
Abstract
In this paper, we present a study on the efficiency of multi-return LIDAR (Light Detection Ranging) data in the estimation of forest stem volume over a multi-layered forest area in the Italian Alps. The goals of this paper are (1) to verify the usefulness of multi-return LIDAR data compared to single-return data in forest volume estimation and (2) to define the optimal resolution of a stem volume distribution raster map over the investigated area. To achieve these goals, raw data were segmented into a net, and different cell dimensions were investigated to maximize the relationship between the LIDAR data and the ground-truth information. Twenty predicting variables (e.g., mean height, coefficient of variation) have been extracted from multi-return LIDAR data, and a multiple linear regression analysis has been used for predicting tree stem volume. Experimental results found that the optimal resolutions of the net square cells were 40 m. The analysis indicated that in a mixed multi-layered forest, characterized by a complex vertical structure, the correct selection of the map spatial resolution and the inclusion of the secondary-return data were important factors for improving the effectiveness of the laser scanning approach in forest inventories. The experimental tests showed that the chosen model is effective for the estimation of stem volume over the analyzed area, providing good results on all the three considered validation methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The assessment of stem volume is of high interest in forest management and is becoming of great global interest especially in the context of the Kyoto protocol rules (Lindner and Karjalainen 2007). Indeed, this protocol states that each nation has to maintain CO2 emissions under a certain threshold, which must be calculated by taking into account both sources and sinks of CO2, including the CO2 absorbed and stored by trees. This quantity can be calculated using tree stem volume; thus, it is of primary importance to obtain a detailed knowledge of forest stem volume at both regional and national levels.
Tree stem volume at stand level is one of the most important parameters in forest management, and the acquisition of such information is very time consuming and expensive because it is normally obtained from field surveys. In the Italian Alps, in an uneven-aged forest, the structure of the canopy is usually obtained maintaining a group of trees per each diameter class (e.g., from 5 to 10 trees/ha, for classes of 10 cm), in order to preserve a mosaic of age and diameter classes (Grassi et al. 2003). Consequently, for the optimal forest management, it is important to know both stem volume of the considered stand (with a typical extension of 5–20 ha) and its structure.
Remote sensing is a fundamental and effective instrument for mapping stem volume. In fact, it provides an objective information over large areas; this information allows one on the one hand to reduce the number of sampling areas and on the other hand to obtain a detailed spatialization of the stem volume distribution.
Many studies exist dealing with stem volume estimation and other forest attributes (e.g., biomass) starting from remote sensing data. In general, almost all different the remote sensing sensors available on the market have been used with this target. In fact, it is possible to find studies based on multi-spectral data (e.g., Muukkonen and Heiskanen 2007; Altun et al. 2008), SAR data (e.g., Wang and Ouchi 2008), and Light Detection and Ranging (LIDAR) data (e.g., Naesset 2009; Naesset and Gobakken 2008; Coops et al. 2007; Gobakken and Naesset 2008).
LIDAR is a recent technology that has been demonstrated to be effective and accurate in the estimation of forest attributes (e.g., stem volume, biomass, and structure). It allows one to have precise measures of both tree height and structure. Indeed to reduce the cost of forest management in mountain areas and to improve the planning methodology of silvicultural regeneration on a stand, LIDAR techniques can be adopted as an integral part of forest surveys.
