
Abstract
We determined whether uncertainty about the location of one’s hand in virtual environments limits the efficacy of online control processes. In the Non-aligned and Aligned conditions, the participant’s hand was represented by a cursor on a vertical or horizontal display, respectively. In the Natural condition, participants saw their hand. During an acquisition phase, visual feedback was either permitted or not during movement execution. To test the hypothesis (Norris et al. 2001) that reliance on visual feedback increases as the task becomes less natural (Natural < Aligned < Non-aligned), following acquisition, participants performed a transfer phase without visual feedback. During acquisition in both visual feedback conditions, movement endpoint variability increased as the task became less natural. This suggests that the orientation of the display and the representation of one’s hand by a cursor introduced uncertainty about its location, which limits the efficacy of online control processes. In contradiction with the hypothesis of Norris et al. (2001), withdrawing visual feedback in transfer had a larger deleterious effect on movement accuracy as the task became less natural. This suggests that the CNS increases the weight attributed to the input that can be processed without first having to be transformed.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Manual aiming (e.g., pushing the start button on a computer) and video aiming movements (e.g., moving a cursor on a computer screen to reach an icon) have been studied extensively because they open a window on how the CNS plans and controls our everyday movements. However, does the CNS process manual aiming and video aiming movements similarly? This question arises from the observation that the endpoint of video aiming movements performed without visual feedback is less accurate (Bédard and Proteau 2005) and more variable (Bédard and Proteau 2005; Messier and Kalaska 1997) than that of manual aiming movements. These differences were interpreted as evidence that, because video aiming movements were performed on a Non-aligned display, the CNS needed to transform information about the cursor and target locations presented on a vertical display into appropriate motor commands for a movement performed on a horizontal surface. Bias and noise in these transformations would cause the differences noted above between video and manual aiming (Bédard and Proteau 2005; Messier and Kalaska 1997). The results of a recent study did not support this proposition in that endpoint accuracy and variability of video aiming movements performed on Aligned and Non-aligned displays did not differ from one another (Veilleux and Proteau 2010). Rather, it could be that the CNS does not use the same information or that it processes it differently in virtual (a dot moving on a screen) and natural (seeing one’s hand) contexts. Although proprioception similarly defines the position of the hand in these two contexts, vision provides a very different representation of the hand. Thus, in a manual aiming task, there is a perfect correspondence between the seen and the felt location of one’s hand, whereas this correspondence is not as tight in a video aiming task because the cursor shown on the screen typically represents the position of the stylus held by the participant. This dissociation between visual and proprioceptive signals in a video aiming task might increase the uncertainty related to the initial hand position and could affect both movement planning and online control processes.
Evidence that movement planning processes are affected by this dissociation between visual and proprioceptive inputs comes from a recent study by Bo, Contreras-Vidal, Kagerer, and Clark (2006). Participants performed an aiming task in either a Natural, Aligned video or a Non-aligned video condition. Bo et al. (2006) noted larger initial direction errors (i.e., 80 ms after movement initiation) in the Non-aligned video than in the Aligned video and normal conditions, the latter two of which did not differ significantly from one another, suggesting a transformation bias in the Non-aligned but not in the Aligned video condition. They also noted that initial direction variability was smaller for the normal condition than for both the Non-aligned and the Aligned video conditions, the latter two of which did not differ significantly from one another, suggesting a more reliable source of information when direct vision of the hand rather than a mere representation of it (a cursor) was available during movement planning.
Other evidence suggests that the dissociation between visual and proprioceptive inputs can also affect online control processes. First, in the study by Graham and Mackenzie (1996), participants performed 3D manual aiming movements toward targets of different sizes in a Natural and an Aligned setting. For the smaller targets (3 and 6 mm in diameter), longer movement times were observed in the Aligned than in the Natural setting. This difference in movement time largely took place between peak deceleration and movement endpoint, suggesting that participants needed more time to use visual feedback to correct their movement online when the visual information provided (2D on the Aligned display) did not match the proprioceptive feedback (3D) available while performing the task. Second, the variability of a series of movements aimed at the same target typically increases between peak acceleration and peak deceleration of the movement’s initial impulse. This increase in variability does not differ regardless of whether the participant’s hand or the cursor representing it is visible during movement execution (Khan et al. 2002; Veilleux and Proteau 2010). In natural aiming movements performed both with or without vision of the hand and the target, Khan et al. (2002) observed a large decrease in variability between peak deceleration of the movements’ initial impulse and movement endpoint, suggesting a strong modulation of the ongoing movement, even when no visual feedback was available. Recent video aiming studies performed on both Non-aligned and Aligned displays replicated Khan et al.’s (2002) observations, specifically when the cursor remained visible throughout movement execution but not when only the target remained visible. In the latter condition, no decrease (Robin et al. 2005) or only a small decrease in movement variability (Proteau and Isabelle 2002; Robin et al. 2005; Veilleux and Proteau 2010) was observed between peak deceleration and movement endpoint. These contradictory findings suggest that when online visual feedback is not available during movement execution, uncertainty about the initial location of the hand in virtual environments dramatically limits the efficacy of online control processes. The first goal of the present study was to test this hypothesis.
To reach our goal, participants performed a manual aiming movement while information about the starting position of a cursor representing their hand was illustrated on either a Non-aligned or an Aligned display, whereas in a third condition, participants performed a 2D natural aiming movement. Each condition was performed either while vision of the cursor/hand was visible throughout movement execution or while vision was blanked out at movement onset. If the larger movement endpoint bias and variability usually observed in video aiming tasks indicate a limit in movement control processes in virtual environments, then the decrease in movement variability observed between peak deceleration and movement endpoint should be significantly smaller in both the Aligned and the Non-aligned conditions than in the natural aiming condition.
Processing of sensory feedback
Norris et al. (2001) reported a prism adaptation study in which participants aimed at a visual target in a natural, video (his or her hand was filmed and represented on a vertical computer screen) or virtual (the hand was represented by a cursor on a vertical computer screen) condition. After adaptation had occurred, participants performed the same task, albeit without the prism. The aftereffect noted in the no prism transfer test was larger in the natural than in the video condition and larger in the video than in the virtual condition (see also Clower and Boussaoud 2000). Norris et al. (2001) interpreted this finding as indicating that reliance on visual feedback decreased as the task became less natural (natural > video > virtual) at the profit of increased reliance on proprioceptive information. Our second goal was to test this hypothesis.
