
Abstract
The rapid evolution of smart services and Internet of Things devices accessing cloud data centers can lead to network congestion and increased latency. Fog computing, focusing on ubiquitously connected heterogeneous devices, addresses latency and privacy requirements of workflows executing at the network edge. However, allocating resources in this paradigm is challenging due to the complex and strict Quality of Service constraints. Moreover, simultaneously optimizing conflicting objectives, e.g., energy consumption and workflow makespan increases the complexity of the scheduling process. We investigate workflow scheduling in fog–cloud environments to provide an energy-efficient task schedule within acceptable application completion times. We introduce a scheduling algorithm, Energy Makespan Multi-Objective Optimization, that works in two phases. First, it models the problem as a multi-objective optimization problem and computes a tradeoff between conflicting objectives while allocating fog and cloud resources, and schedules latency-sensitive tasks (with lower computational requirements) to fog resources and computationally complex tasks (with low latency requirements) on cloud resources. We adapt the Deadline-Aware stepwise Frequency Scaling approach to further reduce energy consumption by utilizing unused time slots between two already scheduled tasks on a single node. Our evaluation using synthesized and real-world applications shows that our approach reduces energy consumption, up to 50%, as compared to existing approaches with minimal impact on completion times.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The use and adoption of heterogeneous Internet of Things (IoT) devices has revolutionized Information and Communication Technology (ICT) [37]. IoT have extended internet connectivity beyond conventional devices such as tablets and phones to a wide range of smart devices such as TV, wearable appliances, vehicles and surveillance cameras [1]. These smart connected devices are integrated into many applications, e.g. intelligent traffic control systems, health monitoring units and security systems. The IoT market is growing rapidly and billions of devices are expected to be connected to the Internet to provide valuable services to the users [33]. The deluge of data being generated needs fast processing and analysis to extract valuable information.
Over the last decade, the storage, analysis, and computations associated with data-intensive applications are performed on resources hosted at centralised cloud data centers [5]. However, due to this centralisation, cloud computing is experiencing challenges to meet the requirements of latency-sensitive IoT applications that require real-time response times [32]. As cloud data centers are further away from data generation sources, by the time the data arrives at the cloud center for analysis and processing, it might already be too late to extract useful information from the received data. Moreover, with the predicted increase in the number of connected IoT devices and large physical distances between these devices and cloud data centers, the conventional architecture will be unable to handle communication requirements for transmitting large data volumes over public networks to a centralised location, due to traffic congestion and communication costs [23]. Therefore, a computing paradigm suitable for handling the variety, velocity, and volume of the data generated by IoT devices is needed.
Fog computing architectures provide cloud-like services near the edge of the network [9, 35]. The network edge is transformed into a distributed computing paradigm by connecting edge devices to provide storage and computation services to run IoT applications [2, 24]. Fog nodes [25] can be deployed near an IoT data source, such as near bus terminals, on University premises or at shopping malls, to offer services for time-critical applications. The computationally-intensive application tasks are offloaded to the cloud data centers for processing and long-term storage while lightweight and time-sensitive tasks can be processed locally on edge devices [12].
In practice, IoT applications are generally composed of modules that execute tasks (e.g. microservices), where each module carries out part of the overall processing (either independently or with dependency/data flow constraints between tasks) [15]. Workflow is one of the most commonly used models in these applications and can be represented as a directed acyclic graph (DAG) [22]. An application workflow can be executed across a number of different types of fog–cloud systems that make up the execution environment for such workflows.
Workflow scheduling algorithms must take dependency constraints and resource properties into account, aiming to improve effective resource utilization (i.e., make most effective use of the available resources), whilst minimising the overall completion time (or makespan) of the application. It is a well-known NP-complete problem [15] and should be optimized using approximate solutions in near polynomial time [4].
Apart from makespan, energy consumption is another crucial parameter in a fog–cloud environment. The energy consumption of cloud data centers has increased considerably during the last decade subsequently resulting in soaring economic costs of energy apart from operational expenses and environmental impacts. Moreover, the resource constrained nature of fog nodes makes energy a serious challenge since they usually run on batteries or have access to limited (renewable) energy, or are deployed in areas with limited and unreliable energy sources [20]. Therefore, green cloud computing has received significant attention in both academia and industry and reducing energy consumption in emerging fog–cloud infrastructure has become a major issue [11].
A scheduling algorithm that can minimize the makespan of an application but consume considerable energy is not an optimal choice for use on fog resources. This becomes more challenging when multiple conflicting objectives must be satisfied simultaneously. For instance, it is challenging to reduce makespan while also reducing the energy consumption required to complete application processing. Therefore, a bi-objective optimization approach is required for finding the right compromise between these optimization objectives.
The scheduling problem has been widely explored for cloud environments, either as a unique objective or a multi-objective optimization problem, however, it is not well-studied for fog–cloud infrastructures. In this paper, we first formulate the problem as a multi-objective optimization model that considers both makespan minimization and reduction in energy consumption. Since both the objectives are conflicting in nature, we apply an adaptive weighted bi-objective cost function. The value of the weight indicates which criteria (makespan or energy) is considered to be more important by a user. The overall aim is to obtain the right compromise between application completion time and energy consumed during workflow execution.
A common power management practice is the Dynamic Voltage and Frequency Scaling (DVFS) technique [14]. DVFS permits the dynamic adjustment of frequency and voltage of a processor. The voltage regulators in modern multi-core processors enable each core to operate at a different frequency and voltage level [29]. We apply a frequency scaling technique to achieve further reduction in energy consumption by utilizing DVFS on the underlying processors while satisfying application completion time constraints. This is achieved by availing possible gaps (empty slots) in a schedule between tasks. We perform experimental evaluation and compare our approach with existing work on synthesized and real-world application workflows, e.g. Cybershake [3] and Montage [40]. The results show that our approach generates efficient schedules with optimized energy consumption. Specifically, we make the following contributions in this paper.
-
We propose a model for workflow scheduling considering fog and cloud resources, where fog nodes have limited computational capacity but are closer to the data source (i.e., with lower latency), and cloud nodes with greater computational capabilities but far from the data source.
-
We design a multi-objective scheduling algorithm considering application completion time and energy consumption for application processing. We use a weighted bi-objective function to address the multi-objective nature of the problem. Furthermore, we apply a deadline-aware stepwise frequency scaling approach and utilize the slack time (the empty slots in the schedule) between two already scheduled tasks on a single node for further reducing energy consumption.
