
Abstract
GIS-based landslide susceptibility maps for the Kankai watershed in east Nepal are developed using the frequency ratio method and the multiple linear regression technique. The maps are derived from comparing observed landslides with possible causative factors: slope angle, slope aspect, slope curvature, relative relief, distance from drainage, land use, geology, distance from faults and mean annual rainfall. The consistency of the maps is evaluated using landslide density analysis, success rate analysis and spatially agreed area approach. The first two analyses produce almost identical quantitative results, whereas the last approach is able to reveal spatial differences between the maps and also to improve predictions in the agreed high landslide-susceptible area.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Fell et al. (2008) defined landslide susceptibility as a quantitative or qualitative assessment of the classification, volume (or area) and spatial distribution of landslides, which exist or potentially may occur in an area. Various researchers (e.g. Brabb 1984; Hansen 1984; Varnes 1984, Cruden and Varnes 1996; Hutchinson 1995) have considered a number of causative factors responsible for landslides. A systematic study of landslides including inventory mapping, susceptibility mapping, hazard mapping and risk assessment has been carried out by different researchers in different parts of the world in the last three decades mainly due to increasing awareness of its socio-economic impacts as well as increasing pressure of urbanization on environment (Aleotti and Chowdhury 1999).
The fragile and geologically young Himalayan mountains of Nepal are characterized by a high relief, high-intensity monsoon rainfall and earth tremors, which contribute to natural disasters such as landslides and floods. Losses caused by these natural disasters are on an increase as a result of accelerating rapid population growth and infrastructural development activities in these areas. Large-scale deforestation, unplanned land use systems and the construction of physical infrastructures, such as irrigation canals, roads and dams in hazardous mountainous regions have contributed to increasing problems of landslides, debris flows, soil erosion and floods (Upreti and Dhital 1996).
Up to date, only a few studies have been carried out on landslide susceptibility, hazard and risk analysis in east Nepal. In the eastern region of Nepal and adjacent parts in India, landslide susceptibility maps have been prepared by different researchers, such as in Darjeeling, India (Sarkar and Kanungo 2004; Kanungo et al. 2006, 2008, 2009; Gupta et al. 2008; Ghosh et al. 2009, 2010), Sikkim, India (Sarkar et al. 2006, 2008), and Panchthar, Nepal (Poudyal et al. 2010). Researchers have attempted to compare landslide susceptibility maps of the same study area using various approaches. Dhakal et al. (2000) evaluated the spatial agreement of the hazard classes between various hazard maps of the Kulekhani watershed in central Nepal. Lee (2004) compared the landslide susceptibility maps of Jang-hung, Korea, obtained from the likelihood ratio method and logistic regression using success rate curves. Gupta et al. (2008) compared the landslide susceptibility zonation maps of Darjeeling, India, based on conventional (i.e. heuristic), artificial neural network black box, and fuzzy weighting procedures, using three different approaches, i.e. landslide density analysis, error matrix analysis and difference image analysis.
Since various investigators have followed different approaches to evaluate the consistency of their susceptibility maps, this paper attempts to evaluate and compare the consistency of GIS-based landslide susceptibility maps in the Himalayan region taking the Kankai watershed of eastern Nepal as an example. For this purpose, bivariate and multivariate statistical methods are applied to generate landslide susceptibility zonation maps. These maps are then compared using landslide density analysis, success rate analysis and spatially agreed area analysis.
Study area
Physiography
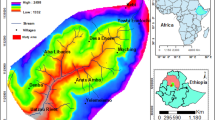
The Kankai watershed (26°39′23″–27°06′15″ N latitude and 87°41′00″–88°09′11″ E longitude) lies in the middle Himalayan Mountains of east Nepal. It has a total area of about 1,175 km2 and occupies parts of the Ilam and Jhapa districts. The northern and southern portions of the watershed are densely forested. The central part is densely populated and is characterized by dry cultivation on upper and middle hill slopes and by wet (paddy) cultivation on river terraces and floodplains.
The Kankai River and its tributaries form essentially a dendritic drainage pattern (Fig. 1). The Kankai River is perennial and characterized by strong temporal and spatial variation in direct runoff and considerable base flow in its lower course. The Sanomai River originates from Lampokhari lying at an altitude of 2,560 m on the northern mountain range and further downstream confluences with the Jogmai River and Puwamai River to form the Mai River. The Mai River joins with the Deumai River from the western part of the watershed and after the confluence becomes the Kanaki River. After the Kankai River joins with the Garuwa River at Garuwa village, it takes a wide and braided course when it emerges from the Siwalik Hills at Domukha.

Location map of the Kankai watershed in Eastern Nepal, with indication of villages, river courses, nearby hydro-meteorological stations and observed landslides
The climate is subtropical and temperate but strongly influenced by altitude and physiographic characteristics. Eight hydro-meteorological stations of the Department of Hydrology and Meteorology, Government of Nepal, are situated inside or just outside of the Kankai watershed, as shown in Fig. 1. A list of the stations location, altitude and recorded average annual precipitation is presented in Table 1. The recorded temperature ranges from 5 to 40 °C in the lower altitudes with hot summers (June–August) and warm winters (December–February) and from 0 to 30 °C in the higher altitudes with warm summers and cold winters. About 80 % of all precipitation occurs during the monsoon starting from June to the end of September.
