
Abstract
Mitigation of power quality events (PQEs) needs an accurate, faster, and efficient detection and classification technique for designing the compensating devices as a remedial measure to the problem. This study motivates on this issue to formulate a better technique based on fractional Fourier transform (FRFT) and extreme learning machine (ELM). FRFT is considered for relevant feature extraction due to its characteristics like enhanced order control and capability to provide time, frequency, and intermediate time–frequency depictions for any non-stationary power signals. The possibility of multi-domain feature extraction capability due to its easy order control arrives at a robust feature matrix, which makes the classification more accurate. An optimal ELM-based classifier is designed by tuning its system parameters applying modified teaching–learning-based optimization (MTLBO). This optimal ELM is implemented in this study along with FRFT to formulate the proposed approach denoted as FRFT–MTLBO–ELM. To give a good reason for the enhanced performance of the proposed technique, noisy and hybrid synthetic signals of ten PQEs are generated and tested considering fully all real-time condition cases. At last, a comparative result is presented with other applied signal processing-based approaches and it is found that the proposed FRFT–MTLBO–ELM approach is very effective and comparatively better justifying its real-time implementation in the monitoring systems.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The fast growth of industrialization, extensive utilization of sensitive electronic devices, nonlinear loads, power electronic converters, and automatic relaying/protecting devices are the major cause of power quality (PQ) degradation [1]. It is highly desirable to make a power system capable of delivering undistorted voltage, current, and frequency signals to supply quality power. Looking at the smart grid and micro-grid structure, recently the integration of various renewable energy resources (REEs), energy storage, and electric vehicle (EV) charging system associated equipment with the conventional power grid is another source of generating power quality disturbances (PQDs) [2]. Under these conditions, it is indispensable to reduce and improve the PQ due to its adverse effect on protective and control equipment, efficiency, and performance of the overall system. To provide the remedial measures and to monitor the system conditions, it is very much essential to detect and classify correctly [3]. The acquisitions of new process equipment that can tolerate the PQ disturbances depend on the understanding of the power quality issues. The expectations from internal facility power quality and electric utility power quality can be determined by a proper power quality study while preparing the above specifications correctly. The remedial measures incorporated in power system for improving the quality of power are briefed as follows: earthing practices, stand by UPS, online UPS, hybrid UPS, local (or) embedded generation, transistor switches, active filters, static breakers and static VAR compensators, passive filters, ferro-resonant transformers, energy storage systems, network equipment and design, tap changing transformers, current limiting switches, de-tuning capacitors, surge arrestors, line shielding, and network sectionalizing. The above points are the major steps taken in the power distribution sectors to reduce the PQ disturbances. The study of PQ event analysis is also necessary for the planning and designing of the power system. In real-time operation from a sensitive load perspective, it is desirable to get always a quality power supply, because poor quality leads to many negative impacts starting from the reduction of device life span, low efficiency of devices, mal-operation of control and protection system, and overall poor performance, etc. Apart from that, it is necessary for prior detection and classification for the correct decision for designing the system architecture. In addition to that, it helps to design the filter parameters computation and relay operation to avoid adverse impact on the system operation. These reasons represent the importance of designing an approach for PQ event detection and classification. Prior study on the various PQ signals helps in future designing and planning that leads to a better and smooth power supply with more security, reliability, and efficiency.
This issue motivates many researchers at the primary level of investigation and design for further action to reduce the PQDs, by finding out a better technique for proper detection and classification of PQ events (PQEs).
Generally, a three-step approach is followed by the computational level for automatic recognition of PQDs. Initially, the disturbance signals are processed through a preprocessing stage having segmentation and feature extraction. Further, for classification, the extracted features are taken as input to another processing unit. Finally, a post-processing stage gives the final decision about the category of PQ events. Similarly, a process also followed in this proposed approach considering different techniques in each stage of the processing unit.