LIDAR sensors can be classified according to the dimension of the footprint (small or large; this parameter is mainly influenced by the platform used: aerial or satellite) and according to the system used to record the data (full waveform or discrete return). For the estimation of forest attributes, the most widely used LIDAR sensors are discrete-return sensors; this is because these kind of sensors are the most common and thus it is quite easy nowadays to collect LIDAR datasets over large areas. The large availability of these kind of data stimulated many studies which can be found in the literature dealing with LIDAR and forest attributes (e.g., stem volume, biomass, and structure): e.g., Naesset (2009); Neasset and Gobakken (2008); Coops et al. (2007); Andersen et al. (2005). As an example, Naesset (2009) analyzed the effects of different sensors (Optech ALTM1233 and ALTM3100), flying altitudes (1,100, 1,200 and 2,000 m), and pulse repetition frequencies (PRF) (33, 50 and 100 kHz) on the estimation of stem volume and mean height at stand level using 1st LIDAR return–derived variables. All the datasets acquired in different conditions appeared to be suitable for the estimation of volume (the “best” model developed has a R 2 of 0.92) and mean height, with a mean error of up to 10.7% for stem volume and 2.5% for mean height. Coops et al. (2007) estimated the canopy structure of a Douglas-fir forest with 1st-return LIDAR data and found high correlations between field data and LIDAR-derived data (R 2 = 0.85 for the mean height, and R 2 = 0.65 for basal area). Neasset and Gobakken (2008) estimated above ground and below ground biomass with airborne LIDAR data. They used a regression model made up of variables describing both height and coverage of the canopy. The final model explained 88 and 85% of the variance for the above and below ground biomass, respectively. Andersen et al. (2005) developed some regression models starting from LIDAR-derived variables for the estimation of crown fuel weight, crown bulk density, canopy base height, and canopy height. They obtained good results for all the estimations with R 2 ranging from 0.77 to 0.98. Garcia et al. (2010) defined several biomass estimation models based on LIDAR height, intensity, or height combined with intensity. The regression analysis carried out on 45 circular plots obtained an R 2 of 0.58 considering no species distinction, and R 2 that ranges from 0.58 to 0.98 dividing the plots per species and considering the different biomass fractions. Magnussen et al. (2010) analyzed the reliability of LIDAR predictors of some forest inventory attributes (e.g., basal area, volume) on 40 spruce-dominated plots in Norway. The authors thinned LIDAR data to five target densities, and they averaged the estimation results over 100 replications for each density. For the volume estimation, they obtained R 2s higher than 0.8 for all the densities considered.
The aforementioned examples confirm the fact that many studies exist on the estimation of the main forest attributes, such as stem volume and biomass, using LIDAR data. On the other hand, in existing studies the use of multi-return LIDAR data are less frequent. In fact, the majority of the existing studies focus only on 1st-return data; some of them analyzes also the contribution of last-return data, but none analyzes in deep detail also the intermediate returns. This limitation is mainly due to the fact that only most recent sensors are able to acquire intermediate returns. According to the increasing use of LIDAR technology in forestry domain, it is important to investigate the contribution of these data in the estimation process. In particular, intermediate returns can be considered crucial, when dealing with multi-layered forests, for intercepting the contribution of the intermediate layers in the total forest stem volume.
According to these issues, the aim of this paper is to assess (1) the accuracy of the estimation of forest volume using multi-return LIDAR data and (2) the optimum resolution of a grid map in this specific forest context.
Methods
Description of the study area
The study area is in a mountainous region and consists of an uneven-aged forest around the town of Lavarone (Trentino district), Italy. The central point of the analyzed area has the following coordinates: 45° 57′ 30.09″N, 11° 16′ 25.17″ E. The topography is moderately complex, ranging from 1,200 to 1,600 meters above the sea level, and the area covers approximately 4 km2.
Forest tree species include Silver Fir (Abies alba Mill.; 50%), Norway spruce (Picea abies Karst.; 38%), Beech (Fagus sylvatica L.; 9%), Larch (Larix decidua Mill.; 9%), Scots pine (Pinus sylvestris L.; 1%), and other less common species (1%). Beech and other broadleaf species are often present in the lower levels of the canopy. In this uneven-aged forest, the structure is quite complex: mean diameters, basal area and number of the trees per plot range from 26 to 63 cm (mean 35 cm, SD 7 cm), from 17 m2 ha−1 to 69 m2 ha−1 (mean 36 m2 ha−1, SD 11 m2 ha−1) and from 97 per ha to 808 per ha (mean 401 per ha, SD 165 per ha), respectively.
LIDAR data
The LIDAR data were acquired by an Optech ALTM 3100 sensor installed on a helicopter on September 4th, 2007, between 11:29 am and 12:07 am. The mean posting density was 8.6 points per square meter for the first return. The laser pulse wavelength and the laser repetition rate were 1,064 nm and 100 kHz, respectively. In this investigation, we used all four LIDAR returns. The total number of LIDAR points measured by the sensor was 42,728,097 for the first return; second, third, and last return detected points were, respectively 27.3, 6.4, and 0.8% of the total measured points.
Ground data
In our experiments, two sources for the ground-truth data set were considered:
-
1.
