
Abstract
Adiponectin is an adipose tissue specific protein that is decreased in subjects with obesity and type 2 diabetes. The objective of the present study was to examine whether variants in the regulatory regions of the adiponectin gene contribute to type 2 diabetes in Asian Indians. The study comprised of 2,000 normal glucose tolerant (NGT) and 2,000 type 2 diabetic, unrelated subjects randomly selected from the Chennai Urban Rural Epidemiology Study (CURES), in southern India. Fasting serum adiponectin levels were measured by radioimmunoassay. We identified two proximal promoter SNPs (−11377C→G and −11282T→C), one intronic SNP (+10211T→G) and one exonic SNP (+45T→G) by SSCP and direct sequencing in a pilot study (n = 500). The +10211T→G SNP alone was genotyped using PCR-RFLP in 4,000 study subjects. Logistic regression analysis revealed that subjects with TG genotype of +10211T→G had significantly higher risk for diabetes compared to TT genotype [Odds ratio 1.28; 95% Confidence Interval (CI) 1.07–1.54; P = 0.008]. However, no association with diabetes was observed with GG genotype (P = 0.22). Stratification of the study subjects based on BMI showed that the odds ratio for obesity for the TG genotype was 1.53 (95%CI 1.3–1.8; P < 10−7) and that for GG genotype, 2.10 (95% CI 1.3–3.3; P = 0.002). Among NGT subjects, the mean serum adiponectin levels were significantly lower among the GG (P = 0.007) and TG (P = 0.001) genotypes compared to TT genotype. Among Asian Indians there is an association of +10211T→G polymorphism in the first intron of the adiponectin gene with type 2 diabetes, obesity and hypoadiponectinemia.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Adiponectin, encoded by the ADIPOQ gene, is one of the adipocyte-expressed proteins that enhances insulin sensitivity and functions in regulating the homeostatic control of glucose, lipid and energy metabolism (Hu et al. 1996; Diez et al. 2003). Recent genome wide scans have mapped a susceptibility locus for type 2 diabetes and obesity/metabolic syndrome to chromosome 3q27, where the ADIPOQ gene is located (Kissebah et al. 2000; Vionnet et al. 2000; Comuzzie et al. 2001; Lindsay et al 2003). Single nucleotide polymorphisms (SNPs) of ADIPOQ gene have been genotyped in large datasets from various ethnic groups and several SNPs associated with hypoadiponectinemia, obesity and type 2 diabetes have been identified (Menzaghi et al. 2002; Vasseur et al. 2003; Gibson et al. 2004; Berthier et al. 2005; Heid et al. 2006).
Asian Indians are known to have increased susceptibility to diabetes compared to Europeans (McKeigue et al. 1992). It has been shown that for any given body mass index (BMI), Asian Indians have higher body fat (particularly visceral adiposity), higher plasma insulin levels and greater insulin resistance compared to Europeans (Mohan et al. 1986; Sharp et al. 1987). They have also been reported to have lower adiponectin levels (Abate et al. 2004). It is possible that some of the metabolic abnormalities can be explained by genetic factors. In this context, the adiponectin gene, which has been associated with important metabolic effects in several populations (Weyer et al. 2001; Mohan et al. 2005) is of great interest. The aim of our study was to examine whether the variants in the regulatory regions of the adiponectin gene contribute to the metabolic abnormalities of type 2 diabetes in Asian Indians. For this, we screened the entire promoter, the first intron (a region where SNPs have been previously associated with type 2 diabetes) and the coding regions of the adiponectin gene for novel variations and evaluated the association of the identified variants with type 2 diabetes, obesity and serum adiponectin levels.
