
Abstract
In climatology, one of the most important pieces of information about the climate of a place or a region is information about the Climatological Normals (CLINO)—the average values of meteorological elements for a 30-year period. This kind of information usually comes in tables and is available for different observation sites from national meteorological services or from World Meteorological Organisation publications. The key issue, then, becomes how to interpolate these values over the entire area of interest to get reliable and accurate estimates (maps) of climatic elements. Here, the regression kriging framework has been applied for mapping of 20 climatological parameters for the 1961–1990 period for the 56,594 km2 of Croatian territory, with a resolution of 1 km. In total, 152 main and climatological and 567 precipitation-measuring stations have been used in the analysis. Extensive pre-processing of metadata on station co-ordinates has been done, as well as completion of missing monthly averages. The final results are 20 climatological maps available in high resolution together with error maps and accuracy assessment measures.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In climatology, one of the most important pieces of information about the climate of a place or a region is the information about the average values of meteorological elements for a 30-year period. This kind of data usually comes in tables and is available for different observation sites from national meteorological services or from World Meteorological Organisation publications (e.g. WMO 1996). It is becoming more important to establish the values of climatological variables, even at places where there are no measurements. This can be achieved by means of geostatistical mapping procedures, defined as the analytical production of maps by using field observations, auxiliary information and a computer programme that calculates the values at locations of interest. This has been done for 20 climatological variables for the 30-year period of 1961–1990 in Croatia. Here, the data preparation, processing and mapping methodology, including quality measures for the final maps, are described in detail. The climatological variables considered were mean monthly and annual temperatures (January/T I, April/T IV, July/T VII, October/T X and annual/T An), mean annual number of cold (t min < 0°C) and warm (t max ≥ 25°C) days, days with warm nights (t min ≥ 20°C), seasonal and annual precipitation amounts (winter/R W, spring/R Sp, summer/R Su, autumn/R A, vegetation period/R Veg and annual/R An), mean annual number of days with precipitation above 1 mm (Rd ≥ 1 mm), mean annual number of days with snow cover ≥1 cm (S ≥ 1 cm), relative humidity/U, solar irradiation/G 0°, sunshine duration/SS and cloudiness/N. To produce the maps, a geostatistical mapping technique was used, i.e. the regression kriging framework explained by Pebesma (2006) and Hengl (2007) was applied. Regression kriging is an advanced mapping methodology now used in various environmental sciences (atmospheric sciences, geosciences, etc.). It uses correlation with multiple environmental predictors through regression and spatial autocorrelation of the targeted values through kriging. This technique has already been used in climatology (Wackernagel 2003; Lloyd 2005). The maps and computational procedures are also available in digital format, suitable for integration into different geographic information systems (GIS; hydrological, ecological applications, etc.).
Following this introduction, the second section gives some theoretical background of the regression kriging method and accuracy assessment procedure. A detailed description of the Croatian weather station network, including spatial coverage, metadata, missing data and applied transformations of the data is presented in the third section. Discussion of regression kriging results and prediction accuracies, of several selected climatological variables, for example, is presented in detail in the fourth section. Comparisons between the existing Croatian maps and those from neighbouring countries and between two existing gridded climatological products for Alpine and worldwide regions are also presented. The discussion and conclusions are given in the fifth chapter.
2 Regression kriging framework
Regression kriging (RK) framework (Fig. 1) typically consists of four steps: (1) the deterministic part of the variation is modelled using the auxiliary maps; (2) the residuals are modelled for spatial autocorrelation (variogram); (3) predictions and prediction errors are computed using the RK model and (4) the accuracy of the predictions is evaluated using cross-validation (CV). In this case, the residuals \( \widehat{e}\left( {{s_i}} \right) \) are the differences between the observed and predicted values at the observation locations, s i .

Computational framework (as implemented in the R computing environment) used to interpolate climatological variables
The first step in the regression kriging model, which is modelling of a spatial trend, has been performed through multiple regressions of target variables with predictors. The multiple linear regression analysis explains the deterministic part of the dependence of the target variable on the predictors, also known as global or large-scale spatial variability (Cressie 1993).
Simple kriging of the residuals in the second step then accounts for the local or small-scale part of spatial variability and models spatial autocorrelation. It assumes a theoretical variogram, according to the sample variogram where semivariances \( \hat \gamma \) (Eq. 2.1) are calculated for regular distance intervals [h j , h j +Δh]:
where N j is the number of point pairs separated by distance, h, which belongs to the distance interval [h j , h j +Δh] and \( {\bar h_j} \), the average of all N j h’s (Pebesma 1997).
Exponential (Eq. 2.2) or spherical (Eq. 2.3) variogram models (below) have been found to be most suitable for this application.
They have several important features. First, for large h values between data (depending on the spatial structure of the data), the variograms level off at the sills (C0 + C1). This means that the variance of differences does not change for distances larger than that. Second, the distance at which this is achieved is called the range (a). The last important feature of the variogram is the nugget, C0, the positive value of semivariance for the lag 0. It describes the residual, spatially uncorrelated noise that is a combination of variance of measurement errors and spatial variations at distances smaller than sample spacing (Burrough and McDonnell 2004). For climatological variables, spatial autocorrelation is typically stronger for data at nearby spatial locations.
Furthermore, a relationship with the predictors and spatial autocorrelation of the residuals allows prediction at unvisited locations where the values of the predictors are known. The procedure is known as regression kriging and produces prediction maps and prediction variance maps. Such geostatistical analyses can be successfully implemented in the “R” open-source package for statistical computing (www.r-project.org) and with the gstat (www.gstat.org) programme for modelling, prediction and simulation of geostatistical data loaded (Pebesma 1997, Pebesma and Wesseling 1998).
