
Abstract
This study addresses a many-to-many hub location-routing problem where the best-found locations of hubs and the best-found tours for each hub are determined with simultaneous pickup and delivery within the hard time window. To find practical solutions, the hubs and transportation fleet have constrained capacity, in which every node can be serviced by multiple allocations with the hard time window and limited tour length. First, a bi-objective optimization model is proposed to balance travel costs among different routes and to minimize the total sum of fixed costs of locating hubs, the costs of handling, traveling, assigning, and transportation costs. The problem is then solved using an augmented ε-constraint technique for small to medium size instances of the problem. Due to the NP-hardness nature of the problem, the proposed multi-objective optimization model is solved by a multi-objective imperialist competitive algorithm (MOICA). To show the superior performance of the MOICA, the solutions are compared with those obtained by the non-dominated sorting genetic algorithm (NSGA-II). For the large-scale problem instances, the comparative results indicate that the MOICA can indeed provide better Pareto optimal solutions compared to NSGA-II for the large-scale problem instances.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The optimal design of the supply chain network plays a vital role in reducing transportation costs and improving system performance [55]. Supply chains have grown rapidly in recent years and focusing solely not only on economic performance but also guarantee sustainability [18, 43]. Hub location problems have significantly taken into account in recent decades due to their high applications in modern transportation and communication systems [1, 37]. The hub location problems aim to meet the demands by moving the individuals, goods, and information through specific facilities called hubs as the distribution intermediates between the pairs of origin and destination nodes [8]. In these networks, the pickup and delivery of demands on the hubs can be two- or one-way depending on demand volumes [53]. Hub location-allocation has various application areas in telecommunication networks [32], air transport [17, 48], freight transportation [33], postal services [6], public and urban transportation [39], rail transport [24, 25], and emergency services [4]. The problem is to locate hub and non-hub facilities in a distribution network and to allocate all the origin and destination points (non-hub) directly to the hub so that the network costs including costs of collection, distribution, and other related costs are minimized [27].
Some studies have only dealt with the allocation problem by determining the location of the hub [19]. However, some others addressed the hub location-allocation decisions together with the routing problem [34]. Having mutually influence each other, these two problems have to be considered simultaneously, as regarded in this study. Hubs prevent any direct connection of all the nodes by reducing the number of these links among the origin and destination nodes which in turn results in reducing costs as compared to the networks with complete graph connections [56]. In general, three assumptions are considered in classic hub location-routing problems including (1) the network structure is based on a complete graph, (2) interactions among hub include the discount factor, (3) direct routes among non-hub nodes are forbidden [28]. However, the freight transport industry faces with network design problem where cargo flows from different origins need to be handled by a number of nodes. In this case, the freight flows are re-routed to other nodes where the items are separated to be transported to the destinations. To efficiently manage this type of transport service, vehicles perform local tours for the pickup and delivery purposes. By growing population, demand for freight increases. By doing so, the importance of properly designing freight networks has become increasingly evident. The use of hubs in the transportation networks and fair routing of vehicles significantly reduces transportation costs and energy consumption. On the other hand, maintaining customer service is a critical task due to the significance of effective supply chain operations [38].
This study is motivated by the need to decide the hub facility locations and vehicle routing decisions with the aim to minimize not only the total cost but also the distance imbalance between the service tours while the capacity and hard time windows constraints are respected. The objective is to coordinate the decisions related to the tour planning, the flow exchange between pairs of clients as well as the inter-hub flow interactions.
2 Literature review
The basic version of location-routing problems (LRPs) was originally addressed by [23], where a schema was proposed to classify the location problems. Wasner and Zäpfel [54] designed an integrated model for multi-depot hub LRP for parcel delivery service networks. The decision model accounts for determining the number, locations of depots and hubs and their allocated service zones as well as the vehicle routes. Due to the complexity of the problem, a heuristic method was applied to solve the large-size instances of the problems.
Several existing types of research addressed the LRP with soft time window constraints [22, 47, 51]. Duhamel et al. [14] proposed a hybrid meta-heuristic algorithm to optimize depot locations together with the fleet sizing and routing decisions under capacity constraints. The solution method employs a greedy randomized adaptive search procedure (GRASP) and local evolutionary search (ELS) to generate optimal solutions for the large-size instances of the problem. Çetiner et al. [10] developed an iterative two-stage optimization approach to hub location routing where the multiple allocations of hubs were allowed. They also considered simultaneous pickup and while considering maximum sub-tour length constraints. In the first step, a decision was made to determine the location of the hubs, and non-hub nodes were multiplied allocated to the hubs. Then, routing decisions were made based on the traveling salesman problem (TSP) for each located hub. Since the problem for each hub was solved separately, it is possible to have a non-hub node at two routes. It was assumed that there is no limitation for hub and vehicle capacity, and only tour length is limited. Also, every vehicle starts from a hub, and all the allocated non-hub nodes are revisited and turned back to the hub. Baños et al. [3] tried to minimize the total costs of the transportation system and additionally reduce the distance differences by the vehicles, called the distance balancing, in the vehicle routing problem (VRP) with a hard time window. They proposed meta-heuristic solution methods in order to find a Pareto optimal solution set.
An innovative formulation of hub location-routing problem with total cost minimization function was introduced by de Camargo et al. [12]. This study has focused on the same shipping and discount coefficient and simultaneous pickup and delivery. However, there are no capacity constraints, and each non-hub node is met one. They proposed a Benders decomposition technique to find optimal solutions for real-world instances of the problem. Zarandi et al. [60] addressed an LRP subject to the time window limits. To deal with the uncertainty associated with the possibility of serving a new customer by a vehicle, a fuzzy chance-constrained model was proposed.
An essential aspect of the LRP is the possibility of combining two well-known problems as VRP and the single assignment hub location [41]. This problem is termed as many-to-many hub location-routing problem (MMHLRP) which is not sufficiently considered in the related literature. In general, MMHLRP is a multi-objective optimization problem in nature. The MMHLRP was first mathematically formulated by Nagy and Salhi [45]. In this formulation, the vehicles are allowed to perform the pickup and the delivery services on separate locations subject to the capacity and maximum distance constraints. They proposed a heuristic technique to find efficient solutions for hub location-routing problem. Despite the novelty of the formulation, the vehicles’ costs the scale economies in the inter-hub connections were neglected.
Yetgin et al. [58] proposed evolutionary multi-objective meta-heuristics, i.e., multi-objective differential evolution (MODE) and non-dominated sorting genetic algorithm-II (NSGA-II) to optimize routing strategies in multi-hop wireless ad hoc network. The solution method considers multiple conflicting objectives, i.e., energy consumption and transmission delay due to bandwidth constraints. Rieck et al. [49] presented a mixed-integer linear program based on a multi-commodity network flow model for a variant of many-to-many location-routing problems (MMLRP). Given the inter-hub transport cost parameters in this model, routing decisions were decided optimally through a variable fixing technique.