To reach that goal, following the acquisition phase described above, all participants completed a transfer phase, performed without visual feedback and knowledge of results. According to the specificity-of-practice hypothesis (Proteau 1992), the more one relies on a given source of sensory feedback during acquisition, the larger the deleterious effect when it is withdrawn in a transfer test (Khan et al. 2003; Mackrous and Proteau 2007; Proteau 2005; Soucy and Proteau 2001; Tremblay and Proteau 1998). Therefore, based on Norris et al.’s (2001) prediction, withdrawing visual feedback in transfer should have larger deleterious effects on movement endpoint accuracy and variability for participants who performed acquisition in the Natural versus the Aligned condition, and in the Aligned versus the Non-aligned condition.
Method
Participants
Sixty undergraduate students were recruited from the Département de kinésiologie from the Université de Montréal. Participants had no previous experience with the experimental task. All participants reported normal or corrected-to-normal vision. The Health Sciences Ethics Committee of the Université de Montréal approved this study.
Task and apparatus
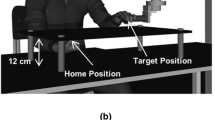
Participants had to perform a 2D manual aiming task in which they moved a computer’s mouse-like device on a horizontal surface from a fixed starting position toward three possible targets. The apparatus (see Fig. 1) consisted of a computer screen, a table, a two-degrees-of-freedom manipulandum, and a starting base.

View of the Non-aligned, Aligned and Natural experimental setups. Note that participants used their right dominant hand
The computer screen (Mitsubishi, Color Pro Diamond 37 inches; resolution: 1,024 × 768; refresh rate: 60 Hz) was mounted on a ceiling-support positioned directly over the table. The computer screen could be set in one of two possible positions: either in a vertical position (Non-aligned) or parallel to the surface of the table (Aligned; see Aligned and Non-aligned tasks section below for further details).
The tabletop was covered by a piece of Plexiglas over which a starting base and the manipulandum were affixed. The manipulandum consisted of two pieces of rigid Plexiglas (43 cm) joined together at one end by an axle. One free end of the manipulandum was fitted with a second axle encased in a stationary base. The other free end of the manipulandum was fitted with a small, vertical aluminum shaft (hereafter called the stylus [length: 16 cm, radius: 3 mm]). Thus, the participant could easily grip the stylus. From the participants’ perspective, the far end of the manipulandum was located 40 cm to the left of the starting base and 70 cm in the sagittal plane. Each axle of the manipulandum was fitted with a 13-bit optical shaft encoder (US Digital, model S2-2048, sampled at 500 Hz, angular accuracy of 0.0439°), which allowed us to track the displacement of the stylus online and illustrate it with a 1:1 ratio on the computer screen. The bottom of the stylus and the bottom of the optical encoder located at the junction of the two arms of the manipulandum were covered with a thin piece of Plexiglas. By lubricating the working surface at the beginning of each experimental session, displacement of the stylus was nearly frictionless.
The starting base consisted of a thin strip of Plexiglas glued to the tabletop. It was parallel to the leading edge of the table and had a small indentation on one of its faces. This indentation was located directly in line with the lateral center of the computer screen and the participants’ midline; it served as the starting base for the stylus. This indentation made it easy for the participants to position the stylus at the beginning of each trial.
Procedures
Participants were asked to execute straight and continuous movements (i.e., no stop and go) and to try stopping the cursor/stylus on the target. The target to be reached was announced verbally by the Experimenter at the beginning of each trial. Participants were randomly assigned to one of six experimental groups. These groups (Normal vision or No vision) were differentiated by the visual feedback available during movement execution and by the condition in which they performed (Non-aligned, Aligned, or Natural). Regardless of the visual feedback condition, participants wore liquid crystal goggles. For the Normal vision condition, the lenses remained in their transparent state for the whole trial. For the No vision condition, the lenses remained transparent until the cursor left the starting base, at which point they went from their transparent state to their translucent state (~3ms). This resulted in the withdrawal of all visual information until movement endpoint, after which the lenses returned to their transparent state. This allowed participants to see the cursor at its final position (knowledge of result) and as they brought it back on the starting base (Khan et al. 2002; Veilleux and Proteau 2010).
For the Non-aligned group, the computer screen was located 330 mm in front of the participants and was positioned in its usual vertical configuration. Thus, visual information (starting base, cursor, and targets) was presented in the vertical plane and illustrated with a 1:1 ratio on the computer screen. Moving the stylus away from the body in the sagittal plane resulted in the vertical displacement (bottom to top) of the cursor on the computer screen; moving the stylus to the right and to the left of one’s midline resulted in the displacement of the cursor to the right and to the left on the computer screen, respectively. The starting base (red, 3-mm radius) was illustrated at the bottom of the computer screen and was aligned with the participant’s midline. The targets were 3-mm-diameter stickers that were positioned directly on the computer screen 320 mm away from the starting base. One target was located directly in front of the starting base (0° target); the other two targets were located 10° to the left and to the right of the 0° target. Note that the same starting base and targets were used in all conditions.
For the Aligned group, the computer screen was mounted on a ceiling-support positioned directly over the table; the computer screen was oriented parallel to the surface of the table. Its image was reflected on a mirror placed directly beneath it and also parallel to the tabletop. Thus, the target, starting base, and cursor were reflected on the mirror. The distance between the computer screen and the mirror was 165 mm, and the distance between the mirror and the tabletop was 165 mm, allowing free displacement of the manipulandum on the tabletop. The mirror prevented participants from seeing their hand and arm during the experimentation.
For the Natural group, the mirror used for the Aligned group was replaced by a transparent sheet of glass, allowing participants to see the stylus and their hand and arm while resting on the starting base. A red sticker (3-mm radius) was fixed on the tip of the stylus, which mimicked the virtual cursor used in both the Aligned and the Non-aligned conditions. The targets were stuck on the interior surface of the sheet of glass. Thus, the vertical distance between the tip of the stylus and the targets was only 5 mm.
Participants took part in four experimental phases. The first phase was a calibration phase performed in the Normal vision condition by all participants. In this phase, participants were required to aim at each target for five consecutive trials in their respective condition (i.e., Natural, Aligned, or Non-aligned condition). They were instructed to take as much time as needed to immobilize the cursor/stylus directly on the target. This procedure allowed us to define the perceived location of the target individually for each participant. The different dependent variables relative to movement endpoint were computed relative to this perceived target location.
In the three remaining phases, participants were asked to initiate their movement as they pleased (note that this was not a reaction-time task) but to execute it in a movement time ranging between 480 and 620 ms (550 ms ± 12.7%; Proteau 2005; Proteau and Isabelle 2002). A movement time bandwidth was used to eliminate the possibility of different speed accuracy trade-offs between the different experimental conditions (Fitts 1954). In all blocks or phases, each target was used equally often and targets were presented in random order, with the only restriction being that each target could not be presented successively on more than two trials. Participants immobilized the stylus on the starting base (1 s) before each movement, at which point they were instructed verbally by the Experimenter toward which target to aim, i.e., center (0°), left (−10°), or right target (+10°).
