
Abstract
Communicating individual identity is essential for stable social systems. It is assumed that there are benefits for both senders and receivers to provide and discriminate identity cues. In this study, we investigate the possible routes senders use to acoustically broadcast their individual identity. Using discriminant function analysis of temporal and spectral acoustic measurements and analysis of song-element order, we explore the means male rock hyrax (Procavia capensis) singers utilize vocalization to express individual identity. Despite the fact that males use only three song elements, the pattern of acoustic characteristics, their temporal and frequency attributes vary according to the identity of singer. We show that in hyrax, individuality is expressed by highly variable, complex signals that are not condition dependent and are stable over years in singers that did not alter their spatial position. We also show that individuality signals are not linked to relatedness or to geographic location. The ability to discriminate individuals from vocal signatures needs to be further tested using controlled playback experiments.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
In many species, advertising individual identity is imperative for social interactions. Recognition is an important part of group living, as familiarity promotes stable social structure (Randall 1994). The ability to identify the sender of messages, and to react according to its reputation and reliability, has important fitness implications (Hare 1998; Charrier et al. 2001; Bee and Gerhardt 2002). Individual identity can be achieved through chemical (Columbelli-Negrel and Gouat 2006; Burgener et al. 2009), visual (Dale et al. 2001; Van Dyk and Evans 2007), or acoustical (see below) recognition. Theory states that traits signaling identity should be highly variable between individuals, yet stable within individuals, not be condition dependent, not be associated with fitness differences, and include a high degree of genetic determination (Dale et al. 2001).
Individual differences are likely to be found in all acoustically communicating species. In systems where this discrimination is important, selection should theoretically favor stereotypic calls, where differences can be easily perceived (Insley 2001). Differences between individuals in vocal signatures can be based on temporal variation or upon frequency (spectral) variation. Although mostly spectral variation is assessed when discussing individual signature in mammals, temporal cues have also been shown to provide important individual information, and both spectral and temporal domains are likely to code the individual signature (Searby et al. 2004).
Since each individual is unique in its physical build, source-filter theory predicts that in mammals, every individual would have its own unique spectral characteristics (Titze 1994). The theory is supported in several species, where individuality has been linked to frequency related parameters [e.g., fundamental frequency; fallow deer (Dama dama), Reby et al. 1998; Vannoni and McElligott 2007]. Temporal variations in vocalizations can be significant in expressing the individual’s condition and motivation, as keeping precise rhythmic pulses is a demanding task (Zahavi 1982). In some species, temporal parameters improved spectral-based discrimination [e.g., barking foxes (Alopex lagopus); Frommolt et al. 2003]. In other species, temporal characteristics were the main means of communicating identity [e.g., kangaroo rats (Dipodomys spectabilis); Randall 1994, rhesus macaques (Macaca mulatta); Ghazanfar et al. 2001, mice; Holy and Guo 2005). Individuals may also have a preference for using specific acoustic characteristics (or vocalization types), or using acoustic elements in individually unique sequence [e.g., harbor seals (Phoca vitulina); Hanggi and Schusterman 1994, African elephants (Loxodonta africana); Soltis et al. 2005]. In the past, we have shown that in rock hyraxes (Procavia capensis), both acoustic characteristics and spectral parameters are associated with individual traits (Koren and Geffen 2009). In this study, we investigate whether specific song elements, temporal variations in songs and bouts, and the order of vocal elements in the song can be used to differentiate individual singers.
The rock hyrax is a social mammal that lives in mixed-sex groups, comprising in our study area (Ein Gedi) several males (one mature immigrant resident and several natal late dispersers) and five to 20 females with their pups. Acoustic communication constitutes the most widely used means of information transfer among rock hyraxes (Fourie 1977). Both males and females produce loud repetitive warning trills, while some adult male hyraxes also engaged in rich and complex vocalizing behavior we term “singing” (Koren et al. 2008). Breeding is seasonal and synchronized (Mendelssohn 1965). Mate guarding and manipulation by the territorial male thus appear to be limited, probably offering subordinates an opportunity occasionally to sire offspring as well (Emlen and Oring 1977). Adolescent males (i.e., 17–24 months old) are forced to disperse (Hoeck et al. 1982) and live on the periphery of colonies or in bachelor groups (Koren et al. 2008). About a third of the sexually mature males in our study area sing: all resident males and some bachelor males (Koren et al. 2008). Singers are on average older, more dominant, and stressed (i.e., have higher cortisol levels) compared with other adult, non-singing, males (Koren et al. 2008). Their cortisol levels are associated with their social status (Koren et al. 2008). Singers perform complex songs throughout most of the year (Koren et al. 2008; Koren and Geffen 2009) and also countersing with neighboring males (Koren et al. 2008). Although the exact function of singing in the rock hyrax is currently unknown, we suspect that it may be related to sexual advertisement since it abruptly decreases for a few months following the mating period (Koren et al. 2008). Using multiple regressions, we showed that vocal elements and their characteristics are associated with specific individual characteristics (Koren and Geffen 2009). Specifically, we found that the overall amount of singing was indicative of the singers’ body weight, and that the chuck element (which is short and repetitive) explained both body size and cortisol levels. The snort element (which advertises formant frequencies due to its broad frequency spectrum) was associated with androgen levels (Koren and Geffen 2009). Two spectral characteristics were also found to be important in explaining individual characteristics: measurements of the fundamental frequency were associated with androstenedione levels and measurements of the formant frequency were associated with fur coverage and social status (Koren and Geffen 2009). However, in the previous analysis we did not investigate individual identity, and the information was not linked to specific hyraxes.
