
Abstract
Electroencephalography (EEG) is almost contaminated with many artifacts while recording the brain signal activity. Clinical diagnostic and brain computer interface applications frequently require the automated removal of artifacts. In digital signal processing and visual assessment, EEG artifact removal is considered to be the key analysis technique. Nowadays, a standard method of dimensionality reduction technique like independent component analysis (ICA) and wavelet transform combination can be explored for removing the EEG signal artifacts. Manual artifact removal is time-consuming; in order to avoid this, a novel method of wavelet ICA (WICA) using fuzzy kernel support vector machine (FKSVM) is proposed for removing and classifying the EEG artifacts automatically. Proposed method presents an efficient and robust system to adopt the robotic classification and artifact computation from EEG signal without explicitly providing the cutoff value. Furthermore, the target artifacts are removed successfully in combination with WICA and FKSVM. Additionally, proposes the various descriptive statistical features such as mean, standard deviation, variance, kurtosis and range provides the model creation technique in which the training and testing the data of FKSVM is used to classify the EEG signal artifacts. The future work to implement various machine learning algorithm to improve performance of the system.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The brain signal is recorded with electroencephalography (EEG) method in which electrical activity of the cerebral cortex is monitored and different electrodes are placed on the scalp. Presently, noninvasively, an electroencephalography signals are recorded and monitored. Clinical diagnosis and sleep disorders are most widely identified by the EEG technique. Data preprocessing is required when the visual inspection artifact is not a final one, and these artifacts may go ahead with ambiguous results. Generally, the segmentation of the whole affected part with the artifacts is difficult to classify that may in turn leads irrelevant data and data loss. An automatic artifact removal from existence to real time processing is very difficult, so this paper proposes the idea to separate the artifacts automatically. Nowadays, the EEG has also ever-increasing concentration in brain computer interface applications (BCI). But EEG electrical activity signal is corrupted with many biological or natural, medical and societal artifacts (Mahajan and Morshed 2015; Shoker et al. 2005; Jung et al. 2000). Then, societal artifacts are originated and taken from external part (i.e., outer part of human body) because of the motor development and interference in EEG from outside devices like electric motor and potential power.
Obviously, these two artifacts are the obstacles of the BCI applications and clinical diagnosis. Conventionally, the artifact removal is done with linear regressions and filters, with respect to the time and frequency of the target artifacts (Gotman et al. 1973; Woestenburg et al. 1983). Filtering in time or frequency acquires the consistent loss of the brain activity due to the overlap between the signal artifacts and neurological activity (de Beer et al. 1995; Guerrero-Mosquera and Navia-Vazquez 2012). Wavelet using multi-resolution analysis is a more effective technique to remove the artifact, while saving the skeleton in EEG includes both time and frequency domains (Zhang et al. 2004; Mamun et al. 2013). The split target function is established with independent component analysis (ICA) where the set is partitioned into independent component (IC) with small set of blind partition (Jung et al. 2000; Mammone et al. 2012). The method uses spatial filters derived by the ICA algorithm and does not require reference channels for each artifact source. Once the independent time courses of different brain and artifact sources are extracted from the data, “corrected” EEG signals can be derived by eliminating the contributions of the artifactual sources. The ICA algorithm is highly effective at performing source separation in domains where (1) the mixing medium is linear and propagation delays are negligible, (2) the time courses of the sources are independent, and (3) the number of sources is the same as the number of sensors; the global or public artifacts are removed by using the technique called ICA with signals cutoff frequency bands (Gallois et al. 2006).
The EEG signal related with visual inspection is recorded by using the combined method of wavelet ICA, or to apply the manual defined function of artifact removal or random threshold value to classify the noisy element from EEG signals (Devipriya and Nagarajan 2018). Default threshold value can be unsuccessful to catch the artifact that is targeted that very near to the randomly characterized artifacts decision margin of the EEG signals. The false rate may get increased when the threshold value was defined manually.
This paper proposes the technique called a novel method of combining the wavelet ICA (WICA) with fuzzy kernel SVM for effective and robust process of artifacts removal of EEG signals and also gives an improved technique of artifact removal by selecting the training and testing the features or data. Both techniques allow the removal of artifacts with minimal error rate for the brain signals. Finally, test the recorded EEG signal in the publicly available dataset in EEGLAB (Delorme and Makeig 2004). In future discusses the ensemble method of many artifacts removal.
