
Abstract
Background
FDG-PET is frequently used as a marker of synaptic damage to diagnose dementing neurodegenerative disorders. We aimed to adapt the items of evidence quality to FDG-PET diagnostic studies, and assess the evidence available in current literature to assist Delphi decisions for European recommendations for clinical use.
Methods
Based on acknowledged methodological guidance, we defined the domains, specific to FDG-PET, required to assess the quality of evidence in 21 literature searches addressing as many Population Intervention Comparison Outcome (PICO) questions. We ranked findings for each PICO and fed experts making Delphi decisions for recommending clinical use.
Results
Among the 1435 retrieved studies, most lacked validated measures of test performance, an adequate gold standard, and head-to-head comparison of FDG-PET and clinical diagnosis, and only 58 entered detailed assessment. Only two studies assessed the accuracy of the comparator (clinical diagnosis) versus any kind of gold−/reference-standard. As to the index-test (FDG-PET-based diagnosis), an independent gold-standard was available in 24% of the examined papers; 38% used an acceptable reference-standard (clinical follow-up); and 38% compared FDG-PET-based diagnosis only to baseline clinical diagnosis. These methodological limitations did not allow for deriving recommendations from evidence.
Discussion
An incremental diagnostic value of FDG-PET versus clinical diagnosis or lack thereof cannot be derived from the current literature. Many of the observed limitations may easily be overcome, and we outlined them as research priorities to improve the quality of current evidence. Such improvement is necessary to outline evidence-based guidelines. The available data were anyway provided to expert clinicians who defined interim recommendations.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Notwithstanding their still limited validation [1], neuroimaging biomarkers that assess neurodegeneration, like magnetic resonance imaging or fluorodeoxyglucose positron emission tomography (FDG-PET), are crucial in the diagnosis of dementing disorders. They help to unveil whether observed cognitive impairment is associated with a neurodegenerative condition, to be further identified with the use of pathophysiological biomarkers, that are, however, not available for all neurodegenerative disorders to date [2]. Moreover, neuroimaging biomarkers can inform about the stage of the disorder. Neuronal damage constitutes the latest biological event in the long pathophysiological course of the most common Alzheimer’s disease (AD) [3], and the one better corresponding to, and predicting the, severity of symptoms [2].
Among neuroimaging biomarkers, FDG-PET is used very frequently to ascertain the presence of neurodegeneration, even at early symptomatic stages, for its sensitivity to synaptic dysfunction, an event that precedes neuronal death. Being able to detect hypofunction in the cerebral regions that are first vulnerable to the disease, the pattern of hypometabolism is also used to address diagnosis, based on current knowledge of the circuits differentially involved in different neurodegenerative disorders. Unfortunately, though, our knowledge of the pathophysiology of such disorders is still limited, and correspondence of clinical symptoms, hypometabolic patterns, and underlying pathologies imperfect.
Given this context, we explored the quality of available FDG-PET diagnostic studies, to see whether they provide the evidence required to assess the clinical validity [4] of this biomarker, very frequently used in the clinical diagnosis of neurodegenerative conditions. Such evidence is required to outline usage guidelines [5, 6], that are still lacking. We performed such assessment for a wide range of clinical scenarios, to assist decisions for the joint European Association of Nuclear Medicine (EANM) and European Academy of Neurology (EAN) recommendations aimed to guide clinicians in the diagnostic use of FDG-PET [7]. The aim of this paper is to describe how we adapted the domains of evidence quality assessment to the field of FDG-PET-based diagnosis within current methodological frameworks specific to diagnostic studies [5, 8,9,10,11,12], and provide an overall report of the quality of current studies.
Methods
Project structure
By an initiative of the EANM, and in association with the EAN, seven experts in FDG-PET and neurodegenerative disorders have been nominated by the two societies [7]. They outlined 21 Population-Intervention-Comparison-Outcome (PICO) questions addressing clinical scenarios requiring guidance for FDG-PET use in the setting of memory clinics (Table 1), and performed the correspondent literature searches (see Table 2). Papers were screened and selected to include those reporting the comparison of interest and quantitatively assessing the index-test performance; the included studies were assessed as outlined in the following sections. The seven panelists were appointed to produce recommendations taking into consideration the so assessed incremental value of FDG-PET, as added to clinical-neuropsychological examination, for the diagnosis and management of patients with different dementing neurodegenerative disorders. Consensus recommendations on whether prescribing FDG-PET in the diagnostic procedure for these scenarios have been produced with a Delphi procedure based on the expertise of panelists, informed about the availability and quality of evidence [7].
Terminology
Throughout the whole project, we distinguished between clinical syndromes and pathophysiological disorders, consistent with the new lexicon made necessary by the advent of biomarkers for AD [13, 14]. The distinction between clinical stage, syndrome and pathophysiology [15] is now explicit for AD, but not yet fully outlined for other disorders, like frontotemporal lobar degeneration (FTLD) or Lewy bodies dementia (LBD), although it is being considered [16]. Although sometimes potentially controversial, such an approach was required to answer PICO questions like those about “detecting DLB (dementia with Lewy Bodies) in MCI patients”.
Although this paper is not aimed at providing an exhaustive definition of methodological assessment for diagnostic studies, we define below some key terms; more information can be found in the methodological literature on evidence assessment of diagnostic tests (http://methods.cochrane.org/sdt/handbook-dta-reviews) [8, 10,11,12, 17, 18].