In the current study, we examine individuality in rock hyrax songs. Our hypothesis is that in order to have a meaningful context, the information (on the morphology, body condition, social status, and endocrine state) the songs store must also include the precise identity of the caller. We examined how identity signals are expressed and whether spectral or temporal domains provide information on individuality. We extracted and measured the spectral information provided by the minimum fundamental frequency and the temporal parameters of the three song elements (wail, chuck, and snort; Koren and Geffen 2009). Furthermore, we looked at the order of the song elements and its contribution to acoustic individuality. Since characters selected to signal individual identity are expected to have different properties from signals of quality (Dale et al. 2001), we concentrated in this paper on the communication of sender identity and also investigated, in this context, the individual acoustic variation in relation to affiliation, geographic distribution, and relatedness, all of which may influence song learning. Geographic proximity and interactions with conspecifics can cause cultural transition and imitation of songs heard from early age, as seen in many animals (e.g., Riebel and Smallegange 2003; Hernandez et al. 2009). In addition to affiliative learning, it is reasonable to assume that genetic relatedness may have some bearing on vocal anatomy, which will in turn explain differences in vocal stereotypy (Charlton et al. 2009). In many systems, it is difficult to distinguish between the two hypotheses. Since offspring often stay close to their natal burrows, their vocal performance may be shaped by both their genetics and by other singers nearby who may happen to be their relatives as well. The hyrax system offers an interesting study case since adult resident males are new immigrants (Koren et al. 2008), thus most likely genetically unrelated.
Methods
Study animals
We have been studying rock hyraxes in the Ein Gedi Nature Reserve (31°28′N, 35°24′E) since 1999 as part of a long-term study. Two 500-m-deep canyons, David and Arugot, constitute the reserve, which is located west of the Dead Sea in the Judean Desert, Israel. The two sites (in the two canyons) where we conduct our study are approximately 5 km apart. Hyraxes are mostly diurnal, and at these study sites they are relatively habituated, tolerating the presence of stationary humans at ≥10–20 m. Permits for capturing and handling the hyrax were issued and reviewed annually by the Israeli Nature and Parks Authority. The data presented in this paper pertaining to male hyrax songs was collected for 6 months annually (February–August; i.e., 1 month before parturition until the end of the mating period) over three consecutive years (2002–2004), under permit numbers 2002/14674, 2003/14674, and 2004/17687.
All singing males (both residents and bachelors; n = 18) were caught using live box traps, which were placed in natural crevices. Traps were set open before first light (approximately 90 min before dawn) and operated until noon, with inspections every 2 h. Trapped males were anesthetized with ketamine hydrochloride (0.1 ml/kg intramuscular injection), which sedated the animals to a state that allowed safe handling. Each male was individually marked using an electronic subcutaneous transponder (DataMars SA, Bedano-Lugano, Switzerland) and a numbered collar (collar weight 5 g; range of 0.125% to 0.2% of hyrax body weight). After marking and measuring, hyraxes were returned to the traps for full recovery (3 h) and thereafter released back at the capture site. All animals resumed full normal activity following their release.
Song recording and analysis
Singing behavior in our study area starts gradually in February (pre-parturition), peaks in August (mating period), and ceases abruptly thereafter. Hyraxes were observed using 10 × 42 binoculars and a telescope with ×50 and ×75 magnifications, from a distance of 10–80 m. Individual animals were recognized by their collars. Singing males were recorded in the morning, when sound propagation is at its peak (Titze 1994). In Ein Gedi, daily strong afternoon winds interfere with sound recordings. Singing is loud and can be heard by humans up to a distance of 500 m from the singer (LK, unpublished data). Song bouts (see definition below) last a few minutes, allowing the observer to locate and identify the recorded singer. The time, singer identity, and social situation (i.e., solo, duet, or chorus) during which songs were recorded were noted.
