
Abstract
The bench-to-bedside development of pro-cognitive therapeutics for psychiatric disorders has been mired by translational failures. This is, in part, due to the absence of pharmacologically sensitive cognitive biomarkers common to humans and rodents. Here, we describe a cross-species translational marker of reward processing that is sensitive to the aminergic agonist, d-amphetamine. Motivated by human electroencephalographic (EEG) findings, we recently reported that frontal midline delta-band power is an electrophysiological biomarker of reward surprise in humans and in mice. In the current series of experiments, we determined the impact of parametric doses of d-amphetamine on this reward-related EEG response from humans (n = 23) and mice (n = 28) performing a probabilistic learning task. In humans, d-amphetamine (placebo, 10 mg, 20 mg) boosted the Reward Positivity event-related potential (ERP) component as well as the spectral delta-band representations of this signal. In mice, d-amphetamine (placebo, 0.1 mg/kg, 0.3 mg/kg, 1.0 mg/kg) boosted both reward and punishment ERP features, yet there was no modulation of spectral activities. In sum, the present results confirm the role of dopamine in the generation of the Reward Positivity in humans, and pave the way toward a pharmacologically valid biomarker of reward sensitivity across species.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Animal models of cognitive processes have been beset by translational difficulties. We recently addressed this problem by identifying common electrophysiological biomarkers of isolated cognitive processes in both humans and mice (Cavanagh et al. 2021). One of the most promising outcomes identified in that project was a common delta-band spectral reflection of the Reward Positivity (RewP), an event-related potential (ERP) component that has been well-described in human particaipants (Holroyd et al. 2008; Proudfit 2015). While the discovery of cross-species biomarkers is an important step, their translational utility requires a demonstration of consistent pharmacological predictive validity (i.e. similar drug effects across species). Here, we tested whether this cortical reward signal had similar sensitivity to d-amphetamine in mice and humans.
The RewP is a positive deflection in the ERP that is most commonly quantified over fronto-central sites around 200–400 ms after reward presentation (Holroyd et al. 2011; Proudfit 2015; Heydari and Holroyd 2016). Both the RewP and its delta-band spectral reflection scale with the degree of positive reward prediction error, whereby “better than expected” outcomes evoke increasingly larger RewP amplitudes (Baker and Holroyd 2011; Cavanagh 2015; Holroyd and Umemoto 2016). These two criteria are notable: they indicate that this reward-related signal is specific and sensitive to positive reward prediction error, fulfilling stringent criteria of being a neural marker of this computational process (Cacioppo and Tassinary 1990).
The RewP is diminished in disorders like major depression (Bress et al. 2013; Webb et al. 2016) and Parkinson’s disease (Brown et al. 2020), suggesting that it might be a trans-diagnostic biomarker of reward responsiveness, learning, and valuation. The emerging mechanistic understanding of this signal increases its appeal: the reward prediction error computation reflected by the RewP mirrors the dopamine-driven learning process underlying reinforcement learning (Sutton and Barto 1998). The cortically generated RewP has been theorized to be modulated by phasic midbrain dopamine (Holroyd et al. 2008); however, empirical tests of this have been sparse and beset by methodological complications (see Discussion), with little evidence for pharmacological predictive validity across species. It remains unknown if these cortical and midbrain systems influence each other in a causal manner, if they are both influenced by a third variable, or if they reflect parallel processes. Despite these uncertainties, the current understanding of the RewP suggests that it should be affected by manipulations of dopaminergic activity. While d-amphetamine evokes non-specific aminergic neurotransmission, its role as a cross-species cognitive enhancer with strong dopaminergic effects suggests that it is an excellent candidate for pharmacological challenge. The current study aimed to provide an initial test of this dopaminergic hypothesis, as well as facilitate the first test of common underlying mechanisms in the homologous mouse cortical signal.
Materials and methods
Human participants
Healthy women and men between the ages 18 and 35 years were recruited from the community via public advertisements and compensated monetarily for study participation. This study was conducted at the UCSD Medical Center and was approved by the UCSD Human Subject Institutional Review Board. Participants first completed a phone screen to assess current and past medical and psychiatric history, medication and recreational drug use and family history of psychosis. During the subsequent in-person screening visit, participants signed the consent form and completed assessments of physical and mental health, including a structured clinical interview, self-report questionnaires about caffeine intake and handedness, a hearing test, physical examination, an electrocardiogram, urine toxicology screen, urine pregnancy test for females, the MATRICS Comprehensive Cognitive Battery (MCCB) and a Wide Range Achievement Test (WRAT) for IQ assessment. See Supplementary Table 1 for these clinical demographics. A total of 12 male and 11 female participants completed all three sessions and are included here.
A double blind, randomized, placebo-controlled, counterbalanced, within-subject design was utilized. Participants received either placebo or one of two active doses of d-amphetamine (10 or 20 mg) orally on each of the three test days which were separated by one week. On all assessment days, participants arrived at 8:30 am after overnight fasting, completed a urine toxicology screen and a urine pregnancy test in females, and ate a standardized breakfast. Vital signs and subjective symptom rating scale scores were obtained at specific intervals pre- and post- administration. Starting 120 min post-administration, subjects completed cognitive tests and simultaneous EEG recording. See Supplementary Table 2 for experimental session information.
