
Abstract
This paper focuses on the hypothesis of stability in the mechanisms of spatial dependence that are usually employed in spatial econometric models. We propose a specification strategy for which the first step is to solve a local estimation algorithm, called the Zoom estimation. The aim of this stage is to detect problems of heterogeneity in the parameters and to identify the regimes. Then we resort to a battery of formal Lagrange Multipliers to test the assumption of stability in the processes of spatial dependence. The alternative hypothesis consists of the existence of several regimes in these parameters. A small Monte Carlo serves to confirm the behaviour of this strategy in a context of finite size samples. As an illustration, we solve an application to the case of the hypothesis of convergence for the per capita income in the European regions. Our results reveal the existence of a strong Centre-Periphery dichotomy in which instability extends to all the elements (coefficients of regression as well as parameters of spatial dependence) that intervene in a classical conditional β-convergence model.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The topics of autocorrelation and heterogeneity constitute the nucleus of the research program in spatial econometrics (Anselin 1988a, b). There is widespread literature devoted to both subjects (Anselin et al. 2004), whose recent development may be attributed to the challenges posed by the necessity of disentangling the role played by space in the mechanisms of economic growth. In short, the positive feed-back that exists between the two research agendas, spatial econometrics and economic growth, should be acknowledged.
However, it is rather surprising that, until recently, the topics of autocorrelation and heterogeneity (or interdependence and instability) have been treated separately. The works of Durlauf et al. (2001), Lopez-Bazo et al. (2004), Parent and Riou (2005) and Ertur and Koch (2007), among others, are singular because they introduce local peculiarities into the mechanisms of spatial interaction in neoclassical-type growth models. Each one of them uses a different approach such as technological externalities, investment spillover effects, knowledge diffusion processes, etc, but they coincide in attaining more flexible specifications. Similar efforts to integrate the two topics are also evident in the most recent literature on spatial econometrics. Let us mention the pioneering work of Brunsdon et al. (1998) and the more recent papers of Páez et al. (2002a, b), LeSage and Pace (2004), Ertur et al. (2007) and Mur et al. (2008, 2009).
The purpose of our paper is to progress in this direction by developing a new approach that facilitates the simultaneous treatment of the features of interdependence and heterogeneity. We focus the discussion on the introduction of instability into the mechanisms of spatial dependence. Our proposal combines two different techniques. In the first place, we will solve the local estimation of the model with the objective of identifying clusters of regions which interact differently with their neighbours (López et al. 2009a). We use the local estimation algorithm as a merely descriptive, exploratory technique which produces valuable information in order to test for the existence of parameter instability. This is the purpose of the battery of Lagrange Multipliers that we use in the second stage: testing for the breaks detected previously.
We apply this discussion to the modelling of regional convergence mechanisms. In recent years, several works have appeared which review the situation of the literature on economic growth and convergence (Fingleton 2003; Magrini 2004; Abreu et al. 2005; Durlauf et al. 2005; Arbia 2006). Overall, they confirm the maturity of the discussion and the variety of techniques used to address the problem. Some of the most interesting pieces explicitly consider the role played by space as stated, for example, in Quah (1996, p. 954): ‘physical location and geographical spillover matter more than do national, macro factors’. Spatial econometric techniques occupy a prominent role here, focusing on two distinctive features of the growth processes, namely, spatial interdependence and the lack of uniformity across space. The former is related to the concept of externality (Kubo 1995) whereas the disparity in the initial conditions appears to be ‘crucial to an improved understanding of regional dynamics’ (Rey and Janikas 2005, p. 160). Specifically, the aim is to show that, at least for the European case, these processes are strongly interdependent but far from being homogeneous over space.
The structure of the paper is as follows. In Sect. 2, we present the combination of techniques that, in our opinion, are most adequate to analyse the assumption of parameter stability in cross-sectional equations. In the third section we discuss the results of a small simulation experiment which confirms the adequacy of these techniques. In the fourth section, we review the case of the distribution of per capita income for the regions of the 27 member states of the current European Union, NUTS II level, in the period 1995–2005. We find clear signs of instability in all the β-convergence equations that we specify. Moreover, there emerges a strong centre-periphery regime that needs to be properly treated. The paper finishes with a section of conclusions.
2 Instability in cross-section econometric models
By instability we mean lack of constancy in some, or all, of the parameters of the model, assuming that the functional form and the group of regressors remain effectively unchanged. This is a very well-known problem in mainstream econometrics where there exists a huge amount of literature devoted to the subject, beginning with Chow (1960) and still in progress (see, for example, Zeileis et al. 2005, for a recent review). The difference is that, in our models, the instability will occur over space in such a way that this element, space, should play a prominent role.
