
Abstract
The influence of movement kinematics on the accuracy of predicting the time course of another individual’s actions was studied. A human point-light shape was animated with human movement (natural condition) and with artificial movement that was more uniform regarding velocity profiles and trajectories (artificial condition). During brief occlusions, the participants predicted the actions in order to judge after occlusion whether the actions were continued coherently in time or shifted to an earlier or later frame. Error rates and reaction times were increased in the artificial compared to the natural condition. The findings suggest a perceptual advantage for movement with a human velocity profile, corresponding to the notion of a close interaction between observed and executed movement. The results are discussed in the framework of the simulation account and alternative interpretations are provided on the basis of correlations between the velocity profiles of natural and artificial movements with prediction performance.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
In the present article, we take a closer look at the ability to predict full-body movement of a character with human shape but non-human movement kinematics. We are interested in action prediction on the kinematic level (see Grafton and Hamilton, 2007 for different levels to describe action), which implies predicting the course of a movement in space and time rather than predicting its goals or the intentions of the agent. Action prediction on the kinematic level is essential in the context of complementary interaction. For instance, a handshake can only be successful if both partners engage in prediction to arrive simultaneously at the appropriate location. Would they be equally effective when shaking hands with a virtual character in a computer animation?
On the kinematic level, certain regularities have been found to characterise human movement kinematics (Viviani & Flash, 1995). More specifically, human movement tends to smoothness (minimum jerk; Flash & Hogan, 1985) and exhibits a typical relation between the curvature of the movement trajectory and the velocity described in the so called “two-third power law” (Lacquaniti, Terzuolo, & Viviani, 1983). This general rule applies to various kinds of human movement such as pointing (Lacquaniti et al., 1983), locomotion in space, as an example of full-body movement (Hicheur, Vieilledent, Richardson, Flash, & Berthoz, 2005) and foot movement during walking (Ivanenko, Grasso, Macellari, & Lacquaniti, 2002).
The present study investigated how individuals use kinematic information to predict the course of an action observed in another individual. To examine this issue, we used videos of human actions in which kinematic laws were violated by manipulating the velocity profiles of natural human movements. These ‘artificial’ actions were then compared to the natural versions of the same actions in an action prediction task. The prediction of natural human actions was shown to be highly accurate even when no perceptual information is available during brief occlusions of the observed action (Graf et al., 2007; Springer & Prinz, 2010; Sparenberg, Springer, & Prinz, 2011). In these studies, action sequences (e.g., picking up an object) were presented as point-light animations (Johansson, 1973) and were briefly occluded for a few hundred milliseconds. After the occlusion, a static frame was presented depicting either a time-coherent or a time-incoherent continuation of the action (Sparenberg et al., 2011). Observers were highly accurate in discriminating time-coherent from time-incoherent continuations, suggesting the use of internal motor programs in a simulation mode (Sparenberg et al., 2011). Specifically, solving the prediction task requires observers to internally generate a continuation of the occluded action sequence in real time and to match its outcome to the actual test stimulus shown after an occlusion.
It is in favour of the real-time simulation account that action prediction failed when point-light characters were presented upside-down (Graf et al., 2007; Sparenberg et al., 2011). Here, the agent moves in a way in which observers have no motor experience. Together with many other studies, these findings point to the influence of motor expertise on the perception of human action. Specifically, movements that are in the observer’s motor repertoire seem to have perceptual advantages (e.g., in detection and discrimination tasks) over movements that the observer is not able to perform (e.g., Viviani & Stucchi, 1992; Shiffrar & Pinto, 2002; Loula, Prasad, Harber, & Shiffrar, 2005; Casile & Giese, 2006). This corresponds to the idea of motor simulation (Gallese & Goldman, 1998; Jeannerod, 2001) implying that motor programs are activated during the perception, imagination and prediction of movement.
The involvement of motor programs in action prediction has been corroborated by brain imaging studies that show increased activation in the motor system, when observers predict upcoming human movements (Kilner, Vargas, Duval, Blakemore, & Sirigu, 2004) or occluded full-body actions (Stadler et al., 2011). Correspondingly, earlier findings in the monkey have demonstrated the activation of mirror neurons during the occlusion of the relevant part of an observed action (Umiltà et al., 2001). Thus, a body of evidence supports the notion that action prediction employs functions that originate from predicting the sensory consequences of our own actions (Blakemore & Decety, 2001; Wolpert & Flanagan, 2001; Kilner, Friston, & Frith, 2007; Schippers & Keysers, 2011). As a consequence, observers should be most precise in predicting particularly those actions that they are able to perform themselves. Several imaging studies that compared the observation of human to non-human actions or movement experts (e.g., athletes) to non-experts support this assumption, indicating stronger motor system activation during the perception of actions that are in the observer’s own motor repertoire (Calvo-Merino, Grezes, Glaser, Passingham, & Haggard, 2006; Cross, Hamilton, & Grafton, 2006; Buccino et al. 2004). Recently, it has been shown that movement obeying human kinematic laws activated the action observation network, including the motor system, more strongly than movement with an altered velocity–trajectory coupling (Dayan et al., 2007; Casile et al., 2010).
The current study aimed to examine the influence of human movement kinematics on action prediction. We tested the hypothesis that observers predict human movement more accurately than non-human movement. This expectation can be inferred from the assumption that predictive functions implemented in motor control are used for predicting the movement of other individuals. Human but not non-human movement is commensurate with events that can be produced in the motor system (Prinz, 1997). However, comparisons between human and non-human movement have the general problem of an asymmetry in visual experience. This means that alternatives to the simulation account have to be considered to explain differences in prediction performance.
In a modified version of the occluder paradigm described above (Graf et al., 2007), point-light actions (as obtained in motion capture recordings) were presented either with natural or with artificial movement kinematics (i.e., natural and artificial condition). To generate artificial versions, the velocity variations typical of human movement were reduced, and the trajectories of the constituent point-light dots were linearized (see “Methods”), producing movement that looked more jerky (see animated examples in supplementary material). Importantly, the artificial movement differed from the natural movement in terms of kinematics while its complexity (determined by the articulated shape), its duration and its path remained unchanged. In other words, the artificial agent had the same human shape that still moved “human-like” to perform actions that humans would perform. The actions were occluded at a given frame for 400 ms (Fig. 1). After an occlusion, the animation was resumed immediately and either continued with coherent timing or from an earlier or later frame in the action sequence. The participants’ task was to discriminate time-coherent continuations from incoherent continuations by pressing one of two response buttons. To test how and when (during which period in the trial) kinematics influenced the performance in the prediction task, the difference between the velocity profiles of natural and artificial movements was compared with the differences in prediction errors in a correlation analysis.

