 4), (4 → 5), (4 → 12), (4 → 7)}. In our proposed EF-NSGA, the genotype is equivalent to the phenotype. Since the branch-based storage form to the tree-shaped genotype is fairly intuitionistic and concise, to evaluate an arbitrary tree-shaped genotype’s performance in terms of transmission delay and instability become pretty easy. According to formula (1), the time complexity of the evaluation procedure is O(|VT |). Therefore, the worst-case time complexity of that is O(|V|), because |VT | is equal to |V| when a source multicasts data packages to all the other nodes in an IP network.

A tree-shaped genotype
In order to generate tree-shaped genotypes in a graph at random, we designed a special algorithm. The description to the designed algorithm is given in the following steps. For ease of description, the tree-shaped genotype to be generated in graph G is noted as g-T and the set of all vertices in g-T is noted as v-T.
The algorithmic step for randomly generating a tree-shaped genotype g-T in a graph G.
Step 1 | Input a graph G = {V, E} Multicasting task assignment: specify the source R; specify the destination set D = {Di | i = 1…|V′|-1}; |
Step 2 | Initialization: g-T = ∅; v-T = ∅; |
Step 3 | Add source R into v-T, i.e. v-T = {R}; Set the current vertex as vcurr = R; |
Step 4 | Choose e = < vcurr, v > (v ∉ v − T) from E at random; Add e into g-T; Add v into v-T; |
Step 5 | If v ∉ D, set the current vertex as vcurr = v; Else, set the current vertex as vcurr = v’, where v’ is randomly chosen from v-T; |
Step 6 | Terminate if D ⊂ v-T, otherwise go back to Step 4; |
Step 7 | Output g-T. |
For ease invocation, we encapsulated the above algorithmic step as an operator referred to as RT-generator(G), where graph G is passed to the generator as an argument and can be arbitrary. This encapsulated operator is a key component in our proposed EF-NSGA and plays a very important role, that will be detailed in the following subsections. Here, we only make an analysis on its worst-case time complexity. In the above algorithmic description, the part from Step 4 to Step 6 is in fact a loop structure, in which the loop body consists of Step 4 and Step 5. The time complexity of the RT-generator(·) is obviously equivalent to that of this loop. For the worst-case, the time complexity of this loop structure is O(|V|), where |V| is the number of the vertices in graph G and namely the loop’s maximum cycle-index.
4.2 Genetic operators
As a result of using the tree-shaped genotype, the commonly used genetic operators acting on linear string-shaped genotypes are no longer applicable. The utilization of the tree-shaped genotype requires new genetic operators. Therefore, we propose new genetic operators including crossover and mutation as follows.
- (1)
Crossover
Crossover is essentially a process in which two parent individuals exchange genetic information and then produce offspring. For the tree-shaped genotype in our proposed EF-NSGA, the genetic information refers to its topology in fact. Therefore, we implement the crossover operator by exchanging two parent individuals’ partial topologies.
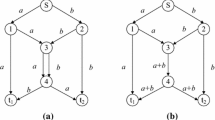
We assume the tree-shaped genotypes shown in Fig. 3 (a) and (b) are parent-1 and parent-2 respectively. Since their genetic information refers to the topologies of their tree-shaped genotypes, we can build a gene pool which contains all their genetic information by merging the topologies in Fig. 3 (a) and (b) together. The built gene pool is the graph shown in Fig. 3 (c). Any tree-shaped genotype being randomly derived from the gene pool can be treated as an offspring individual for inheriting genetic information from both parent-1 and parent-2. Figure 3 (d) and (e) exhibit two offspring individuals randomly derived from the gene pool shown in Fig. 3 (c). It can be seen that, the two offspring individuals indeed inherit genetic information from their parents to different extent. Taking topological features of offspring-1 in Fig. 3 (d) as an instance, the branches (1 → 2 → 3 → 10) and (11 → 6 → 9 → 7) are inherited from parent-2, while the branches (3 → 11 → 4 → 5) and (7 → 12) are inherited from parent-1. As for the method of generating offspring from a gene pool, the afore-mentioned RT-generator(·) can be used by passing the gene pool as its argument. And the invocation form is RT-generator(gene pool).

