
Abstract
The three-dimensional time-resolved Lagrangian particle tracking (3D TR-LPT) technique has recently advanced flow diagnostics by providing high spatiotemporal resolution measurements under the Lagrangian framework. To fully exploit its potential, accurate and robust data processing algorithms are needed. These algorithms are responsible for reconstructing particle trajectories, velocities, and differential quantities (e.g., pressure gradients, strain- and rotation-rate tensors, and coherent structures) from raw LPT data. In this paper, we propose a 3D divergence-free Lagrangian reconstruction method, where three foundation algorithms—constrained least squares (CLS), stable radial basis function (RBF-QR), and partition-of-unity method (PUM)—are integrated into one comprehensive reconstruction strategy. Our method, named CLS-RBF PUM, is able to (1) directly reconstruct flow fields at scattered data points, avoiding Lagrangian-to-Eulerian data conversions; (2) assimilate the flow diagnostics in Lagrangian and Eulerian descriptions to achieve high-accuracy reconstruction; (3) process large-scale LPT datasets with more than hundreds of thousand particles in two dimensions (2D) or 3D; (4) enable inter-frame and inter-particle interpolation while imposing physical constraints (e.g., divergence-free for incompressible flows) at arbitrary time and locations. Validation based on synthetic and experimental LPT data confirm that our method can achieve the above advantages with accuracy and robustness.
Graphical abstract

Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
The high seeding density three-dimensional Time-Resolved Lagrangian Particle Tracking (3D TR-LPT) is a powerful tool for high spatiotemporal resolution flow diagnostics (Schanz et al. 2016; Tan et al. 2020). This technique offers three major advantages in fluid experiments. First, the 3D TR-LPT works in the Lagrangian perspective, which is intuitive and allows for a heuristic interpretation of fluid flows. For example, one of the most famous early Lagrangian flow ‘diagnostics’ is perhaps tracking the movement of tea leaves in a stirred teacup, as elucidated by Einstein’s study on the tea leaf paradox (Einstein 1926; Bowker 1988). Second, the LPT technique, including 3D TR-LPT, facilitates trajectory-based measurements, providing insights into the history of the flows. By following the pathlines of tracer particles, one can recover the past and predict the future of the flows. For example, the LPT has been applied in particle residence time studies (Jeronimo et al. 2019; Zhang and Rival 2020), indoor airflow measurements to improve air quality (Biwole et al. 2009; Fu et al. 2015) and fluid mixing studies (Alberini et al. 2017; Romano et al. 2021). Third, the 3D TR-LPT technique excels at capturing transient and time-correlated flow structures. This feature is crucial for studying complex flows characterized by intricate evolution of the flow structures (e.g., Lagrangian coherent structures (Peng and Dabiri 2009; Wilson et al. 2009; Rosi et al. 2015; Onu et al. 2015) that are the ‘skeleton’ of fluid flows (Peacock and Haller 2013)).
However, processing the raw LPT data is not necessarily trivial for a few reasons. First, key flow quantities, including particle trajectories, velocities, and differential quantities (e.g., pressure gradients, strain- and rotation-rate tensors) are not directly available in raw data. Technically, the raw LPT data only consist of particle spatial coordinates as a time series and anything beyond those requires additional reconstruction. Second, the particle spatial coordinates in the raw data are often subject to measurement errors (Ouellette et al. 2006; Cierpka et al. 2013; Gesemann et al. 2016; Machicoane et al. 2017). Deviations between the true and measured particle locations are inevitable and can challenge the data processing and undermine reconstruction quality. Furthermore, (numerical) differentiation amplifies the noise present in the data when computing derivatives, leading to even noisier reconstructions without careful regularization. This effect is evident when reconstructing velocities and differential quantities. Third, the scattered and nonuniform distribution of LPT data makes it difficult to employ simple numerical schemes, such as finite difference methods, for calculating spatial derivatives. To address the above challenges, several methods have been proposed and we provide a brief summary below.
In the context of trajectory reconstruction, polynomials and basis splines (B-splines) are commonly used, with an order being second (Cierpka et al. 2013), third (Lüthi 2002; Cierpka et al. 2013; Gesemann et al. 2016; Schanz et al. 2016), or fourth (Ferrari and Rossi 2008). Typically, a least square regression is applied to mitigate the impact of noise in the particle coordinates (Lüthi 2002; Cierpka et al. 2013; Gesemann et al. 2016; Schanz et al. 2016). However, polynomials and B-splines may encounter the following difficulties. First, low-order functions cannot capture high-curvature trajectories, while high-order ones may be prone to numerical oscillations known as Runge’s phenomenon (Gautschi 2011). Second, developing self-adaptive schemes that can accommodate trajectories with varied curvatures is not a trivial task. In the existing methods, the same trajectory function with a fixed order is commonly used throughout the entire reconstruction, offering limited flexibility to approximate varied curvature trajectories. Third, achieving a high degree of smoothness with high-order polynomials becomes challenging when the number of frames is limited. For example, with four frames, the maximum attainable order of a polynomial is third. This implies that the particle acceleration varies linearly, and its jerk is a constant, which may not always be true.
Velocity reconstructions are commonly based on either finite difference methods or directly taking the temporal derivatives of trajectory functions (Lüthi 2002; Gesemann et al. 2016; Schanz et al. 2016). For instance, the first-order finite difference method (Malik and Dracos 1993) evaluates a particle’s velocity via dividing the particle displacement between two consecutive frames by the time interval. The finite difference methods rely on the assumption that a particle travels a near-straight pathline within a short time interval. However, when this assumption fails, it may lead to inaccurate reconstruction. On the other hand, a trajectory-based velocity reconstruction first approximates particle pathlines by a continuous function, and next, velocities are calculated from the rate of change of a particle’s location. However, similar to polynomial-based trajectory reconstruction, trajectory-based velocity reconstruction suffers from a lack of global smoothness, and the dilemma of selecting an appropriate order.
Methods for reconstructing differential quantities can be classified into meshless and mesh-based approaches. In mesh-based methods (e.g., Flowfit by Gesemann et al. (2016), Vortex-in-Cell+ by Schneiders and Scarano (2016), and Vortex-in-Cell# by Jeon et al. (2022)), Lagrangian data are first converted onto an Eulerian mesh and differential quantities are then computed on the mesh using finite difference methods or some data conversion functions. However, relying on data conversions not only deviates from the original purpose of LPT but could introduce additional computational errors. LPT data typically exhibit irregular particle distributions (e.g., the distances between the particles may significantly vary over the domain, in space and time), but the Eulerian meshes are often structured. This mismatch between the Lagrangian data and Eulerian mesh is a classic challenge in the approximation theory (Fasshauer 2007). In addition to the data conversion errors, mesh-based methods cannot directly evaluate differential quantities at the location of Lagrangian data. A typical solution is computing differential quantities at Eulerian meshes first and then interpolating Eulerian data back to the Lagrangian data points.
On the other hand, meshless methods avoid projecting Lagrangian data onto an Eulerian mesh and can directly reconstruct flow quantities at scattered LPT data points. These methods approximate velocity fields in each frame using continuous model functions, such as polynomials (Lüthi 2002; Takehara and Etoh 2017; Bobrov et al. 2021) and radial basis functions (RBFs, Sperotto et al. (2022); Li and Pan (2023)). Subsequently, the differential quantities are calculated based on the spatial derivatives of the velocity field. This approach is analogous to velocity reconstruction by taking the time derivative of the pathline.
The current mesh-based and meshless methods may face some difficulties. First, physical constraints may be absent in the reconstruction. The constraints can arise from some a priori knowledge about the fluid flow (e.g., velocity solenoidal conditions for incompressible flows and boundary conditions (Gesemann et al. 2016; Jeon et al. 2022; Sperotto et al. 2022; Li and Pan 2023)). Neglecting these physical constraints could produce unrealistic or inaccurate flow structures in the reconstruction. Second, processing large-scale LPT data can be computationally demanding and unstable. The computational complexity grows rapidly as the number of particles and frames increases, potentially straining computational resources and prolonging processing time. Some meshless methods, such as RBFs, may suffer from numerical instability when addressing a large number of data points without care being taken (Fornberg and Wright 2004; Fornberg et al. 2011). Third, the velocity field in each frame is sometimes described by low-order polynomials or B-splines. While these functions provide the simplicity of computation, they may not be suitable for accurately capturing highly nonlinear flows. Last but not least, the velocities calculated by the temporal derivatives of trajectories (in the Lagrangian perspective) are often decoupled from the velocity field reconstructed for each frame (in the Eulerian perspective). The former is derived from the definition of velocity, while the latter often respects some physical constraints (e.g., velocity divergence-free conditions). However, the velocity field of a given flow is supposed to be unique, no matter looking at it from the Eulerian or Lagrangian perspective. Assimilating these velocities could improve reconstruction quality.
Several comprehensive flow field reconstruction strategies have been proposed. Typically, these strategies begin by initializing particle trajectories, velocities, and acceleration using some simple schemes, then these initialized quantities are used for downstream analysis or data assimilation. One such strategy, introduced by Gesemann et al. (2016), comprises two algorithms: the Trackfit and Flowfit. The Trackfit initializes particle trajectories, velocities, and accelerations along particle pathlines based on the raw LPT data. Particle trajectories are approximated using cubic B-splines with time being its independent variable. The velocity and acceleration are calculated by taking temporal derivatives of the trajectory functions. On the other hand, the Flowfit algorithm is a data assimilation program. It leverages the particle velocities and accelerations obtained from the Trackfit as inputs. In each frame, the Flowfit converts the Lagrangian data onto an Eulerian mesh using 3D weighted cubic B-splines. The Flowfit assimilates data by minimizing cost functions containing some constraints, such as divergence-free conditions for incompressible flows and curl-free conditions for pressure gradients. These constraints regularize the reconstructed flow quantities.
However, in the Trackfit, the trajectory functions are embedded in a cost function that relies on the assumption of minimum change in acceleration. While this practice is helpful to smooth the trajectories, it does not strictly reinforce physical conditions. Additionally, to comply with this assumption, the time interval between adjacent frames must be small, which may not be suitable for data without time-resolved properties. Last, converting Lagrangian data onto Eulerian meshes is needed in the Flowfit.
Lüthi (2002) proposed a meshless comprehensive reconstruction method. This method first uses a localized cubic polynomial function to approximate particle trajectories along pathlines. Second, velocities and accelerations are calculated by taking temporal derivatives of the trajectory functions. Last, linear piece-wise polynomial functions are employed to approximate the velocity field in each frame, using velocities obtained from the previous step as inputs. This method can be considered a more sophisticated version of the Trackfit. However, without further data assimilation, it cannot strictly enforce the velocity divergence-free constraint as intended. Instead, it attempts to incorporate the divergence-free property by using a nonzero divergence as a normalized weight for weighted least squares to improve the reconstruction quality. Additionally, the use of linear piece-wise polynomial functions only provides piece-wise linear smoothness throughout the domain, which may be inadequate to approximate complex velocity fields.
