
Abstract
The paper is based on the acknowledgement that properties of markets stemming from features of demand are too frequently overlooked in the economic literature, particularly among evolutionary scholars. The overall goal is to show that “demand matters” to understand properly observed properties of markets not only because of its exogenous (i.e. non-economic) features, but also because of aspects of consumers’ behavior that fully deserve to be considered in the domain of economics. The paper presents a general model of the consumer based on a bounded rational decision algorithm. The model is shown to be compatible with available evidence on consumers’ behavior and adaptable for theoretical as well as empirical applications. The description of the proposed model’s components provides the opportunity to discuss a number of issues the importance of which for the analysis of markets of markets becomes evident taking a demand-oriented perspective. Among these, we propose a formal definition of preferences meant as decision criteria used by consumers and distinct from the actual decisions made by consumers at each purchasing occasion. We also highlight the potential role of firms’ marketing in shaping consumers’ preferences, suggesting an endogenous channel of influence on consumers’ preferences which is possibly highly relevant in certain markets. We use the model to show that the proposed model can easily replicate a generic market demand function, with the advantage of more robust foundations and greater flexibility in respect of standard consumer theory. We also show that limiting to consider distributional properties of markets, neglecting the type of demand, may lead to serious errors of interpretation.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The major methodological change brought about by evolutionary economics in respect of the mainstream approach (Nelson and Winter 1982) is the shift from assuming exogenously the properties of agents’ behavior, (e.g. optimizing) to describing what agents actually do (e.g. apply routines), so that agents’ properties become an endogenous result. The obvious reason for this change is the increasingly evident inadequacy of standard assumptions of perfect rationality and equilibrium to account for many, relevant phenomena. In particular, these assumptions prevent the very representation and study of innovation and technical change, where un-resolvable uncertainty and heterogeneity are the necessary ingredients of a minimally realistic representation of observed events. It is therefore not surprising that evolutionary economics’ main successes stem from the dynamic analysis of markets for innovative products, concerning phenomena that are simply negated by the standard assumptions.
Although market configurations obviously depend on the interplay between supply and demand, most evolutionary scholars focus their attention on the supply side of markets, relying on an extremely sketchy representation of markets’ internal functioning, and specifically of demand. This is curious, since the most diffused defense of the perfect rationality hypothesis is the ’as if’ hypothesis made popular by Milton Friedman. Ironically, this justification for the rationality assumption is an extremist version of the evolutionary concept of selection: no matter what people actually do, only the best will survive the competitive test, and therefore economists can focus on the only (supposedly optima) surviving behavior, making irrelevant the point as to whether optimality depends on design or luck.
However convincing, this argument can be sustained only when agents are subject to a competitive pressure operating the selective process required to remove sub-optimality. Conversely, there is no justification, not even in principle, supporting the claim of perfect rationality for consumers, since sub-optimal consumers can hardly be supposed to be driven out of a market. In short, perfect rationality applied to consumers is an even weaker assumption than is the case for competitive producers.
Notwithstanding the importance of consumer behavior in shaping markets’ properties and their development patterns, most of the evolutionary economics literature maintained a rather primitive representation of consumers, in many cases even implicitly adopting the perspective of perfect rationality and representativity of agents. Some contributions have already highlighted the relevance of a demand for an evolutionary agenda (Nelson 1994; Metcalfe 2001). Among the works on demand can be included authors who highlight the relevance of demand-side issues for the emergence of new wants (Witt 2001) and for sustainability of variety as the engine of growth (Saviotti 2001). Concerning the analysis at the industrial level, a few works have explicitly considered the role of consumers. A recent work focuses on the importance of variety of preferences and of “experimental” users for the success of innovations (Malerba et al. 2007). Consumers’ properties and demand distributions are also attracting the attention of those concerned with evolutionary analysis (Windrum et al. 2009). Other contributions discuss indirectly demand issues by studying the formation of market segments (Windrum and Birchenhall 1998; Klepper and Thompson 2006). However, little attention has been paid to advancing a generalized model for the actual behavior of consumers (see, for an interesting exception, Aversi et al. 1999). Consequently, there is also a shortage of proposals for a generalized evolutionary model of demand, a task that is increasingly called for (Nelson and Consoli 2010), and to which the present work aims to contribute.
The goal of this paper is to propose a model for consumer compatible with the evolutionary perspective, and to highlight the relevance of economic factors (as opposed to exogenous aspects) affecting demand behavior in shaping observed states. We develop our proposal starting from the definition of a few basic requirements that a consumer model compatible with the evolutionary economic tenets should satisfy.
The first requirement concerns the possibility of the model to deal with heterogeneous products defined over a multidimensional characteristic space. Overcoming the simplifying assumption of homogeneous products is not (only) a problem of realism, but it is also a necessity to study product-embodied innovations, a highly relevant form of technological innovation, particularly for an evolutionary theory keen of its Schumpeterian roots.
The second requirement is the adherence to the assumption of bounded rationality. This requirement stems from the consideration that consumers are generally poorly informed about the technological details of available choices, and have little motivation in investing time and attention for a decision that is likely to be relatively infrequent and of relatively little importance for their overall life. Consequently, the model should be able to tune both the difficulty in assessing available alternatives and the efforts devoted by the consumer to the task, as mandated by the bounded rational paradigm.
The third requirement is that the model should be sufficiently flexible and simple to allow for the analysis of the generative mechanisms of results. A consumer may potentially behave in many, different ways, depending on his expertise, interest, frequency of purchase, etc. We not only wish the model to be able to provide purchasing decisions that reflect different consumption profiles, but also to allow an explanation as to how the ex-ante consumer conditions (e.g. behavioral parameters) lead to the resulting choices. A consumer may opt for a product for several reasons, and lacking the possibility to understand the motivation of a given choice prevents us from using the model for analytical purposes.
A fourth requirement concerns the possibility, at least potentially, to observe and to estimate the core features of the model. This requirement is obviously directed to a possible application of the model beyond purely theoretical uses. However, there is more than mere interest in empirical applications. The possibility to establish reliable connections between theoretical and empirical representations works also in the opposite direction, giving the possibility to generalize specific observations and, therefore, to enrich the theory using empirical evidence (Saviotti 2003).
The rest of the paper provides a description of the proposed model and some examples of its application to represent market demand. The core of the model has its roots in the experimental psychological literature concerning subjects making decisions under uncertainty. The original proposal seems particularly suited to represent consumers in that it has very loose requirements concerning the information available to the decision maker. In particular, the vector of characteristics defining the alternative choices needs not be made of cardinal quantities, but only requires the possibility to establish a weak ordering of available options in respect of a single dimension. The original model for decision making under uncertainty, devised to account for experimental evidence, is here adapted to deal with the general case of consumers’ discrete choice for multi-characteristic products. As a by-product of the consumer model, we also reach a formal definition for preferences, properly considered as general criteria for consumers’ decisions and distinct from any actual decision. The proposed definition of preferences would therefore allow us to transfer consumption profiles across different markets, making our model compatible with the standard classification of consumers’ classes usually adopted by professionals in, e.g., market research.
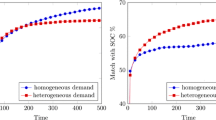
The examples presented have the double purpose of investigating the potential applications of the model and to support the claim that “demand matters”. In the first two examples, we show that the proposed model for consumers can be used to generate well-behaved aggregate market demand functions. Not only can the resulting demand be shown to easily provide standard results for homogeneous as well as heterogeneous (multi-characteristic) products, but it can also provide clear indications on what type of feature lead to a given sales distribution.
The second example tackles directly the issue of the relevance of demand in assessing a given market configuration, represented, for example, by sales distribution. We use two simulation experiments concerning the birth and expansion of an hypothetical market, suitably constructed in order to investigate demand contributions to the eventual configuration. The two experiments have in common all parameters and initial values, apart from two parameters concerning the purchasing behavior of consumers. The two experiments are shown to provide results appearing as almost identical, if evaluated in the usual terms of supply side features and distributional statistics, i.e. neglecting demand’s contribution. However, we can show not only that the two results are actually radically different, but also the (demand-based) motivations for both the different static (ranking of firms by dimension) and dynamic (expected outcome of any change) properties of the market. From this exercise we conclude that, ignoring demand, an observer would be erroneously led to either mistake the two cases as identical, or, in the best case, to assess the differences to un-explained exogenous aspects, missing the opportunity to analyze properly the events taking place in the market.
2 An evolutionary model of the consumer
The appeal of assuming perfectly rational agents in economics is largely motivated by the possibility that, assuming the result of agents’ behavior, we can neglect their actual activities, focusing only on the environmental conditions defining optimality. Besides the usual criticisms (Nelson and Winter 1982), the assumption of perfect rationality for consumers raises further reasons for skepticism. Firstly, while the optimization target for firms has a real-world counter-part, however questionable may be its use in this context,Footnote 1 consumers’ assumed optimization target (utility) is a pure economists’ invention the empirical estimation of which is, at best, highly unreliable. Actually, abundant evidence reports frequent violations of optimization behavior of whatever utility function is used (Kahneman et al. 1982). Nor can any “as if” argument be invoked, since inefficient consumers are not subject to selection. Second, in respect of producers, consumers are likely to be less committed to, and less expert of, the products and services they purchase. In fact, in most cases (and the most economically relevant) the role of a purchase in the buyer’s overall life and income is negligible, and therefore consumers can hardly be expected to devote huge amounts of time and attention on relatively unimportant activities. Of course, people do not like to waste money or buy lemons, as long as they can prevent it. Their capacity to do so will vary, resulting in a larger or smaller probability to identify the best products available. We need, in other terms, to develop a model describing consumers’ behavior, since the results of their action can hardly be predicted without knowledge of their decision procedure.
In the following, we present a model of boundedly rational agents representing the behavior of consumers that, besides being compatible with evidence on actual behavior, is also sufficiently general and simple to be adopted in theoretical applications. The goal is to define a highly general and flexible model to represent a wide range of consumers. We will describe the elements of the model in terms of their contribution to an explanation of consumer behavior. We will also provide one of the possible formal implementations for the elements with the dual purpose of clarifying the working of the model and of building the model in the following section. However, we will clearly distinguish the necessary properties of the model’s components from the implementation used to represent these properties. For example, we will implement products as defined over a set of real-valued variables, though the model only requires variables endowed with weak ordering. The format for the implementation is chosen for both clarity of exposition and for the development of the simulation exercises discussed in the following section.
In the rest of this section, we present the model by starting with the representation for the objects of trade in a market. The next paragraphs discuss how consumers can be represented to gather information, giving the modeller the opportunity to tune different levels of evaluation skills and product categories. We then present the decision making procedure proposed to represent consumer behavior, adapting a proposal for decision making under uncertainty originally proposed by experimental psychologists. Making explicit the decisional procedure naturally leads to a formal definition of preferences respecting the etymologically original meaning of the term as general decision criteria; this definition allows to correct the frequent use of the term as catch-all justification for whatever decisions are observed. Finally, we discuss how preferences may be influenced, besides many exogenous factors, also by activities internal to the markets, suggesting one route of possible endogenization of preferences into a broader market framework.
2.1 Product Space Representation
We consider consumers in a given market as having the task to fulfill a specific need by means of purchasing one among several alternative products or services,Footnote 2 as in discrete choice theory (Anderson et al. 1992).
We can generally assume that the set of products offered in a market can be represented as vectors over a set of dimensions, or characteristics (see, e.g., (Lancaster 1966; Saviotti and Metcalfe 1984; Gallouj and Weinstein 1997)).
In Table 1, the generic value \(v_{X}^{i}\) is the measure of product X in respect of characteristic i. This value must be interpreted as a measure of the quality for the “service” that the product provides in respect of a specific use.Footnote 3 In this representation, we require that there exist a weak ordering on the instances for each characteristic. That is, it is possible to assess one product X as inferior, superior or equivalent to another product Y in respect of a specific characteristic, or dimension.Footnote 4
Given our aim to devise a generalized model for consumers, we will adopt the assumption that the supply side of markets is exogenously fixed, in order to concentrate on the demand side contribution to relevant market features. Obviously, this assumption is a methodological expedient with no claim of realism, meant to investigate demand-only phenomena, and corresponds to the frequently adopted assumption of exogenous and constant demand in most of the literature on industrial economics. Before continuing, however, a few considerations on the supply side representation are worth mentioning.
First, at this stage, we skip the issue of how the set of products potentially relevant to consumers is selected because it involves not only aspects of the supply, but also features specific of consumers (e.g. income, skills, etc.). We will describe later how consumers are assumed to have minimal requirements over each characteristic that, in effect, determine the initial option set for each individual consumer. Sophisticated applications of the model may include a searching phase during which consumers collect information on available products; in any case, this is an issue that can be treated within consumers’ behavior and needs not to be discussed as a feature of the supply side of markets, at least when assuming, as we do, that the supply side is exogenously fixed.
