
Abstract
In this paper, a new Gradient Gabor (GGabor) filter is proposed to extract multi-scale and multi-orientation features to represent and classify faces. Gradient Gabor filters combine the derivative of Gaussian functions and the harmonic functions to capture the features in both spatial and frequency domains to deliver orientation and scale information. The spatial positions are encoded through using Gaussian derivatives which allow it to provide more stable information. An Efficient Kernel Fisher analysis method is proposed to find multiple subspaces based on both GGabor magnitude and phase features, which is a local kernel mapping method to capture the structure information in faces. The experiments on two face databases, FRGC version 1 and FRGC version 2, are conducted to compare performances of the Gabor and GGabor features. The experiment results show that GGabor yield a powerful tool to model faces, and the Efficient Kernel Fisher classifier can improve the efficiency of the original Kernel Fisher Discriminant analysis method.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Feature representation and efficient classification are two important issues in object recognition systems [1, 2]. To achieve the goal of extracting features in a certain scale, Laplacian of Gaussian (LoG) is introduced [3] to simulate the lateral inhibition for edge detection. In order to extract features in certain orientations, oriented filters or steerable filters are introduced by Freeman [4]. However, to be a powerful descriptor, the feature extractor should be anisotropic, which means that it should enhance the feature in a certain scale and orientation simultaneously. Gabor transformation [5] has been widely used as an effective tool in the image processing and pattern recognition tasks. Different from steerable filters [4, 6], Gabor can also include information both in spatial and frequency domains, and it inherits the property of Gaussian, which is a powerful smoothing tool for the image. The derivative of Gaussian is regarded as an important tool to extract the edge feature for images, which is widely used in image processing and computer vision. In face recognition research community, the edge distribution information has been successfully investigated in [7]. In this paper, Gradient Gabor is proposed based on the combination of Fourier transform and the derivative of Gaussian. Gradient Gabor can capture the features in both spatial and frequency domains to deliver orientation and scale information.
In this paper, Kernel Fisher Discriminant Analysis (KFDA) is combined with Gradient Gabor to calculate multiple discriminant subspaces, which can capture nonlinear variations contained in the training database. One problem of the original KFDA lies in that it is defined based on all training samples, which is the curse of the kernel Fisher method when a large training database is available [8–11]. In [11], Liu et al. proposes a method to solve this problem by using kernel trick to select an optimized subset from data and form a subspace of the feature space, however, it is a little complex and not very effective for reducing time consuming or enhancing recognition accuracy according to the reported results [8, 11]. Another problem is that the original kernel fisher method is a global one, which can not exploit the structure information contained in faces. In [10], the KPCA plus LDA framework provides an efficient way to implement KFDA, but it is still global one and need to save all the training samples. In our former work [8], the bagging is used to develop an efficient KFDA, but it still needs to save about half of training samples to get a reasonable performance. Efficient Kernel Fisher (EKF) is proposed based on local kernel mapping and the clustering centers of the training dataset to reserve both local and global information by constructing multiple subspaces. In order to evaluate the performance of the proposed method, we apply it to solve the face recognition problem. Experiments on two face databases, FRGC version 1 and FRGC version 2 [12], are conducted to compare the Gabor and GGabor-based EKF and other kernel fisher methods.
The rest of this paper is organized as follows. The Gradient Gabor filter is proposed in Sect. 2. The recognition method based on Efficient Kernel Fisher (EKF) analysis is described in Sect. 3. The experiments on FRGC version 1 and FRGC version 2 [12] are given in Sect. 4. We conclude the paper in Sect. 5.
2 Motivation of Gradient Gabor filter
In this section, we first briefly review Gabor wavelet, and then define the Gradient Gabor (GGabor) filters. The difference between Gabor and GGabor is then investigated, which shows that GGabor can provide more stable phase information.
