
Abstract
This study proposes a very compact coaxial-fed planar antenna for X band applications. The antenna design includes a tulip-shaped radiator on the FR4 dielectric substrate. The antenna parameters, such as return losses, bandwidth and operating frequency, have close relationships with patch geometry. In order to obtain desired antenna parameters for X band application, patch dimension is necessary to be optimized. In this article, four different hybrid artificial intelligence network models are suggested for optimization. These are particle swarm optimization, differential evolution, grey wolf optimizer and vortex search algorithm. Also, they are combined with artificial neural network for the purpose of estimating dimension of patch. Therefore, the comparison of different proposed algorithms is analyzed to obtain higher characteristics for antenna design. Their results are compared with each other in HFSS 13.0 software. The antenna with the most suitable return loss, bandwidth and operating frequency is selected to be used in antenna design.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Ultra-wideband (UWB) communication technologies have recently had widespread applications in the field of microwave imaging, ground penetrating radar and military communications and also often served in robotics and automotive sectors [1–3]. These systems have some advantages such as low complexity and operating power requirements, high range of data rates and low interferences. Therefore, the antenna is one of the most fundamental parts for UWB system owing to omnidirectional radiation pattern, low profile, lightweight, simple and compatible.
In the literature, many parasitic elements are applied on UWB antenna design such as elliptical, triangular, round, ring and several planar shapes [4–8]. In addition, microstrip lines and coplanar waveguide (CPW) line are usually preferred to feed antenna design. CPW feed technique is proposed for antenna design due to easy integrated electronic circuit, low profile, small size and low radiation loss [9, 10]. On the other hand, many soft computing methods are used in different applications. Wen et al. proposed a novel AdaBoost model for classification of vehicles [11]. It is a probabilistic model that Structural Minimax Probability Machine is tried to classify data in real world [12]. Also, fuzzy c-means performance is tested in image segmentation [13]. Cellular neural network is used for elimination of noise in edge of the image [14]. Effective motion and disparity estimation optimization method is performed in multiview video coding [15].
A novel tulip-shaped CPW-fed planar antenna is presented for X band operation with a small dielectric substrate size only 25 × 16 mm2. The modified tulip shape generally resembles a kind of leaf shape. This type of the design geometry has been compared with pedate, palmate, obtuse, hastate and so forth as in Fig. 1. The modified configuration may efficiently improve antenna’s radiation performance, bandwidth and return loss. The bandwidth of antenna should involve all signals in X band range from 8 to 12 GHz for VSWR <2 in accordance with the designers. In addition to these features, it is required to have omnidirectional radiation pattern and better average peak gain. In order to investigate the relationship between the physical dimension and bandwidth of antenna, some parametric and numerical analyses are required. All numerical studies are computed in using Ansoft HFSS and MATLAB software which are based on the finite elements and hybrid artificial neural network methods.