Materials and methods
Subjects
A total of 4,000 unrelated study subjects (1,762 men and 2,238 women; mean age 46 ± 13 years; mean BMI 24.3 ± 4.7 kg/m2) were recruited from the Chennai Urban Rural Epidemiology Study (CURES), an ongoing epidemiological study conducted on a representative population of Chennai, the fourth largest city in India with a population of about 4.2 million. The methodology of the study is published elsewhere (Deepa et al. 2003) and is briefly outlined here. In Phase I of CURES, 26,001 individuals were recruited based on a systematic random sampling technique. Self reported diabetic subjects on drug treatment of diabetes were classified as ‘known diabetic subjects’. Fasting capillary blood glucose was determined using a One Touch Basic glucometer (Lifescan, Johnson & Johnson, Milpitas, CA, USA) in all subjects. In Phase 2, all the known diabetic subjects (n = 1,529) were invited to the centre for detailed studies on vascular complications. In addition, all subjects with fasting blood glucose levels in the diabetic range based on ADA fasting criteria (The Expert Committee Report 1997), underwent oral glucose tolerance tests (OGTT) using 75 gm oral glucose load (dissolved in 250 ml of water). Those who were confirmed by OGTT to have 2 h plasma glucose value ≥11.1 mmol/L (200 mg/dl) based on WHO consulting group criteria (Alberti et al. 1998) were labeled as ‘newly detected diabetic subjects’. Subjects who had fasting plasma glucose <110 mg/dL and 2-h plasma glucose value of <140 mg/dL were categorized as normal glucose tolerant (NGT) subjects.
Anthropometric measurements including weight, height and waist circumference were measured using standard methods. The body mass index (BMI) was calculated using the formula, weight (kg)/height (m2) and obesity was classified as BMI ≥ 25 according to WHO Asia Pacific Guidelines for Asians (The Asia Pacific perspective 2000). Fasting plasma glucose (glucose oxidase–peroxidase method), serum cholesterol (cholesterol oxidase–peroxidase–amidopyrine method), serum triglycerides (glycerol phosphate oxidase–peroxidase–amidopyrine method) and HDL cholesterol (direct method-polyethylene glycol-pretreated enzymes) were measured using Hitachi-912 Autoanalyser (Hitachi, Mannheim, Germany).
Total serum adiponectin was measured by radioimmunoassay (cat.no. HADP-61 HK;Linco research , St. Charles, MO, USA ) in a subset of study subjects (n = 911) chosen randomly using computer generated random numbers. The intra- and inter-assay coefficients of variation were 0.38 and 0.74, respectively, and the lower detection limit was 1 ng/mL.
The study subjects comprised 2,000 patients with type 2 diabetes (919 men and 1,081 women) and 2,000 normal glucose tolerant subjects (843 men and 1,157 women). Written informed consent was obtained from all subjects before enrollment in the study. This study was approved by the Madras Diabetes Research Foundation Ethical Commitee (Institutional Review Board).
Genetic analysis
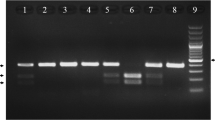
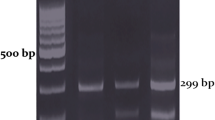
As a pilot screening, the promoter, the first intron and the entire coding regions of the adiponectin gene were screened for variations in the ADIPOQ gene using PCR-SSCP and sequencing on ABI 310 automated sequencer in 500 subjects (250 NGT and 250 type 2 diabetic subjects). SSCP technique was used to screen for SNPs using D Code Universal Mutation Detection System (Biorad, USA). PCR was performed using radioactive α-P33. Electrophoresis was carried out using 8% acrylamide gel, at room temperature (approximately 25°). The gel was run for 2 h at 100 V, 1 h at 150 V and 5 h at 200 V. The gel was transferred to Whatman paper and kept for exposure in a phosphorimager cassette for 12 h and blot was developed in the Phosphorimager facility. SNP +10211T→G was genotyped in a large number by first amplifying a PCR fragment of 228 bp using the forward: 5′-GCTAAGTATTACAGATTTCAGGGCAG-3′ and reverse: 5′-CAGCAACAG CATCCTGAGC-3′ primers and then digesting with HinfI restriction enzyme (MBI Fermentos, Maryland, USA). The assays were performed by a technician who was blinded to the phenotype. To assure that the genotyping was of adequate quality, we performed random duplicates in 20% of the samples and found 98% concordance in genotyping.
