
Abstract
With the recent surge of location-based social networks (LBSNs), e.g., Foursquare and Facebook Places, huge amount of human digital footprints that people leave in the cyber-physical space become accessible, including users’ profiles, online social connections, and especially the places that they have checked in. Different from social networks (e.g., Flickr, Facebook) which have explicit groups for users to subscribe or join, LBSNs usually have no explicit community structure. Meanwhile, unlike social networks which only contain a single type of social interaction, the coexistence of online/offline social interactions and user/venue attributes in LBSNs makes the community detection problem much more challenging. In order to capitalize on the large number of potential users/venues as well as the huge amount of heterogeneous social interactions, quality community detection approach is needed. In this paper, by exploring the heterogenous digital footprints of LBSNs users in the cyber-physical space, we come out with a novel edge-centric co-clustering framework to discover overlapping communities. By employing inter-mode as well as intra-mode features, the proposed framework is able to group like-minded users from different social perspectives. The efficacy of our approach is validated by intensive empirical evaluations based on the collected Foursquare dataset.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the wide adoption of GPS-enabled smart phones, location-based social networks (LBSNs) have been experiencing increasing popularity. Compared with traditional online social networks (e.g., Facebook, Twitter), a distinct feature of LBSNs is the coexistence of online as well as offline social interactions, as shown in Fig. 1. On one hand, LBSNs support typical online social networking facilities, e.g., making friends, sharing comments and photos. On the other hand, LBSNs also support offline social interactions, e.g., checking in places. In other words, LBSNs are heterogeneous social networks which consist of both online social links and offline social links [14]. Meanwhile, vertices in LBSNs usually have multiple attributes, e.g., attributes of a user might include number of followers, number of followings, and number of check-ins; a venue might have attributes such as category, number of visitors and location. The soaring popularity of LBSNs has created a platform for mining cross-domain social networks [13] and understanding collective user behavior in the cyber-physical space on a large scale, which are capable of enabling many applications, such as direct marketing, trend analysis, group tracking, and community sensing [28].

An toy example of LBSNs
Community structure is an common feature of social networks, and great efforts have been devoted to investigating efficient methods for partitioning large networks into meaningful communities [11]. A community is typically thought of as a group of users with more and/or better interactions among its members than between its members and the remainder of the network [18]. However, different from social networks (e.g., Flickr, Facebook) which provide explicit groups for users to subscribe or join, the notion of community in LBSNs is not well defined. Meanwhile, the coexistence of both online social interactions (i.e., single-partite links among users) and offline social interactions (i.e., bipartite links between users and venues) makes the community detection problem much more challenging. Therefore, to capitalize on the large number of potential users as well as the huge amount of heterogeneous social interactions in LBSNs, quality cross-domain community detection approach is needed.
Most of the existing community detection approaches are based on structure features (e.g., links) [4], but the structure information in online social networks is often sparse and weak; thus, it is difficult to detect interpretable overlapping communities by considering only online network links [9]. Fortunately, the heterogenous social interactions in LBSNs provide rich information about users and venues, including not only online/offline links but also user/venue attributes. Apparently, it is ideal to exploit both structure information and node attributes to cluster communities, as we can naturally obtain communities with interpretable information, even though it is a highly challenging task. Meanwhile, it has been well understood that people in a real social network are naturally characterized by multiple community memberships. For example, a person usually belongs to several social groups like family, friends, and colleagues; a researcher may be active in several areas. Thus, it is more reasonable to cluster users into overlapping communities rather than disjoint ones [25].
Classical co-clustering is one way to conduct such kind of community partitioning [10, 29]. However, the identified communities are disjoint which contradicts with the actual social setting, where each user can belong to several communities. Edge clustering has been proposed to detect communities in an overlapping manner [24], but it did not take attribute features into consideration and therefore cannot be directly applied to LBSNs.
As we have mentioned, a significant community in LBSNs should consist of users who are not only structurally close to each other but also share similar attributes. Therefore, the existing evaluation metrics (e.g., maximum modularity [17, 18] and normalized mutual information [24]) for community detection, which are designed from the network topology perspective, are not appropriate for evaluating the quality of the detected communities in LBSNs. Furthermore, existing evaluation metrics are not able to characterize the member’s participation degree within a community. Thereby, novel evaluation metrics and mechanisms are needed, which poses another challenge.
In this paper, to leverage both the online/offline links and user/venue attributes in LBSNs, we choose to detect communities by clustering bipartite links (i.e., check-in relations between users and venues) instead of vertices, leading to groups of check-ins which naturally assign users into overlapping communities with connections to venues. In particular, since there are both single-partite (i.e., online social ties among users) and bipartite links in LBSNs, we transform the single-partite link into a special kind of user attribute by introducing a metric named inclusive neighbors, thus obtain an attributed bipartite network in which overlapping communities can be detected based on an edge-centric co-clustering framework.
In summary, the main contributions of this work include:
-
We formulate the overlapping community detection problem in LBSNs as an attributed bipartite edge-clustering issue which considers both online/offline links and user/venue attributes. Specifically, communities are detected from an edge-centric perspective, with the attributes of users and venues considered.
-
We represent users and venues in LBSNs as two types of nodes (i.e., modes) and select both inter-mode and intra-mode features for clustering, while existing co-clustering methods mainly concern the inter-mode features. We show that different perspectives of social communities can be revealed by introducing different intra-mode features.