Signal processing techniques are gaining the major attraction for appropriate feature extraction of signals to characterize the distortions due to harmonics injection that leads to many PQDs. Fourier transform (FT) is extensively used for the extracting spectrum for stationary signals at specific frequencies. However, this fails to find out any temporary information related to various fluctuations [3]. Later on, as an improvement to Fourier transform, discrete Fourier transform (DFT), fast Fourier transform (FFT), and short-time Fourier transform (STFT) are applied even for power quality analysis and are limited later on due to few prominent limitations. The DFT is unsuitable for the non-stationary type of signals [4]. In FFT analysis, amplitude, frequencies, and phases cannot be computed accurately [5]. Due to limited time–frequency resolution, the STFT fails to analyze non-stationary PQ signals [6, 7]. Afterward, in contrast to FT and all its variants, the wavelet transform (WT) presents time and frequency information of PQ signal simultaneously; however, it fails to analyze further due to the limitations like many levels of signal decomposition, poor performance on the noisy environment, and existing of spectral leakage and picket fencing [8, 9]. A hybrid approach with a combination of WT and STFT known as S-transform is successfully applied due to its efficient phase correction and variable window with enhanced time and frequency signal representation [10, 11]. Again the limitations like the dependency of the width of the frequency window on central frequency, fixed Gaussian window, and large processing time make it unsuitable for PQ analysis and in many cases arrive at an inappropriate measurement of harmonics. Recently, a combined approach of empirical mode decomposition (EMD) and Hilbert transform (HT) known as Hilbert–Huang transform (HHT) has emerged and applied successfully not only for PQ analysis but also for other non-stationary and nonlinear time-series data [12]. Within narrowband signals, the EMD technique helps to distinguish different components [13, 14]. In many studies, the massive use of empirical mode decomposition (EMD) is seen, which itself is a recursive method. But, due to poor mathematical background and less effectiveness in a noisy environment, its performance deteriorates in many cases. HHT is efficient for feature extraction due to its good time resolution property. However, mode mixing and empirical decomposition problems make HHT less suitable for the previous estimation of intrinsic mode functions of a signal. Ensemble EMD is an improved version of EMD, but it has poor performance in many experiments. Apart from the extensively used techniques as mentioned above, other miscellaneous feature extraction techniques like Kalman filter (KF) [3], Gabor–Wigner (GT) [3], hybrid soft computing, etc., are suggested in few PQ analysis problems. The noise tolerance capability of the Kalman filter is preferably better. The full dependency of KF on the filter model sometimes leads to error when there is a mismatch between signal and filter model. The detection of transient and harmonics is better carried out by the use of the state-space model in KF, which applies recursive prediction for analysis of signals. However, KF should have better time resolution with additional support. GT furnishes information about phase and frequency, but the cross-term problem and substandard time resolutions are its limitations. The time–frequency representation provided by the model-based parametric methods (PM) is excellent, but the consumption of resources and time is large. As PQ event detection and classification have to play a major role in the smart grid environment, feature extraction is still an open issue of research. Looking into the possibilities to explore the Fourier transform concept, FRFT is one of the major options, which can handle the above limitations of most of the Fourier variations. The capability of the FRFT is yet to be explored extensively in terms of its efficiency [15]. FRFT has an additional order control which gives the representation of a signal in time, frequency, and intermediate time–frequency domain [16]. Multi-domain extraction of features to get a robust feature matrix is possible due to order control in FRFT. The robust feature matrix can be used in any condition for classification [17]. This study is an attempt to investigate and analyze the FRFT for power quality event detection.
In recent times, various classifiers like artificial neural network (ANN), fuzzy logic (FL), expert system (ES), support vector machine (SVM), and Bayesian classifier (BC) are used for PQ events classification [1, 3]. In the case of ANN, it is found with proper training, it results in high classification accuracy and also provides flexibility in mathematical expression and analysis. However, few limitations such as the dependency on convergence speed, robustness, and correctness of the network architecture and noise in the signal restrict its application in a complex monitoring system. On the other hand, FL has an edge over ANN in terms of simplifying the modeling and analyzing complex systems even under uncertainty and ambiguity [1, 3]. Later on, it is found that the structure and associated rules need to be modified with new disturbances. The robustness of the FL is a crucial point, not to make it so attractive for PQ disturbance classification. In comparison with ANN and FL, SVM gets the attraction for PQ event classification due to its high learning process and capability to handle large feature spaces [18]. In addition to these advantages, SVM also provides a stable solution to the problems of quadratic optimization type [19]. The major limitation of the classifier based on SVM is to arrive at poor classification accuracy during the set of training data which is not adequate or less. Expert system (ES)-based classifier comes as a solution to the above limitation of SVM to provide fairly good results with and without limited data. The associated limitations of the ES-based classifier are slow in execution, expensive to develop, and formulation. The BC-based classifier results fairly well in terms of accuracy level when it works with the Gaussian probability density (GPD) function. High computational cost, necessary to know in advance the probability density function (PDF), and less accuracy value under smaller dataset are the major hindrances to its practical use. Recently, extreme learning machines (ELMs) have been used successfully in many engineering problems due to its simple and feasible fast learning algorithm with strong generalization ability [20]. The capability and mathematical formulations with optimal system parameter values in the case of ELM are yet to be explored extensively. Looking at its perspective and possibility to be a better classifier, ELM is considered in this study for PQ event classification [21].
Among a large number of heuristic stochastic-based optimization techniques, the teaching–learning-based optimization (TLBO) algorithm has emerged recently and applied in many engineering applications [22]. The process of searching in the TLBO algorithm is formulated by imitating the classroom teaching–learning process. The major strengths for which it is considered in this study are simple mathematical formulation, without algorithm-specific parameters, faster convergence, and simple implementation. In the proposed algorithm, an improved TLBO is used to find out the input weights and hidden biases such that it reduces the norm of output weights limiting both the input weights and hidden biases within a realistic range to improve the performance of ELM in terms of convergence and accuracy. In general, the performances of evolutionary-based optimization techniques mostly depend on system parameters. To improve the searching capability, the idea of adaptively varying the system parameters is very often used against constant value. Secondly, the computational strategy modification ends with better result in terms of high convergence rate and better accuracy in terms of searching optimal values of parameters. Both these ideas are implemented in the conventional TLBO technique, and it is named MTLBO in this study. The proposed new classifier combining ELM with a modified TLBO algorithm is denoted as MTLBO–ELM.
The major steps taken for PQ disturbance detection and classification in this study can be summarized as follows:
-
The study presents the feature extraction technique based on FRFT for the PQDs. A wide range of effective features is extracted for accurate classification through FRFT. Secondly, the limitations of all Fourier transform variation techniques as mentioned above to handle non-stationary power signals are successfully taken into care for PQ signals.
