
Abstract
Parkinson disease is a neurodegenerative disorder of the central nerve system which affects body movements. The proposed technique selects best five machine learning models competitively, out of 25 state-of-the-art regression models to generate a robust ensemble. Data from 42 patients having early stage of Parkinson disease were collected which contains a total of 5875 voice recordings. Numerous state-of-the-art machine learning models have been explored to predict the motor Unified Parkinson’s Disease Rating Score (UPDRS) for the collected voice measures. Evaluation parameters such as correlation, R-Square, RMSE, and accuracy have been calculated for comparative analysis. Results from the ensemble model consisting of best five models have been recalculated to analyze the prediction. K-fold validation has been incorporated to measure the robustness of ensembled model. The proposed ensemble yields UPDRS with higher accuracy of 99.6% making it well suitable to assist the diagnose for Parkinson disease.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Parkinson disease (PD) was first studied by Doctor James Parkinson as shaking palsy in 1817 [23]. J. William defined the Parkinson disease as an ailment that influences the piece of human mind to control body movements. It can grow so smoothly that the patient may not notice it at first, during its early stage. After some time, a little instability in the grasp can affect the process of walk, talk, rest, and think. Lau et al. stated that among the elders, Parkinson disease is common, and it is the second common neurological disease after Alzheimer [8, 9]. Rijk et al. [9] studied on the prevalence of Parkinson disease in Europe based on population and found 6000 in the USA approximately are thought to be affected with Parkinson’s disease during annually diagnosis. A clinical examination was utilized to identify potential PD cases. The general ordinariness (per 100 masses) in individuals 65 years of age and more settled was 1.8, with a headway from 0.6 for those age 65–69 years to 2.6 for those 85–89 years. There were no sex separates in commonness of PD.
It is a neurodegenerative disorder of central nerve system which affects the body movements. It is a progressive disorder that affects movements of body. Parkinson’s person’s muscles are weaker than the individual which is healthy and may assume an unusual postures. It belongs to the group of conditions called movement disorder. It describes neurological behavior which includes abnormal body movements such conditions as Tourette syndrome and cerebral palsy. Parkinson’s disease was first introduced by Doctor James Parkinson as shaking palsy in 1817 [23]. This disease is most common among the elders and it is the second disease after Alzheimer [8]. Approximately 60,000 adults are diagnosed out of one million adults annually. The real figure is much higher than that when counting the people those who go undetected. Parkinson disease causes various side effects and signs which can be classified into two categories motor symptoms (MS) and non-motor symptoms (NMS) as shown in Fig. 1.

Parkinson disease symptoms classification
Motor side effects influence movements of muscles and non-motor side effects include problems like brain problems, sleep problems, and sensory problems. After the age of 50, symptoms starts to appear. When signs and symptoms develop ranges 21–40 years in individual, it is called as young-onset Parkinson’s disease [9]. Vocal impairment is also common [17, 19]. Despite the tremor and slow movements, fixed impressive face is also noticed in patients. This is due to poor control upon the facial muscles movements and coordination. Parkinson disease affects the voice too. Degrading performance in voice with PD progression is supported by evidence [18, 21, 43]. Dysphonia (hoarseness, breathiness, and creakiness in the voice) and hypophonia (reduced voice volume) are more generalized speech disorders [5, 17]. Speech disturbance is most common noticed symptom in the patient. It has been found from the research that 90% of the patients are affected with motor problems. The different symptoms of the disease are shown in Fig. 2. Parkinson disease include following common symptoms:
-
Slow body movement
-
Trouble in speaking
-
Stiff muscles
-
Problems in balancing and walking
-
Tremor of arms, hands or legs

Affects of Parkinson’s disease on muscles [2]
1.1 Cause of the disease
The root cause of the disease is falling levels of dopamine in the patients [17]. Dopamine is cerebrum which act as a connection that sends message to the part of mind that controls developments and coordination. In the brain, there are nerve cells (neurons) which are responsible for producing the dopamine. The disease basically affects the neurons as a result of which the level of dopamine decreases because of which the unusual action of the mind prompting the indication of Parkinson, leaves a man unfit to control movements. As dopamine level decreases, the PD progresses its actions. Dopamine level of healthy person is more than those who are prone to Parkinson’s disease. Figure 3 shows the dopamine level of healthy person versus PD patient.

Dopamine level in patient [1]
To track the progression of the disease, the UPDRS score is used [44]. Trained medical staff is required to examine the patient and presence of patient in clinic which is time consuming [6]. The target for these medical measurement is to find UPRDS. The main motive of the work is to train the different machine learning regression models to achieve the best performance for determining the UPDRS score for analyzing the progression of PD. The UPDRS tells the severity and presence of PD symptoms. For untreated patients, its span ranges 0–176 with 0 reflecting healthy status and 176 reflecting the complete disabilities, and consists of three sections: (a) mentation, (b) behavior and temper, and (c) motor. Achieving higher accuracy in prediction of UPDRS for PD is very crucial task. PD has several motor symptoms. It is also important to identify PD as soon as possible so that patient can start their treatment early. Detection at early stage is one of the major tasks. Therefore, if that technique used for UPDRS score prediction gives high accuracy, then it will be good for all the patients and helpful for doctors. This paper proposes an efficient machine learning technique framework to enable early detection of the disease by using the ensemble for UPDRS score prediction for PD. The major contribution of this paper are as follows.
1.2 Contribution
-
1.
To study existing methods for Parkinson disease diagnosis and identifying gaps.
-
2.
To test the proof-of-concept system using 25 machine learning regression models on publicly available datasets of Voice measures of PD patients
-
3.
