
Abstract
This paper reexamines the unintended consequences of the two widely cited models for measuring environmental efficiency—the hyperbolic efficiency model (HEM) and directional distance function (DDF). I prove the existence of three main problems: (1) these two models are not monotonic in undesirable outputs (i.e., a firm’s efficiency may increase when polluting more, and vice versa), (2) strongly dominated firms may appear efficient, and (3) some firms’ environmental efficiency scores may be computed against strongly dominated points. Using the supply-chain carbon emissions data from the 50 major U.S. manufacturing companies, I empirically compare these two models with a weighted additive DEA model. The empirical results corroborate the analytical findings that the DDF and HEM models can generate spurious efficiency estimates and must be used with extreme caution.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The growing awareness for environmental sustainability has made corporate environmental performance become the focus of public attention. Investors, NGOs, and consumers are now paying more and more attention to the environmental aspects of firms (Anton et al. 2004). While the debate over whether “it pays to be green” still continues, one generally recognized fact is that firms can no longer concentrates solely on their financial competitiveness while ignoring their impacts on environmental sustainability. The optimal or efficient pollution level for a firm (given the resources consumed and products produced) is a matter largely subject to technological constraints, and therefore a firm’s eco-efficiency should reflect the firm’s performance relative to other firms in the same industry. The notion of environmental efficiency concerns a similar question: Can a firm produce more desirable outputs while generating lower environmental impacts than its competitors? The answer to this question can provide crucial information for managers and policymakers to act pro-actively in strategy-making and resource allocation to ensure both corporate and environmental sustainability.
However, measuring environmental efficiency can be challenging for several reasons. First, calculating environmental efficiency scores requires an articulation of weights or preferences for productive inputs and outputs, but both eliciting and combining preferences are difficult in a multi-stakeholder environment (Baucells and Sarin 2003; Kerr and Tindale 2004). Second, most undesirable outputs, such as greenhouse gas emissions and toxic releases, do not have a well-established market from which we can obtain reliable price signals. This makes prioritizing different environmental factors difficult. For example, it can be extremely difficult assign specific weights to different dimensions of corporate social performance, such as environmental consciousness and community relationship (Chen and Delmas 2011).
The absence of reliable price information for environmental impacts makes data envelopment analysis (DEA) a useful tool for assessing environmental efficiency. DEA does not require explicit assumptions about weights, production functions, and probability distributions for environmental inefficiency. Weights are optimized based on which input(s) a specific firm excels at utilizing, or which output(s) a firm excels at generating in comparison to the other firms in the sample. In this way, each firm can endogenously determine the weights used to evaluate its eco-efficiency. Applications of DEA to environmental efficiency have also spanned across a variety of problem contexts where undesirable outputs are consequential, including banking and finance, electricity generation, manufacturing, and transportation.
Among different environmental efficiency models, the directional distance function (DDF) (Chung et al. 1997) and hyperbolic efficiency models (HEM) (Färe et al. 1989) are two of the most frequently used models in the literature.Footnote 1 Compared with other competing DEA models (e.g., Seiford and Zhu 2002; Zhou et al. 2007), the DDF and HEM adopt an explicit assumption about the trade-off (and boundary) relationship between the desirable and undesirable outputs in the production possibility set. This assumption is known as weak disposability on undesirable outputs (Shephard 1970).Footnote 2 Despite the prevalence of the weak disposability assumption, however, recent studies have raised a fundamental question about this assumption and the two models. Murty et al. (2012) discover that the reference points of DDF and HEM may not be output efficient. Chen and Delmas (2013) compare five representative DEA models for measuring eco-efficiency (including DDF and HEM) through an extensive Monte-Carlo experiment. They found numerical evidence showing that the DDF and HEM are non-monotonic in pollutant quantities and the DDF and HEM scores exhibited low correlation with the (simulated) true efficiency scores.
Building on recent findings on WDA, this study aims to further explore the analytical structure linked to these issues. This study proves three main problems associated with these two models and the weak disposability assumption: (1) Non-monotonicity in undesirable outputs: the two models are not monotonic in undesirable outputs (i.e., a firm’s efficiency may increase when polluting more, and vice versa), (2) misclassification of efficiency status: strongly dominated firms may be identified efficient, and (3) strongly dominated projection targets: environmental efficiency scores may be computed against strongly dominated points. This study suggests that DDF and HEM should be applied with great caution, as these two models are likely to provide distorted evaluation results. This paper includes a case study based on the carbon emissions data of fifty major U.S. manufacturing firms.
2 Production models of undesirable outputs
The production model that I consider consists of n decision-making units (DMU). Each DMU uses m inputs to produce s desirable outputs along with p different undesirable outputs. The input vector of DMU q is denoted by X q =(x q1,…,x qm ), desirable output vector by Y q =(y q1,…,y qs ), and undesirable output vector by B q =(b q1,…,b qp ). The mapping that links the input vector to the two output vectors is given by:
The function f represents the production technology because it captures the correspondence between inputs and outputs. An implicit assumption underlying the model is that producer q should maximize Y q and minimize B q for a given X q . It follows that output efficiency can be defined as:
Definition 1
(Output efficiency)
DMU q is output efficient if there does not exist a non-zero vector \((S^{Y},S^{B})\in\Re^{s}_{+}\times\Re^{p}_{+}\), such that (Y q +S Y,B q −S B)∈f(X q ).
Definition 1 means that a DMU is output efficient if technologically it cannot improve any of its outputs at its current input level. The above definition of output efficiency is similar to but different from the Pareto-Koopmans efficiency (Cooper et al. 2007, pp. 45–46), in that output efficiency does not consider input-side inefficiency and slacks (i.e., reduction in inputs).
This definition also implies that firms can achieve output efficiency by either increasing Y q , decreasing B q , or both. This relationship then poses the question as to the way to model or axiomatize the trade-off between the desirable and undesirable outputs. One possibility is to assume that such a trade-off does not exist, ceteris paribus. In this situation, what will later be referred to as free disposability, the technology set (X,f(X)) permits a unilateral change in undesirable outputs with respect to desirable outputs; i.e., \((Y_{q},B_{q})\in f(X_{q})\Rightarrow (Y_{q},B_{q}^{*})\in f(X_{q})\) for all \(B_{q}^{*}\geqq B_{q}\), and \((Y_{q},B_{q})\in f(X_{q})\Rightarrow(Y_{q}^{*},B_{q})\in f(X_{q})\), for all \(Y_{q}^{*}\leqq Y_{q}\) and \(Y_{q}^{*}\in\Re^{s}_{+}\), “≦” being the componentwise inequality. Alternatively, one may assume that reducing undesirable outputs should not be “free,” by invoking the weak disposability assumption (WDA) on undesirable outputs. Denoting the technology set under WDA as f w (X q ), the WDA is defined as a production technology satisfying the following three conditions (Shephard 1970): (i)(Y q ,B q )∈f w (X q ) implies that \(( Y_{q}^{*}, B_{q})\in f(X_{q})\) for all \(Y_{q}^{*}\leqq Y_{q}\), (ii) (Y q ,B q )∈f w (X q ) and 0≤θ≤1 implies that (θY,θB)∈f w (X q ), and (iii) (Y q ,B q )∈f w (X q ) implies that \(( Y_{q}, B_{q})\in f(X_{q}^{*})\) for all \(X_{q}^{*}\geqq X_{q}\).
