
Abstract
Remembering object positions across different views is a fundamental competence for acting and moving appropriately in a large-scale space. Behavioural and neurological changes in elderly subjects suggest that the spatial representations of the environment might decline compared to young participants. However, no data are available on the use of different reference frames within topographical space in aging. Here we investigated the use of allocentric and egocentric frames in aging, by asking young and older participants to encode the location of a target in a virtual room relative either to stable features of the room (allocentric environment-based frame), or to an unstable objects set (allocentric objects-based frame), or to the viewer’s viewpoint (egocentric frame). After a viewpoint change of 0° (absent), 45° (small) or 135° (large), participants judged whether the target was in the same spatial position as before relative to one of the three frames. Results revealed a different susceptibility to viewpoint changes in older than young participants. Importantly, we detected a worst performance, in terms of reaction times, for older than young participants in the allocentric frames. The deficit was more marked for the environment-based frame, for which a lower sensitivity was revealed as well as a worst performance even when no viewpoint change occurred. Our data provide new evidence of a greater vulnerability of the allocentric, in particular environment-based, spatial coding with aging, in line with the retrogenesis theory according to which cognitive changes in aging reverse the sequence of acquisition in mental development.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The way we experience the external space changes with aging. From the infancy to the adult age there is a progressive extension of the explored places, whereas during aging there is a reduction of the space of free movement and a retire into private life, as a consequence of the decline of physical and psychological resources and the need of a familiar situation that supports the reduced motor and cognitive abilities (Craik & Salthouse, 2007). Age-related deficits are more pronounced on visuospatial than linguistic tasks (e.g., Jenkins, Myerson, Joerding, & Hale, 2000) and recent data show that elderly subjects perceive walkable extents as farther when verbally estimating distance to targets placed in a hallway (Sugovic & Witt, 2013).
An appealing approach to the study of elderly visuospatial ability is the use of navigation tasks in virtual reality. Several studies have demonstrated an age-related decline in the ability to orient and navigate in virtual environments. In particular, Moffat and colleagues (Moffat & Resnick, 2002; Moffat, Zonderman, & Resnick, 2001) developed a virtual Water Maze Task in which young and elderly adults learned the location of a hidden platform where both proximal and distal cues were available around the virtual room. Compared with younger participants, older volunteers traversed a longer linear distance to locate the hidden platform and, importantly, used proximal objects to locate the goal but did not use room geometry cues to aid navigation. In another study, older subjects required more time than younger subjects to form a cognitive map of the virtual environment and their performance was worse when using it to navigate (Iaria, Palermo, Committeri, & Barton, 2009). Accordingly, recent neuroimaging studies reveal how impairments in the navigational and orientation ability during aging are related to functional and structural brain changes, mainly in the hippocampal complex (e.g., Antonova et al., 2009; Meulenbroek, Petersson, Voermans, Weber, & Fernandez, 2004; Moffat, Elkins, & Resnick, 2006; Moffat, Kennedy, Rodrigue, & Raz, 2007). These regions, and in particular the posterior parahippocampal cortex, are selectively activated when adopting an allocentric environment-based frame of reference, that is a spatial frame centered on enduring environmental features (e.g., Committeri et al., 2004; Galati, Pelle, Berthoz, & Committeri, 2010; Sulpizio, Committeri, Lambrey, Berthoz, & Galati, 2013).
To the best of our knowledge, no data are available on the use of different reference frames within topographical space in aging. The only available work is that by Hort and colleagues (2007), which compared patients affected by mild cognitive impairment (MCI) and Alzheimer’s disease (AD) to healthy elderly participants in a navigational task, finding a deficit of the allocentric component in patients relative to controls. Given the absence of a group of young subjects, it is unknown whether aging affected the performance and whether this happened independently of the kind of adopted spatial coding (allocentric vs. egocentric). An allocentric deficit would be in line with what was observed in patients and with the idea that spatial abilities acquired later in the development are more susceptible to damage with aging (Inagaki et al., 2002). This may be explained by the retrogenesis hypothesis, according to which the functional loss in the normal and pathological aging reverses the order of functional acquisition in normal human development (see Reisberg et al., 1999). The retrogenesis hypothesis has been applied primarily in the context of Alzheimer’s disease (Reisberg et al., 1999; 2002), and recently systematically tested in normal cognitive aging by proposing that later myelinated fibers are more susceptible to damage than early myelinated fibers during aging-related degeneration (e.g., Brickman et al., 2012; Rogalski et al., 2012).
An egocentric deficit, instead, would be in line with previous observations on peripersonal space (Iachini, Ruggiero, & Ruotolo, 2009), which showed a significant impairment of the egocentric component of a distance judgment task (with the allocentric component relatively preserved) starting from 70 years.
The main purpose of the present study was to investigate the use of allocentric and egocentric spatial representations in aging, by asking young and older participants to perform a spatial memory task across viewpoint changes, with a paradigm adapted from Sulpizio and colleagues (Sulpizio et al., 2013). We asked participants to encode the location of a target object in a virtual room in relation either to stable features of the room (environment-based reference frame), or to an unstable and arbitrary objects set (objects-based reference frame), or to the viewer’s viewpoint (egocentric reference frame). After a viewpoint change (with respect to the room or to the objects set), participants judged whether the target was in the same spatial position as before in relation to one of the three reference frames. This paradigm allowed us to test also the effect of the spatial viewpoint change, which is potentially very relevant given that a positive correlation between navigational and mental rotation abilities in aging has been previously described (e.g., Driscoll et al., 2005; Dror, Schmitz-Williams, & Smith, 2005).
According to the literature reviewed above, we expected to find a significant decline of allocentric (especially the environment-based) coding, in older respect to young participants and possibly a different pattern of susceptibility to viewpoint change in the same frames.
