
Abstract
Vascularized microphysiological systems and organoids are contemporary preclinical experimental platforms representing human tissue or organ function in health and disease. While vascularization is emerging as a necessary physiological organ-level feature required in most such systems, there is no standard tool or morphological metric to measure the performance or biological function of vascularized networks within these models. Further, the commonly reported morphological metrics may not correlate to the network’s biological function—oxygen transport. Here, a large library of vascular network images was analyzed by the measure of each sample’s morphology and oxygen transport potential. The oxygen transport quantification is computationally expensive and user-dependent, so machine learning techniques were examined to generate regression models relating morphology to function. Principal component and factor analyses were applied to reduce dimensionality of the multivariate dataset, followed by multiple linear regression and tree-based regression analyses. These examinations reveal that while several morphological data relate poorly to the biological function, some machine learning models possess a relatively improved, but still moderate predictive potential. Overall, random forest regression model correlates to the biological function of vascular networks with relatively higher accuracy than other regression models.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Organ-chips, also known as microphysiological systems (MPS), are an in vitro research tool with increasing applications in pharmaceutics testing/evaluation,29,33,45 tissue engineering and disease modeling,14,42,44 and medical regulation.16,28 Recent success of MPS has been reported in evaluating drug candidates and therapies for rapidly arising diseases,37 predicting outcomes of patient-specific therapies,35,43,47 and even their rapidly increasing complexity with increasing similarity to human tissues and organs.3,4,5,9 An emerging direction within the MPS development is the vascularization of these systems,22,36 where perfusable vasculature anywhere from small capillary beds to large veins and arteries are modeled with human tissues, blood, and biophysical stimuli.25,26,30,32 Vascularized MPS (termed as vMPS) may include the self-assembly of small capillary networks around other cell types, such as cancer organoids, pancreatic islets, lung epithelia, and brain/neural cells.36
Typically, vMPS are engineered by applying a combination of physical and chemical stimulants of network formation,31,46 for example, endothelial cell source and density, proangiogenic/supporting cell source and density, extracellular matrix, biochemical cues, and biophysical stimuli.41 Despite the diversity of ways vMPS may be constructed, the ultimate outcome of these systems is to achieve a vascular bed formation in a tissue microenvironment that mimics an in vivo state. However, we observed that published reports use different evaluation criteria of the network quality and function based on a range of quantification tools, and there is no consistency. These methods mostly quantify the morphology of the microvascular networks using metrics such as junction density, vessel area fraction, vessel density, vessel length, and vessel diameter.31,46 These criteria are often assumed to predict the vascular network performance in a tissue. We argue that the fundamental biological measure of a vascular network is its capacity to deliver and oxygenate a tissue. However, the relation of morphology to the actual function of a vasculature, transport of oxygen to deoxygenated tissues, remains unclear. The use of these several user-dependent and often randomly picked morphological metrics has prevented a standardization of the field that could help its translation to large pharmaceutical, tissue engineering, or clinical studies.7
Our work here assesses the ability of a vascular network to transport oxygen and its correlation with most common morphological metrics that have been reported in the past. Using a large library of images with diverse formations of vMPS, we measured the morphological metrics according to previous in vitro vasculature evaluation methods, as well as computed the biological function of the networks through measures of Normalized Oxygen Flux (NOF), Normalized Vascular Potential (NVP), and Normalized Oxygen Delivery (NOD). Since an exponentially increasing number of advanced statistical and machine learning tools are now readily available to the casual programmer, we have applied several of the most relevant techniques—multiple linear regression (MLR), tree-based regression including random forest—to discover relationships between biological and morphological metrics of vMPS. Our analyses identify several redundant and multicollinear metrics, data handling practices, as well as algorithms consisting a set of few most relevant independent metrics that may be adopted for quantitative analyses of vMPS.
Methods
Microfluidic Device Fabrication
Microfluidic devices were manufactured according to traditional photo- and soft-lithography practices. Detailed methods are listed in the Supplementary Material. Briefly, microfluidic devices were designed containing five parallel and semi-permeable channels. Each channel was bounded along the length of the chip by a series of micro-pillars instead of a solid wall, facilitating loading of viscous hydrogel pre-cursors in some channels without bleeding into adjacent channels. When hydrogels were injected into their channels and crosslinked, cell culture medium can be injected in adjacent chips, thus creating alternating solid–fluid channels across the chip.
Photomasks were designed using Solidworks 2019 (Dassault Systems) and printed onto mylar films (CAD-Art Services; Bandon, Oregon, USA). There were used for exposing UV light to 250 µm layers of SU-8 (Kayaku Advanced Materials; Westborough, MA 01481) on 6-in. silicon wafers (University Wafer; South Boston, MA 02127, USA). Exposed wafers were developed (Kayaku Advanced Materials) and subsequently silanized with trichloro(1H, 1H, 2H, 2H-perfluorooctyl)silane (PFCOTS) (448931-10G, Sigma Aldrich) overnight.
Polydimethylsiloxane (PDMS, Dow Corning) was prepared in a 10:1 base:curing agent ratio, poured over the wafer, degassed, and baked at 70 °C for 2 h. Cured PDMS was peeled from the master mold and port holes were punched. Devices and glass slides were placed in a 100 W plasma cleaner (Thierry Zepto, Diener Electronics; Ebhausen 72224, Germany), treated, bonded together irreversibly, and then left at 70 °C overnight to render the PDMS hydrophobic. Before cell culture, devices were left under UV for 30 min for sterilization.