Singing males were tape recorded from about 50 m (range 10–80 m; by LK) with a Sennheiser ME 67 shotgun microphone (frequency response 50–20,000 Hz ±2.5 dB) powered by a Sennheiser K6 module and covered with a Sennheiser MZW70-1 blimp windscreen. The microphone was hand-held or placed on a tripod, using MZS20-1 shock mount with a pistol grip. Recordings were captured using a battery-operated, portable Marantz PMD-222 cassette recorder (frequency response for CrO2 tape 40–14,000 Hz; signal-to-noise ratio 57 dB) on Maxell XLII-60 analog tapes. Vocalizations were digitized using the Avisoft SAS Lab Pro software (version 4.38; R. Specht, Berlin) at a sampling frequency of 44.1 kHz, with 16 bits. After visual inspection, tracks were downsampled to 22.05 kHz using Avisoft’s antialiasing filter. Spectrograms (e.g., S1) were measured at 256 FFT lengths, 100% frame, using a Hamming window, which gave a frequency resolution of 86 Hz with a 112-Hz bandwidth and a temporal resolution of 5.8 ms at a 50% overlap.
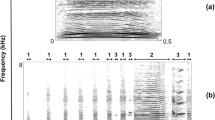
For this study, we analyzed only solo singing bouts where singers were not answered or interupted by other hyraxes. We defined a bout as consisting of several songs (range 3–43, average 16.7), with short pauses between them (< 5 s). We recorded 103 solo bouts from 10 known male singers in 2002, 106 solo bouts from six known singers in 2003, and 61 solo bouts from 12 known singers in 2004. On average, 15.9 different solo bouts were recorded per each of the 18 known singers (range 1–86). We picked vocalizations for analysis on merit of best signal-to-noise ratio. For each hyrax, we selected several (average 4.6; range 1–11) high-quality bouts for analysis. In each song (range 0.6–5.2, average 1.6 s), we identified three key elements: wails, chucks, and snorts, and measured 20 features (see Table 1 and Fig. S1; Koren and Geffen 2009). All songs, but one exception, started with the wail element. Wails are on average 0.6 s (and up to 1.3 s). A series of short (average 0.1 s) chuck elements (range 0–51, average 12.8) followed the wails. The snort element was used by only two thirds of singers (Koren and Geffen 2009) and either preceeded, or most often succeeded, the chucks. On average, 8.2 snorts were used in a song bout (range 0–63). The number of bouts, songs and elements within the song bouts, their durations, rates, and temporal variations were measured from the sonograms using the Avisoft SASLabPro cursors and transferred to Microsoft Excel datasheets for analyses. Using Avisoft’s cursors, we also measured minimum fundamental frequency for each bout. Element temporal and spectral measurements were averaged across each singing bout.

General discriminant function analysis for the acoustic features of male singers in Arugot (a) and David (b). Capital letters donate individual identity and subscripts the year the song was recorded and individual present at the site (2002–2; 2003–3; 2004–4)
Statistical procedures
Individual differences in acoustic song-bout features were analyzed for each site separately, using general discriminant function analysis (GDA; Statistica; StatSoft v. 8). Since the two canyons are located 5 km away, two singers from different canyons could have a similar vocal identity because they are not interacting and thus do not need to sound different from each other to be recognized by their conspecifics. The two sites were considered as independent replicates for testing whether singers have individual vocalization. The song-bout features were used as the response variables and the name of the hyrax as the classification variable. GDA determines a linear or non-linear combination of the dependent variables that best predicts group memberships. Because we used many predictors (20) and it is desired that group sample size be larger than the number of predictors, we applied a forward stepwise procedure with P to enter of 0.05. This process aims to eliminate redundant variables from the analysis. However, stepwise procedures are known to sometimes not select the best variable combination. To optimize model selection, we also looked at all possible predictor subsets from 1 to the number of parameters determined by the stepwise process. We first validated that what the model found by the stepwise procedure is among the best models and whether there are other models that substantially improve the classification of cases. The unique contribution of each variable to the discriminatory power of the model was evaluated by partial Wilk’s lambda and its associated statistics. The a priori classification probabilities were set to give equal weight to each individual. Classification functions were used to calculate the posterior classification probabilities for each song. Assignment of each song to an individual was designated by the highest posterior probability. Leave-one-out cross-validation procedure was used for evaluating the performance of the discriminant functions. Violations of the normality assumption in GDA still result in reliable significance tests as long as non-normality is caused by skewness and not by outliers (Tabachnick and Fidell 1996). Nevertheless, we normalized all the predictors by using the Box–Cox transformation, except singing and rchuck, which were normally distributed.