Geology
The geology of the area was initially derived from a geological map (2006, scale 1:250,000, Department of Mines and Geology, Government of Nepal) and updated by field work in April 2010 (Table 2; Fig. 2). The study area lies partly in the Siwaliks, a narrow belt of the Lesser Himalaya and partly in an extensive tract of the Higher Himalaya (Sharma 1990). The Higher Himalaya and Lesser Himalaya are separated by the Main Central Thrust (MCT). The Lesser Himalayan rocks are further separated from the Siwaliks by the Main Boundary Thrust (MBT), which follows the middle reach of the Mai Khola. The Middle Siwaliks and the Lower Siwaliks are separated by the Mai Khola Thrust (MKT), which is covered at many places by alluvial deposits of the Mai Khola.

Geological map of the Kankai watershed derived from the geological map (2006) of the Department of Mines and Geology, Government of Nepal, and updated by field reconnaissance in April 2010
Higher Himalaya
The Higher Himalayan rocks cover about 73 % of the study area and consist of grey garnet schist, grey kyanite and sillimanite schist, or banded and augen gneisses with infrequent grey to light grey quartzite bands. Most of the Higher Himalayan rocks are deeply weathered and are covered by grey, brown or yellow residual soils of more than 3 m in thickness. Many large landslides are found on the Higher Himalayan rocks.
Lesser Himalaya
This group of rocks of Pre-cambrian age mainly consists of low-grade metamorphic rocks that occupy less than 7 % of the study area. Because of thrusting, these Lesser Himalayan rocks are exposed adjacent to the rocks of Higher Himalaya. They are composed of light grey to white quartzites, grey-green phyllites, grey metasandstones or grey garnetiferous schists with dark grey-green amphibolites. Banded gneisses are also found on the Lesser Himalayan rocks, especially near Soktim. Grey-to-brown colluvial soil is frequently found on top of the Lesser Himalayan rocks and yellow-brown residual soils, which may exceed 3 m in thickness, in locations often associated with geomorphological ridges and saddles.
Siwaliks
The Siwaliks constitute about 15 % of the total watershed area and consist of mudstones, fine- to coarse-grained unconsolidated sandstones or conglomerates ranging in age from Middle Miocene to Pleistocene. These are thrust over the sediments of the Terai and are subdivided into the Lower, Middle and Upper Siwaliks. The Lower Siwaliks are fine-grained, grey sandstones interbedded with purple and green shales. They are distributed as a narrow zone near the MBT and at the foothills near Domukha and Soktim. The Lower Siwaliks are covered by yellow-brown residual soils, often more than 3 m in thickness. The Middle Siwaliks are characterized by fine- to medium-grained arkosic pebbly sandstones with rare grey to dark grey clays and occasionally with silty sandstones and conglomerates. The upper part of the Middle Siwaliks consists of medium- to coarse-grained fine- to medium-grained massive sandstones interbedded with green to greenish grey clays, grey shales with thin bands of pseudo conglomerates and mudstones. The Middle Siwaliks are covered by light grey to brown residual soil. There are also a number of rills and gullies, especially at the contact between the resistant sandstone and soft mudstone. The Upper Siwaliks consist of coarse boulder conglomerates with irregular beds and lenses of sandstones and thin intercalations of yellow, brown and grey sandy clays. On the Upper Siwaliks, thin (less than 1 m) soils made up of gravels and boulders are frequently found.
Quaternary alluvial deposits
Quaternary alluvial deposits are confined mainly to the intermountain valleys of the Mai River, Garuwa River and Kankai River. These deposits constitute alluvial fans, terraces and bars made up of gravels, sands and silts.
Geomorphology
The landforms of the Kankai watershed are controlled by the geological structures and lithology. The watershed incorporates three major physiographic regions, namely, the Siwalik Hills, the Mahabharat Range and the Midlands (Hagen 1969).
Siwalik Hills
The Siwalik Hills (or Churia Range) are the southernmost mountain range of the Himalaya, which abruptly rise from the Terai plain up to an altitude of about 1,500 m. The villages Domukha and Garuwa lie on the Siwalik Hills. This range is very rugged with deeply dissected gullies and low terraces or alluvial fans with thin soil covers. The majority of the rivers originating in this range are ephemeral and carry huge amounts of sediments.
Mahabharat Range
This range abruptly rises from the Siwalik Hills, reaching a maximum altitude of about 3,000 m. The town of Ilam and the villages Gajurmukhi, Sanurumba and Rangapani lie on the Mahabharat Range. The landform consists of high hills and rugged terrain with deep gorges. This range is important from a hydro-meteorological point of view because it acts as a barrier and controls the distribution of precipitation in the watershed. The southeast-, south- and southwest-facing slopes of this range are highly prone to mass movements because of the steep slopes and abundant precipitation (Sharma 1990).