Predict and evaluate unified Parkinson disease rating scale (UPDRS) and evaluate the results using correlation, R-Square, RMSE, accuracy, and time taken.
-
4.
To propose a prediction method to enhance computer-aided diagnosis of Parkinson disease by choosing top five models.
This paper has the following structure: Sect. 1 for introduction of PD and research contribution, Sect. 2 provides the brief review about the existing work, Sect. 3 is about proposed model, Sect. 4 is about result analysis using RMSE, correlation, R-Square, and accuracy, and Sect. 5 gives the conclusion and future possibilities.
2 Literature review
Hanson et al. [17] proposed relationship of vocal variation from the norm and general neurologic side effects with the laryngoscopic examination which prompts the conclusion that the phonatory irregularities noted in Parkinson’s illness are identified with unbending nature in the phonatory stance of the larynx. Ho et al. [19] categorized speech impairment in two hundred PWP into five levels of general seriousness and portrayed the comparing compose (voice, verbalization, familiarity) and degree (appraised on a 5 pt. scale) of impedance for each level. From 2-min conversational discourse tests, features of voice, familiarity and enunciation were surveyed by two prepared raters. Voice was observed to be the main deficiency, as often as possible influenced and impeded to a more prominent degree than different highlights in these underlying levels. Familiarity deficiencies showed after, articulatory hindrance coordinating voice debilitation in recurrence and degree at the ‘Extreme’ level. In the last phase of ‘Profound’ impedance, explanation was the most as often as possible hindered include at the least level of execution. Ho et al. [19] represented the unmistakable quality of voice discourse motor handles shortfalls, and making sync with deficiencies of engine set and engine set unsteadiness in skeletal handles stride and penmanship. Displaying and surrogate information thinks about have indicated noteworthy nonlinear and non-Gaussian irregular attributes in these sounds. Little et al. [25] found that existing apparatuses are restricted to dissecting voices showing close periodicity and do not represent this inalienable biophysical nonlinearity and non-Gaussian haphazardness, frequently utilizing direct flag preparing techniques harsh to these properties. They do not straightforwardly quantify the two primary biophysical side effects. Voice issue emerge because of physiological disease or mental issue, mischance, abuse of the voice, or medical procedure influencing the vocal overlays and profoundly affect the patient’s life. This impact is considerably more outrageous when the people are proficient voice clients, for example, vocalists, performing artists, radio and TV moderators, for instance. Ordinarily utilized by discourse clinicians. Logemann et. al. [27] noted the frequency of occurrence of speech and voice side effects in PD patients and divide the symptoms into five groups.
Holmes et al. [21] analyzed voice attributes of patients with Parkinson’s infection as indicated by malady seriousness. The voice attributes of 30 patients with beginning period PD and 30 patients with later stage PD were contrasted and information from 30 typical control subjects was also collected. In correlation with controls and beforehand distributed standardizing information, both later and early stage voices of PD patients were portrayed perceptually by restricted pitch and din changeability, hoarseness, cruelty and decreased commotion. High modular pitch levels additionally described the voices of guys in both early and later phases of PD. Albeit less understandable, the present information likewise proposed that the voices were described by abundance jitter, a high-talking essential recurrence for guys and a diminished principal recurrence fluctuation for females. While a few of these voice highlights did not seem to weaken with sickness movement (i.e., brutality, high modular contribute and talking key recurrence guys, essential recurrence inconstancy in females, low force), rasp, monoloudness, monopitch, low din, and diminished greatest phonational recurrence run were all more regrettable in the later phases of PD. Harel et al. [18] presented the diagnostics and recovery of Parkinson disease (PD) that showed the present data relating to novel strategies to assess side effects, restoration, new uses of cerebrum imaging and obtrusive techniques to the investigation of PD. Analysts have just as of late centered around the non-motor side effects of PD, which are ineffectively perceived. The non-motor manifestations of PD significantly affect quiet personal satisfaction and mortality, and incorporate psychological disabilities, autonomic, gastrointestinal, and tactile side effects. In-depth dialog of the utilization of imaging devices to consider ailment systems is likewise given, with accentuation on the irregular system association in Parkinson. Profound mind incitement administration is an outlook changing treatment for PD, fundamental tremor. Ongoing years, new methodologies of early diagnostics, preparing projects and medicines have boundlessly enhanced the lives of individuals with PD, generously diminishing indications and fundamentally postponing incapacity. PD comes about basically from the demise of neurons which is called dopaminergic neurons. Present PD medicines treat indications; none stop or retard dopaminergic neuron degeneration. The principle hindrance to creating neuroprotective treatments is a restricted comprehension of the key sub-atomic instruments that incite neurodegeneration. Beforehand involved offenders in PD neurodegeneration, mitochondrial brokenness and oxidative pressure, may likewise act to a limited extent by causing the collection of misfolded proteins, notwithstanding creating different injurious occasions in dopaminergic neurons. Neurotoxin-based models have been vital in explaining the sub-atomic cascade of cell passing in dopaminergic neurons. PD models in view of the control of PD qualities ought to demonstrate profitable in clarifying critical parts of the illness, for example, particular powerlessness of dopaminergic neurons to the degenerative procedure. Ramaker et al. [35] reviewed the clinometric properties of rating scales used for the assessment of PD. He conducted the systematic review of different scales used for the assessment of PD. It is particularly used for motor impairment.He described eleven scales for identifying the PD. It outcomes reliability, responsiveness and validity. Out of these 11 scales he evaluated 3 scales named as NUDS (Northwestern University Disability Scale), UPDRS (Unified Parkinson’s Disease Rating Scale) and CURS (Columbia University Rating Scale). All these scales were used in contrast with the clinical system used for detection of PD. It was noticed that these three scales gave high reliability, validity and accuracy in prediction. From the evidence, it was proved that all these three scales have medium to good validity.