This situation has much in common with the problems addressed in the cases of the LISA (Local Indicators of Spatial Association; Anselin 1995) and the GWR (Geographically Weighted Regressions; Fotheringham et al. 1999). However, we are not only interested in detecting ‘pockets of spatial nonstationarity’ (Anselin 1995, p. 94) as in the case of LISA, but also in testing the extent to which the intensity of the spatial dependence in different zones of space is similar (in fact, the detection of spatial nonstationarities is part of the first stage of our approach). With respect to the GWR, we share the reasoning of Fotheringham et al. (1999): the local estimation will provide biased and inconsistent estimations of the parameters, but the size of the bias will probably be smaller than that of other alternatives that do not deal with the problem of heterogeneity. The local estimation is not the best solution, although it could be acceptable in some circumstances.
LeSage and Pace (2004) transfer the discussion to the autoregressive parameter of a Spatial Lag Model (SLM in what follows), proposing an estimation algorithm that they call SALE (the acronym of Spatial Autocorrelation Local Estimation). Ertur and Koch (2007) resort to the SALE algorithm to estimate a heterogeneous spatially-augmented Solow model specified using data at country level. The Bayesian version of this technique, BSALE, appears in Ertur et al. (2007). Mur et al. (2008) follow a similar approach, introducing the Zoom estimation. The idea is to develop an algorithm which solves, for each point in space, the estimation of an equation with a spatial structure. For example, in the case of an SLM:

y, u and l (R × 1) being vectors of, respectively, the endogenous variable, the error terms and of ones, x an (R, k) matrix of regressors and W an (R, R) weighting matrix; α, β and γ are the (vectors of) parameters that intervene in the ‘global’ model of 1a. Equations 1a and 1b make sense under the assumption of structural parameter homogeneity. However, if the parameters are not stable across space, it is advisable to use the ‘local’ equation which appears in Eq. 1b. The double upper-index ‘(r, m)’ indicates that the data corresponds to the system made up of the (m − 1) nearest regions to the rth. W (r, m) is the weighting matrix corresponding to this local system, which must reflect the (local) connection network used in the original W matrix and \( \mathop y\nolimits_{(r)}^{(r,m)} \) is the corresponding (m, 1) vector of the endogenous (local) variable. Moreover, \( \left\{ {\alpha_{r}^{(r,m)} ,\beta_{r}^{(r,m)} ,\gamma_{r}^{(r,m)} ;\; r = 1,2, \ldots ,R} \right\} \) are the local parameters that intervene at point r.
Both models can be estimated by maximum-likelihood methods (ML in what follows), as explained in Mur et al. (2008) and the results can be represented graphically using maps. If there is homogeneity in the parameters, the local estimates will be very similar but, if the parameters (all or some) vary across space, we will obtain heterogeneous maps. As stated, the aim of the Zoom estimation is merely descriptive and should be combined with other, more formal, approaches to gain a better insight into the problem (López et al. 2009a; Mur et al. 2009, for different extensions).
Obviously the two models of Eqs. 1a, 1b are extreme situations of complete homogeneity and full heterogeneity. In some cases, it would be more interesting to allow some parameters to vary while the others remain fixed. By way of an example, if we assume an SLM with a simple centre-periphery break that only affects the parameter of spatial dependence, we may write:
where γ0 is the autocorrelation parameter that dominates in one part of space (the periphery, for example) while, in the other part (the centre), a different parameter intervenes whose value is \( \gamma_{0} + \gamma_{1} \) (\( \gamma_{1} \) measures the difference between the two regimes). Furthermore, W is the weighting matrix that describes the interaction produced in the whole system. This interaction presents some peculiarities in the form of a different intensity in the centre and in the periphery. We use matrix W* to affect one of these groups (the periphery, for example). It is important to highlight that, in order to assure the interpretation of the model, the structure of the interactions should be respected. That is, matrix W* must reproduce exactly the same information that appears in W for the regions involved; the other regions will have a value of zero. Accordingly, \( w_{ij}^{*} = w_{ij} \) if the ith or the jth region belongs to the centre, otherwise \( w_{ij}^{*} = 0. \)
The discussion does not change if we use a Spatial Error Model (SEM). The specification that corresponds to this case is:
The treatment of a discrete break in the parameter of spatial dependence, of an SLM or an SEM, in two or more regimes does not pose special difficulties and may be solved by ML methods. Huang (1984), Anselin (1990), Rietveld and Wintershoven (1998), LeGallo et al. (2003) and Lacombe (2004), among others, used specifications similar to Eqs. 2 or 3. However, the complexity of the ML algorithm increases rapidly with the number of regimes. For this reason, we think that it is a good idea to test, beforehand, whether it is necessary to introduce some break into the autocorrelation parameter.
