
Abstract
All types of recommender systems have been thoroughly explored and developed in industry and academia with the advent of online social networks. However, current studies ignore the trust relationships among users and the time sequence among items, which may affect the quality of recommendations. Three crucial challenges of recommender system are prediction quality, scalability, and data sparsity. In this paper, we explore a model-based approach for recommendation in social networks which employs matrix factorization techniques. Advancing previous work, we incorporate the mechanism of temporal information and trust relations into the model. Specifically, our method utilizes shared latent feature space to constrain the objective function, as well as considers the influence of time and user trust relations simultaneously. Experimental results on the public domain dataset show that our approach performs better than state-of-the-art methods, particularly for cold-start users. Moreover, the complexity analysis indicates that our approach can be easily extended to large datasets.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In todays Internet era, we live in an information and communications technology-based society in which information is overabundant. To filter irrelevant information, recommender systems are widely used to help users select relevant items. For example, popular recommenders are available for music, books, and movies. Common recommendation techniques include collaborative filtering (CF), matrix decomposition, probabilistic latent semantic analysis, and Bayesian clustering. The underlying assumption of CF is that the given user will like the items that other similar users prefer [1]. Based on this assumption, CF has been widely employed in some commercial systems. Relatively early recommender systems include Tapestry, GroupLens, Ringo, and Video Recommender [2]. Amazon.com, Google, Netflix, TiVo, and Yahoo! are other CF-based recommender systems [3]. At present, most CF methods that were described in the literature are variations of k-nearest neighbor (KNN) or singular value decomposition (SVD). Another CF approach employs graphical models [4]. Different CF techniques have been compared in previous studies [5]. Many issues related to recommender systems, such as the effect of network topology, data scarcity, and diversity of recommendations, have also been considered.
Recommender systems provide personalized recommendations for products that suit the taste of a user [6]. Matching consumers with the most appropriate products is a key to enhancing user satisfaction and loyalty. These recommendation systems often rely on CF. The purpose of CF is to establish connections between users and items by analyzing past transactions or product ratings, which does not require the development of explicit profiles. Two widely studied CF methods are memory- and model-based recommenders.
Several methods based on memory (also called neighborhood-based methods) have been proposed for social recommendation networks [7]. These methods need to calculate the similarity between all users according to the ratings of items by using methods such as Pearsons correlation coefficient or cosine similarity. The missing rate is predicted by aggregating the ratings of KNN of the recommendation. Compared with the model-based methods, memory-based approaches are slow in the test stage because they have to spend a considerable amount of time to explore the social network. An important current research trend in CF is model-based methods, which are also called latent factor models, and their use in recommendation in social rating networks. The model is based on pattern recognition or other machine learning techniques, which transforms both items and users into the same latent factor space to enable their direct comparison. Experimental results show that model-based methods perform better than the memory-based approaches. Probability matrix factorization (PMF) and SVD are two typical model-based methods. Currently, matrix factorization methods mainly include nonnegative matrix factorization (NMF) [8], SVD [9], and PMF. In 1999, Lee and Seung published their NMF algorithm in Nature [10]. The main idea of NMF is that the nature of high-dimensional matrix can be studied in a low-dimensional space [11].
All the above methods for recommender systems ignore social activities between users. For example, we often ask friends or colleagues for recommendations. Consequently, recommender systems based on trust have recently been studied by many researchers. In [12], a trust-based CF method for recommender systems is proposed. This work improved coverage without reducing accuracy. Bedi et al. proposed a semantic web recommender system based on trust by using the web of trust to generate the recommendations [13]. Yuan et al. proposed a time-aware point-of-interest (POI) recommendation [14], which incorporates geographical and temporal information to recommend places that users have not visited before. Jiang et al. proposed a novel recommender method based on hybrid random walk [15], which can cross multiple relational domains. The model links into a star-structured hybrid graph with user graph at the center and performs random walk until convergence is achieved.