-
We propose an entropy-based community structure evaluation framework to ensure optimal community detection. While community interest entropy measures the similarity of community members, community participation entropy estimates how equal users engage in a community. Meanwhile, this framework can also be used to guide the selection of k (number of communities) for community detection.
The rest of this paper is structured as follows. Section 2 presents the related work. Section 3 formally defines the overlapping community detection problem in attributed heterogenous social networks. The proposed community detection approach as well as the community structure evaluation framework is presented in Sect. 4, followed by experimental evaluation in Sect. 5. Afterward, Sect. 6 analyzes the detected communities. We conclude our work in Sect. 7.
2 Related work
We briefly review the related work from three different aspects. The first aspect involves the work on community detection only based on link information, which is a classical task in complex network analysis [8, 11, 18, 23]. A community is typically thought of as a cluster of nodes with more and/or better interactions among its members than between its members and the remainder of the network [11, 18]. To extract such clusters, one typically adopts an objective function which captures the concept that a cluster is a set of nodes with better internal connectivity than external connectivity, and then approximation or heuristics algorithms are used to detect communities by optimizing the objective function. Some popular methods are modularity maximization [8, 23], Girvan–Newman algorithm [18], Louvain algorithm [5], clique percolation [20], link communities [4], etc. It is worth mentioning that while most of the studies in this category focused on online social links, a new trend is to leverage offline social links [12] or both online and offline social links [16]. Our work is different from this category of community detection work because we utilize not only online and offline social links but also node attributes when designing the community detection algorithm.
The second aspect includes studies which leverage both links and node attributes for community discovering, e.g., the partition of attributed graphs, and the basic idea is to design a distance/similarity measure for vertex pairs which combines both link and attribute information. Based on such a measure, standard clustering algorithms like K-Medoids and spectral clustering are then applied to cluster the nodes. Steinhaeuser el al. [22] utilized a weighted adjacency matrix as the similarity measure, where the weight of each edge is defined as the number of attribute values shared by the two end nodes. Zhou et al. [30] defined a unified distance measure to fuse link and attribute similarities. Specifically, attribute nodes and edges are added into the original graph to connect nodes which have similar attribute values, and node similarity on the augmented graph is measured based on a neighborhood random walk model. However, all these works attempted to optimize two contradictory objective functions and aimed to identify disjoint communities. In this work, we focus on discovering overlapping communities by leveraging both online/offline links and node attributes.
The last aspect contains the research on discovering communities in LBSNs. Li et al. [15] proposed two different clustering approaches to identify user behavior patterns on BrightKite. One approach classified users into disjoint groups mainly based on their updates (i.e., check-ins, photos and notes); The other approach clustered users based on attributes such as total number of updates, social features, and mobility characteristics, which led to the identification of five disjoint groups. Noulas et al. [19] used a spectral clustering algorithm to group users based on the categories of venues they had checked in, aiming at identifying communities and characterizing the type of activity in each region of a city. Brown et al. [6] studied the detection of place-focused communities in LBSNs by annotating online social links with check-in information. In the annotated social graph, there exists an edge if and only if they are not only online friends but also place friends. Wang et al. [25, 26] put forward a community detection framework which is able to reveal overlapping communities of LBSNs users. In particular, the authors adopted an edge-centric co-clustering algorithm to cluster offline user–venue links; however, they did not take online social links into consideration. Although the aforementioned studies offer important insights into community detection in LBSNs, none of them worked on overlapping community detection using online/offline social links as well as node attributes. Our work aims to fill in this gap by discovering overlapping communities in heterogeneous social networks. Specifically, we formulate the overlapping community detection problem as an attributed bipartite edge-clustering issue, viewing both online/offline links and node attributes as unified features for clustering.
3 Problem statement
As shown in Fig. 1, in a typical LBSNs, there are two different kind of vertices (i.e., users and venues), where each vertex has several attributes. Meanwhile, there also exist online links among users as well as offline links between users and venues.
Therefore, LBSNs can be seen as a six-tuple graph G < U, V, M (|U| × |A|), M (|V| × |B|), O, M (|U| × |V|) >. Specifically, U is the set of users, and V denotes the venue category set. M (|U| × |A|) and M (|V| × |B|) represent the matrices of user attributes and venue category attributes, where |A| and |B| are the number of user attributes and venue attributes, respectively. O denotes the set of online links which contains o ij if u i , and u j are online friends, and M stands for the offline check-in relationship between users and venue categories where an entry \(M_{ij}\in[0,\infty)\) corresponds to the number of check-ins that u i has performed over v j .
To deal with the coexistence of both single-partite and bipartite social links in LBSNs, we transform the single-partite link into a special kind of user attribute by introducing a metric named inclusive neighbors. In particular, the inclusive neighbors of a user is defined as:
where d(u i , u x ) is the length of the shortest path between u i and u x . In other words, a user’s inclusive neighbors contain herself and her online friends. Apparently, the inclusive neighbors can be seen as a special user attribute, which characterizes the user’s online social connections.
Afterward, we obtain an attributed bipartite graph with user and venue category as its two modes, where each bipartite edge corresponds to a check-in link between the user and the venue. In such a graph, each user can be represented as a vector of venue categories, and each venue category can be denoted as a vector of users. Meanwhile, both users and venue categories have several attributes, and each attribute reveals a certain social aspect of users or venue categories. Therefore, both users and venue categories have two types of representations: an inter-mode representation and an intra-mode representation.
