
Abstract
Rice is one of the most important cereal foods not only for India but also for the world. The production of crop depends upon the favorable climatic conditions. Farmers’ access to more accurate data on crop yields in various climate conditions can aid in crucial agronomic and crop selection decisions. Taking this into account, the motive of the present research was to find the best method of predicting rice crop yield in seven important rice producing districts of Uttarakhand, namely Udham Singh Nagar, Nainital, Haridwar, Dehradun, Champawat, Tehri-Garhwal, and Pauri Garhwal. Data on the weather variables for the crop-growing season (27th to 44th SMW) for 19 years was gathered from the respective district and the NASA power website, while rice production data for the research period was gathered from the Directorate of Economics and Statistics, Ministry of Agriculture and Farmers Welfare. Stepwise multiple linear regression (SMLR), least absolute shrinkage and selection operator (LASSO), ridge regression, elastic net (ELNET), and artificial neural network (ANN) were employed for the model’s development. The 80% data of the total datasets was utilized to calibrate the models, while the remaining 20% data was allocated for the model validation. On examining these models, LASSO was found to be the finest performing model followed by ELNET, while SMLR was the worst performing model during calibration stage. During validation stage, ANN performed better for Champawat, Dehradun, Haridwar, Pauri Garhwal, and Udham Singh Nagar. The performance of ELENT and LASSO was found to be best for Nainital and Tehri Garhwal, respectively. The performance of ridge regression and SMLR were found to be poor as compared to the other models for the rice yield forecasting.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Rice is one of the most significant food crops in the world, as it is ingested by approximately three billion people and provides 35 to 60% more calories than any other crop (Maclean et al. 2002). India is the second-largest rice producer in the world, producing 175.58 million tons annually (FAO 2018). In India, rice farming covers around 29.50 million ha area, demonstrating the crop’s importance (Kumar et al. 2021). The global climate changes have a significant impact on production and distribution of rice around the world. It has been reported that drought can reduce rice production by 30%, while a 1°C increase in global average temperature would reduce global rice production by an average of 3.2% (Kumar et al. 2021). In an agricultural country where modern technologies are not used and spread, weather factors are more important than other factors, as it may directly and indirectly affect the yield (Paltasingh and Goyari 2018). For that reason, it is essential to forecast rice production in order to feed the world’s growing population under present climate conditions. Crop yield forecasting models are vital for agriculture-related decisions involving food procurement, distribution, and pricing. There has been a rise in research on how climate change affects agricultural output (Kumar et al. 2021). Peoples who believe in climate change including farmers, resource management experts, and policymakers have all expressed an interest in learning more about the association between weather and agricultural yields.
The climate is experiencing unprecedented changes; keeping this in view, the government has taken steps to forecast crop yields and production. Several studies have been done to assess rice crop yields through field measurements, but it is very costly and time-consuming (Son et al. 2022). In addition to this, due to the limited number of field samples that are collected from the regional interpolation, the results of the estimation are often inaccurate and unreliable until the rice crop has been harvested. To decrease the labor expenses, crop simulation models have also been used to predict and estimate rice crop yield for certain areas or experimental sites (Jha et al. 2019; Togliatti et al. 2017). Those models possess the advantages of being accurate predictors of future crop yields and of being able to assess the effect of climate change on crop yield. However, these systems have some disadvantages, mainly due to the complex and expensive input of biophysical variables such as rice genotype coefficients, weather factors, soil types, and crop management practices, which are not generally available in many regions. To overcome the limitations of estimating crop yields across large regions, statistical and machine learning methods have been applied.
Several researchers have attempted to build pre-harvest yield forecasting models which are based on weather variables (Kakati et al. 2022; Satpathi et al. 2023; Setiya et al. 2022; Thimmegowda et al. 2023). The methodology for studying the crop and weather relationship has undergone many improvements over time. A majority of the literature investigates how crop yield responds to weather conditions, with an emphasis on weather extremes (Lesk et al. 2016), atmospheric CO2 concentration (Sakurai et al. 2014) in addition to decadal and interannual weather variability (Colville et al. 2011; Schlenker and Roberts 2009; You et al. 2009). The aim of this study to investigate how weather variables affect the rice crop yield for seven districts of Uttarakhand namely Udham Singh Nagar, Nainital, Dehradun, Haridwar, Champawat, Tehri-Garhwal, and Pauri-Garhwal. Along with this, the study aims to identify the method that best predict the crop yield for a given region.