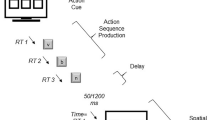
The occluder paradigm. Point-light characters were animated with natural and artificial movement. The duration from the start of the animation until occluder presentation varied between the actions. After an occlusion the animation continued immediately. The action was resumed either with coherent timing or at a frame that was earlier (“too early”) or later (“too late”) in the unfolding action sequence. Participants indicated by button-press whether the action continuation was time-coherent or not
Methods
Participants
20 healthy young adults (10 female; mean age 25.5 ± 2.4 years, range 19–31) gave their informed consent and were paid for participating in the experiment. One male participant misunderstood the instructions and was not included in the analyses. Thus, only 19 participants were in the final sample.
Stimuli
Seven different actions (playing basketball, lifting an object from the floor, getting up from kneeing, getting up from sitting on the floor, jumping, bowling, tennis-forehand) were presented as point-light animations (Johansson, 1973) without showing the objects that were involved in the actions. The points were animated with motion capture recordings of a male right-handed agent (Vicon 612 motion capture system, Vicon Motion Systems Ltd, Oxford, UK). The 3-D positions of 41 reflecting markers were recorded using seven infrared cameras positioned around a space of 10 × 6 m at a temporal sampling rate of 120 Hz (for further details see Graf et al., 2007). After pre-processing of marker trajectories and fitting a kinematic model to the individual actions, marker trajectories were averaged resulting in 13 displayed markers. Marker positions represented the major joints of the agent’s body (shoulders, elbows, wrists, knees and ankles) and the centre of the head, the sternum and the pelvis. Participants were seated at a distance of 64 cm in front of a computer monitor. The displayed dots were 2 mm in diameter (visual angle of 10.8 min), and were black on a light grey background. The azimuth was determined for each action individually, such that the main direction of each movement was towards the right side of the visual field. The point-light character was about 7 cm in height (visual angle of 6.2°) and moved within an area of 340 pixels width and 312 pixels height (about 12 × 11 cm, corresponding to a visual angle of 10.6° × 9.8°) in the centre of the screen. The animations lasted between 3,901 and 2,067 ms (mean 2,863 ± 640 ms), and were presented at a rate of 30 frames per second.
Non-human actions
To generate a non-human version of each natural action, the velocity and trajectory patterns of the original movement were manipulated such that the agent moved with constant velocity on a linearized trajectory between predefined key-frames. The manipulations of the natural movement that were applied to generate the artificial stimuli violated the kinematic laws of biological movement (e.g., Viviani & Flash, 1995). However, due to the complexity of the movement, the correspondence of the original movement with the two-third power law could not be documented and consequently the exact deviations of the typical dependency between velocity and path curvature are not described here. Compared to other studies that manipulated the velocity profile of only one point (e.g., de’Sperati & Viviani, 1997; Pozzo, Papaxanthis, Petit, Schweighofer, & Stucchi, 2006; Press, Cook, Blakemore, & Kilner, 2011), the method used here to reduce human movement characteristics was more superficial. The velocity was averaged between key-frames separately for all 13 points of the original data. However, the key-frames were the same for all 13 points and thus key-frame selection was not adjusted to the velocity profile of individual points. Key-frames were set at the frame that revealed minimum frame-to-frame change in point coordinates (i.e., minimum point velocity) within a search interval of 1,000 ms. The velocity of each point was integrated in 3D space to produce the total distance travelled by each point between any given two frames. The mean distance travelled between two frames was computed by averaging the total distances across all 13 points. After selecting a key-frame in this way, the search interval was moved to start at the frame after the last selected key-frame. Considering that the velocity is minimal at the end of a movement segment (Lacquaniti et al., 1983), we used this method to place the key-frames roughly at the borders between movement segments. After having determined all key-frames, the average velocity within each interval between two key-frames was obtained for each point separately (at 120 Hz sampling rate). In the new manipulated data set, the velocity of the movement between two key-frames was changed for each point such that it corresponded to the average velocity obtained for the respective interval (see Fig. 2).

Natural and artificial velocity profiles in an exemplary action. The black curve represents the natural velocity profile and the dashed curve the artificial velocity profile of the right hand point over the course of an entire action sequence of 67 frames (abscissa). This example shows the jumping action (provided as a video-clip in supplementary material)
To conserve the configural information of the point-light character while changing its velocity, the movement trajectories were also changed. Therefore, the point coordinates in the key-frames were kept from the original data and new coordinates were interpolated for the frames between two key-frames, such that the frame-to-frame distances travelled on the new trajectory corresponded to the average velocity. The new coordinates described a trajectory that was the most direct route between the coordinates in key-frame A and key-frame B. As a consequence of these manipulations, each point moved with constant speed on a linear trajectory between key-frame A and key-frame B. The velocity could then change between key-frame B and key-frame C to the average velocity that was obtained for this following interval. With these manipulations, we aimed for a reduction of typical human velocity characteristics and deviations from a linear trajectory (e.g., as described in the minimum jerk model and in the two-third power law; Viviani & Flash, 1995). The described method can be taken as the reverse of computer animation procedures. In character animation, movement is interpolated by animation software between key-frames that show postures of a static body that are predefined by the animator (e.g., see Chaminade, Hodgins, & Kawato, 2007).