The first condition in WDA means that if (X q ,Y q ,B q ) is observed, it is then technologically feasible to produce a lower amount of desirable outputs, given X q and B q . The second condition stipulates that proportional reduction of the joint output vector (Y q ,B q ) is feasible. The first two conditions combined imply that a reduction in B q must be accompanied by a reduction in desirable outputs Y q , while the converse is not true.Footnote 3 Clearly, the technology set f w (X q ) is a subset of f(X q ), because of these additional constraints associated with WDA.
In the production economics literature, WDA is meant to reflect the notion that disposal of undesirable production outputs are not free (or costly) in a “regulated” market environment (Färe et al. 1989, 2005), and that it is difficult to explicitly (or parametrically) factor in this cost in a DEA model.Footnote 4 In this regulated environment, the process-oriented view offers one clear example as to why the disposal of pollutants can be costly. Yet, there are many other similar but exogenous factors that can also contribute to the costly disposal of pollutants: for example, the imposition of fines, declining demand from environmentally conscious customers, and litigation costs.
Consider for example manufactures of certain consumer products uses labor, plants, and raw materials to produce consumer products but at the same time they generate greenhouse gases (GHG) emissions. Before any regulations or market disincentives on generating GHG emissions are introduced, firms’ production of products and GHGs are independent, meaning that firms may freely adjust GHGs without affecting its productive capability for the products. In contrast, when such a regulation on GHG is enforced, reduction of GHG will come with an implied cost, and this implied cost is expressed in the form of output reduction in the model. The abatement cost can arise due to endogenous factors such as costs for upgrading production facilities, training employees, or switching to renewable raw materials. The abatement cost can also incurred by exogenous factors such as the imposition of fines, losing the demand from environmentally aware customers, and litigation costs. In Sect. 5 I will revisit this problem and present a case study in which we compute carbon efficiencies based on real company data.
The technology f w can be formulated as a linear system under the following axioms: f w (X q ) is convex, and f w (X q ) is the intersection of all sets satisfying the convexity axiom and disposability assumptions; i.e., the production set \(f_{w}=\bigcap_{j=1}^{n} f_{w}'(X_{j})\), where \(f_{w}'(X_{j})\) is any convex set satisfying the disposability assumption for DMU j (Banker et al. 1984). The model can be written as:
The boundary of (2) consists of non-negative linear combinations of all DMUs’ input and output vectors. The λ j represents the production intensity of the jth DMU, which can take different values to populate different areas of (X q ,f w (X q )). The WDA is enforced by the equality constraints associated with undesirable outputs. See p. 50 in Färe and Grosskopf (2004) for the proof that shows (2) satisfies the WDA. If on contrary we assume that undesirable outputs are freely disposable, the new technology set f f (X q ) can be recast by replacing the equality constraints with “≤” inequality constraints, meaning that the efficient level of undesirable outputs are bounded below by the left-hand-side value and undesirable outputs can be improved independently from desirable outputs. Note that the set (X q ,f w (X q )) is convex and (2) also satisfies the constant returns-to-scale technological assumption; i.e., (Y,B)∈f w (X) implies that (δY,δB)∈f w (δX), δ≥0.
3 Output efficiency and models for environmental efficiency
The output set f w allows us to compute the environmental efficiency for each observation as an optimization problems. I focus on two most well-known environmental efficiency models embedded with the WDA: the directional distance function (DDF) (Chung et al. 1997) and hyperbolic efficiency models (HEM) (Färe et al. 1989).
I now introduce a few alternative models capable of incorporating undesirable outputs into efficiency assessment. Seiford and Zhu (2002), for example, inverse the sign of undesirable outputs such that the conventional DEA models are applicable to the transformed data set. Reinhard et al. (2000) develop a stochastic environmental efficiency model that accounts for statistical noise and allows for making statistical inferences. Korhonen and Luptacik (2004) propose several approaches to embed undesirable outputs in the DEA model, including treating undesirable outputs as inputs and assigning negative weights to undesirable outputs. Zhou et al. (2007) develop an environmental efficiency model similar to the HEM model. In their model undesirable outputs does not need to reduce in the same proportion (as it does in the classical DEA model), and their models focus accounting for excessive undesirable outputs but not shortfall of undesirable outputs in the computation of environmental efficiency scores. However, the projection points obtained from the above models are not necessarily output efficient. Then how can we compare different environmental efficiency models? Conducting simulation analysis is one possible way. See Chen and Delmas (2013) for a simulation methodology to simultaneously generate multiple desirable and undesirable outputs, as well as criteria for evaluating environmental efficiency models.
The formulation of the directional distance function (DDF) is given in (3). Specifically, the DDF model calculates the environmental efficiency score of a firm according to the maximum improvement in outputs that this firm can make in the direction (g Y,g B), such that the firm remains in f w (X q ) after this improvement. Therefore environmentally efficient firms in the DDF model are those obtaining a zero optimal value (i.e., β ∗=0), in a sense that these firms cannot improve their outputs following the pre-determined direction.
Similar to DDF, HEM computes environmental efficiency scores according to how far a firm can proportionally increase desirable outputs and reduce undesirable outputs. The formulation of the HEM is (Färe et al. 1989):
The HEM utilizes a radial measure, by which the evaluated firm simultaneously increases desirable outputs and decrease undesirable outputs by a scaling factor γ. The optimal value of this factor (γ≥1) in (4) is the hyperbolic efficiency score. Efficient firms’ efficiency scores are equal to 1, and inefficient firms’ scores are greater than 1 (Färe et al. 1989). The main differences between HEM and DDF include (i) HEM adopts multiplicative efficiency measures, instead of the additive measures used in DDF, and (ii) HEM is a nonlinear (fractional) optimization problem.
We can calculate the projection point for each DMU according to the efficiency score obtained from either (3) or (4). For example, (X q ,Y q +β ∗ g y,B q −β ∗ g B) is the projection point of DMU q under DDF, and (X q ,γ ∗ Y q ,B q /γ ∗) is the projection point of DMU q under HEM, where β ∗ and γ ∗ are the optimal solutions to the corresponding efficiency models. Clearly, the projection point is at the boundary of the production set, and different models or parameter may result in different projection points. As noted, the projection point is the linear combination of different observed DMUs. I define the reference set for an evaluated DMU as the collection of DMUs that forms the projection point. The λ’s associated with these active DMUs are positive in the optimal solution (Cooper et al. 2007). Thus this also means that an efficient DMU is its own reference set and projection point.
This section details the environmental efficiency measurement. I will elaborate on how DDF and HEM fail to achieve the following three common purposes of efficiency measurement: Non-monotonicity in undesirable outputs, misclassification of efficiency status, and strongly dominated projection targets.
3.1 Efficiency classifications
To put the three problems of DDF and HEM in context, I develop a classification system for DMUs, in which DMUs are screened by its output-efficiency status (according to Definition 1) and, for inefficient DMUS, whether their reference sets include inefficient points. Following the classification scheme introduced in Charnes et al. (1991), I divide DMUs into four disjoint sets: E, \(\widetilde{E}\), NE and \(\widetilde{NE}\), which respectively represent “Output efficient DMUs,” “Output inefficient DMUs on the production frontier,” and “inefficient DMUs whose reference set contains only DMUs in E,” and “inefficient DMUs whose reference set contains DMUS in \(\widetilde{E}\).” Note that if λ j >0 in the optimal solution to (3) or (4), DMU j will be in the reference set of the evaluated DMU. More specifically,
Definition 2
(i) The set E consists of DMUs that belong to the boundary set of f w (X) and are output efficient. (ii) The set \(\widetilde{E}\) consists of DMUs that belong to the boundary set of f w (X) and are NOT output efficient. (iii) The set NE consists of DMUs in the relative interior of f w (X) whose reference sets contain only DMUs in E. (iv) The set \(\widetilde{NE}\) consists of DMUs in the relative interior of f w (X) whose reference sets contain at least one DMU in \(\widetilde{E}\).
