
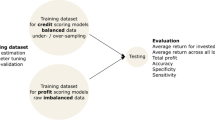
Abstract
In the emerging peer-to-peer (P2P) lending industry, risks such as credit risk and default risk will bring huge losses to online lending platforms and investors. Therefore, it is necessary to design a reasonable evaluation index system of credit risk to scientifically evaluate the risk level of borrowers. This paper studies the design of comprehensive evaluation index system for P2P credit risk of “three rural” (i.e., agriculture, rural areas and farmers) borrowers. Concretely, we construct the feature set for P2P credit risk of “three rural” borrowers. Based on the traditional index system, we add the static indexes specific to the agriculture-related borrowers and the dynamic indexes reflect the Internet as the preliminary indexes of the feature set and select the borrowers data of the “Pterosaur loan” platform as the research sample. Then, 35 borrower credit features are extracted as a feature set of credit risk. Then, we present a two-stage feature selection method based on filter and wrapper to select the main features from 35 initial borrower credit features. In the stage of filter, three filter methods are used to calculate the importance of the unbalanced features. In the stage of wrapper, a Lasso-logistic method is proposed to filter the feature subset through heuristic search algorithm. In the end, 21 main independent features are selected according to the classification accuracy, which constitute the evaluation index system of credit risk of “three rural” borrowers.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The rise of Internet finance provides new lending channels for borrowers. As early as 2005, Zopa was established in the UK, which is an important “sign” of the development of P2P online loan industry. Then, in 2007, the LendingClub has launched, and now it becomes the largest Internet loan company in the world. In the same year, the company of PPDF, the first P2P lending company in China, was established. Subsequently, the P2P online loan industry develops rapidly under the Internet technology (Liu et al. 2019; Gao et al. 2018), and the number increases sharply, making 2013 the “Chinese Internet finance year” in the industry. At this time, the agribusiness online loan platform also becomes a new way to solve the rural financial financing. At present, according to the statistics of WDZJ-OFFICIAL, there are hundreds of lending platforms focusing on “three rural” (i.e., agriculture, rural areas and farmers) in China, where “Pterosaur Loan” and “CreditEase Loan” are known by ordinary people and have high credibility. To some extent, the agriculture-related online loan platform has solved the financing demand of rural economy and alleviated the problem of “difficulty in borrowing and lending” in rural areas. But throughout the entire financial market in China, the net lending industry rises but hidden behind a lot of risk. For example, the domestic P2P online lending platforms are frequently out of business. According to statistics of “2018 annual report for P2P network credit industry,” the total number of platforms in P2P online lending industry has reached 6430 (including platforms out of business and the problematic platforms) by the end of December 2018, and the total number of platforms out of business and the problematic platforms has reached 5409. At the same time, the existence of unreasonable debt structure of the borrowers led to the phenomenon of borrower default is common. These phenomena indicate that there are great hidden dangers in the credit security of online loan platforms.
For agriculture-related platforms, China’s credit rating system for rural households needs to be unified, and the evaluation methods of credit risk of agriculture-related borrowers are insufficient. Therefore, the risks of information asymmetry, moral hazard and lack of integrity still exist on the lending platforms. Risks such as credit risk and default risk will not only bring huge losses to the platform and investors, but also cause a series of serious events endangering personal safety. Therefore, it is very necessary to construct a reasonable assessment index system of credit risk of agriculture-related borrowers to scientifically evaluate their risk level.
In most regions of China, the formal financial system cannot fully meet the loan needs of farmers, but the agriculture-related P2P online loan platform is an effective channel to alleviate the difficulty of farmers’ loan. Therefore, by exploring the risk control platform of “Pterosaurs Loan,” this paper hopes to correctly use the Internet data to identify the risk level of rural household borrowers, reduce the losses of the platform and investors and solve the problems of default and overdue caused by information asymmetry in the online loan industry. This also makes the study of this paper is of practical significance.
2 Literature review
For the factors affecting credit risk, the literature on P2P platforms can be divided into two categories: the relationship between borrower information and loan success rate or default rate and the relationship between loan information and the borrower’s risk level.
Kumar (2007) found that the number of bids submitted by the borrowers was directly affected by their family features, personal income and debt situation, and he also found that the more detailed information the borrower filled in, the higher the loan success rate of borrowing. In addition, scholars also studied the default rate from the statistics perspective of race and gender. For example, based on the transaction data of the Prosper online lending platform, Ravina (2008) found that the borrowers’ physiological features such as race, physical appearance and gender play an important role in the default rate of loans. Because of the existence of racial discrimination, blacks have a lower success rate than whites, and their default rate is higher than that of whites.
Subsequently, Freedman and Jin (2008) studied the information asymmetry problem based on the loan transaction data on the platform of Prosper and found that compared with the traditional bank credit system, the borrower “hard information” on the P2P online loan platform has no details. There is a general lack of “hard information,” but the “soft information” on social networks can alleviate and supplement the lack of information in time. Based on the results of this research, a large number of scholars have shifted the research object to the problem of information asymmetry. Herzenstein et al. (2011) found that the more’ favor, but the fact is that such borrowers tend to have higher default rates. Specifically, Dorfleitner et al. (2016) studied the text information of borrowing descriptions in P2P platform and extracted text length, spelling error rate and emotional word frequency as the borrower features. The research found that there is a certain correlation relationship between these “soft information” features and default rate.
China’s P2P online lending credit started late, but in recent years, people have also begun to pay attention to the credit risk problem of P2P lending. They believes that information asymmetry and user fraud have a significant impact on credit ratings. There is also a corresponding research results on this issue. For example, Yu (2017) explored the relationship between the descriptive information and the default rate. The empirical results showed that borrowers who can honestly talk about their family income and property are more inclined to perform their contracts, while those who emphasize their high credibility and express their integrity with their past credit records are more likely to default. Based on these literature, Su and Cheng (2017) mined the text “soft information” of borrower description through the trading data of “Renrendai” platform and concluded that the borrower’s education level, age, lending rates and loan amount have a significant negative effect on the default rate, and the index of “spelling mistake” in “soft information” has a significant positive effect on the default rate. This study showed that the borrower’s “soft information” cannot be ignored and has important research significance in credit risk.
In recent years, people not only pay attention to the application of models, but also pay more attention to the characteristics of data itself. In order to reduce the influence of overfitting and improve the learning speed and generalization ability of the model, feature selection plays an important role in the whole data mining environment to extract the key information in the data for subsequent classification and prediction when processing massive data. At present, the methods of feature selection can be divided into filtering method and encapsulation method.