This is the approach taken by Mur et al. (2008, 2009), obtaining a test for the existence of a structural break in the parameter of spatial dependence of an SLM, like that of Eq. 2. The final expression of this statistic is the following (see Sect. 6):
where \( \tilde{u} \) is the vector of residuals of the ML estimation of Eq. 2, under the null hypothesis of Eq. 4, \( {\tilde{\mathbf{B}}} = I - \mathop {\tilde{\gamma }}\nolimits_{0} {\mathbf{W}}, \) \( \mathop {\tilde{\sigma }}\nolimits^{2} \) and \( \mathop {\tilde{\gamma }}\nolimits_{0} \) are the ML estimates of the two parameters, also under the null hypothesis of Eq. 4, and \( \mathop {\tilde{\sigma }}\nolimits_{\text{lag}}^{2} \) is the ML estimation of the variance of the restriction that we are testing. In Sect. 6 we complete this test with the corresponding Lagrange Multiplier associated with the SEM of Eq. 3:
All the elements that intervene in the last Multiplier come from the model of Eq. 3, estimated under the null hypothesis. Specifically, \( \tilde{u} \) is the vector of ML residuals, \( {\tilde{\mathbf{B}}} = I - \mathop {\tilde{\rho }}\nolimits_{0} {\mathbf{W}}, \) \( \mathop {\tilde{\sigma }}\nolimits^{2} \) and \( \mathop {\tilde{\rho }}\nolimits_{0} \) are the ML estimations of the two parameters, and \( \mathop {\tilde{\sigma }}\nolimits_{\text{err}}^{2} \) is the estimated variance of the linear restriction of Eq. 5.
Finally, we include a brief reference to the test of common factors of Burridge (1981), a useful technique for discriminating between SLM and SEM (Mur and Angulo 2006). Assuming the existence of a structural break in the mechanisms of spatial dependence, we need (1) to estimate the model of the null hypothesis; (2) to estimate the model of the alternative hypothesis and (3) to compare their likelihoods with the \( \mathop {\text{LR}}\nolimits_{\text{break}}^{\text{COM}} \)statistic:

where \( l(y)_{{\left| {\mathop H\nolimits_{0} } \right.}} \) and \( l(y)_{{\left| {\mathop H\nolimits_{A} } \right.}} \) are the log-likelihoods obtained under the null and alternative hypotheses, respectively. The asymptotic distribution of the test assumes that there are k parameters in vector β which lead to 2k non-linear restrictions in Eq. 6.
3 Small sample behaviour of the \( \mathop {\text{LM}}\nolimits_{\text{break}}^{\text{ERR}} \) Lagrange Multiplier
In this section, we will study the behaviour of the \( \mathop {\text{LM}}\nolimits_{\text{break}}^{\text{ERR}} \) test by means of a Monte Carlo experiment.Footnote 1 In the first part, we present the usual results about the size and power of the test under different scenarios. Then, we check the capacity of the test to identify the spatial units that form part of each of the regimes present in the sample.
The Data Generating Process (DGP in what follows) corresponds to Eq. 3:
Only one regressor appears in the right-hand side of the equation; its values have been obtained from a normal unit distribution, the same as in the case of the random error term ε. The coefficient associated with x takes a value of 3 (β = 3) whereas the value of the intercept is 2 (α = 2). Both values guarantee that, in the absence of spatial effects, the R 2 of the regression will be approximately 0.8. We have used a square regular lattice of order (16 × 16) which results in a sample size of 256 observations. This sample size roughly coincides with the application solved in Sect. 4. The weighting matrix W has been specified following a contiguity criterion and rook-type movements. The matrix has been row-standardised. In order to develop the alternative hypothesis, we have introduced a break in the parameter ρ into two regimes, as is indicated in Eq. 7. One of the regimes is located in the centre and the second in the periphery of the lattice. We tried several configurations of the central regime: made up of 36 cells (grouped in a 6 × 6 grid), of 64 cells (a grid of 8 × 8) and of 100 (10 × 10). Each combination has been repeated 1,000 times.
3.1 Size and power of the \( \mathop {\text{LM}}\nolimits_{\text{break}}^{\text{ERR}} \) test
Table 1 shows the rate of rejections of the null hypothesis of homogeneity in the spatial dependence parameter for different combinations of the parameters ρ0 and ρ1. The size of the test, in the italic row, corresponds to value zero in ρ1. In general, we can confirm that the empirical size of the test does not differ substantially from the nominal size. Specifically, the composition and shape of the central region does not affect the behaviour of the test.
As expected, the power of the \( \mathop {\text{LM}}\nolimits_{\text{break}}^{\text{ERR}} \) test increases when the difference between the spatial dependence parameters of both regimes increases, as measured by ρ1. Also, the results are slightly better when the coefficient of spatial dependence of the central region is higher than that of the periphery (that is, for positive values of ρ1). Lastly, it is evident that the lack of symmetry in the composition of the regimes negatively affects the behaviour of the test: the worst results are produced for central regions composed of a small number of units.
3.2 Identification of the regimes by means of the \( \mathop {\text{LM}}\nolimits_{\text{break}}^{\text{ERR}} \) test
There is no doubt that the behaviour of the test \( \mathop {\text{LM}}\nolimits_{\text{break}}^{\text{ERR}} \) depends on the a priori correct identification of the spatial units that should appear in each regime. In some cases, there will be a well-defined hypothesis that leads us to an initial division of the whole set of regions into a finite number of regimes. In other cases, this information will not be available or the information will be insufficient. The idea is to apply a previous exploratory analysis which may help us in the difficult task of dividing the space into regimes.