- Index test:
-
The test with which diagnostic performance is assessed (FDG-PET in our case);
- Comparator:
-
The test (or diagnostic procedure) with which the performance of the index test is compared, in order to assess its incremental value; in our case, the comparator is the traditional clinical and neuropsychological examination. In the EANM-EAN initiative, FDG-PET is meant as an add-on to the conventional clinical-neuropsychological procedure. However, diagnostic studies designed to compare the performance of index-test and comparator are the tools allowing decision-making also for add-on tests.
- Gold-standard:
-
The most accurate independent test demonstrating absence or presence of the target pathology (e.g., autopsy confirmation).
- Reference-standard:
-
The best available independent diagnostic confirmation under reasonable conditions (e.g., clinical diagnosis at follow-up).
- Critical outcome:
-
Critical outcomes are the quantitative measures that allow objective assessment of literature quality. In the case of diagnostic studies, the appropriate critical outcomes are the validated measures of test performance (sensitivity, specificity, accuracy, area under the curve - AUC, positive predictive value - PPV, negative predictive value - NPV, positive and negative likelihood ratios) quantifying the ability of FDG-PET to detect the appropriate clinical diagnosis, as assessed with comparison with the appropriate gold- or reference-standard.
- Head-to-head comparison:
-
Comparative analysis of the performance of the index test and the comparator, both being assessed versus the same independent gold- or reference-standard.
- Incremental diagnostic value:
-
Difference in the amount of information provided by the examination added to a diagnostic procedure. The computation of such difference requires that both the traditional diagnostic procedure and that the added examination are tested versus the same gold- or reference-standard (see head-to-head comparison).
Literature searches and eligibility
The electronic search strategy was performed using strings composed of an FDG-PET diagnostic component, common to all PICOs, and of parts specific to each PICO question. Terms selection was largely inclusive to pick variations (Table 2). Syntaxes were adapted to the following databases: Embase, Pubmed, Google Scholar and CrossReference. Papers including the comparison of interest and the minimum sample size published up to November 2015 were assessed. No minimum sample size was set whenever pathology-based gold-standard was available; otherwise, it was set by the referent panelist, based on the frequency of the disorder and the sample sizes normally available in the literature (Table 2). Studies were first hand-searched by the referent panelist, who could include additional papers, based on personal knowledge or references tracking. Panelists also made a first screening based on abstracts. The full text of these potentially eligible studies was then independently assessed for eligibility by the methodology team.
Data extraction
Data extraction was set and performed by the methodology team, including researchers with experience in consensus procedures and methodology (MB, CF and DA) and in clinical practice (SO, FG). We extracted a large set of variables (see supplemental material at https://drive.google.com/open?id=0B0_JB3wzTvbpVFYtUGxHdGZWYmc), consistent with currently accepted guidance [5, 8, 12]. The extracted data included:
-
Study characteristics: author, year of publication, citation rate, study design, sample size, duration of follow-up;
-
Population features: demographics, clinical and neuropsychological features of the studied samples (e.g., sample size, age, gender, clinical diagnosis, clinical criteria, MMSE score, CDR score, duration of illness, patient recruitment and accounting; time to conversion or follow-up if pertinent);
-
Index test features: scanner technical details (those older than 2005 being considered as possible cause of inconsistencies [19]), scan reading and statistical analysis;
-
Reference-/gold-standard features: diagnostic criteria, use of biomarkers;
-
Critical outcomes: sensitivity, specificity, accuracy, positive/negative predictive value (PPV/NPV), area under the curve (AUC), or positive/negative likelihood ratios (LR+/LR-); other critical outcomes if applicable.
Data were extracted by a single reviewer for each PICO. If not available, we computed confidence intervals for the critical outcomes whenever possible. In one case of inconsistent findings [20] we recomputed values based on the data provided.
Assessment of the quality of evidence
The assessment was based on study design, scan reading procedure, risk of bias, index test imprecision, applicability, effect size, total number of subjects, and effect inconsistency (Table 3) [10,11,12]. Reviewers assessed the quality of evidence of individual studies independently. Then, the global assessment of each outcome (i.e., each of the different measures of test performance, such as accuracy, AUC, PPV, etc.) across studies [18, 22] was proposed by the data extractor and then discussed and fine-tuned consensually within the methodology team, taking into account the quality of the individual source studies.
Based on the resulting assessment, the quality of evidence was then ranked within the 21 PICOs. More precisely, PICOs lacking critical outcomes entirely were put at the lowest level, while those with soundest methodology, numerous studies, large total number of included subjects, and large and consistent effect size and were graded best. The other PICOs were ranked in between. In this way, we provided information about relative availability of evidence, classified in four levels as “very poor/lacking”, “poor”, “fair” and “good”.