-
We evaluate performance of the proposed algorithm using real-world and synthetic workflows. Our evaluation shows that our approach achieves up to a 50% reduction in energy consumption as compared to existing approaches while providing acceptable application completion time.
The rest of this paper is organized as follows. We summarize related work in Sect. 2. Section 3 introduces the fog–cloud architecture that we consider in this paper. In Sect. 4, we formally define the problem addressed in this paper and present its proposed solution in Sect. 5. We present performance evaluation of our solution in Sect. 6. Finally, we conclude the paper in Sect. 7.
2 Related work
There have been several studies that address the workflow scheduling problem in heterogeneous computing systems. The NP-hard nature of the problem demands more heuristic approaches to approximate optimal solutions.
Heterogeneous Earliest Finish Time (HEFT) is the most commonly adopted scheduling algorithm [31]. HEFT operates in two phases; the task prioritization phase and the processor selection phase. First phase assigns priorities to the tasks on the basis of their upward ranks while the second phase chooses suitable processor for the task execution considering the minimal task completion time. Another well-known algorithm in this category is Predict Earliest Finish Time (PEFT) [6]. In PEFT, the Optimistic Cost Table (OCT) is computed to assign priorities to tasks and it also helps in determining the most appropriate processor for task execution in the scheduling phase. Both HEFT and PEFT are single-objective optimization approaches that take into account only makespan minimization while EM-MOO is a multi-objective optimization approach that considers energy consumption along with makespan.
In [16], a makespan minimization algorithm Minimal Optimistic Processing Time (MOPT) is introduced that modifies the prioritization phase by computing Optimistic Processing Times (OPT) of tasks on all processing nodes and then ranks are assigned based on average OPT values. The node selection phase improves the entry task duplication feature by allowing duplication only in case this helps in minimizing the completion time of successor tasks. Again, MOPT is a single-objective optimization technique as compared to our proposed work in this article. A hybrid meta-heuristic approach combining the Genetic Algorithm (GA) and Ant Colony Optimization (ACO) is suggested in [7] for minimizing makespan in a multi-processor cloud environment. The bottom level (b-level) of a task is used to assign priorities. The b-level is maximum execution time a task takes to traverse all levels of the graph. Then, ACO is applied to identify a suitable path that is further improved by applying GA.
One of the few studies that consider task scheduling in fog computing as a DAG scheduling problem is presented in [27]. It introduces Cost-Makespan aware Scheduling (CMaS) algorithm to satisfy the user’s QoS requirements of makespan and cost optimization and proposes a utility function to determine the tradeoff between both these objectives. The obtained schedule is improved by the task reassignment phase.
Task Scheduling in Fog Computing (TSFC) algorithm is based on the classification mining algorithm [19]. The association rules obtained from the I-Apriori algorithm are combined with the task completion times without taking bandwidth into account between machines. Task scheduling in fog computing supported software-defined embedded systems (FC-SDES) [38] minimizes the makespan. It proposes a low-complexity 3-phase algorithm that incorporates task scheduling, resource management, and I/O request balancing.
The computational requirements of users have increased significantly as a result of cloud computing and the emergence of fog paradigm, therefore energy consumption has become a challenging objective for optimization [13, 34]. This is an active research area and efforts are being made towards developing workflow scheduling algorithms that consider energy consumption factors. Next, we summarize energy optimization algorithms used in cloud and fog environments.
DVFS-enabled Energy Efficient Workflow Task Scheduling (DEWTS) algorithm is a state of the art algorithm in the cloud environment that applies Dynamic Voltage and Frequency Scaling (DVFS) technique to optimize energy usage during unused time slots in the scheduling process [30]. The core idea is to turn-off the less utilized machines and reassign their tasks to the turned-on machines. Next, the algorithm utilizes idle time slots of the machines under lower frequency and voltage to allocate tasks and obtain reduced power consumption.
The energy-efficient scheduling problem in a mobile cloud environment is investigated in [18]. This approach, Energy Makespan in Mobile Cloud Computing (EM-MCC), starts by allocating tasks to machines using the least-delay scheduling approach followed by task reassignment phase that migrates tasks among the local cores or cloud nodes to reduce energy usage. The DVFS technique is then applied for further energy reduction of mobile devices. EM-MCC is one of the algorithms used in the evaluation process of our proposed work. One of the limitations of EM-MCC is that its task migration phase increases the computational complexity of the algorithm.
In [36], an energy-aware processor merging (EPM) algorithm in a heterogeneous parallel and distributed framework is presented. EPM turns off the most effective machine in terms of energy saving. To overcome the high computational complexity of EPM, it introduces a less complex quick EPM (QEPM) algorithm that simply turns off machines with minimum energy consumption. However, QEPM consumes more energy than EPM. In [34], authors handle multiple conflicting objective problems in cloud environments by introducing a pareto-based multi-objective hybrid approach, hybrid Particle Swarm Optimization algorithm (HPSO). The algorithm tries to optimize energy, budget and schedule length of the application by generating a set of Pareto optimal solutions. DVFS approach is used to optimize energy consumption.
An energy-efficient scheduling algorithm for placing tasks on nodes based on their remaining CPU time and energy state is proposed in [20]. Improved Round Robin (IRR) and DVFS approaches are followed to achieve energy-efficient scheduling. The strategy aims to place delay-sensitive tasks to fog devices effectively. Execution time and power optimization for task allocation in fog–cloud environments is studied in [10]. The problem is split into three separate domains; fog, cloud, and WAN. Existing optimization approaches are applied to provide solutions to each sub-problem. The study reveals that fog computing boosts performance as latency and bandwidth are minimized. However, more WAN communications increase overall execution delays and workload on fog nodes increases their energy consumption.
We present a summary of the common scheduling algorithms in Table 1. Although the problem has widely been studied for the cloud environment, there is much space for the NP-hard scheduling problem to be explored in the fog–cloud paradigm. Moreover, existing work mostly focuses on single objective optimization that reduces performance especially in environment where complex applications generated from real-time IoT devices need to be executed. To overcome limitations in the existing studies, we have proposed a simplified and less complex solution to the workflow scheduling problem for finding a tradeoff between energy consumption and makespan. This approach has not been explored much in the fog–cloud context in the related studies. Moreover, our algorithm utilizes DVFS on the underlying processors in order to fill empty scheduling slots and thus, achieves reduced energy consumption with adaptive deadline adjustment.
3 Fog enabled cloud system architecture
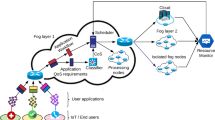
The fog–cloud system architecture, shown in Fig. 1, typically has three layers [26]. The terminal layer or bottom layer consists of IoT devices, e.g., home appliances, sensors, wearable devices, smartphones and smart vehicles [8]. These devices send requests and data to the higher-level layers for application processing. In this paper, we consider IoT devices that are sources of data generation and do not have capabilities to process the generated data.