Parkinson’s ailment is second most general neurodegenerative issue, after Alzheimer’s. Bazazeh et al. [3] proposed the approach in light of machine learning frameworks. The purpose of machine learning (ML) frameworks has been seen over a wide group of employments in bioinformatics. Biomarkers are described as an objective measure of natural parameters that can break down an ailment, screen its development, or envision medicinal pathologies. Biomarkers keep running from genetic. Biomarker recognizing evidence is a back to back and dreary process that involves various essential advances, consisting data preprocessing, show decision, biomarker endorsement and feature extraction. It contains numerous basic advances, including highlight extraction, information preprocessing, demonstrate choice approval. Muhammed et al. [36] composed the equipment to obtain precise displacement from triaxial gyroscope and apply a progression of procedures to separate diverse highlights in time and recurrence spaces. A total of 104 people presented in our study, Clinical Decision Support System (CDSS) with overall accuracy of 82.43% is created by using this dataset. Moreover, CDSS was likewise utilized as a first demonstrative device in a genuine healing facility setting with a precision of 77.78%. For feature selection, Soliman et al. [44] compared the filter and wrapper methods. Reducing the number of features leads to more efficient machine learning algorithms. In filter method, he applied some statistical approach to rank the features according to its importance and then sort based upon the rank. The features having the lowest rank are removed from the dataset. In wrapper method, he chose an arrangement of various features and assessed them. In addition, he contrasted every combination with other combinations and utilized prescient model to assess a group of features. The scores were assigned in light of model performance. Revet et al. [37] proposed rough set theory for feature selection. It is a new technique in data mining used to extract the pattern from data. Its basic concept is to reduce the data elements from the decision tree based on the information associated with the particular attribute or feature.
Dietterich et al. [10] proposed the different ensembling methods like error-correcting output coding, bagging, and boosting. He compared these three methods and gave the conclusion that ensemble methods are better in performance than the individual models. Shrivastava et al. [42] proposed neural network model for prediction of PD with feature selection technique genetic algorithm and achieve 79.93% accuracy and 93.60 % accuracy by using neural network with Binary Bat feature selection technique. Chen [7] proposed a concept of using the KELM classifier which give accuracy 94.19%. Prashanth et al. [33] used boosted tree with multimodel feature selection technique and achieve 95.08% accuracy. Fayyazifar et al. [14] proposed adaboost and Bagging algorithms as models to detect PD and obtained 96.55 percent and 98.28% accuracy by using adaboost and Bagging algorithms. The comparative study of the related literature has been done in this section. All the related techniques applied for PD have been analyzed and compared. The summary of previous methods used in literature review is shown in Table 1.
3 Proposed Methodology
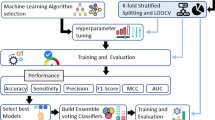
An efficient method to diagnose the Parkinson disease is proposed by detecting the UPDRS score that only uses dataset of voices of PD patients which are captured at patients home. Total 5875 voice samples have been collected from 42 patients during early stage of the disease [47]. Feature extraction has been performed to choose the most relevant variables for the analysis. Most efficient 25 machine learning regression models have been applied to these extracted features with 70–30% ratio of training and testing. Afterward, best five algorithms have been chosen to design the ensemble for best possible results. Diagrammatic representation of methodology is shown in Fig. 4.

Diagrammatic representation of the proposed approach

Proposed approach for Parkinson’s disease detection
The machine learning approach has been used for the prediction of PD. The detailed methodology is described below (as shown in Fig. 5):
-
1.
Different 25 regression models of machine learning are applied on the training dataset to predict the results using R Studio. 70% of the data from the dataset are used to train the system and results are predicted by using 30% of the test data.
-
2.
Features are selected from the dataset using %IncMSE and IncNodePurity to improve the results using Rattle.
-
3.
Executing all the 25 models, top five models with best performance are chosen.
-
4.
Ensemble of top five models is considered and trained using K-fold cross-validation for robust model design.
-
5.
The results are evaluated quantitatively using graphs and tables.
3.1 Dataset Description
This dataset contains the number of biomedical voice measurements. The dataset is collected from 42 persons having early stage Parkinson’s disease [6]. The records were captured at patient’s home. The dataset was made by Max Little and Athanasios Tsanas of University of Oxford, as a team with ten medicinal focuses in the US and Intel Corporation who built up the telemonitoring gadget to capture the signals of speech [26]. The dataset comprises of number of traits those are subject gender, subject, age, total UPDRS, time interim from motor UPDRS, basic recruitment date, subject number and 10 measures for biomedical voice. Jitter, Jitter (Abs), Jitter: PPQ5 are various parameters of variation in base frequency [6, 43].
Different parameters of variation in amplitude are: noise-to-harmonic ratio (NHR), harmonic-to-noise ratio (HNR), and personal protective equipment (PPE). Total numbers of 5875 voice recordings from individuals were present. The main objective of the dataset is to predict the motor UPDRS score from various voice measures. Features used in this methodology are shown in Table 2.
3.2 Feature selection
The primary thought of feature selection is to find out the most reliable features, as they act as an important factor in the whole prediction process.