Observe that a DMU must belong to one and only one of the four efficiency classifications; that is, \(|E\cup\widetilde{E}\cup\widetilde {NE}\cup NE|=n\). When \(\widetilde{E}\) is nonempty, we have the misclassification of efficiency status problem; when \(\widetilde{NE}\) is nonempty, we then have the strongly dominated projection targets problem.
The classification that an output-inefficient DMU falls into may depend on whether DDF or HEM is used (and the directional vector when DDF is used), as was shown in the earlier numerical example. However, as a DMU∈E must be the extreme point of the polyhedra corresponding to both f w and f f (Charnes et al. 1985). Theorem 1 follows directly from Definition 2:
Theorem 1
A DMU is in E under f f if and only if this DMU is in E under f w .
In other words, Theorem 1 means that the set of DMUs in E are the same for DDF and HEM. In addition, the non-emptiness of \(\widetilde{NE}\) also implies the non-emptiness of \(\widetilde{E}\), but the converse is not necessarily true.
4 Problem illustrations & analysis
This section analyzes the aforementioned three limitations associated with the DDF and HEM models. Next I will provide an example to illustrate how the two problematic classifications \(\widetilde{E}\) and \(\widetilde{NE}\) can be non-empty under the weak disposability assumption.
4.1 Illustrative example
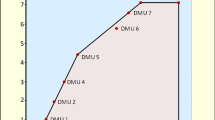
The example is shown in Table 1. The example consists of five observations (firms A to E) with one input, one desirable, and one undesirable output. I assume that all five firms use the same amount of inputs for the ease graphical presentation. Figure 1 illustrates the output set f w for this sample based on the production model (2). The output set f w (X) is represented by the region ‘0ABCDF0’. When WDA is not imposed, the output set expands and becomes the area under the line segment ‘0AB’ and the horizontal line extended from B to its right. More specifically, for the desirable output y, which is freely disposable, the area below the line segments ‘0AB’ are considered feasible (c.f. the inequality constraint for y in (2)). Observe that the frontier under the WDA (i.e., the boundary of f w ) may include points dominated in both y and b, which correspond to the problem of misclassification of efficiency status. For example, firms C and D produce a lower amount of y but more b than firm B. However, firms C and D are in the boundary set of f w (X). Firm E may be projected to the dominated portion of the boundary set (i.e., the line segment between B or C, or between C and D) with certain choices of directional vectors. This potential problem for firm E is called the problem of strongly dominated projection targets.
I use the DDF and HEM models to calculate the efficiency scores based on data in Table 1. As the DDF solutions may depend on the directional vector chosen, I compute the efficiency scores under different directional vectors (g Y,g B)=(cos(ϑ),sin(ϑ)) for ϑ=0 to π/2, such that (g Y,g B) is non-negative. The results are shown in Fig. 2(a). The figure shows that firms C and D will appear efficient under certain directional vectors (zero scores) while appear inefficient under other vectors (positive scores). For example, in Fig. 2(a) firm C is DDF inefficient when ϑ is set to a value higher than the threshold ∼26.6∘; i.e., the angle that the directional vector would pass the \(\overline{BC}\) segment in Fig. 1. Similarly, firm D’s DDF efficiency score drops from around 2.0 to zero once ϑ is larger than ∼56.3∘. Firm E’s DDF efficiency scores fluctuate as ϑ’s value increases from 0 to 26.6∘, then to 63.4∘ and finally to 90∘. Moreover, the DDF scores of all three firms are a non-monotonic and non-smooth function of the directional vector. For the HEM model, Fig. 2(b) shows that firms B and C both appear efficient, although apparently firm C is dominated by firm B (see Table 1).

Output set f w under the weak disposability assumption

DDF efficiency scores of firms C, D, and E in the numerical example
Let us first focus on the non-monotonicity problem:
Theorem 2
Suppose B j and g B are strictly positive for j=1,…,n, then DDF((X q ,Y q ,B q )|g Y,g B) and H((X q ,Y q ,B q )) are non-monotonic in undesirable outputs.
Proof
Please see Appendix A. □
The absence of the monotonicity property has a profound implication on the validity of the DDF and HEM models under WDA: ceteris paribus, an increase in a firm’s undesirable outputs may improve the firm’s efficiency score. Similarly, a reduction in a firm’s undesirable outputs may damage the firm’s efficiency score. In the next Sect. 1 will look into the conditions under which the non-monotonicity and the other two problems mentioned above will occur.
4.2 Diagnosis and analytical results
As noted, the three problems are closely tied to the efficiency classifications developed earlier in this paper. Table 2 shows the correspondences between the classification sets (if they are non-empty) and the three problems. Although the last two problems are related to \(\widetilde{NE}\), these problems are also indirectly related to \(\widetilde{E}\) since the existence of \(\widetilde {NE}\) implies that of \(\widetilde{E}\).
Thus, for a particular set of observations, from Table 2, \(\widetilde{E}\) and/or \(\widetilde{NE}\) is empty if and only if a DMU is associated with any of the three problems. Next I introduce a simple procedure for checking whether \(\widetilde{E}\) and/or \(\widetilde{NE}\) is empty. In this procedure, we solve DDF and HEM under weak and free disposability separately, and then compare the efficiency scores. Theorem 3 describes the properties of this procedure.
Theorem 3
Define DDF as in (3). Then
(i) DDF((X q ,Y q ,B q )|g Y,g B)=0 and DDF f ((X q ,Y q ,B q )|g Y,g B)>0 implies that DMU q belongs to \(\widetilde{E}\).
(ii) If DDF((X q ,Y q ,B q )|g Y,g B)>0 but is not equal to DDF f ((X q ,Y q ,B q )|g Y,g B), then DMU q belongs to \(\widetilde{NE}\).
Proof
Please see Appendix A. □
The idea behind this procedure is that the boundary sets of f w (X) intersects with that of f f (X) only at the output-efficient facet. With minor modification Theorem 3 can be applied to the HEM model, as well, in which case we change the ‘0’ in the theorem to ‘1’ and the lower bound of H((X q ,Y q ,B q )).
Since the directional vector in DDF is a user-specified parameter, one might ask: “Can we find a directional vector(s) for DDF such that the efficiency classifications \(\widetilde{E}\) and \(\widetilde{NE}\) can become empty?” In other words, can we find a directional vector that projects all inefficient DMUs to the output-efficient facet? The next theorem shows that such a directional vector may not always exist, and whether such vectors exist or not may depend on the dispersion of input and output variables. This also means that DDF may be bound to errors for certain data structure (later I will show that when the same condition applies to HEM). Also note that the fact that \(\widetilde {NE}\) is not empty implies that \(\widetilde{E}\) is not empty.
Theorem 4
For a production sets defined as in (2), there does not always exist a (g Y,g B)≧0 such that \(\widetilde{NE}\) is empty and DDF((X j ,Y j ,B j )|(g Y,g B))>0 for all j∉E.
