
Abstract
With the development of cloud computing and big data, stock prediction has become a hot topic of research. In the stock market, the daily trading activities of stocks are carried out at different frequencies and cycles, resulting in a multi-frequency trading mode of stocks , which provides useful clues for future price trends: short-term stock forecasting relies on high-frequency trading data, while long-term forecasting pays more attention to low-frequency data. In addition, stock series have strong volatility and nonlinearity, so stock forecasting is very challenging. In order to explore the multi-frequency mode of the stock , this paper proposes an adaptive wavelet transform model (AWTM). AWTM integrates the advantages of XGboost algorithm, wavelet transform, LSTM and adaptive layer in feature selection, time–frequency decomposition, data prediction and dynamic weighting. More importantly, AWTM can automatically focus on different frequency components according to the dynamic evolution of the input sequence, solving the difficult problem of stock prediction. This paper verifies the performance of the model using S&P500 stock dataset. Compared with other advanced models, real market data experiments show that AWTM has higher prediction accuracy and less hysteresis.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the advent of the era of big data, cloud computing technology is becoming more and more perfect, leading to more and more investors to enter the stock market, trying to capture the potential mode of the market (Hu et al. 2015; Qureshi 2018). Influenced by corporate decisions, government policies, cross-market news and other factors, the stock market is highly volatile and unstable, which makes it more difficult to predict the future price trend (Hu and Qi 2017). Stock price prediction can better understand the operation law of stock market and grasp the transmission mechanism of monetary policy. In practice, stock forecasting can effectively select and implement monetary policy when the stock market fluctuates violently, which helps to alleviate the negative impact of stock market instability (Gupta et al. 2016). The quality of macroeconomic operation of each country will be further improved (Nuij et al. 2013). Therefore, a good stock forecasting model is very valuable.
Time series is a series of data points arranged by time index (Wang et al. 2019b; Cui et al. 2019). Time series analysis methods can be divided into time domain analysis and frequency domain analysis methods (Wang et al. 2014). Time domain analysis regards time series as ordered point series and analyzes their correlation, such as hidden Markov model (Ahuja and Deval 2018; Sharieh and Albdour 2017) and ARIMA model (Wang et al. 2015; Clohessy et al. 2017). Frequency domain analysis uses transform algorithms [such as discrete Fourier transform (Wang et al. 2019a) and EMD decomposition (Wang et al. 2015)] to transform time series into spectrum, which can be used to analyze the characteristics of the original sequence (Zhang et al. 2019). The frequency domain prediction method can lead researchers to go deep into the interior of time series, find problems that cannot be seen from time domain perspective, and mine the deterministic characteristics and motion laws of time series. However, there is a lack of effective modeling of time series in frequency domain. In view of this, this paper proposes an adaptive wavelet transform model based on XGBoost algorithm, wavelet transform and LSTM to mine the frequency domain patterns of stock sequences. The main contributions of this paper are as follows:
- 1.
XGBoost model measures the importance of stock features, which avoids the problem that too few input features produce large prediction errors and too many input features lead to too long model training time.
- 2.
Wavelet transform can fully extract the high-frequency and low-frequency information of stock by analyzing the frequency domain information of stock sequences and refining the sequence in multiple scales and aspects.
- 3.
The core of this paper is to add an adaptive layer after the LSTM, which can automatically pay attention to different frequency components according to the dynamic evolution of the input sequence and mine the frequency pattern of timing information.
- 4.
AWTM combines the advantages of the above methods and has a better prediction result when the stock fluctuates violently.
2 Related work
At present, a variety of statistical models and neural network models have been applied to stock forecasting, and some progress has been made in some fields. Autoregressive moving average model (ARMA) estimates its prediction parameters by analyzing the dynamics of stock index returns (Rounaghi and Zadeh 2016). However, ARMA is more suitable for stationary linear time series. While stock price series are usually highly nonlinear and non-stationary, which limits the practical application of ARMA model in stock price series (Rojas et al. 2008). With the development of machine learning, researchers can build nonlinear prediction models based on a large amount of historical data, for example, gradient boosting decision tree (GBDT) and convolutional neural network (CNN) (Di and Honchar 2016; Haratizadehn 2019). Through iterative training of data, they gradually approach the real data and can obtain more accurate prediction results than traditional statistical models. However, this method does not reflect the dependence of stock data. Later, Jordan et al. proposed a recurrent neural network (RNN) with unique advantages in processing time series prediction (Rather et al. 2015; Akita et al. 2016). RNN can make full use of the dependence between stock data to predict the future trend of the sequence and fit the future data. However, when the number of hidden layers increases, it is easy to produce the problem of gradient disappearance and gradient explosion, which is not suitable for long-term prediction. LSTM is an improvement in recurrent neural network (Gers et al. 1999). Compared with RNN, LSTM effectively solves the problem of gradient disappearance and gradient explosion by increasing the connection of cell states and has better performance in predicting longer stock sequences (Chen et al. 2015).