A vast majority of existing literature primarily focused on investigating how crop yield respond to weather conditions, with emphasis on the decadal and interannual weather variability (Akinbile et al. 2015; Arvind et al. 2022; Boyer 1982) weather extremes (Colville et al. 2011). Agricultural crop yield losses due to weather change are predicted to be as high as 82% by the end of twentieth century for some crops (Ghosh et al. 2014; Jagadish et al. 2015). There has been a growing interest to examine the relation between crop productivity and weather change among advocates of weather change and food security, farmers, resource management professionals, and policy makers.
2 Data and methods
2.1 Data collection
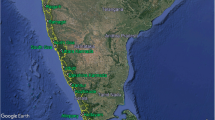
Seven major rice-producing districts of Uttarakhand, namely, Udham Singh Nagar, Nainital, Haridwar, Dehradun, Champawat, Tehri-Garhwal, and Pauri Garhwal have been considered in the present study. All seven study locations are shown in Fig. 1. Data on rice yield from 2001 to 2019 was obtained from the Directorate of Economics and Statistics, Department of Agriculture and Farmers Welfare, Government of India. The daily weather data for six weather variables namely average weekly maximum temperature (°C), minimum temperature (°C), relative humidity (%), wind speed (m/s), solar radiation, and weekly accumulated rainfall (mm) for the period 2001–2019 of four districts, viz. Udham Singh Nagar, Haridwar, Dehradun, and Tehri-Garhwal were collected from the local observatory located at the district, while the weather data of the remaining three districts were taken from the NASA POWER web portal (https://power.larc.nasa.gov/data-access-viewer/).

Study area map
2.2 Detrending of yield time series data
In the context of time series data, “detrending” refers to the act of removing the underlying trend or drift from the time series data. This makes it possible to do an analysis of the variations that remain around the trend in a more straightforward manner. The trend in yield statistics may be attributable to a number of different reasons, including shifts in economic conditions, shifts in monetary policy, and changes in market expectations and so on.
Regression analysis is an approach that is utilized frequently in the process of detrending yield time series data. This strategy involves fitting a linear or non-linear regression model to the available data, with the time as the independent variable and the crop yield as the dependent variable. Following this step, the trend line that was derived from the regression model is then subtracted from the initial data in order to generate the yield data that has been detrended.
Following simple linear regression model has been used to detrend the yield,
where t is the time period, Pt is the crop production or yield at time t, and β0 and β1 are the coefficients. The residuals of this model, which refers to the yield after removing the trend, were utilized in computing the indices. (Trnka et al. 2007). The steps involved in the development of the models are illustrated in Figure 2.

Steps involved in the development of the models
2.3 Weather indices approach
Two distinct indices were constructed for each of the weather variable. The first index was a summation of the values of the weather variables for each week, while the second index was a weighted total. The weights were determined by the correlation coefficient between the detrended yield and the weather variable for each week. The weighted and unweighted weather indices were computed by utilizing the Eqs. (i) and (ii) as suggested by Ghosh et al. (Ghosh et al. 2014) and Das et al. (Das et al. 2018)
where Xiw is the value of ith weather variable in the wth week,\({r}_{iw}^j\)is correlation coefficient of detrended yield with ith weather variable, and m is the week of forecast. Indices with j=0 are unweighted and j=1 are weighted. By following this procedure, a total of 42 weather variables were generated, which are listed in Table 1.