Some leaf-shaped geometries
2 Antenna design
The types of proposed antennas for tulip-shaped antenna configuration are shown in Fig. 1. The antenna patch is placed on a low-cost FR4 (ε r = 4.4) dielectric substrate which has tangent loss tanδ = 0.02 and thickness h = 2.5 mm. A coaxial 50 Ω CPW is used to feed the tulip-shaped antenna design. Moreover, it has connection with SMA connector.
By analyzing planar antenna with regular geometries which are square, circular, triangular and so forth, the proposed cuttings in tulip-shaped antenna are used to enhance the return loss and bandwidth. Parasitic elements are used in antenna design for the purpose of wider bandwidth. At initial, circular patch is one of the basic geometry in tulip-shaped antenna. Nested circles were removed from each well to form the antenna side geometry. In addition, SMA connector is at the fixed point on rectangular strip line instead of investigation of suitable position on all patches. The bottom layer of antenna substrate which is completely covered with copper is used as a ground plane. By means of inspired from the Vivaldi antenna geometry, triangular parasitic element is located in order to increase length of front size of antenna which has direct influence on bandwidth of design.
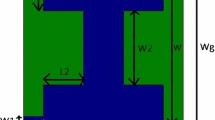
On FR4, size of the antenna boundary is 25 × 16 mm2 (L1 × W1). Parameters for the tulip-shaped patch antenna are as follows: R1, R2, D and W2 in Fig. 2. These parameters are necessary to be optimized for the purpose of obtaining lower return losses, wider bandwidth and optimum operating frequency in X band.
3 Artificial neural network
Studies on the human brain go back thousands of years. Work on this issue has increased with the development of modern electronics. The first artificial neural network (ANN) model was performed in 1943 by Warren McCulloch and Walter Pitts [16]. It was inspired from the calculation capability of the human brain, and therefore, the electrical circuit was modeled as a simple neural network.
ANN has ability to create and explore new knowledge by the way of the most fundamental learning feature without getting any help. Similar to the functional characteristics of the human brain, learning, association, classification, generalization, feature selection and optimization can be implemented successfully [17].
Artificial neural network might consist of many artificial cells which can operate in parallel and hierarchical. These cells are also known as network nodes, and each link is considered to have a value. ANN is the physical cell system which stores and uses experimental data structure. On the other hand, ANN can define a local memory for processing the nonlinear distributed data sets. The main task of a neural network is to identify itself for a set of outcomes that may correspond to a set of input display. Conventional methods are not suitable for processing missing or excessive deviation data due to the risk of obtaining false results. ANN approach has no dependency with missing, incorrect or overly biased data. It can even learn the complex relationships, generalize and find a solution with acceptable error response for optimization problem. Learning algorithms used in ANN is a bit different from a conventional computer algorithms. Learning method provides the ability of generalization for neural network. This generalization is determined by the output sets corresponding to similar events.
In this study, leaf-shaped microstrip patch antenna’s dimensional optimization is implemented by using hybrid artificial neural networks. Patch antenna’s operating frequency, bandwidth and return losses are designed for inputs of artificial neural network. Forecasting models and artificial neural networks are compared to estimate the size and the ability to predict the development of improved models. ANN is not required any assumptions about the distribution of data and variables. Also, it can have ability to tolerate any missing data sets. Data preprocessing is one of the most important parts in soft computing process. Data set can include irrelevant and redundant data. It must be eliminated in data cleaning part. −10 dB in antenna application is accepted as a limit for determining the desired bandwidth. Thus, return loss data over −10 dB must be removed from antenna data set. The normalization process is especially important for improving the performance of optimization. In this way, data set in a wider search space can be squeezed into a smaller range. In addition, normalization is required in mathematical operations which can be made more quickly and easily (Fig. 2).

Antenna configuration
The aim of this study, weights and biases in the multilayered ANN are updated to perform the highest performance and accuracy by popular artificial intelligence algorithms. Generally, conventional ANN methods are not preferred to optimize dimension of microstrip patch antenna owing to fact that changes in the micrometer level size have more effect on the antenna parameters. Update operation in the proposed hybrid neural network model mainly used in artificial intelligence algorithms such as particle swarm optimization, differential evolution algorithm, grey wolf optimizer and vortex search algorithm. The inputs of hybrid neural network are bandwidth (BW), operating frequency (f c) and return loss (S11) in Fig. 3. Number of neuron and hidden layer in this model can be adjusted by the designer. Also, the mean-squared error between training and reference output values is used as objective function. It must be minimized for higher accuracy rate. Thus, optimum weights and biases are obtained for training process in order to be optimized antenna dimension (D, R1, R2 and W2) in the output layer. Hybrid network performance analyzed that bandwidth of proposed antenna is in the X band (8–12 GHz). In addition, hybrid ANN’s results for test data are simulated by HFSS 13.0 antenna design program and have examined the accuracy of the actual value.