Fog–cloud architecture
The fog computing layer is the intermediate layer between IoT devices and cloud data centers and is generally deployed near IoT devices. It is formed by a large number of nodes residing near the edge of the network, e.g., routers, access points, switches, base stations with limited computation, transmission, and temporary storage nodes [21]. Users can access the fog nodes to obtain the required services. The fog layer is connected with the cloud data centers to satisfy complex computing and storage requirements. The nodes at this layer are organized in a hierarchical fashion. The lower level layer is expected to be one or two hops away from the end-users to provide services with low, i.e., few milliseconds, latency requirements [17].
The uppermost cloud layer of the fog–cloud platform comprises of multiple high-performance cloud servers and provides powerful computation and permanent storage services for IoT applications [8]. This layer provides computing services for compute-intensive workloads, and efficient and reliable storage facilities for persistent data. It is desirable to only offload compute-intensive tasks to the cloud layer as it is further away from data sources and incurs high communication delays to transfer the input and output data.
There is a dedicated fog node, known as fog broker, in the fog layer that plays the role of centralized management and task scheduler [28]. It is responsible for collecting user requests, managing resources on fog and cloud nodes and generating most suitable schedules for the input workflows.
4 Problem definition
In this section, we provide a formal definition of the problem tackled in this paper. Workflow scheduling in the fog–cloud system is defined as the problem of allocating tasks of the workflow to the machines of the target system in a way that an optimal schedule is achieved with a tradeoff between energy consumption and makespan minimization. For ease of understanding, Table 2 provides a description of notation used in this paper.
4.1 Application model
An application workflow is defined as a set of interdependent tasks and is modeled as a Directed Acyclic Graph, \(DAG = (V,E)\) whose vertices are the tasks and edges describe data dependencies between them. Let \(V = \lbrace v_1, v_2,...v_t \rbrace \) be the set of t tasks in the workflow and E is the set of edges. An edge \(e_{i,j} \in E\) defines the data flow dependency from task \(v_i\) to \(v_j\) with a precedence constraint that the processing of \(v_i\) must be complete before \(v_j\) could be initialized as former is a predecessor task. The set of all direct predecessors and successors of \(v_i\) are represented as \(pred(v_i)\) and \(succ(v_i) \) respectively. A task \(v_i\) without any predecessor is known as entry task \(v_{entry}\), and a task without any successor is called an exit task, \(v_{exit}\). In this model, we consider only one entry task and one exit task. Therefore, if a DAG has more entry/exit tasks, a dummy task with zero computation and communication costs is added. This does not have any impact on the schedule.
The size of each task is measured in million instructions and each task appears only once in a schedule. Moreover, we assume Non-Preemptive Execution (NPE) of tasks in our model. A task uses two types of inputs: (i) from a predecessor task; (ii) from other data sources on a cloud/fog platform. However, only one of these may be present in some instances.
4.2 System model
The target fog–cloud system has heterogeneous computational nodes: fog and cloud nodes. Former have lower computational capabilities and are located closer to data generation source while latter have higher computational capabilities but are far from data source.
We define the target system \(S=(N,L)\) as a directed graph where \(N =\lbrace n_1, n_2,...n_p\rbrace \) is representing the set of all processing nodes and \(l_{i,j} \in L\) denotes the link that connects \(n_i\) and \(n_j\). Each node in N may be a cloud (\(N_c\)) or a fog node (\(N_f\)). Therefore,
such that, \(w(N_{f}) < w(N_{c}) \forall N\), i.e., as described earlier, computation capability \(w(N_{f})\) of fog nodes is assumed to be less than that of cloud nodes \(w(N_{c})\) due to physical constraints on fog devices. Also, higher stability of LAN as compared to WAN results in better bandwidth between fog nodes than that of cloud nodes. The computational capacity of a node is measured in million instructions per second (MIPS). Let, \(x_{i,j}\) represents the task allocation matrix. If \(v_i\) is allocated to \(n_j\), then \(x_{i,j}=1\), else \(x_{i,j}=0\).
4.3 Makespan model
The makespan represents overall completion time of the application. Minimizing makespan for workflow applications is a crucial problem in the fog–cloud environment to achieve efficient schedules. Suppose a task \(v_i\) is scheduled on a node \(n_j\). Let \(MST(v_i, n_j)\) and \(MCT(v_i, n_j)\) be the Minimum Start Time and Minimum Completion Time for \(v_i\) on \(n_j\) respectively and \(n_j\) is available for the execution of \(v_i\). If \(v_i\) is the entry task then,
For remaining tasks in the graph, MST and MCT are computed recursively, starting from the top, as described in Eqs. (3) and (4) respectively.
where the parameter \(CC(v_i)\) represents average transfer time when all the input data has been transferred to the selected node \(n_j\) for execution of \(v_i\). The cost will be zero in case both the parent and child tasks are assigned to the same node. The term \(W(v_i,n_j)\) represents the computation time of \(v_i\) on \(n_j\). After a task is scheduled on a node, the MST and MCT become Actual Start Time (AST) and Actual Completion Time (ACT) of the task respectively. Eventually, the makespan (M) of the application is equal to the actual completion time of the last task, \(v_{exit}\), of the workflow, i.e.:
4.4 Energy model
In this study, we adopt the classic power model to analyze power and energy consumption [39]:
where, \(P_{static}\) is the power consumption when the system does not execute any workload, i.e., it is power used when the system is turned on. Dynamic power dissipation \(P_{dynamic}\), is the dominant and expensive component of energy and is defined as:
where C is the capacitance load, \(V_{dd}\) is the supply voltage and f is the frequency. Since \(f \propto V^\beta _{dd}\) for (\(0< \beta < 1\)), or \(V_{dd} \propto f^{1 / \beta }\) i.e., the frequency-dependent dynamic power is,
\(P_{dynamic} \propto f^\gamma \) where \(\gamma = 1+2/\beta \ge 3\).
Therefore, in our study, we represent power consumption as:
The maximum operating frequency of the node \(n_j\) is \({f_{n_j}^{max}}\) and there are L scaling factors (\(a_{n,1}< a_{n,2}... < a_{n,L} = 1\)). To acquire our objective of minimizing energy consumption, we will execute the tasks at the lowest frequency whilst ensuring that the completion time deadline is met. Therefore, the actual operating frequency on which \(n_j\) might operate can be computed as:
The power consumed by \(n_j\) on that particular frequency would be:
Therefore the energy consumption for processing \(v_i\) on \(n_j\) is computed as:
where \(W(v_i,n_j)\) is the computation time of \(v_i\) on \(n_j\). The total energy consumption by \(n_j\) for executing all tasks v assigned to it is computed as:
The energy consumption function for running the complete workflow application is obtained by:
where n can be a cloud or a fog node.
4.5 Multi-objective optimization model
When the processing nodes operate at higher frequencies, the performance of the system increases in terms of reduced application completion time but at the cost of higher energy consumption. The two objectives, energy consumption and makespan are therefore conflicting in nature and the energy-makespan tradeoff is faced for appropriate node selection to run the application tasks. The joint minimization of both objectives is a multi-objective optimization problem (MOO). Our objective is to introduce a workflow scheduling solution that achieves a tradeoff for this MOO problem.
We address the scheduling problem in two phases to achieve the desired objectives. First, we formulate a MOO model for the optimization of makespan (M(DAG)) and energy consumption (EC(DAG)) for a workflow application DAG(V, E) with a set V of tasks with aforementioned constraints and a set N as:
subject to the following constraints,
The constraints specify that a task can only be allotted to a single node.
The ever increasing demand for cloud computing and the power-constrained nature of fog devices makes energy consumption a challenging factor. Therefore, in the second phase of our work, we employ a step-wise frequency scaling technique for further reduction in energy consumption. To achieve this, we have put a deadline constraint on the overall execution time of the application produced in the previous phase and then the schedule gaps among the tasks are utilized. This helps in achieving further reduction in energy consumption. Mathematically,
where, D is the deadline for the entire workflow that is computed based on the value of makespan obtained in the first phase.