Based on the above notations, the overlapping community detection in LBSNs can be formulated as an attributed bipartite edge-clustering problem, and a community in LBSNs is a group of bipartite edges which consist of a subset of users as well as a subset of venue categories.
4 Edge-centric co-clustering on attributed bipartite networks
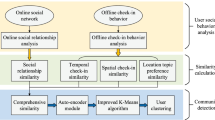
According to the problem formulation in Sect. 3, once we obtain clusters of bipartite edges, overlapping communities of users can be recovered by replacing each edge with its vertices, i.e., a user is involved in a community as long as any of her check-ins falls into the community. In such a way, the obtained communities are usually highly overlapped. The key idea of the proposed framework is shown in Fig. 2.

Community detection framework
As indicated in Fig. 2, we first select features based on the characteristics of LBSNs and then perform feature normalization and fusion. Second, the overlapping community structure is detected by using the proposed edge-centric co-clustering algorithm, where an edge cutting mechanism has been introduced to eliminate trivial community memberships. Finally, by leveraging user/venue metadata, we can analyze the detected communities from various social perspectives to guide real-world applications.
4.1 Edge-centric clustering
We define a community in LBSNs as a group of bipartite edges which are more similar with edges within the group than edges outside the group. Therefore, communities that aggregate similar users and venues together should be detected by maximizing intra-cluster similarity rather than maximizing modularity. This objective function is formulated as:
where k is the number of communities, C = {C j } is the detected community set, e c denotes an edge of community C j , and sim(e c , C j ) is the similarity between e c and C j . With this formulation, the key is to characterize the similarity between an edge and a community. To this end, we first introduce the definition of edge similarity.
In an attributed bipartite network, each edge is associated with a user vertex and a venue vertex. By taking an edge-centric view, each edge is treated as an instance with its two vertices as features. In other words, the similarity between a pair of edges can be defined as the similarity between the corresponding user pair and venue pair as:
where sim u (u i , u j ) is the similarity between two users, sim v (v i , v j ) is the similarity between two venues, and F represents the function used to combine these two similarities, by balancing the weights of the user mode and the venue mode. The formalism of F depends on the characteristics of the expected communities as well as the targeted applications. Considering the similarity trade-off between user mode and venue mode, two widely used formalisms of F are (sim u + sim v )/2 and \(\sqrt{sim_{u}\times sim_{v}}\). In this work, we adopt the second notion to ensure that a pair of edges are of high similarity if and only if they are of high similarity in both user mode and venue mode.
Since each community contains a set of edges, the similarity between an edge e i and a community C j is defined as:
where |C j | refers to the number of edges within community C j and e c represents an edge from C j .
As shown in Eq. 3, the edge similarity is defined based on two mode similarities (i.e., user similarity and venue similarity). In the following subsections, we will first describe the used inter-mode and intra-mode features, followed by feature normalization and fusion.
4.2 Feature description
In this work, we mainly focus on two inter-mode features and three intra-mode features. This section will present the detailed description of these features based on the characteristic of Foursquare dataset.
4.2.1 Inter-mode feature: user–venue similarity
Foursquare classifies venues into 400 categories under nine parent categories. We identify 274 venue categories by merging those similar ones, and consequently based on a user’s check-in venues, each user can be represented as a vector of 274 dimensions. We build a |U| × 274 matrix to represent all the active users within the collected dataset. Afterward, this matrix is refined based on principal component analysis, which is able to convert a set of observations of correlated variables into a set of values of linearly uncorrelated variables under a latent space. By applying principal component analysis on the raw matrix, we obtain a |U| × 100 matrix which covers 95.62 % of the total variance. After the conversion, each user is represented as a vector of 100 dimensions in the latent space.
Based on the above matrix, the user–venue similarity for a pair of users u m and u n is calculated based on cosine similarity as follows:
where u m and u n refer to the feature vectors of u m and u n in the latent space, respectively.
4.2.2 Inter-mode feature: venue–user similarity
As we have mentioned, each venue category of Foursquare can be denoted as a vector by treating users as its features. Following the same approach as the above section, we obtain a 274 × 100 matrix by performing principal component analysis on the original 274 × |U| matrix, which covers 95.34 % of the total variance. As a result, each venue category corresponds to a vector of 100 dimensions in the latent space. Similarly, the venue–user similarity is also defined using cosine similarity.
4.2.3 Intra-mode feature: user social similarity
People usually have different social connections in LBSNs, and in this paper, we introduce a metric named inclusive neighbors to characterize the user’s social relationship. Consequently, two users will be of high similarity if they share a lot of common friends, and they are very likely to belong to the same community. We introduce the first intra-user similarity feature namely user social similarity based on the inclusive neighbors N +. Given a pair of users u m and u n , the social similarity is defined using Jaccard similarity, which has been proved to be an effective metric [4]. Specifically, its formal definition is as follows:
where N +(u m ) and N +(u m ) are the inclusive neighbors of u m and u n , respectively.
4.2.4 Intra-mode feature: user geo-span similarity
The user geo-span (a.k.a. radius of gyration) is another metric that can be used to distinguish the life style of different users, which is defined as the standard deviation of distances between a user’s check-ins and her home location. In LBSNs, a user’s home location is defined as the centroid position of her most popular check-in region [21]. The user geo-span metric is able to indicate not only how frequently but also how far a user moves. Generally, a user with low radius of gyration mainly travels locally (with few long-distance check-ins), while a user with high radius of gyration has many long-distance check-ins. The formal definition for radius of gyration is as follows:
where n is the number of check-ins made by a user, and r i − r h is the distance between a particular check-in location r i and the user’s home location r h .
