
Abstract
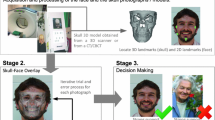
Craniofacial superimposition is a forensic process where photographs or video shots of a missing person are compared with the skull that is found. By projecting both photographs on top of each other (or, even better, matching a scanned three-dimensional skull model against the face photo/video shot), the forensic anthropologist can try to establish whether that is the same person. The whole process is influenced by inherent uncertainty mainly because two objects of different nature (a skull and a face) are involved. In previous work, we categorized the different sources of uncertainty and introduced the use of imprecise landmarks to tackle most of them. In this paper, we propose a novel approach, a cooperative coevolutionary algorithm, to deal with the use of imprecise cephalometric landmarks in the skull–face overlay process, the main task in craniofacial superimposition. Following this approach we are able to look for both the best projection parameters and the best landmark locations at the same time. Coevolutionary skull–face overlay results are compared with our previous fuzzy-evolutionary automatic method. Six skull–face overlay problem instances corresponding to three real-world cases solved by the Physical Anthropology Lab at the University of Granada (Spain) are considered. Promising results have been achieved, dramatically reducing the run time while improving the accuracy and robustness.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Craniofacial superimposition (CS) (Krogman and Iscan 1986; Iscan 1993; Stephan 2009) is a forensic process where photographs or video shots of a missing person are compared with the skull that is found. By projecting both photographs on top of each other (or, even better, matching a three-dimensional skull model obtained scanning an unidentified human skull against the face photo/series of video shots), the forensic anthropologist can try to establish whether that is the same person. This skull–face overlay (SFO) process is usually done by bringing to matching some corresponding anthropometrical landmarks on the skull and the face.
SFO is known to be one of the most time-consuming tasks for the forensic experts (it takes several hours in many real-world situations) (Fenton et al. 2008). In addition, there is no systematic methodology for CS but every expert usually applies a particular process. Hence, there is a strong interest in designing automatic methods to support the forensic anthropologist to put it into effect (Ubelaker 2000).
In particular, the design of computer-aided CS methods has experienced a boom over the past 20 years (Damas et al. 2011). The most recent ones consider the use of laser range scanners to achieve a digital model of the human skull found (see Fig. 1) by means of a manual (Hee-Kyung et al. 2006) or automatic 3D reconstruction procedure (Santamaría et al. 2007, 2009a, 2010), as it is the case in the current contribution.

Acquisition of a skull 3D partial view using the Konica-Minolta\(\texttrademark\) laser range scanner of the Physical Anthropology Lab at the University of Granada (Spain)
In Ibáñez et al. (2009), we developed an automatic method to properly overlay a 3D model of the skull over a 2D photograph of the missing person’s face. For that purpose, we studied and experimented with different evolutionary algorithms (Eiben and Smith 2003) and CMA-ES (Hansen and Ostermeier 2001) demonstrated to be the most accurate and robust approach.
The SFO process is influenced by inherent uncertainty since two objects of different nature are involved (a skull and a face). In Ibáñez et al. (2011), we studied in detail the sources of uncertainty related to the SFO task and proposed the use of imprecise landmarks to overcome most of the limitations associated with them. Using imprecise landmarks, forensic anthropologists are able to properly deal with two different problems. On the one hand, the difficult task of invariably locating anthropometric landmarks (Richtsmeier et al. 1995). On the other hand, the identification of a large enough set of non-coplanar landmarks. These imprecise landmarks were modeled and their use led to a very significant performance improvement of our automatic method.
However, the resulting fuzzy-evolutionary approach relies on a large number of computational operations due to the fact that distances between a crisp point (cranial landmarks) and a fuzzy set of points (facial landmarks) must be computed. Hence, the run time required by the algorithm increases. In particular, the crisp landmark approach ranged in 10–20 s per run while the fuzzy landmark approach ranged in 2–4 min. Up to our knowledge, all the geometrical distance definitions applied to image processing under imprecision need to calculate all the Euclidean distances among the crisp point and all the points that belong to the corresponding fuzzy set.
With the aim of decreasing the run time needed without losing accuracy, we propose the use of a new evolutionary approach based on a coevolutionary algorithm (Paredis 1995). It also takes advantage of handling imprecise landmarks but, unlike the fuzzy approach where distances between a fuzzy set and a crisp point have to be calculated (computationally costly), it only requires to calculate Euclidean distances between pairs of crisp points.
The novel proposal is tested on six SFO problem instances derived from three real-world identification cases previously solved by the Physical Anthropology Lab at the University of Granada (Spain). The results achieved have been actually good, being competitive or even better than previous approaches.