Diagram of crossover operator
In addition, we make further improvements on crossover operator. In normal conditions, two parents generate two offspring, it may result in weak selection pressure, due to the diversity of the potential offspring in a gene pool. In order to make GA fully play its competition-based optimization mechanism, we permit two parents generate k > 2 offsprings during once crossover in order to enhance the algorithm’s local exploitation to the promising regions in the solution space, where k is a new parameter with respect to the commonly used GA. It should be noticed that, nevertheless, only the best two offspring in terms of Pareto rank among the generated k offspring are permitted to be reserved during once crossover. Therefore, the total number of the generated offspring during crossover is equal to N·Pc, as the same as that in the commonly used GAs, where N stands for the population size and Pc represents the crossover probability.
Because the crossover is implemented by using the encapsulated RT-generator(·), its time complexity is thus O(k·|Vgp|), where |Vgp| stands for the number of vertices in the gene pool. For the worst-case of |Vgp| = |V|, the crossover operator runs in time O(k·|V|).
- (2)
Mutation
Mutation alters an individual’s genetic information from its initial state. However, to alter a tree-shaped genotype’s topology at random may result in its topological structure being unconnected even invalid. To avoid this, we implement mutation in a similar way to the crossover.
In order to mutate a tree-shaped genotype, we need to beforehand generate a brand-new tree at random. The purpose of this operation is to generate a gene pool by merging it with the genotype to be mutated. Since the gene pool contains not only the genetic information from the genotype to be mutated but also that from the randomly generated one, any potential tree-shaped genotype derived from the gene pool can be treated as a derived mutant. The reason is that, some topological features of the mutant obtained in that way indeed alters. As for the method of obtaining the mutant from the gene pool, the RT-generator(·) is still used. The obtained mutant will never be unconnected or invalid. During mutation, a total of N·Pm mutants will be obtained, where Pm refers to the mutation probability.
During the mutation procedure, the RT-generator(·) will be used twice. The first time using the RT-generator(·) is to generate a new tree at random for building the gene pool, while the second time is to obtain the mutant. The worst-case time complexity of the mutation operator is thus O(|V|) + O(|V|), i.e. O(2·|V|). Since the coefficient 2 is a constant, the mutation possesses an O(|V|) worst-case running time in fact.
- (3)
Selection
Selection is a process of selecting a portion of the existing population to form a new generation. Unlike the crossover and the mutation, the selection operator acts on the population rather than each genotype. The implementation of the selection operator is thus not affected by the tree-shaped genotype. We still use the non-dominated sorting-based selection operator in the original NSGA-II [26]. The selection of the proposed EF-NSGA is depicted in Fig. 4, where the parent population can generate a certain amount of offspring individuals after crossover and mutation operations, i.e. the offspring set A and B shown in Fig. 4. According to the principle of survival of the fittest, those inferior individuals in terms of Pareto rank should be rejected to keep the population size stable. And we understand that some equivalently finest individuals in the 5th Pareto front in Fig. 4 (i.e. P5) should also be rejected due to the limitation of population volume. The surviving individuals form in a new generation. According to literature [26], the overall complexity is O(M·N2), where M is the number of objectives. In this paper, the value of M equals to 2. Thus, we know the selection operator’s time complexity as O(N2).

The selection operation scheme
4.3 Benefits from “encoding-free”
The most important contribution of this work is to propose an encoding-free NSGA during the ALM routing tree’s optimization. The benefits from “encoding-free” thus need to be analyzed.
One of the benefits is that, heavy computing burden caused by frequent decoding-operations is avoided. In our proposed EF-NSGA, no decoding algorithm is required as a result of encoding-free. As the cost for achieving that, both the crossover operator and the mutation operator become more complex. In spite of this, such a trade-off is cost-efficient. For ease analysis, we consider the original NSGA-II adopting the commonly used 0–1 string to encode tree structures into linear storage form as done by many works [4, 34, 35]. Table 1 lists the worst-case time complexity of each genetic operator or related procedure that would be frequently and repeatedly performed in our proposed EF-NSGA and the original NSGA-II. Among them, the two algorithms have the same worst-case time complexity on Selection and Evaluation. Differences mainly occur on Decoding, Crossover, and Mutation. The mutation in the original NSGA-II runs in time O(1) as a result of it randomly flipping very few 0–1 bits only. The crossover operator in NSGA-II runs in time O(|V|) because there is a loop structure for exchanging one or more gene segments and the number of the exchanged bits is proportionally related to the string-shaped genotype’s length |V|. As for the decoding procedure, it possesses an O(|V|2) worst-case running time, because 0–1 string-shaped genotype requires Prim’s algorithm [36] for decoding, while Prim’s algorithm runs in time O(|V|2) [37]. In general, the EF-NSGA runs in time O(k·|V| + N2) within one iteration, while the NSGA-II runs in time O(|V|2 + N2). Obviously, N impacts the time complexity of them both to the same extent, but k and |V| do not. As a newly introduced parameter, we could have set k as any integer taken from the interval [2, +∞) theoretically. However, only if k < |V|, the proposed EF-NSGA run less time than the original NSGA-II. For visually comparing the two running time complexity, we depicted their landscapes with regard to k and |V| in Fig. 5, where N was set as 100. We know that, the performance gap is increasingly large with the value of |V| increasing under the premise of k < |V|. Such a characteristic is very beneficial to optimize ALM routing tree on large scale networks, because of the large |V|. If a small scale network is concerned, so that k > |V|, the computational complexity of the proposed EF-NSGA would be a little bit larger than that of the original NSGA-II. Nevertheless, since the number of the end-hosts managed by a real IP network is usually counted by hundreds or thousands, k is actually far less than |V|. On the other hand, the performance gap can also increase with k value decreasing under the premise of k < |V|. This observation seems to conflict with our original intention of introducing parameter k, but actually not. It must be emphasized that, decreasing k value may increase the compared two algorithms’ performance gap in terms of time complexity rather than that in terms of optimization efficiency. In the following section, we will investigate the positive impact of k on enhancing the exploiting ability of the proposed EF-NSGA.

