
Abstract
Introduction
Debate continues over the precise causal contribution made by mesolimbic dopamine systems to reward. There are three competing explanatory categories: ‘liking’, learning, and ‘wanting’. Does dopamine mostly mediate the hedonic impact of reward (‘liking’)? Does it instead mediate learned predictions of future reward, prediction error teaching signals and stamp in associative links (learning)? Or does dopamine motivate the pursuit of rewards by attributing incentive salience to reward-related stimuli (‘wanting’)? Each hypothesis is evaluated here, and it is suggested that the incentive salience or ‘wanting’ hypothesis of dopamine function may be consistent with more evidence than either learning or ‘liking’. In brief, recent evidence indicates that dopamine is neither necessary nor sufficient to mediate changes in hedonic ‘liking’ for sensory pleasures. Other recent evidence indicates that dopamine is not needed for new learning, and not sufficient to directly mediate learning by causing teaching or prediction signals. By contrast, growing evidence indicates that dopamine does contribute causally to incentive salience. Dopamine appears necessary for normal ‘wanting’, and dopamine activation can be sufficient to enhance cue-triggered incentive salience. Drugs of abuse that promote dopamine signals short circuit and sensitize dynamic mesolimbic mechanisms that evolved to attribute incentive salience to rewards. Such drugs interact with incentive salience integrations of Pavlovian associative information with physiological state signals. That interaction sets the stage to cause compulsive ‘wanting’ in addiction, but also provides opportunities for experiments to disentangle ‘wanting’, ‘liking’, and learning hypotheses. Results from studies that exploited those opportunities are described here.
Conclusion
In short, dopamine’s contribution appears to be chiefly to cause ‘wanting’ for hedonic rewards, more than ‘liking’ or learning for those rewards.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Some questions endure for ages, faced by generation after generation. Neuroscientists hope the question, ‘What does dopamine do for reward?’ will not be among them, but it still prompts debate after several decades. Fortunately, the answers to the dopamine question are becoming better.
A formal debate on dopamine’s role in reward was held at a Gordon conference on catecholamines in 2005. This article describes the incentive salience case presented in that debate, and compares it to other hypotheses. A debate stance can sometimes help clarify alternative views, and that is the hope here. Therefore, this article is not an exhaustive review of dopamine function. My goal is to provide a useful viewpoint and a critical evaluation of alternatives and to point to new evidence that seems crucial to any decision about what dopamine does for reward.Footnote 1
Dopamine’s causal role in reward
What does dopamine do in reward? This is in essence a question about causation. It asks what causal contribution is made by increases or decreases in dopamine neurotransmission to produce changes in reward-related psychology and behavior. In this article, our focus is on cause and consequence.
How to assign causal status to brain events is a complicated issue, but it is not too much an oversimplification to suggest that in practice, the causal question of dopamine’s role in reward has been approached in several experimental ways. One approach is to ask ‘What specific reward function is lost?’ when dopamine neurotransmission is suppressed (e.g., by antagonist drugs, neurotoxin, or other lesions or genetic manipulations that reduce dopamine neurotransmission). That approach asks about dopamine’s role as a necessary cause for reward. It identifies what reward functions cannot be carried on without it.
A different approach is to ask ‘What reward function is enhanced?’ by elevations in dopamine signaling (e.g., elevated by agonist drugs, brain stimulation, or hyperdopaminergic genetic mutation). That approach asks about dopamine’s role as a sufficient cause for reward. It asks what reward function a dopamine increase is able to enhance (when other conditions in the brain do not simultaneously change so much as to invalidate hopes of obtaining a specific answer).
A third approach is to ask ‘What reward functions are coded?’ by the dopamine neural activations during reward events (e.g., by recording firing of dopamine or related limbic neurons, measuring extracellular dopamine release, or neuroimaging activation in target structures). This question asks about neural coding of function via correlation, often in the hope of inferring causation on the basis of observing correlated functions.
Dopamine function is a multifaceted target, so it helps to combine these multiple approaches. What does it contribute to reward? Let’s put on the table the best answers that have survived until today and evaluate each hypothesis for dopamine’s role against the others. These include activation-sensorimotor hypotheses of effort, arousal and response vigor; the hedonia hypothesis of reward pleasure; reward learning hypotheses of associative stamping-in, teaching signals and prediction errors; and the incentive salience hypothesis of reward ‘wanting’. I will describe each of these hypotheses in turn. Then recent experiments that pit hedonia, reward learning, and incentive salience hypothesis against each other will be considered. Their results indicates that dopamine may more directly mediate reward ‘wanting’ than either ‘liking’ or learning about the same rewards.
Activation-sensorimotor hypothesis
Activation-sensorimotor hypotheses posit dopamine to mediate general functions of action generation, effort, movement, and general arousal or behavioral activation (Dommett et al. 2005; Horvitz 2002; Robbins and Everitt 1982; Salamone et al. 1994; Stricker and Zigmond 1986). These ideas are captured by statements in the literature such as “Dopamine mediates the ‘working to obtain’ (i.e., tendency to work for motivational stimulus and overcome response constraints, activation for engaging in vigorous instrumental actions).” (Salamone and Correa 2002, p. 17) or “this dopamine response could assist in preparing the animal to deal with the unexpected by promoting the switching of attentional and behavioral resources” (Redgrave et al. 1999, p. 151) and “functions of the central DA systems could be explained in terms of an ‘energetic’ construct (i.e., one that accounts for the vigor and frequency of behavioral output) of activation.” (Robbins and Everitt 2006, this issue).
Those sensorimotor hypotheses have much to recommend them and are supported by substantial evidence. Neuroscientists agree that dopamine systems play roles in movement activation and control and attention and arousal (Albin et al. 1995; Dauer and Przedborski 2003; Redgrave et al. 1999; Salamone and Correa 2002; Salamone et al. 2005). As an example from the 2005 Gordon debate, Salamone and colleagues have convincingly shown that low-dose neuroleptics shift choices away from effortful toward easy tasks, even at the cost of a preferred reward.
However, activation-sensorimotor hypotheses are very general in scope, which makes it difficult for them to explain specific aspects of reward. They do not attempt to give clear and specific explanations of why rewards are hedonically pleasant or learned about or sought after. By extension to dopamine’s role in drug addiction and related disorders, they do not attempt to explain why addicts become compulsively motivated to take drugs again. To explain reward-specific aspects of dopamine activation and of addictive drugs, we need hypotheses of dopamine function that address more reward-specific processes themselves.
In short, activation, effort or sensorimotor function does not explain why dopamine effects are rewarding, predictive or motivating—even though general activation function may be valid and important. For the rest of this paper, therefore, I will accept that dopamine does have general sensorimotor-activation functions, and will not challenge those hypotheses. But the discussion must move beyond them for the purpose of understanding dopamine’s more specific contributions to reward. We must turn to specific reward hypotheses of what dopamine does.
Analysis of hedonia hypothesis
The hedonia hypothesis suggests that dopamine in nucleus accumbens essentially is a ‘pleasure neurotransmitter’. It was developed chiefly by Roy Wise and his colleagues in the 1970s and 1980s and became a very influential view. As Wise originally put it: “the dopamine junctions represent a synaptic way station...where sensory inputs are translated into the hedonic messages we experience as pleasure, euphoria or ‘yumminess’” (Wise 1980, p. 94). Continuing echoes of the hedonia hypothesis might perhaps still be heard in more recent neuroscience statements such as: “Clearly, the mesocorticolimbic dopamine system is critical for psychostimulant activation and psychomotor stimulant reinforcement and plays a role in the reinforcing action of other drugs” (Koob and Le Moal 2006, p. 89) or “The ability of drugs of abuse to increase dopamine in nucleus accumbens underlies their reinforcing effects.” (Volkow et al. 2006, p. 6583) and “addictive drugs activate brain-reward mechanisms, most especially the meso-accumbens dopaminergic link, resulting in the ‘hit’, ‘high’, or ‘blast’ sought by human users of such drugs.” (O’Brien and Gardner 2005, p. 24).
There are good reasons why the hedonia hypothesis became popular in neuroscience and in the general media. After all, many pleasant rewards activate mesolimbic dopamine systems, ranging from food, sex, and drugs to social and cognitive rewards (Aragona et al. 2006; Becker et al. 2001; Everitt and Robbins 2005; Fiorino et al. 1997; Koob and Le Moal 2006; Roitman et al. 2004; Small et al. 2003; Thut et al. 1997; Volkow and Wise 2005; Wise 1982, 1985). An alternative phrasing of the hedonia hypothesis is to say that dopamine mediates the positive reinforcing effects of reward stimuli in a hedonic reward sense of the term ‘reinforcement’.Footnote 2
In reverse, the hedonia hypothesis posited that antagonist suppression of dopamine neurotransmission by neuroleptic receptor-blocking drugs caused reduced hedonic impact for rewards, and so, caused ‘anhedonia’, which was held to be seen in behavioral effects such as ‘extinction mimicry’ or gradual decrements in rewarded performance similar to removal of the reward (Wise 1982, 1985) [but compare (Salamone et al. 1997)].
Recent supporting evidence for hedonia statements has come from neuroimaging studies which found subjective pleasure ratings to often correlate with human dopamine receptor occupancy in ventral striatum: for example, drug pleasure ratings for methylphenidate effects and taste pleasure ratings for palatable foods (Small et al. 2003; Volkow et al. 1999). Dopamine agonists may promote some positive subjective labels that people assign to their lives (Reichmann et al. 2003). Further, anhedonia has been suggested to be correlated with low striatal dopamine D2 marker levels in certain populations of clinically obese or addicted individuals (Wang et al. 2001, 2004). It is often difficult to be certain whether low dopamine markers caused the clinical condition in such cases, or instead, whether the clinical condition caused the reduction in dopamine markers; but if one assumes that the low markers occurred first, then such observations are consistent with the original hedonia hypothesis. In that case, low dopamine activity might have produced anhedonia, leading individuals to overconsume food or drug rewards as an attempt to compensate.
Suggestions by the hedonia hypothesis that dopamine is an essential contributing cause of “hedonic messages we experience as pleasure, euphoria or ‘yumminess’” (Wise 1980, p. 94), for sensory pleasures were what originally attracted my colleagues and me to study dopamine. How brain systems generate hedonic ‘liking’ reactions to a pleasant sweet reward was a topic we particularly wished to understand, and we were equipped with a measure particularly suited for assessing natural ‘liking’ reactions elicited by the sensory pleasure of sweet tastes (Movie 1 and Fig. 1: taste ‘liking’ reactions) (Berridge 2000; Grill and Norgren 1978a; Steiner 1973). Personally, when we started, I fully expected to find that the hedonia/anhedonia hypothesis was true. But the data we collected soon forced a change of mind.

‘Liking’ reactions and brain hedonic hotspots. Far left: positive hedonic ‘liking’ reactions are elicited by sucrose taste from human infant and adult rat (e.g., rhythmic tongue protrusion). By contrast, negative aversive ‘disliking’ reactions are elicited by bitter quinine taste (center left; see online video). From Steiner et al. 2001. Right: opioid hedonic hotspot in medial shell of nucleus accumbens where mu opioid agonist DAMGO causes increases in the number of ‘liking’ reactions elicited by sucrose taste (red). Purple shows where opioid activation suppresses ‘liking’ and ‘disliking’ reactions elicited by quinine. Dopamine lacks any identified yellow hedonic hotspot and possesses only suppression regions (purple equivalents) as far as is known. Modified by permission from Peciña and Berridge (2005)
How is it possible to scientifically measure ‘liking’ reactions to hedonic impact? Hedonic pleasure is sometimes regarded as purely subjective, but hedonic stimuli also elicit fundamental reactions from brain systems, with objective neural and behavioral indices.Footnote 3 An objective side to hedonic reactions may exist because brains have evolved to react appropriately to hedonic stimuli, with consequences for physiology, behavior, and eventual gene fitness (Darwin 1872; Nesse 1990). In a sense, hedonic reactions have been too important to survival for hedonia to be exclusively subjective—brains have had to actually do things based on hedonic impact. Neuroscientists can exploit observable hedonic reactions to gain useful insights into the identity of the neural systems that most directly mediate hedonic impact (Damasio 1999; Ekman 1999; LeDoux and Phelps 2000).
Thus, while it may not be possible always to confidently quantify subjective hedonic states, sometimes in people and especially in animals, one can readily quantify objective hedonic reactions if appropriate ones are identified. And while hedonic reaction measurements won’t reveal subjective pleasure feelings, they can give useful new information about the identity of brain mechanisms that causally generate basic ‘liking’ reactions.
The measure of ‘liking’ we’ve used comes from facial affective expressions elicited by hedonic impact of natural taste stimuli, expressions which are homologous in human infants and in many animals, including apes, monkeys, rats, and mice (Berridge 2000; Grill and Norgren 1978a; Steiner et al. 2001) (Movie 1; Fig. 1). Sweet tastes elicit positive ‘liking’ patterns of distinctive orofacial reactions from all these species (e.g., rhythmic or lateral tongue protrusions), whereas, bitter tastes elicit ‘disliking’ expressions that are distinctively opposite (e.g., gapes). Taste ‘liking’–‘disliking’ reactions in rats are sensitive to changes in hedonic impact caused by many brain manipulations, physiological appetite/hunger states, and psychological learned ‘likes’ and aversions that modulate subjective palatability ratings in people (Berridge 2000).
Neuroscience studies of these hedonic reactions have revealed a neural hierarchy of hedonic mechanisms distributed throughout the brain that determine the hedonic impact of pleasant stimuli. For example, our laboratory has identified cubic-millimeter sized hedonic hotspots in the forebrain’s nucleus accumbens and ventral pallidum, where opioid activation amplifies positive ‘liking’ reactions to sweet tastes (Fig. 1) (Peciña and Berridge 2005; Peciña et al. 2006; Smith and Berridge 2005). Related studies have used affective ‘liking’ reactions to identify forebrain limbic neuronal firing patterns that code the hedonic impact of a pleasant sweet or salty taste sensation (Roitman et al. 2005; Tindell et al. 2006). Conversely, other studies have shown that damage or inhibition of forebrain hedonic mechanisms causes bitter-type ‘disliking’ reactions to be elicited even by sweet tastes, involving hierarchical overruling of lower brainstem systems for simpler taste reaction (Cromwell and Berridge 1993; Grill and Norgren 1978b; Peciña and Berridge 2000, 2005; Reynolds and Berridge 2002; Schallert and Whishaw 1978; Smith and Berridge 2005; Stellar et al. 1979).3
Dopamine ≠ hedonic reactions in rats
So what do those natural ‘liking’ reactions tell us about mesolimbic dopamine’s role in causing the hedonic impact of rewards? In the first study in 1989, when we asked if hedonic impact was impaired by massive loss of striatal dopamine caused by neurochemical 6-OHDA lesions of ascending projections through the medial forebrain bundle, Terry Robinson, Isabel Venier, and I were surprised to find that the answer was unambiguously ‘no.’ We found that ‘liking’ reactions to sweet taste were not at all reduced by large 6-OHDA lesions of ascending dopamine projections, although the lesions substantially depleted forebrain dopamine (Berridge et al. 1989). A later follow-up study confirmed that even more massive 6-OHDA lesions that destroyed up to 99% of dopamine in both nucleus accumbens and neostriatum had no detectable effect on taste hedonic impact (or on pharmacological increases in ‘liking’ or on learning of new hedonic ‘dislikes’) (Berridge and Robinson 1998).
Other taste reactivity studies in the 1990s found that pharmacological blockade of dopamine neurotransmission by systemic administration of neuroleptic drugs, such as pimozide, similarly failed to shift the hedonic impact of tastes toward anhedonic ‘disliking’, at least, not when sensorimotor factors were controlled (Kaczmarek and Kiefer 2000; Parker and Leeb 1994; Peciña et al. 1997). The final conclusion of those studies was that dopamine was not necessary for normal ‘liking’ reactions to sweetness. That is consistent also with electrophysiological demonstrations by Schultz and colleagues that dopamine neurons in monkeys cease to fire to juice rewards eventually after prediction is fully learned, indicating that whatever persisting hedonic impact is carried by the reward, it must be mediated without a dopamine signal (Schultz 2006; Schultz et al. 1997).
Conversely, still other taste reactivity studies have consistently found that mesolimbic dopamine activation by at least five different brain manipulations are not sufficient to cause enhancement of natural reward hedonic impact (hyper-dopaminergic mutation, amphetamine microinjection in nucleus accumbens, amphetamine systemic administration, sensitization, electrical brain stimulation reward).
Perhaps most strikingly, increases in extracellular dopamine in mutant mice, produced by genetic manipulation that knocked down the dopamine transporter gene, completely failed to increase hedonic ‘liking’ reactions to sucrose—even though the same hyperdopaminergic mutant mice showed increased ‘wanting’ to obtain sweet rewards in several motivation tests (Cagniard et al. 2005; Peciña et al. 2003) (Fig. 3).
Similarly, hedonic impact is not increased by stimulating dopamine neurotransmission in normal brains. For example, administering amphetamine microinjections directly into the nucleus accumbens of rats failed to increase hedonic ‘liking’ reactions to sucrose, even though the amphetamine microinjections caused increases in ‘wanting’ for sucrose reward (Wyvell and Berridge 2000). Even systemic administration of amphetamine that would activate all brain catecholamine systems failed to increase ‘liking’ reactions to sweetness—again, although it increased the neural signal representing the incentive salience code for sucrose reward (Tindell et al. 2005). Finally, indirect facilitation of dopamine neurotransmission, either by electrical brain stimulation in medial forebrain bundle or by psychostimulant induction of neural sensitization, also failed to increase ‘liking’ reactions to the hedonic impact of sucrose taste, again, even when these same manipulations caused increases in seeking behavior or in actual ingestion of food (Berridge and Valenstein 1991; Tindell et al. 2005; Wyvell and Berridge 2000).Footnote 4
Failures of dopamine activation or suppression to change ‘liking’ reactions in hedonia-appropriate directions imply that dopamine is neither a necessary cause nor a sufficient cause for the hedonic impact of natural sweet reward. Dopamine’s failure to cause appropriate changes in hedonic impact stands in contrast to positive demonstrations of opioid, cannabinoid, and benzodiazepine signals, all of which can markedly boost hedonic ‘liking’ reactions to sweetness (Berridge and Peciña 1995; Ferraro et al. 2002; Jarrett et al. 2005; Kaczmarek and Kiefer 2000; Mahler et al. 2004; Parker 1995; Parker et al. 1992; Peciña and Berridge 1995, 2000, 2005; Smith and Berridge 2005). For example, in the hedonic hotspots of the medial shell of nucleus accumbens or the ventral pallidum, mu opioid neurotransmission can more than double ‘liking’ reactions to sucrose taste (Peciña and Berridge 2005; Peciña et al. 2006; Smith and Berridge 2005). Endocannabinoid circuits may have a similar hedonic hotspot in accumbens (Mahler et al. 2004), and even GABA-benzodiazepine circuits in accumbens and brainstem participate in generating ‘liking’ reactions (Reynolds and Berridge 2002; Söderpalm and Berridge 2000). Contrary to the hedonia hypothesis, by comparison to those other neurochemical systems, dopamine is almost striking in its unique failure to generate increase in sweetness hedonic impact in taste reactivity experiments.
Dopamine ≠ hedonia in humans
Recent evidence from people also now indicates that dopamine may not mediate human subjective ratings for the pleasantness of food or drug rewards after all. For example, patients with the dopamine deterioration of Parkinson’s disease have been reported to have normal subjective pleasure ratings for sweet food rewards: the “perceived pleasantness of the sweet samples (sucrose, chocolate milk, and vanilla milk) did not differ between the PD (Parkinson’s disease patients) and control group” (Sienkiewicz-Jarosz et al. 2005, p. 44).
Another fascinating and revealing study of Parkinson’s patients by Evans et al. found further that dopamine neurotransmission corresponds better to ratings of a drug reward’s ‘wanting’ than to its ‘liking’ (Evans et al. 2006). They focused on an addiction-like phenomenon that occurs in the small percentage of Parkinson’s patients who show a ‘dopamine dysregulation syndrome’ (DDS). Those DDS “individuals typically request extra drugs” from their physicians “despite the external appearance of being well medicated,” and even if the drug causes involuntary dyskinesia movements (Evans et al. 2006, p.852). The DDS patients end up taking far greater amounts of their l-3,4-dihydroxyphenylalanine (l-DOPA) medication than prescribed in an apparently compulsive fashion. Parkinson’s patients with DDS also can develop other compulsive activities, including gambling and obsessive pursuit of certain repetitive trivial activities (‘punding’).
Evans et al. used PET neuroimaging of labeled-raclopride binding to examine dopamine neurotransmission in compulsive DDS Parkinson’s patients and found that the patients were ordinarily similar in dopamine binding to other Parkinson’s patients under baseline conditions. But when they took an l-DOPA dose, the DDS patients showed a sensitized over elevation in drug-stimulated dopamine neurotransmission in ventral striatum, including nucleus accumbens (Evans et al. 2006). Importantly for understanding dopamine’s role, the excessive dopamine release measured by PET correlated strongly with subjective ratings of wanting for l-DOPA (‘do you want to take more of what you consumed, right now?’) (Fig. 2). However, excessive dopamine release did not cause patients to give higher liking ratings to l-DOPA, and there was no correlation found between subjective liking ratings (‘do you like the effects you feel right now?’) and PET-measured dopamine release (Evans et al. 2006). An advantage of Evans et al.’s focus on DDS patients for understanding dopamine’s role in addictive drug taking is that their addiction escapes several confounds that muddle interpretation of ordinary drug addicts. For example, l-DOPA does not have intense euphoric effects that might otherwise introduce hedonic confounds to explain excessive drug consumption nor does it induce profound dysphoric withdrawal. It is also unlikely that peer pressure to ‘fit in’ causes Parkinson’s patients to take excessive amounts of drugs, thus, leaving incentive-sensitization of dopamine-related mesolimbic neurotransmission as one of the remaining possible explanations for the addiction.

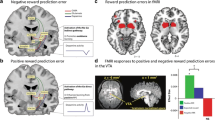
Dopamine in humans may correlate to ‘wanting’ drug rewards more than to ‘liking’ the same rewards. Top: Evans et al. (2006) showed that magnitude of sensitized dopamine release in nucleus accumbens (ventral striatum) of Parkinson’s patients with dopamine dysregulation syndrome correlates with their subjective ratings of how much they ‘want to take more’ of the l-DOPA drug that stimulated the dopamine release (measured by PET detection of raclopride; Left, A), but dopamine release did not correlate with their hedonic ‘like’ ratings of the same L-DOPA drug. Figure 4 from Evans et al. (p. 855) reprinted by permission. Bottom: Leyton et al. (2005) induced dietary depletion of dopamine levels in normal people via ingestion of an amino acid cocktail, which suppressed their subjective wanting ratings given to a subsequent dose of cocaine (especially at 1.5 and 3.0 mg dose) but did not suppress their euphoric liking ratings of the same cocaine. From Fig. 4 and wanting panel of Fig. 10, reprinted by permission from Leyton et al. (2005)
Similarly, Leyton and colleagues found that dopamine levels in the ventral striatum of normal human volunteers (measured by PET measures of raclopride binding) correlated significantly more strongly to their subjective ratings of ‘want drug’ than to ratings of hedonic mood or ‘like drug’ for the same amphetamine reward (Leyton et al. 2002). In another fascinating preliminary study of dopamine’s role in drug reward in normal people, Leyton et al. similarly found that dopamine mediates ‘wanting’ more than ‘liking’ for cocaine (Leyton et al. 2005). Those authors first used a temporary dietary manipulation to deplete brain dopamine levels in normal participants, via ingestion of a deficient amino acid mixture. They then asked the participants to give subjective ratings of pleasure and desire for intranasally administered cocaine reward and found a dopamine-induced dissociation between subjective liking and wanting for cocaine. Leyton et al.’s results showed that dopamine depletion caused a suppression of subjective ratings of wanting/desire to take more cocaine, but left subjective liking ratings for cocaine pleasure essentially unchanged (Leyton et al. 2005) (Fig. 2).
Finally, Volkow and colleagues have reported changes in dopamine receptor occupancy in striatum (at least) to correspond best to “nonhedonic” ratings of food desire (Volkow et al. 2002b). In several psychopharmacological studies, Brauer and colleagues (especially deWit) reported that dopamine blockade by neuroleptic antagonists may suppress wanting ratings or behavioral consumption of amphetamine or cigarettes, yet leave subjective liking ratings for the drugs untouched (Brauer and De Wit 1997; Brauer et al. 1995, 1997, 2001).
