
Abstract
While the SERVQUAL scale has met with greater success than other initiatives in the Internet context, the various adaptations and changes made to the measurement scales often make it difficult to compare results over time; a key aspect that companies must take into account when implementing their market-oriented strategies. Even when the time horizons are the same, it is often impossible to aggregate the results if different types of surveys and measurement scales are used; a practice which is, at the same time, customary. Moreover, the wide range of data collection methodologies and measurement scales used by different companies in the same market prevents comparing the results of surveys to evaluate service quality. In this paper, we present a linguistic multi-criteria decision-making model for aggregating these heterogeneous questionnaires with opinions about quality of the e-service offered by the hotels through several websites taking into account the experience on WWW of such users. The study found that all the scales have been slightly better evaluated for Travel 2.0 websites in general that for the studied hotel and established a ranking depending on the website from best to worst score on all SERVQUAL scales: hotel Tripadvisor webpage, hotel Facebook profile and official hotel blog.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Service quality is considered a key factor for a company’s success in the medium and long term, mainly because it is one of the most difficult aspects for competitors to imitate and is generally the basis of a sustainable competitive advantage. Indeed, good quality service is usually positively correlated with a higher rate of retention of existing clients, attracting potential clients and a good corporate image, which ultimately results in higher rates of return (Cronin et al. 2000; Kang and James 2004; Yoon and Suh 2004). The WWW has become an extension of hotel chains’ global distribution systems (GDSs) and it provides strategies to enhance customer service by providing more and better information (Connolly et al. 1995).
Therefore, hotel professionals often encourage users to express opinions by means of different questionnaires above the quality of the e-service offered by the hotel through several websites. Habitually, these questionnaires also include several questions about the WWW user’s experience, such as social networking skills, knowledge of tourism websites, and others, as this is a fundamental aspect to take into account when evaluating these systems (Lew et al. 2010; Chang-ping and Sheng-li 2006; Su 2003, 2010; Novak et al. 2000).
While SERVQUAL, the most widespread method to measure service quality, is generally not used in a literal way, the fact is that most of the questions that are commonly used can be associated to a greater or lesser extent with one or more of the five dimensions of this scale developed by Parasuraman et al. (1985).
Furthermore, one aspect which has contributed to the subjectivity of service quality measurements is the type of scale used. Although Likert scales have generally been used for this purpose, a controversial aspect of them has been the number of points used in the scale and the way to refer to each point. The Likert scale was developed by Likert (1931), who used this technique for the assessment of attitudes. McIver and Carmines (1981) describe the Likert scale as a set of items, made up of approximately an equal number of favorable and unfavorable statements concerning the attitude object, which is given to a group of subjects. The people are asked to respond to each statement in terms of their own degree of agreement or disagreement. Usually, they are instructed to select one of five responses (five-point Likert scale): “strongly agree”, “agree”, “neutral”, “disagree”, or “strongly disagree”. Of course, these perceptions are characterized by uncertainty and fuzziness (Deng and Pei 2009) such that the same words can indicate very different perceptions (Chiou et al. 2005). Some authors consider that the use of conventional (crisp) numbers is not suitable to model these human perceptions and they consider that a better approach should be based on the use of linguistic assessments. The fuzzy linguistic approach was introduced by Herrera-Viedma et al. (2004) and it is based on the concept of linguistic variables. It is a tool intended to model qualitative information that has been used successfully on many domains including decision making (Alonso et al. 2009; Herrera et al. 2009; Cabrerizo et al. 2013). In short, linguistic variables are variables whose values are not numbers, but words or sentences in a natural or artificial language. Therefore, the fuzzy linguistic approach seems to be an appropriate framework for modeling the information like the one in which the Likert scale is used (Huang and Huang 2005; Hsu et al. 2004).
In this paper, we show a model for aggregating the heterogeneous questionnaires with opinions about WWW hotel e-services quality into a five-point Likert scale with the main objective of obtaining an overall SERVQUAL scale evaluation value of hotel e-services quality taking into account the experience of such users on the WWW. The main requirement of the problem is obtaining this aggregation with higher levels of accuracy while maintaining good linguistic interpretability. For this purpose, we use of 2-tuple linguistic model. We propose a computation model to generate this integrated information, to obtain a value of service quality for each hotel as a three-stage linguistic multi-criteria decision-making (LMCDM) Model. In the LMCDM (Chiou et al. 2005; Herrera et al. 2009, Herrera and Herrera-Viedma 2000) processes, the goal consists in searching the best alternatives according to the linguistic assessments provided by a group of users with respect to a set of evaluation criteria.
In short, we propose a new solution to more accurately measure service quality in an online environment that allows adapting the items of the scale as a more correct designation of the possible responses. Both of these aspects contribute to solving two major problems traditionally associated with the SERVQUAL scale: the environment in which it is applied (online vs. offline) and, very importantly, the experience that customers who respond to the questionnaire have in the topic matter.
The rest of the paper is organized as follows: Sect. 2 revises the preliminary concepts, i.e., the 2-tuple linguistic modeling. In Sect. 3, we propose an adaptation to e-services evaluation of the original SERVQUAL scale. Section 4 shows the model for aggregating heterogeneous questionnaires on e-services quality into this adapted SERVQUAL scale. Section 5 presents an example of an application of our model about the quality of the e-services offered by a hotel located in Tenerife, Spain. Finally, we point out some concluding remarks and future work.
2 Review of the 2-tuple fuzzy linguistic approach
The 2-tuple fuzzy linguistic approach (Herrera and Martínez 2000) is a continuous model of information representation that has been used in many applications including decision-making problems (Carrasco et al. 2012). This model carries out processes of “computing with words” without the loss of information which are typical of other fuzzy linguistic approaches.
The basic notations and operational laws of this approach are introduced in (Herrera and Martínez 2000). Let \(S = \{{{s_0},\ldots ,{s_T}} \}\) be a linguistic term set with odd cardinality, where the midterm represents an indifference value and the rest of the terms are symmetric with respect to it. We assume that the semantics of labels is given by means of triangular membership functions and consider all terms distributed on a scale on which a total order is defined, i.e., \(s_{i} \le s_{j} \Leftrightarrow i < j\). In this fuzzy linguistic context, if a symbolic method (Delgado et al. 1993; Herrera and Herrera-Viedma 1996) aggregating linguistic information obtains a value of \(b \in \) [0,T], and \(b \in [ {0,T} ],{\text { and}}\ b \notin \{ {0,\ldots ,T} \},\) then an approximation function is used to express the result in S.
Definition 1
(Herrera and Martínez 2000). Let b be the result of an aggregation of the indexes of a set of labels assessed in a linguistic term set S, i.e., the result of a symbolic aggregation operation, \(b \in [0,T].\ Let\ i = \mathrm{round}\ (b)\ \mathrm{and} \upalpha = b-i\) be two values, such that \(i \in [0,T] \ \mathrm{and} \ \upalpha \in [\)-\(0.5, 0.5),\ \mathrm{then} \upalpha \) is called a symbolic translation.