-
A hybrid MTLBO–ELM classifier approach is presented for the classification of PQDs. This idea of hybrid approach results with higher accuracy in comparison with conventional ELM as a classifier.
-
The MTLBO is suggested to enhance the searching capability in both the exploration and exploitation stage and to optimally find out the input and bias weights for better convergence performance of ELM. This improves the searching capability of the traditional TLBO technique by varying adaptively to its system parameters which affect the overall performance. In addition to that, the accuracy of ELM is improved due to the setting of its weight parameters optimally. To make the proposed approach feasible to apply in real-time conditions, noisy signals as well as simultaneously occurred multiple disturbances are considered in test cases.
-
All possible real-time power quality events are extracted and used in the simulation process. The detection of PQ events is a crucial issue particularly under noisy conditions in real-time monitoring systems. In the testing phase, this problem is considered for the proposed approach.
The remaining part of the study is organized as follows: In Sect. 2, the mathematical description of FRFT is presented. Section 3 describes the feature extraction method based on FRFT applied to PQ signals. In Sect. 4, the MTLBO–ELM approach for PQ events classification is proposed. Section 5 represents the simulation result. Section 6 concludes the paper with its major findings of the study and future extension.
2 Fractional Fourier transform representation
For a time-domain signal x (t), the FRFT is defined as [23]:
where
where \(\alpha = p\pi /2\) denotes the rotation angle of the transformed signal received from FRFT. The p denotes the transformed order of the FRFT. \(F_{p}\) represents the FRFT operator. The FRFT is periodic with period 4. If and only if \(p = \left( {4n + 1} \right) \left( {\alpha = 2n\pi + \pi /2} \right)\), then the FRFT is equal to the FT. Let \(u = u/\sqrt {2\pi }\) and \(t = t/\sqrt {2\pi }\). Then, Eq. (1) equivalently can be represented as [23]:
Equation (3) indicates the corresponding calculation of the FRFT and can be found out in the following three steps [24]:
-
(a)
product by a chirp, \(g\left( t \right) = \sqrt {\left( {1 - j\cot \alpha } \right)} e^{{j\left( {\frac{{t^{2} }}{2}\cot \alpha } \right)}} x\left( t \right)\);
-
(b)
an FT (with its argument scaled by csc α), \(\tilde{X}_{p} \left( u \right) = G\left( {\csc \alpha u} \right)\) with \(G\left( u \right) = \frac{1}{{\sqrt {2\pi } }}\mathop \int \limits_{ - \infty }^{ + \infty } g\left( t \right)e^{ - jut} {\text{d}}t\);
-
(c)
another product by a chirp, \(X_{p} \left( u \right) = e^{{j\left( {\frac{{u^{2} }}{2}\cot \alpha } \right)}} \tilde{X}_{p} \left( u \right)\).
The FRFT of x(t) exists in the same conditions in which its FT exists. It means, if \(X\left( \omega \right)\) exists, \(X_{p} \left( u \right)\) exists too.
3 Feature extraction based on FRFT
The value of the order control parameter, \(\alpha\), within the range [0, 1] is considered as the sufficient value for pattern recognition. In this study, \(\alpha\) ϵ [0, 1] is taken as the operational range and 0.1 as the step size [24]. The proposed model of feature extraction using FRFT can be recapitulated as follows:
Step 1 The input matrix (STMN) of dimension M × N is prepared, considering M as the total number of PQEs and N as the number of each signal samples.
Step 2 The FRFT process is to be carried out on every row of the input matrix for \(\alpha\) ϵ [0, 1].
Step 3 Signal matrices, ST0, ST0.1, ST0.2 … ST1, of dimension M × N each are to be formed for each value of \(\alpha\). In general, the signal matrix is denoted as STα.
Step 4 Feature matrices, FeM0, FeM0.1, FeM0.2 …FeM1, of dimension M × 8 each obtained for each value of α, considering suitable statistical and spectral measurement parameters. In general, the feature matrix is denoted as FeMα.
A long-time monitoring may not guarantee the availability of real-time data of PQ events. For analysis of PQ events, the synthetic data are widely used. A close representation of real-time data is possible by simulating the PQ events obtained from the numerical models designed as per IEEE Std 1159 [25] in MATLAB. Multiple PQ events are considered in this study for simulation by the mixing of the numerical models of the single-stage PQ events to support the possibility in real-time conditions.
Exploring into the real-time conditions, ten types of PQEs are acknowledged for this analysis. The PQ events are symbolized as various categories ECL1, ECL2, ECL3, ECL4, ECL5, ECL6, ECL7, ECL8, ECL9, and ECL10 for sag, swell, interruption, transient, spike, notch, flicker, harmonics, flicker with sag, and flicker with harmonics, respectively.
More complex signal admixtures prevailed over separate notch, spike, flicker with sag, and harmonics. In real-time conditions, the nature of the signals changes according to the PQ events occurrence individually or simultaneously. These complex conditions are also considered in the present study by simulating with adding multiple PQ events. The various changes in system conditions lead to various PQ conditions. The mathematical expression for each PQ events used in the simulation to extract the similar real-time PQ disturbance signals and cause of occurrence is represented in Table 1.