Midlands
The Midlands consist of low-lying hills, wider river valleys and tectonic basins but are not well developed in east Nepal (Sharma 1990). The Kankai watershed between Lampokhari (to the north) and Ilam (to the south) lies mainly in these Midlands.
Data preparation
General data
Thematic digital maps were generated from data collected from different sources (Table 3) using GIS software ILWIS 3.5, ArcView 3.3 and IDRISI Andes. All maps are raster-based with a cell size of 20 × 20 m. The preparation procedures for each data layer are summarized below.
Landslide inventory map
Aerial photographs and digital topographic maps were used to identify landslide locations, which were verified and further updated by a series of field campaigns in April 2010. The exact location and demarcation of the landslides was carried out in the field using a handheld GPS (accuracy of about 1 m horizontally and 2 m vertically). In this way, a reliable landslide inventory map was prepared (Fig. 1). A total of 256 landslides were observed in the Kankai watershed, which cover an area of about 5.40 km2 or about 0.5 % of the study area and range in size from 400 m2 to 0.61 km2. The field visits showed that most of these slides were already stabilized and consisted mainly of shallow soil or rock slides, plane or wedge failures and rotational slides. Previous studies in Nepal have shown that landslide frequency increases with increasing slope angle up to 35° but then decreases with slope angle (Deoja et al. 1991; Thapa and Dhital 2000; Kayastha et al. 2010). A similar trend has also been found in the present study area. The largest landslide of the study area is located at Sanrumba (Figs. 1 and 3a). It covers an area of about 0.61 km2. This landslide devastated about 600 ha of farmland and some houses. Another large landslide, observed at Rangapani (Fig. 3b), destroyed a stretch of about 150 m of the Soktim–Ilam road.

Examples of some observed landslides: a Sanrumba debris slide (view to SW), b Rangapani debris and rock slide (view to SE); the locations of these slides are indicated in Fig. 1
Topographic factors
A digital elevation model (DEM) of the study area (Fig. 4) was prepared on the basis of the 20-m interval elevation contours using triangular irregular network interpolation. From this DEM, geomorphological thematic data layers such as slope angle, slope aspect, slope curvature and relative relief were prepared. A map of slope classes was generated by separating slope angles into five different classes (Bijukchhen et al. 2012; Kayastha et al. 2012): (1) flat to gentle slope (0–15°), (2) moderate slope (15–25°), (3) fairly moderate slope (25–35°), (4) steep slope (35–45°) and (5) very steep slope (>45°). Aspect, i.e. direction of maximum slope of the terrain surface, was divided into nine classes: north (N), northeast (NE), east (E), southeast (SE), south (S), southwest (SW), west (W), northwest (NW) and flat. Similarly, slope curvature was divided into three different classes: convex, planar (straight) and concave.

Digital elevation model of the Kankai watershed with cell size 20 × 20 m, derived by interpolation from 20-m digital elevation contours (Table 3)
Relative relief is defined as the maximum height dispersion of a terrain normalized by its length or area (Oguchi 1997). In this study, relative relief was computed as the difference between maximum and minimum altitudes (m) per hectare of land. Relative relief was divided into the four classes: (1) <25 m/ha, (2) 25–50 m/ha, (3) 50–100 m/ha and (4) >100 m/ha.
Geological factors
A geological map (Fig. 2) was digitized on the basis of a geological map provided by the Department of Mines and Geology, Government of Nepal, and corrected by field observations in April 2010. Also, fault lines in the study area were digitized from the geological map and verified and modified after the field visit. A digital map of distance from faults was derived based on the Euclidian distance method and classified into three classes: (1) <2 km, (2) 2–5 km and (3) >5 km.
Land use
Land use is one of the most important conditioning factors in slope stability (van Westen et al. 2003). Based on field observations and the land cover maps provided by the Department of Survey, Government of Nepal, eight land use classes were identified, as shown in Fig. 5: cultivation and built-up areas, tea plantation, forest, grass land, bush, sandy area, barren land and water body. Almost half of the study area is covered by forest, whereas the remainder is used for cultivation or tea plantation with few built-up areas.

Land use map of the Kankai watershed with cell size 20 × 20 m, derived from 20-m digital land use maps (Table 3)
Hydrological and climatic factors
Runoff plays an important role in triggering landslides. In the study area, landslides occur frequently on stream banks (Fig. 1). Hence, in order to model the influence of runoff on landsliding, distance from drainage was taken into account. The distance from drainage is represented by the proximity to river courses (Table 3) and computed on the basis of the Euclidian distance method. The study area was classified into four classes: (1) <25 m, (2) 25–50 m, (3) 50–100 m and (4) >100 m.
As the study area is strongly affected by the monsoon climate and the rainy season, it is also necessary to take rainfall into account as a triggering factor for landsliding. The average annual rainfall (Table 1) was considered as factor for landslide analysis. A rainfall map was prepared from the observations at the eight meteorological stations using the Inverse Distance Weighted interpolation method of ArcView 3.3 and reclassified into two classes: (1) 1,750–2,250 mm/year and (2) >2,250 mm/year.