The 2-tuple fuzzy linguistic approach is developed from the concept of symbolic translation by representing the linguistic information by means of 2-tuples (\(s_{i}\), \(\upalpha _{i})\), \({s_i} \in S\) and \({\upalpha _i} \in \)[\(-\)0.5,0.5), where \(s_{i}\) represents the information linguistic label, and \(\upalpha _{i}\) is a numerical value expressing the value of the translation from the original result b to the closest index label, i, in the linguistic term set (\(s_{i} \in S)\).
This model defines a set of transformation functions between numerical values and 2-tuples.
Definition 2
(Herrera and Martínez 2000). \(Let S = \{ {s_1},\ldots ,{s_T}\}\) be a linguistic term set and b \(\in [0,T]\) a value representing the result of a symbolic aggregation operation, then the 2-tuple that expresses the equivalent information to b is obtained with the following function:
where round\((\cdot )\) is the usual round operation, \(s_{i}\) has the closest index label to “b” and \(``\upalpha ''\) is the value of the symbolic translation.
For all \(\Delta \), there exists \(\Delta ^{-1}\), defined as \(\Delta ^{-1}(s_{i}\), \(\upalpha )=i +\upalpha \). Moreover, it is obvious that the conversion of a linguistic term into a linguistic 2-tuple consists of adding a symbolic translation value of 0, i.e., \(s_{i} \in S \Rightarrow \) \((s_{i},\Rightarrow 0)\).
Information aggregation consists of obtaining a value that summarizes a set of values. Hence, the result of the aggregation of a set of 2-tuples must be a 2-tuple. Using the functions \(\Delta \) and \(\Delta -1\) that transform numerical values into linguistic 2-tuples and vice versa without loss of information, any of the existing aggregation operators can be easily extended for dealing with linguistic 2-tuples. As discussed in the Sect. 4, the model proposed in this paper requires a 2-tuple linguistic weighted average operator. In what follows, we describe the aggregation operators used in our model.
-
Arithmetic mean. The arithmetic mean is a classical numerical aggregation operator. Its equivalent operator for linguistic 2-tuples is defined as:
Definition 3
(Herrera-Viedma et al. 2004). \(Let\ A = \{ ({l_1},{\upalpha _1}), \ldots ,({l_n},{\upalpha _n})\}\) be a set of linguistic 2-tuples, the 2-tuple arithmetic mean \(={\bar{A}}^{-e}\) is computed as:
-
Linguistic weighted average operator. The linguistic weighted average is used when different values (\(l_{i}\), \(\alpha _{i})\) have a different linguistic importance, assuming that the weights are also expressed by means of linguistic 2-tuples (\(w_{i}\), \(\alpha _{i}^{w})\):
Definition 4
(Herrera-Viedma et al. 2004). \(Let A = \{ ({l_1},{\alpha _1}), \ldots ,({l_n},{\alpha _n})\}\) be a set of linguistic 2-tuples and \(W = \{ ({w_1},\alpha _1^w),\ldots ,({w_n},\alpha _n^w)\}\) be their linguistic 2-tuple associated weights. The 2-tuple linguistic weighted average \(={A}^{-w} is\):
with \(\beta _{i } = \Delta ^{-1}(l_{i}, \alpha _{i}\ and \beta _{wi} = \Delta ^{-1}(w_{i}, \alpha _{i}^{w})\).
3 The SERVQUAL scale applied to online environments
The SERVQUAL scale is a survey instrument used to measure service quality in service organization, which was first proposed by Parasuraman et al. (1985). They conducted in-depth interviews with service firm executives and customer focus groups, and then defined service quality as the gap between the perceptions and the expectations of customers, which is referred to as the P–E gap. The authors initially proposed a multiple-item scale for measuring ten dimensions of service quality, but later simplified the scale to five dimensions in 1988: “tangibles”, “responsiveness”, “reliability”, “assurance” and “empathy”. (Parasuraman et al. 1988). Ladhari (2009) reviewed the different applications of the SERVQUAL scale from 1988 to 2008, emphasizing the increasing importance of online services in a society where there is still much scientific literature.
Despite the fact that the SERVQUAL method has been widely used throughout the world, it has been subject to criticism in both the academic and professional spheres (Carrillat et al. 2007; Ladhari 2009). The main criticisms include the incorrect application of the same scale in different contexts such as online/offline environments. More specifically, some studies in recent years have shown that the five classic dimensions of the SERVQUAL scale are not transferable to online environments. In this line, Gefen (2002) identified only three dimensions unifying “responsiveness”, “reliability”, and “assurance” on a single scale. Parasuraman et al. (2005) concluded that the measurement of e-service quality requires scale development that extends beyond merely adapting offline scales. For this reason, they decided to develop a new scale called E-S-QUAL, that is composed of 22 items grouped into four dimensions: “efficiency” (which they described as “the ease and speed of accessing and using the site”); “system availability” (the correct technical functioning of the site); “fulfillment” (the extent to which the site promises about order delivery and items availability are fulfilled); and “privacy” (the degree to which the site is safe and protects customer information). Other authors such as Han and Baek (2004) and Zhou et al. (2010) follow a similar approach, considering the five dimensions of quality (tangible, reliability, responsiveness, assurance and empathy). Other examples of authors who have made changes to the original measurement scale to develop new scales are: e-SERVQUAL (Zeithaml et al. 2000, 2002); WEBQUAL (Loiacono et al. 2000, 2007); IRSQ (Janda et al. 2002); PESQ (Cristobal et al. 2007); and SSTQUAL (Wu et al. 2012).
The main disadvantage of these adaptations of the original SERVQUAL scale is when we want to integrate the results of the online assessments with conventional SERVQUAL studies on offline services to obtain an overall assessment of the quality. Thus, several authors have adapted the SERVQUAL instrument to analyze e-services expectations and perceptions about service quality (Han and Baek 2004; González et al. 2008). Therefore, in this paper, we propose the use of the original SERVQUAL instrument and their adaptations to e-services perceptions:
-
Tangibles: the appearance of physical facilities or equipment, namely the interface of the website, ease of operation with the services and accessibility (Han and Baek 2004; Zhou et al. 2010; Wu et al. 2012) and agility of operations (Han and Baek 2004; Wu et al. 2012).
-
Reliability: the ability to perform the promised service dependably and accurately, i.e., the reliability of operations (Jun and Cai 2001; Han and Baek 2004; Yang 2004; Khan and Mahapatra 2009; Zhou et al. 2010; Wu et al. 2012).
-
Responsiveness: the willingness to help customers and provide prompt service, i.e., customer attention (Jun and Cai 2001; Han and Baek 2004; Yang 2004; Khan and Mahapatra 2009; Zhou et al. 2010; Wu et al. 2012).
-
Assurance: the level of protection of confidential information, the security of the operations (Han and Baek 2004; Yang 2004; Brasil et al. 2006; Khan and Mahapatra 2009; Zhou et al. 2010; Wu et al. 2012) and their ability to inspire trust and confidence.