Starting level of evidence and decision flow in data assessment
Based on currently accepted procedures of evidence assessment [18], the strongest quality of evidence needs to ground on randomized clinical trials performed in subjects undergoing and not undergoing FDG-PET-based diagnosis, and comparing relevant clinical outcomes (i.e., patients’ health, survival, quality of life, costs), as the dependent variables, in the two conditions. These studies are currently not available in the FDG-PET literature. In order to allow evidence-based decisions for the use of diagnostic tests, assessment of the quality of currently available diagnostic studies of test performance, or accuracy studies, is deemed acceptable [10, 11], provided that such studies have a good starting quality and strong methodology, i.e., they must report validated measures of test performance and perform head to head comparison between the index test and the comparator. Moreover, evidence must exist, linking test performance to patient outcomes [10, 11]. Again, in the field of FDG-PET such evidence is often not available. The lack of this information prevents demonstration of both utility of the exam or lack thereof (Table 3), and thus prevents deriving any decision to support clinical use from evidence.
We have then assessed FDG-PET diagnostic studies as to any other quality item that was available and pertinent to assess the starting quality of evidence and risk of bias, in order to provide anyway information of the current status of the available literature. We thus assessed study design, the presence of quantitative measures of test performance (constituting the critical outcomes in our assessment) of the index test (FDG-PET), the adequacy of gold- or reference-standards, and factors negatively (section 2.5.2) or positively (section 2.5.3) affecting the starting quality of evidence (Table 3).
Gold- or acceptable reference-standards were pathology, biomarker-based diagnosis, confirmation of diagnosis or decline at clinical follow-up; presence of specified mutations was considered gold-standard for familial AD and Huntington disease; clinical diagnosis was considered gold standard for ALS. In our assessment, we extracted and assessed data also for those papers where the reference-standard used to compute the value of critical outcomes was the mere baseline clinical diagnosis. However, we did not consider these studies as providing evidence of diagnostic utility of FDG-PET, since they do not provide any independent reference standard for the index test.
Factors negatively affecting the starting level of evidence
Factors negatively affecting the starting quality of evidence relate to biases preventing to remove the effect of confounders. They are either the same as for intervention studies or not pertinent to FDG-PET studies (Table 4). Further specifications are reported for the outcomes below.
-
Lack of blinding: to the aim of assessing FDG-PET utility, it is required that scan readers be blind to clinical, diagnosis and gold-standard information for the examined patients.
-
Use of non-validated outcome measures: many studies reported only patterns of hypometabolism associated with the target disease, resulting from regression analyses or t-test comparison of patients versus controls. These are considered as “typical” for the examined disease, but do not provide any quantification of univocal correspondence with the target diagnosis, nor any measures of test accuracy, and were thus considered as providing no evidence of utility, although data were anyway extracted and presented. Exceptions were PICOs 18 and 20, based on the specific target of the PICO question. When available, measures of clinical outcomes like change in diagnosis, diagnostic confidence, treatment and prediction of survival were included in our assessment as proxies.
-
Indirectness: sources for indirectness of evidence relating to the ultimate link with patient outcomes and to the lack of direct comparison with the comparator were already accounted for in the assessment of the starting quality of evidence. Among factors negatively affecting the starting quality of evidence in terms of indirectness, we thus considered only the differences between the study population, intervention or outcomes of interest reported in the study compared to those addressed in the pertinent PICO question. These included sample features limitedly representative of the target population due to different severity, age at onset, ethnic group; the use of semiquantitative methods of image analysis as to intervention, as such methods are not yet widespread in clinical routine; or kinds of comparisons that did not match exactly those required in the PICO.
-
Publication Bias. We did not perform formal analyses, but rather considered the starting quality of evidence to be negatively affected based on a possible publication bias in the cases when more papers providing the same results were from the same research group or dataset.
Factors positively affecting the quality of evidence
Large effect: we considered the effect large for test performance values between 81 and 100%, medium between 71 and 80%, and small between 51 and 70%.
Dose-response gradient is not pertinent to FDG-PET, and the possibility that confounding factors could hide an important effect was not assessable due to the exceedingly large number of methodological limitations that may concur in blurring the target effect (Table 4).
Summaries of evidence assessment
In order to facilitate the communication on available evidence with panelists, we produced, besides the tables with all extracted data for each PICO, summary of findings tables reporting the outcomes assessed globally across papers, and abstracts better elucidating all findings (see [23,24,25,26,27,28,29]. These explained both the quantitative data as based on the methodological assessment described, and the “qualitative” findings, as based on the pattern of hypometabolism correlated to the target disorders for each PICO. Panelists were informed that this final ranking of relative availability of evidence across the 21 PICOs should not have been considered in the same terms as the absolute quality of evidence, as it can be provided based on Cochrane systematic reviews or GRADE assessment. The very frequent lack of the basic methodological requirements of the available studies was clearly reported, as well as the lack of any evidence of utility of studies describing metabolic patterns significantly associated with the target condition but not characterized quantitatively with validated measures of diagnostic performance.
Delphi procedure
The Delphi procedure [30] is already described elsewhere [7]. Briefly, the panel was formed uniquely by clinicians, expert in FDG-PET, nominated within the EANM and EAN. They answered the 21 PICO questions that they defined at the beginning of the project using a web-based platform. Panelists were asked to decide considering both the literature so assessed and their own expertise, and to provide the reasons for their decisions writing them in mandatory windows within the voting system. At each round, they could access statistics on answers from the previous rounds and the anonymized answers and justifications provided by the other panelists. Questions were considered answered, and not re-proposed in further rounds, after a majority of at least 5 vs 2 was achieved.
Results
More specific information on the results reported in this section is provided elsewhere [23,24,25,26,27,28,29].