Effective feature selection eliminates the redundant variables and keep the best variables which will predict better in the model. Feature selection is important so as to reduce the extra computation stress from the model. Lesser number of features which are relevant to the target, would result in better accuracy in less time. When the input data is of high dimension, model usually chokes because:
-
Training time increases exponentially with number of features.
-
Models have increasing risk of overfitting with increasing number of features.
Feature selection methods help with these problems by reducing the dimension of data without losing the total information. It also helps to make sense of the features and its importance of the variables that are described as below:
3.2.1 %INCMSE
It is computed from permuting test data: For each tree, the prediction error on test is recorded which is mean-squared error (MSE). Then after permuting each predictor variable, the same procedure is done. It is the most informative and robust measure. It is an increase in MSE of prediction as a result of any variable i being permuted. The higher the value of %IncMSE, the more important it is. %IncMSE of \(j^{th}\) is calculated by using the following equation:
3.2.2 IncNodePurity
It is the loss function which is chosen by using splits. It is the MSE value for regression. More important variables has the highest value of node purities. This means to search the split which has small intranode variance and higher internode variance.
Table 3 of feature selection shows the values for %IncMSE and IncNodePurity for 21 attributes of PD person’s voice and sex. Based on these values, the features get reduced by 5 attributes which are Jitter, Shimmer, Jitter.DDP, Shimmer.APQ11, Shimmer.Db.
3.3 Evaluation of dataset on different machine learning algorithms
The datasets are evaluated on various machine learning models and their results are compared based on various parameters.
3.3.1 Machine learning regression models
Regression models falls under the class of supervised machine learning which the subset of machine learning algorithms is. One of the principle essential element in the supervised learning is that the connections between target output variable and input features to predict the incentive for new information and the model conditions. Regression is the parametric strategy. It is utilized to anticipate consistent (subordinate) variable given an arrangement of autonomous factors. It is of parametric in nature since it takes some specific suspicions in light of the dataset. Regression algorithms predicts the output values in light of the input features from the information fed in the framework to prepare it. There are two types of analysis techniques:
-
Single variable: It is used to model the relationship between single input independent variable and an output dependent variable using a linear model, i.e., Line.
-
Multi-variable: It is used to model the relationship between multiple independent variables and an output dependent variable using linear model.
Regression problem requires the prediction of a quantity which holds real valued and discrete input variables. Regression is the method of predicting continuous quantity. Here, the target or output variable in the dataset is \(total\_UPDRS\) which holds the continuous values act as a dependent variable in this regression analysis. It is multi-variable regression problem so the multiple independent input variables in this problem are described in Table 2. Different machine learning regression models applied on the dataset and the methods as well as packages used by them to predict the \(total\_UPDRS\) are shown in Table 4.
3.3.2 Model evaluation parameters
The dataset is evaluated by regression models by calculating the following evaluation parameters of regression.
-
Correlation(r): Linear association between the predicted numeric target value and the actual numeric value is measured by the correlation coefficient. Value of the correlation coefficient always lie between \(-\) 1 and + 1. A correlation coefficient of + 1 means that two variables are perfectly related in a positive linear manner, a correlation coefficient of \(-\) 1 means that two variables are perfectly related in a negative linear manner, and a correlation coefficient of 0 means that there is no linear relationship present between the two variables. The correlation between two x and y variables are calculated:
$$\begin{aligned} \mathrm{Corr}(r)=\frac{\sum (x-\mathrm{mean}(x))(y-\mathrm{mean}(y))}{\sqrt{\sum (x-\mathrm{mean}(x))^{2}(y-\mathrm{mean}(y))^{2}}} \end{aligned}$$(2) -
R-Square (\(R^2\)): Coefficient of determination. This value can be interpreted as the proportion of the information in the data that is explained by the model.
$$\begin{aligned} R^{2}=(r)^{2} \end{aligned}$$(3) -
RMSE: The root-mean-square error (RMSE) metric is defined as a distance measure between the predicted value and the actual value.. The smaller the value of the RMSE, the better is the predictive accuracy of the model. RMSE value 0 means a model has perfect and correct predictions. RMSE is calculated by using equation 4.
$$\begin{aligned} \mathrm{RMSE}=\sqrt{\frac{1}{N}\sum \limits _{n=1}^{N}(\mathrm{actual}-\mathrm{predicted})^{2}} \end{aligned}$$(4) -
Accuracy: The prediction accuracy of each machine learning regression method is used to evaluate the overall match between actual and predicted values. Accuracy can be calculated as:
$$\begin{aligned} \mathrm {Accuracy}=\frac{\sum _i \mathrm {if}(|z_i - z_p| \le e_r )}{n} \end{aligned}$$(5) -
Total Time: The time between the starting of the model and the completion of the model that is, the total time taken by the model in seconds to run successfully.
3.4 Ensemble
Ensemble learning includes consolidating numerous predictions determined by various methods with a specific end goal to create a stronger overall prediction. In this methodology, top five models with highest accuracy are ensembled as shown in Fig. 6.

Ensembling of top models
The prediction of the top models is combined and then the average of the combined predictions is found out. Then evaluation parameters (correlation, R-Square, RMSE, and accuracy) between the actual and ensemble prediction are evaluated. The accuracy of the ensembled model becomes more than the individuals top model’s accuracy. In such a way the ensembled model improves the performance and gives the stronger overall prediction results. The top five models selected based on the performance can be described as below:
-
BAGGED MARS: Bagged multivariate adaptive regression splines (MARS) is a type of regression analysis. This analysis given by Jerome H. Friedman in 1991. It is a nonparametric regression method. It can be viewed as an augmentation of linear models that automatically models connections between factors and nonlinearities. MARS is an extension of spline functions and is good for higher-dimensional data regression modeling. The order of the model parameters defines the basis spline functions. Below are the variables required for MARS:
-
1.