Comparison between two algorithms’ time complexity landscapes
An extra benefit is that the ambiguity of genetic expression caused by the 0–1 string representation scheme can be avoided, thus improving the optimization performance. According to the definitions in literatures [4, 33–34], the 0–1 string representation scheme maps the sub-network containing a routing tree into a |V|-dimensional vector, noted as (x1, x2, …, xi,…, x|V|), where xi = 1 if the node i belongs to the sub-network and xi = 0 otherwise. When decoding the routing tree from the sub-network represented by the |V|-dimensional vector, Prim’s algorithm [36] or Kruskal’s algorithm [38] is always required. Table 2 gives an instance for explanation. The two ALM routing trees listed in Table 2 involve the same end-hosts. Namely, they belong to the same sub-network, thus having the same 0–1 string representation. However, they possess different topologies. Suchlike ambiguity with respect to genetic expression brings a large risk on optimization. We assume that the ALM routing tree-1 is the result after decoding via using Prim’s algorithm or Kruskal’s algorithm. In this case, the ALM routing tree-2 can never be generated, because either Prim’s algorithm or Kruskal’s algorithm is deterministic. However, the links (2 → 6) and (10 → 5 → 12), in the ALM routing tree-2 only, may be the essential topological branches for composing high-quality ALM routing trees. Under the circumstance, the optimization algorithm is unable to get the desired tree topology even if it might possess the outstanding optimization framework. This is caused by the employment of 0–1 string representation scheme. Since our proposed EF-NSGA is encoding-free, the phenotype is the genotype. The gene pool-based genetic operators directly act on the tree topology, any arbitrary topological branch could be generated, thus being able to ensure the global search by avoiding the problem in the conventional string representation mentioned above.
The third obvious benefit from “encoding-free” is that, our proposed EF-NSGA is very compact and easy to program. Not only the procedure of initializing the population, but also the genetic operators like crossover and mutation are implemented based on the encapsulated RT-generator(·). As long as this generator is well programmed, the EF-NSGA program is almost finished.
5 Simulation
We implemented the proposed algorithm in C++ and carried out exhaustive simulation experiments to evaluate the performance. All simulation experiments were performed on a computer with an Intel Core i7-3520M @2.9 GHz CPU and 8 GB of RAM (7.73GB available). The operating system running on this computer is Windows 7 sp1 (×64).
5.1 Validity tests on IP networks
Figure 6 exhibits a small-scale IP network in the form of graph, which includes 25 end-hosts and 18 routers. The transmission delay from one node to another has been attached to each corresponding edge in the graph. Moreover, the message processing delay within each node and its leaving probability are both attached to each corresponding vertex in the form of “delay | probability”. For distinguishing end-hosts and routers, they are respectively marked by ‘○’ and ‘□’ as shown in Fig. 6. Assume an ALM session occurs and requires a routing tree to distribute data packages from the source, i.e. end-host 8, to the destination end-hosts 2, 14, 22, 24, 26, 28, 29, 31, 3, 35, and 37. These specified vertices has been highlighted in bold. We use the proposed EF-NSGA to obtain the non-dominated set of ALM routing trees with regard to instability and transmission delay. The algorithm parameters are given in Table 3. It should be noted that the termination criteria of the algorithm is the candidate solution Evaluation Times (ETs) reach to a predefined upper bound. For this test, it is 5 × 105.

A small-scale IP network instance. The mark ‘○’ stands for end-hosts; The mark ‘□’ stands for routers
Figure 7 shows the Pareto front reached by the proposed EF-NSGA, which consists of 26 non-dominated solutions. To evaluate the quality of the obtained Pareto front, we also tested some other reported algorithms [4, 23,24,25, 34, 35, 39] for carrying out exhaustive comparison. Cao’s algorithm [23] requires to specify an end-to-end latency-constraint and a degree-constraint as well, due to the difference between its optimization model and our formulated one. Thus, we separately specified three group of values to the constraints when testing. The end-to-end latency-constraint and the degree-constraint are separately set as 300 and 5 as the first group, 300 and 6 as the second, 200 and 5 as the third. According to the dominating relation demonstrated in Fig. 7, Cao’s algorithm is obviously not capable of returning high-quality solutions like the proposed EF-NSGA. In particular, Cao’s algorithm even failed to return a feasible solution for the third group. In fact, Cao’s algorithm is based on a Steiner tree heuristic, while J. Plesník [32] had pointed out that any Steiner tree heuristic finds a tree with the worst-case tree-cost relative to the least-cost Steiner tree being close to (2–2/p), where p denotes the number of the vertices that the Steiner tree spans. That explains why Cao’s algorithm performs poorly. The situation of the CL-S [24] and the VDM [25] is like that of Cao’s algorithm [23]. When testing, we make the CL-S [24] take the form of transmission delay in our formulated optimization model and construct the virtual distance for the VDM [25] based on the objective in ours as well. Suchlike modification is to ensure the comparability, but that will not alter their performance. According to Fig. 7, the performance of the CL-S [24] and that of the VDM [25] is obviously not that good with respect to simultaneously minimizing ALM routing tree’s transmission delay and instability. The actual performance of the CL-S [24] and the VDM [25] is similar to that of Cao’s algorithm, because the CL-S [24] and the VDM [25] are also based on spanning tree heuristics, thus returning approximating solution as well. In comparison, the intelligence algorithms perform far better [4, 34, 35, 39]. That must be noticed that, the Artificial Fish School Algorithm (AFSA) [4], the Genetic algorithm (GA) [34] and the Particle Swarm Optimization (PSO) [35] are all originally proposed for optimizing one single-objective. Therefore, we ran them each to obtain the optimal ALM routing tree in terms of transmission delay or instability in manner of single-objective optimization. Unlike the AFSA in literature [4], the algorithm reported in literature [39] is a multi-objective version of AFSA, noted as the MO-AFSA. Although the MO-AFSA [39] is not originally intended to reduce the instability of the ALM routing tree, it indeed can be used in solving the problem we formulated if the objectives are substituted with that in our formulated model. According to the results shown in Fig. 7, only the top left solution on the Pareto front that the EF-NSGA obtained is dominated by the least-transmission-delay routing tree obtained by the AFSA [4], nevertheless, the two ALM routing trees possess the same transmission delay and their gap in terms of instability is very little. Apart from that, all the other 25 Pareto solutions obtained by the EF-NSGA are dominated by none of the ALM routing trees obtained by the compared algorithms. This comparison shows that our proposed EF-NSGA is capable of obtaining high-quality Pareto front. Besides, being able to give trade-off solutions between the transmission delay and the instability is another advantage of the EF-NSGA. Although the MO-AFSA [39] also possesses this advantage, the trade-off solutions on its obtained Pareto front are much fewer. That is mainly due to the encoding scheme employed in the MO-AFSA [39] being lack of the ability in regards with expressing topology, while our proposed EF-NSGA does not suffer from that because of encoding-free. Namely, the EF-NSGA has more free degree in regards with expressing topology, thus generating much more trade-off ALM routing trees.