Mokhtari et al. [42] suggested a combination of VNS and PSO meta-heuristics to construct a multiple hub transport network. It was assumed that the hubs and vehicles have an infinite capacity that is far beyond the existing, realistic situation in hub location-routing problems. The result of computational experiments demonstrated the superior performance of the proposed solution method as compared to existing algorithms. The hybrid meta-heuristic method could solve large-size instances of MMHLRPs up to 300 nodes through acceptable optimality gap and solution time. Yang et al. [57] considered a single-objective airline hub-and-spoke system design under stochastic demands. Also, the effect of hub congestion was modeled as a linear function. The problem was formulated as a two-stage stochastic programming model. Boukani et al. [7] studied a robust version of capacitated hub location problems with multiple allocations while neglecting routing decisions. The mathematical model accounts for the uncertainty associated with fixed setup cost and of hub capacity. Kartal et al. [30] proposed three alternative formulations for a single allocation p-hub median LRP with a concurrent pickup and distribution without any time window constraint. To solve the problem, multi-threat simulated annealing (SA) and an ant colony (ACO) meta-heuristic were used. Dukkanci et al. [15] proposed an incapacitated hierarchical hub location-routing model for an airline network. The designed model does not take into account the variable transportation cost and may generate an impractical solution in real-world problems. To solve the problem, a sub-gradient heuristic, some variable fixing strategies, and valid inequalities were designed.
Recently, Khosravi and Jokar [31] studied MMHLRP based on the gravity rule with a single minimization fixed costs objective and without any capacity, time and tour length constraints. Karimi [29] addressed the capacitated hub covering LRPs with instantaneous pickup and distribution systems. The problem was mathematically formulated as a single-objective optimization model without any time window constraint. Ghaffarinasab et al. [20] proposed a continuous approximation model and two heuristic solution methods for hub LRP. The model aims to minimize the total transport cost which includes pickup and delivery costs and line-haul transportation costs.
As reviewed, the literature on MMHLRP is very limited. To the best of our knowledge, this study is the first to develop a bi-objective model for capacitated MMHLRP with the balanced allocation of vehicles at a hard time window. The contributions of the present research are threefold:
-
(1)
To the best of the author’s knowledge, there are no published papers that addressed the multi-objective version of MMHLRP. In this study, a multi-objective mathematical formulation is developed for the capacitated MMHLRP with a hard time window constraint. The first objective concerns minimizing the total cost including the hub installation cost and transportation costs. The second objective is defined to minimize the difference between the minimum and maximum costs of vehicles allocated to each route.
-
(2)
To the best of the authors’ knowledge, this research is the first to introduce the concept of distance balancing in many-to-many hub location-routing problems. Here, the hub location-allocation and vehicle routing decisions are concerned with a fair allocation of vehicles to routes in terms of the traveled distances. The developed model in this study sets its sight on not only minimizing the total distance traveled by the vehicles of the fleet but also minimizing the imbalance in the distances traveled.
-
(3)
In this study, multi-objective evolutionary meta-heuristic algorithms are adopted to find the best hub locations, assignment and routing decisions for test cases. The efficiency of the proposed multi-objective optimization algorithms is also in comparison with state-of-the-art solution methods in the literature.
The rest of the article is organized as follows: In the next section, the formal description of the capacitated MMHLRP is provided. Then, the mathematical formulation of the problem is presented in Sect. 3 as well. In Sect. 4, multi-objective optimization methods are proposed to solve the problem. The solution approaches include the augmented ε-constraint method, NSGA-II (non-dominated sorting genetic algorithm-II), and MOICA) A multi-objective imperialist competitive (algorithms. In Sect. 5, the validity of the mathematical model and the solution methods are examined through numerical test problems. Finally, in Sect. 6, concluding remarks are presented and further research is discussed.
3 Problem definition and formulation
Suppose the capacitated MMHLRP where certain demand flows between pairs of origin and destination nodes are given. This model guarantees that the non-hub points could be allocated to at least one hub. That is, it is possible that some spokes request services to more than one tour. Only if there is a set of potential hubs for installation, it would be possible that some of them become opened for service. In the second stage, their balanced routes will be determined. The capacitated vehicles have to pickup and deliver from multiple origins to multiple destinations passing at least one hub at a hard time window of that by considering maximum travel time and tour length. Complementary assumptions are considered as follows:
-
All the nodes can be changed into the hub and parameter 0 < α < 1 defines the economies of scale as an inter-hub discount factor.
-
Concurrent pickup and delivery are allowed to serve the customers.
-
Hubs are considered as the origin of the vehicle routes.
-
Every vehicle which exits each hub should turn back to that point, and its movement has maximum time and tour length constraints.
-
Multiple allocations are allowed which means that every node can be served by more than one hub.
-
A hard time window is defined for each service visiting a spoke node.
-
The transportation fleet is homogeneous with limited loading capacity.
-
The transport network is a mono-product, single commodity, and single period type.
-
The number of hubs is a variable, and their capacity is limited.
-
The connections between hubs create a complete or fully interconnected graph.
In this study, the aim is to find optimal locations for hub installation among potential locations. The model also decides the best assignment of specific spokes to hubs and the best allocations of vehicles to the travel tours. The first objective is to minimize the total cost including the hub installation cost, the cost of handling demands, the execution cost of the local tours, the cost of allocating vehicles to the hubs, and the inter-hub transportation costs. The second objective is to balance the workload imbalance in the distances traveled by the vehicles used. It is apprehended that, in order to satisfy the second objective, the model is not enthusiastic to establish new hubs. However, to meet the first objective, the model is inclined to employ more new hubs. Therefore, in general, these objective functions are incompatible. To better reflect the advantages of accounting for both conflicting objective functions, a simple illustrative example is provided. The example includes 20 nodes which are labeled in Figs. 1, 2, and 3. The results of a simple case based on three scenarios are illustrated in Figs. 1, 2, and 3, respectively. To note that in each of these scenarios, the maximum number of hubs that could be selected among these 20 potential nodes is 5. After the node number of hubs became clarified, spokes are chosen among the rest of the nodes to assign each hub. In these figures, the opened and closed potential locations for installing hubs are displayed by red squares with the number labeled and dashed-line in the middle, respectively. Figure 1 shows the solution generated in the first scenarios when only the first objective function is minimized. Taken for example that, the optimization model concerns the minimization of the total cost of hubs installation, the cost of demand satisfaction, the cost associated with the allocating vehicles to the hubs, the execution cost of the local tours, the fuel cost, and the inter-hub traveling costs. As can be seen in Fig. 1, among 5 potential locations of hubs, merely two of them are opened and installed (node number “9”, “2”). Moreover, assigned spokes to each hub are shown with blue circles along with the allocation direction of each tour to each hub and inter-hub connection. However, there is no balance between the distances traveled by vehicles on different tours. Although the sum of these costs is decreased, differences in the vehicle distances are significant. Also, Fig. 2 shows the solution generated using the second objective function. In this case, the objective is to balance the workload imbalance in the distances traveled by the vehicles used. As illustrated in Fig. 2, all potential locations for the establishment of hubs are opened. In this case, despite the equal distance traveled by vehicles among different tours, the hub location costs are raised gradually. In conclusion, Fig. 3 depicts an optimized solution when both objective functions are minimized concurrently. In the third scenario, four potential points for the establishment of hub facilities are opened, and the workload in the distances is also balanced to some extent.