2.4 Crop yield forecast using SMLR
In earlier research, simple methods of correlation and linear regression were utilized by researchers to predict the crop yield. Later, the methodology was refined and researchers started using a stepwise multiple linear regression model, where weather variables such as rainfall and temperature (Wit) were regressed on crop yields (Yit) together with other variables comprising direct inputs (Iit) to agriculture. βi is the regression coefficient and εit is the error term. The basic model was designed as follows:
2.5 Crop yield forecast using shrinkage methods
The linear regression model, often known as the ordinary least squares approach, can be improved by using penalized regression instead. The penalized regression (a type of shrinkage method) incorporates a constraint in the form of a penalty into the equation. The use of this penalty has the effect of bringing the coefficient values closer and closer to zero. As a result of this, the less important variables can have coefficients that are very close to zero or even equal to zero. Since all of the independent variables in the study are interconnected, the idea behind penalized regression is to lessen the effect of multicollinearity.
2.6 Crop yield forecast using ANN
Artificial intelligence methods have been found to be superior over the past decade for forecasting crop yields. Models with complicated inputs can be simplified with the help of artificial neural networks. There are three distinct parts to an artificial neural network: the input layer, the hidden layer, and the output layer. The size of the input and output layer neurons depends on the particular dataset that is being utilized. In the present study, time variable and z indices are input variables and crop yield are the output variable. Threefold cross-validation was performed on the dataset, i.e., the dataset was randomly divided into three parts, one of which was kept for validation and the other two of which were utilized to train the model. The procedure is continued until all three components have been utilized for validation. At final, the model with the lowest root mean square percentage error (RMSE) was chosen as the best model. The main challenge in using artificial neural network (ANN) is identifying the optimal number of hidden nodes. In this research, the “train” function of the “caret” package in the R software was employed with the “nnet” method and 10-fold cross-validation to identify the quantity of hidden nodes (Kuhn 2008).
2.7 Error verification
To examine the performance of the models, comparisons was done between the predicted yields with the observed yield by using R2, RMSE, normalized root mean square percentage error (nRMSE), and mean absolute percentage error (MBE). The formulas of these statistical measures are as follows:
\({\hat{y}}_i\) and yirepresents the predicted and observed rice crop yield respectively. When significant differences exist between the two data sets, the RMSE is considered helpful. The square root of the mean squared differences between predicted and actual values is the RMSE. If the RMSE is less than 10%, the model’s accuracy is deemed excellent; if it is between 10 and 20%, it is good; if it is between 20 and 30%, it is fair; and if it is larger than 30%, it is poor (Toscano et al. 2012). The nRMSE is a statistical metric that is frequently used to quantify the accuracy of a prediction or model by comparing it to the true values or observed data. The nRMSE value close to zero indicate better model performance. On the other hand, mean biased error (MBE) helps to identify the under estimation and overestimation of the predicted values.
3 Results
Yield prediction models for the rice crop of Uttarakhand region have been developed using the long-term crop yield data (from 2001 to 2019) and long period daily weather data of the crop growing period (from 27th to 44th standard meteorological week) for respective locations.
3.1 Effects of weather variables on rice yield
The weather variables viz. temperature, solar radiation, rainfall, and humidity, etc. have profound effect on the production of rice. The optimum temperature condition for rice crop ranged from 15–18 to 30–33°C (Quang et al. 1995). The effect of temperature on rice yield was also reported extensively by Sanchez et al. (Sanchez et al. 2014) and Jagadish et al. (Jagadish et al. 2015). The mean weekly maximum temperature and mean weekly minimum temperature during rice-growing season was found to be 24.7–17.2°C for Champawat, 29.6–19.4°C for Dehradun, 30.0–21.2°C for Haridwar, 24.7–17.2°C for Nainital, 25.6–18.3°C for Pauri Garhwal, 20.8–13.4°C for Tehri Garhwal, and 31.7–22.8°C for Udham Singh Nagar. The rice crops are very sensitive to temperature change. Thus, rice yield is expected to decrease in high temperature (>35°C) as well as in low-temperature (<15°C) scenarios. Among all study areas, only Pauri Garhwal has low mean weekly minimum temperature (below optimum value) which can lead to loss of grain yield. Boyer (Boyer 1982) also reported that low temperature is a major environmental factor causing reduction in rice yield.