Cell Culture
Human umbilical vein endothelial cells (HUVECs, C2519A, Lonza; Houston 77047, TX) cultured in endothelial growth medium-2 (EGM-2, C-22111, Promocell; Heidelberg 69126, Germany), human microvascular endothelial cells (HMVECs, CC-2527, Lonza) cultured in endothelial growth medium-2 MV (EGM-2 MV, CC-22121, Promocell), and normal human lung fibroblasts (NHLFs, CC-2512, Lonza) cultured in fibroblast growth medium (FGM, CC-3132, Lonza) were used from passages 4 to 6. NHLFs were used in this study because they are a common supporting cell type in vMPS reports, owing to their pro-angiogenic secretome when embedded in collagen or fibrin hydrogels. After expansion, cells were trypsinized, pelleted, and resuspended in media for counting and viability assessment. Cell suspensions were adjusted to desired concentrations and mixed with thrombin (605157-1KU, Sigma Aldrich) at a final concentration of 5 U/mL. Fibrinogen (F8630-1G, Sigma Aldrich) was dissolved in 1 × PBS, filtered, and supplemented with 0.3 mg/mL collagen I (354236, Corning) and 0.2 U/mL aprotinin (A3248-10MG, Sigma Aldrich). 2 × fibrinogen and 2 × thrombin/cell solutions were mixed 1:1 and injected into hydrogel compartments. Fresh EGM-2 was injected into the fluidic channels, followed by daily media changes for the duration of the 96 h culture.
Immunostaining
Devices were fixed with 4% paraformaldehyde (AAJ19943K2, Fisher Scientific) for 15 min at room temperature, washed, and permeabilized with 0.1 vol% TritonX-100 (T8787-100ML, Sigma Aldrich) in 3% bovine serum albumin (BSA, BP9706100, Fisher Scientific) for 15 min at room temperature. Devices were washed, then stained using AlexaFluor-488-conjugated CD-31 antibody (303110, Biolegend; San Diego, CA 92121, USA) diluted 1:100 in 3% BSA overnight at 4 °C. Devices were washed and stained with rhodamine phalloidin (R415, Thermo Fisher) for 1 h at room temperature, washed, and counterstained with Hoechst (H2570, Thermo Fisher) for 10 min at room temperature.
The 8 × 1.5 mm vascularization region of each sample was imaged using Z-stack and tiling acquisition with a Zeiss Axio Observer Z1 Inverted Microscope (Zeiss; Thornwood, New York 10594, USA). Stitched images were orthogonally projected in the XY direction and cropped to and area of 1 × 1 mm.
Image Processing and Vessel Morphology Quantification40
Three cropped images of each sample’s vascularization region for 3–4 biological replicates per group were processed using REAVER.6 All images were segmented using user-defined parameters (filter size = 64; minimum connected component area = 800; wire dilation threshold = 0; vessel thickness threshold = 1; gray threshold = 0.045). Images were quantified and measurements for all samples were compiled in GraphPad Prism 9 (GraphPad Software, Inc.; San Diego, CA 92180, USA) datasheets.
Numerical Analysis
Detailed coding methods are discussed in the Supplementary Material. Briefly, vMPS images were imported to MATLAB, converted to triangular meshes for the hydrogel and vasculature regions, and composited. AngioMT detected the vessel edges and applied the oxygen boundary conditions of a cell culture incubator. AngioMT added an oxygen permeability flux at the edges and solved a steady-state, two-dimensional transport of oxygen for each node within the vessel, and then within the tissue. The nodal oxygen concentrations were summarized as area averages and normalized to the input concentration.
Data Analysis and Machine Learning
All data analyses were carried out using Python 3.8.8 via Anaconda3, and all code was written in JupyterLab 3.0.14 web browser. REAVER datasets were modified with an additional column for NOF, NVP, and NOD measurements corresponding to each sample and used as input for all analyses.
Detailed coding methods are discussed in the Supplementary Material.
Exploratory Data Analysis (EDA)
The process of EDA included generating histograms, correlation heatmaps, and scatter plots. VIF was calculated to quantify the degree of multicollinearity by
where i represents the index of an independent variable, and R2 is the coefficient of determination.
Principal Component Analysis (PCA)
Feature engineering began with PCA, first by scaling morphological data. For visualization’s sake, the new PCs were segregated based on their input NOD value: Great: 1.0–0.75; Good: 0.50–0.75; OK: 0.25–0.50; Bad: 0.0–0.25 and plotted against PC1–2. Explained variances, eigenvalues, and loadings were obtained from the PCA object, from which scree plots were made. Heatmaps of PCs vs. metrics were generated as previously described.
Factor Analysis (FA)
Input data for FA was scaled similar to the PCA methods. Bartlett Sphericity and KMO tests were generated to test for analysis appropriateness. Unrotated FA was first carried out using six factors, followed by Varimax and Promax rotations. Heatmaps of all Factors 1–2 vs. inputs were generated as previously described.
Machine Learning Analyses
Data for machine learning was split into training and testing sets using with an 80–20% split. MLR was used to fit the training dataset to an ML model. The testing set was predicted with the fit model and evaluated with traditional accuracy metrics (R2, mean absolute error (MAE), mean squared error (MSE), root MSE (RMSE)]. Lines of best fit were plotted over scatter plots of the expected vs. predicted values in order to show the prediction variances. Recursive feature elimination after cross-validation (RFECV) was used to eliminate least-impacting inputs until the R2 value decreased.
Decision tree regression was carried out followed with pruning via cost complexity analysis after determining an optimal effective α value. Random forest models were generated using 100 estimators. Feature importance was represented as decreases in accuracy following morphological metric perturbation.
All plots were exported as SVG files and compiled into publication-ready figures using Adobe Illustrator (Adobe, Inc.; San Jose, CA 95110, USA).