For each singer, we also noted the order in which song elements were used and coded it as a series of binary variables (presence or absence of each element in a song sequence). We used correspondence analysis (CA) to separate between singers using seven possible song element (i.e., wail, chuck, and snort) combinations (Table 2). CA is an exploratory method designed to measure correspondence between the rows and columns in contingency tables. In our case, the results expected to show the tendency of each male to produce specific element combinations, information that can be used to separate singers on the basis of element order.
We used the Mahalanobis distance between individual centroids, generated by the discriminant function analysis, as the measure of differences between individuals based on their vocal profile. The Jaccard Binary distance was used as the measure of difference between individuals based on their vocal elements order. To test whether vocalization-related distances between individuals are associated with the location where singers reside (i.e., geographic distance), their social relationship (probability of association), or kinship (genetic relatedness), we correlated between the above distance matrices using Mantel’s test. Male center of activity was estimated as the mean of all focal observation coordinates during each year. Social relationship was expressed as the probability of association, calculated by the iterative proportional fitting (IPF) procedure following Freeman et al. (1992). This procedure was developed to estimate cell probabilities in contingency tables subject to certain marginal constraints. Calculations of cell probability of association were done using the Dominance Structure Applet developed by Robert Huber.
Genetic analysis
We screened 230 individuals (all hyraxes in our study site between 1999 and 2005) using 12 polymorphic microsatellite loci. All hyraxes were caught using baited live traps (see above). A small sample of ear tissue was cut with sterile surgical scissors and stored in a vial containing dimethyl sulfoxide, EDTA, and NaCl. DNA was extracted using proteinase K followed by two phenol–chloroform extractions. We constructed a “microsatellite-enriched” genomic library following previously described protocols (e.g., Nyakaana and Arctander 1998; Ciofi and Bruford 1998). After isolation of recombinant DNA molecules and sequencing DNA inserts, specific primer pairs were designed for the region immediately flanking the repeat sequence, for each microsatellite identified. Additional primers were designed using a microsatellite-enriched library we received from Dr. Stacey Lance and Jesús E. Maldonado, and from the hyrax genome sequence available at NCBI (ftp.ncbi.nih.gov). In addition, we used two primers previously published for bush and rock hyrax (Gerlach et al. 2000) that were also polymorphic in our population. The mean number of alleles (±SD) was 3.8 ± 1.3, mean expected heterozygosity was 0.49 ± 0.18, and four out of the 12 loci showed heterozygote deficiency (see S2 for more details).
We calculated kinship between males using a maximum-likelihood relatedness measure (MLR; Wagner et al. 2006), which is implemented in the program ML-relate (Kalinowski et al. 2006). We selected MLR because this relatedness index has a desirable range of values between 0 and 1, and it was shown to be more accurate than other estimators (Milligan 2003). In general, MLR r values of 0 correspond to non-relatives and r ≥0.5 to full sibs or parent–offspring. The uncertainty surrounding relatedness estimates was assessed by ML-relate using sampling procedures (Kalinowski et al. 2006). Maximum-likelihood relatedness values were calculated for all possible pairs of individuals in the population, and the relatedness values for all singer pairs in this study were extracted from the larger MLR matrix. Out of 27 singer pairwise combinations, eight had relatedness values equal or larger than full sibs level (relatedness r ≥ 0.5). Detailed data on microsatellite primers loci and variability can be found in Table S2.
Results
Singer classification by song-bout features
We observed four and seven males frequently singing in the Arugot and David canyons, respectively. Two additional males in each location were excluded from the analysis because they rarely sang and had few recordings. The forward stepwise GDA was able to exclude most predictors, and the ones left in the analysis showed considerable classification power of songs in both locations (Fig. 1). The model selected for Arugot was composed of four predictors (singing, maxwail, twail, minf), which correctly classified 93.3% of the songs and also cross-validated correctly 93.3% of cases (Fig. 1a). The tolerance for each of the selected variables was >0.3. Wilk's lambda for the model was 0.02 (F 12,61 = 17.2, P < 0.0001), indicating that most of the variance in the predictors’ matrix is explained by the grouping into singers. Further, all pairwise Mahalanobis distances between singer centroids were significantly larger than expected by random (P ≤ 0.02 in all comparisons). The analysis identified three functions, which accounted for 80.9% (eigenvalue = 9.8), 11.1% (1.3), and 8.1% (1.0), and contributed significantly to the discrimination (P < 0.0001 in all). The factor structure coefficients, which are the correlations between the variables in the model and the discriminant functions, indicated highest correlation between twail and first function, minf and the second function, and maxwail and singing with the last function. Out of 30 songs, only two were misclassified, one for singer B and one for D (Fig. 1a). We scanned all possible models of one to four parameters. There were 38 best subsets composed of four parameters and correctly classified 93.3% of songs. The model selected by the stepwise process was one of them. The most frequent predictors observed in all these equally probable models were maxwail, twail, singing, and rchuck (Fig. 2), which appeared at significantly lower frequencies in David songs (χ 219 = 108.9, P < 0.0001; permutation test). In addition, the best subset procedure discovered a single three-parameter model (maxwail, twail, and rchuck) with similar classification success as the one selected through the stepwise process. All other models had lower classification success.