A second consideration concerns the unit of measure of the characteristic values \(v_{X}^{i}\). As we will see below, the proposed consumer model does not require these measures to be defined as real numbers. The procedure used to implement consumers’ decisions only requires the possibility to identify one or more products as the best in respect of one dimension. The requirement for an ordinal measure of products’ characteristic is much weaker than that of a cardinal measure, consequently boosting the generality and applicability of the model. In the following, however, we will continue to indicate characteristic levels with real-valued variables for simplicity of notation and of implementation, even though the model decision algorithm only makes use of their ordinal character.
Third, even though we are concerned with consumer behaviors and, consequently, we will assume supply aspects as exogenously fixed, it is worth briefly discussing the nature the products’ qualities. There are two possible characteristic spaces to represent products: the space of technical characteristics, defining the content of a product, and the space of users’ characteristics, defining the services provided by the product to users (see, e.g., Gallouj and Weinstein 1997). The mapping from one space to the other resembles the genotype-phenotype mapping in living organisms, dealing with how technological or organizational (genotypic) complexity may affect (phenotypic) performance. In our case, dealing with consumers’ decisions, the relevant space is that of “phenotypic” descriptions, that is, how a given product fulfills users’ needs. Thus, for the purpose of this paper, we define “supply” as the set of alternative products that consumers consider as a potential purchase for a specific use, and their “quality” values must be measured in respect of that use. This set may not coincide with the definition of supply based on the technological content of products, a definition adopted by common industrial classification systems. For example, the market for “urban transportation” may include small cars, bikes, public transport, etc., but exclude sport and luxurious cars (category: status goods, competing with, e.g., diamonds and yachts), inter-city trains (category: middle-range transportation, competing with domestic air companies), etc.Footnote 5 In conclusion, the set of products in the list of potential purchases should be understood as including all products that are perceived as potential alternatives by consumers for a specific need, whether or not these products are actually classified within the same industry.
A fourth consideration concerns possible (and, indeed, likely) functional relations among characteristic values. We can reasonably expect that characteristic variables across products show strong functional relations such as, for example, higher prices associated with higher quality products or more extra features. The relation between characteristic values can be classified into two groups: technological and strategic relations. The first reflects the technological constraints imposing, for example, that a more robust product is generally heavier.Footnote 6 The strategic relations concern sellers’ decisions such as, for example, higher prices for more costly productions or for more recent versions of a product. We will not need to discuss the origins, constraints and possible consequences of the values for product characteristics, since the results we are concerned with depend on consumers’ behaviors only, and therefore would hold for any product characteristic values (see Valente 2000 for an integration of demand and supply actions).
A final property of the multi-characteristic representation of products is that innovation can be expressed not only in terms of improved values on one or more characteristic, but also in variations of the very numbers of characteristics, such as product embodied innovations and adoption of universal standards. In the first case, the features of a product may be expressed as increments of the dimensions defining the products (obviously, old products lacking a novel feature appear as dominated by new products having that feature). The second case can be expressed as the reduction of the space when all products score identically on a set of dimensions. Our model for consumers is potentially compatible with any of these events,Footnote 7 though, for obvious reasons, in this work we will not explore further this issue.
The definition of products by their characteristic values must be considered as an “objective” representation of available products, as, for example, may be agreed upon by experts of the technology. However, the generic user is unlikely to be able to assess properly at least some of the characteristic values, and can be expected to interpret erroneously the information available. In the following, we discuss how consumers elaborate the objective data from the supply side into subjective information used for their purchasing decisions.
2.2 Consumers’ information
The importance of information in influencing consumers’ behavior has long been acknowledged (Nelson 1970). Proposing a consumer model we need to make explicit how consumers may be affected by different types of information.
The proposed model includes three ways to elaborate information which is eventually fed into the decision procedure. Each of these constitutes possible ways to differentiate consumers, and consequently their purchasing behavior, even using the same decision process. Though we will describe in detail the decision procedure in the following paragraph, it is necessary to specify the nature of the elementary unit of information on which the decisions are made, in order to appreciate how the data elaboration by consumers generates the necessary information.
Consumers are assumed to base their decisions on the comparison of available products in respect of a single characteristic. In particular, the basic unit of information required by the proposed decisional algorithm is the identity of the best product, or products, in respect of one single dimension.
We assume that such information is potentially available, accessible to observers with perfect knowledge of the products, but not necessarily to consumers. We assume that the actual decision procedure takes place only after consumers have performed three preceding steps, during which they elaborate the available (objective) data into personal, private information. The first type of data elaboration consists in mere perception, possibly distorting data in respect of the “true” ones. The perceived information is then used in two further steps: assessment of equivalently optimal products and identification of affordable products.
2.2.1 Products’ values perception
In order to extend the generality of the model, we consider the possibility of consumers to differentiate in respect of their skills in assessing products and, therefore, making mistakes in assessing which product is the best in respect of one characteristic. There may be several motivations: buyers may not be experts in the technology embedded in the products they buy; some of the qualities may be difficult to assess at purchase time, becoming evident only after using the product; a consumer may not consider it worth an extensive research to find the exact quality values, preferring to rely on generic, and imprecise, information; sellers may be reluctant to make public detailed information concerning their products. For any of these or other reasons, it is possible that a dominated product (in respect of one characteristic) appears as superior to the actually dominant product.
To implement these mistakes, which we call perception errors, it is sufficient to define the probability that every available product is judged as the best in respect of each characteristic. Data on these probabilities may be collected with surveys for empirical works or imposed exogenously in theoretical models as assumptions concerning the composition of demand. In the following, we present a specific implementation with a compact and pretty general formalization, which makes more evident the nature of the perception errors and allows us to discuss briefly their origins and effects.
As stated above, the basic information required by the adopted decision procedure consists in the identification of the best product(s) in respect of one single characteristic among a set of products. However, for obvious reasons of clarity and without loss of generality, we will consider the most simple case of comparison between two products only, under the assumption that this elementary case can be scaled up to include the generalized case with sets containing more than two products.
We can expect that an erroneous evaluation is less likely the wider is the difference between inferior and superior products and the higher are the skills of the consumer in assessing that particular characteristic. Given the adopted representation of products, we assume that consumers will not consider directly the true values \(v_{X}^i\) as the value of characteristic i for product X but:
where Norm(μ, σ) indicates a draw from a normally distributed random function, and Δ, the variance of the random variable, is a proxy for the consumer’s “ignorance” of the product’s quality. When comparing two products, a consumer draws two values from the two random distributions centered on their respective true values. Δ is the parameter affecting the distribution of perceived values around the true ones. This implementation ensures that the probability of correct identification of the best product ranges from 100 % (no mistakes) to 50 % (pure random) depending directly on the distance between the two quality levels and inversely on the level of the perception error.
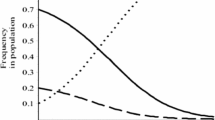
As an example, consider a product, X, the “objective” value of which in respect of a characteristic is v X = 100. Varying Δ we can determine how frequently product X is correctly identified as superior to another product Y with lower quality v Y < v X . Figure 1 reports the probability that a consumer perceives correctly the ranking between the two products, \(\hat{ v_{Y}} < \hat{ v_{X}}\), in respect of different values for v Y and of the error parameter Δ. The figure shows that the probability of perceived values correctly reflecting the actual ranking decreases for smaller quality differences and for increasing levels of Δ.

Probability that product X will be correctly evaluated as superior when compared to Y in respect of a range of values of Δ and of Y. The true value for X is set to v X = 100, while v Y spans the range [90, 100]. The value of the parameter Δ varies in the range [0, 10]
Obviously, the setting of Δ should depend on the nature of the characteristic it affects, besides the skill of the consumer to whom it refers. For example, characteristics such as prices generally allows for no mistakes in assessment, resulting in Δ = 0. Furthermore, Δ can be defined as a variable changing in time reflecting a learning process leading to decreasing chances of making evaluation errors while the consumer increases the knowledge of the product. Any of these options depend on the overall scope of application of the model, and we will not discuss further this aspect, except to note that it permits us to represent a rather wide range of different categories of consumers.
2.2.2 Tolerance on quality differences
Not every quality difference is equally relevant for consumers. We can expect, for example, that consumers caring for the price of products will undoubtedly opt for any product costing half the price of that of competitors; but they are likely not to consider similarly relevant a price difference of, say, 0.1 %. The model should then define how frequently two products are considered as equivalent in respect of one characteristic, even when their perceived values differ.
The proposed implementation includes a parameter representing the tolerance for quality differences. The margin of tolerance indicates that, if the difference between the (perceived) values of two products is smaller than a given threshold, then the two products are considered equivalent, as if they had identical values. In general, comparing two product X and Y on one characteristic, the model considers these products as equivalent if:
where τ is a coefficient in the [0,1] range. When τ = 0, even minimal differences are considered relevant to assess the superiority of one product; conversely, a high value of τ indicates that even large quality differences are considered as irrelevant, and therefore two products will be assessed as equivalent (on that characteristic) even for substantially different values. As noted for the error parameter, the tolerance level may be differentiated for different characteristics, e.g. representing a consumer as accepting no compromises on safety standards, always opting for the (perceived) best options, but being generously tolerant in respect of, say, style differences.
The combined effect of perception errors and tolerance relieves the sensitivity of the results to the choices of units of measures and to possible arbitrary evaluations in case of empirical applications of the model. As already suggested, the proposed model may actually dispense altogether with any quantitative measure of characteristics qualities. The only requirement is to set the probabilities that a product is considered as superior, inferior or equivalent to any other in respect of each characteristic. Such information is much more reliable and easier to collect than numerical evaluations for product characteristics, many of which have a qualitative nature. This is a great advantage in respect of statistical techniques the application of which strictly requires real-valued measures (such as hedonic pricing) which are known to be extremely sensitive to the numerical assessment of qualitative aspects (Hulten 2003). For our purposes, however, we will continue to use numerical values for simplicity of presentation and of interpretation.
2.2.3 Minimal requirements
A consumer can discard a product either because it is not affordable (or judged as wanting in some aspect other than price), or because a competing product appears as more attractive. Though the eventual result is identical (the consumer not buying the product), we need to distinguish the two cases to assess properly the economic conditions of the market. For example, in the second case, the removal of some competitor may lead the consumer to choose the product, but that will not happen in the first case.
In our model, we distinguish the two cases, considering the first as part of a selection process producing a set (possibly empty) of viable products, and the second as a step in the decision process eventually leading to the choice of the product to purchase. This paragraph describes how to implement the selection phase, the discarding of potentially available products because of their failing in some respect such as, most typically but not exclusively, an excessive price.
We consider consumers as endowed with a set of the minimal requirements (one for each characteristic) that a product must satisfy in order to be considered as potentially viable for purchase. Formally, consumer j is associated to a vector \(\vec{m}_{j}=\{m_{j}^{1}, m_{j}^{2}, ..., m_{j}^{m}\}\), containing as many elements as the number of characteristics defining the product. The potential set for the consumer is defined by all products X such that \(\hat{v}_{X}^{i} > m_{j}^{i}\) for all characteristics i.
Choosing appropriately the level of minimal requirement allows us to represent the rejection of options because they violate in some respect the minimal conditions for the product to be of any use. The most obvious and foremost of these cases is the elimination of attractive products because they would violate the consumer’s budget constraint—standard (i.e. not wealthy) consumers will discard beforehand attractive options because of their excessive price. An identical effect can be assumed in principle for any other characteristic of the product, so that we need not distinguish the price from any other characteristics, since, from the viewpoint of consumers, a single insufficient aspect of a product justifies its rejection.
The use of minimum requirements allows us also to remove a potential source of problems in the application of the model: which products’ should be included in the initial option set? For many product categories, the boundaries of classes of products are not well defined, so that the choice of which products should be considered as potential alternatives may be problematic. Making use of minimum requirements removes this problem because consumers would consider all products that fulfill a clear set of requirements, on prices as well as on any other aspect, without the need of a preliminary definition of a given product category. Note that, in effect, we define product categories based on how product features fulfill consumers needs, possibly adopting different technologies.
2.3 Boundedly rational decision strategy
The most challenging issue concerning a consumer model is the decision mechanism for the purchase decisions of consumers among the set of product deemed as potential alternatives. Experimental economics and the bias literature (Tversky and Kahneman 1981; Kahneman et al. 1982) has highlighted a large number of systematic departures from perfect rationality, and even suggested classes of decision mechanisms from evidence routinely observed in experiments. The relevance of these results for the economic theory of consumers has already been noted (Devetag 1999). However, few constructive proposals aiming at representing a general decision mechanism have been advanced. One of these, called Take-The-Best (TTB), concerns classes of decisions compatible with the consumer’s problem, as we stated in our setting: the choice of one item out of a set of possible alternatives defined over a multi-dimensional space (Gigerenzer and Goldstein 1996; Gigerenzer 2000; Gigerenzer and Selten 2000). We describe below the (very simple) decision algorithm proposed as the decision mechanism by consumers acting upon the information elaborated as described above. We will then discuss the implications derived by using this decision procedure for consumers and, in the following section, showing the results provided by a simulated demand made of the aggregation of many consumers.