Results
Generation of Microvascular Networks for Quantitative Standardization and Evaluation
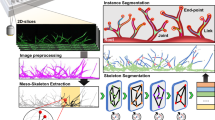
To acquire a broad range and diversity of microvascular networks, we adopted a relatively standard microfluidic device from previous literature that allowed the compartmentalization of alternating hydrogel and fluid channels (Figs. 1a–1d).17,18,19,21 This compartmentalization facilitated the diffusion of paracrine signals from co-cultured cells, or allowed exogenous supplementation of growth factors in cell culture medium, all of which yielded perfusable vascular networks within 96 h (Fig. 1d). In most assemblies, proangiogenic fibroblasts (LFs) were situated in outermost hydrogel compartments, but other assemblies in the dataset included mono-cultures of ECs in central compartments and acellular fibrin gels in outermost channels, the same supplemented with growth factors sourced through media channels, and even fibroblasts co-cultured within the central channel with ECs to facilitate LF–EC cell–cell contacts. In all cases, 500 diverse samples of microvascular networks were self-assembled by a broad range of physical and chemical components (Table S1), from which Z-stack images were compiled, cropped, and prepared for downstream, quantitative analysis.

Machine learning problem definition and development pipeline. (a) Schematic showing the parallel situation of five microchannels terminated in 1- or 5-mm port holes for hydrogel and fluid channels, respectively. (b) Fabricated device. (c) Cell suspensions are encapsulated in hydrogels and injected into the vMPS. After 96 h, endothelial cells form tubular networks similar to an in vivo capillary bed. (d) 3D reconstruction of a vMPS. (e) Input images are processed with AngioMT and REAVER, which give biological/functional and morphological quantitations, respectively. (f) The model development pipeline including data exploration and analysis via feature selection and engineering, as well as model refinement through cost-complexity analyses that eliminate insignificant input variables.
Traditional vascular network evaluation methods include the segmentation, skeletonization, and quantification of individual morphological metrics such as vessel length (mm), diameter (µm), and coverage (%),7 described in Table S2. While these metrics quantitate morphological features of the network, it is unclear if they relate to the biological function of these networks. In a recent work, we created an in silico platform, named as AngioMT, that predicts oxygen transport phenomena within these networks.27 Since a vascular network’s biological performance may be dependent upon the end-to-end movement of oxygen across a network, leakiness or permeability of capillary networks, and actual oxygen delivery into surrounding parenchyma, we derived metrics that quantitated these phenomena and measured them in our AngioMT software. We derived a NVP as a measure of permeability and the amount of oxygen available to be delivered by tissues; a NOD as a measure of the oxygen delivery into hydrogel regions, calculated as the area average of oxygen over all regions representing deoxygenated tissue, and a NOF as a measure of the average oxygen diffusion rate from vessels to tissues describing volumetric transport of oxygen in the tissue regions (Table S2).
While these biological descriptors are directly related to the oxygen tension of vascular networks, the computational cost, time, lack of automated analyses and the requirement of prior user expertise limits AngioMT’s utilization. For example, calculating these biological parameters may require significant image processing over several hours and the process may be user-dependent and not entirely objective. Therefore, due to AngioMT’s high computational cost, and REAVER’s unexplained physiological relevance, we aimed to develop a machine learned regression predicting a vMPS’s function from its morphology. We were inspired to develop a machine learned regression model from which low complexity morphological quantifications could be used to predict the higher complexity functional quantifications (Fig. 1e) using established algorithms (Fig. 1f) for rapid, user-independent and automated outcomes.
Metrics of Vascular Network Function: Statistical Tests of Independence and Multicollinearity
Since all the morphological and biological metrics (Table S2) describe different aspects of the vascular network, the extent to which they are specific, independent, and physiologically relevant is unknown. Further, inclusion of unnecessarily high dimensional data may require unnecessary computational time and redundancies in the machine learning analysis. Since several variables describe the vascular networks (Table S2), we began an EDA to select an optimal number of input features with the goal of reducing the high dimensionality of our dataset and to reduce the model training time. In our vascular networks (vMPS), we first analyzed the variable distribution and interquartile range between their minima and maxima (Table S3), as well as each variable’s proportion of outliers (Table S4), finding that mean tortuosity and mean valency skewed towards a single value. This was confirmed upon an examination of the distributions of density of each morphological variable (Fig. 2a). Further, because mean tortuosity and mean valency required other morphological values for computation (Table S2), we opted to exclude these two metrics from the machine learning analysis. Additionally, we found that max diffusion distance had a high proportion of outliers (Table S4), and thus, may also be excluded. We also found that vessel length density was similar in scale to the vessel length (Fig. 2b), and therefore, using both as input variables is redundant in our downstream regression analyses. In summary, our analyses showed that vessel coverage, vessel length, branchpoint count, segment count, mean segment length, and mean segment diameter are statistically suitable as input variables for machine learning algorithm development and regression analysis.

Exploratory data analysis aids in the generation of a suitable set of variables for downstream machine learning analyses. (a) Histograms with overlaid kernel density estimation curves, topped with boxplots illustrating the mean, minimum and maximum, interquartile (Q1–Q3; 25–75%) range, and outliers. (b) Distributions of vessel length density and vessel length. (c) Heatmap of Pearson R test correlations among all morphological metrics. (d) Kernel density estimation subplots of morphological metrics against biological metrics for pattern recognition.
Input variables in machine learning models ought to be mutually exclusive and independent, or not multicollinear, in most machine learning algorithms. Traditionally, multicollinearity undermines the statistical significance of some independent variables, leading to a redundant multivariate equation, or may limit our ability to probe each of the independent variables’ impact on the predictive model.2,11 Even though the variables were independent, we found through the Pearson R test that all these variables were highly correlated with each other, suggesting significant multicollinearity amongst some metrics (Fig. 2c). We quantified the degree of multicollinearity by performing a variance inflation factor (VIF) test (Eq. 1),8 where a score above 5–10 indicates it being multicollinearly related to other variables in the dataset. Upon calculation, we found that all our input variables scored above this threshold, further confirming our concerns of multicollinearity (Table S5). Therefore, while independent but multicollinear variables can be used in some machine learning algorithms, it limits the reliability of some models.