The scale of the IP network shown in Fig. 6 is relatively small, since it only contains 25 end-hosts. To draw robust conclusions, we further tested the EF-NSGA and the comparison algorithms through 4 larger networks, which are randomly generated with end-hosts of 60, 100, 140, and 180, respectively. For testing, we assigned 4 multicast sessions, involving destinations of 15, 20, 25, and 30 respectively. Figure 8 (a), (b), (c), and (d) respectively show the Pareto front obtained by the EF-NSGA and the ALM routing trees found by the comparison algorithms. The situations are similar to that in Fig. 7. It is worth noting that, three heuristic-based algorithms, i.e. Cao’s algorithm [23], the CL-S [24] and the VDM [25], perform increasingly better as the network vertices increase. Nevertheless, the ALM routing trees obtained by them are still approximation solutions. The intelligence algorithms still find no better ALM routing tree than any a solution on the Pareto fronts obtained by the proposed EF-NSGA. Especially, the MO-AFSA performs increasingly poorly with the network vertices increase. Figure 8 confirms that the EF-NSGA is still capable of obtaining high-quality Pareto front on the networks with larger number of nodes, for multicast sessions with more destinations.

Pareto Front achieved by the EF-NSGA and the ALM routing trees obtained by Cao’s algorithm [23], AFSA [4], GA [34], PSO [35], CL-S [24], VDM [25], MO-AFSA [39]: (a) Network of 60 end-hosts, multicast session of 15 destinations; (b) Network of 100 end-hosts, multicast session of 20 destinations; (c) Network of 140 end-hosts, multicast session of 25 destinations; (d) Network of 180 end-hosts, multicast session of 30 destinations
To avoid the randomness factor effect, we conducted 50-independent-run experiments (Monte Carlo tests) corresponding to each situation of Fig. 8. The results are correspondingly given in Fig. 9 (a), (b), (c), (d). To facilitate analysis, the solution obtained by each involved single-objective algorithm is represented by the average result of all 50 independent runs. Since the Pareto fronts obtained by 50 independent runs cannot be averaged, we treated all the non-dominated solutions among the Pareto sets obtained by the 50 independent runs as the ideal Pareto front, and all the dominated ones during the 50 independent runs as the non-ideal Pareto front. Obviously, the ideal- and non-ideal Pareto fronts respectively implies the corresponding multi-objective algorithm’s upper- and lower-bound in terms of optimization ability. According to Fig. 9, we can see that the ideal Pareto front of the EF-NSGA is always superior to the ideal front the MO-AFSA. Not only that, when the network manages more than 140 end-hosts and the multicast session involves more than 25 destinations, the non-ideal Pareto front of the EF-NSGA is no worse than the ideal Pareto front of the MO-AFSA, as seen from the Fig. 9 (c) and (d). As for the compared single-objective algorithms, none of their obtained average solution dominates any solution on the ideal Pareto front of the EF-NSGA. Instead, some solutions on the ideal pareto front obtained by the EF-NSGA dominate the average solutions obtained by the single-objective algorithms. Even most of the solutions on the non-ideal Pareto front of the EF-NSGA are not dominated by the average solutions obtained by the single-objective algorithms, either. Besides, other algorithms, such as Cao’s algorithm, the CL-S, and the VDM, are inferior as compared to the proposed method.