Additionally, the kriging error map (Burrough and McDonnell 2004), calculated as the square root of the prediction variance map, can be additionally normalised by the standard deviation of the target/transformed variable (Hengl et al. 2004). Like the kriging variance map, it gives valuable information about the reliability of the interpolated values over the domain and reveals the locations or areas with less reliable predictions (e.g. under-sampled regions).
Finally, in the last step, the accuracy of predictions on the station locations is estimated with the leave-one-out CV (LOOCV) procedure. The mean prediction error (ME, Eq. 2.4):
the root mean square prediction error (RMSE, Eq. 2.5):
and the normalised root mean square prediction error (RMSEr, Eq. 2.6):
were calculated for all dependent variables. The ME gives the average difference between observed \( \widehat{z}\left( {{s_j}} \right) \) and predicted (z *(s j )) values and should be close to 0. In general, the ME at validation points proves that the estimation is generally unbiased. The RMSE is the square root of the average squared difference between observed and predicted values. The RMSE should be close to the standard deviation of the data observed at short distances (Hengl 2007). The last measure (RMSEr), that is RMSE divided by the standard deviation of the data (SD from Table 1), gives a normalised accuracy of prediction and it can be considered satisfactory if it is less than 0.4 (or 40%)—the model in this case accounts for more than 85% (1 − RMSEr2) variability at the validation points (Hengl 2007). RMSEr values lower than 0.75 (or 75%) are regarded as fairly satisfactory; above 0.75, the model is probably considered unsatisfactory. In the latter case, the model explains less than 43% of the variability.
In the fourth section, the results of those four steps of the regression kriging procedure are described in detail, referring to climatological data from Croatia.
3 Climatological, meta- and topographic data
Compared with other European countries, Croatia is a relatively small country; nevertheless, it has several different climatic regions. This is a result of its specific position on the Adriatic Sea (Fig. 2) and its fairly diverse topography ranging from plains in the east (the south-western section of Pannonian mega-region), through a hilly central part, to the mountains (part of Dinaric Alps) separating the continental from the maritime part of the country (e.g. Bognar 1996). Weather systems originating in or crossing over Croatian territory are strongly influenced by this topography and thus, their influence on weather and climate is highly dependent on the region. This natural diversity requires a very dense monitoring weather station network, especially for precipitation, which has greater spatial variability than other climatological variables.

Geographical position of Croatia on the European continent and on the east Adriatic coast
3.1 Weather station network
Consequently, the first aspect that needs to be considered before any further analysis is the density and spread of the monitoring network.
In the weather station network in Croatia, there are five types of the meteorological stations, defined according to their organisation (Zaninović et al. 2008):
-
Main meteorological stations, with two to five professional observers
-
Ordinary (climatological) meteorological stations, with nonprofessional observers and observations at 7 a.m., 2 p.m. and 9 p.m. local time and with 24-h observations of meteorological phenomena
-
Precipitation stations, with nonprofessional observers, measuring precipitation at 7 a.m. and observing meteorological phenomena over 24 h
-
Storage rain-gauge stations, collecting annual amounts of precipitation
-
Automatic stations, with automatic registration of meteorological elements and direct connection to the information system
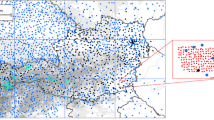
In our climatological research, the data from main (39 stations), climatological (113 stations) and precipitation stations (418 stations) were used (Fig. 3). Precipitation and snow cover data were available from all stations (except if some data are missing), while other climatological elements are available on main and climatological stations.

Weather station network of Croatia during the 1961–1990 period, comprised of main meteorological stations, climatological stations and precipitation stations
Considering the spatial distribution of weather stations it should, and it mainly does, match the topographic variability, but the improvements are possible. For illustration, distribution of altitudes based on a digital elevation model (DEM) was compared with the distribution of station elevations of all weather stations (main, climatological and precipitation stations) and with elevations of main and climatological stations (Fig. 4). There are 10–20% more stations situated at altitudes from 0–100 m compared to the proportion of the DEM altitudes in this range. Further on, in most elevation classes up to 800 m, there is in general small lack of stations compared to the DEM altitude distribution. In particular, at altitudes higher than 800 m (8.5% of the territory), there are only ten main or climatological stations (6.6% of stations) and only 18 stations measuring precipitation-related variables (3.3% of stations) and, in reality, there are many hills above 800 m with no stations at all (Gajić-Čapka et al. 2003; Fig. 5).

Comparison of the frequency distributions for the elevations at 1,000 m DEM (SRTM30), elevations of Croatian weather stations (all stations) and elevations of Croatian main and climatological stations. The width of the elevation classes is 100 m, and the names of class centres are on the x-axis

Weather stations situated in areas above 800 m. Areas without stations at higher elevations are also shown
Likewise, the spatial coverage by weather stations is not ideal considering the shape of the country (the “edge pollution” effect in geostatistical data analysis). This negative effect can be reduced by taking into consideration data from neighbouring countries. For example, when mapping temperature variables, 85 additional stations from the neighbouring countries of Slovenia, Hungary and Bosnia and Herzegovina have been included in the analysis. When mapping precipitation, the edge pollution effect was compensated for by including a larger number of stations in the analysis. Still, the final evaluation of the produced maps will show that, in some less-populated regions, such as Lika and near the country border mountain plateau, prediction errors are larger because of the sparse measurement network.
