
Abstract
Learning disability (LD) is a neurological condition that affects a child’s brain and impairs his ability to carry out one or many specific tasks. LD affects about 10% of children enrolled in schools. There is no cure for learning disabilities and they are lifelong. The problems of children with specific learning disabilities have been a cause of concern to parents and teachers for some time. Just as there are many different types of LDs, there are a variety of tests that may be done to pinpoint the problem The information gained from an evaluation is crucial for finding out how the parents and the school authorities can provide the best possible learning environment for child. This paper proposes a new approach in artificial neural network (ANN) for identifying LD in children at early stages so as to solve the problems faced by them and to get the benefits to the students, their parents and school authorities. In this study, we propose a closest fit algorithm data preprocessing with ANN classification to handle missing attribute values. This algorithm imputes the missing values in the preprocessing stage. Ignoring of missing attribute values is a common trend in all classifying algorithms. But, in this paper, we use an algorithm in a systematic approach for classification, which gives a satisfactory result in the prediction of LD. It acts as a tool for predicting the LD accurately, and good information of the child is made available to the concerned.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Learning disability is a general term that describes specific kinds of learning problems. LD is a neurological condition that affects a child’s brain and impairs his ability to carry out one or many specific tasks. These like children are neither slow nor mentally retarded [1]. An affected child can have normal or above average intelligence. This is why a child with a learning disability is often wrongly labeled as being smart but lazy. A learning disability can cause a child to have trouble in learning and using certain skills. The skills most often affected are: reading, writing, listening, speaking, reasoning, and doing math [8]. Learning disabilities vary from child to child. One child with LD may not have the same kind of learning problems as another child with LD. There is no “cure” for learning disabilities [10]. They are lifelong. However, children with LD can be high achievers and can be taught ways to get around the learning disability. With the right help, children with LD can and do learn successfully.
The rapid increase in sizes of databases recently has lead to a growing interest in the development of tools capable in the automatic extraction of knowledge from data. The term data mining or knowledge discovery in databases has been adopted for a field of research dealing with the automatic discovery of implicit information or knowledge within databases [11, 16]. Data mining is a collection of techniques for efficient automated discovery of previously unknown, valid, novel, useful, and understandable patterns in large databases. A widely accepted formal definition of data mining is given subsequently. Data mining is the nontrivial extraction of implicit previously unknown and potentially useful information about data [4]. Conventionally, the information that is mined is denoted as a model of the semantic structure of the data sets. The model might be utilized for prediction and categorization of new data [1]. Diverse fields such as marketing, customer relationship management, engineering, medicine, crime analysis, expert prediction, web mining, and mobile computing besides others utilize data mining [6]. A majority of areas related to medical services such as prediction of effectiveness of surgical procedures, medical tests, medication, and the discovery of relationship among clinical and diagnosis data also make use of data mining methodologies [2].
The field of neural network was originally kindled by psychologists and neurobiologists who sought to develop and test computational analogous of neurons. A neural network is a set of connected input or output units in which each connection has a weight associated with it. During the learning phase, the network learns by adjusting the weights so as to be able to predict the correct class label of input tuples [6]. An advantage of neural network is their high tolerance of noisy data as well as their ability to classify patterns on which they have not been trained. They can be used when we have little knowledge of the relationship between attributes and classes. They are well suited for continuous valued inputs and outputs, unlike most decision tree algorithm. They have been successful on a wide array of real world data, including hand-written character recognition, laboratory medicine, and pathology. Neural network algorithms are used in the parallelization technique to speed up the computation process. In addition, several techniques have recently been developed for the extraction of rule from trained neural network. These factors contribute toward the usefulness of neural network for classification and prediction in data mining [6].
This research paper demonstrates about the development of a system in artificial neural network and data mining for accurate prediction of learning disabilities in school-age children. The remaining paper is organized as follows. Section 2 describes about LD. The neural network method in data mining is explained in Sect. 3 followed by the proposed approach of the study in Sects. 4, and 5 presents the result analysis and findings. Section 6 gives the comparison of results, and finally, Sect. 7 deals with conclusion and future research work.
