
Abstract
In biomedical image analysis, the applicability of deep learning methods is directly impacted by the quantity of image data available. This is due to deep learning models requiring large image datasets to provide high-level performance. Generative Adversarial Networks (GANs) have been widely utilized to address data limitations through the generation of synthetic biomedical images. GANs consist of two models. The generator, a model that learns how to produce synthetic images based on the feedback it receives. The discriminator, a model that classifies an image as synthetic or real and provides feedback to the generator. Throughout the training process, a GAN can experience several technical challenges that impede the generation of suitable synthetic imagery. First, the mode collapse problem whereby the generator either produces an identical image or produces a uniform image from distinct input features. Second, the non-convergence problem whereby the gradient descent optimizer fails to reach a Nash equilibrium. Thirdly, the vanishing gradient problem whereby unstable training behavior occurs due to the discriminator achieving optimal classification performance resulting in no meaningful feedback being provided to the generator. These problems result in the production of synthetic imagery that is blurry, unrealistic, and less diverse. To date, there has been no survey article outlining the impact of these technical challenges in the context of the biomedical imagery domain. This work presents a review and taxonomy based on solutions to the training problems of GANs in the biomedical imaging domain. This survey highlights important challenges and outlines future research directions about the training of GANs in the domain of biomedical imagery.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Generative adversarial networks (GANs) refer to the class of generative models that generate synthetic data by learning through probability distributions of real data (Goodfellow et al. 2014). GANs are designed with generator and discriminator models. The generator produces realistic-looking synthetic data while taking random vectors as inputs. The discriminator’s task is to classify real data from generated (synthetic) data. GANs use an objective function as a joint loss function with minimax optimization. The generator aims to produce realistic data and misguides the discriminator to classify it as real. Contrarily, the discriminator aims to classify synthetic data as fake and real data as real. The discriminator backpropagates its gradient feedback to the generator. The generator updates its learning to generate realistic synthetic data based on the discriminator’s gradient feedback. Ideally, the training of the GANs should be continued until it achieves the Nash equilibrium so that the actions of the generator and discriminator models do not affect each other’s performance. At this stage, the generator becomes well-trained so that it uses random vectors to generate synthetic data that closely resemble the real data.
In healthcare technology, GANs have been widely utilized for several tasks such as pattern analysis of biomedical imagery (Bhattacharya et al. 2020; Qin et al. 2020; Shi et al. 2020), electronic health records (Lee et al. 2020), as well as drug discovery (Zhao et al. 2020a). Recently, GANs have also been contributing in the context of Coronavirus disease (COVID-19), i.e., disease detection from chest radiography (Waheed et al. 2020). In the domain of biomedical imagery, the availability of data is an obstacle to the application of deep learning. Deep learning models are composed of deep neural networks, that require large training datasets for better predictive analytics (Bhattacharya et al. 2020). Thus, enhancing the size of biomedical datasets is a challenging problem. Another dilemma in the biomedical imaging domain is class-imbalanced datasets. It refers to the datasets with skewed classes when dealing with multiple disease classes. With class-imbalanced datasets, deep neural networks train better on the classes with a large number of images rather than the class with a limited number of images (Saini and Susan 2020). Data augmentation is one of the potential solutions to address the class imbalance, as well as data limitation problems (Qasim et al. 2020).
The utility of GANs in biomedical image analysis has been extensively investigated to perform image recognition (Mao et al. 2020), image synthesis (Zhou et al. 2020), image reconstruction (Li et al. 2021a), and image segmentation (Liu et al. 2019). GANs have demonstrated a capacity to support deep learning models through the generation of synthetic images and thus enlarging the size of biomedical datasets (Tegang et al. 2020; Han et al. 2019; Pollastri et al. 2020). GANs suffer from training challenges such as mode collapse, non-convergence, and instability problems. With these limitations, GANs can generate unrealistic, blurry, and less diverse images. The mode collapse problem occurs when the generator produces similar output images while taking different input features. In the domain of biomedical imaging, the mode collapse problem of GANs has been addressed by using minibatch discrimination (Xue et al. 2019), skip connections (Segato et al. 2020), VAEGAN (Kwon et al. 2019), varying layers of generator and discriminator (Qin et al. 2020), spectral normalization (Xu et al. 2020), perceptual image hashing (Neff et al. 2017), Gaussian mixture model as generator (Wu et al. 2018b), discriminator with conditional information vector (Modanwal et al. 2021), self-attention mechanism (Saad et al. 2023; Abdelhalim et al. 2021), and adaptive input-image normalization (Saad et al. 2022). The non-convergence problem occurs due to the lack of GAN’s ability to reach Nash equilibrium. This problem has been addressed by using modified training updates of generator and discriminator (Biswas et al. 2019), Whale optimization algorithm (Goel et al. 2021), and two time-scale update rules (Abdelhalim et al. 2021). The instability problem of GANs occurs due to the vanishing gradient problem. The Wasserstein loss (Xue et al. 2019; Segato et al. 2020; Kwon et al. 2019; Deepak and Ameer 2020), residual connections (Wei et al. 2020), multi-scale generator (Wu et al. 2018a), and Relativistic hinge loss (Saad et al. 2023) techniques are identified to address the instability problem in the biomedical imagery.
Several survey articles have identified technical solutions to address the problems of mode collapse, non-convergence, and instability (Wiatrak et al. 2019; Jabbar et al. 2021; Sampath et al. 2021; Saxena and Cao 2021). In the general imaging domain, few survey articles discuss each problem with solutions based on objective functions and modified architectures of GANs while missing the definition, identification, and quantification methodologies. The quantification methods are discussed as evaluation metrics in two survey articles (Pan et al. 2019; Gui et al. 2021) while covering almost all aspects of each problem. The existing literature discussed these training challenges of GANs in general and did not cover the significant solutions to address these challenges in the domain of biomedical imaging. There are only four survey articles (Kazeminia et al. 2020; Singh and Raza 2021; You et al. 2022; AlAmir and AlGhamdi 2022) that only cover these challenges with their definitions and identifications in the biomedical imaging domain. These survey articles outline application-based problems of GANs and have no information about quantification, and solutions to the training challenges of GANs in the biomedical imaging domain. In this survey article, we define each training problem of GANs with their definition, identification, quantification, and existing solutions. A detailed comparison of this work with the existing survey articles is indicated in Table 1.
1.1 Contributions of this paper
The main contributions of this survey article are listed as follows:
-
In this article, we discuss training challenges of GANs like mode collapse, non-convergence, and instability in detail.
-
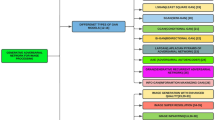
We classify each of these training challenges into four different categories i.e., Definition, Identification, Quantification, and available solutions as shown in Fig. 1.
-
We also review the existing approaches in terms of different biomedical imaging modalities and classify them into applications-based taxonomies for each problem.
-
This survey identifies research gaps and provides future research directions for GANs in the domain of biomedical imagery.

Taxonomy of training challenges in GANs for biomedical image analysis
1.2 Organization of the paper
The rest of the article is organized as follows; Sect. 2 presents the detailed working of GANs including background, basic architecture, and popular variants. Section 3 highlights the applications of GANs in biomedical imagery. Section 4 discusses the benchmark evaluation metrics used for quantifying the training challenges of GANs. Section 5 discusses the mode collapse problem definition, identification, quantification, and existing solutions. Section 6 elaborates on the non-convergence problem in the training of GANs, its identification methods, and how to quantify the problem and its possible existing solutions. Section 7 explains the instability problem in the training of GANs while providing a literature review of existing identification and quantification methods, and possible solutions in biomedical imagery. Section 8 provides a comparative analysis of existing GANs architectures for the biomedical imaging domain. Section 9 discusses the important challenges and future research directions. Finally, Sect. 10 concludes the paper.
2 Generative adversarial networks
GANs are advanced machine learning models that are introduced to generate synthetic images by learning the probability distributions of real images. GANs work as learning agents that try to produce realistic images using probability distributions. To gain an understanding of GANs; the architecture, training, objective function, and GANs variants are elaborated as follows.
2.1 Architecture of GANs
GANs are composed of two models; the generator and the discriminator. The generator’s primary task is to create synthetic data that resembles the real data distribution such as images, sounds, or texts (Wolterink et al. 2021). For image data, it takes random vector z with probability distribution \(p_{z}\) (usually drawn from a normal distribution) as input and generates synthetic image samples G(z) with probability distribution \(p_{g}\). The generator is designed with a series of learnable layers, typically consisting of fully connected (dense) or transposed convolutional (deconvolutional) layers. These layers help the generator to upsample the random noise vector z and generate synthetic images in the desired format. The discriminator consists of learnable layers, such as fully connected or convolutional layers for downsampling the images. The discriminator distinguishes the synthetic image samples from real samples. It aims to output high values (close to 1) for real image data and low values (close to 0) for synthetic image data. Goodfellow et al. (2014) proposed the idea of vanilla GANs (baseline GAN) as shown in Fig. 2. The vanilla GAN’s generator and discriminator models are composed of fully connected layers using multi-layer perceptron (MLP) neural networks.

Architecture of vanilla GANs. The generator G and the discriminator D are trained in an adversarial manner so that G can generate plausible fake samples while D can classify them from real samples. G uses random vector input z for generating fake samples. G loss is described as log\((1-D(G(z)))\) while D loss is log(D(x)). The figure is redesigned from Goodfellow et al. (2014)
2.2 Training of GANs
In GANs, adversarial training is the fundamental training technique that involves training two neural networks, the generator, and the discriminator, in a competitive manner, where they learn from each other through an adversarial process. A GAN’s training initializes with random weights of the generator and the discriminator. The generator takes the random noise vector z as input and produces synthetic images. The synthetically generated images are fed into the discriminator, along with real images from the actual dataset. The discriminator’s task is to distinguish between real and synthetic images and assigns probabilities to each image sample being real or fake. The generator aims to generate images that are realistic enough to misguide the discriminator into classifying it as real. It tries to minimize the discriminator’s ability to differentiate between real and synthetic image samples. The discriminator tries to correctly classify real images as real (assigning high probabilities) and synthetic images as fake (assigning low probabilities) (Wiatrak et al. 2019; Jabbar et al. 2021; Goodfellow 2016).
The training process of GANs continues iteratively, with the generator and discriminator playing a minimax game against each other. The generator aims to generate images that look increasingly realistic, while the discriminator strives to become better at distinguishing real from synthetic images. The training converges to Nash equilibrium when the generator generates images that are indistinguishable from real images, and the discriminator can no longer differentiate between the real and synthetic images. The key idea behind adversarial training in GANs is that the generator gets better at producing realistic images by trying to outsmart the discriminator, and the discriminator becomes more adept at distinguishing real from fake images by learning from the generator’s synthetic image samples. This competition and feedback loop between the generator and discriminator lead to the emergence of a well-trained GAN capable of generating high-quality synthetic images (Salimans et al. 2018; Saxena and Cao 2021; Wang et al. 2021).
2.3 Objective function of GANs
The objective function of a GAN is defined by the distance between the probability distribution of the generated samples (\(p_{g}\)) and the probability distribution of real samples (\(p_{r}\)). The binary cross-entropy loss is used to evaluate the objective function. The binary cross-entropy V(D, G) is a joint loss function of the discriminator and the generator. It minimizes the Jensen–Shannon divergence (JSD) between the distribution of generated data as well as real data distribution. The JSD is defined as Eq. (1) (Goodfellow et al. 2014).
In Eq. (1), KL is defined as the Kullback–Leibler divergence, \({\mathbb {P}}_{r}\) and \({\mathbb {P}}_{g}\) represent the real and generated data distributions. \({\mathbb {P}}_{A}\) denotes the average distribution between real and generated distributions. The objective function becomes minimax V(D, G) of G and D as presented in Eq. (2) reproduced from Gui et al. (2021).
In Eq. (2), minimax is considered as a game in the context of GANs. Generally, the minimax is an optimization problem that aims to optimize the objective function using the given constraints of G loss and D loss. The use of the gradient descent method for an optimization of the objective function is discouraged as it may converge the function to a saddle point. At the saddle point, the objective function gives a minimal value for one model’s weight parameters while the maximal value for the other model’s weight parameters. Hence, the objective function is optimized using the minimax game to find a Nash equilibrium.
2.4 Variant of GANs
In this section, we discuss the most commonly practiced variants of GANs that are proposed with some advancement in architecture and loss functions to the vanilla GAN to address the underlying training challenges.
2.4.1 Deep convolutional GAN (DCGAN)
One of the popular variants of GANs is deep convolutional GAN (DCGAN) (Radford et al. 2015). The DCGAN adopted convolutional neural networks instead of fully connected networks as in vanilla GAN for the generator and the discriminator. Besides, batch normalization is used in most of the layers. The ADAM optimizer (Kingma and Ba 2014) is adopted instead of SGD. DCGAN provides a meaningful solution in terms of a stable architecture as compared to a vanilla GAN. However, DCGAN lacks in generating diverse, realistic, and free of artifacts images which are fundamental challenges that need more advanced solutions.
2.4.2 Conditional GAN (CGAN)
In vanilla GAN, the generator produces synthetic images only based on latent input z which is considered to be limited information for high-performance image synthesis. Authors Mirza and Osindero (2014) proposed an idea of conditional GAN that utilizes additional information y together with the random vector input z as well as input to the discriminator. The y can be a class label or any other conditional information that acts as an additional information feed to the generator as well as the discriminator. The CGAN architecture is presented in Fig. 3. The modified objective function is shown in Eq. (3) that is reproduced from Gui et al. (2021). The idea of CGAN has proven to be advantageous in terms of image synthesis as it can generate realistic and diverse images. CGAN shows a more stable training behavior as compared to vanilla GAN and DCGAN.