3.2 Horizontal resolution
Another important issue for the success of geostatistical mapping is the selection of the horizontal resolution for the output maps, i.e. the selection of the grid cell size. The total land area of Croatia is 56,594 km2 (DZS 2007) and data from 152 main and climatological stations have been used, suggesting that, on average, one station represents a 19 × 19 km2 block of land. This means that such a monitoring network can be used only to produce maps of scale 1:1–5 M (Hengl 2006). The maps are intended to be printed at a scale of 1:2.2 M in the Climate Atlas of Croatia (Zaninović et al. 2008). According to cartographic rules (Hengl 2006) for maps of a working scale of 1:2 M, a suitable grid cell size for output maps would be 1,000 m and, therefore, this cell size was adopted. It should be noted that the spatial density of precipitation stations together with the main and climatological stations, which also observe precipitation-related parameters (567 stations or one station per 10 × 10 km2 block of land), might allow us to use even finer cell sizes.
3.3 Metadata from stations
For spatial prediction purposes, the original climatological point data were combined with information about station locations, such as co-ordinates and elevations. Here, we first needed to improve the precision of the latitude and longitude co-ordinates, which were set out in the stations metadata in degrees (arcdeg) and minutes (arcmin), i.e. with a positional accuracy of 1 arcmin (around 1,300 m longitudinally and 1,850 m latitudinally over Croatia). This would have obviously been insufficient for the purpose of digital mapping at this level of detail. Moreover, for approximately 60 stations, the co-ordinates set out in the metadata in arcdeg and arcmin had to be corrected, mostly because of two reasons: when overlaid onto a 100-m resolution DEMFootnote 1, some of the stations were misplaced in the sea and some had a difference in height larger than 200 m. This indicated that the positions of the stations were different from the ones indicated in the metadata. To estimate the co-ordinates more precisely, the position of the stations had to be marked (according to the position marked on the paper maps in metadata) on the previously scanned and georeferenced 1:25 K topographic maps and then the co-ordinates were determined with a precision of 1 arcsec.
Also, during this long observation period of 30 years, some of the stations have been moved to different location not more than few kilometres further away and the new data have been attached to the previously collected dataset. It was ensured that the new location did not differ much, climatologically, from the old one.
3.4 Incomplete or missing data
Similarly, a large portion of climatological data from climatological and precipitation stations had also to be pre-processed. Temperature- and meteorological-phenomena-related data observed hourly or at 7 a.m., 2 p.m. and 9 p.m. local standard time (UTC + 1) existed in the digital database for data collected after 1981, and precipitation-related data existed in the digital database for data collected after 1991. To prepare the data for the 1961–1990 period, a large amount of (monthly) data collected previously had to be retrieved from paper reports and entered into a separate database (only for the purpose of this work).
In addition, there were a lot of stations with missing data or shorter-than-standard observation periods, but nevertheless very valuable information. Because it is necessary to have 30 monthly values to be able to calculate 30-year averages, the missing data were replaced by appropriate values according to the following principles:
-
If less than 30% of the monthly values were missing, the missing data were interpolated according to data from neighbouring stations
-
If 30−70% of the monthly data were missing, the corresponding shorter-period average was “extended” to the 30-year average
-
If more than 70% of the monthly values were missing, the station was excluded from the analysis
If less than 30% of the data was missing, the individual missing monthly value, B i , was been calculated as
where A i is the monthly value from the neighbouring station for the same month, and B j − A j are the differences between all available pairs of values on both stations.
When 30–70% of the monthly values were missing filling every missing value was unjustifiable. Instead, the 30-year average from the neighbouring station with a full data set (denoted as A30) was used to estimate the 30-year average for the station with missing data (denoted B30). We assumed that the difference between A30 and B30 was the same as the difference A’ − B’ for the corresponding available, shorter-period averages from both stations. Then, the unknown 30-year average, B30, could be estimated as A30 + (B’ − A’). This kind of estimation is accepted in climatology, and it assumes that particular differences in longer-term climate averages for nearby stations are constant in time. Therefore, this is used to interpolate monthly and estimate 30-year monthly averages of temperature, number of cold and warm days, days with warm nights, sunshine duration and cloudiness.
For cumulative climatological elements, like monthly precipitation, the ratio is supposed to be constant in time, and the missing monthly value can be calculated as
in cases where <30% of data are missing and the 30-year average can be estimated as B30 = A30*(B’/A’), if 30–70% of the data are missing.
3.5 Transformations of target variables
After the pre-processing steps, the exploratory statistical analysis followed. Examination of the distributions of the average monthly and annual temperatures, the number of cold and warm days, sunshine duration, solar irradiation and cloudiness shows, in general, bimodal behaviour, with an almost clear differentiation between the continental and maritime part of the country (Fig. 6). In some cases, the data distribution is also positively skewed towards smaller (precipitation) or larger values (relative humidity), or the data do not follow normal distributions (number of days with warm nights; Table 1). As reported in previous studies (Burrough and McDonnell 2004; Hengl et al. 2004), a natural logarithm scale transformation (ln) of the data is useful for many physical data with positively skewed distributions. Hence, this transformation has been applied to the precipitation data. Additionally, in case of the non-normal distributed data, natural logarithm (ln) and logit transformations (Eqs. 3.3 and 3.4) are useful:
where z ++ is the transformed variable and z + is the target variable standardised to the 0–1 range by:
where z min and z max are the physical minimum and maximum of the target variable (z), adjusted by some small constant (e.g. measurement error) to avoid z ++ = ±∞ (Webster and Oliver 2007). This transformation also ensures that the prediction stays in the physical limits.