Probabilistic learning task (PLT)
This version of the PLT was identical to our previous investigation (Cavanagh et al. 2021), see Fig. 1A. Participants were presented a stimulus pair (e.g., bicycle/phone, chair/clip, plug/flashlight) on a computer monitor and instructed to select the “target” stimulus using a digital 4-switch USB arcade-style joystick. Participants were given feedback after each trial about whether their response was “correct” or “incorrect”. Reward probabilities for the target/non-target stimulus were set within a block of 60 trials (80/20, 70/30, 60/40, 50/50), but stimuli differed between trial blocks (first block was bicycle/phone at 80/20, then the next block was chair/clip at 60/40, etc.). Overall performance was calculated as the total number of correct target selections in each block of 60 trials.

Task and performance. (A) The Probabilistic Learning Task required the subject to select the stimulus that probabilistically led to reward most often. In humans and mice, each trial required a choice between two stimulus icons. (B) Performance, split by block and drug. Humans displayed approximate matching behavior with no difference in performance due to amphetamine dose. In the 50/50 condition there was no chance to learn a ‘better’ stimulus and performance was at chance. Mice struggled to reliably discriminate between each pair of stimuli, but they did perform better than chance in aggregate
Human electrophysiological recording and pre-processing
Continuous electrophysiological (EEG) data were recorded in DC mode from 64 scalp leads using a BioSemi Active Two system. Four electrooculograms (EOG) recorded at the superior and inferior orbit of the left eye and outer canthi of each eye, and one nose and two mastoid electrodes were also collected. All data were collected using a 1048 Hz sampling rate utilizing a first-order anti-aliasing filter. Custom Matlab scripts and EEGLab (Delorme and Makeig 2004) functions were used for all data processing. Data were first down sampled to 500 Hz, epoched around the imperative cues (− 2000 to + 5000 ms) and then average referenced. Bad channels and bad epochs were identified using a conjunction of the FASTER algorithm (Nolan et al. 2010) and EEGLab’s pop_rejchan function, and were subsequently interpolated and rejected respectively. Following that, blinks were removed following independent component analysis.
Animal subjects
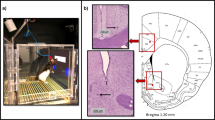
Female and male C57BL/6J mice were obtained from The Jackson Laboratory (Bar Harbor, ME, USA), housed in same sex groupings of 2 per cage in a temperature and humidity controlled vivarium under a reverse 12 h light/dark cycle (lights off 0800 h) and tested during the dark phase. All experimental procedures were performed in accordance with the National Institutes of Health Guide for Care and Use of Laboratory Animals and were approved by the University of New Mexico Health Sciences Center Institutional Animal Care and Use Committee. A total of 15 male and 13 female mice were used. See Supplemental Methods for information on touchscreen pre-training and surgery. Dura-resting skull screws were used to record EEG activity; here we focus on the medial prefrontal cortex lead (AP +2.80, ML +0.00) with a cerebellar ground.
A randomized, placebo-controlled, counterbalanced, within-subject design was utilized. Mice received either placebo or one of three active doses of d-amphetamine (0.1 mg/kg, 0.3 mg/kg, 1.0 mg/kg) on each of the four test days which were separated by a 72 h washout period. These same doses were used in our prior work (MacQueen et al. 2018). Starting 15 min post-administration, subjects completed the PLT with simultaneous EEG recording. Notably, since 1.0 mg/kg leads to significantly increased hyperactivity and significantly decreased task focus (Grilly and Loveland 2001; MacQueen et al. 2018), it was investigated as an upper limit of dosing.
Mouse PLT
This version of the PLT was also identical to our previous investigation (Cavanagh et al. 2021), see Fig. 1A. Each session, mice were presented with three pairs of unique stimuli (fan/marble, spider/fan, honey/cave) in three separate 20 trial blocks, for a total for 60 trials per session. For the first block, the target stimulus was rewarded 90% of the time and the non-target stimulus was rewarded 10% of the time. The next blocks included 80/20 and then 70/30 reinforcement rates. The mice were given 120 min to complete the task. Rewards consisted of the immediate delivery of an auditory tone for 1 s signaling the availability of liquid reward (30 μl strawberry Nesquik, Nestle). Punishments consisted of immediate illumination of the house light for 10 s before the next trial could be initiated.
Human and mouse EEG processing
For the sake of descriptive simplicity, both the scalp-recorded signal in humans as well as the dura-recorded signal in mice are referred to as ‘EEG’. Time–Frequency measures were computed by multiplying the fast Fourier transformed (FFT) power spectrum of single trial EEG data with the FFT power spectrum of a set of complex Morlet wavelets defined as a Gaussian-windowed complex sine wave: ei2πtfe−t^2/(2xσ^2), where t is time, f is frequency (which increased from 1 to 50 Hz in 50 logarithmically spaced steps) and the width (or ‘cycles’) of each frequency band were set to increase from 3/(2πf) to 10/(2πf) as frequency increased. Then, the time series was recovered by computing the inverse FFT. The end result of this process is identical to time-domain signal convolution, and it resulted in estimates of instantaneous power taken from the magnitude of the analytic signal. Each epoch was then cut in length from − 500 to + 1000 ms peri-feedback.