Design and procedure
The point-light actions were occluded at a predefined position, which was kept constant over the repetitions of the actions (Fig. 1). An occluder corresponding in size to the field in which the point-light character moved (340 × 312 pixels) was rendered in light grey with a green frame. Action occlusions lasted for 400 ms, corresponding to one of three durations used in earlier applications of the occluder paradigm (Graf et al., 2007; Springer & Prinz, 2010). In these studies, the overall prediction accuracy was best with an occluder duration of 400 ms. On average, occlusions were presented 1,663 ± 640 ms (range 867–2,700 ms) after the start of an animation, giving the observers’ time to familiarize with the current action. Immediately after an occlusion, the action continued as an animation that lasted for 500 ms. Continuations either resumed at a frame that corresponded to a time-coherent continuation of the action (i.e., 400 ms after the last frame before occlusion) or at a frame too early or too late in the action sequence. The participants were instructed to judge whether the action in each trial was continued coherently in time after an occlusion. One-third of all trials were time-coherent, two-thirds of the trials contained time-incoherent continuations with a time-shift of ±300 ms from the time-coherent continuation. In half of the time-incoherent trials, the action continuation was too early (100 ms after the last visible frame before occlusion). In the other half it was too late (700 ms after the last visible frame before occlusion). Similar time-shifts were used in earlier studies (Graf et al., 2007; Springer & Prinz, 2010). Each of the 14 animations (i.e., natural and artificial versions of the seven actions) was presented 7 times with each of the three possible temporal continuations (too early, coherent or too late), all randomized. This resulted in a total trial number of 294 trials and in 36 min duration of the test-phase. The responses were given as fast as possible after an occlusion with the index fingers of the right and left hand on the right and left cursor k of a PC-keyboard.
The experiment started with a familiarization phase in which the participants watched the human and the artificial version of each action fully, without occlusions. In a subsequent practice, phase participants trained the experimental tasks and received feedback about their performance. In the test phase, the tasks were performed without feedback and responses were registered. For stimulus presentation and response registration the software Presentation (Neurobehavioral SystemsTM, Albany, CA, USA) was used.
Movement analysis
From the 2D coordinates, the velocity was computed for the right hand point and for the sternum point over the whole set of frames in each animation (vxy = sqrt (vx² + vy²)). The right hand point was the point exhibiting peak maxima in local velocity in all actions (except in one in which it was the second most active point). The sternum point was taken to represent the displacement of the whole body in space (translational movement). Three intervals of interest were determined: (1) 400 ms prior to occluder-onset, (2) 400 ms during occlusion and (3) 400 ms after occluder-offset. For each interval, the standard deviation of the mean velocity (vstdev) was obtained. The standard deviation of the mean velocity (vstdev) was taken to point to the amount of velocity variation within an interval, which should constitute a core difference between the natural and the artificial velocity profiles. Thus, velocity changes (that occurred for instance after key-frames) were reflected in vstdev.
To relate the differences in the velocity profiles between the artificial and the natural condition to the differences in error rates, vstdev obtained for natural movement was subtracted from vstdev obtained for artificial movement. Differences were obtained separately for the three intervals before, during and after occlusion. This resulted in three measures of velocity difference (vstdev (artificial) minus vstdev (natural) for the three intervals).
Statistical analysis
In the first place, the influence of natural versus artificial movement kinematics on the accuracy to predict human actions should be tested. Seven rather different full-body actions were employed with the aim to picture an envelope of the human body in action. Choosing a broad range of actions, from highly dynamic sports actions (e.g., basketball) to more static everyday actions (e.g., picking-up an object) resulted in a stimulus set that was inhomogeneous regarding (besides dynamicity) also some other aspects such as object directedness, perspective (frontal or side view) or interactivity. To average out such unsystematic differences, the error rates and reaction times (RT) were collapsed over the seven actions that were used in each condition. Two repeated measures ANOVAs (2 × 3) were then used to test for significance of the effects of kinematics (natural vs. artificial) and time-shifts (slow, coherent, fast) on the two dependent variables error rate and reaction time (RT).
Effect sizes were calculated as eta squared (η2) values. For post hoc pair-wise comparisons between factor levels, t tests (2-tailed) were used. Bonferroni corrections for multiple comparisons were applied when necessary.
To investigate whether the velocity profiles could explain differences between natural and artificial movements, between condition differences in the standard deviations of the mean velocity (vstdev) were correlated with the between condition differences in error rates (Pearson, 2-tailed). The error rates were averaged over the participants and correlations were computed over the seven actions. For two of the 13 points, the right hand point and the sternum point, between condition differences in vstdev for the 3 intervals (before, during, after occlusion) were correlated with 3 behavioural measures (between condition differences in error rates for too early, coherent and too late continuations).
Results
Error rates
Two sided t tests were used to compare the percentage of correct responses within each condition (natural and artificial) to the chance level of 50 %. To obtain one value per condition, the response rates were collapsed over the three time-shifts. Performance differed significantly from chance level in both conditions (ps < 0.01).
Error rates were collapsed over the individual actions to investigate the general influence of whole-body movement kinematics on action prediction in a two-way ANOVA with the factors kinematics and time-shift. In Fig. 3, error rates are shown for the two movement kinematics and for the three time-shifts (slow, coherent and fast). The error rates were higher for artificial movement than for natural movement as expressed in a significant main effect of the factor kinematics (F(1,18) = 48.87, p < 0.001, η2 = 0.11). Moreover, the interaction between kinematics and time-shift was significant (F(2,36) = 11.39, p < 0.001, η2 = 0.03), resulting from a larger difference between natural and artificial kinematics in coherent and too late trials. Corresponding post hoc pair-wise comparisons (t tests) revealed significant differences between natural and artificial movement in coherent (t(18) = −4.76, p < 0.01) and too late (t(18) = −8.38, p < 0.01) time-shifts.

Error rates for slow, coherent and fast continuations compared between natural and artificial movement. Mean error rates are shown for natural kinematics (grey) and for artificial kinematics (white). Black bars indicate standard errors) ** p < 0.01
To test whether the main effect and the interaction persist when considering the factor action (7 levels) in addition to kinematics and time-shift, a three-way ANOVA (7 × 2 × 3) was carried out. It revealed similar effects as the two-way ANOVA: a main effect of kinematics (F(1,18) = 48.98, p < 0.001, η2 = 0.04), interaction between kinematics and time-shift (F(2,36) = 11.34, p < 0.001, η2 = 0.01) in addition to an interaction between action and time-shift (F(12,216) = 6.96, p < 0.001, η2 = 0.08) and a three-way interaction (F(12,216) = 8.31, p < 0.001, η2 = 0.06). No main effect of action was found (F(6,108) = 1.74, p = 0.12, η2 = 0.01), indicating that individual actions had no overall positive or negative impact on prediction accuracy. However, the interactions definitely point to an influence of action specific parameters on prediction, depending on the observed timing.