The power line disruptions are compensated mainly by the following compensating devices. The D-STACOM has been developed using the DSP controller to achieve excellent overall performance. For mitigation of voltage sag which is occurred by the three-phase balanced fault, the D_STATCOM can be used. The PLL is used for detection and mitigation of sag in the control strategy and gives good results if phase jumps are not associated with sag. Dynamic Voltage Restorer (DVR): It is a series compensating device. It can protect a sensitive load from the distortions. The sag and swell voltage regulation compensation, compensation of reactive power, and compensation of unbalanced voltage in the three-phase system are the main functions of the DVR. Active filters: These are the most popular solution for power quality-related problems. The active filters find their use in medium and low voltage systems connected either in series or in the shunt. Unified power flow controller (UPFC): The most versatile controller used in FACTS is the UPFC. The control of the flow of reactive and real power is the major function of the UPFC which is done by the injection of a voltage in series with the transmission line.
Figures 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10 represent the FRFT transform of the above PQEs, which is the graph between magnitude and number of sample points, for the values of 0, 0.5, and 1 of α. However, the FRFT of each PQE signal is considered for \(\alpha\) ϵ [0, 1] in this proposed method. The following parameters are taken as suitable features to be applied as the input of the classifier. The shortlisted features are as follows: (1) variance (Vari), (2) average power (Avpi), (3) standard deviation (Stdi), (4) root sum of squares (Rssi), (5) root mean square (Rmsi), (6) peak to rms ratio (Prri), (7) mean frequency (Mfi), and (8) total harmonic distortion (Thdi). The characterization of the signal variation can be done by the use of Rssi and Prri as per IEEE Std-181. The spectral information can be obtained by the use of features like Avpi, Mfi, and Thdi. Many of the PQ events are characterized by the features which have a direct and close resemblance to the features selected for our study. A brief description is given as follows: (1) impulsive transient: It is normally characterized by its peak value, rise, and decay or duration time. (2) Oscillatory transient: It is characterized by its magnitude, duration, and spectral component. (3) Interruption: It is characterized by duration. (4) Sags/swells: These are characterized by RMS, magnitude, and duration. (5) Harmonics: It is characterized by harmonic spectrum and THD. (6) Notching: It is characterized by a harmonic spectrum. (7) Flicker: It is characterized by variation magnitude and modulation frequency. FRFT is a time–frequency and intermediate stage transformer. The above features can be extracted from the time and frequency representations of FRFT. The mathematical expressions of the above features are given in Table 2.

FRFT of sag and sag

FRFT of swell and swell

FRFT of interruption and interruption

FRFT of transient and transient

FRFT of spike and spike

FRFT of notch and notch

FRFT of flicker and flicker

FRFT of harmonics and harmonics

FRFT of flicker with sag and flicker with sag

FRFT of flicker with harmonics and flicker with harmonics
4 Proposed classification approach
In this section, the proposed classification approach based on ELM and modified TLBO is presented. The classification procedure followed in this study is as follows:
-
Step 1 The ELM classifier is to be optimized by tuning its parameters with the help of the TLBO technique.
-
Step 2 The data from the feature matrices (FeMα) are to be taken as input to the classifier. The data are to be divided into training and testing data. For this study, it is considered 60% and 40% of total data for training and testing, respectively.
-
Step 3 The overall accuracy of classification at different orders is to be found as A0, A0.1, A0.2 …. A1, considering different feature matrices as input to the classifier.
-
Step 4 The maximum value (Amax) among A0, A0.1, A0.2 …. A1 and the corresponding value of \(\alpha\) are to be found out.
4.1 The extreme learning-based classification technique
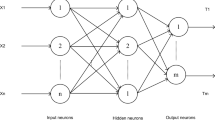
The ELM is a feed-forward neural network having a single hidden layer (SLFNs) [20]. It is a three-layer architecture learning algorithm and is exhibited in Fig. 11. The input neuron, hidden neuron, and output neuron numbers are denoted as n, l, and m, respectively, in this structure.

ELM architecture
N training samples (\(x_{i }\), \(t_{i}\)) are considered here, where \(x_{i}\) = \(\left[ {x_{i1 } , x_{i2} ,x_{i3} , \ldots , x_{in } } \right]^{T} \varepsilon \,R^{n}\), \(t_{i}\) = \(\left[ {t_{i1} , t_{i2 } \ldots , t_{im} } \right]^{T} \varepsilon\, R^{m}\), \(\left( {i = 1,2, \ldots ,N} \right)\). The standard ELM consisting of l hidden nodes can have an output function as expressed in (4):
The functional representation of the hidden layer output h is denoted as in Eq. (5):
Similarly, the result of output neuron is as follows:
where \(G\left( x \right)\) represents the activation function of the hidden layer. The ‘\(a\)’ denotes the weight matrix concerning the input neurons and hidden neurons connections. The ‘\(\beta\)’ denotes the weight matrix concerning the hidden neuron and the output neurons connections. The ‘\(b\)’ represents the weight of the hidden neuron bias input. Considering Eqs. (5) and (6), Eq. (7) can be rewritten as follows [21]:
where H denotes the hidden layer matrix of the output. T denotes the training vector target matrix. \(\beta\) represents the weight matrix of hidden and output neurons connection. The H is denoted in the form of a matrix as:
The computation of output weights is done by using the least square method concept as in (8):
where \(H^{ + }\) denotes the H matrix Moore–Penrose inverse [21]. The \(a\;{\text{and}}\;b\) may be generated at random. The activation function (G) and the number of neurons (l) should be predetermined before training for applying ELM to any type of application. Due to faster computation of β value using only one iteration, the ELM becomes comparably faster than the other contemporary neural networks.