To conclude our EDA, we generated scatter plots of each of our biological metrics against our morphological metrics for pattern recognition in our data (Fig. 2d). We found that the features plotted against NVP and NOD showed density maps that may be fitted with simple geometries such as a linear or logarithmic curve, whereas five of the six same morphological metrics plotted against NOF resulted in parabolic shapes. Further, as NOF relies on the available oxygen from the vasculature (i.e. NVP) and quantifies an oxygen delivery rate as opposed to a mass of oxygen delivered (such as in NOD), we decided that a regression analysis might also benefit from only predicting NVP or NOD.
Dimensional Reduction of Metrics: Principal Component Analysis and Factor Analysis
Since the metrics are multicollinear, we next set out to examine feature engineering to overcome multicollinearity. Dimensional reduction is a common method of engineering new features, and such an exercise is beneficial for applications such as MLR with interacting variables. PCA is a common dimensional reduction technique that generates a new set of linearly combined variables representing decreasing amounts of variance among the entire dataset. For visualization, we classified each sample by labeling them as “Great”, “Good”, “OK”, and “Bad”, determined by splitting normalized biological values equally into four parts. After PCA, we saw a separation between “Great” and “Bad” samples in a scatter plot of Principal Component 1 (PC1) and Principal Component 2 (PC2) (Fig. 3a). The two moderate groups localized in the middle with some overlap. We chose a 2-dimensional plot with only PC1 and PC2 because they accounted for a combined 88.45% of the total variance of the dataset, and the two had eigenvalues of 4.30 and 1.02, respectively (Figs. 3b and 3c). These are traditional norms selecting for principal components (PCs), and we thus found it suitable to explain the entire dataset with only two PCs, or two variables.10 Having two PCs suggests that a regression problem might be defined with two independent variables formed via linear combinations of the original morphological data. To support this, we generated a Pearson R test with the two PCs and the original morphological variables, finding that vessel coverage, vessel length, branchpoint count, and segment count loaded above a threshold of |0.4|15 on PC1, and mean segment length and diameter loaded on PC2 above the same threshold (Fig. 3d and Table S6).

Dimensional reduction of variables with principal component analysis (PCA). PCA is used to determine relationships between all variables and linearly combined variables (PC1 and PC2) encompassing large proportions of variance within the entire dataset. (a) The scatter plot between PC1 and PC2 with classification of data based on great, good, ok, or bad criteria. Scree plots showing the (b) eigenvalue and (c) cumulative proportion of variance, vs. principal components. (d) Correlation heatmap between all morphological variables and the PCs.
Exploratory factor analysis (EFA) is another technique used to determine potential relationships between the original, measurable variables (manifest variables) from our database that may result in new underlying variables (latent variables) that cannot be measured directly. Similar to PCA, exploratory FA may result in new variables that can dimensionally reduce the size of the dataset. To determine the adequacy of this analysis, we ran a Bartlett Sphericity Test, which tests the null hypothesis that the correlation matrix of the manifest variables is an identity matrix, which if not rejected, would mean that the variables are unrelated and unideal for factor analysis.39 We observed a p-value < 0.001 indicating that the dataset is suitable for factor analysis. Additionally, we ran a Kaiser–Meyer–Olkin (KMO) Test, another adequacy benchmark measuring how the factors explain each other.39 A value less than 0.5 indicates FA is unideal, and a value close to 1.0 indicates FA is ideal. We observed a KMO value of 0.71, again indicating FA could be applied in our study.
After FA, we observed that the first two output factors contained eigenvalues above 1 (Fig. 4a), a criterion determined due to this value representing the variance of at least one manifest variable.39 Within these two factors, we found that all manifest variables loaded to one of the latent variables (Factor 1), while branchpoint count, mean segment length, and mean segment diameter loaded on the second (Factor 2) (Fig. 4b and Table S6). These observations suggest that if new interacting factors were assembled to replace the original six morphological variables, the regression equation may still have redundancies due to some morphological values contributing to multiple Factors.

Dimensional reduction of variables with factor analysis (FA). (a) Scree plot of eigenvalues vs. factors; and (b) Unrotated, Promax Rotated, and Varimax Rotated Factor Analyses segregate the morphological inputs based on their correlation values (i.e. loadings on each factor).
Factor rotations are a common technique to decrease the complexity and increase the interpretability of the FA.39 The rotations can be categorized as orthogonal or oblique. Orthogonal rotations may increase the simplicity of the FA model because the output loadings represent correlations between the new factors and the observed features, similar to our PCA results. Upon a Varimax (orthogonal) rotation, we found that vessel coverage correlated highly with both factors, and the remaining five manifest variables were distributed to one or the other of Factors 1 and 2 (Fig. 4b and Table S6). In an oblique rotation, the loadings represent regression coefficients. We used a Promax (oblique) rotation, which resulted in different loading values but the same assignment of morphological variables as the Varimax rotation (Fig. 4b and Table S6). Therefore, these analyses suggested that it might be possible to explain the entire dataset with three variables: vessel coverage, Factor 1 (the combination of vessel length, branchpoint count, and segment count), and Factor 2 (the combination of mean segment length and mean segment diameter). This is slightly different from the PCA results because vessel coverage only significantly loaded on PC1, whereas after FA, vessel coverage significantly loaded on both factors and thus should remain as its own variable in a regression problem with interacting variables.
Finally, when we again analyzed the multicollinearity of the dataset created using vessel coverage, Factor 1, and Factor 2, we found a significant reduction in VIF values, although they were still above the threshold of mutual independence (Table S7). Taken together, our analysis shows that a combination of vessel length, branchpoint count, and segment count, and a combination of mean segment length and mean segment diameter, represents higher independence and lower multicollinearity than these individual variables as inputs in a higher dimensional model.