In the familiarization phase, participants performed three trials toward each target in random order, which was sufficient for them to understand the task and procedures. In the acquisition phase, participants performed four blocks of six trials toward each target. When movements were completed outside the required movement time bandwidth, the participant was reminded of the target movement time. The last phase was a transfer phase. Participants performed six trials toward each target. In this phase, for all participants, the liquid crystal goggles remained in their translucent state from movement onset to the return of the stylus on the starting base, at which point they switched to their transparent state again. This procedure prevented participants to have knowledge of results and dynamic visual information relative to their hand or the cursor.
Data reduction
Movement endpoint
The direction error is the signed difference on the frontal axis (in mm) between the movement endpoint and the target. A positive value indicates a movement ending to the right of the target, whereas a negative value indicates a movement ending to the left of the target. The extent error was defined as the signed difference between movement endpoint and the target on the sagittal axis (in mm). A positive value indicates that the target had been overshot and a negative value that it had been undershot. From these data, we computed the constant (signed) and variable (within-participant variability) aiming errors on the extent and direction dimensions of the task.
The tangential displacement data of the stylus over time were first smoothed using a second-order recursive Butterworth filter with a cutoff frequency of 10 Hz. The filtered data were then numerically differentiated once using a central finite technique to obtain the velocity profile of the aiming movement, a second time to obtain the acceleration profile, and a third time to obtain a jerk profile. Movement initiation was defined as the moment at which tangential velocity of the cursor reached 10 mm/s. Movement was deemed to be complete when the cursor was not displaced by more than 2 mm in a time frame of 50 ms (Proteau and Isabelle 2002). This procedure did not allow participants to produce a secondary corrective impulse for 99.3% of the trials; trials showing a secondary corrective impulse were withdrawn from all analyses. From these profiles, we determined the moment and location of occurrence (in Cartesian coordinates) of peak acceleration, velocity, and deceleration of the movement’s impulse (Meyer et al. 1988).
To facilitate reading of this article, details concerning the dependent variables of interest, the rationale for using them, and the statistical analyses that were computed are defined at the beginning of each subsection of the results presentation. Geisser-Greenhouse correction was applied when Epsilon was smaller than one. All significant main effects involving more than two means were broken down using Dunn’s technique. Significant interactions were broken down by computing simple main effects, which were followed by post hoc comparisons (Dunn’s technique) when they involved more than two means. All effects are reported at P < 0.05 (adjusted for the number of comparisons). Note that, although some dependent variables revealed significant differences across targets (Gordon et al. 1994; Fisk and Goodale 1985; Carey and Otto-de Haart 2001), none of these differences impacted the interpretation of the data concerning the specific goals of the present study. Therefore, for sake of clarity, the data were collapsed over target locations.
Results
Figure 2 illustrates the results of a principal component analysis (Matlab, The Math Works) illustrating 95% confidence ellipses (mean across participants) for all acquisition trials at peak acceleration, peak velocity, peak deceleration, and movement endpoint. Quantitative results are presented in the following sections.

Ninety-five percent (95%) confidence ellipses for the Non-aligned, Aligned and Natural groups in both the Normal vision and the No vision conditions at peak acceleration, peak velocity, peak deceleration and movement endpoint. Confidence ellipses were computed individually for each participant and then averaged across participants
Acquisition phase
Endpoint accuracy
In this section of the results presentation, our objective was to determine whether the different experimental conditions significantly influenced endpoint accuracy. A preliminary analysis of the direction and extent constant error (CE) revealed that some participants were biased to the left of a particular target, whereas other participants were biased to the right of the same target. Similarly, some participants overshot a target whereas others undershot the same target. Thus, instead of reporting the constant error for each target, we opted to report the absolute constant error |CE| for the directional and extent data (Schmidt and Lee 2005). Within-participant variability (i.e., variable error) on both movement extent and direction are also reported. The data of interest were submitted individually to an ANOVA contrasting 3 Groups (Non-aligned, Aligned, and Natural) × 2 Feedback conditions (No vision vs. Normal vision) × 2 Blocks of trials (first vs. last block of acquisition). The results are synthesized in Fig. 3.

Direction and extent, absolute constant and variable errors as a function of group, feedback condition and experimental phase. The large empty circle represents the target (6-mm diameter).The small empty markers illustrate the data of the last acquisition block, whereas the small filled markers illustrate the data of the transfer phase. Markers on the left side of the target illustrate the data from the No vision condition, whereas the markers on the right side of the target illustrate the data from the Normal vision condition. The horizontal and vertical bars represent the direction and extent variable errors, respectively
The Non-aligned group had a significantly larger direction |CE| than the Aligned and Natural groups (9.4, 6.5, and 5.0 mm, respectively), the latter two of which did not differ significantly from one another, F(2, 54) = 3.65, P = 0.033. Participants who performed the task in the No vision condition had a significantly larger direction |CE| than participants who performed the task in the Normal vision condition (10.6 mm vs. 3.3 mm, respectively), F(1, 54) = 30.28, P < 0.001. Finally, there was a significant reduction in direction |CE| with practice (8.1 mm vs. 5.9 mm for the first and last block of acquisition, respectively), F(1, 54) = 14.10, P < 0.001.
Direction variable error significantly decreased with practice for the Non-aligned group (8.2 mm vs. 7.0 mm for the first and last block of acquisition, respectively), but not for the Aligned (5.0 mm vs. 5.4 mm, respectively) and Natural groups (3.4 vs. 3.2 mm, respectively), F(2, 54) = 4.54, P = 0.015. Note that in the last acquisition block, endpoint variability was significantly larger for the Non-aligned than for the Aligned group and significantly larger for the Aligned than for the Natural group. Movements performed in the No vision condition were significantly more variable than those performed in the Normal vision condition (7.1 mm vs. 3.7 mm, respectively), F(1, 54) = 45.5, P < 0.001.
On movement extent, the Non-aligned and Aligned groups did not significantly differ from one another, both having a significantly larger extent |CE| than the Natural group (7.9, 6.9 and 3.6 mm, respectively), F(2, 54) = 8.00, P = 0.001. In addition, performing the task in the No vision condition resulted in a significantly larger extent |CE| than performing the task in the Normal vision condition (8.4 mm vs. 3.8 mm, respectively), F(1, 54) = 25.18, P < 0.001. Finally, extent |CE| significantly decreased with practice (6.8 vs. 5.5 mm, for the first and last block of acquisition, respectively), F(1, 54) = 4.33, P = 0.042.