Solution example obtained based on the optimization of the first objective function

Solution example obtained results based on the optimization of the second objective function

Solution example obtained based on optimizing both objective functions simultaneously
Before presenting the formal mathematical formulation, the notations associated with sets, indices, input parameters, and decision variables are summarized as follows:
Sets
- N :
-
A set of nodes
- K ⊆ N:
-
A set of potential nodes for hub
- A :
-
A set of arcs
- V :
-
A set of vehicles
Indices
- i, j, k, m ∈ N:
-
Index of origin and destination nodes
- (u, v) ∈ A:
-
Index of arcs connecting nodes u, v
- l ∈ V:
-
Index of vehicles
Parameters
- \( w_{ij} \) :
-
The flow of demand from client i to customer j
- \( D_{j} = \mathop \sum \nolimits_{i} w_{ij} \) :
-
The total demand destined to customer j
- \( O_{i} = \mathop \sum \nolimits_{j} w_{ij} \) :
-
The total demand originated from client i
- \( t_{uv} \) :
-
The traveling time of arc) u,v(
- \( st_{v} \) :
-
Time to service node v including loading and unloading time
- T :
-
Maximum duration allowed for completion of the tours
- \( \alpha \) :
-
The discount factor associated with the inter-hub transportation cost, where \( 0 \le \alpha \le 1 \)
- \( a_{k} \) :
-
The fixed cost of locating and installing a facility hub
- \( \hat{c}_{ik} \) :
-
The handling cost of the inbound and outbound demand flows for client i by hub k
- \( \ddot{c}_{uv} \) :
-
The cost of traveling arc) u,v(
- \( \dot{c}_{l} \) :
-
The cost of assigning a vehicle l to a hub
- \( c_{km} \) :
-
The transportation cost for the inter-hub connection (between hubs k and m)
- \( \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{c}_{ij}^{km} \) :
-
The transportation cost of demands \( w_{ij} \) and \( w_{ji} \) with an economic coefficient of \( \alpha \) which is \( \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{c}_{ij}^{km} = \alpha \left( {w_{ij} *c_{km} + w_{ji} *c_{mk} } \right) \)
- \( V_{k} \) :
-
The capacity of hub k
- \( {\text{Cap}}_{l} \) :
-
The maximum loading capacity of vehicle l
- \( E \) :
-
The maximum distance length of vehicle tour
- \( r_{uv} \) :
-
The distance between nodes u, v
- \( M \) :
-
A sufficiently large positive number
- \( \beta_{j} \) :
-
The earliest time for customer j to allow the service
- \( \gamma_{j} \) :
-
The latest time for customer j to allow the service
Decision variables
- \( z_{kk} \) :
-
= 1 if the node k is nominated as a hub facility; otherwise equals to zero
- \( z_{ik} \) :
-
= 1 if the node i is assigned to the hub k; otherwise equals to zero
- \( x_{ijkm} \) :
-
The fraction of the demand from client i to customer j that is routed from hubs k to hub m
- \( q_{kl} \) :
-
= 1 if the vehicle l is assigned to the hub k; otherwise equals to zero
- \( Y_{uv}^{kl} \) :
-
= 1 if the vehicle l assigned to the hub k uses arc u, v in its path; otherwise equals to zero
- \( P_{u}^{kl} \) :
-
= 1 if the vehicle l assigned to the hub provides service to node u; otherwise equals to zero
- \( S_{j}^{l} \) :
-
The time of beginning to serve the jth node by the vehicle l
Considering the defined assumptions and notations, a bi-objective optimization approach to multiple hub location-routing problems with distance balancing and the hard time window is formulated as follows:
The first objective function is defined in Eq. (1). It computes the sum of the cost of hub facility network design, the cost of handling demand flows, the inter-hub transportation costs, the cost execution of the local tours, and the allocation cost of vehicles to the hubs. As Eq. (2) shows, the second objective function is followed by the balance of distance of each vehicle indicating the cost of their tour. It is important to note that these two conflicting objective functions used in the optimization model do not have a common cost component. The second objective function is to balance the cost of transportation on different tours so that balancing the tour distance reduces the need for labor and decrease fuel consumption. Also, it helps to improve the utilization of vehicles.
Constraint (3) indicates that each non-hub node is at least allocated to one hub node. Constraint (4) indicates that a non-hub node is allocated to a node if it is considered as the hub. Constraint (5) guarantee that the exchange of flow between the origin–destination pair i and j, with node \( i \in N \) being serviced by hub \( k \in N \), will only exist if node \( i \in N \) is first allocated to hub \( k \in N \). Likewise, constraint (6) imposes the same logic to node \( j \in N \) and hub \( m \in N \). Constraints (7), (8) establish that an arc must leave and arrive, respectively, at a nod, if a vehicle of a hub is assigned to service that node. Constraints (9) are activation constraints. A vehicle \( l \in V \) of hub \( k \in N \) can only use \( \left( {u,v} \right) \in A \) if this vehicle is first allocated to the hub. Constraint (10) indicates that the lth vehicle cannot be allocated as long as the previous vehicle (l − 1th vehicle) has not been assigned. Thus, this inequality refers to the sequence of allocating vehicles to the routes. Constraint (11) indicates that if a vehicle, which started a tour from a particular hub, is allocated to a node, then the node should be allocated to that hub. Constraint (12) is related to the maximum time allowed for constructing a tour. Constraints (13) and (14) are related to the hub capacity at the origin and destination nodes, respectively. Constraint (15) indicates the maximum tour length. Constraints (16) and (17) are related to the limited capacity of vehicles moving from origin to destination. Inequalities (18) and (19) define the hard time window constraint. Finally, constraints (20), (21), and (22) express variables domains as the binary and nonnegative real variables, respectively.
4 Solution methods
This section proposes the classic and state-of-the-art solution approaches in the domain of multi-objective optimization methods. The aim is to compare the efficiency of the multi-objective solution methods based on the randomly generated test problems of multi-objective MMHLRP. In this context, the decision-makers are intended to find the most preferred solutions called Pareto optimal set, or Pareto frontier. The concept and definition of the Pareto frontier and Pareto optimality conditions can be found in [9, 46, 52]. In this study, we first adopt an exact approach based on classical multi-objective optimization methods. Then, because of the high computational cost of generating the exact Pareto set, two multi-objective meta-heuristic algorithms are proposed.
4.1 Augmented ε-constraint method
The ε-constraint method has been known as one of the most effective existing approaches to generate the exact Pareto optimal set [5]. It has different successful applications to multi-objective optimization problems [5, 26]. In this multi-objective optimization technique, one of the objective functions with the highest priority is optimized by using a lexicographic approach, while the other objective functions are transferred to the constraint set. More discussion on recent development and the details about the ε-constraint method can be found in [11, 36].
In this study, the augmented ε-constraint method (AUGMECON2) is adopted to solve the MMHLRP and to find a Pareto optimal solution set known as the exact Pareto set. AUGMECON2 is an improved version of the ε-constraint method in which an acceleration method is utilized to avoid generating the weakly efficient or infeasible solutions [35]. The notation of the AUGMECON2 is summarized in Table 1. The general formulation of AUGMECON2 is represented in Eqs. (23)–(25). The method and formulation are implemented in GAMS software to generate Pareto optimal solutions.
The algorithm starts with the calculation of the payoff tables using the lexicographic optimization method. In this step, the ranges for objective functions, including the lower and upper bounds are obtained. At the next step, the second objective function is transferred to the set of constraints as equality using a surplus variable. To adjust the number of intermediate solutions, a grid point is defined to suitably dividing the variability range for objective function i. Therefore, the range of objective function i is departed into qi intervals with equal length [36]. As a result, the right-hand side (ei) of objective function i is changed parametrically. The number of generated Pareto optimal solution sets (or solution density) is adjusted by deciding the proper values of qi. It means that the higher the number of grid points, the higher the solution density. When an infeasible solution is found, then the associated values of e2 are disregarded, and finally, the algorithm terminates instantly. In this case, the algorithm exits from the innermost loop and continues with the next grid point.
4.2 Non-dominated sorting genetic algorithm-II
As noticed by Nagy and Salhi [44], due to the NP-hardness of the LRP, exact multi-objective optimization methods possibly fail to obtain the exact Pareto set in reasonable computational time for complicated real-size instances of the location-routing problem. To cope with the tractability of the problem, a non-dominated sorting genetic algorithm-II (NSGA-II) is adopted as one of the most well-known and influential multi-objective evolutionary algorithms. NSGA-II was first introduced by Deb et al. [13] which is adopted for the presented article, and it found different successful applications in supply chain management. It is worth to mention that the main issues in multi-objective evolutionary optimization are: (1) computational complexity, and (2) non-elitism approach. NSGA-II uses a fast non-dominated sorting approach to deal with computational complexity. NSGA-II also uses an efficient constraint-handling method to solve constrained multi-objective optimization problems. It also presents the elite strategy to avoid missing the best solution and improve the robustness along with the calculation speed of the search process. Recently, NSGA-II has been widely implemented as an efficient multi-objective solution method in hub location literature [21, 50, 59].
The algorithm utilizes crossover and mutation operators, as proposed in the genetic algorithm (GA), to generate new individuals known as offspring. At that point, the current solution set and the generated offspring are combined to produce the next generation. Accordingly, the best-found solutions in terms of crowding distance (CD) metric are picked up from a combined population and moved to the next generation. The flowchart of the NSGA-II used for MMHLRP is illustrated in Fig. 4.