-
Empathy: the level of caring, usefulness, actualization of information (Brasil et al. 2006) and suitability to needs of uses of the system (Han and Baek 2004; Brasil et al. 2006; Zhou et al. 2010).
Some authors (Saleh and Ryan 1991) propose a SERVQUAL scale with a basic questionnaire in which customers are presented with a collection of statements (questions) about the five above-mentioned scales to ask them if they are agree or disagree on a five-point Likert scale. In order to obtain a more simplified model in this paper, we will use this five-point Likert scale form type based on customers’ perceptions.
4 A three-stage LMCDM model applied to hotel E-services quality evaluation
In this section, we propose a system based on LMCDM model for aggregating heterogeneous questionnaires above of the quality of the e-services offered by the hotels, with the main objective of obtaining a conventional SERVQUAL scale evaluation value of such electronic services, with the perspective shown in the previous section. An important aspect of this process is that considers the experience of such users on the WWW.
The formal framework that we have used to define our system is the following:
-
Inputs: Let \(\breve{I} = \{\breve{I}_{1},{\ldots }, \breve{I}_{\# \breve{I}}\) with # \(\breve{I}\ge \)1, be a collection of non-empty sets of with five-point Likert type questions above of the quality of the service offered by the hotel H through several websites. These questionnaires also include several questions about the WWW user’s experience, such as social networking skills and knowledge of tourism websites. Therefore, \(\breve{I}\) contains the questionnaires to be aggregated, i.e., the input questionnaires. For each questionnaire, \(\breve{I}_{a}\), \(a \in \) {1,..., #\(\breve{I}\)}, let \(\breve{I}_{a }\)= {\(\breve{i}_{1}^{a}\),...,\( \breve{i}_{\# \breve{I}_a}^{a}\)}, with #\( \breve{I}_{a} \ge \)1, be a set of #\(\breve{I}_{a}\) attributes or features characterizing the opinions answered on a five-point scale. Assuming that we have several groups of users \(Y_{a }\)= {\(y_{1}^{a}\),...,\( y_{\# Ya}^{a}\)}, #\(Y_{a }\ge \) 1, which have filled in the form answering the corresponding attributes on questionnaire \(\breve{I}_{a}\), we consider that \(e_{d}^{a}(\breve{i}_{b}^{a})\), \(\forall a \in \) {1,..., #\(\breve{I}\)}, \(\forall b \in \) {1,..., #\( \breve{I}_{a}\)}, \(\forall d \in \) {1,..., #\(Y_{a}\)}, is the subjective opinion provided by the user \(y_{d}^{a}\) on the attribute \(\breve{i}_{b}^{a}\).
-
Outputs: Let \(\breve{O}=\){\(\breve{o}_{1}\),...,\( \breve{o}_{n}\)}, \(n=\)5, be a questionnaire based on the SERVQUAL scale with five-point Likert type questions described above (Sect. 3): \(\breve{o}_{1 }\)= Tangibles, \(\breve{o}_{2 }\)= Reliability, \(\breve{o}_{3 }\)= Responsiveness, \(\breve{o}_{4 }\)= Assurance and \(\breve{o}_{5 }\)= Empathy. The objective is to obtain a single questionnaire for hotel H based on the SERVQUAL type output questionnaire, \(\breve{O}_{o}\)= {\(\breve{o}_{1}^{o}\),...,\( \breve{o}_{n}^{o}\)}, which integrates the input opinions.
In a LMCDM (Chiou et al. 2005; Herrera and Herrera-Viedma 2000; Carrasco et al. 2012) model, the goal is to search for the best alternatives of the set X = {\(x_{1}\),..., \(x_{n}\)} according to the linguistic assessments {\(V_{1}\),..., \(V_{m}\)} provided by a group of experts {\(P_{1}\),..., \(P_{m}\)} with respect to a set of evaluation criteria. In the linguistic decision analysis of an LMCDM problem, the solution scheme must be formed by the following three steps (Herrera and Herrera-Viedma 2000):
-
The choice of the linguistic term set with its semantics: It consists of establishing the linguistic variable (Zadeh 1975) with a view to providing the linguistic performance values. The five-point Likert scale is used for the output questionnaire of our system and to express the information provided by hotel experts. As we mentioned above, the five-point Likert scale is a set of items made up of an equal number of favorable and unfavorable statements concerning the attitude object. The scale is provided to a group of subjects that are instructed to select one of five responses: “strongly agree”, “agree”, “neutral”, “disagree”, or “strongly disagree”. We can define the linguistic expression domain by means of an ordered set of linguistic terms whose membership functions are triangular and then characterize the linguistic expression domain as follows (Carrasco et al. 2012):
-
The granularity value is five.
-
We consider a linguistic term set on which a total order is defined and distributed on the scale [0, 1], with the midterm representing an assessment of “approximately 0.5”, with the rest of the terms being placed symmetrically around it.
-
We define the semantics by considering that each linguistic term for the pair (\(s_{i}\), \(s_{T-i})\) (T+1 is the cardinality, i.e., 5) is equally informative and by assigning triangular membership functions to each linguistic term.
-
Thus, we can use the set of five linguistic terms shown in Fig. 1:
-
The choice of the aggregation operator of linguistic information. Although the assessments to be aggregated and their importance degrees are terms that belong to S, i.e., the value of the symbolic translation is 0, we propose a 2-tuple aggregator in order to obtain a result without loss of information. Thus, the linguistic weighted average operator \(={A}^{w}\) (see Eq. 1) is used to aggregate this information in our system.
Fig. 1 
Linguistic terms defined for a five-point Likert scale
-
The choice of the best alternatives. In our model, we assume that experts use the linguistic utility function (Yager 1995). In this case, for each criterion k (provided by users or experts) a utility function \(V_{k}\) = [\(v_{1}^{k}\),..., \(v_{n}^{k}\)] is supplied that associates each alternative \(x_{i}\) with a linguistic value \(v_{i}^{k}\), indicating the performance of that alternative. Furthermore, we consider that each of these criteria has a linguistic weight {\(W_{1}\),..., \(W_{m}\)}, i.e., each criterion k has a linguistic weight \(W_{k}\). Here, we assume an indirect approach (Herrera and Herrera-Viedma 2000): {\(V_{1}\),..., \(V_{m}\)}\(\rightarrow \) the best alternatives, providing the best alternatives on the basis of a collective preference, \(V^{C}\), which is a preference of the group of criteria as a whole.

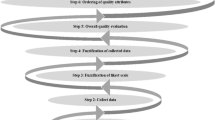
The LMCDM model proposed is composed by the following three stages (see Fig. 2).
We now proceed to explain each of these stages in more detail.