In the application of Filter, Chen (2010) compared four Filter methods, namely decision tree, F-score, rough set and linear discriminant method, based on the credit score data in UCI database, and verified the feasibility and effectiveness of filter methods in feature selection. Chen (2006) established the credit index system of personal housing loan through calculating the information gain of personal housing loan index. But this method is biased in the classification of imbalanced data, and it easily misunderstood when understand equilibrium data. Based on the characteristics of random forest (RF), Ye et al. (2018) used RF to calculate the importance of borrower features and extracted ten features with the highest importance according to the threshold value, which were taken as the input features of Naive Bayes. The Wrapper method is a method to judge the quality of the feature set according to the performance of classification algorithm. About the credit risk rating, Bermejo et al. (2012) used the Wrapper method containing two algorithms to make iterative modeling calculation for several credit features ranking at the top until no new features were selected. However, the Wrapper method has a high computational complexity and the algorithm takes a long time to execute.
Subsequently, some scholars began to study the advantages and disadvantages of Filter and Wrapper and considered the mixed use of various feature selection methods. For example, Wang (2017) used Wrapper and Filter methods in the selection of borrower features. Firstly, several filter methods were used to screen out 115 features, and then, Xgboost algorithm was used to evaluate default risk. In the same year, Jiang et al. (2017) proposed a combined feature selection method, which integrated multiple Filter methods and used RF as the Wrapper classification algorithm to select the effective feature subset, thus improving the default identification rate of borrowers. In addition, common evaluation models also contain the characteristics of variable selection. Tibshirani (1996) proposed Lasso algorithm, which is an efficient algorithm suitable for high-dimensional problems and can carry out parameter estimation while making variable selection, thus preventing too many variables from being selected. In combination with the advantages of the above literature, this paper considers the importance of features from various aspects in Filter and obtains the feature subset that has a significant impact on risk level by combining the Wrapper method.
From existing research, we can see that there are relatively few literatures related to the influencing factors of credit risk of agriculture-related borrowers in the field of “three rural”(agriculture, rural areas and farmers). Based on these research backgrounds, this paper takes the “Pterosaur Loan” platform as the research data sample and constructs an index system for effectively evaluating the credit risk of agriculture-related borrowers in the field of “three rural based on the statistical theory and machine learning method.
The rest of this paper is organized as follows. Section 3 collects and preprocesses the data. The data of “Pterosaur Loan” are selected as the research sample, and the objective information and subjective text information were fused to construct the feature set. Section 4 proposes a two-stage feature selection method of credit risk combined Filter and Wrapper, and constructs a comprehensive evaluation index system for P2P credit risk of “three rural” borrowers. Section 5 concludes the paper.
3 Data collection and data preprocessing
In order to reduce the information asymmetry and reduce the risk of investors and the platform, we fully extracts the credit risk indexes to construct the feature set of credit risk according to the subjective descriptive information and objective information provided by agribusiness borrowers on the lending platform. Firstly, on the basis of indexes selected from existing literatures (Liu et al. 2019; Gao et al. 2018; Freedman and Jin 2008; Herzenstein et al. 2011; Su and Cheng 2017), we add the static indexes specific to the “three rural” borrowers and the dynamic indexes reflect the Internet as the preliminary indexes of the feature set and select the borrowers data of the “Pterosaur Loan” platform as the research sample. Then, real data were crawled from this platform. By quantifying the “hard information” and using text mining method to extract “soft information” features in loan description, then these two kinds of information are fused to form the feature set of credit risk.
3.1 Preliminary selection of credit evaluation indexes
We will design the comprehensive evaluation index system for P2P credit risk of “three rural” borrowers from five first-level indexes, i.e., identity traits, credit history, debt paying ability, loan product information and Internet behavior factors, where the first four are static indexes. Each first-level index is briefly described as follows.
-
1.
Identity traits refer to the borrower’s age, gender, family information and other personal information.
-
2.
Credit history mainly refers to the records of borrowing and spending produced by the borrower in previous debt activities.
-
3.
Debt paying ability is an index that reflects a borrower’s earning power through their occupation, income and so on.
-
4.
Loan product information refers to the product information index of the borrower when borrowing money on the online loan platform.
-
5.
Internet behavior factors refer to the data generated by online lending behavior.
In the existing research in the field of agriculture, different scholars have different perspectives and focus on the evaluation indexes of credit risk of the “three rural” borrowers. On the basis of existing indexes, we consider to integrate some specific indexes of agriculture-related borrowers and the “Internet” indexes that can reflect individual dynamics into the feature set. In the traditional static indexes, “whether the poor households in villages and towns,” “the number of farmers in the family,” “the types of agricultural products” and so on are added; considering the dynamic indexes related to the Internet, the indexes such as “the amount of phone bill owed” and “credit score of Sesame” are added (Ju 2018). Although this kind of data is difficult to obtain, each platform can obtain this part of information through the cooperation with platforms such as Alipay authorized by the borrower. Drawing from the existing related research, together with our new added indexes, 45 s-level preliminary indexes are selected below under the five first-level indexes given above. Specific indexes are listed as follows:
Identity traits: proportion of elderly people, registered permanent residence, marital status, age, proportion of young people in the family, type of residence, gender, education level, number of migrant workers in the family and health status.
Debt paying ability: with or without car guarantee increment, car guarantee increment, cultivated land area, with or without guarantee increment of house property, guarantee increment of house property, income of per Mu land, industry, types of agricultural products operated, annual household income, per capita annual income, years of working, poverty level and value in pledge.
Loan product information: repayment period, borrowing rate, mode of repayment, description of loan, monthly payment day and amount of loan.
Credit history: with or without credit report, with or without default record, debt situation, guarantor, fraud record of online consumption, neighborhood evaluation, years of social security, number of failed bids, overdue information of credit report and commercial insurance.
Internet behavior factors: the amount of phone bill owed, the frequency of Alipay transfer, credit score of Tencent, credit score of Sesame and the borrowing situation of other online loan platforms.
3.2 The data source
Because the information of domestic borrowers in China has not been shared, the values of some borrower features given in Sect. 3.1 are difficult to obtain, for example the neighborhood evaluation, the amount of phone bill owed and so on. Thus, we choose the “Pterosaur Loan” platform as the research sample and crawl the real data from this web platform. Reference to the indexes given in Sect. 3.1, we obtained 27 borrower features on the web platform, which includes two text information of borrowing title and borrowing description. And then, we make the data preprocessing for all crawled data.