LSTM is an excellent variant model of RNN, which can use historical information of stock context to play a strong adaptability in time series analysis (Petersen et al. 2019). However, the deficiency of LSTM is that it does not reveal the multi-frequency characteristics of stocks and the frequency domain of the data cannot be modeled. Zhang et al. (2017) proposed to extract time–frequency information of data by using Fourier transform, and combined time–frequency information with neural network for prediction. Fourier transform connects the characteristics of stock in time domain and frequency domain, observing and analyzing from the time domain and frequency domain of the sequence. But they are absolutely separated, that is, no time domain information is included in the frequency domain, and no frequency domain information can be found in the time domain (Daubechies 1990). Therefore, the contradiction of time–frequency localization often arises when the Fourier transform deals with non-stationary sequences. Compared with Fourier transform, wavelet transform (Pu et al. 2015) effectively solves the above problems by introducing variable scale factor and translation factor. Wavelet transform can refine time series at multiple scales and in many aspects through scaling and shifting, and finally achieve the purpose of frequency segmentation. It also can automatically adapt to the requirements of stock analysis, focus on any aspect of stock data, and solve the difficult problem of Fourier transform (Liu et al. 2013).
The combination of wavelet transform and LSTM can fully extract the time–frequency information of data and establish a model for the frequency of time series. However, the prediction performance is not optimal. Because different sequences depend on different frequency patterns, wavelet transform and LSTM cannot focus on important frequency components. Therefore, an adaptive layer is added after LSTM in this paper. According to the importance relationship between frequency domains , different weights are set for different frequency components to capture the frequency pattern of stocks.
In view of the above discussion, an adaptive wavelet transform model (AWTM) is proposed. AWTM uses wavelet transform to decompose the time–frequency characteristics of stock data and refine the stock in many dimensions to fully extract the high-frequency and low-frequency information of the data. LSTM is used to predict and model the data frequency domain. At the same time, an adaptive layer is added after LSTM to learn different weights for different frequency components, highlight key frequency patterns, and improve the prediction ability of the model. Compared with most existing methods, AWTM can represent trading patterns of different frequencies to infer future trends in stock prices. AWTM is one of the most excellent stock frequency domain prediction models, which has strong robustness, that is, it still has strong prediction ability when the stock fluctuates violently.
3 AWTM model
The goal of stock prediction is to use the data of the first n days to predict the current data (Qin et al. 2017). The n-step prediction is defined as follows:
where f is the nonlinear mapping of the historical price of the previous n day to the current price \(X_T\).
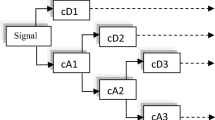
In this paper, AWTM is used to establish an n-step prediction model for stock sequence frequency information, and its overall structure is shown in Fig. 1:

AWTM architecture
AWTM consists of four parts: feature selection and data preprocessing, wavelet decomposition, model prediction, wavelet reconstruction and data output. The detailed operation of stock sequences in the model will be described in the following sections
3.1 Feature selection and data preprocessing
XGBoost is an improved algorithm based on gradient enhancement decision tree (Zheng et al. 2017), which can effectively construct the enhancement tree and conduct parallel operation. Equation (2) is an algorithm description of XGBoost (Jadad et al. 2019). Its core is to use gradient enhancement to build an enhancement tree to intelligently obtain feature scores, so as to indicate the importance of each feature to the training model (Chen and Guestrin 2016).
where \(W_{x}^{2}(T)\) represents the importance score of each prediction feature X, M represents the number of decision trees. Model selection is the feature that provides the maximum estimation improvement in the risk of squared error. There are numerous features of stock sequences, and a single feature cannot well reflect complex application scenarios, but more features will increase the training complexity of the model. Therefore, this paper uses XGBoost algorithm to measure the importance of stock features and select features of high importance to the prediction target.