Let us call \( {\text{LM}}(i,m)_{\text{break}}^{\text{ERR}} \) the value of the statistic \( \mathop {\text{LM}}\nolimits_{\text{break}}^{\text{ERR}} \) obtained for the case of a spatial regime made up of the ith region plus the (m − l) regions nearest to it. Also, for each pair (i, m) we will obtain the corresponding specification of matrix W*. With each of these matrices we can solve the corresponding instability test in the parameter of spatial dependence. Finally, if there is really a break in the parameter of spatial dependence, the sequence of statistics \( {\text{LM}}(i,m)_{\text{break}}^{\text{ERR}} \) will show a peak when the tentative regime better overlaps the real one.
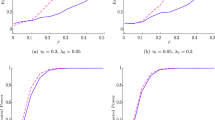
Due to space limitations, we are going to present only the case of a break produced around a central spatial unit and mad up of 64 spatial units in an 8 × 8 regular grid. The combinations simulated in the coefficients are (ρ0 = 0.5; ρ1 = 0.4) and (ρ0 = 0.5; ρ1 = 0.2), respectively. The most important results appear in Fig. 1 where we present the average of the p-values of the \( {\text{LM}}(i,m)_{\text{break}}^{\text{ERR}} \) statistic after 1,000 simulations:
The results are promising given that, overall, the procedure tends to correctly identify the spatial units involved in the problem of parameter instability. The identification is more precise when the difference between the coefficients of spatial dependence (ρ0; ρ1) of the two regimes increases. When this difference is small the procedure is not so well-behaved. Other proposals to deal with the same problem can be found in López et al. (2009a), where they develop a kind of cluster analysis using the local estimates, and in López et al. (2009b), that contains a more formal solution.

p-Values corresponding to the average of the simulated multipliers: \( \bar{\rm L}\bar{\rm M}(i,m)_{\rm break}^{\rm ERR} \)
4 Instability and heterogeneity: an application to the case of the European regions
In this section, we are going to apply the proposal developed in the previous two sections to a well-known case in spatial analysis, the hypothesis of convergence. The literature on this subject reveals a tendency to give greater flexibility to the equation that develops the assumption of convergence. Specifically, we are interested in the simultaneous treatment of the features of heterogeneity and spatial dependence. The papers of LeGallo and Dall’Erba (2006), Fischer and Stirböck (2006) and Ramajo et al. (2008) are some of the most recent on the subject. In general, they use a dummy variables framework with the aim of introducing differences into the convergence rates of regions. This technique is of a discrete nature (that is, there is finite number of regimes) and gives support to the concept of convergence clubs. Ertur and Koch (2007) and Ertur et al. (2007) are exceptions to the discrete approach because they adopt a local approach to the processes of convergence.
We focus on the per capita Gross Domestic Product (GDPpc from now on), in purchasing power parity units, corresponding to a total of 262 regions, NUTS II level, from the 27 countries that are currently members of the European Union (EU27). For different reasons, various regions have been excluded, among them the Canary Islands, Ceuta, Melilla and the Portuguese archipelagos of the Azores and Madeira. The data used in our analysis comes from the Cambridge Econometrics and REGIO databanks and covers the period 1995–2005.
4.1 A first look at the problem of instability in regional convergence models: the European case
Let us call y rt the regional per capita income in region r at the beginning of the period, year t, and \( g_{{y_{rt,t + n} }} \) its corresponding growth rate between the years t and t + n; in our case t = 1,985 and n = 10. In the literature devoted to the topic, there is a clear preference for conditional β-convergence equations such as:
where \( { \ln }y_{{0_{rt} }} \) is the logarithm of the per capita income in region r, t is the base year and \( \{ \mathop x\nolimits_{{\mathop 1\nolimits_{rt} }} ;\,\mathop x\nolimits_{{\mathop 2\nolimits_{rt} }} ; \ldots ;\mathop x\nolimits_{{\mathop k\nolimits_{rt} }} \} \) are a set of conditioning factors. These variables, in our case, are the weight of the agricultural sector in the regional product, x 1, the percentage of the regional working population occupied in technological activities, x 2, and the regional population density, x 3.Footnote 2 The results of the estimation of this model appear in the first column of Table 2. There are clear signs of misspecification due to an omitted spatial structure.
The second column of Table 2 contains the estimation of an SLM:
and the third column the estimation of an SEM:
In both cases, w rs refers to the (r, s) element of a W weighting matrix specified by combining the criteria of distance (with an interaction radius of 100 km) and of the two nearest neighbours (as in Mur et al. 2008, 2009); \( b_{rs}^{ - 1} \) is the corresponding element of the diffusion matrix \( \mathop {\mathbf{B}}\nolimits^{ - 1} = \mathop {\left( {I - \rho {\mathbf{W}}} \right)}\nolimits^{ - 1} \). Clearly the symptoms of misspecification, due to an omitted cross-sectional dependence structure, have almost disappeared. Finally, note that the LRCOM shows a clear preference for the SEM of Eq. 9c.