The structure of the paper is as follows. In Sect. 2 we describe the SFO problem and our previous evolutionary algorithm to tackle it. Then, we review the sources of uncertainty associated with the SFO task (Sect. 3) and summarize our previous fuzzy sets-based approach to deal with them. Section 4 is devoted to introduce our new proposal based on a cooperative coevolutionary algorithm. In Sect. 5, we test and compare the new proposal against two different fuzzy-evolutionary approaches over the six problem instances. Finally, we present some concluding remarks and future works in Sect. 6.
2 Skull–face overlay in craniofacial superimposition
The success of the SFO process requires positioning the skull in the same pose of the face as seen in the given photograph (provided by the relatives of the missing/deceased person). The orientation process is a very challenging and time-consuming part of the CS technique (Fenton et al. 2008).
Most of the existing SFO methods are guided by a number of anthropometrical landmarks located in both the skull and the photograph of the missing person (see Figs. 2 and 3, respectively). The selected landmarks are placed in those parts where the thickness of the soft tissue is low. The goal is to ease their location when the anthropologist must deal with changes in age, weight, and facial expressions.

Main craniometric landmarks: lateral (left) and frontal (right) views

Main facial landmarks: lateral (left) and frontal (right) views
Once these landmarks are available, the SFO procedure is based on searching for the skull orientation leading to the best matching of the two sets of landmarks.
In view of the task to be performed, the relation of the desired procedure with the image registration (IR) problem in computer vision (Zitová and Flusser 2003) can be clearly identified. We aim to properly align the 3D skull model and the 2D face photograph in a common coordinate frame following a 3D–2D IR approach. The required perspective transformation to be applied on the skull was modeled in Ibáñez et al. (2009) as a set of geometric operations involving 12 parameters/unknowns which are encoded in a real-coded vector to represent a superimposition solution. The remainder of this section reviews this formulation.
Formally, SFO can be formulated as follows: given two sets of 2D facial and 3D cranial landmarks, F and C, respectively, both comprising N landmarks:
the overlay procedure aims to solve a system of equations with the following 12 unknowns: a rotation represented by an axis d x , d y , d z and angle θ a center of mass r x , r y , r z a translation vector t x , t y , t z a uniform scaling (s) and a 3D–2D projection function given by a field of view ϕ. These 12 parameters determine the geometric transformation f which projects every cranial landmark cli in the skull 3D model onto its corresponding facial landmark fli in the photograph as follows:
where F′ is the set of cranial landmarks (C) once they have been projected onto the image plane by \(f, R=(A \cdot D_{1} \cdot D_{2} \cdot R_{\theta} \cdot D_{2}^{-1} \cdot D_{1}^{-1} \cdot A^{-1})\) represents a rotation matrix to orient the skull in the same pose of the photograph. Such rotation involves a number of geometric transformations \((A \cdot D_{1} \cdot D_{2} \cdot R_{\theta})\) that aim to:
-
Translate the skull to align the origin of coordinates with the rotation axis \((A).\)
-
Reorient the skull so that the rotation axis coincides with one of the Cartesian axes \((D_1\) and \(D_2).\)
-
Perform the rotation given by \(R_{\theta}.\)
-
Use the inverse rotation matrices in reverse order in order to leave the rotation axis in its original orientation \((D_{2}^{-1}, D_{1}^{-1}, A^{-1}).\)
-
Apply the inverse translation matrix to leave the rotated skull in its original location.
\(S, T,\) and \(P\) are uniform scaling, translation, and perspective projection matrices, respectively. The interested reader is referred to Hearn and Baker (1997) for a detailed description of the matrices in Eq. 1 and their relation with the 12 unknowns of the problem.
Different definitions of the fitness function were also studied and the one achieving the best results was the mean error (ME)Footnote 1 (Ibáñez et al. 2009):
where || · || is the 2D Euclidean distance, N is the number of considered landmarks (provided by the forensic experts), cli corresponds to every 3D craniometric landmark, fli refers to every 2D facial landmark, f is the function which defines the geometric 3D–2D projective transformation, and f(cli) represents the projected skull 3D landmark cli in the image/photo plane.
Solving the SFO problem in the latter fashion results in a really complex optimization task, with a highly multimodal landscape, and forensic experts demand very robust and accurate results. This complex landscape lead us to tackle the problem considering robust evolutionary algorithms (EAs) (Eiben and Smith 2003) to search for the optimal values of the 12 registration transformation parameters. In Ibáñez et al. (2009), CMA-ES (Hansen and Ostermeier 2001) and different real-coded genetic algorithms (RCGAs) (Herrera et al. 1998) were applied, achieving very promising results in some problem instances.
3 Imprecise landmarks: a fuzzy set-based approach
The whole CS process is influenced by uncertainty. In particular, SFO is affected by two different sources of uncertainty of different nature. On the one hand, there is an inherent uncertainty associated with the two different kinds of objects involved in the process, i.e. a skull and a face (see Fig. 4). On the other hand, there is also uncertainty associated with the 3D–2D overlay process that tries to superimpose a 3D model over a 2D image. In both, we can distinguish between landmark location uncertainty and landmark matching uncertainty. A complete description of them is given in Ibáñez et al. (2011), Santamaría et al. (2009b).