4.1 Stage 1: LMCDM processes guided by the information provided by hotel experts
In these decision-making processes, there are m hotel experts \(\{P_{1},\ldots , P_{m}\}\), for example hotel professionals selected owing to their professional knowledge or researchers with research experience on this topic. The experts must provide their levels of expertise \(\{e_{1},\ldots , e_{m}\}\). These values are taken into account when weighing their performance values on a predefined set of options. This phase comprises two LMCDM different processes where the experts are asked to:
-
Associate each attribute of the input opinions to each one of the n (\(n=\)5) SERVQUAL scales. The aim is to obtain \(W_{s}^\mathrm{ab }= \{w_\mathrm{si}^{ab}\}\), where each \(w_\mathrm{si}^{ab}\) represents the 2-tuple linguistic importance degree of the attribute \(\breve{i}_{b}^{a}\) for the SERVQUAL scale \(\breve{o}_{i}\).
-
Provide the subjective importance of each input attribute to evaluate the WWW user’s experience. The aim is to obtain the values \(\{w_{e}^{ab}\}\) that represent the 2-tuple linguistic importance degree of the attribute \(\breve{i}_{b}^{a}\) in order to evaluate the WWW user’s experience.
Since this is a very important step, we consider that experts should have at least 5 years of experience. The number of experts should also be at least five, i.e., \(m\ge \)5. In what follows, we show how to model this LMCDM problem following an indirect linguistic approach.
As mentioned above, the experts express their opinions using a linguistic Likert scale. Moreover, it is possible that the experts do not provide any values. This is denoted by the symbol “-” to express that there is no association of attribute of input opinions with any SERVQUAL scale of the output questionnaire (for the first objective), or that this attribute is fully insignificant for evaluating the WWW user’s experience (for the second aim). The specification of these non-values is a common practice when expressing preferences with linguistic terms.

LMCDM to integrate the input questionnaires into a SERVQUAL form
For our two objectives, the linguistic weighted average operator \(=\bar{A}^{w}\) is used to aggregate the individual linguistic performance values. The basic idea consists of using the value \(e_{k}\in S \)as the linguistic importance degree of all the linguistic matching ratings of the expert \(P_{k}\). Regarding the choice of the best alternatives, we distinguish between two possibilities, according to the objective sought:
-
As regards the first objective, for each criterion k, a utility function is provided for each different attribute characterizing the input opinions: \(V_{k}^\mathrm{ab }\)= [\(v_{1}^{kab}\),..., \(v_{n}^{kab}\)], with \(v_{i}^{kab }\in \quad S\), \(\forall k \in \) {1,..., m}, \(\forall a \in \){1,..., #\(\breve{I}\)}, \(\forall b \in \) {1,..., #\(\breve{I}_{a}\)}, \(\forall i \in \){1,..., n}. Therefore, each expert \(P_{k}\) associates the utility function \(V_{k}^{ab}\) for each attribute \(\breve{i}_{b}^{a}\) with each major conceptual SERVQUAL scale, i.e., the alternative \(x_{i}\), by using the linguistic values of S indicating the performance of that alternative. The proposed choice process is carried out in two phases:
-
Aggregation phase of linguistic information. Using the aggregation operator specified above, the collective linguistic utility function \(V^\mathrm{Cab }\)= {\(v_{1}^{ab}\),..., \(v_{n}^{ab}\)} is obtained for each attribute \(\breve{i}_{b}^{a}\) from the individual ones {\(V_{1}^{ab}\),..., \(V_{m}^{ab}\)} as follows:
$$\begin{aligned}&{V^\mathrm{Cab}} = \{ {{\bar{A}}^w}[(({e_1}0),\,(v_1^{1\,ab},0)), \ldots (({e_m},0),\,(v_1^{m\,\,ab},0))],\ldots , \nonumber \\&\quad \quad \quad \quad \quad {{\bar{A}}^w}\,[(({e_1}0),\,(v_n^{1\,ab},0)), \ldots (({e_m},0),\,(v_n^{m\,\,ab},0))]\}, \nonumber \\&\forall a \in \{ 1, \ldots \# \breve{I}\} ,\,\forall b \in \{ 1, \ldots \# {\breve{I}_a}\} ,\,n = 5 \end{aligned}$$(2)As mentioned above, the result of the aggregation of a set of 2-tuples is a 2-tuple computing without loss of information. Hence, each \(v_{i}^{ab}\in \quad S \times \) [-0.5,0.5), \(\forall i \in \{1, \ldots , n\}\).
-
-
Exploitation phase for the aggregated linguistic information. The goal of this phase is to choose the best alternative from the collective linguistic utility function. Since the linguistic performance values are linguistic utility functions, \(V^\mathrm{Cab}\) is itself a linguistic choice function, i.e., \(V^\mathrm{Cab }=X^\mathrm{Cab}\). In our problem, for each attribute characterizing input opinions, we want to obtain a linguistic value indicating the matching of that attribute with each SERVQUAL scale of the output questionnaire. Therefore, this linguistic choice function is the desired solution, i.e., \(X^\mathrm{Cab }=W_{s}^{ab}\).
-
Regarding the second objective, for each criterion k, a utility function is provided for each different attribute characterizing the input opinions: \(V_{k}^\mathrm{ab }= [v_{k}^{ab}\)], with \(v_{k}^\mathrm{ab }\in \quad S\), \(\forall k \in \{1,{\ldots }, m\}, \forall a \in \{1,{\ldots }, {\#}\breve{I}\}\), \(\forall b \in \) {1,..., #\(\breve{I}_{a}\)}. Therefore, each expert \(P_{k}\) associates the utility function \(V_{k}^{ab}\) for each attribute \(\breve{i}_{b}^{a}\) with an alternative \(x_{i }=s_{i} \in S\), indicating the performance of that alternative to evaluate the WWW user’s experience. The proposed choice process is also carried out in two steps:
-
Aggregation phase of linguistic information. Using the aggregation operator specified above, the collective linguistic utility function \(V^\mathrm{Cab}= \{v_{b}^{a}\}\) is obtained for each attribute \(\breve{i}_{b}^{a}\) from the individual ones \(\{V_{1}^{ab},{\ldots }, V_{m}^{ab}\}\) as follows:
$$\begin{aligned}&{V^\mathrm{Cab}} = \{ {{\bar{A}}^w}[(({e_1}0),\,(v_1^{ab},0)), \ldots (({e_m},0),\,(v_m^{ab},0))]\} , \nonumber \\&\quad \forall a \in \{ 1, \ldots \# I\} ,\,\forall b \in \{ 1, \ldots \# {I_a}\} , \end{aligned}$$(3)where each \(v_{b}^{a} \in \quad S \times [-0.5,0.5)\).
-
Exploitation phase for the aggregated linguistic information. Again \(V^\mathrm{Cab}\) is itself a linguistic choice function, i.e., \(V^\mathrm{Cab }=X^\mathrm{Cab}\). Therefore, this linguistic choice function is the desired solution, i.e., \(X^\mathrm{Cab }=w_{e}^{ab}\).
-
These solution values will be used in the next stage of the LMCDM process.