Knots—points on the regression line.
-
2.
Basis function—for the relation between predictor and response variables.
-
3.
Interaction—a correlation measure among iterations and variables.
Basis functions (which are also known as cubic splines) are used as predictors as a substitute of the original data in MARS model. Details about spline can be found in [.] which briefly is a piecewise polynomial function with first and second continuous differentials and is used for interpolation. In the basis functions, knot is defined as beginning of a new data section with the end of a previous one. Knots are kept constant and their cardinality is found with backward and forward stepwise searches. Knot search is performed using the basis functions involving predictor and target variables as follows:
$$\begin{aligned} f(x)=\alpha _0+\displaystyle \sum _{i=1}^N\alpha _ih_i(x) \end{aligned}$$(6)Here \(\alpha _0\) is an intercept and summation term is the weighted sum of basis functions \(\alpha _i(x)\) with weights as \(h_i(x)\). The MARS model consists of three basic steps. Details can be found in Drucker [11], Quirós et al. [34].
-
1.
Choose all possible basis functions and their knots. \(h_0(x)=1\) is chosen for initial set to include all functions.
-
2.
Selectively remove basis functions using backward algorithm which contribute to lowest residual error, to find out required knots. Generalized cross-validation (GCV) is used, and the goal is to reduce model complexity and generalize it better.
-
3.
Border smoothing for continuous partitions is the final step. It removes the discontinuities for first and second derivative existence.
-
1.
-
k-Nearest Neighbor Model (KNN): k-Nearest neighbors can be utilized for both classification and regression predictive issues. KNN calculation fairs over all parameters of considerations (those are straightforwardness to translate output, calculation time and predictive power). It is usually utilized for its ease of interpretation and low calculation time. KNN algorithm can likewise be utilized for regression issues. The main contrast from the talked about system will utilize averages of nearest neighbors instead of voting from nearest neighbors. k-Nearest neighbors, or KNN, is a group of algorithms in light of similarity (distance) between occasions. Nearest neighbor actualizes repetition learning and it depends on a nearby normal computation as shown in Fig. 7.
-
Random Forest Model: Tin Kam Ho introduced the algorithm for the random forests. It is an ensemble learning method in which the sub-trees are learned so that the resulting prediction from all sub-trees have less correlation so as to solve the problems (Fig. 8). Random forests are an improvement over bagged decision trees. The learning algorithm is permitted to look through all factors and every single variable incentive keeping in mind the end goal to choose the most ideal split point, in CART while choosing the split point. This procedure changed by the random forest so that learning algorithms are restricted to an arbitrary example of highlights of which to search. The number of highlights that can be sought at each split point (m) must be indicated as a parameter to the algorithm. One can try different values and tune it using cross-validation.
-
Project Pursuit Regression Model: PPR is a measurable model which is an expansion of added substance models which is a nonparametric relapse technique and utilizes one-dimensional smoother to fabricate a limited class of nonparametric relapse strategies. It consists of nonlinear transformations which are linear combinations of variables as given by Eq. (7):
$$\begin{aligned} y_i= \alpha _0 + \displaystyle \sum _{k=1}^n f_i(\alpha _k^Tx_i) + \delta \end{aligned}$$(7)Here \(x_i\) and \(y_i\) explanatory and predictor variables. \(f_i\) are family of smooth functions and n is a hyper-parameter which can be computed using cross-validation.\(\alpha _k\) are set of unknown parameters of length n. The goal is to minimize the error \(\delta\).
-
Boosted Generalized Linear Model: The boosted generalized linear model is an adaptable speculation of customary slightest squares relapse. It sums up straight relapse. By enabling the direct model to be identified with the response variable by means of a connection work it sums up linear regression. It provides the ability to fit generalized model of linear nature. It has the following form of equation:
$$\begin{aligned} f(E(y|x) = \alpha _0 + \alpha _1 x_1 + \dots + \alpha _n x_n \end{aligned}$$(8)Here E(y|x) is a conditional probability of the response for the given variable x, with the parameters \(\alpha _i\) and link function f(.). Further details can be found in Tutz and Groll [48].

K-nearest neighborhood model illustration. Euclidean distance measure has been considered

Random forest is the average prediction calculated from individual decision trees
3.5 Cross-validation
Cross-validation provides a way to generalize the trained model by exercising the process of training over the new unseen dataset partitions and averaging their results. It divides the data into k equal sized subsets, out of which union of \(k-1\) subsets used for training while the rest subsets used for evaluation of performance. A way to estimate how well the results learned from a given training data set is going to generalize on unseen new data. It partitions the data into k number of subsets of equal size and then use the union of K \(-\) 1 subsets for training while remaining subsets for performance evaluation. The performance of each subset is calculated first then results are averaged to get final evaluation. A mainstream setting of k and for this situation is called as K-fold validation where k is number of training samples. It is also called LOO (Leave-one-out). Eightfold validation has been shown in Fig. 9.

K-fold cross-validation (Here K = 8)
Cross-validation technique is used to validate the predictive models and analyze statistical results. It estimates how accurately any predictive model will perform. In this technique, the original sample is partitioned into a training set to train the model, and a test set which is used for system evaluation. In this procedure cross-validation is utilized to validate the predicted results, in which data get rearranged or shuffled on irregular premise. The objective of the cross-validation is to characterize a test dataset which is utilized for testing the framework, and it likewise diminishes the issue of overfitting. The dataset is rearranged eight times and the outcomes are cross-validated. Cross-validation comes about regarding different assessment parameters such as accuracy, correlation, R-Square, and RMSE.