Of course, other studies have found closer correlations between wanting and liking ratings, too, which surely is not surprising. The two are typically bound together, rewards are typically both liked and wanted together, and it is recognized that teasing apart from subjective ratings of liking vs wanting for the same reward is a difficult task. That is, in part, because people may not have direct access to the underlying processes of basic ‘liking’ and ‘wanting’, and in part, because they may usually try to make the answers they are asked to elaborate stay internally consistent (“I just said I want it, so I must like it too.”). But as demonstrated by the cases of subjective wanting/liking dissociations described above, carefully constructed studies can sometimes succeed in teasing subjective ratings apart. When that is done, dopamine appears to correspond more closely to ratings of reward wanting than to reward liking.
Summary of evidence that dopamine does not cause hedonic impact
To conclude this section, despite early evidence for the anhedonia hypothesis, dopamine does not appear to be necessary to cause normal ‘liking’ reactions to the hedonic impact of food or drug rewards, at least, as far as we can tell for either rats or humans; nor are dopamine increases sufficient to amplify hedonic impact when ‘wanting’ is considered separately from ‘liking’. In short, dopamine activation does not appear to cause the hedonic impact of reward. Finally, fairness requires acknowledging that Roy Wise, who chiefly originated the hedonia dopamine hypothesis, is on record, as subsequently changing his mind: “I no longer believe that the amount of pleasure felt is proportional to the amount of dopamine floating around in the brain,” he said in an interview published in the journal Science (Wickelgren 1997, p. 35). Thus, it seems that many neuroscientists, generally, now agree that dopamine’s main causal contribution must be to mediate some other nonhedonic component of reward. We must turn to nonhedonic hypotheses: reward learning and incentive salience.
Analysis of reward learning hypothesis
The hypothesis that dopamine signals between neurons are an important link in the neural chain that causes reward learning has gained great prominence in recent years. Neurobiologically, it posits the dopamine signal to modulate synaptic plasticity in target neurons or to adjust synaptic efficacy in the appropriate neuronal circuits of input layers of the learning networks, especially in neostriatum and nucleus accumbens. Psychologically, it suggests that dopamine acts to ‘stamp in’ and associatively reinforce new links between S–S or S–R events, as a teaching signal for new learning or a computational prediction generator. Learning hypotheses may be captured by statements such as: “Whatever the mechanism, brain dopamine seems to stamp in response–reward and stimulus–reward associations...” (Wise 2004a, p. 492) and “There is now much evidence that integration of dopamine and glutamate-coded signals at the cellular and molecular level is a fundamental event underlying long-term plasticity and reward-related learning...” (Kelley 2004a, p. 166) or “Dopamine neurons appear to emit a reward prediction error signal...” (Schultz 2004, p. 4) or “We have presented theoretical evidence that phasic bursts and pauses in midbrain dopaminergic activity are consistent with the formal construct of a reward-prediction error used by reinforcement learning systems” (Montague et al. 2004, p. 761), and “Thus, by signalling reward prediction errors, DA may act as a teaching signal for striatal learning. There is also evidence for dopaminergic consolidation of S–R (habit) learning.” (Everitt et al. 2001, p. 133).
The appeal of learning hypotheses for dopamine function has been driven by groundbreaking electrophysiological data, supportive neurochemical release, and neuroimaging data, the stunning elegance of computational models that fit such data, attractive familiarity based on a century of associative concepts, and congruence with molecular biology data on neuronal plasticity mechanisms (Berke and Hyman 2000; Di Chiara 2002; Ljungberg et al. 1992; Montague et al. 2004; Schultz 1997, 2006; Wise 2004a).
First, elegant studies led by Wolfram Schultz and colleagues, and now supported by many other laboratories too, showed that dopamine and other limbic neurons are often activated in anticipation of reward by conditioned stimuli (CS) that predict a subsequent rewarding unconditioned stimulus (UCS) (de la Fuente-Fernandez et al. 2002; Ito et al. 2002; Phillips et al. 2003b; Tobler et al. 2005b). In addition, UCS activation of dopamine neurons obeys prediction error models, so that activation depends on the UCS reward being surprising, whereas, a fully predicted UCS reward may not activate the same neurons (Tobler et al. 2003; Waelti et al. 1998, 2001).
So, it now seems well established that the activation of dopamine systems often codes prediction error rules. The question to be raised here is not whether dopamine activations obey prediction error rules, but rather, whether dopamine activation causes the rest of the brain to learn, or instead, whether learning by other brain systems causes dopamine activation. Does dopamine actually cause a UCS prediction error to be registered by the brain to establish new learning? Does it ever cause a learned CS prediction for a future reward? Or instead, is dopamine activation an output consequence of learning mechanisms operating elsewhere, rather than part of the causal mechanism for learning?
Before addressing these causal questions, I should first acknowledge that some who have studied learning-related activation in dopamine neural systems would decline to posit a causal role for dopamine in learning, and my critique of learning below does not apply to them. For example, it has been pointed out to me that several original studies of dopamine neuronal prediction error coding never themselves concluded dopamine to be a mechanism that causes prediction error learning—rather, only that dopamine neuronal activation coded the learning (with direction of causation left open) (W. Schultz, personal communication, May 2006). That is an important distinction that deserves recognition. Second, I also acknowledge that no one suggests the dopamine synapse to be the sole locus of reward learning; rather, learning hypotheses posit dopamine neurotransmission to be just one event in the neuronal series that results in reward learning. However, the notion is still prevalent that dopamine neurotransmission is an especially crucial teaching signal or stamping-in reinforcement signal for causing reward learning. It seems fair to say that many neuroscientists have assigned a central role to dopamine neurotransmission as a causal signal that sends important teaching or predictive information from one mesolimbic neuron to another. It is common to read assertions that dopamine activation triggered by an unexpected UCS acts as a teaching signal to directly cause new learning and that dopamine activation triggered by a CS causes a psychological prediction of future reward to follow. Most clearly, causation is always implied whenever learning dopamine hypotheses are used to explain a clinical phenomenon, such as addiction (or schizophrenia, etc): without causation, the hypotheses would have no explanations to offer.
The idea that dopamine is a crucial teaching signal or reinforcement signal is precisely what I wish to scrutinize here, and I will suggest that dopamine activation is not a direct cause of reward learning after all. Instead, it is more likely that dopamine activation is actually only a consequence of learning (and a cause of something else). Dopamine contributions to learning may be restricted essentially to indirect routes via attention, consolidation, and other nonteaching signal mechanisms.
To say dopamine acts as a prediction error to cause new learning may be to make a causal mistake about dopamine’s role in learning: it might, without much injustice, be called a “dopamine prediction error.” Such an error, in my opinion, can powerfully confuse our understanding of dopamine’s role in reward. To see why this is an error, it may be helpful to lay out first what is meant by dopamine-learning hypotheses, and then, examine how new evidence contradicts their causal assumptions, and finally, consider how dopamine function might be better understood.
Dopamine learning hypotheses
The hypothesis that dopamine causes reward learning actually is a family of several different but closely related hypotheses. All posit dopamine to mediate learning but in somewhat different ways. The simplest idea is that dopamine signals ‘stamp in’ S–R (stimulus–response) or S–S (stimulus–stimulus) associations whenever a reward follows. A related idea is that dopamine activation causes new habit learning and enhances habit performance. The most sophisticated version is that dopamine systems mediate computational teaching signals via UCS prediction errors and mediate resulting associative CS predictions in ways that obey the equations of computational reinforcement learning models. Some of the most crucial evidence on dopamine’s causal role is relevant to all of these hypotheses in one blow, so I will first simply describe each hypothesis, and then, turn to evidence that bears on all.
Associative stamping-in?
A straightforward way for dopamine to cause reward learning would be simply to act as a UCS reinforcement signal that causally “stamps in” learned associations about preceding reward-related stimuli or responses when the UCS reinforcer occurs (Di Chiara 2002; Hyman 2005; Kelley 2004a; Wise 2004a).
Thorndike originally proposed more than 100 years ago that rewards act to ‘stamp in’ or reinforce stimulus–response associations in one of the oldest psychological hypotheses of learning (Thorndike 1898). In one of several modern applications of this idea to dopamine, Wise and others recently have adopted Thorndike’s language to characterize dopamine function: “dopamine seems to stamp in ... associations” (Wise 2004a,b). Appropriately, the transition from hedonia to stamping-in for dopamine reinforcement function by Wise and other neuroscientists with similar hypotheses nearly mirrors Thorndike’s own transition, a century earlier, about the psychological nature of reinforcement. Thorndike originally posited reinforcement to depend on hedonic ‘satisfying effects’ (in answer to his own question, ‘what do animals feel?’) but he and other behaviorists dropped hedonic mechanisms a decade later and simply posited ‘stamping-in’ to strengthen S–R habits or S–S memory links as a purely associative Law of Effect mechanism with no hedonic connotations (Thorndike 1898, 1911; Watson 1913).
For S–R psychology of a century ago, the eventual nonhedonic version of behaviorist stamping-in drained all pleasure out of the idea of reinforcement, leaving only an associative strengthening of S–R or S–S links remaining. Applied to dopamine function by modern S–R and S–S connection stamping-in advocates, learning reinforcement essentially means the same pure associative strengthening idea, and the mechanism of associative stamping-in is simply assigned to dopamine neurotransmission. Evidence for associative ‘stamping-in’ hypotheses includes the original neuroleptic ‘extinction-mimicry’ data that once prompted the anhedonia hypothesis (Wise 1982, 1985, 2004a, 2006), plus recent molecular biology demonstrations that dopamine modulates cellular and molecular plasticity mechanisms of long-term potentiation and long-term depression inside neurons in ways possibly relevant to memory (Kelley 2004a,b; Wickens et al. 2003; Berke and Hyman 2000). Further evidence for associative modulation roles for dopamine include important demonstrations that dopamine manipulations performed soon after a learning trial can alter the consolidation or reconsolidation of memories, similar in respect, to other memory consolidation phenomena (Dalley et al. 2005; Everitt and Robbins 2005; Fenu and Di Chiara 2003; Hernandez et al. 2005; McGaugh 2002; Robertson and Cohen 2006). For example, dopamine D1 receptor blockade in nucleus accumbens given just after Pavlovian autoshaping trials disrupts later autoshaping performance, and dopamine manipulations in striatum modulate consolidation of recently experienced instrumental associations similarly to intracellular manipulations of cAMP-dependent protein kinase (Andrzejewski et al. 2005; Baldwin et al. 2002; Kelley 2004b; Packard and White 1991; Wickens et al. 2003).
Similarly, dopamine manipulations just before a learning trial may modulate acquisition of new associations, whether by direct influences on engram formation or through attention or other processes (Phillips et al. 1994; Robbins and Everitt 1996; Wolterink et al. 1993). Finally, dopamine agonists given subsequently after initial training powerfully potentiate the ability of previously learned Pavlovian cues for reward to serve as conditioned reinforcers themselves (that is, rats will learn to work for a CS that was previously paired with reward more if given amphetamine at the time of instrumental training), conceivably disrupting stamping in of new associations by the cue (Everitt and Robbins 2005; Robbins and Everitt 1996). The important point for all dopamine stamping-in interpretations is the notion that dopamine neurotransmission may strengthen S–S or S–R associations at the moment it occurs.
Habit learning?
Related to stamping-in is the more specific hypothesis that dopamine causes new stimulus-response habits to be learned (and/or modulates the strength of already learned S–R habits) and that addictive drugs that promoted dopamine release cause abnormally strong S–R habits to be formed (Berke 2003; Everitt et al. 2001; Robbins and Everitt 1999). For example, Everitt, Robbins, and Dickinson and colleagues, and others, have shown that addictive drugs can indeed establish or sensitize stronger than normal learned habits (Everitt and Robbins 2005; Faure et al. 2005; Miles et al. 2003, 2004; Nelson and Killcross 2006; Robbins and Everitt 1999; Schoenbaum and Setlow 2005; Vanderschuren et al. 2005; Vanderschuren and Everitt 2004). A stronger habit is defined by such experiments as a goal-directed response that persists after the goal itself (food reward) is suddenly devalued (by conditioning an aversion to it or by inducing satiety). Conversely, blockade of dopamine neurotransmission, especially in dorsal neostriatum, may disrupt habit formation or performance of previously learned habits (Faure et al. 2005; Vanderschuren et al. 2005).
In favor of a habit interpretation of dopamine function, it is beyond dispute that dopamine manipulations affect the performance strength of action patterns. Learned S–R habits are among those action patterns affected, as studies above have shown. Dopamine also modulates the performance of nonlearned action patterns, including both new stereotyped action patterns that have never been emitted before (e.g., amphetamine stereotypy) and instinctive action patterns that while ‘habitual’ in the sense that they have occurred many times, still probably never needed to be learned in an S–R sense. For example, dopamine agonist drugs at high doses can cause novel combinations and intensities of simple perseverative motor stereotypies (e.g., sniffing, biting) the first time the drug is given (Cooper and Dourish 1990; Sahakian et al. 1975).
Dopamine agonists and antagonists also modulate the strength of instinctive chains of 25 or so grooming movements that all rodents show, apparently by acting on dorsolateral striatum (Berridge et al. 2005; Cromwell and Berridge 1996; Deveney and Waddington 1997). Those action patterns are not only nonlearned, they are also centrally patterned by brain systems rather than being guided by S–R chains of responses to discrete stimuli. Thus, the hypothesis that dopamine strengthens some previously learned habitual action patterns might be a subcategory of an equally valid but larger hypothesis that dopamine strengthens some action patterns regardless of whether they are S–R habits, new stereotypies, or instinctive fixed action patterns. The pattern-strengthening effects of acute dopamine on behavior is logically quite different from the reinforcing of habits that is posited by S–R hypotheses to occur after a behavior, but in practical terms, much of the evidence that has been taken to indicate a dopamine role in strengthening previously learned habits can equally well be explained by a more global pattern-strengthening function. If true, this reasoning suggests that learned S–R links may not be unique in their relation to dopamine modulation of performance strength, but rather reflect a larger dopamine function. In short, like the sensorimotor hypothesis, some sort of habit modulation hypothesis for dopamine should probably be accepted, and possibly, expanded to encompass other types of behavior. But also again, habit strengthening is not generally suggested to provide a full explanation of dopamine’s role in reward-related behavior.
Regarding addiction in particular, it is admittedly difficult to dissect excessive stimulus-response habits from motivational compulsions. An S–R habit account of addiction deserves to remain on the table at least until that is done. But it is possible to imagine scenarios, even from human addiction, that might tease apart habit from compulsion, and clarify whether abnormal S–R habits contribute strongly or not to real-life addictive behaviors. For example, moving targets might pose a less complicated alternative to goal devaluation. Do addicts perseveratively repeat the same action again and again inappropriately when their responses should change? Do addicts find it difficult to shift their habitual route of taking a drug, say from intravenous injection to smoking or vice versa? Or do they shift quite easily when motivated to obtain a better drug experience? Similarly, do addicts return habitually to the location of an old drug supplier even when their source of drug moves? Or do they readily shift behavior patterns to find the new supplier? Contrasts between habit rituals and motivational compulsions that track their targets as motivational magnets might provide good ways to pull these ideas apart. When addicts’ habits are pitted against their motivational targets, which one wins? The answer will help reveal how much habits contribute to addiction.
But for the present purpose of evaluating the fundamental role of dopamine in reward, the habit learning hypothesis can be tested similarly to the stamping-in hypothesis, because both hypotheses emphasize a dopamine-mediated UCS signal that establishes what is learned. They each assert that dopamine signals cause establishment of new associative links (either S–R or S–S links) whenever the UCS occurs. They can both be tested by asking whether habits or other associations require dopamine to be formed. That is, can learning of S–S or S–R links proceed normally in the absence of dopamine neurotransmission between neurons in nucleus accumbens, striatum or other limbic structures? Evidence that it can, may be found from studies of dopamine-deficient mutant mice or dopamine lesions in rats described below.
Prediction error learning models
Prediction error hypotheses are the most sophisticated form of the dopamine learning hypothesis. These draw on computational models of associative learning to assign precise roles to phasic dopamine activations. Namely, they posit dopamine to mediate the prediction value carried by a CS previously associated with reward and to mediate prediction errors carried by a UCS or actual reward whenever it is surprising.
Prediction error or teaching signal concepts are the distinguishing feature of these models. Briefly, a prediction error is an update in information about a reward delivered at the moment of reward receipt. The prediction error is positive if the true reward impact turns out to be greater than predicted, and negative, if actual reward received is less than predicted. Prediction errors correlate impressively with dopamine activation in many situations, including associative blocking and conditioned inhibition situations (Tobler et al. 2003; Waelti et al. 2001).
Prediction error models of dopamine draw on equations that have been suggested to describe the trial-by-trial progression of simple associative learning, especially Pavlovian learning. An early influential model was the Rescorla–Wagner law of Pavlovian conditioning (ΔV = αβ(λ−V)). That model describes the learning that occurs in a single trial where CS is paired with reward UCS (Rescorla and Wagner 1972). In the Rescorla Wagner model, the value, V, is the learned associative prediction already carried by the CS on a given learning trial, and ΔV is the change in learning gained on the learning trial. The highest asymptotic value of learning about the UCS that will eventually be reached is λ (equivalent to the final fully trained V value). Finally, α and β are stimulus-specific rate constants. The amount of learning on any trial is equivalent to the difference that remains between maximal λ value and the current V value learned, so far, and this difference can be imagined to be instantiated by the size of a dopamine signal at the moment of UCS. The rule implies that learning is greatest on early trials (when V is low and the difference is large), and declines on later trials (as V approaches λ and the difference approaches zero). Applied to dopamine function, the model suggests that boosts in dopamine neurotransmission might increase predictions of future reward (V) to a CS. It does so chiefly by positing an increase in dopamine signal to elevate the prediction error (λ−V) generated by the hedonic or associative impact of UCS (λ) at the moment of reinforcement, which boosts the amount of learning on that trial (ΔV).
A more sophisticated recent equation comes from temporal difference models of reinforcement learning, which incorporates time more explicitly into expectations of reward as a series of future events \({\left( {V{\left( {s_{t} } \right)} = {\left\langle {{\sum\limits_{i = 0} {\gamma ^{i} r_{{t + 1}} } }} \right\rangle }} \right)}\), (Bayer and Glimcher 2005; Daw et al. 2005; Dayan and Balleine 2002; Montague et al. 2004; Schultz 2002, 2006; Tobler et al. 2005a,b). V similarly represents expectations of future reward, but separately considers a series of future times starting from state, s, and a temporal discounting factor, γ, discounts the value of rewards that are farthest away in the future. V becomes more accurate through learning about actual rewards, via prediction errors that modulate synaptic weights in circuits involved in future predictions.
A prediction error (δ(t)) occurs whenever a received reward fails to equal its prediction, and the prediction error is defined as: \(\delta {\left( t \right)} = r_{t} + \gamma {\mathop V\limits^ \wedge }{\left( {s_{{t + 1}} } \right)} - {\mathop V\limits^ \wedge }{\left( {s_{t} } \right)}.\) Prediction error differs from the raw hedonic impact of a UCS (r t ), in that, if the UCS is accurately predicted, there will be zero prediction error even though its hedonic impact remains positive. The prediction error is essentially any difference between the predicted impact of the UCS and its actual impact when it arrives. If the reward is exactly as good as predicted then the prediction error is zero. If the UCS is better than predicted then prediction error is positive, and if the actual reward is less than predicted, then the prediction error is negative.
When dopamine is claimed to cause reward learning via prediction errors, these equations make precise assertions about its causal role. By acting as a teaching signal, dopamine-mediated prediction errors (δ(t) for temporal difference, (λ−V) for Rescorla-Wagner) are posited to gradually train learning mechanisms to make correct predictions (V) in an incremental and trial-by-trial fashion.
The most beautiful feature of prediction error learning hypotheses, from the viewpoint of someone who wants to test them, is that they suggest dopamine neurotransmission to embody specific parameters of the computational learning equations: V and δ(t). Dopamine neuronal activation at the moment of CS is posited to mediate the learned prediction strength of future reward: V. In addition, dopamine activation at the moment of rewarding UCS is posited to mediate the teaching signal of prediction errors, that is, the mismatch between predicted reward and actual reward: δ(t) (or (λ−V) in Rescorla-Wagner).
Dopamine can, in these ways, be imagined to cause the synaptic teaching signal that trains forebrain targets. For example, Montague et al. describe dopamine’s role as essentially floating a δ(t) teaching signal from one neuron to another: “movement of dopamine through the extracellular space carries prediction-error information away from the synapse.” (Montague et al. 2004, p. 765). Thus, dopamine is suggested to carry new learning about rewards between neurons. Similarly, once trained, dopamine activation triggered by a reward-associated CS can be imagined to cause already learned predictions of future reward, as V.
In addition, prediction error learning models have been applied to explain the causation of addiction as forms of overlearning (and to explain some other clinical phenomena in related fashion). These addiction explanations simply add the postulate that addictive drugs cause especially high dopamine release to generate an extra large prediction error, essentially causing overlearning that leads essentially to excessively optimistic predictions of future drug rewards or to excessively strong habits (Berke 2003; Everitt et al. 2001; Montague et al. 2004; Redish 2004). A good example of this type of explanation is the Redish computational model of addiction, which suggests that addictive drugs cause abnormally high δ(t) that elevates addicts’ predictions of future drug reward (Redish 2004). The extra strength of the drug prediction error always magnifies the difference between its expected reward and actual reward whenever the drug UCS is received (Redish 2004). Excessive δ(t) drives excessive learning of future predictions, as if drug reward were surprisingly high whenever it was taken.
Such a model postulates that learned V predictions cannot fully accommodate the abnormally high δ(t) of a dopamine-activating drug, so essentially, the drug impact is always a surprise, always better than expected no matter how high the expectation. The resulting mismatch leads to further inevitable increments in V or ever higher and higher learned expectations in the future. The mismatch might presumably escalate even further as the addiction progresses, if neural sensitization increases the drug-induced amounts of dopamine release, leading to even bigger jumps in V. In other words, such models of dopamine function essentially portray addiction as a form of super-learning, in which the drugs train optimistic overpredictions. The addict becomes forced to look at the prospective drug through a rose-colored lens of exaggerated prediction, always expecting the next drug reward to be more enormous than it is, expecting the next again to larger still. In sum, learning computational models of addiction assert that an addict excessively seeks the drug because of excessively exaggerated expectations. Clearly, given these broad implications, it is crucial to know whether dopamine, indeed, causes the teaching signals that makes the brain learn to predict rewards.
Evaluating learning models
Does dopamine actually cause new learning? Does it contribute a necessary or sufficient teaching signal such as δ(t)? After learning, does it cause learned predictions by contributing V values needed to anticipate future rewards?
If elegance were sufficient to make the hypotheses true, then the dopamine = reward learning hypotheses deserve to be true. The beautiful rigor of computational learning models of dopamine function is widely recognized. Still, more than elegance is required to be an accurate hypothesis. Prediction error as an answer to the question ‘What does dopamine do for reward?’ implies a causal role. Dopamine clearly makes many indirect contributions to both learning and learned performance (e.g., attention, motivation, cognition, rehearsal, and consolidation; see Robbins and Everitt, this volume).Footnote 5 It is surely no accident that psychostimulant drugs, including amphetamine-related drugs, have long been abused as study aids or test performance enhancers: the drugs help students achieve what they otherwise could not. But that does not necessarily mean that dopamine provides the crucial teaching signal, prediction error, or stamping-in signal that causes new reward associations form.
Evaluating direct roles in learning mechanism
Does dopamine directly cause the reward associations involved in learning? Here, we look at recent evidence about dopamine consequences that appears problematic for the learning causation hypothesis. The evidence seriously questions whether dopamine neurotransmission between neurons in nucleus accumbens, striatum, or other limbic structures directly acts to form new S–S or S–R associations, either as teaching signal or stamping-in reinforcer. The evidence also questions whether dopamine triggered in advance by a learned CS directly causes the prediction of future reward. To see the evidence more easily, it may be helpful to divide ‘does dopamine directly cause learning’ into separable questions that can be tackled experimentally: First, regarding necessary causation: is dopamine needed for normal reward learning (necessary for δ(t) or (λ−V))? Second regarding sufficient causation: is ‘extra dopamine’ able to cause excessive learning (sufficient to amplify UCS stamping-in or prediction errors (δ(t) or (λ−V))? And finally, for predicting a future reward based on previous learning, does dopamine ever cause a learned CS to elicit excessive predictions (V)?
