
Abstract
Hispanic and African American populations exhibit an increased risk of obesity compared with populations of European origin, a feature that may be related to inherited risk alleles from Native American and West African parental populations. However, a relationship between West African ancestry and obesity-related traits, such as body mass index (BMI), fat mass (FM), and fat-free mass (FFM), and with bone mineral density (BMD) in African American women has only recently been reported. In order to evaluate further the influence of ancestry on body composition phenotypes, we studied a Hispanic population with substantial European, West African, and Native American admixture. We ascertained a sample of Puerto Rican women living in New York (n=64), for whom we measured BMI and body composition variables, such as FM, FFM, percent body fat, and BMD. Additionally, skin pigmentation was measured as the melanin index by reflectance spectroscopy. We genotyped 35 autosomal ancestry informative markers and estimated population and individual ancestral proportions in terms of European, West African, and Native American contributions to this population. The ancestry proportions corresponding to the three parental populations are: 53.3±2.8% European, 29.1±2.3% West African, and 17.6±2.4% Native American. We detected significant genetic structure in this population with a number of different tests. A highly significant correlation was found between skin pigmentation and individual ancestry (R 2=0.597, P<0.001) that was not attributable to differences in socioeconomic status. A significant association was also found between BMD and European admixture (R 2=0.065, P=0.042), but no such correlation was evident with BMI or the remaining body composition measurements. We discuss the implications of our findings for the potential use of this Hispanic population for admixture mapping.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The study of the biological differences in body composition that exist between populations will certainly contribute to the unraveling of the genetic and environmental basis of complex diseases that disproportionately affect specific populations. Higher rates of overweight and obesity have been reported among Hispanics compared with European Americans (Wang et al. 1996; NHANES III http://www.cdc.gov/nchs/nhanes.htm). As a result, increased body fat is likely to underlie the higher prevalence in Hispanics of other conditions, such as diabetes mellitus type 2 (Okosun 2000), syndrome X (Gower 1999), and heart disease (Sundquist et al. 2001). The Pima Indians of Arizona have been shown to be, on average, more obese than the rest of the population nationwide, and therefore, it has been suggested that the elevated rates observed in Hispanics could be attributable in part to genetic risk factors of Native American origin (Weiss et al. 1984). Since Pima Indians in Mexico do not experience excess obesity, it is probable that the effects of underlying obesity risk alleles become apparent only once their traditional lifestyle (i.e., low fat diet, high physical activity) is abandoned (Fox et al. 1999). Furthermore, African Americans are affected by obesity and obesity-related diseases more frequently than non-Hispanic whites. An association of West African and Native American ancestry and high body mass index (BMI) has been found for African American women (Fernández et al. 2003), and Hispanic (Gardner et al. 1984; Samet et al. 1988) or Native American individuals (Williams et al. 2000). In addition, several studies have shown that total-body bone mineral content and bone mineral density (BMD) are significantly greater in African Americans (Wagner and Heyward 2000) who, as a consequence, present a lower fracture risk than European Americans (Melton et al. 2002). A link between BMD and individual admixture has recently been described by Fernández et al. (2003). Considering these findings and the fact that Puerto Ricans have European, West African, and Native American ancestry, we set out to explore whether such associations were detectable in this population and to what extent Puerto Ricans are appropriate for future ancestry/phenotype and admixture mapping (AM) studies. A method for mapping genes by using admixed populations was conceived by Chakraborty and Weiss (1988) and takes advantage of the finding that admixed groups have increased levels of linkage disequilibrium as a result of the admixture process. However, several conditions must be met before this method, named AM by McKeigue et al. (2000), can be applied in a particular admixed population. Essentially, there should be sufficient admixture in the population, selected genetic markers should exhibit large allele frequency differences (delta) between parental groups, and the phenotypic trait to be mapped must show a difference in prevalence between ancestral populations. Additionally, it is important to detect and to be able to correct for population structure, as this is a major confounder of genetic association studies (Kittles et al. 2002).
Mainland Puerto Ricans currently represent 1.2% of the US population and 9.6% of the Hispanic population in the US (US Census Bureau 2000, http://www.census.gov). Although largely concentrated on the east coast in cities such as New York and Philadelphia, there are sizable Puerto Rican communities in Chicago and in the states of Connecticut, New Jersey, and Ohio. The population of Puerto Rico, like other Latin American populations, originated as a result of the Spanish conquest of the Americas and subsequent admixture between Native American, European, and West African individuals. The island of Puerto Rico was discovered by the Spaniards in 1493, during Columbus’ second voyage to the New World. At that time, the island was inhabited by Taino Indians, Arawakan speakers, whose ancestors had migrated from the Amazon Basin and arrived in Puerto Rico 2200 years before present (Martínez-Cruzado et al. 2001). The Tainos also inhabited other Caribbean islands, such as the Bahamas and all of the Greater Antilles, and had frequent exchanges with neighboring Guanahatabeys in western Cuba and with Island-Caribs who inhabited the Winward Islands and Guadeloupe (Rouse 1992). The Tainos were agriculturalists organized into complex chiefdoms (Rouse 1992). The arrival of the Spaniards toward the end of the 15th century led to the collapse of the Taino groups because of exploitation, introduced diseases, malnutrition, migration, and warfare. According to Rouse (1992), by 1524, the Tainos no longer existed as a separate population. However, individuals claiming Taino ancestry have survived until today.