Frequency of song-bout variables in the best 38 GDA models for Arugot (black bars) and best 13 GDA models for David (white bars)
The classification of songs for David singers was much more complex (Fig. 1b). The stepwise model for David was composed of maxchuck, rbout, tbout, nsnort, and minf. Of these, only minf was shared between the models selected for Arugot and David. The stepwise model for David correctly classified 78.9% of the songs but cross-validated correctly only 55.3% of cases (Fig. 1b). The tolerance for each of the selected variables was >0.45. Wilk's lambda for the model was 0.04 (F 30,110 = 4.6, P < 0.0001). All pairwise Mahalanobis distances between singer centroids were significantly larger than expected by random (P ≤ 0.05 in all comparisons), except for four cases (males E–G, H–I, H–J, and I–J). The analysis identified five functions, which accounted for 54.0% (eigenvalue = 3.1), 25.1% (1.4), 11.4% (0.7), 7.6% (0.4), and 1.9% (0.1), but only the first four contributed significantly to the discrimination (P < 0.025). Out of 38 songs, eight songs were misclassified and only songs of two singers were classified with error (F and G; Fig. 1b). We scanned all possible models of one to five parameters. The three best subsets composed of five parameters correctly classified 87.8% of songs. The 10 next best models classified correctly 84.2% of songs. The model selected by the stepwise process was the 77th best model; however, the difference in classification performance between these models is not great. Examining the first 13 best five-parameter models showed that maxchuck, nsnort, and minf are the most frequent predictors (Fig. 2), which appeared at significantly lower frequencies in Arugot songs (χ 219 = 108.9, P < 0.0001; permutation test). The three best models identified did not improve on the cross-validation classification success (45–53%) compared to the model selected by the stepwise process. Close examination of Fig. 1 clearly shows that individuals H, I, J, and K occupy the same space, which means that based on distances from their centroids, these singers are inseparable. However, a clear temporal partition is notable. Males J and K were present mostly during 2002, I in 2003, and H in 2004. Exclusion of singers not present at a specific year resulted in 75.0% of cases correctly classified in 2002, 95% in 2003, and 95.5% in 2004. These results imply that the space cluttered with H, I, J, and K was in fact dominated by one to two males at any given year. In sum, in both sites classification success of singers by their vocal profile is reaching above 80% and can approach 95% when temporal overlap is considered.
Our DFA analysis suggests little change in the vocal profile for singers that were spatially stable over the course of this study. This is apparent mostly in Arugot where the male turnover was low. Specifically, individuals B and C were singers during 2002–2004 (Fig. 1a). The correct assignment of songs for individuals B and C was 88% and 100%, respectively, regardless of the year. The correct assignment for D was 88%, and that was due to one 2002 song that was clumped with individual A. However, individual A was present at this site only during 2004 (Fig. 1a). The singer turnover in the David canyon was more rapid, and the only stable case, over years, was singer F (100% correct assignment of songs; Fig. 1b).
Singer classification by vocal elements order
All but one male (A) produced the WC combination more often than any other elements combination (Table 2). Male A mostly chucked and snorted, a rare combination in other males. Further, males D and G tended, relative to others, to produce only the wail element; males G and H produced more often the chuck element; and males A, G, and H produced more often the WS elements combination (Table 2). We used correspondence analysis to test for these associations between males and song elements (Fig. 3). The contingency table chi square is highly significant (χ 260 = 476.6, P < 0.0001; permutation test), indicating an association between specific song elements and individual males. The first three dimensions accounted for 37.0% (inertia = 0.259), 27.7% (inertia = 0.195), and 22.5% (inertia = 0.158) of the variance, respectively. Those differences in song element frequencies may provide the initial step for discriminating among individuals. An animal like male A is distinctively different from others (Fig. 3a, b). Combining the CA outcome and temporal data allows us limited separation among individuals. The Arugot males (A–D) are clearly separated on the CA dimensions; the only two that are fairly close to each other are B and C (Fig. 3a, b). Individuals G and H are the only ones from the David canyon males that are clearly distinct (Fig. 3a, b). We also know that males J and K were around only in 2002, I mostly in 2003, and E and F mostly in 2004 (Fig. 1b).