Is dopamine a necessary cause for reward learning?
Elimination of dopamine should markedly impair reward learning if dopamine is needed to mediate learned associations. So is dopamine actually needed to learn about a reward? Recent evidence that dopamine may not be necessary to cause new reward learning comes from mutant mice designed to show a genetic inability to manufacture dopamine (Zhou and Palmiter 1995).
DD mice lack the enzyme, tyrosine hydroxylase, and so, cannot synthesize dopamine. They show pronounced Parkinsonian symptoms of akinesia, aphagia, and adipsia (except for a few hours after they are medicated with l-DOPA, which is done on a near daily basis so that they eat and drink before lapsing back into inactivity). An impressive demonstration of reward-learning-without-dopamine was shown first by Cannon and Palmiter in these dopamine-deficient (DD) mice (Cannon and Palmiter 2003). Cannon and Palmiter showed that unmedicated DD mice, at a time when they had virtually no dopamine in their brains, still were able to learn a preference for a spout that delivered sucrose solution and to choose that sucrose spout over a spout that delivered water. Without medication, DD mice do not eat or drink enough to maintain themselves, so they drank only tiny amounts of either liquid when they drank at all. But when the unmedicated DD mice did drink, they drank more sucrose, choosing the spout that had been learned to deliver sucrose over the other spout that delivered water—and their learned spout preference was proportionally equal to that of control mice (Cannon and Bseikri 2004; Cannon and Palmiter 2003) (Fig. 4).
Subsequently, Siobhan Robinson et al. and Hnasko et al. showed that DD mice are also capable of learning normally without dopamine in the t-maze and place conditioning tasks, at least when the DD mice were pretreated with caffeine before training (Hnasko et al. 2005; Robinson et al. 2005). Caffeine appears to activate DD mice by a nondopaminergic mechanism (for example, failing to induce the Fos in neostriatum that l-DOPA reliably induces) (Robinson et al. 2005). Robinson et al. found that caffeine activated DD mice enough to find food rewards, eat them, and learn about them (Robinson et al. 2005). Their learning-without-dopamine was not immediately evident in their maze choice on the training day, when they were on caffeine itself: the caffeinated mutant mice appeared to choose randomly that day, and only ate the reward when they made the correct choice by chance. But it became clear that the mice had learned normally without dopamine when they were tested the next day with dopamine replaced. Normal reward memories were revealed on the test day as soon as dopamine function was restored by l-DOPA administration—on the very first test trial (indicating that they must have been guided by associations learned the day before) (Fig. 4).
On the l-DOPA test day, the DD mice that had learned under caffeine showed as strong a learned maze choice as mice that had been previously learned under l-DOPA (as well as being tested under l-DOPA). Their normal maze choice indicated that normal learning must have been established under caffeine on the training day (Robinson et al. 2005). Robinson et al. concluded that “dopamine is not necessary for mice to like or learn about rewards but is necessary for mice to seek (want) rewards during goal-directed behavior” (Robinson et al. 2005), p. 5. Similarly, in a conditioned place preference task where a place was paired with morphine administration, Hnasko et al. showed that caffeine-pretreated DD mice learned normally to prefer the morphine-predictive place, despite again having virtually no dopamine in their brains at the time of training (Hnasko et al. 2005).
Of course, caveats apply to mutants (i.e., compensatory changes in development), and caffeine’s adenosine mechanism in mutant mesocorticolimbic circuits is not fully understood. But two considerations suggest that DD mice results may be accurate indicators that dopamine is causally superfluous in learning. First, the DD mice behave as they ought to if they lack dopamine function, showing extensive Parkinsonian symptoms typical of massive loss of brain dopamine (akinesia, adipsia, aphagia). If the mice accurately depict dopamine’s role in those sensorimotor and motivational functions, then they may do so for learning functions too. Second, it can be noted that these conclusions about normal learning without dopamine in DD mice are also consistent with earlier results from normal rats that lost mesolimbic dopamine by adult neurochemical lesions rather than by early mutation. For example, a neurochemical depletion study by Terry Robinson and me found that rats with virtually no dopamine in the nucleus accumbens or neostriatum could still learn new values about sweet tastes as well as normal rats (Berridge and Robinson 1998). Rats learned normal conditioned aversions for a sweet taste paired associatively with LiCl-induced illness even when they lacked up to 99% of dopamine in both nucleus accumbens and neostriatum (because of large 6-OHDA lesions placed bilaterally in lateral hypothalamus to interrupt ascending projections).
The newer results of Palmiter and colleagues show that dopamine is not needed to learn new positive reward associations, any more than it is needed to learn new decrements in reward value. In all these examples, learning of new values occurred in a nearly dopamine-free brain, so dopamine could not have been the teaching signal for them. Normal learning-without-dopamine can only mean that dopamine is not necessary to stamp in S–S or S–R associations or to act as teaching signal or prediction error.
Perhaps, further studies will alter the conclusion that dopamine is not needed to learn about rewards; but after all, these seem to provide the most relevant evidence so far, and their results deserve serious consideration as possible indicators of future results to come. Their thrust, so far, indicates that dopamine is unnecessary for normal reward learning, and so, is not a necessary cause for learning. If dopamine contributes any learning causation as a teaching signal, prediction error, or stamping-in mechanism, it seems at best a redundant one.
Is dopamine a sufficient cause for reward learning?
So is dopamine at least a contributing sufficient cause for reward learning? If so, perhaps boosts in dopamine neurotransmission would be sufficient to increase UCS teaching signals to cause better or faster learning about reward, as postulated by stamping-in habit, or prediction error hypotheses of learning and addiction.
New evidence is available from genetic mutant engineering studies to bear on this question, and results to date, suggest the answer may again be no. In a series of studies on the reward effects of dopamine activation, Zhuang and colleagues have examined the learning consequences of elevating synaptic dopamine levels in DAT-knockdown mutant mice (Cagniard et al. 2005; Peciña et al. 2003; Yin et al. 2006). DAT knockdown mutant mice have only 10% of dopamine transporter levels compared to control wild-type mice and have elevated extracellular dopamine levels of 170% above control mice (Zhuang et al. 2001). These hyperdopaminergic mutant mice appear to ‘want’ sweet rewards more than wild-type mice in incentive motivation tasks (though not to ‘like’ sweet rewards more) (Cagniard et al. 2005; Peciña et al. 2003; Yin et al. 2006). But to answer the learning question, hyperdopaminergic mutant mice, so far, appear no faster at learning S–S reward predictions or instrumental associations than control wild-type mice, nor do mutants develop stronger or more persistent S–R habits (Cagniard et al. 2005; Yin et al. 2006).
Higher motivational ‘wanting’ of hyperdopaminergic mutant mice is reflected in their faster mastery and performance of a running task to obtain sweet rewards, greater resistance to distractions from their rewarded runway goal, and willingness to work harder for food reward on a breakpoint bar-press task (Peciña et al. 2003; Sanders et al. 2003) (Fig. 3). However, when learning per se is examined, the actual reward learning abilities of these hyperdopaminergic mice seem to be merely normal, despite their higher incentive motivation for learned rewards (Cagniard et al. 2005; Peciña et al. 2003; Yin et al. 2006) (Fig. 3). For example, DAT knockdown mice do not learn a Pavlovian conditioned approach association to a food dish mice faster than wild-type mice (Cagniard et al. 2005) (Fig. 4)—even when assessed with sophisticated techniques designed to sensitively detect faster learning curves (Gallistel et al. 2004). Similarly, hyperdopaminergic mutants do not learn to bar press for food reward in an instrumental task any more quickly than wild-type mice (Cagniard et al. 2005). Note that faster learning should result if hyperdopaminergic mutants have higher UCS prediction errors (δ(t) or (λ−V)). So, their failure to learn faster indicates that dopamine synaptic elevation has not magnified a stronger δ(t) teaching signal (Cagniard et al. 2005).

Hyperdopaminergic mutant mice show higher ‘wanting’ but only normal learning and normal or lower ‘liking’. Left: Higher ‘wanting’. Cagniard et al. found that hyperdopaminergic mutant mice (DAT knockdown; 10% DAT and 170% elevated extracellular dopamine) show higher breakpoints, and are willing to work harder for food reward on instrumental bar press task (top) (Cagniard et al. 2005). Peciña et al. found that hyperdopaminergic mice run more directly to obtain sweet reward in a runway and resist distractions en route (bottom) (Peciña et al. 2003). Right top: Normal ‘learning’. Cagniard et al. found that hyperdopaminergic mice learn an instrumental bar press task no faster than wild-type mice (left top), and also learned a Pavlovian approach task no faster than control mice (Cagniard et al. 2005). Right bottom: Normal or lower ‘liking’ reactions to sucrose taste. Peciña et al. found that hyperdopaminergic mutant mice showed normal or lower numbers of positive hedonic ‘liking’ reactions to three concentrations of sucrose solution in a taste reactivity test, even though the same mice ‘wanted’ sweet rewards more. The mutants also showed normal minimal ‘disliking’ reactions to sucrose tastes (Peciña et al. 2003). Reproduced by permission

Dopamine deficient (DD) mutant mice show normal reward learning without dopamine. Left: Cannon and Palmiter found that unmedicated DD mice learned a normal preference to drink from a spout that delivered sucrose solution over another that delivered water (even though DD mice drank much lower absolute amounts than control mice) (Cannon and Palmiter 2003). Right: S. Robinson et al. found that DD mice trained in a T-maze for food reward performed poorly but learned normally when given only caffeine (Redrawn from Robinson et al. 2005). The normal learning was demonstrated on the subsequent test when they were first given l-DOPA medication. On the l-DOPA test, mice that had trained under caffeine performed similar to mice that had trained under l-DOPA (in addition to being tested under l-DOPA), indicating that both groups had learned similar amounts during the training phase. Reproduced by permission
Similarly, if extra dopamine stamps in stronger S–R habits, then, hyperdopaminergic mutants ought to show habits that are stronger and more perseverative. But evidence to date indicates that hyperdopaminergic mutant mice do not have stronger habits: for example, when the mice were trained to press a lever to obtain food or sugar reward, and then, one reward was suddenly devalued (by pre-feeding to satiety), hyperdopaminergic mutant mice ceased pressing for their devalued reward as quickly as control mice, and did not persist in S–R habit perseveration (Yin et al. 2006). The lack of any apparent stronger habit was especially striking because the hyperdopaminergic mutants had pressed the lever more for reward before devaluation. The authors concluded that “the underlying learning was intact in these mice, and that the differences between DAT KD and wild-type mice can be attributed to a difference specifically in performance” (Yin et al. 2006).
Perhaps, it is not so great a surprise, after all, if elevated dopamine neurotransmission does not cause higher δ(t) or (λ−V) or related prediction errors, or stronger S–R stamping-in, that produces elevation in learning. After all, tonic and phasic dopamine signals are likely to be differentially affected by mutation-induced elevation (Zhuang et al. 2001). But if excessive learning doesn’t happen in hyperdopaminergic mutants, then it cannot be the explanation for increases in the mutants’ reward seeking and consumption behavior. If learning is excluded as explanation of mutant’s elevated motivation for reward (and other examples below), it may not be needed to explain other forms of dopamine-elevated motivation either, including addiction.
Why does dopamine neuronal firing look like prediction error—if it is not?
If dopamine is not necessary or sufficient to learn about rewards, then why do mesolimbic dopamine neurons so elegantly code learning in the sense that their firing often obeys prediction error equations (Schultz 2006)? The reason may be because dopamine neurons code an informational consequence of learning signals, reflecting learning and prediction that is generated elsewhere in the brain but do not cause any new learning themselves. The proposition that dopamine activation is a consequence but not a cause of reward learning may contradict the premise of dopamine learning models, even if it is not necessarily a surprise to investigators of dopamine firing codes themselves or to other neuroscientists who have doubted that dopamine neurons are a primary source of teaching signals. Dopamine neurons originating in the midbrain are recognized by many neuroscientists to have relatively sparse direct access to all the associative-related signals information that needs to be integrated by an associative learning mechanism (Dommett et al. 2005). Instead, signals that dopamine neurons receive are likely to be highly processed already by forebrain structures before dopamine cells get much learning-relevant information (Diaz-Mataix et al. 2006; Dommett et al. 2005; Goto and Grace 2005; Jones and Bonci 2005; Marinelli et al. 2006; O’Donnell 2003; Panksepp 2005). Exactly where dopamine-relevant learned or teaching signals first originate in the brain is not known, but the translation of those learning signals into dopamine firing patterns might well include glutamate afferent signals onto tegmentum dopamine neurons that come from prefrontal cortex or hippocampus, which are known to influence bursting states in dopamine neurons (Diaz-Mataix et al. 2006; Dommett et al. 2005; Goto and Grace 2005; Jones and Bonci 2005; Marinelli et al. 2006; O’Donnell 2003). In summary, dopamine neurons may not be the source of their own learning-related changes in firing patterns. Instead, their associative signals are a consequence, not a cause, of learning elsewhere in the brain.
So again, if dopamine neurons code associative signals as a consequence of reward learning but not its cause, then why does their firing pattern so closely follow prediction error rules? The answer may be that dopamine neurons take learning as an input and do something else with it. It might be helpful here to have an analogy with a simpler neural system that obeys learning rules: imagine that an early electrophysiologist of the last century had collaborated with Pavlov, who described the basic rules of classical conditioning for salivation and related conditioned reflexes (Pavlov 1927). Together the team might have studied how learning altered firing in a brainstem neuron that projected to the salivary nerve in one of the famous dogs trained to emit salivation as a conditioned reflex to a food-signaling bell. During initial trials, the electrophysiologist would observe that the salivary nerve fires mostly only to the food UCS. Gradually, during training, the nerve would begin to ‘learn’ to fire an anticipatory burst to the CS that predicts the UCS, before food actually arrived. Pavlov’s imaginary electrophysiologist might perhaps be tempted to suppose for a moment that the salivary nerve firing was the cause or the locus of the observed learning, but of course, would be justified in quickly rejecting that hypothesis. In reality, salivary nerve firing is just a consequence of learning that happened elsewhere in the brain, a number of synapses earlier. A similar logic may apply to interpreting observations of predictive or teaching signal firing in dopamine neurons. In both cases, the neuronal firing may be a consequence, and not a cause, of activity in other neural systems that are more directly responsible for learning computations.
The question then becomes, what does the learned neuronal firing cause in turn? For a salivary nerve, the answer is salivation. For a mesolimbic dopamine neuron, the answer might be incentive motivation. That is, predictive dopamine neuron firing might reflect a conditioned ‘wanting’ response of the brain. That possibility brings us to the hypothesis that dopamine’s chief causal contribution to reward is incentive salience.
Analysis of incentive salience hypothesis
The central premise of incentive salience is that reward is a composite construct that contains multiple component types: wanting, learning, and liking. Dopamine mediates only a ‘wanting’ component, by mediating the dynamic attribution of incentive salience to reward-related stimuli, causing them and their associated reward to become motivationally ‘wanted’. Originally, incentive salience probably evolved to mediate motivation for a few unconditioned rewards, but today, most often acts to add incentive value to learned Pavlovian conditioned stimuli that predict a wide variety of learned rewards (Berridge and Robinson 1998; Dayan and Balleine 2002; Elliott et al. 2003; Everitt and Robbins 2005; Hyman and Malenka 2001; Ikemoto and Panksepp 1999; Insel 2003; Kelley et al. 2005b; McClure et al. 2003; Robinson and Berridge 1993; Volkow et al. 2002b).
It may help first to define what incentive salience is not to make clearer what it is. Incentive salience is not hedonic ‘liking’ or a sensory pleasure of any sort (even if it makes the world more attractive, engaging and ‘wanted’). Yet, it is needed to complete a reward. Pleasure ‘liking’ by itself would simply be a free-floating hedonic state—perhaps something to be enjoyed but without an object of desire or incentive target. The ‘wanting’ motivation for reward needs to be added separately to its neural representation to make a ‘liked’ reward into a ‘wanted’ one.
Second, incentive salience is similarly not reducible to learning (although learning guides ‘wanting’ assignment to specific and appropriate targets). An individual with only a pure associative prediction might well comfortably sit back and simply wait for reward to occur, at least in a Pavlovian situation. But pure prediction almost never occurs alone, and a conditioned stimulus that predicts reward also does other things, in addition, to carry its prediction. It also motivates the individual to obtain the hedonic reward and often motivates the individual to obtain more of the conditioned stimulus itself, so that the individual almost can’t sit still. Incentive salience is a mechanism that helps accomplish these motivational tasks. It is a separate form of value added to neural representations of learned signals that predict hedonic rewards and which translates the mere prediction into motivation.
Incentive salience attribution makes a specific associated stimulus or action into an object of desire and can tag a specific behavior as the rewarded response the individual is motivated to perform. Conversely, incentive salience still requires the other two components also for normal reward to occur. ‘Wanting’ by itself would be merely a sham or partial reward, without true sensory pleasure or ‘liking’. Thus, reward in the full sense cannot happen without incentive salience, even if both hedonic ‘liking’ and predictive learning are present. It takes all three types of components coordination together to produce the full phenomenon we usually think of as reward.
Finally, it is worth noting that none of these basic reward components are equivalent to their respective subjective feelings of reward.3 Activation of basic ‘liking’ and ‘wanting’ components may often be accompanied by feelings of subjective liking and wanting, but they also may sometimes occur implicitly without those subjective feelings (just as implicit learning can occur without explicit memories). The hypothesis posits the subjective feeling to be a secondary consequence, which requires recruitment of additional brain mechanisms to occur (e.g., cortical) and not identical to the basic ‘liking’ and ‘wanting’ processes that are largely subcortical. For this reason, my colleagues and I use the quote marks around basic ‘liking’ and ‘wanting’ terms to denote that those basic processes of hedonic impact and incentive salience are distinguishable from their subjective feelings. Because component and feeling are not quite identical, there may be some cases where basic ‘wanting’ may occur without conscious wanting feelings even in normal humans. For example, people’s ingestive behavior and consumption of a beverage can be stimulated by subliminal visual exposures to happy emotional faces (viewed briefly to be consciously perceived) before the beverage is presented, without ever producing conscious feelings of either wanting more or liking more at the moment the emotional reaction and incentive salience are subliminally generated (Winkielman et al. 2005).3
Origins of the hypothesis
The incentive salience hypothesis was developed with my colleagues at the University of Michigan, most especially Terry Robinson. Incentive salience was offered to try to explain the effect of dopamine-based manipulations of reward: specifically, to reconcile why dopamine appeared to mediate the hedonic impact of rewards in so many studies, yet, clearly did not cause sweetness ‘liking’ in our more specific tests of natural reward. The hypothesis was originally summarized by statements such as “Incentive salience attribution: the active assignment of salience and attractiveness to visual, auditory, tactile, or olfactory stimuli that are themselves intrinsically neutral. Salience attribution possesses the qualities of wanting and desiring, but these need to be distinguished from the experience of sensory pleasure.” (Berridge and Valenstein 1991, p. 9) and “In other words, dopamine systems are necessary for ‘wanting’ incentives, but not for ‘liking’ them or for learning new ‘likes’ and ‘dislikes’ (Berridge and Robinson 1998, p. 309).
Many predecessor hypotheses shaped our early formulation of incentive salience. These included the hedonia hypothesis of dopamine’s role in reward (Wise 1985), but also hypotheses that dopamine mediated incentive motivation (Crow 1973), appetitive phases of motivated behavior (Fibiger and Phillips 1986), expectancy of motivational targets (Panksepp 1986), and sensorimotor arousal or activation (Robbins and Everitt 1982; Salamone 1991; Stricker and Zigmond 1976). On the psychological side, the rules by which incentive salience is posited to work were derived from frameworks for expectancy learning and conditioned incentive motivation in reward (Bolles 1972; Bindra 1978) and frameworks for motivational interaction with physiological homeostatic states and with associative and cognitive learning systems (Cabanac 1979; Dickinson and Balleine 2002; Toates 1986).
What is incentive salience?
Incentive salience is essentially a conditioned motivation response of a brain, usually triggered by and assigned to a reward-related stimulus. Incentive salience is related to but not reducible to the stimulus’s sensory representation or what has been learned about it. Formally, incentive salience is a motivational transformation of a reward-related neural representation, such as a perceived or recalled CS or UCS. The incentive salience value of the stimulus is posited to be dynamically generated anew by mesolimbic systems each time the reward stimulus occurs. That has the consequence that motivation value can sometimes be suddenly changed at the moment of stimulus reexposure, via physiological modulation of mesolimbic mechanisms that generate it. Generation of the incentive salience value draws on both preexisting reward-related associations and current neurobiological states.
This dynamic generation feature of incentive salience is what allows dopamine manipulations to powerfully influence incentive salience attributions, and will be drawn on in experiments below to distinguish incentive salience from learning hypotheses of dopamine function. When incentive salience is attributed to the reward-related stimulus, it transforms the brain’s representation from a mere perception or memory into a motivationally potent incentive. Whether attributed to an unconditioned reward or to a conditioned stimulus that predicts reward, incentive salience makes those stimuli more attractive and ‘wanted’.
The neural machinery responsible for attribution of incentive salience involves dopamine neurotransmission as one link in a larger chain of mesocorticolimbic circuits and signals. It is too simple to say that dopamine = incentive salience; the chain contains other neuronal and neurotransmitter links too. However, many dopamine-based brain manipulations of reward do powerfully and specifically change incentive salience, without changing ‘liking’ or learning, indicating that dopamine is pivotal in causing motivational ‘wanting’ for rewards (Berridge and Robinson 1998; Berridge et al. 1989; Robinson and Berridge 1993). I should acknowledge that incentive salience is not the only form of incentive motivational value carried by a reward: there are other more cognitive and predominantly cortically mediated forms of motivational value, which use explicit representations of reward outcome value and representations of act–outcome relationships (Dickinson and Balleine 2002; Kringelbach 2005; Rolls 2005). Neither of those are necessarily involved in incentive salience, but incentive salience is perhaps the form of incentive motivational value that is most directly linked to mesolimbic dopamine function and to the motivation impact of the presence of reward stimuli (Dickinson et al. 2000; Berridge 2001).
To evaluate the incentive salience hypothesis against learning and hedonia hypotheses of dopamine function, it is helpful to have a clear idea in mind of how certain features of incentive salience work. Those features include how incentive salience makes reward CSs into ‘motivational magnets’, and how it endows CSs with the ability to provoke cue-triggered ‘wanting’ for their rewards. They include especially how previously learned ‘wants’ for food, water, or other rewards are dynamically modulated by physiological hunger–appetite states that influence attributions of incentive salience, in part, by acting through mesolimbic mechanisms involving dopamine neurotransmission. So first, I will describe some of the important features of incentive salience mechanisms that bear on experimental tests. Then we will consider recent experiments that pit incentive salience against reward learning and hedonia hypotheses for dopamine’s role in reward.
Learning inputs
Incentive salience is attributed to Pavlovian conditioned stimuli or cues for reward, and this makes cues ‘wanted’ themselves and able to trigger further ‘wanting’ for their reward. The reason this happens is that CS literally can take on certain incentive motivational properties of its UCS via associatively guided attributions, thus, becoming ‘wanted’ and ‘liked’ in much the same way as the UCS (though ‘liking’ and ‘wanting’ features have separable neural substrates both for CS and UCS) (Berridge 2004; Bindra 1978; Dickinson and Balleine 2002; Shaham et al. 2003; Toates 1986).
One consequence of incentive salience attribution is that a CS for reward itself can become a motivational magnet, in some cases, ‘wanted’ powerfully enough to produce bizarre behaviors. Motivational magnet effects of a CS are visible in ‘autoshaped’ rats, pigeons, or monkeys: those animals are motivated not only to approach a reward CS for reward, but also to carry out consummatory transactions with it as though it were the UCS: for example, pigeons try in UCS-appropriate ways to ‘eat peck’ or conditioned stimulus keylight to ‘drink peck’ a keylight for water reward, and rats may gnaw a lever CS for food reward but simply approach and sniff one for cocaine reward (Jenkins and Moore 1973; Tomie 1996; Uslaner et al. 2006). Related CS effects may be visible in human crack cocaine addicts who ‘chase ghosts’ and visible CSs, scrabbling on the kitchen floor after white crumbs resembling crack crystals, even if they know the crumbs are only sugar (Rosse et al. 1993).