The input of the model is \(X=\{X_1,X_2,\ldots ,X_T\} \) , which represents the stock sequence of T moments. Each moment includes the following characteristics: stock trading volume, yield, price change, Ma5, Ma10, MACD, 5-day average of trading volume, 10-day average of trading volume, and PriceChangeRatio. The first step of the model is to use XGBoost to measure the importance of the above nine stock features.

XGBoost experiment diagram
The experimental results of XGBoost are shown in Fig. 2. Figure 2a is the test error and training error curve of XGBoost. The training error is within the range of test error, indicating that the model is highly explanatory. The importance of the feature depends on whether the prediction performance changes significantly when the feature is replaced by random noise. In order to ensure the clarity of experimental results, the above 9 characteristics are represented in order of 0 to 8 in Fig. 2b. It can be seen from the figure that the prediction error of feature 3 (ma5) and feature 5 (MACD) is relatively large when they are replaced by random noise, indicating that the two features have a great influence on the prediction performance and are of high importance. Therefore, this paper takes ma5 and MACD as selected features and uses Eq. (3) together with price information of stocks (closing price, opening price, high price and low price) for standardization, so as to accelerate the convergence speed of the model.
where \({\tilde{X}}\) is a standardized feature sequence and \({\bar{X}}\) is the mean of frequency components. The standardized features will be used as the input of the model for wavelet decomposition.
3.2 Wavelet decomposition
Wavelet transform is a sequence analysis method with time–frequency localization, whose key is wavelet decomposition (Zhang and Benveniste 1992). When the random sequence f(t) is processed by wavelet transform, the scaling operation and translation operation are usually carried out at some discrete points, and the scaling factor a and translation factor b are discretized, which is called discrete wavelet transform (Ribeiro et al. 2019).
where \(\varPsi (t)\) is the wavelet basis function and \( W_{f}(m,n)\) is the wavelet transform coefficient.
The second step of the model is to decompose the normalized sequence into frequency components by discrete wavelet transform. The low-frequency signal and high-frequency signal generated by wavelet layer i decomposition are expressed as \({\tilde{X}}_{T}^{L}(i)\) and \({\tilde{X}}_{T}^{H}(i)\), respectively. Low-frequency signals continue to enter the next layer and are decomposed into \({\tilde{X}}_{T}^{L}(i+1)\) and \({\tilde{X}}_{T}^{H}(i+1)\).

Wavelet decomposition graph
The decomposition schematic diagram of feature sequences is shown in Fig. 3a. \({\tilde{X}}=\left\{ {\tilde{X}}_{1}, {\tilde{X}}_{2},\ldots ,{\tilde{X}}_{T}\right\} \) represents the standardized sequence at time T; C stores decomposed low-frequency information and high-frequency information, L records the length of decomposed feature sequence in C. Wavelet decomposition is applied to the original sequence or the low-frequency sequence of the previous layer. The result of decomposition is a low-frequency sequence and a high-frequency sequence, and the length is half of the previous sequence information. In this paper, a large number of experiments show that the optimal number of decomposition layers is 2, and the 2-layer wavelet decomposition diagram with single feature is shown in Fig. 3b.

Characteristic frequency components
The decomposition results of standardized feature sequences are shown in Fig. 4, where Fig. 4a–c, respectively, corresponds to the 2-layer low-frequency components, the 2-layer high-frequency components and the 1-layer high-frequency components of the six features. These frequency components retain most of the valid information of the original data.
3.3 Model prediction
LSTM is an excellent time domain prediction model, including input vector, two LSTM hiding layer, dense layer and output layer (Nelson et al. 2017). Theoretically, the more LSTM layers there are, the stronger the nonlinear fitting ability is. However, due to the large amount of time spent on training, the scheme with better effect and less time is generally selected. In this paper, the 2-layer LSTM can achieve a good effect in less time. The number of neurons in LSTM of the first layer is 128, and the number of neurons in LSTM of the second layer is 64, so as to reduce the volume of data flow and reduce the interference of redundant data. The role of the adaptive layer is to assign weights to the frequency components, highlighting the influence of different frequency components on the prediction target.