Bobrov et al. (2021) employed a meshless least-squares approach for computing spatial derivatives of velocities and accelerations, as well as reconstructing pressure fields from raw LPT data. This method approximates particle trajectories using weighted cardinal B-splines (Gesemann et al. 2016). Velocities and accelerations are calculated by differentiating the trajectory functions. Then, the gradients of velocities and accelerations are directly evaluated on scattered particle points using a least-squares method. After retrieving their derivatives, pressure fields are calculated in a way similar to those of velocity and acceleration derivatives, further incorporating constraints from the Navier-Stokes and pressure Poisson equations. This method is effective; however, divergence-free for the incompressible velocity field is not enforced. Instead, it is reserved as a metric of trajectory reconstruction quality.
In the current research, we propose a meshless comprehensive reconstruction strategy for processing raw data measured by 3D TR-LPT systems. This strategy incorporates (1) a stable RBF method to approximate particle trajectories and velocities along pathlines, as well as velocity fields and differential quantities in each frame; (2) the constrained least squares (CLS) algorithm to enforce physical constraints and suppress noise; and (3) the partition-of-unity method (PUM) to reduce computational costs and improve numerical stability. We refer to our strategy as the CLS-RBF PUM method.
This paper is organized as follows: in Sect. 2, the three foundation algorithms (i.e., the stable RBF, CLS, and PUM) are introduced. Section 3 elaborates on how these three foundation algorithms are integrated into one comprehensive reconstruction method. Section 4 shows validations of our method based on synthetic and experimental data. Section 5 concludes the paper.
2 Foundation algorithms
2.1 Stable radial basis function (RBF)
The classic RBF, also known as RBF-direct (Fornberg et al. 2011), is a kernel-based meshless algorithm for data approximation. It uses the Euclidean norm between two data points as an independent variable. With a specific kernel, such as a Gaussian or multiquadric kernel, the RBF-direct enjoys infinitely smoothness and can be easily extended to high dimensions. Various versions of RBFs have been widely applied in computer graphics (Carr et al. 2001; Macêdo et al. 2011; Drake et al. 2022), machine learning (Keerthi and Lin 2003; Huang et al. 2006), as well as flow field reconstruction in some recent works (Sperotto et al. 2022; Li and Pan 2023).
However, as pointed out by Fornberg and Wright (2004), the RBF-Direct faces a critical dilemma regarding its shape factor. The shape factor controls the profile of RBF kernels: a small shape factor, corresponding to the near-flat kernel, offers an accurate approximation but leads to an ill-conditioned problem. On the other hand, a large shape factor, corresponding to a spiky kernel, provides a well-conditioned but inaccurate approximation. It was conventionally believed that a trade-off must be made regarding the shape factor to strike a balance between accuracy and stability until stable RBFs emerged.
The stable RBFs can achieve numerical stability without compromising accuracy. The ill-conditioning problem due to a small shape factor can be overcome by a handful of stable RBFs (e.g., RBF-CP by Fornberg and Wright (2004), RBF-GA by Fornberg et al. (2013), RBF-RA by Wright and Fornberg (2017) and polynomial embedded RBF by Sperotto et al. (2022)). The RBF-QR (Fornberg and Piret 2008; Fornberg et al. 2011) is one such stable RBF. The RBF-QR kernel \(\psi\) is converted from an RBF-Direct kernel \(\phi\), via a process of factorization, Taylor expansion, coordinate conversion, Chebyshev polynomial substitution, QR factorization, etc. The RBF-QR kernels enjoy well-conditioning and stability for any small shape factor, i.e., \(\varepsilon \rightarrow 0^+\). Details about the RBF-QR can be found in Fornberg et al. (2011); Larsson et al. (2013), and here we briefly summarize its application for interpolation as an example.
For an RBF-QR interpolation problem, given scalar data \(\hat{f}_i^\text {c} \in \mathbb {R}\) located at a center \(\hat{{\varvec{\xi }}}_i^\text {c} \in \mathbb {R}^d\), i.e., \((\hat{{\varvec{\xi }}}_i^\text {c},\hat{f}_i^\text {c})\), an interpolant \(\tilde{s}(\varepsilon ,{\varvec{\xi }})\) can be written as a linear combination of N RBF-QR kernels \(\psi\):
where N is the number of centers, \({\varvec{\lambda }}=(\lambda _1,\lambda _2,\dots ,\lambda _N)^{\text {T}}\) is the vector of expansion coefficients in which \(\lambda _i\) controls the weights of the kernels, \(\varepsilon\) is the shape factor, \(\Vert {\varvec{\xi }}-\hat{{\varvec{\xi }}}_i^\text {c}\Vert\) denotes the Euclidean norm between evaluation points \({\varvec{\xi }}\) and the center \(\hat{{\varvec{\xi }}}_i^\text {c}\). The evaluation points \({\varvec{\xi }}\) are where data are interpolated at. The expansion coefficient \(\lambda _i\) can be calculated by forcing the evaluation points coinciding with the centers, and then substituting interpolants with the given data: \(\left. \tilde{s}(\varepsilon ,{\varvec{\xi }}) \right| _{\hat{{\varvec{\xi }}}^{\text {c}}_i}=\tilde{s}(\varepsilon ,\hat{{\varvec{\xi }}}^{\text {c}}_i) =\hat{{\varvec{f}}}^{\text {c}}\), where \(\hat{{\varvec{f}}}^{\text {c}}=(\hat{f}_1^\text {c},\hat{f}_2^\text {c},\dots ,\hat{f}_N^\text {c})^{\text {T}}\) is the vector of the given data.
The derivative approximation can be calculated using the same expansion coefficients but with an RBF-QR derivative kernel \(\psi _\mathcal {D}\):
where \(\mathcal {D}\) denotes a linear derivative operation. With its scattered data approximation ability and easy derivative calculation, the RBF-QR is suitable for LPT data processing. In the CLS-RBF PUM method, we use the RBF-QR as a model function to approximate particle trajectories, velocities, and differential quantities. One can consider the RBF-QR as a one-layer neural network that is fully ‘transparent’ and interpretable, and the need for hyperparameter tuning is minimized.
2.2 Constrained least squares (CLS)
The CLS-RBF PUM method relies on four types of points (listed below), each playing a distinct role in the flow reconstruction. We use one-dimensional (1D) unconstrained and constrained RBF-QR regression for demonstration as shown in Fig. 1.
-
1.
Centers \(\hat{{\varvec{\xi }}}^\text {c}\) (x coordinates of the orange crosses): they are locations of the given data. The centers are determined by experiments and are typically ‘randomly’ scattered throughout the flow domain.
-
2.
Reference points \({\varvec{\xi }}^\text {ref}\) (x coordinates of scarlet crosses): a linear combination of kernels (see dashed curves) centered at the reference points can approximate the given data with a continuous function (i.e., the approximation function \(\tilde{s}({\varvec{\xi }})\), indicated by the blue solid curves). Note, the number of reference points should be fewer than that of the centers to ensure effective regression. The reference points do not have to be a subset of the centers, and they can be placed ‘arbitrarily’ with specific preferences. A quasi-uniform layout such as the Halton points for 2D and 3D, and a uniform point layout for 1D are considered desirable reference point placement strategies (Fasshauer 2007; Larsson 2023). A uniform structured reference point layout may lead to rank deficiency in RBF-QR matrices in 2D or 3D, while a random reference point layout may result in inefficient and inaccurate approximation (e.g., reference points are too sparse in some critical flow regions).
-
3.
Constraint points \({{\varvec{\xi }}}^{\text {cst}}\) (x coordinates of scarlet squares): they are where physical constraints are enforced. In the current work, we impose divergence-free constraints at the centers to guarantee that velocity divergence at measured LPT data points is zero. Generally, there is no limitation to the placement of the constrained points (e.g., locations or numbers of the constraints), as long as the linear constrained system is well-posed.
-
4.
Evaluation points \({\varvec{\xi }}^\text {eva}\) (x coordinates of blue dots): the locations where \(\tilde{s}({\varvec{\xi }})\) is reconstructed are the evaluation points. The number or the locations of evaluation points have no limitations. This means that the evaluation points can be densely placed in the domain to achieve temporal and spatial interpolation or placed at the centers \(\hat{{\varvec{\xi }}}^\text {c}\) to directly evaluate at locations of LPT data.

A demonstration of RBF-QR approximation and its centers, reference points, constraint points, and evaluation points in 1D. The RBF-QR a unconstrained and b constrained regression have six kernels. Gray solid curves: the ‘ground truth’ based on an exact function \(f(\xi )=\sin {(\xi )}+0.5\), \(\xi \in [0,2\pi ]\); blue solid curves: RBF-QR reconstruction; dashed curves: RBF-QR kernels ‘centered’ at different reference points; orange crosses: the given data, which are sampled from the ground truth with random perturbation to simulate the corrupted experimental data; scarlet crosses: the reference points; scarlet squares: constraints of function values or function derivatives; the scarlet square with an arrowhead indicates the derivative constraint; blue dots: reconstructed results at the evaluation points
The CLS is based on the least squares regression with constraints enforced by the Lagrangian multiplier method. The Lagrangian objective function \(\mathcal {L}\) is created by appending an equality constraint \({{\textbf {C}}} {{\varvec{\lambda }}}={\varvec{d}}\) to a residual \(\mathcal {R}\):
where \(\mathcal {R}=\sum ^N_i \Vert \tilde{s}(\varepsilon ,\hat{{\varvec{\xi }}}_{i}^{\text {c}})-\hat{f}_{i}^{\text {c}} \Vert ^2\) is the residual between the measurements \(\hat{f}_{i}^{\text {c}}\) and RBF-QR model function \(\tilde{s}(\varepsilon ,\hat{{\varvec{\xi }}}_{i}^{\text {c}})={{\textbf {B}}}(\varepsilon ,\hat{{\varvec{\xi }}}_{i}^{\text {c}}){\varvec{\lambda }}\), where \({{\textbf {B}}}(\varepsilon ,\hat{{\varvec{\xi }}}_{i}^{\text {c}})=B_{ij}=\psi (\varepsilon ,\Vert \hat{{\varvec{\xi }}}_i^{\text {c}}- {\varvec{\xi }}_j^{\text {ref}} \Vert )\) is the RBF-QR system matrix constructed by N centers \(\hat{{\varvec{\xi }}}_{i}^{\text {c}}\) and M reference points \({\varvec{\xi }}_{j}^{\text {ref}}\), \(i=1,2,\dots ,N\) and \(j=1,2,\dots ,M\). \({\varvec{\eta }} = (\eta _1,\eta _2,\dots ,\eta _J)^{\text {T}}\) is the vector of Lagrangian multipliers. \({\textbf {C}}\) is a generalized constraint matrix; it can be a constraint matrix \({{\textbf {C}}}_\mathcal {O}\) for function values and/or \({{\textbf {C}}}_\mathcal {D}\) for function derivatives. \({\textbf {C}}\) is established by J constraint points \({\varvec{\xi }}_{l}^{\text {cst}}\) and M reference points \({\varvec{\xi }}_{j}^{\text {ref}}\) with entries
\(l=1,2,\dots ,J\). \({\varvec{\lambda }} = (\lambda _1,\lambda _2,\dots ,\lambda _M)^{\text {T}}\) is the vector of expansion coefficients. \({\varvec{d}}\) is the vector of constraint values; in this work, \({\varvec{d}}\) is a null vector to comply with the divergence-free constraint. An oversampling ratio is defined as \(\beta =N/M\). \(\beta >1\) is required for regression and a large \(\beta\) provides smooth reconstruction.