The numerical example shown in Table 3 provides intuition for the problem and can serve as a proof by contradiction for Theorem 4. Figure 3 displays the 8 observations (firm A to firm H) with two undesirable outputs (b 1 and b 2) and one desirable output (y). Without loss of generality, I assume that the input of all firms are equal. The efficient facet in this example is shaded. Firms, such as C, E, and F, are in the interior of f w () and therefore they are inefficient. Firms, such as A, B, D, G, and H, are the extreme points f w () and are on the boundary of the output set. Observe that firms A and H, while being dominated in outputs, are still located on the boundary of f w (). Now our question is then to find a directional vector that can project both firms A and H to the efficient facet and hence \(\widetilde{E}\) becomes empty. Based on (2) and (3), we can formulate the set of permissible directional vectors for firm A as the set

Graphical illustration of the numerical Example 2
Here \((g^{B}_{b1},g^{B}_{b2},g^{Y}_{y})\) is the directional vector to be determined, and \(\lambda_{B}^{A}\), for example, represents the intensity of firm B in forming the efficient facet for firm A. Similarly, we can formulate the set of directional vectors for firm H as
where δ is a positive number used for scaling the directional vector \((g^{B}_{b1},g^{B}_{b2},g^{Y}_{y})\).
Now our question is reduced to one of checking whether Ω A ∩Ω H is empty; i.e., whether these two systems of constraints combined are feasible. If Ω A ∩Ω H is empty, there does not exist a directional vector such that firms A and H can be projected onto the efficient facet. First let us look at Ω A . By the last two constraints of Ω A , it must hold that s b1≤5 and s b2≥6 for any s y ≥0. Hence s b2>s b1. For Ω H , we can similarly show that s b2<s b1. Therefore Ω A ∩Ω H is empty, which also means that for any nonnegative directional vectors, at least one of firms A or H will obtain a zero DDF score.
Let us now look back into the DDF formulation for more insights and intuitions. Suppose the directional vector is not given, we may express the constraints of DDF as (for DMU ‘0’) as \(g^{Y}_{r}\le\sum_{j\in E} \lambda_{j} y_{jr} - y_{0r},\;r=1,\ldots,s\), \(g^{B}_{k}= \sum_{j\in E} \lambda_{j} b_{jk} - b_{0k},\;k=1,\ldots,p\), and ∑ j∈E λ j x ji ≤x 0r , i=1,…,m. In the reference set is limited to output-efficient DMUs only, so the projection point (if exists) will be output efficient. Given that X 0 is not too high compared to those of the DMUS in E, then if one of the undesirable output of DMU 0 (say u) is relatively high, u will drive up the value of \(g^{B}_{u}\) (compared with other \(g^{B}_{k}\)’s) to maintain feasibility, since high values of λ’s may violate the input constraints. Now suppose there exists another DMU whose undesirable output v (v≠u) also assumes high value, this DMU would impose a similar requirement on the relative magnitude between \(g^{B}_{v}\) and all the other \(g^{B}_{k}\)’s. Putting these conditions together will then result in infeasibility in the search of a common directional vector that projects both DMUs onto the output-efficient facet. Note that in certain industrial sectors it is not uncommon that the majority of the pollution is produced by a small proportion of producers. For example, Freudenburg (2005) finds evidence of the disproportion of emissions at the macro and industrial level. Using the toxic release inventory data in the United States, he finds that around 80 % of the toxic release is usually produced by only 20 % of the firms in an economy or sector.
Theorem 5 shows that the HEM model also has the misclassification problem.
Theorem 5
The non-emptiness of \(\widetilde{E}\) under DDF for all non-negative directional vectors implies the non-emptiness \(\widetilde{E}\) under HEM.
Proof
Please see Appendix A. □
Theorem 5 and the above discussion indicate that DMUs producing more undesirable outputs can appear environmentally efficient than other DMUs in DDF under akk directional vectors. In summary, the above analysis confirms that DDF and HEM are subject to the three efficiency measuring problems, especially when extremely output-inefficient observations are present. As noted earlier, the projection targets must be strongly efficient if an (weighted) additive model is used (Charnes et al. 1985). Weighted additive models are a general class of models that include many variants (Charnes et al. 1985; Seiford and Zhu 2005). Next I will compare DDF and HEM with a weighted additive model, which is adapted from the range-adjusted model (Cooper et al. 1999) and is called Median Adjusted Measure (MAM), by means of empirical data from major U.S. manufacturing firms. Please refer to Appendix B for detail about the MAM model. I conclude this section by the following theorem (the proof can be found in Charnes et al. 1985):
Theorem 6
For all weighted additive model is used, all DMUs either belong to E or \(\widetilde{E}\); or equivalently NE and \(\widetilde{NE}\) are empty sets.
5 Measuring the supply chain carbon-efficiency of major U.S. manufacturing firms
As environmental problems such as climate changes and resource scarcity continue to grow, companies are faced with mounting pressure to mitigate their environmental impacts beyond the legal requirement—one of the most noticeable among them is corporate carbon emissions. Foreseeing the development of carbon-control mechanisms such as carbon tax and cap-and-trade systems, more and more managers and investors begin to view excessive carbon emissions as an indication of corporate misgovernance, as well as a major source of risk and uncertainty (Hoffman 2005; Carmona and Hinz 2011). Many leading companies across different industries therefore have attempted to seek ways to improve and measure their carbon-related performance compared with their competitors’.
The sample used in the application consists of 50 publicly traded manufacturing companies with the highest total assets according to 2-digit NAICS codes (31, 32 and 33) in year 2009. Data about total assets, cost of goods sold, and revenue are collected from the Standard & Poor’s COMPUSTAT database; the GHG emission data are compiled by Trucost (http://www.trucost.com). I consider total assets and cost of goods sold as the inputs, annual revenues as the desirable output, and annual direct and supply chain GHG emissions as the two undesirable outputs. Specifically, direct GHG emissions are those generated within the firm, and supply chain GHG emissions are those generated by the firm’s first-tier suppliers. Summary statistics of the input and output variables are provided in Table 4. The financial variables are measure in million U.S. dollars, and the GHG emissions are measured in CO2e tons. The Carbon Dioxide Equivalent (CO2e) is a measurement unit used to aggregate the impact caused by different greenhouse gases. In CO2e, different greenhouse gases are expressed as the amount of carbon dioxides that can cause a similar global warming effect in the atmosphere. For DDF, the sample average revenues and emission values are used as the directional vector. Efficiency scores obtained from the MAM model, as well as DDF and hyperbolic models for the fifty firms can be found in Table 5. In this application I focus on GHG as the environmental output from business operation. Note that these are other indicators that are also critical to environmental sustainability (e.g., water contamination and waste generation). Hence the evaluation results presented in this paper should be interpreted with care. The efficiency classification for each firm under DDF and HEM is also shown in the results. The classifications is determined by calculating a firm’s projection points under DDF and HEM and then running the MAM model to evaluate the efficiency of the projection points.
The results provide several interesting observations. First, some of the firms that appear efficient in the DDF and HEM models are in fact output-dominated (i.e., the misclassification problem). Specifically, there are three instances of \(\widetilde{E}\) for DDF (Qualcomm, Evraz Group, and Alcoa), and two for HEM (Qualcomm and Evraz Group). Take Evraz and Xerox as two contrasting examples. Evraz is efficient in the DDF and HEM models, but has extremely poor performance in the MAM model (46th among the 50 firms). Contrastingly, Xerox are considered inefficient across all three models, but its MAM ranking is much better than Evraz’s. In fact, however, these two firms are close in their total assets and cogs levels, but, while Evraz’s annual sales in 2009 is only 64 % of Xerox’s, its estimated direct emissions are more than 100 times higher than Xerox’s, and its first-tier supply chain GHG emissions are 2.55 times of Xerox’s counterparts. This shows that DDF and HEM may easily provide distorted evaluation results.