Machine Learning Applied to Vascular Networks: Multiple Linear Regression
After our evaluation of the input metrics, MLR emerged as an obvious first candidate for quantitating the vascular networks using machine learning. Also, based on the positively linear shapes of the scatter plots between each of the independent and dependent variables (Fig. 2d), we determined that a linear regression rather than logistical, logarithmic, or exponential, is more appropriate. We split the dataset randomly into two sub-groups: a training set (80% of the entire dataset) to train our machine learned model, and a test set (20% of the entire dataset) to evaluate the accuracy of the model. We decided that standard accuracy metrics such as the R2 value, MAE, MSE, and RMSE would be adequate for evaluating the performance of our regression models.
For each dependent variable (NVP or NOD), we generated three MLR equations: (1) an equation with all six morphological values; (2) the same equation after eliminating insignificantly contributing morphological values via RFCEV; and (3) an equation using vessel coverage, Factor 1, and Factor 2 from the feature engineering experiment. As the equations become more simplified, we expected the elimination of insignificantly contributing variables would increase the accuracy of the regression equation. Further, we were interested in examining whether the engineered, less multicollinearly related features might result in more accurate predictions of each of NVP and NOD. Finally, before generating the regression equations, all morphological values were scaled to dimensionless units between 0 and 1 to aid in later analyses determining feature importance via regression coefficient sign and magnitude.
The two MLR equations resulted in models with good predictive performance shown qualitatively in scatter plots of the predicted vs. actual values after testing (Figs. 5a–5c) and quantitatively with the traditional accuracy metrics (Table S8). An MLR equation using all input features generated models predicting the NVP (Fig. 5a-i) and NOD (Fig. 5a-ii) with moderate accuracy, where the models had an R2 value of 0.64 and 0.74 and a MAE of 0.14 and 0.09 for NVP and NOD, respectively (Table S8). Interestingly, RFECV eliminated a single morphological variable in the NVP equation (Fig. 5b-i), but no variables in the NOD equation (Fig. 5b-ii), highlighting that our feature selection experiment yielded a good, non-redundant set of inputs. Eliminating a single variable from the NVP equation resulted in a slight and insignificant decrease in accuracy. Also, models using interacting, combinational factors performed similar to the models using non-interacting variables (Table S8 and Fig. 5c-i–ii), highlighting that dimensional reduction reduces prediction time via a lower dimensional model, but similarly performing models using raw morphological data may still be used without this intermediate step.

Machine learned multiple linear regression shows moderate success in predicting biological metrics. Analyses include (a) regression using all six morphological metrics; (b) regression following recursive feature elimination with-cross validation (RFCEV); and (c) regression analysis consisting of combinatorial variables from exploratory FA (vessel coverage, Factor 1, and Factor 2). Regression analyses using (a–c-i) Normalized Vascular Potential as the dependent variable; and (a–c-ii) Normalized Oxygen Delivery as the dependent variable.
Simple observation of the regression coefficients is a common method of determining which of the input metrics influences the prediction. However, the multicollinearity of our data makes this analysis limited due to the mutual dependence amongst the variables. Nevertheless, we found that the regression coefficients for vessel coverage outweighed all others in every case by 2–3-fold (Table S9), but the next most impacting metric differs for each biological variable. For example, vessel length gives a slightly negative coefficient for NVP, suggesting higher vessel lengths can decrease the available oxygen to diffuse into the hydrogel region. This observation is not true for NOD, however, as vessel length was the least contributing variable with a regression coefficient of 0.02, causing its elimination during RFECV. Finally, we observed that the morphological data explains the highest amount of variance among the NOD data (71–74%), shown by the R2 scores (Fig. 5 and Table S8), confirming our original hypothesis that vascular morphology may describe vascular function. Thus, this model is a quick and simple method of predicting AngioMT values from morphological data with ± 15% error, and suggests vessel coverage to be most predictive of a highly functional vascular network.
Machine Learning Applied to Vascular Networks: Random Forest Regression
Decision tree based-regression is a machine learning technique that is not limited by multicollinearity, which our dataset exhibits. Hence, we first established a decision tree regressor, despite their known susceptibility to overfitting of the training dataset, which limits their power with unknown data. Expectedly, the decision tree regression model showed poor accuracy when undergoing testing (Table S10). However, the residuals show a normalized distribution centered at 0 for each biological metric (Fig. 6a-i). Interestingly, a scatter plot of the expected vs. predicted oxygen delivered shows that higher values give higher errors, but lower values tend to be predicted accurately (Fig. 6a-ii). Further, vessel coverage is the most important metric (Fig. 6a-iii), proven via a computation of the mean decrease in accuracy of the tree as each metric is randomly permutated, a common technique for feature importance identification. Similar to MLR, the other morphological metrics contribute to each prediction at least 2-fold less.

Tree-based regression methods demonstrate comparable accuracies but overcome problems of multicollinearity (a) unpruned decision tree testing results. (i) Residuals histogram. (ii) Expected vs. predicted scatter plots. (iii) Random permutation of input variables to measure the chief governor of the model. (b) Results of testing to generalize the overfit, unpruned tree. (i) Tuning effective α to increase leaf impurity. (ii) Training and testing data performance as effective α is increased. (iii) Node number as effective α is increased. (iv) Tree depth as effective α increases. (c) Accuracy results after pruning the decision tree. (i) Residuals histogram. (ii) Expected vs. predicted scatter plot. (iii) Random permutation of the input variables to determine the most important input. (d) Random forest regressor testing results. (i) Residuals histogram. (ii) Expected vs. predicted scatter plots. (iii) Random permutation of inputs to determine greatest contributor to the model.
A common technique to improve the accuracy of a decision tree regressor is pruning. Instead of arbitrarily limiting the depth of the tree or the number of leaves, we methodically pruned using a cost-complexity analysis.23 Here, we used a tree score employing a penalty score (Effective α), that characterizes the extent of pruning, which generalizes the tree but also increases the impurity of the leaves (Fig. 6b-i), or decreases the accuracy of the model during training (Fig. 6b-ii). Further, as we prune more of the tree by increasing the effective α, we decrease the number of nodes (Fig. 6b-iii) and the depth of the tree (Fig. 6b-iv), thus making a more generalized tree that might predict the testing data better than an unpruned tree.