Next, we minimize the Lagrangian objective function Eq. (1) for expansion coefficients that will be used for approximation. By setting the gradient of \(\mathcal {L}\) with respect to the vectors \({\varvec{\lambda }}\) and \({\varvec{\eta }}\) to zero (i.e., \(\partial {\mathcal {L}}/\partial {{\varvec{\lambda }}} =0\) and \(\partial {\mathcal {L}}/\partial {{\varvec{\eta }}} =0\)), a linear system is established:
where \({{\textbf {G}}}={{\textbf {B}}}^{\text {T}}(\varepsilon ,\hat{{\varvec{\xi }}}_{i}^{\text {c}}){{\textbf {B}}}(\varepsilon ,\hat{{\varvec{\xi }}}_{i}^{\text {c}})\) and \({{\textbf {F}}}={{\textbf {B}}}^{\text {T}}(\varepsilon ,\hat{{\varvec{\xi }}}_{i}^{\text {c}}) \hat{{\varvec{f}}}^{\text {c}}\). The Eq. (2) can be solved using the QR-factorization:
After retrieving \({\varvec{\lambda }}\) from Eq. (2), the RBF-QR approximation and its derivative functions are calculated by:
where the RBF-QR evaluation matrix \({{\textbf {E}}}(\varepsilon ,{\varvec{\xi }}_{k}^{\text {eva}})\) and its derivative matrix \({{\textbf {E}}}_{\mathcal {D}}(\varepsilon ,{\varvec{\xi }}_{k}^{\text {eva}})\) are constructed by P evaluation points \({\varvec{\xi }}^{\text {eva}}_k\) and M reference points \({\varvec{\xi }}^{\text {ref}}_j\) with entries:
where \(k=1,2,\dots ,P\).
Equations (2) and (3) cannot be directly applied in 3D when subject to divergence-free constraints without proper extensions. The matrix elements in these two equations must be extended to each direction of the coordinates since the reconstruction is in 3D and divergence-free constraints consist of derivatives in three directions. The extended linear system is written as
In Eq. (5), \({\bar{{\textbf {C}}}}=\begin{bmatrix}{{{\textbf {C}}}}_x&{{\textbf {C}}}_y&{{\textbf {C}}}_z\end{bmatrix}\) is the extended constraint matrix, where \({{\textbf {C}}}_x\), \({{\textbf {C}}}_y\), and \({{\textbf {C}}}_z\) are first-order spatial derivative constraint matrices based on \({{\textbf {C}}}_\mathcal {D}\) in the x, y, and z directions, respectively. The extended matrices \({\bar{{\textbf {G}}}}\) and \({\bar{{\textbf {F}}}}\) are block diagonal matrices with entries
where \(\hat{{\varvec{f}}}^{\text {c}}=\begin{pmatrix} {\varvec{u}}&{\varvec{v}}&{\varvec{w}} \end{pmatrix}^{\text {T}}\), and \({\varvec{u}}\), \({\varvec{v}}\), and \({\varvec{w}}\) are the velocity vectors in the x, y, and z directions, respectively; \({\bar{{\varvec{d}}}}\) is a null column vector corresponding to the divergence-free constraints. After solving \({\bar{{\varvec{\lambda }}}}\) in Eq. (5) using the QR-factorization, the CLS RBF-QR approximation function \(\tilde{s}(\varepsilon ,{\varvec{\xi }}_k^{\text {eva}})\) and its differentiation function \(\tilde{s}_{\mathcal {D}}(\varepsilon ,{\varvec{\xi }}_k^{\text {eva}})\) are calculated by:
where \({\bar{{\textbf {E}}}}\) and \({\bar{{\textbf {E}}}}_{\mathcal {D}}\) are extended diagonal block matrices based on \({{\textbf {E}}}\) and \({{\textbf {E}}}_{\mathcal {D}}\) in Eq. (4), respectively:
Up to this point, a CLS RBF-QR framework is established for a 3D Lagrangian flow field reconstruction with divergence-free constraints as an example. This method can enforce other constraints in a similar fashion, if needed.
2.3 Partition-of-unity method (PUM)
The PUM (Melenk and Babuška 1996; Babuška and Melenk 1997) is applied in reconstruction to further enhance numerical stability and efficiency. The ill-conditioning issue in the RBF-Direct is not only caused by a small shape factor but also by a large-scale dataset (Fornberg and Wright 2004; Fornberg et al. 2011). The same ill-conditioning problem due to large-scale data persists in stable RBFs. In addition, processing a large number of data at once can be prohibitively expensive.
The PUM can partition the domain and localize flow field reconstruction. Here, we briefly summarize the implementation of RBF-QR with PUM, which was introduced by Larsson et al. (2017). First, identical spherical PUM patches \(\Omega _m\), \(m=1, 2, \dots , N_P\), are created to cover the entire 3D flow domain \(\Omega\). \(N_P\) is the number of PUM patches. These patches are overlapped and the overlap ratio is defined as \(\gamma\). As recommended by Larsson et al. (2017), the overlap ratio of PUM patches is always set to \(\gamma =0.2\) in this work to strike a balance between accuracy and computational cost. The radius of PUM patches is calculated as \(\rho =(1+\gamma )\rho _0\), where \(\rho _0\) is the radius of patches that have no overlaps in the diagonal direction. For example in Fig. 2b, \(\rho _0 =\overline{AO}\), and the diagonal directions refer to the lines \(\overline{AC}\) and \(\overline{BD}\). Next, every patch is assigned a weight function \(W_{m}({\varvec{\xi }})\). The weight function becomes zero outside a patch, i.e., \(W_{m}({\varvec{\xi }})=0\); and the sum of all weight functions from all patches at an arbitrary point in the domain is unity, i.e., \({\textstyle \sum _{m=1}^{N_P}{W_{m}({\varvec{\xi }})}=1}\). The weight functions are based on Shepard’s method (Shepard 1968) following Larsson’s work:
where \(\varphi _m({\varvec{\xi }})\) is a compactly supported generating function, and the Wendland \(C^2\) function \(\varphi (r)=(1-r^4)_{+}(4r+1)\) (Wendland 1995) is chosen here. Last, the global evaluation function on the fluid domain \(\Omega\) can then be assembled by a weighted summation of local approximation functions:
where \(W_{\mathcal {D},m}({\varvec{\xi }})\) is linear derivatives of weight functions in the patch m and \(\tilde{s}_{\mathcal {D},m}(\varepsilon ,{\varvec{\xi }})\) is a linear derivative approximation in the same patch, both are derived by the chain rule. Figure 2 presents a 3D example of PUM patches in a unit cubic domain with an overlap ratio \(\gamma =0.2\).

Example PUM patch layout in 3D. The domain is partitioned by eight spherical PUM patches. b is the top view of a. The gray lines indicate the edges of the domain \(\Omega\). Spheres in different colors are PUM patches, whose centers are marked by green dots; red dots indicate the reference points of a Halton layout; randomly distributed blue dots are the given data points
3 CLS-RBF PUM method
We integrate the aforementioned three foundation algorithms (i.e., BRF-QR, CLS, and PUM) as one comprehensive reconstruction method. This method consists of four steps, which will be elaborated on in this section. Then, an important by-product of this method, i.e., the capability of inter-frame and inter-particle data interpolation, is discussed. Last, we look into the free parameters in our method and their optimal choice. Hereafter, the generalized independent variable \({\varvec{\xi }}\) used in Sect. 2 is substituted by particle spatial coordinates \({\varvec{x}}\) or time t. Figure 3 sketches the CLS-RBF PUM method processing TR-LPT data in 2D as a demonstration.

A 2D demonstration of the CLS-RBF PUM method. Only three out of N frames and reconstruction at three particles are highlighted here
3.1 Step 1: initialize particle trajectory and velocity
Step 1 initializes smooth particle trajectories (and velocities) by fitting the particle spatial coordinates provided by an LPT system. This fitting is based on Eq. (2) with time being its independent variable, without any constraints.
Trajectory fitting is performed for all coordinates of each particle. Here, we use the x coordinate of a particle as an example. The vector of spatial coordinates \(\hat{{\varvec{x}}}=(\hat{x}_1,\hat{x}_2,\dots ,\hat{x}_{N_\text {trj}})^\text {T}\) are measured at \(N_{trj}\) time instants \({\varvec{t}}^{\text {c}}= (t^{\text {c}}_{1},t^{\text {c}}_{2},\dots ,t^{\text {c}}_{N_{\text {trj}}})^{\text {T}}\) by an LPT system. We refer to \({\varvec{t}}^{\text {c}}\) as the vector of temporal centers. Based on Eq. (3), the trajectory function is given by:
where \({{\textbf {B}}}^{+}(\varepsilon ,{\varvec{t}}^{\text {c}})=(({{\textbf {B}}}^{\text {T}}(\varepsilon ,{\varvec{t}}^{\text {c}}){{\textbf {B}}}(\varepsilon ,{\varvec{t}}^{\text {c}}))^{-1}{{\textbf {B}}}^{\text {T}}(\varepsilon ,{\varvec{t}}^{\text {c}})\) is a generalized inverse of the RBF-QR system matrix \({{\textbf {B}}}(\varepsilon ,{\varvec{t}}^{\text {c}})\) that has entries:
where \(i=1,2,\dots ,N_{\text {trj}}\) and \(j=1,2,\dots ,M_{\text {trj}}\); \({{\varvec{t}}}^{\text {ref}}=({t}^{\text {ref}}_{1},{t}^{\text {ref}}_{2},\dots ,{t}^{\text {ref}}_{M_{\text {trj}}})^{\text {T}}\) is the vector of temporal reference points. The trajectory evaluation matrix \({{\textbf {E}}}(\varepsilon ,{\varvec{t}}^{\text {c}})\) has the entries:
A temporal oversampling ratio is defined as \(\beta _0=N_{\text {trj}}/M_{\text {trj}}\), and \(\beta _0>1\) is essential for regression.
The initial velocity is calculated based on the temporal derivatives of trajectory functions:
where \({{\textbf {E}}}_t (\varepsilon ,{\varvec{t}}^{\text {c}})\) is the velocity evaluation matrix based on Eq. (4) with \([\cdot ]_t\) denoting the first-order temporal derivative:
Acceleration can be computed accordingly if needed. Reconstruction of trajectories and velocities for y and z coordinates are similar. After computing the velocities in all three directions, the velocity field at each measured particle location in each frame is known in turn.
Hereafter, the particle location output from Step 1 is referred to as the modified particle location, as the raw particle locations are slightly modified by the regression process. The computed velocity fields from this step are called initial velocities as the velocity of each particle or the velocity field in each frame is known for the first time. Note, the initial velocities are computed from Lagrangian perspectives based on the definition of the velocity; however, they are not subject to any physical constraints.