As explained in the Methods section, we did not intend to investigate the effects of individual actions and their particular characteristics in the present study. In correspondence with the main hypothesis, only differences between the actions regarding the movement velocity in particular phases of a trial were addressed in a correlation analysis (presented here after).
Reaction times
In a two-way ANOVA that was carried out for RT, a main effect of kinematics (F(1,18) = 49.54, p < 0.001, η2 = 0.05) and a significant interaction between kinematics and time-shift (F(2,36) = 6.75, p < 0.01, η2 = 0. 04) were found (Fig. 4). In addition, the factor time shift had a main effect on RT (F(2,36) = 9.35, p < 0.01, η2 = 0.27) resulting from a decrease in RT from too early to too late trials. Post hoc pairwise comparisons (t tests) yielded significant RT differences between natural and artificial kinematics for too early (t(18) = −3.16, p < 0.05) and for too late (t(18) = −5.14, p < 0.01) time-shifts.

Reaction times for slow, coherent and fast continuations compared between natural and artificial movement. Mean reaction times (RT) are shown for natural kinematics (grey) and for artificial kinematics (white). Black bars indicate standard errors) ** p < 0.01
Correlations between error rates and the velocity of the right hand and the sternum
Figure 5 shows the relations between differences in vstdev and differences in error rates for the right hand point and for the sternum point. For the right hand point, the difference in vstdev between natural and artificial kinematics that was obtained for the occluder interval correlated significantly with the difference in error rates in time-coherent trials ((vstdev (artificial) − (vstdev (natural)) × (error rate (artificial) − error rate (natural)) (r = −.81, p < 0.05, n = 7)). The negative correlation suggests that the more constant the velocity was in the artificial condition (i.e., the lower the variation in the artificial compared to the natural condition), the higher was the number of misses (time-coherent trials judged as incoherent). This effect resulted to a large extent from actions that exhibited a high and variable velocity during occlusion in the natural condition that was strongly flattened in the artificial movement. The differences in vstdev in the right hand point obtained for the intervals before and after occlusion did not correlate with differences in error rates and no significant correlations were found for too early and too late trials.

Relation between velocity and error rates. Differences in velocity between natural and artificial movement kinematics correlated with differences in error rates in the prediction task. Graphs show results for a the right hand point and b the sternum point. In both graphs, the points represent the seven single actions. The differences in vstdev, the standard deviation of the mean velocity (artificial minus natural) are shown on the abscissa. The differences in error rates (artificial minus natural) are shown on the ordinate. Negative values resulted from higher values in the natural condition than in the artificial condition (notice that this is frequent for vstdev and rare for error rates). a Right hand point: the differences in vstdev are shown for the interval during occlusion. The differences in error rates are shown for the coherent trials. In the right hand point, only these values correlated significantly. The error rates in the artificial condition increased with low variation in velocity during occlusion. b Sternum point: the differences in vstdev are shown for the interval after occlusion. The differences in error rates are shown for the too late trials. In the sternum point, only these values correlated significantly. The lower the variation in velocity was after occlusion in the artificial condition (compared to the natural condition) the higher were the error-rates (too late continuations judged as coherent)
For the sternum point, the difference in vstdev between natural and artificial kinematics that was obtained for the interval after occlusion correlated significantly with error rates in the too late trials ((vstdev (artificial) − (vstdev (natural)) × (error rate (artificial) − error rate (natural)) (r = −0.83, p < 0.05, n = 7). The negative correlation suggests that the error rates increased with more constant velocity in artificial trials compared to natural trials. Here, too late continuations were erroneously judged as coherent continuations. The velocity measures obtained in the sternum point for the intervals before and during occlusion did not correlate with differences in error rates and no significant correlations were found for the error rates in too early and time-coherent trials.
Discussion
We examined whether the accuracy to predict the time course of briefly occluded full-body actions is affected by the movement kinematics of the observed agent. Accuracy in an action prediction task was compared between non-human kinematics and natural human kinematics (artificial vs. natural condition). According to the simulation account (Gallese & Goldman, 1998; Jeannerod, 2001) and to the principle of common representational codes for produced and perceived actions (Prinz, 1997; Hommel, Müsseler, Aschersleben, & Prinz, 2001), action prediction was expected to be impaired when the predicted movement was not commensurate with the observer’s motor repertoire. As hypothesized, prediction accuracy was significantly decreased in the artificial condition compared to the natural condition. In line with the simulation account, this finding suggests that the observers simulated the occluded actions in their own motor system to solve the prediction task. Accordingly, the simulated movement was commensurate with the observed natural kinematics but not with the artificial kinematics, leading to less accurate prediction in the artificial condition.
Importantly, the present results suggest that simulation is not the only function involved in predicting occluded actions. First, visual extrapolation may play a role (as explained below). Second, the natural and artificial conditions of the present study were not matched with respect to visual experience. Thus, the results might also reflect an asymmetry in visual familiarity. It is a general problem of comparisons between human and non-human stimuli that lifelong visual experience with human movement can hardly be levelled out by the exposure to computer animations or by the brief familiarisation with the stimulus material in the beginning of an experiment. To get an impression of the role of motor experience for movement perception relative to visual experience, earlier studies have to be taken into consideration (e.g., Aglioti, Cesari, Romani, & Urgesi, 2008; Loula et al., 2005). For instance, expert athletes are more efficient in predicting observed movement than experienced observers (Aglioti et al., 2008). This difference is reflected in stronger motor system activation associated with motor expertise relative to visual familiarity (Calvo-Merino et al., 2006). The activation of the neural substrate of movement planning and execution during action observation (Gallese, Fadiga, Fogassi, & Rizzolatti, 1996; Kilner et al., 2004; Rizzolatti & Craighero, 2004) and prediction (Umiltà et al., 2001; Stadler et al., 2011) is evidence for common functions underlying the observation and production of movement. Moreover, convincing evidence for an effect of movement training on movement perception was provided by Casile and Giese (2006) showing that visual sensitivity increased after the training of a complex movement during which participants were blindfolded. Recently, visual training was found to increase the accuracy to predict complex human and non-human movement (Cross et al., 2011) highlighting the effectiveness of visual experience. To contrast the relative contributions of visual and motor experience, more direct comparisons between effects of controlled motor and visual training would be desirable in future studies (e.g., Cross, Kraemer, Hamilton, Kelley, & Grafton, 2009). With the present study, we cannot provide direct and self-contained support of the simulation account. Instead, it complements earlier findings (e.g., Viviani & Stucchi, 1992; de’Sperati & Viviani, 1997; Pozzo et al., 2006; outlined below), by pointing to perceptual advantages of human kinematics, using a direct test of internal real-time simulation.