The emergence of social websites such as Facebook, Digg, and Twitter, in which users directly use connections between the members of a society, have shifted the model of recommender systems to the social level. Recommendation methods based on social networks have been developed with the advent of online social networks. These methods assume that a social network among users exists, and they recommend based on the ratings of the users who have some social relations with the given user. Social networks enable users to create all kinds of personal items. Recommendation systems based on social networks are exploited because people tend to relate to people with similar attributes such that people in a social network become more similar via their influence on each other. Traditional recommender systems assume that users are independent. This assumption ignores social interactions or connections among users. Social networks provide an important means that can be exploited to improve the quality of recommendations. Most existing recommender systems suffer from the cold start and data sparsity problems, which presents a challenge to modeling users and items on social networks. To overcome such weaknesses, social network and user-item rating matrices should be fused, which can improve the accuracy of recommender systems.
The contributions of this work are as follows:
-
(1)
We propose a novel approach called TrustSeqMF, which incorporates time sequential information and trust propagation into the matrix factorization model.
-
(2)
We successfully combine trust propagation and time sequential information, which are crucial technologies in social network recommendation systems.
-
(3)
TrustSeqMF significantly improves the recommendation accuracy, particularly for cold-start users.
The remainder of this paper is organized as follows: Section 2 provides an overview of several major approaches for recommender systems and related work. Section 3 presents our recommendation model on social recommendation. The results and analysis of the experiment are presented in Section 4, followed by the conclusion and suggestions for future work in Section 5.
2 Related work
Here, we review related work on temporal information and trust propagation in social recommendation networks.
User preferences for items change over time. Item popularity is constantly changing when a new selection emerges. At the same time, user inclinations are evolving, which redefines the taste of users. Therefore, modeling temporal dynamics is necessary to design user preference models. In some sense, leveraging temporal information is more important than integration of some different models. Notable discussions of temporal effects include Koren, who proposed a method called TimeSVD++ for modeling time drifting user preferences [16], which improved predictive performance. Ding and Li [17] proposed a time weighting scheme for a similarity-based CF, which computed the time weights for different items. In this method, the transformation for the purchase preference of each customer was traced and a personalized decay factor was introduced based on the purchase behavior of the customer. Sun et al. proposed a model that captures the sequential behaviors of users and items [18]. This approach determined the set of neighbors that were most influential to the given users (items) and was successfully applied into the recommendation process based on PMF. The experimental results showed that the approach performs better than the conventional methods using only social relations. Online CF methods can incorporate new data in real time. Khoshneshin et al. proposed an evolutionary co-clustering method that was useful in improving the quality of predictions while maintaining scalability, thereby mitigating the time problem by parallelizing the co-clustering operations. Ren et al. considered the problem that user preference patterns (PP) and the preference dynamic effect were ignored in social network recommendation [19]. PP was formalized as a sparse matrix. They adopted a PP subspace to iteratively model the personal and global PP, and proposed an algorithm called PrepSVD-I, with the Top-N recommendation transformed into a pairwise preference learning process. Liang et al. proposed a factor-based algorithm called BPTF [20], introducing additional factors for time. BPTF described the model as a tensor factorization on the time dimension. The experimental results demonstrated the superiority of BPTF temporal model. Li et al. adopted the cross-domain CF framework [21], which was based on a Bayesian latent factor and can share the rating matrix across temporal domains. This method can realize visualization of user preference drift and perform explicit tracking over time.