Correspondence analysis for male singers (A–K) and song element (W wail, C chuck, S snort) combinations (in parentheses). The figure shows the canonical dimension 1 versus canonical dimension 2 (a), and canonical dimension 1 versus canonical dimension 3 (b)
Variables explaining stereotypy
The Mahalanobis distances between male centroids, reflecting the differences in vocal profile, did not significantly correlate with the probability of social association (Mantel's test; r 6 = 0.13, P = 0.809, power = 0.05 and r 21 =−0.33, P = 0.148, power = 0.30 for Arugot and David, respectively) or with genetic relatedness (r 6 =−0.01, P = 0.984, power = 0.05 and r 21 = 0.12, P = 0.610, power = 0.08 for Arugot and David, respectively). The geographic distances between male centers of activity did not correlate with Mahalanobis distance in either site (2002—r 21 = 0.048, P = 0.837, power = 0.05; 2003—r 10 =−0.093, P = 0.798, power = 0.06; 2004—r 28 =−0.095, P = 0.632, power = 0.08). The Jaccard distances between males, reflecting differences in elements order, did not significantly correlate with the probability of association (r 6 = 0.44, P = 0.388, power = 0.12 and r 21 =−0.20, P = 0.389, power = 0.13 for Arugot and David, respectively) or genetic relatedness (r 6 = 0.12, P = 0.820, power = 0.05 and r 21 = 0.21, P = 0.352, power = 0.15 for Arugot and David, respectively). The geographic distances between male centers of activity did not correlate with Jaccard distances in either site (2002—r 21 = 0.111, P = 0.633, power = 0.08; 2003—r 10 = 0.157, P = 0.665, power = 0.07; 2004—r 28 = 0.048, P = 0.806, power = 0.06). In sum, neither the geographic distances between singers nor the level of social association or genetic relatedness between them explained the variance in their vocal stereotypy.
Discussion
A unique individual signature assists recognition, which is the basis for social systems. Our results show that in the social rock hyrax, their unique acoustic features and temporal data can individually identify males. Based on our results, we cannot conclude whether temporal or spectral information is more important in communicating individuality. Both are important and used differently by different individuals in different geographical areas. We clearly show that various song variables and attributes contribute to the communication of individuality. Regardless of the large variation and usage of song elements, separation based on element order was less powerful, which may support the theory that in systems where individual discrimination is important, stereotypic calls, which highlight individual differences, are favored (Insley 2001). Despite that, some males have very strong tendencies to use element combinations not used by others, making them distinctive.
Dale et al. (2001) suggested that traits signaling identity should be highly variable, not be condition dependent, and include a high degree of genetic determination (Dale et al. 2001). In our data, we found that identity is not stored in a specific feature. It is, indeed, as shown in Fig. 2, based on various features, and different between our two study sites (i.e., Arugot and David). In other words, there are many possible combinations of features to generate a reliable identity signal, supporting Dale et al.’s theory. This finding greatly contrasts quality-advertising elements and features, which are consistent across individuals and geographic locations (Koren and Geffen 2009). For example, formant frequencies were associated with age and body condition in singing hyraxes in both our study sites (Koren and Geffen 2009) and were therefore not suspected as identity signals. Although vocalizations are known to change with age or body condition (Titze 1994), individual differences persisted in adult hyraxes, which retained their vocal identity over several years. Our data could not support Dale et al.’s theory pertaining to genetic determination. Although voices of relatives are expected to be similar (Price 1998), in hyraxes we found that identity signature was not related to the genetic relatedness between males. Similarity between voices of relatives in hyrax could also be encoded in different parameters or in a different way from the individual signature, which has not been tested in this study. In giant pandas (Ailuropoda melanoleuca), for example, genetically related pairs used similar amplitude modulation rate and fundamental frequency range (Charlton et al. 2009), features that we did not test in this study. We also failed to find relations between vocal identity signature and level of social interaction between individuals, or geographical position. We expected to see a relation between male geographical location and their individual song, similar to that found in male common loons (Gavia immer) where individually characteristic yodels change when they change their territories, clearly differentiating themselves from the last resident of the new territory (Walcott et al. 2006). Male hyraxes also need to differentiate themselves from potential opponents, yet geography alone is not the trigger for the vocal differentiation. On the other hand, geographic vicinity can facilitate learning and imitation, allowing animals that share a physical space to share vocal repertoires or preferences (Hernandez et al. 2009). In the hyrax system, neighboring individuals did not share more vocal components than distant ones. We know from other systems that vocal recognition is important for various social and survival means. For example, playback experiments in the red deer (Cervus elaphus) showed that females were able to discriminate between the roars of their harem-holding stag and those of other neighboring stags (Reby et al. 2001). In juvenile Richardson's ground squirrels (Spermophilus richardsonii), identifying an alarm caller as a familiar group member, as opposed to a stranger, elicits greater vigilance (Hare 1998).