2 Learning disability
Learning disability is a classification including several disorders in which a child has difficulty learning in a typical manner, usually caused by an unknown factor or factors. The unknown factor is the disorder that affects the brain’s ability to receive and process information. This disorder can make it problematic for a child to learn as quickly or in the same way as some child who isn’t affected by a learning disability. Learning disability is not indicative of intelligence level. Rather, children with a learning disability have trouble performing specific types of skills or completing tasks if left to figure things out by themselves or if taught in conventional ways. Learning disability is a general term that describes specific kinds of learning problems. A learning disability cannot be cured or fixed [15]. There are also certain clues, most relate to elementary school tasks, because learning disabilities tend to be identified in elementary school, which may mean a child has a learning disability. A child probably will not show all of these signs or even most of them [9].
Individuals with learning disabilities can face unique challenges that are often pervasive throughout the lifespan. Depending on the type and severity of the disability, interventions may be used to help the individual learn strategies that will foster future success. Some interventions can be quite simplistic, while others are intricate and complex. Teachers and parents will be a part of the intervention in terms of how they aid the individual in successfully completing different tasks. School psychologists quite often help to design the intervention and coordinate the execution of the intervention with teachers and parents. Social support can be a crucial component for students with learning disabilities in the school system and should not be overlooked in the intervention plan. With the right support and intervention, people with learning disabilities can succeed in school and go on to be successful later in life.
LDs affect about 10 percent of all children enrolled in schools. The problems of children with specific learning disabilities have been a cause of concern to parents and teachers for some time. Pediatricians are often called on to diagnose specific learning disabilities in school-age children. Learning disabilities affect children both academically and socially [8]. Specific learning disabilities have been recognized in some countries for much of the twentieth century, in other countries only in the latter half of the century, and yet not at all in other places [10]. These may be detected only after a child begins school and faces difficulties in acquiring basic academic skills. A learning disability can cause a child to have trouble learning and using certain skills. The skills most often affected are: reading, writing, listening, speaking, reasoning, and doing math [12]. If a child has unexpected problems or struggling to do any one of these skills, then teachers and parents may want to investigate more. The child may need to be evaluated to see if he or she has a learning disability.
Learning disabilities vary from child to child. One child with LD may not have the same kind of learning problems as another child with LD. Learning disabilities are formally defined in many ways in many countries. However, they usually contain three essential elements: a discrepancy clause, an exclusion clause, and an etiologic clause. The discrepancy clause states there is a significant disparity between aspects of specific functioning and general ability; the exclusion clause states the disparity is not primarily due to intellectual, physical, emotional, or environmental problems; and the etiologic clause speaks to causation involving genetic, biochemical, or neurological factors.
The most frequent clause used in determining whether a child has a learning disability is the difference between areas of functioning. When a child shows a great disparity between those areas of functioning in which she or he does well and those in which considerable difficulty is experienced, this child is described as having a learning disability [13]. The most frequent clause used in determining whether a child has a learning disability is the difference between areas of functioning. When a child shows a great disparity between those areas of functioning in which she or he does well and those in which considerable difficulty is experienced, this child is described as having a learning disability [7]. When a LD is suspected based on parent and/or teacher observations, a formal evaluation of the child is necessary. A parent can request this evaluation, or the school might advise it. Parental consent is needed before a child can be tested [11]. Many types of assessment tests are available. Child’s age and the type of problem determines the tests that child needs. Just as there are many different types of LDs, there are a variety of tests that may be done to pinpoint the problem. A complete evaluation often begins with a physical examination and testing to rule out any visual or hearing impairment [3]. Many other professionals can be involved in the testing process. The purpose of any evaluation for LDs is to determine child’s strengths and weaknesses and to understand how he or she best learns and where they have difficulty [12]. The information gained from an evaluation is crucial for finding out how the parents and the school authorities can provide the best possible learning environment for the child.