3.2 Step 2: calculate intermediate divergence-free velocity field
Step 2 calculates an intermediate divergence-free velocity field in each frame by the constrained least squares. This step uses the modified particle locations and initial velocities as the inputs. To calculate the intermediate velocity fields, the matrices \({\textbf {B}}\), \({\textbf {C}}\), \({\textbf {E}}\), and \({{\textbf {E}}}_\mathcal {D}\) (described in Sect. 2.2) are constructed first. For example in the \(\kappa\)-th frame, an RBF-QR spatial system matrix \({{\textbf {B}}}(\varepsilon ,\tilde{{\varvec{x}}}^{\text {c}})\) is formulated based on N modified spatial points \(\tilde{{\varvec{x}}}^{\text {c}}_i\) and \(M_1\) spatial reference points \({\varvec{x}}^{\text {ref}}_j\) with entries:
where \(\tilde{{\varvec{x}}}^{\text {c}}=[\tilde{{\varvec{x}}}^{\text {c}}_1,\tilde{{\varvec{x}}}^{\text {c}}_2,\dots ,\tilde{{\varvec{x}}}^{\text {c}}_N]^\text {T}\) and \(\tilde{{\varvec{x}}}_i^{\text {c}}=(\tilde{x},\tilde{y},\tilde{z})^{\text {c}}_i\); \({\varvec{x}}^{\text {ref}}=[{\varvec{x}}^{\text {ref}}_1, {\varvec{x}}^{\text {ref}}_2, \dots ,{\varvec{x}}^{\text {ref}}_{M_1}]^\text {T}\), and \({\varvec{x}}^{\text {ref}}_j=({x},{y},{z})^{\text {ref}}_j\), \(i=1,2,\dots ,N\), and \(j=1,2,\dots ,M_1\). An RBF-QR spatial derivative constraint matrix \({{\textbf {C}}}_{\mathcal {D}}(\varepsilon ,\tilde{{\varvec{x}}}^{\text {c}})\) is established between N modified spatial centers \(\tilde{{\varvec{x}}}^{\text {c}}_i\) and \(M_1\) spatial reference points \({\varvec{x}}^{\text {ref}}_j\):
Here, the constraint points \({\varvec{x}}^{\text {cst}}\) coincide with modified particle locations \(\tilde{{\varvec{x}}}^{\text {c}}\) since we enforce the velocity divergence at the measured particle location to be zero. The RBF-QR spatial evaluation matrix \({{\textbf {E}}}(\varepsilon ,\tilde{{\varvec{x}}}^{\text {c}})\) is established by N modified particle locations \(\tilde{{\varvec{x}}}^{\text {c}}_i\) and \(M_1\) spatial reference points \({\varvec{x}}^{\text {ref}}_j\):
In Step 2, the evaluation points are placed at the same locations as the modified spatial centers \(\tilde{{\varvec{x}}}^{\text {c}}_i\). A spatial oversampling ratio in Step 2 is defined as \(\beta _1=N/M_1\) and chosen to be slightly larger than unity.
After constructing the extended matrices, the expansion coefficients \({\bar{{\varvec{\lambda }}}}\) is solved from Eq. (5), and the intermediate velocity field \(\tilde{{\textbf {U}}}^{\text {div}}_{\kappa } =(\tilde{{\varvec{u}}}^{\text {div}}_{\kappa },\tilde{{\varvec{v}}}^{\text {div}}_{\kappa },\tilde{{\varvec{w}}}^{\text {div}}_{\kappa })^{\text {T}}\) is computed based on Eq. (6):
The velocity fields \(\tilde{{{\varvec{u}}}}^{\text {div}}_{\kappa }\), \(\tilde{{{\varvec{v}}}}^{\text {div}}_{\kappa }\), and \(\tilde{{{\varvec{w}}}}^{\text {div}}_{\kappa }\) can be extracted from \(\tilde{{{\textbf {U}}}}^{\text {div}}_{\kappa }(\varepsilon ,\tilde{{\varvec{x}}}^{\text {c}})\). The velocities reconstructed in Step 2 are divergence-free from the Eulerian perspective. However, they are not necessarily the same as the velocity fields obtained from Step 1, which are based on the definition of the velocity but are not divergence-free. This discrepancy is due to errors in measured particle spatial coordinates. To resolve this conflict, we assimilate the results from Steps 1 and 2 in Step 3.
3.3 Step 3: update particle location by data assimilation
Step 3 incorporates the Lagrangian and Eulerian reconstructions by updating the particle trajectories using least squares regression for all particles in all frames. The underlying motivation is that the velocities calculated by temporal derivatives of trajectories for each particle (i.e., velocities output from Step 1, which is a Lagrangian reconstruction) should be identical to the velocities reconstructed by the constrained regression in each frame (i.e., velocities output from Step 2, which is an Eulerian reconstruction). However, due to the errors in the measured particle spatial coordinates, these two velocity reconstructions are not necessarily equal to each other for the same flow field. Nevertheless, the velocities calculated in Step 2 are assumed to be more accurate than those in Step 1 since they respect physical constraints (incompressibility in this case). Therefore, solenoidal velocities output from Step 2 can be used to update particle locations.
The expansion coefficients of the trajectory function are re-calculated to update particle locations. The update in particles’ x coordinates is presented as an example. First, a linear system is constructed based on a modified trajectory matrix \(\tilde{{\textbf {X}}}(\varepsilon ,{\varvec{t}}^\text {c})\) and a divergence-free velocity matrix \(\tilde{{\textbf {V}}}(\varepsilon ,\tilde{{\varvec{x}}}^{\text {c}})\):
where \({\varvec{\Lambda }}\) is an expansion coefficient matrix to be determined. The elements in \(\tilde{{\textbf {X}}}(\varepsilon ,{\varvec{t}}^{\text {c}})\) are from Eq. (8) in Step 1, and \(\tilde{{\textbf {X}}}(\varepsilon ,{\varvec{t}}^{\text {c}})\) has entries:
The elements in \(\tilde{{\textbf {V}}}(\varepsilon ,\tilde{{\varvec{x}}}^{\text {c}})\) are calculated by Eq. (10), and \(\tilde{{\textbf {V}}}(\varepsilon ,\tilde{{\varvec{x}}}^{\text {c}})\) has entries:
the matrices \({{\textbf {E}}}(\varepsilon ,{\varvec{t}}^{\text {c}})\) and \({{\textbf {E}}}_t(\varepsilon ,{\varvec{t}}^{\text {c}})\) are the same as those in Eqs. (8) and (9).
The Eqs. (11a) and (11b) are established based on explicit physical intuition. From the Lagrangian perspective, the particle trajectory reconstructed by the RBF-QR regression (i.e., the Right-Hand Side (RHS) of Eq. (11a)) should be as close as possible to the modified particle locations (i.e., the Left-Hand Side (LHS) of Eq. (11a)), as the modified particle locations from Step 1 are the best estimates available based on the raw LPT measurement. From the Eulerian perspective, the particle velocities along pathlines (i.e., the RHS of Eq. (11b)) should be equal to the divergence-free velocity field reconstructed by the constrained regression in each frame (i.e., the LHS of Eq. (11b)). Enforcing Eqs. (11a) and (11b) simultaneously achieves data assimilation from both Lagrangian and Eulerian perspectives.
Next, we solve the expansion coefficient \({\varvec{\Lambda }}\) to update particle locations. Combining Eqs. (11a) and (11b) to share the same expansion coefficient \({\varvec{\Lambda }}\), an over-determined system is established:
where \({{\textbf {K}}} = [ {{\textbf {E}}}^\text {T}(\varepsilon ,{\varvec{t}}^{\text {c}})~{{\textbf {E}}}_{t}^\text {T}(\varepsilon ,{\varvec{t}}^{\text {c}}) ]\) and \({{\textbf {H}}} = [ \tilde{{\textbf {X}}}(\varepsilon ,{\varvec{t}}^\text {c})~\tilde{{\textbf {V}}}(\varepsilon ,\tilde{{\varvec{x}}}^{\text {c}}) ]\). The update expansion coefficient \({\varvec{\Lambda }}\) is solved by \({\varvec{\Lambda }} = {{\textbf {H}}}{{\textbf {K}}}^{+}\), where \({{\textbf {K}}}^{+}=({{\textbf {K}}}^{\text {T}}{{\textbf {K}}})^{-1}{{\textbf {K}}}^{\text {T}}\). The matrix \({\varvec{\Lambda }}\) has dimensions of \(N \times M_{\text {trj}}\) with entries:
In each row of \({\varvec{\Lambda }}\), the expansion coefficients are used to approximate a trajectory for a certain particle, while in each column of \({\varvec{\Lambda }}\), the expansion coefficients are used to approximate a velocity field for all particles in a certain frame. Each row of \({\varvec{\Lambda }}\) is used to update trajectories modeled by Eq. (8) in Step 1. For example, for a particle \(\tilde{{\varvec{x}}}^{\text {c}}_i\), its updated trajectory is calculated by \(\tilde{{\varvec{x}}}_{i}^{\text {up}}(\varepsilon ,{\varvec{t}}^{\text {c}})={{\textbf {E}}}(\varepsilon ,{\varvec{t}}^{\text {c}}){\varvec{\lambda }}_i^{\text {trj}}\), where \({\varvec{\lambda }}_i^{\text {trj}}=(\lambda _{i,1}, \lambda _{i,2}, \ldots , \lambda _{i,M_{\text {trj}}})^{\text {T}}\) is extracted from Eq. (13). The update of particle trajectories in the y and z directions follows the same procedure.
The expansion coefficient matrix \({\varvec{\Lambda }}\) connects the physical knowledge in both spatial and temporal dimensions. This is justified by the intuition that the Eulerian (measuring over each flow field at a certain time instant) and Lagrangian (tracking each particle over time) observations of the same flow should provide the same information. The shared expansion coefficient \({\varvec{\Lambda }}\) in Eq. (12) implies that no ‘discrimination’ is projected to temporal and spatial dimensions, as well as to the Lagrangian and Eulerian descriptions of the flow.
3.4 Step 4: calculate final velocity and differential quantity
Step 4 calculates the final divergence-free velocity field in each frame using the same algorithms as those in Step 2. The updated particle locations from Step 3 and intermediate divergence-free velocities from Step 2 are used as the inputs for this step. A spatial oversampling ratio in Step 4 is defined as \(\beta _2=N/M_2\). Similar to \(\beta _1\), \(\beta _2\) is chosen to be larger than one.
Step 4 also computes velocity gradients. For example, in the x direction the velocity gradient at \(\kappa\)-th frame is given by:
where \({\varvec{\lambda }}_{\kappa }\) is the vector of the expansion coefficient in the x direction. \({\varvec{\lambda }}_{\kappa }\) is extracted from \({\bar{{\varvec{\lambda }}}}\) that is solved by Eq. (5). \({{\textbf {E}}}_{x}(\varepsilon ,\tilde{{\varvec{x}}}^{\text {up}})\) is the RBF-QR derivative matrix based on \({{\textbf {E}}}_{\mathcal {D}}\):
where \({\varvec{x}}^{\text {ref}}=[{\varvec{x}}^{\text {ref}}_1,{\varvec{x}}^{\text {ref}}_2,\dots ,{\varvec{x}}^{\text {ref}}_{M_2}]^\text {T}\) is the spatial reference points used in Step 4, \({\varvec{x}}^{\text {ref}}_j=({x},{y},{z})^{\text {ref}}_j\), \(j=1,2,\dots ,M_2\), and \(M_2\) is the number of spatial reference points in Step 4. Velocity gradients in other directions can be calculated similarly. Other differential quantities based on the velocity gradients, such as strain- and rotation-rate tensors, can be calculated accordingly (see Appendix A).