Hyraxes in Ein Gedi are highly social. While female membership in groups is stable over years, adult males may reside with a group of females for only up to 3 years (Koren et al. 2008). Bachelor males stay in the vicinity and interact with mixed-sex groups mainly around feedings. Bachelors have been observed mating with females (Koren et al. 2008), thus directly competing with resident males. Although hyrax use chemical (odor) and visual cues to communicate and recognize each other, acoustic recognition between group members is vital due to the complexity of their habitat. Hyrax song can provide accurate information on body size, weight, condition, social status, and hormonal profile of the singer (Koren and Geffen 2009). All of this information is individually specific, and is pertinent in advertising newcomers to the area, which are the majority of the singers (Koren and Geffen 2009). These messages are communicated via sound frequency and occurrence or presence of vocal components (Koren and Geffen 2009). Multiple pathways are also used to accentuate individual-based differences, which, as we show here, are independent of relatedness and geographic or social affiliation. Multiple advertising pathways are more stable at withstanding potential corruption due to environmental distortion or interruption by other singers. Such mechanisms ensure long-lasting dependable communication networks. These various pathways may also be used to advertise identity to various audiences (e.g., potential mates vs. potential competitors). The ability to differentiate male vocalization based on song features and pattern must be further tested, in the field, using manipulative playback experiments.
References
Bee MA, Gerhardt HC (2002) Individual voice recognition in a territorial frog (Rana catesbeiana). Proc R Soc B 269:1443–1448
Burgener N, Dehnhard M, Hofer H, East ML (2009) Does anal gland scent signal identity in the spotted hyaena? Anim Behav 77:707–715
Charlton BD, Zhihe Z, Snyder RJ (2009) Vocal cues to identity and relatedness in giant pandas (Ailuropoda melanoleuca). J Acoust Soc Am 126:2721–2732
Charrier I, Mathevon N, Jouventin P (2001) Mother's voice recognition by seal pups—newborns need to learn their mother's call before she can take off on a fishing trip. Nature 412:873–873
Ciofi C, Bruford MW (1998) Isolation and characterization of microsatellite loci in the Komodo dragon Varanus komodoensis. Mol Ecol 7:134–136
Columbelli-Negrel D, Gouat P (2006) Male and female mound-building mice, Mus spicilegus, discriminate dietary and individual odours of conspecifics. Anim Behav 72:577–583
Dale J, Lank DB, Reeve HK (2001) Signaling individual identity versus quality: a model and case studies with ruffs, queleas, and house finches. Am Nat 158:75–86
Emlen ST, Oring LW (1977) Ecology, sexual selection, and evolution of mating systems. Science 197:215–223
Fourie PB (1977) Acoustic communication in rock hyrax, Procavia capensis. J Comp Ethol 44:194–219
Freeman LC, Freeman SC, Romney AK (1992) The implications of social structure for dominance hierarchies in red deer, Cervus elaphus. Anim Behav 44:239–245
Frommolt KH, Goltsman ME, MacDonald DW (2003) Barking foxes, Alopex lagopus: field experiments in individual recognition in a territorial mammal. Anim Behav 65:509–518
Gerlach G, Derschum HS, Martin Y, Brinkmann H (2000) Characterization and isolation of DNA microsatellite primers in hyrax species (Procavia johnstoni and Heterohyrax brucei, hyracoidea). Mol Ecol 9(10):1675–1677
Ghazanfar AA, Smith-Rohrberg D, Hauser MD (2001) The role of temporal cues in rhesus monkey vocal recognition: orienting asymmetries to reversed calls. Brain Behav Evol 58:163–172
Hanggi EB, Schusterman RJ (1994) Underwater acoustic displays and individual variation in male harbor seals, Phoca vitulina. Anim Behav 48:1275–1283
Hare JF (1998) Juvenile Richardson's ground squirrels, Spermophilus richardsonii, discriminate among individual alarm callers. Anim Behav 55:451–460
Hernandez AM, Pfaff JA, MacDougall-Shackleton EA, MacDougall-Shackleton SA (2009) The development of geographic song preferences in female song sparrows Melospiza melodia. Ethology 115:513–521
Hoeck HN, Klein H, Hoeck P (1982) Flexible social organization in hyrax. J Comp Ethol 59:265–298
Holy TE, Guo ZS (2005) Ultrasonic songs of male mice. PLoS Biol 3:2177–2186
Insley SJ (2001) Mother–offspring vocal recognition in northern fur seals is mutual but asymmetrical. Anim Behav 61:129–137