Architecture of CGANs. The generator G and the discriminator D are trained in an adversarial manner so that G can generate plausible fake samples while D can classify them from real samples. y is a class label or any additional information conditioned with input samples for G and D. G loss is described as log\((1-D(G(z)))\) while D loss is log(D(x)). The figure is redesigned from Mirza and Osindero (2014)
2.4.3 Wasserstein GAN (WGAN)
To address the instability problem in vanilla GANs caused by the use of Jensen–Shannon divergence, authors in Arjovsky et al. (2017) proposed the idea of measuring the distance between two data distributions instead of minimizing the divergence. So, an Earth-mover (EM) or Wasserstein-1 distance is introduced in the Wasserstein-GAN (WGAN). The Wasserstein-1 distance is described as a metric instead of cross-entropy to measure the loss for optimizing the objective function. The objective function of the WGAN is shown in Eq. (4) that is reproduced from Wang et al. (2021).
In Eq. (4), \(\Pi \left( p_{r}, p_{g}\right) \) denotes all the joint distributions and \(\gamma ({\textbf{x}}, {\textbf{y}})\) based on the marginals of \(p_{r}\) and \(p_{g}\). During the training of GAN, when there is no overlap between \(p_{r}\) and \(p_{g}\), the Jensen–Shannon divergence returns no values. However, the EM distance can reflect the distance measured continuously. Thus, WGAN can propagate meaningful gradient feedback to train the generator and avoid vanishing gradient problems. The main contribution of the WGAN is the use of a discriminator as a regressor instead of a binary classifier.
2.4.4 StyleGAN
StyleGAN is a state-of-the-art GAN variant that was proposed with several key features to generate diversified and high-quality synthetic images (Karras et al. 2019). The architecture of StyleGAN is designed with a style generator, adaptive instance normalization (AdaIN), and a progressive growing training technique as depicted in Fig. 4. Unlike traditional GANs where the generator directly maps noise to images, StyleGAN separates the learned “style” (high-level features) from the learned “structure” (low-level features) of the image using a mapping network f. This separation allows for more control over the generation process and results in more realistic and appealing images. AdaIN is used to combine the learned style and structure information in StyleGAN. It aligns the statistics (mean and variance) of the intermediate feature maps to match the desired style (Wang et al. 2021). The progressive growing training of StyleGAN starts with a low resolution and gradually increases the resolution of generated images during training. This approach helps stabilize the training process and allows the generator to focus on generating coarse details first before adding finer details, resulting in more coherent and realistic images.

Generator architecture of StyleGAN. This figure is redesigned from Karras et al. (2019)
StyleGAN is known for its ability to generate diverse and unique images from the same latent code. By controlling the style and structure separately, it allows for the manipulation of individual aspects of the generated image, such as changing the pose, color, and facial expressions while keeping the underlying structure consistent (Saxena and Cao 2021).
2.4.5 CycleGAN
The variants of GANs, such as vanilla GAN, DCGAN, CGAN, and WGAN, are limited to the generation of a single image domain using latent input z. However, architectures of these GANs variants were designed to synthesize training images to similar domains and synthetic images have the same mapping as real training images.
The idea of generating images of different mappings and different modalities as compared to the real training images is known as image-to-image translation (Zhu et al. 2017). For this purpose, CycleGAN architecture is proposed. The CycleGAN learns a mapping using the generators G: A \(\xrightarrow {}\) B such as image distributions of A from G(A) must be indistinguishable from the image distributions of B using an adversarial loss (Singh and Raza 2021). To this end, two generators and two discriminators with a cycle consistency loss are proposed in CycleGAN architecture as depicted in Fig. 5. In CycleGAN, the generator \(G_{AB}\) and discriminator \(D_{B}\) work for a single pair using an adversarial loss \(L_{\text{GAN}}\left( G_{A B}, D_B\right) \) as defined in Eq. 5. However, the adversarial loss for reverse mapping pair \(G_{BA}\) and \(D_{A}\) is denoted as \(L_{\text{GAN}}\left( G_{B A}, D_A\right) \). So, a cycle-consistency loss is proposed to minimize the reconstruction error from image translation of one domain to another domain. The cycle-consistency loss is defined in Eq. 6. The final loss of the CycleGAN is formulated as Eq. 7.
The CycleGAN is trained using the objective function defined in Eq. 8. The Eqs. 5, 6, 7, and 8 are reported from Singh and Raza (2021).

Architecture of CycleGAN. The generators \(G_{AB}\) and \(G_{BA}\) are trained in an adversarial manner by taking real samples from one domain as input and generating plausible fake image samples for another domain as output. \(x_{a}\) and \(x_{b}\) are two different unaligned image domains. The discriminators \(D_{A}\) and \(D_{B}\) distinguish the generated fake samples from real samples and provide feedback to the generators to update their learning accordingly. This figure is redesigned from Singh and Raza (2021)
2.4.6 DiscoGAN
DiscoGAN is another unsupervised GAN variant used for image-to-image translation tasks, but it focuses on discovering cross-domain relations between two distinct domains (Kim et al. 2017). The main goal of DiscoGAN is to learn the cross-domain relationships between two unpaired datasets, without using any paired data during the training process. DiscoGAN uses reconstruction losses to discover relations among different domains as depicted in Fig. 6. It aims to learn the shared structure between two domains, allowing for translation between the two domains in both directions.

Architecture of DiscoGAN. The generator and discriminator models are designed with reconstruction losses (\(L_{const}\)) to discover the cross-domain relationship between two unpaired, unlabeled datasets (Kim et al. 2017)
2.4.7 U-Net
The U-Net is a popular model that is widely used for image segmentation tasks in the domain of biomedical image analysis (Punn and Agarwal 2022). In GANs, U-Net is integrated into GAN architectures to perform segmentation tasks efficiently for biomedical images (Mubashar et al. 2022).
U-Net is a U-shaped network that combines low-level and high-level information to extract the complex features of segmented regions. The U-Net is proposed by Ronneberger et al. (2015). The architecture of U-Net is depicted in Fig. 7. U-Net is designed with a symmetrical ordering of encoder-decoder blocks to distinguish every pixel by extracting multi-scale feature maps using encoding the input and decoding it to output using the same resolution (Punn and Agarwal 2022). The U-Net is operated to segregate the overlapping regions using background pixels with an individual loss of each pixel. This process is defined through an energy function E as represented in Eq. 9.
In Eq. 9 reported from Punn and Agarwal (2022), softmax is defined as Eq. 10.
In 9 and 10, The \(w_c\) indicates a weight map while \(d_1\) and \(d_2\) denote the distances to the boundary pixels at the first and second nearest positions respectively. \(w_0\) and \(\Omega \) are the constants. The \(a_k(x)\) denotes an activation for channel k with pixel \(x \in \Omega \) and \(\Omega \in {\mathbb {Z}}^2\).

Architecture of U-Net (Ronneberger et al. 2015)
3 Applications of GANs in biomedical image analysis
In the domain of biomedical imaging, GANs have been utilized in several applications such as image synthesis (Kazeminia et al. 2020), image segmentation (Román et al. 2020), image reconstruction (Yedder et al. 2021), image detection (Yi et al. 2019), image denoising (Tian et al. 2020), image super-resolution (Li et al. 2021b), and image registration (Haskins et al. 2020). The performance of these applications is affected by the training challenges of GANs. This section presents a high-level discussion on the impact of training challenges of GANs for the applications such as image synthesis, image segmentation, image reconstruction, image detection, image denoising, image super-resolution, and image registration in biomedical image analysis. How these training challenges affect applications is also discussed. A few state-of-the-art survey articles are identified to get insights into these applications for readers that are shown in Fig. 8.