3 Neural network method in data mining
There are several common methods and techniques of data mining such as methods of statistical analysis, rough sets, covering positive and rejecting inverse cases, and fuzzy method. Neural network is used for classification, clustering, feature mining, prediction, and pattern recognition. The neural network can be broadly divided into 3 viz., feed-forward networks, feedback network, and self-organization network. At present neural network that commonly used in data mining is back propagation network.
MLP neural network architecture is known to be strong function approximation for prediction and classification problems. It is capable of learning arbitrarily complex nonlinear functions to an arbitrary accuracy level. The back propagation algorithm performs learning on a multilayer feed-forward neural network. It iteratively learns a set of weights for prediction of the class label of tuples. A multilayer feed-forward neural network consists of an input layer, one or more hidden layers, and an output layer. Each layer is made up of units. The input to the network corresponds to the attribute measured for each training tuple. The inputs are fed simultaneously into the units making up the input layer. These input pass through the input layer and are then weighted and fed simultaneously to a second layer known as hidden layer. The output of the hidden layer units can be input of another hidden layer and so on. The weighted outputs of the last hidden layer are input to units making up the output layer. This emits the network’s prediction for given tuples.
Back propagation learns iteratively processing a data set of training tuples, comparing the network’s prediction for each tuple with the actual known targets value known as class labels. For each training tuple, the weights are modified so as to minimize the mean squared error between the network prediction and the actual target value. These modifications are made in the backward direction.
4 Proposed methodology
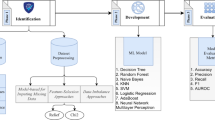
The proposed classification methodology of this research work, for predicting the learning disability, is as shown in the system flow chart given at Fig. 1.

System flowchart
4.1 Data sets
Data mining techniques are useful for predicting and understanding the frequent signs and symptoms of behavior of LD. There are different types of learning disabilities. If we study the signs and symptoms (attributes) of LD, we can easily predict which attribute is from the data sets more related to learning disability. The first task to handle learning disability is to construct a database consisting of the signs, characteristics, and level of difficulties faced by those children. Data mining can be used as a tool for analyzing complex decision tables associated with the learning disabilities. Our goal is to provide concise and accurate set of diagnostic attributes, which can be implemented in an user friendly and automated fashion. After identifying the dependencies between these diagnostic attributes, classification is performed using MLP classifier.
A checklist is used to investigate the presence of learning disability. This checklist is a series of questions that are general indicators of learning disabilities. It is not a screening activity or an assessment, but a checklist to focus our understanding of learning disability. The attributes used in this study are the same signs and symptoms of learning disabilities used in LD clinics. These attributes are shown in the attribute list given at Table 1.
In this study, we have used 513 real-world data sets. The data are collected from learning disability clinics and schools in and around Cochin, India. For choosing the data, a check list, which containing the same signs and symptoms of LD, is used. After conducting direct interview with the children, with the help of teachers and/or parents as required, the check list is filled, which is ultimately used for preparing the data for conducting our study.
4.2 Data preprocessing
Before the data is analyzed by neural network, it has to be preprocessed in order to increase the accuracy of the output and to facilitate the learning process of the neural network. This is a critical operation since neural networks are pattern matches, thus, the way data are represented directly influence their behavior. It is the step to be applied to make the data more suitable for data mining. Data preprocessing is a broad area and consists of a number of different strategies and techniques that are interrelated in complex ways. The different process exist in the preprocessing stage is dimensionality reduction, feature subset selection, removal of noise from the data, and imputing the missing values. In the case of LD data sets, the checklist is the only one assessment method for the prediction. It solely depends on the mood of child. So, we cannot obtain a filled checklist. Incomplete, noisy, and inconsistent data are commonplace properties of large real-world databases and data warehouses [6]. Incomplete data can occur for a number of reasons. On assessment of learning disability, relevant data may not be recorded due to misunderstanding. Our aim is to apply the preprocessing step to make the data more suitable for data mining. Data preprocessing is a broad area and consists of a number of different strategies and techniques that are interrelated in complex ways [19]. In this study, we are proposing the closest fit algorithm for imputing the missing values of attributes. Many data mining approaches including MLP are usually ignoring either the case having an attribute with missing values or the attribute having the missing value. Hence, in this study, we have applied the closest fit algorithm for imputing the missing values and then applied the tool for finding the attribute reduction and classification. The closest fit algorithm for missing attribute value is based on replacing a missing attribute value by existing values of the same attribute in another case that resembles as much as possible the case with the missing attribute values [5]. In searching for the closest fit case, we need to compare two vectors of attribute values of the given case with missing attribute values and of a searched case. In a case where any attribute values are missing, we may look for the closest fitting case within that case or among all cases, and then these algorithms are called concept closest fit or global closest fit, respectively. On another way, the search can be performed on cases with missing attribute values or among cases without missing attribute values. During the search, the entire training set is scanned and for each case, a distance is computed. The case for which the distance is the smallest is the closest fitting case. That case is used to determine the missing attribute values. We have implemented the closest fit algorithm using the Mathworks Software, MatLab.