Histograms of the main climatological target variables. First row T An (°C), t min ≥ 20°C (days), G 0° (MJ m−2); second row R An (mm), Rd ≥ 1 mm (days), S ≥ 1 cm (days); third row N(10/10), SS(h), U(%)
4 Mapping results
4.1 Climate factors
For every climatological variable, point values were prepared and first examined visually to get an impression of spatial trends. As expected, the strong influence of climate factors such as altitude (alt), distance to the coast and, to some extent, latitude (lat) and longitude (lon) was obvious. Therefore, these variables were selected as possible predictors in the regression model. In addition, we assumed that the variation in climatological variables such as relative humidity might be explained by land cover, but this correlation turned out to be insignificant.
Altitude explains most of the spatial variation of all climatological variables. However, this influence can be inherent through indirect correlation with other modifying factors. For example, solar irradiation is generally stronger at higher altitudes, but this is usually hidden by pronounced cloudiness and orographic precipitation during the summer. This is statistically confirmed with regression statistics that revealed strong dependency of solar irradiation on July temperature and altitude. Spatial temperature distribution is affected by elevation directly through the temperature lapse rate, while cloudiness and precipitation are subject to different kinds of orographic modifications. Relative humidity strongly depends on temperature, and temperature is controlled by altitude. Latitude has been included because it affects average daily solar irradiation (Perčec Tadić 2004) and, consequently, modifies all other climatological variables.
The Adriatic Sea significantly affects the climate along the coast and at some distance inland, mainly acting as a source of heat and moisture (e.g. Penzar et al. 2001). Along some parts of the coast, this influence is modified and suppressed by the presence of high and long mountain ridges stretching along the coast. Consequently, for this type of coastal areas, the maritime influence cannot be modelled with simple predictors such as distance to the coast. This is because the maritime effect is weaker where mountains stretch along the coast compared to areas where such mountain chains do not exist, with the distance from the coast being constant. Here, it was assumed that the distance to the coast is effectively larger where mountains are present along the coast compared to the mainly flat coastal areas. Hence, the maritime influence is smaller in the former and larger in the latter case. Therefore, as a new potentially valuable predictor, weighted distance to the coast (wdc) was introduced. Weighted distance to the coast was derived from the algorithm adopted in ILWIS Open 3.4 GIS (ILWIS 3.0 User’s Guide), an open-source software where simple distance calculation to the coast can be modified by introducing the weight map. In the weight map, weight factors simulate the difficulty of crossing pixels that form barriers such as rivers or mountains. In our case, the weight factors were represented with height of orography from DEM. ILWIS was also used for the preparation of predictor maps and for the visualisation of the final maps.
4.2 Multiple regression model
The selected auxiliary predictors have been derived based on the Digital Elevation Model and Global Land Cover map (GLC2000, Global Land Cover 2000 database 2003). Four predictor variables were derived based on the DEM: (1) altitude (elevation), (2) latitude, (3) longitude and (4) weighted distance to the sea coast. Seven indicator variables were derived from the GLC according to eight different types of land cover. These were: (1) cultivated areas, (2) deciduous broad-leaved tree cover, (3) evergreen shrub cover, (4) mixed leaf tree cover, (5) evergreen needle-leaved tree cover, (6) herbaceous cover, (7) deciduous shrub cover and (8) artificial surfaces.
From the set of DEM-derived predictors, four factor components (FC1, FC2, FC3 and FC4) were extracted and used as independent predictors in the multiple linear regression model. Mostly, the principal component analysis (PCA) and similar factor analysis (FA) are used in different types of research when large numbers of spatial patterns have to be reduced to a finite number of spatial structures that concisely capture the variability within a given dataset. Recently, there were many applications of PCA analysis in climate regionalisation problems for various climatological variables such as temperature, wind, precipitation, etc. (Abatzoglou et al. 2009; Jimenez et al. 2009; Neal and Phillips 2009). In our case, the intention was not to reduce the number of variables but to improve the presumptions for the multiple linear regression procedure. In the multiple linear regression model the assumption is that the predictors are linearly independent variables (Draper and Smith 1998; Neter et al. 1983). That is not the case with the initial set of predictors used in this study, particularly because the wdc was based on elevation. In such cases, it is advisable to reduce the multicolinearity effect in the initial set of predictors by running the PCA or FA and then to use transformed, mutually independent components instead of original set of predictors (Hengl 2007).
According to the output matrix (Table 2) of the FA operation (ILWIS 3.0 User’s Guide), the main FC1 component was explained primarily by the variation in the weighted distance to the sea. The second component (FC2) accounted mainly for the variation in latitude and FC3 mainly for the variation in altitude. The fourth component, FC4, explaining less than 4% of the total variation, was also mainly explained by the variation in weighted distance to the sea. Additionally, for less densely sampled variables, other climatological variables (T An, T I, T IV, T VII, T X, G 0°, R Veg) sampled at higher density were added as predictors (in addition to the factor components). In case of precipitation the nonlinear influence was recognised and included in the regression model using FC5 = FC12. The best combination of predictors for multiple regression was further selected using the stepwise procedure, as implemented in the “R” base package. The selected predictors can be seen in Table 3, where the order of the predictor is related to their significance according to the t value of the corresponding coefficient in the regression equation. FC3, mainly explained by variation in elevation, was the most relevant predictor in nine out of 12 cases where only factor components were used as predictors in regression models (April, July and annual temperature, seasonal and annual precipitation amounts). For the remaining three variables (January and October temperature and relative humidity), the most relevant predictor was the first component (FC1), mainly explained by variation in the weighted distance to the coast. For the prediction of relative humidity, this can be explained by the fact that the sea is the main source of moisture in the atmosphere and this affects the maritime part of the country more than the continental part (note that the relative humidity unlike the absolute humidity is lower on the coast because of the inverse relation to the temperature). Regarding temperature, January and October mean air temperatures were significantly more affected by the sea, which acted as a heat container that additionally heated the air, compared to the April and July air temperatures. This coastal influence was a consequence of much higher sea than soil temperatures not only in October and January but also in all months from October through February. The differences in temperatures between the sea and the soil can be illustrated by comparing sea temperature at the coastal station of Rovinj (m.s.l. = 20 m, lat = 45°5′) and soil temperature at the continental station of Slavonski Brod (m.s.l. = 88 m, lat = 45°10′) that are situated at similar altitudes and latitudes (Zaninović et al. 2008). The sea is warmer than the soil by 6.2°C in October and by 9.7°C in January but only by 0.6°C in April and 0.8°C in July. Additionally, the continental area in January is much colder than the coastal region because of more pronounced cooling during winter anticyclonic situations. These differences in temperature between the coast and the hinterland during the cold half of year are reflected in pronounced bimodal distributions when compared with all other variables.