Statistical analysis
Statistical Package for Social Sciences (SPSS) Windows, version 10.0, was used for statistical analysis. The effects of the polymorphisms on quantitative and categorical variables were analyzed. Chi-square test was used to compare the proportions of genotypes or alleles. The genotypic frequencies in both cases and controls showed no significant departure from the HWE (P > 0.05). One-way ANOVA was used to compare groups for continuous variables. Logistic regression analysis (simple logistic model) was used to identify the risk of the genotypes for type 2 diabetes and obesity. Type 2 diabetes or obesity was taken as the dependent variable and the genotypes as the independent variable; both additive and dominant models were explored. For additive model, using TT as reference, odds ratio for TG and GG were computed. For dominant model, both TG and GG were combined together as XG (TG + GG) and compared against TT as reference. As subjects with diabetes were older and had higher BMI, we adjusted for age, sex and BMI in all the logistic regression analysis. It is possible that some of our controls which are younger in age will develop diabetes since the prevalence of diabetes increases with age. In order to circumvent this problem age was adjusted for in the logistic analysis.
Further to adjust for the possible confounding effect of age, sex and BMI, these were included as covariates in the analysis of type 2 diabetes. For analyzing the risk of obesity, age, sex and type 2 diabetes were included as covariates. Adiponectin values were log transformed to obtain a normal distribution. P < 0.05 was considered statistically significant. Bonferroni correction (adjusting for four tests) for testing multiple phenotypes was carried out.
Results
The type 2 diabetic subjects were older (51 ± 11 years) compared to the NGT subjects (39 ± 12 years; P < 0.0001) and also had higher BMI (P < 0.0001 ) and waist circumference (P < 0.0001). Total cholesterol (P < 0.0001), serum triglycerides (P < 0.0001), systolic and diastolic blood pressure (P < 0.0001) were also significantly higher in the type 2 diabetic subjects (Table 1).
We identified two proximal promoter SNPs, −11377C→G (rs266729) and −11282T→C (rs266732), one intronic SNP, +10211T→G (rs17846866), and one exonic SNP, +45T→G (rs2241766), by SSCP and direct sequencing in the pilot screening (Fig. 1). Among the four variants studied, the +10211T→G alone was significantly associated with type 2 diabetes in the pilot study and hence, this SNP alone was genotyped on a larger population of 4,000 subjects, comprising of 2,000 type 2 diabetic subjects (919 men and 1,081 women) and 2,000 NGT subjects (843 men and 1,157 women).

Adiponectin gene showing the location of the SNPs identified in the present study
Table 2 shows that the frequency of the TG genotype of +10211T→G SNP was significantly higher in type 2 diabetic patients (21.4%) than the NGT subjects (16.6%; TTvsTG; P = 0.000308). The frequency of the GG genotype of +10211T→G SNP was also higher among type 2 diabetic patients (2.0%) compared to NGT subjects (1.2%). The difference was marginally significant (P = 0.046) but this was lost after multiple correction (TTvsGG; P = 0.18). The frequency of the ‘G’ allele was significantly higher in type 2 diabetic subjects (0.13) compared to NGT subjects (0.10; P = 0.000009).
Logistic regression analysis revealed that subjects with TG genotype of the SNP had significantly higher risk for diabetes compared to TT genotype [Odds ratio 1.28; 95% Confidence Interval (CI) 1.07–1.54; P = 0.008]. However, there was no association of the GG genotype with diabetes (Odds ratio 1.38; 95% CI 0.83–2.29; P = 0.22) (Table 2). The lack of association with the GG genotype may be due to low frequencies of that genotype in both the type 2 diabetes and NGT groups. We accordingly performed a logistic regression analysis under an additive model by coding the genotypes as 0, 1 and 2. The regression showed that the odds ratios for TT vs. GG and TG vs. GG were not statistically significant (Table 2). Thus, it is unlikely that an additive model of inheritance can explain the effect of the SNP in modulating the risk for type 2 diabetes. This raised the possibility of a dominant mode of inheritance since one copy of the G allele (TG) conferred significantly higher risk compared to TT while two copies of the allele (GG) did not have higher risk than one copy. When the TG and GG genotypes were combined as XG, it was significantly different compared to the TT genotype with an adjusted odds ratio of 1.28 (95% CI 1.07–1.53; P = 0.006) with a significant genotypic difference between the two groups (P = 0.000068) (Table 2). This is consistent with a dominant model.