Soon after settling in Puerto Rico, Spanish colonizers started importing enslaved West Africans, initially to help in the gold mines and, later, when it was apparent that the island had little gold, to work in the sugar cane plantations. By 1530, when the first census of the island was conducted, there were 2,292 black slaves and only 327 whites (Díaz Soler 1953). During the subsequent centuries Puerto Rico’s production of sugar, rum, molasses, and tobacco intensified, as did trade with North America, especially after the US declaration of independence in 1776 (Sánchez Korrol 1994). This flourishing link between the US and the island resulted in the Spanish-American war of 1898, after which Puerto Rico became a US colony. Emigration of workers to the mainland started soon afterwards and increased after 1917 when Puerto Ricans became US citizens. The Puerto Rican migratory movement that took place after World War II was fundamentally one of wage labor but, unlike Mexican migration, which began for agricultural purposes, Puerto Ricans concentrated in the cities of the northeast from the start (Bean and Tienda 1987).
In spite of the growing numbers of Puerto Ricans in the US and the fact that Puerto Rico is currently a commonwealth, admixture studies in Puerto Ricans, either in the island or the mainland, have been scarce. Ancestral contributions to the Puerto Rican population have been estimated by using polymorphic blood group and protein marker data, as 45% European, 37% West African, and 18% Native American by Hanis et al. (1991). More recently, Fernández-Cobo et al. (2001) reported the presence in Puerto Rico of strains of the JC virus derived from Asia, Europe, and Africa. Although consistent with the history of admixture in Puerto Rico, the distribution of these viral strains showed an excess (61%) of the Asian/Native American type. Interestingly, analysis of mitochondrial DNA in Puerto Ricans living in the island revealed a high Native American contribution of ~53% in a random sample from the city of Mayagüez (Martínez-Cruzado et al. 2001).
We have determined the contributions of the three parental populations to contemporary Puerto Ricans by using a set of 35 autosomal ancestry informative markers (AIMs). Our findings provide evidence of a Puerto Rican gene pool having European, West African, and Native American origins, with larger European and West African components but an unquestionable Native American contribution. Additionally, we have analyzed the relationship between individual ancestry and several phenotypes that have been collected for this sample, namely skin pigmentation, BMI and other obesity-related traits, and BMD, and we have searched for significant associations between these phenotypes and marker genotypes. In a previous study of the Hispanic population of the San Luis Valley in Colorado with low West African ancestry (~3%), we found a positive correlation between individual Native American admixture and darker skin (Bonilla et al. 2004). We obtained similar results in African Americans from Washington, DC and in African Caribbeans from Britain where a higher proportion of West African ancestry correlates with higher skin pigmentation (Shriver et al. 2003).
Materials and Methods
Study population
We ascertained 64 Puerto Rican women aged 60–75, who live in New York city. The sample was collected as part of an obesity study following the IRB regulations of Saint Luke’s-Roosevelt Hospital Center (no. 00–149) and Columbia University (no. 13712). The demographic and socioeconomic characteristics of this sample are shown in Table 1.
Phenotypes
Body composition was assessed for all subjects by measuring height, weight, fat mass (FM), fat-free mass (FFM), percent body fat (%BF), and BMD. The BMI for each individual was calculated as weight (kg)/height (m)2 . Measures of FM, %BF, FFM, and BMD were obtained by dual-energy X-ray absorptiometry (DXA, model DPX-L, Lunar Radiation Corporation, Madison, Wis., USA).
Constitutive skin color was measured by using reflectance spectroscopy, on the upper inner side of both arms of each subject, with a DermaSpectrometer (Cortex Technology, Hasund, Denmark), following a standard protocol (Shriver and Parra 2000). The DermaSpectrometer is a narrow-band spectroscopy instrument with a green diode centered on 568 nm and a red diode centered on 655 nm. The melanin (M) index, is computed from the reflectance of the green diode and is well documented as an accurate measure of constitutive pigmentation level (Shriver and Parra 2000; Wagner et al. 2002).
DNA extraction and amplification
Peripheral blood (10 ml) was drawn from each subject. About 20 ml cell lysis buffer (0.3 M sucrose, 10 mM TRIS-Cl pH 7.5, 5 mM MgCl2, 1× Triton X-100) was added to each sample, and the tubes were placed on ice for 30 min after thorough mixing by inversion. Tubes were centrifuged at 2,800 rpm (1,660×g) for 10 min at 4°C, and the supernatant was discarded. This washing step, without the ice incubation, was repeated once more. Subsequently, 15 ml salting-out digestion buffer (50 mM TRIS-Cl pH 7.5, 5 mM EDTA, 0.4 M NaCl) was added, and the samples were centrifuged again at 2,800 rpm for 10 min at 4°C. After the supernatant had been discarded, the extraction of genomic DNA was completed by using an IsoQuick kit (ORCA Research, Bothell, Wash.) according to the manufacturer’s instructions. Extracted DNA was resuspended in TE buffer (10 mM TRIS-Cl pH 8.0, 1 mM EDTA pH 8.0) for storage. The polymerase chain reaction (PCR) was performed in 96-well OmniUltra plates with a PCR MBS thermal cycler, both obtained from ThermoHybaid (Oxford, UK). Amplifications consisted of buffer (50 mM KCl + 10 mM TRIS-HCl pH 8.9), 1.0–2.5 mM MgCl2, 200 μM each deoxynucleotide triphosphate (dNTPs), 0.5 μM each primer, 1 U Taq polymerase, 20 ng genomic template, and sterile filtered water (Sigma) up to 25 μl. PCR conditions were as follows: 5 min at 94°C; 35 cycles at 94°C/specific annealing temperature/72°C, 30 s each; and 5 min at 72°C. Restriction analysis was performed as recommended by the supplier.