Indeed, upon evaluating the best performing pruned decision tree regressor with the unseen testing data, we found that the accuracy metrics improve (Table S10) and the histogram of residuals remained normally distributed around 0 (Fig. 6c-i). A scatter plot of the expected vs. predicted values showed that the predicted data arranged in tiers, a common outcome of a pruned decision tree regressor (Fig. 6c-ii). Strikingly, random permutation of vessel coverage tended to decrease the accuracy almost 80%, confirming that this metric influences the regression model (Fig. 6c-iii).
Lastly, we employed random forest regression, an algorithm that employs a large ensemble of different, uncorrelated regression trees operating in committee that outperforms any single tree. Following training and subsequent testing, we found that a random forest performed significantly better than the previous tree architectures, with an R2 value of 0.70 (Table S10 and Fig. 6d). We again generated a histogram of the residuals, finding that the random forest model had the smallest range distributed normally around an error of 0 (Fig. 6d-i). The expected vs. predicted scatter plot also showed that predicted values followed the expected trend to a closer extent than other tree-based regression models, yet some outliers still emerge (Fig. 6d-ii). Finally, an analysis of the mean decreases in accuracy following random perturbation of each morphological metric showed that vessel coverage was again the most important metric for this model (Fig. 6d-iii). Therefore, random forest regression is a predictor of AngioMT data using morphological data as input, even when multicollinear data is presented. Further, random forest regression outperforms simpler tree-based regressors, and may thus be adopted for approximating AngioMT quantifications of the vMPS without dedicating high computational resources to their image processing pipeline.
Discussion
This exercise in EDA, dimensional reduction, and superficial machine learning provides a framework for designing vMPS with a biological motivation. Our key findings include a reduction of morphological variable inputs into the model, two new linearly combined variables encompassing the morphology with lower multicollinearity, and evidence that machine learning algorithms may be able to assist in predicting the biological function of capillary networks cultivated in vMPSs. Importantly, random forest regression emerged as an optimal algorithm for predicting oxygenation given the nature of our morphological data. This model is now available for future vMPS engineers to optimize their networks without having to run their own numerical analyses to measure biological metrics of oxygen transport.
Our analysis also revealed that among all singular metrics used, vessel coverage is a morphological measure of vascular networks that is statistically most relevant. However, exclusively relying on the vessel coverage could lead to improper outcomes from vMPS. For example, Kim et al., found that some vMPS exhibited characteristics of hyperplasia and subsequently engineered thinner networks with lower vessel coverages via pericyte co-culture.20 They found that pericytes reduced the vessel diameter and increased the number of junctions and branches, and even decreased the vessel permeability. Thus, the other five morphological metrics included in our own analyses might still play an important role in the biologically motivated engineering of vascular networks in MPS. Further, for the remaining five morphological metrics, RFECV after linear regression found that the other five morphological metrics generally increased the accuracy of the predictions, and random feature perturbation in tree models showed some impact on the prediction accuracy. Therefore, all six metrics variably contribute when predicting oxygen delivering potential.
Oxygen delivering potential is a significant endpoint measure of assessment in future vMPS and tissue engineering studies. All cells and tissues posses an oxygen sensing ability which ultimately influences transduction pathways that alters a cell’s genotype and phenotype.13 Hypoxia caused by inefficient oxygen delivery causes ATP levels to drop, thus limiting cellular function which can cause cell death.34 A classic example of hypoxia effects on cells is the hypoxia-inducible factor (HIF) pathway, which influences inflammation, diabetes, and aging.13 Relatedly, cancer cells induce hypoxia which recruits neighboring vasculature via growth factor and cytokine release.1 Thus, relying on the traditional morphological metrics may not capture the influence of these biological events induced by vascular networks. In contrast, the analysis presented here could potentially be more representative of this biology and thus have a better potential use in quality scoring compared to morphological analyses.
One possible limitation of the model is that it does not currently include oxygen convection. Even though the limited current literature on in vivo measurements suggest that oxygen transport is primarily diffusive within a tissue, there may be cases (for example, when vessels become leaky due to inflammation) when oxygen transport becomes convective. If permeability measurements and oxygen measurements in future studies of the vMPS suggest such phenomena, we may have to adapt the AngioMT and include the physics of convective transport in our model. Some other improvements can be made in future works. For example, other deep learning regression methods that are not limited by multicollinearity may provide more accurate predictions than the two strategies investigated herein. Such regression models carry some advantages over image classifiers, namely shorter training times, smaller memory allocation, and less processing power. Image classifiers are known to require higher training times and computational resources, and also require investigators to annotate images for sorting. With AngioMT and/or the machine learning models established here, future vMPS or machine learning engineers may annotate the vMPS images in our database based on quantitative oxygen delivering measurements which can then be used to train an image classifier.
Ultimately, this exercise represents a need for the MPS and vMPS fields to begin adopting advanced quantification methods. We see that with simple programming, we can extract a large amount of data that relates a computationally inexpensive set of morphological metrics to a more computationally taxing numerical analysis of the potential oxygen transport and delivery through the same samples. While other softwares exist quantifying vascular morphology, such as, REAVER6 and/or employing machine learning to predict vessel density of a network,38 we are applying machine learning to vascular networks in tissue engineering models, such that these algorithms predict their biological function, and not just morphology. As more complex assays are developed, especially towards the use of MPSs in medical regulation, pharmaceutics, and tissue engineering, more complex data analysis techniques may be adopted. Further, as more data is generated, machine and deep learning methods may be employed over manual data analysis.12,24 Machine learning models can also be shared between labs, offering a way of standardizing MPS design procedures, such as the establishment of vMPS with tissue-specific organoids. As MPSs continue to increase in complexity, similar exercises in machine learning can be undertaken following the examples we completed herein.