The proponents of the TTB convincingly sustain that the algorithm is both empirically supported by observations of actual people’s behavior and very efficient under uncertainty and poor information, conditions frequently occurring in real-world decisions. The decision algorithm is meant to individuate one option among many defined over a set of characteristics. The procedure consists in cyclically repeating the following steps until the exit condition on step 3 is satisfied:
-
1.
Consider initially all options that may potentially be chosen.
-
2.
Choose one characteristic among the m available.
-
3.
If one single option scores highest in respect of that characteristic, this is the choice.
-
4.
Otherwise, if more than one option scores similarly in respect of the adopted characteristic, remove the options with values lower than the maximum, and restart from step 2.
In essence, the TTB consists in considering initially all options as potential choices. Subsequently, the decision maker performs a sequence of rounds during each of which a filtering is applied using as criterion the condition that only the options scoring highest in respect of one characteristic remain as potential choices, while dominated options (in respect of that characteristic) are discarded. If, after a round of filtering, more than one candidate score equivalently to the optimum, then a new filtering round is performed, adopting another, as yet un-used, characteristic as criterion. The procedure terminates when a filtering round identifies one single option scoring optimally in respect of the currently adopted characteristic.Footnote 8
The authors proposing this strategy argue convincingly that it is an algorithm respecting the principles of bounded rationality (Simon 1982), which seems quite adapted to represent the generality of consumers’ behavior. In fact, most of the purchasing decisions, and by far the ones of larger economic impact in modern markets, are made by people buying items the costs and importance of which are very limited in respect of their overall life and income. Therefore, they have relatively little interest in investing time and attention just to be sure of making the optimal choice, and would rather risk the costs of choosing a dominated alternative, possibly a little more expensive in price or of slightly lower quality, but by far easier to be decided upon. Concerning the realism of TTB, there is a huge amount of literature suggesting that, when people face the choice between different alternatives “[...] they resolve the conflict by selecting the alternative that is superior on the more important dimension, which seems to provide a compelling reason for choice” (Shafir et al. 1993, p. 15). TTB can then be considered a “reason-based” decision procedure, where the decision maker uses as compelling reason the superiority of a product in respect of one dimension.
Our previous discussions on the perception of product values, tolerance levels and minimal requirements add further sophistication to the original TTB proposal, providing a flexible representation for consumers in both abstract and empirical applications. In the next section, we will support this view using the model in a few exercises meant to explore the relevance of demand in explaining market configurations. Before doing so, however, we need to counter a possible criticism to the use of TTB as a general model for consumer behavior. In the following, we will maintain that this apparent weakness of the proposed algorithm leads to a theoretically and empirically relevant definition: the nature of consumer preferences and the identification of one of their sources.
2.4 Consumer preferences
The results provided by applying the TTB algorithm to a given set of products are obviously influenced by the order in which characteristics are used to filter the set of available products. This indeterminacy may appear as a weakness of TTB as a model for consumer, since, for any given set of alternative options available to consumers, TTB does not provide a unique result; conversely, it generally returns different results depending on the order of the characteristics adopted. However, a more careful consideration shows that this very feature leads to a formal result with relevant consequences both in theoretical as well as applied uses: a definition of consumer preferences. The proposed definition not only formalizes a central concept for the theory of consumer, but, due to its intuitive and empirically robust nature, it also allows us to investigate the manner in which consumers construct their preferences. Here, we first provide a formal definition of preferences, and then discuss two factors affecting preferences that, we sustain, are empirically relevant but rarely considered in economics: marketing and social information.
2.4.1 Definition of preferences
The concept of preferences technically should refer to the criteria used by consumers to choose a product, a separate concept in respect of other elements concerning consumers: (i) the decision procedure used by the consumer, which exploits preferences but is not itself an expression of preferences; and (ii) the actual decisions made by consumers, which are the final results of information, preferences and the decision procedure. However, in the economic literature, preferences are mostly “appealed to” in order to (avoid to) explain, ex-post, how consumers reached a specific decision. Even the “lexicographic preferences” literature (which, apparently, closely resembles the TTB model) defines the ranking of bundles of features or goods, ignoring how this ranking is produced. Consequently, preferences-as-criteria and preferences-as-decisions are confused in a tautological concept by which decision criteria and the resulting decisions cannot be distinguished from one another.
Besides surrendering the possibility to explain observed behavior, mixing criteria and actual decisions also prevents the possibility to make predictions about hypothetical decisions by agents with known preferences when offered a different set of alternatives. Identifying the criteria adopted by consumers for their decisions, conversely, would greatly extend the possibilities of economic analysis and its applications because we can predict the results produced by relatively stable preferences applied onto different and potentially fast changing sets of alternative options.
From a theoretical perspective, considering preferences as decision criteria would add a further layer of explanation between exogenous features and observed behaviors of consumers, motivating the latter on the base of the criteria adopted. Another possibility is to predict likely outcomes in respect of given changes, by simply applying the same criteria to hypothetical markets including new, or changed, products. For example, a firm may evaluate the effects in the current market conditions of a potential price discount or a quality improvement, choosing the most profitable alternative. These and other highly interesting analyses depend on the possibility to define preferences as criteria distinct from the actual decisions to which those criteria (and many other factors) lead.
The structure of TTB naturally provides a definition of decision criteria that, in the case of consumer decisions, can be proposed as representing preferences:
Consumer preferences are the ordered set of a product’s characteristics ranked according to their descending relevance in the consumer purchasing decision.
Note that the nature of general decision criteria is guaranteed by the lack of reference to specific products or characteristic values. Given the proposed decision procedure, TTB, preferences consist in an ordered list of product characteristics.
As an example of preferences, suppose that there were only two characteristics defining a given type of product: quality and price. The proposed definition implies that there are two possible types of preferences: quality-first or price-first. The “quality oriented” buyers will prefer the cheapest products among those scoring highest in quality, while “price oriented” buyers will buy the highest quality products among the cheapest ones. In the general case of many dimensions, the number of preferences is given by the number of all possible permutations of the characteristics.Footnote 9
The proposed decisional algorithm and the resulting definition of preferences leads to an interesting conjecture. Suppose that a given product can be defined over a number of characteristics, some of which are decidedly of higher importance than others. For example, a consumer evaluating cars may consider of primary importance (i.e. among the top position in the preferences) characteristics such as price, reliability, safety, fuel consumption, etc. Other characteristics may also be relevant, but in lower positions in the preferences: satellite navigator, fashionable colors, sophisticated sound systems, etc. We may expect that, since consumers give a determinant importance to the first group of variables, firms should also devote most of their efforts in improving these aspects. However, the proposed definition suggests that something different may occur.
Suppose that a mature and widely diffused technology ensures that all competing products score similarly in respect of the most relevant characteristics. We will then observe that firms will try to differentiate and to compete on secondary aspects only because no differentiation actually exists in respect of the primary aspects. A casual observation of how car producers tend to promote their offerings seems to support the conjecture. For example, we will hardly find a commercial reassuringly claiming that “our car’s brakes never fail”, while they seem focused on (apparently) far less relevant aspects. Thus, when technological advancement and diffusion reduces drastically differences on core aspects, these become an irrelevant aspect for distinction, and therefore competition focuses on minor, fringe aspects.
Our proposal allows many applications and directions for further investigation. For example, our definition of preferences provides detailed indications on how to collect such information, that is, the relative importance of a product’s characteristics for consumers. Indeed, such information is routinely collected and used by market research companies for techniques such as the conjoint analysis (Green and Srinivasan 1978). Considering that preferences can be observed would allow us to deepen our understanding of demand by explaining at least one step from exogenous factors to observed behaviors of consumers. In the experiments at the end of this work, we will explain patterns of sales in a simulated market on the basis of features of consumer behavior that are potentially observable. Further examples are the possibility to predict the expected level of sales across a range of competing product on the basis of observed preferences, or to predict changes in sales levels as a consequence of changes in preferences.
Having provided a clear and formal definition for consumer preferences, it is possible to exploit this proposal in order to investigate the origin preferences. In the next two sections, we will describe one of the mechanisms contributing to shape consumer preferences. The purpose of these notes is not to provide a full account of preference generation. We agree with most economists that preferences, even meant as decision criteria, originate from a wide variety of sources, such as psychological conditions, life styles, culture, etc. Consequently, preferences can be expected to differ, even substantially, for different classes of products and classes of consumers, with a large number of exogenous conditions, not pertaining to economics, motivating these differences. However, the existence of exogenous factors does not imply the lack economic, potentially endogenous, contributions to the shape of consumer preferences. In the following, we will present two of the potential sources of influence on preferences that should be of interest to economists: one originated by producers and the other from other fellow consumers.
2.4.2 Marketing induced preferences
Most economists consider consumer preferences as exogenous, referring to psychological, social and other determinants of behavior as falling outside the realm of economics (Bowles 1998). Unfortunately, this reasonable assumption is frequently (mis-)used as a justification to avoid the economic analysis of consumers altogether: any consumer decisions are, ex-ante, potentially observable, and we can only justify ex-post the observed results as due to exogenous preferences. Economic analysis, therefore, cannot but register consumer decisions as expressed in their actual purchases, and declare itself unable to explain further demand events.
While it is undeniable that consumer preferences are largely determined by non-economic factors, the assumption that these are the only sources of influence on preferences sits uncomfortably with empirical evidence from both experimental and cognitive psychology, on the one hand, and from the observation of real markets, on the other hand.
Concerning experimental evidence, preferences seem to be “[...] actually constructed—not merely revealed—during their elicitation.” (Shafir et al. 1993, p. 34). The contextual generation and application of preferences weakens the argument of preference exogeneity, particularly when the presentation of available options can be influenced by actors interested in pushing decision makers to opt for a particular option. Indeed, it has long been known that it is possible to influence people’s decisions by manipulating the presentation of alternative choices, the so-called framing effect (Tversky and Kahneman 1981; Kahneman et al. 1982). This further reinforces the conjecture that an interested party would be able to steer people’s decisions towards a specific option and away from others by influencing decision makers’ preferences. Concerning consumption, competing firms are obviously interested in affecting consumers’ decisions, and there is plenty of evidence that they are fully aware of the possibility.
The activities of firms generally considered in economic theory are those concerning the production process (e.g. technology and costs), product qualities (R&D), and the internal organization of the firm (agency theory). However, even a casual observation of real companies shows that a very large share of their expenses (frequently the highest) is devoted to a fourth activity ignored by economic theory: marketing.Footnote 10 The relevance of the sums invested in marketing in respect of those for production, research and managing the organization is strikingly consistent across a wide range of sectors and countries. For example, it is well known that pharmaceutical companies spend more on marketing than on R&D. Also, during the dot.com bubble, start-up’s were encouraged to devote at least 50 % of their seed money to marketing initiatives. In general, most operators share the opinion that a company with good marketing and a bad product is likely to survive, at least temporarily, while bad marketing puts at serious risk any firm, no matter how good the product.
The definition of preferences as ranking of characteristics in order of importance offers the opportunity to fill the gap that economic thinking has left in explaining such common and widespread evidence. In the following, we will discuss how marketing can be considered the link between the supply side of markets (providing resources and a strategic direction) and the demand side (where preferences are affected by supplier marketing). In so doing, we can close the circle formed by consumers determining firm performance by means of their purchasing decisions, and firms influencing the very preferences affecting those consumer decisions.
A firm’s marketing is designed to press buyers to adopt a particular perspective of the product. Obviously, it is a perspective that is expected to exalt the features of the product most likely to provide a competitive advantage in respect of competitors. One of the means to pursue these goals broadly supports the definition of preferences we provided above, showing how firms, among other techniques, try to manipulate consumer preferences defined as general criteria formed by a characteristic’s relevance.
In many modern commercials, firms do not limit (and, in some cases, conspicuously underplay) their own brand name or specific product. Rather, they try to push reasonable and acceptable general principles that just happen to imply the superiority of the sponsor’s product in respect of those of competitors. For example, a commercial may largely focus on the importance of protecting the environment from pollution, presenting, say, wonderful natural landscapes under risk of an ever growing cloud of smog. Only during the last few seconds of the commercial does the producer’s brand appear, with a small text highlighting the low environmental impact of its models. A competitor may, instead, show an embarrassed family struggling to squeeze too many cases into too small a car, in order to highlight the large room available in the trunk of the advertised model.
The two examples are cases in which competitors do not directly promote their offerings by means of underlining their positive features. Rather, they remind the potential customers of the importance of some aspects, which is indirectly expected to lead consumers to choosing their products because, on those aspects, they happen to beat the competitors.