Literature selection
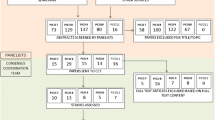
For the 21 searches, a total of 1435 papers was identified and screened for subsequent processing. After excluding papers not addressing the comparison of interest and duplicate papers, a total of 186 papers was assessed in greater detail to evaluate the quality of evidence (Fig. 1).

Literature search performed to assess evidence supporting the use of FDG-PET for the 21 PICO questions detailed in Table 1. The search and a first screening were performed by the group of panelists, clinicians expert of FDG-PET from EANM and EAN. An independent methodology team extracted the data and assessed the evidence. There were 186 papers that addressed the comparisons of interest for the 21 PICOs. Among these, only 58 reported the critical outcomes allowing assessing evidence.
Of these, most (128) did not provide validated measures of test performance, reporting only the patterns of hypometabolism associated with the disease of interest based usually on correlation analyses or t-test comparison with the specific control groups. While six PICOs (2, 3, 5, 12, 14, 18) lacked entirely any critical outcome, only 31% of the total set of papers including the comparison of interest did report proper quantification in terms of accuracy, AUC, predictive value or likelihood ratios (Table 5). Among these, only two studies, both pertaining to PICO 21, performed a head-to-head comparison of FDG-PET versus clinical comparison. Sixty-two percent of the included studies assessed the performance of the index-test versus an acceptable gold- or reference-standard (green or yellow boxes in Table 6).
Studies reporting critical outcomes
The 14 PICOs reporting critical outcomes had a minimum of one study and a maximum of 13, the median being one paper. The total number of subjects per PICO with critical outcomes was very variable, from 13 for PICO 6 to 1361 for PICO 1. Most studies with critical outcomes reported values of accuracy. Only a minority (N = 21/58 papers) reported positive and negative predictive values or likelihood ratios. As well, effect sizes had large variability, ranging from 38 to 100% for sensitivity, 41–100% for specificity, and 58–100% for accuracy (Table 5). Pico-specific values are reported in detail in the specific reviews in this issue [7, 23,24,25,26,27,28,29].
Relative availability of evidence
Considering overall the quality of methodology (type of gold- or reference-standard and head-to-head comparison between index-test and comparator), the number of total subjects for PICO, effect sizes, and consistency of results across studies (see [23,24,25,26,27,28,29]), PICO 21 resulted in the only one with relatively good evidence. PICO 21 had a total of nine studies with validated measures of accuracy as proper critical outcomes, with a total of 586 subjects, and considerably high and consistent values of effect size (Tables 5 and 6; [28]); for this PICO, only three studies had inadequate reference standard (only baseline clinical diagnosis) [28]. The relatively higher strength of PICO 17 on ALS was due to the fact that baseline clinical diagnosis was considered an appropriate gold standard in this specific case [23].
Lower total number of subjects, strength, and consistency of results (as from Table 5 and [23,24,25,26,27,28,29]) were observed progressively for the PICOs receiving lower ranking as from Table 6.
Research priorities
Based on the considerations done while making decisions on evidence assessment, we could spot, besides the many limitations typical of FDG-PET literature, many aspects that can be importantly improvement in the short term. In particular:
-
Head-to-head comparison with the comparator. All but two studies reporting critical outcomes lack the direct comparison between the index test and the comparator, required for proper methodology as the starting level of evidence. All of these studies, that do assess the accuracy of FDG-PET-based diagnosis versus an appropriate gold- or reference-standard, can use the same reference to assess the performance of the baseline clinical diagnosis, independently of the FDG-PET results, and thus compare this performance with that of the FDG-PET-based diagnosis, to provide the measure of the incremental diagnostic value. Such values can already be computed using the very same datasets already used to produce the published results. This information would immediately provide a measure of the incremental value of FDG-PET-based diagnosis as compared to traditional clinical and neuropsychological diagnosis, that is currently lacking entirely, and would importantly increase the quality of the available evidence.
-
Computation of measures of test performance independent on the prevalence of the disease in the population. Most studies provide measures of test performance that are widely accepted, although they are critically dependent on the prevalence of the disease in the examined population (i.e., sensitivity, specificity, accuracy). The same datasets employed to produce the published data allow also the computation of other measures of test performance, i.e., positive and negative predictive values and likelihood ratios, that are independent of disease prevalence, and thus critically more informative to clinicians.
-
Biomarker-based diagnosis. To date, the possibility of performing pathophysiological diagnoses with biomarkers is increasingly concrete. Changes in diagnosis based on information of brain amyloidosis can amount to about 30% [31], thus this kind of improvement should be highly recommended for the next papers on FDG-PET diagnostic performance whenever possible.
Discussion
In this study, we have detailed the procedure performed to assess the quality of evidence of FDG-PET diagnostic studies in the field of dementing neurodegenerative disorders. This work was aimed at producing European recommendations [7] to support or not the prescription of FDG-PET in the diagnostic work-up. From the comprehensive literature searches performed for 21 PICO questions, resulting in 1435 papers, only 58 reported validated measures of test performance, and were thus eligible for proper evidence assessment according to currently acknowledged methodology [8, 17, 18, 22]. However, almost all lacked other relevant methodological requirements (like head-to-head comparisons, adequate gold standard). We outline that while, to date, some requirements or findings cannot be provided within reasonable costs or time limits (e.g., the assessment of FDG-PET-based diagnosis on patient outcome in randomized trials), many other relevant requirements may easily be complied with, based on the information already available in currently used datasets. We have thus outlined research priorities addressing very feasible and significant improvements of evidence quality in the short term. Whilst interim decisions on clinical use of FDG-PET have been taken based on currently available data and panelists’ expertise [7], such improvements may allow deriving decisions directly from evidence, consistent with current methodological guidance, in a hopefully near future [5].