2.1 Gabor wavelet
The Gabor wavelets (kernels, filters) can be defined as follows [13]:
where \( \mathop {k_{u,v} }\limits^{ \to } = \left( \begin{gathered} k_{v}\; cos\Upphi_{u} \hfill \\ k_{v} \;sin\Upphi_{u} \hfill \\ \end{gathered} \right),k_{v} = {{f_{\max } } \mathord{\left/ {\vphantom {{f_{\max } } {2^{v + 2} }}} \right. \kern-\nulldelimiterspace} {2^{v + 2} }},\Upphi_{u} = u{\frac{\pi }{8}}, \) v is the scale and u is the orientation with f max = π/2. In this paper, 4 scales and 4 orientations are used. Gabor wavelet can enhance the features in certain scales and orientations, which is widely used in image processing and object recognition. The Gabor transformation of a given image is defined as its convolution with the Gabor kernel functions:
where z = (x, y), and the symbol * denotes the convolution operator. G u,ν(z) is the convolution result corresponding to the Gabor kernel at scale v and orientation u. The Gabor wavelet coefficient G u,ν(z)is a complex, which can be rewritten as:
with a magnitude item A u,v(z), and a phase item θ u,v(z). It is well known that the magnitude varies slowly with the spatial position, while the phases rotate in some rate with positions, even preserving more detailed information. Due to this rotation, the phases taken from image points only a few pixels apart have very different values, although representing almost the same local feature [13]. This can cause severe problems for object (face) matching, and it is just the reason that most previous works make only use of the magnitude for face classification. In the following part, we introduce a new Gradient Gabor filter, which can provide a relatively stable representation of faces.
2.2 Gradient Gabor filters
The Gradient Gabor (GGabor) filters are defined based on the derivative of Gaussian function:
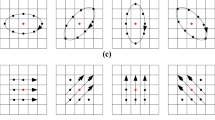
where C is used to make Gradient Gabor DC-free (see the Appendix). Gabor wavelet is modulated by a Gaussian function, which can be regarded as the weighted Fourier transform. The weights for Gabor wavelets are actually exponentially declining with increasing distance. However, Gradient Gabor is defined based on a weighted Gaussian function, which is not declining in an exponential speed as in Gabor wavelets, because it is slowed down by a linear function as shown in Eq. 4 and Fig. 1. Different from original Gabor filters, it can be more stable and provide a robust presentation of the face object by using the multi-scale and multi-orientation local features. Samples of 2D Gabor and GGabor filters are shown in Fig. 2.

Visualization of real parts of 1-D Gradient Gabor and Gabor Filters

Visualization of real parts of 2-D Gradient Gabor and Gabor Filters, a is for Gradient Gabor, b is for Gabor (four scales and four orientations)
3 Ensemble-based Efficient Kernel Fisher classifier
Face recognition is still an ongoing topic in computer vision research [8–14], because the current systems only perform well under the controlled environment but tend to fail in complex situations with variations in different factors such as pose, illumination, and expression. Major statistics-based approaches for face recognition include Eigenface [14] and Fisherface [14]. Eigenface and Fisherface are the statistical learning methods based on Principal Component Analysis (PCA) and Fisher Discriminant Analysis (FDA), which are well-known linear feature extraction approaches. In recent years, the kernelized feature extraction[15–17] methods have been paid much attention, such as Kernel Principal Component Analysis (KPCA) [10, 17] and Kernel Fisher Discriminant Analysis (KFDA) [8, 9], which are nonlinear extensions to PCA and FDA, respectively. However, one of the problems in KFDA lies in its high dimensionality, when the size of the training database is very large. To solve the problem, we utilize local kernel mapping method to efficiently find discriminant subspaces. As shown in Fig. 3, we divide the face image into several subregions, from which we calculate Gabor and GGabor features to train an ensemble of classifiers. To preserve the global distribution information, the clustering centers are further incorporated into the local kernel mapping scheme, which are the so-called EKF method.

An example of face image divided into 48 subregions
3.1 Kernel Fisher discriminant analysis
Kernel Fisher Discriminant Analysis is exploited to calculate a discriminant transformation subspace, and the input data is first projected into an implicit feature space F by a nonlinear mapping \( \Upphi :x \in R^{N} \ge f \in F \). In its implementation, Φ is implicit by just computing the inner product of two vectors in F using a kernel function [8, 9]:
The between-class scatter matrix S b and within-class scatter matrix S w are defined as follows:
where \( u_{i} = \left( {{1 \mathord{\left/ {\vphantom {1 n}} \right. \kern-\nulldelimiterspace} n}} \right)\sum\limits_{j = 1}^{{n_{i} }} {\phi \left( {x_{ij} } \right)} \) denotes the sample mean of class i, u is the mean value of all training images, and p(ϖ i )is the prior probability.