The adjusted coefficients of determination (R a 2) for the regression models range from 0.94 (the highest) for April’s temperature, solar irradiation and sunshine duration to 0.65 for relative humidity (the lowest; Table 3).
4.3 Variogram modelling
In the second step of the regression kriging framework, the spatial dependence for the target variables is modelled by estimating variogram model parameters and fitting sample variogram of the residuals. There are three variogram parameters that determine the spatial continuity: the nugget (C0), sill (C0 + C1) and the range (a). If anisotropy is detected two other parameters are also used: anisotropy angle (direction of the maximum continuity) and anisotropy ratio (Table 4 and Fig. 7). For most of the climatological variables on Croatian territory, anisotropy caused by the direction of the main mountain chain (around 135°) was removed from the residuals through regression; however, for the annual number of cold days and the number of days with precipitation exceeding 1 mm, anisotropy remained in the residuals. For mean monthly and annual temperatures, where the variables were not transformed prior to regression kriging, the highest nugget and sill and the shortest range was detected for the January temperature (Fig. 7). Together with the highest variability in the data (SD = 3.9, Table 1) and the lowest prediction power of the regression model (R a 2 = 0.89, Table 3), it describes typical winter temperature fields with distinct local characteristics. The lowest values for the nugget and sill and the longest range were found for April temperature which was also the month with the lowest variability in the data (SD = 2.6, Table 1) and the highest coefficient of determination (R a 2 = 0.94, Table 3) of the regression model. In case of precipitation, the strongest short range variability (C0) was noticed in the winter and spring precipitation fields (frequent and strong cyclonic activity). These also had the shortest variogram range, with the exception of autumn. The smoothest was the summer precipitation field (also with the smallest precipitation amounts), with a wide variogram range and low sill. For other target variables, it was not possible to make such comparisons because factors other than climatological ones affected the fields; (e.g. lower quality of the data for cloudiness or relative humidity).

Sample variograms and fitted variogram models for mean January and April temperatures (top figures), mean winter and summer precipitation (log transformed—in the middle) and mean annual number of days with warm nights and mean annual number of days with snow cover ≥1 cm (logit transformed—bottom figures)
4.4 Predictions and normalised prediction error maps
Final predictions and normalised prediction error maps for six selected climatological variables are presented for temperature-related fields in Fig. 8 and for precipitation-related fields in Fig. 9. The monthly mean January temperature, monthly mean April temperature and mean annual number of days with warm nights, together with normalised prediction error maps, are presented in Fig. 8. The temperature variation in January is from −8°C on the highest mountains, to 10°C on the most southern islands (Fig. 8(a1)). The prediction is accurate with normalised prediction errors below the 0.4 threshold value (Fig. 8(b1)). In April, the temperature ranges from 1 to 15°C (Fig. 8(a2)) with accurate predictions within the whole research domain (Fig. 8(b2)). The mean annual number of days with warm nights ranges between 0 and 1 on the continent to 60 days on the coast (Fig. 8(a3)). Prediction errors are slightly higher than the threshold value of 0.4 on some isolated hills (orange areas on Fig. 8(b3)), indicating a fairly satisfactory prediction there.

Prediction maps (a1–a3) and prediction error maps (b1–b3) for mean January (a1, b1) and April (a2, b2) temperatures and mean annual number of days with warm nights (a3, b3). Grey areas on b1–b3 maps represent accurate predictions, while the orange colour on b3 mark areas with fairly satisfactory predictions

Prediction maps (a1–a3) and prediction error maps (b1–b3) for mean winter (a1, b1) and summer (a2, b2) precipitation and mean annual number of days with snow cover ≥1 cm (a3, b3). Grey areas on b1–b3 maps represent accurate predictions, while the orange or red colour on b1–b3 mark areas with fairly satisfactory or unsatisfactory predictions, respectively
The precipitation (Fig. 9(a1)) in the winter season shows the largest precipitation range among all seasons, from 102 to 1,334 mm. Normalised prediction errors larger than 0.4 threshold value (orange colour on Fig. 9(b1)) can be found in the mountain areas higher than 1,000 m without meteorological stations in operation (compare with Figs. 4 and 5). Especially in the mountain area near the border with Bosnia and Herzegovina and on the Biokovo Mountain near the coast, the errors can have values larger than 0.75, suggesting unsatisfactory predictions there (red colour on Fig. 9(b1)). Data from the neighbouring country would probably improve the predictions in that narrow area. Summer is the driest season, with precipitation between 44 and 555 mm (Fig. 9(a2)) and predictions were fairly satisfactory or unsatisfactory on the tops of the Psunj and Papuk hills in the continental parts of Croatia, in the narrow mountain area near the Bosnia and Herzegovina border and on Biokovo Mountain (Fig. 9(b2)). Otherwise, summer precipitation was the most accurately predicted precipitation field, according to the R a 2 and RMSEr (Tables 3 and 5). Finally, the mean annual number of days with snow cover ≥1 cm was less than 5 days on the coast and can be higher than 170 days on the highest mountains (Fig. 9(a3)). The prediction error was higher than 0.4 threshold on the isolated Psunj and Papuk hills (Fig. 9(b3)).