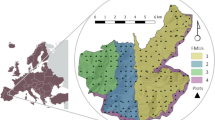
the stem volume calculated from 50 plots distributed over the study area (inventory-level A; plot-level C; Table 1, Fig. 1)
Table 1 Descriptive statistics of forest data acquired using an inventory-approach A, stand-approach B, and plot-approach C. The sample points of the inventory-approach were used also as the dataset to train the models Fig. 1 
Study area and 2 approaches of analysis: inventory-approach A (study area) and stand-approach B (6 forest stands)
-
2.
the stem volume of 6 stands of variable dimension collected by the Forest Service of the Province of Trento for the provincial forest inventory (stand-level B; Table 1, Fig. 1).

In the first case, in order to obtain a statistically significant representation of stem volume in the study area, ground-truth points were distributed randomly across the analyzed forest area using a GIS software according to an unaligned systematic sampling design (see US EPA guidance QA/G-5S, 2002). A square grid with cells of 250 × 250 m was superimposed on the orthophoto of the area. In each square, a sample point was randomly selected according to the forest area under investigation and 50 of these points were sampled within the boundaries of the study area.
The ground data were collected during a field campaign which took place from August to September 2007. The selected sample points were located with a GPS, and the positions acquired were post-processed with a differential correction. The final uncertainty of their horizontal position of the point was on average 1.70 m (the error is with respect to the correct position of the points).
For each sampling point, trees were selected according to the Bitterlich method, in which the probability of tree selection is proportional to its Diameter at Breast Height measured at 1.30 m (DBH) (Shiver and Borders 1996). This means that the dimension of the plot is not fixed, but it depends on the specific characteristics of the analyzed forest. For each sampling point, a standard cluster of five angle count sampling (ACS) was collected. The basal area of the plot was calculated as the mean value of the five ACS. The stem volume of each tree was calculated using species-specific equations based on height and diameter provided by the Forest Service of the Province of Trento (Salvadori and Ambrosi 2005). To select the appropriate equation for each sample plot, about 4–6 of the tallest trees were selected using random stratified sampling for each species that was observed in the central ACS. The height of these trees was measured using a Vertex hypsometer (Haglöf, Sweden). The DBH was measured for all trees with DBH > 17.5 cm.
The second source of ground truth was provided from six stands owned by the local Forest Service (stand-level B; Table 1, Fig. 1). For all the trees with DBH values higher than 17.5 cm, height and diameter were measured and used to compute stem volume using the same equations of the previous case.
Data processing
In order to retrieve the height of the trees, we subtracted to each LIDAR pulse the value of the Digital Terrain Model in that point. Subsequently, a height filter was applied: pulses with an elevation value (Ih) lower than 2 m were fixed to zero; values higher than 2 m were considered as canopy hits (Ihc).
Around each sample point, a square cell of a given dimension was centered. In our analysis, we considered cells of 20 × 20, 30 × 30, 40 × 40, 50 × 50, and 60 × 60 m. A series of variables were considered within these cells. This procedure was based on the assumption that, in each cell, there is a relationship between stem volume (as the sum of the individual tree stem volumes) and the predictor variables derived from the height distribution of laser pulses (Ihc). In this respect, Ihc was used to calculate 20 predictor variables, reported in Table 2. The considered variables were widely used in the existing literature, and they showed to be effective for stem volume estimation (e.g., Naesset 2009; Naesset and Gobakken 2008). These variables were generally extracted from first-return data and sometimes from last-return data. In this study, we also considered variables extracted from intermediate returns (second and third). Stepwise forward regression (Zar 1996) was used to select the most informative variables, which were included in a multiple (linear) regression model. A 5% significance level was chosen as a threshold for the inclusion of the model variables.
Design of experiments
In order to reach the goals of this study, an analysis based on two steps was carried out. In the first step, we analyzed the best resolution for the final estimation map; in the second step, the map at three different levels was validated.
The 50 sample plots dataset were divided into two groups: a training set comprising 40 plots and a validation set of 10 plots (see Table 1). These sets were selected randomly with the constraint to have a similar distribution of stem volume values among the two sets. The 40 training plots were used to chose the optimal cell size (20 × 20, 30 × 30, 40 × 40, 50 × 50 and 60 × 60 m) for the final stem volume map. To obtain an effective choice, the goodness of fit of the regression model associated with each cell size was analyzed, considering the adjusted coefficient of determination (R 2adj ) and the Root Mean Square Error % (RMSE%) of the training set (Zar 1996).