Correspondences between facial and craniometric landmarks: lateral (left) and frontal (right) views
We summarize our previous proposal to deal with the SFO sources of uncertainty as follows. Our approach is based on allowing the forensic anthropologist to perform an imprecise location of cephalometric landmarks. By using imprecise landmarks, (s)he can locate the landmark as a region instead of as a crisp point as usual. The size of the region defined by the forensic expert will become a measure of the landmark uncertainty: the broader the region, the higher the uncertainty in the location of that landmark. Of course, (s)he can both define precise and imprecise cephalometric landmarks in a face photo, thus keeping the chance to properly locate the unquestionably identified ones.
Notice that, by marking landmarks in an imprecise way, we manage to solve the problems related to three of the four uncertainty sources analyzed (Ibáñez et al. 2011) at the same time. First, the inherent uncertainty of the landmark location in the missing person photograph can be properly tackled. In the same way, the forensic experts would be able to deal with the location of landmarks whose position they cannot determine accurately due to the photograph conditions with the proper level of confidence (using imprecise regions of different sizes). As a consequence, we will allow them to deal with the extremely difficult task to increase the number of selected landmarks. These additional landmarks are essential to face the coplanarity problem in the automatic search of the best SFO (Santamaría et al. 2009b).
The imprecise landmark location approach is based on allowing the forensic experts to locate the cephalometric landmarks using ellipses and on considering fuzzy sets to model the uncertainty related to them. Besides, we have also considered fuzzy distances to model the distance between each pair of craniometric and cephalometric landmarks.
Following the idea of fuzzy plane geometry in Buckley and Eslami (1997) and of metric spaces in Diamond and Kloeden (2000) we have defined a fuzzy landmark as a fuzzy convex set of points having a nonempty core and a bounded support. That is, all its α-levels are nonempty bounded and convex sets. In our case, since we are dealing with 2D photographs with an \(x\times y\) resolution, we have defined the fuzzy landmarks as 2D masks represented as a matrix M with \(m_{x}\times m_{y}\) points (i.e., a discrete fuzzy set of pixels). Each fuzzy landmark will have a different size depending on the imprecision on its localization but at least one pixel (i.e., crisp point related to a matrix cell) will have membership with degree one.
These masks are easily built starting from two triangular fuzzy sets \(\tilde{V}\) and \(\tilde{H}\) modeling the approximate vertical and horizontal position of the ellipse representing the location of the landmark, thus becoming two-dimensional fuzzy sets.
An example of these fuzzy cephalometric landmarks is given in Fig. 5, where the corresponding membership values (calculated using the product t-norm) of the pixels of one of those landmarks is depicted on the right. Left and rights bounds of the \(\tilde{V}\) and \(\tilde{H}\) fuzzy sets correspond to the most left/right–upper/lower point of the ellipse, while the mode correspond to the center of the ellipse.

Example of fuzzy location of cephalometric landmarks (on the left) and representation of an imprecise landmark using fuzzy sets (on the right)
Now we can calculate the distance between a point (which will be the pixel constituting the projection of a 3D craniometric landmark on the 2D face photo) and a fuzzy landmark (the discrete fuzzy set of pixels representing the imprecise position of the cephalometric landmark).
If we denote the distance from point x to the α-level set \(\tilde{F}_{\alpha_i}\) as \(d_{i}= d(x,\tilde{F}_{\alpha_i})\) (in this specific case, this is the minimum Euclidean distance from point x to the all the points in \(\tilde F_{\alpha_i}\)), then the distance from the point to the fuzzy landmark \(\tilde{F}\) can be expressed by Dubois and Prade (1983), Bloch (1999):
Therefore, the original definition of our evolutionary SFO technique’s fitness function (Eq. 2) was modified in Ibáñez et al. (2011) as followsFootnote 2
where N is the number of considered landmarks; cli corresponds to every 3D craniometric landmark; f is the function which defines the geometric 3D–2D transformation; f(cli) represents the position of the transformed skull 3D landmark cli in the projection plane, that is to say, a crisp point; \(\tilde{F}^{i}\) represents the fuzzy set of points of each 2D cephalometric landmark; and, finally, \(d^{*}(f(C_{i}),\tilde{F}^{i})\) is the distance between a point and a fuzzy set of points.
4 A cooperative coevolutionary algorithm tackling the landmark location uncertainty in skull–face overlay
Along this section we first introduce the coevolutionary paradigm, its different types and main characteristics. Then, we present our novel proposal, based on this paradigm, to tackle the landmark location uncertainty in the skull–face overlay stage.