Proposed hybrid ANN model

Velocity and position update

PSO block diagram

Steps of differential evolution algorithm

Hierarchy of grey wolf

Pseudo-code of the GWO algorithm

Vortex search process

Pseudo-code f the VSA
4 Artificial intelligence algorithms
4.1 Particle swarm optimization
Particle swarm optimization (PSO) was originally invented by Kennedy and Eberhart in 1995 [18]. The preliminary idea about basic particle swarm algorithm to solve modeling problem had been proposed by Sheta. PSO was applied on estimation of delayed s-shaped parameter by Malhotra [19]. The stochastic evolutionary method is based on behaviors of flying particles through search space. Each particle has own position and velocity in all multidimensional search area. Every particle represents a solution for optimization problem. Random distributed particles try to look for the better value with predefined stochastic rule. The update process of position and velocity is iterated until the minimum error or the maximum iteration number is reached.
Each particle in PSO improves themselves by imitating from swarm’s local (lbest) and global (gbest) best members. When particles search better position, they exchange information about the best position in the swarm. Thus, particles’ movement is not only affected by local best but also guided by the global best. If a particle is obtained the best optimized position, gbest will be replaced with this new location as Fig. 4. On such way, they investigate in the solution space to be shifted to the better location result and the operation can lead to the global best result [20].
PSO is easy to be implemented in optimization problem by a fitness function for exploring optimum maximum and minimum of the problem. Velocity is vital part of PSO and influences on swarm performance toward optimum solution. Calculation of velocity is rate of step change for current member of swarm compared to its prior position, lbest and gbest in Fig. 5. Each particle of PSO updates velocity as following equation:
c 1 and c2 are the weighting social constants, respectively. rand1 and rand2 are generated random numbers within [0,1]. Random numbers provide to be randomly located all particles to a different position than current optimized position. Also, V kid is the kth iteration velocity vector of i particle in the d-th dimension; X kid is kth iteration position of i particle in the d-th dimension; P id is the best position of i particle in the d-th dimension; P gd is the best position of swarm in the d-th dimension. W is the self-adapting function.
The lbest in optimization problem is updated by following criteria:
gbest can be chosen from n s total number of actual lbest values as Eq. 4:
4.2 Differential evolution algorithm
Differential evolution (DE) is heuristic robust optimization algorithm based on scaled vector difference and updated solution vector. It is inspired by Charles Darwin theory which is the survived fittest strategy. DE was designed by Storn and Price in the year 1995 [21]. It is a searching technique to globally optimize the real design parameters in the defined search space. Additionally, this optimization method is efficient to implement on nonlinear, non-differentiable and multidimensional problems owing to advantages of high performance, reliability and complexity [22]. However, these types of general methods have low performance when they cannot transfer private information about the problems to their algorithm design. Limited features in arranged space domain for optimization process can be specific information to improve the performance of algorithm.
DE algorithm is coded in the similar structure to genetic algorithm. It is an improved evolution algorithm for numerical optimization rather than a discrete optimization. Initially, algorithm starts with generating random vector population for search space. Two individual vectors are randomly selected from population to obtain a difference vector. F is scaling factor to produce a weighted vector difference. Randomly selected reverse mutation process is used in DE algorithm in contrast to be based on the previously defined probability distribution function. This simple mutation process improves the performance of algorithm and makes it more robust. Before the crossover operation with target vector, the vector difference is mutated by selected third individual vector. There are some crossover operations between mutant vector and target vector to form a new vector. If new vector’s fitness value is better than target vector’s fitness value, new vector will be participated in the next population as Fig. 6.