Methods
Participants
Forty healthy male participants took part in the study, including 20 young participants (mean age: 25.65 years, SD = 4.17) and 20 older participants (mean age: 54.40 years, SD = 3.23). To make the sample more homogeneous, we chose to include only male participants because it has been suggested that there are significant gender differences in spatial abilities due to different strategies used to solve orientation tasks (Driscoll et al., 2005; Palermo, Iaria & Guariglia, 2008; see also Coluccia & Louse, 2004 for a complete review on this topic). The mean years of education were 12.75 (SD = 2.59) and 11.10 (SD = 2.92) for young and older participants, respectively. No significant difference was found in the educational level between young and older participants (t (38) = 1.89, p = 0.07).
An a priori sensitivity power analysis (G*Power 3 software; Faul, Erdfelder, Buchner, & Lang, 2009) revealed that our sample size was large enough to detect a within-between interaction of interest corresponding to an effect size as small as η 2 p = 0.04 with a statistical power of (1 − β) = 0.95 (given α = 0.05 and a correlation between repeated measures of r = 0.75; note that the mean correlation between repeated measures was 0.79 in Sulpizio et al.’s study and it is 0.80 in our study).
All participants were right handed, as assessed by the Edinburgh Handedness Inventory (Oldfield, 1971). None reported a history of neurological disease or mental illness. According to self-reports, no older participants reported memory problems or deficit in performing daily life and work-related activities. All participants were naïve as the purpose of the study and provided the written informed consent. This study was performed in accordance with the ethical standards of the 1964 Declaration of Helsinki.
Materials
The participants sat comfortably in a sound- and light-attenuated room, facing a LCD 15-in. laptop monitor (resolution: 1,080 × 800 pixels) at a distance of 50 cm. They were instructed to maintain their gaze on the center of the screen throughout the experimental task. The responses were recorded via the laptop touchpad buttons. The presentation of stimuli and the recording of participants’ responses were controlled by custom software (Galati et al., 2008), implemented in MATLAB (The MathWorks, Natick, MA).
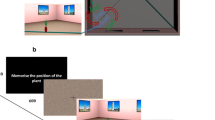
The virtual environment was designed using 3Dstudio Max 9 (Autodesk Inc., 128 San Rafael, CA, USA), and represented an internal view of a living room, containing both fixed cues on the walls, and unstable cues on a carpet on the floor (see Sulpizio et al., 2013, for a detailed description of the virtual environment and stimuli). The fixed cues were stable elements of the room (such as one door, windows, etc.; see Fig. 1a) while the unstable cues were five pieces of furniture (such as table, stool, lamp etc.; see Fig. 1a) arranged in different configurations on a circular carpet stably located at the center of the room. Close to the carpet, a plant (the target object) was added, at different locations, on the room floor to test memory.

Virtual environment and stimuli for the experimental task. a Survey perspective of the virtual environment used in the experiment. Yellow and green numbers mark the possible positions of the virtual cameras used to take the snapshots employed as stimuli, and the possible positions of the target object, respectively. In both cases the eight possible positions were arranged around two concentric circles, also shown in yellow and green, respectively. The green dashed line represents the imaginary circle where the plants (target) are distributed. A particular configuration of the furniture set is shown as an example. b Temporal structure of a trial. c–e Examples of trials for the Room (c), Objects (d), and Viewer (e) reference frames. The left panel shows a survey perspective of the example trials, indicating the rotation of the camera (yellow arrow), of the target (green arrow), and of the furniture set (red arrow), occurring between the study and test phases. The middle and right panels show the two corresponding snapshots for the study and test phases, respectively. In all the three examples, there is a 45° viewpoint change. For the object reference frame it was defined relative to the furniture set, i.e., as the difference between the camera and the furniture set rotation, which defined the angular change in the observer’s perspective on the furniture set. In all the three examples, the correct response was “same position”: for the room frame, the plant remained steady in the room; for the object frame, the plant rotated by the same amount as the furniture set, thus remaining in the same position relative to it; for the Viewer frame, the plant rotated by the same amount as the camera, thus remaining in the same position relative to the viewer
During the experiment, the participants were shown different snapshots of the virtual environment. Each snapshot simulated a photograph of the environment taken with a 24-mm lens (74° by 59° simulated field of view) from one of eight different viewpoints. Each viewpoint corresponded to the position of a virtual camera (shown in yellow and numbered 0–7 in Fig. 1a). The different virtual cameras were distributed at 45° intervals along a circle whose center corresponded to the center of the virtual room. Each camera was directed towards the center of the room, where the furniture set was placed. Each snapshot also included a plant, used as the target object, which was located outside the carpet but quite close to it, in one of eight possible positions, distributed every 45° along a smaller concentric circle (shown in green and numbered 0–7 in Fig. 1a). The target was never presented directly in front of the observer or directly behind the carpet (for example, for snapshots obtained from camera 1, the target could be neither in position 1 nor 5), and was presented half of the times on the left and the remaining half on the right of the observer. Each snapshot depicted the virtual room so as to include the whole furniture set on the carpet, the target and some of the fixed cues on the walls.
Procedure
Before starting the experiment, we presented participants with a 52-s video clip showing a 360° tour of the virtual environment in which only the fixed landmarks and the carpet, but no pieces of the objects set, were present. To assure that the participants had acquired a long-term knowledge of the room layout, they watched the movie until they were able to reproduce the correct map of the virtual environment.
In different blocks, the participants were administered three experimental tasks, corresponding to the three reference frames: Room frame (a stable, environmental allocentric frame), Objects frame (an unstable, objects-based allocentric frame), Viewer frame (an egocentric frame). Each task comprised 48 experimental trials in which participants watched a first view of the room from an unpredictable viewpoint for 4,000 ms (study phase: examples in the central column of Fig. 1c–e). After a short delay of 1,000 ms (see Fig. 1b for the trial temporal structure), participants watched a second view of the room until they responded (but for no longer than 8,000 ms), again from an unpredictable viewpoint (test phase: examples in the right column of Fig. 1c–e). The viewpoint in the test phase could either be the same as in the study phase (no viewpoint change or 0°), or be rotated by 45° (small viewpoint change) or by 135° (large viewpoint change). The following trial started after an intertrial interval (ITI) of 2,500 ms. Participants were asked to indicate spatial displacements of the target object with respect to any of the three types of reference frames. In particular, participants reported either (a) changes in the absolute spatial location of the target in the room (Room frame, Fig. 1c), or (b) changes in its location relative to the furniture set on the central circular carpet (Objects frame, Fig. 1d), or (c) changes in its location relative to the viewer (Viewer frame, Fig. 1e). Subjects responded “same” by pressing the left touchpad button with the index finger if the target was in the same position as in the study phase, and “different” by pressing the right touchpad button with the middle finger if the target was in a different position, relative to the relevant reference frame.