After temperature, another important weather variable that affects the rice yield is precipitation. The average yearly rainfall during crop-growing season was 847 mm for Champawat, 1378 mm for Dehradun, 941 mm for Dehradun, 941 mm for Haridwar, 847 mm for Nainital, 970 mm for Pauri Garhwal, 922 mm for Tehri Garhwal, and 1162 mm for Udham Singh Nagar. So there is sufficient rainfall throughout the growing season on all locations. Apart from this, during the crop growth period, frequent occurrence of wet and dry spells may lead to retarded growth and development. Prolonged periods of rainfall (flooding) during the initial stages of crop may lead to stunted crop growth and yield reduction (Lansigan et al. 2000).
Solar radiation has direct impact on the biomass accumulation of the rice crop (Akinbile et al. 2015). Reduction in solar radiation during critical growth stages can directly lead to reduction in the final yield (Rai et al. 2012). Zhang et al. (Zhang et al. 2010) and Yang et al. (Yang et al. 2015) reported that solar radiation is an important variable that can affect the rice yield. Additionally, high relative humidity during the crop growing period may lead to higher infestation of insects and diseases which can also reduce the crop yield. Wind can affect the crop yield indirectly by change in the evaporative cooling, vapor pressure deficit, and rate of evapotranspiration.
3.2 Model comparison at district level
A comparison was made among all the models used for different locations. There is variability in the yield as well as weather at different locations, so it is not necessary that a particular model perform well for all the locations. This section reports the model performance based on the location considered in the present study. The performances of different models were assessed here based on the R2, RMSE, nRMSE, and MBE during both calibration and validation stages which are presented hereunder for different locations. Performance of the models developed using different techniques for rice yield forecasting of all district is shown in Table 2.
For Champawat district, the performance of ANN was excellent during both calibration (R2 = 0.999, RMSE = 0.003 ton ha−1, nRMSE = 0.279%) as well as validation stage (R2 = 0.999, RMSE = 0.003 ton ha−1, nRMSE = 0.279%). The performance of other models, i.e., SMLR, LASSO, ELNET, and ridge regression, was excellent during calibration (R2: SMLR =0.89; LASSO = 0.99; ridge = 0.83; ELNET =0.99) but at validation these models perform poor (R2: SMLR =0.11; LASSO= 0.02; ridge =0.12; ELNET =0.03). For Dehradun district, the performance of ANN was also found to be better as compared to the other models during calibration (R2 = 0.841, RMSE = 0.045 ton ha−1, nRMSE = 2.230%) as well as validation period (R2 = 0.779, RMSE = 0.138 ton ha−1, nRMSE = 5.964%). Based on the overall performance, the best model for prediction of rice crop yield for Dehradun was ANN followed by Ridge, LASSO, and ELNET. Using ANN, around 84% of the variation in crop yield is explained by weather variables at calibration stage and 77% during the validation stage. For Haridwar district, during calibration stage, the performance of LASSO (0.722) was better followed by ELNET (0.705), SMLR (0.669), ANN (0.664), and ridge regression (0.648), though, during validation, the model performances were poor for all models, where the value of coefficient of determination (R2) ranging from 0.001 (SMLR) to 0.279 (ELNET).
For Nainital, during calibration the models, R2 value is ranging between 0.979 for SMLR and 0.827 for ridge regression indicating good performance for all models. During validation, R2 values ranged from 0.014 for LASSO to 0.417 for ANN, which suggest that ANN is a good choice for rice crop yield prediction for Nainital district as compared to the other models. For Pauri Garhwal, during calibration stage, the coefficient of determination (R2) for all models ranged between 0.012 for SMLR and 0.952 for LASSO, suggesting best model performance for LASSO followed by ELNET, ANN, ridge regression, and SMLR. During validation, the performance of ANN (0.844) was good followed by SMLR (0.767), ridge regression (0.765), ELNET (0.589), and LASSO (0.199). The overall performances of different models suggest that ANN is a better choice over other rice yield predicting models for Pauri-Garhwal district.