Landslide susceptibility mapping
Various statistical methods exist to obtain landslide susceptibility zonation maps, which can broadly be classified into two types: bivariate and multivariate. Bivariate methods measure, directly or in weighted form, the relative or absolute abundance of landslide area or number in different terrain categories. The main difference among the bivariate methods is the way in which the weights are produced, e.g. information value method (Yin and Yan 1988), certainty factor (Chung and Fabbri 1993), statistical index method (van Westen 1997), surface percentage index (Uromeihy and Mahdvifar 2000), frequency ratio (Lee and Min 2001), weights of evidence (Lee et al. 2002) and weighting factor (Çevik and Topal 2003).
Frequency ratio method
In this study, the frequency ratio method of Lee and Min (2001) is used to obtain the weight values for each parameter class as follows:
where W ij is the weight value or frequency ratio of class i of parameter j, \( f_{ij}^{\ast}={{{A_{ij}^{\ast}}} \left/ {{{A^{\ast}}}} \right.} \) is the frequency of observed landslides in class i of parameter j, \( {f_{ij }}={{{\left( {{A_{ij }}-A_{ij}^{\ast}} \right)}} \left/ {{\left( {A-{A^{\ast}}} \right)}} \right.} \) is the frequency of non-observed landslides in class i of parameter j, \( A_{ij}^{\ast} \) is the area of landslides in a class i of parameter j, A ij is the area of class i of parameter j, A * is the total area of landslides in the study area and A is the total area of the study area. The weight values are shown in Table 4. A weight value less than 1 indicates a lower probability of landslide occurrence, whereas a weight value greater than 1 indicates a higher probability of landslide occurrence.
In order to combine all weight values of the different parameters, an overall landslide susceptibility index (LSI) is calculated by adding all parameter weight maps:
where n is the number of parameters. The resulting LSI map is categorized into low, moderate, high and very high susceptibility zones, in such a way that 40 % of the study area has low LSI values, 30 % of the study area has moderate values, 20 % has high values and the remaining 10 % of the study area has the highest LSI values (Bijukchhen et al. 2012; Kayastha et al. 2012). The resulting landslide susceptibility zonation map is shown in Fig. 6.

Landslide susceptibility zonation map of the Kankai watershed based on the frequency ratio method. Areas of landslide susceptibility zones and of observed landslides on each zone are given in the upper part of Table 6
Multiple linear regression method
The disadvantage of bivariate techniques, as the frequency ratio method, is that all parameters are considered independently from each other and possible correlations between parameters are ignored. On the other hand, multivariate statistical methods determine the relative contribution of thematic data layers to the total susceptibility all together with one overall model approach. Hence, these methods involve the analysis of a large volume of data and are, therefore, time consuming. Frequently used techniques are: multiple linear regression (Carrara 1983; Chung et al. 1995), discriminant analysis (Reger 1979) and logistic regression (Dai et al. 2001). Principal component analysis is also often used to reduce the number of variables and to limit their interdependence when too many factors are available (Baeza and Corominas 2001). In this study, the multiple linear regression technique is used. A linear relationship is assumed between the occurrence of landslides and the presence of certain causative factors. The multiple linear regression equation can be written as (Guzzetti et al. 1999; Lee and Min 2001; Dai et al. 2001; Dai and Lee 2002; Ohlmacher and Davis, 2003):
where P is the occurrence (probability) of landsliding, with an observed value of 1 in case of an existing landslide and 0 if otherwise, (P ij ) k are binary variables expressing the presence of a certain class i of parameter , i.e. 1 in case the class is present and 0 if otherwise, a is the intercept, b k is the regression coefficient and N is the total number of classes. However, it is not possible to consider all classes because of the perfect collinearity between the binary variables within one parameter, i.e. ∑i P ij = 1. Hence, for each parameter, at least one class has to be excluded from the multiple regression equation. This does not mean that this class is ignored because if all other classes of a parameter are not present (P ij =0), this automatically implies that the left-out class prevails. It is accustomed to leave out the class, which has the least impact on landsliding (Chung et al. 1995). In the present study, the following classes were excluded from the model: (1) for slope angle, class <15°, (2) for slope aspect, class west, (3) for slope curvature, class straight, (4) for relative relief, class <25 m/ha, (5) for distance from drainage, class 50–100 m, (6) for geology, class river bed, (7) for land use, classes cultivation and built-up area because both have a similar (very low) impact on landsliding, (8) for distance from faults, class >5 km and (9) for rainfall, class >2,250 mm/year.
IDRISI GIS software was used to process the multiple linear regression model with the current data. The results of the regression analyses are given in Table 5. The F-test value is 539.3, which indicates that the regression equation is highly significant as the critical value of the F distribution with degrees of freedom 37 (i.e. total number of considered classes, N) and 2,936,941 (i.e. total number of pixels minus N) is 1.64 for a 99 % probability level. The regression coefficients express the individual contribution of each class to the occurrence of landslides, and their significance is expressed in the form of a Student t-statistic, which verifies the coefficient values’ departure from 0 (i.e. no effect). The critical value of the Student t-distribution with 2,936,941 degrees of freedom is 2.58 for a two-tailed 99 % probability level. Hence, all classes with absolute t-values greater than 2.58 are highly significant. Only land use tea plantation, slope aspects north and northwest and slope curvature convex fail this test. Figure 7 shows the landslide susceptibility zonation map resulting from the multiple linear regression method by considering the obtained P-values as LSI values and categorizing into low, moderate, high and very high susceptibility zones, similar to the frequency ratio method as described before.