On the whole, the work of evidence assessment performed within this EANM-EAN initiative is partly analogous to previous efforts. In a literature assessment based on GRADE and including a large metanalysis [32], high values were obtained for PET imaging in providing early and differential diagnosis of AD, indicating better performance of automated versus visual assessment. However, it is difficult to assess similarities and differences with our assessment procedure due to lack of details about assessment and decisions on how to evaluate evidence quality in the absence of requirements as from [17, 18, 22], in [32]. In the Cochrane review examining the evidence of FDG-PET utility in supporting the diagnosis of AD in MCI [33], the assessment was based on QUADAS-2 [9], according to the Cochrane methodology [8, 17]. In this case, both the selection of papers and the final conclusions were very similar to those obtained in our work [24], and evidence was considered insufficiently strong to support clinical use. Similarly, our PICO 1, relating to the ability of FDG-PET to support AD diagnosis in MCI, ranked relatively well compared to the availability of evidence of the 21 PICOs (Table 6); however, also in our assessment, the absolute quality of evidence was low, as shown by the large range of values per outcome and their wide confidence intervals (Table 5), and by the “Low” quality assigned to most outcomes (see the last column of the summary of findings “Table PICO 1” in [24]).
Short-term feasible improvements
-
a)
Quantitative assessment of test performance. In the clinical field, the reliance on so-called “typical patterns of hypometabolism” is widespread. However, the circular overlap of metabolic patterns with clinical syndromes, together with the limited correspondence of syndromes and pathology [34] makes studies lacking validated measures of test performance useless to the aim of deriving decisions relative to clinical use. Moreover, even when providing validated measures of test performance, most studies limit the analysis to accuracy, sensitivity and specificity. The computation of values such as PPV-NPV or likelihood ratios, is rare, but very valuable to support its clinical utility, and can be provided based on currently available datasets.
-
b)
Quantitative assessment of incremental diagnostic value. The lack of any quantification of performance for the comparator, i.e., traditional clinical-neuropsychological diagnosis, prevents the quantification of the incremental value of FDG-PET over traditional work-up. This may have relatively little importance to clinicians, searching for independent confirmation and using the exam as an add-on to clinical assessment. However, a formal assessment may also outline a detrimental or null value, and is necessary to clinical as well as to policy decisions on diagnostic procedures and health refunders. Currently, changes in diagnosis, diagnostic confidence and treatment are frequently provided in clinical studies, included FDG-PET [35, 36]; although accepted due to current constraints, they do not clarify whether the exam does allow formulating a more exact diagnosis.
Medium-term methodological improvements
-
a)
Gold standard. On the other hand, other methodological requirements, also necessary to the proper outline of evidence-based guidelines [18, 37], may not be equally achievable in the short term. These include, for example, the difficulty in obtaining pathological specimens as the gold standard. The use of biomarker-based diagnoses to date may be relatively weak due to their still incomplete validation [21]; however, this would represent a very valuable improvement, in the lack of pathology confirmation.
-
b)
Evidence from randomized clinical trials (RCT). The most proper evidence allowing drawing decisions requires that randomized clinical trials assess clinically relevant outcomes in patients diagnosed with or without FDG-PET. Besides the relatively high costs and the likely lack of potential sponsors for FDG-PET, sharing a similar destiny as the “orphan drugs”, proper completion of RCTs requires rather univocal treatment courses downstream to diagnosis, and possibly the availability of disease modifiers. Methodological adaptations have been proposed that may allow deriving decisions from data lacking RCT-derived evidence for diagnostic tests in evolving fields like those of dementia [10, 11, 38, 39]; however, the basic methodological requirements outlined in this paper as short term priorities can be complied with and should no longer be disregarded, in order for these adaptations to be properly adopted.
The many methodological problems in the available literature may not be allowing a clinical utility of FDG-PET to emerge, nor can such literature demonstrate any lack of utility of the exam. These negative findings should be read as a lack of evidence, both in support or against clinical use of FDG-PET, and proper evidence still needs to be collected in future studies. On the other hand, the criticism may be noted that our PICOs addressed too specific questions, that cannot be properly answered by FDG-PET, i.e., the attempt to identify underlying pathophysiology of a variety of neurodegenerative disorders. FDG-PET is indeed acknowledged as a biomarker of downstream neurodegeneration and progression of neurodegenerative diseases. Despite this, current diagnostic criteria do recommend its use as a supportive feature for different kinds of neurodegenerative disorders [16, 40,41,42,43,44,45] mainly because in several conditions pathophysiological biomarkers are to date under development, at a very different stage. Whereas alpha-synuclein (CSF and tissue biopsy) and Tau biomarkers (CSF and PET) are a step forward, others are much less advanced, such as those for TDP-43. At present, thus, the topographic patterns of hypometabolism in those conditions lacking the possibility to be confirmed with pathological biomarkers keep being an important guide to clinicians in approaching the right diagnosis. This explains both our definition of the 20 clinical PICOs, and the reason why the seven experts from the two Societies considered FDG-PET to provide clinical utility in most symptomatic neurodegenerative conditions, consistent with the perceived utility of clinicians [7].