CF cannot make recommendations for the so-called cold-start users and does not know how confident they are in the recommendations. Recommendation approaches based on trust assume that the information of a trust network among users can better deal with the cold start problem when users simply connect to the trust network. Modeling trust propagation resulted in a substantial increase in recommendation accuracy, particularly for cold-start users. Notable discussions of trust propagation include Yu [22], who combined topic maps with trust relations among users to solve the cold start and sparsity problem. The experiment results demonstrated the superiority of the combination model. Golbeck proposed an algorithm called TidalTrust [23], which performs an improved breadth-first search in the trust network to calculate a prediction ratting. Essentially, this method finds all raters with the shortest path distance from the source user and takes only the most trusted paths available at that depth between the source user and these raters. The difficulty problem is how to compute the trust value between users u and v that are not directly connected. Massa et al. proposed an algorithm called MoleTrust [24] to propagate trust over the trust network and estimate a trust weight that can be used in place of the similarity weight. This approach can gain the trust value between u and v by performing a backward exploration. Jamali et al. proposed a random walk model by combining the trust relation and CF method for recommendation in social networks. [25]. The model can define and measure the confidence of a recommendation. The same authors in [26]proposed another method for trust-based recommendation. Advancing previous work, they incorporated the mechanism of trust propagation into the model that employs MF techniques for recommendation. Trust propagation has proved to be a crucial phenomenon in trust-based recommendation. Gao et al. provided an overview of personalized location recommendation in location-based social networks. [27]. Guo et al. introduced unified ranking framework that combines contextual information and social relations, which used implicit feedback information [28].
However, these methods have some difficult problems. First, CF recommends items to users based on their historical ratings. In real-world scenarios, user preference may change over time because they are affected by contexts and moods. Moreover, the relationship between the user-item matrix and social network has not yet been studied systematically. Finally, existing social recommendation algorithms consider only the trust relationship between users or the influence of time sequence separately, that is, they cannot combine the two factors.
To solve the above problems and model the recommender systems more accurately, we proposed a method called TrustSeqMF to integrate time sequential information and trust propagation into the rating matrix model based on PMF. The experimental results on the Epinions dataset showed that our approach outperformed state-of-the-art CF algorithms, particularly when active users have very few ratings or even none at all. Moreover, the complexity analysis indicated that TrustSeqMF can be easily extended to large datasets.
3 Recommendation framework
In this section, we first introduce the user-item matrix factorization model for social recommendation based on latent factor analysis. Then, we provide two examples, namely, SocialMF and SequentialMF, which are recommendation methods that use social relationship information between users and items. Subsequently, we describe the social network problem that we are studying. Finally, we focus on how time sequential information and trust propagation can be integrated into the rating matrix model based on PMF.
3.1 User-item matrix factorization
Salakhutdinov et al. proposed PMF algorithm in [29].The PMF model is shown in Fig. 1.

The graphical model for PMF
Suppose the recommendation system has N users and M items [30]. The set of users is U={u 1,u 2,⋯ ,u N }, and the set of items is I={i 1,i 2,⋯ ,i M },R u,i represents the rating value of user on item u(e.g., movie)i. The ratings are given in matrix R=[R u,i ] N×M . \(U\in \mathbb {R}^{K\times N}\) and \(V\in \mathbb {R}^{K\times M}\) be latent user and item feature matrices, with column vectors U u and V i representing K-dimensional user-specific and item-specific latent feature vectors, respectively. We place zero-mean spherical Gaussian priors on latent user and item feature vectors.
CF algorithm based on the PMF model determines the user and item feature vectors, and then predicts the unknown rating. User rating for the items is the combination of a series of probability and the conditional distribution over the observed ratings as follows:
where \(N\left (x|\mu ,{\sigma _{R}^{2}}\right )\)denotes the Gaussian distribution with mean μ and variance \({\sigma _{R}^{2}}\) and \(I_{u,i}^{R}\) is the indicator function that is equal to 1 if user rates item and equal to 0 otherwise.Function g(x)=1/(1+e x p(−x))is the logistic function, which bounds the value of predictions(\({U_{u}^{T}}V_{i}\) ) within the range [0,1].
Based on the above statement, the posterior probability of the latent variables U and V can be obtained through a Bayesianinference.
According to (4), the latent feature vectors of both users and items can be determined only from the user-item rating matrix. However, this model is based only on the user-item rating matrix and does not consider the social relation of users and the correlation of items. Thus, the recommendation accuracy needs to be further improved.
3.2 SocialMF model
Jamali et al. proposed a model-based approach for recommendation in social networks by incorporating trust propagation into a matrix factorization model. Similar to [26], the social trust graph is shown in Fig. 2, and the posterior distribution for the recommendation is given as follows:

The social trust graph
The graphical model of SocialMF that corresponds to (5) is shown in Fig. 3.