Another major consequence of CS incentive salience is its ability to elicit ‘wanting’ for its UCS, priming incentive motivation just as a small UCS would prime further consumption, by associative spread of incentive salience among linked representations. Just as a small taste of food UCS can prime appetite to eat more, or a small jolt of free brain stimulation or drug reward can prime self-administration of the same reward, conditioned priming by a CS for many of these rewards acts to elicit motivation to obtain the UCS reward (Berridge 2004; Bindra 1978; Dickinson and Balleine 2002; Shaham et al. 2003; Toates 1986).
Although the neural mechanisms of priming are not fully known, it seems clear that incentive priming by a CS draws on some of the same psychological processes and neurobiological substrates as its UCS reward. Dopamine powerfully modulates the incentive salience of reward UCS and CS stimuli in a variety of paradigms. For example, in cases where the CS occurs spontaneously and unexpectedly when the individual is working for a reward UCS (e.g., Pavlovian-instrumental transfer paradigm), conditioned incentive salience can be seen as a stimulus-bound peak of cue-triggered ‘wanting’ that is manifested at the CS as a sudden and frenzied burst of effort to obtain the UCS reward. Dopamine activation or suppression specifically modulates the strength of this cue-triggered burst of ‘wanting’ motivation, which decays away soon after the reward cue is removed, only to reappear again when the cue is reencountered later (Dickinson et al. 2000; Wyvell and Berridge 2000, 2001). In other cases where the CS itself is a motivational target that must be earned rather than freely received (i.e., in conditioned instrumental reinforcement), contingent CS delivery supports acquisition of the new instrumental response that earns it, and dopamine activation may powerfully strengthen ‘wanting’ for the CS so that rats work harder to obtain it (Everitt et al. 1999; Robbins and Everitt 1996). Similarly, in related cases where an earned CS is combined with an earned UCS earning (e.g., some seeking–taking paradigms) the addition of CS ‘wanting’ motivates behavior more strongly than the UCS would alone, and dopamine manipulations effectively modulate the cue-induced enhancement of motivation for reward (Di Ciano et al. 2003; Everitt and Robbins 2005).
A reason why dopamine manipulations can so powerfully modulate the motivational value of reward cues is because they tap into mesocorticolimbic mechanisms by which the dynamic generation of ‘wanting’ is normally modulated by physiological homeostatic states. ‘Wanting’ attributions to stimuli are normally determined by the integration of two major inputs to these mesocorticolimbic mechanisms: 1) learned reward associations to the CS, and 2) current physiological states relevant to the biological reward that influence mesolimbic neurobiological function (e.g., states of caloric hunger, satiety, thirst, salt appetite, and drug-induced mesolimbic activation and sensitization). Drugs can circumvent normal physiological signals that amplify ‘wanting’ for specific rewards.
This learning–physiology interaction is highlighted by what my colleagues and I sometimes call the ‘Bindra-Toates’ psychological framework of incentive motivation (Berridge 2001, 2004; Bindra 1978; Toates 1986). Physiological interaction with CS and UCS alike influences motivation for many biologically relevant rewards including food, sex, and drugs (Ahn and Phillips 1999; Berridge 2001; Fiorino and Phillips 1999; Hellemans et al. 2006; Toates 1986). It may be helpful to unpack the several stages of incentive salience assignment and attribution to see this better (Berridge and Robinson 1998; Robinson and Berridge 1993) (Fig. 5).

Stages of incentive salience attribution. Three stages in the acquisition of a new reward according to the incentive salience model. (1) The first time the unconditioned hedonic pleasure (‘liking’) is encountered, it acts as the normal trigger for the reward-building process, and activates the associative and incentive salience steps. But ‘liking’ by itself is not sufficient to motivate behavior. (2) Associative learning systems target incentive salience attributions to conditioned stimuli associated with the ‘liked’ reward. Associative learning signals are an input into attributions of incentive salience, primarily for determining the direction to specific targets, but learned associations by themselves are not sufficient to generate ‘wanting’. ‘Reboosting’ of incentive salience is also important on continued learning trials, involving dopamine participation, to maintain attributions of incentive salience. (3) On subsequent occasions, incentive salience is attributed to conditioned stimuli by activation of dopamine-related systems, guided by associative learning, making the conditioned stimulus a target of ‘wanting’ and a trigger of increased ‘wanting’ for its UCS reward (conditioned stimuli may also activate conditioned ‘liking’ via separate hedonic brain systems other than dopamine). Reproduced by permission from Fig. 6 (Berridge and Robinson 1998)
Stages involved in attributing incentive salience
Stage 1: CS ‘wanting’ assignment based on ‘liked’ UCS
Originally, a CS has no motivational value beyond novelty—it is merely a perceptual stimulus that is intrinsically insignificant. Even the sight of most foods is, at first, merely a jumble of colors and shapes—it becomes attractive via experience. The occurrence of reward ‘liking’ for the UCS—produced by actual taste of the food or other hedonic reward sensation, whether first encountered by curiosity, design or chance—is usually the event that assigns incentive salience ‘wanting’ to the CS that predicted it.
The ability of ‘liking’ to cause ‘wanting’ is seen in several ways. Even at the first moment of UCS, ‘liking’ often appears to activate ‘wanting’. This is a reason why pleasant rewards often exert psychological priming effects that temporarily increase a pulse of motivation to get that incentive again. It is also a likely reason why dopamine neurons are often activated by a rewarding UCS during training trials (Schultz 1998, 2006; Volkow et al. 2002a). Another way is that brain manipulations that cause ‘liking’ almost always alter ‘wanting’ too. For example, in our lab, virtually all brain manipulations that amplify ‘liking’ reactions to sweetness, so far, such as mu opioid stimulation in the hedonic hotspots of nucleus accumbens shell or ventral pallidum or benzodiazepine stimulation in the brainstem pontine parabrachial region, also at the same time turn out to directly increase some ‘wanting’ aspects of behavior, such as stimulating voluntary food intake or increasing cue-triggered ‘wanting’ for sugar pellets in a pure incentive Pavlovian-instrumental transfer paradigm (Peciña and Berridge 2005; Peciña et al. 2006; Smith and Berridge 2005). That is, whereas ‘wanting’ can be made to occur without activating ‘liking’ (e.g., by dopamine-related neural stimulation), ‘liking’ stimulation of neural substrates often appears to secondarily activate the ‘wanting’ neural substrates that increase incentive salience [except in double-manipulation cases when ‘wanting’ is deliberately and simultaneously suppressed during the ‘liking’ enhancement, such as when a 6-OHDA dopamine lesion suppresses ‘wanting’ while combined with phasic benzodiazepine administration to stimulate ‘liking’ (Berridge and Robinson 1998)]. In general, manipulations that alter the hedonic impact of a UCS, may therefore, modulate the activation of incentive salience and its assignment to CSs. This is chiefly why ‘liked’ UCSs cause their predictive CSs to become not merely learned but also ‘wanted’.
Stage 2: CS ‘wanting’ reboosting
Learning–physiology interactions also occur at later stages of incentive salience attribution after initial learning, when a previously learned CS is reencountered again. One consequence is evident during later training phases after the initial association: reboosting of incentive salience assignment. Normally, when an expected reward is obtained, reboosting by the hedonic UCS strengthens the incentive salience assignment to rewarded stimuli and actions that correctly predicted it. Reboosting at that moment is crucial to keep the reward ‘wanted’ in the future.
Reboosting is especially relevant to understanding ‘extinction mimicry’ effects that are sometimes produced by neuroleptic drugs at low doses (Wise 1985, 2004a). This may be of special interest due to suggestions that those neuroleptic effects, which gave rise to anhedonia and stamping-in interpretations of dopamine function, falsify the incentive salience concept by their very existence: “This argument seems to be falsified by the finding that neuroleptic-treated rats usually continue to approach rewards and reward predictors until they have had considerable experience with the reward while under the influence of the neuroleptic” (Wise 2004a, p. 7). The logic of that critique is essentially that if rats must sometimes experience a reward under a dopamine antagonist drug before the drug will suppress their responding, then, the drug cannot be acting by suppressing incentive salience.
At face value, the observation that the effect of low-to-moderate doses of neuroleptic drugs on reward-focused behavior is sometimes delayed is certainly problematic for incentive motivation hypotheses of dopamine. The validity of that critique was recognized in early formulations of incentive salience, which offered a reboosting explanation (Berridge and Robinson 1998; Berridge and Valenstein 1991; Robinson and Berridge 1993). The solution my colleagues and I suggested 15 years ago, which still seems to me valid now, is that extinction mimicry effects of dopamine antagonist drugs may be understood as due to selective disruption by the drug of the incremental reboosting of incentive salience that ordinarily would occur on each training trial (Berridge and Robinson 1998; Berridge and Valenstein 1991; Robinson and Berridge 1993). Suppression of reboosting gradually degrades the previously established incentive salience and reducing future incentive attributions to the CS. Ordinarily reboosting keeps the CS and its reward ‘wanted’ on later trials. Without reboosting, the reward becomes progressively less ‘wanted’. The important point for understanding extinction mimicry is that reboosting of incentive salience is apparently especially vulnerable to neuroleptic suppression. That means that low-to-moderate doses of neuroleptic may leave highly well-established CS and UCS incentives still attractive (established in stage 1), yet still disrupt stage 2 reboosting. As a result, reboosting is usually the first function to go under dopamine antagonist administration. As far as I know, the reboosting explanation of neuroleptic extinction mimicry effects has never been critiqued in print, and so, perhaps still stands unchallenged.
Recently, McClure and colleagues have suggested a computational model of reboosting for incentive salience and neuroleptic effects (McClure et al. 2003). They suggest that incentive salience reboosting is generated because the prediction error δ(t) of each UCS reward [r(t)] reboosts reassignment of ‘wanting’ to its own CS. That updates the assignment of V expected value to the CS, leading the CS to be more ‘wanted’ in the future. I should note that this McClure et al. model of reboosting is purely associative, using only learning mechanisms, and does not take into account appetite/satiety physiological factors that dynamically modulate incentive salience. It essentially equates incentive salience to associative V prediction. In that sense, it differs from my colleagues and my view of incentive salience as an integrative motivational transformation in which current physiological–neurobiological states multiply the incentive value of stable learned signals (Berridge 2004; Robinson and Berridge 2003; Tindell et al. 2005). However, the McClure al. model is valuable as a demonstration that reboosting can be computationally and rigorously defined, and is a good example of how computational modeling of incentive salience might be approached.
Stage 3: Attribution of ‘wanting’ to a CS
A reward CS is posited to be actively attributed with incentive salience generated afresh each time it is perceived in the future, even after initial learning is established. That feature is to explain why a new hunger, thirst, or related state can modulate the incentive value of a CS for relevant reward, even if it has never yet been learned in that state. In other words, CS incentive salience is generated as a conditioned motivational response of the brain (the associative control of which likely involves amygdala and cortical participation), but the motivational value of the CS is not merely what has been learned about it—the value also draws on physiological states of the moment that are relevant to the reward. Generation of incentive salience is the dynamic process for which mesolimbic dopamine neurotransmission may be most essential and through which many dopamine manipulations cause changes in reward-oriented behavior. Incentive salience depends on current states of brain mesocorticolimbic systems, especially dopamine neurotransmission, because each new stimulus requires its own incentive salience to be actively generated. Many physiological states, including drug states, modulate attributions of incentive salience in part by influencing mesocorticolimbic system function at the moment of CS reencounter.
Physiological state inputs
Physiological modulation can powerfully amplify motivation for natural rewards at all three stages of incentive salience attribution. This is useful for teasing apart learning vs incentive salience hypotheses of dopamine function, and so, it is important to describe how the modulation is posited to work. Incentive salience attribution is strongly modulated by reward-relevant physiological states of an individual at the moment a stimulus is encountered. That means that hunger states and dopamine activation and learned reward associations, can promote incentive salience attributions to relevant stimuli (Berridge 2004; Robinson and Berridge 1993; Toates 1986). The interaction between learning and physiological state goes both ways between learned stimuli and physiological state. In other words, a learned incentive CS can potentiate the motivation strength of a relevant physiological state, just as an appetite state can potentiate the incentive value of a relevant CS. For example, sudden food cues can sometimes promote appetite almost as effectively as greater physiological deprivation (as when an appetizing reminder suddenly makes you want to eat lunch). In animal experiments, this has been shown as conditioned appetite and may involve linked activation of limbic and hypothalamic systems (Petrovich et al. 2005; Weingarten and Martin 1989). Conversely, physiological hunger states dramatically amplify the incentive salience of food cues.
Physiological multiplication of incentive value is highly specific: relevant reward stimuli become more ‘wanted’, but other irrelevant reward stimuli are relatively unaffected (Berridge 2004; Toates 1986). Incentive/physiological interaction is crucial for motivation to be directed to appropriate targets and is highly specific in target. In people and animals, food tastes better when hungry, while water may not; water is a stronger incentive when thirsty while food is not; and so on (Cabanac 1992). Incentive motivational consequences of hunger states make food cues (but not water or other rewards) more attractive than they are when sated; thirst makes water more ‘wanted’ (but not food) and sodium appetite makes the taste of salt more ‘wanted’ than others. Likewise, for drug addicts, drugs may be ‘wanted’ more than other rewards.Footnote 6 As a general rule, physiological deprivation states do not powerfully motivate behavior as simple drives, but instead, motivate and direct chiefly by enhancing the motivational and hedonic values of their relevant external incentive stimuli and that is a function for which mesolimbic mechanisms may be important (Berridge 2004; Toates 1986). Even drug withdrawal states may fail to promote drug seeking directly and rely surprisingly on incentive mediation that might involve similar mechanisms (Hellemans et al. 2006; Hutcheson et al. 2001; Shaham et al. 2003).
Just as the relative incentive-hedonic impact of food, water, and other UCS incentives is directly modulated by relevant physiological states, so too, are the conditioned incentive-hedonic values of Pavlovian learned CS stimuli that have been associated with a particular UCS (Berridge 2001; Toates 1986). A purely learned CS, which was merely associated with a reward UCS in the past, can have its incentive value and hedonic impact suddenly and directly elevated by a new physiological state relevant to that UCS—even if the UCS itself has never been experienced in the new physiological state that would make it ‘liked’. For example, a bitter–sour taste CS that has been associatively paired with unpleasant saltiness in the past, suddenly becomes attractive on its own, is avidly consumed, and elicits ‘liking’ reactions from rats when a physiological sodium appetite state is induced for the first time, even if the salt UCS itself has never yet been tasted in a ‘liked’ mode (Berridge and Schulkin 1989; Fudim 1978).
This instant CS value shift is clearly a consequence of relevant changes in physiological states. It is a hallmark of incentive salience for a number of natural rewards (food, water, salt, sex, etc). It is also useful to teasing apart whether dopamine and related limbic systems code reward learning vs incentive salience by pitting dopamine’s influence on dynamically shifted motivation values against more stable learned reward values (V) (see below). Dopamine is important to dynamic modulation because it is a crucial component of the mesocorticolimbic circuitry that mediates the integration of learned signals with hunger/satiety states to dynamically transform the motivational value of stimuli (Ahn and Phillips 1999; Fiorino et al. 1997; Fulton et al. 2000; Laviolette et al. 2002; Nader et al. 1997; Shizgal 1999; Shizgal et al. 2001; Wilson et al. 1995). Neural mechanisms for that integration involve inputs from other brain systems, such as hypothalamic orexin and other signals about physiological homeostasis, that impact on mesolimbic function (Baldo et al. 2003; Harris et al. 2005; Kelley et al. 2005a; Narita et al. 2006; Zheng et al. 2003).
Experimental tests of incentive salience vs learning hypotheses
Incentive salience and other hypotheses of dopamine function must stand or fall by experimental data. What data indicate that mesolimbic dopamine activation amplifies incentive salience attributed to specific reward stimuli? Or that mesolimbic systems activation causes a dynamic motivational transformation of previously learned stimuli, without needing any new prediction error teaching [by δ(t), (λ−V)] or new stamping-in by associated experiences with enhanced reward impact [r(t)]? Or finally that dopamine-magnified incentive salience is different from magnification of a learned CS prediction value of future reward (V)? I will now briefly summarize two lines of recent evidence that support these incentive salience claims. The first line of evidence comes from studies of electrophysiological effects of dopamine boosts on the neurobiological signals about reward CSs and UCSs that flow out of limbic circuits. The second line comes from measuring behavioral consequences of dopamine boosts in animals on cue-triggered ‘wanting’ for reward.
A brain’s eye view of causal dopamine role: coding of ‘learning’, ‘wanting’ and ‘liking’ in ventral pallidum
What does dopamine activation do to brain representations of reward? Does it enhance coded signals for reward learning, ‘wanting’ or for ‘liking’? The key would be to observe how dopamine activation magnifies a neuronal code for one or another of these signals. If that could be done, dopamine effects on those three different reward codes could be pitted against each other, so to see which was most enhanced.
That probably can be done. An initial attempt to do it was recently made in a limbic neuronal recording study led by Amy Tindell conducted in the electrophysiology laboratory of my Michigan colleague, J. Wayne Aldridge (Tindell et al. 2005). Their goal was to ask whether dopamine activation influenced neuronal codes for (a) CS incentive salience (‘wanting’), (b) CS learned prediction value of future reward (V in temporal difference and Rescorla–Wagner models), and (c) UCS prediction error [δ(t) or (λ−V)] or hedonic impact [‘liking’ or r(t)].
The first issue faced was where in the brain to record neurons? Activity in dopamine neurons themselves, of course, reveals what dopamine is coding, but not necessarily what it is causing. Causal impact might better be gauged by recording consequences of dopamine neurotransmission in a downstream limbic target. Nucleus accumbens is the primary target of mesolimbic dopamine release and accumbens neurons perform further reward computations integrating glutamate, GABA, opioid and other neurotransmitter signals. The consequence of such neuronal integrations might of course modulate biochemical and molecular responses in neurons to depolarization and modulate accumbens firing itself. Given such considerations, to measure final impact, Tindell et al. decided to look one step further downstream: the ventral pallidum (Fig. 6).

The ventral pallidum, as the next step after accumbens in the mesolimbic neural chain, is a useful structure in which to ask what dopamine causes for reward because it gets convergent impact of whatever dopamine is doing. Ventral pallidum receives densest projections from nucleus accumbens in a highly compressed form and electrodes in the ventral pallidum may pick up multiple learning, ‘wanting’, and ‘liking’ functions in a single location (Tindell et al. 2004). Ventral pallidum also receives direct mesolimbic dopamine projections itself from the ventral tegmentum (Zahm 2000). Thus, the ventral pallidum sits at the converging intersection of dopamine-driven reward signals from accumbens and tegmentum. It is also a chief ‘final common path’ for outputs of mesocorticolimbic reward circuits, both those that flow back up to the thalamocortico reentry loops and those that flow down to the brainstem motor outputs (Kalivas and Volkow 2005; Kelley et al. 2005a; McFarland et al. 2004; Napier and Chrobak 1992; Zahm 2000, 2006) (Fig. 6). Recording reward signals from ventral pallidal neurons during dopamine activation converts the theoretical question “What does dopamine do in reward?” into the more empirical question “What does dopamine causally do to limbic reward signals for ‘liking’, learning, and ‘wanting’?”
Ventral pallidal neurons fire to a learned CS that predicts sucrose reward (Tindell et al. 2004) (Fig. 7), just as dopamine neurons and nucleus accumbens neurons do (Bayer and Glimcher 2005; Carelli 2004; Cromwell et al. 2005; Cromwell and Schultz 2003; Day et al. 2006; Ghitza et al. 2003; Hsu et al. 2005; Knutson et al. 2001; Tindell et al. 2004; Wakabayashi et al. 2004). When two CSs in series (CS+1 followed by CS+2) always predict a sugar pellet reward (UCS), ventral pallidal neurons also gradually learn to shift firing forward, so that they eventually fire most to the first CS+1 tone (Tindell et al. 2004). Thus, the ventral pallidum neurons apparently code a learned prediction of future reward (V). That actor–critic prediction characteristic of maximally signalling the first predictor in a chain is also shared by dopamine neurons (Schultz et al. 1997). Finally, ventral pallidal neurons also fire to a ‘liked’ sucrose UCS reward itself, even when it is predicted by CSs (Tindell et al. 2004). This means that both learning and ‘liking’ codes, at least, can readily be explored.

Amphetamine and sensitization amplify incentive firing rate peaks in ventral pallidum neurons. Histograms show firing rates in ventral pallidum elicited by CS+2 click stimulus that had highest incentive salience. Normal firing shown by vehicle and control histograms. Amphetamine and sensitization histograms show increases in firing rates. Bottom shows stimulus presentation timeline for the three reward-related stimuli: CS+1 (maximal predictor stimulus), CS+2 (maximal incentive stimulus, and the only stimulus reliably enhanced by amphetamine or sensitization), sucrose UCS (maximal ‘liked’ hedonic impact). Modified by permission from Fig. 1 (Tindell et al. 2005)
What does mesolimbic activation by sensitization or amphetamine do to ventral pallidum codes for learning, ‘wanting’, and ‘liking’? Neural sensitization of mesolimbic systems by repeated drug exposures facilitates dopaminergic neurotransmission by increasing levels of dopamine release elicited by drugs such as amphetamine and makes dopamine D1 receptors hypersensitive in nucleus accumbens (and changing glutamate and other neurochemical signals and structural features in several mesocorticolimbic structures) (Robinson and Berridge 2000; Vanderschuren and Kalivas 2000). Acute amphetamine administration causes dopamine neurons to directly release stored dopamine into extracellular space. These two manipulations were used by Tindell et al. to activate mesolimbic systems.
To distinguish CS incentive salience (‘wanting’) from CS learned predictions (V) and from UCS learning prediction errors [λ or r(t) or δ(t)] and hedonic ‘liking’, Tindell and colleagues (2005) exploited a useful informational feature of the two serial CSs that predicted sucrose reward. The first CS (CS+1; a 10-s auditory tone) carries the highest V prediction value when it invariably signals the rest of the series, because it reliably predicts everything that follows: CS+2 and then UCS reward (prediction was always 100% in the study). The CS+2 (a 1-s auditory click) is a redundant predictor by contrast and adds essentially no new V or prediction information about the upcoming reward. However, the CS+2 still carries something special of its own as a marker of immediate reward: highest incentive salience. For example, highest incentive motivation during the CS+2 is suggested by the observation that rats make the most frenzied approaches to the sugar bowl that delivers the UCS pellet during the moment of the CS+2. When the CS+1 initially sounds, a rat typically looks around for a few seconds, and then, begins to approach the bowl where sucrose will appear. By the time the CS+2 happens (which occurs immediately before UCS pellet delivery), the rat is typically at the bowl with its mouth ready to catch the sucrose pellet as it falls (Tindell et al. 2005). In other words, conditioned incentive motivation ramps towards a peak as the reward approaches in time (Corbit and Balleine 2003). Thus, incentive salience was likely maximal at the moment of CS+2 in the experiment of Tindell and colleagues. Finally, the sugar pellet that arrives within 1 s later was probably the most hedonically ‘liked’ of these three stimuli, and so, carries the highest hedonic impact [r(t)] and highest UCS associative stamping-in impact or prediction error [λ or δ(t)]. Armed with these features for distinguishing learning, ‘wanting’ and ‘liking’ events, Tindell et al. simply boosted dopamine function after training by inducing neural sensitization or giving acute amphetamine, or both, and observed which signal changed in neuronal reward codes in the ventral pallidum.
The crucial feature of the Tindell et al. (2005) experiment is that the three CS and UCS stimuli essentially stand in as markers, respectively, for maximal learning, ‘wanting’ and ‘liking’ signals. The CS+1 = moment of maximal V prediction; the CS+2 = maximal incentive salience; and the sucrose UCS = maximal prediction error [λ or δ(t)] [also, incidentally, maximal moment of S–S and S–R stamping-in and reward hedonic impact r(t)]. By asking which of these three stimulus signals dopamine activation most enhances, one can surmise which of the functions is most causally affected by dopamine. After training, Tindell sensitized some rats with an escalating dose regimen of amphetamine followed by a month of incubation and left other rats not sensitized. Then on several test days, she compared their ventral pallidum firing to CS and UCS stimuli after dopamine activation by acute amphetamine administration and in a control state after vehicle administration.