2 Literature review
A single event-related trial-based potentials are separated for the source of blind using 2nd order statistics for correcting the artifacts automatically (Chang et al. 2006). Event-related potentials are normally hided with a variety of artifacts. The properties of artifacts are attenuated with different techniques like epoch removal, electrooculogram (EOG) linear regression and feature extraction. Since the existing techniques are not focused on the automatic removal of artifacts from one ERP epoch, ICA integrating with nth-order form, i.e., higher-order statistics that require the huge volume of input samples to achieve the robust result, this proposed work deals with the technique of automatic identification of artifacts in given raw data by giving the purpose eligibility of different artifacts. Time domain signal amplitude acts as the base for the eligibility.
In Lee (1998), the problem of artifacts selection and extraction in EEG was given, then proposes a novel method to remove the artifacts with combined exercise of wavelet transform that is integrated with ICA. This is contrasted through wavelet denoising. An efficient artifact from EEG recordings using wavelet ICA is proposed. Mainly, four different kinds of waves identified and denoted as alpha, beta, delta and theta. The frequency range from 0 to 4 Hz denotes delta waves, and it is correlated by deep sleep stage. The frequency range from 4 to 8 Hz denotes theta wave, and it is related by drowsiness. The frequency range from 8 to 12 Hz denotes alpha wave, and it is related by relaxed stage. Finally, the frequency range above 12 Hz is related with beta wave which is in active stage.
In Mammone et al. (2012), a novel method for automatic ICA is proposed for removing the artifacts and to trough the AWICA, the performance is increased and the multichannel artifact removal from recorded EEG signal is automated. This provides combined form of wavelet ICA: it contains two major flow process of artifact removal: (1) Kurtosis, (2) entropy, both are synthesized and processed with proposed method. The main objective is to avoid the disadvantages of feature extraction technique of ICA.
In Lu et al. (2006), the EEG artifacts are removed by the effective method of independent component analysis (ICA). During eye blink, an important step is used to classify correctly and indentify the component which is artifacts within the independent component. This component automatically projects the eye blink artifacts depends on the template or pattern of the brain structure that could exemplified as a pattern identical technique. So only feature relevant with spatial is engaged in singleton away from the eye blink element, and this technique is proven to be effective and easier to execute. Finally, this method proves that artifacts are rejected when eyes are blinked while considering the brain activities.
When considering long time periods, multiple factors make it necessary to treat the EEG signal as a nonstationary, stochastic process, i.e., whose mean, correlation and higher-order moments are time varying (Blanco et al. 1995). Short intervals, on the other hand, can reasonably be considered stationary, that is of time-invariant statistical properties, the validity of which depends on the type of signal. Stationarity really depends on the recording conditions, with statistical tests revealing that EEG may be stationary for just a few seconds to several minutes.
3 Methodology
3.1 Limitations of ICA in an artifact removal
ICA can accept widely in which the given artifact is not statistically dependent from the rest of the signals. If the artifacts are considered to be an external, then the hypothesis is defined with clear way when it is in internal state is also selected because of the generating events initially started in the brain field at that time course of artifacts have no information about the triggered event. This is the main purpose to use the ICA for artifact removal. ICA normally carries artifactual information as individual element and many different time elements have non-artifactual knowledge and it can give data loss most of the time. However, the performances of the ICA can fully depend upon the dimension of the samples. When the dimension of an input get increases, the probability of the given number of input is conquered with total amount of channels because the amount of the communication is fixed. This case produces redundancy, and it is not mandatory to calculate the sources in an effective way. Otherwise, algorithm cannot possible to divide signal that is considered as artifacts from the sources. In controversy, the small amount of input samples will lead hard evaluation of arguments with ICA performance that will also get low. So as to overcome the difficulty of this technique, the proposed work includes wavelet ICA (WICA).
3.2 Wavelet ICA technique
According to the limitation of ICA in an artifacts extraction, the proposed WICA allows to increase the redundancy, then use various features/attributes of EEG signal artifacts of frequency domain.
The wavelet extraction related with mother wavelet ψ(t) and scaling function φ(t) of the input signal x(t)
Here, j0 is the random inputting scale. The 1st part of the Eq. 1 is not an exact value of the scale j0. Second part represents summation of inputs.
The approximation coefficients mj0k are represented by
and
Equations (2) and (3) are denoted as scaling functions and related coefficients that are defined with the following equationFootnote 1
and
Equations (4) and (5) are denoted as a wavelet functions.