Applications of GANs in biomedical image analysis
3.1 Image synthesis
GANs are used to generate synthetic images of training images. Conventionally, GANs are introduced as unsupervised models and can be leveraged with unannotated image datasets. Therefore, synthesizing training images using GANs is known as image synthesis. Training challenges of GANs can affect the synthetic images during the image synthesis process. For example, the generation of similar synthetic images for distinct input images, blurry images, and low-quality images indicates the training challenges of GANs. GANs have been used for two types of image synthesis; unconditional image synthesis and conditional image synthesis (Singh and Raza 2021; Kazeminia et al. 2020; Yi et al. 2019). Each type of image synthesis is discussed as follows.
3.1.1 Unconditional image synthesis
In unconditional image synthesis, GANs rely only on random noisy inputs in the latent space without any prior conditions to generate new synthetic image samples. The unconditional image synthesis of biomedical images is affected most by the training challenges of GANs such as mode collapse and training instability. For example, direct generation of magnetic resonance images, computed tomography images, cell images, and dermoscopic images encounter these training challenges. Being an unsupervised framework, this approach has been widely utilized for biomedical image analysis to address data limitation and class imbalance issues. A detailed discussion and technical papers can be found in Kazeminia et al. (2020), Yi et al. (2019).
3.1.2 Conditional image synthesis
In conditional image synthesis, GANs consider some prior conditional information together with z to generate new synthetic images. This type of image synthesis faces training challenges of GANs during the image-to-image translation tasks. When a GAN generates a biomedical image from the same modality input or cross-modality input images, it can miss salient features of input images during the training to translate into new images. Due to instability problems, the quality of synthetic images can be affected during the generation of biomedical images. There are two types of applications in conditional image synthesis. Generation of new images from real images with some prior conditions in the same modalities such as CT to CT, MRI to MRI, and PET to PET. Generation of new images from different modalities like MRI to CT, MRI to PET, etc. The survey article Singh and Raza (2021) discussed these applications in detail and can be studied.
3.2 Image segmentation
GANs provide a significant contribution to the domain of biomedical imagery for image segmentation tasks. It has been utilized for the segmentation of tumors, pathology, and lesions from different body parts like the brain or liver, etc. GANs use segmented masks with input images to generate synthetic images with the segmentation of the target masks. Sometimes, during the training of GANs, the segmented masks are difficult to learn and GANs generate poorly segmented synthetic images or low-quality images. The literature Yi et al. (2019), Nalepa et al. (2019), Román et al. (2020), Iqbal et al. (2022) can be explored for more discussion on biomedical image segmentation.
3.3 Image reconstruction
GANs have been utilized to improve the quality of reconstructed images like estimating full-dose CT images from low-dose CT images with reduced aliasing artifacts. Usually, GANs do not reduce these aliasing artifacts effectively due to the training instability problem. GANs face difficulty in generating plausible images reconstructed from training images due to poor image quality. The mode collapse occurs during the training of GANs while learning the distribution of low-quality images. The reader can be referred to the survey article Yedder et al. (2021) for a detailed insight on biomedical image reconstruction using GANs.
3.4 Image detection
GANs have been used for unsupervised anomaly detection in biomedical imagery. The discriminator model can be used to detect anomalies like lesions or tumors. This contribution helps to work with unannotated data and address the problem of anomaly detection. The survey articles Kazeminia et al. (2020), Yi et al. (2019) are identified for more detail on the underlying GANs application.
3.5 Image denoising
Image denoising techniques are required to remove the noise and recover the original latent information from the noisy images. GANs can be used as an excellent tool to produce sharp, plausible, and noise-free images. A powerful GAN model is required to denoise biomedical images because it is usually incorporated with the training challenges of GANs. These challenges can affect the denoising of biomedical images as GANs are unable to learn low-quality or noisy images effectively and can reflect a poor generation of output images. A more detailed overview of biomedical image denoising techniques with the utility of GANs can be studied in the literature Kazeminia et al. (2020), Tian et al. (2020).
3.6 Image super resolution
GANs can be utilized to produce super-resolution images from low-resolution images. The training instability problem should be addressed completely to achieve better high-resolution biomedical images as the optimality of the GANs is difficult to achieve. The mode collapse and non-convergence problems can also degrade the quality of synthetic images. GANs have performed various super-resolution tasks in biomedical image analysis and the reader can find a detailed review of those tasks in the review paper Li et al. (2021b).
3.7 Image registration
Conventional registration techniques suffer from parameter dependency problems and high optimization loads. GANs have good capabilities of image transformations that can serve as excellent candidates for the extraction of a more optimal registration mapping. GANs have limitations of training challenges as they can miss the location of an object or feature in the biomedical image during the image registration process. Usually, 3D volumes of biomedical images face these challenges as the generator can not learn 3D volumes effectively to generate diverse, un-blurred, and high-quality synthetic images. More details can be found in the survey article of Haskins et al. (2020).
4 Evaluation metrics
Several evaluation metrics have been proposed to assess the technical training challenges of GANs, such as mode collapse, non-convergence, and unstable training. These metrics include Inception Score (IS), Maximum Mean Discrepancy (MMD), Multi-scale Structural Similarity Index Measure (MS-SSIM), Fréchet Inception Distance (FID), Peak signal-to-noise ratio (PSNR), Dice Score (DS), and classification performance metrics (Precision and Recall). Each metric is discussed in detail as follows.
4.1 Inception score (IS)
Inception score is a metric used for the evaluation of GANs (Salimans et al. 2016). It provides an assessment of generated images for high-quality and diverse characteristics. IS utilizes a pre-trained Inception-Net (Szegedy et al. 2016) and measures the KL divergence between class conditional probability distribution \(p(y \mid {\textbf{x}})\) of generated sample and the marginal probability distribution p(y) obtained from a set of generated images.
In Eq. (11) that is reproduced from Borji (2019), \(p(y \mid {\textbf{x}})\) shows the class conditional probability distribution with image x, p(y) is a marginal probability distribution, and H(x) denotes the entropy of variable x (Borji 2019). IS measures the lowest score as 1 while the highest score depends on the number of classes of the dataset. The higher IS score shows that the model can generate high-quality as well as diverse images.
4.2 Maximum mean discrepancy (MMD)
The maximum mean discrepancy is used to measure the dissimilarity between real image distribution \(p_{r}\) and generated image distribution \(p_{g}\) (Gretton et al. 2012). The higher value of MMD indicates that the generator is collapsing and doesn’t generate realistic and diverse images.
Mathematically, it uses Hilbert’s space of functions. In Hilbert space functions, two functions are supposed to be point-wise closed if they are closed in the norm (Segato et al. 2020). So, MMD can be calculated by measuring the squared distance between the embeddings of \(p_{r}\) and \(p_{g}\) as shown in Eq. (12) that is reproduced from Borji (2019).
4.3 Multi-scale structural similarity index measure (MS-SSIM)
MS-SSIM is a metric that is used to assess the diversity of synthetic images in GANs. MS-SSIM is introduced to measure the similarity score using human perception similarity analysis. It computes the similarity between two images with the help of pixels and structures (Odena et al. 2017). MS-SSIM considers luminance (realizing the brightness of a color) and contrast estimations for a metric score. Luminance (l), contrast (c), and structure (s) can be computed using Eq. (13) as reproduced from Borji (2019).
In Eq. (13), x and y are two images. \(\mu _{x}\) and \(\mu _{y}\) represent the mean, whereas \(\sigma _{x}\) and \(\sigma _{y}\) denote the variance (standard deviation) of pixel intensities. The correlation between corresponding pixels is represented by \(\sigma _{xy}\). For the numerical stability of the fractions, constant C is added in all three quantities. The single-scale similarity index is then computed by Eq. (14) [reproduced from Borji (2019)] by considering the fixed distance perspective, as well as sampling density of images (Wang et al. 2004).
The multi-scale SSIM is a variant of the single-scale SSIM metric. It considers all scales of iteratively downsampled images for computing contrast and structural scores. The luminance quantity is measured at the last iteration known as the coarsest scale (M). Conversely, it gives weightage to the contrast and structure at each scale. The MS-SSIM is computed by Eq. (15) as reproduced from Borji (2019).
The range of MS-SSIM scores lies between 0.0 and 1.0. An important point to note is that a higher MS-SSIM score shows lower diversity between images of the same class. This metric is useful for evaluating GANs to compute the diversity between generated images of a single class.
4.4 Fréchet inception distance (FID)
FID is an evaluation metric used to assess the quality of synthetic images. It is proposed by Heusel et al. (2017). FID computes the mean and covariance of synthetic and real images as shown in Eq. (16) that is reproduced from Borji (2019). It visualizes an embedded layer that contains a set of synthetic images in the Inception-Net and uses it as the continuous multivariate Gaussian.
In Eq.(16), r and s shows real and synthetic images while \(\left( \mu _{r}, \Sigma _{r}\right) \) and \(\left( \mu _{s}, \Sigma _{s}\right) \) denote mean and covariances of real and synthetic images. FID score measures the distance between real and synthetic images in GANs. A higher FID score shows a larger distance between synthetic and real data distributions (Borji 2019).
4.5 Peak signal-to-noise ratio (PSNR)
In GANs, PSNR is used to check the quality of synthetic images to the corresponding real images. PSNR is applied to monochrome images. It is measured in decibels (dB). The higher value of PSNR represents a better quality of synthetic images. PSNR is computed as shown in Eq. (17) reproduced from Borji (2019).
By simplifying,
Whereas
The Eqs. (17), (18), and (19) are reported in Borji (2019). I and K represent two monochrome images. In Eq. (18), MAXI denotes the highest possible pixel value of an image such as 255 in the case of 8-bit representation.
4.6 Dice score (DS)
Dice score is a popular metric that is used to evaluate the targeted segmented images as compared to their real ground truth images (Bertels et al. 2019). In GANs, DS is also utilized to assess the quality of synthetic segmented images. DS compares the area of segmented regions of the generated synthetic images and real ground truth images with the total area of both regions (Ghaffari et al. 2019). The formula for DS is calculated using Eq. 20:
In Eq. 20 reported in Ghaffari et al. (2019), \(Y_{pred}\) indicates the ground truth, \(Y_{pred}\) indicates the predicting label and \(\varepsilon \) is a small number used for avoiding division by zero. Perfect segmentation is indicated by the DS of 1.0.
4.7 Classification performance metrics (precision and recall)
In GANs, classification metrics such as recall and precision are also used to evaluate the quality and diversity of synthetic images (Borji 2019). In literature, studies have been proposed to measure the recall and precision to quantify the mode collapse and instability problem (Lucic et al. 2018; Sajjadi et al. 2018). In Lucic et al. (2018), authors argued that these classification metrics can evaluate the quality and diversity of synthetic images. Sajjadi et al. (2018) argued that high precision and low recall scores indicate low quality and diversity of synthetic images while higher quality and diversity of synthetic images are indicated by low precision and high recall scores.
5 The mode collapse problem
5.1 Definition
The basic purpose of the GANs is to produce realistic and a variety of synthetic output images. The synthetic images should be of different styles (modes of distribution) for each random input. In practice, the generator learns to produce synthetic images just to misguide the discriminator for being classified as real. Once the generator finds the best way to fool the discriminator by producing particular plausible images, it focuses on the generation of similar images repetitively. The discriminator gets fooled each time and classifies the synthetic images as real. Eventually, the discriminator gets stuck in this trap and is unable to get out of this trap. Consequently, the generator starts producing a similar style of images. The underlying problem is known as mode collapse (Goodfellow 2016).
5.2 Identification
The mode collapse problem is identified during the training of GANs by looking at the nature of generated images. The mode collapse refers to the generation of less diversified synthetic images where salient features of input (real) images are overlooked by the generator during the training of GANs (Saad et al. 2022). Therefore, GANs with mode collapse generate synthetic images with similar distribution modes repetitively rather than having input images with diverse distribution modes as indicated in Fig. 9. The mode collapse problem can be divided into two categories based on the number of classes within the datasets (Alotaibi 2020). Firstly, when the generator produces a similar style of output images for multi-class input images then it will affect the inter-class diversity, and the problem is known as inter-class mode collapse. Secondly, when the generator produces a similar style of output images for single-class input images then the problem is termed as intra-class mode collapse and affects the intra-class diversity. The mode collapse problem can also be identified using the loss curves of the generator during the training of GANs. Figure 10 illustrates the mode collapse during the training of GANs using a non-converging generator loss (G) for X-ray image synthesis. Consequently, a converging generator loss (G) in Fig. 11 shows the balanced training of GANs indicating no mode collapse for X-ray image synthesis.

Identification of mode collapse in GANs for X-ray image synthesis. The red areas highlighted illustrate the repetition of synthetic X-ray images with a similar distribution of features such as lungs. The chest bones are also suppressed indicating the occurrence of a mode collapse problem in GANs

Identification of the mode collapse problem using the non-converging generator loss of GANs for X-ray image synthesis. The generator loss depicted by label (G) illustrates the non-converging behavior as compared to the discriminator losses (\(D\_real\) and \(D\_fake\))

Identification of the no-mode collapse in GANs for X-ray image synthesis. The generator loss depicted by label (G) illustrates the converging and balanced behavior as compared to the discriminator losses (\(D\_real\) and \(D\_fake\))
5.3 Quantification
The diversity and similarity of generated synthetic images can be computed by several evaluation metrics. The occurrence of mode collapse and diversity of synthetic images is quantified by MS-SSIM (Wang et al. 2003; Odena et al. 2017) using image similarity features while IS (Salimans et al. 2016), MMD (Gretton et al. 2012), and FID (Heusel et al. 2017) using distance measures as discussed in Sect. 4. However, PSNR, SSIM, and classification metrics such as recall and precision are also used to quantify the diversity of synthetic images.
5.4 Solutions to the problem
5.4.1 Regularization
In deep learning models, we aim to find minimum loss that is difficult to achieve when using large weight sizes. This will lead the model to overfit the data and provide poor prediction results. To alleviate this problem, a regularization term is used to reduce the weight size of the network or limit the model capacity (Goodfellow et al. 2016). In GANs, neural networks are used in the generator as well as in the discriminator. So, when the discriminator produces ambiguous gradients as feedback to the generator continuously, the generator learns to generate similar images again and again to fool the discriminator which leads to the mode collapse problem. Here, regularization is used as weight normalization.
5.4.1.1 Weight normalization (WN)
In GANs, weight normalization (WN) uses specialized training algorithms to update the weight matrices regularly while training the GANs. WN does not use additional loss. It backpropagates the gradients by computing them according to the normalized weights during the training of GANs (Lee and Seok 2020). Several normalization techniques such as spectral normalization (Miyato et al. 2018), batch normalization (Radford et al. 2015), and self-normalization (Klambauer et al. 2017) have been proposed to use as a weight normalization in GANs.
Xu et al. (2020) alleviated the mode collapse problem in a GAN using spectral normalization for a super-resolution of low-dose X-ray images. Spectral Normalization is a type of weight normalization that employs the spectral norm of weight matrices as shown in Fig. 12 while training GANs. The spectral norm is equivalent to the L2 norm and corresponds to the largest singular vector. The largest singular vector can be approached to the Lipschitz constant. The spectral normalization is used to normalize the weight matrices in the discriminator of the proposed Spectral Normalization Super Resolution GAN (SNSRGAN) which controls the Lipschitz constant to 1. The authors utilized IS and MS-SSIM scores to evaluate the diversity of super-resolution synthetic images generated by the SNSRGAN. Results demonstrate that SNSRGAN achieved improved scores of IS with 6.56 and MS-SSIM with 0.986 as compared to the baseline SRGAN (Ledig et al. 2017).

Spectral normalization utilizes the largest singular values of \(W_i\) as their spectral norms (\(\sigma \) \(W_i\)) to divide the actual gradient weights of the discriminator. The figure is redesigned from Miyato et al. (2018)
5.4.1.2 Input normalization (IN)
Input normalization refers to the normalization of input image features so that a GAN can better train on those normalized images and alleviate the mode collapse problem for biomedical image synthesis.
A similar idea of input image normalization is proposed by Saad et al. (2022) to the DCGAN for generating diversified chest X-ray images. The authors alleviated the mode collapse in the DCGAN using a preprocessing technique namely an adaptive input-image normalization (AIIN). The AIIN normalizes the input X-ray images using a contrast-based histogram equalization to highlight the diverse features of X-ray images as depicted in Fig. 13. A DCGAN learns X-ray image features more accurately with these normalized images having highlighted features and can generate improved diversified X-ray images. Several experiments with varying batch sizes, window sizes, and contrast thresholds have been conducted. They used MS-SSIM and FID evaluation metrics to evaluate the mode collapse problem in DCGAN and the diversity of synthetic images.

The block diagram of an adaptive input-image normalization. The figure is redesigned from Saad et al. (2022)
The authors demonstrated improved results of AIIN-DCGAN over DCGAN with high diversity scores using the MS-SSIM and FID evaluation metrics. Moreover, synthetic images with the best MS-SSIM and FID scores are used to augment the imbalanced dataset. A baseline CNN classifier is trained on the standard and augmented datasets to compare the classification score including accuracy, recall, specificity, etc. The improved accuracy of 91.50% and specificity of 0.79 are achieved with the augmented dataset having AIIN-DCGAN synthetic images as compared to the alternate datasets.
5.4.2 Modified architecture
In GANs, if a new architecture is defined with an alternative generator or discriminator or both as compared to the vanilla GAN then we describe it as modified architecture.
5.4.2.1 Generator
An alternative generator introduced in the proposed architecture of GAN is described as the modified generator. To avoid the mode collapse problem, a widely adopted approach is to use multiple generators instead of a single as in vanilla GAN which has proved effective to alleviate the problem (Hoang et al. 2018). However, optimizing multiple generators is complicated and costs extensively large computations.
To address this limitation, Wu et al. (2018b) proposed the idea to use multiple distributions instead of using multiple generators to synthesize human cell images. A Gaussian Mixture Model (GMM) based generator is used to cover each data distribution in the latent space as indicated in Fig. 14. It helps the proposed MDGAN to generate diverse image samples using a mixture of data distributions. Moreover, the authors argued that more distributions can aid in generating more diverse synthetic image samples but can lead to huge computational costs. The generated human cell images are then used to augment the dataset for classification tasks. To evaluate generated images, no quantitative analysis is reported in the paper. While authors discussed that the generated synthetic images aid in data augmentation and improve the classification performance of CNN by 4.6% precision value.

The generator architecture of MDGAN. The figure is redesigned from Wu et al. (2018b)
The hierarchy of layers of the generator and discriminator models. To interpret this idea, Qin et al. (2020) proposed an extension to the StyleGAN as skin-lesion StyleGAN (SL-StyleGAN) for synthesizing skin lesion images. In Qin et al. (2020), the authors discussed that changing the number of fully-connected layers in a mapping network of the generator can control the generation of different modes of images. In baseline Style-GAN (Karras et al. 2019), a generator consists of a non-linear mapping network that maps latent input z to an intermediate latent space W using MLP network and then passes the W information to the original generator model. Furthermore, the authors attempted 2, 4, and 6 fully-connected layers and evaluated the generated images with a recall score. They investigated that the generator with 2 fully-connected layers can generate relatively more diverse images than 6 but results in scattered defects like artifacts, etc. The generator model with 4 fully-connected layers can generate relatively good diverse images with no artifacts. The final SL-StyleGAN architecture with a generator of 4 fully-connected layers achieved a 0.263 recall score which is higher than alternate fully-connected layer combinations. The authors concluded that the final synthetic images are not fully diverse as indicated by the lower recall score which needs more work in the future to address this problem.
5.4.2.2 Discriminator
An alternative discriminator introduced in the proposed architecture of GAN is known as the modified discriminator. In GANs, when the generator collapses to a single mode and produces identical image samples then the discriminator backpropagates identical gradients for several generator updates. There is no coordination between the discriminator and its gradients because it deals with each training sample independently. So, no mechanism guides the generator to produce diverse image samples. To address this problem in MR to MR image translation of breast slices, Modanwal et al. (2021) use a small field of view 34 \(\times \) 34 instead of 70 \(\times \) 70 in standard Patch discriminator as depicted in Fig. 15 in the CycleGAN. The small field of view encourages the transformation learned by the generator to maintain the sharp and high-frequency details. This modification of the CycleGAN preserves the structural information of breast and dense tissues during the training of GAN to perform image translation tasks.