The NGT subjects with GG (27.8 ± 4.4 kg/m2; P < 10−7) and TG (23.9 ± 4.7 kg/m2; P = 0.018) genotypes of +10211T→G had significantly higher BMI compared to TT (23.2 ± 4.6 kg/m2). Therefore, in order to analyze the possible association of the +10211T→G SNP with obesity, the study subjects were stratified based on BMI as non-obese (<25 kg/m2) and obese (≥25 kg/m2). The minor allele frequency (G) was significantly higher in obese (0.14) compared to non-obese subjects (0.09; P < 10−7). The frequency of the TG genotype of +10211T→G SNP was significantly higher in obese subjects (23.1%) compared to non-obese subjects (16.1%; P < 10−7). Also, the frequency of the GG genotype was significantly higher among obese subjects (2.4%) compared to non-obese subjects (1.1%; P = 0.0016) after correcting for multiple testing (Table 2). However, when the GG genotype was compared to TG genotype there was no significance (P = 0.115). Logistic regression analysis revealed the odds ratio (adjusted for age, sex and type 2 diabetes) for obesity for the individuals carrying the TG genotype to be 1.53 (95% CI 1.3–1.8; P < 10−7), while for those carrying GG genotype it was 2.10 (95% CI 1.3–3.3; P = 0.002). However, a comparison of TG versus GG showed no significance (Table 2). We compared the TT versus XG (1.57; 95% CI 1.35–1.84; P < 10−7) and found statistical significance. Hence, the association of this genotype with obesity is also consistent with a dominant model.
Based on the pilot screening, linkage disequilibrium (LD) was computed among the four SNPs and it was found that the r 2 values are consistent in the two groups and did not provide evidence of pairwise LD between the SNPs (Table 3).
Linear regression analysis using BMI as the dependent variable and genotypes as independent variable revealed the β-coefficient to be 0.14 which was highly significant (P < 0.0001).
As the SNP showed association with both diabetes and obesity, we further investigated its possible association with serum adiponectin levels. The mean serum adiponectin levels were measured in 911 randomly selected subjects (408 NGT and 503 type 2 diabetic subjects) and the results were analyzed using a mixed effects model with BMI as a covariate, along with age and diabetic status as a factor. The mean serum adiponectin levels were found to be lower in carriers of the TG and GG genotype compared to the TT genotype.
Among NGT subjects, the mean serum adiponectin levels (adjusted for age, sex and BMI) were significantly lower in subjects with GG (4.99 μg/mL; 95% CI 3.78–6.56; P = 0.007) and TG (6.00 μg/mL; 95% CI 5.54–6.50; P = 0.001) compared to TT (7.31 μg/mL; 95% CI 6.80–7.84). Similar results were observed in diabetic subjects (adjusted for age, sex and BMI) (GG 4.54 μg/mL; 95%CI 3.81–5.4; P = 0.017; TG 4.75 μg/mL; 95%CI 4.40–5.11; P < 10−5; TT 6.03 μg/mL; 95% CI 5.61–6.46) (Fig. 2).

Serum adiponectin values in subjects with TT, TG and GG genotypes of +10211T→G polymorphism
Discussion
The novel finding of our study is that the subjects carrying the +10211T→G polymorphism in the first intron of the adiponectin gene are at a higher risk of type 2 diabetes, obesity and hypoadiponectinemia in this Asian Indian population. As this is the first association study of this polymorphism, we are unable to compare the genotypic and allelic frequencies of this SNP with other populations.
Though the study was hypothesized to address the association of diabetes with +10211T→G polymorphism, secondary analyses revealed this polymorphism to be associated with obesity and serum adiponectin levels. With diabetes and obesity the mode of inheritance was dominant. Given that type 2 diabetes and obesity are highly correlated, it is likely that a similar mode of inheritance applies to both the traits.
Recently it was shown (Qiao et al. 2005) that the DNA encoding the first intron of the ADIPOQ gene containing adipocyte-specific regulatory elements highly sensitive to the adipogenic transcription factor C/EBPα, confers significant activity on the ADIPOQ promoter. This intron was shown to contain a 34-bp enhancer, which regulates adiponectin gene expression in an adipose tissue specific manner. Our finding of the polymorphism close to the enhancer in the region of the first intron is, therefore, of great significance. Further studies on the expression levels of adiponectin could clarify whether the SNP +10211T→G alters the binding site and also will help understanding the functional significance of this polymorphism in relation to the lower serum adiponectin levels observed in this study.