4.1 Coevolutionary algorithms
EAs have been applied to many different types of difficult problem domains, such as parameter optimization and machine learning. Both the successes and failures of EAs have led to many enhancements and extensions to these systems. Some problems are characterized either by potentially complex domains or by the difficulty or impossibility to assess an objective fitness measure. A very natural and increasingly popular extension of EAs for the problem is the class of so-called coevolutionary algorithms (CEAs) (Paredis 1995). In such algorithms, fitness itself becomes a measurement of interacting individuals. This assumption allows the potential for evolving greater complexity by allowing pieces of a problem to evolve in tandem. Besides, the potential for evolving solutions to problems in which such a subjective fitness may, in fact, be necessary (i.e., game playing strategies). Hence, a CEA is an EA (or collection of evolutionary algorithms) in which the fitness of an individual depends on the relationship between that individual and other individuals (Wiegand 2003).
Depending on the nature of the interactions among individuals we can distinguish between competitive and cooperative CEAs. In the former, each species competes with the rest (Rosin and Belew 1997), while, in the latter, all the species collaborate to build a solution for the problem (Potter and De Jong 2000). The originally stated aim of cooperative CEAs (CCEAs) was to attack the problem of evolving complicated objects by explicitly breaking them into parts, evolving the parts separately, and then assembling the parts into a working whole.
This is the goal of the current proposal in which two different but complementary problems arise. On the one hand, we want to know the best set of transformation parameters resulting in the best possible SFO (see Sect. 2). On the other hand, SFO quality is measured based on the distances between two sets of landmarks, where the location of the cephalometric landmarks set is uncertain (see Sect. 3). We only know that they are located inside a region delimited by the forensic expert (imprecise landmark). Hence, we can try to find the precise locations of the cephalometric landmarks in that region. However, the only way to determine them is by looking for the best SFO, assuming that the optimal location of the landmarks implies the chance to achieve the most precise SFO. That is to say, we need to look, at the same time, for the best set of transformation parameters and for the most precise cephalometric landmarks locations.
To do so, we have implemented a CCEA where two populations optimize the set of transformation parameters and the location of the cephalometric landmarks, respectively. The former population considers a real coding scheme to represent the 12 registration transformation parameters in Sect. 2. The latter deals with a variable-length integer-valued chromosome, whose size corresponds to the number of landmark pairs used. Both populations need to collaborate/interact to construct a solution for the main problem, that is to achieve the best possible SFO.
The question of how collaborators or competitors are determined may be among the most important design decisions for the successful application of CEAs (Wiegand et al. 2001). The most obvious (and computationally expensive) method to evaluate an individual in a coevolutionary setting is to make it interact with all possible collaborators or competitors from the other populations. In the case of binary interactions, this is sometimes called complete pairwise interaction. An alternative extreme is to make an individual be only involved in a single interaction. Such choice leaves open the obvious question of how to pick the collaborator or competitor. Of course, between these two extremes there is a whole host of possibilities involving some subset of interactions. Again, collaborators/competitors for such interactions may be chosen in a variety of ways ranging from uniformly random, to fitness-biased choice methods. There are mainly three attributes to be specified for this choice, suggesting a wide range of possible strategies:
-
Interaction sample size: the number of collaborators from each population to use for a given fitness evaluation.
-
Interaction selective bias: the degree of bias of choosing a collaborator/competitor. For example, an individual could be selected either randomly or based on the fitness value.
-
Interaction credit assignment: the method of credit assignment of a single fitness value from multiple interaction-driven objective function results. The main examples here are the minimum, the maximum, and the mean of the fitness values of all the selected interactions.
4.2 Cooperative coevolutionary algorithms for skull–face overlay
As said, our novel proposal to tackle the landmark location uncertainty is based on CEAs. In particular, two variants of CCEAs (actually, the same CCGA with different fitness functions) are presented. in the following we define both CCEAs as well as the common components they share.
4.2.1 Crisp fitness
Taking the analysis developed in Wiegand et al. (2001) as base, we defined our collaboration mechanisms in the same way, i.e., using a pool of best and random individuals of one population to evaluate a specific individual of the other population.
Therefore, assuming that P is the population of the transformation parameters and L is the population of landmark locations, the fitness function for each population is as follows:
and,
where f is one of the credit assignment methods; B L and R L are, respectively, the set of best and random individuals selected as collaborators from population L; B P and R P are, respectively, the set of best and random individuals selected as collaborators from population P; \(fl^{i}_{j}\) refers to every 2D facial landmark of individual j from population L; and \(f(cl^{i}_{j})\) represents the projected skull 3D landmark cli in the image/photo plane using the transformation parameters coded in individual j from population P. The rest of parameters are the same as in Eq. 2.