Once the best cell size has been selected, we validated the map at three spatial levels: (i) inventory-level A; (ii) stand-level B; and (iii) plot-level C. The inventory-level A consists of a comparison between the mean and the coefficient of variation (CV) values of the ground-truth stem volume of the training set (40 plots), using the same statistics of the whole final map (2,605 pixels). The comparison was made using an independent two-sample t-test. This comparison allows to determine the ground-truth plots representativeness of the study area and consequently if the reliability of the estimations. The stand-level B was a comparison between the stem volume of six stands inside the study area, estimated by the forest inventory of the Forest Service of the Province of Trento and the values derived by our LIDAR model. The comparison was made with a dependent samples t-test and the RMSE%. The plot-level C was a comparison between the stem volume predicted by the chosen model and the ground-truth values of the 10 test set plots (Table 1, Fig. 1) (tested with a dependent two-sample t-test and RMSE%). In the results, we computed the RMSE% as a percentage by dividing the absolute RMSE by the observed mean values.
Results
Table 3 and 4 show the regression models obtained at different resolutions between LIDAR variables and stem volume. In all the models, the first variable selected is H mean1stR. Considering only the first return (Table 3), other two variables have been selected, C 2m1stR with a cell of 50 m and C q901stR for 40 and 60 m. The selection of a second variable improved significantly the accuracy of the model respect to the 20- and 30-m cell. Using all the LIDAR returns, in all the adopted models, the second (and last) variable selected was H q502ndR.
The use of multiple-returns variables improved the regression values for all the considered resolutions. On average, the coefficient of determination increased by 17% (from 0.58 to 0.68), while RMSE% decreased by 2% (from 20.4 to 18.8%). This confirms the higher precision of the multi-return LIDAR data, in comparison with the first-return data only.
In the first case, where only first-return variables were used, the most suitable cell size was 50 m; introducing also variables belonging to other returns, the optimal cell size value decreased to 40 m.
As 40 m was found to be the optimal cell size, the tree stem volume (\( \hat{V} \)) was predicted and mapped according to the following linear model:
where H mean1stR was the mean value of canopy hits of the first return, and H q502ndR was the 50th quantile of the canopy hits of the second return. The adjusted coefficient of determination was 0.72 (Fig. 2), and the RMSE% was 16.7%. In this worth noting that using multi-return instead of first-return data, the R 2adj increased from 0.62 to 0.72 (+16%) (see Tables 3, 4).

Field-measurement versus predicted volume in multi-return model with 40-m pixel size. The dotted line shows a 1:1 relationship
No significant differences were found (Table 5) between the tree stem volume obtained from the proposed model and with both the inventory of the study area (inventory-level A) and the stands data (stand-level B). To verify the predictive model, we also applied it to 10 ACS test plots (plot-level C). The estimated volume was compared to the ground-truth values and we found a RMSE% of 14.7%, slightly lower than the one obtained from the 40 ACS training points (16.7%). Moreover, it is worth noting that no significant differences between the predicted and observed values emerged using a dependent samples t-test (see Table 5).
Finally, Eq. (1) was used to generate a map that shows the distribution of tree stem volume across the study area (Fig. 3).

Elevation (m) of the first return of the LIDAR data over the investigated area (upper map). Maps of stem volume (m3 ha−1) within the study area (400 ha) at a resolution of 40 m (lower map)
Discussion and conclusions
An accurate estimation of stem volume in an uneven-aged forest characterized by a complex horizontal and vertical structure is essential for correct forest management. In particular, it is of primary importance to assess the distribution of tree stem volume within the stands. In this study, an experimental approach using field forest inventories was compared to a laser scanning technique.