Patch discriminator of CycleGAN. The figure is redesigned from Modanwal et al. (2021)
The generated images are evaluated by dice coefficient and compared with the standard CycleGAN. The standard CycleGAN has a mean value of 0.8913 and a standard deviation of 0.0941 for GE to SE translation while the mean value of 0.9089 and a standard deviation of 0.0471 for SE to GE translation. GE Healthcare and Siemens are the two source scanners for image acquisition. Authors have achieved an improved mean value of 0.9801 and a standard deviation of 0.0061 for GE to SE translation while a mean value of 0.9813 and a standard deviation of 0.0049 for SE to GE translation on the test data.
Cervical histopathology images contain fine-grained information that is difficult to learn by GANs and can cause the mode collapse problem. To address the mode collapse in synthesizing cervical histopathology images, authors in Xue et al. (2019) utilize mini-batch discrimination in the discriminator of CGAN to generate realistic diverse samples. The Minibatch discrimination enables the coordination between gradients of discriminator and training samples using mini-batches for training image samples as depicted in Fig. 16. In this way, the generator is penalized if it collapses to a single mode and is regulated to produce diverse images (Salimans et al. 2016). However, synthetic images are not evaluated by any metric to check the diversity or similarity measures with real images. The generated synthetic images are then used to augment the dataset for classification tasks.

The workflow of minibatch discrimination. The figure is redesigned from Salimans et al. (2016)
A similar problem of generating diverse synthetic image samples occurs in CGAN when dealing with distinct CT scans of different body parts for a super-resolution task. To address this problem, a conditional information vector w based modified discriminator is proposed in Kudo et al. (2019). The discriminator is composed of a 3-dimensional fully convolutional neural network as shown in Fig. 17. The conditional vector w contains information about input image data such as leg, head, abdomen, or chest. This information is used by the discriminator to evaluate the generated slices of CT data and encourages the generator to produce diverse image samples. The generated super-resolution images are evaluated through SSIM and PSNR scores. The highest score of SSIM (0.933) and PSNR (35.73) are achieved respectively as compared to the CGAN without conditional vector w. The SSIM score shows a similarity measure and realistic nature of generated images towards ground truth images.

5.4.2.3 Generator-discriminator combined
In this section, we describe the architecture of GANs where the generator and the discriminator are updated or modified. The generation of diversified synthetic 3-dimensional (3D) Magnetic Resonance images is a challenging task. This is due to the complexity of the structure of 3D image data. To address this limitation, authors in Kwon et al. (2019) adopted an \(\alpha \)-GAN with few modifications in the activation functions, batch normalization, and loss function. The \(\alpha \)-GAN is composed of a Variational Auto-encoder (VAE) and a code discriminator network. The VAE is a generative model that explicitly learns the likelihood distributions of training data rather than the other model’s feedback as in GANs to generate synthetic image samples (Kingma and Welling 2014). A GAN combined with VAE can learn the likelihood distributions of images which results in the generation of diversified synthetic images as shown in Fig. 18. In contrast, VAE generates blurry images. \(\alpha \)-GAN utilizes the advantage of VAE in alleviating the mode collapse problem in 3D MR image generation. The authors of Kwon et al. (2019) proposed an Auto-encoding GAN and generated 3D MR images with different latent input z sizes like 100, 1000, and 2048. With a latent vector input of 1000, the proposed Auto-encoding GAN can generate diverse image samples while it fails to escape mode collapse with too small (100) or too large (2048) latent vector input sizes.

The architecture of VAEGAN. The figure is redesigned from Kwon et al. (2019)
To evaluate the diversity of synthetic images, authors Kwon et al. (2019) calculated average MMD \(\times \) \(10^{-4}\) and MS-SSIM scores. The results show that the proposed GAN can perform better with a latent input value of 1000 with an average MMD \(\times \) \(10^{-4}\) score of 0.072 and MS-SSIM of 0.829. The MS-SSIM of real data is 0.846. MS-SSIM score of synthetic 3D MR images shows a good similarity measure with the real data and can be a good candidate for generating diverse images. However, there is a gap in generating more robust and diverse images with smooth and artifact-free images.
To bridge this gap, authors in Segato et al. (2020) extend this work (Kwon et al. 2019) by applying a refiner network based on ResNet blocks (Targ et al. 2016) to generate realistic 3D MR images. The ResNet uses skip connections with deep convolutions as shown in Fig. 19 which controls the skipping of some training layers to smooth the shapes of generated images and make them more realistic. However, this work delivers a low diversity score evident from the MS-SSIM score of 0.9991 between generated images which indicates the lowest diversity of synthetic images as compared to the real images. The proposed deep convolutional refiner GAN (Segato et al. 2020) achieved a good score of MMD as (0.2240 ± 0.0008) \(\times \) \(10^{4}\) as compared to the previous score of MMD as (0.5932 ± 0.0004) \(\times \) \(10^{4}\) which shows the realistic nature of generated images.

The deep convolutional refiner architecture of DCR-AEGAN. The figure is redesigned from Segato et al. (2020)
The mode collapse can occur in a GAN when biomedical images contain complex information of salient features which are difficult to learn and model a relationship between them. A similar type of limitation is addressed for Dermoscopic skin lesion images in a progressive growing GAN (PGGAN) using a self-attention mechanism by authors in Abdelhalim et al. (2021). They discussed that most image synthesis tasks in biomedical imagery utilize PGGAN built with convolutional layers. While in convolutional layers, the convolutional filters are dependent on local neighborhood information to process the convolution operations. It is computationally inefficient for convolutional filters to capture the long-range dependencies in images by relying only on convolutional layers. So, a self-attention mechanism is adapted that enables the discriminator to preserve image features with relevant activations to a particular task. It utilizes feature attention maps that help the generator to produce synthetic images in which coordination should be observed between fine details at every location and fine details in distant portions of the images as shown in Fig. 20. Besides, the discriminator can judge the consistency of highly detailed features in distant portions of the image. In this way, the generator becomes capable of generating diverse image samples using a self-attention mechanism in PGGAN (SPGGAN).

Self-attention mechanism. The figure is redesigned from Zhang et al. (2019)
Different feature level maps are used for evaluating the performance of the self-attention mechanism in image synthesis of resolution 128 \(\times \) 128 pixels. The (N − 1)-to-(N) stage in SPGGAN and PGGAN is monitored which represents the \(2^{N-1}\)-to-\(2^{N}\) level feature maps where \(N = 7\). As a result, SPGGAN performs better with 70.1% as compared to PGGAN with 67.7% for the training set at \(N = 6\). Similarly, SPGGAN performs better with 62.2% as compared to PGGAN with 60.8% for the test set at \(N = 6\). However, the real dataset has feature maps of 78.2%. It shows that the proposed SPGGAN attains better diversity and realistic image synthesis performance than PGGAN yet is distant from real images.
Saad et al. (2023) also utilized a self-attention mechanism in the multi-scale gradient GAN (MSG-GAN) to generate diversified X-ray images. They integrated a self-attention layer into each layer of the generator and discriminator models. The self-attention utilizes attention feature maps to help the MSG-GAN to learn and focus on the diverse features of X-ray images as shown in Fig. 20. The authors demonstrated an improvement in the diversity of generated synthetic images using an improved FID score of 139.6.
5.4.3 Adversarial training
This section discusses the alterations made during the training of GANs such as making buffer storage (Lau et al. 2018) or using perceptual image hash (Neff et al. 2017) to identify and address the mode collapse problem.
5.4.3.1 Buffer storage scheme
Generation or simulation of diverse scar tissues in the myocardium of the left ventricle from a segmented healthy Late-gadolinium enhancement (LGE) imaging scan using GANs is always a challenging task. Scar tissue is a fibrosis tissue that appears when healthy tissue gets destroyed by some disease. Lau et al. (2018) proposed a variant of GAN namely ScarGAN that is composed of a convolutional U-Net-based architecture (Ronneberger et al. 2015) both in the generator as well as in the discriminator. In ScarGAN, an experience replay buffer scheme (Shrivastava et al. 2017) is used to prevent the generator from producing similar shapes of scar tissue. In this scheme, half of the generated masks are stored in a buffer for an experience replay. From this buffer, the discriminator uses half of the training batches randomly to check previously generated scar tissue samples and prevent the generator from producing similar shapes of scar tissue.
The generated images from ScarGAN (Lau et al. 2018) are evaluated by experienced physicians. These physicians are provided with 15 generated and 15 real images in a mixed dataset. They classify them with an accuracy of 53% which reflects a good score for the realism of generated images. However, the authors concluded that ScarGAN still generates less diverse shapes of scar tissues i.e. similar shapes that require to be researched in the future.
5.4.3.2 Perceptual image hashing
Generating new segmentation masks and ground-truth images separately from GANs is a time-consuming task. To generate new chest X-ray images and segmentation masks, Neff et al. (2017) proposed a variant of DCGAN that forces the generator to produce a segmentation mask together with ground truth images. During the adversarial training, the generator starts producing identical image-segmentation pairs with few artifacts that lead to a mode collapse problem. To address this problem, the authors use the perceptual image hash function to remove the identical generated image-segmentation pair. Perceptual image hash functions calculate hash values of real and generated images based on specific image features as shown in Fig. 21. These hash values are compared further to evaluate the difference between generated and real images.

A flow methodology of image hash generation. The figure is redesigned from Du et al. (2020)
The generated image-segmentation pair is evaluated in data augmentation for the segmentation task. The U-Net is trained on 30 real and 120 generated images. The lowest Hausdorff distance of 7.2885 has been observed as compared to the results when U-Net trained on only real images or only generated images. However, the authors concluded that a mild form of mode collapse occurred which resulted in less diverse images.
5.4.4 Summary
In this section, technical papers are reviewed to address the mode collapse problem in the biomedical imagery domain. The mode collapse problem can be alleviated by using different methods such as regularization, modified architectures, and adversarial training. These methods are reviewed as solutions to the underlying problem in the domain of biomedical imagery. A taxonomy is created based on these solutions as shown in Fig. 22. In Fig. 22, each sub-category is further divided into different methods like regularization has weight normalization, modified architectures are divided into the generator, discriminator, and generator-discriminator combined. Similarly, adversarial training is further divided into possible solutions like buffer schemes and perceptual image hash. The application-based taxonomy is also created as shown in Fig. 23. This taxonomy 23 helps to analyze the effect of mode collapse for the specific type of biomedical images.

Taxonomy of different proposed solutions for addressing the mode collapse problem of GANs in biomedical imagery analysis

An application-based taxonomy of different approaches for addressing the mode collapse problem of GANs in biomedical imagery analysis
From the technical literature, it is reviewed that all of the papers have utilized technical approaches that partially alleviate the problem of mode collapse in biomedical imagery. The Auto-encoding GAN (Kwon et al. 2019) provides relatively more diverse synthetic images while addressing the problem in biomedical imagery. Table 2 provides a comparative analysis of contributing papers to address the underlying training challenges in GANs for biomedical imagery.
Moreover, a detailed overview of each solution is also listed in Table 3 where each solution is based on three categories such as preprocessing, modified GAN architectures, and loss functions. Table 3 summarises how each solution addressed the mode collapse problem in GANs for the biomedical imagery domain.
6 The non-convergence problem
6.1 Definition
In GANs, it is important that the training of the generator and the discriminator should converge at a global point (Nash equilibrium). The training of GANs is performed as a minimax game to reach this Nash equilibrium. The discriminator and the generator should be trained with the best training strategies to achieve better training. As the generator’s performance improves, it becomes increasingly difficult for the discriminator to distinguish synthetic images from real images. When the generator is producing the best plausible (realistic-looking) images, the discriminator will have a classification accuracy of 50%. Consequently, the discriminator has no meaningful feedback to update the weights of the generator. This will affect the synthetic images produced by the generator. As a result, the training of GANs leads to a non-convergence problem (Arjovsky and Bottou 2017).
6.2 Identification
The non-convergence problem has a direct effect on the generation of synthetic images. The underlying problem is identified by analyzing the nature of synthetic images. The non-convergence problem leads the generator to produce plane color images such as black or white in the case of gray-scale images as indicated in Fig. 24.