In the original kernel fisher method, \( {\mathbf{w}} \in F \) should lie in the span of all the samples in F, named Basis Support Vectors:
where N is the total number of the training samples. The kernel matrices are defined as follows:
where \( \eta_{j} = \left( {k\left( {x_{1} ,x_{j} } \right),k\left( {x_{2} ,x_{j} } \right), \ldots ,k\left( {x_{n} ,x_{j} } \right)} \right)^{T} ,m_{i} = \left( {{\frac{1}{{n_{i} }}}\sum\nolimits_{j = 1}^{{n_{i} }} {k\left( {x_{1} ,x_{j} } \right)} ,{\frac{1}{{n_{i} }}}\sum\nolimits_{j = 1}^{{n_{i} }} {k\left( {x_{2} ,x_{j} } \right)} , \ldots ,{\frac{1}{{n_{i} }}}\sum\nolimits_{j = 1}^{{n_{i} }} {k\left( {x_{n} ,x_{j} } \right)} } \right)^{T} , \) and \( \mathop m\limits^{\_} \) are the mean vector of all η j .
In [8], we can find that the definition of w based on all training samples is the curse of the kernel fisher method, which requires to save the whole training database. In the following part, we propose a new Efficient Kernel Fisher (EKF) scheme to solve this problem.
3.2 Efficient Kernel Fisher analysis for ensemble-based face recognition
In this part, we try to redefine w by using the local region features and the clustering centers of the training samples. The new Basis Support Vectors are
where C m is the number of clustering centers, and X is the clustering center calculated from the training data by applying K-means method on the training set with C m ≪ N. X j i is the Gabor or Gradient Gabor feature extracted from the local region R i , i = 0, 1,…, L − 1 of the jth clustering face image. From Eq. 13, we can see that \( {\mathbf{w}}^{'} \) is based on both training samples and local region features. Each subclassifier can preserve the information about the relationship among local features across the training database by using local kernel method.
In the classification procedure, v 1, v2 are the discriminant feature vectors corresponding to two face images P 1, P 2, the similarity of which can be calculated by using the cosine rule as
From Eq. 15, we can easily know that the proposed method is based on the sum rule, which actually can exploit the spatial structure information of the face image.
4 Experiments
To validate usefulness of the proposed method, experiments on FRGC version 1 and version 2 databases are conducted. For the experiment 4 on the FRGC version 1, the training set contains 366 images, the target set (Gallery) contains 943 controlled images, and the query set (Probe) has 943 uncontrolled images. For experiment 4 of FRGC version 2, the training set contains 12,776 images, the target set contains 16,028 controlled images, and the query set has 8,014 uncontrolled images. In our study, the polynomial kernel function, k(x, y) = (x.y)2 is used to test the performance of the proposed method.
As shown in [12], the experimental setting is designed for indoor controlled still images versus uncontrolled still images, which is the most challenging FRGC experimental condition. In both experiments, face images are cropped and normalized to the 64 × 72 images, which are further divided into 8 × 12-sized subregion, and the downsample factor for GGabor and Gabor features is 2. In the recognition performance evaluation experiment, we choose features step by step to get the best recognition rates for all comparative methods.
4.1 Comparisons based on FRGC version 1
In this experiment, the mean sample for each class is calculated in the target set. The experiment is conducted to compare the performance of the original Kernel Fisher method and EKF based on Gabor and Gradient features. The P_GGabor or P_Gabor is based on the phase information, M_GGabor or M_Gabor uses the magnitude information, and A_GGabor or A_Gabor exploits both magnitude and phase information. A_Gabor (K) and A_GGabor (K) denote that the methods are based on the original Kernel fisher method, while A_Gabor (E) and A_GGabor (E) are based on the Efficient Kernel Fisher (EKF) method. The Ensemble-GFC method is based on the linear Fisher analysis, details about which can refer to [18, 19]. From Table 1, we can see that A_Gabor (E) and A_GGabor (E) have achieved better performances than the original kernel Fisher method partly for their reserving the structure or local information in faces. While the global information is preserved by using 40 clustering centers. Compared to the original kernel Fisher method using all 366 model samples, EKF is more suitable to the real-world applications. It should be noted that the proposed method achieved a much better performance than the well-known result in [17], which only uses part of FRGC version 1. Compared to the result of LBP (40%) [20], the proposed method also achieves a much better performance as shown in Table 1. The comparative performances of different kernel functions for EKF are also evaluated as shown in Table 2, which shows that the performance of the proposed method is better when the nonlinear kernel is used, because it can capture more complex information contained in the training database.