In this study, the +45T→G SNP failed to show an association with type 2 diabetes and obesity, which is similar to an earlier report in a French Caucasian population (Gibson et al. 2004). SNP -11377C→G was also not associated with type 2 diabetes, which is in contrast to the study in a Swedish Caucasian population (Gu et al. 2004). The novel variant −11282 was present in less than 1% in the population and was seen only in the non-obese subjects.
The LD was computed among the four SNPs and it was found that the r 2 values are consistent in the two groups and did not provide evidence of pairwise LD between the SNPs (Table 2). The absence of LD possibly explains why the +10211 was associated with type 2 diabetes and obesity while the other SNPs were not. The adiponectin gene haplotype blocks have been extensively studied in healthy Caucasians (Gibson et al. 2004). However, additional SNPs need to be analyzed in order to understand the LD structure in our population.
The adiponectin gene is known to be very polymorphic: many exonic, intronic and promoter SNPs have been reported and this has been recently reviewed (Vasseur et al. 2006). Associations with adiponectin levels and phenotypes associated with the metabolic syndrome have been reported for three groups of genetic variants in numerous populations: in the 5′ sequences (−11282, −11426, −11391 and −11377); in the exon 2 and intron 2 regions (+45 and +276); and in exon 3 (mostly missense mutations G84R, G90S, Y11H, R112 C and 1164 T) (Pratley et al. 1998; Waki et al. 2003; Gibson et al. 2004; Gu et al. 2004; Pollin et al. 2005). The promoter, intronic and synonymous exonic SNPs of the ADIPOQ gene are thought to modulate expression of the gene (or are in linkage disequilibrium with functional variants that modulate expression of the gene) whereas missense mutations may not only modulate adiponectin secretion but also its activity. Therefore, our finding of the intronic SNP +10211T→G showing association with adiponectin levels strengthens this hypothesis.
Further, the contribution of adiponectin SNPs to hypoadiponectinaemia, decreased insulin sensitivity and type 2 diabetes has been confirmed in several populations, although the SNPs involved and populations investigated vary in different studies (Woo et al. 2006; Hotta et al. 2001; Daimon et al. 2003). Most studies also agree that variations at the ADIPOQ locus modulate the genetic risk for type 2 diabetes and other components of the metabolic syndrome through their effects on both adiponectin secretion and activity. It is in this context, that our findings gain importance as they add to the repertoire of SNPs that likely contribute to the genetic risk of diabetes and obesity.
To address the issue of population stratification, Devlin et al. (2001) suggested the use of genomic control markers to estimate the inflation of the false positive rate. We performed a limited genomic control analysis based on six neutral markers not related to type 2 diabetes and obesity earlier reported from our country (Roychoudhury et al. 2001). The allele frequency difference between cases and control subjects (classified based on diabetic status and BMI) was not statistically significant at any of the six loci indicating that the findings in this study are not an artefact of population sub-structuring.
In summary, the present study shows for the first time, that the +10211T→G polymorphism in the first intron of the adiponectin gene is associated with type 2 diabetes, obesity and hypoadiponectinemia in this Asian Indian population. Further studies are needed to determine the functional significance of these findings and to replicate these findings in other populations.