Averaged power was normalized by conversion to a decibel (dB) scale (10*log10[power(t)/power(baseline)]), allowing a direct comparison of effects across frequency bands. The baseline consisted of averaged power − 300 to − 200 ms before all imperative cues. A 100-ms duration is often used as an effective baseline in spectral decomposition since pixel-wise time–frequency data points have already been resolved over smoothed temporal and frequency dimensions with the wavelets. For ERPs, a baseline correction of − 300 to − 200 ms was applied and data were 20 Hz low-pass filtered prior to averaging. Feedback-locked analysis was conducted at electrode FCz in humans and the frontal lead in rodents.
Statistical analysis
Analytic methods are either identical to our previous report (Cavanagh et al. 2021), or they are new analyses. Analysis of the same time–frequency region of interest (tf-ROI) was proposed to be a major constraint within our ‘learn-confirm’ strategy between experimental phases (Cavanagh et al. 2021). ERPs were not reported in our prior ‘learn phase’ investigation; we now show the relevant mouse ERPs from that previous investigation in Supplementary Fig. 1. We also report additional analyses that were facilitated by this novel ‘confirm’-stage multi-session, within subject design. As in our previous report, hypotheses were specific to the reward-related EEG; however, punishment-related EEG signals are again reported here for consistency. The number of epochs for each condition is shown in Supplementary Fig. 2.
Species were analyzed with separate mixed effects models. In contrast to an Analysis of Variance where independence is assumed across levels of a variable, linear mixed models are appropriate for investigating group-level patterns of individual change across levels a variable (Singer and Willett 2003; Yu et al. 2022). Accordingly, each mouse was treated as a random effect, similar to humans. Drug condition and sex were treated as fixed effects, although there were no a priori hypotheses for sex effects. Given the established inverted-U effects of dopamine agonism on frontal cortical activities (see: Cools and Arnsten 2022), either linear or quadratic effects of the drug condition could be expected (depending on dose and individual differences). Fitting with the demands of parsimony and the inferential affordance allowed by the number of drug conditions, we used linear contrasts for humans (placebo, 10 mg, 20 mg) but we included quadratic contrasts (drug*drug) for mice (placebo, 0.1 mg/kg, 0.3 mg/kg, 1.0 mg/kg). Analyses were conducted using the MIXED command in SPSS v26 with random intercepts for each participant and the default diagonal covariance structure for repeated measurements. Mixed models don’t yield a widely accepted measure of effect size, but for t-tests the effect sizes were calculated as Cohen’s dz, where the z indicates the within-subjects difference (Lakens 2013).
Scalar values of spectral power were derived from the same spatial, temporal, and frequency windows as in our foundational paper. For these expectation-based contrasts, comparisons were split based on the probabilistic aspect of the reward feedback, creating high probability (i.e. target response followed by reward) vs. low probability (i.e. non-target response followed by reward) contrasts. We adhered to our previously defined tf-ROIs and we again omitted data from the 50/50 condition in humans (human reward: 1.3 Hz to 2 Hz, 250 to 550 ms; human punishment: 4 to 6.5 Hz, 450 to 750 ms; mouse reward: 1 to 4 Hz, 250 to 550 ms; mouse punishment: 4.5 to 7.5 Hz, 500 to 800 ms). However, this study design offered an additional chance for inference.
Unlike our previous study, this multi-session design facilitated a comparison of similar feedback processes across levels of the fixed effect (drug) without the requirement of deriving a performance-based contrast to serve as a fixed contrast (expectation). This design enabled a comparison of the grand average feedback-related response outside the constraints of behavioral performance. This is beneficial, given the poor performance of mice on the task (Fig. 1B). Critically, human feedback-locked EEG activities are most often assessed in un-learnable tasks with 50/50 reward probabilities (e.g. the two-door task: Foti and Hajcak 2009; Angus et al. 2015; Proudfit 2015; Mulligan and Hajcak 2017), highlighting how learning is not a necessary requirement for eliciting these cortical signatures of feedback receipt.
Due to this affordance, here we investigated grand average ERPs for the first time. ERP components were de novo defined based on the grand average over all drug conditions (human reward: 250 to 400 ms, human punishment: 250 to 500 ms. mouse feedback: 400 to 600 ms), see Fig. 2. In humans, the grand average time–frequency activity peaked earlier than the expectation-defined contrasts, so we defined new time ranges based on the grand average over all drug conditions. For reward, this earlier window was from 100 to 400 ms and for punishment, this earlier window was 250 to 550 ms. There was no apparent simple grand average peak for feedback in mice, so the previously defined tf-ROIs were used in all analyses.