The question now is what happens with the (maintained) assumption of stability. We begin by solving the local Zoom estimation of the conditional β-convergence model of Eq. 9a, which can be expressed as:Footnote 3
The results corresponding to the series of local estimates, \( \left\{ {\beta^{(r,m)} ,r = 1,2, \ldots ,R} \right\} \) for different values of m, are summarized in Fig. 2.

Local estimation of the parameter of β-convergence: Eq. 9a
The regions where the local estimate of β(r, m) is not significant are coloured in light grey. If the coefficient is significant and negative the region appears in black and if it is significant and positive in dark grey. It is clear that, as we increase the size of the Zoom (using a higher value of m), a more regular spatial pattern emerges. There is a homogenous block made up of French, British, Dutch, Belgian and German regions always in light and dark grey, implying the absence of convergence at a local scale; on the contrary, the colour black, synonym of convergence at a local scale, extends towards the periphery of the continent.
In Fig. 3, we present the results of the procedure of identifying regimes based on the sequence of values of the \( {\text{LM(}}i,m)_{\text{break}}^{\text{ERR}} \) statistic. Depending on the simulation, we used two values for the parameter m, 40 and 80.

Regimes of spatial interaction according to a SEM approach
Once again, in Fig. 3 a central-periphery structure which affects the mechanisms of spatial dependence clearly emerges. Specifically, the regions situated in the centre of the continent maintain a greater interaction with their neighbours than those situated in the exterior zones.
Figure 4 shows the quartiles of the local estimation of the parameter of spatial dependence of the SEM of Eq. 9c:
where \( \mathop b\nolimits_{rs}^{{\mathop {(r,m)}\nolimits^{ - 1} }} \) refers to the (r, s) element of the local diffusion matrix \( \mathop {\mathbf{B}}\nolimits^{{\mathop {(r,m)}\nolimits^{ - 1} }} = \mathop {( {I - \mathop \rho \nolimits_{r}^{(r,m)} \mathop {\mathbf{W}}\nolimits^{(r,m)} } )}\nolimits^{ - 1} \) that operates around region r and \( \mathop \rho \nolimits_{r}^{(r,m)} \) is the corresponding local spatial dependence parameter.

Locally estimated spatial dependence parameter \( \mathop \rho \nolimits_{r}^{(r,m)} \). SEM case. m = 40
Lastly, Fig. 5 summarizes the structure of spatial regimes that emerges by combining all the previous information.

Regimes of spatial dependence for the European case: centre and periphery
The centre is made up of a macro-region characterized by weak symptoms of convergence but strong relationships of spatial dependence. This cluster includes a total of 125 units from Western Germany, Holland, Belgium, Luxembourg, Austria, the South of the United Kingdom, Ireland, Northern France and Italy. The other 137 regions constitute the periphery and are characterized by a lower income, the existence of an apparently homogeneous tendency towards convergence and weaker spatial relations.
4.2 Duality in the mechanisms of convergence and of spatial dependence
According to this Centre-Periphery dichotomy, we can not accept the null hypothesis of homogeneity in the coefficient of regression in any of the models in Eqs. 9a–9c, as indicated by the Chow test that appears in Table 2. This evidence confirms the suspicions of structural instability. Below, in Eqs. 12a and 12b, we allow the mechanism of β-convergence to differ between the two groups of regions:
The estimations included in the respective columns of Table 2 corroborate the importance of the break. In general, there is a higher speed of convergence in the periphery than in the central regions. The differences also extend to the other parameters. Interestingly, the LRCOM test continues in favour of the SEM of Eq. 12b.
Nevertheless, there are still signs of instability in the parameters of spatial dependence in both equations, as shown by the \( {\text{LM}}_{\text{break}}^{\text{LAG}} \) and \( {\text{LM}}_{\text{break}}^{\text{LAG}} \) tests. The solution is to extend the break also to the spatial dependence mechanisms, as in the specifications of 12c and 12d:
The matrix W* affects only the regions belonging to the Central regime and has been specified according to Fig. 5. Both equations appear to be acceptable in the sense that they do not fail the specification tests. Moreover, the estimations, which now differ only slightly, are always produced in the expected sense. The \( {\text{LR}}_{\text{break}}^{\text{COM}} \) test indicates that we cannot reject the restrictions of common factors underlying the model of Eq. 12d, although the evidence in favour of SEM structures is weaker than in previous cases. So we may conclude by choosing Eq. 12d as the best specification for explaining the European experience in the period 1995–2005.
According to our estimates, it is clear that the discrepancy between the two regimes directly affects the processes of cross-sectional dependence. For example, in model given by Eq. 12d, where these mechanisms are assumed to be constant, the estimation of the coefficient of spatial dependency is relatively high, 0.614, compared to other studies. If we introduce a break into the two regimes, as is done in Eq. 12d, we obtain a significantly lower estimation for the periphery, with a value of 0.493, while the coefficient corresponding to the regions of the centre of the continent is almost 50% higher, with a value of 0.713 (adding the values of γ = 0.493 and γ c = 0.238).