Let e and e′ be the two cases from the training set.
The distance between cases e and e′ is computed as follows
where
-
distance \( (e_{i} ,e_{i}^{\prime } ) \) = 0 if \( (e_{i} ,e_{i}^{\prime } ), \)
-
distance \( (e_{i} ,e_{i}^{\prime } ) \) = 1 if \( e_{i} ,e_{i}^{\prime } \) are symbolic and \( e_{i} \ne e_{i}^{\prime } \) or \( e_{i} = ?\,\,{\text{or}}\,\,e_{i}^{\prime } = ? \) and distance \( (e_{i} ,e_{i}^{\prime } ) \) = \( \frac{{\left| {e_{i} - e_{i}^{\prime } } \right|}}{{\left| {a_{i} - b_{i} } \right|}} \) if \( e_{i} ,e_{i}^{\prime } \) are numbers and \( e_{i} \ne e_{i}^{\prime } \), where, a i is the maximum of values of
-
Ai, b i is the minimum of values of Ai, and Ai is an attribute.
4.3 Data reduction using principal component analysis
Principal component analysis (PCA) is a method of dimensionality reduction. The data to be reduced consists of tuples or data vectors described by n attributes or dimensions are called PCA [6]. The PCA searches for k n-dimensional orthogonal vectors that can be used to represent the data where k ≤ n. The original data are thus, projected onto a much smaller space, resulting in dimensionality reduction. The basic procedures behind PCA are (i) the inputs data are normalized, so that each attribute falls within the same range. This helps ensure that attributes with large domains will not dominate attributes with smaller domains, (ii) PCA computes k orthonormal vectors that provides a basis for the normalized input data. These are unit vectors that each point in a direction perpendicular to the others. These vectors are referred to as the principal components, and (iii) the principal components are sorted in the order of decreasing strength.
In our study, we have used the LD data sets, which have 16 attributes. When we study this data set, it is seen that some of the attributes are irrelevant. In this study, these irreverent attributes are removed by applying the PCA using weka, a data mining tool, and the number of attributes is reduced to seven. After applying the 513 data sets in weka, we got the ranked reduced attributes as shown in Table 2 later. For reducing the number of attributes after removing the irrelevant ones, we have applied principal component analysis (PCA) which performs PCA and transformation of data. Using conjunction with a ranker search, dimensionality reduction is accomplished by choosing enough eigenvectors to account for some percentage (95%) of the variance in the original data. Attribute noise is filtered by transforming to the principal component space, eliminating some of the worst eigenvectors and then transforming back to the original. In PCA, the eigenvectors are conventionally arranged so that the one with the largest eigenvalue is “first,” which is equivalent the largest variance being “first”. After applying PCA, using the data mining tool weka, we have obtained seven attributes.
4.4 Classification of learning disability
Neural networks are one among the widely recognized artificial intelligence machine learning models. A general conviction is that the number of parameters in the network needs to be associated with the number of data points and the expressive power of the network [18]. The proposed approach utilizes a multilayer perceptron (MLP) with back propagation algorithm to train the selected significant LD cases. The most widely used neural network learning method is the back propagation algorithm.