References
Al Tameemi, W., T. P. Dale, R. M. K. Al-Jumaily, and N. R. Forsyth. Hypoxia-modified cancer cell metabolism. Front. Cell Dev. Biol. 7:4, 2019. https://doi.org/10.3389/fcell.2019.00004.
Allen, M. P. In: Understanding Regression Analysis, edited by M. P. Allen. New York: Springer, 1997, pp. 176–180.
Campisi, M., et al. 3D self-organized microvascular model of the human blood–brain barrier with endothelial cells, pericytes and astrocytes. Biomaterials. 180:117–129, 2018. https://doi.org/10.1016/j.biomaterials.2018.07.014.
Candiello, J., et al. 3D heterogeneous islet organoid generation from human embryonic stem cells using a novel engineered hydrogel platform. Biomaterials. 177:27–39, 2018. https://doi.org/10.1016/j.biomaterials.2018.05.031.
Chen, A. X., et al. Controlled apoptosis of stromal cells to engineer human microlivers. Adv. Funct. Mater. 2020. https://doi.org/10.1002/adfm.201910442.
Corliss, B. A., et al. REAVER: a program for improved analysis of high-resolution vascular network images. Microcirculation. 27:e12618, 2020. https://doi.org/10.1111/micc.12618.
Corliss, B. A., C. Mathews, R. Doty, G. Rohde, and S. M. Peirce. Methods to label, image, and analyze the complex structural architectures of microvascular networks. Microcirculation. 26:e12520, 2019. https://doi.org/10.1111/micc.12520.
Craney, T. A., and J. G. Surles. Model-dependent variance inflation factor cutoff values. Qual. Eng. 14:391–403, 2002. https://doi.org/10.1081/QEN-120001878.
Cui, H., et al. Engineering a novel 3D printed vascularized tissue model for investigating breast cancer metastasis to bone. Adv. Healthc. Mater. 9:e1900924, 2020. https://doi.org/10.1002/adhm.201900924.
David, C. C., and D. J. Jacobs. Principal component analysis: a method for determining the essential dynamics of proteins. Methods Mol. Biol. 1084:193–226, 2014. https://doi.org/10.1007/978-1-62703-658-0_11.
Farrar, D. E., and R. R. Glauber. Multicollinearity in regression analysis: the problem revisited. Rev. Econ. Stat. 49:92–107, 1967. https://doi.org/10.2307/1937887.
Galan, E. A., et al. Intelligent microfluidics: the convergence of machine learning and microfluidics in materials science and biomedicine. Matter. 3:1893–1922, 2020. https://doi.org/10.1016/j.matt.2020.08.034.
Giordano, F. J. Oxygen: both a passenger and a biological determinant in the vasculature. Arterioscler. Thromb. Vasc. Biol. 30:641–642, 2010. https://doi.org/10.1161/ATVBAHA.110.202945.
Gold, K., A. K. Gaharwar, and A. Jain. Emerging trends in multiscale modeling of vascular pathophysiology: organ-on-a-chip and 3D printing. Biomaterials. 196:2–17, 2019. https://doi.org/10.1016/j.biomaterials.2018.07.029.
Guadagnoli, E., and W. F. Velicer. Relation of sample size to the stability of component patterns. Psychol. Bull. 103:265–275, 1988. https://doi.org/10.1037/0033-2909.103.2.265.
Ingber, D. E. Is it time for reviewer 3 to request human organ chip experiments instead of animal validation studies? Adv. Sci. (Weinh.). 7:2002030, 2020. https://doi.org/10.1002/advs.202002030.
Jeon, J. S., et al. Generation of 3D functional microvascular networks with mural cell-differentiated human mesenchymal stem cells in microfluidic vasculogenesis systems. Integr. Biol. (Camb.). 6:555–563, 2014. https://doi.org/10.1039/b000000x/NIH-PA.
Jeon, J. S., et al. Human 3D vascularized organotypic microfluidic assays to study breast cancer cell extravasation. Proc. Natl Acad. Sci. USA. 112:214–219, 2015. https://doi.org/10.1073/pnas.1417115112.
Jeon, J. S., I. K. Zervantonakis, S. Chung, R. D. Kamm, and J. L. Charest. In vitro model of tumor cell extravasation. PLoS ONE. 8:e56910, 2013. https://doi.org/10.1371/journal.pone.0056910.
Kim, J., et al. Engineering of a biomimetic pericyte-covered 3D microvascular network. PLoS ONE. 10:e0133880, 2015. https://doi.org/10.1371/journal.pone.0133880.
Kim, S., H. Lee, M. Chung, and N. L. Jeon. Engineering of functional, perfusable 3D microvascular networks on a chip. Lab Chip. 13:1489–1500, 2013. https://doi.org/10.1039/c3lc41320a.
Lee, S., et al. Microfluidic-based vascularized microphysiological systems. Lab Chip. 18:2686–2709, 2018. https://doi.org/10.1039/c8lc00285a.
Lewis, R. J. In: Proceedings of the 2000 Annual Meeting of the Society for Academic Emergency Medicine, 2000, pp. 1–14.
Li, J., et al. An overview of organs-on-chips based on deep learning. Research (Wash DC). 9869518:2022, 2022. https://doi.org/10.34133/2022/9869518.
Mathur, T., et al. Organ-on-chips made of blood: endothelial progenitor cells from blood reconstitute vascular thromboinflammation in vessel-chips. Lab Chip. 19:2500–2511, 2019. https://doi.org/10.1039/c9lc00469f.
Mathur, T., J. J. Tronolone, and A. Jain. Comparative analysis of blood-derived endothelial cells for designing next-generation personalized organ-on-chips. J. Am. Heart. Assoc. 10:e022795, 2021. https://doi.org/10.1161/JAHA.121.022795.