We propose this work as an input to help improve current accuracy studies in the field, and to better focus future efforts in achieving evidence-based guidelines for the use of FDG-PET.
References
Frisoni GB, Perani D, Bastianello S, Bernardi G, Porteri C, Boccardi M, et al. Biomarkers for the diagnosis of Alzheimer’s disease in clinical practice: an Italian intersocietal roadmap. Neurobiol Aging. 2017;52:119–31.
Dubois B, Feldman HH, Jacova C, Hampel H, Molinuevo JL, Blennow K, et al. Advancing research diagnostic criteria for Alzheimer’s disease: the IWG-2 criteria. Lancet Neurol. 2014;13(6):614–29.
Jack CR Jr, Knopman DS, Jagust WJ, Petersen RC, Weiner MW, Aisen PS, et al. Tracking pathophysiological processes in Alzheimer’s disease: an updated hypothetical model of dynamic biomarkers. Lancet Neurol. 2013;12(2):207–16.
Boccardi M, Gallo V, Yasui Y, Vineis P, Padovani A, Mosimann U, et al. The biomarker-based diagnosis of Alzheimer’s disease. 2-lessons from oncology. Neurobiol Aging. 2017;52:141–52.
Leone MA, Brainin M, Boon P, Pugliatti M, Keindl M, Bassetti CL. Guidance for the preparation of neurological management guidelines by EFNS scientific task forces—revised recommendations 2012. Eur J Neurol. 2013;20(3):410–9.
Leone MA, Keindl M, Schapira AH, Deuschl G, Federico A. Practical recommendations for the process of proposing, planning and writing a neurological management guideline by EAN task forces. Eur J Neurol. 2015;22(12):1505–10.
Nobili F, Arbizu J, Bouwman FH, Drzezga A, Agosta F, Nestor P, et al. EANM-EAN recommendations for the use of brain 18F-Fluorodeoxyglucose Positron Emission Tomography (FDG-PET) in neurodegenerative cognitive impairment and dementia: Delphi consensus. Eur J Neurol. 2018; submitted (March 13, 2018), MS: EJoN-18-0310.
Reitsma JB, Rutjes AWS, Whiting P, Vlassov VV, Leeflang MMG, Deeks JJ. Chapter 9: assessing methodological quality. In: Deeks JJ, Bossuyt PM, Gatsonis C, editors. Cochrane handbook for systematic reviews of diagnostic test accuracy, Version 1.0.0. The Cochrane Collaboration; 2009. Available from: http://srdta.cochrane.org/.
Whiting PF, Rutjes AW, Westwood ME, Mallett S, Deeks JJ, Reitsma JB, et al. QUADAS-2: a revised tool for the quality assessment of diagnostic accuracy studies. Ann Intern Med. 2011;155(8):529–36.
Hsu J, Brozek JL, Terracciano L, Kreis J, Compalati E, Stein AT, et al. Application of GRADE: making evidence-based recommendations about diagnostic tests in clinical practice guidelines. Implement Sci. 2011;6:62.
Schunemann HJ, Oxman AD, Brozek J, Glasziou P, Jaeschke R, Vist GE, et al. Grading quality of evidence and strength of recommendations for diagnostic tests and strategies. BMJ. 2008;336(7653):1106–10.
Guyatt GH, Oxman AD, Vist G, Kunz R, Brozek J, Alonso-Coello P, et al. GRADE guidelines: 4. Rating the quality of evidence–study limitations (risk of bias). J Clin Epidemiol. 2011;64(4):407–15.
Jack CR Jr, Knopman DS, Jagust WJ, Shaw LM, Aisen PS, Weiner MW, et al. Hypothetical model of dynamic biomarkers of the Alzheimer’s pathological cascade. Lancet Neurol. 2010;9(1):119–28.
Dubois B, Feldman HH, Jacova C, Cummings JL, Dekosky ST, Barberger-Gateau P, et al. Revising the definition of Alzheimer’s disease: a new lexicon. Lancet Neurol. 2010;9(11):1118–27.
Dubois B, Hampel H, Feldman HH, Scheltens P, Aisen P, Andrieu S, et al. Preclinical Alzheimer’s disease: definition, natural history, and diagnostic criteria. Alzheimers Dement. 2016;12(3):292–323.
McKeith IG, Boeve BF, Dickson DW, Halliday G, Taylor JP, Weintraub D, et al. Diagnosis and management of dementia with Lewy bodies: fourth consensus report of the DLB consortium. Neurology. 2017;89(1):88–100.
Bossuyt PM, Leeflang MM. Developing criteria for including studies. In: Cochrane handbook for systematic reviews of diagnostic test accuracy, Version 0.4. [updated September 2008]. The Cochrane Collaboration, 2008.
Guyatt G, Oxman AD, Akl EA, Kunz R, Vist G, Brozek J, et al. GRADE guidelines: 1. Introduction-GRADE evidence profiles and summary of findings tables. J Clin Epidemiol. 2011;64(4):383–94.