An occurrence of artifact is detected in a particular channel that is used to divide the given input channel into particular amount of wavelet components (WCs), if an artifactual substances of the spectral content not fully focused on the levels of the decomposition, ICA will be applied in wavelet components and can take the advantages of an improved redundancy, because of the occurrence of the event that is visible to single channel is turned to be visible in more than that single channel
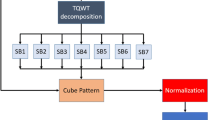
The block diagram of EEG artifacts removal using WICA is shown in Fig. 1. The first step is denoting the wavelet disintegration that used to separate the given dataset into four parts of cerebrum activity, for example, the taken input dataset into n-dimensional vector space in which the ICA is implemented. This new vector space contains scaling and wavelet functions denoted with n − 1 number of decomposition so that the scaling and wavelet function uniformly depends upon the given wavelet family. This paper proposes the Daubechies-4 wavelet family (Ten 1992), and the raw dataset is processed into n-feature/dimensional vector space once the ICA process is selected when the wavelet component is attached to the artifactual activity. The following terms represent the observed random vector in Eq. (6)
and
where k = 1, 2, …, n:
The above equation is also represented in Eq. (7)
the basic vector ak represents the random vector p form the value of e.
where p denotes n-dimensional vector; this has to be used to extract the IpCs. Here, p denotes the dataset which selects the wavelet component and e represents the estimation of IpCs and M denotes the matrix. The matrix M is estimated with respect to additional learning rule (Lee 1998). This rule is used to extract the effective artifacts removal such as eye blinks and line noise occurred when electrical signal happens from brain.

The block diagram of wavelet independent component analysis of EEG artifacts
3.3 Fuzzy kernel support vector machine classification
Support vector machine (SVM) generally used as a binary classifier under machine learning technique of supervised learning (Chang and Lin 2011). The main objective is to build an optimal hyperplane by using training dataset as shown in Fig. 2 that is used to test two or more datasets in the classification for testing the dataset. Vapnik proposes the technique of SVM which is used to extend the study of classification and regression (Belousov et al. 2002). The best hyperplane is selected to calculate the maximal margin with the closet dataset which is different from support vectors. Increasing the general characteristics, maximal of margin is used to construct the capabilities. The optimization problem is quadratic when training the SVM.

Optimal hyperplane. The structure of hyperplane WTX + b = 0 separates 2 labels: the crosses and the circles
The construction of SVM hyperplane is defined as
Here W is the weight vector and b is defined as offset parameter. In order to maximize the margin, the hyperplane and their closest point denoted as support vectors.
This type of decision boundary classification is called as linear SVM, and kernel trick used for decreasing the complexity of classification in a nonlinear margin is known as nonlinear SVM. Nonlinear margin function is defined as Eq. (9)
where the d(x) represents the distance function, \( \alpha_{i} \) represents the Lagrange multiplier, n represents the amount of support vectors, and b denotes offset parameter.
The kernel function K \( \left( {x, x_{i}^{n} } \right) \) used to compute the nonlinear mapping function Eq. (10)
where the kernel K \( \left( {x, x_{i}^{n} } \right) \) function commonly used for BCI (brain computer interface) research represented as Gaussian or radial basis function (RBF) Kernel is denoted as
If RBF kernel is used by SVM, two main parameters are considered (1) kernel parameter (\( \sigma \)) and (2) trade-off parameter. In traditional way, the above two parameters are optimized for good performance by using the n-fold cross-validation. All these calculation are taken place solely for training data.
3.4 Fussy kernel support vector machine (FKSVM)
The optimal hyperplane calculated by the SVM classifier depends upon the low amount of data. It leads to errors or outliers in training data. To overcome this problem, FKSVM is proposed with fuzzy SVM membership of input data. FKSVM (Devipriya and Nagarajan 2018) is also used to concentrate on maximization of margin like traditional SVM but at the same while considering the outliers with less membership prevents the noises to make a narrow data points in terms of higher probability (Lin and Wang 2004).