The graphical model for SocialMF
Although the social trust relation of users is integrated into the recommender systems by factorizing the social trust matrix in the SocialMF model, the time sequence information between the items is ignored. This method does not consider the fact that the relationship between items is an important factor that affects user decision.
3.3 SequentialMF model
In [18], Sun et al. proposed a model that captures the sequential behaviors of items. The item consumption network is shown in Fig. 4.The conditional probability of item latent features given the latent features of his direct neighbors is defined as follows:
The graphical model of SequentialMF that corresponds to (6) is shown in Fig. 5.

The item consumption network

The graphical model for SequentialMF
SequentialMF captures the sequential behaviors of users and items to find the most influential neighbor sets, which are successfully applied in the recommendation process based on PMF. However, this method does not consider the trust relation among users. Consequently, the real-world recommendation processes are not reflected in the model.
3.4 TrustSeqMF recommendation model
We proposed a method called TrustSeqMF, which integrates time sequential information and trust propagation into the rating matrix model based on probabilistic matrix factorization for recommendation in social networks.
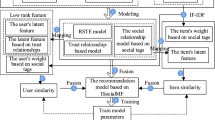
Suppose we have a directed social network graph G=(U∪V,E), where the vertex set \(U=\{u_{i}\}_{i=1}^{N}\) represents all the users in the network, the vertex set \(V=\{v_{j}\}_{j=1}^{M}\) represents all the items in the network, and the edge set E represents the relations between users or items. Let u 1,u 2∈U be the users and v 1,v 2∈V be the items. Edge (u 1,u 2)∈E represents user u 1 trust on u 2. Edge (v 1,v 2)∈E represents both items v 1 and v 2,which have been consumed by the same user in a period of time. Let u∈U be the users and v∈V be the items. Edge (u,v)∈E represents user u rates item v . The notation N u denotes the direct neighbor set of user u and the notation N i denotes the direct neighbor set of item i . Figure 6 shows the process of a real-world recommendation scenario, including three central elements, namely, the user trust network, the item consumption network, and the user-item rating matrix.

Example for recommendation based on TrustSeqMF
Figure 6(a) illustrates the user trust and the item consumption network graphs that comprise six relations among five users (from u 1 to u 5 ) and three relations among three items (from v 1 to v 3 ). In the user trust graph, each node corresponds to a user, and each edge corresponds to a trust relation. Let T={t i j } denote N×N matrix of the user trust graph, which is also called the social trust matrix. Each edge is associated with a weight T i j in the range (0,1] to denote the value of social trust that u i has on u j . The value 0 indicates no trust, and the value 1 indicates full trust. T is an asymmetric matrix given that user u 1 trusts u 2 is not equivalent to user u 2 trusts u 1 in a trust-based social network. In the item consumption network graph, the number in the parentheses near the node v i denotes the user number who consumes the item v i . Each edge is associated with a weight ω i→j , which denotes how many users consumed both items v i and v j in a period of time. If both items v i and v j have been consumed
by the same user in a given period(e.g., 1 day), the weight ω i→j increases by 1. Traversing through all the users, the number of users that complied with this condition is the edge weights from v i to v j . According to the consumption network graph, we define the weight of influence relationship of the item as follows:
where g(v i ,v j ) denotes the union set of users who consume item A or B, and S i→j denotes the degree to which item v i affects on item v j . Let S denote the item consumption matrix , which is asymmetric.