Extent variable error significantly increased as the task became less natural (4.7, 7.1, and 9.6 mm, for the Natural, the Aligned, and the Non-aligned task, respectively), F(1, 54) = 39.07, P < 0.001. Extent variability was also significantly larger in the No vision than in the Normal vision condition (9.2 vs. 5.0 mm, respectively), F(1, 54) = 84.45, P < 0.001.
The ANOVA computed on the movement time data revealed a significant Group × Block interaction, F(2, 54) = 4.92, P = 0.011. Its breakdown did not reveal any significant difference in movement time across conditions for the first block (P > 0.882). However, movement time in the last block was significantly shorter for the Aligned than for the Natural group (543 ms vs. 558 ms, P = 0.032) and the Non-aligned group (557 ms, P = 0.050). The Natural and the Non-aligned groups did not differ significantly from one another (P = 1). Because movement variability is proportional to its velocity (Schmidt et al. 1979), we computed an additional analysis on mean movement velocity (length of the movement vector at movement endpoint divided by movement time) to ensure that the difference in endpoint accuracy and variability reported above (i.e., different speed accuracy trade-offs) did not result from a difference in movement time. The results of this analysis did not reveal significant differences across groups (all ps > 0.14).
Summary
Direction accuracy was significantly better for both the Natural and the Aligned groups than for the Non-aligned group, whereas extent accuracy was significantly better for the Natural than for both the Aligned and the Non-aligned groups, which did not differ significantly from each other. More interestingly, the between-group differences in endpoint accuracy did not differ significantly between the No vision and the Normal vision conditions.
Initial directional bias
Bo et al. (2006) observed a larger directional bias early after movement initiation in the Non-aligned condition than in either the Aligned or the Natural condition, suggesting differences in movement planning as a function of the display orientation. To determine whether movement planning differed as a function of the task and visual feedback conditions, we determined the orientation (in degrees) of the movement vector at peak acceleration. We submitted this dependent variable to an ANOVA contrasting 3 Groups (Non-aligned, Aligned, and Natural) × 2 Feedback conditions (No vision vs. Normal vision) × 2 Blocks of trials (first and last) with repeated measures on the last factor.
The results of the ANOVA only revealed a marginally significant main effect of Group, F(2, 54) = 2.58, P = 0.085. As for Bo et al. (2006), we observed a somewhat larger directional bias for the Non-aligned group (2.40°) than for either the Aligned (−0.21º) or the Natural (0.02º) group.
Within-participant variability in movement trajectories
The differences in movement endpoint accuracy (Fig. 3) observed among the Non-aligned, Aligned, and Natural groups might reflect less efficient planning processes, online control processes (feedforward and feedback), or both as a function of the environments. To gain some insight into that issue, we computed the within-participant variability in the location of occurrence of four kinematic markers: peak acceleration, peak velocity, peak deceleration, and movement endpoint. If movement execution only reflects the outcome of response planning and execution processes, and if one accepts that those processes are variable (i.e., noise) (van Beers et al. 2004; Schmidt et al. 1979; Meyer et al. 1988), the within-participant variability in Cartesian space of the position reached at any given moment for a series of movements should increase as movements unfold. A reduction in the rate of increase of the within-participant variability during movement execution coupled with a small aiming error would provide evidence of efficient online control processes (Khan et al. 2002; Lhuisset and Proteau 2002; Proteau 2005; Proteau and Isabelle 2002). Alternatively, a constant increase in variability from movement initiation to movement endpoint would suggest that movements progressed as planned. Direction and extent within-participant variability data for the last block of acquisition were submitted individually to an ANOVA contrasting 3 Groups (Non-aligned, Aligned, and Natural) × 2 Feedback conditions (No vision vs. Normal vision) × 4 Markers (peak acceleration, peak velocity, peak deceleration, and movement endpoint).
Direction
The ANOVA revealed a significant Feedback × Group × Marker interaction, F(6, 162) = 2.22, P = 0.044. This interaction is illustrated in Fig. 4 (left panels). Its breakdown revealed the following. For all three groups, in the No vision condition, directional variability significantly increased between peak acceleration and peak deceleration. Direction variability further increased between peak deceleration and movement endpoint for the Non-aligned and Aligned groups but not for the Natural group. In the Normal vision condition, direction variability also significantly increased between peak acceleration and peak deceleration. Finally, for all three groups and in contrast with what was observed in the No vision condition, there was a decrease in variability between peak deceleration and movement endpoint. This decrease in variability was significant only for the Aligned (P = 0.001) and Natural (P < 0.001) groups, however (P = 0.239 for the Non-aligned group).

Within-participant variability on the direction and extent components of the task at the occurrence of key kinematic markers (peak acceleration, peak velocity, peak deceleration, and movement endpoint). Data are illustrated as a function of group and feedback conditions. From left to right on the panel: peak acceleration, peak velocity, peak deceleration, and movement endpoint. Filled markers represent data from the No vision condition, whereas empty markers represent data from the Normal vision condition
Extent
The ANOVA revealed significant Group × Marker, F(6, 162) = 2.97, P = 0.009, and Group × Feedback interactions, F(3, 162) = 12.77, P < 0.001. The data of interest are illustrated in Fig. 4 (right panels). The breakdown of the former interaction revealed that extent variability significantly and similarly increased between peak acceleration and peak deceleration (P ≤ 0.003) for all three groups (P ≥ 0.183) and then significantly decreased between peak deceleration and movement endpoint (P ≤ 0.001). The significant interaction resulted from a significantly larger decrease in extent variability in the Normal versus the Aligned condition and in the Aligned versus the Non-aligned condition. The breakdown of the Feedback × Marker interaction revealed that extent variability increased significantly between peak acceleration and peak deceleration in both visual feedback conditions (3.2 to 15.4 mm, P ≤ 0.001 and 4.8 to 13.1 mm, P ≤ 0.002 for the Normal vision and No vision conditions, respectively). However, the decrease in extent variability between peak deceleration and movement endpoint was sharper in the Normal vision than in the No vision condition (68 and 27% reduction in the variability reported at peak deceleration in the Normal vision and No vision conditions, respectively).
Summary
The increase in extent variability between peak acceleration and peak deceleration did not significantly differ among the Non-aligned, Aligned, and Natural groups. The only difference observed in both the No vision and the Normal vision conditions was a sharper modulation between peak deceleration and movement endpoint as the task became more natural (Non-aligned < Aligned < Natural). The increase in direction variability between peak acceleration and peak deceleration was smaller for the Natural group than for the Non-aligned and Aligned groups. This suggests an early and/or more efficient updating of the movement for the Natural group than for the other two groups. In addition, there was a sharper modulation between peak deceleration and movement point for the Natural group than for the Non-aligned group, which had a sharper modulation than the Aligned group.