The angle count samples (ACS) method used to collect ground-truth data did not provide a precise estimate of tree stem volume in a given certain sampling plot area, because the size of the investigated area was dependent on tree diameter (Hollaus et al. 2007). However, this technique is commonly used in forest surveys and could be linked to LIDAR in ordinary management, using the integrated system proposed in this study. In addition, ACS and the proposed method avoided the need for a predetermined size of the final map (size of grid). The final raster map of volume distribution can be modeled in the analyzed area using site-specific parameters. We found that different resolution levels alter the effectiveness of the map in estimating tree volume, and in this study area, a 40-m pixel size was found to be optimal, according to the forest pattern. Hence, the proposed method involved an integrated approach between LIDAR and field data. This kind of approach has been shown to be effective by other studies in the literature. Naesset (1997) showed how a grid approach can be used to assess tree height and that this could reduce the bias, while Hollaus et al. (2007) illustrated how the size of the plot affects the precision of the stem volume estimation. In this paper (Hollaus et al. 2007), the authors found that the influence of the sample plot size to the achievable accuracies is small. However, it is worth noting that they compared a relatively small range of plot sizes (from about 250 to 530 square meters), while in our study we explored a higher range (from 400 to 3,600 square meters).
The integration of ground data and remotely sensed data avoided bias of volume estimation, because the adopted training information was site-specific. For example, Hyyppä et al. (2001) found a systematic overestimation of tree volume due to the fact that no local training data were used. In the same study, the standard error of the tree volume was 10.5%.
Nilsson (1996), in a similar study in Sweden (4.0 ha area and 26 plots), found a coefficient of determination value (R 2) of 0.78 between forest stem volume and variables extracted from LIDAR. The accuracy (R 2) achieved in this study was lower respect to the one achieved in the study of Naesset (2004), where tree stem volume in a mature forest area was predicted from similar independent variables (percentiles of pulses laser heights and canopy density) with an R 2 that ranged from 0.83 to 0.86. Anyway, the CV between the predicted values and the ground reference values found by Naesset ranged from 11.5 to 12.2%, and it is similar to the one showed in our study (10%).
An important consideration that emerges from this study is the importance of the use of multi-return LIDAR data. In particular, the second return can significantly improve the estimate of stem volume in the case of a forest characterized by a complex structure, without need for further analysis of the understory vegetation (i.e., Maltamo et al. 2005). Indeed, for all the investigated map resolutions, the coefficient of determination (R 2adj ) increased when the second return was also included in the model.
It is worth noting that, given a set of 20 possible LIDAR indices, H mean1stR was always selected as the first index in the regression. The second independent variable was consistently a variable extracted from the second return (H q502ndR), demonstrating the importance of the multi-return LIDAR data.
One of the most significant results of this paper is that the second return is important in this area as it is covered by a multi-layered forest. The second return, in fact, can detect other layers, and thus it is possible to add to the final estimation also the contribution of the lower parts of the canopy. An important remark is that it is not possible to define exactly the derivation of the second return, and that it does not necessarily belong to the second layer. In fact, as it has been observed, in canopies where more than 2 layers are present, the second return might belong to an intermediate canopy layer, whereas in a canopy with 2 layers the second return might belong to the bottom canopy layer.
Volume maps (Fig. 3) can be considered as spatially explicit data layers that can be used to plan forest management. Field measurements alone are not able to statistically include all the extreme values that are present in a heterogeneous area, as also discussed by Andersen et al. (2005) in a similar study in Washington State, US. In these few cases, maps should be further verified.
The models presented allowed a satisfactory volume estimation for each of the 3 approaches (inventory-approach A, stand-approach B, and plot-approach C), suggesting that the map could be adopted at different spatial levels. For example, information at the single pixel level (e.g., 30 m) could give an indication of where to cut individual trees within a stand, while the information at stand level (e.g., 15–20 ha) could be useful for property-level management.
Finally, the resolution of the map should also be evaluated according to both the mosaic of canopy openness and the level of landscape fragmentation.