Flowchart of the NSGA-II for MMHLRP
4.2.1 Solution encoding schema
The structure of the solution representation is one of the first steps in the successful implementation of the meta-heuristic algorithms. In the NSGA-II algorithm, the structure of the encoded solution consists of three parts (Fig. 5). Suppose there are \( \left\| A \right\| \) customers/spoke, \( \left\| V \right\| \) vehicles and \( \left\| N \right\| \) candidate points for hub locations. Then, the chromosome length is 2 \( \left\| V \right\| \) + \( \left\| A \right\| \). In the first part, the number of genes is defined as \( \left\| V \right\| \) with integer values between 1 and \( \left\| N \right\| \), which indicates the allocation of vehicles to the hub \( i \). The second part of the chromosome also contains \( \left\| V \right\| \) genes. The values of the genes in the second part include non-repetitive integers between 1 and \( \left\| A \right\| \), indicating the first customer served by the \( l \)th vehicle. The third part of the chromosome also contains \( \left\| A \right\| \) genes, and their values include non-repetitive integers between 1 and \( \left\| A \right\| \). These numbers represent the sequence of serving customers with the assumption that they all are in the same direction. For a better illustration of the encoding scheme, a schematic of the coded solution in an example is shown in Fig. 6.

Solution representation for NSGA-II

Schematic of the coded solution in the example
4.2.2 Genetic operators
The evolving process requires the use of selection, and genetic operators, e.g., crossover and mutation to enrich the elite genes of selected individuals. In this study, a tournament selection is utilized which randomly chooses the best ones among some chromosomes to perform crossover operation. In our implementation, a two-point crossover operator is utilized. Also, the mutation operator follows a uniform alteration method for the selected individual.
4.2.3 Pareto front evaluation
As stated previously, the CD is a well-known metric of the solution diversity and population density of the generated Pareto solutions. This metric is very popular in the domain of multi-objective optimization. It represents an estimation of the density of the points neighboring a specific solution. Let r be the total number of objective functions, the CDi metric is defined as the normalized cost for the ith emperor. This index is calculated in Eq. (26).
where \( f_{k,i + 1}^{p} \) represents the value of kth the objective function for the (i + 1)th solution. Likewise, \( f_{k,i - 1}^{p} \) denotes the value of kth objective function associated with (i − 1)th solution just after sorting the solution set based on CD metric. Also, \( f_{{k,{\text{total}}}}^{{p,{ \hbox{max} }}} \) and \( f_{{k,{\text{total}}}}^{{p,{ \hbox{min} }}} \) are defined as the maximum and minimum value of the kth objective function, respectively. Whenever two different solutions have the same rank, the solution with a higher value of the CD is preferred. In Fig. 7, the non-dominated Pareto set is shown by a set of black circles. Besides, the area surrounded by the dotted line shows the value of CD metric for the solution i.

Schematic of CD metric for a bi-objective minimization problem
In this study, the selection procedure is handled through a binary tournament method. This selection method is utilized in choosing individuals for both the crossover and gene mutation operators. In this selection procedure, two solutions are first selected from the current population size, and then, the front with the lowest number is chosen in the case when two individuals were coming from dissimilar fronts. Otherwise, the solution with the highest value of the CD metric is nominated.
4.3 Multi-objective version of imperialist competitive algorithm
MOICA is the multi-objective version of the imperialist competitive algorithm (ICA) which formerly introduced by Atashpaz-Gargari and Lucas [2]. This meta-heuristic was mainly proposed to solve continuous engineering optimization problems. ICA is an evolutionary search optimization algorithm. This algorithm was inspired by the sociopolitical development and evolution of humanity in order to establish an effective search strategy [16]. ICA starts with an initial solution set (or population) which is considered as countries in the world. Solutions (countries) are divided into two types based on their fitness function value: (1) imperialists and (2) colonies which all together form empires. The algorithm follows a competition between the empires, in which powerful empires dominate their colonies and less powerful empires will be devastated. The competition between empires continues, and the algorithm gradually converges to a specific mode wherein only one empire remains. In this case, all its colonies place in the same status and their cost equals that of the imperialist. The details of the MOICA are explained in the following subsections.
4.3.1 Solution representation
The first step of MOICA is to generate initial solutions. In similar to the genetic algorithm, every solution (i.e., country) corresponds to a “chromosome.” A potential solution is represented by an array, as illustrated in Fig. 8. Let’s assume there are n customers, m vehicles, and d candidate points for the hub. From the left to the right, the first 10 cells (n) define the series of nodes in each path; the 3 yellow cells (m) correspond to the number of nodes to be serviced by the vehicle. Finally, the red cells (d) define the location of the hubs and start point of each vehicle route.