The number of the optimization parameter is determined by D-dimensional vector population. NP is the number of the vector as selected greater than three. Initially, NP number in D size consisting of the initial population of vector (P 0) is produced as:
Mutation is making random changes in some genes on vector population. Thanks to these changes, vector solution can scan the search space. In mutation operation, right amount of movement is necessary for reaching target solution. Three different vectors (r 1, r 2, r 3) are selected except for mutant vector in DE algorithm. The difference between two vectors is weighted with F parameter which is usually between 0 and 2. The obtained weighted difference vector is added to selected third vector [23]. Thus, vector for crossover operation is obtained at the end of mutation.
When crossover is performed, candidate solution vector for next generation is produced by mutant difference vector and x i,G vector. Each gene on candidate vector comes from difference vector with CR probability otherwise present vector with 1 − CR probability. Genetic algorithm has uniform crossover operation which has some possibility for gene selection. In DE algorithm, crossover is modified by CR probability. When randomly generated number between 0 and 1 is smaller CR probability, gene comes from n j,i,G+1 otherwise present vector. CR is in [0,1] and determined by users [24]. Following equation is used to guarantee at least one gene from new vector:
A new vector population is generated by selection operator with evaluating present and new generation. Probability of participation in new vector population depends on its fitness value [25]. The higher compliance comparison with each other is appointed as member of the new generation with Eq. 8:
4.3 Grey wolf optimizer
Many artificial intelligence algorithms are based on behavior of coordination and hunting mechanism in swarm. The grey wolf optimizer (GWO) is proposed by Mirjalili [26] and used to find optimal solution for mathematical problems. In the wild, grey wolves have so strict dominant social hierarchy. Alpha (α) is a leader that guides the members of swarm for hunting and sleeping. It is usually symbolized the fittest solution for numerical problems. Beta (β) is in the second step of grey wolf hierarchy. The beta wolves assist and discipline delta (δ) and omega (ω) wolves in accordance with alpha’s commands. They are the best candidates when alpha wolves are aging or passing away. The third level is delta in pack. Delta wolves are responsible for informing with any danger. Mathematically, they are other proposed solutions about problem. The omega grey wolves are at the lowest ranking of the hierarchy and majority of the grey wolf pack. Although the omega seems to be insignificant, many alpha wolves grow up in omega class for the next generation.
GWO has three main parts such as optimization for social hierarchy, encircling prey, and hunting and attacking prey. Grey wolves have ability to detect quarry’s location instinctively while searching. Alphas are at the best positions and lead the pack before encircling quarry. They continuously update the locations in respect of displacement of quarry until the right position. Finally, hunting is started under alphas’ leadership [27].
In the social hierarchy of grey wolves, the best solution is represented as the alpha (α), and the second and third best solutions are orderly as beta (β) and delta (δ). The rest candidate solutions are assumed as omega (ω). Grey wolves pack is guided by α, β and δ in Fig. 7.
Grey wolves encircle the quarry before hunting. For the purpose of modeled mathematically, following equations are used:
The current iteration is symbolized as t, A and C are coefficient vectors, and X and X p are orderly the position vector of the grey wolves and quarry. To formulate A and C vectors:
When a linearly decreases from 2 to 0, r 1 and r 2 are random vectors in the range [1 0]. α, β, δ have better position about where prey is. The other wolves (ω) update locations with pack guiders (α, β, δ) using following formulations:
In the attacking prey section, wolves approach the quarry leads to A value [−2a 2a]. a’s interval ranges from 2 to 0. A value is decision matrix to move attack or explore new preys. The wolves start to attack the quarry in case of |A| < 1. Otherwise, they update position to search new prey in Fig. 8.
4.4 Vortex search algorithm