Landslide susceptibility zonation map of the Kankai watershed based on the multiple linear regression method. Areas of landslide susceptibility zones and of observed landslides on each zone are given in the lower part of Table 6
Discussion
Factors related to landslides
Statistical methods to determine landslide susceptibility such as the frequency ratio method and the multiple linear regression technique do not identify the causes of landslides but only indicate relations between landslides and terrain properties. Nevertheless, such information may yield insight in landslide occurrences and pinpoint to which terrain features are responsible or have an impact on landslides. In case of the frequency ratio method, factors related to landslides are revealed by their corresponding weight values (Table 4). Weight values larger than 1 indicate that landslides occur more frequently than average given the presence of this factor. For the multiple regression technique, the importance of a factor is revealed by its corresponding regression coefficient and especially by the significance of the Student t-statistic (Table 5).
When the obtained results are compared, the identified factors that relate to landslides are very much the same. Both methods identify that slope angles are positively correlated with occurrence of landslides, and more landslides are found for the highest slope angles (>45°). This is expected as slope angle is an important causal factor for landslides due to gravity. Landslides are also more frequent on southeast-, south- and southwest-facing slopes. This probably has to do with the prevailing direction of the monsoon storms that enter from the southeast and slowly move towards the northwest while producing a lot of precipitation on south-facing slopes (Chalise 2001). For the multiple regression method, flat terrain is also predicted to be associated with landslides. This rather strange result is probably due to debris of landslides on flat terrains, which have been inventoried as part of a landslide area. Both methods indicate concave slopes to be related to landslides, albeit not that very significant. In case of relative relief, landslides are more frequent in the >100-m/ha class, obviously for the same reasons as for slope angle. For distance from drainage, both methods predict a higher probability of landslides closer to drainage axes, which can be explained by undercutting of riverbanks. However, the multiple regression technique also predicts that distance from drainage class >100 m is significant, while this is not the case for the frequency ratio method; the latter seems to be the more plausible result because more landslides have been found in the study area closer to river courses. More landslides are found in the banded gneiss of the Lesser Himalaya and in the Lower and Middle Siwaliks. This can be attributed to the lesser strength of these rocks, i.e. banded gneiss due its layering, while the Lower Siwaliks consist of sandstones interbedded with shale and the Middle Siwaliks predominantly of sandstones intermixed with clay. In case of land use, landslides are more associated with barren land, grassland and forest. These land uses are likely already strongly correlated with steep and unstable slopes and as such are avoided by local inhabitants for cultivation or settlement. The multiple regression technique also indicates bush to be significant, while this is not the case for the frequency ratio method. For distance from faults, a positive association with landslides is obtained for classes <2 and 2–5 km. Proximity to major thrusts such as MBT, MCT and MKT evidently promotes landslides. No important correlation could be detected between rainfall and landslide occurrence with the frequency method, but with the multiple regression technique rainfall class 1,750–2,250 mm/year is found to be highly significant. Probably, the lack of a dense network of hydro-meteorological stations within the study area hinders the possibility of proving that landslide susceptibility increases with increasing rainfall, as is generally expected.
From the above discussion, it can be concluded that, overall, both methods identify the same factors and classes that are strongly related to landslides, while there are some differences with respect to less important factors and classes.
Consistency of landslide susceptibility maps
To assess the overall quality of the landslide susceptibility maps, different approaches have been proposed, such as landslide density, success rate, error matrix, spatially agreed area and image difference analysis (Sarkar and Kanungo 2004; Lee 2004; Gupta et al. 2008). In this study, the consistency of the landslide susceptibility maps is verified by landslide density, success rate and spatially agreed area analysis.
In order to calculate the landslide density, the landslide frequency of each LSI class is calculated as the ratio of existing landslide area to the area of each landslide susceptibility zone (Sarkar and Kanungo 2004). The results are given in Table 6. A perfect landslide susceptibility zonation map should have the highest landslide density for the very high susceptible zone, and there should be a decreasing trend of landslide density values successively from the very high susceptible zone to the low susceptible zone (Gupta et al. 2008). From the table, it can be observed that the landslide density for the very high susceptible zone is 2.02 % for the frequency ratio method and 2.10 % for the multiple linear regression method, which are distinctly larger than for the other susceptible zones. Furthermore, there is a gradual decrease and considerable difference in landslide density values from the very high to the low susceptible zone. Hence, the landslide susceptibility zones reflect the existing field conditions, and the very high and high susceptible zones that are destitute of landslides indicate the potential future failure areas. The obtained landslide densities for the different susceptible zones of the two maps can also be compared with each other (Table 6), which reveals that the maps produced with the two different methods are quantitatively similar.