The classification is performed through the neural network. It is implemented in weka, a machine learning workbench. The architecture of the neural network used in the study is the multilayer back propagation algorithm with 7 input nodes, 5 hidden nodes, and 3 output nodes. The numbers of hidden nodes are determined through trial and error. Learning in a neural network involves modifying the weights and biases of the network in order to minimize cost function. All neural networks are basically trained until the error for each training iteration stopped decreasing. Here, from the 513 data sets, we obtained 98 percent accuracy as shown in Table 3.
MLP can be described as an artificial neural network model capable of mapping sets of input data on to a set of appropriate output. It is an alteration of the typical linear perceptron where it employs one or more layers of neurons with nonlinear activation functions. The primary task of the neuron in the input layer is the division of the input signal among neurons in the hidden layer. Every neuron in the hidden layer adds up its input signals and weights them with the strength of the respective connections from the input layer and determines its output as a function. The back propagation algorithm is used to train the neural networks. It is widely recognized for applications to layered feed-forward networks or multilayer perceptrons [17]. The architecture of MLP obtained from the study is shown in Fig. 2 later. This architecture is obtained after attribute reduction and imputing missing values in the prediction of LD. The architecture consists of 7 attributes, 5 hidden nodes, and 3 output nodes as shown. The output nodes obtained are LD true, LD false, and LD true true.

Architecture of MLP with data mining
5 Result analysis and findings
The proposed method of MLP with data mining is used to predict the status of LD in a child accurately. It is very helpful for the students, parents, and teachers to identify the learning disabilities. MLP with back propagation classification algorithm is used in classification of LD. It is important in this study that we are using data preprocessing for imputing missing attribute values. The missing values have very high impact on the classification algorithm. Obviously, all the classification algorithms ignore the missing values. In our study, we have imputed the missing values in the data set using closest fit algorithm. After this, we found some attributes are irrelevant. So, then by using the PCA, we obtained the reduced attributes, reduced to 7 from 16. These attributes are applied for classification, and we obtained an accuracy of 98.44%. This approach of using neural network, MLP with data mining, gives more accurate results in the prediction of learning disabilities in children. Some researchers are doing the identification of dyslexia, a type of LD, in children [14]. Compared to their works, our work shows accuracy in the tune of above 98%. The importance in our work is that we have performed the data preprocessing and data reduction for LD prediction precisely. The results are very benefit to the parents, teachers, and the institutions. Because they are able to diagnose the child’s problem at an early stage and can go for the proper treatments/counseling at the correct time so as to avoid the academic loss.
6 Comparison with other works
The result of this study is compared with the results of our other similar studies conducted based on J48, Naive Bayes, support vector machines (SVM) and multilayer perceptron classifiers [9]. The comparison of results is shown in Table 4. From this comparison, we can see that MLP with data mining is better in terms of classification and the accuracy. However, the time taken for building the model is slightly higher, but even less than the existing MLP classifier.
7 Conclusion and future works
In this paper, we have developed a new approach in supervised learning algorithm in artificial neural network to effectively and accurately predict the learning disability in school-age children. This study mainly focuses on removing the drawbacks of MLP, because accuracy of decision making can be improved by using our good method of missing value imputing and attributes reduction and applying the classification. This study has been carried out on more than 500 real-world data sets with most of the attributes take binary values and more work need to be carried out on quantitative data as that is an important part of any data set. In future, more research is required to apply the same approach for large data set consisting of all relevant attributes. This study is a true comparison of the proposed approach by applying it to large data sets and analyzing the completeness and effectiveness of the MLP classification with data mining.
Data mining with neural network application on discrete LD data set shows that it is better than other classifiers such as J48, Naïve Bayes, and SVM, in terms of efficiency and complexity. The results from the experiments on these data sets suggest that MLP with data mining gives more precise results for classification and prediction of LD. Our future research work focus on fuzzy-neuro methods for finding the percentage of LD present in each child.