Genotyping
We selected a set of 35 AIMs that exhibit a high level of allele frequency difference among parental populations (Europeans, West Africans, and Native Americans; Shriver et al. 2003; Hoggart et al. 2003). AIMs were typed either by melting curve single-nucleotide polymorphism analysis (Akey et al. 2001; Ye et al. 2002) or by conventional agarose gel electrophoresis. Incubation with the corresponding restriction endonuclease was performed as recommended by the supplier. Table 2 shows the AIMs used in the analysis of this population, together with the primers and restriction enzymes required for their characterization. Detailed information regarding these markers is available at dbSNP http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?db=snp under PSU-ANTH as the submitter handle. A marker was deemed informative if there was at least a 30% allele frequency difference between any two parental groups. Average delta was 0.327, 0.395, and 0.454 for European/Native American, European/West African, and Native American/West African population pairwise comparisons. Nineteen markers were informative to determine European/Native American contributions, whereas 23 and 27 markers were useful to detect European/West African and Native American/West African contributions (Table 3). Average delta considering only the informative markers for a particular pair of populations was 0.536 for European/Native American, 0.538 for European/West African, and 0.551 for Native American/West African.
Parental populations
We determined parental population frequencies from samples of Spanish (n=72), Mayan (n=96), southwestern US Native Americans (Cheyenne, Pima, and Pueblo; n=88), and West Africans (Central African Republic, Nigeria, and Sierra Leone; n=279). We analyzed the parental data to detect and eliminate recently admixed individuals with the program STRUCTURE 2.0 (Pritchard et al. 2000). Parental population frequencies are shown in Table 3.
Data analysis
Group admixture levels were calculated with the program ADMIX (Long 1991), which implements a weighted least squares method. Individual admixture estimates were obtained by using both a maximum likelihood method (Hanis et al. 1986; Chakraborty et al. 1986) and a Bayesian approach implemented in the program STRUCTURE 2.0 (Pritchard et al. 2000). We also employed STRUCTURE to detect population structure in the study sample. Given the parental contributions to the Puerto Rican population, the program was run with K=1, K=2, and K=3 as the predefined setting for the number of populations, with 50,000 iterations for the burn-in period and 100,000 additional iterations to obtain parameter estimates. We used several of the available options of the admixture and linkage models found in the STRUCTURE program, such as independent and correlated allele frequencies, single or separate alphas, and same or different Fst, to determine whether any change in parameters had an influence on the clustering pattern. For comparison purposes and verification of results, two other tests for detecting population structure were conducted. One compared the percentage of associated unlinked marker pairs with the expected value at the 5% significance level. In this test, gametic disequilibrium was estimated by an expectation maximization algorithm by using the program 3LOCUS (Long et al. 1995), which calculated a likelihood ratio statistic (G) to determine allelic association between pairs of loci. An additional test of structure searched for correlation between individual admixture estimates obtained with two subsets of markers, containing half of the markers selected at random each. Probability values of Hardy-Weinberg exact tests were computed in this sample with the GENEPOP 2.0 computer package (Raymond and Rousset 1995).
We used linear regression models available in the program SPSS 10.0 to test the effect of ancestry on each phenotype as a dependent variable (M index, BMI, BMD, FM, FFM, %BF). BMI was transformed to 1/BMI to improve linearity (Fernández et al. 2003). Therefore, all subsequent references to BMI indicate the mentioned transformation. No transformation was performed on the other variables. We tested the impact of income and years of education as proxies for socioeconomic status on each of the dependent variables. Next, we tested for the association of each marker genotype (independent variable) with every phenotypic dependent variable (analysis of variance; ANOVA). In addition, the genotype-phenotype association test was performed with correction for individual ancestry (ANOVA/IAE). Although only M index and BMD were significantly influenced by ancestry levels, we tested each AIM on the rest of the dependent variables to detect any genetic effect on the trait.
Results
Our results indicate the presence of population structure in this sample from New York city, a structure that is detected with each of the three employed tests. The STRUCTURE program consistently assigned individuals to two and three groups with a higher probability than it did to a single group, e.g., ln P(D)=−2661.2 for K=2 and ln P(D)=−2690.4 for K=3, whereas ln P(D)=−2745.1 for K=1. Additionally, 12% of unlinked markers are significantly associated, exceeding the 5% of significant associations expected by chance. Markers AT3 and FY null, linked at a distance of 26 cM, were also associated (G=13.3, p<0.001). Linkage between these two AIMs has been previously reported in African American populations (Parra et al. 1998; Lautenberger et al. 2000; Pfaff et al. 2001). We also detected nonrandom association between AT3 and TSC1102055, which are located 29 cM apart (G=5.5, P<0.05). Finally, when individual ancestry is calculated with two different subsets of markers, both estimates are significantly correlated (R 2 =0.249, P=2.72×10E−5).