The validity of the landslide susceptibility maps can be graphically ascertained with the help of the success rate curve (Chung and Fabbri 1999; van Westen et al. 2003; Dahal et al. 2008). The cumulative percentage of observed landslide occurrence is plotted against the cumulative percentage of decreasing susceptibility index to obtain the success rate curve for each map of the study area (Fig. 8). The analysis indicates that the first 10 % of the area contains about 43.9 and 45.6 % of the observed landslides for, respectively, the frequency ratio and multiple linear regression models. The area under a curve can also be used to assess the success rate qualitatively. The areas are 0.755 and 0.752, which means that the overall success rates are 75.5 and 75.2 % for the frequency ratio and multiple linear regression models, respectively. These results also validate the landslide susceptibility maps with the existing slope instability conditions and indicate that the maps obtained by both statistical methods have a similar performance.

Success rate curve of landslide susceptibility predicted with the frequency ratio method and with the multiple linear regression method. The areas under the curve, 75.5 and 75.2 % for the frequency ratio and multiple linear regression methods, respectively, indicate the overall success rate of each method
A comparison of landslide susceptibility maps using the landslide density analysis and success rate curve analysis indicates that these two statistical methods produce almost identical results. However, these analyses do not assess the spatial agreement of the maps. An extreme example is given in Fig. 9. Shown in this figure are details of the two susceptibility zonation maps for an area where a large landslide has been observed, about 700 m SE of Sanrumba. Though in both maps most of the observed landslide area falls in very high and high susceptibility zones, there is no perfect spatial agreement between the respective susceptibility classes. In particular, in the 6 × 6-pixel zone (i.e. 120 × 120 m) indicated by the white box, there is a 100 % mismatch between the two maps. Hence, although the landslide density and success rate analyses seem to indicate that the models produce similar results, there can be a large mismatch of the predicted susceptibility values. It is therefore necessary to compute the spatially agreed areas between the two landslide susceptibility maps in order to evaluate their consistency.

Example showing a mismatch between the predicted landslide susceptibility zones for an area of about 700 m SE of Sanrumba, where a large landslide was observed: a map based on the frequency ratio method and b map based on the multiple linear regression method. In the 6 × 6-pixel zone (i.e. 120 × 120 m) indicated by the white box, there is a 100 % mismatch between the two maps
The spatially agreed area between two landslide susceptibility maps, expressed in pixels, km2, or as percentage of the total area, is determined as the total area having the same landslide susceptibility zonation on both maps (van Westen et al. 2003; Gupta et al. 2008). Also, the percentage of observed landslides in the spatially agreed area of two landslide susceptibility maps can be calculated to assess the overall performance. The results are shown in Table 7. It follows that only 72.3 % of the total watershed falls in identical (common) susceptibility zones of the two maps. Hence, there is a total mismatch of 27.7 % in the four susceptibility zones, of which about half occur between low and moderate susceptibility zones. These deviations may be related to the uncertainties in the weight and rating assignment procedures and the relatively small area of observed landslides compared to the total area. Nevertheless, the percentage of observed landslides in the total agreed areas is 77.6 %, of which 40.3 % are situated in the agreed very high susceptible zone that covers only 7.6 % of the total catchment area. This corresponds to a predicted landslide density in the agreed very high susceptible zone of 2.44 %, which shows that the predictive capacity of the agreed areas of the maps is very good and that maps produced from both statistical methods are fairly consistent.
Conclusions
In the Kankai watershed in east Nepal, many landslides have occurred in the recent past involving soil slides, rockslides, plane and wedge failures and rotational slides. An inventory of these slides was developed in the form of a digital map with a cell size of 20 × 20 m. Similar maps were created out of possible causative parameters, such as slope angle, slope aspect, slope curvature, relative relief, distance from drainage, geology, land use, distance from faults and rainfall. To analyse the relationship between the landslides and possible causative factors, two techniques were used, i.e. the bivariate frequency ratio method and the multivariate multiple regression technique. Both techniques indicate that high slope angle, south slope aspects, high relative relief, close distance to drainage, banded gneiss, Lower and Middle Siwaliks, barren land, forest, grassland and proximity to faults are significantly associated with landslide occurrences. However, the results of the frequency ratio method are more consistent and trustworthy than those of the multiple regression technique.
With these techniques, landslide susceptibility maps that categorize the catchment into low, moderate, high and very high susceptible zones with respect to landsliding were developed. For a comparison of these maps, three different approaches were used, i.e. landslide density analysis, success rate analysis and spatially agreed area analysis. The first two approaches suggest that the results are very similar, in particular, a predicted landslide density for the very high susceptible zone of about 2 % and an overall success rate of 75 % for predicting the observed landslides. However, the spatially agreed area analysis shows that the two maps only agree partially as there is a total mismatch of about 28 % in the four susceptibility zones. Nevertheless, in the agreed very high susceptible zone that covers about 8 % of the total catchment area, the percentage of observed landslides is about 40 %, which corresponds to a predicted landslide density for the very high susceptible zone of 2.4 %. Hence, the agreed area analysis is capable of spatially evaluating the consistency of landslide susceptibility zonation maps obtained with different techniques, thereby indicating areas of mismatch and improving predictions in agreed areas.