In Fig. 4, the relationship between the number of clustering centers and recognition rates is depicted, which indicates that the more clustering centers are used, the better performance can be achieved due to more global information reserved. From Fig. 5, we can also find that the phase part of GGabor achieved a better performance than that of Gabor wavelet in terms of rank-1 recognition rates, which confirms that Gradient Gabor can provide more stable information than Gabor. Furthermore, the full magnitude and phase information can be used to enhance the performance of the face recognition system.

Recognition rates of A_GGabor(E) for different numbers of clustering centers on FRGC version 1

Recognition rates of the EKF method (40 clustering centers) with different kinds of GGabor and Gabor features on FRGC version 1. P_GGabor and P_Gabor, M_GGabor and M_Gabor, A_GGabor and A_Gabor are base on the phase part, magnitude part, and full part of GGabor and Gabor features, respectively
4.2 Comparisons based on FRGC version 2
In this scheme, another bigger database is used to evaluate the performance of the face recognition system. As for the high complexity of the original kernel fisher method for a large training database, we choose a subset of 5,000 samples as basis support vectors to train kernel fisher discriminant subspaces using the bagging-based method as in [8], which are A_Gabor (BK) and A_GGabor (BK). For the EKF method, five subclassifiers are trained for each 100 clustering centers resulting in a total of 500 model size, which greatly decreased the model size with an acceptable performance as shown in Table 3. Therefore, the EKF method is a more promising way for real applications.
To compare with the results in [17], we conduct another experiment on the FRGC version 2 database. In the experiment, the size of the normalized image is 128 × 144, and the subregion size is 16 × 24. To further increase the performance, we choose five scales and eight orientations for Gabor wavelet. The downsample parameters for x and y directions are set as 2 and 4, respectively. The recognition rate for the GGabor-based EKF is 78.4% when FAR is 0.1%, and the comparative result is 76% in [17], which show that the performance of the proposed method is better.
5 Summary
This paper proposes a new face recognition method based on the Gradient Gabor feature and EKF, in which both magnitude and phase are used to represent the face. The main contributions of the proposed method are (1) A new Gradient Gabor is proposed for face recognition. Different from Gabor phase, the GGabor phase can offer relatively stable information for face recognition. (2) An Efficient Kernel Fisher method based on local kernel mapping and clustering centers of training dataset is proposed to find discriminant subspaces. We have validated the proposed method by conducting the experiments on two face databases, FRGC version 1 and FRGC version 2.
Although the performance of Gradient Gabor and Efficient Kernel Fisher is successfully applied for face recognition, it is interesting to apply the proposed method to other object recognition tasks in future research.