Correlation analyses
The results reported in the preceding section suggest that movements largely progressed as planned up to peak deceleration and, depending on the visual feedback condition, task, and movement component, were either modulated or not between peak deceleration and movement endpoint. If this is true, the position of the cursor at peak acceleration or peak velocity should be a good predictor of its position at peak deceleration (Heath 2005; Heath et al. 2004; Gordon and Ghez 1987; Desmurget et al. 2005; Messier and Kalaska 1999; for a review see: Khan et al. 2006). In the same vein, if the decrease in variability noted for some conditions between peak deceleration and movement endpoint is indicative of a modulation, for these conditions, the position of the marker at peak deceleration should be a poor predictor of its location at movement endpoint. To test our first prediction, we computed Pearson’s correlation between the position of the stylus, both at peak acceleration and at peak velocity, with the position of the stylus at peak deceleration. These data were submitted to Fisher’s transformation (r to Z) and contrasted in a 3 Groups (Non-aligned, Aligned, and Natural) × 2 Feedback conditions (No vision vs. Normal vision) × 2 Comparisons (peak acceleration vs. peak deceleration, peak velocity vs. peak deceleration) ANOVA. To test our second prediction, we computed the correlation between the position of the stylus at peak deceleration and its position at the movement endpoint. These data were submitted to Fisher’s transformation and contrasted in a 3 Groups (Non-aligned, Aligned, and Natural) × 2 Feedback conditions (No vision vs. Normal vision) ANOVA. The data of interest are summarized in Table 1.
Direction
Concerning the first prediction, the ANOVA revealed a significant Comparison main effect F(1, 54) = 306.84, P < 0.001. Post hoc comparisons revealed that, for all three tasks, the position of the stylus at peak velocity was a significantly better predictor of its position at peak deceleration than was the position of the stylus at peak acceleration (P < 0.001).
Concerning the second prediction, the ANOVA revealed significant Group, F(2, 54) = 36.2, P < 0.001, and Feedback, F(1, 54) = 44.2, P < 0.001, main effects. The Group main effect indicated that the position of the stylus at peak deceleration was a significantly better predictor of its position at movement endpoint for the Non-aligned than for the Aligned group (P = 0.018), and for the Aligned than for the Natural group (P < 0.001). The Feedback main effect revealed that the position of the stylus at peak deceleration was a significantly better predictor of its position at movement endpoint in the No vision than in the Normal vision condition (P < 0.001).
Extent
Concerning the first prediction, the ANOVA revealed significant main effects of Comparison, F(1, 54) = 91.15, P < 0.001, and Feedback, F(1, 54) = 8.88, P = 0.004. The Comparison main effect revealed that the position of the stylus at peak velocity was a significantly better predictor of its position at peak deceleration—although not a very good one (R 2 = 0.186 and 0.046 for the No vision and Normal vision conditions, respectively)—than its position at peak acceleration (P < 0.001). The Feedback main effect revealed that the position of the stylus at peak deceleration was predicted significantly better in the No vision than in the Normal vision condition (P = 0.004).
Regarding the second prediction, the ANOVA revealed significant Group, F(2, 54) = 5.39, P = 0.007, and Feedback, F(1, 54) = 22.57, P < 0.001, main effects. The Group main effect indicated that the position of the stylus at peak deceleration was a significantly better predictor of its position at movement endpoint for the Non-aligned than for the Natural group (P = 0.007), whereas no significant differences were revealed between the Aligned group and either the Non-aligned (P = 0.956) or the Natural groups (P = 0.096). The Feedback main effect revealed that the position of the stylus at movement endpoint was predicted significantly better in the No vision than in the Normal vision condition (P < 0.001).
Summary
The location of the cursor or of one’s hand at peak deceleration was better predicted by its location at peak velocity than at peak acceleration. Decreases in afferent information (No vision < Normal vision) and in task “naturalness” (Non-aligned < Aligned < Natural) resulted in the location of the hand/cursor at peak deceleration becoming a good predictor of endpoint location and, thus, suggests a decrease in the efficacy of the modulation observed between these two kinematic landmarks.
Transfer
Norris et al. (2001) proposed that, as the task becomes less natural, the role of visual information for movement planning and control decreases at the profit of increased reliance on proprioceptive information. If this is true, withdrawing visual information should have more deleterious effects on movement endpoint accuracy and variability for the Natural group than for the Aligned group and for the Aligned group than for the Non-aligned group. To test this prediction, we computed the increase in direction and extent, absolute constant and variable errors when going from acquisition to transfer (a positive value indicates an increase in error when going from acquisition to transfer, whereas a negative value indicates a decrease in error when going from acquisition to transfer). The dependent variables of interest were individually submitted to an ANOVA contrasting 3 Groups (Non-aligned, Aligned, and Natural) × 2 Feedback conditions in acquisition (No vision vs. Normal vision).Footnote 1
The ANOVAs computed on direction and extent |CE| and variability all revealed significant main effects of Group, F(2, 54) = 8.74, 4.93, 5.97, and 5.33, all ps < 0.011, and Feedback, F(2, 54) = 18.90, 8.10, 8.34, and 8.09, all ps < 0.006 (for direction and extent |CE|, and direction and extent endpoint variability, respectively). On movement direction, the Group main effect showed a significantly larger |CE| increase for the Non-aligned group than for both the Aligned (P = 0.043) and the Natural groups (P < 0.001), which did not differ significantly from one another (P = 0.332). For extent |CE| and for both direction and extent variability going from late acquisition to transfer resulted in significantly larger performance deterioration for the Non-aligned than for the Natural group (P = 0.012), whereas the Aligned group did not differ significantly from both the Non-aligned (P > 0.085) and the Natural groups (P > 0.459). Finally, for all four dependent variables, the Feedback main effect indicated a significantly larger performance deterioration for the Normal vision than for the No vision condition (all ps < 0.006).
Discussion
In the present study, we sought to determine whether the increase in movement endpoint error and variability observed in virtual aiming tasks is caused solely by the orientation of the visual display or whether it could also be attributed to the virtual representation of one’s hand by a cursor. To reach our goal, we contrasted manual aiming performance in three different tasks (Natural, Aligned, and Non-aligned) under two visual feedback conditions (Normal vision and No vision).