Except for this issue, our results largely coincide with others in the literature dealing with the convergence hypothesis for the European regions. For example, as underlined by Fingleton and Lopez-Bazo (2006), there exists a preference in favour of SEM structures that, in our case, is consistently corroborated by the LRCOM test. The same can be said in relation to the differences in the rate of convergence (Baumont et al. 2003): after discounting the differences in the long-run steady state between the centre and the periphery, there is still a slightly higher speed of convergence in the central regions (of almost four hundredths). The recent incorporation of a large group of regions from Eastern Europe, with a much lower income level, has not significantly altered this situation; on the contrary, it has served to accentuate the centre-periphery dichotomy. There are also some discrepancies, especially in the estimated values, that may be attributed to differences in the temporal span, in the spatial breakdown or, simply, to the source of the data used in our analysis.
5 Conclusions
Heterogeneity and dependence are characteristic features of econometric models with a spatial base and are very often confused because they produce similar symptoms. In this work, we have explored a new approach which combines the two mechanisms in a more general framework of spatial instability.
Some other authors have previously discussed the same problem (as in Brunsdon et al. 1998; Páez et al. 2002a, b; LeSage and Pace 2004; Egger and Pfaffermayr 2006). The contribution of our paper focuses on the part of the diagnostic, as a necessary previous step before resorting to costly algorithms of local estimation. We present a strategy organized in three steps. The first one is of an exploratory nature and consists of the application of an intensive local estimation algorithm, looking for spatial regimes and symptoms of structural breaks. The second stage is of a confirmatory nature and we have to test the significance of the spatial break identified in the first stage, using some of the Lagrange Multipliers presented in Sect. 3. The third stage estimates the corresponding specification.
To illustrate our proposal, we present an application to the case of the per capita income of the European regions. Using data for 262 regions observed during a rather short time period (1995–2005), our evidence reveals the existence of a strong break in the process of convergence in terms of a classical centre-periphery model. Some of the results found in the paper are similar to other studies like, for example, the preference for SEM structures or the detection of a slightly higher rate of convergence in the central regions of the continent. Our work completes this picture by extending the break also to the mechanisms of spatial dependence that operate in both areas, centre and periphery. We find that the dependence is stronger in the central regions, probably due to the existence of more and better infrastructures of transport and communications that facilitate the interaction between them.
Notes
Due to length restrictions, we have not included the results for the \( \mathop {\text{LM}}\nolimits_{\text{break}}^{\text{SLM}} \) which are in line with those obtained for the \( \mathop {\text{LM}}\nolimits_{\text{break}}^{\text{SEM}} \) test. They are available from the authors upon request.
This selection has been clearly constrained by the availability of information for the whole set of regions. In addition, we have included three dummy variables in all the models to reduce the harmful impact of a group of outlying regions.
This part of the Appendix partly coincides with the discussion of Mur et al. (2008). However, we decided to maintain this material in order to give a more complete view of the entire proposal.
References
Abreu M, de Groot H, Florax R (2005) Space and growth: A survey of empirical evidence and methods. Rég et Dév 21:13–44
Anselin L (1988a) Spatial econometrics methods and models. Kluwer, Dordrecht
Anselin L (1988b) Lagrange multiplier test diagnostics for spatial dependence and spatial heterogeneity. Geogr Anal 20(1):1–17
Anselin L (1990) Spatial dependence and spatial structural instability in applied regression analysis. J Reg Sci 30(2):185–207
Anselin L (1995) Local indicators of spatial association—LISA. Geogr Anal 27(2):93–115
Anselin L, Bera A (1998) Spatial dependence in linear regression models with an introduction to spatial econometrics. In: Giles D, Ullaah A (eds) Handbook of applied economic statistics. Dekker, New York, pp 237–289
Anselin L, Bera A, Florax R, Yoon M (1996) Simple diagnostic tests for spatial dependence. Reg Sci Urban Econ 26(1):77–104
Anselin L, Florax R, Rey S (eds) (2004) Advances in spatial econometrics. Springer, Berlin
Arbia G (2006) Spatial econometrics statistical foundations and applications to regional convergence. Springer, Berlin
Baumont C, Ertur C, LeGallo J (2003) Spatial convergence clubs and the European regional growth process, 1980–1995. In: Fingleton B (ed) European regional growth. Springer, Berlin, pp 131–158