Suppose the task of binary classification with t training data represented as [X1, y1, m1], …, [Xt, yt, mt]. For each and every training data set
Output label yi ∈ {+ 1, − 1} and fuzzy membership mi ∈ [\( \sigma \), 1].
i is represented as i = 1,…, m, and it is enough when \( \sigma > \, 0 \) the training data point equal to 0 represent for empty then it should deleted in the training data without affecting training dataset. Then, optimal hyperplane is determined with minimum error by the term used to measure error in SVM. To minimize error function using Eq. (13)
With respect to
where
The best possible (optimal) hyperplane was calculated by finding the quadratic equation by using the Kuhn–Tucker conditions and Lagrange multiplier.
The method of Lagrange multipliers is a strategy for finding the local maxima and minima of a function subject to equality constraints (i.e., subject to the condition that one or more equations have to be satisfied exactly by the chosen values of the variables). The basic idea is to convert a constrained problem into a form such that the derivative test of an unconstrained problem can still be applied.
The Lagrange multiplier theorem roughly states that at any stationary point of the function that also satisfies the equality constraints, the gradient of the function at that point can be expressed as a linear combination of the gradients of the constraints at that point, with the Lagrange multipliers acting as Coefficients. The relationship between the gradient of the function and gradients of the constraints rather naturally leads to a reformulation of the original problem, known as the Lagrangian function.
To select the appropriate fuzzy memberships is a crucial step for designing the fuzzy SVM classifiers. The objective rule is to process a membership value which is appropriate to the input information points can only depend upon the corresponding information points of their own classes. The below section discusses the statistical measures (feature selection) projected to find out the accuracy of the performance system.
4 Results and discussion
In this research, used a dataset that is taken from the database available ftp://ieee.org/uploads/press/rangayyan/. This contains eight channels without artifacts signal of EEG. It is processed under sampling rate of frequency 100 Hz; time taken for recording the signal considered as 7.5 s. The scalp electrode position/placement of EEG is represented in Mammone et al. (2007). Delorme et al. (2007) simulated the different methods of artifacts described here: (i) eye blink, (ii) electrical power shift and (iii) temporal motor movement signal. This temporal random motor movement signal artifact is filtered with band pass filter with the frequency between 20 and 70 Hz and simultaneously filters the eye blink artifacts by random band pass filtered between 2 and 5 Hz.
To facilitate a visual artifactual EEG, correlate the one to one with artifacts of central and frontal electrodes placed in the scalp, therefore acquired four different datasets of eight channels brain signals degraded with artifacts.
4.1 Artifacts removal
MATLAB® was used for implementing the artifact removal by applying the method of WICA and fuzzy kernel SVM. The frequency range is subdivided into various subbands relevant with the EEG measure because entire frequency range in the EEG is decomposed with four levels wavelet and this measure is considered as an enough to separate the frequency range into sub-bands. The EEG measure is categorized as delta: 0–4 Hz, theta: 4–8 Hz, alpha: 8–12 Hz, beta: 12 Hz and higher. The EEG measure used to extract the signal from the EEG artifact is described in the below algorithm

The EEG measures project the clear output such as delta and theta range inclined with wavelet components (Daubechies-4) of visual condition. So delta and theta waves are instructed to correlate with eye blinks. Very high frequency such as beta and alpha concentrate on the motor movement activity, and majorly beta measures are correlated with motor movement activity. Because of equal influence of the various waves, the decrease in artifact loss was also possible in order to obtain the efficiency of the artifacts removal; optimization is accomplished for further processing.
4.2 Automatic selection of artifact component correlated with wavelet
Various statistical measures were estimated for measuring the artifacts with the correlated wavelet components. The statistical measures such as: (µ) mean, (σ) standard deviation, (k) kurtosis and (E) entropy are described in the below section.
4.2.1 Mean (M)
This term mean refers to measure the central tendency in the data points
4.2.2 Standard deviation (SD)
SD is used to calculate the quantity of variation or dispersion of data, and this used a feature as time domain. It is regularly evaluated with the following expression
4.2.3 Hjorth parameters (HP)
HP is design to calculate the mobility, movement and density of the EEG signals (Hjorth 1975). This is estimated using the EEG signal, m(n) and 1st and 2nd orders are defined as m′(n) and m″(n) as follows
4.2.4 Renyi entropy (RE)
RE is used to estimate the entropy of the Gaussian distribution G = (G1, G2, …, Gn) (Renyi 1960). RE is represented as
where m denotes the array of Renyi entropy, when m is > 0, then m is not equal to 1.