We can also see that a high proportion of the firms have been misclassified in HEM and DDF model. Specifically, 23 firms are assigned to either \(\widetilde{E}\) or \(\widetilde{NE}\) in the HEM model (46 % occurrence rate), and 39 in the DDF model (78 % occurrence rate). I apply a Wilcoxon matched-pairs sign-rank test to detect if rankings change significantly across these three models. To test the difference between the MAM score and the HEM score, the null hypothesis is rejected at the 5 % significance level (p=0.0143); I obtain a similar result for the case of MAM vs. DDF at the 1 % significance level (p<1 %). Both the F variance ratio test and the Levene’s test lead to the same conclusion that the scores have significantly unequal variance at the 1 % significance level.
6 Discussion
6.1 The debate over weak-vs.-free disposability
Recall that Shephard’s production set is founded on the following axioms: convexity, minimal extrapolation, free disposability on inputs and desirable outputs, and WDA on undesirable outputs (Banker et al. 1984; Kuosmanen and Podinovski 2009; Färe and Grosskopf 2009). Studies that advocate WDA argue that the environmental technology set should satisfy null-jointness; see Färe and Grosskopf (2004), pp. 76–77. Specifically, the null-jointness property is described as “…if some positive amount of the good output is produced then some bad output must also be produced. (Färe and Grosskopf ( 2004 ), p. 47).” Null-jointness rules out the possibility to produce positive outputs with zero pollution, while this situation is considered feasible in the model without WDA (such as (A.2)). Although this property may be of certain importance for some ideological reasons, its empirical significance is limited. A DMU with nonzero B will never be associated with a projection point with zero undesirable outputs (see (2)), and therefore no DMUs’ efficiency score will rely on points that violate the null-jointness property. If instead a DMU q whose Y q ≧0 but B q =0 is observed, then this DMU can be viewed as a proof that null-jointness is not an adequate assumption for this sample. Several other desirable properties for efficiency measures has been suggested in the production economics literature, including, for example, monotonicity, indication, homogeneity, unit invariance, and continuity; see, e.g., Russell (1985) for a formal discussion. Scheel and Scholtes (2003) proved that the additive model is almost everywhere continuous in the input-output space. Murty et al. (2012) propose a production model that combines technologies with WDA and technologies that treat undesirable outputs as inputs. However, their technical efficiency index belongs to the Farrel-type of radial measure, and therefore the index is not monotonic in undesirable output. In conclusion, although these properties all have their distinct theoretical importance, the monotonicity property is arguably the most fundamental property for the purpose of empirical applications.
6.2 Variable returns-to-scale technology
The models presented in this paper all satisfy the constant returns-to-scale (CRS) assumption. In the standard DEA model, the variable returns-to-scale (VRS) formulation can be easily expressed as the CRS formulation with an additional convexity constraint on the intensity variables λ j ’s (Banker et al. 1984). The VRS formulation under WDA, however, is more complicated. Specifically, the classical VRS formulation under WDA first appeared in Shephard (1970) but the formulation is highly nonlinear. Recently, Kuosmanen (2005) extends Shephard’s original formulation and proposes a linear model that satisfies VRS and WDA. See also Chen (2013) for a comparative discussion. Details about the Kuosmanen’s VRS production model are provided in Appendix C, where we also use the formulation to repeat the carbon-efficiency exercise based on the application data used in Sect. 5.
Comparing the VRS and CRS results shows that the error rates for these the VRS and CRS models are very close (cf. Tables 5 and 6). Under the CRS assumption, the DDF model generates 3 observations in \(\widetilde {E}\) and 36 observations in \(\widetilde{NE}\), while the HEM model generates 2 observations in \(\widetilde{E}\) and 21 observations in \(\widetilde{NE}\) (Table 5). When switching to the VRS assumption, the HEM generates the same number of observations in \(\widetilde{E}\) and \(\widetilde{NE}\) as in the CRS case, while for DDF the number of observations in \(\widetilde{NE}\) decreases to 25 and the number of observations in \(\widetilde{E}\) increases to 4. This shows that, at least for our sample, under the two alternative assumptions on returns-to-scale the error rate largely remains stable for the \(\widetilde{E}\) class. Extending from the above observation, I want to underline that the implication of non-monotonicity is not really limited to non-monotonicity per se, partly because one can only observe non-monotonicity in a dynamic setting, which is not our focus. Rather, in a static setting, the non-monotonicity property means that some inefficient firms may be wrongly identified as efficient in the evaluation result. However, even when only a few (or even just one) DMUs are wrongly identified as efficient, this can generate a profound consequence for the other DMUs. For example, as illustrated in the paper, these dominated DMU(s) will serve as the reference points forming the efficient facet (as if they were efficient), which will be used to benchmark other inefficient DMUs in the sample. Then the efficiency scores of these inefficient DMUs will be distorted in a sense that the scores are computed based on dominated DMUs. As a result, the rankings of efficiency scores will lose its fundamental meaning, even when only very few dominated DMUs are mistakenly deemed efficient due to WDA.
In addition, some firms’ efficiency scores remain stable or unchanged under both CRS and VRS assumptions. These include, for example, Coca-Cola Co., Lockheed Martin Corp., and ABB Ltd, among others. The main reason for this situation to occur is that in the VRS model these companies are projected to a point either on the efficient frontier exhibiting CRS or a point close to it. As a result, the efficiency scores for these companies show very limited variations under different returns-to-scale assumptions.
7 Conclusion
This paper examines critical implementation issues of the two most widely applied environmental efficiency models: non-monotonicity, misclassification of efficiency status, and strongly dominated projection targets. This paper shows that for samples with certain structures (loosely speaking, when the sample contains heavily polluting firms), these three issues are bound to arise. This paper also shows that the classical weak disposability assumption on undesirable outputs can create a portion of the output-dominated frontier, which can be considered the root cause for the three issues. Our findings provide important implications for both empirical and theoretic researchers of environmental efficiency. Our findings suggest that researchers should be cautious when invoking the classical weakly disposability assumption on undesirable outputs, which has been the standard assumption in a large stream of studies. As corporate environmental efficiency is growing in its importance, findings from this study have an important theoretical implication. Further, the application areas of the environmental efficiency model should not be limited by its name. In many other dimensions of corporate operations, we also need to consider both positive and negative consequences of an activity or policy (e.g., debts, labor accidents, and litigations). Promising application areas may include but not limit to banking, transportation, and manufacturing. I encourage researchers to explore more application areas in other emerging contexts.
Notes
These two models together have accumulated over 1300 citations according to Google Scholar and the citations are increasing at an accelerated rate (Access date: 15 July 2013).
To economize on page space, this study will mostly focuses on the constant returns-to-scale (CRS) model, as the CRS model was also adopted in Chung et al. (1997) and Färe et al. (1989). The key analytical insights derived from the CRS model are similarly applicable to the variable returns-to-scale (VRS) model. For a more comprehensive discussion on the VRS model under the weak disposability assumption, readers are referred to Kuosmanen (2005), Kuosmanen and Podinovski (2009), and Chen (2013).
See Murty et al. (2012) for an alternative formulation that combines WDA with a technology set that treats undesirable outputs as inputs.
The regulated market in this context is not limited to the case of a legally regulated market but refers more generally to a market where participants have an intrinsic interest in reacting to firms’ polluting behaviors.
References
Anton, W., Deltas, G., & Khanna, M. (2004). Incentives for environmental self-regulation and implications for environmental performance. Journal of Environmental Economics and Management, 48(1), 632–654.
Banker, R., Charnes, A., & Cooper, W. (1984). Some models for estimating technical and scale inefficiencies in data envelopment analysis. Management Science, 30(9), 1078–1092.
Baucells, M., & Sarin, R. (2003). Group decisions with multiple criteria. Management Science, 49(8), 1105–1118.