-
(1)
Selection reasons of empirical platform
With the help of Internet technology, the “Pterosaur Loan” platform optimizes financing channels of “three rural” and provides quick and timely financial information matching service. Over the past 10 years since its establishment, the “Pterosaur Loan” has introduced the surplus social funds to the fields and helped farmers to realize poverty reduction, increase income and get rich and helped farmers gradually establish credit records. At present, the online and offline business of “Pterosaur Loan” has penetrated into 28 provinces, autonomous regions and tens of thousands of villages and towns across the country in China, which provides effective financial support for peasant households, individual industrial and commercial households and small and microenterprises. Therefore, the data of “Pterosaur Loan” platform are representative in the field of “three rural,” and the credit risk rating is also authoritative, which has a high reference value.
-
(2)
Data acquisition mode
Because the agricultural-related information released by “Pterosaur Loan” platform is relatively comprehensive, it is selected as the research object. This platform displays the loan data of nearly 2 months on the web page. We use Python to write the web crawler and capture part of the data from June to August, 2018. When investors bid, they can not only know the credit rating of the borrower, but also know some personal information of the borrower. In addition, the borrowing purpose and detailed description of borrowers can be found on the borrowing demand of each application.
3.3 Preprocessing of structured data
The “magic mirror” risk control system of “Pterosaurs Loan” platform divides the borrower’s credit risk level into 8 grades (see Table 1). In order to facilitate calculation, we convert these eight grades of borrowers into two risk grades, i.e., “low risk” and “high risk.” The conversion results are shown in Table 1.
In this paper, nearly 4000 borrower data were crawled from the web page. Because the dimensionality of data is different, the data structure was inconsistent, and the partial data were missing and other problems, so the crawled data could not be directly used for data modeling. In order to improve data quality, data should be preprocessed before modeling.
-
(1)
Processing of the missing values
Data crawler may bring incomplete data, and the data containing missing values cannot be effectively modeled. There are two common processing methods of missing values (Seijo-Pardo et al. 2019):
-
1.
Deletion of useless features
The data set of “Pterosaurs Loan” contains 27 features. The data collected in this paper are from June to August 2018, and the time is relatively concentrated, so “borrowing time” is removed as a useless feature. In addition, deletion is considered when the vacancy probability of the missing sample reaches 90%. Therefore, 22 non-text features and two text messages (borrowing title and borrowing description) are remained after deleting several useless features, i.e., the publishing time, specific urban area where people live and so on.
-
2.
Data filling
In this paper, the missing data are less, so the mean value method is used to fill the continuous numerical variables, and the modal method is used to fill the multivariate discrete data. In the end, 3410 loan data were obtained, where 459 data are for minority class (high-risk borrowers) and 2951 data for majority class (low-risk borrowers). These data are used for subsequent feature selection and modeling.
-
(2)
Quantification of classified variables
After addition and deletion of the obtained data, a total of 3410 complete sample data were obtained. Since the sample data contain quantitative data and qualitative data, it is necessary to clean the data and quantify the structured data before modeling. For the classified variables, we adopt the method of sequential value coding, that is, using natural numbers to represent different categories. The structured data variable information (including 22 non-text variables) is described in detail in Table 2.
3.4 Preprocessing of unstructured data
P2P credit rating evaluation mainly relies on the data filled by users, while the serious information asymmetry problem on the online loan platform will increase the difficulty of credit risk rating, and an effective way to alleviate this problem is to obtain a large amount of real information. At present, it is found that the “soft information” with rich content can provide more valuable information for risk rating. Therefore, when the “hard information” of the borrowers is not enough, the platform can use the “soft information” to assist decision-making and find the credit features related to the risk level of the borrowers. In P2P network loan, the “hard information” mainly refers to verifiable objective information provided to the platform, such as the age and work of the borrower. “soft information” is mainly the descriptive text information that the borrower voluntarily discloses its own situation, which is unprovable subjective information. In view of the importance of “soft information,” this section preprocesses the text information such as loan title and detailed loan description, which adopts a series of methods to extract the text features of borrowers (Michels 2012).
3.4.1 The text word segmentation of loan description
In order to extract the document set and loan demand words of loan description, in this section, we will sort out and analyze the loan title and detailed loan description crawled from the web page, which includes two aspects: text word segmentation and text representation.
Text word segmentation is the first step in processing text, and we do this work by the program in Python and the word segmentation tool of Jieba. Stopwords are meaningless noise in text analysis. In order to carry out text word segmentation effectively, the stopwords in the borrowing text should be removed. In this section, we make the text word segmentation for the borrowing title and detailed description of borrowing and obtain the word cloud map after removing the stopwords. The larger the font of a word is, and the closer the word is to the center, the higher the frequency of this word in corpus is.
Text classifier cannot process text information directly, so it needs to digitize the content and convert the text information into information that can be recognized by the computer. The quantification of this unstructured information is called text representation. After word segmentation, each word has a different frequency in the borrowing description. In order to extract keywords that can represent the demand for borrowing from a paragraph, it is necessary to judge the subject words in each paragraph by the weight of words. After the text word segmentation of loan description, we use TF-IDF algorithm (Kim et al. 2019) to obtain important words in the document set. TF-IDF is a statistical method that can calculate the importance of a word to a document to understand the main meaning of the document. On the processing of text representation, we use TF-IDF algorithm to filter the words with low discrimination, retain the keywords in the title set of loan and convert the text after word segmentation into structural data.
3.4.2 Loan topic recognition based on LDA
-
(1)
LDA topic model
Latent Dirichlet allocation (LDA) topic model is a kind of unsupervised machine learning techniques and is also a kind of document generation model, which can dig large hidden topic content in each document of large document set (Blei et al. 2003). The so-called generative model refers to that each word in each article is obtained through the process of “selecting a certain topic with a certain probability and selecting a certain word from the topic with a certain probability,” and finally, these words constitute a document. In summary, the main idea of the LDA model is that each loan description is a mixed probability distribution of all loan topics, and each loan topic is a mixed probability distribution of various vocabularies (Zhang et al. 2019)
Suppose that the loan description set is D, and the topic set is T, then the generation steps of LDA are given as follows.
-
1.
For each loan description in the loan description set D of the entire loan data, z topic is extracted from the document-topic distribution.
-
2.