Mathur, T., J. J. Tronolone, and A. Jain. AngioMT: an in silico platform for digital sensing of oxygen transport through heterogeneous microvascular networks. bioRxiv. 2023. https://doi.org/10.1101/2023.01.09.523275.
Pang, L., et al. Workshop report: FDA workshop on improving cardiotoxicity assessment with human-relevant platforms. Circ. Res. 125:855–867, 2019. https://doi.org/10.1161/CIRCRESAHA.119.315378.
Phan, D. T. T., et al. A vascularized and perfused organ-on-a-chip platform for large-scale drug screening applications. Lab Chip. 17:511–520, 2017. https://doi.org/10.1039/c6lc01422d.
Rajeeva Pandian, N. K., B. K. Walther, R. Suresh, J. P. Cooke, and A. Jain. Microengineered human vein-chip recreates venous valve architecture and its contribution to thrombosis. Small. 16:e2003401, 2020. https://doi.org/10.1002/smll.202003401.
Rambol, M. H., E. Han, and L. Niklason. Microvessel network formation and interactions with pancreatic islets in 3D chip cultures. Tissue Eng. A. 2019. https://doi.org/10.1089/ten.TEA.2019.0186.
Saha, B., et al. OvCa-Chip microsystem recreates vascular endothelium-mediated platelet extravasation in ovarian cancer. Blood Adv. 4:3329–3342, 2020. https://doi.org/10.1182/bloodadvances.2020001632.
Saha, B., et al. Human tumor microenvironment chip evaluates the consequences of platelet extravasation and combinatorial antitumor–antiplatelet therapy in ovarian cancer. Sci. Adv. 7:eabg5283, 2021. https://doi.org/10.1126/sciadv.abg5283.
Sendoel, A., and M. O. Hengartner. Apoptotic cell death under hypoxia. Physiology (Bethesda). 29:168–176, 2014. https://doi.org/10.1152/physiol.00016.2013.
Shin, Y. C., et al. Three-dimensional regeneration of patient-derived intestinal organoid epithelium in a physiodynamic mucosal interface-on-a-chip. Micromachines (Basel). 2020. https://doi.org/10.3390/mi11070663.
Shirure, V. S., C. C. W. Hughes, and S. C. George. Engineering vascularized organoid-on-a-chip models. Annu. Rev. Biomed. Eng. 2021. https://doi.org/10.1146/annurev-bioeng-090120-094330.
Si, L., et al. A human-airway-on-a-chip for the rapid identification of candidate antiviral therapeutics and prophylactics. Nat. Biomed. Eng. 5:815–829, 2021. https://doi.org/10.1038/s41551-021-00718-9.
Strobel, H. A., A. Schultz, S. M. Moss, R. Eli, and J. B. Hoying. Quantifying vascular density in tissue engineered constructs using machine learning. Front. Physiol. 12:650714, 2021. https://doi.org/10.3389/fphys.2021.650714.
Taherdoost, H., S. Sahibuddin, and N. Jalaliyoon. In: Advances in Applied and Pure Mathematics Vol. 27 Mathematics and Computers in Science and Engineering Series, edited by B. Jerzy. Athens: WSEAS, 2014, pp. 375–382.
Tronolone, J. J., et al. Electric field assisted self-assembly of viruses into colored thin films. Nanomaterials (Basel). 2019. https://doi.org/10.3390/nano9091310.
Tronolone, J. J., and A. Jain. Engineering new microvascular networks on-chip: ingredients, assembly, and best practices. Adv. Funct. Mater. 2021. https://doi.org/10.1002/adfm.202007199.
Tronolone, J. J., J. Lam, A. Agrawal, and K. Sung. Pumpless, modular, microphysiological systems enabling tunable perfusion for long-term cultivation of endothelialized lumens. Biomed. Microdevices. 23:25, 2021. https://doi.org/10.1007/s10544-021-00562-3.
van den Berg, A., C. L. Mummery, R. Passier, and A. D. van der Meer. Personalised organs-on-chips: functional testing for precision medicine. Lab Chip. 19:198–205, 2019. https://doi.org/10.1039/c8lc00827b.
Wang, J., et al. A virus-induced kidney disease model based on organ-on-a-chip: pathogenesis exploration of virus-related renal dysfunctions. Biomaterials. 219:119367, 2019. https://doi.org/10.1016/j.biomaterials.2019.119367.
Weber, E. J., et al. Human kidney on a chip assessment of polymyxin antibiotic nephrotoxicity. JCI Insights. 2018. https://doi.org/10.1172/jci.insight.123673.
Whisler, J. A., M. B. Chen, and R. D. Kamm. Control of perfusable microvascular network morphology using a multiculture microfluidic system. Tissue Eng. C. 20:543–552, 2014. https://doi.org/10.1089/ten.TEC.2013.0370.
Yi, H. G., et al. A bioprinted human-glioblastoma-on-a-chip for the identification of patient-specific responses to chemoradiotherapy. Nat. Biomed. Eng. 3:509–519, 2019. https://doi.org/10.1038/s41551-019-0363-x.
Acknowledgments
This material is supported by an American Heart Association Predoctoral Fellowship under Grant No. 906239, a National Science Foundation Graduate Research Fellowship under Grant No. 1650114, and a Texas A&M Biomedical Engineering Department National Excellence Fellowship to J.J.T.; and by the NHLBI of NIH under Award Number R01HL157790, NSF CAREER Award Number 1944322, and Texas A&M University President’s Excellence in Research Award (T32/X-Grant) to A.J.
Author information
Authors and Affiliations
Corresponding author
Additional information
Associate Editor Aleksander S. Popel oversaw the review of this article.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Tronolone, J.J., Mathur, T., Chaftari, C.P. et al. Evaluation of the Morphological and Biological Functions of Vascularized Microphysiological Systems with Supervised Machine Learning. Ann Biomed Eng 51, 1723–1737 (2023). https://doi.org/10.1007/s10439-023-03177-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10439-023-03177-2