4.2.5 Kraskov entropy (KE)
KE measures Shannon entropy used with maximum of n samples multiplied with m-dimensional random vectors x. KE is represented as follows:
4.2.6 Organized spectral entropy (OSE)
OSE measured from power band normalization (Sabeti et al. 2009). It is estimated as follows
where f1 and f2 are the lower and upper frequency, S denotes power density, and Nf denotes total amount of frequencies between the range.
4.3 Minimum and maximum
The max() and min() functions return the maximum and minimum value in a vector.
4.3.1 Mode
The mode is another representative value that may be used to describe a group of numbers. It is the value that occurs most often in the group. The mode of a set of data is the number with the highest frequency.
4.3.2 Variance
The variance to be represented as
4.3.3 Kurtosis (K)
K is a measure unconditional form of the probability in the dataset, and it is defined as
The computation of the WCs correlated with EEG measures is shown in Fig. 3. Entropy detects the wavelet component 3 and wavelet components 4 successfully, simultaneously represent the motor movement activity and kurtosis detect wavelet component 11 and 12 to represent the electrical power. At end, kurtosis detects the wavelet component 1, 2, 9 and 10 to represent the visual inspection.

Entropy and kurtosis used to measure the artifact wavelet component
The performance of the WICA was compared with enhanced ICA methodology (Makarov and Castellanos 2006). The quantitative results of the (RMSE) root mean square error and correlation within the original artifact EEG signals with processed EEG signals are shown in Table 1.
4.3.4 Machine performance evaluation
The main four measures can be used to estimate the performance of the proposed work. Generally, classification parameters are defined as performances such as accuracy, sensitivity, specificity and confusion matrix as follows
TP, TN, FP and FN represent true positives, true negatives, false positives and false negatives, respectively.
N-fold cross-validation is used for estimating machine parameters and to perform the machine performance. N denotes total amount of inputs. Each and every fold one input is used for testing; then other inputs are used for training and testing (validating) input. This type of procedure was iterated until n times. The average value of k-fold results is taken and visualized as a machine performance as shown in Fig. 4.

Machine performance measures comparison
Classification performance for RMSE rate is depicted in Fig. 5.

RMSE for proposed methodology
Table 2 shows the FKSVM that reported the classification accuracy 86.1% as an output using an input dataset, and comparison of the performance of FKSVM is shown in Table 3
5 Conclusions and future work
An identification and removal of artifacts of EEG signal implemented through a novel technique of fuzzy kernel SVM to classify the artifacts in WICA is proposed. The FKSVM continuously increases the identification of artifacts components and to give better classification accuracy mentioned as 86.1%. Moreover, different types of artifacts features are selected using the training data. Our proposed system automatically removes the artifacts of EEG signal from the raw dataset. To conclude, different kinds of features are taken for removal of artifacts of EEG signal and various system performance measures are considered for estimating the accuracy of the proposed work. Future work could find out the best feature, which is used to remove the artifacts while presenting the process of eye blink. The method dependency model is evaluated for the number of source components. It is reassuring that the performances of the methods, relative to each other, remain at a similar level for a wide range of numbers of components retained. This indicates that there are indeed true differences between the methods that do not strongly depend on whether a strict or mild cleaning policy is used.
Change history
12 August 2024
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1007/s00500-024-10017-5
Notes
The best possible (optimal) hyperplane was calculated by finding the quadratic equation by using the Kuhn–Tucker.