Feedback-locked ERPs from humans and mice. Grand average plots show feedback-locked ERP activity averaged over all drug conditions. Low-frequency trends around the time-locking event (0 ms) reflect motor activities in each species. Time windows for quantification are shown with grey bars. Below, each feedback condition ERP is shown, split by drug dose. The same time window quantifications are shown with grey bars. Human ERPs topographical plots demonstrate drug condition differences; the purple square identifies the FCz electrode that was a priori chosen for analysis. Line plots (mean + / − SEM) detail the drug effects on each ERP component. In humans, only the RewP component was significantly affected by d-amphetamine using model with a linear slope. Mouse ERP features were characterized by quadratic effects with increasing d-amphetamine dose (i.e. including the data level in the grey background); however, if this ceiling-level condition of 1.0 mg/kg was removed, a similar linear trend as humans was statistically identified. *p < .05 **p < .01
Results
Performance
The full statistical results for performance data are reported in Supplementary Table 3. In humans, there was a main effect of block (easier pairs were more accurate, see Fig. 1B) and a drug*sex interaction, which revealed a tendency for females to perform slightly worse under higher amounts of d-amphetamine whereas males were unaffected (see Supplementary Fig. 3). In mice, there was no effect of block nor any effect with drug. This indicates that mice had poor performance discriminating the probabilities between difficulty conditions, although they managed to perform above chance when all drug and block conditions were collapsed (one sample t-test vs. chance: t(27) = 2.15, p = 0.04), see Fig. 1B.
ERPs
Figure 2 shows the ERPs for each species, condition-specific breakdowns, and statistical patterns in the ERP component amplitudes across levels of drug. All statistical results for ERP data are reported in Table 1. In humans, there was a main effect of drug with a linear trend for increased RewP amplitude with increasing dose of d-amphetamine. This effect was not present in the corresponding punishment condition, which showed a trend toward a quadratic effect (although the quadratic contrast was not significant either). In mice, there was a quadratic effect of drug on reward and punishment ERP amplitudes. Since 1.0 mg/kg of d-amphetamine was at ceiling-level tolerance and is thus not ideally suitable for comparison to humans (see Methods), we examined if the same linear effect observed in humans was present in the first three drug conditions alone. Similar to the pattern observed in humans, there was a linear effect of drug for the first three conditions for both reward and punishment ERP features.
TF-ROI: grand average
Figure 3 shows time–frequency plots for each species, including expectation-related learning contrasts (low vs. high probability conditions) and grand average plots (collapsed across probability conditions). First, we discuss grand average activities to detail the spectral response to each feedback type separately. All statistical results for grand average tf-ROIs are reported in Table 1. In humans, there were main effects of drug with linear trends for increased reward delta power and punishment theta power with increasing dose of d-amphetamine (Fig. 3A). For reward, there was also a main effect of sex where males had higher reward delta power. In mice, there were no significant outcomes for either reward or punishment (Fig. 3C).

Time–frequency grand averages and expectation-related contrasts. (A) Human FCz lead: grand average, (B) Human FCz lead: expectation difference (feedback from low vs. high probability conditions), (C) Mice: anterior lead grand average, (D) Mice: anterior lead expectation difference. The magenta box shows each tf-ROI. Human figures: grand average topographic plots: + / − 5 dB, expectation difference topographic plots: + / − 0.5 dB. Line plots (mean + / − SEM) detail the drug effects on each tf-ROI. *p < .05 **p < .01
TF-ROI: expectation
All statistical results for tf-ROI learning-related expectation contrasts (low probability minus high probability) are reported in Table 1. In humans, there was a main effect of drug with.
a linear trend for increased reward delta power with increasing dose of d-amphetamine (Fig. 3B). This effect was not present in the corresponding punishment condition. There was also a main effect of sex (higher power in males) and an interaction between drug and sex, where this expectation difference declined slightly in males and increased in females with increasing dose of d-amphetamine. In mice, there were no effects of d-amphetamine on tf-ROI expectation contrasts (Fig. 3D); however, this is likely due to the poor performance learning the behavioral discriminations (Fig. 1B). In sum, only humans displayed an effect of d-amphetamine on reward-related tf-ROI power, both for the simple presentation of rewards (Fig. 3A) as well as the learning-related enhancement of this signal (Fig. 3B).
Small-scale replication of mouse ERP findings
We further aimed to replicate these mouse ERP findings in a separate small-scale cohort with easier learning discriminations (a single pair of stimuli: target 80% correct vs. non-target 20% correct). Nine mice were run on placebo or 0.3 mg/kg of d-amphetamine across multiple sessions. All mice learned to perform around 80% accuracy with no difference between drug conditions (t(8) = 1.03, p = 0.33). Supplementary Figure S4 shows that this drug-related enhancement of ERP amplitude could be replicated, although it did not achieve statistical significance (t(8) = 1.64, p = 0.14, dz = 0.55). However, the p-value is a poor metric for assessing replicability; effect sizes and confidence intervals are more useful for assessing the utility of an experimental outcome (Halsey et al. 2015; Colquhoun 2017). The effect size from this small-scale replication cohort is larger than the one for cohort shown in Fig. 2: for that group, the paired t-test between placebo and 0.3 mg/kg d-amphetamine on reward ERP amplitudes was t(27) = 2.02, p = 0.05, dz = 0.38.