ELM pseudo-code can be presented as follows:
-
1.
Input data: (\(x_{i }\), \(t_{i}\)), l, \(G\left( x \right)\).
-
2.
Randomly generate the input weights (a) and biased weights (b) of the hidden neurons.
-
3.
The hidden layer output matrix (H) is computed using Eq. (7).
-
4.
The output weights (β) are computed by using Eq. (8).
-
5.
From the above computation, the output T is calculated.
4.2 TLBO algorithm
The TLBO can be considered as a population-based heuristic and stochastic searching methodology. The basic searching algorithm concept is formulated from the classroom teaching–learning dynamics [22, 26]. Learners are considered as one–one searching points in the solution space. The learner with the best fitness is designated as the class teacher. The iterating evolution process comprised of two phases as the teaching phase and the learning phase. The basic concept of learning is based on how every individual learns better in the subsequent iterations. In the teaching phase, the learner learns to be better among others from the teacher, and in the learning phase, the knowledge level is improved by the mutual interaction with other learners. The TLBO algorithm can be presented in three major stages. The major stages are as follows:
4.2.1 Initialization of learner
The ith learner \(X_{i} = \left( {x_{i1} ,x_{i2} , \ldots ,x_{iD} } \right)\) with D-dimensional decision variables and NP number of learners in the population are randomly generated within its lower and upper bounds \(X_{j}^{\hbox{min} }\) and \(X_{j}^{\hbox{max} }\), respectively, as follows:
where \(i = 1,2, \ldots .,NP\) and \(j = 1,2, \ldots ,D\). The rand denotes a random number within the range [0,1]. The fitness value \(f\left( {X_{i} } \right)\) of each learner is computed from a fitness function (i.e., objective function).
4.2.2 Teaching phase
The difference between the teacher and the entire class mean value is computed based on the fitness value evaluation. The learners enhance their knowledge levels proportionately based on this difference. This updating mechanism for the ith learner \(X_{i}\) can be represented as follows:
where \({\text{new}}X_{i}\) denotes the new state of the learner \(X_{i}\). The Teacher denotes the learner having the best fitness. \({\text{Mean}} = \frac{1}{NP}\mathop \sum \nolimits_{i = 1}^{NP} X_{i}\) denotes the mean state of the class. \({\text{TF}} = {\text{round}}\left[ {1 + {\text{rand}}\left( {0,1} \right)} \right]\) denotes a teaching factor that decides and changes the magnitude of the mean. rand denotes a random vector. Its every element denotes a random number in the range [0,1]. Based on the fitness value, better learners are selected among the existing learners and newly generated learners. These selected learners are only allowed to enter the learning phase.
4.2.3 Learning phase
The updating learning mechanism for the ith learner, \(X_{i}\) during the learning phase can be represented as follows:
where \({\text{new}}X_{i}\) denotes the ith learners \(X_{i}\) new positions. \(X_{k}\) denotes a randomly selected learner among all the learners present in the class. The \(f\left( {X_{i} } \right) \;{\text{and}}\;f\left( {X_{k} } \right)\) denote the fitness values for the learner \(X_{i}\) and \(X_{k}\), respectively. The rand denotes a random vector within the range [0, 1]. Like the teaching phase, the improved learners are selected among the existing learners and newly generated learners in the learning phase. These selected learners are used for the teaching phase in the next iteration.
4.3 Modified TLBO (MTLBO)
To enhance the searching capability of the two-stage learning process, both the teaching and learning phases need to be modified for acquiring better knowledge and by this process to find a better learner. For any optimization technique, during the exploration and the exploitation stage the searching capability is an important factor to arrive at an optimal point. This has been taken care of by using an adaptively varying teaching factor TF during the teaching phase. Initially, during the exploration stage, a higher value of TF is considered, and later during the exploitation stage, a low value of TF is taken. This idea of using an adaptively varying TF value is proposed in this study. The TF value computed in each iteration is as follows:
where \({\text{TF}}_{{{\text{max}}}}\) denotes maximum weight. The \({\text{TF}}_{{{\text{min}}}}\) denotes the minimum weight. The \({\text{max}} {\text{iteration}}\) denotes the maximum iteration number. The \({\text{iteration}}\) denotes the current iterative number. In this study, the values of \({\text{TF}}_{ \hbox{max} }\) and \({\text{TF}}_{ \hbox{min} }\) are taken as \(2\) and \(0.5\), respectively.
In the learning phase, the TLBO algorithm neglects the learning from a teacher and adapts a decoupled learning strategy in both the phases of learning. Due to that, there is a chance the solution may be diverted from the teacher. Looking to this issue, the learning phase is modified considering the other two factors based on teacher phase and neighborhood learning as follows:
where \(C_{1}\) and \(C_{2}\) control the teaching searching and neighborhood searching range. The respective initial values for both \(C_{1}\) and \(C_{2}\) are considered as 0.5 and 0.1.