The human shape of the point-light agent in the present study might have led observers to expect human movement dynamics (see Saygin and Stadler 2012). Thus, the artificial condition employed a highly familiar agent with an unfamiliar movement. Such a conflict is avoided when only one dot is presented that moves either with a biological or a non-biological velocity profile. Several behavioural and brain imaging studies used simple dots to compare movement with a biological velocity profile (i.e., with a coupling between velocity and path curvature that corresponds to the two-third power law) to movement with altered velocity and to constant velocity. These studies come to the conclusion that although non-biological movement is often physically simpler, human observers process such movement less sensitively. For instance, Pozzo et al. (2006) compared movement prediction between points that moved either biologically or with an altered velocity profile. The participants overestimated the end position of a point that moved behind an occluder considerably more, when it moved with non-human kinematics than when its movement corresponded to the kinematics of a human pointing movement (Pozzo et al., 2006). In a previous study by Viviani and Stucchi (1992), participants were required to adjust the velocity of a moving point until they perceived it to be constant. Interestingly, they adjusted the velocity of a constantly moving point more than that of a biological point. Thus, the biological movement that varied considerably in velocity was perceived as more uniform than the dot that actually moved with constant velocity. Similar advantages were found for eye movement that pursued a dot moving on an elliptic path (de’Sperati & Viviani, 1997), for predicting observed handwriting (Kandel, Orliaguet, & BoÎ, 2000), for the imitation of pointing movements (Bisio, Stucchi, Jacono, Fadiga, & Pozzo, 2010) and also when movement information is conveyed in the kinaesthetic modality (Viviani, Baud-Bovy, & Redolfi, 1997). Two recent studies compared brain activation induced by human and non-human movement kinematics (Dayan et al., 2007; Casile et al., 2010). The motor system and other regions in the action observation network were most efficiently activated when the observed movement had a velocity profile that obeyed the two-third power law compared to movement with altered velocity profiles. Participants in these studies either observed an animated human body drawing circles in the air (Casile et al., 2010) or moving dot clouds (Dayan et al., 2007). Moreover, the temporal variation of oscillatory encephalographic (EEG) activity recorded over the motor system points in a similar direction (Press et al., 2011): only movement with biological kinematics induced variations in β-rhythm suppression during action observation that corresponded to action production. Conversely, movement with constant velocity did not induce a comparable pattern.
The primary aim of the present study was to investigate the ability to explicitly predict full-blown action sequences performed with non-human kinematics. Therefore, more complex movements were used with a less fine-tuned manipulation of the natural velocity profile, compared to the studies discussed above. In correspondence to these studies, the present findings indicate that the prediction of full-body movement profits from human kinematics (corresponding to the observer’s own motor experience).
The effect that movement kinematics had on prediction was modulated by the time-shift of the continuation after occlusion. The differences in error rates between the natural and the artificial condition were highest in too late and smallest in too early time-shifts. Committing an error in too early or too late trials means erroneously judging time-incoherent action continuations as coherent. From the perspective of the real-time simulation account (Graf et al., 2007; Prinz & Rapinett, 2008; Sparenberg et al., 2011), judging too early continuations as time-coherent suggests that the occluded action was simulated too slowly. Conversely, perceiving too late continuations as time coherent points to simulation that is faster than real-time. It is discussed in the next section how the more constant velocity in the artificial condition may have contributed to the errors in too late continuations.
Differences between the conditions were also found in RT. Reaction times were longer in the artificial condition than in the natural condition. However, these differences were only found for the time-incoherent trials (too early and too late) and not for time-coherent trials. Reaction times generally decreased from too early to too late continuations. This main effect of timing relates to a study by Watanabe (2008) showing that the speed of observed biological movement influenced the response latencies in a reaction time task.
Correlations between velocity and error rate
To investigate how the differences between the velocity profiles of natural and artificial kinematics affected prediction accuracy, a correlation analysis was carried out. For the right hand point and for the sternum point, differences in the velocity profiles (more precisely, in the standard deviation of the mean velocity) between the two stimulus types were correlated with differences in error rates. The right hand point was chosen because it was the local motion with maximum velocity. The sternum point was taken to represent full body translational movement. Overall, the results of this analysis suggest that the more constant the velocity was in the artificial condition the higher were the error rates. The artificial velocity of the right hand affected task performance mainly during occlusion. For this effect, the simulation account would suggest the following interpretation. Time-coherent artificial trials were erroneously judged as incoherent when biological variability was simulated although the actual stimulus moved with constant velocity.