Discussion
This report validated our previous finding of a common electrophysiological marker of cortical reward processing in mice and humans as seen here during placebo (Cavanagh et al. 2021). The current work went further however, by demonstrating similar sensitivity of both species to increasing doses of d-amphetamine, demonstrating pharmacological predictive validity for this biomarker of reward sensitivity. While our previous cortical marker was based on the expectation-modulated spectral power, this study only found common cross-species amphetamine effects in the grand average ERP component. Unfortunately, the specific influence of d-amphetamine on learning-related spectral power in mice could not be definitively assessed due to poor learning. Yet, these findings already suggest that the influence of d-amphetamine is intrinsic to the generation of the RewP in both humans and mice.
As noted earlier, the RewP is sensitive to learning-related prediction errors, yet it is elicited by any rewarding feedback even in un-learnable environments (Foti and Hajcak 2009; Angus et al. 2015; Proudfit 2015; Mulligan and Hajcak 2017). This tendency appears to be preserved in the mice, who performed above chance but not at a level indicative of active successful learning. Our second small-scale replication cohort with good performing mice suggests that the enhancing effect of d-amphetamine on the RewP is reliable. However, two major issues remain to be addressed: (1) the specificity of d-amphetamine effects on reward vs. punishment conditions, and (2) the effect of d-amphetamine on reward signal generation vs. learning-related enhancements of this reward signal.
Specificity vs. generality of d-amphetamine effects on reward
In humans, there were general facilitating effects of d-amphetamine, although the effects were strongest for the reward-related conditions. The reward-related ERP (Fig. 2), grand average tf-ROI (Fig. 3A), and expectation tf-ROI (Fig. 3B) were all significantly affected by d-amphetamine in humans, whereas punishment-related effects were smaller and had some different overall trends than the RewP. In mice, there were also general facilitating effects of d-amphetamine on reward ERP amplitudes (Fig. 2; Supplementary Fig. 4) but not spectral activities (Fig. 3C-D). Why did d-amphetamine affect spectral power in humans but not mice? One reason might be the much lower peak frequency of the mouse delta band phenomenon, which makes effective time–frequency quantification more difficult, particularly in the absence of a learning-related contrast (see section below). In sum, the cumulative cross-species similarities demonstrate that d-amphetamine boosts reward-related EEG signals in humans as well as mice, although the specificity of this effect to rewards could not be definitively determined (smaller effect sizes are not indicative of functional dissociation).
Previous evidence of dopaminergic sensitivity of these cortical signals in humans has been mixed, partially due to methodological reasons. Some studies have examined pharmacological effects on the punishment-related EEG signal or the difference between reward and punishment conditions, and have generally failed to find effects of the dopamine D2 receptor antagonists haloperidol (Forster et al. 2017) or sulpiride (Mueller et al. 2014a; Lueckel et al. 2018) unless moderated by genotype (Mueller et al. 2014b). However, conceptual issues about different generative systems underlying reward and punishment EEG signals casts doubt on the suitability of this common “difference wave” contrast (Meyer et al. 2017; Brown and Cavanagh 2020). One experiment revealed a reduction in the condition-specific RewP in response to the dopamine D2/3 receptor agonist pramipexole (Santesso et al. 2009), yet there are no other studies of parametric or enhancing effects of dopaminergic agents specific to the RewP in humans. A recent report observed that although the condition-specific RewP is specifically diminished in Parkinson’s disease, L-dopa administration did not alter this signal (Brown et al. 2020). This surprising lack of acute dopaminergic influence might be due to combined issues of cortical degeneration in Parkinson’s and the differential influence of L-dopa on striatal vs. cortical dopamine tone (Cools 2006). The findings from this report extend the specificity of pharmacological electrophysiology in humans, demonstrating a clear influence of cortical dopaminergic agonism on the RewP and associated EEG spectral signatures of reward receipt.
Reward signal generation vs. learning-related enhancements
Our previous investigation of similar cross-species cortical feedback signals was limited by the need to create a well-controlled analytic contrast within each species (i.e. low vs. high probability outcomes corresponding to high vs. low reinforcement prediction error), without interference from different sensory or imperative stimuli (Cavanagh et al. 2021). Since rewarded actions for mice were signaled with a tone indicating strawberry milkshake but punishments were signaled with the house lights, outcome valences were inherently incomparable. The expectation-defined tf-ROI was thus an excellent beginning to the identification of a common reward-specific biomarker; however, the expression of learning-related modulations is only a part of the relevant variance in this reward signal.
Expectation-related contrasts are ideal for identifying the specificity of pharmacological manipulations on these reward signals: the significant tf-ROI enhancement of delta power in humans due to d-amphetamine (Fig. 3B) is powerful evidence for a selective and specific enhancing effect of dopamine agonism on this reward-responsive biomarker. Unfortunately, the absence of a learning effect in mice makes the null effect in this contrast (Fig. 3D) less informative. Yet positive findings in the ERP component generation of this signal across both species is still particularly meaningful.
An emerging literature is revealing that appetitive motivation and affective value boost the RewP outside any influence of learning or expectation (Threadgill and Gable 2017; Brown and Cavanagh 2018; Peterburs et al. 2019; Brown et al. 2021; Huvermann et al. 2021; Pegg et al. 2021). This dissociation in affective vs. informational value might be critical for understanding altered reward dysfunction: for instance, major depression is associated with a diminished RewP but no change in the information representation of positive prediction error in the RewP (Cavanagh et al. 2018). This dissociation suggests that mood reveals a difference between variance related to the generation of the signal and variance related to learning-dependent modulation of the signal (akin to an intercept vs. slope dissociation).