4 Result analysis
Parkinson disease causes different indications and signs. These signs and manifestations can be characterized into two classes: motor and non-motor side effects. Motor side effects influence development of muscles and non-motor side effects incorporate issues like neurobehavioral issues, rest issues, tangible issues. A standout among widely recognized engine issues of Parkinson’s infection is discourse unsettling influence.
4.1 Dataset
The dataset is gathered from UCI machine learning repository [47] which consists of 42 people having beginning time Parkinson sickness. The records were caught at patients home. The dataset comprises of number of traits those are subject sexual orientation, date, motor UPDRS, subject number, subject, age, add up to UPDRS, and ten biomedical voice measures. Jitter, Jitter: PPQ5, Jitter (Abs) are different measures of variety in central recurrence. A few measures of variety in adequacy. Add up to quantities of 5875 voice chronicles from patients are taken. The primary target of the dataset is to anticipate the engine UPDRS score from different voice measures. Different machine learning regression models applied on the dataset to evaluate the performance of the models to predict the UPDRS score. The evaluation parameter calculated by the models are correlation, R-Square, RMSE, Accuracy and Time taken. The models are trained by the 70% of the data available and 30% of data used for testing the data. When you run the algorithm over your training data, what you get and what you use to make predictions on new data is called model.
4.2 Performance comparison
This section covers the performance comparison of various machine learning models used. Tools used are the following: RATTLE, WEKA, R Studio. The coefficient of correlation quantifies the degree to which the two variables are related which ranges between \(-\) 1 and + 1.
In Table 5, the values of correlation such as 0.98 and 0.99 are more closer to the 1 which shows the model predicted values are closely related to the actual observed values of data. Coefficient of determination (\(r^2\)) gives the measure of how well the regression represents the data and its value 0.98 and 0.96 (\(r^2>0.95\)) denotes the strength of the association between the actual and predicted \(total\_UPDRS\) values. Coefficient of determination measures the proportion of variability in the dependent variable (\(total\_UPDRS\)) obtained by the regression model and it is simply the square of r, the coefficient of correlation. RMSE calculates the standard deviation of the residuals which are the spread of points around the regression curve. For example, in Table 5, comparison of R values 0.97 tells that 97% of total variation in actual can be explained by the relationship between actual and predicted. It shows the strength of the regression equation which is used to predict the \(total\_UPDRS\).

Scatter plots of top five models
RMSE gives the result of difference between predicted and actually observed values of the model. It defines the error between the data’s actual values and predicted values (shown in Table 5). It tells how close the actual data points are to the predicted data values. From Table 5 values of RMSE, it is observed lesser the value of the RMSE value more will be the accuracy of model. Accuracy is used to calculate the overall match between actual and predicted \(total\_UPDRS\) values (shown in Table 5) given by the model. More the accuracy better the performance of the model to predict the \(total\_UPDRS\).
4.2.1 Scatter plot
It contains the set of points plotted on horizontal and vertical axes. It shows the relationship between the two set of values and find out the correlation between them. The Y-axis shows the actual \(total\_{UPDRS}\) and the X-axis shows the predicted value of the \(total\_{UPDRS}\) by the models. Each dot in these plots represents the person’s actual \(total\_{UPDRS}\) value versus their predicted \(total\_{UPDRS}\) value. Data points are grouped very close to each other in these scatter plots that indicates the strong +ve correlation such that it represents the linear relationship. The scatter plots of the top five models are shown in Fig. 10.
4.3 Ensemble model results
Ensemble learning involves combining multiple model predictions. It gives better performance than an individual model. In this methodology, top five models with highest accuracy are ensembled to get the averaged accuracy as explained in Eq. (9).
The updated performance parameters are calculated for the ensembled model in Table 6.

Scatter plot of ensemble model
-
Bagged MARS
-
Kknn
-
randomForest
-
projection pursuit regression
-
Boosted generalized linear
The correlation signifies the degree of relation, 0.99 is closer to 1 which indicates the models predicted value is in strong relation with the observed actual value. The R value 0.98 shows the 98% of data is closest to the line of best fit. The RMSE shows the error of 1.18 indicates the difference between the actual observed values and the models prediction. The accuracy defines the performance of model to predict the new data point after training and testing which is 99.6%. The comparison between the actual values and predicted values of \(total\_UPDRS\) calculated by the ensemble model is shown scatter plot in Fig. 11. Each dot in this plots represents the person’s actual \(total\_UPDRS\) value versus their predicted \(total\_UPDRS\) value.
4.4 Cross-validation results
It is a technique in which original dataset is partitioned into training set to train the model and the test data to evaluate it by the predictive models. In this work the original data set is partitioned into 70% to train the model and 30% to validate the model. Original sample is divided into 8 subset randomly. Out of 8 subset 1 subset is used for testing the data and rest 7 subsets used as training data. Table 7 shows the eightfold cross-validation results for \(R^2\), accuracy, correlation, and RMSE, respectively.
These eightfold results are then combined to get single estimation by averaging them as shown in Table 8. The average accuracy has been found to be 99.43% with the standard deviation of 0.25 over eight trials.
The advantage of this method is that all observations are used for both training and validation. It helps improve machine learning results by combining multiple models.
4.5 Comparative analysis
The results of research work is compared with neural network, boosted tree, KELM classifier, adaboost, bagging algorithms, on the basis of accuracy and from our results it is seen that proposed method gives better results than all these models. Table 9 and Fig. 12 show comparison of different models.