By using the radius of gyration metric, we introduce the second intra-user similarity feature named user geo-span similarity. Specifically, for a pair of users u m and u n , the calculation of this feature is defined as:
where r g (u m ) and r g (u n ) represent the geo-spans of u m and u n , respectively. Apparently, the value of user geo-span similarity falls into the interval [0, 1].
4.2.5 Intra-mode feature: venue temporal similarity
Generally, people visit and check in different kind of venues at different time, such that different venue categories can be distinguished according to their temporal check-in patterns [27]. This paper partitions a week into 168 (7 × 24) time slots, and each time slot corresponds to 1 h in a certain day of the week, reflecting the temporal characteristic of each user check-in. In such a way, we build a weekly temporal check-in band for each venue category at the hour granularity, which means each temporal band corresponds to a vector of 168 dimensions (7 × 24).
Since we have identified 274 venue categories, a matrix of 274 × 168 is constructed, and then principal component analysis is performed on this matrix, producing a new matrix of 274 × 20 which covers 99.92 % of the total variance. Consequently, the venue temporal similarity between a pair of venues can also be defined based on cosine similarity.
4.3 Feature normalization and fusion
Due to the characteristic of various similarity features, different calculation methods might be used which lead to different value ranges. Therefore, the absolute values of different features must be normalized. To this end, we simply normalize each similarity measure sim x into the interval [0, 1] as follows:
where \(sim_x^{\prime}\) is the normalized format of measure sim x .
Afterward, another issue is to fuse different features. Considering that each edge consists of two nodes, we first defined user similarity and venue similarity as:
where |f u | and |f v | represent the number of selected features for user mode and venue mode, respectively; \(sim_{u*}^{\prime}\) and \(sim_{v*}^{\prime}\) refer to the normalized similarity. Then, based on Eq. 3, the edge similarity is calculated as follows:
4.4 Clustering algorithm
Based on the above formulation, the attributed bipartite edge-clustering problem is converted into an ordinary clustering issue, which can be handled by adjusting k-means as follows:
-
While k-means selects the mean (i.e., geometric center) of all the instances (i.e., edges) in a cluster as its centroid, we represent each centroid by using the whole set of instances within the cluster. According to the definition of the similarity between an edge and a cluster in Eq. 4, if a set of attributed bipartite edges are denoted by a single vector, the obtained similarity will be significantly different.
-
The similarity between a given pair of instances is not directly calculated but based on the similarity between the corresponding pair of vertices. As each edge includes two vertices and each vertex consists of multiple attributes which are usually represented as feature vectors of different dimensions (i.e., length), it is difficult to define a unified distance measure to characterize the similarity between a pair of attributed bipartite edges.
-
While representing each centroid as a set of instances ensures the precision of the obtained similarity, the computation complexity increases from O(k × N) to O(N 2). To improve the time efficiency, each centroid C j is denoted as a structure which consists of four components: a list of current instances within the centroid \((E_{C_{j}})\), a list of instances that are assigned to the centroid during last iteration \((E_{A,C_{j}})\), a list of instances that are removed from the centroid during last iteration \((E_{R,C_{j}})\), and the similarity array between the previous centroid and the whole set of instances \((sim(E_{P,C_{j}},E))\).
Based on the above adjustments, the proposed k-means-based clustering method is presented in Algorithm 1.
At the beginning, k edges are randomly selected (line 1) based on which a set of initial centroids are constructed (lines 2–7). Afterward, during the iteration, given a centroid C j , we compute the similarity that each edge e i has obtained (line 14) as well as the similarity it has lost (line 15) during the last reassignment, based on which the current similarity between e j and C j is calculated (line 16). Edge e i is assigned to the centroid that is most similar to itself, and the corresponding similarity is marked as maxsim i (lines 17–20). Centroid updating is performed based on the reassignment of edges (line 23). At the end of each iteration, the current value of the objective function is calculated (Obj cur , line 24) to compare with the previous value Obj pre (line 25). The iteration terminates if and only if the absolute difference between these two values is smaller than the predefined threshold \(\epsilon\) (line 26). Experiments based on our dataset show that the algorithm usually converges within 100 iterations.
4.5 Edge cutting
Sometimes, the LBSN users perform occasional check-ins, which do not reflect their preferences or interests and may bring negative effect on community detection. To deal with this issue, we put forward a progressive edge cutting mechanism by introducing a threshold τ to restrict the minimum participation. This threshold determines whether a user should or should not be a member of a given community. We denote the set of edges corresponding to the check-ins of user u m as E m . For each community C j that u m belongs to, if the ratio between E m,j and E m (E m,j is the subset of E m which falls into C j ) is lower than τ, u m will be excluded from community C j and the edges within E m,j will be eliminated.
Algorithm 2 presents the proposed edge cutting mechanism. Firstly, the initialization part of Algorithm 1 (lines 1–8 of Algorithm 1) is invoked. Afterward, within each iteration, a community structure is formed based the rest of Algorithm 1 (lines 9–26 of Algorithm 1). Based on the output of Algorithm 1, edge cutting is performed for each user according to the threshold τ (lines 4–10), and the remained edges E R as well as the remained community structure will be used as the input to Algorithm 1 in the next clustering process (line 4). The process continues until the proportion of newly eliminated edges (i.e., \(\frac{|E|-|E_R|}{|E|}\)) is lower than the predefined terminate threshold \(\epsilon_{\rm cut}\) (line 12).