4.4 Proposed MTLBO–ELM approach
ELM, a kind of neural network with random weight, is widely used and has major contributions to many fields. However, a full investigation of the relation between ELMs performance and its parameters is needed. The investigation must focus on the impact of types of activation functions, the range of randomization of the threshold of hidden nodes, and the number of hidden nodes.
-
The random selection of a higher number of hidden layer nodes might not always guarantee the enhanced performance of ELM. There is a chance of under-fitting or over-fitting for the number of hidden nodes chosen arbitrarily. Here, in our work, we found the number of hidden layer nodes to be 150 which gives better performance. Beyond 150, we found there is no substantial improvement in performance in terms of increase in computation and convergence. Looking at the saturation in the improvement of accuracy beyond 150, we fix the minimum number of hidden layer nodes in our study as 150.
-
The random selection within the range (i.e., [− 1, 1]) of weight parameter among the input layer and hidden layer and the range of the threshold (bias) (i.e., [0, 1]) of the hidden nodes may not always guide to improved performance of the ELM model. To handle this issue, an optimal ELM-based classifier is designed by tuning its system parameters applying modified teaching–learning-based optimization (MTLBO). The input weights and hidden bias are optimally found out in this study to enhance the accuracy.
-
The sigmoidal activation function in most of the cases gives better performance. Here, we use the sigmoidal function as activation function due to its simplistic approach, extensive application to many engineering problems successfully, and high possibility to arrive at a desirable result.
TLBO and ELM are two known methods. Here in our study, we have a hybridized model combining the two methods. As there is a modification in the TLBO method, we use the word modified for this hybridized method. The modification in the TLBO method is by using an adaptively varying teaching factor (TF) during the teaching phase. Though the ELM method is faster and having high accuracy, sometimes it suffers from the problems of over-fitting and under-fitting if the weights, bias, and the number of hidden nodes are properly set. To overcome these problems, a suitable optimization technique should be used for proper selection of ELM parameters such as input weights, input bias, and the number of hidden nodes. In this study, we have used the MTLBO method for the above purpose.
The data samples of all PQ events are split into a training sample set and a testing sample set. Initially, the learner matrix characterizing the solution is randomly generated and is comprised of a set of input weights and hidden biases as expressed in Eq. (14):
where n and l denote the number of input neurons and the number of hidden neurons, respectively. So, the dimension of each learner (solution vector) is \(\left( {n + 1} \right) \times l\) and the corresponding values are randomly generated within the range [− 1, + 1]. The fitness function used for evaluating the optimal solutions in terms of misclassification of the algorithm is as follows:
where N and \({\text{MCR}}_{i}\) denote the number of training samples and misclassification of the algorithm, respectively.
5 Results and discussion
All PQE signals are simulated with 9.6 kHz sampling frequency and power–frequency as 50 Hz. The signal matrix has a dimension of 1000 × 1920 with 100 signals per class and samples per signal as 1920. The dimension of every FRFT processed signal is 1 × 1920, and the final feature matrix has a size 1000 × 8. With a step size of 0.1, the process is repeated for orders α = [0, 1]. The ratio of sampling frequency to total samples per signal is known as frequency resolution and has a value of 5 Hz (= 9600/1920). For simplicity of representation, only the FRFT for α = 0.5 is shown instead of all fractional orders. At α = 0, the time-domain representation and at α = 1 the frequency domain representation can be seen. The above conditions are represented in Figs. 1, 2, 3, 4, 5, 6, 7, 8, 9, and 10 for respective PQEs.
For performance assessment of the proposed FRFT–MTLBO–ELM technique for PQ event detection, four different classification procedures are suggested. To test the proposed approach, PQ event data with noisy conditions and complex hybrid forms are generated synthetically. Noisy data are collected in confirmation of real-time conditions by adding the PQ event data with 50, 30, 20 dB white Gaussian noise.
The occurrence of simultaneous PQ events is happening very often in real-time conditions. Considering the real-time conditions, mixed PQ events data from MATLAB simulation are collected. To compute the unique features representing the PQE signals, FRFT is applied to the signals obtained from the MATLAB environment. The inputs to the MTLBO–ELM classifier are the features extracted by FRFT.
To compute the accuracy of detection and classification, 1000 PQE synthetic signals are tested using the proposed approach. From the MATLAB programming environment, the synthetic signals are generated by considering the real-time conditions. 60% of data are considered for training and 40% for testing referring to the standards followed. A 2.20 GHz Intel Core i3-8130u CPU has been applied, and the corresponding computational time for training/testing is shown.
5.1 Process-1 of classification
The hidden layer nodes considered in this approach are 150, and maximum accuracy is achieved for this number. Considering the success rate in many applications, the activation function considered here is the sigmoidal function. In Tables 3 and 4, the classification process-1 results and confusion matrix at αc = 0.6 for power signals are shown, respectively.
5.2 Process-2 of classification
Considering the real-time conditions, a 20 dB WGN is added to the synthetic PQE signals. 60% of data are considered for training and 40% of data for testing according to the standard followed. The result implies a better performance of the proposed FRFT–MTLBO–ELM-based classification and detection technique under this condition. In Tables 5 and 6, the classification process-2 results and confusion matrix at αc = 0.8 for 20 dB noisy signals are shown, respectively. The results imply a better performance of the proposed approach FRFT–MTLBO–ELM.