The Room and Object frames crucially differed for the use of enduring information about stable features of the environment and volatile information about locations of objects, respectively. When encoding room-absolute spatial locations, observers can of course rely upon their long-term knowledge of the room layout, and in particular of the position of stable and distal cues such as doors, windows, and staircases. We arranged the position of the pieces of furniture so that this was not possible by design when encoding objects-relative locations (see also Sulpizio et al., 2013, for more details about the experimental paradigm). For the Viewer frame, participants encoded the position of the plant relative to their current point of view, i.e., in viewer-based coordinates. Although participants again could undergo an unpredictable viewpoint change, this manipulation by design should not produce any effect, because by definition viewer-based judgments are the same across viewpoint changes.
The experimental design crucially depends on the complete disentanglement between the Room and Object frames. This was obtained by rotating the carpet (and thus the furniture set as a whole) within the room by an unpredictable amount across the two consecutive views of each single trial. In same viewpoint (0°) trials the viewpoint remained the same relative to the relevant frame (either Room or Objects), but changed relative to the other (irrelevant) frame. This was ensured, for the room frame, by rotating the furniture set relative to the room, without moving the camera and, for the objects frame, by rotating both the camera and the furniture set by the same amount, thus leaving the spatial relationships between the observer and the furniture set the same, while changing those between the observer and the room. In the Viewer frame, the viewpoint stayed the same relative to both room and objects frames, i.e., the camera and furniture set did not rotate. In different viewpoint (45° and 135°) trials, the test camera was always different from the study camera (thus dissociating the room from the viewer frame), the furniture set always rotated in the room (thus dissociating the room from the objects frame), and the amount of rotation of the camera was always inconsistent with that of the furniture set (thus dissociating the objects from the viewer frame) (see examples in Fig. 1c–e for a demonstration). The viewpoint change was computed relative to the room (i.e., camera rotation) for the Room and Viewer frames, and relative to the furniture set (i.e., as the difference between camera and furniture rotation) for the Objects frame. The target position during the test phase was arranged so that in half of the trials it remained the “same” as in the study phase (as in all examples in Fig. 1c–e), relative to the relevant reference frame. In the remaining half of the trials, the plant underwent a displacement of 135°, either in clockwise or counterclockwise direction, with respect to the relevant frame. Importantly, the target never remained in the same location relative to the other two reference frames (except in the Viewer-0° condition, where the three frames were aligned). A further set of 24 trials for each reference frame (Room, Objects and Viewer) was administered to participants for a training session. Half of these trials represented the “same” response, and the other half the “different” response.
Both the order of presentation of the different reference frames and that of the view pairs within a particular reference frame were randomized across participants. In total, each participant completed 72 practice trials and 144 experimental trials.
After completing the experimental session we asked participants to explain the strategy that they used to solve the three tasks to ensure that our reference frames were actually coded according to the coordinates we designed. Importantly, for the environment condition, almost all of the participants (19 out of 20 young participants and 19 out of 20 older participants) reported to have encoded the target position relative to the fixed cues on the walls of the room. In the Objects condition, all the volunteers memorized the position of the target in relation to one or two objects of the set of furniture. For the egocentric reference, all of the participants encoded the target position using the body as a spatial reference system.
Data analysis
We recorded response times and accuracy. Trials in which participants failed to respond correctly (13 %) were excluded from the analysis on response times (RTs). Mean RTs was calculated for each condition, and correct responses longer or shorter than 2 standard deviations from the individual mean were treated as outliers and not considered (≈ 5 %). We analyzed RT data using a mixed design analysis of variance (ANOVA) with Age Group (Young, Older) as between-subjects factor and Reference Frame (Room, Objects, Viewer) and Viewpoint Change (0°, 45°, 135°) as within-subjects factors.
We also assessed the performance in terms of sensitivity by calculating the proportion of hits (displacement absent and subject responds “same”) and false alarms (displacement present and subject responds “same”) for each participant, and then calculating the signal detection measure for sensitivity as d’ = z(Hit) - z(False Alarms) according to Stanislaw and Todorov (1999). Higher d’ values indicate higher amounts of signal detection relative to noise and suggests, in this case, better discrimination between absence and presence of the target’s displacement. We analyzed d’ by carrying out a mixed design ANOVA with Age Group (Young, Older) as between-subjects factor and Reference Frame (Room, Objects, Viewer) and Viewpoint Change (0°, 45°, 135°) as within-subjects factors.
Post-hoc Newman–Keuls’s test was used when necessary. We chose to carry out the Newman–Keuls post hoc test that mitigates the risk of inflated Type I error rate due to multiple comparisons compared both to other post hoc tests and to a series of uncorrected t tests. When post hoc analyses revealed viewpoint-dependent differences within a given reference frame for both groups, we carried out contrast analyses testing whether the pattern of performance across viewpoints in each group was better explained by a linear or a step function.
Results
Response times
The ANOVA on RTs revealed a number of significant main effects and interactions. First, we found main effects of Age Group (F (1, 38) = 13.80, p < 0.001, η 2 p = 0.27), Reference Frame (F (2, 76) = 97.19, p < 0.0001, η 2 p = 0.72) and Viewpoint Change (F (2, 76) = 92.63, p < 0.0001, η 2 p = 0.71). Moreover, the interaction between Reference Frame and Viewpoint Change was significant (F (4, 152) = 29.87, p < 0.0001, η 2 p = 0.44). Importantly, also the highest order three-way interaction resulted significant (F (4, 152) = 2.99, p < 0.021, η 2 p = 0.07).