4.5 Accuracy assessment through cross-validation
Besides general prediction error maps, the accuracy of prediction was estimated with the LOOCV procedure and described with statistical quality measures of ME, RMSE, RMSEr and 1 − RMSEr2, presented in Table 5. This shows that the mean error is very close to 0 for the mean monthly and annual temperatures and cloudiness. For the other variables, the ME was slightly larger because the range of the variables was also larger. When predicting the mean annual number of warm nights (t min ≥ 20°C), cloudiness and relative humidity, the RMSE was not considerably smaller than the standard deviation (SD in Table 1), suggesting that the overall accuracy (RMSEr) in mapping these variables was relatively poor. All other variables had an accuracy of prediction above 86% (1 − RMSEr2 in Table 5), which indicated that the maps could be considered accurate.
For mapping the average monthly temperature, the model using only Croatian data was compared with a model using data from neighbouring countries. Improvements were visible near the borders, but the validation tests showed that they were not significant.
4.6 Comparison of the prediction maps with the existing maps for Croatia and neighbouring countries
The final output maps were also visually compared with the existing Croatian maps and maps from the neighbouring countries and discussed with experienced climatologists. Several maps existed for Croatia for the similar time range: mean annual cloudiness and mean annual sunshine duration for 1961−1980 (Poje et al. 1984), mean annual irradiation for 1961–1980 (Žibrat and Gajić-Čapka 1986), mean annual temperature for 1961–1980 (Zaninović et al. 1985) and mean annual precipitation for 1969–1978 (Pleško et al. 1984). They have been based on regional regression coefficients, with elevation as the only predictor, and regression-based predictions were additionally adjusted according to the station observations and expert knowledge of the climatologist. Besides the general agreement in the spatial structures between old and new climatological fields, more distinct spatial variability of the new maps was noticed as a result of more sophisticated methodology and new technical capabilities. Additionally, precipitation on islands was not analysed in detail on the old precipitation maps.
Comparisons of the map values at the borders with the neighbouring countries of Slovenia (Cegnar 1996) and Hungary (Mersich et al. 2000) were also performed and discussed. The mean annual temperature map of Slovenia was more smoothed and the temperature classes were wider (2°C), but the values were comparable, except the discontinuities at higher altitudes (Hiebl et al. 2009). The Croatian and Slovenian annual precipitation maps were very similar at the borders. Maps of mean annual number of days with snow cover differed at higher elevations. Comparison with Hungarian maps was more general because they were drawn with gradual colour ranges, making it difficult to distinguish the exact values. Nevertheless, general agreement exists for the monthly and annual temperature maps, annual number of cold and warm days, annual precipitation, number of days with precipitation ≥1 mm and number of days with snow cover. Due to the gradual colour range of Hungarian maps, it was not possible to compare irradiation maps. The sunshine duration map for Croatia predicted lower values at the borders compared to the Hungarian one.
4.7 Comparison with other high-resolution data sets
Recently, two other projects performed spatial analyses of temperature/precipitation data that also covered the Croatian territory. We participated in the ECSN/HRT-GAR (European Climate Support Network/High Resolution Temperature-Greater Alpine Region) project, which produced 12 high-resolution monthly temperature maps for the period 1961–1990 for the greater Alpine region (Hiebl et al. 2009).
The other project, WORLDCLIM (Hijmans et al. 2005), produced high-resolution climatological maps, which showed monthly precipitations, in addition to mean, minimum and maximum temperatures for the global land areas. Both had comparable spatial and temporal resolutions, and both differed in interpolation methods and density of the stations (Table 6).
The predicted range of values in all three cases is summarised in Table 7. The comparison of the minimum and maximum predicted values from the CROCLIM, HRT-GAR and WORLDCLIM temperature fields (Table 7) showed that predicted temperature ranges were comparable. This was expected in the case of the HRT-GAR fields because those used all available Croatian data, and interpolation methods were also based on multilinear regression with altitude, weighted distance to the coast, latitude and longitude. Similarity of WORLDCLIM temperature fields with CROCLIM was surprising because the density of the stations was much lower in the WORLDCLIM dataset. An inspection showed that there were altogether 21 Croatian stations used in the WORLDCLIM temperature dataset. WORLDCLIM used data from the Global Historical Climate Network Dataset (GHCNFootnote 2, Peterson and Vose 1997), from the WMOFootnote 3 (1996) and FAOCLIM 2.0 global climate databases (FAO 2001).
On the other hand, comparison of the precipitation amounts for CROCLIM and WORLDCLIM (Table 7) showed that the precipitation prediction is two to three times underestimated in the WORLDCLIM fields for the Croatian territory. Inspection showed that that the number of Croatian stations available in the GHCNFootnote 4, WMO and FAOCLIM 2.0 databases was the same as for the temperature assessment. Comparison of the mean annual precipitation for Croatia (Fig. 10a) with the WORLDCLIM, (Fig. 10b), revealed the highest differences in the areas with pronounced orography (Fig. 10c) which has been also reported in Hijmans et al. (2005) comparison of the WORLDCLIM with PRISM (Daly et al. 2002) and Daymet (Thornton et al. 1997) fields for Washington and Oregon states. This clearly showed that station density was crucial for the spatial prediction of precipitation and other spatially more variable climatological fields.