Experimental results show that edge cutting is not only able to limit the overlapping degree (i.e., the average number of communities that each user belongs to) but also improve the community purity. The detailed performance of edge cutting will be presented in the evaluation section.
4.6 Optimization measure
Modularity is a widely adopted measure to evaluate community detection methods which aim to cluster nodes based on inter-mode connection. Specifically, given a dataset, the optimal community structure can be discovered by maximizing modularity, since the modularity first increases along with k and achieves its extreme at a specific k and then it starts to decrease. However, as we have mentioned, this work aims to group together similar users by maximizing intra-cluster similarity, where the intra-cluster similarity consistently increases as k increases. Therefore, for similarity based community detection, it is necessary to propose a new measure to evaluate the quality of the detected community structure, which is not a trivial task.

We deal with this issue based on the following two assumptions. On one hand, a significant community should consist of a certain number of users who are about equally engaged in the community. To this end, our first assumption is that the size of a meaningful community should not be very small and its members should have similar participation degree. On the other hand, the interests of a significant community should mainly focus on only a few social activities. Therefore, our second assumption is that an effective community in LBSNs should consist of a small number of venue categories. Accordingly, we introduce two different community entropies: community participation entropy and community interest entropy, based on which an optimization function is constructed to assess the quality of the detected communities.
4.6.1 Community participation entropy
Community participation entropy takes into account both the community size (i.e., number of members) and the relative proportion of each member’s participation (i.e., check-in times). A community has high-participation entropy if it consists of a large number of users with similar participation degree. Conversely, a community has low-participation entropy if it is dominated by several users. Specifically, community participation entropy is defined as:
where |C j | is the number of check-ins within C j , and |u i | denotes the number of edges within C j which is from u i . Obviously, social interactions are mostly like to occur within communities of high-participation entropy.
4.6.2 Community interest entropy
Community interest entropy measures the evenness of the member’s check-in preferences within a community. Specifically, a community in this paper corresponds to a cluster of user check-ins, and each check-in is associated to a particular venue category. Therefore, a community C j can be represented as a vector of venue categories \(\left\langle {\omega_{C_j,V_1},\omega_{C_j,V_2},{\ldots},\omega_{C_j,V_N}} \right\rangle\), where ω C_j,V_n denotes the occurrence count of category V n within C j . Accordingly, community interest entropy can be formalized as:
where |C j | is the number of check-ins within C j which is equal to \(\sum{\omega_{C_j,V_n}}\). A community will have low-interest entropy if it only consists of a small number of venue categories with high-occurrence counts; it will have high-interest entropy if even occurrence counts spread over a big number of venue categories.
4.6.3 Optimization function
According to the above definitions, given a dataset, both the average community participation entropy and the average community interest entropy will decrease as k increases. Meanwhile, an optimal community structure should consist of communities with high-participation entropy and low-interest entropy. Therefore, the estimation of community structure is formulated as a multi-objective optimization problem as:
In Model I, {C k} denotes the set of communities detected when the number of communities is set as k and C k j is a member of { C k }. To solve I, we first normalize the two community entropies as:
and
where H P is the expected maximum community participation entropy and h P denotes the expected minimum community participation entropy, and H I is the expected maximum community interest entropy and h I denotes the expected minimum community interest entropy. Afterward, the above optimization model can be translated into the following format:
In Model II, F represents a function on μ P,k and μ I,k . Obviously, the optimal solution for Model II is also an efficient solution for Model I. To this end, we combine the two objectives in Model II by introducing an optimization function as follows:
On one hand, for a given k, the optimization function measures the average quality of the detected communities. On the other hand, this function can also be used to compare different community structures that are discovered under different k-values. Therefore, based on the proposed function, we are able to select an optimal k and consequently reveal the optimal community structure. Detailed evaluation of the proposed optimization function will be presented in the Sect. 5.
5 Performance evaluation
This section presents the evaluation results of the proposed overlapping community detection approach by performing experiments from different perspective based on multiple feature sets. We begin with the description of the data collection, followed by experiment setup and benchmark, and then present the obtained results.
5.1 Data collection
Foursquare is a popular LBSNs which has more than 30 million registered users till January 2013, and millions of check-ins are performed per day [1]. In this section, an empirical study is conducted to evaluate the proposed community detection approach. The Foursquare API provides limited authorized access for retrieving check-in information; therefore, we resort to the Twitter streaming API [2, 11] to get the publicly shared check-ins in this work. Figure 3 presents the process of our data collection, which utilizes both the Twitter API and the Foursquare API. Our data collection started from October 24, 2011, and lasted for 8 weeks, which results in a dataset of more than 12 million check-ins performed by almost 720,000 users over 3 million venues. Meanwhile, we also crawled the metadata related to users and venues.

Data collection flow
Before detecting communities, we pre-process the collected dataset as follows. First of all, we excluded check-ins that are performed over invalid venues. In this paper, invalid venues refer to those that cannot be resolved by Foursquare API. Secondly, we only keep users who have performed at least one check-in per week on the average (referred as active users), which means inactive users together with their check-ins is excluded. Finally, users who used agent software conducting remote or automatic check-ins (with a check-in speed faster than 1,200 km/h, which is the common airplane speed) are defined as sudden move users [7], and check-ins from these users are eliminated.