4.2.2 Fuzzy sets-based fitness
From the study of both fitness functions it is clear that there is no term related with fuzzy set theory. The current coevolutionary approach uses imprecise landmarks which are not modeled using fuzzy techniques. As a consequence, only one Euclidean distance has to be calculated for each pair of landmarks, thus reducing dramatically the number of computational operations. However, this approach presents an important drawback; it is omitting an important part of the information provided by the forensic expert. Assuming the central pixel of the imprecise landmark to be the most likely actual location of the landmark, the remaining pixels inside the imprecise landmark should decrease their membership (i.e., their possibility to be the actual location) as they move further away from the center. This is not the case in the coevolutionary approach where all the points on the imprecise landmarks are equally taken into account.
In order to take advantage of this information also in the coevolutionary approach, we have developed a mixed approach combining the use of fuzzy sets with the coevolutionary model. In this proposal, the same 2D masks calculated for the fuzzy landmarks (see Sect. 3) are used for weighting each landmark. The new fitness functions are as follows:
and,
where \(T(\tilde{V}_{i}(x),\tilde{H}_{i}(y))\) is a t-norm (product) applied on the two triangular fuzzy sets \(\tilde{V}_{i}\) and \(\tilde{H}_{i}\) for the values x and y, respectively. That is to say, the value of the 2D mask for the specific location of landmark \(i.\)
4.2.3 Common components
In our implementation of the CCEA two-genetic algorithms cooperate to achieve the best possible SFO. Thus, we call our approaches CCGA-1 and CCGA-2 referring to the same cooperative coevolutionary genetic algorithm that uses two different sets of fitness functions (Eqs. 4–5 and 6–7, respectively). Both CCGAs uses a SBX crossover (Deb and Beyer 1999) [which reported very good performance in Ibáñez et al. (2009)] for the transformation parameters population and two-point crossover for the landmark locations population. Random initial populations and random mutation are used in both cases, constraining the possible values for the landmark location to all the pixels inside the region corresponding to the imprecise landmark the forensic expert located in the image.
5 Experiments
Our experimental study will involve six different SFO problem instances corresponding to three real-world cases previously addressed by the staff of the Physical Anthropology Lab at the University of Granada (Spain) in collaboration with the Spanish scientific police.
All those identification cases were positively solved following a computer-supported but manual approach for SFO (Damas et al. 2011). We will consider the available 2D photographs of the missing people and their respective 3D skull models acquired at the lab by using its Konica-Minolta© 3D Lasserscanner VI-910.
The experiments developed in this section are devoted to study the performance of the coevolutionary approach to model the imprecise location of cephalometric landmarks within our SFO method in comparison with the previous fuzzy sets-based proposal. With this aim, we first show the parameter setting considered. Then, we introduce each of the six selected real-world SFO problems to be tackled together with the obtained results and their analysis. Finally, we compare the performance of our coevolutionary approach (using the two different fitness functions, CCGA-1 and CCGA-2) against that of the RCGA (with the SBX crossover) and the CMA-ES developed in Ibáñez et al. (2009), both including the fuzzy modeling of imprecise landmarks (Ibáñez et al. 2011).
5.1 Experimental design
Our coevolutionary approach is based on the cooperative coevolution of species corresponding to each of the populations P and L by means of two different genetic algorithms (GAs). As the authors in (Wiegand et al. 2001) pointed out, the ideal interaction sample size, selective bias, and credit assignment depends on the problem characteristics. Hence, we tried many different combinations of parameter values in preliminary experimentations. In particular, we delimited them to the following set:
Generations = 600, 1,000 |
P size = 1,000 |
L size = 100, 150 |
P and L crossover probability = 0.9 |
P and L mutation probability = 0.2 |
P and L tournament size (for RCGA) = 2 |
SBX η parameter (for population P) = 1 |
Interaction sample size and selective bias |
B P = 1, 2, 5 |
R P = 0, 1, 2 |
B L = 1, 2, 5 |
B L = 0, 1, 2 |
f c = m |
where \(m\) corresponds to the minimum values from the multiple interaction-driven objective function results. Other interaction credit assignment were dismissed as suggested in Wiegand et al. (2001).
After testing all these combinations we can conclude that the CEA is quite robust to the parameter setting. Even though the rest of the parameters provided similar results we have selected the following combination as a good performing one: generations (1,000), B size (150), \(B_{P}\) (2), \(R_{P}\) (1), \(B_{L}\) (1), \(R_{L}\) (0).
For the case of the RCGA-SBX and the CMA-ES we used the parameter values which resulted in the best performance of each algorithm (Ibáñez et al. 2009; 2011). In particular, for the case of the RCGA-SBX:
Generations = 600 |
Population size = 1,000 |
Crossover probability = 0.9 |
Mutation probability = 0.2 |
Tournament size (for RCGA) = 2 |
SBX η parameter (for RCGA) = 1 |
and for the case of CMA-ES:
Initial θ (mutation distribution variance) = 0.1 |
λ (population size, offspring number) = 100 |
μ (number of parents/points for recombination) = 15 |
μ (number of evaluations) = 560,000 |
Tournament size (for RCGA) = 2 |
Restart operator every 25,000 evaluations |
Finally, 30 independent runs were performed for each problem instance in order to avoid any possible bias in the results and to compare the robustness of both proposals.