4.2 Stage 2: LMCDM processes guided by the opinions provided by WWW users
This stage consists of integrating these input opinions of users \(Y_{a}\) (decision makers) with the following aims:
-
The first objective is to obtain a SERVQUAL scale evaluation value of the hotel quality information under the user’s perspective, i.e., the set \(\breve{O}_{d}^{a}\)= \(\breve{o}_{1}^{ad}\),...,\(\breve{o}_{n}^{ad}\) n=5.
-
The second aim is to obtain an assessment of the WWW user’s experience, i.e., the set \(\breve{E} = \{\breve{e}_{d}^{a}\}\).
Again, the linguistic weighted average operator \(=\bar{A}^{w}\) is used to aggregate the individual linguistic performance values, i.e., the attributes characterizing the input opinions \(e_{d}^{a}(i_{b}^{a})\in \) S. The proposed choice process of the best alternatives is carried out using this operator according to the objective sought:
-
For the first objective, the integration process is weighted with the 2-tuple linguistic values included in set \(W_{s}^{ab}\) obtained in the previous stage that represent the consensus importance of the attributes \(i_{b}^{a}\) for each SERVQUAL scale:
-
Aggregation phase of linguistic information. The collective linguistic utility function \(V^\mathrm{Cad}\) = {\(v_{1}^{ad}\),..., \(v_{n}^{ad}\)} is obtained for each user \(y_{d}^{a}\) and for each scale \(o_{i}\) as follows:
-
This result is a 2-tuple value computing without loss of information, i.e., \(v_{i}^{ad} \quad \in \quad S \times \) [-0.5,0.5), \(\forall i \in \){1,..., n}.
-
Exploitation phase for the aggregated linguistic information. Since the linguistic performance values are linguistic utility functions, \(V^\mathrm{Cad}\) is a linguistic choice function, i.e., \(V^{Cad }=X^\mathrm{Cad}\). Therefore, this collective vector is the desired solution for our first objective, i.e., \(V^{Cad }=\breve{O}^{ad}\).
-
For the second objective the process is weighted with the previously obtained 2-tuple linguistic values {\(w_{e}^{ab}\)} that represent the consensus importance degree of the input attributes to evaluate the WWW user’s experience:
-
Aggregation phase of linguistic information. The collective linguistic utility function \(V^\mathrm{Cad}\) = {\(v_{d}^{a}\)} is obtained for each user \(y_{d}^{a}\):
With \(v^{d} \in S \times \) [\(-\)0.5, 0.5).
-
Exploitation phase for the aggregated linguistic information. As in the previous objective, \(V^\mathrm{Cad}\) is a linguistic choice function, i.e., \(V^{Cad }=X^\mathrm{Cad}\), and is therefore the desired solution for this objective, i.e., \(V^{Cad }=\breve{e}_{d}^{a}\).
4.3 Stage 3: LMCDM process to obtain the SERVQUAL evaluation value according to the WWW user’s experience
Once the previous objectives have been achieved, for each user \(y_{d}^{a}\) we have a SERVQUAL scale evaluation value and an assessment of the WWW user’s experience. The aim now is to obtain a single SERVQUAL aggregate evaluation value of service quality for hotel H, i.e., the set \(\breve{O}_{o}\).
The proposed choice process of the best alternatives is carried out using the linguistic weighted average operator \(=\bar{A}^{w}\). The basic idea of this integration process is to aggregate the individual SERVQUAL scale evaluation value of service quality of each user weighted with her/his WWW experience assessment:
-
Aggregation phase of linguistic information. The collective linguistic utility function \(V^{C} = \{v_{1},{\ldots }, v_{n}\}\) is obtained for each scale \(\breve{o}_{i}\) as follows:
This result is a 2-tuple value computing without loss of information, i.e., \(v_{i} \in S \times [-0.5,0.5), \forall i \in \{1,{\ldots },n\}.\)
-
Exploitation phase for the aggregated linguistic information. Again, \(V^{C}\) is a linguistic choice function and is therefore the desired solution for this objective, i.e., \(V^{C }=X^{C }=\breve{O}_{o}\).
5 Example of an application
In this section, we present an example of an application of our model using users’ opinions about the quality of the e-services offered by the Hotel Botánico (HotelBotanico 2013) located in Tenerife, Spain. The hotel appears on several websites, namely Tripadvisor (HotelBotanicoTripadvisor 2013), Facebook (HotelBotanicoFacebook 2013) and the official hotel blog (HotelBotanicoBlog 2013). Participation in the survey was voluntary. Research data were collected from 8th to 28th of September 2013 by means of a web survey. A total of 3269 regular Internet users (those who connect to Internet more than three times a week) were invited to take part in the survey.
The sample size comprised valid 616 questionnaires (see Table 1). The final response or retention rate after sending the first invitation and a second reminder was 18.84 %.
The problem we are trying to solve can be described as follows: Let H = hotel Botánico, and \(\breve{I} \)= {\(\breve{I}_{1}\),..., \(\breve{I}_{\# I}\)}, with #\(\breve{I}=\)3, be the set of input questionnaires with the items answered on a five-point scale. As these attributes are often common or quite similar in all the questionnaires about website adoption or acceptance, they are shown in summarized form in Table 2. In addition, these questionnaires share some information in common on users who have responded to the questions such as date of fulfillment, gender or age.
As mentioned in Sect. 4, three stages are needed to solve this integration problem. In what follows, we explain these stages and then provide examples of analyses that a business analyst can perform using the integrated information that is obtained.
5.1 Stage 1: LMCDM processes guided by the information provided by hotel experts
In this step, and for our example application, we have had the collaboration of the following five hotel experts:
-
\(P_{1}\): Full Professor of the Faculty of Tourism Management at our University with more than 20 years of experience in researching and rating tourism services.
-
\(P_{2}\): Associate Professor of the Faculty of Tourism Management at our University with more than 15 years of experience in researching and rating tourism services.
-
\(P_{3}\): Assistant Professor of the Faculty of Tourism Management at our University with 2 years of experience in researching and rating tourism services.
-
\(P_{4}\): Hotel professional with more than 25 years of experience.
-
\(P_{5}\): Hotel professional with more than 10 years of experience.
The experts were asked to express their linguistic performance values on each attribute of the input opinions (see Table 2) to associate them with each SERVQUAL scale and evaluate the WWW user’s experience. Let us remember that it is possible that experts do not provide any values (“-”) to some questions. The linguistic levels of expertise provided by the experts have been the highest except for the second expert, which was Agree. Therefore, \(e_{1 }=e_{2 }=e_{4}=e_{5 }=\) SA and \(e_{3 }=A\).