5.2 Experiment setup and overall design
To evaluate the performance of the proposed framework, we chose three big cities (i.e., New York, Paris, and Tokyo) as the target societies.
We first calculated the home location of all the active users, and then, a set of users for each city are selected based on the distance between their home locations and the geometric center of the corresponding city. Specifically, we set the distance threshold as 10 km, yielding 3,503, 1,432, and 2,674 users for New York, Paris, and Tokyo, respectively. Afterward, all the check-ins produced by these users during the data collection period are extracted, resulting 108,451, 49,160, and 120,494 check-ins, respectively. Meanwhile, all the inter-mode and intra-mode features used in the experiments are calculated.
Based on the dataset of these three cities, we mainly conducted experiments from the following aspects:
-
Assessing the proposed framework’s ability to discover overlapping communities.
-
Evaluating the algorithm using the proposed metrics and optimization function.
-
Investigating the impact of the edge cutting mechanism.
5.3 Benchmark
In this work, we conduct a series of experiments to evaluate the performance of different feature sets as shown in Table 1, where each feature set corresponds to a specific social perspective. Specifically, edge clustering (i.e., Feature Set I) [24] is used as the baseline, which is a state-of-the-art overlapping community detection method. Meanwhile, different k-values (ranging from 1 to 200) as well as edge cutting thresholds (including 0.00, 0.05, and 0.10) are used for each feature set.
5.4 Clustering results
5.4.1 Ability to uncover overlapping communities
One principal objective of the proposed framework is to discover overlapping communities in LBSNs. In order to show an overall structure of overlapping communities, without loss of generality, we select the parameters as follows: set k as 30 and edge cutting threshold as 0.1, adopt Feature Set II, and use Paris dataset. The overall structure of the detected communities is shown in Fig. 4 based on [3]. To make the result more clear, we cluster the detected communities into ten groups based on the venue categories.

Overall structure of the detected overlapping communities. Each tag cloud represents a community; the number at the top right corner of a tag cloud denotes the user number of the community; two communities are linked if the overlapping degree is larger than 30 % (thick links) or 20 % (thin links). The overlapping degree is calculated as the ratio of the size of the intersection and the union of two communities
According to Fig. 4, we can see the size of a community (as shown by the number), the main activities of a community (from the tag size), and the overlapping degree between any two communities (from the links). For example, the biggest community in Paris is Office (362 users), which has more than 30 % overlapping users with the Bar community (129 users), the French Restaurant community (187 users), as well as the Food and Drink Shop community (152 users). Apparently, it depicts the lifestyle of the white-collar workers. Assume there are two highly overlapping communities and one of them is a mature market, the advertisers can then penetrate the other community by using the existing marketing channels.
Meanwhile, we also study how different feature sets impact the overlapping degree (i.e., the average number of communities that each user belongs to) of the detected communities. We compared the proposed framework with edge-clustering (i.e., Feature Set I) which only takes into account inter-mode features. As shown in Fig. 5, community detection methods which have leveraged not only inter-mode but also intra-mode features are able to achieve much higher overlapping degrees. The result implies that intra-mode features are capable of capturing certain aspects of human behavior patterns that cannot be characterized by inter-mode features, even though a high overlapping degree does not necessarily represent the quality of a community detection method. Particularly, the overlapping degrees of Feature Set II and Feature Set IV are much higher than Feature Set III and Feature Set V, indicating that feature sets which take into account user social similarity tend to achieve lower overlapping degrees. This should be due to the fact that online social connections are quite sparse in LBSNs.

Overlapping degrees of different feature sets
5.4.2 Evaluation based on the optimization function
For each feature set, we study the correlation between the number of communities and the corresponding results of community interest entropy, community participation entropy, and the optimization function. Afterward, we study whether the results are consistent across different feature sets. We give the experimental results of the Paris dataset as an example in Fig. 6.

Results of community interest entropy, community participation entropy, and optimization function of different feature sets. a Community interest entropy, b community participation entropy, c optimization function
As indicated in Fig. 6a and b, while k changes both the achieved community interest entropy and community participation entropy declines rapidly when k is small (k < 50) and the decrease becomes much slower when k is getting bigger (k > 100). An interesting finding is that the value of the optimization function increases at first and achieves its maximum value when k reaches a certain value, then the value starts to decrease, as shown in Fig. 6c, even though the extreme points of different feature sets slightly vary (mainly around 20–60). Similar results can be obtained when performing experiments on the dataset of the other two cities.
5.4.3 The impact of edge cutting
In this section, we study the influence of edge cutting from the following two aspects. First, we explore the correlation between different edge cutting threshold and the overall performance (i.e., results of all the metrics). Second, we study the influence of edge cutting from the user perspective, i.e., how edge cutting affects the communities that a specific user belongs to.
Figure 7 shows the performance of Feature Set IV where three different edge cutting thresholds (i.e., 0.0, 0.05, and 0.1) are used. As shown in Fig. 7a, the overlapping degree has a notable decline as the edge cutting threshold increases from 0.0 to 0.1. It is easy to understand since weak community memberships are excluded. Meanwhile, both the community interest entropy and the community participation entropy have a slight decrease when the edge cutting threshold becomes higher, as shown in Fig. 7b and c. It should be due to the fact that communities consist of less edges on average after edge cutting. An interesting finding is that, as indicated in Fig. 7d, edge cutting has no significant impact on where the optimization function achieves its extreme. This implies that edge cutting does not change the main characteristic of the detected community structure.