We would like to have a quantitative measure allowing us to benchmark the achieved outcomes. Unfortunately, the ME values obtained by each approach are not fully significant to perform a comparison because of the different objective functions to be minimized. In addition, there is no direct correspondence between ME values and the visual representations as was pointed out by the experts from the Physical Anthropology Lab at the University of Granada (Spain) in Ibáñez et al. (2011).
Due to the latter reasons, we adopted an alternative, specifically designed image processing scheme to evaluate the performance of every SFO approach called “area deviation error” (ADE) (Ibáñez et al. 2011; Santamaría et al. 2009). In ADE the percentage of the head boundary that is not covered by the area of the projected skull is computed as a measure of the quality of the overlay. Figure 6 shows an example of the application of this evaluation procedure.

Example of area deviation error procedure. From left to right, original photographs (top) and projected skull (bottom), intermediate images with the head boundary (top) and binary skull (bottom), and final XOR image (right most) with the corresponding ADE value below the image
5.2 Case studies
As said, all the SFO instances tackled in this work are real-world cases previously addressed by the Physical Anthropology Lab at the University of Granada (Spain). We briefly introduce them as follows.
The first case study happened in Málaga, Spain. The facial photograph of this missing lady was provided by the family and the final identification done by CS has been confirmed. For the current experimentation, the forensic experts manually selected a set of 15 2D cephalometric landmarks on the face present in the photo, following an imprecise approach (first photograph of Fig. 7).

Case studies: photographs of the missing person with the corresponding set of imprecise landmarks. First row first image corresponds to case study 1. First row second image corresponds to case study 2. The other four images (the last image of the first row and the three images in the second row) belong to case study 3, poses 1, 2, 3 and 4, respectively
The second real-world case corresponds to a Moroccan woman whose corpse was found in the South of Spain. There is a single available photograph corresponding to the one in the alleged passport. In this case study, the forensic experts identified 16 cephalometric landmarks following an imprecise approach (second photograph of Fig. 7).
Finally, the third case study happened in Cádiz, Spain. Four different photographs were provided by the relatives, which acquired them at different moments and in different poses and conditions. Hence, this case study consists of four distinct SFO problem instances. The forensic experts were able to locate 14, 16, 15, and 8 landmarks following a imprecise landmark approach for poses 1, 2, 3 and 4, respectively (third to sixth photograph of Fig. 7).
5.3 Coevolution versus fuzzy sets-based modeling
As said, we are going to compare the proposed CCGA against two variants of our previous fuzzy sets-based evolutionary approaches: f-RCGA and f-CMAES, based on the RCGA-SBX and CMA-ES proposed in Ibáñez et al. (2009). On the one hand, comparing the performance of CCGA and f-RCGA allows us to clearly assess the advantages suggested in this work. It seems to be the best way to check how the performance of the coevolutionary approach differs from the fuzzy-set approach, since the search algorithm is the same in both cases. On the other hand, f-CMAES has demonstrated to be the best algorithm solving the SFO problem (Ibáñez et al. 2009, 2011) so it could be the best benchmark to test the global performance of the proposed CCGA.
Table 1 presents the ADE values for the obtained SFOs in the six cases considered, distinguishing between fuzzy-evolutionary (CMA-ES, RCGA) and coevolutionary (CCGA-1, CCGA-2) approaches. The minimum (m), maximum (M), mean (\(\varpi\)), and standard deviation (\(\sigma\)) values of the 30 runs performed are shown for each case.
Our analysis will start by a direct comparison between both coevolutionary approaches. Looking at the minimum and mean values, the performance of the CCGA-2 is better than that of the CCGA-1 in four of the six cases. In addition, maximum and standard deviation values are better in five of the six cases in the former approach. Then, we can conclude that CCGA-2 performs better than CCGA-1, that is to say, the fitness function using fuzzy sets for weighting each landmark achieves better results. Regarding the comparison against the f-RCGA, they both perform robustly (mean values), achieving really good minima. No significant differences can be pointed out in the overall behavior over the six cases tested.
Similar conclusions are drawn if we compare CCGA-2 and f-CMAES. On the one hand, CCGA-2 achieves better minima in four of the six cases and better mean values in half of the cases. On the other hand, f-CMAES achieves better maximum and standard deviation values in five of the six cases. Anyway, most of the numerical differences are really small.