Proposed methodology: EM-MOO algorithm
5 Energy-makespan based multi-objective optimization (EM-MOO)
We design a novel workflow scheduling algorithm EM-MOO to minimize energy consumption and makespan and find a tradeoff between these conflicting objectives. Figure 2 shows the proposed methodology and the interactions between different components. Initially, the algorithm assigns ranks to the tasks to determine their scheduling order. Next, an appropriate processing node is selected for each task based on the bi-objective cost function.
5.1 Task selection phase
The task selection phase assigns weights to tasks to determine their execution order, primarily to achieve efficient schedules during the node selection phase. We assign weights to the tasks based on their Optimistic Processing Times (OPT), which is the key parameter that defines the overall completion time of the workflow application [16]. OPTs are computed before tasks are mapped to any node and are therefore called optimistic. To compute OPT for a task \(v_i\) on a node \(n_j\), \(OPT(v_i,n_j)\), first the Optimistic Minimum Start Time (OMST) of \(v_i\) on \(n_j\) is determined using the following equation.
The inner function of Eq. (14) calculates the OPTs for the predecessors of \(v_i\). Then, the \(OPT(v_i,n_j)\) is computed as:
where \(W(v_i, n_j)\) is the computation cost of \(v_i\) on \(n_j\). Once the OPT values for all tasks have been computed, the rank assignment is calculated using the following equation.
Finally, a Task Priority Queue (TPQ) is maintained with the tasks arranged in the increasing order of \(rank_{opt}\) and the task with the least rank value has the highest priority. Thus, priority is given to smaller tasks that result in reducing the waiting time for execution of the other tasks.
5.2 Node selection phase
The highest priority task \(v_i\) from TPQ is picked for execution that can only begin when all the predecessor tasks of \(v_i\) have completed execution and the input data of \(v_i\) has reached the target execution node. The MST and MCT for \(v_i\) are computed on all \(n_j \in N\) using Eqs. (3) and (4) respectively. Besides the minimum completion time, the proposed algorithm also incorporates the energy consumption for selecting an appropriate node by using Eq. (11).
The proposed solution provides the joint optimization of minimum completion time and energy usage. However, time and energy are different metrics with different units. Therefore, to make these metrics comparable, we apply normalization to both the objectives so they are normalised to lie between 0 and 100. The normalized value for \(MCT(v_i,n_j)\) is obtained as:
and the energy consumption is normalized as:
Using Eqs. (17) and (18) we can define a weighted bi-objective function that computes tradeoff between the two objectives.
where \(\alpha \) (\(0 \leqslant \alpha \leqslant 1\)) is the weight/tradeoff factor. We use the terms weight and tradeoff interchangeably in this paper. Note that for \(\alpha =\) 0 or 1, the function becomes a single objective optimization problem with energy or makespan minimization respectively. Task \(v_i\) is assigned to the node \(n_j\) that provides the minimum value of the cost function. After \(v_i\) is scheduled on \(n_j\), \(MST(v_i, n_j)\) and \(MCT(v_i, n_j)\) become the Actual Start Time, (\(AST(v_i)\)), and the Actual Completion Time, (\(ACT(v_i)\)), of \(v_i\) respectively and the makespan of the entire workflow is equal to the \(ACT(v_{exit})\) as defined in Eq. (5). Similarly, total energy consumption for workflow scheduling is obtained by Eq. (13). The algorithm to determine the schedule and mapping of tasks to nodes is presented in Algorithm 1.