References
Belousov AI, Verzakov SA, von Frese J (2002) A flexible classification approach with optimal generalization performance: support vector machines. Chemometr Intell Lab Syst 64:15–25
Blanco S, Garcia H, Quiroga RQ, Romanelli L, Rosso OA (1995) Stationarity of the EEG series. IEEE Eng Med Biol Soc 14:395–399
Chang CC, Lin CJ (2011) LIBSVM: a library for support vector machines. ACM Trans Intell Syst Technol 2:27
Chang CQ, Chan FH, Ting KH, Fung PC (2006) Automatic correction of artifact from single-trial event-related potentials by blind source separation using second order statistics only. Med Eng Phys 28(8):780–794
de Beer NA, van de Velde M, Cluitmans PJ (1995) Clinical evaluation of a method for automatic detection and removal of artifacts in auditory evoked potential monitoring. J Clin Monit 11:381–391
Delorme A, Makeig S (2004) EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J Neurosci Methods 134:9–21
Delorme A, Sejnowski T, Makeig S (2007) Enhanced detection of artifacts in EEG data using higher-order statistics and independent component analysis. Neuroimage 34:1443–1449
Devipriya A, Nagarajan N (2018) A novel method of segmentation and classification for meditation in health care systems. J Med Syst 42(10):193
Gallois P, Vasseur C, Boudet S, Peyrodie L (2006) A global approach for automatic artifact removal for standard EEG record. In: Proceedings of IEEE engineering in Medicine and Biology Society (EMBC 2006), Orlando, FL, pp 5719–5722
Gotman J, Skuce DR, Thompson CJ, Gloor P, Ives JR, Ray WF (1973) Clinical applications of spectral analysis and extraction of features from electroencephalograms with slow waves in adult patients. Electroencephalogr Clin Neurophysiol 35:225–235
Guerrero-Mosquera C, Navia-Vazquez A (2012) Automatic removal of ocular artefacts using adaptive filtering and independent component analysis for electroencephalogram data. IET Signal Proc 6:99–106
Hjorth B (1975) Time domain descriptors and their relation to a particular model for generation of EEG activity. In: Dolce G, Künkel H (eds) CEAN: computerized EEG analysis. Gustav Fischer-Verlag, Stuttgart, pp 3–8
Jung TP, Makeig S, Humphries C, Lee TW, McKeown MJ, Iragui V et al (2000) Removing electroencephalographic artifacts by blind source separation. Psychophysiology 37:163–178
Lee T-W (1998) Independent component analysis—theory and applications. Kluwer Academic Publishers, New York
Lin C, Wang S (2004) Training algorithms for fuzzy support vector machines with noisy data. Pattern Recogn Lett 25:1647–1656
Lu Z, Li Y, Li Y, Ma Z (2006) Automatic removal of the eye blink artifact from EEG using an ICA-based template matching approach. Physiol Meas 27(4):425–436
Mahajan R, Morshed BI (2015) Unsupervised eye blink artifact denoising of EEG data with modified multiscale sample entropy, kurtosis, and wavelet-ICA. IEEE J Biomed Health Inform 19:158–165
Makarov VA, Castellanos NP (2006) Recovering EEG brain signals: artifact suppression with wavelet enhanced independent component analysis. J Neurosci Methods 158(2):300–312
Mammone N, Morabito FC, Inuso G, La Foresta F (2007) Wavelet-ICA methodology for efficient artifact removal from electroencephalographic recordings. In: Proceedings of international joint conference neural networks (IJCNN 2007), Orlando, FL, pp 1524–1529
Mammone N, Foresta FL, Morabito FC (2012) Automatic artifact rejection from multichannel scalp EEG by wavelet ICA. IEEE Sens J 12:533–542
Mamun M, Al-Kadi M, Marufuzzaman M (2013) Effectiveness of wavelet denoising on electroencephalogram signals. J Appl Res Technol 11:156–160
Renyi A (1960) On measures of information and entropy. In: Proceedings of 4th Berkeley symposium on mathematical statistics and probability, pp 547–561
Sabeti M, Katebi S, Boostani R (2009) Entropy and complexity measures for EEG signal classification of schizophrenic and control participants. Artif Intell Med 47(3):263–274
Shoker L, Sanei S, Chambers J (2005) Artifact removal from electroencephalograms using a hybrid BSS-SVM algorithm. IEEE Signal Process Lett 12:721–724
Ten Daubechies I (1992) Lectures on wavelets. Society for Industrial and Applied Mathematics, Philadelphia
Woestenburg JC, Verbaten MN, Slangen JL (1983) The removal of the eye-movement artifact from the EEG by regression analysis in the frequency domain. Biol Psychol 16:127–147
Zhang JH, Janschek K, Bohme JF, Zeng YJ (2004) Multi-resolution dyadic wavelet denoising approach for extraction of visual evoked potentials in the brain. IEE Proc Vis Image Signal Process 151:180–186
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All author states that there is no conflict of interest.
Human and animals rights statement
Humans/animals are not involved in this work.
Additional information
Communicated by V. Loia.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article has been retracted. Please see the retraction notice for more detail: https://doi.org/10.1007/s00500-024-10017-5
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Yasoda, K., Ponmagal, R.S., Bhuvaneshwari, K.S. et al. RETRACTED ARTICLE: Automatic detection and classification of EEG artifacts using fuzzy kernel SVM and wavelet ICA (WICA). Soft Comput 24, 16011–16019 (2020). https://doi.org/10.1007/s00500-020-04920-w
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-020-04920-w