Morbelli S, Garibotto V, Van De Giessen E, Arbizu J, Chetelat G, Drezgza A, et al. A Cochrane review on brain [(1)(8)F]FDG PET in dementia: limitations and future perspectives. Eur J Nucl Med Mol Imaging. 2015;42(10):1487–91.
Matias-Guiu JA, Cabrera-Martin MN, Garcia-Ramos R, Moreno-Ramos T, Valles-Salgado M, Carreras JL, et al. Evaluation of the new consensus criteria for the diagnosis of primary progressive aphasia using fluorodeoxyglucose positron emission tomography. Dement Geriatr Cogn Disord. 2014;38(3–4):147–52.
Frisoni GB, Boccardi M, Barkhof F, Blennow K, Cappa S, Chiotis K, et al. Strategic roadmap for an early diagnosis of Alzheimer’s disease based on biomarkers. Lancet Neurol. 2017;16(8):661–76.
Balshem H, Helfand M, Schunemann HJ, Oxman AD, Kunz R, Brozek J, et al. GRADE guidelines: 3. Rating the quality of evidence. J Clin Epidemiol. 2011;64(4):401–6.
Agosta F, Altomare D, Festari C, Orini S, Gandolfo F, Boccardi M, et al. Clinical utility of FDG-PET in amyotrophic lateral sclerosis and Huntington’s disease. Eur J Nucl Med Mol Imaging. 2018. https://doi.org/10.1007/s00259-018-4033-0.
Arbizu J, Festari C, Altomare D, Walker Z, Bouwman FH, Rivolta J, et al. Clinical utility of FDG-PET for the clinical diagnosis in MCI. Eur J Nucl Med Mol Imaging. 2018. https://doi.org/10.1007/s00259-018-4039-7.
Bouwman FH, Orini S, Gandolfo F, Altomare D, Festari C, Agosta F, et al. Diagnostic utility of FDG-PET in the differential diagnosis between different forms of primary progressive aphasia. Eur J Nucl Med Mol Imaging. 2018. https://doi.org/10.1007/s00259-018-4034-z.
Drzezga A, Altomare D, Festari C, Arbizu J, Orini S, Herholz, et al. Diagnostic utility of FDG-PET in asymptomatic subjects at increased risk for Alzheimer’s disease. Eur J Nucl Med Mol Imaging. 2018. https://doi.org/10.1007/s00259-018-4032-1.
Nestor P, Altomare D, Festari C, Drzezga A, Rivolta J, Walker Z, et al. Clinical utility of FDG-PET for the differential diagnosis among the main forms of dementia. Eur J Nucl Med Mol Imaging. 2018. https://doi.org/10.1007/s00259-018-4035-y.
Nobili F, Festari C, Altomare D, Agosta F, Orini S, Van Laere, et al. Automated assessment of FDG-PET for the differential diagnosis in patients with neurodegenerative disorders. Eur J Nucl Med Mol Imaging. 2018 https://doi.org/10.1007/s00259-018-4030-3.
Walker Z, Gandolfo F, Orini S, Garibotto V, Agosta F, Arbizu J, et al. Clinical utility of FDG-PET in Parkinson’s disease and atypical Parkinsonisms associated to dementia. Eur J Nucl Med Mol Imaging. 2018. https://doi.org/10.1007/s00259-018-4031-2.
Murphy MK, Black NA, Lamping DL, McKee CM, Sanderson CF, Askham J, et al. Consensus development methods, and their use in clinical guideline development. Health Technol Assess. 1998;2(3):i–iv, 1–88.
Barthel H, Sabri O. Clinical use and utility of amyloid imaging. J Nucl Med. 2017;58(11):1711–7.
Perani D, Schillaci O, Padovani A, Nobili FM, Iaccarino L, Della Rosa PA, et al. A survey of FDG- and amyloid-PET imaging in dementia and GRADE analysis. Biomed Res Int. 2014;2014:785039.
Smailagic N, Vacante M, Hyde C, Martin S, Ukoumunne O, Sachpekidis C. (1)(8)F-FDG PET for the early diagnosis of Alzheimer’s disease dementia and other dementias in people with mild cognitive impairment (MCI). Cochrane Database Syst Rev. 2015;1:Cd010632.
Beach TG, Monsell SE, Phillips LE, Kukull W. Accuracy of the clinical diagnosis of Alzheimer disease at National Institute on Aging Alzheimer disease centers, 2005–2010. J Neuropathol Exp Neurol. 2012;71(4):266–73.
Laforce R Jr, Buteau JP, Paquet N, Verret L, Houde M, Bouchard RW. The value of PET in mild cognitive impairment, typical and atypical/unclear dementias: a retrospective memory clinic study. Am J Alzheimers Dis Dement. 2010;25(4):324–32.
Laforce R Jr, Tosun D, Ghosh P, Lehmann M, Madison CM, Weiner MW, et al. Parallel ICA of FDG-PET and PiB-PET in three conditions with underlying Alzheimer’s pathology. NeuroImage Clin. 2014;4:508–16.
GRADE handbook for grading quality of evidence and strength of recommendations. 2013.
Gopalakrishna G, Mustafa RA, Davenport C, Scholten RJ, Hyde C, Brozek J, et al. Applying grading of recommendations assessment, development and evaluation (GRADE) to diagnostic tests was challenging but doable. J Clin Epidemiol. 2014;67(7):760–8.