Extract the word w from the corresponding topic-word distribution of the borrowing topic mentioned above.
-
3.
Repeat above two steps until each word in the loan description is obtained.
For the loan information of “Pterosaur Loan” platform, in order to identify the topic distribution of loan description, it is necessary to make backward calculation through the loan text and the probability distribution of each word. Let j be a potential borrowing topic, and \( w_{i} \) is the ith word in the loan description d; then, the probability that wj belongs to the loan topic j is
where \( P(w_{j} ) \) is the probability of word \( w_{i} \) appearing in loan description \( d \); \( P(w_{i} |z_{j} = j) \) is the probability that the word \( w_{i} \) belongs to the borrowing topic \( j \), which is denoted as \( \varphi \); \( P(z_{j} = j) \) is the topic probability that \( j \) is the loan description \( d \), which is denoted as \( \theta \).
The solution process of the LDA model is to estimate the parameters of \( \theta \) and \( \varphi \) and to establish the LDA three-layer model. Based on Gibbs sampling, we use Python programming tools to estimate parameters \( \theta \) and \( \varphi \) and then calculate the parameters and posterior distribution of the model. Then, the model is used to extract several potential loan topics in the loan title set, to calculate the distribution probability of various topics in each loan title and to measure the degree of closeness between each title and these loan topics with probability value, that is, to take the probability value as the assignment of the generated topic variable and take it as the quantitative results of the text features.
-
(2)
Identification of borrowing purpose based on LDA
The loan title is the loan demand filled in when the borrower issues the loan application, such as “the loan is mainly used for the purchase of saplings.” In this paper, LDA topic model is used to analyze the loan title, and all the loan title texts are taken as a document set to calculate the distribution of each topic on the text, that is, to classify the hidden loan purposes. After the text word segmentation of loan title, we use the gensim toolkit to realize text categorization. In the process of establish the topic model, in order to set the appropriate number of topics, the entire document set was firstly browsed and the range of the topics number was subjectively given, and then, the parameters were determined by the experimental method. The number of topics was set to 3–15, and topics were extracted iteratively and circularly and manually judged by the related terms distribution of each extracted topic words (Guo 2015). After several iterations, when the number of borrowing topics is finally determined by 7, the generated model has the best explanatory power, that is, the meaning of each topic entry obtained by the model is similar. In the process of establishing the model, only the words with probability greater than 0.001 are displayed, and each topic shows eight words. The final distribution of relevant terms of the topic is shown in Table 3.
According to the related items distribution of topic words, we conclude the borrowing purpose as seven kinds of topics, i.e., “expand planting scale,” “business management,” “cash flow,” “purchase of breeding materials,” “land contract,” “household spending” and “purchase of machinery and equipment,” and transform them into seven text feature variables, that is, calculate the distribution probability value of each borrowing title for seven topics and regard the distribution probability value as the topic probability, which means the text information is transformed into seven credit features.
When filling in the loan demand, the borrowers should not only abbreviate the loan title, but also describe their borrowing purpose and other conditions in detail. The borrower’s self-statement is rich in content, which can be an expression of his work situation and family situation, or it can be an expression of his strong desire to borrow the fund. Since most loan descriptions contain loan title content, the LDA model is difficult to summarize other loan topics than the above seven loan topics. Therefore, this paper obtains the features of borrower’s “soft information” from the perspective of language content and takes the text length of loan description as the features of borrowers.
Language content is a language feature easily recognized in loan description. In the existing literature (Chen and Lin 2017), language dimensions such as “honesty,” “family-oriented,” “upandcomer” and “quality” have been proposed. Based on the dimensions selected by the existing literature and the overall borrowing description features of the “Pterosaur Loan” platform, this paper proposes five language dimensions for detailed description from the aspect of language content: “commitment,” “sincerity,” “quality,” “family” and “urgency.” For these five variables, if the detailed loan description contains these language dimension information, the variable value is denoted as 1, otherwise is denoted as 0. The definitions of these five language dimensions are shown in Table 4.
From the discussion above, we select the loan topic probability extracted from the LDA topic model, the language dimension and the text length of loan description as the “soft information” obtained from the loan description and combine it with the 22 “hard information” variables preprocessed in Sect. 3.3; then, we obtain the following feature set of credit risk which includes 35 borrower features.
“Pterosaur Loan” feature variable set of credit risk: gender, marital status, urgent, the borrowing situation of other online loan platforms, age, registered permanent residence, guarantor, text—land contract, education level, type of residence, debt situation, text—household spending, annual household income, industry, borrowing rate, purchase of machinery and equipment, house property, years of working, the length of the text, expand planting scale, repayment period, commitment, years of social security, text—cash flow, monthly payment day, sincerity, commercial insurance, text—business management, mode of repayment, quality, with or without credit report, text—purchase of breeding materials, amount of loan, family, overdue information of credit report.
4 Two-stage feature selection of credit risk based on filter and wrapper
This section makes feature selection based on the credit feature set constructed in Sect. 3. For the unbalanced data, the traditional single feature selection method tends to ignore the combined utility of features and selects the features with strong correlation with most classes, that is, the problem of feature preference is generated. In order to improve this shortcoming, a two-stage feature selection method based on filter (Hancer 2019) and wrapper (Jadhav et al. 2018) is proposed, which first sorts the features comprehensively and then encapsulates and filters the feature subset. Different from other two-stage feature selection methods in the existing literature (Solorio-Fernández et al. 2016; Rao et al. 2017; Zhang et al. 2018), we calculate the importance of features from three aspects: distance, probability statistics and classification performance in the stage of Filter. This calculation method can effectively solve the preference problem of feature selection for unbalanced data. Moreover, in order to increase the differentiation degree between categories, we change the voting system to comprehensively rank the importance of features according to the vector length. In the stage of Wrapper, we calculate the classification accuracy of different subsets by the Lasso-logistic model and then realize the feature selection by using the Lasso method, so as to establish an assessment index system of credit risk.
4.1 Filter method
For the high-dimensional unbalanced data, the unbalanced distribution of sample categories is often accompanied by the imbalance of features, that is, the distribution of feature attributes is unbalanced, which leads to the loss of information and unclear meaning at the feature level, and it is difficult for the classification model to correctly identify a small number of class samples. Therefore, it is necessary to adopt the feature selection method which can preserve the distinguishing features and improve the classification accuracy of a few classes.