Carmona, R., & Hinz, J. (2011). Risk-neutral models for emission allowance prices and option valuation. Management Science, 57(8), 1453–1468.
Charnes, A., Cooper, W., Golany, B., Seiford, L., & Stutz, J. (1985). Foundations of data envelopment analysis for Pareto-Koopmans efficient empirical production functions. Journal of Econometrics, 30(1–2), 91–107.
Charnes, A., Cooper, W., & Thrall, R. (1991). A structure for classifying and characterizing efficiency and inefficiency in data envelopment analysis. Journal of Productivity Analysis, 2(3), 197–237.
Chen, C. M. (2013). A critique of non-parametric efficiency analysis in energy economics studies. Energy Economics, 38, 146–152.
Chen, C. M., & Delmas, M. (2011). Measuring corporate social performance: an efficiency perspective. Production and Operations Management, 20(6), 789–804.
Chen, C. M., & Delmas, M. (2013). Measuring eco-inefficiency: a new frontier approach. Operations Research, 60(5), 1064–1079.
Chung, Y., Färe, R., & Grosskopf, S. (1997). Productivity and undesirable outputs: a directional distance function approach. Journal of Environmental Management, 51(3), 229–240.
Cooper, W., Park, K., & Pastor, J. (1999). RAM: a range adjusted measure of inefficiency for use with additive models, and relations to other models and measures in dea. Journal of Productivity Analysis, 11(1), 5–42.
Cooper, W., Seiford, L., & Tone, K. (2007). Data envelopment analysis: a comprehensive text with models, applications, references and DEA-solver software. New York: Springer.
Cooper, W. W., Pastor, J. T., Borras, F., Aparicio, J., & Pastor, D. (2011). BAM: a bounded adjusted measure of efficiency for use with bounded additive models. Journal of Productivity Analysis, 35(2), 85–94.
Färe, R., & Grosskopf, S. (2004). New directions: efficiency and productivity. New York: Springer.
Färe, R., & Grosskopf, S. (2009). A comment on weak disposability in nonparametric production analysis. American Journal of Agricultural Economics, 91(2), 535–538.
Färe, R., Grosskopf, S., Lovell, C., & Pasurka, C. (1989). Multilateral productivity comparisons when some outputs are undesirable: a nonparametric approach. Review of Economics and Statistics, 71(1), 90–98.
Färe, R., Grosskopf, S., Noh, D., & Weber, W. (2005). Characteristics of a polluting technology: theory and practice. Journal of Econometrics, 126(2), 469–492.
Freudenburg, W. (2005). Privileged access, privileged accounts: toward a socially structured theory of resources and discourses. Social Forces, 84(1), 89–114.
Hoffman, A. (2005). Climate change strategy: the business logic behind voluntary greenhouse gas reductions. California Management Review, 47(3), 21–46.
Kerr, N., & Tindale, R. (2004). Group performance and decision making. Annual Review of Psychology, 55, 623–655.
Korhonen, P., & Luptacik, M. (2004). Eco-efficiency analysis of power plants: an extension of data envelopment analysis. European Journal of Operational Research, 154(2), 437–446.
Kuosmanen, T. (2005). Weak disposability in nonparametric production analysis with undesirable outputs. American Journal of Agricultural Economics, 87(4), 1077–1082.
Kuosmanen, T., & Kazemi Matin, R. (2011). Duality of weakly disposable technology. Omega, 39(5), 504–512.
Kuosmanen, T., & Podinovski, V. (2009). Weak disposability in nonparametric production analysis: reply to Färe and Grosskopf. American Journal of Agricultural Economics, 91(2), 539–545.
Murty, S., Russell, R., & Levkoff, S. (2012). On modeling pollution-generating technologies. Journal of Environmental Economics and Management, 64(1), 117–135.
Reinhard, S., Lovell, K., & Thijssen, G. (2000). Environmental efficiency with multiple environmentally detrimental variables; estimated with SFA and DEA. European Journal of Operational Research, 121(2), 287–303.
Russell, R. (1985). Measures of technical efficiency. Journal of Economic Theory, 35(1), 109–126.
Scheel, H., & Scholtes, S. (2003). Continuity of DEA efficiency measures. Operations Research, 51(1), 149–159.
Seiford, L., & Zhu, J. (2002). Modeling undesirable factors in efficiency evaluation. European Journal of Operational Research, 142(1), 16–20.
Seiford, L., & Zhu, J. (2005). A response to comments on modeling undesirable factors in efficiency evaluation. European Journal of Operational Research, 161(2), 579–581.
Shephard, R. (1970). Theory of cost and production functions. Princeton: Princeton University Press.
Steinmann, L., & Zweifel, P. (2001). The range adjusted measure (RAM) in dea: comment. Journal of Productivity Analysis, 15(2), 139–144.
Zhou, P., Poh, K., & Ang, B. (2007). A non-radial dea approach to measuring environmental performance. European Journal of Operational Research, 178(1), 1–9.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: Proofs of theorems
Proof of Theorem 2
For the proof, it suffices to show that a DMU originally deemed inefficient can become efficient with a sufficient increase in any b k . We first show the proof for the non-monotonicity of the DDF model. Consider \((X_{j},Y_{j},B_{j})\in\Re_{+}^{m+s+p}\) for j=1,…,n. Without loss of generality, we consider DMU n and suppose \(\beta ^{*}_{n}=\mathit{DDF}(X_{n},Y_{n},B_{n}|g^{Y},g^{B})>0\) for a directional vector \((g^{Y},g^{B})\in \Re^{s+p}_{++}\). We will show that DMU n can become efficient in the DDF model after a sufficient increase in one of its undesirable output b np . By construction in optimality it must hold that \(\lambda_{1}^{*} B_{1}+ \lambda_{2}^{*}B_{2}+\cdots+ \lambda_{n}^{*} B_{n}=B_{n}-\beta^{*}_{n}g^{B}\), where \(\lambda_{1}^{*},\lambda_{2}^{*},\ldots,\lambda_{n}^{*},\beta^{*}\) are the optimal solution to (3); namely, \(B_{n}-\beta^{*}_{n}g^{B}\) is in the convex cone generated by vectors B 1 to B n . To formalize the feasible region for (2), define the convex cones generated by the B vector of all except for DMU n’s as C ∖n ={B|λ 1 B 1+⋯+λ n−1 B n−1,λ i ≥0,i=1,…,n−1} and the one including B n as C ∗(B n )={B|λ 1 B 1+⋯+λ n−1 B n−1+λ n B n ,λ i ≥0,i=1,…,n}.