This suggestion is supported by another recurring feature of many marketing claims: every competitor, even in crowded markets, advertises its position as the market leader. Though all of these claims but one should necessarily be un-deserved, a more careful consideration reveals that they are not, after all, void of any credibility. Statements such as “leading firm in the market”, the best product “in its category”, cheapest “in its segment”, etc., seem, at first, to signify that all firms represent themselves as market leaders. But a more careful consideration of these claims shows that each of them defines the reference market in different ways, and therefore it is well possible that all of them are market leaders. In short, the real competition appears to be not directly among products, but about setting in the mind of consumers a specific perspective on the product category, perspective that implicitly defines the criteria by which a product should be assessed.
In our setting, this translates into an effort to convince buyers that some characteristics are more important then others, so urging potential consumers to develop a specific set of preferences, i.e. a given ranking of importance of characteristics. Obviously, we can expect producers to design the desired preferences so that their product gets the best chance of being chosen by consumers. This may not be easy, since a marketing strategy must take into account the strengths (and weaknesses) of the firm’s own product as compared to those of all competing products, besides the general tastes and constraints of consumers. Designing the appropriate strategy to promote indirectly the appeal of the product can be highly difficult and risky; indeed, there are a large number of examples of marketing campaigns failing to reach their goals, and even that spectacularly backfired, seriously damaging the sponsor’s competitive position.Footnote 11
For the purpose of modeling this effect, we present here a possible way to represent the marketing strategies of firms. We assume producers to have their own “ideal” ranking of characteristics, i.e. consumer preferences, that they would like to push through consumers, supposedly exalting their own product against those of competitors. Formally, the marketing strategies can be represented as a vector of values for each producer, containing a value for each characteristic.
The generic element \(k_{X}^{i}\) in Table 2 must be interpreted as the relative importance that producer X gives to characteristic i for the promotion of its product. The ranking in descending order of all the values for a producer constitutes the producer’s marketing strategy. In practice, it consists in the ranking of the characteristics that the producer would like consumer preferences to respect, supposedly because they would allow its product to emerge above those of competitors. The choice of using real-valued numbers must be considered merely as a convenient implementation for the producer’s “desired” preferences. That is, the producer assigns higher values to the characteristics it would like to be in the top positions in consumer preferences, and lower values to those aspects of its product more likely to be dominated by competing products. Ranking the characteristics according to the descending order of marketing values provides the “desired” preferences by the producer.
Concerning the producers’ decisions about their marketing strategies, we may expect that the more important is a characteristic for a producer, the higher will be its value compared to other the marketing values for other characteristics. The importance depends on the comparison between the producer’s and competitors’ products on each specific quality. In principle, a coherent producer X should set its \(k_{X}^{i}\) higher the more its product is better than those of his competitors in respect of the characteristic i. However, we can expect these strategies to be difficult to elaborate, depending on a large number of factors. As for other aspects concerning the supply side of markets, we limit ourselves here to defining the general concept (marketing strategies), their function (influence preferences) and one possible implementation (real-valued vector, the ranking in descending order of which corresponds to the desired preferences), without entering into details of how producers actually determine their decisions.Footnote 12 The next paragraph describes how the proposed implementation of the firms’ marketing strategies can be used to affect the consumer preferences as described above.
2.4.3 Social influences
By their very nature, competing firms’ marketing messages are likely to be mutually inconsistent, and their effect on consumers’ preferences will depend on the the relative trust associated to firms. In this section we describe how to represent a mechanism to determine the formation of preferences when consumers are targeted by conflicting marketing messages.
In Smallwood and Conlisk (1979), the authors propose a model where buyers choose their purchases randomly with probabilities proportional to the market shares of the competing firms. The justification for this is obvious: there is no better advertising that having many users showing your product around. This method seems even better adapted to represent the relative diffusion not of products, but of preferences. Consumers pass to each other “perspectives” of the product, and the probability of choosing a given perspective is likely to depend on the number of fellow consumers who have adopted it in the past. In other terms, households are sensitive to each other’s “life styles”, as implemented and transmitted by the motivation they supply to explain a given choice. Though in different ways, other works in the literature support this interpretation. For example, Cowan et al. (1997) assume that consumers pursue two goals in deciding their purchases: the distance of your consumption pattern from the one adopted by members of lower social classes (distinction), and imitation of those used by members of higher classes (aspiration). In our case, neglecting the existence of different social classes, we can limit to consider the aspiration effect only, consisting in pursuing a consumption profile similar to that of the majority of the society.
Formally, we use the following algorithm when a consumer forms his preferences, assuming that many competing firms are engaged in (potentially conflicting) marketing activities. Assuming a consumer forms his preferences exclusively under the effect of marketing, the target is to generate consumer preferences defined as the ordered set of integers referring to the m characteristics representing the product space:
where c i indicates the characteristic ranked at the ith position in the preferences. For example, if m = 3, the possible sets of preferences is composed by all permutations of the three characteristics:
To determine the preferences for a consumer, we propose to weight the firms’ marketing strategies by their respective market shares, used as proxies for their popularity. We assume that a consumer draws randomly one characteristic per time, starting from the most relevant, c 1 and continuing with all characteristics for the descending ranking position in the preferences.
The procedure is based on the following indicators, computed for all characteristics i:
where s j represent the market shares of firm j, \(k_{j}^{i}\) is the marketing level of firm j in respect of characteristic i, n is the number of firms. The parameter δ is a coefficient flattening or steepening the differences among these indicators. A value of δ approaching 0 means that the indicators for all characteristics will tend to be equal, irrespective of marketing strategies. Conversely, higher values of δ will increase the differences between the indicators, resulting in indicators with sharply higher values for the characteristics most relevant in the marketing strategies of the most popular firms.
The indicators p i represent the importance that the supply side of the market as a whole gives to the ith characteristic, using market shares as weights to balance the marketing strategies. The more firms (weighted by their market shares) press for one characteristic, the more likely users will consider this as more relevant in their preferences.
To generate the preferences for one consumer we proceed incrementally in m steps, choosing first the most important characteristic, then the second most relevant, and continuing for all the m characteristics, concluding with the least relevant.
The first step, producing the first characteristic in the preferences, c 1, is obtained by drawing randomly one of the m characteristic with probabilities equal to:
The same indicators are used to compute the probabilities to draw the second characteristic in the preferences, c 2, after setting to 0 the probability for the characteristic already chosen, \(p_{c_1}=0\). That is:
Iteratively, the same procedure is used to assign probabilities for all the subsequent extractions, each time resulting in the choice of a characteristic to be placed in descending ranking position. The final result will be the ordered set of integers representing the characteristics of the product space. The likelihood that a given characteristic will appear higher in the ranking of a consumer’s preferences (and, therefore, that it will be highly relevant for the purchasing decisions) will be higher the higher is the marketing value for that characteristic in the strategies of the highest selling firms. The parameter δ can be considered as indicating the general trust given by the consumer to market as a whole.
The proposed generation mechanism is only one possible way to model the generation of preferences depending solely on marketing strategies and no exogenous determinants. Specific applications may require different generation mechanisms or, trivially, an exogenous setting of preferences. A similar approach may also be used to represent the change in preferences resulting by changes in marketing. For example, in Valente (2000) firms update their marketing endogenously according to the indications on which characteristic are the most sensitive among their actual and potential customers, and consumers continuously update their preferences following the changes in marketing strategies.
In this first section, we described a model for consumer based on a bounded rational algorithm for decision making under uncertainty. In the process of adapting the algorithm to the case of consumer decisions, we discussed the nature of the information (and possible biases) used by the consumer, and reached a formal definition of preferences considered as criterion for, and not merely as justification of, decision making. Finally, we suggested one source of influence on preferences, marketing, which is particularly interesting because it suggests a partial endogenization of preferences, where producers’ success depends on preferences that are partly influenced by the producers themselves.
Overall, the proposed model includes several parameters governing its behavior, which can be used to generate a wide range of different types of consumers. The following section presents a few simulation exercises showing the implications of the proposed model to represent a generic demand side for a market.
3 Micro-founded market demand
The consumer model presented in the previous section represents the generalized behavior of a potential consumer considering the purchase of one product among a number of competing alternatives defined over a multi-dimensional product space. A first goal, it should be noted, has already been reached by means of the mere specification of the model. The definition of preferences and the possible role of marketing in shaping them are noteworthy results, derived by the simple requirement of logical consistency and the observation of reality from the new perspective of the model. In this section, we want to provide an initial, necessarily partial, assessment of the model in its capacity to represent the demand side of markets. For this purpose, we will test the model generating simulation experiments and investigate the possibility that the use of the proposed model can increase our understanding of some properties of markets.
There are obviously a large number of possible experiments in which this generic model may be used, once both the model internal parameters and other external conditions, such as supply side features, are specified.Footnote 13 In this work, we don’t aim at representing specific markets, but only to support the general claim that economic aspects of demand (as opposed to its exogenous features) can be highly relevant to correctly interpret market properties, and to suggest by which means economic factors from demand affect markets. The goal is to show that deman not only matters because, trivially, it is the consumers’ tastes, culture, etc. that ultimately determine observed market conditions. It also matters because, we maintain, there are relevant properties of markets that depend on economic activities by consumers in the market, given their exogenous features. The ultimate goal is to show that neglecting demand properties risks, at best, unnecessarily limiting the scope of economic analysis. It may even result, in the worst cases, in serious mistakes leading to wrong analytical as well as empirical conclusions.
We present two applications of the model with the double goal of showing the power and flexibility of the model, and to support our claim that economic factors concerning the demand side of markets are worth as much attention as those concerning the supply side. The first two exercises are meant to show that our proposal does not imply a revolutionary modification of basic concepts such as aggregate market demand functions. We will show that our model can actually be considered a generalization of a standard demand function to a multi-dimensional product space, with the additional advantage that the underlining micro-foundations are robustly rooted in empirical evidence and depend on intuitive and easy-to-collect data. In short, the aim of this application of the model is to show that throwing away the dirty water of perfect rationality and well-behaved utility functions still allows us to keep the baby of generalized market demand functions and all the results derived from this analytical tool.
The second exercise provides an example of the potential errors to which ignoring demand may lead. We build an artificial market in which two sets of consumers with identical exogenous features, but different purchasing (and observable) attitudes, have apparently similar distributional results. Yet, we will see that the two configurations are actually radically different in both static (relative ranking of firms dimensions, and their motivations) and, possibly more importantly, dynamic terms (what would be the effects of a given innovation, and why), allowing us to conclude that demand, indeed, does matter.
3.1 A micro-founded demand function
A market demand function reports the level of sales expected at different levels of price. According to the standard textbooks, the market demand function is built as the sum of (unobservable) individual consumer demand functions, and therefore its properties are theoretically inherited from consumers’ own demand functions. In this section, we show how the proposed model can be used to generate standard market demand functions, with the additional advantages of direct dependence on observable consumers’ features and of an extensive flexibility.
An apparent difficulty is that the proposed model does not represent an individual consumer demand function, i.e. a map price-quantity, but a generalized discrete choice problem: which product to buy among those on offer, if any. The market demand is therefore formed by the sum of all consumers who decide to buy a product, but the properties of the market demand function cannot be justified with non-existent individual consumer demand functions. How do we find, then, the market demand features when we apply the proposed model?
To show how a market demand can be generated, we start by considering the simplest of the possible cases for demand (and, generally, the only one treated in economic textbooks): the case of an homogeneous product. The demand in this case consists in the relation between all possible prices with the relative quantities purchased by the population of consumers. To build a demand function for this purpose, we neglect the choice based on different features of the products, and consider a product defined by one single characteristic: the price. Lacking the possibility to represent heterogeneous products, there is no need to apply (and even to conceive) preferences. The only aspect of the model that matters is the application of the consumers’ constraints that, in this case, consist in the maximum price for which the consumer accepts to buy a unit of the product.
If every consumer had the same threshold for the maximum price, the market demand would be a made of a single, giant step at the point of the threshold, where all consumers switch from buying the product at lower price to none at higher prices. However, the generality of markets includes differentiated consumers. We can safely assume that the number of consumers having more stringent budget constraints (lower maximum price) will be larger than the number of consumers with looser constraints. To test the model, we consider a demand composed by consumers differentiated for minimal requirements on price.