For Tehri Garhwal district, during calibration stage, the coefficient of determination (R2) shows excellent model performance for all models ranging between 0.836 for ridge regression to 0.938 for LASSO. Based on these values rice crop prediction for Tehri Garhwal during calibration stage, LASSO performed best followed by ELNET, ANN, ridge regression, and SMLR. During validation, the model performances were poor for all the models, which suggest that these models are not accurate in rice crop yield prediction for Tehri Garhwal district.
For Udham Singh Nagar, during calibration stage, the coefficient of determination (R2) for all models ranged between 0.814 for SMLR and 0.927 for LASSO, suggesting best model performance for LASSO followed by ELNET, ANN, ridge regression, and SMLR. During validation, the coefficient of determination (R2) value was good for SMLR (0.682), while poor for other methods. The overall performance of the models suggests that SMLR is a good choice over other rice crop yield predicting models for Udham Singh Nagar district. Figure 3 illustrates the scatter plot of different model’s observed and predicted yield for all the study locations.

Comparison of observed and predicted yield of different models through scatter plot
3.3 Inter comparison of the models
The overall rankings of the models based on R2 and RMSE at calibration stage shows that the performance of LASSO was followed by ELNET, while SMLR was found to be the poorest performing model. During the calibration process, the model’s performance fell into the following order: LASSO > ELNET > ANN > Ridge regression > SMLR. The results are consistent with those found by Das et al. (Das et al. 2018), Kumar et al. (Kumar et al. 2021), and Singh et al. (Singh et al. 2019) where the researchers concluded that the LASSO performed better than SMLR. LASSO and ELNET work well because they use a feature selection procedure that penalizes large coefficients. The penalization process helps to prevent the overfitting of the data and reduces the overall complexity of the model by taking some coefficients zero. It provides great computation advantage to LASSO and ELNET method over other methods.
ANN performed better during the validation stage for Champawat, Dehradun, Haridwar, Pauri Garhwal, and Udham Singh Nagar. For Nainital and for Tehri Garhwal, ELNET and LASSO, respectively, were found to be the best model with very little difference in nRMSE as compared to ANN. Hence, the rankings of the models using nRMSE of validation were found as follows: ANN > LASSO > ELNET > Ridge regression > SMLR. Arvind et al. (Arvind et al. 2022) also reported similar findings and concluded that during prediction of wheat yield for Patiala district ANN performs better as compared to SMLR, LASSO, and ELNET. Uno et al. (Uno et al. 2005) also concluded that ANN yield models achieved better prediction accuracy in validation stage as compared to conventional models. The variable importance of different models for study locations is shown in Fig. 4.


Variable importance unit for different models at different locations
4 Conclusion
Machine learning techniques offer intriguing substitutes or complementary tools to support the crop simulation model that is typically used for yield prediction; nevertheless, their usefulness must be tested before they can be used to the yield prediction of a particular crop or cropping system. Due to the fact that the crop performance is influenced by multiple external factors, including weather and the interaction between weather variables, a specialized method is necessary to assess the effects of these variables on crop yield. Previously, several linear models were developed that relied on the direct relationships between yield and weather. These models were used to predict future yields. However, those models failed to quantify the influence of the multicollinearity that exists between the many meteorological conditions on the yield. In light of this, an attempt was made in the current research to establish the significance of this influence by employing penalized regression model and artificial neural network (ANN) contrasting the straightforward regression model such as SMLR. For the purpose of forecasting rice yields in the key rice-growing areas of Uttarakhand, India, SMLR, LASSO, ELNET, ridge regression, and the ANN multivariate models were utilized. The results showed that penalized regression models and ANN can give satisfactory results for yield prediction for the given area as compared to the stepwise multiple linear regression. Penalized regression models and ANNs offer a solid systematic alternative to traditional regression procedures, which are frequently constrained by rigid assumptions of normality, linearity, variable independence, and other such things. This is one of the many ways in which ANNs and penalized regression models excel in comparison to traditional methods. ANNs are capable of capturing interactions between independent variables; they make it feasible to describe the complex agricultural phenomena in a rapid and straightforward manner, which would otherwise be practically hard to explain. For the present study, the results revealed that the performance of ELNET and ANN was at par with LASSO. So, these models can be used well for the rice yield forecasting in all the studied locations. The performance of ridge regression and SMLR were poor as compared to the other models in the study region for rice yield prediction.