For the sternum point, a significant correlation was found for the interval after occlusion. Interestingly, only performance in too late continuations correlated with the velocity measures. The artificial velocity of the sternum point, hence, affected task performance during the matching of the predicted with the perceived continuation after occlusion. This correlation suggests that the decision process was influenced by the visual information perceived after occlusion. The rather long response latencies (over 1,300 ms) indeed suggest that observers evaluated several frames of the post-occluder action sequence before initiating a response. Due to the lack of a hypothesis for the meaning of this interval in the present task, an interpretation of these results is not obvious. However, it is tempting to come up with a speculation that may explain the bias to judge too late continuations as coherent in the artificial condition. During the interval after occlusion, the velocity in the natural condition decreased. This was contrasted by more or less constant velocity in the artificial condition. The lack of a velocity decrease could have induced the impression of a relatively fast movement in the artificial condition. Consequently, the observers might have concluded that the movement was actually faster than they had assumed during internal prediction. This affected their judgments particularly in too late continuations (in which the action had advanced too fast during occlusion), which they tended to judge as time-coherent. It makes sense that this effect was found for the sternum point which contained information about the agent’s translational movement. This underlines that information about general speed was deduced from full-body movement rather than from the local motion of the hand. This finding relates to recent evidence for the relevance of the post-occluder interval (Experiment 3; Parkinson et al., 2012). Parkinson and colleagues varied the amount of movement information that was presented after occlusion and found an influence on the participants’ judgments about the temporal action continuation.
The correlations further suggest that action simulation might have interacted with visual extrapolation in the present prediction task. The predominance of the respective function varied over the different phases in the trial and presumably was influenced by the perceived kinematics. In the following, we present evidence for simulation in a first step and in a second step, evidence for visual extrapolation.
First, the correlation obtained for the interval during occlusion points to simulation in the motor system. It suggests that in the artificial condition, the actions’ natural velocity profiles were simulated. Movement simulation resulted in a higher error rate due to the limited commensurability between observed and simulated movement. This finding may seem to contradict experiences from everyday life showing that we can coordinate well with artificial entities. However, only humans and possibly related species approach us with movement of comparable complexity. Our cognitive abilities might have adapted to the frequent exposure and relevance of human movement, leading for instance to the formation of specialized brain networks that underlie the integration of biological stimuli (e.g., Oram & Perrett 1996; Sarkheil, Vuong, Bulthoff, & Noppeney, 2008). Consequently, simulation in the motor system might have become the most appropriate solution for predicting the movement of an articulated body. For the current experiment, this means that the perception of a human body may have activated associated motor programs. Saygin and colleagues (2011) and Saygin and Stadler (2012) discuss in more detail how top-down expectancies induced by the agent’s appearance could influence action perception and prediction. They investigated differences in action prediction accuracy between a human agent, an android with a realistic human appearance (i.e., skin, hair, clothes etc.) and a robot. Interestingly, both artificial agents had exactly the same kinematics. The robot was the undressed machine that worked underneath the android. Notably, the performance in an action prediction task was highly similar between human and android which both differed from the robot. These data suggest that the shape of a stimulus can bias the prediction of its movement.
As a second process, visual extrapolation could have played a role in the present task. Particularly, the correlations of the error rates with kinematics in the post-occluder interval suggest that this function became increasingly involved when the movement was more constant and linear. This notion is supported by the strong tendency to judge too late continuations as coherent in artificial trials. Note that the movement in the artificial condition was physically simpler compared to the natural movement (as demonstrated in the analysis of velocity profiles). Thus, even higher prediction accuracy might be expected. More uniform and linear movement should allow extrapolating the occluded movement by integrating perceived movement information. Visual movement extrapolation was previously shown to be susceptible to overshoot (Hubbard, 2005 for a review). Mental extrapolation on a higher cognitive level can be influenced by many variables such as attention, internalized physical laws, stimulus animacy and the surrounding context and was shown to be error-prone (Hubbard, 2005). For instance, the term “representational momentum” refers to a tendency to over-extrapolation that results in a miss-localisation of the final position of a moving object ahead of its actual position in the direction of the movement (Hubbard, 2005). There is evidence for representational momentum also in point-light characters (Jarraya, Amorim, & Bardy, 2005). Here, we assume that over-extrapolation might have contributed to the errors in the artificial condition, when simulation was insufficient and when the linearity of the movement facilitated extrapolation. From a theoretical perspective, it is likely that predictive functions of the motor system interact with other (predictive) functions, and strategies (Nijhawan, 2008; Bubic, von Cramon, & Schubotz, 2010) for which those based on visual extrapolation may be an example.
Limitations and implications
For perceiving biological motion from a point-light display, the global integration of motion signals over space and time is required (Ahlstrom, Blake, & Ahlstrom, 1997). The correlation analysis performed here certainly has the limitation that it is far from meeting the level of complexity at which such stimuli are analysed in the brain (e.g., Oram & Perrett, 1996; Giese & Poggio, 2003). However, it emphasised the different time intervals (during and around occlusion) in which the stimulus velocity differentially influenced action prediction performance in this task (see also Parkinson et al., 2012).
Further, it is clearly a limitation that the agent–observer commensurability in movement kinematics is confounded with differences in stimulus physics. This is a confound that the present study shares with other studies investigating the perception of biological velocity profiles relative to altered (e.g., constant) velocity profiles. Higher scores that are observed for biological movement could be explained by the particular physical properties of these stimuli. Stimulus physics can provide more or less useful cues for prediction. For instance, patterns of acceleration and deceleration (that follow particular rules) make it more predictable when, e.g., an action segment is about to end. In contrast, constant velocity does not contain comparable cues. The correlations found here between velocity measures and the error rates provide some (although preliminary) evidence in favour of this alternative explanation. Note that these considerations are not specific to human movement. Similar advantages could be expected for the movement of inanimate objects that follows particular rules, as for instance the velocity profile of a pendulum. Altering the velocity profile of a pendulum should have similar consequences on predictability. Advantages for predicting movement with a biological velocity profile were also found when only a dot was presented (e.g., Pozzo et al., 2006).
To avoid confounds with stimulus physics when studying the influence of motor experience on visual movement perception, it would be useful to match the stimulus sets with respect to their velocity profiles. Another possibility is to present the same stimuli to groups of subjects that differ according to their expertise with the movements that they observe (Calvo-Merino et al., 2006; Casile & Giese, 2006; Cross et al., 2006). A study comparing the prediction of occluded figure skating moves between young and older experts and non-experts (Diersch et al., 2011) revealed an effect of expertise on real-time prediction accuracy. Another way to avoid that stimulus categories differ with respect to kinematic laws is to compare biological movement of non-human animals with human movement. The movement of related species such as dogs should follow related regularities, but in a spatio-temporal resolution that humans are not able to produce.