Figure 2 presents the results obtained by counting the number of consumers willing to buy a product at different prices. Consumers are grouped into classes, where the consumers in the same class are assigned the same maximum price level. These levels are arbitrarily assigned linearly increasing levels across classes. The number of consumers across the classes changes in inverse relation to the maximum price: the higher the maximum price in a class, the smaller the number of consumers. For the exercise, in the figure we assigned the number of consumers in each class proportionally to the number of households for different income classes in USA.Footnote 14

Market demand function for a homogeneous product. Demand formed by 37 classes with linearly increasing levels of maximum price in the range from 5 to 10. Number of consumers in each class proportional to US income distribution of households. Data generated counting the number of consumers willing to buy a unit of a product for each price level in the range 4.87 to 10
The motivations for the results are rather trivial: at each price level, the simulation cumulates all consumers for which the maximum price constraint allows the purchase. In essence, the demand function merely depends on the classes’ minimum price and dimension. The figure, however, shows that it is not necessary to assume consumers as endowed with well-behaved demand functions in order to obtain a market-level (well-behaved) demand. Moreover, the properties of the demand function depend on relatively easy to collect and robust data: population distribution and price constraints. This example is merely meant to show how an aggregate demand with all the properties familiar to economists can be obtained with the proposed model for consumers, but does not make use of the most prominent feature of the model, the capacity to deal with heterogeneous products. In the following example, we take a second step in the analysis by considering a multi-dimensional demand function.
3.2 A multi-dimensional demand function
A demand function cannot work for heterogeneous products, since the relation between price and quantity is biased by differences in quality. The standard approach to this problem is to force a sort of re-homogenization based on the estimation of hedonic prices, the differences of which with the actual prices are supposed to compensate for quality differences among products. The use of hedonic prices faces, however, serious difficulties from both a theoretical and empirical perspective because of the very demanding hypotheses required for their use and the notorious unreliability of their estimates. Using the proposed model to represent consumers’ decisions, we can provide a much more robust foundation to a generalized market demand.
Having shown that a price-quantity relation for homogeneous products can easily be constructed by the proposed model, we move now to consider a generalized demand function for heterogeneous products, doing away with heroic and unsupported assumptions (utility maximization), as well as with statistically challenging and unreliable operations (forced homogenization via hedonic prices).
Considering a generalized set of competing (differentiated) products defined over a multidimensional space of characteristics, we posit a demand function for these products as a map from each vector of characteristic values for each product to the level of sales for all products available. In fact, the demand for a product depends, besides on its own properties (e.g. price), both on the features of consumers (e.g. incomes, preferences, etc.) and on the properties of competing products. Consequently, a demand function for the market will be the sum over the demand functions for all products on the market which, in turn, are mutually dependent. To summarize, we can state that a market demand function for heterogeneous products should support the following properties:
-
Other things being equal, improving one product in respect of one characteristic should increase its sales.
-
Other things being equal, improving one product in respect of one characteristic should decrease the sales of other products.
-
Other things being equal, improving one product in respect of one characteristic should increase the total sales of the market.
As in the previous example, we build a simulation exercise in which the demand of a market is made of a set of independent consumers, each represented by the modified TTB model. Considering as established the capacity of the model to deal with the price changes for an homogenous product, we consider now the case for a market including heterogeneous products, where the demand function concerns not necessarily a price-quantity map, but a map from generic multi-dimensional vector of characteristics to a vector of sales, one value for each available product. To interpret better the results, we consider all consumers having the same minimal requirements, in practice limiting the analysis to a consideration of the portion of demand coming from the same income class. Results for the whole consumers, not presented here, can easily be constructed by summing up the values for each class.
To generate a demand function capable of being represented in a three dimensional space, we restrict the number of characteristics to two and consider the competition between two products only, X and Y. The two characteristics may be any aspect of products relevant for consumers, as, e.g., price and quality. To simplify the interpretation of the results, we assume both characteristics to be positive, that is, consumers prefer products with higher values on both aspects. Thus, we may interpret one dimension as “cheapness” (positive) rather than price (negative).Footnote 15
For presentation clarity, and without loss of generality, we assume product Y as constant, and evaluate the sales of the two products for different values of the two characteristics relative to product X. The constant quality levels for Y are set to \(v_{Y}^{1}=v_{Y}^{2}=10\). For product X, we explore the results for each value of the characteristics in the range \(v_{X}^{1}, v_{X}^{2} \in[5,15]\).
The demand is made of 20,000 consumers evenly divided into two classes for the two types of preferences available in this setting: < 1, 2 > and < 2, 1 >. That is, consumers in one class will select initially the product(s) with the best score in respect of the first characteristic, using the second characteristic as a tie-breaker. Consumers in the second class follow the opposite criterion.
The other parameters governing consumer behavior are set to identical values for all consumers. The error level, affecting quality perception, is set to Δ = 0.4; the tolerance level determining the range of values to be considered as equivalent to the optimum is set to τ = 0.1; the minimal quality levels below which a product is discarded are set to m 1 = m 2 = 8.
The simulation program generates 10,000 points distributed in a bi-dimensional space for the independent variables, the characteristic values for X, \(v_{X}^{1}\) and \(v_{X}^{2}\), spanning the range [5, 15] for both axes of the plane. For each point, the program computes the choice for each consumer, first removing the product(s) perceived as having one characteristic value below the minimal requirement and then, if both products are perceived as satisfying the minimal requirements, using the modified TTB algorithm. In case the two products are perceived as equivalent on both available dimensions, the consumer is assumed to choose randomly with identical probabilities.Footnote 16
Figure 3 shows the sales for product X and the total sales on the market measured on the vertical axis for each combination of the values of the characteristics \(v_{X}^{1}\) and \(v_{X}^{2}\). The total dimension of the market (obviously the upper surface) shows that only half of the consumers actually buy a product when product X is set to its minimal values, [5, 5]. This is because, at this low level, product X fails clearly to pass the pre-screening stage. Because of the relatively high Δ, many consumers also perceive either \(v_{Y}^{1}\) or \(v_{Y}^{2}\) as below the threshold of 8, and therefore reject even this product (the actual “true” values of which are 10).

Model of a demand function for a market made of two products defined over two characteristics. The two surfaces report the data concerning sales of product X and total sales on the market in respect of different values for the characteristics of firm X, while the other product is assumed to maintain constant quality values
For increasing values of the characteristics of product X, more and more consumers find that either Y or X, or both, pass the minimal requirement threshold, and consequently we observe that the total sales of the market increase, until reaching some 90 % of total consumers with \(v_{X}^{1}=v_{X}^{2}=15\).
Concerning the distribution of consumers over the two products, the graph clearly shows that product X gains market share for increasing values of its characteristics,Footnote 17 fulfilling the first two requirements for an aggregate demand stated above. The graph also shows that total sales increase for increasing levels of the characteristics, proving that the aggregate effects of the proposed model enjoys the compensatory property, in that different combinations of \(v_{X}^{1}\) and \(v_{X}^{2}\) can generate the same level of sales. This result is worth noting because compensation is not implemented in the individual decision procedure, but it emerges as the result of the aggregation of consumers applying the (non-compensatory) modified TTB algorithm.
The exercise shows that the proposed consumer model can generate market demand functions enjoying the expected properties. These properties do not depend on un-supported assumptions concerning consumer rationality or properties of the products, such as homogeneity, either un-realistically assumed or unreliably forced through statistical machinery. Rather, they stem from robust findings on people’s every-day behavior and can be assessed in any desired level of detail by collecting data easily available. For example, the model does not need quantitative estimation of product qualities (which are the major cause of troubles for the estimation of hedonic prices), but simply requires the results of two-by-two simple comparisons, a much easier burden. The robust micro-foundation and the low level of requirement provide two useful advantages in respect of the utility-maximizing approach: the possibility to provide detailed explanations, rather than appealing to exogenous factors; and the possibility to apply the theoretical model for empirical purposes.
Concerning the increased explanatory power of demand based on the proposed model for the consumer, a consequence of our proposal is that every feature of the aggregate behavior, such as, for example, the level of sales of a firm at a particular point, can be directly explained on the basis of the underlining consumers’ behavior. For example, it is possible to assess precisely how many sales are due to the combined effect of minimal requirements or to the superiority of a product in respect of others deemed potentially accessible. Obviously, the net effect may be identical, but the underlying logic and hence economic consequences are very different. In short, every property of the aggregate demand is liable to be explained in terms of consumer economic behavior, rather than justified as depending on un-observable exogenous factors. As we will discuss in greater detail when commenting on the following exercise, this extra layer of economic explanations for consumer behavior between aggregate market results and exogenous factors gives the possibility to assess properly observed phenomena and to make predictions that would be impossible, or far less reliable, otherwise.
Though this work is not primarily concerned with empirical issues, it is worth briefly highlighting how the proposed model’s properties depend on data that have a direct empirical meaning and can be easily collected. This feature makes the model easy to calibrate and its results directly comparable with observation, neatly contrasting with the standard approach the use of which requires complex and difficult to estimate data, providing highly unreliable results. The implementation proposed above for the model adopts functional forms chosen for the clarity of exposition. However, the same conceptual model can be implemented in different formats, much less demanding in terms of information required for its calibration. Concerning preferences, the proposed model requires the ranking of characteristics on which products are defined. This type of information is already regularly surveyed by market research companies to perform specific tests, such as the conjoint analysis (Green and Srinivasan 1978; Marder 1999). Data concerning perception errors and minimal requirements can also be approximated by targeted polls aiming at identifying what motivates consumers in their decisions. The data necessary for the calibration of the model are limited to the percentage of consumers who tend to prefer one or another (or are indifferent) of two product features, and the frequencies can then be turned into probabilities for the events in the TTB comparisons. Similarly, the probabilities of consumers to discard products because they do not satisfy some the minimal requirement may be easily estimated on the base of elementary details on products (e.g. prices) and of socio-demographic data.
The proposed model considers the price of products on offer as merely one among potentially many characteristics. This assumption may appear as problematic, given the particular role of prices for consumers in respect of other aspects of a product. For example, the price elasticity to income is a standard tool that (apparently) is lost with the proposed representation. In fact, the combined effect of minimal requirements and preferences-as-ranking of characteristics not only can implement any property of a demand function, as seen above, but can even root these properties to observable features of consumers improving the interpretative power of the analysis of demand. For example, considering prices, increasing incomes can impact the sales of a product in two distinct ways. First, by increasing the share of the population that can afford high-price items, and second, by relaxing the trade-off between price and other qualities by consumers who, though always potentially able to afford high-price products, find the purchase cost less and less important. Clearly, the two ways in which increasing incomes affect sales are very different, calling for different strategies by sellers.
In conclusion, we have shown that the proposed model can easily be adapted to generate a standard market demand function, made of boundedly rational consumers rather than perfectly rational ones. The resulting demand function is not only fully compatible with those obtained with the standard model, but enjoys further advantages: it relies on easily available data, and does not require complex and unreliable elaborations to deal with multi-dimensional and heterogeneous products. In the next section, we apply the consumer model to support the claim that ignoring demand contributions in the analysis of markets leads to potentially serious mistakes.
3.3 Demand-driven market dynamics
The statement that demand determines the structure of a market may appear trivial, since, ultimately, it is the consumers who decide whether or not to buy a product. However, this statement is usually interpreted in the sense that all that matters about demand is the outcome of consumers’ decisions as reported by sales distribution. According to this perspective, tastes and preferences are the determinants for these decisions and economic analysis cannot but take these decisions as exogenous. A direct consequence from this approach is that markets with the same distribution of sales would be identical for all economic purposes. The goal of the experiments presented below is to challenge this opinion, showing that stopping at the distributional properties of markets and neglecting the economic activities of consumers leads to possibly serious errors.
For this purpose, we compare the results from two simulation experiments representing the development of hypothetical markets made of the same set of suppliers and (almost) identical set of consumers. The demand side in the both experiments represents consumers having identical preferences and constraints, differing for only one of the aspects concerning the way in which consumers make their purchasing decisions. As we will see, the two experiments appear to provide highly similar results, if judged by the mere distributional properties of the market. Conversely, we will show that the two simulation settings generate very different results, proving the importance of demand to understand fully how markets work. We will show that, though the distributions of firms’ sales are similar, the ranking of firms in the two markets is very different in that a leading firm in one case is frequently a mediocre player in the other, and vice versa.
Besides proving our main point on the importance of demand, the simulative nature of the model permits us to investigate the mechanisms by which consumers contribute to shape a market configuration. This possibility will not only lead to a discovery of the reasons for failure or success of firms in respect of different demands (comparative static analysis), but will also permit us to make conjectures on the mechanisms acting in a dynamic analysis, such as the likely events following a supply modification, as, for example, a price change or a product innovation.
In the following, we introduce the common settings of the experiments and then describe the results for the two cases considered. The last paragraph in this section compares the two results and draws the conclusions.