In the stage of Filter, we change the original single feature selection method and consider the importance of unbalanced features from three aspects and comprehensively rank the importance of 35 features. As information gain ratio (GR) can avoid the occurrence of selection preference by adding penalty factors, and the method of SCSRF introduces the idea of cost-sensitive in random forest, which considers the disequilibrium degree of data set; thus, we use the Fisher criterion and GR to measure the correlation between features and categories from the perspective of distance and probability, respectively. In addition, RF is used to improve the classification ability of features, weaken the volatility and features preference and increase the classification degree between categories. Therefore, we present three feature selection methods based on Fisher score, GR and SCSRF (syncretic cost-sensitive random forest).
-
(1)
Fisher score
This method is to calculate the Fisher score according to Fisher’s rule (Solorio-Fernández et al. 2016). The larger the Fisher score of the feature is, the stronger its ability to separate samples of different kinds will be; otherwise, its ability to classify will be weaker.
In this paper, the training set and test set are divided into 2: 8 proportions, that is, 2728 borrower sample information are selected for feature selection, where 2376 data are for low-risk borrowers and 352 data are for high-risk borrowers. The training set sample are denoted as \( \{ (x_{1} ,y_{1} ),(x_{2} ,y_{2} ), \ldots ,(x_{i} ,y_{i} )\} \), where \( (x_{i} ,y_{i} ) \) is the feature variable value and risk level of a sample i, and \( y_{i} = \{ - 1,1\} \) is the category, − 1 is the positive category, which means the high-risk borrower, and 1 is the negative category, which means the low-risk borrower. The Fisher score is denoted as \( F_{k} \), and then,
where \( S_{b} \) is the distance between the samples of two categories, i.e., high risk and low risk, namely the interclass dispersion; \( S_{w} \) is the dispersion between homogeneous samples, i.e., the intra-class dispersion. The calculation formula is as follows.
where \( p_{1} = 352 \) is the number of samples in the high-risk sample set, \( p_{2} = 2376 \) is the number of samples in the low-risk sample set, and \( \bar{m}_{1} \), \( \bar{m}_{2} \) and \( \bar{m} \) are the mean values of the high-risk, low-risk and all samples, respectively.
The Fisher score of the kth feature variable can be expressed by
where \( \bar{m}_{1,k} \), \( \bar{m}_{2,k} \) and \( \bar{m}_{k} \) are the mean values of high risk samples, low risk samples and data sets for the kth attribute, respectively. And \( \delta_{1,k}^{2} \) and \( \delta_{2,k}^{2} \) are the variance of high-risk and low-risk samples for the kth attribute, respectively.
-
(2)
Information gain ratio
Information gain (Zhang et al. 2018) is a Filter method based on sample information. It measures the correlation degree between a feature and a category from the perspective of nonlinearity and measures the partition effect of current feature on sample set D mainly based on the difference values of set entropy before and after partition. The larger the value is, the stronger the correlation between variables will be.
For the high-dimensional data with unbalanced categories, the problem of information gain in feature selection tends to select features with more values, which leads to the occurrence of overfitting. Information gain ratio (penalty factor added) can reduce the occurrence of selection preference, so this paper uses information gain ratio to calculate the importance of borrower features.
-
1.
Suppose there are K categories, then calculate the empirical entropy H(D) of data set D, where
$$ H(D) = - \sum\limits_{k = 1}^{K} {\frac{{|C_{k} |}}{|D|}} \log_{2} \frac{{|C_{k} |}}{|D|}. $$(5) -
2.
Calculate the empirical conditional entropy H(D|A) of borrower feature A to D (n is the number of different values of A) as follows.
$$ H(D|A) = \sum\limits_{i = 1}^{n} {\frac{{|D_{i} |}}{|D|}} H(D_{i} ) = \sum\limits_{i = 1}^{n} {\frac{{|D_{i} |}}{|D|}} \sum\limits_{i = 1}^{n} {\frac{{|D_{ik} |}}{{|D_{i} |}}} \log_{2} \frac{{|D_{ik} |}}{{|D_{i} |}}. $$(6) -
3.
Calculate the information gain
$$ g(D,A) = H(D) - H(D|A). $$(7) -
4.
Calculate the information gain ratio
$$ g_{R} (D,A) = \frac{g(D,A)}{{H_{A} (D)}}, $$(8)where
$$ H_{A} (D) = \sum\limits_{i = 1}^{n} {\frac{{|D_{i} |}}{|D|}} \log_{2} \frac{{|D_{i} |}}{|D|} . $$(9) -
(3)
SCSRF (syncretic cost-sensitive random forest)
Random forest (RF) (Mercadier and Lardy 2019; Wu and Liu 2019; Mantas et al. 2019) is an integrated learning algorithm, which can calculate the importance of variables and sort them, so as to screen out the features with higher importance. In this paper, the data are unbalanced, and the dependent variable is a binary classification variable, so we use the average accuracy reduction method (a method for detecting errors of data). Due to the unbalanced distribution of categories and features of “Pterosaurs Loan” data, SCSRF was proposed to calculate the importance of features for 35 borrowers in order to improve the recognition rate of a few categories. The calculation steps are as follows:
Suppose that the forest contains N decision trees. In order to measure the importance of the jth feature attribute to the risk level, each decision tree \( i \) should be processed.
-
1.
Construct a decision tree by randomly selecting m samples and k features and calculate the out-of-bag error of the decision tree by using OOB (Out-of-Bag) data, which is denoted as \( errOOB1 \). N decision trees have N\( errOOB1 \), where \( errOOB \) is the ratio of the number of misclassification to the total number of samples, which is regarded as the misclassifications ratio of the RF OOB data.
-
2.
Calculate the importance of all credit risk features. Add noise interference to all samples corresponding to credit feature X in OOB data (that is, randomly change the sample value of credit risk feature X), or randomly disrupt the value order of the external bag observation on the attribute of feature X.
-
3.
Calculate the OOB (Out-of-Bag) data of the corresponding decision tree again. So the values of \( errOOB2 \) can be obtained for each decision tree, and N decision trees have N\( errOOB2 \). \( errOOB2 - errOOB1 \) is the variation value of the out-of-bag error of the ith decision tree caused by the addition of noise to the feature X.
-
4.
Suppose that there are \( N \) decision trees in the cost-sensitive RF, then the importance of credit feature X can be expressed by:
$$ {\text{MDA}} = \frac{{\sum\limits_{i = 1}^{N} {(errOOB2_{i} - errOOB1_{i} )} }}{N} $$(10)
The rules of interpretation is as follows: If the noise is randomly added to a feature, the accuracy of the OOB decreases significantly, which indicates that the feature has a great impact on the classification effect of the model and reflects its high importance ranking.