When the datasets are large (e.g., more than ten thousand particles), applying the PUM is preferred. The above velocity reconstruction is first performed in each PUM patch, and then the velocity field in the entire domain is assembled using Eq. (7). The PUM settings are the same for Step 2 and Step 4 since the computational domain remains unchanged in this work. In Step 4, the same PUM assembly practice is applied for differential quantity fields. We recommend that the number of spatial reference points in each patch is always fewer than 1,000 in 3D. Being more than 1,000 in 3D may lead to ill-conditioning in RBF-QR (Fornberg et al. 2011; Larsson et al. 2013, 2017). On the contrary, too few reference points (i.e., a high oversampling ratio, we will mention this in Sect. 3.6) may be inadequate to resolve fine structures of complex flows.
3.5 Inter-frame and inter-particle interpolation
The CLS-RBF PUM method can readily interpolate flow quantities between given frames along particle trajectories or between particles for each frame. To achieve this, a pseudo-particle can be placed at an arbitrary location in the domain (e.g., \((x_{\text {s}},y_{\text {s}},z_{\text {s}}) \in \Omega\)) at any time instant t between the first and last frames. In Step 1, all modified particle locations and initial velocities are calculated at time t. Next, an intermediate divergence-free velocity field is reconstructed in Step 2, and then the given particle locations are updated in Step 3. Last, the final velocities and differential quantities are calculated based on the updated particle locations from Step 3 and the intermediate velocity fields from Step 2. Because the final velocity and differential quantity fields are recovered by continuous functions (i.e., the stable RBF), the velocity and velocity gradient at the location of the pseudo-particle \((x_{\text {s}},y_{\text {s}},z_{\text {s}})\) at time t can be evaluated.
3.6 Parameter tunning
Our method has four major free parameters subject to tuning: i) the shape factor \(\varepsilon\), ii) the temporal oversampling ratio \(\beta _0\) in Step 1, iii) the spatial oversampling ratio \(\beta _1\) in Step 2, and iv) the spatial oversampling ratio \(\beta _2\) in Step 4. Selecting the optimal parameters is semi-empirical, and our method is not too sensitive to the parameter choice. Based on the tests (Larsson et al. 2017; Li et al. 2022; Li 2023), we have the following suggestions for parameter tuning:
-
i)
The shape factor \(\varepsilon\) can be any sufficiently small value (e.g., \(0< \varepsilon \le 1 \times 10^{-4}\)) to ensure high accuracy. When \(\varepsilon\) is sufficiently small, the reconstruction accuracy is independent of \(\varepsilon\). This is a superior advantage by the stable virtue of the RBF-QR, and it avoids the need to pick a specific optimal \(\varepsilon\).
-
ii)
The temporal oversampling ratio \(\beta _0\) should be larger than unity, but as small as possible. Setting \(\beta _0 >1\) formulates least square regression to suppress noise. A smaller \(\beta _0\) allows more basis functions to resolve complex trajectories. \(\beta _0\) can be chosen starting from around 1.1 based on our tests. If nonphysical oscillations emerge in reconstructions—this usually happens when the noise in the particle location is high—one can slightly increase \(\beta _0\) until these phenomena disappear.
-
iii)
The spatial oversampling ratios \(\beta _1\) and \(\beta _2\) can be selected larger than two in practice. Similar to \(\beta _0\), small \(\beta _1\) and \(\beta _2\) are preferred. When the noise in the particle location is high and/or the flow structures are simple (e.g., velocity gradients are low), large \(\beta _1\) and \(\beta _2\) are used for smooth reconstruction, quick computation, and noise suppression.
4 Result and discussion
4.1 Validations
We first used synthetic LPT data generated by adding artificial noise to the ground truth to test our method. The ground truth data are time series of particle spatial coordinates, which are based on a 3D Taylor-Green vortex (TGV) (Taylor and Green 1937) or a direct numerical simulation (DNS) of a turbulent wake flow (TWF) behind a cylinder (Khojasteh et al. 2022). The artificial noise was zero-mean Gaussian noise with standard deviation \(\sigma\) that was proportional to the spatial span of the domain in a direction. For example, in the x direction, the standard deviation \(\sigma\) of the noise was \(\sigma = \zeta L\), where \(\zeta\) was the noise level and L was the spatial span of the domain in the x direction. \(\zeta =0.1\%\) and \(\zeta =1.0\%\) were chosen in the current work to represent a medium and high noise level in an LPT experiment, respectively. Details of the synthetic data generation can be found in Appendix B.
We benchmark our method with some baseline algorithms. In the trajectory and velocity reconstruction, six algorithms, i.e., first- and second-order finite difference methods (1st and 2nd FDM), second-, third-, fourth-order polynomial regressions (2nd, 3rd, and 4th POLY), and cubic basis splines (B-splines) are used as ‘baselines’ to compare against our method. The baseline algorithms are briefed in Appendix C. To assess reconstruction quality, relative errors and normalized velocity divergence are introduced. Relative errors (\(\mathcal {E}\)) of reconstructed particle spatial coordinates, velocities, and velocity gradients are quantified as:
where \(\tilde{f}\) is the reconstruction result (e.g., particle locations, velocities, and velocity gradients), and \(f_0\) is the ground truth. A normalized velocity divergence is defined as:
following Lüthi (2002), where \({\tilde{{\textbf {U}}}}\) is the reconstructed velocity vector; \(\frac{\partial \hat{u}}{\partial x}\), \(\frac{\partial \hat{v}}{\partial y}\) or \(\frac{\partial \hat{w}}{\partial z}\) is either the ground truth (if available) or reconstructed velocity gradients.
We tested the frequency response of our method. Following Scarano and Riethmuller (2000); Schneiders et al. (2017), we used the TGV with varying predefined flow frequencies to test the spatial and temporal frequency response of our method. We can see the low-pass filter property of our method in space and time. We also used artificially contaminated Homogeneous and Isotropic Turbulence (HIT) data to illustrate how our method mitigates noise through temporal frequency response tests. These HIT-based tests show that our method can suppress high-frequency noise and is especially effective for high amplitude noise. Readers can refer to Appendix D for details.
Our method needs four predefined free parameters to reconstruct flow fields (see Sect. 3.6 for details). The parameters for reconstruction are listed below. We emphasize that these parameter sets are not always optimal and our method does not have strict requirements on them (Table 1).
4.2 Validation based on Taylor–Green vortex
The validation based on the synthetic TGV data is presented in Figs. 4, 5, 6, 7. The TGV synthetic data have 20,000 particles scattered in the domain \(\Omega\) of \(x \times y \times z \in [0,1]\times [0,1]\times [0,1]\), with a time interval \(\Delta t = 0.1\) between two consecutive frames. The data consist of 11 frames and the temporal sampling frequency is 10. Details about these data can be found in Appendix B.1. As shown in Fig. 4, the reconstructed particle trajectories and velocity fields were almost identical to their ground truth, regardless of noise levels. In Fig. 4c2 – c3, only some minor distortions on the iso-surfaces appeared near the domain boundaries when high noise (\(\zeta = 1.0\%\)) was added to generate the synthetic data.

3D validation based on the synthetic TGV data. Left column: particle trajectories with temporal interpolation. Middle column: particle velocity vector fields in the sixth of 11 frames. Right column: the iso-surfaces of coherent structures based on the Q-criterion (iso-value = 0.001) in the sixth of 11 frames with spatial interpolation. Top row: ground truth; middle and bottom rows: reconstruction based on the synthetic data with the noise level of \(\zeta \approx 0.1\%\) and \(1.0\%\), respectively. The particle trajectories are colored by time; the velocity fields and iso-surfaces are colored by the amplitude of velocity. One hundred particle trajectories and 2,000 velocity vectors out of 20,000 are shown in a1–a3 and b1–b3, respectively

Reconstruction errors of particle coordinates in the TGV validation. From upper to lower rows: reconstruction based on synthetic data with 0.1% and 1.0% noise level, respectively. From left to right columns: reconstruction errors in spatial coordinates of x, y, and z, respectively. Note that the green dashed & solid lines are overlapped in all sub-figures because the finite difference methods only evaluate velocities. Therefore, the particle locations from the synthetic data are directly used as the trajectory outputs of the 1st and 2nd FDMs

Reconstruction errors of particle velocities in the TGV validation. From upper to lower rows: reconstruction based on synthetic data with the noise level of \(\zeta = 0.1\%\) and \(1.0\%\), respectively. From left to right columns: reconstruction errors in velocity components of u, v, and w, respectively
Figures 5 and 6 present the relative errors of reconstructed trajectories and velocities, respectively. Although the reconstruction errors are relatively higher at the two ends of particle pathlines than the other frames for all methods, our method outperformed the baseline algorithms (see Appendix C for the baseline algorithms) as the errors from our method were almost always lower than those of the baseline algorithms. The red lines in Fig. 5, which represent the errors in the trajectory reconstruction based on our method, lie below the green lines that denote the errors of the input data. This evidences that our method can effectively mitigate noise in particle spatial coordinates.
Iso-surfaces of the reconstructed strain- and rotation-rate tensors based on synthetic data with high noise (\(\zeta = 1 \%\)) are shown in Fig. 7. The major structures of the flow were smooth and recognizable despite that the iso-surfaces are slightly distorted near the domain boundaries and edges (lower two rows in Fig. 7). The reconstructed iso-surfaces of coherent structures based on medium noise data (\(\zeta =0.1\%\)) were almost the same as the ground truth (not shown here for brevity).
We assessed the mean and standard deviation of the relative errors in the reconstructed velocity gradients. For noise level \(\zeta =0.1\%\), the mean and standard deviation of the errors were below \(2.62\%\) and \(5.50\%\) for all frames, respectively. The errors at the two ends of the pathlines (the boundaries in time) were higher than those in the frames in between. If the reconstruction results on the temporal boundaries were excluded, the overall reconstruction quality can be significantly improved. For example, after excluding the first and last frames, the mean and standard deviation of the errors were below \(1.38\%\) and \(1.90\%\), respectively. For high-level artificial noise, \(\zeta =1.0\%\), the mean and standard deviation of the errors were below \(4.16\%\) and \(4.65\%\) for all frames, respectively. After excluding the first and last frames, they were below \(3.74\%\) and \(3.91\%\), respectively. The absolute value of the normalized velocity divergence \(\Vert \nabla \cdot {\tilde{{\textbf {U}}}} \Vert ^{*}\) is almost always below \(5.7 \times 10^{-7}\) regardless of the noise level in the synthetic data. This shows that our method effectively achieves divergence-free reconstruction.

The iso-surfaces of strain- and rotation-rate tensors (iso-value = \(\pm 0.50\)). Red and blue colors correspond to positive and negative iso-values, respectively. Upper two rows: the ground truth; lower two rows: reconstruction using our method. Reconstruction was in the sixth of 11 frames based on the synthetic data with 1.0% noise added to the raw LPT data of TGV
4.3 Validation based on turbulent wake flow
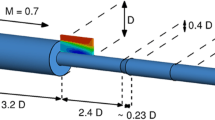
The validation based on the synthetic data of the turbulent wake flow (TWF) behind a cylinder is presented in Figs. 8 and 9. The synthetic data have 105,000 particles scattered in the domain \(\Omega\) of \(x \times y \times z \in [6D,8D]\times [3D,5D]\times [2D,4D]\), with a time interval \(\Delta t = 0.00375U/D\) between two successive frames, where U is free stream velocity and D is the diameter of the cylinder. The data consist of 11 frames. This computational region is right behind the cylinder. Large velocity variation and high shear in this region render a suitable challenge for our method. Readers could refer Khojasteh et al. (2022) and Appendix B.2 for details about the data.