Identification of the non-convergence problem in GANs for X-ray image synthesis. The plane black color synthetic images with no information show the imbalanced training of the GANs for X-ray image synthesis. It shows a failure of the generator and discriminator models during the training of GANs for generating X-ray images
6.3 Quantification
To evaluate the problem of non-convergence in GANs, evaluation metrics are proposed to judge the quality of generated images. So, several evaluation metrics are proposed such as peak signal-to-noise ratio (PSNR) (Borji 2019) and FID (Heusel et al. 2017) to quantify the quality of generated images as discussed in Sect. 4.
6.4 Solutions to the problem
6.4.1 Nash equilibrium
This section discusses the possible solutions in terms of using optimization algorithms and controlling the training iteration (k) to find a Nash equilibrium.
In vanilla GAN (Goodfellow et al. 2014), Goodfellow demonstrated that an equilibrium can be achieved with an optimal discriminator during the training of GAN. However, this is an ideal case, and in practice, GAN does not meet the condition. So, the author Goodfellow et al. (2014) proposed an algorithm to update the discriminator multiple times (k) per generator’s training update to get the discriminator close to an ideal. In vanilla GAN, the discriminator is updated only once \((k = 1)\) per generator’s training update which was suitable for that specific experiment. Similarly, WGAN (Arjovsky et al. 2017) uses \((k = 5)\) for discriminator updates per generator’s training update for attaining an equilibrium state.
6.4.1.1 Updating algorithm
It is a very critical and sensitive approach to control the training updates of the generator and discriminator models to reach a balanced state of training. Biswas et al. (2019) proposed a uGAN with separate parameters (k) for the discriminator and (r) for the generator to control the updates of the training iteration of both of these models. The authors investigated that the similar number of updates for both models yields balanced training and the generation of high-quality retinal synthetic images. It is also analyzed that k with large values can generate high-quality realistic images by keeping \(r = 1\). In contrast, noisy images are generated using larger values of r with \(k = 1\).
The synthetic images are evaluated with an SSIM metric. The mean, maximum, and mean-maximum values of SSIM are measured between synthetic and real images to check the quality and similarity between images. A higher score of SSIM shows higher similarity and high-quality measures. The mean SSIM score of 0.61, maximum SSIM score of 0.73, and mean-maximum SSIM score of 0.81 are achieved.
6.4.1.2 Learning rate
The idea of using learning rates to stabilize and balance the training of GANs is proposed by Heusel et al. (2017). The authors introduced a novel algorithm namely the Two Time-scale Update Rule (TTUR) to achieve a local Nash equilibrium using distinct learning rates of the discriminator and the generator instead of using multiple update algorithms. TTUR uses stochastic gradient learning \({\varvec{g}}(\varvec{\theta }, {\varvec{w}})\) of the discriminator’s loss and \({\varvec{h}}(\varvec{\theta }, {\varvec{w}})\) of the generator’s loss. It defines the true gradients of \({\varvec{g}}(\varvec{\theta }, {\varvec{w}})=\nabla _w {\mathcal {L}}_D\) and \({\varvec{h}}(\varvec{\theta }, {\varvec{w}})=\nabla _\theta {\mathcal {L}}_G\) with random variables \({\varvec{M}}^{(w)}\) and \({\varvec{M}}^{(\theta )}\) as shown in Eq. 21 reported from Heusel et al. (2017). So, it uses stochastic learning b(n) and a(n) for updating the discriminator and generator steps respectively as defined in Eq. 22 reported from Heusel et al. (2017). However, the choice of appropriate learning rates depends on the GAN architecture, type of experiments, and nature of the datasets.
Abdelhalim et al. (2021) investigated the use of both TTUR (Heusel et al. 2017) and discriminator updates in SPGGAN for skin lesion image synthesis. The authors updated the discriminator five times for every single update of the generator’s training. The update algorithm slows down the training process while TTUR tries to balance it to generate noise-free images.
SPGGAN-TTUR (Abdelhalim et al. 2021) shows visually appealing results of generated images as compared to SPGGAN. The results are evaluated through a paired t-test with \(95\%\) confidence (p-value < 0.05). Paired t-test gives the mean difference between two sample observations. The p-value of the t-test (PVT) is calculated to check the performance of SPGGAN-TTUR for generating synthetic train and test sets images. The PVT of \(68.1 \pm 0.8\%\) for the training set while \(60.8 \pm 1.5\) for test sets are achieved which outperformed the SPGGAN. However, SPGGAN-TTUR (Abdelhalim et al. 2021) suffers from artifacts in the generated image that need to be researched.
6.4.1.3 Hyperparameter optimization
In GANs, the choice of appropriate hyperparameters to control the discriminator and the generator is a challenging task. To address this problem, optimization techniques can be used to obtain adaptive losses for updating the weights of the generator.
Goel et al. (2021) proposed an optimized GAN to generate synthetic chest CT images of COVID-19 disease. The optimized GAN utilizes a CGAN with Whale Optimization Algorithm (WOA) (Mirjalili and Lewis 2016) to optimize its hyperparameters. A flow of the Whale optimization algorithm is shown in Fig. 25. In this algorithm, the hunting trick of humpback whales is adapted to optimize the prey’s location. This hunting trick determines the generator’s best search agents with the given discriminator. To update the position of search agents, the optimization of hyperparameters follows three rules; first, the leader whale finds the prey’s position and encircles it. Similarly, the generator’s search agents calculate the fitness function at each iteration to achieve the best position and then update their positions. Second, the distance between the prey and the location of the generator’s search agents is measured and then the generator’s search agents update their position based on these measures. Third, it is the same as the first rule but it updates the position of search agents based on the random search instead of the best search as in the first rule. The Optimized GAN (Goel et al. 2021) improves the performance of the discriminator and can generate adaptive losses to update weights of the generator to produce good quality diverse images.

The flow diagram of the Whale optimization algorithm. The figure is redesigned from Goel et al. (2021)
The performance of optimized GAN (Goel et al. 2021) is compared with the baseline CGAN. The generated images are used with training images for classification tasks. So, the F1-score and accuracy of 98.79% and 98.78% respectively are achieved with Optimized GAN while 91.60% accuracy and 90.99% F1-score are achieved with the baseline CGAN. It shows that Optimized GAN can perform better with accuracy and F1-score measures, as well as in optimizing hyperparameters for a balanced GAN.
6.4.2 Summary
In this section, technical papers of GANs are reviewed to address the non-convergence problem in the domain of biomedical imagery. Achieving a Nash equilibrium during the training of GANs is a remedy to this non-convergence problem (Goodfellow 2016). Training GANs at an equilibrium state is not an easy task. By keeping this concept in mind, the reviewed papers are classified into three different categories as shown in Fig. 26. First, updating algorithms (Biswas et al. 2019), second, learning rate (Abdelhalim et al. 2021), and third hyperparameter optimization (Goel et al. 2021). Another taxonomy is also proposed for application-based biomedical imagery as shown in Fig. 27. This is further classified into image modality types such as dermoscopic (Abdelhalim et al. 2021), CT (Goel et al. 2021), and retinal images (Biswas et al. 2019).

Taxonomy of different proposed solutions for addressing the non-convergence problem of GANs in biomedical imagery analysis

An application-based taxonomy of different approaches for addressing the non-convergence problem of GANs in biomedical imagery analysis
The updating algorithm is reviewed for vanilla GAN (Goodfellow et al. 2014), WGAN (Arjovsky et al. 2017), and then state-of-the-art uGAN (Biswas et al. 2019). The updating algorithms in vanilla GAN (Goodfellow et al. 2014) and WGAN (Arjovsky et al. 2017) are proposed for the general imagery domain while updating algorithm in uGAN (Biswas et al. 2019) is proposed for the biomedical imagery domain. All of these propose strategies to update discriminator time-steps per generator time-steps during the training of GANs. They show that their proposed solutions work better in attaining an equilibrium state while training the GANs.
Another idea of achieving equilibrium in training the GANs is proposed by Heusel et al. (2017). It also helps to achieve an equilibrium using adaptive learning rates for the discriminator and the generator. This technique is used by Abdelhalim et al. (2021) to address the non-convergence problem in the biomedical domain. The Hyperparameter optimization approach is also helpful in reaching the Nash equilibrium. For this, Goel et al. (2021) investigated the use of optimization algorithms such as the Whale optimization algorithm (WOA) (Mirjalili and Lewis 2016) for biomedical imagery.
To summarize this section, Table 2 shows a comparison of proposed techniques adapted by the contributing papers based on the underlying problem. It is observed that all of the technical papers belong to the image synthesis of CT, dermoscopic, and retinal image modalities. Among all of the contributed solutions, the TTUR (Heusel et al. 2017) scheme provides relatively good performance to address the non-convergence problem in the biomedical imaging domain. High-quality realistic images can be achieved using this approach in biomedical imagery.
Moreover, a detailed overview of existing solutions to address the non-convergence problem in GANs is also reported in Table 4 where the methodology of each solution to the non-convergence problem in GANs is summarized for the domain of biomedical imagery.
7 The instability problem
7.1 Definition
The training of the GANs can get unstable due to the vanishing gradient problem. The vanishing gradient problem occurs when the discriminator becomes an optimal classifier and produces smaller values of gradients (approaching zero) for back-propagation. These gradients are unable to update the weights of the generator due to which the generator stops producing new images and the overall training of the GANs becomes unstable (Goodfellow 2016).
7.2 Identification
The instability during the training of GANs is identified by the generation of blurry or low-quality synthetic images as indicated in Fig. 28. Moreover, the underlying problem takes a longer time to train GANs with unstopping behavior which results in generating poor-quality images. Another drawback of the instability problem is that it will lead the generator to produce synthetic images with artifacts. These artifacts include noise or additional objects that are not meant for generated.

Identification of the instability problem in GANs for X-ray image synthesis. The noisy synthetic X-ray images show unstable training of the GANs for X-ray images. The blurriness in the images is generated due to the vanishing gradient problem which is a basic reason for the unstable training of GANs
7.3 Quantification
The instability problem of training GANs can be evaluated by the same metrics that are used for mode collapse and non-convergence problems such as MS-SSIM (Odena et al. 2017), FID (Heusel et al. 2017), and PSNR (Borji 2019). The quality of generated images can be evaluated in terms of similarity measures as discussed in Sect. 4. Furthermore, classification metrics such as recall and precision are also used to quantify the quality of synthetic images.
7.4 Solutions to the problem
In synthetic image generation using GANs, the stability of GANs is an important aspect to consider. If the training of GANs becomes unstable, the network cannot generate high-resolution realistic images. To alleviate this problem, the following possible solutions are proposed for the domain of biomedical imagery.
7.4.1 Modified architecture
The architecture of GANs plays a key role to avoid the vanishing gradient problem. The selection of the generator and the discriminator have a great impact on the training performance of GANs. To synthesize PET images from multi-sequence MR images, a Refined CF-SAGAN is proposed (Wei et al. 2020). In the proposed architecture (Wei et al. 2020), the problem of vanishing gradient occurs when the long-skip connections are used in the generator to recover the lost spatial information during the down-sampling operations. Then, short skip connections are used to handle this problem. This process is known as the residual connections (He et al. 2016). The residual connection helps to mitigate the problem of vanishing gradient by allowing an alternative shortcut track for the gradient to flow through as shown in Fig. 29 the training of GANs. It also enhanced the feature exchanges across layers. The generated synthetic PET images are evaluated with the PSNR for image quality. The proposed Refined CF-SAGAN outperformed by \(9.07\%\) in PSNR (p < 0.05).

A flow of residual learning in CF-SAGAN. The figure is redesigned from He et al. (2016)
The generation of high-dimensional synthetic images is a challenging task using GANs. To address this problem in biomedical imaging, a modified architecture namely ciGAN is proposed (Wu et al. 2018a). The ciGAN (Wu et al. 2018a) utilizes a multi-scale generator architecture as depicted in Fig. 30 to infill a segmented area in a target image of breast Mammography. The proposed generator uses a cascaded refinement network that helps to generate features at multiple scales before being concatenated. This process improves the training stability at high resolutions. The generated synthetic images are used for data augmentation in the cancer detection task using ResNet-50. Traditional augmentation techniques like rotation, flipping, and rescaling are also used. The proposed ciGAN with traditional augmentation achieved an area under the curve (AUC) score of 0.896 while the real dataset with no augmentation achieved a 0.882 AUC score.