4.2 Wrapper method
In this paper, since this paper proposes the two-stage feature selection method, in the stage of Wrapper, an internal classifier is required to perform feature selection and know the classification accuracy of different feature subsets at the same time. The essence of the Lasso method is to add the penalty function to the residual sum of squares, in order to reduce the variable set and compress the coefficient of some variables as 0, and the feature of this compression coefficient can just realize the feature selection of the model (Kapetanios and Zikes 2018). Moreover, Algamal and Lee (2015) showed that the Lasso-logistic algorithm is better than both logistic algorithm and Ridge-logistic algorithm in both model classification effect and running time.
Considering the simple calculation of the Lasso-logistic algorithm, and the feature subset can be selected through the compressed variable coefficient, and the strong practicability in the credit risk assessment, we adopt the Lasso-logistic model in the stage of Wrapper and use SBS search algorithm to select the feature subset based on the classification accuracy.
Suppose that the observed values \( (X^{i} ,y_{i} ),i = 1,2, \ldots ,2728 \) in this paper are independent and identically distributed, where \( y_{i} \) is the credit risk level, and \( y_{i} \in \) {high risk = − 1, low risk = 1}, then the conditional probability of the logistic linear regression model is
where \( X^{i} = (x_{i1} ,x_{i2} , \ldots ,x_{ip} ) \) are the sample values of the p (\( p = 1,2, \ldots ,35 \)) credit features for the borrower i.
The coefficient estimation \( \hat{\beta }_{\lambda } \) in the Lasso-logistic model is given by the minimum value of convex function, which is given as follows.
where \( l( \cdot ) \) is the logarithmic likelihood function and \( l(\beta ) \) is defined as
where the function \( \eta_{\beta } ( \cdot ) \) is defined by Eq. (11), which means the logarithmic value for the ratio of the probability of the borrower being at low risk to the probability of the borrower being at high risk, that is, the logarithmic value for the dominance ratio of an event.
The regression coefficient \( \hat{\beta } \) in the Lasso-logistic model is denoted as
By controlling the harmonic parameter \( \lambda \), the borrower features can be selected.
4.3 Two-stage feature selection method
For the 35 feature variables given in Sect. 3.4.2, the Filter method is used to measure the importance of features from the perspective of distance, probability and statistics and classification ability, respectively.
Consider the dimensionality of different evaluation indexes is different, we must normalize the data, and the specific normalized formulas are given as follows.
where \( m_{i} \) is the value of MDA given in Eq. (10), \( fs_{i} \) is the Fisher score given by Eq. (4) and \( g_{i} \) is the value of information gain given by Eq. (7); \( \overline{{m_{i} }} \), \( \overline{{fs_{i} }} \) and \( \overline{{g_{i} }} \) are the normalized values, which construct a three-dimensional vector \( \overrightarrow {{c_{i} }} = (\overline{{m_{i} }} ,\overline{{fs_{i} }} ,\overline{{g_{i} }} ) \). That is, comprehensive measurements are made from three dimensions, and the length of the vector \( \overrightarrow {{c_{i} }} \) expresses the importance of feature X.
In order to generate a noise-free feature subset, we comprehensively rank features from three different dimensions and then encapsulates and filters the set. In the encapsulation stage, the SBS method is used to rank variables, and the features with the least importance are deleted successively. Meanwhile, the subset after deleting variables is modeled, and the quality of feature subset is compared according to the classification accuracy, until the feature set with the best prediction effect is selected, and this selected feature set will be used as the input data of the external classifier.
Based on the above encapsulation filtering idea, the algorithm flow is shown in Fig. 1.

Algorithm flowchart for encapsulation and filtering of features
Input: The original training set \( F = \{ f_{1} ,f_{2} , \ldots ,f_{k} \} \), where k = 35 is the number of features.
Output: The feature subset with the highest classification accuracy A.
4.4 Two-stage feature selection for the “Pterosaur Loan” data
4.4.1 Two-stage feature selection results
-
(1)
Feature ordering in the stage of Filter
According to the method in Sect. 4.1, we conduct an empirical analysis with 35 borrower features (i.e., training set with 2728 borrower sample information, where 2376 data are for low-risk borrowers and 352 data are for high-risk borrowers). According to the Filter method, the importance of borrower features is calculated and ranked. After the values are normalized by Eqs. (15)–(17), the comprehensive importance of features is measured by Eq. (18). The ranking results are listed in Table 5.
According to the ranking results in Table 5, we can see that the seven text features and extracted language dimensions extracted through text mining are top ranked in importance, which indicates that the information contained in these features has a significant impact on the credit risk level of borrowers. The importance degree of features in this section provides a basis for selecting variables by the Wrapper method.
-
(2)
Feature subset screening in the stage of wrapper
In the stage of Wrapper, we use the glmnet package in R software to select the variables of the Lasso-logistic model. By using the backward selection method and combining the comprehensive ranking results of features, we delete the variables with the lowest ranking in turn and then calculate the classification accuracy of feature subsets with different numbers. Since the harmonic parameter \( \lambda \) plays a key role in the Lasso method, which value is related to the variable selection result of the Lasso-logistic model. Therefore, in order to obtain appropriate parameters \( \lambda \), we use the generalized cross-validation method to encapsulate and filter features, and the results are shown in Fig. 2.

Influence of feature number on classification accuracy
According to the trend of accuracy in Fig. 2, when 25 features are retained, the Lasso-logistic model has the highest classification accuracy, which is 82.38%. Figure 3 shows the variation relationship between the model error and the value of \( \lambda \) obtained by cross-validation. The dotted line on the left represents the harmonic parameter \( \lambda \) taking the value of Lambda.min, which is the minimum value when the model error is the minimum, and the dotted line on the right is the value of Lambda.1se when the model is the simplest within one standard deviation. Tibshirani (1996) thought that when the variation deviation of the model and the AUC value were relatively small between the two dotted lines, the value \( \lambda \) should be set within this interval. Generally, it is recommended to choose the value of \( \lambda \) that make the model in its simplest form.