Limitations and future directions
Cross-species comparisons in electrophysiological responses are complicated by a number of factors. There are differences between species in cortical homologies and the scale of neural activity in each recording type (i.e. scalp vs. dura). Still, there are comparable midfrontal cortical structures (Balsters et al. 2020; Schaeffer et al. 2020; Preuss and Wise 2022) and increasing evidence confirms empirical similarities in EEG responses between humans and rodents (Narayanan et al. 2013; Ehlers et al. 2014, 2020; Warren et al. 2015; Featherstone et al. 2018; Robble et al. 2021). There are also inherent differences between species in task experience, motivation, and difficulty. We addressed these methodological difficulties with a highly constrained analytic strategy: we used the same task and the same time–frequency region of interest (tf-ROI) within our ‘learn-confirm’ strategy between experimental phases (Cavanagh et al. 2021).
While this methodological conservation was designed to constrain interpretation, continued methodological advancements will be required to optimally hone this field of research. For example, our small-scale replication study identified a better technique for enhancing reinforcement learning in mice (i.e. one 80/20 pair). Our findings reported here only contained a single electrode in humans with a single dura lead in mice. While this theory-driven reduction of spatial dimensionality was appropriate for the constrained methodological approach of this study, it offers only a fraction of assessable EEG activities in each species. In the future, depth recordings might provide more signal to noise than dura screws while simultaneously revealing the source generators of this reward-specific signal.
The use of pharmacological manipulation is a powerful tool for causal inference, although this technique also has inherent limitations. It is important to note that d-amphetamine enhances release of both norepinephrine and serotonin in addition to dopamine, and it is thus conceivable that some of the drug effects detected in this study reflect increases in non-dopaminergic neurotransmission. Yet in contrast to difficult and expensive human clinical trials, future rodent studies using this described paradigm could provide a relatively simple test of the aminergic specificity of the RewP.
Summary
This study demonstrated that the RewP is a pharmacologically valid biomarker of reward sensitivity across species. Moreover, we provided a confirmatory test on the role of dopamine in the generation of the RewP. The RewP appears to be a trans-diagnostic biomarker of reward responsiveness, learning, and valuation. The cross-species translatability of this bio-signal will further bolster our mechanistic understanding of reward-related disfunctions in major depression, schizophrenia, and Parkinson’s disease.
Data availability
All data and Matlab code to re-create these analyses are available at OpenNeuro.org, accession #ds003987.
References
Angus DJ, Kemkes K, Schutter DJLG, Harmon-Jones E (2015) Anger is associated with reward-related electrocortical activity: evidence from the reward positivity. Psychophysiology 52:1271–1280. https://doi.org/10.1111/psyp.12460
Baker TE, Holroyd CB (2011) Dissociated roles of the anterior cingulate cortex in reward and conflict processing as revealed by the feedback error-related negativity and N200. Biol Psychol 87:25–34. https://doi.org/10.1016/j.biopsycho.2011.01.010
Balsters JH, Zerbi V, Sallet J et al (2020) Primate homologs of mouse cortico-striatal circuits. Elife 9:1–24. https://doi.org/10.7554/eLife.53680
Bress JN, Foti D, Kotov R et al (2013) Blunted neural response to rewards prospectively predicts depression in adolescent girls. Psychophysiology 50:74–81. https://doi.org/10.1111/j.1469-8986.2012.01485.x
Brown DR, Cavanagh JF (2018) Rewarding images do not invoke the reward positivity: they inflate it. Int J Psychophysiol. https://doi.org/10.1016/j.ijpsycho.2018.02.012
Brown DR, Cavanagh JF (2020) Novel rewards occlude the reward positivity, and what to do about it. Biol Psychol 151https://doi.org/10.1016/j.biopsycho.2020.107841
Brown DR, Richardson SP, Cavanagh JF (2020) An EEG marker of reward processing is diminished in Parkinson’s disease. Brain Res 1727https://doi.org/10.1016/j.brainres.2019.146541
Brown DR, Jackson TCJ, Cavanagh JF (2021) The reward positivity is sensitive to affective liking. Cogn Affect Behav Neurosci. https://doi.org/10.3758/s13415-021-00950-5
Cacioppo JT, Tassinary LG (1990) Inferring psychological significance from physiological signals. Am Psychol 45:16–28
Cavanagh JF (2015) Cortical delta activity reflects reward prediction error and related behavioral adjustments, but at different times. Neuroimage 110:205–216. https://doi.org/10.1016/J.NEUROIMAGE.2015.02.007