Solution representation for MOICA
Consider a matrix of \( 1*\left( {n + p} \right) \), where \( n \) is the total number of nodes and \( p \) is the number of hubs to be installed in the supply chain network. Matrix numbers consist of bits 1 to \( n \) (random numbers between zero and one) and bits \( n \)th to \( \left( {n + p} \right) \)th (natural numbers between 1 and n). The numeric value for the \( n + p \)th bit is the total number of nodes in the network. For example, suppose there are 10 potential nodes in the solution matrix (Fig. 8). It is assumed that from these 10 nodes, 3 nodes must be selected as the hub. Initially, bits of numbers 1 to 10 are generated with uniform random numbers in the interval [0,1]. Then, random values of bits 11 and 12 are generated with integers between 1 and 9, and the 10th node is placed in the 13th bit. Then, the largest random number from the values in bits 1–13 is identified and a numeric value of 1 is assigned. At that point, the second-largest numeric value is searched and a numeric value of 2 is assigned. This process continues the same way for all 10 random numbers. The numbers in bits 11–13 show the location of the hubs which is illustrated in yellow. In other words, the numbers inside the yellow cells (bits 2, 7, and 10) represent the location of the hubs in the first part of the solution matrix. The locations of the hubs belong to nodes 1, 6, and 7. Other numbers in the solution matrix also represent non-hub nodes, each node being assigned to the hubs positioned to its right. In this numerical example, node 8 is assigned to the 1st hub, nodes 2, 4, 9, 10 are assigned to the 6th hub, and nodes 3 and 5 are assigned to the 7th hub. To determine the number of vehicles, a 1 × V matrix is generated on the right-hand side of the chromosome in which, for each cell, a numerical value of continuous uniform distribution within the interval [0,1] is generated. The location of the larger numeric value indicates the number of assigned vehicles to each hub. For example, suppose V = 5, indicating that 4 vehicles are used. To allocate vehicles to the hubs, random numbers are first multiplied by the number of hubs and then it rounds to the highest integer. The resulting number indicates how many vehicles are assigned to each hub.
4.3.2 Generating initial empires
The generation of the initial empires is handled through the method suggested by Mohammadi et al. [40]. In the first step, a non-dominance sorting procedure is performed. Then, the individuals are selected from the current population and ranked based on their CD. The best-found solutions (known as the imperialists) are selected from the current population. The solutions belong to the first front are also archived, and the remaining solutions move to the colonies. The colonies are distributed among the imperialist based on the relative power of each imperialist country. In order to find the relative power of each imperialist, the cost functions for each imperialist are calculated as follows:
where \( C_{i,n} \) shows the normalized value associated with the ith objective function obtained for nth imperialist. Likewise, \( f_{i,n}^{p} \) corresponds to the value of the ith objective function obtained for nth imperialist. \( f_{i}^{{p,{\text{best}}}} ,\,\, f_{{i,{\text{total}}}}^{{p,{ \hbox{max} }}} , \) and \( f_{i,total}^{p,min} \) define the best, lower and upper bounds for the ith objective function obtained during the search process, respectively. Given the notation above, the normalized value of the cost function for each imperialist is calculated as follows:
The dominance level associated with each imperialist is computed as indicated in Eq. (29).
Let \( N_{\text{col}} \) denoted the total number of all colonies. Eventually, the number of colonies dominated by each empire is simply computed as follows:
where \( N \cdot C_{n} \) corresponds to the initial number of the colonies possessed by the nth imperialist. The colonialism process continues by dominating the colonies. During this process, the emperors attempt to have more colonies.
The fitness function values for each potential solution are computed so as to satisfy the elitism criteria. The infeasible solutions are also allowed during the search process in order to have a better diversification in the proposed algorithm. The solution infeasibility is measured by the amount of violations for capacity and hard time window constraints. However, whenever the constraints are violated, a penalty term is summed up with the evaluation function which penalizes infeasible solutions. Thus, the fitness function includes the cost of two objective functions and the penalty of violating the capacity and time horizon constraints of each country.
4.3.3 Assimilation procedure
To model the competition between empires, the colony’s movement toward the imperialist is simulated based on their power. This evolution process is known as fusion or assimilation policy which is schematically illustrated in Fig. 9. Let y denotes the initial space between colony and imperialist and θ specifies the direction of the movement. The movement of the colony toward the imperialist is measured by d units. d is a random variable that follows a uniform probability distribution between 0 and β × y, and β is a parameter within the range [1,2]. Here, parameter θ is defined as a random angle which varies between –γ and γ randomly where γ is an adjusting parameter to control the deviation between the original and the actual movement path.

Schematic representation of the assimilation process
The position of an imperialist and a colony may change due to the higher power (lower cost) gained by the colony compared with that of its imperialist. The total cost of an empire (or equivalently the overall power) is essentially a weighted function of the imperialist’s power and the average power of its colonies. Thus, the total power of the nth empire (\( T \cdot C_{n} \)) can be obtained by:
where ξ is a weight factor that varies between 0 and 1. As a good setting, it was reported that ξ = 0.1 yield superior results in most of the previous applications of ICA.
In the assimilation phase, an order crossover operator is utilized, in which a crossover point is selected randomly. The utilized crossover operator is also illustrated in Fig. 10.

Single-point crossover operator used for MMHLRP
4.3.4 Imperialistic possession
The competition between the empires allows them to gain more power (lower cost). Given the structure of MOICA, each empire can achieve a top position by possessing the colonies of other empires in a probabilistic way. The empires with a higher power are more likely to beat the other empires. During the competition, some weaker empires will be discarded. The competition process is terminated when only one imperialist remains. The normalized power of an imperialist (\( N \cdot T \cdot C_{n} \)) is estimated as follows:
Given the new colonies, the power of nth imperialist is then normalized by the following equation:
To escape from local optimum, the revolution policies are employed as insertion, inversion, and swap. The process involves random alteration for the position of the countries in a way that a colony gains more power that helps to be exchanged by an empire. During the revolution process, a weak empire may lose all of its colonies and then it collapses. Based on the explained features of the MOICA, the pseudo-code of this algorithm is summarized in Fig. 11. In this study, the algorithm is stopped when it reaches a predefined number of function calls (\( N_{\text{FC}} \)).