In acquisition, largely regardless of the visual feedback condition, our results confirm previous observations indicating less accurate and more variable movements when using a Non-aligned versus an Aligned display (Bédard and Proteau 2005; Messier and Kalaska 1999). When both the starting base and the target are visible, as in the present study, movement planning requires computation of a movement vector in visual (extrinsic) space by subtracting the initial stylus position from the target location. To determine the origin of the vector, the CNS combines both visual and proprioceptive information about the initial hand position (Bagesteiro et al. 2006; Lateiner and Sainburg 2003; Rossetti et al. 1995; Sainburg et al. 2003). The origin of the movement vector is likely not as well defined when using a Non-aligned rather than an Aligned display because on a Non-aligned display, the proprioceptive definition of this initial position does not match the seen position of the cursor as closely as on an Aligned display. Then, the movement vector is transformed into appropriate joint-based (intrinsic) motor commands (Ghilardi et al. 1995; Goodbody and Wolpert 1999). Thus, in the Non-aligned condition, the CNS needs to perform a rotation of this movement vector from a vertical frame of reference to a horizontal one before determining the appropriate motor commands (Bédard and Proteau 2005; Mandryk and MacKenzie 1999; Messier and Kalaska 1997). This additional transformation produces bias (Bo et al. 2006; Bédard and Proteau 2005) and variability (Vindras and Viviani 1998). Our results add to these previous findings by showing that this difference in performance is caused not only by display orientation but also by the virtual representation of one’s hand by a cursor (see also Graham and MacKenzie 1996).
The only difference between the Aligned and the Natural conditions concerned the representation of the stylus position. There are at least two non-mutually exclusive reasons that could explain why this representation could have impacted movement control processes. Using a horizontal display, Sober and Sabes (2005) showed that, when a virtual representation of one’s arm is available to participants, they give more weight to visual information for movement planning and control processes than when the position of their hand is represented by a cursor. It could be that representing the hand/arm position by a cursor on the computer screen results in a loss of relevant visual information relative to the arm configuration. In the same vein, Ghez and coworkers (Ghez et al. 1995) showed that deafferented patients benefited from viewing the arm prior to movement execution, resulting in a better performance than when only a cursor was illustrated at the starting position on the computer screen. According to these authors, the deafferented patients were able to use static visual information about limb configuration (joint angles and segment lengths) to optimize their performance. However, Ghez et al. (1995) reported that control participants did not benefit from vision of the arm on the starting base. This latter observation needs to be interpreted with caution because the task was performed on a Non-aligned display and vision of the arm in this condition might not be as relevant as in an Aligned condition. Thus, one possible explanation of the less accurate/more variable movements observed for the Aligned than for the Natural group could be that, for the former group, vision of the arm configuration was not available to the participant, which decreased the reliability of the initial stylus position.Footnote 2
An alternative explanation is that the position of one’s hand is better defined by the CNS when congruent sensory inputs are available. Graziano, Cooke and Taylor (Graziano et al. 2000) reported the presence of bimodal neurons in the primate posterior parietal cortex, receiving both visual and proprioceptive inputs regarding arm position. These neurons discharged when the initial position of the upper limb was represented by a fake stuffed arm positioned in a natural anatomic position but not when it was represented by paper triangles. It is possible that these bimodal neurons do not discharge when the position of one’s hand is represented by a cursor, resulting in suboptimal integration of visual and proprioceptive information relative to the initial stylus position.
Consequence for movement planning
Bo et al. (2006) reported a significantly larger directional planning bias in a Non-aligned condition than in both an Aligned and a Natural condition. We observed a similar trend in the present study, suggesting a transformation bias (Lhuisset and Proteau 2002) when one’s movement is not performed in the same plan as the information used for movement planning (cursor location on the starting base and the target). This transformation bias is likely to be eliminated by online control process. We will address this issue in the next section.
Consequences for online control
Regardless of the group or visual feedback condition, the data showed that movement variability increased significantly from peak acceleration to peak deceleration, reflecting that movement planning and execution process are variable/noisy processes (Meyer et al. 1988; Schmidt et al. 1979; van Beers et al. 2004). If movements had progressed strictly as planned up to peak deceleration, the position of the hand/stylus at peak acceleration would have been a good predictor of its location at peak deceleration. This was clearly not the case, both for movement direction and for movement extent. There are two contradictory interpretations of this finding. First, because of the noise present in movement execution processes (Harris and Wolpert 1998), from movement initiation to movement endpoint, the better predictor for the location of the cursor at peak deceleration would be that located closest to it, thus, its location at peak velocity rather than at peak acceleration. Second, this finding supports previous observations indicating that the output of the movement planning processes is quickly updated prior to peak velocity (Grierson et al. 2009; Lhuisset and Proteau 2004; Mackrous and Proteau 2007; Messier and Kalaska 1999; Proteau and Masson 1997; Vindras and Viviani 1998). In that perspective, our results add to these previous observations by showing that this updating depends on how the position of the hand is represented and the movement component (i.e., direction or extent) that is considered. At the present time, the data available do not enable us to favor one interpretation of our finding over the other.
The movement variability and correlation analyses concur and suggest a close visual monitoring of the stylus/hand direction up to peak deceleration, which led to quick online control that limited the increase in variability as movements progressed toward the target. No such evidence of either close monitoring or quick online control was observed prior to peak deceleration on the extent component of the task. Nonetheless, a modulation of the movement was observed on both dimensions of the task between peak deceleration and movement endpoint. This modulation was larger in the Normal vision than in the No vision condition and was larger for the Natural task than for both virtual tasks and larger for the Aligned than for the Non-aligned task.
The modulation observed in the No vision condition is consistent with previous findings (Desmurget et al. 1995; Rossetti et al. 1994). In the study of Desmurget et al. (1995), participants aimed at a visual target without vision of their ongoing movement. In one condition, participants never saw their hand (“never”), whereas in the “static” condition, participants saw their hand resting on the starting base prior to movement onset. Endpoint variability was smaller in the “static” than in the “never” condition. The smaller variability in the “static” condition was associated with a shorter acceleration phase and a proportional lengthening of the deceleration phase relative to the “never” condition. Moreover, in a subsequent experiment, Desmurget et al. showed that turning the target off during the last part of the deceleration phase had no effect in the “never” condition, but resulted in a significant increase in pointing variability in the “static” condition. Thus, our results, together with those of Rossetti et al. (1994) and Desmurget et al. (1995), suggest that some online control occurs during the last part of the deceleration phase, even when the hand is not visible. Our results further suggest that the efficacy of this control process increases as the internal representation of one’s hand on the starting base becomes more accurate/reliable, either because vision of the hand is available prior to movement onset (Desmurget et al. 1995) or because visual and proprioceptive information are tightly coupled to each other (Natural > Aligned > Non-aligned). The more reliable the initial position of one’s hand, the better the CNS can predict its position as movement progresses and the more effectively it can modulate the movement (Bourdin et al. 2006; Desmurget and Grafton 2003).