Graphical representation of different models based on accuracy
From Table 9 and Fig. 12, it can be analysed that the proposed ensemble model outperforms the state-of-the-art techniques.
5 Conclusion
Parkinson disease is a dynamic issue that influences the nerve cells in the mind which produces dopamine. The voice is most regularly influenced and weakened to more noteworthy degree than some other element in the underlying phase of the Parkinson’s illness. The UPDRS scale is utilized for the evaluation of the seriousness of Parkinson disease side effects. As there are number of features present in the dataset, the feature selection techniques are applied on the dataset to get the important features which are only required for the evaluation. The system is executed by using 25 machine learning regression models to evaluate the performance parameters like RMSE, Correlation, R and Accuracy. The results are sorted on the basis of the accuracy of the models. Out of the 25 machine learning models, the performance of the models Bagged MARS> kknn> Random Forest> Projection Pursuit Regression> Boosted Generalized Linear as in terms of the accuracy (in %) \(99.38> 98.47>97.62>95.01>88.43>88.2\) is evaluated and these models are selected for ensemble model. The ensembled accuracy obtained is 99.6%. After this, all the results of eightfold cross-validation is then averaged to give single estimation value of 99.4% accuracy.
As a future work a laboratory is planned to collect data from the individuals affected with Parkinson disease and healthy persons. The dataset can be collected by using vocal tests from other languages and tested. Progression of dysprosody in Parkinson disease with overtime can also be predicted from the voice dataset by machine learning methods.
Change history
17 July 2024
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1007/s00521-024-10102-8
References
health advisor. http://www.newhealthadvisor.com/Early-Onset-Parkinson’s-Disease.html. Accessed 6 June 2018
Parkinson’s disease. https://www.joinusworld.org/community/3649-parkinson%E2%80%99s-disease. Accessed 6 June 2018
Bazazeh D, Shubair RM, Malik WQ (2016) Biomarker discovery and validation for parkinson’s disease: a machine learning approach. In: 2016 international conference on bio-engineering for smart technologies (BioSMART), IEEE, pp 1–6
Blatman G, Sudret B (2009) Sparse polynomial chaos expansions based on an adaptive least angle regression algorithm. In: Congrès français de mécanique. AFM, Maison de la Mécanique, 39/41 rue Louis Blanc-92400 Courbevoie
Boka G, Anglade P, Wallach D, Javoy-Agid F, Agid Y, Hirsch E (1994a) Immunocytochemical analysis of tumor necrosis factor and its receptors in Parkinson’s disease. Neurosci Lett 172(1–2):151–154
Boka G, Anglade P, Wallach D, Javoy-Agid F, Agid Y, Hirsch E (1994b) Immunocytochemical analysis of tumor necrosis factor and its receptors in parkinson’s disease. Neuroscience letters 172(1):151–154
Chen H-L, Wang G, Ma C, Cai Z-N, Liu W-B, Wang S-J (2016) An efficient hybrid kernel extreme learning machine approach for early diagnosis of Parkinson’s disease. Neurocomputing 184:131–144
De Lau LM, Breteler MM (2006) Epidemiology of Parkinson’s disease. Lancet Neurol 5(6):525–535
De Rijk M, Launer L, Berger K, Breteler M, Dartigues J, Baldereschi M, Fratiglioni L, Lobo A, Martinez-Lage J, Trenkwalder C (2000) Prevalence of Parkinson’s disease in Europe: a collaborative study of population-based cohorts. Neurologic diseases in the elderly research group. Neurology 54(5):S21–S23
Dietterich TG (2000) Ensemble methods in machine learning. In: International workshop on multiple classifier systems, Springer, pp 1–15
Drucker H (1997) Improving regressors using boosting techniques. ICML 97:107–115
Efron B, Hastie T, Johnstone I, Tibshirani R et al (2004) Least angle regression. Ann Stat 32(2):407–499
Faraway JJ (2016) Extending the linear model with R: generalized linear, mixed effects and nonparametric regression models. Chapman and Hall/CRC, London
Fayyazifar N, Samadiani N (2017) Parkinson’s disease detection using ensemble techniques and genetic algorithm. In: Artificial intelligence and signal processing conference (AISP), IEEE, pp 162–165
Friedman JH, Stuetzle W (1981) Projection pursuit regression. J Am Stat Assoc 76(376):817–823
Hans C (2009) Bayesian lasso regression. Biometrika 96(4):835–845
Hanson DG, Gerratt BR, Ward PH (1984) Cinegraphic observations of laryngeal function in parkinson’s disease. Laryngoscope 94(3):348–353
Harel B, Cannizzaro M, Snyder PJ (2004) Variability in fundamental frequency during speech in prodromal and incipient parkinson’s disease: a longitudinal case study. Brain Cognit 56(1):24–29
Ho AK, Iansek R, Marigliani C, Bradshaw JL, Gates S (1999) Speech impairment in a large sample of patients with Parkinson’s disease. Behav Neurol 11(3):131–137
Hoerl AE, Kannard RW, Baldwin KF (1975) Ridge regression: some simulations. Commun Stat Theory Methods 4(2):105–123
Holmes RJ, Oates JM, Phyland DJ, Hughes AJ (2000) Voice characteristics in the progression of Parkinson’s disease. Int J Lang Commun Disord 35(3):407–418
Kramer S (1996) Structural regression trees. In: AAAI/IAAI, Citeseer, Vol 1, pp 812–819