3D validation based on the synthetic TWF data. Upper row: the ground truth. Lower row: reconstruction based on the synthetic data with 0.1% artificial noise added. a1–a2: particle trajectories. b1–b2 and c1–c2: particle velocity fields in the sixth of 11 frames. The particle trajectories & velocity vector fields are colored by particle velocities. 5,000 pathlines & 2,000 velocity vectors out of 105,000 are shown in particle trajectories & velocity fields, respectively. c1 and c2 are top views from the \(+z\) axis of b1 and b2, respectively
As shown in Fig. 8, the reconstructed particle trajectories and velocity fields were almost identical to the ground truth. As illustrated in Fig. 9, similar to the validation based on the TGV, the relative errors of reconstructed trajectories and velocities were almost always lower than those of the baseline algorithms (see Appendix C for the baseline algorithms). Note, our method significantly outperformed the baseline algorithms at the two ends of particle pathlines and suppressed noise in particle spatial coordinates. The absolute value of the normalized velocity divergence \(\Vert \nabla \cdot {\tilde{{\textbf {U}}}} \Vert ^{*}\) was mostly below \(8.6 \times 10^{-5}\). The performance of our method on different flows (e.g., TGV or TWF) with various noises (\(\zeta = 0.1\%\) and \(\zeta = 1.0\%\)) is consistent.

Reconstruction errors in the TWF validation. a–c: reconstruction errors of spatial coordinates of x, y, and z, respectively; d–f: reconstruction errors in velocity u, v, and w, respectively. The reconstruction is based on synthetic data with 0.1% noise level
4.4 Experimental validation based on a pulsing jet
Next, we validated our method using experimental LPT data from a low-speed pulsing jet. The experiment was conducted by Sakib (2022) at Utah State University, US. The jet flow had a Reynolds number \(Re_{\delta _\nu } = 400\) based on the thickness of the Stokes boundary layer. About 7,100 particles with 11 frames were chosen from the original dataset that had about 15,000 particles with 100 frames.Footnote 1 This down-sampling led to a sparse dataset to challenge our method. The reconstruction was carried out within the domain of \(x \times y \times z \in [-20,30]\times [-30,25]\times [-10,10]~{\text {mm}}^3\) and the time interval between two consecutive frames was \(5\times 10^{-4}~{\text {s}}\). The data reported an average of about 0.016% nominal uncertainty in the particle spatial coordinates. To further assess the robustness, we tested our method on artificial error-contaminated LPT data. These contaminated data had a noise level of \(\zeta =0.2\%\). Details about the experimental setups and data can be found in Appendix B.3.

The experimental validation. From left column to right: reconstruction using DaVis 10 based on raw LPT data, reconstruction using our method based on raw and contaminated LPT data, respectively. From top row to bottom: reconstructions of particle trajectories, velocities, and iso-surfaces of the coherent structures based on the Q-criterion, respectively. The magenta, blue, and gray contours in b1–b3 show the reconstruction using VIC# (iso-value = 40,000 \(\text {s}^{-2}\)), and our method based on raw (iso-value = 1,000 \(\text {s}^{-2}\)) and contaminated (iso-value = 500 \(\text {s}^{-2}\)) LPT data, respectively. The iso-surfaces in c1–c3 are based on spatial interpolation, and their iso-values are the same as those used in b1–b3. a1–a3 and b1–b3 are views from the \(+z\) axis; c1–c3 are the zoomed-in views near the jet core. The velocity fields and iso-surfaces are from the sixth of 11 frames. Particle trajectories, velocity fields, and iso-surfaces are colored by particle velocities
The experimental validation results are shown in Figs. 10 and 11. The top row (i.e., Fig. 10a1–a3) shows reconstructions of particle trajectories. The virtual size of particles is proportional to their velocities for visualization purposes. The middle row illustrates reconstructed velocity fields. We only visualized the velocity vectors within the range of \(z \in [-3,+3]\) mm, which covered the jet core. To emphasize the directions of the particle velocities, the length of the vectors was normalized and projected on the \(z=0\) plane. The bottom row represents iso-surfaces of the coherent structures based on the Q-criterion. Intersections between the iso-surfaces and \(z=0\) plane are contours identifying the vertical region of the flow sliced at \(z=0\), and are overlaid on the quiver plots in the middle row (i.e., Fig. 10b1–b3).
As shown in Fig. 10a2–a3, smooth particle trajectories were recovered by our method, whose profiles resembled those obtained from DaVis 10 (see Fig. 10a1), regardless of particle coordinates being significantly contaminated by the artificial noise (see Fig. 10a3). In addition, two trailing jets (at \(y \approx -5\) and \(-15\) mm) were revealed in the wake of the leading pulsing jet (at \(y \approx 5\) mm). Note, our method was able to reconstruct trajectories with temporal interpolation, where each pathline consists of 51 frames (see Fig. 10a2–a3).
Compared Figs. 10b2–b3 with 10b1, the velocity fields reconstructed by our method were virtually smoother, in terms of the transition of the vector directions over the space. This observation is more apparent near the core of the trailing jets. Furthermore, our method effectively captured major structures of the flow (illustrated by blue and gray contours in Fig. 10b1–b3, and the coherent structures in Fig. 10c2–c3). We can observe three vortical structures associated with the leading pulse jet and the two trailing jets (see e.g., Fig. 10a1). The normalized velocity divergence \(\Vert \nabla \cdot {\tilde{{\textbf {U}}}} \Vert ^{*}\) was below \(3.13 \times 10^{-7}\) in all frames for our method (e.g., Fig. 10b2–b3), regardless of the added artificial noise or not. This exhibits that the divergence-free constraint was enforced. On the contrary, the VIC# had a normalized velocity divergence of about 3.18.
Figure 10c2–c3 represents the reconstructed coherent structures based on the Q-criterion. One large and two small toroidal structures emerged in the domain and their locations corresponded to the three high-speed areas observed in Fig. 10a1–a3. This agreement between the coherent structures and the particle trajectory and velocity data further validates our method. Comparing the middle and right columns in Fig. 10, despite the overwhelming artificial noise added to the down-sampled data, no discernible difference was observed between the two reconstruction results. This indicates that our method is robust on noisy sparse data.
The iso-surfaces of strain- and rotation-rate tensors are illustrated in Fig. 11. They show the kinematics of fluid parcels that may not be visually apparent from the velocity or vorticity fields alone. As examples, we interpret two components of the strain-rate tensor. For \(\tilde{S}_{12}\), two major tubular structures with reversed colors adhering to each other, developed along the y axis, and two minor vortical structures warped the major ones. The reversed colors of the major structures indicate shear deformations near the jet core, which were caused by the radial velocity gradients of the jet. The wavy tubular structure with three bumps reflects the leading pulsing jet and the two trailing ones. The two minor structures suggest that fluid parcels experienced shear deformations in opposite directions compared to the closest major structure, generating reversed flows that brought fluid parcels back to the jet. Regarding \(\tilde{S}_{13}\), the staggering pattern parallel to the \(x-z\) plane indicates the shear deformation of fluid parcels in the front and back of the core of the leading jet. The fluid parcels at the leading front plane of the vortex rings tended to be elongated along the circumferential direction and shrunk along the radial directions, while the fluid parcels just behind them underwent reversed deformations. This explains the forward movement of the vortex rings. Noting that the front patterns were larger than the back ones, one can tell that the vortex ring was expanding by observing this single frame.

The iso-surfaces of reconstructed strain- & rotation-rate tensors in the sixth of 11 frames using the CLS-RBF PUM method (iso-value = \(\pm 15\) \(\text {s}^{-1}\)). Red and blue colors correspond to positive and negative iso-values, respectively. Only nine components are shown here
5 Conclusion and future works
In this paper, we propose the CLS-RBF PUM method, a novel 3D divergence-free Lagrangian flow field reconstruction technique. It can reconstruct particle trajectories, velocities, and differential quantities (e.g., pressure gradients, strain- and rotation-rate tensors, and coherent structures based on the Q-criterion) from raw Lagrangian particle tracking (LPT) data. This method integrates the constrained least squares (CLS), a stable radial basis function (RBF-QR), and the partition-of-unity method (PUM) into one comprehensive reconstruction strategy. The CLS serves as a platform for LPT data regression and enforcing physical constraints. The RBF-QR approximates particle trajectories along pathlines, using the time as an independent variable, and approximates velocity fields for each frame, with the particle spatial coordinates being their independent variables. The PUM localizes the reconstruction to enhance computational efficiency and stability.
The intuition behind our method is straightforward. By assimilating the velocity field reconstructed based on Lagrangian and Eulerian perspectives, we intrinsically incorporate the information in the temporal and spatial dimensions with physical constraints enforced to improve flow field reconstruction and offer several advantages. This method directly reconstructs flow fields at scattered data points without Lagrangian–Eulerian data conversions and can achieve data interpolation at any time and location and enforce physical constraints. The constraints are velocity solenoidal conditions for incompressible flows in the current work while accommodating other constraints as needed. Large-scale LPT datasets with a substantial number of particles and frames can be efficiently processed and parallel computing is achievable. It demonstrates high accuracy and robustness, even when handling highly contaminated data with low spatial and/or temporal resolution.
The tests based on synthetic and experimental LPT data show the competence of our method. Validation based on synthetic data has exhibited the superior trajectory and velocity reconstruction performance of our method compared to various baseline algorithms. The tests based on a pulsing jet experiment further confirm the effectiveness of our method. In summary, our method offers a versatile solution for reconstructing Lagrangian flow fields based on the raw LPT data with accuracy, robustness, and physical constraints being satisfied, and can be the foundation of other downstream post-processing and data assimilation.
Our method can be extended in several aspects and we name a few here. First, the PUM in time can process LPT data with more frames (e.g., data recorded on tens or hundreds of frames and even more). Second, upgrade the CLS to a weighted CLS to leverage the uncertainty information of the LPT data and enhance reconstruction accuracy and robustness. Third, more and/or alternative constraints can be imposed to process other flow quantities, such as adding curl-free constraints to the pressure gradients for accurate pressure reconstruction.
Availability of data and materials
Datasets and codes are available from the corresponding author, Z.P. on resaonable request.
Notes
In the current experimental data, the maximum number of particles that existed in all 11 frames was about 7,100.
The number of frames is set to 11 throughout the paper for the following reasons: (1) directly using more frames without the PUM in time is computationally expensive; (2) having fewer frames might be insufficient to resolve complex trajectories.