Using our panel of 35 autosomal markers, we estimated the parental contributions to this sample as 53.3±2.8% European, 29.1±2.3% West African, and 17.6±2.4% Native American. Individual admixture estimates obtained with a maximum likelihood algorithm are depicted on the triangle plot shown in Fig. 1. Individual ancestry proportions estimated with STRUCTURE were highly correlated with the maximum likelihood estimates whether two or three parental populations were used (West African ancestry estimate, R 2 =0.980 and 0.995, respectively). Mean ancestry proportions computed with STRUCTURE under different models ranged from 46.7% to 54.6% European, 30.4% to 31.5% West African, and 15.0% to 22.1% Native American contribution. Under a two parental population model, the estimates ranged from 63.4% to 66.6% and from 33.4% to 36.6% for the European and West African contributions, respectively. Since according to STRUCTURE the probability for K=2 is higher than that for K=3, we tested the way in which individual ancestry estimates change when obtained by using either two or three parental groups. We plotted the European and West African ancestry coefficients obtained by using two parental populations against the same coefficients obtained by using three parental populations and found a high correlation between them (R 2 =0.812 for the European estimates, R 2 =0.963 for the West African estimates, data not shown). It is likely that the greater consistency of West African estimates is related to our marker set being more informative for determining West African ancestry than for European ancestry.

Triangle plot showing the distribution of individual admixture estimates obtained by using a maximum likelihood approach in the population of Puerto Rico. Each of the three founder populations constitutes a vertex of the triangle. Each circle represents an individual and its position in the graph depends on the ancestry proportions of the subject
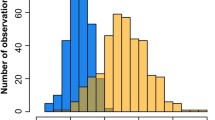
The existence of population stratification is also apparent from the relationship between individual ancestry and skin pigmentation measured by the M index. There is a positive correlation between West African ancestry levels and skin color, which is highly significant whether ancestry proportions are estimated by using two parental groups (R 2 =0.578, P=5.02×10E−13) or three parental groups (R 2 =0.597, P=1.21×10E−13, Table 4, Fig. 2). As expected, European ancestry is negatively correlated with skin pigmentation (R 2 =0.417, P=1.12×10E−8). Interestingly, no effect of Native American ancestry is observed on this trait (R 2 =0.051, P=0.074). There was no detectable influence of socioeconomic status on the M index (years of education, P=0.852; income, P=0.807). The range of M values for this population extends from 26.6 to 59.7, with a mean of 36.8±0.753, which is intermediate between the M index levels of European Americans from Pennsylvania (29.9±0.274), and two populations of West African ancestry (African Americans from Washington, DC, 53.4±0.630; and African Caribbeans, 57.8±0.739) reported in a previous study (Shriver et al. 2003), and is also significantly different from them (P<0.001). We tested each marker for association with skin pigmentation, correcting (ANOVA/IAE) and without correcting (ANOVA) for individual ancestry. In the ANOVA, 15 out of 35 (43%) AIMs exhibited a significant result. After correction, only three markers (9%) appeared to be associated with skin color (TSC1102055, P=0.010; FY-null, P=0.018; and F13B, P=0.023; Table 5). If adjustment is carried out with two-parental instead of three-parental estimates, the same three markers plus SGC-30610 (P=0.002) show a significant association.

Correlation of skin pigmentation, measured as M index, and percentage of West African admixture for each subject in the Puerto Rican population
Additionally, BMD was negatively associated with European admixture (R 2 =0.065, P=0.042; Table 4, Fig. 3), but this effect was only apparent when European ancestry estimates were determined by using three parental populations. No correlation was evident between BMI or any of the obesity-related phenotypes and individual ancestry (Table 4). Unlike the findings with skin pigmentation, the ANOVA and ANOVA/IAE detected a similar number of significant associations for BMD and the weight-related traits (Table 6). After correction for individual ancestry, TYR-192 on chromosome 11 exhibited a significant association with BMD (P=0.008), BMI (P=0.045), and FM (P=0.048). MID-187 (1p34.1) was significantly associated with FM (P=0.013) and BMI (P=0.033), whereas WI-9231 (7p22.3) was associated with FM (P=0.036) and %BF(P=0.025). Other significant results were: (1) the association of BMI with WI-11909 (9q21.31, P=0.033), and MID-161 (20q11.22, P=0.039); (2) the association of CKM (19q13.32) with BMD (P=0.034); (3) the association of MID-161 with FM (P=0.040).

Correlation between bone mineral density (BMD) and European ancestry for each subject in the Puerto Rican population
Six markers (CKM, RB1, WI-14867, WI-17163, P<0.05; PV92, P<0.01; GC, P<0.001) deviated from Hardy-Weinberg equilibrium. In all cases, there was a reduction in heterozygosity, probably as a consequence of population substructure attributable to variable degrees of individual admixture.