The vortex search algorithm is an effective metaheuristic numerical optimization method. The algorithm’s design is predicated on the assumption of vertical flow of stirred fluids. It has a good balance between the exploration and exploitation by means of adaptive step size technique in vortex pattern [28]. Many nested circles are used to model vortex pattern for multidimensional optimization problems. To calculate center (µ 0) of outer circle at initial:
The boundary of optimization is from lower limit (lowLim) to upper limit (upLim) as d × 1 vector. Candidate solutions around center of outer circle C t(s) = {s 1 , s 2, s 3,…, s k} (t and k represents the iteration index and the total number of solution) are generated by using random Gaussian distribution equation in Eq. 17.
x is a d × 1 random variable vector, and also ∑ is the covariance matrix which is computed by using equal diagonal variances with zero off-diagonal covariance as Eq. 18 [29].
Additionally, covariance matrix can be calculated cross product of Gauss distribution variance (σ) and d × d identity matrix in respect of Eq. 19.
At the initial, variance of distribution (σ 0) can be accepted as radius (r 0) of the outer circle for optimization problem. r 0 is determined as a large value for full convergence of search space [30]. The best solution (s ı) is selected from random candidate solutions (C 0(s)) and must be shifted inside valid boundary by using Eq. 20 in case exceeding in Fig. 9. Finally, s ı is assigned to new center of the current circle instead of µ 0.
k = 1, 2, …, n, i = 1,2, …, d, and also rand represents a random distributed number. The center of the outer circle is updated by exchanging for best solution (s i). In each steps for generation, the innovative radius (σ k) of new circle is gradually decreased and then, a new solution set C k(s) is distributed around the new center. If s i is better than the global best solution, it is assigned to be the new center of following process. When the radius is decreased depending on iteration, the algorithm only saves the best solution owing to having a poor memory. Similarly, iterated local search and particle swarm algorithm uses the single-solution-based memory approach. At the end of the process, searching algorithm can be completed by maximum iteration or minimum error condition.
The radius reduction technique can be illustrated as an adaptive step size adjustment method in order to implement in random search algorithms. In the VSA, the inverse incomplete gamma function is responsible for minimization of radius value during each iteration process. Also, it particularly bases on involving Chi-square distribution as Eq. 21.
The shape parameter (a) and random variable (x) are greater than zero. Numerical calculation of incomplete gamma function (Г(x, a)) represents in Eq. 22. The gamma function (Г(a)) is known as sum of inverse and incomplete gamma function.
MATLAB has several libraries for effective computing of functions and also includes the gamma function (gamma), incomplete gamma function (gammainc) and inverse incomplete gamma (gammaincinv). The inverse incomplete gamma function calculates via integration between 0 and x incomplete gamma function and is assigned as gammaincinv(x, a) in MATLAB. The shape parameter (a) values are within [0, 1] and continuously is updated at each iteration by computed with Eq. 24.
To guarantee convergence of all search space, a is selected as 1 at initial. t is the iteration index, and MaxItr represents the maximum iteration number. When the value of the iteration number rises up, function value gradually decreases. In the half of iterations, function has linear behavior. Therefore, the function can be analyzed in two separate regions. Initial radius value r0 can be formulated as Eq. 25. Then, value of radius is calculated as a general formula at each iteration term.
The inverse incomplete gamma function is successful method to search space. Radius is dependent of convergence speed in respect of number of iteration. The lower the step size is, the better resolution of the search is obtained. Therefore, the all search spaces are explored as Fig. 10.
5 Results
To study the effects of changes in critical design parameters on the bandwidth of the presented geometry, the antenna characteristics are investigated. Figure 11 shows the simulated bandwidth and return losses on the proposed antenna in X band. For training results, the antenna bandwidth is in 500 MHz–4 GHz interval. Also, its return loss is between −10 and −50 dB. It is clearly observed that operating frequency is around 8–13 GHz. Therefore, dimensional parameters on the microstrip patch play an important role in bandwidth, return loss and operating frequency.