Electrophysiological results revealed that amphetamine and sensitization both specifically amplified incentive salience as indicated by elevated peaks of neuronal firing triggered by the CS+2 click that immediately preceded reward (Tindell et al. 2005) (Figs. 8 and 9). Amphetamine caused a robust 150% increase in the coded signal carrying maximal incentive salience (compared to control = 100%). The CS+2 firing peak returned to normal in nonsensitized rats on a subsequent ‘washout’ test day when amphetamine was not given, showing that the incentive salience enhancement by the dopamine-boosting drug was reversible and required an activated mesolimbic state.

Mesolimbic activation magnifies decision utility coding by neuron firing in ventral pallidum. Population profile vector shifts toward incentive coding with mesolimbic activation. Profile analysis shows stimulus preference coded in firing for all 524 ventral pallidum neurons VP (among CS+1, CS+2 and sucrose unconditioned stimulus (UCS). The shifts are graphed in a computational space, a two-dimensional plane in which each of the three reward stimuli is represented by its own axis (CS+1, CS+2, reward UCS). Every neuron’s firing can be plotted as a point somewhere in this plane, and the entire population of ventral pallidum neurons is represented in the outlined shapes. The overall coding bias of the population is shown by an arrow for each condition. The direction of an arrow shows the population’s preference among the three reward stimuli, and the arrow size shows the magnitude of that relative preference for prediction coding (CS+1) vs incentive salience coding (CS+2) vs hedonic or prediction error coding (UCS). Amphetamine and sensitization add together to prime the decision utility pump of incentive salience towards CS+2 ‘incentive-coding’ region. The cue with highest incentive salience, CS+2, increasingly dominates the neuronal population profile vector for all recorded neurons in ventral pallidum as mesolimbic activation increases. Normal rats (control rats during vehicle tests) had a neuronal profile dominated by prediction utility coding (CS+1 bias = maximal V in temporal difference models of reward learning), while firing in sensitized animals during amphetamine challenge revealed a profile dominated by decision utility or incentive salience coding (CS+2 bias = maximal ‘wanting’). \({\text{Direction}}\,\theta = \tan ^{{ - 1}} {\left( {{\left[ {\surd {{\left( {{\text{CS}}1 - {\text{UCS}}} \right)}} \mathord{\left/ {\vphantom {{{\left( {{\text{CS}}1 - {\text{UCS}}} \right)}} 2}} \right. \kern-\nulldelimiterspace} 2} \right]}{{\left( {2{\text{CS}}2 - {\text{CS}}1 - {\text{UCS}}} \right)}} \mathord{\left/ {\vphantom {{{\left( {2{\text{CS}}2 - {\text{CS}}1 - {\text{UCS}}} \right)}} 2}} \right. \kern-\nulldelimiterspace} 2} \right)}\), and \({\text{Magnitude}}\,r = \surd {{\left[ {{\left( {{\text{CS}}1 - {\text{CS}}2} \right)}^{2} + {\left( {{\text{CS}}2 - {\text{UCS}}} \right)}^{2} + {\left( {{\text{UCS}} - {\text{CS}}1} \right)}^{2} } \right]}} \mathord{\left/ {\vphantom {{{\left[ {{\left( {{\text{CS}}1 - {\text{CS}}2} \right)}^{2} + {\left( {{\text{CS}}2 - {\text{UCS}}} \right)}^{2} + {\left( {{\text{UCS}} - {\text{CS}}1} \right)}^{2} } \right]}} 2}} \right. \kern-\nulldelimiterspace} 2\)). Modified by permission from Figs. 6 and 7, p. 2628 and 2629 (Tindell et al. 2005)

Decision utility increment happens too fast for relearning. Timeline and alternative outcomes for neuronal firing coding of reward cue after mesolimbic activation of sensitization and/or amphetamine in ventral pallidum recording experiment (Tindell et al. 2005). The incentive salience model predicts that mesolimbic activation dynamically increases the decision utility of a previously learned CS+. The increased incentive salience coding is visible the first time the already-learned cue is presented in the activated mesolimbic state. Learning models by contrast require relearning to elevate learned predicted utilities. They predict merely gradual acceleration if mesolimbic activation increases rate parameters of learning, and gradual acceleration plus asymptote elevation if mesolimbic activation increase prediction errors. Actual data supporting the incentive salience model were described from (Tindell et al. 2005)
Sensitization caused a similar specific increase in the CS+2 incentive signal. The ventral pallidum neurons of sensitized rats fired higher in response to CS+2, and not to CS+1 or CS−, compared to nonsensitized rats. Sensitized rats showed the enhancement of incentive salience coding even on vehicle control days when they had no amphetamine on board. That persisting CS+2 enhancement indicated that prior sensitization produces specific neuronal coding changes among reward cues that mimic those caused by pharmacological mesolimbic activation. Strikingly, incentive sensitization enhances neural ‘wanting’ signals embedded in the ventral pallidum firing codes in an enduring fashion that lasts weeks or months after drugs have been cleared from the brain.
By contrast, neither amphetamine nor sensitization magnified firing to the CS+1 tone that carried maximum prediction value (V). Similarly, neither amphetamine nor sensitization effectively amplified neuronal coding of the sugar UCS that carried maximum UCS teaching signals of prediction error (λ−V) or δ(t), S–S, or S–R stamping-in, or hedonic impact r(t).
The effect of mesolimbic dopamine activation in shifting the coding pattern of limbic neuronal activity away from its normal bias of reward prediction (V = CS+1) and towards the marker for peak incentive salience (CS+2) can be seen vividly in a firing profile depiction devised by Jun Zhang working with Tindell et al. (2005) (Fig. 8). In it, the coding biases of the entire population of recorded neurons in ventral pallidum are represented computationally in a three-axis graph space or profile and can be seen to normally code reward prediction (V) on the vehicle control day. But the neurons’ preferred signal dynamically jumps towards the moment of maximal incentive salience on the day when amphetamine was administered (at the expense of pure prediction and without altering moderate signals coded for UCS impact or prediction error [δ(t)]). Furthermore, sensitization produced essentially the same dynamic increase in the incentive salience signal.
Finally, adding amphetamine on the test day to previously sensitized rats magnified the incentive salience signal even more. Firing rates elicited by the CS+2 became even higher than the already elevated sensitized level and even higher than amphetamine by itself produced in normal nonsensitized rats (Fig. 8). This high elevation of the incentive signal was unmatched by any other manipulation. That additive priming combination of sensitization plus drug on board would be dangerous if it did the same thing in an addict because it might doubly prime the incentive salience of particular drug stimuli above the levels achieved by either condition alone.6 It suggests a mechanism for why taking even ‘just one hit’ might precipitate a recovering addict back into compulsive ‘wanting’ to take more drug again and again: the hit could elevate the already sensitized incentive salience of immediate drug cues to an even higher level. A combined enhancement (sensitization plus drug-on-board) could make those drug cues into irresistibly attractive triggers of intense ‘wanting’ to take more of the associated drug.
What about UCS prediction errors?
Probably the reward event of most interest for disentangling learning from incentive salience is the moment of actual UCS reward receipt when learning hypotheses posit dopamine to cause a learning prediction error or to stamp in S–S or S–R associations [via δ(t) or (λ−V) as prediction errors or r(t) as reward impact]. Several computational learning models of addiction posit sensitization to enhance prediction errors and explain dopamine-related increases in behavior for reward as due to extra strong reward or habit associations. It is, thus, worth focusing on what amphetamine or sensitization actually does to a UCS signal in a limbic final common path. Regarding that, the most important point to note about dopamine enhancement of UCS prediction error signals for neurons in the ventral pallidum is that basically it did not happen (Tindell et al. 2005). There was no evidence that dopamine activation caused limbic neurons to shift their preference towards coding a UCS prediction error (Fig. 8). At most, there was a slight persistence in the elevation of CS+2 firing peak into the onset of the UCS when dopamine systems were activated, but even then, the incentive coding increase was always larger so that it pulled neuronal coding biases toward the maximum incentive salience signal (Tindell et al. 2005). Nor was there any evidence that neurons treated amphetamine administration itself as an exciting UCS prediction error, by firing more, in general, when amphetamine was on board. Instead, baseline firing by the ventral pallidal neurons was suppressed by amphetamine, not enhanced (Tindell et al. 2005). In short, despite theoretical expectations of learning models to the contrary, elevated dopamine neurotransmission was not a sufficient cause to magnify UCS signals that passed through ventral pallidum in a way that would increase prediction errors.
Also, we can note that the dynamic enhancement of incentive coding was produced too quickly to have been learned by temporal difference models, even if the UCS prediction error had been enhanced by mesolimbic activation (Fig. 9).Footnote 7 Enhanced firing to the maximal incentive stimulus was produced dynamically by the first time it was encountered in the activated mesolimbic states of amphetamine and sensitization (Tindell et al. 2005). Neurons fired faster to the incentive CS+2 stimulus right away without needing to experience further reinforced trials with positive UCS prediction errors. This ‘prescient enhancement’ is exactly what is expected under the incentive salience hypothesis, which posits mesolimbic dopamine-related activation to multiply the motivational value of the incentive CS higher than its previously learned level. The multiplication is possible because the mesolimbic activation short circuits mechanisms that evolved for ordinary physiological appetite states to amplify the incentive salience of their reward CS signal, without needing new learning about the enhanced UCS value under those appetite states. By contrast, existing computational dopamine-learning models cannot explain the sudden appearance of amplified incentive value on the dopamine-elevated test day because all current models rely on UCS prediction errors to gradually and incrementally retrain elevations of V over repeated trials with the elevated [δ(t)] before they can magnify a CS signal (Dayan and Balleine 2002; McClure et al. 2003; Montague et al. 2004; Schultz 2002).
What is the dopamine-modulated transformation mechanism that adds incentive salience to a CS signal? That is not yet known, but might involve dopamine-related changes in the signal-to-noise balance between up states and resting states of neurons in nucleus accumbens or other structures that feed forward into altered inputs into the ventral pallidum or direct dopamine modulation of the ventral pallidum itself (Goto and Grace 2005; Kelley 2004a; O’Donnell 2003; Onn et al. 2000). In any case, clearly the enhancement of the neural signal related to ‘wanting’ does not ‘float all boats’ to raise firing to all reward stimuli, but instead appears to focus dynamic amplification on the stimulus with the most incentive salience: in this case the CS+2.
It might be objected that ventral pallidum recordings do not reveal whether dopamine neurons themselves might code enhanced prediction error signals under these conditions. That objection is correct, but it is irrelevant to the central question of what dopamine causes. Dopamine firing reveals how dopamine neurons respond to reward events but not necessarily how dopamine postsynaptic release alters reward signals that pass on through the rest of the brain. The ventral pallidum firing reveals more about the consequences of dopamine elevation than dopamine neuronal firing can because ventral pallidum neurons receive significantly more causal impact of elevated postsynaptic dopamine signals. It remains an open question whether dopamine neuronal firing codes enhanced prediction error, or instead, behaves similarly to ventral pallidum neurons under these conditions. However, regardless of the answer to that, the findings of Tindell et al. (2005) raise serious doubt about whether dopamine elevation causally magnifies the passage of reward prediction error signals through forebrain limbic circuits.
Temporal discounting mechanism?
A possible neural mechanism for temporal discounting in choice situations (preference for immediate reward over delayed larger reward) is suggested by the very sharp focus of dopamine-amplified incentive salience on the cue immediately closest in time to hedonic reward (Tindell et al. 2005). Temporal discounting is well known in choice phenomena and is associated with mesolimbic activation (Ainslie 1992; McClure et al. 2004). Discounting often is accepted as a given in descriptions of choice behavior without there being necessarily a clear neural or psychological mechanism available to explain how it arises. The findings of Tindell and colleagues imply that brain dopamine activation (e.g., by drugs, natural appetites, or stress) might provide a mechanism: cue-triggered discounting would arise by amplification of ‘wanting’ for an immediately cued reward, which was available right away (comparable to CS+2), and the amplification would not apply to the same extent to a delayed reward signaled by other cues (comparable to CS+1) (Loewenstein and Schkade 1999). If so, mesolimbic dopamine activation could, thus, especially precipitate giving into immediate gratification, at least in situations influenced by cue-triggered ‘wanting’.
Behavioral consequence of dopamine amplification of CS incentive salience: PIT cue-triggered ‘wanting’
Does amplification of neuronal coded signals for CS incentive salience have actual consequences for behavior, visible as enhanced cue-triggered ‘wanting’ to obtain reward? Results of behavioral studies of dopamine-activation effects on cue-triggered ‘wanting’ suggest the answer is yes. A useful illustration comes from a behavioral technique for measuring incentive salience, based on Pavlovian-instrumental transfer paradigm (PIT). The pure conditioned incentive PIT procedure is especially useful because it isolates incentive salience (in the form of cue-triggered ‘wanting’) from most other potential explanations of enhanced reward-directed behavior (by stripping away the influence of reward hedonic enhancement, S–R stamping-in, prediction error learning, S–R habit potentiation, and other mechanisms).
For pitting incentive salience against learning or hedonia hypotheses, the most crucial point to test is whether dopamine manipulation dynamically modulates incentive motivation for reward when performed after learning has already finished, and even in the absence of the UCS, as postulated by the incentive salience hypothesis (stage 3 enhancement by mesolimbic activation). It would be a fatal observation for the dynamic transformation postulate of incentive salience if mesolimbic activation always had to be performed before learning occurred. Likewise, it would be equally fatal if the actual UCS always had to be present in order for dopamine manipulations to act on behavioral ‘wanting’ triggered by its CS. In both cases, the reason is because enhancement of UCS is equally compatible with dopamine roles in δ(t) or (λ−V) prediction error learning, stamping-in reinforcement learning, habit learning, and hedonia hypotheses. So it is useful to test for cue-triggered ‘wanting’ in extinction conditions, withholding delivery of the actual UCS sugar reward, and to withhold mesolimbic activation until after learning about the UCS has already finished.
By capitalizing on these features, Cindy Wyvell in our laboratory asked if dopamine activation can specifically and dynamically increase the incentive salience of a CS (30 s tone) that previously predicted sugar reward (Wyvell and Berridge 2000, 2001). First, rats were trained to press a lever to instrumentally earn sugar pellet rewards, and then, were separately trained to learn that the Pavlovian CS predicted a free sugar pellet UCS reward that they did not have to work for. Then, once training was over, some rats were sensitized by repeated amphetamine administration as in the Tindell et al. (2005) study above, and weeks were allowed for sensitization to incubate. All rats also were implanted with microinjection cannulae in their nucleus accumbens for later manipulation of mesolimbic dopamine activation.
Just before some PIT tests, Wyvell gave rats a microinjection of amphetamine directly into their nucleus accumbens (bilaterally) to activate mesolimbic dopamine release. Before other tests, she gave the same rats a control vehicle microinjection. Then, she tested for cue-triggered ‘wanting’ by measuring pressing behavior on the lever that previously had earned sugar pellets, in a half-hour test session during which the 30-s CS came and went several times (for control purposes, another CS− that rats previously had learned predicted nothing also came and went several times; finally, as mentioned above regarding UCS extinction, no sugar rewards were actually delivered during the test).
Ordinarily, a CS for reward elicits a momentary peak in pressing on the reward lever that lasts about a minute (the basic PIT effect). Wyvell found that activating mesolimbic dopamine-related circuits by amphetamine microinjection or by sensitization specifically magnified this peak of pressing, tripling its magnitude (Wyvell and Berridge 2000, 2001). If rats either got amphetamine on the test day or had been sensitized by drugs weeks before, they specifically tripled their bursts of pressing on the lever that once had produced sucrose to frenzied levels whenever they heard the auditory tone CS for the reward. Their intense bursts of pressing lasted throughout the 30-s CS and then disappeared within a minute or so after the cue ended. In other words, the dopamine-enhanced CS caused sudden phasic peaks of cue-triggered ‘wanting’. Peaks of elevated ‘wanting’ were intense, reversible, and repeatable. They came and went with the physical CS for reward (Fig. 10). But the rats did not press more when they heard nothing during baseline periods or when they heard another different and meaningless CS−. In other words, amphetamine or sensitization had no effect in the absence of the reward CS cue, even though dopamine neurotransmission would have been high throughout most of the entire half-hour test sessions (showing that the ‘wanting’ effect was not explained by sensorimotor arousal or activation or generally overoptimistic predictions sustained after amphetamine microinjections).

Irrational cue-triggered “wanting.” Transient irrational “wanting” comes and goes with the cue (left). Amphetamine microinjection in nucleus accumbens magnifies “wanting” for sugar reward—but only in presence of reward cue (CS+). Cognitive expectations and ordinary wanting are not altered (reflected in baseline lever pressing in absence of cue and during irrelevant cue, CS−) (right). Modified by permission from Wyvell and Berridge (2000)
Thus, similar to dopamine-related enhancement of limbic incentive signals found by Tindell et al. (2005), amphetamine or sensitization caused rats to dynamically attribute higher incentive salience to the CS next time they encountered it (Wyvell and Berridge 2001). Such neural and behavioral demonstrations of incentive salience enhancement are also compatible with many other demonstrations that sensitization enhances incentive motivation to obtain reward, including reports of increases in instrumental break-point (willingness to work harder and harder for reward) and conditioned instrumental reinforcement (willingness to work for a reward-related CS) (Deroche et al. 1999; Piazza et al. 1989; Shippenberg and Heidbreder 1995; Vanderschuren and Kalivas 2000; Vezina 2004; Vezina et al. 2002).
Finally, while it would have been fatal to the dynamic transformation aspect of incentive salience to find that the motivating value of reward CS remained stable once learned until new learning was allowed, these behavioral and neuronal coding data show enhanced incentive salience the first time the relevant CS was encountered in an activated mesolimbic state. Sensitization and amphetamine each magnified the ability of a specific CS+ to elicit ‘wanting’ for reward. Both were caused directly by the mesolimbic activation states at stage 3 of incentive salience attribution. The important point for distinguishing ‘wanting’ from learning is that the enhancements could not have been caused by new exaggerated prediction errors or other forms of enhanced S–S or S–R habits or stamping-in by UCSs [δ(t) or (λ−V)] as posited by temporal difference models and other learning models of dopamine’s role in reward. That is because neither neurobiological manipulation was performed until well after all CS–UCS training trials were finished and learning was over (additionally, lever pressing behavior was not potentiated by dopamine as an S–R habit for the CS because the two events had never occurred together in the same session before the test day). Finally, neither amphetamine microinjections nor sensitization caused any increase in UCS hedonic impact as assessed through behavioral ‘liking’ reactions elicited by the taste of sucrose (Tindell et al. 2005; Wyvell and Berridge 2000).
In such results on cue-triggered ‘wanting’, the power of CS presence is striking: dopamine activation generally needs a CS on which to act. There is a synergy to these enhancements of incentive salience, in that both dopamine activation and CS presence seem required simultaneously. Similarly, in reverse, dopamine receptor blockade in a similar PIT experiment selectively reduced cue-triggered ‘wanting’ for the reward CS without suppressing baseline, again supporting a synergistic role between dopamine neurotransmission and CS presence in generating conditioned incentive motivation (Dickinson et al. 2000). For people in states of mesolimbic activation, it is conceivable that vivid imagery of the reward (CS or UCS) might sometimes substitute for CS presence. If so, excessive ‘wanting’ might sometimes occur spontaneously during vivid mental images of the reward in addition to being triggered by reward cues, especially during mesolimbic activation states. In any case, synergy seems likely a consequence of the interaction with physiological hunger/satiety states that normally modulates the dynamic mesolimbic attribution of incentive salience onto learned cues that predict relevant rewards.
Sufficient cause summary
These lines of evidence from cue-triggered ‘wanting’ and limbic neuronal coding studies raise serious problems for the hypothesis that dopamine elevation directly causes an increase in either reward learning or hedonic ‘liking’ per se. Neither seemed to happen. Dopamine activation failed to enhance signals that maximally coded learned predictive values (V) of cues already learned or coded new learning in the form of prediction errors [(λ−V) or δ(t)]. These results, instead, support the hypothesis that mesolimbic dopamine-related activation magnifies quite specific attributions of incentive salience. For example, acute amphetamine and neural sensitization both seemed to dynamically magnify behavioral peaks of cue-triggered ‘wanting’ for a particular reward CS, in a fashion distinct from either learning or ‘liking’. Correspondingly, the same manipulations also dynamically and selectively amplified limbic ‘final common path’ signals in ventral pallidum that maximally coded the incentive salience of the reward cue.
Finally, a quite independent example of pure dopamine-driven ‘wanting’ may be the DAT knockdown mutant of Zhuang and colleagues, which almost seems to be a poster mouse for exaggerated incentive salience (Cagniard et al. 2005; Peciña et al. 2003; Yin et al. 2006). That hyperdopaminergic mouse, with 170% higher levels of extracellular striatal dopamine, shows higher behavioral ‘wanting’ for sweet rewards on several instrumental, approach, and consumption measures. But the hyperdopaminergic mutant does not show better or faster instrumental learning or Pavlovian S–S learning, nor do its learned S–R habits seem stronger than normal (Cagniard et al. 2005; Yin et al. 2006). The hyperdopaminergic mutant also fails to show higher ‘liking’ reactions to sucrose taste, despite its higher ‘wanting’ for sweet rewards (Peciña et al. 2003). Those hyperdopaminergic mutant results suggest that elevated dopamine is a sufficient cause for elevated ‘wanting’ (but not for elevated ‘liking’ or learning), thus, mirroring the evidence from the dopamine-deficient mutant mouse of Palmiter and colleagues that dopamine is necessary to cause normal ‘wanting’ (but not necessary for normal ‘liking’ or learning) (Cannon and Palmiter 2003; Hnasko et al. 2005; Robinson et al. 2005).
Altogether, these various results suggest the same conclusion about what happens when ‘wanting’, ‘liking’, learning hypotheses of dopamine function are actually pitted against each other. They all indicate that increased dopamine neurotransmission causes a greater increase in incentive salience than in either reward learning or hedonic impact. Of course, these demonstrations are not proof of the incentive salience hypothesis. Their evidence is still too early and too little to draw final conclusions, and the idea of proof imposes an extremely high standard. The balance of evidence might well yet change as future results come in. Still, these are all the studies I am aware of that have explicitly attempted to pit ‘wanting’, learning, and ‘liking’ hypotheses against one another in experiments designed to tease them apart. So far, their evidence suggests that manipulations which enhance dopamine neurotransmission can dynamically amplify the mesolimbic transformation of learned signals into incentive salience that gives them motivation value, without amplifying either ‘learning’ computational parameters or hedonic ‘liking’. That seems to be a legitimate conclusion, though tentative, which deserves serious consideration in the future.
Negative aversion: opposite side of the dopamine coin
Before ending, I acknowledge that several important topics have been left untouched here, including remaining weaknesses in the incentive salience hypothesis.Footnote 8 Perhaps the single most pressing issue for many readers will be the question of what it will mean for reward hypotheses if dopamine also causes motivational states other than reward, including aversive states of fear, anxiety, or stress. Dopamine release is implicated in many motivationally negative events, dopamine neurons may fire at least to nonreward neutral-attentional events, and dopamine manipulations can clearly modulate fear-related behavior and reward-related behavior (Dommett et al. 2005; Horvitz 2002; Killcross et al. 1994; Levita et al. 2002; Salamone 1994; Salamone et al. 2005; Schmajuk et al. 2001). Thus, there is a degree of generality in dopamine functions, even if dopamine neurons fire more to positive rewards than to aversive events (Levita et al. 2002; Mirenowicz and Schultz 1996; Ungless et al. 2004). Clinical implications follow, of course, from any extension of dopamine’s role into aversive states (Kapur 2003; Sarter et al. 2005).