3.3.1 A synthetic model for the evolution of markets
The goal of this exercise is to test the effects of strictly economic behaviors of consumers in shaping observed market configurations. Since our ultimate goal is to identify demand’s contribution to observed market properties, we purposefully build a highly abstract (and, essentially, unrealistic) market in which all possible sources of differentiation other than the economic behavior of consumers are either suppressed or controlled. In the following, we list the common features for both the experiments.Footnote 18
The supply side in both experiments is made of 100 producers each offering one product, defined by a vector of 10 characteristic values. For the purpose of our experiments, we are not interested in assessing specific technological or marketing strategies, and therefore we simply draw randomly the characteristic values and the marketing strategies for each producer. The same random values are used in both experiments, effectively generating two identical supply sides facing two different sets of consumers. During the period covered by the simulation, producers are not allowed to introduce modifications to their products, nor to alter in any way the availability of their products (e.g. no varying costs, supply rationing, entry or exit, etc.). Finally, no product fails to meet any of the minimum requirements for the consumers, so that a consumer has only a problem of choice among different alternatives, each potentially accessible.
The demand side is made up of several thousands of individual consumers, each requiring one unit of the product every few periods, representing the general case of a market for a semi-durable product. The simulation experiments mimic the evolution of a market starting from the sale of the very first item to the earliest customer, up to the saturation of the market when all consumers buy only to replace their previous, supposedly depleted, product.
The dynamic of entry of new customers follows a contagion dynamic, during which the share of actual customers in respect of the population of potential customers changes from 0 to 100 % . The contagion dynamic states that every consumer using the product spreads the bug of being a user to a group of friends, who can be considered as a successive generation of consumers in respect of the “parent” consumer. The number of friends who have never used the product, and can be convinced to enter the market, is supposed to decline steadily through the generations of consumers, under the assumption that late adopters find most of the acquaintances already using the product. As a result of the contagion dynamic, the aggregate dynamic for the dimension of the market, i.e. the number of consumers owning the product, follows the typical s-shaped pattern (see Fig. 4a). We assume that a product lasts a random number of periods before requiring a replacement, so that the level of sales is a fraction of the total number of users, with some noise due to the randomness of product life span (see Fig. 4b).

General settings common for both simulation runs: a the dynamics of consumer entry; b the level of total sales; c the level of \(\Delta^{i}_t\) for single consumers (starting and limit values change for different exercises); d average \(\Delta^{i}_t\) for the whole population of consumers
Each simulated consumer is assumed to be initially poorly trained in assessing the novel technology, causing, during its earliest purchases, comparatively large errors of evaluations when comparing products in respect of one characteristic (see paragraph 2.2.1). Considering that the consumers are supposed to make repeated purchases, we assume that the skills of consumers in assessing product values improve through time. This is represented by imposing a time-dependent dynamic on the error term that, starting from a relatively high value at the time of the first purchases, decreases constantly, approaching an asymptotical value. In a sense, we assume our consumers to “learn” how to evaluate correctly the different products, with high probability of misjudging product values during earlier purchases and increasing precision for later ones.
Formally, we consider that the error term for consumer i at time t \(\Delta^{t}_{t}\) approaches the asymptotic level \(\hat{\Delta}\) with the following dynamic:
For simplicity of interpretation, each consumer is assumed to follow the same “learning” pattern for all the characteristics, and the dynamic is identical for all consumers, with the starting level set at the time of first purchase of the consumer.Footnote 19 Figure 4c reports the resulting pattern, while Fig. 4d shows the resulting population average error term \(\sum_{i=1}^{N} \frac{\Delta_{t}^{i}}{N}\). Parameter \(\hat{\Delta}\) expresses the minimal error possible with maximal experience; this parameter is one of the two elements differentiating the two experiments presented below.
Consumer preferences, defined as the ranking by relevance in descending order of the characteristics, are defined for each consumer at the time of entry. They are set using the algorithm presented above, which takes into account the current market shares of the competing products and the marketing strategies of their producers (see paragraph 2.4.2). Given the relatively low relevance to the parameter affecting the importance of market shares, the distribution of consumer preferences is practically identical in both experiments, resulting in the uniform distribution of characteristics in the consumers’ preferences. That is, there will be the same share of consumers having characteristic j as the most important characteristic in their preferences, as well as any other position in their characteristic ranking.
In the following, we present the results produced with these common settings and varying the values of two parameters. The first is the tolerance level τ, determining the maximum distance between products values on one characteristic that are considered as irrelevant, and therefore assess the two products as equivalent (see paragraph 2.2.2). Setting τ = 0 implies that even minimal quality differences result in a consumer to discard the inferior product. Conversely, in the setting where τ > 0, consumers will consider as equivalent to the best product those with quality levels close to the maximum.
The second parameter differentiating the two experiments is the minimum error allowed to “experienced” consumers (\(\hat{\Delta}=\lim_{t=\infty} \Delta^{i}_{t}\)). Setting this value to 0 permits consumers, after an initial period of “learning”, to observe perfectly the true values of products, avoiding any perception error. Conversely, if this value is strictly positive, even expert consumers continue to make (small) perception errors when observing product values.
In the next two sections we will report the results from two simulation experiments sharing these identical settings but for the values of τ and \(\hat{\Delta}\), so as to assess their role in affecting results. It is worth repeating that, in both cases, we have identical firm features (e.g. products’ characteristic values); also, consumers have the same preferences and any other exogenous conditions (e.g. income constraints). Consequently, any difference in the results derives exclusively from the only differences between the two initializations, parameter τ and \(\hat{\Delta}\). These parameters, affecting the range by which two products are perceived as equivalent and the dispersion of perceived quality values around the actual ones, concern how consumers act on the market and are likely to be heavily influenced by suppliers’ features and choices in real-world conditions. Therefore, our comparison concerns two markets where the supply sides and most of the traditionally considered “exogenous” features of demand (preferences, budget and quality constraints) are identical. We will show that, even in these cases, apparently minor differences in consumer behavior are shown to affect radically firms’ sales rankings and provide diverging indications on the effectiveness of a changes such as price modifications or quality improvements.
3.3.2 Segmentation caused by perception error
As a first exercise, we set τ = 0 and \(\hat{\Delta}>0\).Footnote 20 That is, we assume that consumers have no tolerance for quality differences, implying that they discard a product if its value, in respect of the currently used characteristic, is even slightly lower than the highest value. Since the products’ characteristic values are randomly chosen (as real-valued numbers), this option means that, in effect, consumers will never consider two products as equivalent since there will always be a single dominant product in respect of each characteristic. Consequently, according to the decision algorithm, consumers will only make use of one characteristic to determine which product to buy, since one single round of comparisons of products always produces a single winner. The (only) characteristic used is the highest ranking in their preferences. We may, therefore, consider this setting as if demand were composed by 10 classes, each made by consumers choosing their product simply as the best in respect of one of the 10 characteristics.
The second assumption in this experiment, \(\hat{\Delta}>0\), implies that even experienced consumers (those who have used the product for a long time and have made several rounds of purchases) cannot observe the true values of product characteristics. During each purchase decision, they will make (small) random errors in reading product values that may lead then to misinterpret an actually inferior product as if it were the best. Given the nature of the error (see paragraph 2.2.1), the probability of a product appearing as the best is proportional to its actual value in respect of those of competitors. For example, two products with similar values on one characteristic will have the same probability of being chosen by consumers using that characteristic as decision criterion.
Figure 5 shows the time series of the number of consumers for each product produced with this setting.Footnote 21 The simulated market starts with very few consumers and then expands until reaching full saturation (when all consumers own a product and regularly purchase a replacement). During the first periods of the simulation (until about period 150), all producers enjoy positive growth with relatively small differentiation. This is due to the fact that the growing number of consumers making a purchase in this time frame are relatively unexperienced, with high \(\Delta^{i}_{t}\)’s. Consequently, their perception of product values is likely to be very far from the true values, and consequently their assessment of the best product is essentially random.

Market segmentation by perception errors. One hundred firms are assigned random values for quality and marketing strategies. Consumers are set with τ = 0 and, even in the long term, a limited capacity to read product values: \(\Delta^{i}_{\infty}=\hat{\Delta}>0\)
After this initial period, the first cohorts of consumer starts to gain sufficient experience (i.e. low \(\Delta^{i}_{t}\)’s) to avoid the worst products, causing the fall of sales for many products. This pattern is due to the dynamics of the perception error and is, consequently, common to both experiments. The impact of the specific setting we are considering can then be appreciated only in the second half of the simulation run.
In this experiment, during the final stage of the simulation, consumers always decide by selecting the best product according to one single characteristic because of the zero tolerance level. One may then expect to observe that, at most, 10 firms should maintain positive market shares as leaders in respect of each of the 10 characteristics. Actually, this result would be produced if consumers were perfectly able to read the true characteristic values of products, i.e. \(\hat{\Delta}=0\). Instead, having set \(\hat{\Delta}>0\), we force consumers to make random perception errors even during the final stage of the simulation; this (apparently minor) difference causes very different results.
As the graph clearly shows, there is a relatively high number of firms (much larger than ten) with positive shares, generating a rather varied market configuration. The nature of this market structure can be explained by considering the behavior of the consumers. Given the lack of tolerance, they essentially select their product on the basis of a single characteristic only. However, given the persistence of the perception error, many different firms have positive probabilities to appear as the best in respect of that characteristic. Consequently, even though the criteria adopted by all consumers are just 10 (i.e. the number of characteristics), the number of firms with positive sales is higher because consumers adopting the same criterion (“find the best in respect of characteristic i”) end up choosing different products because of the perception error. The randomness of the error also explains the persistent fluctuations of the series.
The result produced with this setting generates consumers who distribute their choices across several producers, with probabilities depending on the relative values of products in respect of one characteristic. The sales of each product are, therefore, the sum of all consumers the firm is able to attract because of the relative quality on each of the 10 characteristics. These “segments” of demand are independent from each other, since consumers evaluating the best product in respect of one characteristic pay no attention to any other aspect of the product.
Knowing the demand structure of the market allows for a given perspective on the current state of the market and its possible dynamics. For example, a firm may be serving 90 % of consumers aiming at the best product in respect of characteristic i and 30 % of consumers caring for characteristic j. That is, observers can exploit the knowledge of the way consumers behave in the market in order to construct statistics relevant for that specific type of market, for example, defining segments of consumers with similar behaviors.
Concerning the dynamic aspects, suppose that a firm has the opportunity to improve one of the characteristics of its product (say, allocating a given R&D budget or reducing the price). It could estimate the number of additional consumers by comparing the relative quality of competitors’ products in respect of its own improved product for each characteristic. It would then consider how the hypothetical improvement would increase the sales for the two segments of consumers it currently serves, or even consider trying to tap a third segment of consumers by focusing on a characteristic the quality of which is currently too poor to attract any buyer. The decision would then depend jointly on technological conditions (e.g. expected success of the R&D project) as well as on demand features (expected sales gain).
3.3.3 Segmentation caused by complex selection
In the second exercise, we use the same set of producers and general setting as in the first simulation, but we allow experienced consumers to observe perfectly the true characteristic values (\(\hat{\Delta}=0\)) and we impose a positive level of tolerance τ = 0.02. This means that, when comparing products along one characteristic, consumers do not discard dominated products if their values fall within 2 % of the best value among competing products. Consequently, and contrary to the former exercise, there are, in general, several products with equivalent values in respect of any given characteristic. Consumers will then need several rounds of selection to reach a decision, making use of more than one characteristic in their preferences (on average they use 2.4 characteristics). Figure 6 reports the results from this experiment.

Complex segmentation. One hundred firms are assigned random values for quality and marketing strategies. Consumers are set with τ = 0.02 and with perfect capacity to read product’s values, \(\hat{\Delta}=0\)
The earliest periods resemble the previous experiments, since the dominant effect at this stage is the high level of errors of newly entered consumers. The final stage shows some differences and some similarities in respect of the previous experiments. The most prominent difference is the lack of fluctuations in the final half of the simulation. The reason is that, since consumers become sufficiently expert to stop making perception errors (\(\Delta^{i}_{t} \sim 0\)), there is no more randomness in their decisions, and consequently they systematically reach the same decision at any purchasing time. We consider this difference in respect of the previous exercise merely an esthetic issue, since it depends on a technical aspect that plays no role in respect of the results with which we are concerned.Footnote 22 The only consequence is that, when comparing the final market profile between the two experiments, we will use the final sales level for this setting, and the average sales in the final 100 steps for the first exercise.
Besides this difference, this setting replicates a similarly varied market configuration, where many firms enjoy positive market shares. However, this is due to a different mechanism: in this case, we observe the result of the full unfolding of the TTB algorithm (see page 13). The variety of decisions by consumers is due to the variety in the ranking of characteristics of consumers, i.e., in our context, consumer preferences. To clarify how this can lead to such a richly diverse market configuration, consider the following hypothetical example.
Consider two consumers both reaching their purchasing decision after a selection round based on the same characteristic, say 3. If the two consumers have previously used as selection criteria two different characteristics (one, say, characteristic 1 and the other 2), they will then likely apply the final selection round on different sets of products: those scoring highest in respect of characteristic 1, for the first consumer, and the best products in respects of characteristic 2, for the second. Consequently, their choices will likely differ, even though both of them have used the same characteristic, 3, as final criterion. This result shows that consumers, allowing for equivalence among similarly scoring products and with differentiated preferences, will generate a complex market configuration, where many firms will be able to find a customer base even, as in this case, when consumers are not subject to perception errors.