As shown in Fig. 2, this higher-order interaction was driven by the fact that the two groups of participants differed in the effect of viewpoint change within the allocentric frames, especially within the Room frame, but not within the Viewer frame. To facilitate reading, we will describe the results of the post hoc analysis for each spatial frame of reference separately. In particular, we first describe age-related effects of interest, by presenting differences between older and young participants in each viewpoint change condition. Subsequently, we describe within-group differences related to the viewpoint change, with the aim of disclosing possible different patterns (i.e. linear vs. step function) across groups.

Response times are shown as a function of age group (Young, Older), reference frame (Room, Objects, Viewer) and viewpoint change (0°, 45°, 135°). Error bars indicate S.E.M. Asterisks indicate significant differences (p < 0.05)
In the Room frame, the two age groups significantly differed in the condition of no viewpoint change (Young: M = 1,217 ms, SD = 417 ms; Older: M = 1,735 ms, SD = 505 ms; p = 0.05) and when a small viewpoint change (45°) occurred (Young: M = 1,951 ms, SD = 539 ms; Older: M = 2,467 ms, SD = 801 ms; p = 0.02), with slower RTs for older than young participants. On the contrary, no difference emerged between the two groups when a large viewpoint change (135°) occurred (Young: M = 2,355 ms, SD = 607 ms; Older: M = 2,536 ms, SD = 928 ms; p = 0.55). These between-groups differences were due to different patterns of performance in relation to viewpoint change in young and older participants. Indeed, young participants presented significantly slower RTs (compared to the no viewpoint condition) after both small (p < 0.0001) and large (p < 0.0001) viewpoint changes, which in turn differed from each other (p < 0.0001) (i.e., 0° < 45° < 135°). The contrast analyses confirmed this pattern, by showing that a linear function (0° < 45° < 135°) better explained young performance across viewpoints (F (1, 38) = 56.24, p < 0.0001, η 2 p = 0.60) compared to a step function (0° < 45° = 135°; F (1, 38) = 49.50, p < 0.0001, η 2 p = 0.57). Instead, in older participants no difference emerged between the two viewpoint changes (p = 0.415) because RTs were already as slow after a small viewpoint change (p < 0.0001) as after a large viewpoint change (p < 0.0001) compared to no viewpoint change (i.e., 0° < 45° = 135°). This pattern was supported by the contrast analyses, which revealed that the older performance was better explained by a step function (F (1, 38) = 33.15, p < 0.0001, η 2 p = 0.47), compared to a linear contrast (F (1, 38) = 27.82, p < 0.0001, η 2 p = 0.42).
In the Objects frame, the pattern of results was similar. Indeed, the two age groups significantly differed also in this allocentric spatial frame of reference, but in this case only in presence of a viewpoint change. As revealed by the Newman–Keuls’ post-hoc analysis, reaction times were slower for the older participants after both a small (Young: M = 1,340 ms, SD = 434 ms; Older: M = 1,939 ms, SD = 661 ms; p = 0.008) and a large (Young: M = 1,459 ms, SD = 428 ms; Older: M = 2,014 ms, SD = 544 ms; p = 0.023) viewpoint change, but not at 0° (Young: M = 1,178 ms, SD = 402 ms; Older: M = 1,569 ms, SD = 352 ms; p = 0.268). Again, these between-groups differences were due to different patterns of performance in relation to viewpoint changes in young and older participants. Indeed, the RTs of young participants were slower only for the large viewpoint change compared to no viewpoint change (0° < 135, p = 0.011), and no difference emerged for the two intermediate comparisons (0° vs. 45°: p = 0.30, 45° vs. 135°: p = 0.159). As for the Room frame, this difference was better explained by a linear contrast (0° < 45° < 135°; F (1, 38) = 160.07, p = 0.0003, η 2 p = 0.30) compared to a step function (0° < 45° = 135°; F (1, 38) = 9.12, p = 0.004, η 2 p = 0.19). Again, older participants did not show differences between the two viewpoint changes (p = 0.644), because RTs were already as slow after a small viewpoint change (p < 0.0001) as after a large viewpoint change (p < 0.0001) compared to no viewpoint change (i.e., 0° < 45° = 135°). Their performance was better explained by a step function (F (1, 38) = 40.16, p < 0.0001, η 2 p = 0.51), compared to a linear contrast (F (1, 38) = 30.67, p < 0.0001, η 2 p = 0.45).
Importantly, in the Viewer frame the Newman–Keuls’ post-hoc analyses revealed a different pattern of results. Indeed, there were no significant differences either between the two groups (all ps > 0.23) or within the young (all ps > 0.44) and the older group (all ps > 0.35).
To sum up, the RT analysis revealed that young and older participants selectively differed in the allocentric reference frames. Older participants were indeed slower than young participants in this kind of spatial coding and, compared to them, showed a different pattern of susceptibility to viewpoint change.
D prime
The ANOVA on d’ showed results in line with RT analysis. We found main effects of Age Group (F (1, 38) = 12.504, p = 0.001, η 2 p = 0.25), Reference Frame (F (2, 76) = 52.293, p < 0.0001, η 2 p = 0.58) and Viewpoint Change (F (2, 76) = 430.019, p < 0.0001, η 2 p = 0.53), as well as the Reference Frame by Viewpoint Change interaction (F (4, 152) = 21.775, p < 0.0001, η 2 p = 0.36) and the Age Group by Reference Frame by Viewpoint Change interaction (F (4, 152) = 2.929, p < 0.0228, η 2 p = 0.07) (see Fig. 3).