References
Abate N, Chandalia M, Snell PG, Grundy SM (2004) Adipose tissue metabolites and insulin resistance in non-diabetic Asian Indian men. J Clin Endocrinol Metab 89:2750–2755
Alberti KG, Zimmet PZ (1998) Definition, diagnosis and classification of diabetes mellitus and its complications. Part 1: diagnosis and classification of diabetes mellitus, provisional report of a WHO consultation. Diabet Med 15:539–553
Berthier MT, Houde A, Cote M, Paradis AM, Mauriege P, Bergeron J, Gaudet D, Despres JP, Vohl MC (2005) Impact of adiponectin gene polymorphisms on plasma lipoprotein and adiponectin concentrations of viscerally obese men. J Lipid Res 46:237–244
Comuzzie AG, Funahashi T, Sonnenberg G, Martin LJ, Jacob HJ, Black AE, Maas D, Takahashi M, Kihara S, Tanaka S, Matsuzawa Y, Blangero J, Cohen D, Kissebah A (2001) The genetic basis of plasma variation in adiponectin, a global endophenotype for obesity and the etabolic syndrome. J Clin Endocrinol Metab 86:4321–4325
Daimon M, Oizumi T, Saitoh T, Kameda W, Hirata A, Yamaguchi H (2003) Decreased serum levels of adiponectin are a risk factor for the progression to type 2 diabetes in the Japanese Population: the Funagata study. Diabetes Care 26:2015–2020
Deepa M, Pradeepa R, Rema M, Mohan A, Deepa R, Shanthirani S, Mohan V (2003) The Chennai Urban Rural Epidemiology Study (CURES) study design and methodology (urban component) (CURES-1). J Assoc Physicians India 51:863–870
Devlin B, Roeder K, Wasserman L (2001) Genomic control, a new approach to genetic-based association studies. Theor Popul Biol 60:155–166
Diez JJ, Iglesias PB (2003) The role of the novel adipocyte-derived hormone adiponectin in human disease. Eur J Endocrinol 148:293–300
Gibson F, Froguel P (2004) Genetics of the ADIPOQ locus and its contribution to Type 2 diabetes susceptibility in French Caucasians. Diabetes 53:2977–2983
Gu HF, Abulaiti A, Ostenson CG, Humphreys K, Wahlestedt C, Brookes AJ, Efendic S (2004) Single nucleotide polymorphisms in the proximal promoter region of the adiponectin (ADIPOQ) gene are associated with Type 2 diabetes in Swedish Caucasians. Diabetes 53:S31–S35
Heid IM, Wagner SA, Gohlke H, Iglseder B, Mueller JC, Cip P, Ladurner G, Reiter R, Stadlmayr A, Mackevics V,Illig T,Kronenberg F, Paulweber B (2006) Genetic architecture of the APM1 gene and its influence on adiponectin plasma levels and parameters of the metabolic syndrome in 1,727 healthy Caucasians. Diabetes 55:375–384
Hotta K, Funahashi T, Bodkin NL, Ortmeyer HK, Arita Y, Hansen BC (2001) Circulating concentrations of the adipocyte protein adiponectin are decreased in parallel with reduced insulin sensitivity during the progression to type 2 diabetes in rhesus monkeys. Diabetes 50:1126–1133
Hu E, Liang P, Spiegelman BM (1996) AdipoQ is a novel adipose-specific gene dysregulated in obesity. J Biol Chem 271:10697–10703
Kissebah AH, Sonnenberg GE, Myklebust J, Goldstein M, Broman K, James RG, Marks JA, Krakower RG, Jacob HW, Weber J, Martin L, Blangero J, Comuzzie AG (2000) Quantitative trait loci on chromosomes 3 and 17 influence phenotypes of the metabolic syndrome. Proc Natl Acad Sci USA 97:14478–14483
Lindsay RS, Funahashi T, Krakoff J, Matsuzawa Y, Tanaka S, Kobes S, Bennett PH, Tataranni PA, Knowler WC, Hanson RL (2003) Genome-wide linkage analysis of serum adiponectin in the Pima Indian population. Diabetes 52:2419–2425
McKeigue PM, Pierpoint T, Ferrie JE, Marmot MG (1992) Relationship of glucose intolerance and hyperinsulinaemia to body fat pattern in South Asians and Europeans. Diabetologia 35:785–791
Menzaghi C, Ercolino T, Di Paola R, Berg AH, Warram JH, Scherer PE, Trischitta V, Doria A (2002) A haplotype at the adiponectin locus is associated with obesity and other features of the insulin resistance syndrome. Diabetes 51:2306–2312
Mohan V, Sharp PS, Cloke HR, Burrin JM, Schumer B, Kohner EM (1986) Serum immunoreactive insulin responses to a glucose load in Asian Indian and European type 2 (non-insulin-dependent) diabetic patients and control subjects. Diabetologia 29:235–237