Additionally, an important new finding from the present study is that the presumed increased reliability of one’s initial hand position (vs. the cursor) resulted in a larger decrease in extent and direction variability between peak deceleration and movement endpoint, even in the Normal vision condition. This clearly indicates that visual feedback is not the sole input to this late modulation process. Rather, a more reliable estimation of the initial hand position results in more accurate forward modeling and better prediction of the position of the cursor/hand at any one time. In turn, as the match between the predicted and actual position of the cursor/hand increases, so does the efficacy of the late modulation process, even when the hand or its virtual representation is visible during movement execution.
Increased reliance on visual feedback in the most abstract tasks
The second goal of the present study was to test Norris et al.’s (2001) hypothesis that the reliance on visual feedback for movement planning and control would increase as the task became more natural (Non-aligned < Aligned < Normal). If that had been the case, going from late acquisition to transfer would have resulted in a larger decrease in endpoint accuracy and a larger increase in endpoint variability as the task became more natural. The results showed the opposite.
Both the results of the present study and those of Norris et al. (2001) suggest that when spatial disparities are introduced between visual and proprioceptive inputs (Natural vs. Non-aligned groups), the CNS increases the weight attributed to the less variable input (Harris and Wolpert 1998) or to that which could be processed without first having to be transformed in one way or another (Sober and Sabes 2005). For the Non-aligned group in the present study, vision provided direct information concerning the location of the cursor, whereas this was not the case for proprioception. Therefore, it is likely that, in the acquisition phase, the CNS weighted vision more heavily than proprioception for the Non-aligned group, but less so for the Natural group, for which neither the visual nor the proprioceptive inputs needed transformation. This would explain why withdrawing vision in transfer resulted in larger deleterious effects for the Non-aligned than for the Natural group. In Norris et al.’s (2001) study, vision could be processed directly but transformations were required for proprioception in their video (participants’ hands were filmed and represented on a vertical computer screen) and virtual (hands were represented by a cursor on a vertical computer screen) conditions. Therefore, we propose that vision was weighted more heavily than proprioception in their video and virtual conditions than in their natural condition. In their prism condition, this led to a lesser realignment of the proprioceptive information. This smaller realignment explains why smaller aftereffects were observed in the no prism transfer test for the video and virtual conditions than for the natural condition.
Conclusion
Our results indicate that movement planning and online control processes are largely dependent on the task’s characteristics. These results are important because unnatural contexts lead to a decrease in performance, even when visual feedback is available during movement planning and execution. In practical terms, this means that when one performs a virtual or a video task, optimal performance requires the task setting to be as close as possible to reality. If not, the decrease in performance observed in the Aligned and Non-aligned conditions of the present study might prove to be problematic when one is under stringent accuracy conditions, such as during laparoscopic surgery or telemanipulation.
Notes
In transfer, within-participant variability at key kinematic markers showed no difference between Feedback conditions. As in acquisition, variability increased up to peak deceleration, although more importantly for the Non-aligned condition than for the other two conditions. There was a significant decrease in variability between peak deceleration and movement endpoint. This decrease was significantly larger in the Natural than in the Aligned condition and in the Aligned than in the Non-Aligned condition.
This position might appear difficult to reconcile with recent observations reported by van Beers et al. (1999), who asked participants to match the position of their right index finger with their left index finger. In one condition, the participants could see their entire right arm, whereas in a second condition, they could only see the tip of their right index finger. The results did not reveal any significant difference in position matching variability between the two conditions, which contradicts our hypothesis. However, in that study, the position of the right index finger was also “known” through proprioceptive information transiting via the corpus callosum. Therefore, when there is no direct interhemispheric transfer of information concerning the position of one’s finger, it remains possible that seeing one’s entire arm rather than only one’s finger tip prior to movement initiation increases the reliability of the initial stylus position.
References
Bagesteiro LB, Sarlegna FR, Sainburg RL (2006) Differential influence of vision and proprioception on control of movement distance. Exp Brain Res 171(3):358–370
Bédard P, Proteau L (2005) Movement planning of video and of manual aiming movements. Spat Vis 18(3):275–296
Bo J, Contreras-Vidal JL, Kagerer FA, Clark JE (2006) Effects of increased complexity of visuo-motor transformations on children’s arm movements. Hum Mov Sci 25(4–5):553–567
Bourdin C, Bringoux L, Gauthier GM, Vercher JL (2006) Vision of the hand prior to movement onset allows full motor adaptation to a multi-force environment. Brain Res Bull 71(1–3):101–110
Carey D, Otto-de Haart E (2001) Hemispatial differences in visually guided aiming are neither hemispatial nor visual. Neuropsychologia 39(9):885–894
Clower DM, Boussaoud D (2000) Selective use of perceptual recalibration versus visuomotor skill acquisition. J Neurophysiol 84(5):2703–2708
Desmurget M, Grafton ST (2003) Feedback or feedforward control: end of a dichotomy. In: Johnson-Frey SH (ed) Taking action: cognitive neuroscience perspectives on intentional acts. MIT press, Cambridge, pp 289–338
Desmurget M, Rossetti Y, Prablanc C, Stelmach GE, Jeannerod M (1995) Representation of hand position prior to movement and motor variability. Can J Physiol Pharmacol 73(2):262–272
Desmurget M, Turner RS, Prablanc C, Russo GS, Alexander GE, Grafton ST (2005) Updating target location at the end of an orienting saccade affects the characteristics of simple point-to-point movements. J Exp Psychol Hum Percept Perform 31(6):1510–1536
Fisk JD, Goodale MA (1985) The organization of eye and limb movements during unrestricted reaching to targets in contralateral and ipsilateral visual space. Exp Brain Res 60(1):159–178