Cavanagh JF, Bismark AW, Frank MJ, Allen JJB (2018) Multiple Dissociations between comorbid depression and anxiety on reward and punishment processing : evidence from computationally informed EEG. Comput Psychiatry. https://doi.org/10.1162/cpsy
Cavanagh JF, Gregg D, Light GA et al (2021) Electrophysiological biomarkers of behavioral dimensions from cross-species paradigms. Transl Psychiatry 11:1–11
Colquhoun D (2017) The reproducibility of research and the misinterpretation of P values. R Soc Open Sci 4:1–22. https://doi.org/10.1101/144337
Cools R (2006) Dopaminergic modulation of cognitive function-implications for L-DOPA treatment in Parkinson’s disease. Neurosci Biobehav Rev 30:1–23. https://doi.org/10.1016/j.neubiorev.2005.03.024
Cools R, Arnsten AFT (2022) Neuromodulation of prefrontal cortex cognitive function in primates: the powerful roles of monoamines and acetylcholine. Neuropsychopharmacology 47:309–328. https://doi.org/10.1038/s41386-021-01100-8
Delorme A, Makeig S (2004) EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J Neurosci Methods 134:9–21. https://doi.org/10.1016/j.jneumeth.2003.10.009S0165027003003479[pii]
Ehlers CL, Phillips E, Wills D et al (2020) Phase locking of event-related oscillations is decreased in both young adult humans and rats with a history of adolescent alcohol exposure. Addict Biol 25:1–12. https://doi.org/10.1111/adb.12732
Ehlers CL, Wills DN, Desikan A et al (2014) Decreases in energy and increases in phase locking of event-related oscillations to auditory stimuli occur during adolescence in human and rodent brain. Dev Neurosci 36:175–195. https://doi.org/10.1159/000358484
Featherstone RE, Melnychenko O, Siegel SJ (2018) Mismatch negativity in preclinical models of schizophrenia. Schizophr Res 191:35–42. https://doi.org/10.1016/j.schres.2017.07.039
Forster SE, Zirnheld P, Shekhar A et al (2017) Event-related potentials reflect impaired temporal interval learning following haloperidol administration. Psychopharmacology 234:2545–2562. https://doi.org/10.1007/s00213-017-4645-2
Foti D, Hajcak G (2009) Depression and reduced sensitivity to non-rewards versus rewards: evidence from event-related potentials. Biol Psychol 81:1–8. https://doi.org/10.1016/j.biopsycho.2008.12.004
Grilly DM, Loveland A (2001) What is a “low dose” of d-amphetamine for inducing behavioral effects in laboratory rats? Psychopharmacology 153:155–169. https://doi.org/10.1007/s002130000580
Halsey LG, Curran-Everett D, Vowler SL, Drummond GB (2015) The fickle P value generates irreproducible results. Nat Methods 12:179–185. https://doi.org/10.1038/nmeth.3288
Heydari S, Holroyd CB (2016) Reward positivity: reward prediction error or salience prediction error? Psychophysiology 53:1185–1192. https://doi.org/10.1111/psyp.12673
Holroyd CB, Krigolson OE, Lee S (2011) Reward positivity elicited by predictive cues. NeuroReport 22:249–252. https://doi.org/10.1097/WNR.0b013e328345441d
Holroyd CB, Pakzad-Vaezi KL, Krigolson OE (2008) The feedback correct-related positivity: sensitivity of the event-related brain potential to unexpected positive feedback. Psychophysiology 45:688–697. https://doi.org/10.1111/j.1469-8986.2008.00668.x (PSYP668 [pii])
Holroyd CB, Umemoto A (2016) The research domain criteria framework: the case for anterior cingulate cortex. Neurosci Biobehav Rev 71:418–443. https://doi.org/10.1016/j.neubiorev.2016.09.021
Huvermann DM, Bellebaum C, Peterburs J (2021) Selective devaluation affects the processing of preferred rewards. Cogn Affect Behav Neurosci. https://doi.org/10.3758/s13415-021-00904-x
Lakens D (2013) Calculating and reporting effect sizes to facilitate cumulative science: a practical primer for t-tests and ANOVAs. Front Psychol 4:1–12. https://doi.org/10.3389/fpsyg.2013.00863
Lueckel M, Panitz C, Nater UM, Mueller EM (2018) Reliability and robustness of feedback-evoked brain-heart coupling after placebo, dopamine, and noradrenaline challenge. Int J Psychophysiol 132:298–310. https://doi.org/10.1016/j.ijpsycho.2018.01.010
MacQueen DA, Minassian A, Kenton JA et al (2018) Amphetamine improves mouse and human attention in the 5-choice continuous performance test. Neuropharmacology 138:87–96. https://doi.org/10.1016/j.neuropharm.2018.05.034
Meyer A, Lerner MD, De Los RA et al (2017) Considering ERP difference scores as individual difference measures: issues with subtraction and alternative approaches. Psychophysiology 54:114–122. https://doi.org/10.1111/psyp.12664
Mueller EM, Burgdorf C, Chavanon ML et al (2014a) Dopamine modulates frontomedial failure processing of agentic introverts versus extraverts in incentive contexts. Cogn Affect Behav Neurosci 14:756–768. https://doi.org/10.3758/s13415-013-0228-9
Mueller EM, Burgdorf C, Chavanon ML et al (2014b) The COMT Val158Met polymorphism regulates the effect of a dopamine antagonist on the feedback-related negativity. Psychophysiology 51:805–809. https://doi.org/10.1111/psyp.12226