R u,i represents user u rates item i on a five-point integer scale to express the degree of interest (normally, 5, 4, 3, 2, and 1, which represent “love”, “like”, “neutral”, “dont like”, and “hate”, respectively) as shown in Fig. 6(b). The task of a recommender is determining how the missing values R u,i for the users u on item i can be predicted by effectively employing the user-item rating matrix R, the user social trust matrix T and the item consumption matrix S.The posterior probability of latent feature vectors is as follows:
The graphical model that corresponds to (8) is shown in Fig. 7, which combines trust propagation, time sequential information and user-item rating matrix. Based on Fig. 7, the log of the posterior distribution can be computed as follows:
Maximizing the log-posterior over four latent features is equivalent to minimizing the following objective function, which is a sum of squared errors with quadratic regularization terms.
where \(\lambda _{U}={\sigma _{R}^{2}}/{\sigma _{U}^{2}},\lambda _{V}={\sigma _{R}^{2}}/{\sigma _{V}^{2}}, \lambda _{T}={\sigma _{R}^{2}}/{\sigma _{T}^{2}},\lambda _{S}={\sigma _{R}^{2}}/{\sigma _{S}^{2}}\), a local minimum of the objective function given by (10) can be found by performing gradient descent in U u ,V i .
where g′(x)=e x p(x)/(1+e x p(x))2 is the derivative of logistic function g(x).

The graphical model for TrustSeqMF
3.5 Complexity analysis
The TrustSeqMF recommendation algorithm mainly includes two steps. First, we need to establish the consumption network graph to mine the corresponding social relationship. Second, an item is recommended to a user by obtaining the relationship of influence. The time complexity in step 1, as stated in the literature [18], is \(O(M\overline {t}^{2}+M\overline {r}^{2})\), where \(\overline {r}\) denotes the average number of ratings per user and \(\overline {t}\) denotes the average number of direct neighbors per user.
In step 2, the object function L and its gradients against feature vectors of users and items are computed. \(\overline {r}\) and \(\overline {t}\) are relatively small because the rating matrix R and trust matrix T are sparse. The complexity of evaluation of L is \(O(N\overline {r}K+N\overline {t}K)\), which indicates that the computation of the objective function L is fast and linear in the number of observations in the two sparse matrices. The total time complexity of computing the gradients is \(O(N\overline {t}^{2}K+Nl^{2}K+M\overline {r}K+Ml^{2}K)\), which does not increase the time complexity much compared with SequentialMF and SocialMF, because matrices R,T, and S are sparse, in which l denotes the number of neighbors that affect the current user. The above analysis showed that our proposed model and method can achieve a good recommendation effect and can scale to large datasets.
4 Experimental results and analysis
In this section, we report our experimental results and compare the recommendation qualities of our approach with other existing state-of-the-art CF methods including basic matrix factorization method, trust-aware recommendation methods, and the algorithm with only time sequential information. Then we investigate how the model parameters λ T and λ S affect the quality of prediction.
4.1 Dataset description
We use Epinions [31] as the data source of our experiments. Epinions.com is a well-known review site that was established in 1999. Users can submit their personal opinions on topics such as products or movies and assign to products or reviews integer ratings from 1 to 5, which will influence the decision of customers. Every member of Epinions maintains a trust list, which presents the trust relationships between users. The dataset we collected from Epinions consisted of 51,670 users who have rated a total of 83,509 different items. The statistics of the Epinions user-item rating matrix and this data source are summarized in Tables 1 and 2, respectively.
4.2 Metrics
The evaluation metric we used in our experiments was RMSE, which was used to measure the prediction quality of our proposed approach in comparison with other CF methods. RMSE is defined as follows:
where R u i denotes the rating user u gave to item i, \(\hat {R}_{ui}\) denotes the rating user u gave to item i as predicted by our approach, and N denotes the number of tested ratings.
4.3 Comparison
We compared our algorithm with basic PMF, SocialMF, and SequentialMF to evaluate the performance improvement of our TrustSeqMF recommendation method. Table 3 reports the experimental results with different settings of dimensionality K of latent feature vectors. The parameter settings in our experiment were λ U =0.001,λ V =0.001,λ T =λ S =λ, and the maximum iteration times were set to 100. Table 3 indicates that TrustSeqMF outperformed the existing approaches in RMSE metrics. Our method improved the accuracy by 4.4 %, 2.62 %, and 0.9 % with respect to PMF, SocialMF, and SequentialMF respectively when K=10, which indicates the significance of our social recommendation method. PMF method performed the worst because it used only the user-item rating matrix, which showed that utilizing the historical tastes of users alone was not applicable. Moreover, the experiment results indicated that the item relations can help to improve the prediction performance of user preferences. Fig. 8 shows the effects of dimensionality K on RMSE in different methods.