Discussion
Ancestry estimates by using AIMs
By means of a set of 35 AIMs, we can see clear evidence that the Puerto Rican population is indeed a trihybrid population as it has had major contributions from all three parental groups, i.e., 53.3±2.8% European, 29.1±2.3% West African, and 17.6±2.4% Native American. Our results are similar to those reported by Hanis et al. (1991) concerning Puerto Ricans living on the island; based on classical polymorphism data, these researchers estimated admixture proportions in the population of Puerto Rico as 45% European, 37% West African, and 18% Native American. The difference in the estimates of European and West African contribution between this previous work and our study is probably attributable to both the characteristics of the samples and the markers that were analyzed. As there is no description of the Puerto Rican samples in the previously mentioned study, it is difficult to explore this issue further. The demographic information on our sample is provided in Table 1. The present set of markers, nevertheless, constitutes a unique panel with large frequency differences between the parental groups. As such, our admixture estimates are thus more reliable than those obtained with classical markers.
The distribution of individual admixture estimates in this population encompasses the whole range of West African and European proportions (see Fig. 1). There are a few individuals on the extremes (0% West African or 0% European), but the majority of the population is widely distributed throughout the axis. Native American ancestry, on the other hand, exhibits a more restricted pattern of variation.
Population structure and complex phenotypes
All tests of stratification performed in this sample were positive for the presence of genetic structure, a feature that is not surprising since this population was formed by admixture between three ancestral populations. Sixty-nine out of 573 (12%) pairwise comparisons yielded significant associations of unlinked markers, a high indication of structure considering that only 29 are expected by chance at an alpha level of 5%. In Spanish Americans of the San Luis Valley in Colorado (a Hispanic population with approximately 63% European, 34% Native American, and 3% West African admixture, and moderate levels of structure), we found that only 5.9% of unlinked marker pairs were associated (Bonilla et al. 2004). Similar to this Puerto Rican sample, populations of West African ancestry with significant genetic structure, such as African Americans from Mississippi and South Carolina exhibited higher than expected percentages of significant associations (37% and 20%, respectively; Pfaff et al. 2001). Population structure was also identified by the STRUCTURE program, which assigned a slightly higher probability to two over three population clusters. In addition, individual admixture estimates appear highly correlated when using different subsets of AIMs. This is expected only when there is substructure caused by admixture in the sample (Shriver et al. 2003), which is likely to confound linkage associations between markers and candidate genes of complex traits if used for admixture mapping. Despite this difficulty, this population could still be used for admixture mapping as long as the confounding effects of genetic structure attributable to different levels of ancestry are adjusted, for example, by using structured association (Pritchard et al. 2000) or another Bayesian approach such as that implemented in the program ADMIXMAP (Hoggart et al. 2003). Indeed, results of the ANOVA test with the M index as the dependent variable and each AIM as a fixed factor indicated that 43% of the markers are correlated with melanin concentration. However, after correction by individual ancestry, the correlation persists only with 9% of the AIMs (TSC1102055, FY-null, and F13B). Most probably, significance will disappear with a more stringent test, as these markers exhibit high frequency differences between West African and European populations. Nonetheless, as TSC1102055, FY-null, and F13B lie on chromosome 1 (q23.2–q32.1), it may well be that this region harbors a pigmentation candidate gene. A nearby region (1q42.1–q42.2) is involved in Chediak-Higashi syndrome (MIM 214500, http://www.ncbi.nlm.nih.gov/Omim/), in which decreased pigmentation of hair and eyes is caused by a mutation in the lysosomal trafficking regulator gene.
In spite of the fact that this sample exhibits a lower average M index consistent with its lower proportion of West African admixture, markers on genes TYR and OCA2, which have been previously associated with the variation in skin pigmentation between populations of West African and European ancestry (Shriver et al. 2003), surprisingly did not show a significant association with the M index in this study. The reduced sample size might be an explanation for this result, although we cannot dismiss the possibility of different genes contributing to pigmentation in different populations. For instance, it has been reported that mutations in the MC1R gene result in red hair and fair skin phenotype (Sturm et al. 2001). Melanin content and composition and melanosome size have been observed to vary extensively between populations (Alaluf et al. 2002); several pigmentation candidate genes could potentially be involved in generating such differences (Sturm et al. 2001). Gene interaction to modify the pigmentation phenotype is also likely, as has been suggested between MC1R and OCA2 (King et al. 2003; Duffy et al. 2004).
Contrary to previous findings reported in another Hispanic population (Bonilla et al. 2004), we did not find any correlation between Native American ancestry and skin pigmentation in Puerto Ricans. This result may be explained in part by the small sample size, but also by the more restricted distribution of Native American ancestry estimates (0%–53%). Spanish Americans from the San Luis Valley had higher Native American admixture (~34%) distributed over a wider range (0%–100%; Bonilla et al. 2004). In addition, this Puerto Rican sample shows greater West African ancestry and definite contributions of three parental groups, as opposed to the San Luis Valley Hispanics, which constitute mostly a dihybrid population with low West African admixture (~3%). Furthermore, the correlation between skin pigmentation (or any other phenotype) and individual ancestry depends also on the presence of genetic structure related to admixture, the admixture model (hybrid isolation vs continuous gene flow, see Pfaff et al. 2001), and the existence of assortative mating.