HFSS results of test data
The performance of hybrid artificial intelligence neural networks is evaluated by means of mean square error. In Table 1, their optimization performance is computed by the following formula:
where N represents the number of data items for optimization (test data); n is index of N.
The optimization algorithms are performed with Aspire 5930 Intel Core 2 Duo P8600 2.0 GHz Montevina processors, and 2 GB RAM with 256 MB GDDR3 GeForce supported system memory with nVIDIA 9600 M GT graphics card is used.
Significant differences in simulation result from changes in μm level of the antenna dimension at high frequency. Therefore, each optimization results may be not same with each other. As in Fig. 11, vortex search algorithm (VSA) seems to be closer to real values. In light of these observations, VSA is proposed for optimum antenna design in X band. Thanks to dimension result of this algorithm, the tulip-shaped antenna is implemented in Fig. 12. The simulation and measurement result of VSA are shown in Fig. 13. Desired simulation result indicates that the proposed antenna can achieve a wide bandwidth from 9.23 to 13.31 GHz, −29.5 dB return loss and 9.75 GHz operating frequency thanks to D = 7.2345 mm, R2 = 6.6073 mm, R1 = 6.5832 mm and W2 = 2.4657 mm. In the measurement result, the antenna implementation has 9.68 GHz operating frequency, 9.19 to 13.41 GHz bandwidth and −34.03 dB return loss. Both results are very close with each other in Fig. 13.