References
Leonardis A, Bischof H (2000) Robust recognition using eigenimages. Comput Vis Image Underst 78(1):99–118
Moeslund TB, Granum E (2001) A survey of computer vision-based human motion capture. Comput Vis Image Underst 81(3):231–268
Marr D, Hildreth E (1980) Theory of edge detection. Proc Royal Soc London 207:187–217
Freeman WT, Adelson EH (1991) The design and use of steerable filters. IEEE Trans Pattern Anal Mach Intell 891–906
Gabor D (1946) Theory of communication. J Inst Electrical Eng 93(26):429–457
Zhang X, Jia Y (2006) Local steerable phase (LSP) feature for face representation and recognition. Proc IEEE Comput Soc Conf Comput Vis Pattern Recognit 2:1363–1368
Ahonen T, Hadid A, Pietikainen M (2006) Face description with local binary pattern: application to face recognition. IEEE Trans Pattern Anal Mach Intell 28(12):2041–2307
Li Y, Zhang B, Shan S, Chen X, Gao W (2006) Bagging based Efficient Kernel Fisher Discriminant Analysis for Face Recognition. Int Conf Pattern Recognit 523–526
Yang MH (2002) Kernel Eigenfaces vs. kernel Fisherfaces: face recognition using kernel methods. Int Conf Autom Face Gesture Recognit 215–220
Jian Yang, Yang Jing-Yu, Zhang D, Jin Z (2005) KPCA plus LDA: a complete kernel Fisher discriminant framework for feature extraction and recognition. IEEE Trans Pattern Anal Mach Intell 27(2):230–244
Liu Q, Huang R, Lu H, Ma S (2002) Kernel-based optimized feature vectors selection and discriminant analysis for face recognition. ICPR
Philips PJ, Flynn PJ, Scruggs T, Bowyer KW, Chang J, Hoffman K, Marques J, Min J, Worek W (2005) Overview of the face recognition grand challenges. Proc IEEE Comput Soc Conf Comput Vis Pattern Recognit 947–954
Zhang B, Shan S, Chen X, Gao W (2007) Histogram of gabor phase patterns: A novel object representation for face recognition. IEEE Trans Image Process 16(1):57–68
Belhumer P, Hespanha P, Kriegman D (1997) Eigenfaces vs. Fisherfaces: recognition using class specific linear projection. IEEE Trans Pattern Anal Mach Intell 711–720
Wang J-g, Lin Y-s, Yang W-k, Yang J-y (2008) Kernel maximum scatter difference based feature extraction and its application to face recognition. Pattern Recogn Lett 29(13, 1):1832–1835
Hotta K (2008) Robust face recognition under partial occlusion based on support vector machine with local Gaussian summation kernel. Image Vis Comput 26(11, 1):1490–1498
Liu C (2006) Capitalize on dimensionality increasing techniques for improving face recognition grand challenge performance. IEEE Trans Pattern Anal Mach Intell 725–737
Liu C, Wechsler H (2002) Gabor feature based classification using the enhanced fisher linear discriminant model for face recognition. IEEE Trans Image Process 11(4):467–476
Su Y, Shan S, Chen X, Gao W (2006) Hierarchical ensemble of gabor fisher classifier for face recognition. Int Conf Automatic Face Gesture Recognit 91–96
Tan X, Triggs B (2007) Enhanced local texture feature sets for face recognition under difficult lighting conditions. Proc IEEE Int Workshop Anal Model Faces Gestures 168–182
Acknowledgments
We thank Yu Su from JDL lab for sharing Ensemble-GFC algorithm, Heather Ford from Griffith University for proofreading the manuscript. We also thank for the support from mmlab in the Chinese University of Hong Kong. This work is supported by The Natural Science Foundation of China (NSFC) under Contract No. 60903065, Beihang Lantian XinXiu under Contract No. 221521, and Beihang Qingnian ChuangXin Foundation under Contract No. 911901339. We would like to express our appreciation to the anonymous reviewers for their suggestions to improve the manuscript.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
The 1D Gradient Gabor filter has a form of
It is known that the Fourier transform of a Gaussian function exp(−πx 2) has a Gaussian form:
The Fourier transform of the derivative of a Gaussian function −xexp(−πx 2) is
By setting \( \mathop {G\psi (0)}\limits^{\_\_\_\_\_} = 0 \), then \( C = if_{0} \exp \left( { - \pi f_{0}^{2} } \right). \)
The 2D Gradient Gabor wavelet in Eq. 17 can be reformulated as
Then we define a DC-free Gradient Gabor wavelet as follows:
if \( \mathop {G\psi_{u,v} (0,0)}\limits^{\_\_\_\_\_\_\_\_\_} = 0, \) then
Rights and permissions
About this article
Cite this article
Zhang, B., Qiao, Y. Face recognition based on gradient gabor feature and Efficient Kernel Fisher analysis. Neural Comput & Applic 19, 617–623 (2010). https://doi.org/10.1007/s00521-009-0311-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-009-0311-x