We observed no correlation between individual admixture levels and BMI or related phenotypes. On the contrary, a significant association was detected between BMD and European admixture, in the anticipated direction, i.e., a lower BMD was observable in individuals with more European genes. West African ancestry has been reported as a risk factor for higher mean BMI in African American populations (Crawford et al. 2001). Moreover, individual admixture was associated with BMI (P<0.01) and BMD (P<0.05) in African American women from Alabama, Maryland, and New York (Fernández et al. 2003). Likewise, Native American ancestry has been suggested to constitute a risk factor for the development of obesity in Hispanic groups (Weiss et al. 1984). Nevertheless, even though our sample is characterized by almost 30% West African admixture and 18% Native American admixture, a small sample size may be the reason that no correlation with BMI, FM, FFM, or %BF has been detected. Lack of correlation between ancestry and obesity-related phenotypes is also evident from the lack of difference between the ANOVA test and the test adjusted by individual admixture (ANOVA/IAE), unlike the analysis of the M index. Thus, the signals that we detect with particular markers may be associated with genes that influence the phenotype. Marker TYR-192 (11q14.3) was significantly associated with BMD, BMI, and FM. A gene that might be responsible for BMD variation has been described in a region close to tyrosinase, viz., low-density lipoprotein receptor-related protein 5 (LRP5) at 11q13.4 (MIM 601884). Moreover, linkage with BMI has been reported at 11q24 (MIM 607447). Additional significant signals have been detected on chromosomes 1 (MID187 with BMI and FM), 7 (WI-9231 with %BF and FM), 9 (WI-11909 with BMI), 19 (CKM with BMD), and 20 (MID-161 with BMI, and FM). However, if a Bonferroni correction, which is conservative, is used to adjust for multiple testing, the significance threshold becomes P=0.0014 for each test, and thus these results are no longer significant. Fernández et al. (2003) identified significant associations of BMI with regions on chromosomes 1, 11 and 12 and of BMD with a region on chromosome 1, in a sample of African American women. Associated chromosomal regions detected by Fernández and colleagues (2003) are coincident with our findings for chromosome 11, but fairly distant for chromosome 1 (1q vs. 1p).
We should like to emphasize that this study was conducted on a small sample (n=64) and as such should be viewed as a preliminary analysis of a Puerto Rican population, although being promising with respect to AM feasibility. With a larger sample size, an association of BMI with ancestry might be distinguished.
Another possible aspect to consider is that the absence of correlation between individual ancestry and traits that determine body composition may be related to the number of years that these women have been living in the US, as most of them migrated to the mainland during the decades of 1940 and 1950. It has been described that acculturation influences the incidence of diabetes and obesity in Mexican American populations (Hazuda et al. 1988; Stern et al. 1991). Individuals who have recently immigrated to the US are affected by the change from a more traditional to a modern life-style that includes a highly caloric diet and sedentary routine, and therefore they exhibit higher rates of obesity. As these individuals become more acculturated after a longer time of residence in the country, they become increasingly health conscious and change their nutrition and exercise habits and, as a consequence, obesity rates decline. Since obesity-related phenotypes are shaped by both genetic and environmental factors, AM may be helpful for uncovering the effects of genes in the admixed population under a new environment.
Conclusions
We have previously discussed the importance of studying Hispanic populations from the perspective of the ethnic background of each group, i.e., Puerto Rican and Mexican American populations are genetically and culturally very different even if both are considered to be Hispanic (Bonilla et al. 2004). In this paper, we have studied a group of women of Puerto Rican origin most of whom have lived in the US during the last 50 years. The admixture proportions in this population indicate that the contribution from European and West African populations has been large, as expected from the history of the Caribbean. However, because of the early extinction of the native groups of the island, a low Native American admixture was anticipated. Surprisingly, nearly 20% of the Puerto Rican gene pool is of Native American ancestry, a large amount of which was contributed by females (C. Bonilla et al., unpublished data). As opposed to our findings in the Hispanic population of the San Luis Valley in Colorado, the population of Puerto Rico exhibits marked genetic structure. Additionally, we were able to detect a clear association of ancestry levels with skin pigmentation and BMD, but no such correlation was observed for weight-related traits. Population stratification causes an additional problem to admixture mapping methods, as it can generate false-positive results (Pfaff et al. 2001). However, false positives can be greatly reduced if the analysis is performed by using individual ancestry as a conditioning variable or by using Bayesian methods (McKeigue et al. 2000). On the other hand, associations between markers and candidate genes will persist over longer distances in a population such as Puerto Rico, making mapping feasible provided the confounding effects of structure attributable to admixture are taken into account.