CROCLIM (a) and WORLDCLIM (b) mean annual precipitation [mm] and the difference [mm] between the two (c)
5 Discussion and conclusion
Finally, we would like to mention some critical points that map users should consider. The accuracy of predicting climatological values at unvisited locations depends on the density of the samples and also on the predictive power of the applied models. As mentioned earlier, the data were under-sampled at higher altitudes and in areas with a lower population density. Hence, one might expect mapping accuracy to be lower at higher altitudes and in the highlands. This has proven correct, especially for the Lika region, which is both under-populated and at high altitudes. In addition, some well-known, smaller-scale effects were not modelled successfully, e.g. the Zagreb urban heat island, which is, according to measurements, 0.5−1.5°C warmer than its surroundings. Furthermore, some expected wintertime cold air pools during temperature inversions were not captured in the model because of their local character, which is not accounted for in the general temperature lapse rate. The annual number of warm nights was especially difficult to model because it was strongly influenced by local characteristics and circulation (see also Perry and Hollis 2005).
Cross-validation showed that the average annual cloudiness and the average annual relative humidity maps were generally of lower quality, mainly because of the considerably lower accuracy of the related measurements. Cloudiness is not a measured parameter but is visually observed in tenths of sky cover (traditionally in climatology versus the 1/8 in synoptic meteorology), with a stated precision of one-tenth, but the inaccuracy of observation is typically larger. However, because of the small range (three- to seven-tenths) of values and historical reasons, this map has been drawn with intervals of 0.5-tenths, which is above observation precision. It is expected that satellite-derived cloud climatology could improve this map, if it is used as a predictor in a regression model.
Average annual humidity values are also less reliable because of more complex and error-sensitive measurement methods. In our case, relative humidity was estimated by using a psychrometer consisting of two thermometers. The final value was calculated from the thermodynamic wet- and dry-bulb temperatures of the atmosphere, but the procedure for preparing the thermometers and the reading of these temperatures requires a precision that nonprofessional observers rarely have. Because small errors in readings (especially during cold weather) lead to large errors in relative humidity, this results in lower accuracy.
A comparison with other available high-resolution datasets demonstrated that station density was crucial for the accuracy of the predictions.
The maps of climatic elements could be further improved by using more sophisticated topo-climatic predictors derived from DEMs, such as the sky-view factor, the cold airflow distribution and the depth of sinks (Böhner and Antonić 2008), but also by using remote-sensing-based images such as night-light images/urban activities. Thus, temperature inversions due to fine scale topography and urban-heat islands could also be depicted with higher accuracy. Future developments will include the use of spatio-temporal interpolation frameworks, including time series of meteorological images that aim for greater (temporal and local) precision in predicting climatic elements.
Notes
SRTM_DEM_RH_100m.zip obtained from http://spatial-analyst.net
Data downloaded from: ftp://ftp.ncdc.noaa.gov/pub/data/ghcn/v2/zipd/v2.mean.zip
For list of stations see: http://cdo.ncdc.noaa.gov/cdo/3500stn.txt
Data downloaded from: ftp://ftp.ncdc.noaa.gov/pub/data/ghcn/v2/zipd/v2.prcp.zip
References
Abatzoglou JT, Redmond KT, Edwards LM (2009) Classification of regional climate variability in the state of California. J Appl Meteorol Climatol 48:1527–1541
Bognar A (1996) Croatia−the land and natural features. GeoJournal 38:407–416
Böhner J, Antonić O (2008) Land-surface parameters specific to topo-climatology. In: Hengl T, Reuter HI (eds) Geomorphometry: concepts software applications. Developments in soil science vol. 33. Elsevier, Amsterdam
Burrough PA, McDonnell RA (2004) Principles of Geographical Information Systems. Oxford University Press, Oxford
Cegnar T (ed) (1996) Climate of Slovenia. Hydrometeorological Institute of Slovenia, Ljubljana
Cressie N (1993) Statistics for Spatial Data. Revised Ed. Wiley, New York
Daly C, Gibson WP, Taylor GH, Johnson GL, Pasteris P (2002) A knowledge-based approach to the statistical mapping of climate. Clim Res 22:99–113
Draper NR, Smith H (1998) Applied regression analysis, 3rd edn. Wiley, New York
DZS (2007) Statistički ljetopis/Statistical Yearbook: Geografski i meteorološki podaci/Geographical and meteorological data. Državni zavod za statistiku/Central Bureau of Statistics, Zagreb
FAO (2001) FAOCLIM 2.0 A World-Wide Agroclimatic Database. Food and Agriculture Organization of the United Nations, Rome
Gajić-Čapka M, Perčec Tadić M, Patarčić M (2003) Digitalna godišnja oborinska karta Hrvatske (A digital annual precipitation map of Croatia). Hrv. meteor. časopis 38:21–34 in Croatian with eng. summary
GLC2000 Global Land Cover 2000 database (2003) European Commission Joint Research Centre http://bioval.jrc.ec.europa.eu/products/glc2000/products.php