50-independent-run comparison corresponding to each situation of Fig. 8: (a) Network of 60 end-hosts, multicast session of 15 destinations; (b) Network of 100 end-hosts, multicast session of 20 destinations; (c) Network of 140 end-hosts, multicast session of 25 destinations; (d) Network of 180 end-hosts, multicast session of 30 destinations
For the purpose of analyzing how ALM routing tree’s topological structure impacts on its transmission delay and instability, we further investigated three non-dominated solutions chosen from the Pareto front shown in Fig. 7 and listed them in Table 4, which are the solution at the top left, the one at the bottom right, and a randomly chosen Pareto solution other than the above two. The top left one possesses the least transmission delay; the bottom right possesses the smallest instability degree; and the third chosen from the Pareto front ought to be a trade-off solution.
We noticed that the solution listed in the first row of Table 4 uses vertex 30 as a forwarding node to distribute data duplications to vertices 2, 14, 29, 28, and 31. This can be explained from two perspectives. First, the unicast from vertex 30 to 2, as well as that to vertices 14, 29, 28, 31, possess relatively small transmission delay; Second, the message processing delay on vertex 30 is small, forwarding data copies to more end-hosts will not significantly increase forwarding delay. For the same reasons, vertex 38 serves as a forwarding node too and distributes data copies to vertices 22, 37 35, 24, and 26. Furthermore, vertex 38 receives data packages from vertex 14 rather than the others, is because the unicast from vertex 14 to 38 possesses the smallest transmission delay. Such a topological structure obviously contributes to the minimization of transmission delay. However, it is not conducive to the multicast transmission’s stability. For example, the leaving probability of vertex 14 is not low. Once it leaves from the multicast session, its sub-tree will lose communication.
The topological structure of the solution listed in the second row of Table 4 is far different from that in the first row. The source node 8 directly forwards data copies to vertices 2, 14, 22, 24, 26, 28, 29, 31, 3, 35, and 37. Such a tree structure is obviously very stable, because all the destination nodes serve as the routing tree’s leaf nodes and the abrupt departure of any leaf node would not influence the other destinations’ data reception. Nevertheless, the instability risk of such a tree structure still exists, because the source node 8 leaves the multicast session with probability 0.0001. It must be emphasized that, such a routing tree essentially becomes several unicasts, distributing data copies separately from the source to each destination. This explains why the transmission delay of such a routing tree is long. This also demonstrates the importance of ALM from another viewpoint.
As for the topological structure of the solution listed in the third row of Table 4, it is obviously a trade-off between the two objectives. There exists 23 more such trade-off solutions on the obtained Pareto front as shown in Fig. 7.
5.2 Impact of parameter k
We introduced a new parameter k to control the number of offspring to be generated during crossover in order to enhance the local exploitation ability of the proposed algorithm. It is necessary to investigate the contribution of such an improvement on the optimization efficiency. We thus carried out a control experiment to compare the Pareto front obtained by the EF-NSGA for different k. According to the definition of k, k = 2 is equivalent to the ordinary case of k being not introduced. Thus, the Pareto front obtained by the proposed algorithm when k = 2 is compared.
The optimization task in Fig. 7 is used in this control experiment. The parameters are set as the same as in Table 3. In order to avoid the impact of randomness on the comparison results, the algorithm was run 50 times independently for a k value. The Pareto fronts obtained by 50 independent runs are given in Fig. 10. The comparison shows that the proposed algorithm is more likely to achieve Pareto front close to the reference points in the objective space when k = 18 rather than k = 2. Obviously, the newly introduced parameter k is indeed beneficial to enhance the algorithm’s optimization efficiency.

All Pareto fronts obtained by 50 independent runs of the EF-NSGA for k = 2 and k = 18
In order to make a quantitative comparison, we use the frequently used Inverted Generational Distance (IGD) indicator [40, 41] as the convergence index of each independent run. IGD indicator implies the average distance from each reference point to its nearest solution. When a set of well-distributed reference points over the entire Pareto front is used, a small value of the IGD indicator suggests the good convergence of solutions to the Pareto front and the good distribution over the entire Pareto front. We use all the non-dominated solutions in Fig. 10 as the reference points. Based on these reference points, the IGD-value for each independent run can be calculated. Figure 11 presents the IGD-data of 50 independent runs for different k in the manner of box plot. Box plot is a convenient way to graphically depict groups of numerical data through the quartiles. The lines extending vertically from the boxes indicating variability outside the upper and lower quartiles. Each red cross ‘+’ stands for an outlier. From Fig. 11, we conclude that the proposed EF-NSGA converges better and more steadily when k = 18, compared with the case of k = 2. This phenomenon validates the paremeter k’s postive impact on enhancing the algorithm’s ability. Exhaustive trials indicate that our proposed EF-NSGA always performs better if k takes integer value from 12 to 60 with respect to k = 2, that is a relatively wide range in fact.

Box plots of the convergence index (IGD-indicator) obtained by EF-NSGA based on 50 independent runs when k = 2 and k = 18
5.3 Running time evaluation of the proposed EF-NSGA
The running time of the EF-NSGA depends on both the network size and the given multicasting task. In this paper, the network size is equal to |V| and the destination number equals to (|V′|-1). To evaluate the running time of the proposed EF-NSGA in all cases is impossible. We thus sampled a limited number of their combinations and conduct regression analysis on the relationship between the running time and them both.
We generated 4 networks, with end-hosts of 60, 100, 140, and 180 respectively; we also assigned 8 multicast sessions, involving destinations of 10, 15, 20, 25, 55, 95, 130, and 165 respectively. The proposed EF-NSGA’s average running time of 10 independent runs for different combinations of |V| and (|V′|-1) were calculated. Since V′ is a subset of V, (|V′|-1) is always less than |V|. Table 5 lists the obtained results. The fitting surface by regression analysis is depicted in Fig. 12. It is quite clear that, the algorithm’s average running time would increase along with the increasing of |V| and (|V′|-1). Nevertheless, the almost linearly increasing trend is reasonable and acceptable.