References
Akey JM, Sosnoski D, Parra E, Dios S, Heister K, Su B, Bonilla C, Jin L, Shriver MD (2001) Melting curve analysis of SNPs (McSNP): a simple gel-free low-cost approach to SNP genotyping and DNA fragment analysis. BioTechniques 30:358–367
Alaluf S, Atkins D, Barrett K, Blount M, Carter N, Heath A (2002) Ethnic variation in melanin content and composition in photoexposed and photoprotected human skin. Pigment Cell Res 15:112–118
Bean FD, Tienda M (1987) The Hispanic population of the United States. Russel Sage Foundation, New York
Bonilla C, Parra EJ, Pfaff CL, Dios S, Marshall JA, Hamman RF, Ferrell RE, Hoggart CL, McKeigue PM, Shriver MD (2004) Admixture in the Hispanics of the San Luis Valley, Colorado, and its implications for complex trait gene mapping. Ann Hum Genet 68:139–153
Chakraborty R, Weiss KM (1988) Admixture as a tool for finding linked genes and detecting that difference from allelic associations between loci. Proc Natl Acad Sci USA 85:9119–9123
Chakraborty R, Ferrell RE, Stern MP, Haffner SM, Hazuda HP, Rosenthal M (1986) Relationship of prevalence of non-insulin dependent diabetes mellitus to Amerindian admixture in the Mexican Americans of San Antonio, Texas. Genet Epidemiol 3:435–454
Crawford PB, Story M, Wang MC, Ritchie LD, Sabry ZI (2001) Ethnic issues in the epidemiology of childhood obesity. Pediatr Clin North Am 48:855–878
Díaz Soler LM (1953) Historia de la esclavitud negra en Puerto Rico (1493–1890). Ediciones de la Universidad de Puerto Rico, Puerto Rico
Duffy DL, Box NF, Chen W, Palmer JS, Montgomery GW, James MR, Hayward NK, Martin NG, Sturm RA (2004) Interactive effects of MC1R and OCA2 on melanoma risk phenotypes. Hum Mol Genet 13:447–461
Fernández JR, Shriver MD, Beasley TM, Rafla-Demetrious N, Parra E, Albu J, Nicklas B, Ryan AS, McKeigue PM, Hoggart CJ, Weinsier RL, Allison DB (2003) Association of African genetic admixture with resting metabolic rate and obesity among women. Obes Res 11:904–911
Fernández-Cobo M, Jobes DV, Yanagihara R, Nerurkar VR, Yamamura Y, Ryschkewitsch CF, Stoner GL (2001) Reconstructing population history using JC virus: Amerinds, Spanish, and Africans in the ancestry of modern Puerto Ricans. Hum Biol 73:385–402
Fox C, Esparza J, Nicolson M, Bennett PH, Schulz LO, Valencia ME, Ravussin E (1999) Plasma leptin concentrations in Pima Indians living in drastically different environments. Diabetes Care 22:413–417
Gardner LI Jr, Stern MP, Haffner SM, Gaskill SP, Hazuda HP, Relethford JH, Eifler CW (1984) Prevalence of diabetes in Mexican Americans. Relationship to percent of gene pool derived from Native American sources. Diabetes 33:86–92
Gower BA (1999) Syndrome X in children: influence of ethnicity and visceral fat. Am J Hum Biol 11:249–257
Hanis CL, Chakraborty R, Ferrell RE, Schull WJ (1986) Individual admixture estimates: disease associations and individual risk of diabetes and gallbladder disease among Mexican-Americans in Starr County, Texas. Am J Phys Anthropol 70:433–441
Hanis CL, Hewett-Emmett D, Bertin TK, Schull WJ (1991) Origins of US Hispanics. Implications for diabetes. Diabetes Care 14:618–627
Hazuda HP, Haffner SM, Stern MP, Eifler CW (1988) Effects of acculturation and socioeconomic status on obesity and diabetes in Mexican Americans. The San Antonio heart study. Am J Epidemiol 128:1289–1301
Hoggart CJ, Parra EJ, Shriver MD, Bonilla C, Kittles RA, Clayton DG, McKeigue PM (2003) Control of confounding of genetic associations in stratified populations. Am J Hum Genet 72:1492–1504
King RA, Willaert RK, Schmidt RM, Pietsch J, Savage S, Brott MJ, Fryer JP, Summers CG, Oetting WS (2003) MC1R mutations modify the classic phenotype of oculocutaneous albinism type 2 (OCA2). Am J Hum Genet 73:638–645
Kittles RA, Chen W, Panguluri RK, Ahaghotu C, Jackson A, Adebamowo CA, Griffin R, Williams T, Ukoli F, Adams-Campbell L, Kwagyan J, Isaacs W, Freeman V, Dunston GM (2002) CYP3A4-V and prostate cancer in African Americans: causal or confounding association because of population stratification? Hum Genet 110:553–560
Lautenberger JA, Stephens JC, O’Brien SJ, Smith MW (2000) Significant admixture linkage disequilibrium across 30 cM around the FY locus in African Americans. Am J Hum Genet 66:969–978
Long JC (1991) The genetic structure of admixed populations. Genetics 127:417–428
Long JC, Williams RC, Urbanek M (1995) An E-M algorithm and testing strategy for multiple-locus haplotypes. Am J Hum Genet 56:799–810
Martínez-Cruzado JC, Toro-Labrador G, Ho-Fung V, Estevez-Montero MA, Lobaina-Manzanet A, Padovani-Claudio DA, Sanchez-Cruz H, Ortiz-Bermudez P, Sanchez-Crespo A (2001) Mitochondrial DNA analysis reveals substantial Native American ancestry in Puerto Rico. Hum Biol 73:491–511