Much still remains to be known about how dopamine’s role in aversive motivations relates to its role in incentive motivation and reward. But in advance, it is important to recognize that a role for dopamine in mediating aversive motivation does not, by itself, mean that dopamine does not specifically contribute to reward motivation too. A neurotransmitter can do more than one thing, and specific roles may be modulated by many factors. For example, dopamine might contribute to mesolimbic mechanisms of negative fearful salience of CSs that predict punishers in a way that parallels its role in the positive incentive salience of CSs for rewards (Kapur 2003; Reynolds and Berridge 2002). There are several potential mechanisms by which dopamine might contribute distinctly to both positive and negative motivation (Berridge and Robinson 1998; Levita et al. 2002). One possibility is that positive vs negative events might activate different dopamine anatomical subsystems, just as opioid activation can potentiate pleasure in one structure but ameliorate pain in another structure. Or coactivation of other nondopamine neural substrates might modulate the positive/negative valence effects of dopamine neurotransmission in the same structure. As a general point, most everything said above about what dopamine does for reward can remain valid in principle even if dopamine also does something for aversive motivations too. In practice, of course, the details will be crucial for interpreting dopamine’s relative contributions to positive vs negative motivational valence.
Conclusion
What is the role of dopamine in reward? Here, I have tried to assess some major contemporary answers. First, does dopamine cause general activation, sensorimotor initiative, effort, and pattern strength? The answer suggested above is yes—but we need more than general sensorimotor activation to understand reward.
Second, does dopamine cause ‘liking’, the hedonic impact of pleasant sensory rewards? The answer here is no: dopamine just sometimes looks like it causes pleasure—but it does not after all.
Third, does dopamine directly cause new learning about rewards? Or does it generate learned predictions of the future rewards elicited by a learned CS? Again, the answer to these is probably no (even if dopamine makes indirect causal contributions to learning and learned performance via consolidation, attention, motivation, etc). The direct causation of teaching signals, prediction errors, and most S–S or S–R reward associations can happen quite independently of dopamine. Again, dopamine just sometimes looks like a direct cause for reward learning—a particularly elegant illusion.
Fourth, does dopamine cause incentive salience to be attributed to reward stimuli? The point of this essay is that the answer is ‘yes’. Dopamine neurotransmission contributes both ‘necessary cause’ and ‘sufficient cause’ features to this motivational function. Dopamine neurotransmission is needed for normal incentive salience, and elevation of dopamine neurotransmission magnifies a specific form of ‘wanting’ for reward that is focused on CS and UCS stimuli.
The incentive salience hypothesis has an advantage of being able to explain much of the evidence that gave rise to the learning and hedonia hypotheses, even if those hypotheses turn out not to be true themselves. But a more important advantage is that incentive salience makes specific and unique predictions in situations that pull apart ‘liking’–learning–‘wanting’ hypotheses, such as the studies described above. So far, incentive salience predictions appear to best fit the data from situations that explicitly pit the dopamine hypotheses against each other. Thus, the best short answer to the question of what dopamine does in reward is that it causes ‘wanting’ for rewards but not learning or ‘liking’ for the same rewards.
Emerging consensus?
Debates are useful to help clarify competing ideas, but they also may overemphasize differences and under-recognize agreement that exists among investigators and among different points of view.
Stepping back from an argumentative mode, let me emphasize that not all is strife and disagreement in the field of reward neuroscience in current thinking about dopamine and reward. Indeed, a degree of consensus might even be forming on a role for dopamine in incentive salience. I will end by simply listing a few quotes: “A potential resolution to this apparent difference of opinion could perhaps be achieved ...Thus, accumbens DA depletions appear to dissociate between different components of ‘wanting’, impairing some aspects, while leaving others intact” (Salamone and Correa 2002, p. 17). “In a general way, the incentive salience model is quite compatible with the anergia hypothesis...Indeed, it has been suggested that overcoming response costs can be viewed as a specific ‘subtype’ of wanting” (Kelley et al. 2005b, p. 788). “Habitual responding by itself, however, does not capture the persistent, indeed, compulsive aspects of ‘out-of-control’ drug bingeing; some additional factor seems to be required. In the ‘incentive-sensitization’ model, the potentiated responding is postulated to depend on drug-induced sensitization of behavior.” (Everitt and Robbins 2005, p. 1487); or “the present data are consistent with the notion that DA increases the incentive salience of a conditioned cue (e.g., the sight, smell, and taste of food), causing the cue to increase the motivational state of “wanting” for the reward without necessarily enhancing its hedonic properties” (Volkow et al. 2002b, p. 179). Finally, “Our working hypothesis is that dopamine levels influence behavior as occasion setters, not as eliciting stimuli, determining on a moment-to-moment basis the incentive salience—the drawing power—of the lever.” (Wise 2004b, pp. 183–184) (italics added to all).
Postscript
Could it be that neuroscientists are beginning to agree about what dopamine does for reward? That conclusion is perhaps too optimistic, as several commentators on this essay have pointed out. The quotes above might simply mean that many colleagues are more open minded than I am about dopamine’s function in reward, rather than that they agree dopamine mediates incentive salience. But whatever the state of current agreement, it will surely be of use in the future to have more explicit comparisons of learning, ‘wanting’, and ‘liking’ hypotheses. If ‘what is the role of dopamine in reward?’ is not to become an eternal question, we would do well to navigate between lurking dangers of either hypothesis isolation or uncritical amalgamation.
On the one side, it would be unhelpful if the field were to fracture into isolated camps or schools of thought that proceed to consider only their own single hypothesis while ignoring other hypotheses as if alternatives did not exist. Isolation prolongs the half-life of ideas that would not stand up to critical analysis, ideas which would better be dropped or modified on the basis of opposing evidence. On the other side, it may not help to postpone hard decisions by simply accepting all hypotheses as if they were equally valid. That would throw together all hypotheses into a general mix that combines strong and weak and lose the clear explanatory value of any single one. Dopamine is probably not a wonder neurotransmitter for reward. If it did each and every reward function is contained in the current hypotheses, then dopamine would have to cause the hedonic feel good of pleasure, new S–S associations and S–R habit stamping-in, a prediction error that teaches new learned predictions, increased activation and sensorimotor function, and incentive salience attributions that make reward-related events ‘wanted’, and other functions too. Can all those be correct as answers to what dopamine contributes to reward? That might be a bit too much even for dopamine. If they are not all equally valid answers, then pruning is needed.
The best course of action to clarify the precise role of dopamine in reward is to pit these reward hypotheses against one another. The solution will emerge by comparing how each one holds up under close scrutiny against evidence from experiments designed to pull the reward functions apart. That will be a true test of this essay’s central thesis: that incentive salience is the best available answer to the question, ‘what does dopamine contribute to reward?’
Notes
Preliminary caveats
Beyond dopamine caveat. In this paper, ‘the role of dopamine in reward’ is taken to be a short-hand term for the dopaminergic component of mesocorticolimbic systems. Dopamine is just one link in that chain of neuronal signals, and of course, we must go beyond dopamine neurons and synapses to understand reward function. Still, many causal manipulations powerfully affect reward by acting directly or indirectly on dopamine neurotransmission, and dopamine neural activation clearly codes reward events. Thus, dopamine deserves the special attention it has received as a crucial node of reward, and its precise role needs to be understood.
Anatomical caveat. This discussion centers on mesolimbic dopamine projections especially to nucleus accumbens, but in practice, it is often difficult to distinguish the role of mesolimbic dopamine from neostriatal, cortical, and other dopamine systems. That is because many experiments use systemic drug administration, genetic manipulations or neural sensitization to alter reward, and all are bound to impact many dopamine systems simultaneously. Dopamine might well mediate different functions in different targets, even if involving similar cellular and molecular mechanisms in each structure, but the functional dividing lines between structures cannot yet be fully drawn. For that reason, I will de-emphasize specific anatomical targets here and attempt to consider dopamine’s most dominant role in reward. Still, we can, at least, surmise certain points about particular structures by a process of elimination. For example, if a reward function survives unchanged after dopamine is suppressed throughout the entire brain, then that function probably does not need dopamine in any particular brain structure.
Tonic-phasic caveat. Similarly, phasic vs tonic dopamine signals might well have consequences that differ from each other, but we cannot tell them apart in most experiments that manipulate reward. So although the distinction’s importance is not denied, I will mostly focus on what we can say about the role of dopamine in reward more generally without trying to assign causal responsibility specifically to phasic or tonic signals.
‘Reinforcing’ terminology is slightly ambiguous: ‘Reinforcement’ often means the positive affective value or hedonic impact of a reward stimulus, as when applied to the hedonia hypothesis. It was long used as a technical term for hedonic impact, and some neuroscientists still use positive reinforcement as their chief synonym for positive affect or emotion today (Rolls 2005). Alternatively, reinforcement can sometimes mean a purely associative strengthening of learned S–S or S–R links without any affective connotations. Yet, a third meaning is radical behaviorist, where it refers simply to an observed strengthening of prior responses on which the reinforcer is contingent, with no explanatory connotations at all of underlying neural or psychological mechanisms. In any case, reinforcement was often used in a hedonic sense by many dopamine-reward papers in the 1980s–1990s and apparently in the hedonia quotes mentioned above.
Even in ordinary people, purely objective or non-subjective affective reactions can be demonstrated under certain conditions in the form of unconscious ‘liking’. For example, a subliminal happy or fearful facial expression, viewed too briefly to be consciously perceived, can produce affective reactions that markedly change a person’s subsequent affective rating and consumption of a subsequent hedonic stimulus (sweet beverage), without ever being felt at the moment the hedonic reaction was caused (Berridge and Winkielman 2003; Winkielman et al. 2005). To become subjectively felt, such ‘unconscious liking’ reactions may require further brain processing, presumably including orbitofrontal and related cortical mechanisms (Kringelbach 2005). But the point here is that if ‘unconscious liking’ reactions ever exist at all, then it means that objective indicators of hedonic reactions can sometimes reveal more about underlying pleasure mechanisms than verbal reports, even in people.
The probable homology of taste ‘liking’ reactions in humans and rats is indicated by several observations. For example, microfeatures of taste reactivity patterns show taxonomic clustering across species: humans share the greatest number of reaction details with other hominids (great apes such as orangutans and chimpanzees), share moderately with old world monkeys and new world monkeys (which cluster into their own groups), and share lightly with rodents (rats and mice; also cluster together) (Berridge 2000; Steiner et al. 2001). But all primates and rodent species tested so far share at least a half dozen reaction details all in common (e.g., rhythmic tongue protrusions to sweet tastes and negative ‘disliking’ gapes to bitter tastes). The homology of those shared components is further indicated by the fact that those shared components also share the same identical rule for generating certain aspects of expression microstructure, such as allometric timing, in primates (including humans) and rodents alike. For example, the duration of expression components observes the equation:
$${\text{duration}}{\left( {{\text{in}}\,{\text{ms}}} \right)} = 0.26 \times {\left( {{\text{adult}}\,{\text{species}}\,{\text{weight}}\,{\left[ {{\text{in}}\,{\text{kg}}} \right]}} \right)}^{{0.32}} $$That allometry rule means that the human or gorilla tongue protrusion or gape is relatively slow, whereas, the same reaction in a rat or mouse reaction is much faster, yet all have identical timing ‘deep structure’ scaled to their evolved size. Finally, other observations indicate that those timing rules for ‘liking’ and ‘disliking’ reactions for each species are actively programmed by brain circuits For example, infants and adults share the same species timing, despite their different sizes, which further indicates homology of brain mechanisms and that timing is not passively produced by actual size acting on the physics of movement (Berridge 2000; Steiner et al. 2001). The implication of the probable homology of taste ‘liking’ reactions for affective neuroscience studies of hedonic impact is that identification of hedonic hotspots and neurochemical bases of ‘liking’ in rats can provide insights that probably apply also to brain hedonic mechanisms in humans.
Several demonstrations reveal that hedonic neural hierarchies control the expression of ‘liking’ reactions used in our taste reactivity studies. For example, microinjections of opioid agonists and other neurotransmitter agents in forebrain structures such as the nucleus accumbens and ventral pallidum cause increases in ‘liking’ reactions, whereas, forebrain lesions of the ventral pallidum or ‘thalamic’ ablation of telencephalon cause increases in ‘disliking’ reactions (Cromwell and Berridge 1993; Grill and Norgren 1978b; Peciña and Berridge 2000, 2005; Reynolds and Berridge 2002; Smith and Berridge 2005). Taste reactivity ‘liking’ patterns have also been used to guide positive identification of neural firing patterns in the forebrain that code hedonic impact (e.g., rate codes by neurons in ventral pallidum) (Tindell et al. 2006). Such forebrain-related observations extend traditional notions of taste reactivity as a brainstem response, which were grounded on basic taste reactions elicited from decerebrate rats or cats or from anencephalic humans (Grill and Norgren 1978b; Sherrington 1906; Steiner 1973), by demonstrating that forebrain hedonic circuits normally exert overriding dominance over brainstem circuits in the control of ‘liking’ reactions, and that forebrain hedonic signals are normally reflected in behavioral ‘liking’ reactions.
In fact, many of the dopamine activations described that caused ‘wanting’-without-‘liking’ in our taste reactivity studies slightly reduced the number of ‘liking’ reactions to sweet taste while simultaneously stimulating ‘wanting’ for food reward, a potential hedonic suppression that is opposite from what the hedonia hypothesis should predict (dopamine-mediated suppression of ‘liking’ appears to be independent of incentive salience attribution; the mechanism of hedonic suppression is not fully understood but might conceivably involve interaction with known opioid or gamma-aminobutyric acid (GABA) hedonic mechanisms in nucleus accumbens).
Direct vs indirect roles in learning: Clear evidence for indirect roles of dopamine
It can be useful to distinguish between potential direct causal roles of dopamine, as part of an associative mechanism that learns associative links between S–S or S–R events (teaching signal δ(t), engram stamping-in, prediction V), and indirect roles on other extrinsic mechanisms separate from learning that feed back secondarily to modulate learning or later use of learned information.
Dopamine and other catecholamine activation may facilitate the capacity to extract new information from training trials, facilitate consolidation after learning, and facilitate learned performance later. For example, dopamine manipulations before training can modulate learning features such as latent inhibition for reward or fear CSs (Gray et al. 1999; Phillips et al. 2003a; Schmajuk et al. 2001), dopamine agonists given before performance tests enhance the motivational value of CSs in conditioned reinforcement and other tasks (and the enhancement can be blocked by accumbens 6-OHDA lesions) (Robbins and Everitt 1996; Taylor and Robbins 1984, 1986). In addition, elegant recent studies have demonstrated that dopamine may contribute to consolidation processes that continue for many minutes after a S–S or S–R learning trial has ended and that help make an already learned association more readily available for later use (Dalley et al. 2005). These consolidation effects appear related to the consolidation effects that have been well documented for norepinephrine, stress hormones, and certain other neurochemical modulators (Dalley et al. 2005; Everitt and Robbins 2005; McGaugh 2002; Smith-Roe and Kelley 2000). Thus, dopamine may indirectly affect the extraction of information from environments or the later use of learned information in many ways. Those roles may remain, even if dopamine in not the primary teaching signal that directly causes new learning.
Why do addicts ‘want’ just drugs? An extension of salience specificity
Dopamine drugs that activate mesolimbic systems short circuit normal physiological-learning interaction, by plugging directly into the neurobiological mechanism that ordinarily adjusts learned incentive salience in accordance with physiological states. Drugs that activate dopamine neurotransmission or induce neural sensitization may thus directly elevate ‘wanting’ for rewards in a manner that will still be cue-sensitive and reward-specific. Similarly, more enduring effects of addictive drugs, such as neural sensitization, may permanently elevate mesolimbic neural responsiveness to certain motivational stimuli, and increase incentive salience or ‘wanting’ for those rewards, especially drug rewards. This is the basis for the incentive-sensitization theory of addiction, the development of which was led by my colleague Terry Robinson (Robinson and Berridge 1993). It combines the incentive salience hypothesis of what dopamine-related mesolimbic systems contribute to reward with the idea that drugs of abuse may sensitize the same mesolimbic systems in susceptible human addicts.
It is sometimes objected that incentive-sensitization could not possibly be specific enough to make drugs ‘wanted’ more than other stimuli. For example, Vanderschuren and Everitt engagingly proposed that “incentive sensitization caused by repeated drug exposure can explain the exaggerated motivation for drugs associated with addiction, but not the fact that drug-related activities prevail at the expense of previously important social and professional activities” (Vanderschuren and Everitt 2005). That proposal seems to suppose that incentive-sensitization must necessarily make all things equally more ‘wanted’: drugs and social or professional success alike, similar to the adage that ‘a rising tide floats all boats’. But recent evidence indicates that it is probably more accurate to say that sensitization amplifies ‘wanting’ in ways that can be quite specific to one motivational target rather than another. For example, sensitization may make drugs more ‘wanted’ than natural rewards for some individuals but for others make food or sex more ‘wanted’ than drug (Nocjar and Panksepp 2002). In other experiments described under incentive salience, sensitization can more than triple the ability of some particular cues to trigger ‘wanting’ for their reward, while leaving other cues and baseline motivation in the absence of cues, essentially unchanged (e.g., CS+2 vs CS+1 for incentive coding by ventral pallidum neuronal firing; CS+ vs CS− for behavioral cue-triggered ‘wanting’ in PIT (Tindell et al. 2005; Wyvell and Berridge 2001). Thus, incentive-sensitization can often enhance ‘wants’ for some rewards much more than other rewards, and at some moments, much more than other moments.
Still, in accordance with Vanderschuren and Everitt’s proposal of broad motivational ‘wanting’, sensitized incentive salience can sometimes spillover, too, in humans and animals at least under some conditions. For example, Fiorino and Phillips observed that “As many as 70% of patients admitted to a New York cocaine addiction treatment program were also reported to suffer from compulsive sexuality” in a study showing that amphetamine sensitization also amplified sexual behavior and dopamine release in rats (Fiorino and Phillips 1999; Washton and Stone-Washton 1993). Parkinson’s patients with dopamine dysregulation who become addicted to over-consuming l-DOPA, may also show other motivational compulsions including gambling, sexual behavior, and obsessive desire to repeat trivial pursuits like sorting drawers (punding) (Dodd et al. 2005; Evans et al. 2006). But even in such cases, some motivational targets are ‘wanted’ much more than others. Thus, target specificity, more than generality, probably is the guiding rule for dopamine-enhanced ‘wanting’, and there might even be cases where ‘winner takes all’.
In addiction, drugs might be specifically enhanced as targets for sensitization of incentive salience because they have a privileged Bindra–Toates associative relationship as UCS to predictive drug-related CSs, in addition to being strong stimuli for activating and sensitizing dopamine systems directly. In short, activating mesolimbic systems by dopamine agonist drug or by sensitization may amplify and distort the normal specificity by which some stimuli become ‘wanted’ much more than others, but the specificity is not abolished. That may be why addicts ‘want’ their drugs more than other rewards or social success.
The test situation occurred too soon—that is, before new relearning of dopamine-augmented reward value was possible—for any existing prediction error model to produce an increment in CS-triggered V, the associative prediction of future reward, in the studies of Tindell et al. (2005) or Wyvell and Berridge (2000, 2001). V increments require retraining with an elevated UCS teaching signal. Because mesolimbic activation (sensitization and/or acute amphetamine) was delayed until after training finished, there were no opportunities for prediction error to enhance a teaching signal for V before the first test trial (even if dopamine activation had increased the prediction error UCS signal). Thus, V could not possibly have been enhanced on the first test trial without doing serious violence to the right side of the V equation of the temporal difference model. However, conceivably future computational learning models will escape the ‘need-another-UCS-experience’ constraint of cache-based models and become better able to cope with sudden shifts in value that are not gradually relearned. For example, recent tree-search models have been proposed that exhaustively examine all potential outcomes, pulling up each one for a thorough reevaluation of its utility values—but only so far applied to cortex function and explicitly not to mesolimbic dopamine function (Daw et al. 2005). Still, perhaps a related future model, if applied to mesolimbic dopamine function, might be able to allow ‘instant increases’ in CS predicted utility produced by post-learning sensitization or drug administration. Even if so, though, such future ‘prescient-V-increment’ models still will encounter a major obstacle in the finding by that dopamine activation enhanced the strength of the CS incentive code (CS+2) at the expense of the CS prediction V code strength (CS+1) in the computational profile analysis of neuronal coding in ventral pallidum in Tindell et al. (2005).
Remaining difficulties with the incentive salience hypothesis. Many readers may have noted explanatory gaps that were skipped over in the section above. Though it means momentarily stepping aside from my debate mission here, my colleagues and I readily acknowledge that incentive salience is by no means a complete theory, but only an interim and skeletal hypothesis of dopamine and mesocorticolimbic function that needs additional development on many points. It is based on data available to date, but that is incomplete on several points. The gaps are real and need to be plugged by further research.
For example, one gap needing attention concerns the relative roles of stage 2 reboosting and stage 3 dynamic generation of incentive salience attributions to a CS. Reboosting is the one feature of the incentive salience hypothesis that was added as a purely post hoc postulate to explain hedonia-type dopamine phenomena from other laboratories. It was added purely to explain why dopamine antagonist drugs sometimes produced what looked like anhedonia effects on instrumental reward tasks, such as the ‘extinction mimicry’ effects described by Wise and others (Ettenberg and McFarland 2003; Wise 1985, 2004a; though compare Salamone et al. 1997). My colleagues and I were quite familiar with extinction mimicry reports by the late 1980s. Indeed, I had been convinced by them that dopamine did mediate hedonic impact, at least, until we began to find ourselves that basic hedonic ‘liking’ reactions were not at all suppressed by dopamine reduction. We devised reboosting as a postulate specifically to reconcile extinction mimicry effects with preserved hedonic impact, in an effort to explain why dopamine could look as though it mediated pleasure when it actually did not (Berridge and Valenstein 1991; Robinson and Berridge 1993).
As a consequence, reboosting is an add-on feature, somewhat messy though still quite necessary. It operates to influence incentive salience attributions to CSs during pairing with UCSs in stage 2, in addition to the stage 3 integration of prior UCS value and relevant physiological state that occurs when the CS is next encountered. But this degree of messiness may be an acceptable theoretical price that must be paid to buy the most data. In addition, reboosting might prove important in explaining some cases of resistance to goal devaluation, cases in which a reward CS remains ‘wanted’ even after its UCS goal is suddenly devalued and becomes no longer attractive (e.g., by pairing UCS food reward with LiCl illness). In those cases, the incentive salience of the CS may become independent of its UCS, so the CS may be no longer dynamically adjusted in stage 3 based strictly on current UCS value (perhaps persisting especially when additional associative layers such as aversion conditioning or sensory-specific habituation, rather than a direct physiological state shift such as hunger, are used to revalue the UCS). One possible explanation is that repeated reboosting of incentive salience to CS, before the devaluation, sometimes builds up ‘wanting’ for the cue in a way that to some degree becomes independent from stage 3 integration with the current state. In that case, the CS might remain attractive even after the UCS incentive value is gone. Of course, this account of resistance to devaluation is purely speculative, but it could be evaluated empirically that the relation between stage 2 reboosting and stage 3 dynamic integration become clarified by future results. To sum up reboosting, the evidence available suggests that dopamine influences incentive salience both via reboosting (during UCS training) and via dynamic mesolimbic generation (later at moment of CS reexposure). Both routes can be modeled computationally and studied experimentally. Together, they may cover much of the dopamine-related evidence on reward that gave rise originally to hedonia and stamping-in reinforcement hypotheses and motivation ‘wanting’ effects.
Another difficulty that needs addressing in the future is to develop a more complete account of how dopamine effects on CS incentive salience are translated into UCS-directed instrumental actions beyond simple approach behaviors. The puzzle to be explained is how incentive salience becomes attributed to reward representation targets of instrumental responses or even sometimes to instrumental acts themselves. The evidence shows it does. One clear example is cue-triggered ‘wanting’ based on Pavlovian-instrumental transfer (chosen because it strips away alternative explanations) (Dickinson et al. 2000; Peciña et al. 2006; Wyvell and Berridge 2000, 2001). Cue-triggered ‘wanting’ is arguably potent in many human situations, such as addictive cue-triggered relapse. Instrumental application of incentive salience might also contribute to conditioned instrumental reinforcement situations, where individual work simply to gain a reward cue. Dopamine activation potently magnifies conditioned reinforcement (Everitt et al. 1999; Everitt and Robbins 2005). In such cases, animals must use a central neural representation of the CS incentive to guide their action because the physical cue does not occur until after the action (though contextual cues likely serve as occasion setters to activate the cue representation and incentive salience attribution). A similar logic might also apply the role of cues in seeking–taking situations or cases where earning a cue (in addition to drug reward) contributes an increment to motivation for earning the unconditioned reward by itself (Nicola et al. 2005; Vanderschuren and Everitt 2005). But a good theoretical account of how incentive salience is attributed by dopamine-related mechanisms precisely to motivate instrumental actions will need future work (Dickinson and Balleine 2002).