Data availability
The datasets used in this study are available upon request.
Code availability
The software used MS excel and R Studio and scripts used in R Studio are can be shared on request.
References
Akinbile CO, Akinlade GM, Abolude AT (2015) Trend analysis in climatic variables and impacts on rice yield in Nigeria. J Water Clim Chang 6:534. https://doi.org/10.2166/wcc.2015.044
Arvind KS, Vashisth A, Krishnan P, Das B (2022) Wheat yield prediction based on weather parameters using multiple linear,neural network and penalised regression models. J Agrometeorol 24:18–25. https://doi.org/10.54386/jam.v24i1.1002
Boyer JS (1982) Plant productivity and environment. Science 218:443–448. https://doi.org/10.1126/science.218.4571.443
Colville EJ, Carlson AE, Beard BL, Hatfield RG, Stoner JS, Reyes AV, Ullman DJ (2011) Sr-Nd-Pb isotope evidence for ice-sheet presence on southern Greenland during the Last Interglacial. Science 333(6042):620–623
Das B, Nair B, Reddy VK, Venkatesh P (2018) Evaluation of multiple linear, neural network and penalised regression models for prediction of rice yield based on weather parameters for West Coast of India. Int J Biometeorol 62:1809–1822. https://doi.org/10.1007/s00484-018-1583-6
FAO Statistical Databases, Food and Agriculture Organization of the United Nations (2018) http://faostat.fao.org. Accessed 25 Jan 2023
Ghosh K, Balasubramanian R, Bandopadhyay S, Chattopadhyay N, Singh KK, Rathore L (2014) Development of crop yield forecast models under FASAL –a case study of kharif rice in West Bengal. J Agrometeorol 16(1):1–8
Jagadish SVK, Murty MVR, Quick WP (2015) Rice responses to rising temperatures - challenges, perspectives and future directions. Plant Cell Environ 38:1686–1698. https://doi.org/10.1111/pce.12430
Jha PK, Athanasiadis P, Gualdi S, Trabucco A, Mereu V, Shelia V, Hoogenboom G (2019) Using daily data from seasonal forecasts in dynamic crop models for yield prediction: a case study for rice in Nepal’s Terai. Agric For Meteorol 265:349–358
Kakati N, Deka RL, Das P, Goswami J, Khanikar PG, Saikia H (2022) Forecasting yield of rapeseed and mustard using multiple linear regression and ANN techniques in the Brahmaputra valley of Assam, North East India. Theor Appl Climatol 150:1–15
Kuhn M (2008) Building Predictive Models in R Using the caret Package. J Stat Softw 28:1–26
Kumar J, Devi M, Verma D, Malik DP, Sharma A (2021) Pre-harvest forecast of rice yield based on meteorological parameters using discriminant function analysis. J Agric Food Res 5:100194
Lansigan FP, de los Santos W, Coladilla J (2000) Agronomic impacts of climate variability on rice production in the Philippines. Agric, Ecosystems Environ 82:129–137. https://doi.org/10.1016/S0167-8809(00)00222-X
Lesk C, Rowhani P, Ramankutty N (2016) Influence of extreme weather disasters on global crop production. Nature 529(7584):84–87
Maclean JL, Dawe DC, Hettel GP (eds) (2002) Rice almanac: Source book for the most important economic activity on earth. Int Rice Res Inst, Philippines
Quang VD, Van Hai T, Dufey JE (1995) Effect of temperature on rice growth in nutrient solution and in acid sulphate soils from Vietnam. Plant and soil 177:73–83
Paltasingh KR, Goyari P (2018) Statistical modeling of crop-weather relationship in India: a survey on evolutionary trend of methodologies. Asian J Agric Dev 15(1362-2018-3540):43–60
Rai YK, Ale BB, Alam J (2012) Impact assessment of climate change on paddy yield: a case study of Nepal agriculture research council (NARC), Tarahara Nepal. J Inst Eng 8:147–167. https://doi.org/10.3126/jie.v8i3.5941