In summary, our results show that observed kinematics influence temporal judgements when predicting occluded full-body actions. Action prediction was more accurate when the agent moved with natural human relative to artificial kinematics. In contrast to artificial movement, natural kinematics are commensurate with the observer’s own movements. In the artificial condition, the observed point-light character had constant velocity and linear trajectories between key-frames. Due to the more uniform movement in this condition, over-extrapolation may have affected task performance, particularly when too late continuations after occlusions occurred (implying a faster progress relative to the actual action). Hence, the results indicate that the movement kinematics inherent in visually perceived actions affect the prediction of briefly occluded actions.
Regarding the increasing use of computer-animated movement, for instance, in work environments or in therapeutic settings (e.g., in neuro-rehabilitation), our findings highlight the importance of approaching human kinematics when designing virtual characters to provide an optimal and pleasant interaction with human users.
References
Aglioti, S., Cesari, P., Romani, M., & Urgesi, C. (2008). Action anticipation and motor resonance in elite basketball players. Nature Neuroscience, 11(9), 1109–1116.
Ahlstrom, V., Blake, R., & Ahlstrom, U. (1997). Perception of biological motion. Perception, 26(12), 1539–1548.
Bisio, A., Stucchi, N., Jacono, M., Fadiga, L., & Pozzo, T. (2010). Automatic versus voluntary motor imitation: effect of visual context and stimulus velocity. PLoS ONE, 5(10), e13506.
Blakemore, S. J., & Decety, J. (2001). From the perception of action to the understanding of intention. Nature Reviews Neuroscience, 2(8), 561–567.
Bubic, A., von Cramon, D., & Schubotz, R. (2010). Prediction, cognition and the brain. Frontiers in Human Neuroscience, 4, doi:0.3389/fnhum.2010.00025.
Buccino, G., Lui, F., Canessa, N., Patteri, I., Lagravinese, G., Benuzzi, F., et al. (2004). Neural circuits involved in the recognition of actions performed by nonconspecifics: an FMRI study. Journal of Cognitive Neuroscience, 16(1), 114–126.
Calvo-Merino, B., Grezes, J., Glaser, D. E., Passingham, R. E., & Haggard, P. (2006). Seeing or doing? Influence of visual and motor familiarity in action observation. Current Biology, 16(19), 1905–1910.
Casile, A., Dayan, E., Caggiano, V., Hendler, T., Flash, T., & Giese, M. A. (2010). Neuronal encoding of human kinematic invariants during action observation. Cerebral Cortex, 20(7), 1647–1655.
Casile, A., & Giese, M. A. (2006). Nonvisual motor training influences biological motion perception. Current Biology, 16(1), 69–74.
Chaminade, T., Hodgins, J., & Kawato, M. (2007). Anthropomorphism influences perception of computer-animated characters’ actions. Social Cognitive and Affective Neuroscience, 2(3), 206–216.
Cross, E. S., Hamilton, A. F., & Grafton, S. T. (2006). Building a motor simulation de novo: observation of dance by dancers. Neuroimage, 31(3), 1257–1267.
Cross, E., Kraemer, D., Hamilton, A., Kelley, W., & Grafton, S. (2009). Sensitivity of the action observation network to physical and observational learning. Cerebral Cortex, 19(2), 315–326.
Cross, E. S., Liepelt, R., Hamilton, A Fd C, Parkinson, J., Ramsey, R., Stadler, W., et al. (2011). Robotic movement preferentially engages the action observation network. Human Brain Mapping,. doi:10.1002/hbm.21361.
Dayan, E., Casile, A., Levit-Binnun, N., Giese, M., Hendler, T., & Flash, T. (2007). Neural representations of kinematic laws of motion: evidence for action-perception coupling. Proceedings of the National academy of Sciences of the United States of America, 104(51), 20582–20587.
De’Sperati, C., & Viviani, P. (1997). The relationship between curvature and velocity in two-dimensional smooth pursuit eye movements. Journal of Neuroscience, 17(10), 3932–3945.
Diersch, N., Cross, E. S., Stadler, W., Schütz-Bosbach, S., & Rieger, M. (2011). Representing others' actions: the role of expertise in the aging mind. Psychological Research. doi:10.1007/s00426-011-0404-x.
Flash, T., & Hogan, N. (1985). The coordination of arm movements—an experimentally confirmed mathematical model. Journal of Neuroscience, 5(7), 1688–1703.
Gallese, V., Fadiga, L., Fogassi, L., & Rizzolatti, G. (1996). Action recognition in the premotor cortex. Brain, 119(2), 593–609.
Gallese, V., & Goldman, A. (1998). Mirror neurons and the simulation theory of mind-reading. Trends in Cognitive Sciences, 2(12), 493–501.
Giese, M. A., & Poggio, T. (2003). Neural mechanisms for the recognition of biological movements. Nature Reviews Neuroscience, 4(3), 179–192.
Graf, M., Reitzner, B., Corves, C., Casile, A., Giese, M., & Prinz, W. (2007). Predicting point-light actions in real-time. Neuroimage, 36(Suppl 2), T22–T32.
Grafton, S., & Hamilton, A. (2007). Evidence for a distributed hierarchy of action representation in the brain. Human Movement Science, 26(4), 590–616.
Hicheur, H., Vieilledent, S., Richardson, M., Flash, T., & Berthoz, A. (2005). Velocity and curvature in human locomotion along complex curved paths: a comparison with hand movements. Experimental Brain Research, 162(2), 145–154.
Hommel, B., Müsseler, J., Aschersleben, G., & Prinz, W. (2001). The Theory of Event Coding (TEC): a framework for perception and action planning. Behavioral and Brain Sciences, 24(5), 849–878.
Hubbard, T. L. (2005). Representational momentum and related displacements in spatial memory: a review of the findings. Psychonomic Bulletin & Review, 12(5), 822–851.
Ivanenko, Y., Grasso, R., Macellari, V., & Lacquaniti, F. (2002). Control of foot trajectory in human locomotion: role of ground contact forces in simulated reduced gravity. Journal of Neurophysiology, 87(6), 3070–3089.
Jarraya, M., Amorim, M., & Bardy, B. (2005). Optical flow and viewpoint change modulate the perception and memorization of complex motion. Perception & Psychophysics, 67(6), 951–961.