Steps of the proposed MOICA to solve MMHLRP
5 Computational results and insights
This section provides the computational results of standard experiments to investigate the accuracy of the mathematical optimization model and to test the performance of the proposed multi-objective optimization methods. The source of the data is adopted from the hub location data set, known as the CAB, available in the literature. First, the validity and tractability of the mathematical optimization model presented in Sect. 3 are tested by solving small-size instances of the MMHLRP. Then, the result of the augmented ɛ-constraint method is compared with those attained by MOICA. The algorithmic framework is implemented in the GAMS programming environment.
5.1 Model validation
In this section, the validity of the bi-objective optimization model is verified using the solutions obtained by GAMS/CPLEX solver. The problem instances are based on the data of road freight transport in Iran. Road transport is a significant contributor to freight logistic in Iran. 90% of cargo and passenger transportation in Iran is carried out with overnight work of more than 600 thousand drivers in 40 thousand kilometers of roads of the country. One of the most critical problems in the Iran road transport sector is the lack of proper distribution of vehicles in the main distribution centers. In this research, the aim is to present a suitable solution to this problem by implementing an optimization model. The real-world problem instances consist of a maximum of ten nodes and five potential locations for hub installation. The data of the tonnage of goods transferred daily between the origin and destination pairs are provided in Table 2. Also, the distance matrix between the origin and destination pairs (\( r_{uv} \)) is given in Table 3. The results of GAMthe S/CPLEX solver for real-world test problems are provided in Table 4. The augmented ε-constraint method is implemented in the GAMS version 24.2 optimization software tool. All the test problems are implemented on a laptop with Intel Core i5-4210U 2.40 GHz processor with 6 GB RAM running Windows 10.
In numerical experiments, the first objective function is regarded as the primary objective function f1, and the cost balance of every vehicle was considered as a constraint. Table 5 shows the output with 10 nodes, 4 vehicles, and 5 hubs using GAMS/CPLEX. Table 6 reports the minimum total cost of transportation based on different epsilon (ɛ) values. Figure 12 also shows the Pareto set generated by the augmented ε-constraint method. The schematic graph of the solution obtained for MMHLRP in the case study is illustrated in Fig. 13.

Pareto front generated by the augmented \( \varepsilon \)-constraint method

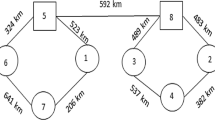
Schematic graph of the solution obtained for MMHLRP in the case study
The comparative results of the multi-objective optimization problem are provided in Table 7. To compare the algorithm solution time, a test problem with 10 nodes and 4 vehicles is used. It should be noted that the dimensions of this problem are the largest dimensions that GAMS software has been able to solve optimally. Table 7 shows the values of the objective functions of the various Pareto optimal solutions extracted by the meta-heuristic algorithms. The Pareto front obtained for augmented \( \varepsilon \)-constraint and MOICA methods is also shown in Fig. 14. Based on the obtained results, it can be seen that the optimality of the MOICA algorithm is acceptable compared to the augmented ε-constraint algorithm.

Pareto front obtained for augmented \( \varepsilon \)-constraint and MOICA methods
5.2 Parameter setting
The distributions for generating input data for numerical test problems are presented in Table 8. The initial population size of solutions for small- and large-scale test problems is 100 and 200, respectively. Also, the mutation and crossover probabilities are 0.2 and 0.8, respectively. The maximum number of iterations allowed to run the NSGA-II algorithm for small- and large-scale test problems are 200 and 500, respectively.
Before the execution of the meta-heuristic algorithms, a fine-tuning method is used that aims to design a high-performance setting for computational experiments. The best-coded values for MOICA’s parameters are obtained by response surface methodology (RSM). RSM is a regression-based statistical method used to optimize an output variable (known as the response). Since the response variable is influenced by the value of the independent inputs, the optimal design of the algorithm needs an appropriate selection of these parameters. Here, the fine-tuning procedure is handled by examining two classes of small and large sizes of test problems. Also, the algorithm parameters are considered in two levels (low and high) for each parameter. Let \( X_{i} \) and \( R_{i} \) denote coded variable and real variable, respectively. Given the high and low levels of algorithm parameters, the coded variable is calculated as follows:
The coded values for algorithm parameters are provided in Table 9. The coded values are defined as − 1 and 1 which correspond to the low and high levels. The optimal of real value and coded values for all factors used in small-, medium- as well as large-scale problem instances are found by using RSM, and the final values are summarized in Table 10.
5.3 Performance evaluation
The effectiveness of the proposed MOICA is measured by running on real-size test problems. The outcomes of the MOICA are compared with those of NSGA-II based on a variety of Pareto optimality performance indices. Here, four indices including quality metric (QM), diversity metrics (DM), spacing metric (SM) and mean ideal distance metric (MID) are used to compare the solution of the MOICA with those of the NSGA-II algorithm.
Quality metric (QM) This metric indicates the number of obtained solutions which are not dominated by the other solutions. The process involves the comparison of the number of solutions belonging to each algorithm with a reference set (total number of found non-dominated solutions). The higher value of the quality metric indicates a better outcome of the multi-objective optimization algorithm.
Spacing metric (SM) This metric measures the standard deviation of the distances between Pareto optimal solutions, in which smaller value is superior. It was proposed to measure how uniformly the solutions of an approximate Pareto front are distributed.
Diversity metrics (DM) This metric measures the spread of the solution set and is calculated by:
where \( d_{i} \) defines the Euclidian distance between two Pareto solutions in the solution space. Furthermore, \( \bar{d} \) corresponds to the average value of the Euclidian distances. Based on this metric, the higher the DM’s value, the better the corresponding Pareto set.
Mean Ideal Distance Metric (MID) It measures how the Pareto solutions are close to the ideal point (0,0). Here, smaller values are more desirable.
The comparative performance and method accuracy of the proposed solution method is linked with NSGA-II by using these performance metrics. The comparative outcomes of the multi-objective performance metrics for the small-, medium- and large-scale test problems are provided in Tables 11, 12, and 13, respectively.
Pareto front generated by the MOICA and NSGA-II methods is shown in Fig. 15 (N. nodes = 100, N. vehicle = 19). In this large-size test example, the comparison between the Pareto fronts indicates the superior performance of the MOICA as against the NSGA-II. To better highlight the difference between these two algorithms, the results of convergence tests and statistical analysis of the outputs are provided in the next following subsections.

Pareto front generated by the MOICA and NSGA-II methods (N. nodes = 100, N. vehicle = 19)
5.4 Algorithm convergence tests
Despite the fast search capability of the NSGA-II and MOICA, the computational costs of multi-objective meta-heuristic approaches would be a problem, especially for large-size hub networks. As shown in Figs. 16, 17, 18, and 19, the convergence ratio plots for NSGA-II and MOICA are provided. Based on what computational results show, the proposed algorithm generates more efficient solutions as compared to NSGA-II for large-scale instances of the MMHLRP. According to the obtained results, comparing MOICA and NSGA-II, for quality, spacing, and mean ideal distance metrics, MOICA shows a higher convergence rate as compared to NSGA-II. The outcomes indicate that the parameter fine-tuning process achieves superior results in each generation of MOICA by decreasing the number of iterations required to achieve algorithm convergence. Figure 20 illustrates the box plot for the convergence speed of the meta-heuristic algorithms. As the results show, the convergence speed of the MOICA algorithm is significantly higher than that of the NSGA-II algorithm.