References
Altun L, Başkent EZ, Bakkaloğlu M, Günlü A (2008) Comparing methods for determining forest sites: a case study in Gümüşhane-Karanlikdere forest. Eur J Forest Res 127:395–406
Andersen HE, Robert J, McGaughey RJ, Reutebuch SE (2005) Estimating forest canopy fuel parameters using LIDAR data. Remote Sens Environ 94:441–449
Coops NC, Hilker T, Wulder MA, St-Onge B, Newnham G, Siggins A, Trofymow JA (2007) Estimating canopy structure of Douglas-fir forest stands from discrete-return LiDAR. Trees 21:295–310
Garcia M, Fiano D, Chuvieco E, Danson FM (2010) Estimating biomass carbon stocks for a Mediterranean forest in central Spain using LiDAR height and intensity data. Remote Sensi Environ 114:816–830
Gobakken T, Naesset E (2008) Assessing effects of laser point density, ground sampling intensity, and field sample plot size on biophysical stand properties derived from airborne laser scanner data. Can J For Res 38:1095–1109
Grassi G, Minotta G, Giannini R, Bagnaresi U (2003) The structural dynamics of managed uneven-aged conifer stands in the Italian eastern Alps. For Ecol Manage 185:225–237
Hollaus M, Wagner W, Maier B, Schadauer K (2007) Airborne laser scanning of forest stem volume in a mountainous environment. Sensors 7:1559–1577
Hyyppä J, Kelle O, Lehikoinen M, Inkinen M (2001) A segmentation-based method to retrieve stem volume estimates from 3-D tree height models produced by laser scanners. IEEE Trans Geoscie Remote Sens 39(5):969–975
Lindner M, Karjalainen T (2007) Carbon inventory methods and carbon mitigation potentials of forests in Europe: a short review of recent progress. Eur J Forest Res 126:149–156
Magnussen S, Naesset E, Gobakken T (2010) Reliability of LiDAR derived predictors of forest inventory attributes: a case study with Norway spruce. Remote Sens Environ 114:700–712
Maltamo M, Packalén P, Yu X, Eerikäinen K, Hyyppä J, Pitkänen J (2005) Identifying and quantifying structural characteristics of heterogeneous boreal forests using laser scanner data. For Ecol Manage 216:41–50
Muukkonen P, Heiskanen J (2007) Biomass estimation over a large area based on standwise forest inventory data and ASTER and MODIS satellite data: a possibility to verify carbon inventories. Remote Sens Environ 107:617–624
Naesset E (1997) Determination of mean tree height of forest stands using airborne laser scanner data. ISPRS J Photogramm Remote Sens 52:49–56
Naesset E (2004) Practical large-scale forest stand inventory using small-footprint airborne scanning laser. Scand J Fore Res 19:164–179
Naesset E (2009) Effects of different sensors, flying altitudes, and pulse repetition frequencies on forest canopy metrics and biophysical stand properties derived from small-footprint airborne laser data. Remote Sens Environ 113:148–159
Naesset E, Gobakken T (2008) Estimation of above- and below-ground biomass across regions of the boreal forest zone using airborne laser. Remote Sens Environ 112:3079–3090
Nilsson M (1996) Estimation of tree heights and stand volume using an airborne lidar system. Remote Sens Environ 56:1–7
Salvadori C, Ambrosi P (2005) EFOMI Valutazione ecologica di cenosi forestali sottoposte a monitoraggio integrato. Museo Tridentino di Scienze Naturali, Trento. Studi Trentini di Scienze Naturali. Acta Biologica 81:1–276
Shiver BD, Borders BE (1996) Sampling techniques for forest resource inventory. John Wiley & Sons Inc, New York
U.S. Environmental Protection Agency (2002) Guidance on choosing a sampling design for environmental data collection. EPA QA/G-5S. Washington, D.C
Wang H, Ouchi K (2008) Accuracy of the K-distribution regression model for forest biomass estimation by high-resolution polarimetric SAR: comparison of model estimation and field data. IEEE Trans Geosci Remote Sens 46(4):1058–1064
Zar JH (1996) Biostatistical analysis, 3rd edn. Prentice-Hall International, London
Acknowledgments
The authors gratefully acknowledge A. Cescatti for the help in data elaboration. This work was supported by the CARBOITALY project funded by the FISR program of the Italian Ministry of University and Research. We are grateful to F. Salvagni, R. Zampedri, L. Frizzera, R. Moreschini and M. Cavagna for the sampling.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by D. Mandallaz.
Rights and permissions
About this article
Cite this article
Tonolli, S., Dalponte, M., Vescovo, L. et al. Mapping and modeling forest tree volume using forest inventory and airborne laser scanning. Eur J Forest Res 130, 569–577 (2011). https://doi.org/10.1007/s10342-010-0445-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10342-010-0445-5