K Impacts on accuracy of algorithm
4.4 Effect of Parameters λ
Parameters λ controls the effects of the trust and time sequential information on the behavior of users and items. When λ has a large value in the objective function of (10), the influence of the trust and time sequential information on the preference of users is great. When λ has a small value, the influence of the trust and time sequential information on the relation of items is small. We perform the prediction by integrating both time sequential information and trust propagation into the rating matrix model based on PMF. Figure 9 compares the RMSE of our model for different ranges of values with the λ in Epinions. TrustSeqMF has the best results on Epinions for λ=5.

Impact of parameter λ(K=10)
We observe that the values of parameters in Fig. 9 significantly affect the accuracy of the algorithm, which demonstrates that incorporating time sequential information and trust propagation information greatly improved the recommendation accuracy. The results also showed that as λ increased, the prediction accuracy increased initially. However, when the values of λ were beyond a certain threshold, the prediction accuracy decreased. This result indicated that using only one kind of social network information for recommendations cannot generate better performance than appropriately integrating them.
5 Conclusion
We propose a novel method for recommendation in social networks. This method incorporates trust propagation and time sequential information into a user-item rating matrix for recommendation. Trust propagation and time sequential information are crucial technologies in the recommendation systems of social networks. TrustSeqMF determines the latent feature vectors of users and items, and handles the trust relations. We can determine the user feature vectors via a social relation even if a user has not rated any item. Hence, TrustSeqMF is better than existing methods at addressing the cold start problem.
Experimental results on the real-world data sets showed that our approach outperformed the existing methods in social network-based recommendation. The complexity analysis indicated that the model can be easily extended to large datasets. Based on this work, we will explore several interesting research directions in the future. We only established the items consumption network in this paper. In a future study, we will establish the user consumption network. Moreover, we considered only trust relations among users and ignored distrust relations. We plan to study distrust-based social recommendation and model them in an actual recommender system in future work.
References
Ma H, King I, Lyu M R (2007) Effective missing data prediction for collaborative filtering. In: Proceedings of the 30th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, pp 39–46
L L, Medo M, Yeung CH, et al. (2012) Recommender systems. Phys Rep 519(1):1–49
Ricci F, Rokach L, Shapira B (2011) Introduction to recommender systems handbook. Recommender Systems Handbook. Springer, US, pp 1–35
Salakhutdinov R, Mnih A, Hinton G (2007) Restricted Boltzmann machines for collaborative filtering. In: Proceedings of the 24th international conference on Machine learning. ACM , pp 791–798
Breese J S, Heckerman D, Kadie C (1998) Empirical analysis of predictive algorithms for collaborative filtering. In: Proceedings of the Fourteenth conference on Uncertainty in artificial intelligence. Morgan Kaufmann Publishers Inc., pp 43–52
Adomavicius G, Tuzhilin A (2005) Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans Knowl Data Eng 17(6):734–749
Koren Y (2008) Factorization meets the neighborhood: a multifaceted collaborative filtering model. In: Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, pp 426–434
Gu Q, Zhou J, Ding C H Q (2010) Collaborative Filtering: Weighted Nonnegative Matrix Factorization Incorporating User and Item Graphs. SDM:199–210
Zhang S, Wang W, Ford J, et al. (2005) Using singular value decomposition approximation for collaborative filtering. In: E-Commerce Technology. Seventh IEEE International Conference on. IEEE, pp 257–264