Mohan V, Deepa R, Pradeepa R, Vimaleswaran KS, Mohan A, Velmurugan K, Radha V (2005) Association of low adiponectin levels with the metabolic syndrome—the Chennai Urban Rural Epidemiology Study (CURES-4). Metabolism 54:476–481
Pollin TI, Tanner K, O’Connell JR, Ott SH, Damcott CM, Shuldiner AR, McLenithan JC, Mitchell BD (2005) Linkage of plasma adiponectin levels to 3q27 explained by association with variation in the APM1 gene. Diabetes 54:268–274
Pratley RE, Thompson DB, Prochazka M, Baier L, Mott D, Ravussin E, Sakul H, Ehm MG, Burns DK, Foroud T, Garvey WT, Hanson RL, Knowler WC, Bennett PH, Bogardus C (1998) An autosomal genomic scan for loci linked to prediabetic phenotypes in Pima Indians. J Clin Invest 101:1757–1764
Qiao L, Maclean PS, Schaack J, Orlicky DJ, Darimont C, Pagliassotti M, Friedman JE, Shao J (2005) C/EBPα regulates human adiponectin gene transcription through an intronic enhancer. Diabetes 54:1744–1754
Roychoudhury S, Roy S, Basu A, Banerjee R, Vishwanathan H, Usha Rani MV, Sil SK, Mitra M, Majumder PP (2001) Genomic structures and population histories of linguistically distinct tribal groups of India. Hum Genet 109(3):339–350
Sharp PS, Mohan V, Levy JC, Mather HM, Kohner EM (1987) Insulin resistance in patients of Asian Indian and European origin with non-insulin dependent diabetes. Horm Metab Res 19:84–85
The Expert Committee on the Diagnosis and Classification of Diabetes (1997) Mellitus report of the Expert Committee on the Diagnosis and classification of Diabetes Mellitus. Diabetes Care 20:1183–1197
The Asia Pacific perspective (2000) Redefining obesity and its treatment. Regional Office for the Western Pacific of the World Health Organization. World Health Organization, International Association for the Study of Obesity and International Obesity Task Force. Health Communications Australia Pty Limited, pp 22–29
Vasseur F, Lepretre F, Lacquemant C, Froguel P (2003) The genetics of adiponectin. Curr Diab Rep 3:151–158
Vasseur F,Meyre D, Froguel P (2006) Adiponectin, type 2 diabetes and metabolic syndrome: lessons from human genetic studies. Expert Rev Mol Med 8:1–12
Vionnet N, Hani EH, Dupont S, Gallina S, Francke S, Dotte S, De Matos F, Durand E, Leprêtre F, Lecoeur C, Gallina P, Zekiri L, Dina C, Froguel P (2000) Genomewide search for type 2 diabetes-susceptibility genes in French Whites: evidence for a novel susceptibility locus for early-onset diabetes on chromosome 3q27–qter and independent replication of a type 2-diabetes locus on chromosome 1q21-q24. Am J Hum Genet 67:1470–1480
Waki H, Yamauchi T, Kamon J, Ito Y, Uchida S, Kita S (2003) Impaired multimerization of human adiponectin mutants associated with diabetes. Molecular structure and multimer formation of adiponectin. J Biol Chem 278:40352–40363
Weyer C, Funahashi T, Tanaka S, Hotta K, Matsuzawa Y, Pratley RE, Tataranni PA (2001) Hypoadiponectinemia in obesity and type 2 diabetes: close association with insulin resistance and hyperinsulinemia. J Clin Endocrinol Metab 86:1930–1935
Woo JG, Dolan LM, Deka R, Kaushal RD, Shen Y, Pal P, Daniels SR, Martin LJ (2006) Interactions between noncontiguous haplotypes in the adiponectin gene ACDC are associated with plasma adiponectin. Diabetes 55:523–529
Acknowledgments
The study was supported by a grant from the Department of Biotechnology (DBT) and Department of Science and Technology (DST), New Delhi, India. We also thank the Indian Council of Medical Research (ICMR). We thank the Chennai Wellingdon Corporate Foundation for their support for the CURES field studies. This is publication no 60 from CURES (CURES-60).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Vimaleswaran, K.S., Radha, V., Ramya, K. et al. A novel association of a polymorphism in the first intron of adiponectin gene with type 2 diabetes, obesity and hypoadiponectinemia in Asian Indians . Hum Genet 123, 599–605 (2008). https://doi.org/10.1007/s00439-008-0506-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00439-008-0506-8