Breusch T, Pagan A (1979) A simple test for heteroscedasticity and random coefficient variation. Econometrica 47(5):1287–1294
Brunsdon C, Fotheringham S, Charlton M (1998) Spatial nonstationarity and autoregressive models. Environ Plan A 30(6):957–973
Burridge P (1981) Testing for a common factor in a spatial autoregression model. Environ Plan A 13(7):795–800
Chow C (1960) Tests of equality between sets of coefficients in two linear regressions. Econometrica 28(3):591–605
Durlauf S, Kourtellos A, Minkin A (2001) The local solow growth model. Eur Econ Rev 45(4–6):928–940
Durlauf S, Johnson P, Temple J (2005) Growth econometrics. In: Aghion P, Durlauf P (eds) Handbook of economic growth. Elsevier, Amsterdam, pp 555–677
Egger P, Pfaffermayr M (2006) Spatial convergence. Pap Reg Sci 85(2):199–216
Ertur C, Koch W (2007) Growth, technological interdependence and spatial externalities: theory and evidence. J Appl Econ 22(6):1033–1062
Ertur C, LeGallo J, LeSage J (2007) Local versus global convergence in Europe: a bayesian spatial econometric approach. Rev Reg Stud 37(1):82–108
Fingleton B (ed) (2003) European regional growth. Springer, Berlin
Fingleton B, Lopez-Bazo E (2006) Empirical growth models with spatial effects. Pap Reg Sci 85(2):177–198
Fischer M, Stirböck C (2006) Pan-European regional income growth and club-convergence insights from a spatial econometric perspective. Ann Reg Sci 40(4):693–721
Fotheringham A, Charlton M, Brunsdon C (1999) Geographically weighted regression a natural evolution of the expansion method for spatial data analysis. Environ Plan A 30(11):1905–1927
Huang J (1984) The autoregressive moving average model for spatial analysis. Aust J Stat 26(2):169–178
Kubo Y (1995) Scale economies, regional externalities, and the possibility of uneven development. J Reg Sci 35(1):29–42
Lacombe D (2004) Does econometric methodology matter? an analysis of public policy using spatial econometric techniques. Geogr Anal 36(2):105–118
LeGallo J, Dall’Erba S (2006) Evaluating the temporal and spatial heterogeneity of the European convergence process, 1980–1999. J Reg Sci 46(2):269–288
LeGallo J, Ertur C, Baumont C (2003) A spatial econometric analysis of convergence across european regions, 1980–1995. In: Fingleton B (ed) European regional growth. Springer, Berlin, pp 99–130
LeSage J, Pace K (2004) Spatial autoregressive local estimation. In: Getis A, Mur J, Zoller H (eds) Spatial econometrics and spatial statistics. Palgrave, London, pp 31–51
López F, Mur J, Angulo A (2009a) Local estimation of spatial autocorrelation processes. In: Páez A, Le Gallo J, Buliung R, Dall’Erba S (eds) Progress in spatial analysis: theory, computation and thematic applications. Springer, Berlin, pp 111–140
López F, Angulo A, Mur J (2009b) Maps of continuous spatial dependence. Regions et Développement 30:1–24
Lopez-Bazo E, Vayá E, Artís M (2004) Regional externalities and growth: evidence from European regions. J Reg Sci 44(1):43–73
Magrini S (2004) Regional (di)convergence. In: Henderson V, Thisse V (eds) Handbook of regional and urban economics. Elsevier, Amsterdam, pp 2741–2796
Mur J, Angulo A (2006) The spatial Durbin model and the common factor tests. Spat Econ Anal 1(2):207–226
Mur J, López F, Angulo A (2008) Symptoms of instability in models of spatial dependence. Geogr Anal 40(2):189–211
Mur J, López F, Angulo A (2009) Testing the hypothesis of stability in spatial econometric models. Pap Reg Sci 88(2):409–444
Páez A, Uchida T, Miyamoto K (2002a) A General framework for estimation and inference of geographically weighted regression models 1: location-specific kernel bandwidth and a test for locational heterogeneity. Environ Plan A 34(4):733–754
Páez A, Uchida T, Miyamoto K (2002b) A general framework for estimation and inference of geographically weighted regression models 2: spatial association and model specification tests. Environ Plan A 34(5):883–904
Parent O, Riou S (2005) Bayesian analysis of knowledge: spillovers in European regions. J Reg Sci 45(4):747–775
Quah D (1996) Regional convergence clusters across Europe. Eur Econ Rev 40(3–5):951–958
Ramajo J, Márquez M, Hewings G, Salinas M (2008) Spatial heterogeneity and interregional spillovers in the European union: do cohesion policies encourage convergence across regions? Eur Econ Rev 52(3):551–567
Rey S, Janikas M (2005) Regional convergence, inequality and space. J Econ Geogr 5(2):155–176
Rietveld P, Wintershoven H (1998) Border effects and spatial autocorrelation in the supply of network infrastructure. Pap Reg Sci 77(3):265–276
Zeileis A, Leisch F, Kleiber C, Hornik K (2005) Monitoring structural change in dynamic econometric models. J Appl Econ 20(1):99–121
Acknowledgments
A preliminary version of this paper was published in 2007 by FUNCAS (Fundación de las Cajas de Ahorro) as the Working Paper 2007/367. Furthermore, project ECO2009-10534/ECON of the Ministerio de Ciencia e Innovación del Reino de España also contributed to the financial support of this research.