Mulligan EM, Hajcak G (2017) The electrocortical response to rewarding and aversive feedback: the reward positivity does not reflect salience in simple gambling tasks. Int J Psychophysiol 0–1https://doi.org/10.1016/j.ijpsycho.2017.11.015
Narayanan NS, Cavanagh JF, Frank MJ, Laubach M (2013) Common medial frontal mechanisms of adaptive control in humans and rodents. Nat Neurosci 16:1–10. https://doi.org/10.1038/nn.3549
Nolan H, Whelan R, Reilly RB (2010) FASTER: Fully Automated Statistical Thresholding for EEG artifact Rejection. J Neurosci Methods 192:152–162. https://doi.org/10.1016/j.jneumeth.2010.07.015
Pegg S, Jeong HJ, Foti D, Kujawa A (2021) Differentiating stages of reward responsiveness: Neurophysiological measures and associations with facets of the behavioral activation system. Psychophysiology 58:1–16. https://doi.org/10.1111/psyp.13764
Peterburs J, Sannemann L, Bellebaum C (2019) Subjective preferences differentially modulate the processing of rewards gained by own vs. observed choices. Neuropsychologia 132:107139. https://doi.org/10.1016/j.neuropsychologia.2019.107139
Preuss TM, Wise SP (2022) Evolution of prefrontal cortex. Neuropsychopharmacology 47:3–19. https://doi.org/10.1038/s41386-021-01076-5
Proudfit GH (2015) The reward positivity: From basic research on reward to a biomarker for depression. Psychophysiology 52:449–459. https://doi.org/10.1111/psyp.12370
Robble MA, Schroder HS, Kangas BD, et al (2021) Concordant neurophysiological signatures of cognitive control in humans and rats. Neuropsychopharmacology 1–11https://doi.org/10.1038/s41386-021-00998-4
Santesso DL, Evins AE, Frank MJ et al (2009) Single dose of a dopamine agonist impairs reinforcement learning in humans: evidence from event-related potentials and computational modeling of striatal-cortical function. Hum Brain Mapp 30:1963–1976. https://doi.org/10.1002/hbm.20642
Schaeffer DJ, Hori Y, Gilbert KM et al (2020) Divergence of rodent and primate medial frontal cortex functional connectivity. Proc Natl Acad Sci U S A 117:21681–21689. https://doi.org/10.1073/pnas.2003181117
Singer J, Willett JB (2003) Applied Longitudinal Data Analysis. Oxford University Press, Oxford
Sutton RS, Barto AG (1998) Reinforcement learning : an introduction. MIT Press, Cambridge, Mass
Threadgill AH, Gable PA (2017) The sweetness of successful goal pursuit: approach-motivated pregoal states enhance the reward positivity during goal pursuit. Int J Psychophysiol. https://doi.org/10.1016/J.IJPSYCHO.2017.12.010
Warren CM, Hyman JM, Seamans JK, Holroyd CB (2015) Feedback-related negativity observed in rodent anterior cingulate cortex. J Physiol Paris 109:87–94. https://doi.org/10.1016/j.jphysparis.2014.08.008
Webb CA, Auerbach RP, Bondy E et al (2016) Abnormal neural response to feedback in depressed adolescents. J Abnorm Psychol 126:19–31
Yu Z, Guindani M, Grieco SF et al (2022) Beyond t test and ANOVA: applications of mixed-effects models for more rigorous statistical analysis in neuroscience research. Neuron 110:21–35. https://doi.org/10.1016/j.neuron.2021.10.030
Funding
The project was funded by NIMH UH3 MH109168.
Author information
Authors and Affiliations
Contributions
JFC: Conceptualization, Methodology, Software, Formal analysis, Writing—Original Draft, Funding acquisition.
SLO: Investigation.
JAT: Investigation, Data curation, Supervision, Project Administration.
JEK: Investigation, Data curation, Supervision, Project Administration.
BZR: Investigation, Data curation, Supervision, Project Administration.
JAN: Investigation, Data curation, Supervision, Project Administration.
JS: Investigation, Data curation, Supervision, Project Administration.
DG: Investigation.
SGB: Conceptualization, Methodology, Investigation, Data curation, Supervision, Project Administration, Writing—Review & Editing, Funding acquisition.
GAL: Conceptualization, Methodology, Resources, Writing—Review & Editing, Funding acquisition.
NRS: Conceptualization, Methodology, Writing—Review & Editing, Investigation, Data curation, Supervision, Project Administration, Funding acquisition.
JWY: Conceptualization, Methodology, Writing—Review & Editing, Funding acquisition.
JLB: Conceptualization, Methodology, Resources, Writing—Review & Editing, Funding acquisition.
Corresponding author
Ethics declarations
Conflict of interest
JWY has received pharmaceutical funding from Sunovion Pharmaceuticals unrelated to the current work. All other authors report no biomedical financial interests of potential conflicts of interest.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Cavanagh, J.F., Olguin, S.L., Talledo, J.A. et al. Amphetamine alters an EEG marker of reward processing in humans and mice. Psychopharmacology 239, 923–933 (2022). https://doi.org/10.1007/s00213-022-06082-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00213-022-06082-z