The results of this study can be used to find suitable locations for implementing new developments by concerned authorities, planners and engineers. Possibly, this study can also be of great help to prepare risk maps for the Kankai watershed and to be used in disaster management planning such as preparation of rescue routes, service centres and shelters.
References
Aleotti P, Chowdhury R (1999) Landslide hazard assessment: summary, review and new perspectives. Bull Eng Geol Environ 58:21–44
Baeza C, Corominas J (2001) Assessment of shallow landslide susceptibility by means of multivariate statistical techniques. Earth Surf Process Landf 26(12):251–1263
Bijukchhen SM, Kayastha P, Dhital MR (2012) A comparative evaluation of heuristic and bivariate statistical modelling for landslide susceptibility mappings in Ghurmi–Dhad Khola, east Nepal. Arab J Geosci. doi:10.1007/s12517-012-0569-7
Brabb EE (1984) Innovative approaches to landslide hazard and risk mapping. Fourth Int Symp Landslides Can Geotech Soc Tor Can 1:307–324
Carrara A (1983) Multivariate models for landslide hazard evaluation. Math Geol 15(3):403–426
Çevik E, Topal T (2003) GIS-based landslide susceptibility mapping for a problematic segment of the natural gas pipeline, Hendek (Turkey). Environ Geol 44:949–962
Chalise SR (2001) An introduction to climate, hydrology, and landslide hazards in the Hindu Kush–Himalayan region. In: Tianchi L, Chalise SR, Upreti BN (eds) Landslide hazard mitigation in the Hindu Kush–Himalayas. ICIMOD, Kathmandu, pp 51–62
Chung CF, Fabbri AG (1993) Representation of geoscience information for data integration. Nat Resour Res 2(2):122–139
Chung CF, Fabbri AG (1999) Probabilistic prediction models for landslide hazard mapping. Photogram Eng Remote Sens 65(12):1389–1399
Chung CF, Fabbri AG, van Westen CJ (1995) Multivariate regression analysis for landslide hazard zonation. In: Carrara A, Guzzetti F (eds) Geographical information systems in assessing natural hazards. Kulwer Academic, Dordrecht, pp 107–133
Cruden DM, Varnes DJ (1996) Landslide types and processes. In: Turner AK, Schuster RL (eds) Landslides—investigation and mitigation. Special report 247, Transportation Research Board, National Research Council, pp 36–75
Dahal RK, Hasegawa S, Nonomura A, Yamanaka M, Dhakal S, Paudyal P (2008) Predictive modeling of rainfall-induced landslide hazard in the Lesser Himalaya of Nepal based on weights-of-evidence. Geomorphology 102:496–510
Dai FC, Lee CF (2002) Landslide characteristics and slope instability modeling using GIS Lantau Island, Hong Kong. Geomorphology 42:213–238
Dai FC, Lee CF, Li J, Xu ZW (2001) Assessment of landslide susceptibility on the natural terrain of Lantau Island, Hong Kong. Environ Geol 40(3):381–391
Deoja BB, Dhital MR, Thapa B, Wagner A (1991) Mountain risk engineering handbook. International Centre for Integrated Mountain Development (ICIMOD), Kathmandu, p 875
Dhakal AS, Amada T, Aniya M (2000) Landslide hazard mapping and its evaluation using GIS: an investigation of sampling schemes for a grid-cell based quantitative method. Photogram Eng Remote Sens 66(8):981–989
Fell R, Corominas J, Bonnard C, Cascini L, Leroi E, Savage WZ, JTC-1 Joint Technical Committee on Landslides and Engineered Slope (2008) Guidelines for landslide susceptibility, hazard and risk zoning for land use planning. Eng Geol 102:85–98
Ghosh S, van Westen CJ, Carranza EJM, Ghosal TB, Sarkar NK, Surendranath M (2009) A quantitative approach for improving the BIS (Indian) method of medium-scale landslide susceptibility. J Geol Soc India 74:625–638
Ghosh S, Günther A, Carranza EJM, van Westen CJ, Jetter VG (2010) Rock slope instability assessment using spatially distributed structural orientation data in Darjeeling Himalaya (India). Earth Surf Process Landf 35(15):1773–1792
Gupta RP, Kanungo DP, Arora MK, Sarkar S (2008) Approaches for comparative evaluation of raster GIS-based landslide susceptibility zonation maps. Int J App Earth Obs Geoinf 10:330–341
Guzzetti F, Carrara A, Cardinali M, Reichenbach P (1999) Landslide hazard evaluation: a review of current techniques and their application in a multi-scale study, central Italy. Geomorphology 31:181–216
Hagen T (1969) Report on the geological survey of nepal, vol. 1. Preliminary reconnaissance. Mém De La Soc Helvétique Des Sci Nat 86(1):1–185
Hansen A (1984) Landslide hazard analysis. In: Brunsden D, Prior DB (eds) Slope instability. Wiley, New York, pp 523–602
Hutchinson JN (1995) Keynote paper: Landslide hazard assessment. In: Bell DH (ed) Landslides. Balkema, Rotterdam, pp 1805–1841