Author information
Authors and Affiliations
Corresponding author
Appendix: Tests for the existence of a structural break in the mechanisms of spatial interaction
Appendix: Tests for the existence of a structural break in the mechanisms of spatial interaction
In this Appendix, we are going to obtain the expressions of the Lagrange Multipliers of Eqs. 4 and 6 with which we test for the existence of a break in the parameter of spatial dependence. The first part of the appendix is dedicated to the SLM and the second to a SEM.
1.1 The case of the SLM Footnote 4
The equation for this case appears in expression given by Eq. 4 in the text:
whose log-likelihood function is:
where φ is the vector of parameters of the model, φ = [β, γ0, γ1, σ2]′, and B is a square matrix of order (R, R), \( {\mathbf{B}} = I - \mathop \gamma \nolimits_{0} {\mathbf{W}} - \mathop \gamma \nolimits_{1} \mathop {\mathbf{W}}\nolimits^{*} \). The score vector is the following:
Under the assumption that there is no break in the coefficient of spatial dependence, this vector simplifies to:
where \( \mathop {\tilde{\gamma }}\nolimits_{0} \) and \( \mathop {\tilde{\sigma }}\nolimits^{2} \) are the ML estimations of γ0 and σ2 and \( \tilde{u} \) is the corresponding series of residuals of the restricted model:
The structure of the Hessian matrix is a bit complex:
The information matrix evaluated under the null hypothesis is the following:
The Lagrange Multiplier for the test of Eq. A4 is obtained in the usual way:
The term \( \mathop {\tilde{\sigma }}\nolimits_{\text{lag}}^{2} \) in the denominator is the asymptotic variance of the restriction corresponding to the null hypothesis, obtained as:
Matrix \( \mathop {{\tilde{\mathbf{V}}}\left[ {\tilde{\varphi }} \right]}\nolimits_{{\left| {\mathop H\nolimits_{0} } \right.}} \) is the ML estimation of the corresponding variance matrix of the vector of parameters under the null hypothesis of Eq. A8. The Lagrange Multiplier of Eq. A8 can easily be generalized to the more general case in which there are p different regimes in the coefficient of autocorrelation. The extended model corresponding to this case is:
The null hypothesis will be of the joint type:
The score will reproduce the structure indicated in Eq. A4, with an equation such as \( {\frac{{y^{\prime}\mathop {\mathbf{W}}\nolimits_{s}^{*} \tilde{u}}}{{\mathop {\tilde{\sigma }}\nolimits^{2} }}} - {\text{tr}}\mathop {{\tilde{\mathbf{B}}}}\nolimits^{ - 1} \mathop {\mathbf{W}}\nolimits_{s}^{*} \) for each regime. The Hessian and information matrices must be similarly extended.
1.2 The case of the SEM
The specification that we must use in this case is that of Eq. 5:
The log-likelihood function is the following:
where φ is the vector of parameters φ = [β, ρ0, ρ1,σ2]′ and B is the diffusion matrix, of order (R, R), \( {\mathbf{B}} = I - \mathop \rho \nolimits_{0} {\mathbf{W}} - \mathop \rho \nolimits_{1} \mathop {\mathbf{W}}\nolimits^{*} \). The score vector is:
with \( u = y - x\beta \) and \( \varepsilon = {\mathbf{B}}u = {\mathbf{B}}(y - x\beta ) \). Under the assumption that there is no break in the coefficient of spatial dependence, the model of Eq. A12 simplifies to:
so the score becomes:
where \( \mathop {\tilde{\rho }}\nolimits_{0} \) and \( \mathop {\tilde{\sigma }}\nolimits^{2} \) are the ML estimations of ρ0 and σ2 in the model of Eq. A15 and \( \tilde{u} \) is the associated series of residuals. From the score of Eq. A14, it is straightforward to obtain the Hessian matrix:
as well as the information matrix corresponding to the null hypothesis:
Finally, the Lagrange Multiplier for the hypothesis of Eq. A16 takes the following expression:
\( \mathop {\tilde{\sigma }}\nolimits_{err}^{2} \) is the asymptotic variance of the restriction of the null hypothesis, which is equal to:
As in the previous case, the Multiplier of Eq. A19 can be generalized to treat with p different regimes. The extended model will be:
The null hypothesis is again of the joint type:
The score will be obtained as in A16, with an equation of the type \( {\frac{{\tilde{u}^{\prime}\mathop {\mathbf{W}}\nolimits_{s}^{*} {\tilde{\mathbf{B}}}\tilde{u}}}{{\mathop {\tilde{\sigma }}\nolimits^{2} }}} - {\text{tr}}\mathop {{\tilde{\mathbf{B}}}}\nolimits^{ - 1} \mathop {\mathbf{W}}\nolimits_{s}^{*} \) for each of the p regimes considered. The Hessian and information matrices must be similarly extended.
Rights and permissions
About this article
Cite this article
Mur, J., López, F. & Angulo, A. Instability in spatial error models: an application to the hypothesis of convergence in the European case. J Geogr Syst 12, 259–280 (2010). https://doi.org/10.1007/s10109-009-0101-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10109-009-0101-0