References
Blackwell Synergy (2006) Learning disabilities and research practice, vol 22
Chapple M About.com guide. http://databases.about.Com/od/datamining/g/classification.html
Crealock C, Kronick D (1993) Children and young people with specific learning disabilities. Guides for special education, no. 9. UNESCO, France
Frawley WJ, Piatetsky G (1991) Knowledge discovery in database: an overview. The AAAI/MIT Press, Menlo Park
Grzymala-Busse JW, Grzymala-Busse WJ, Goodwin LK (2001) Coping with missing attribute values based on closest fit in preterm birth date: a rough set approach. Int J Comput Intell 17(3):425–434
Han J, Kamber M (2008) Data mining: concepts and techniques, 2nd edn. Morgan Kaufmann—Elsevier Publishers. ISBN:978-1-55860-901-3
Chen H, Fuller SS, Friedman C, Hersh W (2005) Knowledge discovery in data mining and text mining in medical informatics, chap 1, pp 3–34
Julie MD, Kannan B (2010) Significance of classification techniques in prediction of learning disabilities in school age children. Int J Artif Intell Appl 1(4):111–120. doi:10.5121/ijaia.2010.1409
Julie MD, Kannan B (2010) Machine learning approach for prediction of learning disabilities in school age children. Int J Comput Appl. ISSN: 0975-8887 9(11):7–14
Julie MD, Kannan B (2011) Prediction of key symptoms of learning disabilities in school-age children using rough sets. Int J Comput Electr Eng 3(1):163–169
Julie MD, Kannan B (2008) Paper on prediction of learning disabilities in school age children using data mining techniques. In: Thrivikram T, Nagabhushan P, Samuel MS (eds) Proceedings of AICTE sponsored national conference on recent developments and applications of probability theory, random process and random variables in computer science, pp 139–146
Julie MD, Kannan B (2009) Paper on prediction of frequent signs of learning disabilities in school age children using association rules. In: Proceedings of the international conference on advanced computing, pp 202–207. Mac Million Publishers India Ltd., NYC. ISBN:10:0230-63915-1, ISBN:13:978-0230-63915-7
Julie MD, Kannan B (2010) Paper on prediction of learning disabilities in school age children using decision tree. In: Meghanathan N, Selma B, Nabendu C, Dhinaharan N (eds) Proceedings of the international conference on recent trends in network communications: communication in computer and information science, vol 90, Part 3. Verlag, Berlin, pp 533–542. ISSN: 1865-0929(print) 1865-0937(online), ISBN:978-3-642-14492-9(print) 978-3-642-14493-6(online), doi:10.1007/978-3-642-14493-6_55
Maitrei K, Prasad TV (2010) Paper on identifying dyslexic students by using artificial neural networks. In: Proceedings of the World engineering congress on engineering, vol 1. ISSN: 2078-0966 (online)
Paige R (2002) US Department of Education. In: Proceedings of the twenty-fourth annual report to congress on the implementation of the individuals with disabilities education act-to assure the free appropriate public education of all children with disabilities
Cunningham SJ, Holmes G (1999) Developing innovative applications in agricultural using data mining. In: Proceedings of the southeast Asia regional computer confederation conference
Savcovic-Stevanovic J (1994) Neural networks for process analysis and optimization: modeling and applications. Comput Chem Eng 18(11–12):1149–1155
Patil SB, Kumaraswamy YS (2009) Intelligent and effective heart attack prediction system using data mining and ANN. Eur J Sci Res 31(4): 642–656. ISSN:1450-216X
Tan PN, Steinbach M, Kumar V (2008) Introduction to data mining, Low Price Edition. Pearson Education, USA. ISBN:978-81-317-1472-0, 2008
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Julie, M.D., Kannan, B. Attribute reduction and missing value imputing with ANN: prediction of learning disabilities. Neural Comput & Applic 21, 1757–1763 (2012). https://doi.org/10.1007/s00521-011-0619-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-011-0619-1