Trenti T, Schunemann HJ, Plebani M. Developing GRADE outcome-based recommendations about diagnostic tests: a key role in laboratory medicine policies. Clin Chem Lab Med. 2016;54(4):535–43.
Albert MS, DeKosky ST, Dickson D, Dubois B, Feldman HH, Fox NC, et al. The diagnosis of mild cognitive impairment due to Alzheimer’s disease: recommendations from the National Institute on Aging-Alzheimer’s Association workgroups on diagnostic guidelines for Alzheimer’s disease. Alzheimers Dement. 2011;7(3):270–9.
Gorno-Tempini ML, Hillis AE, Weintraub S, Kertesz A, Mendez M, Cappa SF, et al. Classification of primary progressive aphasia and its variants. Neurology. 2011;76(11):1006–14.
McKhann GM, Knopman DS, Chertkow H, Hyman BT, Jack CR Jr, Kawas CH, et al. The diagnosis of dementia due to Alzheimer’s disease: recommendations from the National Institute on Aging-Alzheimer’s Association workgroups on diagnostic guidelines for Alzheimer’s disease. Alzheimers Dement. 2011;7(3):263–9.
Rascovsky K, Hodges JR, Knopman D, Mendez MF, Kramer JH, Neuhaus J, et al. Sensitivity of revised diagnostic criteria for the behavioural variant of frontotemporal dementia. Brain J Neurol. 2011;134(Pt 9):2456–77.
Hoglinger GU, Respondek G, Stamelou M, Kurz C, Josephs KA, Lang AE, et al. Clinical diagnosis of progressive supranuclear palsy: the movement disorder society criteria. Mov Disord. 2017;32(6):853–64.
Strong MJ, Abrahams S, Goldstein LH, Woolley S, McLaughlin P, Snowden J, et al. Amyotrophic lateral sclerosis-frontotemporal spectrum disorder (ALS-FTSD): revised diagnostic criteria. Amyotroph Lateral Scler Frontotemporal Degener. 2017;18(3–4):153–74.
Acknowledgements
The procedure for assessing scientific evidence and defining consensual recommendations was funded by the European Association of Nuclear Medicine (EANM) and by the European Academy of Neurology (EAN). We thank the Guidelines working group of EAN, particularly Simona Arcuti and Maurizio Leone, for methodological advice.
Collaborators for this paper are: Federica Agosta7, Javier Arbizu8, Femke Bouwman9, Alexander Drzezga10, Peter Nestor11, Zuzana Walker12.
7Neuroimaging Research Unit, Institute of Experimental Neurology, Division of Neuroscience, San Raffaele Scientific Institute, Vita-Salute San Raffaele University, Milan, Italy.
8Department of Nuclear Medicine. Clinica Universidad de Navarra. University of Navarra. Pamplona, Spain.
9Department of Neurology & Alzheimer Center, Amsterdam Neuroscience, VU University Medical Center, Amsterdam, the Netherlands.
10Department of Nuclear Medicine, University Hospital of Cologne, University of Cologne and German Center for Neurodegenerative Diseases (DZNE), Germany.
11German Center for Neurodegenerative Diseases (DZNE), Magdeburg, Germany; Queensland Brain Institute, University of Queensland and at the Mater Hospital Brisbane.
12University College London, Division of Psychiatry & Essex Partnership University NHS Foundation Trust, UK.
Funding
This project was partially funded by the European Association of Nuclear Medicine (EANM) and the European Academy of Neurology (EAN).
Author information
Authors and Affiliations
Consortia
Corresponding author
Ethics declarations
Conflict of interest
Marina Boccardi has received funds from the European Association of Nuclear Medicine (EANM) to perform the evidence assessment and the global coordination of the present project. Moreover, she has received research grants from Piramal and served as a paid member of advisory boards for Eli Lilly.
Cristina Festari: declares that she has no conflict of interest.
Daniele Altomare was the recipient of the grant allocated by the European Academy of Neurology (EAN) for data extraction and evidence assessment for the present project.
Federica Gandolfo: declares that she has no conflict of interest.
Stefania Orini: declares that she has no conflict of interest.
Flavio Nobili: received personal fees and non-financial support from GE Healthcare, non-financial support from Eli-Lilly and grants from Chiesi Farmaceutici.
Giovanni B Frisoni is principal investigator of industry-sponsored trials funded by AbbVie, Acadia, Altoida, Amoneta, Araclon, Biogen, Janssen, Novartis, Piramal; has received funding for investigator-initiated trials from GE, Piramal, and Avid-Lilly; and has received speaker fees from a number of pharma and imaging companies.
Ethical approval
This is a review article that does not contain any original study with human participants performed by any of the authors. Ethical approval is shown in each of the quoted original papers.
Informed consent
Not applicable to this review article. Informed consent statement is declared in each of the revised papers.
Rights and permissions
About this article

Cite this article
Boccardi, M., Festari, C., Altomare, D. et al. Assessing FDG-PET diagnostic accuracy studies to develop recommendations for clinical use in dementia. Eur J Nucl Med Mol Imaging 45, 1470–1486 (2018). https://doi.org/10.1007/s00259-018-4024-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00259-018-4024-1