As mentioned above (Sect. 4.1), the choice of the best alternatives depends on the objective sought. In what follows, we provide an example for each objective:
-
To obtain \(W_{s}^{ab}\), i.e., the 2-tuple linguistic importance degree of each question for the SERVQUAL scale. For question Q06 (see Table 2), i.e., attribute number six of questionnaire \(\breve{I}_{1}(\breve{i}_{ 6}^{1})\), attribute number seven of questionnaire \(\breve{I}_{2}(\breve{i}_{7}^{2})\) or attribute number 5 of questionnaire \(\breve{I}_{3}(\breve{i}_{5}^{3})\), the linguistic utility functions provided by the experts were:
$$\begin{aligned} V_1 ^{16}= & {} V_1 ^{27}=V_1 ^{35}=\left[ {SA,-,D,N,A} \right] ,\\ V_2 ^{16}= & {} V_2 ^{27}=V_2 ^{35}=\left[ {N,-,D,A,N} \right] , \\ V_3 ^{16}= & {} V_3 ^{27}=V_3 ^{35}=\left[ {SA,-,D,D,A} \right] ,\\ V_4 ^{16}= & {} V_4 ^{27}=V_4 ^{35}=\left[ {A,-,N,A,N} \right] , \\ V_5 ^{16}= & {} V_5 ^{27}=V_5 ^{35}=\left[ {A,-,A,SA,N} \right] . \\ \end{aligned}$$Using Eq. (2), we obtained the following collective linguistic preference relation, i.e., the linguistic choice function:
$$\begin{aligned} \begin{array}{l} {V}^{C 1 6}={V}^{C 2 7}= {V}^{C 3 5}={{X}^{C}}^{1 6}={{X}^{C}}^{2 7}={{X}^{C}}^{3 5}={{W}_{s}} ^{1 6}\\ ={{W}_{s}} ^{2 7}={{W}_{s}} ^{3 5}=\{\bar{A}^w[((SA,0),( {SA,0)}),((SA,0),\\ ( {N,0)}),((A,0),( {SA,0)}),((SA,0),( {A,0)}),(\left( {SA,0),( {A,0)})} \right] ,\\ \quad -,((SA,0),( {D,0)}),((SA,0),( {D,0)}),((A,0),( {D,0)}),\\ ((SA,0),( {N,0)}), (\left( {SA,0),( {A,0)})} \right] , \\ ((SA,0),( {N,0)}),((SA,0),( {A,0)}),((A,0),( {D,0)}),((SA,0),\\ \quad ( {A,0)}),(\left( {SA,0),( {SA,0)})} \right] , \\ ((SA,0),( {A,0)}),((SA,0),( {N,0)}),((A,0),( {A,0)}),((SA,0),\\ ( {N,0)}),(\left( {SA,0),( {N,0)})} \right] \} \\ \quad =\left\{ {( {A,+0.050}),-,( {D,+0.067}),( {N,+0.083}),( {N,+0.117})} \right\} . \\ \end{array} \end{aligned}$$ -
To obtain {\(w_{e}^{ab}\)},which represents the 2-tuple linguistic importance degree of each question in order to evaluate the WWW user’s experience. For question Q05 (Table 2), i.e., attribute number 5 of questionnaire \(\breve{I}_{1}(\breve{i}_{5}^{1})\) or attribute number six of questionnaire \(\breve{I}_{2}(\breve{i}_{6}^{2})\), the linguistic utility functions the experts provided were:
$$\begin{aligned}&V_1 ^{1 5}=V_1 ^{2 6}=\left[ {SA} \right] ,V_2 ^{1 5}=V_1 ^{2 6}=\left[ {SA} \right] ,V_3 ^{15}=V_1 ^{2 6}=\left[ A \right] ,\\&\quad V_4 ^{1 5}=V_1 ^{2 6}=\left[ {SA} \right] \mathrm{and} V_5 ^{1 5}=V_1 ^{2 6}=\left[ {SA} \right] . \end{aligned}$$Using Eq. (3), we obtained the following collective linguistic preference relation, i.e., the linguistic choice function:
$$\begin{aligned} \begin{array}{l} {V}^{C 1 5}={V}^{C 2 6}={X}^{C 1 5}=X^{C 2 6}={{w}_{e}} ^{15}={{w}_{e}}^{26}= \\ \quad =\left\{ \bar{A}^w[((SA,0),( {SA,0)}),((SA,0),( {SA,0)}),((A,0),\right. \\ \qquad \left. ( {A,0)}),((SA,0),( {SA,0)}),((SA,0),( {SA,0)})] \right\} \\ \quad =\left\{ {( {SA,-0.050})} \right\} \end{array} \end{aligned}$$
Using the same LMCDM processes for the remaining questions, i.e., applying Eqs. (2) and (3) to each attribute of the input questionnaires, we obtained the results shown in Table 3.
5.2 Stage 2: LMCDM processes guided by the opinions provided by WWW users
In this stage, the decision makers of the LMCDM processes are the users which have completed the corresponding questionnaires. Examples of the responses to questionnaire \(\breve{I}_{2 }\) are shown in Table 4.
As mentioned in Sect. 4.2, the integration of these input opinions depends on the objective sought. In what follows, we show some examples:
-
To obtain \(\breve{O}_{d}^{a}\), i.e., the SERVQUAL scale evaluation value under the perspective of each user \(y_{d}^{a}\). For instance, the assessment for the Responsiveness scale (the third SERVQUAL scale) is obtained for user \(y_{1}^{2}\), i.e., user number 1 of questionnaire \(\breve{I}_{2}\) using Eq. (3) with the user’s responses to the questionnaire, i.e., \(e_{1}^{2}(\breve{i}_{b}^{2})\) (shown in Table 4) and with the previously obtained 2-tuple linguistic importance degree of each question for the third SERVQUAL scale, i.e., \(w_{s3}^{2b }\)(see Table 3), \(\forall b \in \){1,..., 21} as follows:
-
To obtain {\(\breve{e}_{d}^{a}\)}, i.e., an assessment of the WWW user’s experience. For user \(y_{1}^{2}\) using \(e_{1}^{2}(\breve{i}_{b}^{2})\) (Table 4) and the previously obtained 2-tuple linguistic importance degree of each question to evaluate the WWW user’s experience, i.e., \(w_{e}^{2b}\) (see Table 3), \(\forall b \in \{1,{\ldots }, 21\}\), the assessment is obtained using Eq. (4):
Using the same LMCDM processes for the remaining questions, i.e., applying Eqs. (4) and (5) to each attribute of the input questionnaires, we obtained the rest of the results of this stage (some examples are provided in Table 5).
5.3 Stage 3: LMCDM process to obtain the SERVQUAL evaluation value according to the WWW user’s experience
We then proceeded to aggregate the individual SERVQUAL scale evaluation value of service quality for each user weighted with her/his WWW experience assessment using Eq. 6. In this way, we obtain the single \(\breve{O}_{o}\) questionnaire shown in Table 6. This table shows that the Responsiveness and Assurance scales were assessed in a similar way above Neutral. Reliability is the most poorly rated scale, but also the one with a value higher than Neutral. The highest value of the scales corresponds to Tangibles followed by Empathy, both of which were rated below Agree.
We can successively apply our model at different subsets of the total user pool according to their common features (e.g., date of fulfillment, gender or age). Thus, a business analyst may conduct different surveys and benchmarking on these dimensions under a SERVQUAL perspective. To do so, we consider \(e_{d}^{a}(\breve{i}_{b}^{a})\) to be the set of responses of the corresponding subgroup.