Results of Feature Set IV under three different edge cutting thresholds. a Overlapping degree, b community interest entropy, c community participation entropy, d optimization function
We present the tag clouds of a Paris Foursquare user (marked as Mary) and the communities that she belongs to under different edge cutting thresholds in Fig. 8. The results are obtained by using Feature Set IV when k is set as 60. Obviously, when the threshold increases from 0.0 to 0.1, Mary consistently falls into 3 communities (i.e., French Restaurant, Bar-Nightclub and Office). The only change is that she no longer belongs to the Train Station community, which should be due to the impact of edge cutting.

Tag clouds of a Foursquare user in Paris under two different edge cutting thresholds. The cloud at the left side of the figure denotes the check-ins of Mary, and the other 7 clouds represent communities. Specifically, the 4 clouds at the top right correspond to communities that Mary falls into when the edge cutting threshold is 0.0, and the other 3 clouds at the bottom right are communities that Mary belongs to when the edge cutting threshold is 0.1
To sum up, while edge cutting has no significant influence on community interest entropy, community participation entropy, and the optimization function, it mainly impacts the overlapping degree of the detected community structures. Specifically, edge cutting is capable of excluding weak memberships, thereby limiting the overlapping degree and enhancing the purity of the detected communities.
6 Community analysis
In this section, we aim to see whether the detected communities can be used to guide real-world applications, such as the advertisement for group purchasing. Since some parameters (e.g., k) can take different values, it is interesting to understand the impact of these parameters on the detected community structure. Particularly, we keep other parameters unchanged and compare different k-values (e.g., 30 and 60) as well as various feature sets.
6.1 Transition of community membership across different granularity
The granularity of communities is mainly determined by the given community number k. To uncover how the k-values impact the detected communities, we perform community detection using the parameters described in Sect. 5.4.1 except assigning 60 to k, and then compare the obtained community structure with the one when k is 30 (see Fig. 4). We find lots of one-to-many corresponding relationships between communities from these two community structures. An example is depicted in Fig. 9.

Membership transition when k changes from 30 to 60 under Feature Set II. The numbers on arrows denote how many users transit from the left community to the right communities. Specifically, the left side is a community with 227 users discovered when k is 30, and the right side enumerates three communities detected when k is 60
According to Fig. 9, we can see that most check-ins of the left community were performed over Government Building and University, and the rest of check-ins were performed over College Academic Building and other venue categories. After splitting the 30 communities further into 60 communities (k = 30\(\rightarrow\)60), we observe that three new and smaller communities with dominated venue category of Government Building, University and College Academic Building are generated to inherit the main characteristics of the original community shown on the left side. This indicates that, on one hand, when k is smaller larger communities are formed with more diverse user features; on the other hand, while k is larger, these large communities are divided into smaller ones with more focused and homogenous features. Thus, the original community has the trend to split based on different user feature dimensions. From a macroscopic view, the membership transition is a refining process in the same feature space where the instances (i.e., users) do not change their positions in the space. This observation can be used to guide market segmentation.
6.2 Reassignment of community membership under different approaches
To target various applications, different combinations of features might be used. Consequently, the obtained community structures would differ from each other, and we call this phenomenon as user membership reassignment. In this subsection, we compare the results of Feature Set II and Feature Set IV by using the same parameters (k = 30, and edge cutting threshold = 0.10). The results show that the users are reassigned as expected according to the newly introduced features. An example is illustrated in Fig. 10.

The membership reassignment of 338 users when using Feature Set II and Feature Set IV. The left side includes three communities from the result ofFeature Set II, which are dominated by French Restaurant, Bar and Movie Theater, respectively (including 555 unique users). The right side consists of three communities from the result of Feature Set IV, where each community includes all these three venue categories (including 574 unique users). The numbers on the arrows denote the quantity of users transfer from the left community to the right community
Merely based on the tag cloud, we cannot explain what leads to the reassignment shown in Fig. 10. Therefore, we investigate the new feature of Feature Set IV in these communities. The average geo-spans of members in these three communities on the right side is 108.19, 1.58, and 8.07 km (from top to bottom), respectively. Obviously, these three communities are distinguished mainly due to the difference of their geo-spans, which suggests that newly introduced features are able to influence the membership assignment. This phenomenon is inevitable when the feature space changes. We can choose and combine different features to discover suitable user groups based on the characteristic of a given service or product.
7 Conclusion
With the growing popularity of mobile social networking services, such as LBSNs, people’s online and offline social activities/experiences are merging in the cyber-physical space, which results in the arising of heterogeneous social networks.
In this paper, by exploring both online/offline social links and user/venue attributes, we identify overlapping community detection in LBSNs as a co-clustering issue. Specifically, communities are discovered by partitioning the attributed bipartite network for an edge-centric perspective. Meanwhile, we also propose an entropy-based measure to evaluate the quality of the detected communities. Experimental results show that the proposed framework is able to detect high-quality overlapping communities from different perspective and granularity, which can be used to facilitate various applications, such as group advertising and marketing.