\( \lambda \) and model error
Figure 3 shows that the compression degree of borrower feature variable is affected with the change of harmonic parameter value \( \lambda \). When the number of features is 21, the Binomial Deviance fluctuates around 0.9. It can be observed from the solution path of Lasso variable coefficient in Fig. 4 that if \( \lambda \in (e^{ - 3} ,e^{ - 2} ) \), only 2–5 indexes are selected. Based on the experience of Tibshirani, in order to select important and non-overlapping indexes within a certain range, Lambda.1se method is selected for parameter estimation in this paper, that is, 21 borrower features are selected to constitute the comprehensive evaluation index system of credit risk of “three rural” borrowers.

\( \lambda \) and the solution path of the variables
Due to the compression effect of Lasso on variables, the coefficients of some borrower features are compressed to 0, and the estimated coefficients of model parameters are shown in Table 6.
Table 6 shows that Lasso compresses the variable coefficients of business management, cash flow, mode of repayment and years of social security into 0, which indicates that the four variables have no significant influence on credit risk. The coefficients of some text variables and language dimension variables are nonnegative, which indicates that text information has a significant impact on credit risk rating, that is, the borrower’s “soft information” cannot be ignored. From the regression coefficient, we can conclude that the higher the annual income, the higher the education level and the lower the risk, which is also consistent with the intuitive feeling of reality. The coefficient of quality is negative, which may be explained as follows: In order to conceal their true feature, borrowers falsely mention good quality, so borrowers with low credit rating tend to disclose more descriptive information, but the actual default rate and risk are higher. The negative coefficient of the length of text may be explained by the borrower’s deliberate efforts to improve the authenticity of the information, so the longer the length of text is, the risk level does not necessarily go down. According to the analysis of marital status, if the borrower is urban residents and the life is relatively happy, then his corresponding borrowing risk will be greatly reduced. It can be observed from the regression coefficient of guarantors that in villages and towns, neighbors are close to each other and they know the behavior of borrowers. Therefore, whether there is a guarantor or not is of certain importance in the field of “three rural,” and the borrowers with a guarantor are generally less risky.
Specifically, for the algorithm for encapsulation and filtering of features shown by Fig. 1, the execution numbers are described as follows. In the Filter method, the importance order of the features is obtained after one execution of calculating the values of Fisher score and information gain. In the computation stage of SCSRF (syncretic cost-sensitive random forest), ten times of simulation training are conducted, and then, the average value of ten times of feature importance is taken as the final importance of a feature, which as the final result of feature ordering in this method. In addition, the total execution time of the algorithm for encapsulation and filtering of features shown in Fig. 1 is 573 s, where the execution time of calculating the Fisher score and information gain is 56 s, the execution time in the computation stage of SCSRF is 496 s, and the execution time in the computation stage of Lasso logistic is 21 s.
From the above analysis and discussion, we can select 21 effective features from 35 borrower features by using the internal classifier Lasso logistic in the stage of Wrapper, that is, guarantor, household spending, land contract, expand planting scale, purchase of breeding materials, amount of loan, age, years of working, borrowing rate, industry, debt situation, annual household income, house property, quality, the borrowing situation of other online loan platforms, education level, the length of the text, marital status, registered permanent residence, repayment period and sincerity.
4.4.2 Variable correlation analysis
In order to test the correlation degree between 21 borrower features selected in Sect. 4.4.1, the method of Pearson correlation coefficient (Mu et al. 2018) is used in this section. The borrower feature is denoted as \( x_{i} ,i = 1,2, \ldots ,21 \), and \( r_{ij} \) is a statistic measuring of the correlation degree between two borrower features \( i \) and \( j \), and its value satisfies \( r_{ij} \in [ - 1,1] \). Pearson correlation coefficient is defined as the quotient of covariance and standard deviation between two borrower features, and the computational formula is as follows.
From the computational results given by (19), we give the visual correlation coefficient figure for the 21 selected borrower features, which are shown in Fig. 5.

Visual correlation coefficient figure
In Fig. 5, the meaning of V1 to V21 is explained in the following Table 7.
The color depth of the circle in Fig. 5 represents the correlation degree between any two variables. The darker the color is, the greater the correlation degree between the two variables. Thus, we can see that the correlation degree between any two variables of 21 selected features is weak, and the correlation coefficients between any two variables are all at the range of \( [ - 0.2,0.2] \). We can almost think there is no correlation between any two variables. Therefore, 21 selected features V1 to V21 listed in Table 7 are just the indexes which construct the index system of evaluating the credit risk of P2P network loans for “three rural” individual.
5 Conclusions
This paper mainly focuses on the design of comprehensive evaluation index system for P2P credit risk of “three rural” borrowers. Firstly, by combining with the platform of “Pterosaur Loan,” the borrower data of “Pterosaur Loan” are selected as the data modeling sample, and then, the preprocessing methods such as text mining is used to extract and construct the original feature set of the borrower’s credit risk. Finally, a two-stage feature selection method is proposed to select the optimal subset from the original feature set, which constitute the evaluation index system of credit risk of “three rural” borrowers. The specific work is summarized as follows:
-
1.
Based on the traditional credit indexes, we integrate the indexes reflecting the features of “three rural” borrowers and “Internet,” and preliminarily select 45 indexes of credit risk assessment. Based on the degree of difficulty in index data acquisition, the indexes are initially screened. Then, the “Pterosaur Loan” platform is selected as the research object. By means of numerical processing of classification variables, text mining and other preprocessing methods, the extracted “soft” and “hard” information features are combined to construct the index set of borrower credit risk with 35 features.
-
2.
By considering the unbalanced data in the index set of borrower credit risk, a two-stage feature selection method based on Filter and Wrapper is proposed. In this method, the feature importance was measured by the length of a three-dimensional vector, and the Lasso-logistic method and heuristic search algorithm are combined to filter and select the feature subset. At last, 21 borrower features are remained in the feature subset. Based on this result, an evaluation index system of credit risk of “three rural” borrowers is constructed.
Compared with the existing literature, the main contribution of this paper is as follows: (1) By considering both “soft information” and “hard information,” we designed a comprehensive evaluation index system, especially for P2P credit risk of “three rural” borrowers. (2) By considering the unbalanced data features of “Pterosaur Loan” borrowers, we proposed a two-stage selection method based on Filter and Wrapper to select the main features of credit risk of “three rural” borrowers. Especially, in the stage of Filter, the importance of unbalanced features is comprehensively considered from three aspects, and the length of a three-dimensional vector is taken as the ranking criterion. Thus, the volatility of features and the probability of selection preference are reduced, and the features affecting risk rating are effectively identified.