Lee D D, Seung H S (1999) Learning the parts of objects by non-negative matrix factorization. Nature 401 (6755):788–791
Tu D D, Shu C C, Yu H Y (2013) Using unified probabilistic matrix factorization for contextual advertisement recommendation. J Softw 24(3):454–464
Massa P, Avesani P (2004) Trust-aware collaborative filtering for recommender systems. On the Move to Meaningful Internet Systems 2004: CoopIS, DOA, and ODBASE. Springer, Berlin Heidelberg, pp 492–508
Bedi P, Kaur H, Marwaha S (2007) Trust Based Recommender System for Semantic Web. IJCAI 7:2677–2682
Yuan Q, Cong G, Ma Z, et al. (2013) Time-aware point-of-interest recommendation. In: Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval. ACM, pp 363–372
Jiang M, Cui P, Wang F, et al. (2012) Social recommendation across multiple relational domains. In: Proceedings of the 21st ACM international conference on Information and knowledge management. ACM, pp 1422–1431
Koren Y (2010) Collaborative filtering with temporal dynamics. Commun ACM 53(4):89–97
Ding Y, Li X (2005) Time weight collaborative filtering. In: Proceedings of the 14th ACM international conference on Information and knowledge management. ACM, pp 485–492
Sun G F, Wu L, Liu Q, et al. (2013) Recommendations Based on Collaborative Filtering by Exploiting Sequential Behaviors. J Softw 24(11):2721–2733
Ren Y, Zhu T, Li G, et al. (2013) Top-N Recommendations by Learning User Preference Dynamics. Advances in Knowledge Discovery and Data Mining. Springer, Berlin Heidelberg, pp 390–401
Xiong L, Chen X, Huang T K, et al. (2010) Temporal Collaborative Filtering with Bayesian Probabilistic Tensor Factorization. SDM 10:211–222
Li B, Zhu X, Li R, et al. (2011) Cross-domain collaborative filtering over time. In: Proceedings of the Twenty-Second international joint conference on Artificial Intelligence-Volume Volume Three. AAAI Press, pp 2293–2298
Yu Z, Song W W, Zheng X, et al. (2013) A Recommender System Model Combining Trust with Topic Maps. Web Technologies and Applications. Springer, Berlin Heidelberg, pp 208–219
Golbeck J A (2005) Computing and applying trust in web-based social networks. PhD thesis, University of Maryland College Park
Massa P, Avesani P (2007) Trust-aware recommender systems. In: Proceedings of the 2007 ACM conference on Recommender systems. ACM, pp 17–24
Jamali M, Ester M (2009) TrustWalker: a random walk model for combining trust-based and item-based recommendation. In: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, vol 397, p 406
Jamali M, Ester M (2010) A matrix factorization technique with trust propagation for recommendation in social networks
Gao H, Tang J, Liu H (2014) Personalized location recommendation on location-based social networks. In: Proceedings of the 8th ACM Conference on Recommender systems. ACM, pp 399–400
Guo L, Ma J, Chen Z, Zhong H (2014) Learning to recommend with social contextual information from implicit feedback. Soft Comput:1–12
Mnih A, Salakhutdinov R (2007) Probabilistic matrix factorization. Advances in neural information processing systems, pp 1257–1264
Zhang Z, Liu H (2014) Application and Research of Improved Probability Matrix Factorization Techniques in Collaborative Filtering. Int J Control Autom 7(8):79–92
Ma H, Yang H, Lyu MR, King I (2008) SoRec: Social Recommendation Using Probabilistic Matrix Factorization. In: Proceedings of the 17th ACM Conference on Information and Knowledge Management. ACM, pp 931–940
Acknowledgments
This paper is supported by the National Natural Science Foundation of China (No. 61272094), Natural Science Foundation of Shandong Province (ZR2010QL01, ZR2012GQ010), Science and Technology Development Planning of Shandong Province (2014GGX101011), A Project of Shandong Province Higher Educational Science and Technology Program (J12LN31, J13LN11), Jinan Higher Educational Innovation Plan (201401214, 201303001) and Shandong Provincial Key Laboratory Project.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Zhang, Z., Liu, H. Social recommendation model combining trust propagation and sequential behaviors. Appl Intell 43, 695–706 (2015). https://doi.org/10.1007/s10489-015-0681-y
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-015-0681-y