Sensitivity (d’) is shown as a function of age group (Young, Older), reference frame (Room, Objects, Viewer) and viewpoint change (0°, 45°, 135°). Error bars indicate S.E.M. Asterisks indicate significant differences (p < 0.05)
As for the analyses on response times, this higher-order interaction was driven by the fact that the two groups of participants differed in the effect of viewpoint change within the allocentric frames, especially within the Room frame, but not within the Viewer frame. As shown by the post hoc analysis, in the Room frame the two age groups differed significantly in the conditions with no (0°; Young: M = 5.41, SD = 10.09; Older: M = 3.67, SD = 1.59; p = 0.031) and small (45°; Young: M = 2.60, SD = 2.12; Older: M = 10.02, SD = 0.92; p = 0.013) viewpoint change, with lower sensitivity for the older participants in this frame, but not in the large viewpoint change condition (Young: M = 1.74, SD = 1.44; Older: M = 1.45, SD = 1.49; p = 0.568). These between-groups differences were again due to different patterns of performance in relation to viewpoint changes in young and older participants. Indeed, as found for the RT’s analysis, young participants showed a better sensitivity for the no viewpoint change condition than both the small (p < 0.0001) and large (p < 0.0001) viewpoint change conditions, which in turn differed from each other (p = 0.017) (i.e., 0° > 45 > 135°). On the contrary, compared to the no viewpoint change condition, older participants’ sensitivity after a small viewpoint change was already as worse (p < 0.0001) as after a large viewpoint change (p < 0.0001), thus no difference emerged between the two (p = 0.225) (i.e., 0° > 45° = 135°). In this case, the contrast analyses showed that a step-function contrast (0° < 45° = 135°) better explained the performance not only for the older (F (1, 38) = 62.74, p < 0.0001, η 2 p = 0.62) but also for the young (F (1, 38) = 110.86, p < 0.0001, η 2 p = 0.74) participants compared to a linear contrast (Older: F (1, 38) = 35.46, p < 0.0001, η 2 p = 0.48; Young: F (1, 38) = 96.95, p < 0.0001, η 2 p = 0.72), thus not completely supporting what observed for the reaction times (i.e. a different pattern of viewpoint susceptibility).
Unlike for the Room allocentric frame, for the Objects frame the two age groups did not significantly differ (all ps > 0.086). The within-group comparisons, however, revealed that while the sensitivity decrease after viewpoint changes did not reach significance in the young participants (0° vs. 45°, p = 0.986; 45° vs. 135°, p = 0.063; 0° vs. 135°, p = 0.063), the decrease was significant after a large viewpoint change compared to no viewpoint change in the older participants (0° vs. 135°, p = 0.016; 0° vs. 45°, p = 0.134; 45° vs. 135°, p = 0.371).
Finally, in the Viewer frame the Newman–Keuls’ post hoc analyses did not show significant differences either between the two groups (all ps > 0.26) or within the young (all ps > 0.58) and the older group (all ps > 0.59).
In sum, the d’ analysis showed that young and older participants directly differed only in the allocentric Room frame at 0° and 45°. In both allocentric Objects and egocentric Viewer frames, the two groups did not significantly differ.
Discussion
Remembering object positions across different views is a fundamental competence for acting and moving appropriately in large-scale space. For this reason, it is of particular interest to understand how older individuals use different spatial frames of reference within the environment they live in. Behavioural and neurological changes in elderly participants suggest that the spatial representations of the environment around them might be impaired compared to young participants. However, to the best of our knowledge, only few attempts have recently been made to directly compare allocentric and egocentric spatial coding in aging, which have not reached conclusive results (e.g., Iachini et al., 2009; Lemay, Bertram, & Stelmach, 2004; Parkin, Walter, & Hunkin, 1995). Moreover, none of them have compared the use of environment-based and objects-based allocentric frames of reference.
Here, we compared young and older performance in a visuospatial memory task, by adapting a paradigm recently developed by Sulpizio et al. (2013) that allows both to discriminate between egocentric (i.e., viewer-based) and different allocentric (i.e., environment- and objects-based) frames of reference, and to manipulate the amount of experienced viewpoint change. In particular, we asked participants to report spatial displacements of a target object across viewpoint changes with respect to any of the three types of reference frames. We expected a worse performance in the allocentric frames, especially in the environmental frame of reference, for the older participants compared to young participants.
Results provided support for our hypotheses. No differences emerged between young and older participants either for response times and d prime in the egocentric condition, for which viewpoint change was irrelevant because viewer-based judgments do not change across perspectives. This first result allows to exclude general and aspecific between-groups effects due, for example, to lower speed of processing or deficit of working memory in our older group.
The main result of the present study is the worst performance, in terms of reaction times, for the older than young participants in the allocentric conditions, and especially in the Room frame, for which a significantly lower sensitivity (d’) was revealed as well. These effects were modulated by the viewpoint change, as highlighted by the three-way interaction on RTs. Indeed, although young participants showed a graded decline in performance across progressively greater viewpoint changes, older participants were substantially impaired following even a small viewpoint change when the target was judged relative to the Room or Objects, speaking in favour of a different susceptibility to viewpoint change in both allocentric reference frames.
These results are consistent with studies which showed a greater worsening of performance in older than their young counterparts on mental rotation tasks (e.g., Dollinger, 1995) and on the ability of imagining to assume a new perspective (e.g., Herman & Coyne, 1980; Inagaki et al., 2002). More importantly, these results are in line also with those obtained by King and colleagues (2002) on an amnesic patient with bilateral hippocampal damage. They showed a greater impairment for the patient than controls during a recognition task of object locations when a viewpoint change occured, suggesting that hippocampus underpins viewpoint independence in the spatial memory (King, Burgess, Hartley, Vargha-Khadem and O’Keefe, 2002). Thus, the older participants’ susceptibility to the viewpoint change in allocentric frames found by us could be a consequence of age-related hippocampal degeneration.