5.3 Process-3 of classification
Considering the real-time conditions, a 30 dB WGN is added to the synthetic PQE signals. In Tables 7 and 8, the classification process-3 results and corresponding confusion matrix at αc = 0.1 for 30 dB noisy signals are shown, respectively. The results imply a better accuracy of the proposed approach FRFT–MTLBO–ELM. The tuning of the parameters of ELM by MTLBO enhances the overall accuracy of up to 99.75%.
5.4 Process-4 of classification
Considering the real-time conditions, a 50 dB WGN is added to the synthetic PQE signals. In Tables 9 and 10, the classification process-4 results and the corresponding confusion matrix at αc = 0.1 for 50 dB noisy signals are shown, respectively. The results imply a better accuracy of the proposed FRFT–MTLBO–ELM-based classification and detection technique under this condition.
5.5 Performance evaluation and discussion
This investigation commits to arrive at a better method to detect PQ events. Analyzing the results of the proposed method derived from FRFT and MTLBO–ELM seems to be adequate for real-time implementation due to its substantial improvement in performance under noisy environments and for various PQ disturbances. Process-1 is simulated using general PQEs considering all PQ conditions. The results indicate the ability of detection and classification of PQ-based signals for the proposed approach in comparison with other methods. The processes 2, 3, and 4 are simulated for the proposed method with 20, 30, and 50 dB noise distortions, respectively. The results reveal the capability of classifying the PQDs accurately and make a possibility to be used for real-time monitoring systems for PQ signals even under the presence of nonlinear load and other components. Further, the results present the robustness of the proposed approach FRFT–TLBO–ELM for PQEs under normal and noisy environments. The selection of features has a measure for the proper classification of the PQ events. The selection of features depends upon the potential of the extraction method. The same features set may act differently for different feature extraction methods. The deviation of features has a direct impact on the accuracy of the system. However, close observation on the results of different outcomes on PQ classification reveals that there is a maximum 1% variation inaccuracy due to deviation in the feature set. Here in this work, the deviation of the feature set has an impact of a maximum 0.5% deviation on the accuracy of the system. FFT-based convolution is a step in FRFT, and also two chirp multiplications are being carried out. The chirp multiplication requires multiplication of a constant over the signal length, and each has the complexity of O(N). The complexity of FFT routine is O(N log N); therefore, FRFT computational complexity is obtained as O(N) + O(N log N) + O(N) = O(N log N). The most dominating term is the important factor to decide the complexity of any process. Considering the above points of discussion, it may be concluded that the computational complexity of FRFT is fairly less than other contemporary methods. FRFT-based classification methodology may not outperform all the existing methods but can be considered as an alternative with more advantages. A comparison of results in terms of the overall classification accuracy is shown in Table 11.
The classification accuracy of ELM is presented in comparison with other techniques like ANN, SVM, NBA (Naïve Bayesian Approach) applied for the same application for power quality detection and classification. The various feature extraction techniques are considered in the comparison Table 12 as Fourier transform (FT), wavelet transform (WT), S-transform (ST), fast discrete S-transform (FDST), Hilbert–Huang transform (HHT), and variational mode decomposition (VMD) [3].
6 Conclusion
This paper presents an FRFT and MTLBO–ELM-based detection and classification model for PQDs. The major findings from the results can be summarized as: (1) FRFT results comparatively give almost equal and some cases better performance in comparison with other signal processing techniques. (2) MTLBO–ELM classifier also shows an enhanced performance and arrives at better results in comparison with other conventional approaches. (3) This combined FRFT–MTLBO–ELM approach can be considered for real-time application as it successfully applied not only for normal PQ events but also under combined and noisy PQ events. The future extension of the proposed approach can be suggested in two directions. Firstly, to confirm the real-time application feasibility, it is required to test in real-time PQ data. Secondly, in the proposed approach FRFT–MTLBO–ELM is considered and so improved versions of these techniques may give better results in terms of accuracy and robustness.