Fitts PM (1954) The information capacity of the human motor system in controlling the amplitude of movement. J Exp Psychol 47(6):381–391
Ghez C, Gordon J, Ghilardi MF (1995) Impairments of reaching movements in patients without proprioception. Ii. Effects of visual information on accuracy. J Neurophysiol 73(1):361–372
Ghilardi MF, Gordon J, Ghez C (1995) Learning a visuomotor transformation in a local area of work space produces directional biases in other areas. J Neurophysiol 73(6):2535–2539
Goodbody SJ, Wolpert DM (1999) The effect of visuomotor displacements on arm movement paths. Exp Brain Res 127(2):213–223
Gordon J, Ghez C (1987) Trajectory control in targeted force impulses. Iii. Compensatory adjustments for initial errors. Exp Brain Res 67(2):253–269
Gordon J, Ghilardi MF, Cooper SE, Ghez C (1994) Accuracy of planar reaching movements. Ii. Systematic extent errors resulting from inertial anisotropy. Exp Brain Res 99(1):112–130
Graham E, MacKenzie C (1996) Physical versus virtual pointing. In: Conference on human factors in computing systems: Proceedings of the SIGCHI conference on human factors in computing systems: common ground, Vancouver, British Columbia, Canada, ACM, pp 292–299
Graziano MS, Cooke DF, Taylor CS (2000) Coding the location of the arm by sight. Science 290(5497):1782–1786
Grierson LE, Gonzalez C, Elliott D (2009) Kinematic analysis of early online control of goal-directed reaches: a novel movement perturbation study. Mot Control 13(3):280–296
Harris CM, Wolpert DM (1998) Signal-dependent noise determines motor planning. Nature 394(6695):780–784
Heath M (2005) Role of limb and target vision in the online control of memory-guided reaches. Mot Control 9(3):281–311
Heath M, Westwood DA, Binsted G (2004) The control of memory-guided reaching movements in peripersonal space. Mot Control 8(1):76–106
Khan MA, Elliott D, Coull J, Chua R, Lyons J (2002) Optimal control strategies under different feedback schedules: kinematic evidence. J Motor Behav 34(1):45–57
Khan MA, Lawrence GP, Fourkas A, Franks IM, Elliott D, Pembroke S (2003) Online versus offline processing of visual feedback in the control of movement amplitude. Acta Psychol 113(1):83–97
Khan MA, Franks IM, Elliott D, Lawrence GP, Chua R, Bernier PM, Hansen S, Weeks DJ (2006) Inferring online and offline processing of visual feedback in target-directed movements from kinematic data. Neurosci Biobehav Rev 30(8):1106–1121
Lateiner JE, Sainburg RL (2003) Differential contributions of vision and proprioception to movement accuracy. Exp Brain Res 151(4):446–454
Lhuisset L, Proteau L (2002) Developmental aspects of the control of manual aiming movements in aligned and non-aligned visual displays. Exp Brain Res 146(3):293–306
Lhuisset L, Proteau L (2004) Planning and control of straight-ahead and angled planar movements in adults and young children. Can J Exp Psychol 58(4):245–258
Mackrous I, Proteau L (2007) Specificity of practice results from differences in movement planning strategies. Exp Brain Res 183(2):181–193
Mandryk R, MacKenzie C (1999) Superimposing display space on workspace in the context of endoscopic surgery. In: Conference on human factors in computing systems, Pittsburgh, Pennsylvania, ACM, pp 284–285
Messier J, Kalaska JF (1997) Differential effect of task conditions on errors of direction and extent of reaching movements. Exp Brain Res 115(3):469–478
Messier J, Kalaska JF (1999) Comparison of variability of initial kinematics and endpoints of reaching movements. Exp Brain Res 125(2):139–152
Meyer DE, Abrams RA, Kornblum S, Wright CE, Smith JE (1988) Optimality in human motor performance: ideal control of rapid aimed movements. Psychol Rev 95(3):340–370
Norris SA, Greger BE, Martin TA, Thach WT (2001) Prism adaptation of reaching is dependent on the type of visual feedback of hand and target position. Brain Res 905(1–2):207–219
Proteau L (1992) On the specificity of learning and the role of visual information for movement control. In: Elliott D, Proteau L (eds) Vision and motor control, vol 85. North Holland, Amsterdam, pp 67–103
Proteau L (2005) Visual afferent information dominates other sources of afferent information during mixed practice of a video-aiming task. Exp Brain Res 161(4):441–456
Proteau L, Isabelle G (2002) On the role of visual afferent information for the control of aiming movements toward targets of different sizes. J Motor Behav 34(4):367–384
Proteau L, Masson G (1997) Visual perception modifies goal-directed movement control: supporting evidence from a visual perturbation paradigm. Q J Exp Psychol A 50(4):726–741
Robin C, Toussaint L, Blandin Y, Proteau L (2005) Specificity of learning in a video-aiming task: modifying the salience of dynamic visual cues. J Motor Behav 37(5):367–376
Rossetti Y, Stelmach G, Desmurget M, Prablanc C, Jeannerod M (1994) The effect of viewing the static hand prior to movement onset on pointing kinematics and variability. Exp Brain Res 101(2):323–330
Rossetti Y, Desmurget M, Prablanc C (1995) Vectorial coding of movement: vision, proprioception, or both? J Neurophysiol 74(1):457–463
Sainburg RL, Lateiner JE, Latash ML, Bagesteiro LB (2003) Effects of altering initial position on movement direction and extent. J Neurophysiol 89(1):401–415
Schmidt RA, Lee TD (2005) Motor control and learning: a behavioral emphasis, 4th edn. Human Kinetics Champaign, IL
Schmidt RA, Zelaznik HZ, Hawkins B, Frank JS, Quinn JT (1979) Motor-output variability: a theory for the accuracy of rapid motor acts. Psychol Rev 47(5):415–451
Sober SJ, Sabes PN (2005) Flexible strategies for sensory integration during motor planning. Nat Neurosci 8(4):490–497
Soucy MC, Proteau L (2001) Development of multiple movement representations with practice: specificity versus flexibility. J Motor Behav 33(3):243–254
Tremblay L, Proteau L (1998) Specificity of practice: the case of power lifting. Res Q Exercise Sport 69(3):284–289
van Beers RJ, Sittig AC, van der Gon JJD (1999) Localization of a seen finger is based exclusively on proprioception and on vision of the finger. Exp Brain Res 125(1):43–49
van Beers RJ, Haggard P, Wolpert DM (2004) The role of execution noise in movement variability. J Neurophysiol 91(2):1050–1063
Veilleux LN, Proteau L (2010) Factors influencing online control of video-aiming movements performed without vision of the cursor. Psychol Res 74(2):182–195
Vindras P, Viviani P (1998) Frames of reference and control parameters in visuomanual pointing. J Exp Psychol Hum Percept Perform 24(2):569–591
Acknowledgment
This work was supported by a Discovery grant (L. P.) provided by the Natural Sciences and Engineering Research Council of Canada.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Veilleux, LN., Proteau, L. Suboptimal online control of aiming movements in virtual contexts. Exp Brain Res 208, 345–358 (2011). https://doi.org/10.1007/s00221-010-2487-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00221-010-2487-9