A further important result is that older participants showed a worse performance on the environmental frame of reference, compared to young participants, even when no viewpoint change occurred. In contrast, in the Objects frame the response times of the two age groups differed only when a viewpoint change occurred. The most plausible explanation of these findings lies in the intrinsic difference between the two allocentric frames of reference: only the environment-based frame is linked to a stable representation or cognitive map of the environment. In accordance with the present findings, previous behavioural navigational studies showed that elderly participants, compared to young participants, have more difficulty in forming and using an environmental cognitive map (Iaria et al., 2009). Moreover, the difference between the two allocentric frames of reference is also evident on a neuronal level, as the allocentric environment- and object-based frames of reference are implemented in different cerebral networks, with the parahippocampal and retrosplenial regions selectively involved in the environmental frame (Sulpizio et al., 2013). Accordingly, hippocampal lesions in rats lead to deficits in using distal (i.e., the type of environment-based landmark) but not proximal landmarks (Save & Poucet, 2000) and subjects with high gray-matter density in the hippocampus tend to prefer an allocentric strategy compared to an egocentric one (Bohbot, Lerch, Thorndycraft, Iaria, & Zijdenbos, 2007). Therefore, our finding of an age-related impairment in using the environmental frame of reference could be due to a reduced activity in the cerebral network devoted to these processes. Supporting this proposal, previous neuroimaging studies showed reduced or no activation in the posterior hippocampus, parahippocampal gyrus and retrosplenial cortex in older participants compared to young participants when performing navigation tasks in virtual reality (e.g., Antonova et al., 2009; Meulenbroek et al., 2004; Moffat et al., 2006). The reduced/absent activation of these regions suggests that older participants could not adequately use strategies tapping into these cerebral areas (that is, allocentric environment-based strategies).
Previous works (Moffat et al., 2006; Wiener, de Condappa, Harris & Wolbers, 2013) suggest that elderly subjects would be constrained to change strategy, relying more on egocentric strategies, to compensate for the difficulty in using the environmental frame (Moffat, 2009, but see also Wolbers, Dudchenko & Wood, 2014), which might be due to reduced hippocampal-prefrontal functional connectivity (e.g., Harris & Wolbers, 2013). Moreover, this preference for using egocentric strategies persists even when an allocentric strategy would be more beneficial to task performance (Wiener et al., 2013). In line with this idea, it has been shown that elderly participants, compared to young participants, take more advantage of proximal cues than distal cues relative to the layout of a virtual room (Moffat & Resnick, 2002), and that allocentric strategies tend to decrease with age (Driscoll et al., 2005). Further support comes from an animal study, which found that elderly rats used mostly a self-based strategy to solve the maze, while young rats prefer to solve the task with an allocentric strategy (Barnes, Nadel, & Honig, 1980). An alternative explanation of this egocentric preference comes from Harris and colleagues, which suggested that aging induces deficits in strategy switching in navigational tasks (e.g., Harris, Wiener & Wolbers, 2011; Harris & Wolbers, 2013). More specifically, as strategy switching is thought to be coordinated by the prefrontal cortex and mediated by the locus coeruleus-noradrenaline system (e.g., Aston-Jones & Cohen, 2005), and as the deficit specifically impairs switching from an egocentric to an allocentric strategy, it might relate to reduced functional connectivity between the prefrontal-noradrenergic strategy-switching network and the hippocampus (Harris & Wolbers, 2013).
However, this compensatory shift in strategy, which is possible when performing navigational tasks, is not helpful in our Room condition, in which participants must use a type of allocentric strategy to best solve the task. Note also that in the Room frame of reference, participants could use an egocentric strategy only in the condition without viewpoint change (0°), but it is highly unlikely that participants would change strategy from trial to trial, especially as our experimental design was divided in blocks, corresponding to the three conditions (Room, Objects and Viewer). Thus, older participants showed a greater difficulty in the Room frame of reference probably because they could not compensate for the allocentric strategy with the egocentric one. This conclusion is supported also by the debriefing interview we performed at the end of the experiment (see Procedure section), which suggests that all of the participants used a type of allocentric strategy for solving the Room task.
Taken together, our findings support the retrogenesis model according to which the cognitive changes in normal and pathological aging reverse the sequence of acquisition in mental development (Reisberg et al., 1999). Similarly, de Ajuriaguerra and colleagues (e.g., de Ajuriaguerra & Tissot 1968; de Ajuriaguerra & Tissot, 1975) showed that the cognitive decline in dementia follows the Piaget’s hierarchy of developmental stages in reverse (e.g., Piaget, 1960, 1973). Allocentric coding is indeed acquired later than egocentric coding in children (Huttenlocher & Presson, 1979; Piaget & Inhelder, 1956). As recently found in literature, this mechanism postulates that late myelinating regions of the brain, such as the parahippocampal cortex, which is involved in allocentric environmental coding, are more susceptible to myelin breakdown in aging than early myelinating regions (Rogalski et al., 2012).
Conclusions
In sum, in the present study we provided new evidence of an aging-related impairment in the allocentric coding, supporting the retrogenesis theory. Our main contribution has been to show a greater vulnerability of older subjects for allocentric, and especially environmental, spatial frames of reference, by comparing directly two kinds of allocentric frames of reference, with an experimental paradigm developed recently by our group. In addition, this experimental paradigm allowed us to investigate the effect of viewpoint change in older participants, highlighting that viewpoint change differently affects older compared to young participants’ performance in allocentric tasks. Further studies are needed to better investigate this age-related susceptibility to viewpoint change and to confirm the link between age-related behavioural and neural changes in the use of different frames of reference within topographical space.
References
Antonova, E., Parslow, D., Brammer, M., Dawson, G. R., Jackson, S. H., & Morris, R. G. (2009). Age-related neural activity during allocentric spatial memory. Memory, 17(2), 125–143. doi:10.1080/09658210802077348.
Aston-Jones, G., & Cohen, J. D. (2005). An integrative theory of locus coeruleus-norepinephrine function: adaptive gain and optimal performance. Annual Review of Neuroscience, 28, 403–450. doi:10.1146/annurev.neuro.280.061604.135709.