An additional difficulty is how to reconcile the apparent failure of dopamine to directly cause learning with other evidence that dopamine indirectly modulates learning. As noted above, numerous studies have indicated a role for dopamine neurotransmission in modulating cellular plasticity (e.g., long-term potentiation) and in memory consolidation after learning and modulating attention and other functions that act during training and during test performance based on learned information (Dalley et al. 2005; Everitt and Robbins 2005; McGaugh 2002; Smith-Roe and Kelley 2000). Yet at the same time, recent evidence suggests that dopamine is not serving as a prediction error δ(t) to stamp-in new S–S or S–R associations or to generate learned predictions as V (e.g., ability of mutant mice to learn without dopamine; merely normal learning in other mutant mice with excessive dopamine; failure of dopamine activation to elevate limbic neural coded signal for learning δ(t) or V in recorded mesolimbic outputs in ventral pallidum). Clearly, it is of great importance to understand better exactly what dopamine does to indirectly modulate learning-related mechanisms.
There are other deficiencies too: for example, there is a pressing need for computational models that better capture dynamic integrative features of incentive salience described above (Zhang et al. 2005). But these difficulties generally seem to be challenges that can be reasonably expected to be met in time and are not insurmountable obstructions. Most important, to return to the central theme of dopamine function, the incentive salience hypothesis is sufficiently developed at present that it can be empirically tested, as in experiments above. It makes specific predictions that can be quite feasibly pitted against learning and ‘liking’ hypotheses of dopamine function in reward. In the cases above where that has been done, the data, so far, support the hypothesis that dopamine causes ‘wanting’ more directly than either learning or ‘liking’ for reward.
References
Ahn S, Phillips AG (1999) Dopaminergic correlates of sensory-specific satiety in the medial prefrontal cortex and nucleus accumbens of the rat. J Neurosci 19:B1–B6
Ainslie G (1992) Picoeconomics. Cambridge University Press, Cambridge University Press
Albin RL, Young AB, Penney JB (1995) The functional anatomy of disorders of the basal ganglia. Trends Neurosci 18:63–64
Andrzejewski ME, Spencer RC, Kelley AE (2005) Instrumental learning, but not performance, requires dopamine D1-receptor activation in the amygdala. Neuroscience 135:335–345
Aragona BJ, Liu Y, Yu YJ, Curtis JT, Detwiler JM, Insel TR, Wang Z (2006) Nucleus accumbens dopamine differentially mediates the formation and maintenance of monogamous pair bonds. Nat Neurosci 9:133–139
Baldo BA, Daniel RA, Berridge CW, Kelley AE (2003) Overlapping distributions of orexin/hypocretin- and dopamine-beta-hydroxylase immunoreactive fibers in rat brain regions mediating arousal, motivation, and stress. J Comp Neurol 464:220–237
Baldwin AE, Sadeghian K, Holahan MR, Kelley AE (2002) Appetitive instrumental learning is impaired by inhibition of cAMP-dependent protein kinase within the nucleus accumbens. Neurobiol Learn Mem 77:44–62
Bayer HM, Glimcher PW (2005) Midbrain dopamine neurons encode a quantitative reward prediction error signal. Neuron 47:129–141
Becker JB, Rudick CN, Jenkins WJ (2001) The role of dopamine in the nucleus accumbens and striatum during sexual behavior in the female rat. J Neurosci 21:3236–3241
Berke JD (2003) Learning and memory mechanisms involved in compulsive drug use and relapse. In: Wang JQ (ed) Drugs of abuse: neurological reviews and protocols (Methods in Molecular Medicine). Humana, Totowa, NJ, pp 75–101
Berke JD, Hyman SE (2000) Addiction, dopamine, and the molecular mechanisms of memory. Neuron 25:515–532
Berridge KC (2000) Measuring hedonic impact in animals and infants: microstructure of affective taste reactivity patterns. Neurosci Biobehav Rev 24:173–198
Berridge KC (2001) Reward learning: reinforcement, incentives, and expectations. In: Medin DL (ed) The psychology of learning and motivation. Academic, NY, pp 223–278
Berridge KC (2004) Motivation concepts in behavioral neuroscience. Physiol Behav 81:179–209
Berridge KC, Peciña S (1995) Benzodiazepines, appetite, and taste palatability. Neurosci Biobehav Rev 19:121–131
Berridge KC, Robinson TE (1998) What is the role of dopamine in reward: hedonic impact, reward learning, or incentive salience? Brain Res Rev 28:309–369
Berridge KC, Schulkin J (1989) Palatability shift of a salt-associated incentive during sodium depletion. Q J Exp Psychol [b] 41:121–138
Berridge KC, Valenstein ES (1991) What psychological process mediates feeding evoked by electrical stimulation of the lateral hypothalamus? Behav Neurosci. 105:3–14
Berridge KC, Winkielman P (2003) What is an unconscious emotion? (The case for unconscious “liking”). Cogn Emot 17:181–211
Berridge KC, Venier IL, Robinson TE (1989) Taste reactivity analysis of 6-hydroxydopamine-induced aphagia: implications for arousal and anhedonia hypotheses of dopamine function. Behav Neurosci 103:36–45
Berridge KC, Aldridge JW, Houchard KR, Zhuang X (2005) Sequential super-stereotypy of an instinctive fixed action pattern in hyper-dopaminergic mutant mice: a model of obsessive compulsive disorder and Tourette’s. BMC Biol 3:4
Bindra D (1978) How adaptive behavior is produced: a perceptual-motivation alternative to response reinforcement. Behav Brain Sci 1:41–91
Bolles RC (1972) Reinforcement, expectancy, & learning. Psychol Rev 79:394–409
Brauer LH, De Wit H (1997) High dose pimozide does not block amphetamine-induced euphoria in normal volunteers. Pharmacol Biochem Behav 56:265–272
Brauer LH, Rukstalis MR, de Wit H (1995) Acute subjective responses to paroxetine in normal volunteers. Drug Alcohol Depend 39:223–230
Brauer LH, Goudie AJ, de Wit H (1997) Dopamine ligands and the stimulus effects of amphetamine: animal models versus human laboratory data. Psychopharmacology (Berl) 130:2–13
Brauer LH, Cramblett MJ, Paxton DA, Rose JE (2001) Haloperidol reduces smoking of both nicotine-containing and denicotinized cigarettes. Psychopharmacology (Berl) 159:31–37
Cabanac M (1979) Sensory pleasure. Q Rev Biol 54:1–29
Cabanac M (1992) Pleasure: the common currency. J Theor Biol 155:173–200
Cagniard B, Balsam PD, Brunner D, Zhuang X (2005) Mice with chronically elevated dopamine exhibit enhanced motivation, but not learning, for a food reward. Neuropsychopharmacology 31(7):1362–1370
Cannon CM, Bseikri MR (2004) Is dopamine required for natural reward? Physiol Behav 81:741–748
Cannon CM, Palmiter RD (2003) Reward without dopamine. J Neurosci 23:10827–10831
Carelli RM (2004) Nucleus accumbens cell firing and rapid dopamine signaling during goal-directed behaviors in rats. Neuropharmacology 47 Suppl 1:180–189
Cooper SJ, Dourish CT (1990) Neurobiology of stereotyped behaviour. Oxford University Press, Oxford University Press
Corbit LH, Balleine BW (2003) Instrumental and Pavlovian incentive processes have dissociable effects on components of a heterogeneous instrumental chain. J Exp Psychol Anim Behav Processes 29:99–106
Cromwell HC, Berridge KC (1993) Where does damage lead to enhanced food aversion: the ventral pallidum/substantia innominata or lateral hypothalamus? Brain Res 624:1–10
Cromwell HC, Berridge KC (1996) Implementation of action sequences by a neostriatal site: A lesion mapping study of grooming syntax. J Neurosci 16:3444–3458
Cromwell HC, Schultz W (2003) Effects of expectations for different reward magnitudes on neuronal activity in primate striatum. J Neurophysiol
Cromwell HC, Hassani OK, Schultz W (2005) Relative reward processing in primate striatum. Exp Brain Res 162:520–525
Crow TJ (1973) Catecholamine-containing neurones and electrical self-stimulation. 2. A theoretical interpretation and some psychiatric implications. Psychol Med 3:66–73
Dalley JW, Laane K, Theobald DEH, Armstrong HC, Corlett PR, Chudasama Y, Robbins TW (2005) Time-limited modulation of appetitive Pavlovian memory by D1 and NMDA receptors in the nucleus accumbens. PNAS 102:6189–6194
Damasio AR (1999) The feeling of what happens: body and emotion in the making of consciousness, 1st edn. Harcourt Brace, Harcourt Brace
Darwin C (1872) The expression of the emotions in man and animals. Murray, London
Dauer W, Przedborski S (2003) Parkinson’s disease: mechanisms and models. Neuron 39:889–909
Daw ND, Niv Y, Dayan P (2005) Uncertainty-based competition between prefrontal and dorsolateral striatal systems for behavioral control. Nature Neurosci 8:1704–1711
Day JJ, Wheeler RA, Roitman MF, Carelli RM (2006) Nucleus accumbens neurons encode Pavlovian approach behaviors: evidence from an autoshaping paradigm. Eur J Neurosci 23:1341–1351
Dayan P, Balleine BW (2002) Reward, motivation, and reinforcement learning. Neuron 36:285–298
de la Fuente-Fernandez R, Phillips AG, Zamburlini M, Sossi V, Calne DB, Ruth TJ, Stoessl AJ (2002) Dopamine release in human ventral striatum and expectation of reward. Behav Brain Res 136:359–363
Deroche V, Le Moal M, Piazza PV (1999) Cocaine self-administration increases the incentive motivational properties of the drug in rats. Eur J Neurosci 11:2731–2736
Deveney AM, Waddington JL (1997) Psychopharmacological distinction between novel full-efficacy “D-1-like” dopamine receptor agonists. Pharmacol Biochem Behav 58:551–558
Di Chiara G (2002) Nucleus accumbens shell and core dopamine: differential role in behavior and addiction. Behav Brain Res 137:75–114
Di Ciano P, Underwood RJ, Hagan JJ, Everitt BJ (2003) Attenuation of cue-controlled cocaine-seeking by a selective D-3 dopamine receptor antagonist SB-277011-A. Neuropsychopharmacology 28:329–338
Diaz-Mataix L, Artigas F, Celada P (2006) Activation of pyramidal cells in rat medial prefrontal cortex projecting to ventral tegmental area by a 5-HT1A receptor agonist. Eur Neuropsychopharmacol 16:288–296
Dickinson A, Balleine B (2002) The role of learning in the operation of motivational systems. In: Gallistel CR (ed) Stevens’ handbook of experimental psychology: learning, motivation, and emotion. Wiley, New York, pp 497–534
Dickinson A, Smith J, Mirenowicz J (2000) Dissociation of Pavlovian and instrumental incentive learning under dopamine antagonists. Behav Neurosci 114:468–483
Dodd ML, Klos KJ, Bower JH, Geda YE, Josephs KA, Ahlskog JE (2005) Pathological gambling caused by drugs used to treat Parkinson disease. Arch Neurol 62(9):1377–1381
Dommett E, Coizet V, Blaha CD, Martindale J, Lefebvre V, Walton N, Mayhew JE, Overton PG, Redgrave P (2005) How visual stimuli activate dopaminergic neurons at short latency. Science 307:1476–1479
Ekman P (1999) Basic emotions handbook of cognition and emotion. Wiley, Chichester, England, pp 45–60
Elliott R, Newman JL, Longe OA, Deakin JFW (2003) Differential response patterns in the striatum and orbitofrontal cortex to financial reward in humans: a parametric functional magnetic resonance imaging study. J Neurosci 23:303–307
Ettenberg A, McFarland K (2003) Effects of haloperidol on cue-induced autonomic and behavioral indices of heroin reward and motivation. Psychopharmacology (Berl) 168:139–145
Evans AH, Pavese N, Lawrence AD, Tai YF, Appel S, Doder M, Brooks DJ, Lees AJ, Piccini P (2006) Compulsive drug use linked to sensitized ventral striatal dopamine transmission. Ann Neurol 59:852–858
Everitt BJ, Robbins TW (2005) Neural systems of reinforcement for drug addiction: from actions to habits to compulsion. Nat Neurosci 8:1481–1489
Everitt BJ, Parkinson JA, Olmstead MC, Arroyo M, Robledo P, Robbins TW (1999) Associative processes in addiction and reward. The role of amygdala–ventral striatal subsystems. Ann N Y Acad Sci 877:412–438
Everitt BJ, Dickinson A, Robbins TW (2001) The neuropsychological basis of addictive behaviour. Brain Res Rev 36:129–138
Faure A, Haberland U, Conde F, Massioui NE (2005) Lesion to the nigrostriatal dopamine system disrupts stimulus-response habit formation. J Neurosci 25:2771–2780
Fenu S, Di Chiara G (2003) Facilitation of conditioned taste aversion learning by systemic amphetamine: role of nucleus accumbens shell dopamine D-1 receptors. Eur J Neurosci 18: 2025–2030
Ferraro FM 3rd, Hill KG, Kaczmarek HJ, Coonfield DL, Kiefer SW (2002) Naltrexone modifies the palatability of basic tastes and alcohol in outbred male rats. Alcohol 27:107–114
Fibiger HC, Phillips AG (1986) Reward, motivation, cognition: Psychobiology of mesotelencephalic systems. In: Bloom FE (ed) Handbook of Physiology—The Nervous System. American Physiological Society, Bethesda, MD. pp 647–675
Fiorino DF, Phillips AG (1999) Facilitation of sexual behavior and enhanced dopamine efflux in the nucleus accumbens of male rats after d-amphetamine-induced behavioral sensitization. J Neurosci 19:456–463
Fiorino DF, Coury A, Phillips AG (1997) Dynamic changes in nucleus accumbens dopamine efflux during the Coolidge effect in male rats. J Neurosci 17:4849–4855
Fudim OK (1978) Sensory preconditioning of flavors with a formalin-produced sodium need. J Exp Psychol Anim Behav Process 4:276–285
Fulton S, Woodside B, Shizgal P (2000) Modulation of brain reward circuitry by leptin [published erratum appears in Science 2000 Mar 17;287(5460):1931]. Science 287:125–128
Gallistel CR, Fairhurst S, Balsam P (2004) The learning curve: implications of a quantitative analysis. Proc Natl Acad Sci USA 101:13124–13131
Ghitza UE, Fabbricatore AT, Prokopenko V, Pawlak AP, West MO (2003) Persistent cue-evoked activity of accumbens neurons after prolonged abstinence from self-administered cocaine. J Neurosci 23:7239–7245
Goto Y, Grace AA (2005) Dopaminergic modulation of limbic and cortical drive of nucleus accumbens in goal-directed behavior. Nat Neurosci 8:805–812
Gray JA, Kumari V, Lawrence N, Young AMJ (1999) Functions of the dopaminergic innervation of the nucleus accumbens. Psychobiology 27:225–235
Grill HJ, Norgren R (1978a) The taste reactivity test. I. Mimetic responses to gustatory stimuli in neurologically normal rats. Brain Res 143:263–279
Grill HJ, Norgren R (1978b) The taste reactivity test. II. Mimetic responses to gustatory stimuli in chronic thalamic and chronic decerebrate rats. Brain Res 143:281–297
Harris GC, Wimmer M, Aston-Jones G (2005) A role for lateral hypothalamic orexin neurons in reward seeking. Nature 437:556–559
Hellemans KG, Dickinson A, Everitt BJ (2006) Motivational control of heroin seeking by conditioned stimuli associated with withdrawal and heroin taking by rats. Behav Neurosci 120:103–114
Hernandez PJ, Andrzejewski ME, Sadeghian K, Panksepp JB, Kelley AE (2005) AMPA/kainate, NMDA, and dopamine D1 receptor function in the nucleus accumbens core: a context-limited role in the encoding and consolidation of instrumental memory. Learn Mem 12:285–295
Hnasko TS, Sotak BN, Palmiter RD (2005) Morphine reward in dopamine-deficient mice. Nature 438:854–857
Horvitz JC (2002) Dopamine gating of glutamatergic sensorimotor and incentive motivational input signals to the striatum. Behav Brain Res 137:65–74
Hsu M, Bhatt M, Adolphs R, Tranel D, Camerer CF (2005) Neural systems responding to degrees of uncertainty in human decision-making. Science 310:1680–1683
Hutcheson DM, Everitt BJ, Robbins TW, Dickinson A (2001) The role of withdrawal in heroin addiction: enhances reward or promotes avoidance? Nat Neurosci 4:943–947
Hyman SE (2005) Addiction: a disease of learning and memory. Am J Psychiatry 162:1414–1422
Hyman SE, Malenka RC (2001) Addiction and the brain: the neurobiology of compulsion and its persistence. Nat Rev Neurosci 2:695–703
Ikemoto S, Panksepp J (1999) The role of nucleus accumbens dopamine in motivated behavior: a unifying interpretation with special reference to reward- seeking. Brain Res Rev 31:6–41
Insel TR (2003) Is social attachment an addictive disorder? Physiol Behav 79:351–357
Ito R, Dalley JW, Robbins TW, Everitt BJ (2002) Dopamine release in the dorsal striatum during cocaine-seeking behavior under the control of a drug-associated cue. J Neurosci 22:6247–6253
Jarrett MM, Limebeer CL, Parker LA (2005) Effect of delta9-tetrahydrocannabinol on sucrose palatability as measured by the taste reactivity test. Physiol Behav 86:475–479
Jenkins HM, Moore BR (1973) The form of the auto-shaped response with food or water reinforcers. J Exp Anal Behav 20:163–181
Jones S, Bonci A (2005) Synaptic plasticity and drug addiction. Curr Opin Pharmacol 5:20–25
Kaczmarek HJ, Kiefer SW (2000) Microinjections of dopaminergic agents in the nucleus accumbens affect ethanol consumption but not palatability. Pharmacol Biochem Behav 66:307–312
Kalivas PW, Nakamura M (1999) Neural systems for behavioral activation and reward. Curr Opin Neurobiol 9:223–227
Kalivas PW, Volkow ND (2005) The neural basis of addiction: a pathology of motivation and choice. Am J Psychiatry 162:1403–1413
Kapur S (2003) Psychosis as a state of aberrant salience: a framework linking biology, phenomenology, and pharmacology in schizophrenia. Am J Psychiatry 160:13–23
Kelley AE (2004a) Memory and addiction: shared neural circuitry and molecular mechanisms. Neuron 44:161–179
Kelley AE (2004b) Ventral striatal control of appetitive motivation: role in ingestive behavior and reward-related learning. Neurosci Biobehav Rev 27:765–776
Kelley AE, Baldo BA, Pratt WE (2005a) A proposed hypothalamic–thalamic–striatal axis for the integration of energy balance, arousal, and food reward. J Comp Neurol 493:72–85
Kelley AE, Baldo BA, Pratt WE, Will MJ (2005b) Corticostriatal–hypothalamic circuitry and food motivation: integration of energy, action and reward. Physiol Behav 86:773–795
Killcross AS, Dickinson A, Robbins TW (1994) Effects of the neuroleptic alpha-flupenthixol on latent inhibition in aversively- and appetitively-motivated paradigms: evidence for dopamine–reinforcer interactions. Psychopharmacology (Berl) 115:196–205
Knutson B, Fong GW, Adams CM, Varner JL, Hommer D (2001) Dissociation of reward anticipation and outcome with event-related fMRI. Neuroreport 12:3683–3687
Koob GF, Le Moal M (2006) Neurobiology of addiction. Academic, London
Kringelbach ML (2005) The human orbitofrontal cortex: linking reward to hedonic experience. Nat Rev Neurosci 6:691–702
Laviolette SR, Nader K, van der Kooy D (2002) Motivational state determines the functional role of the mesolimbic dopamine system in the mediation of opiate reward processes. Behav Brain Res 129:17–29
LeDoux JE, Phelps EA (2000) Emotional networks in the brain. In: Lewis M, Haviland-Jones JM (eds) Handbook of emotions. Guilford, New York, pp 157–172
Levita L, Dalley JW, Robbins TW (2002) Nucleus accumbens dopamine and learned fear revisited: a review and some new findings. Behav Brain Res 137:115–127
Leyton M, Boileau I, Benkelfat C, Diksic M, Baker G, Dagher A (2002) Amphetamine-induced increases in extracellular dopamine, drug wanting, and novelty seeking: a PET/[11C]raclopride study in healthy men. Neuropsychopharmacology 27:1027–1035
Leyton M, Casey KF, Delaney JS, Kolivakis T, Benkelfat C (2005) Cocaine craving, euphoria, and self-administration: a preliminary study of the effect of catecholamine precursor depletion. Behav Neurosci 119:1619–1627
Ljungberg T, Apicella P, Schultz W (1992) Responses of monkey dopamine neurons during learning of behavioral reactions. J Neurophysiol 67:145–163
Loewenstein G, Schkade D (1999) Wouldn’t it be nice? Predicting future feelings. In: Kahneman D, Diener E, Schwarz N (eds) Well-being: the foundations of hedonic psychology. Russell Sage Foundation, New York, NY, pp 85–105
Mahler SV, Smith KS, Berridge KC (2004) What is the ‘motivational’ mechanism for the marijuana munchies? The effects of intra-accumbens anandamide on hedonic taste reactions to sucrose. Society for Neuroscience Conference, San Diego
Marinelli M, Rudick CN, Hu XT, White FJ (2006) Excitability of dopamine neurons: modulation and physiological consequences. CNS Neurol Disord Drug Targets 5:79–97
McClure SM, Daw ND, Read Montague P (2003) A computational substrate for incentive salience. Trends Neurosci 26:423–428
McClure SM, Laibson DI, Loewenstein G, Cohen JD (2004) Separate neural systems value immediate and delayed monetary rewards. Science 306:503–507
McFarland K, Davidge SB, Lapish CC, Kalivas PW (2004) Limbic and motor circuitry underlying footshock-induced reinstatement of cocaine-seeking behavior. J Neurosci 24:1551–1560
McGaugh JL (2002) Memory consolidation and the amygdala: a systems perspective. Trends Neurosci 25:456
Miles FJ, Everitt BJ, Dickinson A (2003) Oral cocaine seeking by rats: action or habit? Behav Neurosci 117:927–938
Miles FJ, Everitt BJ, Dalley JW, Dickinson A (2004) Conditioned activity and instrumental reinforcement following long-term oral consumption of cocaine by rats. Behav Neurosci 118:1331–1339
Mirenowicz J, Schultz W (1996) Preferential activation of midbrain dopamine neurons by appetitive rather than aversive stimuli. Nature 379:449–451
Montague PR, Hyman SE, Cohen JD (2004) Computational roles for dopamine in behavioural control. Nature 431:760–767
Nader K, Bechara A, van der Kooy D (1997) Neurobiological constraints on behavioral models of motivation. Annu Rev Psychol 48:85–114
Napier TC, Chrobak JJ (1992) Evaluations of ventral pallidal dopamine receptor activation in behaving rats. Neuroreport 3:609–611
Narita M, Nagumo Y, Hashimoto S, Narita M, Khotib J, Miyatake M, Sakurai T, Yanagisawa M, Nakamachi T, Shioda S, Suzuki T (2006) Direct involvement of orexinergic systems in the activation of the mesolimbic dopamine pathway and related behaviors induced by morphine. J Neurosci 26:398–405
Nelson A, Killcross S (2006) Amphetamine exposure enhances habit formation. J Neurosci 26:3805–3812
Nesse RM (1990) Evolutionary explanations of emotions. Human Nat 1:261–289
Nicola SM, Taha SA, Kim SW, Fields HL (2005) Nucleus accumbens dopamine release is necessary and sufficient to promote the behavioral response to reward-predictive cues. Neuroscience 135:1025–1033
Nocjar C, Panksepp J (2002) Chronic intermittent amphetamine pretreatment enhances future appetitive behavior for drug- and natural-reward: interaction with environmental variables. Behav Brain Res 128:189–203
O’Brien CP, Gardner EL (2005) Critical assessment of how to study addiction and its treatment: human and non-human animal models. Pharmacol Ther 108:18–58