For instance, the results of applying our model for three age groups (from 16 to 24, from 25 to 44 and from 45 to 64 years old) are shown in Table 7. This table reveals that there is no significant differences between the group in the interval [16, 24] and the interval [25, 44] for any SERVQUAL scale. However, group [45, 64] shows a significantly better evaluation for these scales.
In addition, we have applied our model separately to each of the questionnaires \(\breve{I}_{1}\), \(\breve{I}_{2}\), \(\breve{I}_{3}\) and a fourth questionnaire\( \breve{I}_{4}\) listing Travel 2.0 websites in general, i.e., H = “Travel 2.0 websites”. This questionnaire contains the same items as questionnaire \(\breve{I}_{2}\) shown in Table 1, with X = Travel 2.0 websites.
The basic idea is to use this questionnaire as a control group to determine the SERVQUAL assessment of the hotel websites regarding Travel 2.0 websites.
The results of these four processes of integration are summarized in Table 8. We can conclude that all the scales have been evaluated slightly better for Travel 2.0 websites in general (questionnaire \(\breve{I}_{4 }\)in Table 8) than for our hotel (Table 5). Moreover, we can also establish the following ranking depending on the website from the best to worst score on all the SERVQUAL scales: hotel Tripadvisor webpage (\(\breve{I}_{3}\); see Fig. 3), hotel Facebook profile (\(\breve{I}_{2}\); see Fig. 4) and official hotel blog (\(\breve{I}_{1}\); see Fig. 5).

EG3—Tripadvisor

EG2—Facebook

EG1—blog
6 Concluding remarks and future work
In recent decades, marketing professionals have reached consensus that measuring customer satisfaction is key to developing customer-oriented strategies (Kohli and Jaworski 1990; Narver and Slater 1990) with a view to improving relationship marketing (Grönroos 1996). However, there has been less agreement regarding the development of uniform methodologies and scales to measure service quality.
Given these shortcomings, an approach for measuring the different items of a questionnaire should be based on the use of linguistic assessments instead of numerical values.
Although it is habitual to measure human perceptions with quite accurate instruments, such perceptions are characterized by uncertainty and fuzziness. Furthermore, variations in individual perceptions and personality mean that the same words can indicate very different perceptions. In this context, the procedure based on the 2-tuple fuzzy linguistic approach (Herrera and Martínez 2000) is an appropriate framework for modeling this kind of information and obtaining its aggregation with the highest level of accuracy.
Given this heterogeneous context, we have developed a methodology for aggregating different questionnaires to achieve greater homogeneity. This methodology can be used for making comparisons over time or between companies with a view to undertaking more precise decision-making processes. Concretely, we have presented the problem of integrating semantically heterogeneous data from various web questionnaires with opinions about e-tourism services.
Several authors have adapted the SERVQUAL instrument to analyze e-services expectations and perceptions about service quality (Han and Baek 2004; González et al. 2008), but none have adopted a fuzzy linguistic approach which also takes into account users’ experience on the WWW and even less so in e-tourism services.
Specifically, in our methodological proposal we develop a computational model to generate this integrated information in order to obtain a value for hotel e-service quality as a three-stage LMCDM. In the example application, we proceeded in this way:
-
Stage 1: LMCDM processes guided by the information provided by hotel experts. In this step, the system computes, from the information provided by the experts, the 2-tuple linguistic importance degrees of each attribute of the input opinions: (a) to each one of the five SERVQUAL scales and (b) to evaluate the WWW user’s experience.
-
Stage 2: LMCDM processes guided by the opinions provided by WWW users. This stage consists of integrating these input opinions and obtaining the 2-tuple linguistic assessments for each user: a) for each SERVQUAL scale and b) of his/her WWW experience.
-
Stage 3: LMCDM process to obtain the SERVQUAL evaluation value under the WWW user’s experience. This step obtains a single SERVQUAL aggregate evaluation value of service quality for the hotel by aggregating the individual SERVQUAL scale evaluation value of service quality of each user weighted with her/his WWW experience assessment.
The five-point scale has been used to express the opinions of users and experts, while the 2-tuple representation model was used to aggregate these opinions without loss of information.
We can successively apply our model at different subsets of the total user pool according to their common features (e.g., date of fulfillment, gender, age, etc.). Thus, a business analyst may conduct different surveys and benchmarking on these dimensions under a SERVQUAL perspective.
We found that all the scales were evaluated slightly better for Travel 2.0 websites in general than for our hotel and that it is possible to establish a ranking depending on the website from the best to worst score on all the SERVQUAL scales. In our case, we found this order: hotel Tripadvisor webpage, hotel Facebook profile and official hotel blog.
Finally, future research should focus on comparing the results obtained by dividing the sample according to other classification variables of the customer such as date of registration in the electronic service, customer’s location, place of residence, or others. Moreover, it would be interesting to benchmark different companies in the sector by applying this linguistic integration process.
References
Alonso S, Cabrerizo FJ, Chiclana F, Herrera F, Herrera-Viedma E (2009) Group decision-making with incomplete fuzzy linguistic preference relations. Int J Intell Syst 24(2):201–222
Brasil RMN, García FC, Antonialli LM (2006) Qualidade percebida em serviços: o caso dos clientes de correspondentes bancários da Caixa Econômica Federal. Anais ENAMPAD, Brasil
Cabrerizo FJ, Herrera-Viedma E, Pedrycz W (2013) A method based on PSO and granular computing of linguistic information to solve group decision making problems defined in heterogeneous contexts. Eur J Oper Res 230(3):624–633
Carrasco RA, Villar P, Hornos MJ, Herrera-Viedma E (2012) A linguistic multicriteria decision making model applied to hotel service quality. Int J Intell Syst 27:704–731
Carrillat FA, Jaramillo F, Mulki JP (2007) The validity of the SERVQUAL and SERVPERF scales: a meta-analytic view of 17 years of research across five continents. Int J Serv Ind Manag 18(5):472–490
Chang-ping H, Sheng-li D (2006) Elements and models analysis of website information architecture based on user experience. Inf Sci 3:321–325
Chiou HK, Tzeng GH, Cheng DC (2005) Evaluating sustainable fishing development strategies using fuzzy MCDM approach. Omega 33:223–234
Connolly DJ, Olsen MD, Moore RG (1995) The Internet as a distribution channel. Cornell Hotel Restaur Adm Q 39(4):42–54