Jeannerod, M. (2001). Neural simulation of action: a unifying mechanism for motor cognition. Neuroimage, 14(1), S103–S109.
Johansson, G. (1973). Visual perception of biological motion and a model for its analysis. Perception & Psychophysics, 14(2), 201–211.
Kandel, S., Orliaguet, J. P., & BoÎ, L. J. (2000). Detecting anticipatory events in handwriting movements. Perception, 29(8), 953–964.
Kilner, J., Friston, K., & Frith, C. (2007). Predictive coding: an account of the mirror neuron system. Cognitive Processing, 8(3), 159–166.
Kilner, J. M., Vargas, C., Duval, S., Blakemore, S. J., & Sirigu, A. (2004). Motor activation prior to observation of a predicted movement. Nature Neuroscience, 7(12), 1299–1301.
Lacquaniti, F., Terzuolo, C., & Viviani, P. (1983). The law relating the kinematic and figural aspects of drawing movements. Acta Psychologica, 54(1–3), 115–130.
Loula, F., Prasad, S., Harber, K., & Shiffrar, M. (2005). Recognizing people from their movement. Journal of Experimental Psychology—Human Perception and Performance, 31(1), 210–220.
Nijhawan, R. (2008). Visual prediction: psychophysics and neurophysiology of compensation for time delays. Behavioral and Brain Sciences, 31(2), 179–198.
Oram, M., & Perrett, D. (1996). Integration of form and motion in the anterior superior temporal polysensory area (STPa) of the macaque monkey. Journal of Neurophysiology, 76(1), 109–129.
Parkinson, J., Springer, A., & Prinz, W. (2012). Before, during and after you disappear: effects of timing and dynamic updating of the real-time action simulation of human motions. Psychological Research. doi:10.1007/s00426-012-0422-3.
Pozzo, T., Papaxanthis, C., Petit, J., Schweighofer, N., & Stucchi, N. (2006). Kinematic features of movement tunes perception and action coupling. Behavioural Brain Research, 169(1), 75–82.
Press, C., Cook, J., Blakemore, S. J., & Kilner, J. (2011). Dynamic modulation of human motor activity when observing actions. Journal of Neuroscience, 31(8), 2792–2800.
Prinz, W. (1997). Perception and action planning. European Journal of Cognitive Psychology, 9(2), 129–154.
Prinz, W., & Rapinett, G. (2008). Filling the gap: dynamic representation of occluded action. In F. Morganti, C. A. & G. Riva (Eds.), Enacting intersubjectivity: A cognitive and social perspective on the study of interactions (pp. 223-236). Amsterdam: IOS Press.
Rizzolatti, G., & Craighero, L. (2004). The mirror-neuron system. Annual Reviews in Neuroscience, 27, 169–192.
Sarkheil, P., Vuong, Q., Bulthoff, H., & Noppeney, U. (2008). The integration of higher order form and motion by the human brain. Neuroimage, 42(4), 1529–1536.
Saygin, A. P., & Stadler, W. (2012). The role of appearance and motion in action prediction. Psychological Research. doi:10.1007/s00426-012-0426-z.
Saygin, A. P., Chaminade, T., Ishiguro, H., Driver, J., & Frith, C. (2011). The thing that should not be: predictive coding and the uncanny valley in perceiving human and humanoid robot actions. Social Cognitive and Affective Neuroscience,. doi:10.1093/scan/nsr025.
Schippers, M. B., & Keysers, C. (2011). Mapping the flow of information within the putative mirror neuron system during gesture observation. Neuroimage, 57(1), 37–44.
Shiffrar, M., & Pinto, J. (2002). The visual analysis of bodily motion. In W. Prinz & B. Hommel (Eds.), Common mechanisms in perception and action. Oxford: Oxford University Press.
Sparenberg, P., Springer, A., & Prinz, W. (2011). Predicting others’ actions: evidence for a constant time delay in action simulation. Psychological Research, 76(1), 41–49.
Springer, A., & Prinz, W. (2010). Action semantics modulate action prediction. Quarterly Journal of Experimental Psychology, 63(11), 2141–2158.
Stadler, W., Schubotz, R., von Cramon, D., Springer, A., Graf, M., & Prinz, W. (2011). Predicting and memorizing observed action: differential premotor cortex involvement. Human Brain Mapping, 32(5), 677–687.
Umiltà, M. A., Kohler, E., Gallese, V., Fogassi, L., Fadiga, L., Keysers, C., et al. (2001). I know what you are doing? A neurophysiological study. Neuron, 31(1), 155–165.
Viviani, P., Baud-Bovy, G., & Redolfi, M. (1997). Perceiving and tracking kinesthetic stimuli: further evidence of motor-perceptual interactions. Journal of Experimental Psychology—Human Perception and Performance, 23(4), 1232–1252.
Viviani, P., & Flash, T. (1995). Minimum-Jerk, 2/3-power law, and isochrony—converging approaches to movement planning. Journal of Experimental Psychology—Human Perception and Performance, 21(1), 32–53.
Viviani, P., & Stucchi, N. (1992). Biological movements look uniform: evidence of motor-perceptual interactions. Journal of Experimental Psychology—Human Perception and Performance, 18(3), 603–623.
Watanabe, K. (2008). Behavioral speed contagion: automatic modulation of movement timing by observation of body movements. Cognition, 106(3), 1514–1524.
Wolpert, D., & Flanagan, J. (2001). Motor prediction. Current Biology, 20(11), R729–R732.
Acknowledgments
The authors would like to thank Marcus Daum, Erik Türke and Ulrike Riedel for lab assistance. We further thank Ferdinand Tusker for help with the movement analysis and Joachim Hermsdörfer for critical feedback. The first author is grateful to Deutsche Forschungsgemeinschaft (DFG) for financial support of this research (Project: STA 1076/1-1).
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article
Cite this article
Stadler, W., Springer, A., Parkinson, J. et al. Movement kinematics affect action prediction: comparing human to non-human point-light actions. Psychological Research 76, 395–406 (2012). https://doi.org/10.1007/s00426-012-0431-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00426-012-0431-2