Kanungo DP, Arora MK, Sarkar S, Gupta RP (2006) A comparative study of conventional, ANN black box, fuzzy and combined neural and fuzzy weighting procedures for landslide susceptibility zonation in Darjeeling Himalayas. Eng Geol 85:347–366
Kanungo DP, Arora MK, Gupta RP, Sarkar S (2008) Landslide risk assessment using concepts of danger pixels and fuzzy set theory in Darjeeling Himalayas. Landslides 5:407–416
Kanungo DP, Arora MK, Sarkar S, Gupta RP (2009) A fuzzy set based approach for integration of thematic maps for landslide susceptibility zonation. Georisk: Assess Manag Risk Eng Syst Geohazards 3(1):30–43
Kayastha P, De Smedt F, Dhital MR (2010) GIS based landslide susceptibility assessment in Nepal Himalaya: a comparison of heuristic and statistical bivariate analysis. In: Malet JP, Glade T Casagli N (eds) Mountain risks: bringing science to society. CERG Editions, pp 121–128
Kayastha P, Dhital MR, De Smedt F (2012) Landslide susceptibility mapping using the weight of evidence method in the Tinau watershed, Nepal. Nat Hazards 63(2):479–498
Lee S (2004) Application of likelihood ratio and logistic regression models to landslide susceptibility mapping using GIS. Environ Manag 34(2):223–232
Lee S, Min K (2001) Statistical analysis of landslide susceptibility at Yongin, Korea. Environ Geol 40:1095–1113
Lee S, Choi J, Min K (2002) Landslide susceptibility analysis and verification using the Bayesian probability model. Environ Geol 43:120–131
Oguchi T (1997) Drainage density and relative relief in humid steep mountains with frequent slope failure. Earth Surf Process Landf 22(2):107–120
Ohlmacher CG, Davis CJ (2003) Using multiple regression and GIS technology to predict landslide hazard in northeast Kansas, USA. Eng Geol 69:331–343
Poudyal CP, Chang C, Oh H, Lee S (2010) Landslide susceptibility maps comparing frequency ratio and artificial neural networks: a case study from the Nepal Himalaya. Environ Earth Sci 61:1049–1064
Reger JP (1979) Discriminant analysis as a possible tool in landslide investigations. Earth Surf Process Landf 4(3):267–273
Sarkar S, Kanungo DP (2004) An integrated approach for landslide susceptibility mapping using remote sensing and GIS. Photogram Eng Remote Sens 70(5):617–625
Sarkar S, Kanungo DP, Patra AK, Kumar P (2006) GIS based landslide susceptibility mapping—a case study in Indian Himalaya. In: Marui H et al (eds) Disaster mitigation of debris flows, slope failures and landslides. Universal Academy, Tokyo, pp 617–624
Sarkar S, Kanungo DP, Patra AK, Kumar P (2008) GIS based spatial data analysis for landslide susceptibility analysis. J Mt Sci 5:52–62
Sharma CK (1990) Geology of Nepal Himalaya and adjacent countries. Sangeeta Sharma, Kathmandu, p 479
Thapa PB, Dhital MR (2000) Landslide and debris flows of 19–21 July 1993 in the Agra Khola watershed of central Nepal. J Nepal Geol Soc 21:5–20
Upreti BN, Dhital MR (1996) Landslide studies and management in Nepal. ICIMOD, Nepal, p 87
Uromeihy A, Mahdavifar MR (2000) Landslide hazard zonation of the Khorshrostam area, Iran. Bull Eng Geol Environ 58:207–213
van Westen C (1997) Statistical landslide hazard analysis ILWIS 2.1 for Windows application guide. ITC, Enschede, pp 73–84
van Westen CJ, Rengers N, Soeters R (2003) Use of geomorphological information in indirect landslide susceptibility assessment. Nat Hazards 30(3):399–419
Varnes DJ (1984) International association of Engineering geology commission on landslides and other mass-movements: Landslide hazard zonation: A review of principles and practice. UNESCO, Paris, p 63
Yin KL, Yan TZ (1988) Statistical prediction model for slope instability of metamorphosed rocks. In: Bonnard C (ed) Proc. 5th Int. Sym. on Landslides, Lausanne. Balkema, Rotterdam, pp 1269–1272
Acknowledgments
The Department of Survey, the Department of Hydrology and Meteorology and the Department of Mines and Geology, Government of Nepal, provided data used in this study. The Flemish Inter-University Council (VLIR), Belgium, provided a Ph.D. scholarship for the first author to carry out this research. The authors would also like to acknowledge the anonymous reviewers for their constructive suggestions.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Kayastha, P., Dhital, M.R. & De Smedt, F. Evaluation of the consistency of landslide susceptibility mapping: a case study from the Kankai watershed in east Nepal. Landslides 10, 785–799 (2013). https://doi.org/10.1007/s10346-012-0361-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10346-012-0361-5