Prediction model
As shown in Fig. 5, the third step of the model is to input the low-frequency components and high-frequency components obtained in Sect. 3.2 into LSTM as separate sequences. The model is trained by the objective function. The training function is:
where \({\hat{y}}\) is the predicted value obtained by the model and y is the actual value. Equation (6) is the optimization function of the model, \(\varTheta \) is the optimization parameter of the model, and \(\eta \) is the adjustable learning rate. The model uses BPTT algorithm to update optimization parameters iteratively until each LSTM predicts the frequency information of a group of original sequences. After obtaining the predicted frequency components, LSTM will enter the adaptive layer, which weights different frequency components.
where f is the activation function of the adaptive layer, \({\hat{y}}\) is the predicted frequency component, and g is the weighted frequency characteristic.
The last step of AWTM model is wavelet reconstruction. The inverse transformation of Eq. (4) is used to fuse the predicted frequency components to obtain the predicted stock sequence and output the predicted results
4 Experiment
This section is divided into three sections. Section 4.1 discusses model complexity. Section 4.2 compares AWTM with baseline model. Section 4.3 is the interpretive analysis of the model. Considering the impact of the 2008 global financial crisis on financial markets, a large number of experiments were carried out with stock data from 2009 to date to prove the excellent performance of the model. In terms of quantitative comparison of experimental results, this paper used MAPE and RMSE to evaluate the performance of the model.
4.1 Complexity analysis
The complexity of the model has a direct impact on the predictive ability. The complexity of the model in this paper can be measured by two parameters: wavelet decomposition layers and time step. In the following sections, we examine the impact of two parameters on predictive performance and reveal some insights into AWTM parameter settings.

Parameter comparison chart
The effect of the number of wavelet decomposition layers on the model is shown in Fig. 6a. Both the 1-layer decomposition and the 3-layer decomposition can capture the change trend of the sequence, but the 2-layer decomposition has a better prediction effect.
As can be seen from the error analysis in Table 1, AWTM’s prediction results in the 1-layer decomposition and the 3-layer decomposition have large errors. The reason for this phenomenon is that the frequency information is not fully extracted by the 1-layer decomposition , and the excessive frequency generated by the 3-layer decomposition leads to noise and increase in experimental errors in the process of prediction and reconstruction. Therefore, the 2-layer decomposition is adopted in this model.
As shown in Fig. 6b, the fitting curves of 1-step prediction and 3-step prediction basically coincide, but the deviation between the predicted curve and the true value curve under the state of 5-step is relatively large. Table 2 shows the MAPE and RMSE values of AWTM for 1-step, 3-step and 5-step, from which it can be seen that the experimental error of 3-step prediction is small, but the experimental error of 5-step is large. This is due to the increase in cell memory information during the 5-step prediction process, which is beyond the scope of the cell ability.
It can be seen from the above two experiments that the parameters of wavelet decomposition layer and time step have important influences on AWTM prediction results. In addition, through a lot of experiments, the time step is set as 3 and the number of wavelet decomposition layers is 2.
4.2 Baseline model comparison
To further verify the performance of the model, AWTM was compared with the following baseline models :ARMA, CNN, RNN.

Baseline comparison chart
Figure 7 is the broken line graph of the predicted value and the actual value of the above model. It can be seen from the figure that all the four algorithms can fit the future trend of the sequence, but there is a big difference in the degree of fitting. The prediction curve of AWTM has the highest accuracy compared with the other three models, which is basically consistent with the change trend of the actual curve. Table 3 is a summary of the errors of the actual and predicted values of different models. It shows that the average percentage error and mean square error of AWTM are lower than other three models. It is worth noting that AWTM’s fitting curves at peaks and troughs have smaller deviations than other models, which highlights AWTM’s excellent performance in predicting non-stationary sequences.
4.3 Model interpretive analysis
In traditional models, single feature is used as the model input for prediction. In this paper, XGBoost algorithm is used to select high-importance features for multivariate prediction of stocks. In order to verify the necessity of multivariable prediction, LSTM and AWTM are used for single-feature prediction and multi-feature prediction, respectively. Figure 8 shows the single-feature and multi-feature prediction curve fitting graph of the above model. It can be seen from the figure that the prediction results of the multi-feature model are closer to the real value and have less hysteresis. The error analysis in Table 4 shows that the multi-feature prediction error of both LSTM and AWTM is smaller than that of single-feature prediction, which also reflects the superiority of multi-feature prediction.