References
Ahn YY, Bagrow JP, Lehmann S (2010) Link communities reveal multiscale complexity in networks. NATURE 466(7307):761–764
Blondel VD, Guillaume JL, Lambiotte R, Lefebvre E (2008) Fast unfolding of communities in large networks. J Stat Mech Theory Exp 10:P10,008
Brown C, Nicosia V, Scellato S, Noulas A, Mascolo C (2012) The importance of being placefriends: discovering location-focused online communities. In: Proceedings of the 2012 ACM workshop on workshop on online social networks, WOSN ’12. ACM, New York, pp 31–36
Cheng Z, Caverlee J, Lee K, Sui DZ (2011) Exploring millions of footprints in location sharing services. In: Proceedings of ICWSM’11. The AAAI Press, Menlo Park, CA, USA, pp 81–88
Clauset A, Newman MEJ, Moore C (2004) Finding community structure in very large networks. Phys Rev E 70:66111–66116
Cruz JD, Bothorel C, Poulet F (2011) Entropy based community detection in augmented social networks. In: Proceedings of CASoN’11. IEEE, pp 163–168
Dhillon IS (2001) Co-clustering documents and words using bipartite spectral graph partitioning. In: Proceedings of KDD’01. ACM, New York, pp 269–274
Fortunato S (2010) Community detection in graphs. Phys Rep 486(3–5):75–174
Guo B, He H, Yu Z, Zhang D, Zhou X (2012) Groupme: supporting group formation with mobile sensing and social graph mining. In: Proceedings of MobiQuitous’12
Guo B, Yu Z, Zhou X, Zhang D (2012) Hybrid SN: interlinking opportunistic and online communities to augment information dissemination. In: Proceedings of UIC/ATC’12, pp 188–195
Guo B, Yu Z, Zhou X, Zhang D (2012) Opportunistic IoT: exploring the social side of the internet of things. In: Proceedings of CSCWD’12. IEEE, pp 925–929
Li N, Chen G (2009) Analysis of a location-based social network. In: Proceedings of CSE’09. IEEE Computer Society, Washington, DC, USA, pp 263–270
Liu X, He Q, Tian Y, Lee WC, McPherson J, Han J (2012) Event-based social networks: linking the online and offline social worlds. In: Proceedings of KDD’12. ACM, New York, pp 1032–1040
Newman MEJ (2006) Modularity and community structure in networks. PNAS 103:8577–8582
Newman MEJ, Girvan M (2004) Finding and evaluating community structure in networks. Phys Rev E 69:26113–26127
Noulas A, Scellato S, Mascolo C, Pontil M (2011) Exploiting semantic annotations for clustering geographic areas and users in location-based social networks. In: Proceedings of ICWSM’11. The AAAI Press, pp 32–35
Palla G, Derenyi I, Farkas I, Vicsek T (2005) Uncovering the overlapping community structure of complex networks in nature and society. NATURE 435:814–818
Scellato S, Noulas A, Lambiotte R, Mascolo C (2011) Socio-spatial properties of online location-based social networks. In: Proceedings of ICWSM’11. The AAAI Press
Steinhaeuser K, Chawla NV (2008) Community detection in a large real-world social network. In: Liu H, Salerno JJ, Young MJ (eds) Social computing, behavioral modeling, and prediction. Springer, USA, pp 168–175
Wakita K, Tsurumi T (2007) Finding community structure in mega-scale social networks. In: Proceedings of WWW’07. ACM, New York, pp 1275–1276
Wang X, Tang L, Gao H, Liu H (2010) Discovering overlapping groups in social media. In: Proceedings of ICDM’10, pp 569–578
Wang Z, Zhang D, Yang D, Yu Z, Zhou X (2012) Detecting overlapping communities in location-based social networks. In: Proceedings of the 4th international conference on social informatics, SocInfo’12. Springer, Berlin, pp 110–123
Wang Z, Zhang D, Yang D, Yu Z, Zhou X, Yu Z (2012) Investigating city characteristics based on community profiling in LBSNs. In: Proceedings of SCA’12. IEEE, pp 578–585
Ye M, Janowicz K, Mülligann C, Lee WC (2011) What you are is when you are: the temporal dimension of feature types in location-based social networks. In: Proceedings of GIS’11. ACM, New York, pp 102–111
Zhang D, Guo B, Yu Z (2011) The emergence of social and community intelligence. IEEE Comput 44(7):21–28
Zhang D, Wang Z, Guo B, Yu Z (2012) Social and community intelligence: technologies and trends. IEEE Softw 29(4):88–92
Zhou Y, Cheng H, Yu JX (2009) Graph clustering based on structural/attribute similarities. Proc VLDB Endow 2(1):718–729
Acknowledgments
This work is partially supported by the National Basic Research Program of China (No. 2012CB-316400), the EU FP7 Project SOCIETIES (No. 257493), the National Natural Science Foundation of China (No. 61222209, 61103063), the Specialized Research Fund for the Doctoral Program of Higher Education (No. 20126102110043), the Natural Science Basic Research Plan in Shaanxi Province of China (No. 2012JQ8028), the Scholarship Award for Excellent Doctoral Student Granted by Ministry of Education of China, and the Doctorate Foundation of Northwestern Polytechnical University (No. CX201018). The authors would like to thank all the colleagues for their discussion and suggestion. Zhu WANG would like to thank the China Scholarship Council (CSC) for his joint PhD funding.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Wang, Z., Zhou, X., Zhang, D. et al. Cross-domain community detection in heterogeneous social networks. Pers Ubiquit Comput 18, 369–383 (2014). https://doi.org/10.1007/s00779-013-0656-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00779-013-0656-0