Langston JW (2002) Parkinson’s disease: current and future challenges. Neurotoxicology 23(4):443–450
Liaw A, Wiener M et al (2002) Classification and regression by randomforest. R News 2(3):18–22
Little MA, McSharry PE, Roberts SJ, Costello DA, Moroz IM (2007) Exploiting nonlinear recurrence and fractal scaling properties for voice disorder detection. BioMed Eng OnLine 6(1):23
Little MA, McSharry PE, Hunter EJ, Spielman J, Ramig LO (2009) Suitability of dysphonia measurements for telemonitoring of Parkinson’s disease. IEEE Trans Biomed Eng 56(4):1015–1022
Logemann JA, Fisher HB, Boshes B, Blonsky ER (1978) Frequency and cooccurrence of vocal tract dysfunctions in the speech of a large sample of parkinson patients. J Speech Hear Disord 43(1):47–57
Lotharius J, Brundin P (2002) Pathogenesis of parkinson’s disease: dopamine, vesicles and \(\alpha\)-synuclein. Nat Rev Neurosci 3(12):932
Meinshausen N (2007) Relaxed lasso. Comput Stat Data Anal 52(1):374–393
Paurat D, Oglic D, Gärtner T (2013) Supervised pca for interactive data analysis. In: Proceedings of the conference on neural information processing systems (NIPS) 2nd workshop on spectral learning. Citeseer
Pedrycz W, Kwak K-C (2006) Boosting of granular models. Fuzzy Sets Syst 157(22):2934–2953
Politis M, Wu K, Molloy S, Bain PG, Chaudhuri KR, Piccini P (2010) Parkinson’s disease symptoms: the patient’s perspective. Mov Disord 25(11):1646–1651
Prashanth R, Roy SD, Mandal PK, Ghosh S (2016) High-accuracy detection of early parkinson’s disease through multimodal features and machine learning. Int J Med Inf 90:13–21
Quirós E, Felicísimo Á, Cuartero A (2009) Testing multivariate adaptive regression splines (mars) as a method of land cover classification of terra-aster satellite images. Sensors 9(11):9011–9028
Ramaker C, Marinus J, Stiggelbout AM, Van Hilten BJ (2002) Systematic evaluation of rating scales for impairment and disability in parkinson’s disease. Mov Disord Off J Mov Disord Soc 17(5):867–876
Raza MA, Chaudry Q, Zaidi SMT, Khan MB (2017) Clinical decision support system for parkinson’s disease and related movement disorders. In: 2017 IEEE International conference on acoustics, speech and signal processing (ICASSP), IEEE, pp 1108–1112
Revett K, Gorunescu F, Salem A-BM (2009) Feature selection in parkinson’s disease: a rough sets approach. In: 2009 IMCSIT’09 international multiconference on computer science and information technology, IEEE, pp 425–428
Safavian SR, Landgrebe D (1991) A survey of decision tree classifier methodology. IEEE Trans Syst Man Cybern 21(3):660–674
Schilling C, Mortimer D, Dalziel K, Heeley E, Chalmers J, Clarke P (2016) Using classification and regression trees (cart) to identify prescribing thresholds for cardiovascular disease. Pharmacoeconomics 34(2):195–205
Schliep K, Hechenbichler K, Lizee A (2016) kknn: Weighted k-nearest neighbors. R package version 1(1)
Shao X, Wang W, Hou Z, Cai W (2006) A new regression method based on independent component analysis. Talanta 69(3):676–680
Shrivastava P, Shukla A, Vepakomma P, Bhansali N, Verma K (2017) A survey of nature-inspired algorithms for feature selection to identify parkinson’s disease. Comput Methods Prog Biomed 139:171–179
Skodda S, Rinsche H, Schlegel U (2009) Progression of dysprosody in parkinson’s disease over time-a longitudinal study. Mov Disord Off J Mov Disord Soc 24(5):716–722
Soliman AB, Fares M, Elhefnawi MM, Al-Hefnawy M (2016) Features selection for building an early diagnosis machine learning model for parkinson’s disease. In: International conference on artificial intelligence and pattern recognition (AIPR), IEEE, pp 1–4
Specht DF (1991) A general regression neural network. IEEE Trans Neural Netw 2(6):568–576
Steinberg D, Colla P (2009) Cart: classification and regression trees. Top Ten Algorithms Data Min 9:179
Tsanas A, Little MA, McSharry PE, Ramig LO (2010) Accurate telemonitoring of Parkinson’s disease progression by noninvasive speech tests. IEEE Trans Biomed Eng 57(4):884–893
Tutz G, Groll A (2010) Generalized linear mixed models based on boosting. In: Statistical modelling and regression structures, Springer, pp 197–215
Vinzi VE, Chin WW, Henseler J, Wang H et al (2010) Handbook of partial least squares, vol 201. Springer, Berlin
Wold S, Esbensen K, Geladi P (1987) Principal component analysis. Chemometrics Intell Lab Syst 2(1–3):37–52
W-X XU, X-C YU, S-X WANG (2011) Research on hyperspectral image classification based on bagged cart and boosted cart. Image Technol 5:4
Zhang Z, Lai Z, Xu Y, Shao L, Wu J, Xie G-S (2017) Discriminative elastic-net regularized linear regression. IEEE Trans Image Process 26(3):1466–1481
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
There is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article has been retracted. Please see the retraction notice for more detail: https://doi.org/10.1007/s00521-024-10102-8
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Kaur, H., Malhi, A.K. & Pannu, H.S. RETRACTED ARTICLE: Machine learning ensemble for neurological disorders. Neural Comput & Applic 32, 12697–12714 (2020). https://doi.org/10.1007/s00521-020-04720-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-020-04720-1