O’Donnell P (2003) Dopamine gating of forebrain neural ensembles. Eur J Neurosci 17:429–435
Onn SP, West AR, Grace AA (2000) Dopamine-mediated regulation of striatal neuronal and network interactions. Trends Neurosci 23:S48–S56
Packard MG, White NM (1991) Dissociation of hippocampus and caudate nucleus memory systems by posttraining intracerebral injection of dopamine agonists. Behav Neurosci 105:295–306
Panksepp J (1986) The neurochemistry of behavior. Annu Rev Psychol 37:77–107
Panksepp J (2005) Affective consciousness: core emotional feelings in animals and humans. Conscious Cogn 14:30–80
Parker L, Leeb K (1994) Amphetamine-induced modification of quinine palatability: analysis by the taste reactivity test. Pharmacol Biochem Behav 47:413–420
Parker LA (1995) Chlordiazepoxide enhances the palatability of lithium-, amphetamine-, and saline-paired saccharin solution. Pharmacol Biochem Behav 50:345–349
Parker LA, Maier S, Rennie M, Crebolder J (1992) Morphine- and naltrexone-induced modification of palatability: analysis by the taste reactivity test. Behav Neurosci 106:999–1010
Pavlov IP (1927) Conditioned reflexes; an investigation of the physiological activity of the cerebral cortex. Oxford University Press, Humphrey Milford
Peciña S, Berridge KC (1995) Central enhancement of taste pleasure by intraventricular morphine. Neurobiology 3:269–280
Peciña S, Berridge KC (2000) Opioid eating site in accumbens shell mediates food intake and hedonic ‘liking’: map based on microinjection Fos plumes. Brain Res 863:71–86
Peciña S, Berridge KC (2005) Hedonic hot spot in nucleus accumbens shell: Where do mu-opioids cause increased hedonic impact of sweetness? J Neurosci 25:11777–11786
Peciña S, Berridge KC, Parker LA (1997) Pimozide does not shift palatability: separation of anhedonia from sensorimotor suppression by taste reactivity. Pharmacol Biochem Behav 58:801–811
Peciña S, Cagniard B, Berridge KC, Aldridge JW, Zhuang X (2003) Hyperdopaminergic mutant mice have higher “wanting” but not “liking” for sweet rewards. J Neurosci 23:9395–9402
Peciña S, Schulkin J, Berridge KC (2006) Nucleus accumbens corticotropin-releasing factor increases cue-triggered motivation for sucrose reward: paradoxical positive incentive effects in stress? BMC Biol 4:8
Peciña S, Smith KS, Berridge KC (2006) Hedonic hotspots in the brain. Neuroscientist 12(6):1–12
Petrovich GD, Holland PC, Gallagher M (2005) Amygdalar and prefrontal pathways to the lateral hypothalamus are activated by a learned cue that stimulates eating. J Neurosci 25:8295–8302
Phillips GD, Robbins TW, Everitt BJ (1994) Mesoaccumbens dopamine–opiate interactions in the control over behaviour by a conditioned reinforcer. Psychopharmacology (Berl) 114:345–359
Phillips GD, Setzu E, Hitchcott PK (2003a) Facilitation of appetitive pavlovian conditioning by D-amphetamine in the shell, but not the core, of the nucleus accumbens. Behav Neurosci 117:675–684
Phillips PE, Stuber GD, Heien ML, Wightman RM, Carelli RM (2003b) Subsecond dopamine release promotes cocaine seeking. Nature 422:614–618
Piazza PV, Deminiere JM, Le Moal M, Simon H (1989) Factors that predict individual vulnerability to amphetamine self-administration. Science 245:1511–1513
Redgrave P, Prescott TJ, Gurney K (1999) Is the short-latency dopamine response too short to signal reward error? Trends Neurosci 22:146–151
Redish AD (2004) Addiction as a computational process gone awry. Science 306:1944–1947
Reichmann H, Brecht MH, Koster J, Kraus PH, Lemke MR (2003) Pramipexole in routine clinical practice: a prospective observational trial in Parkinson’s disease. CNS Drugs 17:965–973
Rescorla RA, Wagner AR (1972) A theory of Pavlovian conditioning: variations in the effectiveness of reinforcement and nonreinforcement. In: Black AH, Prokasy WF (eds) Classical conditioning II: current research and theory. Appleton-Century-Crofts, New York, pp 64–99
Reynolds SM, Berridge KC (2002) Positive and negative motivation in nucleus accumbens shell: bivalent rostrocaudal gradients for GABA-elicited eating, taste “liking”/“disliking” reactions, place preference/avoidance, and fear. J Neurosci 22:7308–7320
Robbins TW, Everitt BJ (1982) Functional studies of the central catecholamines. Int Rev Neurobiol 23:303–365
Robbins TW, Everitt BJ (1996) Neurobehavioural mechanisms of reward and motivation. Curr Opin Neurobiol 6:228–236
Robbins TW, Everitt BJ (1999) Drug addiction: bad habits add up. Nature 398:567–570
Robbins TW, Everitt BJ (2006) A role for mesencephalic dopamine in activation: commentary on Berridge (2006). Psychopharmacology (Berl), this issue
Robertson EM, Cohen DA (2006) Understanding consolidation through the architecture of memories. Neuroscientist 12:261–271
Robinson TE, Berridge KC (1993) The neural basis of drug craving: an incentive-sensitization theory of addiction. Brain Res Rev 18:247–291
Robinson TE, Berridge KC (2000) The psychology and neurobiology of addiction: an incentive-sensitization view. Addiction 95:91–117
Robinson TE, Berridge KC (2003) Addiction. Annu Rev Psychol 54:25–53
Robinson S, Sandstrom SM, Denenberg VH, Palmiter RD (2005) Distinguishing whether dopamine regulates liking, wanting, and/or learning about rewards. Behav Neurosci 119:5–15
Roitman MF, Stuber GD, Phillips PEM, Wightman RM, Carelli RM (2004) Dopamine operates as a subsecond modulator of food seeking. J Neurosci 24:1265–1271
Roitman MF, Wheeler RA, Carelli RM (2005) Nucleus accumbens neurons are innately tuned for rewarding and aversive taste stimuli, encode their predictors, and are linked to motor output. Neuron 45:587–597
Rolls ET (2005) Emotion explained. Oxford University Press, London
Rosse RB, Fay-McCarthy M, Collins JP Jr, Risher-Flowers D, Alim TN, Deutsch SI (1993) Transient compulsive foraging behavior associated with crack cocaine use. Am J Psychiatr 150:155–156
Sahakian BJ, Robbins TW, Morgan MJ, Iversen SD (1975) The effects of psychomotor stimulants on stereotypy and locomotor activity in socially-deprived and control rats. Brain Res 84:195–205
Salamone JD (1991) Behavioral pharmacology of dopamine systems: a new synthesis. In: Willner P, Scheel-Kruger J (eds) The mesolimbic dopamine system: from motivation to action. Wiley, New York, pp 599–611
Salamone JD (1994) The involvement of nucleus accumbens dopamine in appetitive and aversive motivation. Behav Brain Res 61:117–133
Salamone JD, Correa M (2002) Motivational views of reinforcement: implications for understanding the behavioral functions of nucleus accumbens dopamine. Behav Brain Res 137:3–25
Salamone JD, Cousins MS, Bucher S (1994) Anhedonia or anergia? Effects of haloperidol and nucleus accumbens dopamine depletion on instrumental response selection in a T-maze cost/benefit procedure. Behav Brain Res 65:221–229
Salamone JD, Cousins MS, Snyder BJ (1997) Behavioral functions of nucleus accumbens dopamine: empirical and conceptual problems with the anhedonia hypothesis. Neurosci Biobehav Rev 21:341–359
Salamone JD, Correa M, Mingote SM, Weber SM (2005) Beyond the reward hypothesis: alternative functions of nucleus accumbens dopamine. Curr Opin Pharmacol 5:34–41
Sanders AE, Cagniard B, Manning SN, Zhuang X (2003) Dissecting aspects of motivation that are differentially modulated by dopamine and serotonin. Abstract Viewer/Itinerary Planner. Society for Neuroscience, Washington, DC
Sarter M, Nelson CL, Bruno JP (2005) Cortical cholinergic transmission and cortical information processing in schizophrenia. Schizophr Bull 31:117–138
Schallert T, Whishaw IQ (1978) Two types of aphagia and two types of sensorimotor impairment after lateral hypothalamic lesions: observations in normal weight, dieted, and fattened rats. J Comp Physiol Psychol 92:720–741
Schmajuk NA, Cox L, Gray JA (2001) Nucleus accumbens, entorhinal cortex and latent inhibition: a neural network model. Behav Brain Res 118:123–141
Schoenbaum G, Setlow B (2005) Cocaine makes actions insensitive to outcomes but not extinction: implications for altered orbitofrontal–amygdalar function. Cereb Cortex 15:1162–1169
Schultz W (1997) Dopamine neurons and their role in reward mechanisms. Curr Opin Neurobiol 7:191–197
Schultz W (1998) Predictive reward signal of dopamine neurons. J Neurophysiol 80:1–27
Schultz W (2002) Getting formal with dopamine and reward. Neuron 36:241–263
Schultz W (2004) Neural coding of basic reward terms of animal learning theory, game theory, microeconomics and behavioural ecology. Curr Opin Neurobiol 14:139–147
Schultz W (2006) Behavioral theories and the neurophysiology of reward. Annu Rev Psychol 57:87–115
Schultz W, Dayan P, Montague PR (1997) A neural substrate of prediction and reward. Science 275:1593–1599
Shaham Y, Shalev U, Lu L, de Wit H, Stewart J (2003) The reinstatement model of drug relapse: history, methodology and major findings. Psychopharmacology (Berl) 168:3–20
Sherrington CS (1906) The integrative action of the nervous system. C. Scribner’s, New York
Shippenberg TS, Heidbreder C (1995) Sensitization to the conditioned rewarding effects of cocaine: pharmacological and temporal characteristics. J Pharmacol Exp Ther 273:808–815
Shizgal P (1999) On the neural computation of utility: implications from studies of brain stimulation reward. In: Kahneman D, Diener E, Schwarz N (eds) Well-being: the foundations of hedonic psychology. Russell Sage Foundation, New York, pp 500–524
Shizgal P, Fulton S, Woodside B (2001) Brain reward circuitry and the regulation of energy balance. Int J Obes 25:S17–S21
Sienkiewicz-Jarosz H, Scinska A, Kuran W, Ryglewicz D, Rogowski A, Wrobel E, Korkosz A, Kukwa A, Kostowski W, Bienkowski P (2005) Taste responses in patients with Parkinson’s disease. J Neurol Neurosurg Psychiatry 76:40–46
Small DM, Jones-Gotman M, Dagher A (2003) Feeding-induced dopamine release in dorsal striatum correlates with meal pleasantness ratings in healthy human volunteers. Neuroimage 19:1709–1715
Smith KS, Berridge KC (2005) The ventral pallidum and hedonic reward: neurochemical maps of sucrose “liking” and food intake. J Neurosci 25:8637–8649
Smith-Roe SL, Kelley AE (2000) Coincident activation of NMDA and dopamine D-1 receptors within the nucleus accumbens core is required for appetitive instrumental learning. J Neurosci 20:7737–7742
Söderpalm AHV, Berridge KC (2000) The hedonic impact and intake of food are increased by midazolam microinjection in the parabrachial nucleus. Brain Res 877:288–297
Steiner JE (1973) The gustofacial response: observation on normal and anencephalic newborn infants. Symp Oral Sens Percept 4:254–278
Steiner JE, Glaser D, Hawilo ME, Berridge KC (2001) Comparative expression of hedonic impact: affective reactions to taste by human infants and other primates. Neurosci Biobehav Rev 25:53–74
Stellar JR, Brooks FH, Mills LE (1979) Approach and withdrawal analysis of the effects of hypothalamic stimulation and lesions in rats. J Comp Physiol Psychol 93:446–466
Stricker EM, Zigmond MJ (1976) Brain catecholamines and the lateral hypothalamic syndrome. In: Novin D, Wyrwicka W, Bray G (eds) Hunger: basic mechanisms and clinical implications. Raven, New York, pp 19–32
Stricker EM, Zigmond MJ (1986) Brain monoamines, homeostasis, and adaptive behavior handbook of physiology: intrinsic regulatory systems of the brain. American Physiological Society, Bethesda, MD, pp 677–696
Taylor JR, Robbins TW (1984) Enhanced behavioural control by conditioned reinforcers following microinjections of d-amphetamine into the nucleus accumbens. Psychopharmacology (Berl) 84:405–412
Taylor JR, Robbins TW (1986) 6-Hydroxydopamine lesions of the nucleus accumbens, but not of the caudate nucleus, attenuate enhanced responding with reward-related stimuli produced by intra-accumbens d-amphetamine. Psychopharmacology (Berl) 90:390–397
Thorndike EL (1898) Animal intelligence: an experimental study of the associative processes in animals. Macmillan, New York
Thorndike EL (1911) Animal intelligence: experimental studies. Macmillan, New York
Thut G, Schultz W, Roelcke U, Nienhusmeier M, Missimer J, Maguire RP, Leenders KL (1997) Activation of the human brain by monetary reward. Neuroreport 8:1225–1228
Tindell AJ, Berridge KC, Aldridge JW (2004) Ventral pallidal representation of pavlovian cues and reward: population and rate codes. J Neurosci 24:1058–1069
Tindell AJ, Berridge KC, Zhang J, Peciña S, Aldridge JW (2005) Ventral pallidal neurons code incentive motivation: amplification by mesolimbic sensitization and amphetamine. Eur J Neurosci 22:2617–2634
Tindell AJ, Smith KS, Pecina S, Berridge KC, Aldridge JW (2006) Ventral pallidum firing codes hedonic reward: when a bad taste turns good. J Neurophysiol 96:2399–2409
Toates F (1986) Motivational systems. Cambridge University Press
Tobler PN, Dickinson A, Schultz W (2003) Coding of predicted reward omission by dopamine neurons in a conditioned inhibition paradigm. J Neurosci 23:10402–10410
Tobler PN, Fiorillo CD, Schultz W (2005a) Adaptive coding of reward value by dopamine neurons. Science 307:1642–1645
Tobler PN, O’Doherty JP, Dolan RJ, Schultz W (2005b) Human neural learning depends on reward prediction errors in the blocking paradigm. J Neurophysiol (1):301–310
Tomie A (1996) Locating reward cue at response manipulandum (CAM) induces symptoms of drug abuse. Neurosci Biobehav Rev 20:31
Ungless MA, Magill PJ, Bolam JP (2004) Uniform inhibition of dopamine neurons in the ventral tegmental area by aversive stimuli. Science 303:2040–2042
Uslaner JM, Acerbo MJ, Jones SA, Robinson TE (2006) The attribution of incentive salience to a stimulus that signals an intravenous injection of cocaine. Behav Brain Res 169(2):320–324
Vanderschuren LJ, Everitt BJ (2005) Behavioral and neural mechanisms of compulsive drug seeking. Eur J Pharmacol 526:77–88
Vanderschuren LJMJ, Everitt BJ (2004) Drug seeking becomes compulsive after prolonged cocaine self-administration. Science 305:1017–1019
Vanderschuren LJMJ, Kalivas PW (2000) Alterations in dopaminergic and glutamatergic transmission in the induction and expression of behavioral sensitization: a critical review of preclinical studies. Psychopharmacology (Berl) 151:99–120
Vanderschuren LJMJ, Di Ciano P, Everitt BJ (2005) Involvement of the dorsal striatum in cue-controlled cocaine seeking. J Neurosci 25:8665–8670
Vezina P (2004) Sensitization of midbrain dopamine neuron reactivity and the self-administration of psychomotor stimulant drugs. Neurosci Biobehav Rev 27:827–839
Vezina P, Lorrain DS, Arnold GM, Austin JD, Suto N (2002) Sensitization of midbrain dopamine neuron reactivity promotes the pursuit of amphetamine. J Neurosci 22:4654–4662
Volkow ND, Wise RA (2005) How can drug addiction help us understand obesity? Nat Neurosci 8:555–560
Volkow ND, Wang GJ, Fowler JS, Logan J, Gatley SJ, Wong C, Hitzemann R, Pappas NR (1999) Reinforcing effects of psychostimulants in humans are associated with increases in brain dopamine and occupancy of D-2 receptors. J Pharmacol Exp Ther 291:409–415
Volkow ND, Fowler JS, Wang GJ, Ding YS, Gatley SJ (2002a) Role of dopamine in the therapeutic and reinforcing effects of methylphenidate in humans: results from imaging studies. Eur Neuropsychopharmacol 12:557–566
Volkow ND, Wang GJ, Fowler JS, Logan J, Jayne M, Franceschi D, Wong C, Gatley SJ, Gifford AN, Ding YS, Pappas N (2002b) “Nonhedonic” food motivation in humans involves dopamine in the dorsal striatum and methylphenidate amplifies this effect. Synapse 44:175–180
Volkow ND, Wang G-J, Telang F, Fowler JS, Logan J, Childress A-R, Jayne M, Ma Y, Wong C (2006) Cocaine cues and dopamine in dorsal striatum: mechanism of craving in cocaine addiction. J Neurosci 26:6583–6588
Waelti P, Mirenowicz J, Dickinson A, Schultz W (1998) Activity of primate dopamine neurons in a discrimination and blocking paradigm. Eur J Neurosci 10:302
Waelti P, Dickinson A, Schultz W (2001) Dopamine responses comply with basic assumptions of formal learning theory. Nature 412:43–48
Wakabayashi KT, Fields HL, Nicola SM (2004) Dissociation of the role of nucleus accumbens dopamine in responding to reward-predictive cues and waiting for reward. Behav Brain Res 154:19–30
Wang GJ, Volkow ND, Logan J, Pappas NR, Wong CT, Zhu W, Netusil N, Fowler JS (2001) Brain dopamine and obesity. Lancet 357:354–357
Wang GJ, Volkow ND, Chang L, Miller E, Sedler M, Hitzemann R, Zhu W, Logan J, Ma Y, Fowler JS (2004) Partial recovery of brain metabolism in methamphetamine abusers after protracted abstinence. Am J Psychiatry 161:242–248
Washton AM, Stone-Washton N (1993) Outpatient treatment of cocaine and crack addiction: a clinical perspective. NIDA Res Monogr 135:15–30
Watson JB (1913) Psychology as the behaviourist views it. Psychol Rev 20:158–177
Weingarten HP, Martin GM (1989) Mechanisms of conditioned meal initiation. Physiol Behav 45:735–740
Wickelgren I (1997) Neuroscience: getting the brain’s attention. Science 278:35–37
Wickens J, Reynolds J, Hyland B (2003) Neural mechanisms of reward-related motor learning. Curr Opin Neurobiol 13:685–690
Wilson C, Nomikos GG, Collu M, Fibiger HC (1995) Dopaminergic correlates of motivated behavior: importance of drive. J Neurosci 15:5169–5178
Winkielman P, Berridge KC, Wilbarger JL (2005) Unconscious affective reactions to masked happy versus angry faces influence consumption behavior and judgments of value. Pers Soc Psychol Bull 31:121–135
Wise RA (1980) The dopamine synapse and the notion of ‘pleasure centers’ in the brain. Trends Neurosci 3:91–95
Wise RA (1982) Neuroleptics and operant behavior: the anhedonia hypothesis. Behav Brain Sci 5:39–87
Wise RA (1985) The anhedonia hypothesis: Mark III. Behav Brain Sci 8:178–186
Wise RA (2004a) Dopamine, learning and motivation. Nat Rev Neurosci 5:483–494
Wise RA (2004b) Drive, incentive, and reinforcement: the antecedents and consequences of motivation. Nebr Symp Motiv 50:159–195
Wise RA (2006) Role of brain dopamine in food reward and reinforcement. Philos Trans R Soc Lond B Biol Sci 361:1149–1158
Wolterink G, Phillips G, Cador M, Donselaar-Wolterink I, Robbins TW, Everitt BJ (1993) Relative roles of ventral striatal D1 and D2 dopamine receptors in responding with conditioned reinforcement. Psychopharmacology (Berl) 110:355–364
Wyvell CL, Berridge KC (2000) Intra-accumbens amphetamine increases the conditioned incentive salience of sucrose reward: enhancement of reward “wanting” without enhanced “liking” or response reinforcement. J Neurosci 20:8122–8130
Wyvell CL, Berridge KC (2001) Incentive-sensitization by previous amphetamine exposure: increased cue-triggered ‘wanting’ for sucrose reward. J Neurosci 21:7831–7840
Yin HH, Zhuang X, Balleine BW (2006) Instrumental learning in hyperdopaminergic mice. Neurobiol Learn Mem (3):238–283
Zahm DS (2000) An integrative neuroanatomical perspective on some subcortical substrates of adaptive responding with emphasis on the nucleus accumbens. Neurosci Biobehav Rev 24:85–105
Zahm DS (2006) The evolving theory of basal forebrain functional–anatomical ‘macrosystems’. Neurosci Biobehav Rev 30(2):148–172
Zhang J, Tindell A, Berridge K, Aldridge J (2005) Profile analysis of integrative coding in ventral pallidal neurons. Society for Neuroscience, Washington, DC
Zheng HY, Corkern M, Stoyanova I, Patterson LM, Tian R, Berthoud HR (2003) Peptides that regulate food intake—appetite-inducing accumbens manipulation activates hypothalamic orexin neurons and inhibits POMC neurons. Am J Physiol Regul Integr Comp Physiol 284:R1436–R1444
Zhou QY, Palmiter RD (1995) Dopamine-deficient mice are severely hypoactive, adipsic, and aphagic. Cell 83:1197–1209
Zhuang X, Oosting RS, Jones SR, Gainetdinov PR, Miller GW, Caron MG, Hen R (2001) Hyperactivity and impaired response habituation in hyperdopaminergic mice. Proc Natl Acad Sci USA 98:1982–1987
Acknowledgements
I am grateful to many colleagues who have participated in developing these ideas especially my long-term Michigan collaborators Terry Robinson, who co-developed the incentive salience hypothesis at every step and developed the incentive-sensitization theory, and J. Wayne Aldridge, who has led investigations into its neural coding. I am grateful also to Jill Becker, who arranged the Gordon Conference 2005 debate, and to the editors of this special issue, who arranged for it to be put to paper. Talented colleagues conducted the experiments in our labs that produced the data mentioned here, especially Susana Peciña, Cindy Wyvell, Amy Tindell, Jun Zhang, Casey Cromwell, Sheila Reynolds, Kyle Smith, Stephen Mahler, and Alexis Faure. Xiaoxi Zhuang and Barbara Cagniard also collaborated at a distance on the hyperdopaminergic mice project. Our experiments were supported by NIH (DA015188, DA017752, and MH63649).
This essay was written while on leave at the University of Cambridge, supported as a J.S. Guggenheim Fellow. I am deeply indebted to the kind generosity of Barry Everitt, Anthony Dickinson, Trevor Robbins, Wolfram Schultz, Jeff Dalley, Nicky Clayton, Paul Fletcher, Barbara Sahakian, Angela Roberts, Andrew Calder, Andrew Lawrence, Graham Murray, Todd Braver, Deanna Barch, Anthony Marcel, Susan Jones, Phil Corlett, and many other Cambridge colleagues and students in the Department of Experimental Psychology, Downing College, the Behavioral and Clinical Neuroscience Institute, and the MRC Cognition and Brain Sciences Unit for stimulating discussions and hospitality during the academic year in Cambridge.
Finally, I especially thank Barry Everitt, Terry Robinson, Wolfram Schultz, Trevor Robbins, J. Wayne Aldridge, Jill Becker, Martin Sarter, Anthony Dickinson, Joshua Berke, Jeff Dalley, Jaak Panksepp, John Salamone, Susana Pecina, Kyle Smith, Steve Mahler and anonymous reviewers for enormously helpful comments on an earlier draft of this essay.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Movie 1
Hedonic taste reactions. Examples of positive facial ‘liking’ reactions elicited by sweet taste of sucrose solution from newborn human infants (via oral dropper) and adult rats (via oral cannula). Negative ‘disliking’ reactions elicited by bitter taste of quinine solution. Human infant reactions from Steiner et al. (2001); Rat reactions from Berridge (2000) (MPG 12 mb)
Rights and permissions
About this article
Cite this article
Berridge, K.C. The debate over dopamine’s role in reward: the case for incentive salience. Psychopharmacology 191, 391–431 (2007). https://doi.org/10.1007/s00213-006-0578-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00213-006-0578-x