The architecture of multi-scale generator of ciGAN. The generator takes input at multi-level layers with multiple image resolutions. This figure is redesigned from Wu et al. (2018a)
7.4.2 Loss function
7.4.2.1 Adversarial
In vanilla GANs, a cross-entropy loss is introduced that is usually described as an adversarial loss. This loss can cause a vanishing gradient problem. To address this problem, WGAN loss is introduced to utilize as an adversarial loss. (Please refer to Sect. 2.4.3 (WGAN) for more detail). A similar study was found in the task of reconstructing low-dose PET images from full-dose PET images (Zhao et al. 2020b). Authors Zhao et al. (2020b) use a 1-Wasserstein distance instead of cross-entropy in supervised CycleGAN namely S-CycleGAN to improve the training stability of the proposed network. To evaluate the quality of generated low-dose images, authors Zhao et al. (2020b) utilized a learned perceptual image patch similarity (LPIPS) score. The lower value of the score shows better image quality regarding the actual image patches. The S-CycleGAN achieved a 0.026 LPIPS score which is small compared to the actual low-dose PET images of 0.035. The results show better performance of S-CycleGAN regarding training stability.
Saad et al. (2023) proposed a novel MSG-SAGAN with a relativistic hinge loss function. Relativism in the hinge loss helps the discriminator to improve its learning using approximate predictions of the real images as half of the images are fake on average instead of taking them all as real. This prior training information helps the discriminator to classify and predict the real and fake images more accurately and stabilizes the training of MSG-SAGAN. An improved FID score of 139.6 is achieved for X-ray image synthesis using the proposed MSG-SAGAN.
7.4.2.2 Regularization
This section elaborates on the use of regularization terms with additional loss functions in GANs to stabilize the training of GANs.
Gradient penalization (GP) is used to force the discriminator for producing meaningful gradients. For this, the discriminator D is enforced to be Lipschitz continuous (Gulrajani et al. 2017). GP enables D to target the \(\Vert D\Vert _{L i p}\) to 1. The \(\Vert D\Vert _{L i p}\) is defined as Lipschitz continuity as shown in Eq. (23) reproduced from Lee and Seok (2020).
In Eq. (23), \(\Vert D\Vert _{L i p}\) denotes the left side of the equation. K is the real constant, known as Lipschitz constant (Lee and Seok 2020), and implies within the range \(K \ge 0\) where \(\forall x_{1}, x_{2} \in {\mathbb {R}}^{p}\). To address the training instability problem, GP is applied as a \({\mathcal {L}}_{G P}\) using L2 norm. The \({\mathcal {L}}_{G P}\) is defined as \({\mathbb {E}}_{{\hat{x}}}\left[ \left( \left\| \nabla _{{\hat{x}}} D({\hat{x}})\right\| _{2}-1\right) ^{2}\right] \). In this way, gradients that vary from one are penalized.
The gradient penalty regularization term is investigated by Gulrajani et al. (2017) with WGAN loss to improve the training stability of the network.
In the biomedical imaging domain, WGAN-GP loss is used as an additional loss in many GANs architectures for biomedical image analysis tasks such as synthesis of cervical histopathology images (Xue et al. 2019) and MR images (Segato et al. 2020; Kwon et al. 2019) to improve the training stability of GANs. In multi-scale Gradient GAN (MSG-GAN) (Deepak and Ameer 2020), a WGAN-GP loss is used to train the MSG-GAN and improve the training stability (Table 5).
7.4.3 Summary
In this section, technical papers of GANs are reviewed to address the instability problem in the domain of biomedical imagery. The problem of unstable training triggers due to the vanishing gradient problem when the discriminator becomes optimal and sends no feedback to update the generator’s weights as shown in Fig. 2. So, to stabilize the training of GANs, the generator should receive significant feedback in the form of gradients from the discriminator to produce high-quality realistic images. Considering this aim, many work solutions have been proposed in the domain of biomedical imaging. With this aim, the technical papers are classified into two taxonomies. The first is based on solutions in terms of modified architectures and loss functions as shown in Fig. 31. The second is based on the applications with different image modalities as shown in Fig. 32.

Taxonomy of different proposed solutions for addressing the instability problem of GANs in biomedical imagery analysis

An application-based taxonomy of different approaches for addressing the instability problem of GANs in biomedical imagery analysis
With modified architecture, technical papers provide their solutions by changing the generator either its layers such as Wei et al. (2020) or complete generator like Wu et al. (2018a). Both of the solutions provide a stable conditioned training of proposed GANs but found some artifacts generated in the output images. The loss function plays a key role in addressing the vanishing gradient problem. The reason behind this phenomenon is that the loss function backpropagated feedback in the form of gradients to update the generator weights. When the discriminator becomes optimal then its loss approaches zero which can’t provide feedback to the generator. Technical papers are reviewed that provide solutions in biomedical imagery. In the loss function Sect. 7.4.2, technical papers are further classified into adversarial loss (Zhao et al. 2020b) and regularization loss (Xue et al. 2019; Segato et al. 2020; Kwon et al. 2019). The WGAN loss is used as an adversarial loss in Zhao et al. (2020b). The WGAN-GP loss is used as regularization loss in Xue et al. (2019), Segato et al. (2020), Kwon et al. (2019), Deepak and Ameer (2020) to address the instability problem in different application-based solutions.
To address the instability problem in the biomedical imaging domain, Table 2 shows a comparative analysis of different approaches provided in the literature. It is analyzed that WGAN-GP loss (Gulrajani et al. 2017) can be a suitable candidate to address the training instability problem in biomedical imagery as it works with various GANs architectures to alleviate the problem. The generated images can be obtained from GANs with high-quality and realistic nature.
Moreover, a detailed overview of existing solutions to address the instability problem in GANs is reported in Table 4 where the methodology of each solution to the instability problem in GANs is summarized for the domain of biomedical imagery.
8 A comparative analysis of state-of-the-art GANs on COVID-19 chest X-ray image dataset
In this section, state-of-the-art GAN architectures such as DCGAN (Neff et al. 2017; Kora Venu and Ravula 2021), AIIN-DCGAN (Saad et al. 2022), MSG-GAN (Deepak and Ameer 2020), and MSG-SAGAN (Saad et al. 2023) are re-implemented for the COVID-19 chest X-ray image dataset (Rahman et al. 2021). The same dataset of X-ray images is used to perform all these experiments. The X-ray dataset is selected because it is a widely used image modality to analyze the disease in human beings. X-ray provides a wide spectrum of affected parts of the body. These images are widely used by radiologists and clinicians to inspect the targeted segments of the disease. GANs have been utilized to train on these X-ray image datasets to generate synthetic images (Aggarwal et al. 2021).
Results are evaluated using two benchmark unified metrics such as MS-SSIM and FID. The MS-SSIM and FID metrics are selected because these metrics provide a compact evaluation of GAN’s synthetic images as compared to real images. The MS-SSIM computes salient features of images such as structure, brightness, and contrast to measure the diversity of synthetic images. FID computes the distance based on Inception Version-3 between real and synthetic images. Therefore, a combination of these two metrics provides a fair and significant analysis of a GAN’s performance regarding the generation of desirable synthetic images. Literature Odena et al. (2017), Miyato et al. (2018), Karnewar and Wang (2020), Han et al. (2020) demonstrates that these two metrics have been widely adopted for the evaluation of GANs training challenges in the research community and are significant as compared to the alternate evaluation metrics in the domain of natural and biomedical imaging.
A Table 6 comparing the experimental results of DCGAN, AIIN-DCGAN, MSG-GAN, and MSG-SAGAN for the X-ray image dataset using MS-SSIM and FID evaluation metrics is added. Moreover, a comparative analysis of these GAN architectures via bar graphs of MS-SSIM and FID scores is also shown in Fig. 33. The bar graphs show the impact of different solutions to the training challenges of GANs on the generation of synthetic X-ray images using MS-SSIM and FID scores. The adaptive input-image normalization technique has a significant impact on the MS-SSIM score because MS-SSIM considers the perpetual features of images to measure the similarity score. Therefore, synthetic X-ray images generated by AIIN-DCGAN indicate a lower score of MS-SSIM than the alternate solutions. However, a combined score of MS-SSIM and FID shows that MSG-SAGAN is the most performant GAN architecture to generate diversified synthetic X-ray images. The MSG-SAGAN has the advantages of self-attention and a multi-scale gradient learning scheme that enable the generator and discriminator models to guide each other significantly while focusing on learning the salient features of X-ray images.