McKeigue PM, Carpenter JR, Parra EJ, Shriver MD (2000) Estimation of admixture and detection of linkage in admixed populations by a Bayesian approach: application to African-American populations. Ann Hum Genet 64:171–186
Melton LJ III, Marquez MA, Achenbach SJ, Tefferi A, O’Connor MK, O’Fallon WM, Riggs BL (2002) Variations in bone density among persons of African heritage. Osteoporos Int 13:551–559
Okosun IS (2000) Ethnic differences in the risk of type 2 diabetes attributable to differences in abdominal adiposity in American women. J Cardiovasc Risk 7:425–430
Parra EJ, Marcini A, Akey J, Martinson J, Batzer MA, Cooper R, Forrester T, Allison DB, Deka R, Ferrell RE, Shriver MD (1998) Estimating African American admixture proportions by use of population-specific alleles. Am J Hum Genet 63:1839–1851
Pfaff CL, Parra EJ, Bonilla C, Heister K, McKeigue PM, Kamboh MI, Hutchinson RG, Ferrell RE, Boerwinkle E, Shriver MD (2001) Population structure in admixed populations: effect of admixture dynamics on the pattern of linkage disequilibrium. Am J Hum Genet 68:198–207
Pritchard JK, Stephens M, Rosenberg NA, Donnelly P (2000) Association mapping in structured populations. Am J Hum Genet 67:170–181
Raymond M, Rousset F (1995) Genepop, version 2.0, http://wbiomed.curtin.edu.au/genepop/http://wbiomed.curtin.edu.au/genepop/
Rouse I (1992) The Tainos: rise and decline of the people who greeted Columbus. Yale University Press, New Haven
Samet JM, Coultas DB, Howard CA, Skipper BJ, Hanis CL (1988) Diabetes, gallbladder disease, obesity, and hypertension among Hispanics in New Mexico. Am J Epidemiol 128:1302–1311
Sánchez Korrol V (1994) From colonia to community: the history of Puerto Ricans in New York city. University of California Press, Berkeley
Shriver MD, Parra EJ (2000) Comparison of narrow-band reflectance spectroscopy and tristimulus colorimetry for measurements of skin and hair color in persons of different biological ancestry. Am J Phys Anthropol 112:17–27
Shriver MD, Parra EJ, Dios S, Bonilla C, Norton H, Jovel C, Pfaff C, Jones C, Massac A, Cameron N, Baron A, Jackson T, Argyropoulos G, Jin L, Hoggart CJ, McKeigue PM, Kittles RA (2003) Skin pigmentation, biogeographical ancestry and admixture mapping. Hum Genet 112:387–399
Stern MP, Knapp JA, Hazuda HP, Haffner SM, Patterson JK, Mitchell BD (1991) Genetic and environmental determinants of type II diabetes in Mexican Americans. Is there a “descending limb” to the modernization/diabetes relationship? Diabetes Care 14:649–654
Sturm RA, Teasdale RD, Box NF (2001) Human pigmentation genes: identification, structure and consequences of polymorphic variation. Gene 277:49–62
Sundquist J, Winkleby MA, Pudaric S (2001) Cardiovascular disease risk factors among older black, Mexican-American, and white women and men: an analysis of NHANES III, 1988–1994. Third National Health and Nutrition Examination Survey. J Am Geriatr Soc 49:109–116
Wagner DR, Heyward VH (2000) Measures of body composition in blacks and whites: a comparative review. Am J Clin Nutr 71:1392–1402
Wagner JK, Parra EJ, Norton HL, Jovel C, Shriver MD (2002) Skin responses to ultraviolet radiation: effects of constitutive pigmentation, sex, and ancestry. Pigment Cell Res 15:385–390
Wang J, Thornton JC, Burastero S, Shen J, Tanenbaum S, Heymsfield SB, Pierson RN Jr (1996) Comparisons for body mass index and body fat percent among Puerto Ricans, blacks, whites and Asians living in the New York City area. Obes Res 4:377–384
Weiss KM, Ferrell RE, Hanis CL (1984) A New World syndrome of metabolic diseases with a genetic and evolutionary basis. Yearbook Phys Anthropol 27:153–178
Williams RC, Long JC, Hanson RL, Sievers ML, Knowler WC (2000) Individual estimates of European genetic admixture associated with lower body-mass index, plasma glucose, and prevalence of type 2 diabetes in Pima Indians. Am J Hum Genet 66:527–538
Ye J, Parra EJ, Sosnoski DM, Hiester K, Underhill PA, Shriver MD (2002) Melting curve SNP (McSNP) genotyping: a useful approach for diallelic genotyping in forensic science. J Forensic Sci 47:593–600
Acknowledgements
We are grateful to all participants in this research study. We also thank Dr. Rick Kittles for helpful comments on the manuscript and Lane Destro for helping with the genotyping. This work was supported in part by grants from NIH/NIDDK (DK53958) and NIH/NHGRI (HG002154) to M.D.S., NIH grant 1P30AG/NR15294 to J.R.F., and a Wenner-Gren Foundation Developing Countries Training Fellowship to C.B.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Bonilla, C., Shriver, M.D., Parra, E.J. et al. Ancestral proportions and their association with skin pigmentation and bone mineral density in Puerto Rican women from New York city. Hum Genet 115, 57–68 (2004). https://doi.org/10.1007/s00439-004-1125-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00439-004-1125-7