Comparison of single-feature and multi-feature model prediction
In order to validate the feasibility of adaptive frequency domain modeling, AWTM is compared with LSTM, Wavelet-LSTM (Sugiartawan et al. 2017) and mLSTM (Wang et al. 2018). LSTM is a typical classical neural network applied to stock prediction. Wavelet-LSTM is an effective method recently put forward that utilizes Wavelet transform and LSTM to model frequency information. mLSTM is a new neural network which embedded wavelet transform into LSTM.

Model comparison chart
In order to ensure the scientificity and effectiveness of the experiment, this experiment is multi-feature prediction, and the other parameters are the same. It can be seen from Fig. 9 that AWTM has the highest curve fitting accuracy and the smallest hysteresis, and the curve basically coincides with the real sequence. It is also easy to find from the error analysis in Table 5 that the MAPE and RMSE of AWTM are only 1.6556 and 0.5604, which are the minimum values of the above models. The above experiments prove the feasibility and superiority of AWTM in multi-feature modeling of stocks.
5 Conclusion and future work
The frequency information of the stock reflects the trading pattern of the stock with different regularity. The discovery of stock frequency patterns provides useful clues to future trends. In order to explore the multi-frequency patterns of stock, an adaptive wavelet transform model (AWTM) is designed in this paper. AWTM adopts XGBoost algorithm to realize multi-feature prediction and combines the wavelet transform and LSTM to predict different frequency components of stocks. The main idea of AWTM is to add an adaptive layer, through which AWTM can automatically focus on different frequency components according to the dynamic evolution of the input sequence and reveal the multi-frequency pattern of stocks. In this paper, the performance of the model is tested by using \( {S \& P500}\) real market data. Experimental results show that AWTM is more predictive and less hysteresis than other traditional models.
However, there are still some shortcomings in our works. For example, only the time–frequency information of stocks is considered, other text information, such as news and comments, are not mined. The research on the deficiency of this paper will continue to explore the further use of time–frequency information and text information, so as to achieve better prediction effect.
References
Ahuja SP, Deval N (2018) On the performance evaluation of iaas cloud services with system-level benchmarks. Int J Cloud Appl Comput 8(1):80–96
Akita R, Yoshihar A, Matsubara T, Uehara K (2016) Deep learning for stock prediction using numerical and textual information. In: 2016 IEEE/ACIS 15th international conference on computer and information science (ICIS), pp 1–6
Chen K, Zhou Y, Dai FY (2015) A lstm-based method for stock returns prediction: a case study of china stock market. In: 2015 IEEE international conference on big data (big data), pp. 2823–2824
Chen TQ, Guestrin C (2016) Xgboost: a scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pp 785–794
Clohessy T, Acton T, Morgan L (2017) The impact of cloud-based digital transformation on it service providers: evidence from focus groups. Int J Cloud Appl Comput 7(4):1–19
Cui C, Li FY, Li T, Yu JG, Ge R, Liu H (2019) Research on direct anonymous attestation mechanism in enterprise information management. Enterp Inf Syst, pp 1–17
Daubechies I (1990) The wavelet transform, time-frequency localization and signal analysis. IEEE Trans Inf Theory 36(5):961–1005
Di LP, Honchar O (2016) Artificial neural networks architectures for stock price prediction: comparisons and applications. Int J Circuits Syst Sig Process 10:403–413
Gers AF, Schmidhuber J, Cummins F (1999) Learning to forget: continual prediction with LSTM. 12(10):2451–2471
Gupta B, Agrawal DP, Yamaguchi S (2016) Handbook of research on modern cryptographic solutions for computer and cyber security, IGI Publishing Hershey, PA, USA
Hoseinzadeand E, Haratizadehn S (2019) CNNpred: CNN-based stock market prediction using a diverse set of variables. Expert Syst Appl 129:273–285
Hu H, Qi GJ (2017) State-frequency memory recurrent neural networks. In: Proceedings of the 34th international conference on machine learning, vol. 70, pp 1568–1577
Hu Y, Feng B, Zhang XZ, Ngai E, Liu M (2015) Stock trading rule discovery with an evolutionary trend following model. Expert Syst Appl 42(1):212–222