MS-SSIM and FID scores analysis of DCGAN, AIIN-DCGAN, MSG-GAN, and MSG-SAGAN models for COVID-19 chest X-ray images. A lower MS-SSIM score of synthetic images than real images indicates a better diversity and quality of synthetic images as compared to real images. A lower FID score indicates a better diversity and quality of synthetic images as compared to real images
9 Challenges and future research directions
The implementation effects such as computational cost, memory consumption, and pros and cons of benchmark GANs architectures for alternate biomedical imaging modalities have been discussed in Table 7. Table 7 provides a comprehensive overview of experimental effects that impact the re-implementation of these architectures for diverse biomedical imaging modalities. This table will guide a reader to the best appropriate GAN architecture for targeted biomedical images.
9.1 The mode collapse problem
In biomedical image analysis, the mode collapse problem is one of the severe problems that occur during the training of GANs. The mode collapse problem has a direct impact on the diversity of synthetic images generated by GANs. Synthetic images lack diversity as compared to real images. Due to this problem, the generator in the GAN misses salient features of the image and repeats the same features in the generation of new synthetic images. It is challenging for researchers to train a GAN completely to avoid the mode collapse problem and its subsequent impact on the synthetic images. The underlying problem behaves differently for a number of GAN-based applications of biomedical image analysis. For example, a mode collapse occurs when a GAN uses a segmented mask with ground truth chest radiographs to generate segmented radiographs. Similarly, significant features of cell images can be affected and missed during the GAN-based generation of synthetic images. The mode collapse problem also occurs due to the complexity of 3-dimensional brain MR images in the process of image synthesis. For instance, modifications in GANs such as perceptual image hashing (Neff et al. 2017), the mixture of distributions in the generator (Wu et al. 2018b), and VAEGAN-based architectures (Segato et al. 2020) have been used to alleviate the mode collapse problem. In biomedical imaging applications, GANs can also cause feature hallucinations when generating new synthetic data (Laino et al. 2022). Hallucination in GANs refers to the generation of novel, unwanted artificial features or missing significant features in synthetically generated images that can lead to the risk of misdiagnosing diseases (Wolterink et al. 2021). The hallucinated features are generated due to the problem of mode collapse in GANs. Hallucinated features are usually generated in the synthetic images when performing the image-to-image translation task (Cohen et al. 2018). The solutions for alleviating mode collapse can also reduce the effects of hallucination in synthetic biomedical images.
In GANs, several techniques have been used to address the mode collapse problem in biomedical image analysis. It is critical for a GAN to train the generator and the discriminator in such a manner that the generator can learn a complete distribution of features and anatomical structure of biomedical images while the discriminator returns constructive feedback to the generator. The modifications in the generator or discriminator architectures or their loss functions can alleviate the mode collapse but do not solve the problem completely. Thus, there is a research gap to find a significant solution either based on architecture or loss function that should be capable of addressing the mode collapse problem in biomedical image analysis. The proposed solutions may consider the performance of generated images to analyze the effect of mode collapse. The analysis of generated images can better direct researchers to propose an effective solution in this field. However, it is important to address the mode collapse problem during the training of GANs so that the GAN-based applications can be utilized effectively in biomedical image analysis. Future research directions include modified architectures based on state-of-the-art attention networks, novel regularization techniques, capsule networks, and advanced normalization techniques to address the mode collapse problem in biomedical image generation. Autoencoders are also recognized as a significant technique to address the mode collapse problem in GANs. However, autoencoders generate blurry images. Nevertheless, autoencoders with powerful discriminators can improve the existing solutions in the biomedical imaging domain.
9.2 The non-convergence problem
In GANs, the non-convergence is a major failure of the generator and the discriminator models to reach an imbalanced state. When the training of GANs becomes imbalanced, there is a direct impact on the performance of synthetic images generated by GANs. Synthetic images can be generated blurry or with artifacts. It is very critical to train a GAN in a way that both models train in a balanced state during the whole training time. One solution is to reach a Nash equilibrium. It is very difficult to reach Nash equilibrium in practice. The issue is that a GAN sticks to the saddle point where the objective function gives minimal weight parameters for one model while the maximal weight parameters are for the other model. However, a minimax game can be used to find a Nash equilibrium. In biomedical image analysis, researchers devise new methodologies to address the non-convergence problem. For example, optimization algorithms such as Whale optimization, improving learning rate, and novel updating algorithms for training the generator and the discriminator have been used.
The non-convergence problem is a potential challenge faced by GANs during training. Updating algorithms proposed in vanilla GAN are limited to their initial experiments. The updating algorithm of WGAN can work for a few applications to achieve a Nash equilibrium. Similarly, TTUR and hyperparameter optimization techniques can also work for limited architectures while lacking generalization ability. So, there is a need for a compact and generalized solution to achieve the Nash equilibrium during the training of GANs. Recently, non-convergence is a generic problem for GANs, and researchers use JS divergence to find a balanced state during the training of GANs that is difficult to achieve in practice. Different techniques have been proposed to cope with this problem, such as f-divergence and improved Wasserstein loss functions that still need improvement. These approaches can be used with different GANs architectures to address the underlying problem in biomedical image analysis. However, future research directions should focus on advancing JS divergence to balance the training of GANs while considering different optimization techniques such as stochastic gradient descent, Pareto-optimization, etc. Novel game theories with divergences can also be explored based on existing schemes that will be helpful for GANs to address the non-convergence problem.
9.3 Instability problem
The training stability of GANs is important to achieve for any GAN-based application of biomedical image analysis. The problem occurs due to the vanishing gradient problem. Thus, there are solutions proposed to address the vanishing gradient problem such as modified architectures and modified loss functions. The loss function has a great impact on stabilizing the training of GANs. In this survey article, WGAN-GP loss (Gulrajani et al. 2017) is analyzed in almost all of the reviewed technical papers. The WGAN-GP loss helps in acquiring stable training of GANs in the technical solutions but there is no guarantee or generalization criterion about its suitability and utility for other applications as well as other imaging modalities. It is important to consider that if GANs can handle the training strategy to achieve the Nash equilibrium and try to reach the optimal discriminator then a vanishing gradient problem gets triggered due to the optimality of the discriminator as discussed in Sect. 7.1. It is also suspected that the stability of training depends on the mode collapse and non-convergence problems as well but sometimes, it can be seen that architecture is trained in stable conditions but has been affected by mode collapse. So, this situation could be a question of the performance of GANs. Therefore, all of these technical training challenges must be addressed in biomedical image analysis.
Future research directions should consider the above-mentioned constraints and propose novel techniques to address the instability problem in the biomedical imaging domain. There have been several approaches that are experimented with GANs to stabilize the training while addressing the vanishing gradient problem. There is a need for devising novel regularization, normalization, and game theory techniques to be used in the GANs which are unexplored previously. WGAN-GP is a widely used loss to cope with this problem in the general imaging domain yet requires more work and modifications to reach the stable training of GANs. Hybrid multiple GAN-based architectures based on WGAN-GP loss, attention mechanisms, novel regularization, and optimization techniques can also be explored to address the underlying problem. In recent times, alternate generative models such as diffusion models have also become popular in the domain of biomedical imaging (Ali et al. 2022). Diffusion models have their pros and cons in terms of training stability, computational cost, diversity of synthetic images, and learning high-dimensional latent spaces as compared to GANs. A detailed review of several applications of diffusion models has been conducted for biomedical images (Kazerouni et al. 2022). It is an important research direction to investigate the solutions to the GANs training challenges for addressing the training challenges of diffusion models in biomedical image analysis.
9.4 Evaluation metrics
In GANs, evaluation metrics play a key role in representing the performance of GANs. These metrics provide a quantification of the problems such as mode collapse, non-convergence, and training instability during the training of GANs. Although, evaluation metrics like IS, FID, MS-SSIM, MMD, and PSNR have been used to evaluate the performance of GANs based on the generated images. Nevertheless, these metrics are application-dependent and lack the capacity to visualize the occurrence of the challenges during the training of GANs.
In relation to the training challenges of GANs, evaluation metrics are used to capture the diversity and quality of the generated images. Generally, for the mode collapse problem, the diversity of images is quantified by the IS, MS-SSIM, and MMD metrics. While, for the non-convergence and instability problems, PSNR and FID are used. IS and FID metrics are frequently used to evaluate generated images via the quality of images. Both of these metrics are pretrained on ImageNet (Deng et al. 2009) dataset. The ImageNet dataset lacks the class of biomedical images thus IS and FID metrics are not recommended to be used in the biomedical imaging domain. Similarly, MS-SSIM is a human perceptual metric that only considers luminance and contrast estimations to measure the similarity of image features between two images. PSNR is a widely used metric to measure the quality of images but is limited to monochrome images. In biomedical image analysis, the performance parameters vary based on the type of imagery domain as every domain-specific image has different characteristics and features in it.
Several unified evaluation metrics such as MS-SSIM, IS, MMD, FID, and PSNR have been utilized to evaluate the training performance of GANs based on the nature of application tasks in different imaging domains. There are two evaluation methods used to measure the performance of GANs. One method includes the direct comparison of the real image dataset to the synthetic image dataset using distance-based evaluation metrics such as IS, MMD, and FID. Another method is to measure the similarity and diversity of synthetic images using some features-based evaluation metrics such as SSIM, MS-SSIM, and PSNR. The score of the evaluation metric of the synthetic image dataset is compared with the score of the similar evaluation metric of the real image dataset. However, the deep learning community mostly relies on using two benchmark metrics such as MS-SSIM for feature-based evaluation and FID for distance-based evaluation to measure the performance of GANs (Borji 2019).
In biomedical image analysis, researchers utilize traditional pixel-wise evaluation metrics to quantify the performance of GANs. Most traditional metrics are suitable for supervised learning tasks that require reference images. In the biomedical imagery domain, the availability of reference images is limited due to privacy issues and inaccurate manual annotation. This ensures the use of unsupervised learning in the biomedical imagery domain. Furthermore, it is also important to evaluate the training performance of GANs because of the randomization of initialization, optimization, and technical challenges. The evaluation of generated images as compared to real images remains challenging and needs to be explored. There has been a list of metrics reported in Borji (2019) to evaluate the performance of GANs. Despite all these proposed metrics, there is still a research gap in finding a metric that can capture salient features such as the texture and shape of objects in biomedical images. It is important to analyze the symptoms of each training problem of GANs for several applications in biomedical image analysis. An evaluation metric that can capture the pre and post-training dynamics of a GAN model is important to investigate. The proposed metric should work with most of the image modalities such as X-rays, MR images, Dermoscopic images, Ultrasound, and PET images to measure the efficacy of GANs in the domain of biomedical imaging.
10 Conclusion
In this survey article, training challenges of GANs such as mode collapse, non-convergence, and instability have been reviewed in detail for the domain of biomedical imagery. The three challenges are discussed via definitions, identifications, quantifications, and possible solutions. To address these training challenges in the biomedical imagery domain, technical literature has been discussed based on applications and solutions taxonomies. Existing literature shows that addressing these challenges entirely is a challenging task, but few techniques have been proposed that can partially alleviate these training challenges. In the architecture of GANs, the mode collapse problem can be addressed by using minibatch discrimination, skip connections, VAEGAN as part of the generator and discriminator, varying layers of generator and discriminator, spectral normalization, perceptual image hashing, Gaussian mixture model as a generator, discriminator with conditional information vector, self-attention mechanism, and adaptive input-image normalization. The non-convergence problem can be addressed by using modified training updates of the generator and discriminator, the Whale optimization algorithm, and two time-scale update rules. The instability problem can be addressed by using the Wasserstein loss, residual connections, multi-scale generator, and Relativistic hinge loss. Each solution contributes to alleviating the mode collapse problem based on the type of GAN architecture. The effectiveness and suitability of the solutions also depend on the types of GAN architecture and biomedical imagery. Moreover, this survey also elaborated that how each training problem can affect the quality of generated biomedical images in terms of realistic nature, diversity, resolution, and artifacts. This survey also highlights possible future research directions to address the underlying training challenges of GANs for biomedical images. In this survey, it is concluded that all three technical challenges faced during the training of GANs need more research work to bridge this gap for biomedical image analysis. This motivates the researchers to propose advanced solutions to address the underlying training challenges of GANs in the domain of biomedical imagery.
References
Abdelhalim ISA, Mohamed MF, Mahdy YB (2021) Data augmentation for skin lesion using self-attention based progressive generative adversarial network. Expert Syst Appl 165:113922
Aggarwal R, Sounderajah V, Martin G, Ting DS, Karthikesalingam A, King D, Ashrafian H, Darzi A (2021) Diagnostic accuracy of deep learning in medical imaging: a systematic review and meta-analysis. npj Digit Med 4(1):1–23
AlAmir M, AlGhamdi M (2022) The role of generative adversarial network in medical image analysis: an in-depth survey. ACM Comput Surv 55(5):1–36
Ali H, Murad S, Shah Z (2023) Spot the fake lungs: generating synthetic medical images using neural diffusion models. In: Artificial intelligence and cognitive science: 30th Irish conference, AICS 2022, Munster, Ireland, December 8–9, 2022, revised selected papers. Springer, pp 32–39
Alotaibi A (2020) Deep generative adversarial networks for image-to-image translation: a review. Symmetry 12(10):1705
Arjovsky M, Bottou L (2017) Towards principled methods for training generative adversarial networks. arXiv Preprint. https://arxiv.org/abs/1701.04862
Arjovsky M, Chintala S, Bottou L (2017) Wasserstein generative adversarial networks. In: International conference on machine learning. PMLR, pp 214–223
Bertels J, Eelbode T, Berman M, Vandermeulen D, Maes F, Bisschops R, Blaschko MB (2019) Optimizing the dice score and Jaccard index for medical image segmentation: theory and practice. In: Medical image computing and computer assisted intervention–MICCAI 2019: 22nd international conference, Shenzhen, China, October 13–17, 2019, proceedings, part II 22. Springer, pp 92–100
Bhattacharya D, Banerjee S, Bhattacharya S, Shankar BU, Mitra S (2020) GAN-based novel approach for data augmentation with improved disease classification. In: Advancement of machine intelligence in interactive medical image analysis. Springer, pp 229–239
Biswas S, Rohdin J, Drahanskỳ M (2019) Synthetic retinal images from unconditional GANs. In: 2019 41st annual international conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE, pp 2736–2739
Borji A (2019) Pros and cons of GAN evaluation measures. Comput Vis Image Underst 179:41–65