Comparison of convergence plots of NSGA-II and MOICA on MID index

Comparison of convergence plots of NSGA-II and MOICA on DM index

Comparison of convergence plots of NSGA-II and MOICA on SM index

Comparison of convergence plots of NSGA-II and MOICA on QM index

Box plot for the convergence speed of meta-heuristic algorithms
5.5 Statistical results
To compare the significance of the difference between the performance of the NSGA-II and MOICA algorithms, a paired t test is conducted. The significant difference is examined based on the result of four multi-objective performance indices, e.g., QM, SM, DM, MID. Suppose Di equals to the difference between the values of the performance metrics in the ith test problem. Therefore, the t test statistic is calculated as \( t = \frac{{\sqrt n \times \bar{D}}}{{S_{\text{D}} }} \) where \( \bar{D} = \frac{{\sum D_{i} }}{n} \) and \( S_{\text{D}} = \sqrt {\frac{{\sum \left( {D_{i} - \bar{D}} \right)^{2} }}{n - 1}} \).
In this study, the paired t-test is conducted for 30 test problems using SPSS software. The calculated test statistic is equal to the seventh column (t) for each comparison as represented in Table 14. The result shows the significance (2-tailed) is 0.00, referring to the values of the t-table. The detailed statistics along with 95% confidence intervals (CI) are shown in Table 14. This test shows that there is a statistically significant difference between solutions obtained by MOICA and NSGA-II for each performance index. According to the last column of Table 14, since the significance (2-tailed) (p value) is lower than 0.05 for each performance index. Thus, it is concluded that the proposed MOICA has superior performance as compared to the NSGA-II.
6 Conclusion
Effective flow management of goods between different origins and destinations requires optimized hub networks that allow fully connected links to be substituted with fewer indirect links. The main aim is to provide a cost-effective plan for the design of the hub-and-spoke facilities and the routing plan for the vehicles. However, when the number of local tours increases, there is a need to find a trade-off between the maximum and minimum costs of vehicles allocated to each sub-tour.
This study proposed a new multi-objective mathematical modeling formulation for capacitated many-to-many hub location-routing problem with a hard time window. The model has different applications such as in parcel delivery network design problems. The proposed model was capable of determining the optimal locations of hubs and the optimal tours for each hub. The aim was to minimize the total sum of fixed costs of locating hubs, the costs of handling, traveling, assigning, and transportation and the vehicle costs. The small to medium size instances of the problem was first solved using an augmented ε-constraint method. Due to the complexity of the hub location-routing problem, MOICA and NSGA-II were used to generate near-optimal solutions. The performance of the MOICA and NSGA-II was compared using Pareto solution indicators. The computational results indicate that the MOICA can provide better Pareto optimal solutions compared with NSGA-II for the large-scale problem instances. As the numerical results showed, the proposed MOICA was efficaciously satisfied with the goal to find optimal or near-optimal Pareto solutions for large-size applications of the MMHLRP in expected computational time.
Future research may focus on extending the modeling framework and solution method to address the uncertainty associated with the travel time or demand flow between different origins and destinations. Future research can also be directed toward the extension of the model to include more details of commodities within a dynamic planning horizon. As another field for further research, the effects of flow congestion in hubs and links, due to the existence of the capacitated resources, can be handled within the mathematical modeling framework.
References
Amin-Naseri MR, Yazdekhasti A, Salmasnia A (2018) Robust bi-objective optimization of uncapacitated single allocation p-hub median problem using a hybrid heuristic algorithm. Neural Comput Appl 29:511–532
Atashpaz-Gargari E, Lucas C (2007) Imperialist competitive algorithm: an algorithm for optimization inspired by imperialistic competition. In: IEEE congress on evolutionary computation, 2007. CEC 2007. IEEE, pp 4661–4667
Baños R, Ortega J, Gil C, Márquez AL, De Toro FJC, Engineering I (2013) A hybrid meta-heuristic for multi-objective vehicle routing problems with time windows. Comput Ind Eng 65:286–296
Bashiri M, Rezanezhad M, Tavakkoli-Moghaddam R, Hasanzadeh HJAMM (2018) Mathematical modeling for a p-mobile hub location problem in a dynamic environment by a genetic algorithm. Appl Math Model 54:151–169
Bérubé J-F, Gendreau M, Potvin J-Y (2009) An exact ϵ-constraint method for bi-objective combinatorial optimization problems: application to the Traveling Salesman Problem with Profits. Eur J Oper Res 194:39–50
Bostel N, Dejax P, Zhang M (2015) A model and a metaheuristic method for the Hub location routing problem and application to postal services. In: 2015 international conference on industrial engineering and systems management (IESM), IEEE, pp 1383–1389
Boukani FH, Moghaddam BF, Pishvaee MSJ (2016) Robust optimization approach to capacitated single and multiple allocation hub location problems. Comput Appl Math 35:45–60
Campbell JF (1994) Integer programming formulations of discrete hub location problems. Eur J Oper Res 72:387–405
Censor Y (1977) Pareto optimality in multiobjective problems. Appl Math Optim 4:41–59
Çetiner S, Sepil C, Süral HJ (2010) Hubbing and routing in postal delivery systems. Ann Oper Res 181:109–124
Cohon JL (2004) Multiobjective programming and planning. Courier Corporation, Chelmsford
de Camargo RS, de Miranda G, Løkketangen AJAMM (2013) A new formulation and an exact approach for the many-to-many hub location-routing problem. Appl Math Model 37:7465–7480
Deb K, Agrawal S, Pratap A, Meyarivan T (2000) A fast elitist non-dominated sorting genetic algorithm for multi-objective optimization: NSGA-II. In: International conference on parallel problem solving from nature. Springer, pp 849–858
Duhamel C, Lacomme P, Prins C, Prodhon C (2010) A GRASP × ELS approach for the capacitated location-routing problem. Comput Oper Res 37:1912–1923
Dukkanci O, Kara BY (2017) Routing and scheduling decisions in the hierarchical hub location problem. Comput Oper Res 85:45–57
Enayatifar R, Yousefi M, Abdullah AH, Darus AN (2013) MOICA: a novel multi-objective approach based on imperialist competitive algorithm. Appl Math Comput 219(17):8829–8841
Esmaeili M, Sedehzade S (2018) Designing a hub location and pricing network in a competitive environment. J Ind Manag Optim 13(5):1271–1295
Feili H, Ahmadian P, Rabiei E, Karimi J, Majidi B (2015) Ranking of suitable renewable energy location using AHP method and scoring systems with sustainable development perspective. In: 6th International conference on economics, management, engineering science and art. Brussels, Belgium