Hengl T (2006) Finding the right pixel size. Comput Geosci 32(9):1283–1298
Hengl T (2007) A Practical Guide to Geostatistical Mapping of Environmental Variables. EUR 22904 EN Scientific and Technical Research series Office for Official Publications of the European Communities, Luxemburg
Hengl T, Heuvelink G, Stein A (2004) A generic framework for spatial prediction of soil variables based on regression-kriging. Geoderma 120:75–93
Hiebl J, Auer I, Böhm R, Schöner W, Maugeri M, Lentini G, Spinoni J, Brunetti M, Nanni T, Perčec Tadić M, Bihari Z, Dolinar M, Müller-Westermeier G (2009) A high-resolution 1961–1990 monthly temperature climatology for the greater Alpine region. Met Zeith 18(5):507–530
Hijmans RJ, Cameron SE, Parra JL, Jones PG, Jarvis A (2005) Very high resolution interpolated climate surfaces for global land areas. Int J Climatol 25:1965–1978
ILWIS 3.0 User’s Guide. http://52north.org/images/stories/52n/admin/ilwis_documentation/chap09.pdf
Jimenez PA, Gonzalez-Rouco JF, Montavez JP, Garcia-Bustamante E, Navarro J (2009) Climatology of wind patterns in the northeast of the Iberian peninsula. Int J Climatol 29:501–525
Lloyd CD (2005) Assessing the effect of integrating elevation data into the estimation of monthly precipitation in Great Britain. J Hydrol 308(1–4):128–150
Mersich I et al. (ed) (2000) Climate Atlas of Hungary. Hungarian Meteorological Sevice, Budapest
Neal RA, Phillips ID (2009) Summer daily precipitation variability over the East Anglian region of Great Britain. Int J Climatol 29:1661–1679
Neter J, Wasserman W, Kutner MH (1983) Applied linear regression models. Richard D. Irwin, Burr Ridge
Pebesma EJ (1997) Gstat user’s manual. Program manual (http://www.geog.uu.nl/gstat/manual/gstat.html)
Pebesma EJ (2006) The role of external variables and GIS databases in geostatistical analysis. T GIS 10(4):615–632
Pebesma EJ, Wesseling CG (1998) Gstat: a program for geostatistical modelling prediction and simulation. Comput Geosci 24(1):17–31
Penzar B, Penzar I, Orlić M (2001) Vrijeme i klima hrvatskog Jadrana (Weather and climate of the Croatian part of the Adriatic). Nakladna kuća dr. Feletar, Zagreb in Croatian
Perčec Tadić M (2004) Digitalna karta srednje godišnje sume globalnog Sunčeva zračenja i model proračuna globalnog Sunčeva zračenja na nagnute različito orijentirane plohe (Digital Map of the Mean Annual Global Solar Radiation Sum and Calculation Model for Global Solar Radiation on Inclined Variously Oriented Surfaces). Hrv. meteor. časopis 39:41–50 in Croatian with eng. summary
Perry M, Hollis D (2005) The generation of monthly gridded datasets for a range of climatic variables over the UK. Int J Climatol 25(8):1041–1054
Peterson TC, Vose RS (1997) An overview of the global historical climatology network temperature database. B Am Meteorol Soc 78:2837–2849
Pleško N, Gajić-Čapka M, Zaninović K (1984) Meteorološke oborinske podloge za projekt “Katastar malih vodnih snaga u SR Hrvatskoj” (Meteorological analysis of precipitation for the study “Water resource menagement in Croatia”). Državni hidrometeorološki zavod, Zagreb (in Croatian–unpublished)
Poje D, Žibrat Z, Gajić-Čapka M (1984) Osnovne karakteristike naoblake i insolacije na području SR Hrvatske (Main features of cloudiness and insolation in the area of Croatia). Rasprave 19:49–74 in Croatian with eng. summary
Thornton PE, Running SW, White MA (1997) Generating surfaces of daily meteorological variables over large regions of complex terrain. J Hydrol 190:214–251
Wackernagel H (2003) Multivariate geostatistics: an introduction with applications, 2nd edn. Springer, New York
Webster R, Oliver MA (2007) Geostatistics for environmental scientists. Wiley, New York
WMO (1996) Climatological normals (CLINO) for the period 1961–1990. World Meteorological Organization Document WMO/OMMNo. 847, Geneva also in WMO Global Standard Normals (DSI−9641A). Digital data set available from the National Climatic Data Center (NCDC) at http://ols.nndc.noaa.gov/plolstore/plsql/olstore.prodspecific?prodnum=C00058-CDR-A0001
Zaninović K, Gajić-Čapka M, Pleško N (1985) Prostorna raspodjela srednje godišnje temperature zraka na području SR Hrvatske (Spatial distribution of mean annual temperature over the area of Croatia) Državni hidrometeorološki zavod, Zagreb (in Croatian–unpublished)
Zaninović K, Gajić-Čapka M, Perčec Tadić M et al (2008) Klimatski atlas Hrvatske/Climate atlas of Croatia 1961–1990, 1971–2000. Državni hidrometeorološki zavod, Zagreb
Žibrat Z, Gajić-Čapka M (1986) Globalno zračenje na području SR Hrvatske (Global radiation in the area of Croatia). Rasprave 21:47–58 in Croatian with eng. summary
Acknowledgement
The author is grateful to the organisers of the GEOSTAT summer school (Tomislav Hengl, Roger Bivand, Edzer J. Pebesma, Olaf Conrad and Victor Olaya Ferrero) for their inspiring course and comments and suggestions on the subject of geostatistics, R and Google Earth... The author is also very grateful to the anonymous revisers for constructive comments that helped improve this manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Perčec Tadić, M. Gridded Croatian climatology for 1961–1990. Theor Appl Climatol 102, 87–103 (2010). https://doi.org/10.1007/s00704-009-0237-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00704-009-0237-3