Cohen JP, Luck M, Honari S (2018) Distribution matching losses can hallucinate features in medical image translation. In: Medical image computing and computer assisted intervention–MICCAI 2018: 21st international conference, Granada, Spain, September 16–20, 2018, proceedings, part I. Springer, pp 529–536
Deepak S, Ameer P (2020) MSG-GAN based synthesis of brain MRI with meningioma for data augmentation. In: 2020 IEEE international conference on electronics, computing and communication technologies (CONECCT). IEEE, pp 1–6
Deng J, Dong W, Socher R, Li L-J, Li K, Fei-Fei L (2009) ImageNet: a large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. IEEE, pp 248–255
Du L, Ho AT, Cong R (2020) Perceptual hashing for image authentication: a survey. Signal Process Image Commun 81:115713
Ghaffari M, Sowmya A, Oliver R (2019) Automated brain tumor segmentation using multimodal brain scans: a survey based on models submitted to the brats 2012–2018 challenges. IEEE Rev Biomed Eng 13:156–168
Goel T, Murugan R, Mirjalili S, Chakrabartty DK (2021) Automatic screening of COVID-19 using an optimized generative adversarial network. Cogn Comput. https://doi.org/10.1007/s12559-020-09785-7
Goodfellow I (2016) NIPS 2016 tutorial: generative adversarial networks. arXiv Preprint. https://arxiv.org/abs/1701.00160
Goodfellow IJ, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2014) Generative adversarial nets. In: Proceedings of the 27th international conference on neural information processing systems—volume 2, ser. NIPS’14. MIT Press, Cambridge, MA, USA, pp 2672–2680
Goodfellow I, Bengio Y, Courville A, Bengio Y (2016) Deep learning, vol 1, no 2. MIT Press, Cambridge
Gretton A, Borgwardt KM, Rasch MJ, Schölkopf B, Smola A (2012) A kernel two-sample test. J Mach Learn Res 13(1):723–773
Gui J, Sun Z, Wen Y, Tao D, Ye J (2021) A review on generative adversarial networks: algorithms, theory, and applications. IEEE Trans Knowl Data Eng 35(4):3313–3332
Gulrajani I, Ahmed F, Arjovsky M, Dumoulin V, Courville A (2017) Improved training of Wasserstein GANs. In: Proceedings of the 31st international conference on neural information processing systems, ser. NIPS’17. Curran Associates Inc., Red Hook, NY, USA, pp 5769–5779
Han T, Nebelung S, Haarburger C, Horst N, Reinartz S, Merhof D, Kiessling F, Schulz V, Truhn D (2020) Breaking medical data sharing boundaries by using synthesized radiographs. Sci Adv 6(49):eabb7973
Han C, Rundo L, Araki R, Furukawa Y, Mauri G, Nakayama H, Hayashi H (2019) Infinite brain MR images: PGGAN-based data augmentation for tumor detection. In: Neural approaches to dynamics of signal exchanges. Springer, pp. 291–303
Haskins G, Kruger U, Yan P (2020) Deep learning in medical image registration: a survey. Mach Vis Appl 31(1):1–18
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 770–778
Heusel M, Ramsauer H, Unterthiner T, Nessler B, Hochreiter S (2017) GANs trained by a two time-scale update rule converge to a local Nash equilibrium. In: Proceedings of the 31st international conference on neural information processing systems, ser. NIPS’17. Curran Associates Inc., Red Hook, NY, USA, pp 6629–6640
Hoang Q, Nguyen TD, Le T, Phung D (2018) MGAN: training generative adversarial nets with multiple generators. In: International conference on learning representations. https://openreview.net/forum?id=rkmu5b0a-
Hong Y, Hwang U, Yoo J, Yoon S (2019) How generative adversarial networks and their variants work: an overview. ACM Comput Surv (CSUR) 52(1):1–43
Iqbal A, Sharif M, Yasmin M, Raza M, Aftab S (2022) Generative adversarial networks and its applications in the biomedical image segmentation: a comprehensive survey. Int J Multimed Inf Retr 11(3):333–368
Jabbar A, Li X, Omar B (2021) A survey on generative adversarial networks: variants, applications, and training. ACM Comput Surv (CSUR) 54(8):1–49
Karnewar A, Wang O (2020) MSG-GAN: multi-scale gradients for generative adversarial networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp 7799–7808
Karras T, Aila T, Laine S, Lehtinen J (2018) Progressive growing of GANs for improved quality, stability, and variation. In: International conference on learning representations. https://openreview.net/forum?id=Hk99zCeAb
Karras T, Laine S, Aila T (2019) A style-based generator architecture for generative adversarial networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp 4401–4410
Kazeminia S, Baur C, Kuijper A, van Ginneken B, Navab N, Albarqouni S, Mukhopadhyay A (2020) GANs for medical image analysis. Artif Intell Med 109:101938
Kazerouni A, Aghdam EK, Heidari M, Azad R, Fayyaz M, Hacihaliloglu I, Merhof D (2022) Diffusion models for medical image analysis: a comprehensive survey. arXiv Preprint. https://arxiv.org/abs/2211.07804
Kim T, Cha M, Kim H, Lee JK, Kim J (2017) Learning to discover cross-domain relations with generative adversarial networks. In: International conference on machine learning. PMLR, pp 1857–1865
Kingma DP, Ba J (2014) Adam: a method for stochastic optimization. arXiv Preprint. https://arxiv.org/abs/1412.6980
Kingma DP, Welling M (2014) Stochastic gradient VB and the variational auto-encoder. In: Second international conference on learning representations, ICLR, vol 19
Klambauer G, Unterthiner T, Mayr A, Hochreiter S (2017) Self-normalizing neural networks. In: Advances in neural information processing systems, vol 30
Kora Venu S, Ravula S (2021) Evaluation of deep convolutional generative adversarial networks for data augmentation of chest X-ray images. Future Internet 13(1):8
Kossale Y, Airaj M, Darouichi A (2022) Mode collapse in generative adversarial networks: an overview. In: 2022 8th international conference on optimization and applications (ICOA). IEEE, pp 1–6
Kudo A, Kitamura Y, Li Y, Iizuka S, Simo-Serra E (2019) Virtual thin slice: 3D conditional GAN-based Super-resolution for CT slice interval. In: International workshop on machine learning for medical image reconstruction. Springer, pp 91–100
Kwon G, Han C, Kim D-S (2019) Generation of 3D brain MRI using auto-encoding generative adversarial networks. In: International conference on medical image computing and computer-assisted intervention. Springer, pp 118–126
Laino ME, Cancian P, Politi LS, Della Porta MG, Saba L, Savevski V (2022) Generative adversarial networks in brain imaging: a narrative review. J Imaging 8(4):83
Lau F, Hendriks T, Lieman-Sifry J, Sall S, Golden D (2018) ScarGAN: chained generative adversarial networks to simulate pathological tissue on cardiovascular MR scans. In: Deep learning in medical image analysis and multimodal learning for clinical decision support. Springer, pp 343–350
Ledig C, Theis L, Huszár F, Caballero J, Cunningham A, Acosta A, Aitken A, Tejani A, Totz J, Wang Z et al (2017) Photo-realistic single image super-resolution using a generative adversarial network. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 4681–4690
Lee M, Seok J (2020) Regularization methods for generative adversarial networks: an overview of recent studies. arXiv Preprint. https://arxiv.org/abs/2005.09165
Lee D, Yu H, Jiang X, Rogith D, Gudala M, Tejani M, Zhang Q, Xiong L (2020) Generating sequential electronic health records using dual adversarial autoencoder. J Am Med Inform Assoc 27(9):1411–1419
Li Y, Li J, Ma F, Du S, Liu Y (2021a) High quality and fast compressed sensing MRI reconstruction via edge-enhanced dual discriminator generative adversarial network. Magn Reson Imaging 77:124–136
Li Y, Sixou B, Peyrin F (2021b) A review of the deep learning methods for medical images super resolution problems. IRBM 42:2 120–133
Liu S, Hong J, Lu X, Jia X, Lin Z, Zhou Y, Liu Y, Zhang H (2019) Joint optic disc and cup segmentation using semi-supervised conditional GANs. Comput Biol Med 115:103485
Lucic M, Kurach K, Michalski M, Gelly S, Bousquet O (2018) Are GANs created equal? A large-scale study. In: Advances in neural information processing systems, vol 31
Mao Y, Xue F-F, Wang R, Zhang J, Zheng W-S, Liu H (2020) Abnormality detection in chest X-ray images using uncertainty prediction autoencoders. In: International conference on medical image computing and computer-assisted intervention. Springer, pp 529–538
Mirjalili S, Lewis A (2016) The whale optimization algorithm. Adv Eng Softw 95:51–67
Mirza M, Osindero S (2014) Conditional generative adversarial nets. arXiv Preprint. https://arxiv.org/abs/1411.1784
Miyato T, Kataoka T, Koyama M, Yoshida Y (2018) Spectral normalization for generative adversarial networks. In: International conference on learning representations. https://openreview.net/forum?id=B1QRgziT-
Modanwal G, Vellal A, Mazurowski MA (2021) Normalization of breast MRIs using cycle-consistent generative adversarial networks. Comput Methods Progr Biomed 208:106225
Mubashar M, Ali H, Grönlund C, Azmat S (2022) R2u++: a multiscale recurrent residual U-Net with dense skip connections for medical image segmentation. Neural Comput Appl 34(20):17723–17739
Nalepa J, Marcinkiewicz M, Kawulok M (2019) Data augmentation for brain-tumor segmentation: a review. Front Comput Neurosci 13:83
Neff T, Payer C, Stern D, Urschler M (2017) Generative adversarial network based synthesis for supervised medical image segmentation. In: Proceedings of the OAGM &ARW joint workshop 2017. Verlag der Technischen Universität Graz, pp 140–145
Odena A, Olah C, Shlens J (2017) Conditional image synthesis with auxiliary classifier GANs. In: International conference on machine learning. PMLR, pp 2642–2651
Pan Z, Yu W, Yi X, Khan A, Yuan F, Zheng Y (2019) Recent progress on generative adversarial networks (GANs): a survey. IEEE Access 7:36322–36333
Pollastri F, Bolelli F, Paredes R, Grana C (2020) Augmenting data with GANs to segment melanoma skin lesions. Multimed Tools Appl 79(21):15575–15592
Punn NS, Agarwal S (2022) Modality specific U-Net variants for biomedical image segmentation: a survey. Artif Intell Rev 55(7):5845–5889
Qasim AB, Ezhov I, Shit S, Schoppe O, Paetzold JC, Sekuboyina A, Kofler F, ipkova J, Li H, Menze B (2020) Red-GAN: attacking class imbalance via conditioned generation. Yet another medical imaging perspective. In: Medical imaging with deep learning. PMLR, pp 655–668
Qin Z, Liu Z, Zhu P, Xue Y (2020) A GAN-based image synthesis method for skin lesion classification. Comput Methods Progr Biomed 195:105568
Radford A, Metz L, Chintala S (2015) Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv Preprint. https://arxiv.org/abs/1511.06434
Rahman T, Khandakar A, Qiblawey Y, Tahir A, Kiranyaz S, Kashem SBA, Islam MT, Al Maadeed S, Zughaier SM, Khan MS et al (2021) Exploring the effect of image enhancement techniques on Covid-19 detection using chest x-ray images. Comput Biol Med 132:104319
Román KL-L, Ocaña MIG, Urzelai NL, Ballester MÁG, Oliver IM (2020) Medical image segmentation using deep learning. In: Deep learning in healthcare. Springer, pp 17–31
Ronneberger O, Fischer P, Brox T (2015) U-Net: convolutional networks for biomedical image segmentation. In: International conference on medical image computing and computer-assisted intervention. Springer, pp 234–241
Saad MM, Rehmani MH, O’Reilly R (2022) Addressing the intra-class mode collapse problem using adaptive input image normalization in GAN-based x-ray images. In: 2022 44th annual international conference of the IEEE Engineering in Medicine & Biology Society (EMBC). pp 2049–2052
Saad MM, Rehmani MH, O’Reilly R (2023) A self-attention guided multi-scale gradient GAN for diversified x-ray image synthesis. In: Artificial intelligence and cognitive science: 30th Irish conference, AICS 2022, Munster, Ireland, December 8–9, 2022, revised selected papers. Springer, pp 18–31
Saini M, Susan S (2020) Deep transfer with minority data augmentation for imbalanced breast cancer dataset. Appl Soft Comput 97:106759
Sajjadi MS, Bachem O, Lucic M, Bousquet O, Gelly S (2018) Assessing generative models via precision and recall. In: Advances in neural information processing systems, vol 31
Salimans T, Goodfellow I, Zaremba W, Cheung V, Radford A, Chen X, Chen X (2016) Improved techniques for training GANs. In: Lee D, Sugiyama M, Luxburg U, Guyon I, Garnett R (eds) Advances in neural information processing systems, vol 29. Curran Associates, Inc. https://proceedings.neurips.cc/paper/2016/file/8a3363abe792db2d8761d6403605aeb7-Paper.pdf
Salimans T, Zhang H, Radford A, Metaxas D (2018) Improving GANs using optimal transport. arXiv Preprint. https://arxiv.org/abs/1803.05573
Sampath V, Maurtua I, Aguilar Martin JJ, Gutierrez A (2021) A survey on generative adversarial networks for imbalance problems in computer vision tasks. J Big Data 8:27
Saxena D, Cao J (2021) Generative adversarial networks (GANs) challenges, solutions, and future directions. ACM Comput Surv (CSUR) 54(3):1–42
Segato A, Corbetta V, Di Marzo M, Pozzi L, De Momi E (2020) Data augmentation of 3D brain environment using deep convolutional refined auto-encoding alpha GAN. IEEE Trans Med Robot Bionics 3:269–272
Shamsolmoali P, Zareapoor M, Granger E, Zhou H, Wang R, Celebi ME, Yang J (2021) Image synthesis with adversarial networks: a comprehensive survey and case studies. Inf Fusion 72:126–146
Shi G, Wang J, Qiang Y, Yang X, Zhao J, Hao R, Yang W, Du Q, Kazihise NG-F (2020) Knowledge-guided synthetic medical image adversarial augmentation for ultrasonography thyroid nodule classification. Comput Methods Progr Biomed 196:105611
Shrivastava A, Pfister T, Tuzel O, Susskind J, Wang W, Webb R (2017) Learning from simulated and unsupervised images through adversarial training. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 2107–2116
Singh NK, Raza K (2021) Medical image generation using generative adversarial networks: a review. In: Patgiri R, Biswas A, Roy P (eds) Health informatics: a computational perspective in healthcare. Springer Singapore, Singapore, pp 77–96. https://doi.org/10.1007/978-981-15-9735-0_5
Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z (2016) Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 2818–2826
Targ S, Almeida D, Lyman K (2016) ResNet in ResNet: generalizing residual architectures. arXiv Preprint. https://arxiv.org/abs/1603.08029
Tegang NHN, Fouefack J-R, Borotikar B, Burdin V, Douglas TS, Mutsvangwa TE (2020) A Gaussian process model based generative framework for data augmentation of multi-modal 3D image volumes. In: International workshop on simulation and synthesis in medical imaging. Springer, pp 90–100
Tian C, Fei L, Zheng W, Xu Y, Zuo W, Lin C-W (2020) Deep learning on image denoising: an overview. Neural Netw 131:251–275
Waheed A, Goyal M, Gupta D, Khanna A, Al-Turjman F, Pinheiro PR (2020) CovidGAN: data augmentation using auxiliary classifier GAN for improved Covid-19 detection. IEEE Access 8:91916–91923
Wang Z, Simoncelli EP, Bovik AC (2003) Multiscale structural similarity for image quality assessment. In: The thirty-seventh Asilomar conference on signals, systems & computers, 2003, vol 2. IEEE, pp 1398–1402
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP (2004) Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process 13(4):600–612
Wang Z, She Q, Ward TE (2021) Generative adversarial networks in computer vision: a survey and taxonomy. ACM Comput Surv (CSUR) 54(2):1–38
Wei W, Poirion E, Bodini B, Tonietto M, Durrleman S, Colliot O, Stankoff B, Ayache N (2020) Predicting PET-derived myelin content from multisequence MRI for individual longitudinal analysis in multiple sclerosis. NeuroImage 223:117308
Wiatrak M, Albrecht SV, Nystrom A (2019) Stabilizing generative adversarial networks: a survey. arXiv Preprint. https://arxiv.org/abs/1910.00927
Wolterink JM, Mukhopadhyay A, Leiner T, Vogl TJ, Bucher AM, Išgum I (2021) Generative adversarial networks: a primer for radiologists. Radiographics 41(3):840–857
Wu E, Wu K, Cox D, Lotter W (2018a) Conditional infilling GANs for data augmentation in mammogram classification. In: Stoyanov D, Taylor Z, Kainz B, Maicas G, Beichel RR, Martel A, Maier-Hein L, Bhatia K, Vercauteren T, Oktay O, Carneiro G, Bradley AP, Nascimento J, Min H, Brown MS, Jacobs C, Lassen-Schmidt B, Mori K, Petersen J, San José Estépar R, Schmidt-Richberg A, Veiga C (eds) Image analysis for moving organ, breast, and thoracic images. Springer International Publishing, Cham, pp 98–106
Wu Y, Yue Y, Tan X, Wang W, Lu T (2018b) End-to-end chromosome karyotyping with data augmentation using GAN. In: 2018 25th IEEE international conference on image processing (ICIP). IEEE, pp 2456–2460
Xu L, Zeng X, Huang Z, Li W, Zhang H (2020) Low-dose chest X-ray image super-resolution using generative adversarial nets with spectral normalization. Biomed Signal Process Control 55:101600
Xue Y, Zhou Q, Ye J, Long LR, Antani S, Cornwell C, Xue Z, Huang X (2019) Synthetic augmentation and feature-based filtering for improved cervical histopathology image classification. In: International conference on medical image computing and computer-assisted intervention. Springer, pp 387–396
Yedder HB, Cardoen B, Hamarneh G (2021) Deep learning for biomedical image reconstruction: a survey. Artif Intell Rev 54:215–251
Yi X, Walia E, Babyn P (2019) Generative adversarial network in medical imaging: a review. Med Image Anal 58:101552
You A, Kim JK, Ryu IH, Yoo TK (2022) Application of generative adversarial networks (GAN) for ophthalmology image domains: a survey. Eye Vis 9(1):1–19
Zhang H, Goodfellow I, Metaxas D, Odena A (2019) Self-attention generative adversarial networks. In: International conference on machine learning. PMLR, pp 7354–7363
Zhao L, Wang J, Pang L, Liu Y, Zhang J (2020a) GANsDTA: predicting drug-target binding affinity using GANs. Front Genet 10:1243
Zhao K, Zhou L, Gao S, Wang X, Wang Y, Zhao X, Wang H, Liu K, Zhu Y, Ye H (2020b) Study of low-dose PET image recovery using supervised learning with CycleGAN. PLoS ONE 15(9):e0238455
Zhou T, Fu H, Chen G, Shen J, Shao L (2020) Hi-Net: hybrid-fusion network for multi-modal MR image synthesis. IEEE Trans Med Imaging 39(9):2772–2781
Zhu J-Y, Park T, Isola P, Efros AA (2017) Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE international conference on computer vision. pp 2223–2232
Funding
Open Access funding provided by the IReL Consortium. This study was supported by Munster Technological University Cork, Ireland under Risam Scholarship Award.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Saad, M.M., O’Reilly, R. & Rehmani, M.H. A survey on training challenges in generative adversarial networks for biomedical image analysis. Artif Intell Rev 57, 19 (2024). https://doi.org/10.1007/s10462-023-10624-y
Published:
DOI: https://doi.org/10.1007/s10462-023-10624-y