References
Mahela OP, Shaik AG, Gupta N (2015) A critical review of detection and classification of power quality events. Renew Sustain Energy Rev 41:495–505
Montoya F, Baños R, Alcayde A, Montoya M, Manzano-Agugliaro F (2018) Power quality: scientific collaboration networks and research trends. Energies 11(8):2067
Mishra M (2018) Power quality disturbance detection and classification using signal processing and soft computing techniques: a comprehensive review. Int Trans Electr Energy Syst 29:e12008
Szmajda M, Górecki K, Mroczka J (2007) DFT algorithm analysis in low-cost power quality measurement systems based on a DSP processor. In: 2007 9th international conference on electrical power quality and utilisation. IEEE, pp 1–6
Heydt GT, Fjeld PS, Liu CC, Pierce D, Tu L, Hensley G (1999) Applications of the windowed FFT to electric power quality assessment. IEEE Trans Power Deliv 14(4):1411–1416
Jurado F, Saenz JR (2002) Comparison between discrete STFT and wavelets for the analysis of power quality events. Electr Power Syst Res 62(3):183–190
Wright PS (1999) Short-time Fourier transforms and Wigner–Ville distributions applied to the calibration of power frequency harmonic analyzers. IEEE Trans Instrum Meas 48(2):475–478
Huang SJ, Hsieh CT, Huang CL (1999) Application of Morlet wavelets to supervise power system disturbances. IEEE Trans Power Deliv 14(1):235–243
Santoso S, Grady WM, Powers EJ, Lamoree J, Bhatt SC (2000) Characterization of distribution power quality events with Fourier and wavelet transforms. IEEE Trans Power Deliv 15(1):247–254
Dash PK, Panigrahi BK, Sahoo DK, Panda G (2003) Power quality disturbance data compression, detection, and classification using integrated spline wavelet and S-transform. IEEE Trans Power Deliv 18(2):595–600
Lee IW, Dash PK (2003) S-transform-based intelligent system for classification of power quality disturbance signals. IEEE Trans Industr Electron 50(4):800–805
Sahani M, Dash PK (2018) Automatic power quality events recognition based on Hilbert Huang transform and weighted bidirectional extreme learning machine. IEEE Trans Industr Inf 14(9):3849–3858
Sahani M, Dash PK (2019) FPGA-based online power quality disturbances monitoring using reduced-sample HHT and class-specific weighted RVFLN. IEEE Trans Industr Inf 15(8):4614–4623
Achlerkar PD, Samantaray SR, Manikandan MS (2016) Variational mode decomposition and decision tree based detection and classification of power quality disturbances in grid-connected distributed generation system. IEEE Trans Smart Grid 9(4):3122–3132
Ozaktas HM, Kutay MA (2001) The fractional Fourier transform. In: 2001 European control conference (ECC). IEEE, pp 1477–1483
Bultheel A, Sulbaran HEM (2004) Computation of the fractional Fourier transform. Appl Comput Harmonic Anal 16(3):182–202
Ozaktas HM, Kutay MA (2001) The fractional Fourier transform. In: 2001 European control conference (ECC). IEEE, pp 1477–1483
Kapoor R, Gupta R, Jha S, Kumar R (2018) Detection of power quality event using histogram of oriented gradients and support vector machine. Measurement 120:52–75
Khokhar S, Zin AABM, Mokhtar ASB, Pesaran M (2015) A comprehensive overview on signal processing and artificial intelligence techniques applications in classification of power quality disturbances. Renew Sustain Energy Rev 51:1650–1663
Huang GB, Zhou H, Ding X, Zhang R (2011) Extreme learning machine for regression and multiclass classification. IEEE Trans Syst Man Cybern B Cybern 42(2):513–529
Huang GB, Zhu QY, Siew CK (2006) Extreme learning machine: theory and applications. Neurocomputing 70(1–3):489–501
Rao RV (2016) Teaching-learning-based optimization algorithm. In: Teaching learning based optimization algorithm. Springer, Cham, pp 9–39
Almeida LB (1994) The fractional Fourier transform and time-frequency representations. IEEE Trans Signal Process 42(11):3084–3091
Singh U, Singh SN (2017) Application of fractional Fourier transform for classification of power quality disturbances. IET Sci Meas Technol 11(1):67–76
IEEE Recommended Practice for Monitoring Electric Power Quality. In: IEEE Std 1159-2019 (revision of IEEE Std 1159-2009), pp 1–98, 13 Aug 2019. https://doi.org/10.1109/ieeestd.2019.8796486
Sahu BK, Pati S, Mohanty PK, Panda S (2015) Teaching–learning based optimization algorithm based fuzzy-PID controller for automatic generation control of multi-area power system. Appl Soft Comput 27:240–249
Mishra S, Bhende CN, Panigrahi BK (2007) Detection and classification of power quality disturbances using S-transform and probabilistic neural network. IEEE Trans Power Deliv 23(1):280–287
Wang H, Wang P, Liu T (2017) Power quality disturbance classification using the S-transform and probabilistic neural network. Energies 10(1):107
Huang N, Lu G, Cai G, Xu D, Xu J, Li F, Zhang L (2016) Feature selection of power quality disturbance signals with an entropy-importance-based random forest. Entropy 18(2):44
Erişti H, Yıldırım Ö, Erişti B, Demir Y (2014) Automatic recognition system of underlying causes of power quality disturbances based on S-transform and extreme learning machine. Int J Electr Power Energy Syst 61:553–562
Ahila R, Sadasivam V, Manimala K (2015) An integrated PSO for parameter determination and feature selection of ELM and its application in classification of power system disturbances. Appl Soft Comput 32:23–37
Manimala K, Selvi K, Ahila R (2012) Optimization techniques for improving power quality data mining using wavelet packet based support vector machine. Neurocomputing 77(1):36–47
Decanini JG, Tonelli-Neto MS, Malange FC, Minussi CR (2011) Detection and classification of voltage disturbances using a fuzzy-ARTMAP-wavelet network. Electr Power Syst Res 81(12):2057–2065
Lee CY, Shen YX (2011) Optimal feature selection for power-quality disturbances classification. IEEE Trans Power Deliv 26(4):2342–2351
Muscas C (2010) Power quality monitoring in modern electric distribution systems. IEEE Instrum Meas Mag 13(5):19–27
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
We authors do not have any conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Samanta, I.S., Rout, P.K. & Mishra, S. An optimal extreme learning-based classification method for power quality events using fractional Fourier transform. Neural Comput & Applic 33, 4979–4995 (2021). https://doi.org/10.1007/s00521-020-05282-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-020-05282-y