Fitting landscape of the algorithm’s running time
It must be pointed out that, the running time listed in Table 5 is merely the result from the simulation on the laptop rather than the real time consumption for establishing an ALM routing tree on practical ALM system. ALMI [42] and HBM [43] are two widely accepted protocols for carrying out ALM. Either ALMI or HBM requires a Rendezvous Point (RP) as a session controller, taking in charge of maintaining the network topology and establishing multicast routing trees. Multicast routing algorithm runs on the RP node. On one aspect, the laptop used to carry out the simulation experiments has very large gap in computing performance compared with the RP node. The proposed EF-NSGA can run much faster on the RP node. On another aspect, the running time resulted by transforming the IP network to the application layer network is practically nonexistent on practical ALM system because the RP node is a specially deployed session controller, which is in charge of grasping the whole application layer network topology, such that the running time of the proposed EF-NSGA is further decreased.
6 Discussion
6.1 On the method of selecting a trade-off solution
Our proposed EF-NSGA is capable of achieving the high-quality Pareto front set for the multi-objective optimization model formulated in Section 2. It should be noted that, the core task of ALM routing is to establish a routing tree rather than a batch of non-dominated routing trees. How to select a trade-off solution out of the obtained Pareto front set is an open issue until now. In this section, we discuss a potential method for choosing a trade-off solution out of the Pareto front.
Among the non-dominated solutions on the Pareto front, some increase the transmission delay to reduce the instability, while some others increase the instability to decrease the transmission delay. The most cost-effective trade-off between the two objectives is preferred. Neither of the two objectives should be over-emphasized, according to the law of diminishing marginal utility. In the objective space, the origin (0, 0) can be treated as a datum point, because it dominates all the other points. A solution on the Pareto front must be far away from the origin (0, 0) if it prefers to minimize one of the two objectives rather than well balance both. Therefore, we suppose to choose the non-dominated solution being closest to the origin (0, 0) as a balanced choice for ALM routing tree.
Considering the different magnitudes of the transmission delay and the instability being likely to influence the preference on the two objectives, we suggest to normalize the objective space according to formula (2) before choosing the preferred solution, where Tright denotes the rightmost solution on the Pareto front, Tleft denotes the leftmost one, and Ti denotes the solution to be normalized. Figure 13 demonstrates a schematic diagram of normalization. The objective space normalization would not alter the original rank of the non-dominated solutions on the Pareto front.

Schematic diagram to our suggested method of choosing a solution
It needs to be emphasized that, how to select a proper trade-off solution out of the Pareto front depends on the specific application scenarios to a large extent. The above-described method is given as a universal approach merely.
6.2 On the reason why genetic programming is not used?
The success of our proposed EF-NSGA in optimizing ALM routing trees mainly benefits from the utilization of the tree-shaped genotype. As a matter of fact, the genotype used in the genetic programming (GP) is also tree-like, referred to as the syntax tree, which consists of multiple symbol nodes and may represent an algebraic expression, a computer program, even a circuit for achieving a certain function [44]. From this perspective, the GP seems to be also suitable to solve the ALM routing problem, but we did not use it. In fact, the GP is not suitable for solving the ALM routing problem, due to some inherent characteristics of the ALM routing tree. In an ALM routing tree, the source node and the destination nodes of a multicast session must appear and only appear once. Not only that, each leaf node of an ALM routing tree must be the destination node. Most importantly, loop is forbidden in an ALM routing tree. However, the syntax tree in the GP cannot guarantee these restrictions, thus it is not suitable for representing an ALM routing tree.
We take a simple example to explain this point. Both of the ALM routing trees shown in Fig. 14 (a) and (b) deliver data packages from vertex 1 to vertices 2, 7, 8, 5, 6, and 3. Assume that they are two parent individuals for crossover operation. In the GP, crossover operation is carried out by exchanging the subtrees of both parent individuals with each other. In terms of the example in Fig. 14, the parts surrounded by the dash lines are the exchanged subtrees. After crossover, two offspring syntax trees shown in Fig. 14 (c) and (d) are generated. Obviously, neither of them is capable of correctly delivering data packages. In the ALM routing tree shown in Fig. 14 (c), the vertex 7 should appear but it is absent, while the vertices 5, 6, and 3 will receive data packages more than once. Especially, the branch link 3 → 8 → 6 → 3 forms a loop, which is forbidden. As for the routing tree shown in Fig. 14 (d), it is not able to deliver data packages to the vertices 5, 6, and 3, the vertex 7 will receive data packages more than once.

Diagrammatic crossover in GP
The example given above confirms that the GP is indeed not suitable for optimizing the ALM routing tree even if it utilizes tree-shaped genotype as well. It is worth noting that, the GP does not imply encoding-free. The syntax tree in the GP is still a tree-like encoding scheme, which is suitable to map those phenotypes that can be grammatically formalized, like algebraic expression but excluding the ALM routing tree. But in the proposed EF-NSGA, the genotype and the phenotype are not only identical formly but also identical semantically, i.e., an ALM routing tree, thus being referred to as encoding-free.
6.3 On the possibility of making other evolutionary algorithms encoding-free
The main contribution of this paper is to carry out the optimization of treelike topology using the proposed encoding-free genetic-operating mechanism, while the NSGA-II merely supplies the optimization framework. As a matter of fact, if appropriately introducing the proposed encoding-free mechanism, other algorithms in the field of evolutionary computation like particle swarm optimization (PSO) [45] can also be used as well. Surely, that will not be an effortless task, but one that is indeed possible. We take the PSO as an instance to discuss if we make PSO encoding-free.
Formulas (3) and (4) describe the rules of particles being updated in the PSO, which is suitable to the case of the candidate solutions being dimensionally represented. Such particle updating rules seem not to be compatible with “encoding-free”, unless we re-understand the formulas (3) and (4) from some certain new perspectives. For this purpose, we substituted the formula (3) into the formula (4), thus getting the formula (5). This newly obtained formula reveals the essence of particle flight in the solution space. Namely, the new position of a particle depends on four parts, including its current position X, the velocity V, its individual best position Pb and social best position Pg. Therefore, we could consider the particle flight as the process of each particle respectively inheriting genetic information from four parts. That coincides with the concept of gene-pool, which is the key to carrying out “encoding-free” PSO.