Gelareh S, Monemi RN, Nickel SJ (2015) Multi-period hub location problems in transportation. Transp Res Part E Logist Transp Rev 75:67–94
Ghaffarinasab N, Van Woensel T, Minner S (2018) A continuous approximation approach to the planar hub location-routing problem: modeling and solution algorithms. Comput Oper Res 100:140–154
Ghezavati V, Hosseinifar P (2018) Application of efficient metaheuristics to solve a new bi-objective optimization model for hub facility location problem considering value at risk criterion. Soft Comput 22:195–212
Govindan K, Jafarian A, Khodaverdi R, Devika KJ (2014) Two-echelon multiple-vehicle location–routing problem with time windows for optimization of sustainable supply chain network of perishable food. Int J Prod Econ 152:9–28
Hamacher HW, Nickel SJLS (1998) Classification of location models. Locat Sci 6:229–242
Hassannayebi E, Boroun M, Jordehi SA, Kor H (2019) Train schedule optimization in a high-speed railway system using a hybrid simulation and meta-model approach. Comput Ind Eng 138:106110
Hassannayebi E, Memarpour M, Mardani S, Shakibayifar M, Bakhshayeshi I, Espahbod S (2019) A hybrid simulation model of passenger emergency evacuation under disruption scenarios: a case study of a large transfer railway station. J Simul. https://doi.org/10.1080/17477778.2019.1664267
Hassannayebi E, Zegordi SH, Amin-Naseri MR, Yaghini MJ (2017) Train timetabling at rapid rail transit lines: a robust multi-objective stochastic programming approach. Oper Res Int J 17:435–477
Ishfaq R, Sox CRJ (2011) Hub location–allocation in intermodal logistic networks. Eur J Oper Res 210:213–230
Karimi H, Setak M (2018) A bi-objective incomplete hub location-routing problem with flow shipment scheduling. Appl Math Model 57:406–431
Karimi H (2018) The capacitated hub covering location-routing problem for simultaneous pickup and delivery systems. Comput Ind Eng 116:47–58
Kartal Z, Hasgul S, Ernst A (2017) Single allocation p-hub median location and routing problem with simultaneous pick-up and delivery. Transp Res Part E Logist Transp Rev 108:141–159
Khosravi S, Jokar M (2018) Many to many hub and spoke location routing problem based on the gravity rule. Uncertain Supp Chain Manag 6:393–406
Kim H, O’Kelly M (2009) Reliable p-hub location problems in telecommunication networks. Geogr Anal 41:283–306
Lin C-C, Lee S-C (2018) Hub network design problem with profit optimization for time-definite LTL freight transportation. Transp Res Part E Logist Transp Rev 114:104–120
Lopes MC, de Andrade CE, de Queiroz TA, Resende MG, Miyazawa F (2016) Heuristics for a hub location-routing problem. Networks 68:54–90
Mavrotas G, Florios K (2013) An improved version of the augmented ε-constraint method (AUGMECON2) for finding the exact pareto set in multi-objective integer programming problems. Appl Math Comput 219:9652–9669
Mavrotas G (2009) Effective implementation of the ε-constraint method in multi-objective mathematical programming problems. Appl Math Comput 213:455–465
Meier JF (2017) An improved mixed integer program for single allocation hub location problems with stepwise cost function. Int Trans Oper Res 24:983–991
Memarpour M, Hassannayebi E, Miab NF, Farjad A (2019) Dynamic allocation of promotional budgets based on maximizing customer equity. Oper Res Int J. https://doi.org/10.1007/s12351-019-00510-3
Mogale D, Kumar SK, Márquez FPG, Tiwari MKJC, Engineering I (2017) Bulk wheat transportation and storage problem of public distribution system. Comput Ind Eng 104:80–97
Mohammadi M, Jolai F, Rostami HJM, Modelling C (2011) An M/M/c queue model for hub covering location problem. Math Comput Model 54:2623–2638
Mohammed MA, Ghani MKA, Hamed RI, Mostafa SA, Ahmad MS, Ibrahim DA (2017) Solving vehicle routing problem by using improved genetic algorithm for optimal solution. J Comput Sci 21:255–262
Mokhtari N, Abbasi M (2015) Applying VNPSO algorithm to solve the many-to-many hub location-routing problem in a large scale. Eur Online J Nat Soc Sci Proc 3:647–656
Moraga R, Rabiei Hosseinabad E (2017) A system dynamics approach in air pollution mitigation of metropolitan areas with sustainable development perspective: a case study of Mexico City. J Appl Environ Biol Sci 7:164–174
Nagy G, Salhi S (2007) Location-routing: issues, models and methods. Eur J Oper Res 177:649–672
Nagy G, Salhi S (1998) The many-to-many location-routing problem. Top 6:261–275
Newbery DM, Stiglitz J (1984) Pareto inferior trade. Rev Econ Stud 51:1–12
Nikbakhsh E, Zegordi S (2010) A heuristic algorithm and a lower bound for the two-echelon location-routing problem with soft time window constraints. Sci Iran Trans E Ind Eng 17:36
Qu B, Weng K (2009) Path relinking approach for multiple allocation hub maximal covering problem. Comput Math Appl 57:1890–1894
Rieck J, Ehrenberg C, Zimmermann J (2014) Many-to-many location-routing with inter-hub transport and multi-commodity pickup-and-delivery. Eur J Oper Res 236:863–878
Sajedinejad A, Chaharsooghi SK (2018) Multi-criteria supplier selection decisions in supply chain networks: a multi-objective optimization approach. Ind Eng Manag Syst 17:392–406
Song B, Zhuo FJSE (2003) An improved genetic algorithm for vehicle routing problem with soft time windows. Syst Eng 6:12–15
Tomoiagă B, Chindriş M, Sumper A, Sudria-Andreu A, Villafafila-Robles R (2013) Pareto optimal reconfiguration of power distribution systems using a genetic algorithm based on NSGA-II. Energies 6:1439–1455
Tong L, Nie L, Guo G-C, Leng N-N, Xu R-X (2018) Layout scheme of high-speed railway transfer hubs: bi-level modeling and hybrid genetic algorithm approach. Clust Comput 22(Suppl 5):12551
Wasner M, Zäpfel G (2004) An integrated multi-depot hub-location vehicle routing model for network planning of parcel service. Int J Prod Econ 90:403–419
Winsper M, Chli M (2013) Decentralized supply chain formation using max-sum loopy belief propagation. Comput Intell 29:281–309
Xu X, Zheng Y, Yu L (2018) A bi-level optimization model of LRP in collaborative logistics network considered backhaul no-load cost. Soft Comput 22:5385–5393
Yang T-H, Chiu T-YJJOI (2016) Airline hub-and-spoke system design under stochastic demand and hub congestion. J Ind Prod Eng 33:69–76
Yetgin H, Cheung KTK, Hanzo L (2012) Multi-objective routing optimization using evolutionary algorithms. In: IEEE, pp 3030–3034
Zade AE, Sadegheih A, Lotfi MM (2014) A modified NSGA-II solution for a new multi-objective hub maximal covering problem under uncertain shipments. J Ind Eng Int 10:185–197
Zarandi MHF, Hemmati A, Davari S, Turksen IB (2013) Capacitated location-routing problem with time windows under uncertainty. Knowl-Based Syst 37:480–489
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors reported no potential conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Basirati, M., Akbari Jokar, M.R. & Hassannayebi, E. Bi-objective optimization approaches to many-to-many hub location routing with distance balancing and hard time window. Neural Comput & Applic 32, 13267–13288 (2020). https://doi.org/10.1007/s00521-019-04666-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-019-04666-z