5.3 Deadline aware stepwise frequency scaling algorithm (DAFS)
The scheduling algorithm attempts to find minimum completion time and energy consumption during task execution and depends on the value of tradeoff factor \(\alpha \). In that phase, we assume the nodes are operating at a maximum frequency that results in higher energy consumption. To further reduce energy consumption, we apply a stepwise frequency scaling approach. However, decreasing the operating frequency of a node can result in increased task completion times and makespan for the entire workflow. For real-world application workflows, the output schedule must meet the application performance requirements and the completion time specified by the user at the time of job submission. In our algorithm, this deadline is dependent on the value of weight parameter \(\alpha \). We classify maximum deadline limit \(D_{max}\) into two categories based on \(\alpha \), loose deadline and tight deadline. In the case of former, we restrict the deadline not to be more than 25% of the original makespan obtained in the previous phase while the latter case does not allow to increase more than 10% of the previous makespan. For \(\alpha \ge 0.5\), the user is inclined more towards makespan. Therefore, we observe a tight deadline limit, i.e.,
For \(\alpha \leqslant 0.5\), we set deadline limit in an adaptive way such that for \(\alpha \) = 0, it may not increase more than 25% of the initial makespan (\(T_{total}\)). The deadline is adaptively chosen as,
where
Our proposed approach does not change the task to node mapping produced in the node selection phase and thus avoids task rescheduling during the DAFS phase. The precedence constraints and communication delays involved before task execution can generate slack time between two consecutive tasks’ execution on a single node. Our algorithm uses these slack times during the stepwise frequency scaling phase. For a task \(v_i\) scheduled on \(n_j\), we compute slack time, SlackTime, of \(v_i\) using Eq. (22). \(SlackTime_{v_i}\) is the maximum value that can be added to the completion time of \(v_i\) without affecting the start time of the next scheduled task \(v_k\) on \(n_j\), and the start time of the successor tasks, \(v_s\in succ(v_i)\), of \(v_i\).
and the slack time for the exit task, i.e., \(SlackTime_{v_{exit}}\), is computed as,