Based on the evaluation index system of credit risk of “three rural” borrowers constructed in this paper, our future work is to establish an evaluation model of credit risk via syncretic cost-sensitive random forest (SCSRF) and make an empirical analysis.
References
Algamal ZY, Lee MH (2015) Penalized logistic regression with the adaptive LASSO for gene selection in high-dimensional cancer classification. Expert Syst Appl 42(23):9326–9332
Bermejo P, Luis DLO, Mez J et al (2012) Fast wrapper feature subset selection in high- dimensional data sets by means of filter re-ranking. Knowl Based Syst 25(1):35–44
Blei DM, Ng AY, Jordan MI et al (2003) Latent dirichlet allocation. J Mach Learn Res 3:993–1022
Chen X (2006) Constructing evaluating indexes system with decision tree method. J Comput Appl 26(2):368–370
Chen FL (2010) Combination of feature selection approaches with SVM in credit scoring. Expert Syst Appl 37(7):4902–4909
Chen Q, Lin FR (2017) A study on the influence of descriptive information on overdue rate of borrowers-based on the analysis of P2P online lending platforms. Sci Manag Res 3:137–145
Dorfleitner G, Priberny C, Schuster S et al (2016) Description-text related soft information in peer-to-peer lending-evidence from two leading European platforms. J Bank Finance 64(4):169–187
Freedman S, Jin GZ (2008) Do social networks solve information problems for peer-to-peer lending? Evidence from Prosper.com. Seth Freedman 1:8–43
Gao Y, Yu SH, Shiue YC (2018) The performance of the P2P finance industry in China. Electron Commer Res Appl 30:138–148
Guo L (2015) Loan Descriptions and Online P2P lending behavior. Harbin Institute of Technology, Harbin
Hancer E (2019) Differential evolution for feature selection: a fuzzy wrapper–filter approach. Soft Comput 23(13):5233–5248
Herzenstein M, Sonenshein S, Dholakia UM (2011) Tell me a good story and I may lend you money: the role of narratives in peer-to-peer lending decisions. J Mark Res 48(2):138–149
Jadhav S, He HM, Jenkins K (2018) Information gain directed genetic algorithm wrapper feature selection for credit rating. Appl Soft Comput 69:541–553
Jiang CQ, Wang RY, Ding Y (2017) The default prediction combined with soft information in online peer-to-peer lending. Chin J Manag Sci 25(11):12–21
Ju QX (2018) Research on the evaluation mechanism of personal credit in the internet era—a case study of sesame credit. Mod Manag Sci 302(5):111–113
Kapetanios G, Zikes F (2018) Time-varying Lasso. Econ Lett 169:1–6
Kim D, Seo D, Cho S, Kang P (2019) Multi-co-training for document classification using various document representations: TF-IDF, LDA, and Doc2Vec. Inf Sci 477:15–29
Kumar S (2007) Bank of one: empirical analysis of peer-to-peer financial marketplaces. In: Proceedings of the 2007 America conference on information systems. AMCIS, USA, pp 1–8
Liu H, Qiao H, Wang SY, Li YZ (2019) Platform competition in peer-to-peer lending considering risk control ability. Eur J Oper Res 274(1):280–290
Mantas CJ, Castellano JG, Moral-García S, Abellán J (2019) A comparison of random forest based algorithms: random credal random forest versus oblique random forest. Soft Comput 23:10739–10754
Mercadier M, Lardy JP (2019) Credit spread approximation and improvement using random forest regression. Eur J Oper Res 277(1):351–365
Michels J (2012) Do unverifiable disclosures matter? Evidence from peer-to-peer lending. Acc Rev 87(4):1385–1413
Mu YH, Liu XD, Wang LD (2018) A Pearson’s correlation coefficient based decision tree and its parallel implementation. Inf Sci 435:40–58
Rao CJ, Xiao XP, Goh M, Zheng JJ, Wen JH (2017) Compound mechanism design of supplier selection based on multi-attribute auction and risk management of supply chain. Comput Ind Eng 105:63–75
Ravina E (2008) Beauty, personal characteristics, and trust in credit markets. Soc Sci Res Netw Electron J 67(1):1–76
Seijo-Pardo B, Alonso-Betanzos A, Bennett KP, Bolón-Canedo V, Guyon I (2019) Biases in feature selection with missing data. Neurocomputing 342:97–112
Solorio-Fernández S, Carrasco-Ochoa J, Martínez-Trinidad JF (2016) A new hybrid filter–wrapper feature selection method for clustering based on ranking. Neurocomputing 214:866–880
Su Y, Cheng CL (2017) An empirical study on the influencing factors of P2P online borrowers’ default behavior. J Financ Dev Res 1:70–76
Tibshirani R (1996) Regression shrinkage and selection via the Lasso. J R Stat Soc 58(1):267–288
Wang JY (2017) P2P network loan default prediction based on user behavior data. Shanghai Normal University, Shanghai
Wu SW, Wu W, Yang XM, Lu L, Liu K, Jeon G (2019) Multifocus image fusion using random forest and hidden Markov model. Soft Comput 23:9385–9396
Ye X, Dong LA, Ma D (2018) Loan evaluation in P2P lending based on random forest optimized by genetic algorithm with profit score. Electron Commer Res Appl 32:23–36
Yu J (2017) A study on the relationship between descriptive information and default behaviors: the analyze based on P2P lending platform. Contemp Econ Manag 39(5):86–92
Zhang XL, Zhang Q, Chen M, Sun YT, Li H (2018) A two-stage feature selection and intelligent fault diagnosis method for rotating machinery using hybrid filter and wrapper method. Neurocomputing 275:2426–2439
Zhang ZW, He J, Gao GG, Tian YJ (2019) Sparse multi-criteria optimization classifier for credit risk evaluation. Soft Comput 23(9):3053–3066
Acknowledgements
This work is supported by the National Natural Science Foundation of China (No. 71671135), the 2018 Soft Science Research Project of Technology Innovation in Hubei province (No. 2018ADC044) and the 2019 Fundamental Research Funds for the Central Universities (WUT: 2019IB013).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants performed by any of the authors.
Informed consent
Informed consent was obtained from all individual participants included in the study.
Additional information
Communicated by V. Loia.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Rao, C., Lin, H. & Liu, M. Design of comprehensive evaluation index system for P2P credit risk of “three rural” borrowers. Soft Comput 24, 11493–11509 (2020). https://doi.org/10.1007/s00500-019-04613-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-019-04613-z