An overall comparison of the four approaches is depicted in Table 2. It includes a ranking of their performance for the minimum, mean and maximum values obtained over the six skull–face overlay problems tackled.
From the analysis of this table it is clear the similar performance of f-CMAES, f-RCGA, and CCGA-2. Each of them performs as the best one in one of the categories, \(M, m,\) and \(\varpi,\) respectively. However, the CCGA-2 approach could be considered the best one since it performs the second in two of the categories (\(M\) and \(m\)) and the first in the other \((\varpi).\)
If we focus now on the visual SFO results (see Fig. 8) the comparison among the four approaches becomes really tough. Experts from the Physical Anthropology Lab at the University of Granada visually inspected each case and they cannot make conclusions regarding the superiority of any of the methods.

Best superimposition obtained using f-RCGA (first row), f-CMAES (second row), CCGA-1 (third row), and CCGA-2 (fourth row). From left to right, case studies 1, 2, and 3 (poses 1–4)
Finally, Table 3 shows the run time needed by all the approaches in each of the SFO instances. In contrast to the previous analysis where there are no significant differences among the analyzed approaches, the coevolutionary approach is, at least, four times faster than the fuzzy-evolutionary ones and up to ten times in some cases. These big differences arise mainly because of the high computational effort needed to calculate each fuzzy distance between each pair of crisp–fuzzy landmarks (operation repeated every fitness evaluation). In addition, the run time of the fuzzy approaches is higly influenced by the number and size of the fuzzy landmarks. Notice that, despite the use of fuzzy sets in the CCGA-2, it does not imply a significant increment in the run time since this approach is also avoids the calculation of fuzzy distances.
6 Concluding remarks and future works
In this paper we have proposed a novel and alternative approach to deal with imprecise cephalometric landmarks in the SFO process. By using a CCEA we are able to look for both the best transformation parameters and the best landmark locations at the same time.
Two different fitness functions were analyzed. One of them measures the mean distance between the pairs of landmarks. The other weights those distances by the corresponding value in a bidimensional fuzzy set that models the imprecision in the location of each cephalometric landmark. The resulting approach has been tested on six complex real-world identification cases and it has been compared with our two previous fuzzy-evolutionary approaches using the ADE measure. Results are promising due to the very short time required by the coevolutionary process, being 5−10 times faster than the fuzzy-evolutionary methods, and because of the high-quality overlays obtained, as good as those achieved by the state-of-the-art f-CMA-ES.
In addition, there is ground to improve the coevolutionary paradigm. Other selective bias could be implemented and tested like, for example, pareto-based ones (Bucci and Pollack 2005). Another opportunity for future work is to develop a coevolutionary version of the CMA-ES algorithm.
Due to the inability of the ME to be in concordance with the visual SFO results we are planning to design new the fitness function
Finally, we are planning to tackle the inherent matching uncertainty regarding each pair of cephalometric–craniometric landmarks (see Sect. 3). With the support of the forensic anthropologists collaborating with us and taking Stephan and Simpson’s works (Stephan and Simpson 2008a, 2008b) as a base, we aim to deal with this partial matching situation by using fuzzy sets and fuzzy distance measures.
Notes
Notice that, mean square error is not used because of its negative effect when image ranges are normalized in [0,1].
Despite Fuzzy ME is not a fuzzy number but a number, we use the same notation proposed in Ibáñez et al. (2011) to avoid misunderstanding.
References
Bloch I (1999) On fuzzy distances and their use in image processing under imprecision. Pattern Recognit 32:1873–1895
Bucci A, Pollack JB (2005) On identifying global optima in cooperative coevolution. In: Genetic and evolutionary computation conference (GECCO’05), ACM, pp 539–544
Buckley JJ, Eslami E (1997) Fuzzy plane geometry I: points and lines. Fuzzy Sets Syst 86(2):179–187
Damas S, Cordón O, Ibáñez O, Santamaría J, Alemán I, Navarro F, Botella M (2011) Forensic identification by computer-aided craniofacial superimposition: a survey. ACM Comput Surv 43(4). http://doi.acm.org/1978802.1978806
Deb K, Beyer H (1999) Self-adaptation in real-parameter genetic algorithms with simulated binary crossover. In: Proceedings of the genetic and evolutionary computation conference
Diamond P, Kloeden P (2000) Metric topology of fuzzy numbers and fuzzy analysis. In: Dubois D, Prade H (eds) Fundamentals of fuzzy sets. The handbooks of fuzzy sets, chap 11, Kluwer Academic, pp 583–637