Barnes, C. A., Nadel, L., & Honig, W. K. (1980). Spatial memory deficit in senescent rats. Canadian Journal of Experimental Psychology, 34(1), 29–39. doi:10.1037/h0081022.
Bohbot, V. D., Lerch, J., Thorndycraft, B., Iaria, G., & Zijdenbos, A. P. (2007). Gray matter differences correlate with spontaneous strategies in a human virtual navigation task. Journal of Neuroscience, 27(38), 10078–10083. doi:10.1523/JNEUROSCI.1763-07.2007.
Brickman, A. M., Meier, I. B., Korgaonkar, M. S., Provenzano, F. A., Grieve, S. M., Siedlecki, K. L., et al. (2012). Testing the white matter retrogenesis hypothesis of cognitive aging. Neurobiology of Aging, 33(8), 1699–1715. doi:10.1016/j.neurobiolaging.20110.060.001.
Clancy Dollinger, S. M. (1995). Mental rotation performance: age, sex, and visual field differences. Developmental Neuropsychology, 11(2), 215–222. doi:10.1080/87565649509540614.
Coluccia, E., & Louse, G. (2004). Gender differences in spatial orientation: a review. Journal of environmental psychology, 24(3), 329–340. doi:10.1016/j.jenvp.20040.080.006.
Committeri, G., Galati, G., Paradis, A. L., Pizzamiglio, L., Berthoz, A., & LeBihan, D. (2004). Reference frames for spatial cognition: different brain areas are involved in viewer-, object-, and landmark-centered judgments about object location. Journal of Cognitive Neuroscience, 16(9), 1517–1535. doi:10.1162/0898929042568550.
Craik, F. I. M., & Salthouse, T. A. (2007). The handbook of aging and cognition (3rd ed.). New York: Psychology Press.
de Ajuriaguerra, J., & Tissot, R. (1968). Some aspects of psychoneurologic disintegration in senile dementia (pp. 69–84). Senile Dementia: Clinical and Therapeutic Aspects. Bern, Huber.
de Ajuriaguerra, J., & Tissot, R. (1975). Some aspects of language in various forms of senile dementia (comparisons with language in childhood). Foundations of language development, 1, 323–339.
Driscoll, I., Hamilton, D. A., Yeo, R. A., Brooks, W. M., & Sutherland, R. J. (2005). Virtual navigation in humans: the impact of age, sex, and hormones on place learning. Hormones and Behavior, 47(3), 326–335. doi:10.1016/j.yhbeh.2004.110.013.
Dror, I. E., Schmitz-Williams, I. C., & Smith, W. (2005). Older adults use mental representations that reduce cognitive load: mental rotation utilizes holistic representations and processing. Experimental Aging Research, 31(4), 409–420. doi:10.1080/03610730500206725.
Faul, F., Erdfelder, E., Buchner, A., & Lang, A. G. (2009). Statistical power analyses using G*Power 3.1: tests for correlation and regression analyses. Behavior Research Methods, 41(4), 1149–1160. doi:10.3758/BRM.41.4.1149.
Galati, G., Committeri, G., Spitoni, G., Aprile, T., Di Russo, F., Pitzalis, S., et al. (2008). A selective representation of the meaning of actions in the auditory mirror system. Neuroimage, 40(3), 1274–1286. doi:10.1016/j.neuroimage.2007.120.044.
Galati, G., Pelle, G., Berthoz, A., & Committeri, G. (2010). Multiple reference frames used by the human brain for spatial perception and memory. Experimental Brain Research, 206(2), 109–120. doi:10.1007/s00221-010-2168-8.
Harris, M. A., Wiener, J. M., & Wolbers, T. (2011). Aging specifically impairs switching to an allocentric navigational strategy. Frontiers in aging neuroscience, 4, 29. doi:10.3389/fnagi.20120.00029.
Harris, M. A., & Wolbers, T. (2013). How age-related strategy switching deficits affect wayfinding in complex environments. Neurobiology of Aging,. doi:10.1016/j.neurobiolaging.2013.100.086.
Herman, J. F., & Coyne, A. C. (1980). Mental manipulation of spatial information in young and elderly adults. Developmental Psychology, 16(5), 537. doi:10.1037/0012-1649.16.5.537.
Hort, J., Laczo, J., Vyhnalek, M., Bojar, M., Bures, J., & Vlcek, K. (2007). Spatial navigation deficit in amnestic mild cognitive impairment. Proceeding of the National Academyof Sciences, 104(10), 4042–4047. doi:10.1073/pnas0.0611314104.
Huttenlocher, J., & Presson, C. C. (1979). The coding and transformation of spatial information. Cognitive Psychology, 11(3), 375–394. doi:10.1016/0010-0285(79)90017-3.
Iachini, T., Ruggiero, G., & Ruotolo, F. (2009). The effect of age on egocentric and allocentric spatial frames of reference. Cognitive Processing, 10(2), S222–S224. doi:10.1007/s10339-009-0276-9.
Iaria, G., Palermo, L., Committeri, G., & Barton, J. J. (2009). Age differences in the formation and use of cognitive maps. Behavioural Brain Research, 196(2), 187–191. doi:10.1016/j.bbr.20080.080.040.
Inagaki, H., Meguro, K., Shimada, M., Ishizaki, J., Okuzumi, H., & Yamadori, A. (2002). Discrepancy between mental rotation and perspective-taking abilities in normal aging assessed by Piaget’s Three-mountain task. Journal of Clinical and Experimental Neuropsychology, 24(1), 18–25. doi:10.1076/jcen.24.1.18.969.
Jenkins, L., Myerson, J., Joerding, J. A., & Hale, S. (2000). Converging evidence that visuospatial cognition is more age-sensitive than verbal cognition. Psychology and Aging, 15(1), 157–175. doi:10.1037/0882-7974.15.1.157.
King, J. A., Burgess, N., Hartley, T., Vargha-Khadem, F., & O’Keefe, J. (2002). Human hippocampus and viewpoint dependence in spatial memory. Hippocampus, 12(6), 811–820.