To make the PSO encoding-free, all the operations involved in the formula (5) ought to be topology-based. Figure 15 gives a schematic explanation. To be specific, Fig. 15 (a) shows a particle’s current position X, which is a tree. Figure 15 (b) and (c) respectively show the individual best position (topology) Pb and the social best position (topology) Pg associated with particle X. Obviously, either the Pb or the Pg is a tree. The topology shown in Fig. 15 (d) stands for the velocity V. According to our previous analysis on the formula (5), we could build a gene pool by merging X, Pb, Pg, and V, as shown in Fig. 15 (e). The built gene pool shown in Fig. 15 (e) contains all the components in the topologies of X, Pb, Pg, and V. Given this, the encapsulated RT-generator(·) can be used for generating the particle’s next position X’ from the built gene pool (X + V + Pb + Pg). Namely, X’ = RT-generator(X + V + Pb + Pg). Figure 15 (f) gives an instance. It is obvious that the obtained X’ inherits topological structures from X, Pb, Pg, and V. In this sense, the formula (5) can be implemented using gene pool and the RT-generator(·), i.e., X’ = φ1·X + φ2·V + φ3·Pb + φ4·Pg. The velocity V can be updated according to the formula (4), i.e., V′ = X’-X. The velocity V′ is the sub-topology in X’ that is different from X. Therefore, the topology of the velocity V can never be an intact tree.