We begin with the lowest frequency scaling factor and try \(v_i\) execution on each frequency level (with total L levels) iteratively until we acquire a frequency level from which further reduction will result in delayed task completion times and higher makespan. The pseudo-code of the algorithm is given in Algorithm 2.

UML diagram of EM-MOO implementation

Experimental setup
6 Performance analysis and evaluation
We develop the simulation platform to evaluate the proposed algorithm in MATLAB environment. The UML Diagram of the implementation setup is shown in Fig. 3 while Fig. 4 displays the experimental setup. We consider 40 processing nodes, out of which 15 are fog nodes (FN) and 25 are cloud nodes (CN) [27]. The processing capability of fog nodes is assumed to be lesser than that of cloud nodes and bandwidth in fog environment is higher than the cloud environment. We evaluate our work in two environments. The first environment considers synthesized workflows comprising of [100–500] tasks while for every evaluation, task size is randomly generated from [5000–50000] MI tasks. The density /shape parameter determines height of the graph. The processing capacity of the fog nodes is [10–500] MIPS and that of the cloud nodes is [500–1500] MIPS. For fog environment, the bandwidth is fixed at 1024 Mbps while the bandwidth for cloud environment is set as [10, 100, 512, 1024]. The second set is carried out on two types of benchmark workflows, i.e, Cybershake [3] and Montage [40], provided by the Pegasus workflow management system. To evaluate our work, we implemented EM-MCC [18], PEFT [6] and MOPT [16] algorithms. EM-MCC is multi-objective that optimizes energy as well as makespan, however, PEFT and MOPT are single objective makespan optimization approaches.