References
Alberini F, Liu L, Stitt E, Simmons M (2017) Comparison between 3-D-PTV and 2-D-PIV for determination of hydrodynamics of complex fluids in a stirred vessel. Chem Eng Sci 171:189–203
Babuška I, Melenk JM (1997) The partition of unity method. Int J Numer Methods Eng 40(4):727–758
Biferale L, Bonaccorso F, Buzzicotti M, Calascibetta C (2023) TURB-Lagr. A database of 3d Lagrangian trajectories in homogeneous and isotropic turbulence. arXiv preprint arXiv:2303.08662
Biwole PH, Yan W, Zhang Y, Roux J-J (2009) A complete 3D particle tracking algorithm and its applications to the indoor airflow study. Meas Sci Technol 20(11):115403
Bobrov M, Hrebtov M, Ivashchenko V, Mullyadzhanov R, Seredkin A, Tokarev M, Zaripov D, Dulin V, Markovich D (2021) Pressure evaluation from Lagrangian particle tracking data using a grid-free least-squares method. Meas Sci Technol 32(8):084014
Bowker KA (1988) Albert Einstein and meandering rivers. Earth Sci Hist 7(1):45
Carr JC, Beatson RK, Cherrie JB, Mitchell TJ, Fright WR, McCallum BC, Evans TR (2001) Reconstruction and representation of 3D objects with radial basis functions. In: Proceedings of the 28th annual conference on Computer graphics and interactive techniques, pp 67–76
Cierpka C, Lütke B, Kähler CJ (2013) Higher order multi-frame particle tracking velocimetry. Exp Fluids 54:1–12
Drake KP, Fuselier EJ, Wright GB (2022) Implicit surface reconstruction with a curl-free radial basis function partition of unity method. SIAM J Sci Comput 44(5):A3018–A3040
Einstein A (1926) Die Ursache der Mäanderbildung der Flußläufe und des sogenannten Baerschen Gesetzes. Naturwissenschaften 14(11):223–224
Fasshauer GE (2007) Meshfree approximation methods with MATLAB, vol 6. World Scientific, Singapore
Ferrari S, Rossi L (2008) Particle tracking velocimetry and accelerometry (PTVA) measurements applied to quasi-two-dimensional multi-scale flows. Exp Fluids 44:873–886
Fornberg B, Piret C (2008) A stable algorithm for flat radial basis functions on a sphere. SIAM J Sci Comput 30(1):60–80
Fornberg B, Wright G (2004) Stable computation of multiquadric interpolants for all values of the shape parameter. Comput Math Appl 48(5–6):853–867
Fornberg B, Larsson E, Flyer N (2011) Stable computations with Gaussian radial basis functions. SIAM J Sci Comput 33(2):869–892
Fornberg B, Lehto E, Powell C (2013) Stable calculation of Gaussian-based RBF-FD stencils. Comput Math Appl 65(4):627–637
Fu S, Biwole PH, Mathis C (2015) Particle tracking velocimetry for indoor airflow field: a review. Build Environ 87:34–44
Gautschi W (2011) Numerical analysis. Springer, Berlin
Gesemann S, Huhn F, Schanz D, Schröder A (2016) From noisy particle tracks to velocity, acceleration and pressure fields using B-splines and penalties. In: 18th international symposium on applications of laser and imaging techniques to fluid mechanics, Lisbon, Portugal, vol 4
Haller G (2005) An objective definition of a vortex. J Fluid Mech 525:1–26
Huang G-B, Chen L, Siew CK et al (2006) Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Trans Neural Netw 17(4):879–892
Hunt JC, Wray AA, Moin P (1988) Eddies, streams, and convergence zones in turbulent flows. In: Proceedings of the 1988 summer program studying turbulence using numerical simulation databases, vol 2
Jeon YJ, Müller M, Michaelis D (2022) Fine scale reconstruction (VIC#) by implementing additional constraints and coarse-grid approximation into VIC+. Exp Fluids 63(4):70
Jeronimo MD, Zhang K, Rival DE (2019) Direct Lagrangian measurements of particle residence time. Exp Fluids 60:1–11
Keerthi SS, Lin C-J (2003) Asymptotic behaviors of support vector machines with Gaussian kernel. Neural Comput 15(7):1667–1689
Khojasteh AR, Laizet S, Heitz D, Yang Y (2022) Lagrangian and Eulerian dataset of the wake downstream of a smooth cylinder at a Reynolds number equal to 3900. Data Brief 40:107725
Laizet S, Lamballais E (2009) High-order compact schemes for incompressible flows: a simple and efficient method with quasi-spectral accuracy. J Comput Phys 228(16):5989–6015
Larsson E (2023) Private communication
Larsson E, Lehto E, Heryudono A, Fornberg B (2013) Stable computation of differentiation matrices and scattered node stencils based on Gaussian radial basis functions. SIAM J Sci Comput 35(4):A2096–A2119
Larsson E, Shcherbakov V, Heryudono A (2017) A least squares radial basis function partition of unity method for solving PDEs. SIAM J Sci Comput 39(6):A2538–A2563
Li L (2023) Lagrangian flow field reconstruction based on constrained stable radial basis function. Master’s thesis, University of Waterloo
Li L, Pan Z (2023) Three dimensional divergence-free Lagrangian reconstruction based on constrained least squares and stable radial basis function. In: 15th international symposium on particle image velocimetry, vol 1
Li L, Sakib N, Pan Z (2022) Robust strain/rotation-rate tensor reconstruction based on least squares RBF-QR for 3D Lagrangian particle tracking. In: Fluids engineering division summer meeting, volume 85833, page V001T02A009. American Society of Mechanical Engineers
Lüthi B (2002) Some aspects of strain, vorticity and material element dynamics as measured with 3D particle tracking velocimetry in a turbulent flow. PhD thesis. ETH Zurich
Macêdo I, Gois JP, Velho L (2011) Hermite radial basis functions implicits. In: Computer graphics forum, vol 30. Wiley Online Library, pp 27–42
Machicoane N, López-Caballero M, Bourgoin M, Aliseda A, Volk R (2017) A multi-time-step noise reduction method for measuring velocity statistics from particle tracking velocimetry. Meas Sci Technol 28(10):107002
Malik NA, Dracos T (1993) Lagrangian PTV in 3D flows. Appl Sci Res 51:161–166
Melenk JM, Babuška I (1996) The partition of unity finite element method: basic theory and applications. Comput Methods Appl Mech Eng 139(1–4):289–314
Onu K, Huhn F, Haller G (2015) LCS Tool: a computational platform for Lagrangian coherent structures. J Comput Sci 7:26–36
Ouellette NT, Xu H, Bodenschatz E (2006) A quantitative study of three-dimensional Lagrangian particle tracking algorithms. Exp Fluids 40:301–313
Peacock T, Haller G (2013) Lagrangian coherent structures: the hidden skeleton of fluid flows. Phys Today 66(2):41–47
Peng J, Dabiri J (2009) Transport of inertial particles by Lagrangian coherent structures: application to predator–prey interaction in jellyfish feeding. J Fluid Mech 623:75–84
Romano M, Alberini F, Liu L, Simmons M, Stitt E (2021) Lagrangian investigations of a stirred tank fluid flow using 3d-PTV. Chem Eng Res Des 172:71–83
Rosi GA, Walker AM, Rival DE (2015) Lagrangian coherent structure identification using a Voronoi tessellation-based networking algorithm. Exp Fluids 56:1–14
Sakib MN (2022) Pressure from PIV for an oscillating internal flow. Ph.D. thesis, Utah State University
Scarano F, Riethmuller ML (2000) Advances in iterative multigrid PIV image processing. Exp Fluids 29(Suppl 1):S051–S060
Schanz D, Gesemann S, Schröder A (2016) Shake-the-box: Lagrangian particle tracking at high particle image densities. Exp Fluids 57(5):1–27
Schneiders JF, Scarano F (2016) Dense velocity reconstruction from tomographic PTV with material derivatives. Exp Fluids 57:1–22
Schneiders JF, Scarano F, Elsinga GE (2017) Resolving vorticity and dissipation in a turbulent boundary layer by tomographic PTV and VIC+. Exp Fluids 58:1–14
Shepard D (1968) A two-dimensional interpolation function for irregularly-spaced data. In: Proceedings of the 1968 23rd ACM national conference, pp 517–524
Sperotto P, Pieraccini S, Mendez MA (2022) A meshless method to compute pressure fields from image velocimetry. Meas Sci Technol 33(9):094005
Takehara K, Etoh T (2017) Direct evaluation method of vorticity combined with PTV. In: Selected papers from the 31st international congress on high-speed imaging and photonics, vol 10328. SPIE, pp 193–199
Tan S, Salibindla A, Masuk AUM, Ni R (2020) Introducing OpenLPT: new method of removing ghost particles and high-concentration particle shadow tracking. Exp Fluids 61:1–16
Taylor GI, Green AE (1937) Mechanism of the production of small eddies from large ones. Proc R Soc Lond Ser A Math Phys Sci 158(895):499–521
Wendland H (1995) Piecewise polynomial, positive definite and compactly supported radial functions of minimal degree. Adv Comput Math 4:389–396
Wilson MM, Peng J, Dabiri JO, Eldredge JD (2009) Lagrangian coherent structures in low Reynolds number swimming. J Phys Condens Matter 21(20):204105
Wright GB, Fornberg B (2017) Stable computations with flat radial basis functions using vector-valued rational approximations. J Comput Phys 331:137–156
Zhang K, Rival DE (2020) Direct Lagrangian method to characterize entrainment dynamics using particle residence time: a case study on a laminar separation bubble. Exp Fluids 61(12):243
Acknowledgements
We thank Prof. Elizabeth Larsson at Uppsala University for discussing the RBF-QR and sharing codes with us. We are also thankful to Dr. Md Nazmus Sakib at Utah State University for conducting experiments and providing data and timely support. L.L. thanks for the support from the Natural Sciences and Engineering Research Council of Canada (NSERC) and the Digital Research Alliance of Canada. We thank an anonymous reviewer 2 for thorough comments and constructive suggestions.
Funding
This research is partially supported by the Natural Sciences and Engineering Research Council of Canada (NSERC), 2020-04486.
Author information
Authors and Affiliations
Contributions
Z.P. conceived the research. L.L. and Z.P. programmed the algorithm and performed the computations. All authors discussed the results and contributed to the final manuscript.
Corresponding author
Ethics declarations
Ethical approval
Not applicable.
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendices
A Differential quantity
1.1 A.1 Strain-rate and rotation-rate tensor
Strain-rate and rotation-rate tensors are kinematics quantities that describe the rate of change of a fluid parcel regarding deformation and rotation, respectively. The strain-rate tensor \({{\varvec{S}}}\) and rotation-rate tensor \({{\varvec{R}}}\) are the symmetric and anti-symmetric parts of the velocity gradient \(\nabla {{\textbf {U}}}\), respectively: \(\nabla {{\textbf {U}}} =\frac{1}{2}( U _{i,j}+ U _{j,i})+\frac{1}{2}( U _{i,j}- U _{j,i})\), \({{\varvec{S}}} = S_{ij} =\frac{1}{2}( U _{i,j}+ U _{j,i})\), and \({{\varvec{R}}} = R_{ij} =\frac{1}{2}( U _{i,j}- U _{j,i})\). Once all components of \(U _{i,j}\) are calculated in Step 4, \({{\varvec{S}}}\) and \({{\varvec{R}}}\) can be evaluated.
1.2 A.2 Coherent structure based on Q-criterion
The Q-criterion is a vortex identification method first proposed by Hunt et al. (1988) to identify vortical structures in the flow. The Q-criterion is given by (Hunt et al. 1988; Haller 2005):
where \({\varvec{R}}\) is the rotation-rate tensor, and \({\varvec{S}}\) is the strain-rate tensor. After \({{\varvec{S}}}\) and \({{\varvec{R}}}\) are calculated, vortices can be found using Eq. (15). Other criteria can be achieved similarly.