Jadad HA, Touzene A, Day K, Alziedi N, Arafeh B (2019) Context-aware prediction model for offloading mobile application tasks to mobile cloud environments. Int J Cloud Appl Comput 9(3):58–74
Liu H, Tian HQ, Pan DF, Li YF (2013) Forecasting models for wind speed using wavelet, wavelet packet, time series and artificial neural networks. Appl Energy 107:191–208
Nelson D, Pereira ACM, de Oliveira R (2017) Stock market’s price movement prediction with LSTM neural networks. In: 2017 International joint conference on neural networks (IJCNN), pp 1419–1426
Nuij W, Milea V, Hogenboom F, Frasincar F, Kaymak U (2013) An automated framework for incorporating news into stock trading strategies. IEEE Trans Knowl Data Eng 26(4):823–835
Petersen CK, Rodrigues F, Pereira FC (2019) Multi-output bus travel time prediction with convolutional lstm neural network. Expert Syst Appl 120:426–435
Pu H, Xie A, Sun DW, Kamruzzaman M, Ma J (2015) Application of wavelet analysis to spectral data for categorization of lamb muscles. Food Bioprocess Technol 8(1):1–16
Qin Y, Song DJ, Chen HF, Cheng W, Jiang GF, Cottrell G (2017) A dual-stage attention-based recurrent neural network for time series prediction. arXiv preprint arXiv:1704.02971
Qureshi B (2018) An affordable hybrid cloud based cluster for secure health informatics research. Int J Cloud Appl Comput 8(2):27–46
Rather AM, Agarwal A, Sastry V (2015) Recurrent neural network and a hybrid model for prediction of stock returns. Expert Syst Appl 42(6):3234–3241
Ribeiro GT, Mariani VC, dos Santos Coelho L (2019) Enhanced ensemble structures using wavelet neural networks applied to short-term load forecasting. Eng Appl Artif Intell 82:272–281
Rojas I, Valenzuelaand O, Rojas F, Guillén A, Herrera LJ, Pomares H, Marquez L, Pasadas M (2008) Soft-computing techniques and arma model for time series prediction. Neurocomputing 71(4–6):519–537
Rounaghi MM, Zadeh FN (2016) Investigation of market efficiency and financial stability between S&P 500 and london stock exchange: monthly and yearly forecasting of time series stock returns using ARMA model. Phys A 456:10–21
Sharieh A, Albdour L (2017) A heuristic approach for service allocation in cloud computing. Int J Cloud Appl Comput 7(4):60–74
Sugiartawan P, Pulungan R, Sari AN (2017) Prediction by a hybrid of wavelet transform and long-short-term-memory neural network. Int J Adv Comput Sci Appl 8(2):326–332
Wang JY, Wang Z, Li JF, Wu JJ (2018) Multilevel wavelet decomposition network for interpretable time series analysis. In: Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery and data mining, pp 2437–2446
Wang YL, Liu Z, Wang H, Xu QL (2014) Social rational secure multi-party computation. Concurr Comput: Pract Exp 26(5):1067–1083
Wang YL, Zhao C, Xu QL, Zheng ZH, Chen ZH, Liu Z (2015) Fair secure computation with reputation assumptions in the mobile social networks. Mobile Information Systems 2015
Wang YL, Bracciali A, Li T, Li FY, Cui XC, Zhao MH (2019a) Randomness invalidates criminal smart contracts. Inf Sci 477:291–301
Wang YL, Zhao MH, HuYM, Gao YJ, Cui XC (2019b) Secure computation protocols under asymmetric scenarios in enterprise information system. Enterp Inf Syst, pp 1–21
Zhang LF, Wang YL, Li FY, Hu YM, Au MA (2019) A game-theoretic method based on q-learning to invalidate criminal smart contracts. Inf Sci 498:144–153
Zhang LH, Aggarwal C, Qi GJ (2017) Stock price prediction via discovering multi-frequency trading patterns. In: Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, pp 2141–2149
Zhang QH, Benveniste A (1992) Wavelet networks. IEEE Trans Neural Netw 3(6):889–898
Zheng HT, Yuan JB, Chen L (2017) Short-term load forecasting using EMD-LSTM neural networks with a Xgboost algorithm for feature importance evaluation. Energies 10(8):1168
Acknowledgements
This study was funded by National Natural Science Foundation of China (Grant No. 61873145, U1609218 and 61572286). The author is highly grateful to the editor and the anonymous referees for their valuable comments and suggestions.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author declares that he has no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Communicated by B. B. Gupta.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Liu, X., Liu, H., Guo, Q. et al. Adaptive wavelet transform model for time series data prediction. Soft Comput 24, 5877–5884 (2020). https://doi.org/10.1007/s00500-019-04400-w
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-019-04400-w