Synthesized workflows: average makespan as a function of the number of tasks
6.1 Performance metrics
Three comparative metrics are used to evaluate our proposed work from various perspectives. The first metric used is makespan, which is the primary optimization objective and is widely used for evaluating workflow scheduling algorithms. It gives completion time of the entire workflow application. Energy consumption is another important metric that we consider in our multi-objective optimization approach. We conduct 1000 iterations for each set of experiments and compare average makespan and average energy consumption of EM-MOO with comparative algorithms. Moreover, to demonstrate that our work can acquire better tradeoff between energy and makespan than comparative approaches, we compute a third metric energy-makespan tradeoff (EMT) for all the algorithms as:
where \(Alg =\lbrace A_1, A_2,...A_k\rbrace \) is the set of all the algorithms. The maximum achievable EMT for any algorithm is 1, which is possible only if the algorithm produces the best results for both makespan and energy as compared to other algorithms. Otherwise, the higher the EMT for an algorithm, the better tradeoff it has achieved between both metrics.
6.2 Evaluation using synthesized workflows
Figure 5 shows the average makespan comparison of the algorithms as a function of the workflow size that ranges from 100 to 500 tasks. PEFT and MOPT produce reduced makespan as compared to EM-MOO and EM-MCC because the former algorithms consider only makespan optimization while the latter also incorporates energy consumption. EM-MOO produces better makespan as compared to EM-MCC as it puts strict deadline limits during step-wise frequency scaling phase by using \(\alpha \) while the latter decreases energy consumption at the cost of increased makespan.

Synthesized workflows: average energy consumption as a function of the number of tasks
Figre 6 illustrates that although PEFT and MOPT provide better performance in terms of makespan as compared to EM-MOO, the energy consumption by both algorithms is very high. On the other hand, our approach contributes towards achieving a balance between the optimization of makespan and energy consumption. The results confirm that the EM-MOO algorithm makes effective use of schedule gaps (slack). By putting a limit on the maximum deadline of the application with respect to the value of \(\alpha \), the improvements achieved in terms of energy reduction for workflows with 100 tasks are 17.12% as compared to EM-MCC and almost 50% as compared to both MOPT and PEFT. Similar improvements can be observed for other workflow sizes. Although both EM-MOO and EM-MCC do not change processing nodes during the frequency scaling phase, EM-MOO makes better resource utilization by considering the energy consumption parameter during the node selection phase apart from the completion time.

Synthesized workflows: boxplot of makespan as a function of the number of tasks

Synthesized workflows: boxplot of energy consumption as a function of the number of tasks
A statistical analysis of the outputs for both metrics, i.e., makespan and energy consumption, are shown in Figs. 7 and 8 respectively. The plots show minimum, first quartile (25%), median, third quartile (75%) and maximum values from all the iteration results produced by the algorithms. The outcomes show the better performance of EM-MOO over other algorithms as discussed above.

Synthesized workflows: energy-makespan tradeoff
Figure 9 provides the energy-makespan tradeoff comparison of EM-MOO with comparative algorithms. The proposed approach, EM-MOO, achieves the highest tradeoff for all workflow sizes as compared to its competitors. For workflow size of 500 tasks, EM-MOO achieves 12%, 33%, and 39% improvement as compared to EM-MCC, MOPT, and PEFT respectively. The cost function and adaptive deadline-aware stepwise frequency scaling phase help our approach in achieving a better tradeoff between the conflicting objectives.

Synthesized workflows: impact of the number of cloud nodes on makespan

Synthesized workflows: impact of the number of cloud nodes on energy consumption
We also examine the behavior of EM-MOO by varying the number of cloud nodes and observing the impact on makespan and energy consumption for a fixed number of workflow tasks. We use 40 processing nodes in fog and cloud environment and change the computing environment by increasing the number of cloud nodes from 5 nodes to 25 nodes. The result of this experiment is shown in Fig. 10. We observe that increasing the number of cloud nodes provides better processing capability and leads to reduced makespan. The significant impact due to an increase in cloud nodes on energy consumption is displayed in Fig. 11.

Makespan and energy consumption as a function of weight factor (\(\alpha \))
Table 3 shows makespan and energy consumption for all values of the weight factor for a synthesized DAG with 100 tasks. Note that the refinement in makespan or energy reduction is linked with the value of the weight factor. Thus, depending upon the end-user requirements, the weight factor can be adjusted within the range (\(0 \leqslant \alpha \leqslant 1\)) such that one of the objectives is achieved by realizing an acceptable compromise for the other objective. Figures 12a, b show the graphical representation of the data.
6.3 Evaluation using real world application workflows
In the second set of experiments, we use real-world workflow applications Cybershake [3] and Montage [40], which are widely used for evaluating scheduling algorithms, from the Pegasus workflow management system. Cybershake is used by the Southern California Earthquake Center (SCEC) to identify the earthquake within the region. It is relatively simpler workflow, but it can handle large datasets. Montage application workflow is employed in space industry to create mosaics of the sky by stitching together the input images. The size of workflow depends on the number of input images used to create the mosaic.

Cybershake application: average makespan as a function of the number of tasks

Cybershake application: average energy consumption as a function of the number of tasks

Cybershake application: boxplot of makespan as a function of the number of tasks

Cybershake application: boxplot of energy consumption as a function of the number of tasks
The analysis for Cybershake application is carried out on workflow sizes of 30, 50 and 100 tasks. The average makespan comparison is shown in Fig. 13 that indicates better EM-MOO performance as compared to EM-MCC but higher makespan as compared to MOPT and PEFT due to their single objective optimization approach. The comparison of the average energy consumption can be analyzed in Figure 14. The performance of EM-MOO is better than other popular alternatives that we have used in this paper. By restricting the deadline according to the value of \(\alpha \), the reductions in energy consumption are 9%, 29% and 30% as compared to those of EM-MOO, MOPT, and PEFT respectively for workflows with 100 tasks. Similar improvement trends are observed for workflows with 30 and 50 tasks. Figrues 15 and 16 provide the performance analysis of makespan and energy consumption, respectively, for varying number of tasks, and show that EM-MOO consumes less energy as compared to other alternatives while providing an acceptable makespan.