Kalinowski ST, Wagner AP, Taper ML (2006) ML-Relate: a computer program for maximum likelihood estimation of relatedness and relationship. Mol Ecol Notes 6:576–579
Koren L, Geffen E (2009) Complex call in male rock hyrax (Procavia capensis): a multi-information distributing channel. Behav Ecol Sociobiol 63:581–590
Koren L, Mokady O, Geffen E (2008) Social status and cortisol levels in singing rock hyraxes. Horm Behav 54:212–216
Mendelssohn H (1965) Breeding in the Syrian hyrax. Int Zoo Yearb 5:116–125
Milligan BG (2003) Maximum-likelihood estimation of relatedness. Genetics 163:1153–1167
Nyakaana S, Arctander P (1998) Isolation and characterization of microsatellite loci in the African elephant, Loxodonta africana. Mol Ecol 7:1436–1437
Price JJ (1998) Family- and sex-specific vocal traditions in a cooperatively breeding songbird. Proc R Soc B 265:497–502
Randall JA (1994) Discrimination of footdrumming signatures by kangaroo rats, Dipodomys spectabilis. Anim Behav 47:45–54
Reby D, Joachim J, Lauga J, Lek S, Aulagnier S (1998) Individuality in the groans of fallow deer (Dama dama) bucks. J Zool 245:79–84
Reby D, Hewison M, Izquierdo M, Pepin D (2001) Red deer (Cervus elaphus) hinds discriminate between the roars of their current harem-holder stag and those of neighbouring stags. Ethology 107:951–959
Riebel K, Smallegange IM (2003) Does zebra finch (Taeniopygia guttata) preference for the (familiar) father's song generalize to the songs of unfamiliar brothers? J Comp Psychol 117:61–66
Searby A, Jouventin P, Aubin T (2004) Acoustic recognition in macaroni penguins: an original signature system. Anim Behav 67:615–625
Soltis J, Leong K, Savage A (2005) African elephant vocal communication II: rumble variation reflects the individual identity and emotional state of callers. Anim Behav 70:589–599
Tabachnick BG, Fidell LS (1996) Using multivariate statistics. Harper Collins, New York
Titze IR (1994) Principles of vocal production. Prentice-Hall, Englewood Cliffs.
Van Dyk DA, Evans CS (2007) Familiar–unfamiliar discrimination based on visual cues in the Jacky dragon, Amphibolurus muricatus. Anim Behav 74:33–44
Vannoni E, McElligott AG (2007) Individual acoustic variation in fallow deer (Dama dama) common and harsh groans: a source-filter theory perspective. Ethology 113:223–234
Wagner AP, Creel S, Kalinowski ST (2006) Estimating relatedness and relationships using microsatellite loci with null alleles. Heredity 97:336–345
Walcott C, Mager JN, Piper W (2006) Changing territories, changing tunes: male loons, Gavia immer, change their vocalizations when they change territories. Anim Behav 71:673–683
Zahavi A (1982) The pattern of vocal signals and the information they convey. Behaviour 80:1–8
Acknowledgments
We are obliged to B. Sanzenbacher, I. Aravot, and E. Tauber for their extensive help with the trapping of the hyraxes as well as to the many project students, field guides, and park rangers who helped in the field. We wish to thank the Nature and Parks Authority for permission to work at the Ein Gedi Nature Reserve and the Ein Gedi Field School for their hospitality and logistic help. Stacey L. Lance from Savannah River Ecology Laboratory, Aiken, SC and Jesús E. Maldonado from The Smithsonian Institution generously assisted in the setup of microsatellite libraries. Amiyaal Ilani, M. Ross Lein, and two anonymous reviewers provided excellent comments. This study was supported by two grants from the Israel Academy of Sciences and Humanities (ISF 577/99 and 488/05).
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by G. Wilkinson
Electronic supplementary material
Below is the link to the electronic supplementary material.
S1
Sample sonogram of hyrax song containing the elements wail, chucks, and snort (from left to right). Most songs begin with a wail, followed by multiple chucks and sometimes snorts (taken from Koren and Geffen 2009) (PDF 110 kb)
S2
Locus name, primer sequence, repeat unit (RU), source, number of alleles (N), expected heterozygosity (H e ), and the probability of allelic deficiency (P ad ) for the population of hyrax in Ein Gedi (n = 230) (DOC 104 kb)
Rights and permissions
About this article
Cite this article
Koren, L., Geffen, E. Individual identity is communicated through multiple pathways in male rock hyrax (Procavia capensis) songs. Behav Ecol Sociobiol 65, 675–684 (2011). https://doi.org/10.1007/s00265-010-1069-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00265-010-1069-y