Cristobal E, Flavián C, Guinaliu M (2007) Perceived e-service quality (PeSQ): measurement validation and effects on consumer satisfaction and web site loyalty. Manag Serv Qual 17(3):317–340
Cronin JJ, Brady MK, Hult GTM (2000) Assessing the effects of quality, value, and customer satisfaction on consumer behavioral intentions in service environment. J Retail 76(2):193–218
Delgado M, Verdegay JL, Vila MA (1993) On aggregation operations of linguistic labels. Int J Intell Syst 8:351–370
Deng W, Pei W (2009) Fuzzy neural based importance-performance analysis for determining critical service attributes. Expert Syst Appl 36(2):3774–3784
Gefen D (2002) Customer loyalty in E-commerce. J Assoc Inf Syst 3:27–51
González ME, Dentiste MR, Rhonda MW (2008) An alternative approach in service quality: an e-banking case study. Qual Manag J 15(1):41
Grönroos C (1996) Relationship marketing: strategic and tactical implications. Manag Decis 34(3):5–14
Han SL, Baek S (2004) Antecedents and consequences of service quality in online banking: an application of the SERVQUAL instrument. Adv Consum Res 31:208–214
Herrera F, Herrera-Viedma E (2000) Linguistic decision analysis: steps for solving decision problems under linguistic information. Fuzzy Sets Syst 115(10):67–82
Herrera F, Martínez L (2000) A 2-tuple fuzzy linguistic representation model for computing with words. IEEE Trans Fuzzy Syst 8(6):746–752
Herrera F, Herrera-Viedma E, Verdegay JL (1996) Direct approach processes in group decision making using linguistic OWA operators. Fuzzy Sets Syst 79:175–190
Herrera F, Alonso S, Chiclana F, Herrera-Viedma E (2009) Computing with words in decision making: foundations, trends and prospects. Fuzzy Optim Decis Mak 8(4):337–364
Herrera-Viedma E, Herrera F, Martínez L, Herrera JC, López AG (2004) Incorporating filtering techniques in a fuzzy linguistic multi-agent model for information gathering on the web. Fuzzy Sets Syst 148:61–83
HotelBotanico (2013) Official webpage of the hotel Botánico located in Tenerife, Spain. http://www.hotelbotanico.com
HotelBotanicoBlog (2013) Official blog of the hotel Botánico located in Tenerife, Spain. http://www.hotelbotanico.com/blog
HotelBotanicoFacebook (2013) Faceebook blog of the hotel Botánico located in Tenerife, Spain. http://www.hotelbotanico.com/blog
HotelBotanicoTripadvisor (2013) Tripadvisor blog of the hotel Botánico. http://www.tripadvisor.es/hotelbotanico
Hsu TH, Chang KC, Pan FC (2004) Service quality evaluation in Taiwan’s international chain hotels using fuzzy MCDM. In: Proceedings of 17th international conference on multiple criteria decision making. Whistler British Columbia, Canada, pp 1–10
Huang TT, Huang WT (2005) Using statistical data and signed distance of fuzzy aggregate evaluation method on application of measuring service quality of hotel. Int J Inf Manag Sci 16(3):17–35
Janda S, Trocchia PJ, Gwinner KP (2002) Consumer perceptions of Internet retail service quality. Int J Serv Ind Manag 13(5):412–431
Jun M, Cai S (2001) The key determinants of Internet banking service quality: a content analysis. Int J Bank Mark 19(7):276–291
Kang GD, James J (2004) Service quality dimensions: an examination of Gronroos’s service quality model. Manag Serv Qual 12(4):266–277
Khan MS, Mahapatra SS (2009) Service quality evaluation in internet banking: an empirical study in India. Int J Indian Cult Bus Manag 2(1):30–46
Kohli AK, Jaworski BJ (1990) Market orientation: the construct, research propositions and managerial implications. J Mark 54:1–18
Ladhari R (2009) A review of twenty years of SERVQUAL research. Int J Qual Serv Sci 1(2):172–198
Lew P, Olsina L, Zhang L (2010) Quality, quality in use, actual usability and user experience as key drivers for web application evaluation. LCNS 6189:218–232
Likert R (1931) A technique for the measurement of attitudes. Columbia University Press, New York Archives of Psychology
Loiacono ET, Watson RT, Goodhue DL (2000) Webqual: a website quality instrument, working paper 2000–126-0, University of Georgia
Loiacono ET, Watson RT, Goodhue DL (2007) WebQual: an instrument for consumer evaluation of web sites. Int J Electron Commer 11(3):51–87
McIver JP, Carmines EG (1981) Unidimensional scaling. Sage, Newbury Park, CA
Narver JC, Slater SF (1990) The effect of a market orientation on business profitability. J Mark 54:20–35
Novak TP, Hoffman DL, Yung Y (2000) Measuring the customer experience in online environments: a structural modeling approach. Mark Sci 19(1):22–24
Parasuraman A, Zeithaml VA, Berry LL (1985) A conceptual model of service quality and its implications for future research. J Mark 49(Fall):41–50
Parasuraman A, Zeithaml VA, Berry LL (1988) SERVQUAL: a multiple-item scale for measuring consumer perceptions of service quality. J Retail 64:12–40
Parasuraman A, Zeithaml VA, Malhotra A (2005) E-S-QUAL: a multiple-item scale for assessing electronic service quality. J Serv Res 7(3):213–233
Saleh F, Ryan C (1991) Analysing service quality in the hospitality industry using the SERVQUAL model. Serv Ind J 11(3):324–345
Su LT (2003) A comprehensive and systematic model of user evaluation of web search engines: II. and evaluation by undergraduates. J Am Soc Inf 54:1193–1223
Su LT (2010) User experience evaluation methods: current state and development needs. In: 6th Nordic conference on human-computer interaction: extending boundaries, pp 521–530
Wu YL, Tao YH, Yang PC (2012) Learning from the past and present: measuring Internet banking service quality. Serv Ind J 32(3):477–497
Yager RR (1995) An approach to ordinal decision making. Int J Approx Reason 12:237–261
Yang Z, Jun M, Peterson R (2004) Measuring customer perceived online service quality scale development and managerial implications. Int J Oper Prod Manag 24(11):1149–1174
Yoon S, Suh H (2004) Ensuring IT consulting SERVQUAL and user satisfaction: a modified measurement tool. Inf Syst Front 6(4):341–351
Zadeh LA (1975) The concept of a linguistic variable and its applications to approximate reasoning, Pt I. Inf Sci 8:199–249 Pt II, Information Sciences 8:301–357. Pt III, Information Sciences 9:43–80
Zeithaml VA, Parasuraman A, Malhotra A (2000) e-service quality: definition, dimensions and conceptual model. Working paper. Marketing Science Institute, Cambridge, MA
Zeithaml VA, Parasuraman A, Malhotra A (2002) Service quality delivery through web sites: a critical review of extant knowledge. J Acad Mark Sci 30(4):362–375
Zhou T, Zhang S, Ji B (2010) Exploring the effect of online banking service quality on users’ continuance usage. In: 2nd international conference on e-business and information system security (EBISS), pp 1–4
Acknowledgments
This work has been developed with the financing of FEDER funds in National Project TIN2013-40658-P and the Andalusian Excellence Project TIC-5991.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Communicated by V. Loia.
Rights and permissions
About this article

Cite this article
Carrasco, R.A., Sánchez-Fernández, J., Muñoz-Leiva, F. et al. Evaluation of the hotels e-services quality under the user’s experience. Soft Comput 21, 995–1011 (2017). https://doi.org/10.1007/s00500-015-1832-0
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-015-1832-0