Montage application: average makespan as a function of the number of tasks

Montage application: average energy consumption as a function of the number of tasks

Montage application: boxplot of makespan as a function of the number of tasks

Montage application: boxplot of energy consumption as a function of the number of tasks
Similar experiments are conducted for Montage application, using workflows with 25, 50 and 100 tasks. Again, we note from Fig. 17 that the average makespan obtained by EM-MOO is better than EM-MCC as we have applied tight deadline constraints during the frequency scaling phase resulting in realizing a better tradeoff between energy consumption and makespan objectives. Since MOPT and PEFT are single objective makespan optimization algorithms, they generate lower makespans at the cost of high energy consumption, as shown in Fig. 18. The EM-MOO achieves a minimum improvement of 11.75% in terms of energy consumption for Montage workflow with 100 tasks compared to EM-MCC, to a maximum improvement of 43.33% for 25 tasks as compared to the PEFT approach. The average makespan for a similar number of nodes is improved by 3.54% from EM-MCC and decreased from PEFT by 20%. This is because our multi-objective approach is intended towards achieving a better tradeoff by putting a limit on the workflow completion time. Figures 19 and 20 provide boxplot analysis of the algorithms using Montage application for makespan and energy consumption respectively. Since PEFT and MOPT are single objective optimization approaches, they produce a lower makespan compared to EM-MOO but at the cost of high energy consumption. Overall, the EM-MOO algorithm achieves minimum energy consumption within acceptable makespan as compared to other algorithms.
These results show that our approach achieves a good tradeoff between conflicting objectives and is a viable option for energy-efficient time-sensitive applications.
We analyze the computational complexity of the proposed algorithm in terms of workflow size t, the number of processing nodes p, and edge count e. The task selection phase takes \(O(t \times p)\) time to compute the optimistic processing times of the tasks, O(t) time for rank assignment and O(tlogt) time for task sorting. The node selection phase requires \(O(t \times p)\) time. The complexity therefore, becomes \(O(t^2 \times p)+ O(tlogt) + O(p)\). For the worst-case scenario with dense graphs, e becomes \(t^2\) and complexity increases to \(O(t^2 \times p)\). The stepwise frequency scaling phase has \(O(t \times l\)) complexity where l is the number of frequency scaling levels. The overall computational complexity of the algorithm becomes \(O(t^2 \times p)\) which is comparable to PEFT and MOPT but less than the EM-MCC algorithm that has higher complexity of \(O(t^3 \times p)\) due to task migration phase. Thus, the proposed EM-MOO achieves a trade-off between energy and makespan with significantly less complexity.
7 Conclusion
With the rapid increase in latency-sensitive applications and with the evolution of power-constrained Internet of Things (IoT) devices, the workflow scheduling problem remains a crucial yet open challenge. The fog–cloud architecture provides a promising platform for the efficient processing of emerging applications because computing resources and services are distributed in fog nodes and lie near the edge of the network making them a viable alternative for data processing. The processing time of workflow applications and energy consumption of the cloud data centers and power-constrained IoT devices during the process are key challenges in the integrated IoT and cloud computing environments. In this paper, we propose a scheduling algorithm, energy-makespan multi-objective optimization (EM-MOO), to find a tradeoff between these conflicting objectives of reducing energy consumption and makespan. Initially, a weighted bi-objective cost function is introduced for selecting a processing node that minimizes task completion time and energy consumption based on a user-defined weighting factor. Next, we perform a further reduction in energy consumption by applying deadline constrained frequency scaling. The proposed work ensures completion of the workflow applications within the proposed deadline whilst also reducing energy consumption. The evaluation of our proposed approach using synthetic and real-world applications show that our proposed approach achieves better tradeoff between energy consumption and makespan as compared to the popular alternatives.
In future, we plan to explore meta-heuristics such as differential evolution and particle swarm optimization to solve the multi-objective optimization problem in fog–cloud paradigms.
References
Aazam M, Zeadally S, Harras KA (2018) Offloading in fog computing for IOT: review, enabling technologies, and research opportunities. Future Gener Comput Syst 87:278–289
Agarwal S, Yadav S, Yadav AK (2016) An efficient architecture and algorithm for resource provisioning in fog computing. Int J Inf Eng Electron Bus 8(1):48
Ahmad SG, Liew CS, Rafique MM, Munir EU (2017) Optimization of data-intensive workflows in stream-based data processing models. J Supercomput 73(9):3901–3923
Alkhanak EN, Lee SP (2018) A hyper-heuristic cost optimisation approach for scientific workflow scheduling in cloud computing. Future Gener Comput Syst 86:480–506
Almi’ani K, Lee YC, Mans B (2018) On efficient resource use for scientific workflows in clouds. Comput Netw 146:232–242
Arabnejad H, Barbosa JG (2013) List scheduling algorithm for heterogeneous systems by an optimistic cost table. IEEE Trans Parallel Distrib Syst 25(3):682–694
Basu S, Karuppiah M, Selvakumar K, Li KC, Islam SH, Hassan MM, Bhuiyan MZA (2018) An intelligent/cognitive model of task scheduling for IOT applications in cloud computing environment. Future Gener Comput Syst 88:254–261
Bittencourt L, Immich R, Sakellariou R, Fonseca N, Madeira E, Curado M, Villas L, da Silva L, Lee C, Rana O (2018) The internet of things, fog and cloud continuum: Integration and challenges. Internet of Things 3:134–155
Chiang M, Zhang T (2016) Fog and IOT: an overview of research opportunities. IEEE Internet Things J 3(6):854–864
Deng R, Lu R, Lai C, Luan TH, Liang H (2016) Optimal workload allocation in fog–cloud computing toward balanced delay and power consumption. IEEE Internet Things J 3(6):1171–1181
Duan H, Chen C, Min G, Wu Y (2017) Energy-aware scheduling of virtual machines in heterogeneous cloud computing systems. Future Gener Comput Syst 74:142–150
Fu JS, Liu Y, Chao HC, Bhargava BK, Zhang ZJ (2018) Secure data storage and searching for industrial IOT by integrating fog computing and cloud computing. IEEE Trans Ind Inf 14(10):4519–4528
Gia TN, Jiang M, Sarker VK, Rahmani AM, Westerlund T, Liljeberg P, Tenhunen H (2017) Low-cost fog-assisted health-care iot system with energy-efficient sensor nodes. In: 13th international wireless communications and mobile computing conference (IWCMC). IEEE, pp. 1765–1770
Hosseinioun P, Kheirabadi M, Tabbakh SRK, Ghaemi R (2020) A new energy-aware tasks scheduling approach in fog computing using hybrid meta-heuristic algorithm. J Parallel Distrib Comput 143:88–96
Hu H, Li Z, Hu H, Chen J, Ge J, Li C, Chang V (2018) Multi-objective scheduling for scientific workflow in multicloud environment. J Netw Comput Appl 114:108–122
Ijaz S, Munir EU (2018) Mopt: list-based heuristic for scheduling workflows in cloud environment. J Supercomput 75:1–29
La QD, Ngo MV, Dinh TQ, Quek TQ, Shin H (2018) Enabling intelligence in fog computing to achieve energy and latency reduction. Digit Commun Netw 5:3–9
Lin X, Wang Y, Xie Q, Pedram M (2014) Task scheduling with dynamic voltage and frequency scaling for energy minimization in the mobile cloud computing environment. IEEE Trans Serv Comput 8(2):175–186
Liu L, Qi D, Zhou N (2018) Wu Y (2018) A task scheduling algorithm based on classification mining in fog computing environment. Wirel Commun Mobile Comput 2018:1–11
Mahmoud MM, Rodrigues JJ, Saleem K, Al-Muhtadi J, Kumar N, Korotaev V (2018) Towards energy-aware fog-enabled cloud of things for healthcare. Comput Electr Eng 67:58–69
Mahmud R, Ramamohanarao K, Buyya R (2018) Latency-aware application module management for fog computing environments. ACM Trans Internet Technol (TOIT) 19(1):9
Masdari M, ValiKardan S, Shahi Z, Azar SI (2016) Towards workflow scheduling in cloud computing: a comprehensive analysis. J Netw Comput Appl 66:64–82
Mukherjee M, Shu L, Wang D (2018) Survey of fog computing: fundamental, network applications, and research challenges. IEEE Commun Surv Tutor 20(3):1826–1857
Naha RK, Garg S, Georgakopoulos D, Jayaraman PP, Gao L, Xiang Y, Ranjan R (2018) Fog computing: survey of trends, architectures, requirements, and research directions. IEEE Access 6:47980–48009
Naranjo PGV, Pooranian Z, Shojafar M, Conti M, Buyya R (2018) Focan: a fog-supported smart city network architecture for management of applications in the internet of everything environments. J Parallel Distrib Comput 132:274–283
Peng L, Dhaini AR, Ho PH (2018) Toward integrated cloud-fog networks for efficient IOT provisioning: key challenges and solutions. Future Gener Comput Syst 88:606–613
Pham XQ, Man ND, Tri NDT, Thai NQ, Huh EN (2017) A cost-and performance-effective approach for task scheduling based on collaboration between cloud and fog computing. Int J Distrib Sens Netw 13(11):1550147717742073
Stavrinides GL, Karatza HD (2018) A hybrid approach to scheduling real-time IOT workflows in fog and cloud environments. Multimed Tools Appl 78:1–17
Stavrinides GL, Karatza HD (2019) An energy-efficient, QOS-aware and cost-effective scheduling approach for real-time workflow applications in cloud computing systems utilizing DVFS and approximate computations. Future Gener Compu Syst 96:216–226
Tang Z, Qi L, Cheng Z, Li K, Khan SU, Li K (2016) An energy-efficient task scheduling algorithm in DVFS-enabled cloud environment. J Grid Comput 14(1):55–74
Topcuoglu H, Hariri S, Wu MY (2002) Performance-effective and low-complexity task scheduling for heterogeneous computing. IEEE Trans Parallel Distrib Syst 13(3):260–274
Tortonesi M, Govoni M, Morelli A, Riberto G, Stefanelli C, Suri N (2019) Taming the IOT data deluge: an innovative information-centric service model for fog computing applications. Future Gener Comput Syst 93:888–902
Tsai CW (2018) Seira: an effective algorithm for IOT resource allocation problem. Comput Commun 119:156–166
Verma A, Kaushal S (2017) A hybrid multi-objective particle swarm optimization for scientific workflow scheduling. Parallel Comput 62:1–19
Wan J, Chen B, Wang S, Xia M, Li D, Liu C (2018) Fog computing for energy-aware load balancing and scheduling in smart factory. IEEE Trans Ind Inf 14(10):4548–4556
Xie G, Zeng G, Li R, Li K (2017) Energy-aware processor merging algorithms for deadline constrained parallel applications in heterogeneous cloud computing. IEEE Trans Sustain Comput 2(2):62–75
Yassine A, Singh S, Hossain MS, Muhammad G (2019) IOT big data analytics for smart homes with fog and cloud computing. Future Gener Comput Syst 91:563–573
Zeng D, Gu L, Guo S, Cheng Z, Yu S (2016) Joint optimization of task scheduling and image placement in fog computing supported software-defined embedded system. IEEE Trans Comput 65(12):3702–3712
Zhang L, Li K, Li C, Li K (2017) Bi-objective workflow scheduling of the energy consumption and reliability in heterogeneous computing systems. Inf Sci 379:241–256
Zhou X, Zhang G, Sun J, Zhou J, Wei T, Hu S (2019) Minimizing cost and makespan for workflow scheduling in cloud using fuzzy dominance sort based heft. Future Gener Comput Syst 93:278–289
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Ijaz, S., Munir, E.U., Ahmad, S.G. et al. Energy-makespan optimization of workflow scheduling in fog–cloud computing. Computing 103, 2033–2059 (2021). https://doi.org/10.1007/s00607-021-00930-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00607-021-00930-0