This example shows that, contrary to the former case, the classification of consumers in respect of the characteristic (eventually) used to reach a decision is of little importance in general. Asked for why he decided for a given product, a consumer will give a more articulated explanation than in the previous case: the product is the best in respect of i, but the set among which I chose had already been restricted using characteristics j, k, h, .... The share of the market served by a given firm is composed by widely differentiated sets of consumers, each opting for a product for different reasons. This complexity is also reflected in the estimation of likely events in case of changes in product features. For example, a firm may discover that the poor quality in respect of one characteristic is a bottleneck preventing it from tapping into a large number of consumers. Others will instead find that their product needs only small improvements in several characteristics to become attractive to a larger pool of customers. Though complex, the information required to make sense of this market configuration essentially depends on a few parameters concerning consumer behavior, and the data required to estimate these parameters can easily be collected.
For the purposes of this work, we need not further discuss the properties of the simulated market, but note that they descend from the features of consumers in the market: preferences, information on products, evaluation of differences. Not only are these clearly economic factors, but they are also likely to be heavily influenced by producers, and therefore they fully deserve to be considered not (only) as depending upon non-economic factors but as being part of the elements with which economics deal. Having shown that demand is influenced by economic factors one point remains to clarify: how relevant are these influences in assessing market properties.
3.4 Demand matters
The two experiments presented above generate essentially similar results in that both provide a rather complex distribution of firm size. The results do have some differences, for example, in the small volatility present in the first experiment and its absence in the second. But we consider these differences as merely esthetic, not relevant in respect of the core result in which we are interested: that both settings generate a varied distribution of firms.Footnote 23
Given that, in both experiments, we use the same set of products and that the consumers have identical exogenous features, an observer presented with the two market distributions generated at the end of the two exercises would conclude that, in both cases, we observe a roughly similar ranking of firm size, provided, that is, that demand exogenous features were all that mattered in shaping market configurations. This conclusion is implied by the assumption that sales distribution is sufficient to represent market properties, and only supply side features (and exogenous properties of demand) would matter. Such an approach considers differences in economic activities by consumers (such as our τ and \(\hat{\Delta}\)) merely as different patterns leading to roughly similar eventual results.
It is important to stress the logic behind the claim stated above. Economists generally refer to “preferences” as a catch-all concept referring to any aspect governing the behavior of consumers. Since preferences are assumed to be determined by exogenous factors, with which economists should not deal, it follows that any difference found in markets with identical consumers’ preferences should depend on suppliers’ properties.
Counter to this approach, we proposed an explicit definition of preferences (i.e. ranking of characteristic) to be used as a decision criterion for purchases, distinct from the decision procedure carrying on the purchase activities. The properties concerning the proposed decision algorithm, such as τ and \(\hat{\Delta}\), are part of the consumers’ economic behavior related to, but distinct from, preferences (whether exogenous or not). In a sense, this is the same difference we can consider concerning technological conditions for a firm (exogenous) and, say, the mark-up level, that is part of the economic activities of the firm and, consequently, of interest to economists. The issue we are investigating is whether economic aspects of consumer behavior affect market conditions in any relevant way.
To answer this question, we compare the size of each firm in the final stages for the two experiments. Figure 7 reports these data, showing on the two axes the number of customers recorded in the two experiments, with each point in the graph representing a firm.

Demand-based differentiation. The graph compares the results produced with identical suppliers but different setting for consumers. The graph plots a point for each firm in the model, where the co-ordinates report the average installed base values at the end of simulation runs as produced by the complex segmentation setting on the horizontal axis (data from Fig. 6) and segmentation by perception error setting on the vertical axis (Fig. 5)
If firm ranking in the two experiments were roughly equivalent not only in aggregate distributional terms (e.g. concentration, number firms with positive shares, etc.), but also in the relative ranking of producers, then we would expect to see the points representing firms organized along a positively sloped line. That is, a high selling producer in one experiment would also be a relevant firm in the other, and the differences in the two experiments would be irrelevant to explain firm success. Conversely, the graph shows that firms topping the market ranking in one experiment are, at best, only second league players in the other experiment. For example, the highest selling firm in the second experiment (measured on the horizontal axis) is only the eighth producer in the ranking of the first experiment, selling about half as much as the two largest firms. Many firms lie on the vertical axis, meaning that there are producers, some even with half the size of market leaders in one setting, just failing to get any customer at all in the other setting. In short, the graph shows that the two settings provide radically different market configurations.
This result supports the claim that demand matters not only in the trivial sense that budget constraints, tastes, cultural preferences etc. (i.e. exogenous factors from an economist’s perspective) influence the competitive environment. But also that firm performance is determined by how consumers carry on their purchasing decisions. The means by which consumers’ deploy their tastes and general (exogenous) conditions actually to reach a purchasing decision are activities worthy of being considered within the domain of economics as much as firms’ activities concerning production or R&D that, though ultimately descending from exogenous conditions (cost functions and technological possibilities), are universally considered a legitimate object of study of the discipline. In both cases, we have economic agents taking decisions under the influence of both exogenous and endogenous factors, such as those controlled by other actors. Both consumers and producers reach decisions that can be measured and motivated on the basis of (potentially) observable features, and the aggregate result can be fully explained by economic analysis only considering both sides of markets.
The relevance of demand’s endogenous factors should not be limited to compare static market configurations, as we have done. Though we have no space for discussing the issue, our claim that endogenous demand factors are relevant matters also (and possibly more) for the dynamic analysis of markets. Consider, for example, the estimation of the market reaction one may expect in respect of changes to some aspects of product features, such as a change in price or the modification of some aspects of product quality. Depending on the endogenous features of consumers, the changed supply condition may result in a huge modification or may have only minor, if any, impact on the resulting market configuration. The effect of a change, in fact, depends on how consumers’ decisions are affected by the changes. In our setting, we could, for example, answer questions such as: for a given firm, is it better to have a large improvement in a single characteristic, or relatively small improvements over a large number of different characteristics? The answer is not unique, since it depends on the type of consumers facing the firm. Different types of demands will require different innovation strategies, which our proposed model can, in principle, represent for theoretical as well as for applied investigations.
4 Conclusions
The goal of this work is three-fold. First, and more generally, we want to raise attention to the role of demand in interpreting market properties, particularly among of scholars of evolutionary inspiration. As noted by an increasing number of authors, demand issues are both a crucial aspect of static as well as dynamic properties of markets. Moreover, the traditional assumption of economic rationality is even less defensible for consumers, not subject to any selection, and therefore an alternative representation should be a priority for economists aiming at reforming the mainstream approach. Finally, empirical evidence overwhelmingly shows that firms consider activities such as marketing and sales support as critical to their success, clearly indicating that demand is not treated as an exogenous factor by real-world actors.
The second goal of this work consists in proposing a model for the consumer developed on sound theoretical as well as empirical bases. The aim of the model is to provide a highly general representation for consumers, easily applicable to markets for goods as well as services defined on a multi-dimensional characteristic space. Moreover, further increasing its generality, the model simply demands each alternative choice to be merely assessed as superior or inferior (or equivalent) to others in respect of individual characteristics, admitting ordinal evaluations that are far easier to collect and more reliable than the standard approach to address heterogeneous products. Finally, the features of consumer behavior governing the model are shown to be intuitive and generally depending on data easy to collect, supporting the model not only as a tool for theoretical research, but also, potentially, as an instrument for empirical applications.
The third goal of the work is to provide a preliminary assessment of the model as a tool for addressing both theoretical and empirical issues. It is, first, used to suggest a formal definition of preferences considered, appropriately, as decision criteria rather than, as frequently happens in the literature, a vague justification for whatever consumer behavior may be observed. As a second application, the individual consumer model is used to construct a market demand function defined over two characteristics. This exercise shows the possibility of the proposed model to generate standard market demand functions, with the relevant advantage, in respect of the utility-based, perfect rationality approach, that it can be easily applied to markets for heterogeneous products and its properties rely on few, intuitive and observable parameters.
The last, and most ambitious, application of the proposed consumer model aims at assessing if (and how) the analysis of demand provides relevant information concerning a given market configuration. A negative answer would mean that all we need to know about demand is its outcome as expressed in sales levels or market shares; in this case, an in-depth investigation of how consumers behave is of little interest in respect of the general properties of markets. Conversely, discovering that consumers sharing identical exogenous factors but different purchasing (i.e. economic) activities produce different market configurations would mean that the source of this differentiation does matter. We describe two agent-based simulations representing the same hypothetical, highly stylized, market. All conditions are identical in the two exercises but for two aspects concerning how consumers reach their purchasing decisions. Simulation results for the two cases are shown to be highly similar if evaluated in terms of aggregate distributional properties as represented by firms’ size distribution. However, the two cases are shown to be actually radically different in two respects: first, in a static sense, because the ranking of the (identical) firms in the two cases is totally different, proving that you can only explain a firm success or failure by considering, together with tastes and other external factors, the way in which consumers behave on the market, i.e. their economic activities; second, in a dynamic sense, because the same event in the two hypothetical conditions would trigger very different results, making the economic analysis of demand determinant for the assessment of possible competitive strategies, such as innovations, pricing, etc. From this result, we conclude that any investigation of a market cannot prescind from an analysis of its demand side, which should be given as much relevance as the supply side in describing market properties.
Given its generality and relatively simplicity of implementation, the proposed model can be easily embodied in broader models for markets, so as to make possible the study of market dynamics as the interaction between demand and supply, and not, as too frequently happens, only as a supply-centered analysis dealing with suppliers’ costs, innovations, organizational issues, etc.
The adoption of the proposed model for consumer opens many possible lines of research. Focusing on the role of demand, the consumer model can be applied to study different combinations of its parameters, as well as different distributions of consumers. Exploring the results produced by different configurations will lead to a detailed analysis of the effects of the model’s parameters and their results on observed properties. Another, interesting goal is to use the model to identify classes of market configurations each including markets with common features, such as conditions mandating similar innovation strategies to participant firms.
In a broader perspective of market evolution, the model may be exploited to study the effects of endogenous interactions between supply and demand. In fact, innovation and marketing strategies can be designed to react adaptively to a firm customer base, either actual or potential. The suppliers’ changes will then affect demand by influencing not only the set of products available for purchase, but also the preferences guiding consumer decisions. The study of supply-demand interaction may then lead to potentially fruitful results concerning the pattern of markets’ evolution (Valente 2000).
In a theoretical perspective, it would be interesting to test the limits of the claimed generality of the model, for example, studying its applicability in specific types of markets, such as business-to-business markets, on-line sales, etc. It may be useful as either a confirmation of the validity of the model to span its applicability across different types of demand, or identifying inadequacies that may lead to amendments, improving the model for general applications.
Another promising field is the deployment of the model in empirical studies. The data necessary for the model are relatively few and easy to collect or, at least, to derive from existing data sets collected by companies in the market research sector. The proposed model can be tested by assessing its capacity to replicate historical records, and may be used to investigate how hypothetical changes (prices or quality changes, new competitors or new regulation, etc.) will affect specific properties. These applications may contribute to the analyses by all subjects interested in markets features: firms, regulators and policy makers. The current techniques are based on a theory seriously biased in favor of features from the supply side of markets. A more balanced theoretical analysis of markets, giving demand its fair share of attention, can be expected to find uses in many fields.
Notes
For example, optimizing short-term profits may undermine longer term measures of success, and vice-versa.
For simplicity, in the following we will refer to products only, dropping the reference to services, even though the model proposed, and the results presented, apply to both types of markets.
We ignore the case of products that may have different uses. In this case, the same product feature may be evaluated in different ways depending on the use considered, complicating the representation (e.g. requiring consumers to be stratified in different classes) but not affecting the theoretical results, which are our main concern.
For simplicity of exposition and without loss of generality, we assume that all characteristics are positive, so that product X is preferred to Y if \(v_{X}^{i} > v_{Y}^{i}\). For example, a characteristic may not be “price”, but rather “cheapness”, possibly defined as the inverse of price.
A recent literature questions whether industrial classification systems are valid instruments for competition studies, since producers sharing the same technology may actually target quite different sets of consumers. Similarly, a given user need can be served by products based on rather different technologies, and therefore classified in distant industries. The combined effect of the two errors may generate misleading results from empirical data. For example, firms sharing the same pool of potential consumers should show negative correlation between their market shares, at least in some cases. Conversely, it has been shown that such an event is rare (Sutton 2007) and that the empirical evidence is much more complex than what could be expected (Coad and Valente 2010).
These constraints form technological paradigms, a change in which leads to new technological trajectories (Dosi 1982).