Schematic illustration of PSO with encoding-free mechanism
Formula (3) actually contains several parameters, including w, c1 and c2. These parameters determine the proportion of X’ inheriting genetic information from V, Pb, and Pg, which can be designed similarly as that mentioned above. Since such a potential work is worth to further investigate in depth in another paper, we would stop here in this paper.
7 Conclusion
This paper formulates the ALM routing problem as a multi-objective optimization problem to minimize the tree-like ALM’s instability and transmission delay simultaneously. Then the paper proposes an EF-NSGA to solve it. The proposed algorithm is capable of obtaining high-quality Pareto front set. Benefiting from “encoding-free”, the proposed EF-NSGA no longer requires decoding operation during the optimizing process. For the networks of larger sizes and the multicast sessions with more destinations, the presented EF-NSGA has almost linearly increasing running time, which is much less than that of the NSGA-II. Moreover, some conceptions and insights given in this paper, such as the gene pool and the implementations of crossover and mutation for encoding-free algorithm, are of practical significance for solving such problems related to the topological optimization.
References
Deering SE (Aug. 1988) Multicast routing in internetworks and extended LANs. ACM Symposium proceedings on Communications architectures and protocols:55–64
Deering SE (1989) Host extensions for IP multicast. Ietf Rfc Sri Network Information
Wang JH, Cai J, Lu J, Yin K, Yang J (Oct. 2015) Solving multicast problem in cloud networks using overlay routing. Comput Commun 70:1–14
Qing Liu, Tomohiro Odaka, Jousuke Kuroiwa, et al., “An artificial fish swarm algorithm for the multicast routing problem,” IEICE Trans Commun, vol.E97-B, no.5, pp.996–1011, May. 2014, E97.B
Matsuura H (Nov. 2016) Multi-agent Steiner tree algorithm based on branch-based multicast. IEICE Trans Inf Syst, vol.E99-D E99.D(11):2745–2758
Din D-R, Lien C-Y (May. 2017) Delay-constrained survivable multicast routing problem on WDM networks for node failure case. Comput Commun 103:165–192
Kim M, Choo H, Mutka MW, Lim H-J, Park K (Jul. 2013) On QoS multicast routing algorithms using k-minimum Steiner trees. Inf Sci 238:190–204
C. Diot, B.N. Levine, B. Lyles, H. Kassan, D. Balensiefen, “Deployment issues for the IP multicast service and architecture,” IEEE networks spec. Issue multicasting, vol.14, issue.1, pp.78–88, Jan./Feb. 2000, 14
C.K. Yeo, B.S. Lee, M.H. Er, “A survey of application level multicast techniques,” Comput Commun, vol.27, pp.1547–1568, Sept. 2004
Song H, Lee DS, Oh HR (May. 2006) Application layer multicast tree for real-time media delivery. Comput Commun 29(9):1480–1491
Y. Chu, S.G. Rao, S. Seshan, H. Zhang, “A case for end system multicast,” IEEE J Selected Areas in Communications, vol.20, no.8, pp. 1456–1471, Sept. 2006
D. Pendarakis, S. Shi, D. Verma, M. Waldvogel, “ALMI: an application level multicast infrastructure,” in Proc. 3rd Usenix symposium on internet technologies and systems, San Francisco, USA, Mar. 2001
K. Sripanidkulchai, A. Ganjam, B. Maggs, H. Zhang, “The feasibility of supporting large-scale live streaming applications with dynamic application end-points,” in Proc ACM SIGCOMM Conf Applications, Technologies, Architectures and Protocols for Computer Communication, Portland, USA, Aug 2004, pp.107–120
Chawathe Y, McCanne S, Brewer EA (2000) RMX: reliable multicast for heterogeneous networks. Proc IEEE INFOCOM, Tel Aviv, Israel, Mar:795–804
S. Shi, J.S. Turner, “Routing in overlay multicast networks,” in Proc. IEEE INFORCOM, New York, USA, Jun. 2001, pp.1200–1208
J. Jannotti, D.K. Gifford, K.L. Johnson, M.F. Kaashoek, et al., “Overcast: reliable multicasting with an overlay network,” in Proc. 4th Conf. Symposium on operating systems design and implementation, San Diego, USA, Oct. 2000
Li Lao, Jun-Hong Cui, Mario Gerla, Dario Maggiorini, “A comparative study of multicast protocols: top, bottom, or in the middle?” in Proc. IEEE INFOCOM, Miami USA, Mar. 2005, pp.2809–2814
Su J, Cao J, Zhang B (Mar. 2009) A survey of the research on ALM stability enhancement. Chinese J Computers 32(3):576–590 (in Chinese)
Castro M, Druschel P, Kermarrec A M, et al., “SplitStream: high-bandwidth multicast in cooperative environments,” in Proc. 19th ACM symposium on operating systems principles, New York, USA, Oct. 2003, pp.298–313
Kostic D, Rodriguez A, Albrecht J, Vahdat A, “Bullet: high bandwidth data dissemination using an overlay mesh,” in Proc. 19th ACM symposium on operating system principles, New York, USA, Oct. 2003, pp.282–297
Padmanabhan VN, Wang H J, Chou P A, Sripandidkulchai, “distributing streaming media content using cooperative networking,” in Proc. 12th ACM NOSSDAV, Miami, USA, May. 2002, pp. 177–186
Cao J, Su J, Wu C (2008) Modeling and analyzing the instantaneous stability for application layer multicast. Proc IEEE Asia-Pacific Services Computing Conference, Yilan, Taiwan, Dec:217–224
Cao J, Su J (Dec. 2010) Delay-bounded and high stability spanning tree algorithm for application layer multicast. J Software 21(12):3151–3164 (in Chinese)
Lin H, Deshun L, Yinglu T (2012) Algorithms of spanning tree based on the stability and contribution link of nodes for application layer multicast. J Computer Research and Development 49(12):2559–2567 (in Chinese)
Mercan S, Yuksel M (2016) Virtual direction multicast: an efficient overlay tree construction algorithm. J Commun Netw 18(3):446–459
Deb K, Pratap A, Agarwal S, Meyarivan T (Apr. 2002) A fast and elitist multi-objective genetic algorithm: NSGA-II. IEEE Trans on Evolutionary Computation 6(2):182–197
E.W. Dijkstra. “A note on two problems in connexion with graphs,” Numer Math, vol.1, no.1, pp.269–271, Dec. 1959
S. Kunwadee, B. Maggs, H. Zhang, “An analysis of live streaming workloads on the internet,” in Proc. the 4th ACM SIGCOMM Conf. On internet measurement, Taormina, Italy, Oct. 2004, vol.282, pp.41–54
Veloso E, Almeida V, Meira W, Bestavros JA, Jin S (Feb. 2006) A hierarchical characterization of a live streaming media workload. IEEE/ACM Trans on Networking 14(1):133–146
Drefus SE, Wagner RA (1971) The Steiner problem in graphs. Networks 1(3):195–207
M.R. Garey, D.S. Johnson, Computer and intractability: A guide to the theory of NP-completeness. W.H. Freeman & Co. New York, NY, USA© 1990. ISBN:0716710455
Plesník J (1991) Worst-case relative performances of heuristics for the Steiner problem in graphs. Acta Math Univ Comenianae, vol. LX (2):269–284
Gong MG, Jiao LC, Yang DD, Ma WP, “Research on evolutionary multi-objective optimization algorithms,” J Software, vol.20, no.2, pp.271–289, Feb. 2009. (in Chinese)
Leung Y, Li G, Xu ZB (Nov. 1998) A genetic algorithm for multiple destination routing problems. IEEE Trans on Evolutionary Computation 2(4):150–161
Zhong WL, Huang J, Zhang J (2008) A novel particle swarm optimization for the Steiner tree problem in graphs. IEEE World Congress on Evolutionary Computation, Hong Kong, China, Jun:2460–2467
R.C. Prim, “Shortest connection networks and some generalizations,” Bell Labs Technical J, vol.36, no.6, pp.1389–1401, Nov. 1957
Douglas B. West. Introduction to graph theory. 2nd ed. Longman, 2001
Kruskal JB (1956) On the shortest spanning subtree of a graph and the traveling salesman problem. Proc Am Math Soc 7(1):48–50
Xuan Ma, Rongjun Tang, Jingyan Kang, etc., “Optimizing application layer multicast routing via artificial fish swarm algorithm.” International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), 2016
Coello C.A.C., Sierra M.R., “A study of the parallelization of a coevolutionary multiobjective evolutionary algorithm,” in proc. 3rd Mexican international conference on artificial intelligence, LNCS vol. 2972, pp 688–697, Apr. 2004
He Z, Yen GG, Zhang J (Apr. 2014) Fuzzy-based Pareto optimality for many-objective evolutionary algorithms. IEEE Trans on Evolutionary Computation 18(2):269–285
D. Pendarakis, S. Shi, D. Verma, M. Waldvogel, “ALMI: an application level multicast infrastructure,” in Proc. 3rd Conf. USENIX symposium on internet technologies and systems, San Francisco, USA, Mar. 2001
Vincent Roca, Ayman El-Sayed, “A host-based multicast (HBM) solution for group communications,” in Proc 1st Int Conf Networking-Part 1, Colmar, France, Jul. 2001, pp. 610–619
John Koza, “Genetic programming: on the programming of computers by means of natural selection.”, MIT Press, 1992
Kennedy J, Eberhart R. “Particle swarm optimization.” processing of the 1995 IEEE international conference on neural networks. Piscataway: IEEE, pp. 1942–1948, 1995
Deb K, “Multi-objective optimization using evolutionary algorithms,” Chichester: John Wiley & Sons, 2001
Acknowledgements
The work is supported in part by National Science Foundation of China (no. 61502385) and Shaanxi Provincial Special Support Program for Science and Technology Innovation Leader.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Liu, Q., Tang, R., Ren, H. et al. Optimizing multicast routing tree on application layer via an encoding-free non-dominated sorting genetic algorithm. Appl Intell 50, 759–777 (2020). https://doi.org/10.1007/s10489-019-01547-9
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-019-01547-9