Sakurai G, Iizumi T, Nishimori M, Yokozawa M (2014) How much has the increase in atmospheric CO2 directly affected past soybean production? Sci Rep 4(1):1–5
Sanchez B, Rasmussen A, Porter JR (2014) Temperatures and the growth and development of maize and rice: a review. Glob Chang Biol 20:408–417. https://doi.org/10.1111/gcb.12389
Satpathi A, Setiya P, Das B, Nain AS, Jha PK, Singh S, Singh S (2023) Comparative analysis of statistical and machine learning techniques for rice yield forecasting for Chhattisgarh India. Sustainability 15(3):2786
Schlenker W, Roberts MJ (2009) Nonlinear temperature effects indicate severe damages to US crop yields under climate change. Proc Natl Acad Sci 106(37):15594–15598
Setiya P, Satpathi A, Nain AS, Das B (2022) Comparison of weather-based wheat yield forecasting models for different districts of Uttarakhand using statistical and machine learning techniques. J Agrometeorol 24(3):255–261
Singh KN, Singh KK, Sudheer K, Sanjeev P, Bishal G (2019) Forecasting crop yield through weather indices through LASSO. Indian J Agric Sci 89(3):540–544
Son NT, Chen CF, Cheng YS, Toscano P, Chen CR, Chen SL, Tseng KH, Syu CH, Guo HY, Zhang YT (2022) Field-scale rice yield prediction from Sentinel-2 monthly image composites using machine learning algorithms. Eco Inform 69:101618
Thimmegowda MN, Manjunatha MH, Huggi L, Shivaramu HS, Soumya DV, Nagesha L, Padmashri HS (2023) Weather-based statistical and neural network tools for forecasting rice yields in major growing districts of Karnataka. Agronomy 13(3):704
Togliatti K, Archontoulis SV, Dietzel R, Puntel L, VanLoocke A (2017) How does inclusion of weather forecasting impact in-season crop model predictions? Field Crops Res 214:261–272
Toscano P, Ranieri R, Matese A, Vaccari FP, Gioli B, Zaldei A, Silvestri M, Ronchi C, La Cava P, Porter JR, Miglietta F (2012) Durum wheat modeling: the Delphi system, 11 years of observations in Italy. Eur J Agron 43:108–118
Trnka M, Hlavinka P, Semerádová D, Dubrovsky M, Zalud Z, Mozny M (2007) Agricultural drought and spring barley yields in the Czech Republic. Plant Soil Environ 53(7):306
Uno Y, Prasher SO, Lacroix R, Goel PK, Karimi Y, Viau A, Patel RM (2005) Artificial neural networks to predict corn yield from Compact Airborne Spectrographic Imager data. Comput Electron Agric 47:149–161
Yang L, Qin Z, Tu L (2015) Responses of rice yields in different rice-cropping systems to climate variables in the middle and lower reaches of the Yangtze River, China. Food Secur 7:951–963
You L, Rosegrant MW, Wood S, Sun D (2009) Impact of growing season temperature on wheat productivity in China. Agric Forest Meteorol 149(6-7):1009–1014
Zhang T, Zhu J, Wassmann R (2010) Responses of rice yields to recent climate change in China: an empirical assessment based on long-term observations at different spatial scales (1981–2005). Agric For Meteorol 150:1128–1137
Author information
Authors and Affiliations
Contributions
ASN designed the study. AS and PS collected the data, performed the analysis, and drafted the manuscript. ASN provided the guidance throughout the study. All authors have read and approved the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The manuscript is original work of authors and is not being submitted or under consideration apart from this journal.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Setiya, P., Satpathi, A. & Nain, A.S. Predicting rice yield based on weather variables using multiple linear, neural networks, and penalized regression models. Theor Appl Climatol 154, 365–375 (2023). https://doi.org/10.1007/s00704-023-04563-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00704-023-04563-5