Suppose DMU n now increases its b np to \(b_{np}^{*}\) (so \(b_{np}^{*}\gg b_{np}\)) until the new output vector \(B_{n}^{*}\) satisfies: (i) \(B_{n}^{*}\notin C_{\setminus n}\), and (ii) \((B_{n}^{*}-\epsilon g^{B})\notin C^{*}(B_{n}^{*})\) for all ϵ>0 such that \((B_{n}^{*}-\epsilon g^{B})\geqq 0\). There must exist a \(b_{np}^{*}\) satisfying condition (i) because B j is strictly positive for all j and therefore \(C_{\setminus n}\subset\Re_{++}^{p}\). We next show that there must also exist a \(b_{np}^{*}\) satisfying condition (ii). Suppose \((B_{n}^{*}-\epsilon g^{B})\in C^{*}(B_{n}^{*})\). Then according to Farkas’ Lemma, condition (ii) corresponds to the following condition (iii): there does not exist a vector d∈ℜp such that \(\{d'B_{j}\ge0\ \mathrm{for\ all}\ j\neq n\}\) ∧ \(\{d'B_{n}^{*}\ge0\}\) ∧ \(\{d'(B_{n}^{*}-\epsilon g^{B})<0\}\). However, we can further increase \(b_{np}^{*}\) to \(b_{np}^{**}\) (so \(b_{np}^{**}\gg b_{np}^{*}\gg b_{np}\)) and construct a vector d that is component-wise positive except for the pth component (i.e., d p <0), where \(d_{p}\ge-(\sum_{k=1}^{p-1} b_{jk})/b_{jp}\) for j=1,…,n−1, \(d_{p}\ge-(\sum_{k=1}^{p-1} b_{nk}^{*})/b_{np}\), and \(d_{p}< -(\sum_{k=1}^{p-1}b_{nk}-\epsilon g^{B}_{k})/(b_{np}^{**}-\epsilon g^{B}_{p})\). So we can always find such a d and \(b_{np}^{**}\) that meet condition (iii). Denote \(B_{n}^{**}\) as B n with the pth component replaced by \(b_{np}^{**}\). By Farkas’ Lemma, it then holds that \((B_{n}^{**}-\epsilon g^{b})\notin C^{*}(B^{**}_{n})\) and hence condition (ii) is satisfied.
Given that \(B^{**}_{n}\) satisfies conditions (i) and (ii), the only feasible (and optimal) solution to (3) is \(\mathit{DDF}(X_{n},Y_{n},B_{n}^{**}|g^{Y},g^{B})=\beta^{**}_{n}=0\). So DMU n is considered efficient since \(\beta^{**}_{n}=0\). Thus DDF is non-monotonic in undesirable outputs, given that β ∗>0. The proof for HEM can be analogously constructed by replacing g B with a common radial contraction factor θ for undesirable outputs and therefore its proof is omitted. □
Proof of Theorem 3
Part (i): Denote the optimal solution to DDF′ as β ∗>0 and \(\lambda_{j}^{*}\), j=1,…,n, and optimal slack variables as \((S^{Y},S^{B})=(s_{1}^{y},\ldots,s_{s}^{y},s_{1}^{b},\ldots,s_{p}^{b})\in\Re^{s}_{+}\times\Re ^{p}_{+}\). Then by Definition 1, the optimal solution to DDF′ must satisfy: \(\sum_{j=1}^{n}\lambda_{j}^{*} x_{ji} \le x_{qi}\) for i=1,…,m; \(\sum_{j=1}^{n}\lambda_{j}^{*} y_{jr} = y_{qr}+\beta ^{*}g_{r}^{y}+s_{r}^{y}\) for r=1,…,s; and \(\sum_{j=1}^{n}\lambda_{j}^{*} b_{jk} = b_{qk}-\beta^{*}g_{k}^{b}-s_{k}^{b}\) for k=1,…,p.
Now let \((\tilde{g}^{Y},\tilde{g}^{B})=(\beta^{*}g^{Y}+S^{Y},\beta^{*}g^{B}+S^{B})\) be the new directional vector of DDF. It must hold that \(\mathit{DDF} ((X_{q},Y_{q},B_{q}) |\tilde{g}^{Y},\tilde{g}^{B} )=1\), which is a sufficient condition that DMU q is not output efficient. In addition, the original optimal value DDF((X q ,Y q ,B q )|g Y,g B)=0 implies that DMU q is not in the relative interior of f(X) defined in (2). Hence DMU \(q\in\widetilde{E}\).
Part (ii): DDF((X q ,Y q ,B q )|g Y,g B)>0 indicates that DMU q is in the relative interior of f(X q ). This then excludes the possibility that DMU q∈E or DMU \(q\in\widetilde{E}\). In addition, DDF((X q ,Y q ,B q )|g Y,g B)≠DDF f ((X q ,Y q ,B q )|g Y,g B) suggests that the projection points for DMU q under DDF and DDF f are different. Therefore, from part (i) of the theorem, we can conclude that the projection points of DMU q under DDF include DMUs in \(\widetilde{E}\). Therefore DMU \(q\in\widetilde{NE}\). □
Proof of Theorem 5
The proof is basically constructed by showing that, for an inefficient DMU, we can always find a directional vector that leads to a projection point that dominates that of the HEM. Define \(g:\Re_{++}\rightarrow\Re ^{s+p}_{++}\), where g(γ)=(γY,1/γB) to be a function in the HEM model that projects (B,Y) to the boundary of f w (X) in (2). To begin, we first show that the function g is convex with respect to the componentwise inequality “≽” in \(\Re^{s+p}_{+}\) (i.e., the generalized convexity induced by \(\Re^{s+p}_{+}\)). We proceed by comparing the following two functions for λ∈[0,1] and γ 1,γ 2≥1: \({ \lambda g(\gamma_{1})+(1-\lambda)g(\gamma_{2})}=\lambda(\gamma_{1} Y,\frac {1}{\gamma_{1}} B)+ (1-\lambda) (\gamma_{2} Y,\frac{1}{\gamma_{2}} B)= ((\lambda\gamma_{1} + (1-\lambda)\gamma_{2})Y,(\frac{\lambda}{\gamma_{1}} + \frac{1-\lambda}{\gamma_{2}}) B )\), and \(g(\lambda\gamma_{1}+(1-\lambda )\gamma_{2})= ((\lambda\gamma_{1}+(1-\lambda)\gamma_{2})Y,\frac{1}{\lambda \gamma_{1}+(1-\lambda)\gamma_{2}}B )\).
From the first equation, we obtain \((\frac{\lambda}{\gamma_{1}} + \frac {1-\lambda}{\gamma_{2}})B= \frac{\lambda\gamma_{2}+(1-\lambda)\gamma _{1}}{\gamma_{1}\gamma_{2}} B\). To prove g is convex with respect to “≽”, we thus need to show \({ \frac{\lambda\gamma _{2}+(1-\lambda)\gamma_{1}}{\gamma_{1}\gamma_{2}} \ge\frac{1}{\lambda(\gamma _{1})+(1-\lambda)\gamma_{2}}}\), or equivalently \(\frac{(\lambda\gamma _{2}+(1-\lambda)\gamma_{1})({\lambda(\gamma_{1})+(1-\lambda)\gamma_{2}})}{\gamma _{1}\gamma_{2}} \ge1\). Let \(\zeta=\frac{(\lambda\gamma_{2}+(1-\lambda)\gamma _{1})({\lambda(\gamma_{1})+(1-\lambda)\gamma_{2}})}{\gamma_{1}\gamma_{2}}\). Observe that the two points (λγ 2+(1−λ)γ 1) and (λγ 1+(1−λ)γ 2) are symmetric with respect to \(\frac{1}{2}(\min\{\gamma_{1},\gamma_{2}\}+\max\{\gamma_{1},\gamma_{2}\})\) for all λ in [0,1]. Thus we can express ζ as:
where \(\delta\in[0, \frac{1}{2}(\max\{\gamma_{1},\gamma_{2}\}-\min\{\gamma _{1},\gamma_{2}\})]\) is a scalar contingent on λ; also observe that γ 1 γ 2=max{γ 1,γ 2}min{γ 1,γ 2}. Now if we set δ to its upper bound \(\frac{1}{2}(\max\{\gamma _{1},\gamma_{2}\}-\min\{\gamma_{1},\gamma_{2}\})\), we would obtain ζ=1. Since ζ is strictly decreasing in d, the preceding result implies that ζ≥1 as intended.