Implementation of tulip-shaped antenna

Simulation and measurement result of proposed antenna
Frequency range of X band varies according to the standards. Thus, X band consists of downlink, DBS and telecom frequency range (10.7–12.75 GHz and 11.7–12.7 GHz) of Ku band in European standards and American standards. Also, uplink frequency range of X band (7.9–8.395 GHz) can be used as its downlink frequency range.
According to these standards, the bandwidth of proposed antenna satisfies with a great rate in X band except for downlink frequency range. With these design parameters, the proposed tulip-shaped antenna design must be used in wide bandwidth application in X band.
The simulated radiation patterns at the operating frequency (9.75 GHz) of X bandwidth are given in Fig. 14. In 3-D configuration, asymmetrically unidirectional patterns are obtained in x, y and z planes. Additionally, radiation in z plane is slightly larger than others.

Radiation pattern of proposed antenna
6 Conclusion
In this study, a novel leaf-shaped patch antenna fed by a coaxial connector is proposed. In contrast with the reported leaf-shaped antenna, the proposed leaf-shaped patch antenna can give remarkable antenna performance in X band. The bandwidth, return loss and operating frequency of proposed antenna, which are estimated by different hybrid artificial neural networks models, have been investigated. VSA model has been considered as appropriate optimization. A prototype of proposed antenna has been designed and fabricated, and its parameters have been measured in order to justify the simulation design. Up to 4.22 GHz bandwidth, greater than −30 dB return loss and approximately at 9.68 GHz operating frequency have been obtained. The radiation pattern of simulation design has asymmetry and unidirectionality. Therefore, the leaf-shaped antenna with proposed design parameters would be an excellent candidate for X band application or military system.
Change history
15 May 2024
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1007/s00521-024-09946-x
References
Liu L, Cheung SW, Yuk TI (2013) Compact MIMO antenna for portable devices in UWB applications. IEEE Trans Antennas Propag 61:4257–4264
Chiu CC, Ho MH, Liao SH (2013) PSO and APSO for optimizing coverage in indoor UWB communication system. Int J RF Microw Comput Aided Eng 23:300–308
Behdad N, Sarabandi K (2005) A compact antenna for ultrawide-band applications. IEEE Trans Antennas Propag 53:2185–2192
Nazli H, Bicak E, Turetken B, Sezgin M (2010) An improved design of planar elliptical dipole antenna for UWB applications. IEEE Antennas Wirel Propag Lett 9:264–267
Ojaroudi N, Ojaroudi M, Ghadimi N (2012) UWB omnidirectional square monopole antenna for use in circular cylindrical microwave imaging systems. IEEE Antennas Wirel Propag Lett 11:1350–1353
Liu L, Cheung SW, Azim R, Islam MT (2011) A compact circularring antenna for ultra-wideband applications. Microw Opt Technol Lett 53:2283–2288
Thomas P, Gopikrishna M, Aanandan CK, Mohanan P, Vasudevan K (2010) A compact pentagonal monopole antenna for portable UWB systems. Microw Opt Technol Lett 52:2390–2393
Ray KP (2008) Design aspects of printed monopole antennas for ultrawide band applications. Int J Antennas Propag 2008:1–8
Fakharian MM, Rezaei P (2012) Parametric study of UC-PBG structure in terms of simultaneous AMC and EBG properties and its applications in proximity-coupled fractal patch antenna. Int J Eng Trans A Basics 25:389–396
Fakharian MM, Rezaei P (2012) Numerical analysis of mushroomlike and uniplanar EBG structures utilizing spin sprayed Ni (–Zn)–Co ferrite films for planar antenna. Eur J Sci Res 73:41–51
Wen X, Shao L, Xue Y, Fang W (2015) A rapid learning algorithm for vehicle classification. Inf Sci 295(1):395–406
Gu B, Sun X, Sheng VS (2016) Structural minimax probability machine. IEEE Trans Neural Netw Learn Syst. doi:10.1109/TNNLS.2016.2544779
Zheng Y, Jeon B, Xu D, Wu QM, Zhang H (2015) Image segmentation by generalized hierarchical fuzzy C-means algorithm. J Intell Fuzzy Syst 28(2):961–973
Li H, Liao X, Li C et al (2011) Edge detection of noisy images based on cellular neural networks. Commun Nonlinear Sci Numer Simul 16(9):3746–3759
Pan Z, Zhang Y, Kwong S (2015) Efficient motion and disparity estimation optimization for low complexity multiview video coding. IEEE Trans Broadcast 61(2):166–176
Warner B, Misra M (1996) Understanding neural networks as statistical tools. Am Stat 50(4):284–293S
Masters Timothy (1993) Practical neural network recipes in C++. Academic Press Inc, London
Kennedy J, Eberhart RC (1995) Particle swarm optimization Proceeding IEEE international conference on neural networks, 1995, 1942-1948
Poor H (1985) An introduction to signal detection and estimation. Springer-Verlag, New York
Vilovic I, Burum N (2014) Optimization of feed position of circular microstrip antenna using PSO. The 8th European conference on antennas and propagation (EuCAP 2014)
Storn R, Price K (1997) Differential Evolution- a simple and efficient heuristic for global optimization over continuous spaces. J Global Opt 11:341–359
Deb A, Roy JS, Gupta B (2012) Design of short-circuited microstrip antenna using differential evolution algorithm. Microw Rev 18(N0):3
Li JY, Guo JL (2009) Optimization technique using differential evolution for Yagi-Uda antennas. J Electromagn Waves Appl 23(4):449–461
Aksoy E, Afacan E (2009) Planar antenna pattern nulling using differential evolution algorithm. AEU Int J Electro Commun 63:116–122
Tvrdik J (2007) Differential evolution with competitive setting of control parameters. Task Q 11(1–2):169–179
Mirjalili S, Mirjalili SM, Lewis A (2014) Grey wolf optimizer. Adv Eng Softw 69:46–61
Guptai P, Rana KPS, Kumar V, Nair SS (2015) Development of a grey wolf optimizer toolkit in LabVIEW™,” 9th international conference on futuristic trend in computation analysis and knowledge management, 2015
Dogan B, Olmez T (2015) A new metaheuristic for numerical function optimization: vortex Search algorithm. Inf Sci 293:125–145
Dogan B, Olmez T (2015) Analog filter group delay optimization using the vortex search algorithm. 23rd signal processing and communications application conference, Malatya, 2015
Dogan B, Olmez T (2015) Modified Off-lattice AB Model for Protein Folding Problem Using the Vortex Search Algorithm. Int J Mach Learn Comput 5(4):329
Acknowledgments
I would like to thank Scientific Research Projects (BAP) coordinating office of Selcuk University, and the Scientific & Technological Research Council of Turkey (TÜBİTAK) for their valuable supports.
Author information
Authors and Affiliations
Corresponding author
About this article

Cite this article
Ozkaya, U., Seyfi, L. RETRACTED ARTICLE: A comparative study on parameters of leaf-shaped patch antenna using hybrid artificial intelligence network models. Neural Comput & Applic 29, 35–45 (2018). https://doi.org/10.1007/s00521-016-2620-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-016-2620-1