Lemay, M., Bertram, C. P., & Stelmach, G. E. (2004). Pointing to an allocentric and egocentric remembered target in younger and older adults. Experimental Aging Research, 30(4), 391–406. doi:10.1080/03610730490484443.
Meulenbroek, O., Petersson, K. M., Voermans, N., Weber, B., & Fernandez, G. (2004). Age differences in neural correlates of route encoding and route recognition. Neuroimage, 22(4), 1503–1514. doi:10.1016/j.neuroimage.20040.040.007.
Moffat, S. D. (2009). Aging and spatial navigation: what do we know and where do we go? Neuropsycholy Review, 19(4), 478–489. doi:10.1007/s11065-009-9120-3.
Moffat, S. D., Elkins, W., & Resnick, S. M. (2006). Age differences in the neural systems supporting human allocentric spatial navigation. Neurobiology of Aging, 27(7), 965–972. doi:10.1016/j.neurobiolaging.20050.050.011.
Moffat, S. D., Kennedy, K. M., Rodrigue, K. M., & Raz, N. (2007). Extrahippocampal contributions to age differences in human spatial navigation. Cerebral Cortex, 17(6), 1274–1282. doi:10.1093/cercor/bhl036.
Moffat, S. D., & Resnick, S. M. (2002). Effects of age on virtual environment place navigation and allocentric cognitive mapping. Behavioral Neuroscience, 116(5), 851–859. doi:10.1037/0735-7044.116.5.851.
Moffat, S. D., Zonderman, A. B., & Resnick, S. M. (2001). Age differences in spatial memory in a virtual environment navigation task. Neurobiology of Aging, 22(5), 787–796. doi:10.1016/S0197-4580(01)00251-2.
Oldfield, R. C. (1971). The assessment and analysis of handedness: the Edinburgh inventory. Neuropsychologia, 9(1), 97–113. doi:10.1016/0028-3932(71)90067-4.
Palermo, L., Iaria, G., & Guariglia, C. (2008). Mental imagery skills and topographical orientation in humans: a correlation study. Behavioural Brain Research, 192(2), 248–253. doi:10.1016/j.bbr.20080.040.014.
Parkin, A. J., Walter, B. M., & Hunkin, N. M. (1995). Relationships between normal ageing, frontal lobe function, and memory for temporal and spatial information. Neuropsychology, 9, 304–312. doi:10.1016/S0028-3932(96)00073-5.
Piaget, J. (1960). The Psychology of Intelligence. Totowa: Littlefield, Adams.
Piaget, J. (1973). The child and reality: Problems of genetic psychology. New York: Grossman.
Piaget, J., & Inhelder, B. (1956). The child’s concept of space. New York: Humanities Pr.
Reisberg, B., Franssen, E. H., Hasan, S. M., Monteiro, I., Boksay, I., Souren, L. E., et al. (1999). Retrogenesis: clinical, physiologic, and pathologic mechanisms in brain aging, Alzheimer’s and other dementing processes. European Archives of Psychiatry and Clinical Neuroscience, 249(3), 28–36.
Reisberg, B., Franssen, E. H., Souren, L. E., Auer, S. R., Akram, I., & Kenowsky, S. (2002). Evidence and mechanisms of retrogenesis in Alzheimer’s and other dementias: management and treatment import. American journal of Alzheimer’s disease and other dementias, 17(4), 202–212.
Rogalski, E., Stebbins, G. T., Barnes, C. A., Murphy, C. M., Stoub, T. R., George, S., et al. (2012). Age-related changes in parahippocampal white matter integrity: a diffusion tensor imaging study. Neuropsychologia, 50(8), 1759–1765. doi:10.1016/j.neuropsychologia.20120.030.033.
Save, E., & Poucet, B. (2000). Hippocampal-parietal cortical interactions in spatial cognition. Hippocampus, 10(4), 491–499.
Stanislaw, H., & Todorov, N. (1999). Calculation of signal detection theory measures. Behavior Research Methods Instruments and Computers, 31(1), 137–149. doi:10.3758/BF03207704.
Stricker, N. H., Schweinsburg, B. C., Delano-Wood, L., Wierenga, C. E., Bangen, K. J., Haaland, K. Y., et al. (2009). Decreased white matter integrity in late-myelinating fiber pathways in Alzheimer’s disease supports retrogenesis. Neuroimage, 45(1), 10–16. doi:10.1016/j.neuroimage.2008.110.027.
Sugovic, M., & Witt, J. K. (2013). An older view on distance perception: older adults perceive walkable extents as farther. Experimental Brain Research, 226(3), 383–391. doi:10.1007/s00221-013-3447-y.
Sulpizio, V., Committeri, G., Lambrey, S., Berthoz, A., & Galati, G. (2013). Selective role of lingual/parahippocampal gyrus and retrosplenial complex in spatial memory across viewpoint changes relative to the environmental reference frame. Behavioural Brain Research, 242, 62–75. doi:10.1016/j.bbr.2012.120.031.
Wiener, J. M., de Condappa, O., Harris, M. A., & Wolbers, T. (2013). Maladaptive bias for extrahippocampal navigation strategies in aging humans. The Journal of Neuroscience, 33(14), 6012–6017. doi:10.1523/JNEUROSCI0.0717-12.2013.
Wolbers, T., Dudchenko, P. A., & Wood, E. R. (2014). Spatial memory—a unique window into healthy and pathological aging. Frontiers in aging neuroscience, 6, 35. doi:10.3389/fnagi.20140.00035.
Acknowledgments
The work was supported by University G. d’Annunzio grants to GC and by grants from Italian Ministry 1071 of Health – Fondazione Santa Lucia (RC2008-2009) to GG.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Montefinese, M., Sulpizio, V., Galati, G. et al. Age-related effects on spatial memory across viewpoint changes relative to different reference frames. Psychological Research 79, 687–697 (2015). https://doi.org/10.1007/s00426-014-0598-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00426-014-0598-9