We have shown that g is convex because λg(γ 1)+(1−λ)g(γ 2)≽g(λγ 1+(1−λ)γ 2) for λ in [0,1], γ 1≥1, and γ 2≥1. Because g is positive, convex and continuously differentiable for γ≥1, then for (Y q ,B q ), it must hold that g(γ 1)≽(Y q ,B q )+∇g(1)′(γ 1−1), where ∇g(γ) is the tangent vector of g defined as \([\frac{\partial y_{1}}{\partial\gamma },\ldots,\frac{\partial y_{s}}{\partial\gamma},\frac{\partial b_{1}}{\partial \gamma},\ldots,\frac{\partial b_{p}}{\partial\gamma}]\). Setting (g Y,g B)=∇g(1)′(γ 1−1) as the directional vector for (Y q ,B q ), by the strong disposability for Y q and convexity, it hold that \((Y_{q}^{\star},B_{q}^{\star})=(Y_{q},B_{q}) +\theta\nabla g(1)' (\gamma _{1}-1)\in f_{w}(X_{q})\) if \(g(\gamma')=(Y_{q}',B_{q}')\) is feasible, where \(Y_{q}'=Y_{q}^{\star}\). Furthermore, \((Y_{q}',B_{q}')\) is dominated by \((Y_{q}^{\star},B_{q}^{\star})\) in B. Note that \(\widetilde{E}\) and \(\widetilde{NE}\) can be non-empty given (g Y,g B) by Theorem 4. By the above dominance relationship just stated, \(\widetilde{E}\) and \(\widetilde{NE}\) can also be non-empty under g. □
Appendix B: A modified RAM model for environmental efficiency
One important issue for implementing the weighted additive model is that we must specify weights. This is particular a problem as DEA models are known as a weight-free approach and do not require subjective weight assignments. Chen and Delmas (2013) use the DMU’s own outputs to normalize the output improvements and then calculate environmental efficiency as the average normalized score. This approach has a potential limitation in that different DMUs would be based its own production but miss information about distributions of different outputs across the entire sample, which may carry significant practical implications. Some studies assign weights based on the sample statistics, such as the range adjusted measure (RAM) model proposed by Cooper et al. (1999):
where \(R^{+}_{r}\) is the range of the rth desirable output and \(R^{-}_{p}\) is the range of the pth undesirable output. Note that the RAM model can also incorporate slacks variables for inputs. For the purpose of the current paper, we focus on the output-oriented RAM model. For the economic intuition behind the RAM model, see Cooper et al. (1999) for an excellent exposition of the rationale behind the additive efficiency model and its use to measure allocative, technical, and overall inefficiencies.
We propose a model based on the concept from the RAM model, as Cooper et al. (1999) point out that the RAM-type of efficiency models come with a number of desirable properties, including (i) the efficiency score is bounded in [0,1], (ii) the model is unit invariant, (iii) the model is strongly monotonic in slacks, and (iv) the model is translation invariant under the variable returns-to-scale technological assumption (Banker et al. 1984). However, we find using ranges as the normalizing factors problematic, and choose to use other normalizing variables instead of ranges in the original model. For example, it is stated in Cooper et al. (1999) that 0≤Γ≤1, where a zero value indicates efficiency and a value of one indicates full efficiency. As the slacks are usually much lower in magnitude than their corresponding ranges, the efficiency scores obtained from the original RAM model tends to be low in both magnitude and variation (Cooper et al. 1999; Steinmann and Zweifel 2001). Therefore the RAM scores cannot effectively differentiate the performance of different DMUs. Furthermore, if we observe extremely inefficient firms that makes certain \(R^{+}_{r}\) and/or \(R^{-}_{p}\) larger. These extremely inefficient firms may be those that produce lower than minimal observed desirable outputs but higher than maximum observed undesirable outputs at a fixed input level. The efficiency scores of all the other firms may decrease markedly, and most firms would appear more efficient although the efficient frontier remains unaltered. As it is not uncommon to observe “heavy polluters” in applications, using ranges or other dispersion measures of outputs do not seem appropriate. Also note that if a weighted additive model is used, the disposability assumption on undesirable outputs will not have any impact on the resultant efficiency scores (e.g., Theorem 1).
Another problem of using ranges is that ranges cannot reveal the relative magnitude of the output. For example, suppose we obtain for a particular DMU that its slack for an output is 5 and the corresponding range for that output is 50. The managerial implication of this output slack for this DMU may be quite different if the maximum and minimum of the output are respectively 10 and 60 rather than 500 and 550, for example. As the main purpose of the normalizing factors are to obtain unit invariance, we opt for using the median of outputs to replace the range used in the objective function of (A.2), which is more robust than ranges or averages as the basic statistical properties of these measures. We call our efficiency measure based on median the “Median Adjusted Measure” (MAM). The MAM score then has an intuitive interpretation as the average of slacks compared to the sample median of the corresponding output variables. Note that one may designate the normalizing parameters in the original range adjusted model in other ways; see, e.g., Cooper et al. (2011) for a comprehensive discussion.
Appendix C: VRS model under the weak disposability assumption
The following discussion is taken from Kuosmanen (2005) and Kuosmanen and Podinovski (2009); see also Kuosmanen and Kazemi Matin (2011) for a updated summary of the development in the VRS model with WDA. The classical Shephard’s WDA production model under variable returns-to-scale is \(f_{vrs}(X) := \{(Y,B): \sum_{j=1}^{n} \lambda_{j} x_{ji} \le x_{i},\;i=1,\ldots,m;\ \mu\sum_{j=1}^{n} \lambda_{j} y_{jr} \ge y_{r}, \;r=1,\ldots,s;\ \mu\sum_{j=1}^{n} \lambda_{j} b_{jk} = b_{k},\; k=1,\ldots,p;\ \sum_{j=1}^{n} \lambda_{j}=1;\ \lambda_{j} \ge0, \;j=1,\ldots ,n;\;0\le\mu\le1\}\). The constraint that makes λ j ’s sum up to one to express the variable returns-to-scale condition (Banker et al. 1984). The μ variable is meant to reflect that the output space of Ω vrs is the convex combination of the DMU’s output vector proportionally scaled down by the ratio μ. Kuosmanen (2005) generalizes Shephard’s model by allowing each DMU to contribute a different value of μ (i.e., 0≤μ 1≤1,…,0≤μ j ≤1, and thus each DMU can assume a different scale down factor).
The Kuosmanen technology set also rectify the problem that Ω vrs is not convex. Like the Shephard’s model, the Kuosmanen’s VRS model is nonlinear, too. However, Kuosmanen (2005) shows the VRS formulation can be converted into an equivalent linear form: \(f_{vrs}^{TK}(X) := \{(Y,B): \sum_{j=1}^{n} z_{j} x_{ji} \le x_{i},\; i=1,\ldots,m;\ \sum_{j=1}^{n} z_{j} y_{jr} \ge y_{r}, \;r=1,\ldots,s;\ \sum_{j=1}^{n} (z_{j}+\nu_{j}) b_{jk} = b_{k},\;k=1,\ldots,p;\ \sum_{j=1}^{n} (z_{j}+\nu_{j})=1;\ z_{j}, \nu_{j} \ge0, \;j=1,\ldots,n\}\).
Table 6 shows the efficiency scores under the VRS assumption for firms that also appeared in the application presented earlier in this article. As did in that application, we calculate the HAM, DDF, HEM scores for the fifty firms, and the MEM scores of their projection targets using the DDF and HEM models. Finally, the last two columns display the efficiency class of the firms when either DDF or HEM is used for efficiency evaluation.
Rights and permissions
About this article
Cite this article
Chen, CM. Evaluating eco-efficiency with data envelopment analysis: an analytical reexamination. Ann Oper Res 214, 49–71 (2014). https://doi.org/10.1007/s10479-013-1488-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10479-013-1488-z