Dubois D, Prade H (1983) On distance between fuzzy points and their use for pausible reasoning. In: International conference on systems, man and cybernetics, pp 300–303
Eiben AE, Smith JE (2003) Introduction to evolutionary computing. Springer
Fenton TW, Heard AN, Sauer NJ (2008) Skull–photo superimposition and border deaths: identification through exclusion and the failure to exclude. J Forensic Sci 53(1):34–40
Hansen N, Ostermeier A (2001) Completely derandomized self-adaptation in evolution strategies. Evol Comput 9(2):159–195
Hearn D, Baker MP (1997) Computer graphics (2nd edn.) C version. Prentice-Hall, Upper Saddle River
Hee-Kyung P, Jin-Woo C, Hong-Seop K (2006) Use of hand-held laser scanning in the assessment of craniometry. Forensic Sci Int 160:200–206
Herrera F, Lozano M, Verdegay JL (1998) Tackling real-coded genetic algorithms: operators and tools for the behavioural analysis. Artif Intell Rev 12(4):265–319
Ibáñez O, Ballerini L, Cordón O, Damas S, Santamaría J (2009) An experimental study on the applicability of evolutionary algorithms to craniofacial superimposition in forensic identification. Inf Sci 179:3998–4028
Ibáñez O, Cordón O, Damas S, Santamaría J (2011) Modeling the skull–face overlay uncertainty using fuzzy sets. IEEE Trans Fuzzy Syst 19(5):946–959
Iscan MY (1993) Introduction to techniques for photographic comparison. In: Iscan MY, Helmer R (eds) Forensic analysis of the skull, Wiley, pp 57–90
Krogman WM, Iscan MY (1986) The human skeleton in forensic medicine, 2nd edn. Charles C. Thomas, Springfield
Paredis J (1995) Coevolutionary computation. Artif Life 2:355–375
Potter MA, De Jong KA (2000) Cooperative coevolution: an architecture for evolving coadapted subcomponents. Evol Comput 8(1):1–29
Richtsmeier J, Paik C, Elfert P, Cole TM, Dahlman F (1995) Precision, repeatability and validation of the localization of cranial landmarks using computed tomography scans. Cleft Palate-Craniofacial J 32(3):217–227
Rosin CD, Belew RK (1997) New methods for competitive coevolution. Evol Comput 5(1):1–29
Santamaría J, Cordón O, Damas S, Alemán I, Botella M (2007) A scatter search-based technique for pair-wise 3D range image registration in forensic anthropology. Soft Comput 11(9):819–828
Santamaría J, Cordón O, Damas S, García-Torres JM, Quirin A (2009a) Performance evaluation of memetic approaches in 3D reconstruction of forensic objects. Soft Comput 13(8–9):883–904
Santamaría J, Cordón O, Damas S, Ibáñez O (2009b) Tackling the coplanarity problem in 3D camera calibration by means of fuzzy landmarks: a performance study in forensic craniofacial superimposition. In: IEEE international conference on computer vision, Kyoto, Japan, pp 1686–1693
Santamaría J, Cordón O, Damas S (2010) A comparative study of state-of-the-art evolutionary image registration methods for 3D modeling. Comput Vis Image Underst 115(9):1340–1354
Stephan CN, Simpson EK (2008a) Facial soft tissue depths in craniofacial identification (part I): an analytical review of the published adult data. J Forensic Sci 53(6):1257–1272
Stephan CN, Simpson EK (2008b) Facial soft tissue depths in craniofacial identification (part II): an analytical review of the published sub-adult data. J Forensic Sci 53(6):1273–1279
Stephan CN (2009) Craniofacial identification: techniques of facial approximation and craniofacial superimposition. In: Blau S, Ubelaker DH (eds) Handbook of forensic anthropology and archaeology. Left Coast Press, California, pp 304–321
Ubelaker DH (2000) A history of Smithsonian–FBI collaboration in forensic anthropology, especially in regard to facial imagery. Forensic Sc Commun 2(4):(online)
Wiegand RP (2003) An analysis of cooperative coevolutionary algorithms. PhD thesis, George Mason University, Fairfax, Virginia
Wiegand RP, Liles W, De Jong K (2001) An empirical analysis of collaboration methods in cooperative coevolutionary algorithms. In: Proceedings of the genetic and evolutionary computation conference, pp 1235–1242
Zitová B, Flusser J (2003) Image registration methods: a survey. Image Vis Comput 21:977–1000
Acknowledgments
This work is supported by the Spanish Ministerio de Educación y Ciencia (ref. TIN2009–07727), including EDRF fundings. We would like to acknowledge all the team of the Physical Anthropology Lab at the University of Granada (headed by Dr. Botella and Dr. Alemán) for their support during the data acquisition and validation processes. Part of the experiments related to this work was supported by the computing resources at the Supercomputing Center of Galicia (CESGA), Spain.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Ibáñez, O., Cordón, O. & Damas, S. A cooperative coevolutionary approach dealing with the skull–face overlay uncertainty in forensic identification by craniofacial superimposition. Soft Comput 16, 797–808 (2012). https://doi.org/10.1007/s00500-011-0770-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-011-0770-8