B Synthetic and experimental data
1.1 B.1 Taylor–Green vortex (TGV)
To generate the TGV synthetic data for validations, we adopted a velocity field:
where \(\alpha _1=\alpha _2=0.5\), \(\alpha _3=-1\), and \(\omega =2 \pi\); \(d_x=d_y=d_z=0.25\) were the offsets of the TGV flow structure in the x, y and z directions, respectively. In the first snapshot, 20,000 particles were randomly placed in the domain \(\Omega\) of \(x \times y \times z \in [0,1]\times [0,1]\times [0,1]\). The particle locations in the next snapshot were calculated by the forward Euler method: \({\varvec{x}}_{\kappa +1}={\varvec{x}}_{\kappa }+\delta t {{\textbf {U}}}_{\kappa }\), where \({\varvec{x}}_{\kappa }=({x}_{\kappa },{y}_{\kappa },{z}_{\kappa })\) and \({\varvec{x}}_{\kappa +1}\) were the particle locations in the \(\kappa\)-th and \((\kappa +1)\)-th snapshots, respectively; \({{\textbf {U}}}_{\kappa }=(u_{\kappa },v_{\kappa },w_{\kappa })\) was the velocity calculated by Eq. (16) in the \(\kappa\)-th snapshot; \(\delta t\) was the time interval between snapshots and here we chose \(\delta t=5 \times 10^{-5}\). After the integration, particle trajectories with \(2 \times 10^{4}\) snapshots were down-sampled to 11 framesFootnote 2 to generate the ground truth of the raw LPT data. Artificial noise (see Sect. 4 for details) was added to the particle spatial coordinates of the TGV-based ground truth.
1.2 B.2 Turbulence wake flow (TWF)
To generate the synthetic TWF data, we added artificial noise to an available Lagrangian dataset. Details about the dataset can be found in Khojasteh et al. (2022) and we briefly summarize it here. The dataset are created based on a DNS. The DNS was conducted using the Incompact3D solver (Laizet and Lamballais 2009) to simulate a flow with a free stream velocity U passing a cylinder with a diameter D at a Reynolds number of \(Re=3,900\).
In the Lagrangian datasets, about 200,000 particles were scattered in the domain. The particle velocities were calculated by tri-linear interpolations using the nearest eight nodal data in space. The particle trajectories were integrated by a fourth-order Runge–Kutta method. The synthetic data had 105,000 particles that were down-sampled from the Lagrangian dataset. These particles were distributed in a wake region, located 0.5D downstream of the cylinder, with the dimensions of \(x \times y \times z \in [6D,8D]\times [3D,5D]\times [2D,4D]\). The center-line of the cylinder located at \((x,y)=(5D,4D)\) is parallel to the z axis. A total of 11 frames were selected from 350 DNS frames and these 11 frames had a time interval \(\Delta t=0.00375U/D\). The noise was defined the same way as that used in the TGV validation, with \(\zeta =0.1\%\) to represent a typical noise in LPT data.
1.3 B.3 Low-speed pulsing jet
The experimental facility consisted of a hexagonal water tank, a cylindrical piston, an impingement plate, and optical equipment. The synthetic pulsing jet was generated by driving the piston using an electromagnetic shaker, and pushing the water through a circular orifice until impinged on the plate. A dual cavity high-speed laser illuminated the measurement area with the dimensions of \(60 ~\text {mm} \times 57 ~\text {mm} \times 20~ \text {mm}\). Four high-speed cameras recorded the jet flow and provided time-resolved LPT images (see Sakib (2022) for details).
The raw experimental data were acquired using a volumetric system and commercial software LaVision DaVis 10 (Göttingen, Germany). The LPT module of DaVis 10 is based on the shake-the-box (Schanz et al. 2016) algorithm. The velocity data were post-processed by Vortex-In-Cell# (VIC#) algorithm (Jeon et al. 2022) to obtain velocity gradients on a structured mesh.
C Baseline algorithms
1.1 C.1 Finite difference methods
We use the velocity component u calculation as an example. In a given frame, the first- and second-order finite difference methods (FDMs) calculate velocities by the forward Euler method (i.e., Eq. 17a) and central difference method (i.e., Eq. 17b), respectively:
where \(\hat{x}_{\kappa }\) is the particle coordinate along the x direction in the \(\kappa\)-th frame from LPT experiments, \(\Delta {t}\) is the time interval between two consecutive frames, and \(t_\kappa\) is the time instant in the \(\kappa\)-th frame. The velocities of the first and last frames are calculated by the first-order finite difference method. Since the FDMs only evaluate particle velocities, the particle locations that are ‘output’ from the FDMs are assumed to be the same as those in the synthetic data, e.g., \(\tilde{x}(t_\kappa )=\hat{x}(t_\kappa )\).
1.2 C.2 Polynomial regression
We use trajectory and velocity reconstruction in the x direction as an example. First, the trajectory polynomial model function \(\tilde{x}(t)\) is given by \(\tilde{x}(t)=\sum ^m_{j=0}{p_{m,j} t^j}\) where \(p_{m,j}\) is the polynomial coefficient, m is the order of polynomials, and t is the time. For instance, the trajectory and velocity model functions of the 2nd polynomial (2nd POLY) are
The trajectory and velocity approximation functions of the other polynomials are similar to those in the x direction of the 2nd POLY.
Next, we calculate the polynomial coefficient \(p_{m,j}\). A residual \(\mathcal {R}\) between measured particle locations \(\hat{x}_{\kappa }\) and the polynomial model function \(\tilde{x}({t}_{\kappa })\) is minimized \(\min ~ \mathcal {R}=\sum ^{N_{\text {trj}}}_{\kappa =1}\Vert \tilde{x}({t}_{\kappa })-\hat{x}_{\kappa } \Vert ^2,\) where \({t}_{\kappa }\) is the time instant in the \(\kappa\)-th frame. Setting the gradient of the residual \(\mathcal {R}\) regarding \(p_{m,j}\) to zero (i.e., \(\partial {\mathcal {R}}/\partial {p_{m,j}} =0\)) and the polynomial coefficient \(p_{m,j}\) can be explicitly solved. The polynomial coefficients in the y and z directions are the same as that in the x direction. Once all the coefficients are retrieved, the polynomial model functions can be constructed and used to approximate particle trajectories, velocities, and accelerations.
1.3 C.3 Cubic B-splines
The cubic B-spline algorithm is based on the MATLAB built-in functions from the Curve Fitting Toolbox™. We adopt a function spap2(piece,k,x,y) with piece=2 and k=4 to create a cubic spline with two pieces joined together, bypass setting knots. x and y are the given data points and their values, respectively. Then we use a function fnval(f,xe), in which f=spap2(piece,k,xe,y) is the spline function calculated above, and xe is the evaluation points. To calculate first-order derivatives for velocity as an example, we use fnder(f,d), where d=1.
D Spatial and temporal frequency response
We tested the spatial and temporal frequency response of our method using TGV and HIT. The TGV has varying predefined frequencies based on its analytical expressions (i.e., Eq. 16). It is used for both spatial and temporal frequency response analysis. The Lagrangian data based on the HIT have intrinsically varying frequencies along particle trajectories and we use them to test the temporal response.
For the temporal analysis based on the TGV, the velocity amplitudes \(\alpha _1\), \(\alpha _2\), and \(\alpha _3\) in Eq. (16) are varied from 2 to 32 with an increment of 2, corresponding to the non-dimensional temporal frequency \(f'_t\) of the flow varying from 1 to 16. Physically, \(f'_t\) means the number of periodic circulations one particle in the outer layer of the vortex cell can finish within a unit of time. These TGV data consist of 33 frames with a time interval \(\Delta t = 1/32\). For the spatial analysis based on the TGV, \(\omega\) in Eq. (16) is varied from \(\pi\) to \(16 \pi\) with an increment of \(\pi\), in turn, the non-dimensional spatial frequency \(f'_s\) of the flow varies from 0.5 to 8. The frequency response is defined as the ratio of the amplitudes of the reconstructed particle spatial coordinates for temporal analysis, or of the reconstructed particle velocities for spatial analysis, to that of the input data in the frequency space. The frequency spectra are calculated by the fast Fourier transform. The normalized frequency \(f^{*}\) is the spatial or temporal frequency of the flow divided by the Nyquist sampling frequency of the data. The parameters used in the frequency response analysis are listed in Table 2.
The TGV-based frequency response is presented in Fig. 12a and b. With increasing \(f^{*}_t\) or \(f^{*}_s\), the frequency response decreases from unity to approximately zero, with a cutoff frequency varying from about 0.2 to 0.4 for \(f_{s}^*\) and \(f_{t}^*\). This indicates a low-pass filter feature of our method. When the oversampling ratio for space (\(\beta _1\) and \(\beta _2\)) and time (\(\beta _0\)) decreases, the cutoff frequency increases. This observation is expected, as using small oversampling ratios recovers high-frequency components while applying larger ones provides smooth reconstruction.
For the frequency response based on the HIT flow, we use synthetic data with artificial noise to examine how our method attenuates noise of different levels. The synthetic HIT data are generated by adding the artificial noise to the ground truth. Three artificial noise levels \(\zeta =0.1\%\), \(\zeta =1.0\%\), and \(\zeta =5.0\%\) are used and they are defined the same as that in the validation (see Sect. 4). The ground truth is from a DNS of an incompressible flow with a Reynolds number \(Re_{\lambda } \approx 130\) based on the Taylor scale (details about the HIT can be found in Biferale et al. (2023)). The non-dimensional frequency of this HIT flow is \(f'_t=U_{\text {rms}}/L=0.275\), where \(U_{\text {rms}}\) is the root mean squares of the magnitudes of the particle velocities in all frames; L is the length of the cubic computational domain. The \(f'_t\) can be considered a metric describing the characteristic spatial frequency of the particle trajectory in this flow. The synthetic HIT data are sampled to 65 frames with a time interval \(\Delta t = 0.00225\) between two consecutive frames. Therefore, the corresponding temporal frequency f based on sampling varies from 0 to about 215.28, with an increment of about 6.94. We assess the frequency response that is defined as the ratio of the amplitudes of the reconstructed particle spatial coordinates to that of the input noisy data in the frequency space.
The temporal frequency response using the HIT is shown in Fig. 12c. As illustrated in the figure, when the noise is high (e.g., \(\zeta =5.0\%\)), the high-frequency components (mainly noise) in the input data are sufficiently suppressed, while the flow frequency ones (\(f^*_t<0.2\), which is dominated by true flow structures) are preserved. When the noise level decreases (e.g., \(\zeta =1.0\%\) and \(0.1\%\)), our method recovers the particle trajectories at higher frequencies.

The temporal and spatial frequency response of the CLS-RBF PUM method. Temporal (a) and spatial (b) frequency response based on the TGV data; c temporal frequency response based on the synthetic HIT data. c blue, green, and scarlet lines represent the frequency response based on the HIT data with 0.1%, 1.0%, and 5.0% noise, respectively
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Li, L., Pan, Z. Three-dimensional time-resolved Lagrangian flow field reconstruction based on constrained least squares and stable radial basis function. Exp Fluids 65, 57 (2024). https://doi.org/10.1007/s00348-024-03788-y
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00348-024-03788-y