For a thought-provoking discussion on the methodological relevance of the endogenous change of vector dimensions in the science of complexity, see Fontana and Buss (1996), who call for a calculus of objects expected to be as revolutionary as the numerical calculus has been in mathematics.
In case more than one option remains and there are no more characteristics to perform further rounds of filtering, the algorithm mandates choosing randomly from among the surviving options. Alternative tie-breaking rules may easily be devised for particular cases. However, for our purposes, we can ignore this detail, leaving in the implementation the original proposal.
Notice the difference between preferences and tastes. While preferences are the criteria applied to reach a decision, tastes consist in the ordering of the instances of a characteristic. For example, two different users may give high importance to the characteristic “color” in their preferences. However, they may differ in their tastes, so that the instance “white” is evaluated by one consumer as better than “red”, while another consumer may have opposite tastes. For obvious reasons of simplicity, in the following we will assume that all consumers share the same tastes, using real-valued variables as instances of characteristics. Thanks to Marco Guerzoni for raising this point.
By this catch-all term we mean every firm’s activity addressing actual or potential customers including advertising, sales promotions, etc.
At the time of writing, googling “failed marketing” provides about 174 million entries, the first being the self-explaining: http://www.prospectmx.com/15-hilariously-failed-marketing-campaigns/.
For an application of this implementation in a theoretical model, in Valente (2000) a firm’s marketing strategy is endogenized on the basis of information collected from actual and potential (and failed) sales.
Variations of the proposed model has been used in several works: to represent the evolution of a market with product-embodied innovations (Valente 2000); to explore demand’s contribution to a series of particular market configurations (Valente 2009); to represent classes of heterogeneous consumers in a micro-founded macro-economic model (Ciarli et al. 2010); to evaluate environmental policies in markets where consumers face the trade-off between polluting and cheap vs green and expensive products (Bleda and Valente 2009).
We consider the number of households between 15,000$ and 200,000$ of income, generating 37 classes for each 5,000$ bracket. Data from the US Census Bureau for 2010, table HINC-06 (http://www.census.gov/hhes/www/cpstables/032011/hhinc/new06_000.htm). The original figures have been re-proportioned to represent a total of 10,000 households.
An important technical property of the proposed model is that the results are independent to monotonic changes to the variables. Thus, representing “cheapness” as 1/p or as p max − p makes no difference to the results, since decisions are based on comparisons that are invariant to monotonic functions.
All the simulations in the paper have been developed with the simulation platform LSD (Valente 1997, 2000, 2008). LSD can be downloaded from www.labsimdev.org. The model’s code and configurations of the experiments are available upon request.
We do not report the sales level for product Y. However, these values can be induced from the vertical difference between the total sales levels and that for the sales of X, which is clearly narrowing for increasing levels of \(v_{X}^{i}\).
For reading convenience, we leave out from the text most of the numerical details on the model parameterizations. The complete list of values used for the simulations is reported in the Appendix A. The code and configuration files to replicate the model results are available upon request.
It would be easy to implement differentiated error terms for different characteristics, so that, for example, even naive consumers could be perfectly able to assess price differences. However, given the goal of this experiment such a concession to realism (as many others that could be easily introduced) would not contribute in any way to the core result we are pursuing.
The choice adopted for the two values for τ and \(\hat{\Delta}\) is solely motivated by the requirement to compare results under two extreme cases, and there is no implication that these values have some realistic foundation.
This and the following result concern a single simulation run. Since the model includes several random elements, it is theoretically possible that the results presented are unique and could change significantly when the simulation is repeated using different random values. To show that this is not the case, we report in the Appendix B a statistical test of robustness for the results, showing that the effect of random factors on results is minimal, and therefore individual runs are representative of each model setting.
Leaving some randomness in the consumer behavior would have increased the apparent similitude between the two results, but would have not contributed in any way to explaining the factors behind the results discussed below.
To improve the similarity of results between the two experiments, we could have assigned smallish values to τ and \(\hat{\Delta}\) instead of 0, respectively. This choice would have made easier to sustain the similarity of the results, but would have made it more difficult to disentangle the effects of the two parameters and to discuss the contributions of demand to the results in the two experiments.
On purely theoretical grounds, it may also be possible that the random values used to set the suppliers’ conditions affect the result. For example, that our claim holds only for the very specific distribution used, but not for others. Trivially, for example, if all firms were set to identical values, our claim would not hold. However, considering that we used thousands of random values to set those values, we can safely assume that no bias in our reasoning can be derived from this objection.
References
Anderson SP, De Palma A, Thisse J-F (1992) Discrete choice theory of product differentiation, 2nd edn. MIT Press
Aversi R, Dosi G, Fagiolo G, Meacci M, Olivetti C (1999) Demand dynamics with socially evolving preferences. Ind Corp Change 8:353–408
Bleda M, Valente M (2009) Graded eco-labels: a demand-oriented approach to reduce pollution. Technol Forecast Soc Change 76(4):512–24
Bowles S (1998) Endogenous preferences: the cultural consequences of markets and other economic institutions. J Econ Lit 36:75–111
Ciarli T, Lorenz A, Savona M, Valente M (2010) The effect of consumption and production structure on growth and distribution. a micro to macro model. Metroeconomica 61(1):180–218
Coad A, Valente M (2010) Hunting for a bogeyman? in search of statistical evidence of direct competition between firms. Mimeo
Cowan R, Cowan W, Swann P (1997) A model of demand with interaction among consumers. Int J Ind Organ 15:711–32
Devetag M (1999) From utilities to mental models: a critical survey on decision rules and cognition in consumer choices. Ind Corp Change 8(2):289–351
Dosi G (1982) echnological paradigms and technological trajectories: a suggested interpretation of the determinants of technological change. Res Policy 11:147–62
Fontana W, Buss LW (1996) The barrier of objects: from dynamical systems to bounded organizations. In Casti J, Karlqvist A (eds) Boundaries and barriers. Addison-Wesley, Massachusetts
Gallouj F, Weinstein O (1997) Innovation in services. Res Policy 26(4–5):537–556
Gigerenzer G (2000) Adaptive thinking: rationality in the real world. Oxford Universtiy Press
Gigerenzer G, Goldstein D (1996) Reasoning the fast and frugal way: Models of bounded rationality. Psychol Rev 103(4):650–69
Gigerenzer G, Selten R (eds) (2000) Bounded rationality: the adaptive toolbox. MIT Press
Green P, Srinivasan V (1978) Conjoint analysis in consumer research: issues and outlook. J Consum Res 5:103–23
Hulten CR (2003) Price hedonics: a critica review. Econ Pol Rev 9(3):5–15
Kahneman D, Slovic P, Tversky A (eds) (1982) Judgment under uncertainty. Heuristic and biases. Cambridge University Press, Cambridge and New York
Klepper S, Thompson P (2006) Submarkets and the evolution of market structure. Rand J Econ 37–4:861–886
Lancaster K (1966) A new approach to consumer theory. J Polit Econ 74(2):132–157
Malerba F, Nelson R, Orsenigo L, Winter S (2007) Demand, innovation, and the dynamics of market structure: the role of experimental users and diverse preferences. J Evol Econ 17:371–399
Marder E (1999) The assumptions of choice modeling: conjoint analysis and SUMM. Can J Mark Res 18:1–12
Metcalfe J (2001) Consumption, preferences and the evolutionary agenda. J Evol Econ 11(1):37–58
Nelson R (1970) Information and consumer behaviour. J Polit Econ 78(2):311–329
Nelson R (1994) The coevolution of technology, industrial structure and supporting institutions. Ind Corp Change 3(1):47–64
Nelson R, Consoli D (2010) An evolutionary theory of household consumption behavior. J Evol Econ 20(5):665–87
Nelson RR, Winter SG (1982) An evolutionary theory of economic change. Belknap Press, Cambridge, Mass, and London
Saviotti P, Metcalfe J (1984) A theoretical approach to the construction of technological output indicators. Res Policy 13(3):141–51
Saviotti PP (2001) Variety, growth and demand. J Evol Econ 11(1):119–142
Saviotti PP (ed) (2003) Applied evolutionary economics: new empirical methods and simulation techniques. Edward Elgar Publishing
Shafir E, Simonson I, Tversky A (1993) Reason-based choice. Cognition 49(1):11–36
Simon HA (1982) Models of bounded rationality. MIT Press, Cambridge
Smallwood A, Conlisk J (1979) Product quality in markets where consumers are imperfectly informed. Q J Econ 93(1):1–23
Sutton J (2007) Market share dynamics and the ‘persistence of leadership’ debate. Am Econ Rev 97(1):222–241
Tversky A, Kahneman D (1981) The framing of decisions and the psychology of choice. Science 211(4481):453–458
Valente M (1997) Laboratory for simulation development user manual. IIASA Interim Report R-97-020, IIASA, Laxenburg, Wien
Valente M (2000) Evolutionary economics and computer simulations - a model for the evolution of markets. Ph.D. thesis, University of Aalborg, Denmark
Valente M (2008) Laboratory for simulation development user manualy for simulation development - lsd. LEM working papers series 2008/08, LEM, Pisa
Valente M (2009) Markets fo heterogeneous products: a boundedly rational consumer model. LEM working papers series 2009/11, LEM, Pisa
Windrum P, Birchenhall C (1998) Is product life-cycle theory a special case? dominant designs and the emergence of market niches through coevolutionary learning. Struct Chang Econ Dyn 9(1):109–34
Windrum P, Ciarli T, Birchenhall C (2009) Consumer heterogeneity and the development of environmentally friendly technologies. Technol Forecast Soc Change 76(4):533–51
Witt U (2001) Learning to consume - a theory of wants and the growth of demand. J Evol Econ 11(1):23–36
Author information
Authors and Affiliations
Corresponding author
Additional information
This work is a development of part of my doctoral thesis discussed at the University of Aalborg, Denmark, Department of Business Studies, as a member of DRUID, Danish Research Unit for Industrial Dynamics. I wish to thank Esben Sloth Andersen for his careful supervision and plenty of useful suggestions. Preliminary versions of this paper benefited from several readers’ comments, among which I am particularly indebted to: D. Consoli, G. Dosi, G. Fagiolo, K. Frenken, L. Marengo, R. Nelson, E. Sevi, U. Witt. An anonymous referee provided valuable suggestions. I acknowledge financial support from the European Commission 6th FP (Contract CIT3-CT-2005- 513396), Project: DIME - Dynamics of Institutions and Markets in Europe. Usual caveats apply.
Appendices
Appendix A: Simulation data setting
Table 3 reports the parameters values and variables initializations used in the simulations runs for the market segmentation experiments discussed in the paper. The table also briefly describes the main dynamics of the model not described in the main body of the paper. The code used for the generation of the results presented in the paper is available upon request.
Appendix B: Robustness
The concept of robustness concerns the persistence of a claimed result varying the initialization of the model. How to support the claim of robustness of a result depends, obviously, on the nature of the result itself. For example, a simulation model may be used to assess properties of the whole time pattern of (some) variables, or only their final values. It may well be possible that simulation runs generated with different parameter values produce widely different patterns, all leading to essentially identical final values. Without a clear specification of the claimed results, one may contradictorily conclude that the results are at the same time robust and not robust. Hence the need to specify in detail the nature of the result and how it may be confirmed or rejected.
In our case, the claim is that two initializations of the model lead to final distribution of sales across firms with similar aggregate distributional properties, but generated by different ranking of firms by sales. We consider this core point as proven by the evidence presented in the main body of the paper. What we still need to show is the claim that the difference between the two cases depends on the two specific parameters differing in the two settings and not, instead, on other differences between the two models.
To reduce to the minimum the possible sources of differentiation between the two settings, the simulation experiments are purposefully built using exactly the same values for almost all parameters in the model. The only difference between the two experiments, besides the behavioral parameters discussed in the text, are the random values used during the simulation run (the random values drawn before starting the simulations, used to initialize product qualities and marketing strategies, are the same in both settings). Therefore, we need to perform a test directed to measure the robustness of our result in respect of the random events occurring during simulation runs.Footnote 24 We consider each of the two settings independently, aiming to show that each of them systematically provides identical results, and therefore it is legitimate to use a single representative run.
The model generates results depending partly on the deterministic structure of the model (initialization and deterministic equations) and partly on random factors. Random events are used in the following functions:
-
Time of entry of new consumers.
-
Characteristics’ values perceptions
-
Preferences’ formation.
A few sample runs, using the same settings and different random series, show that the structural contributions are dominant in respect of random elements: in each of the test runs performed, every firm obtained almost identical results (i.e. market shares) with only fractional differences between different runs. For the sake of completeness, in this section we provide statistical evidence for the irrelevance of these random variations.
We compute a test for the hypothesis that the final level of sales for each firm is identical across different simulation runs. In other terms, the result would fail the test if we found that, across different repetitions of simulations with the same settings and different random events, firm sales assume very different values. In the following, we formalize the test reporting some statistical indicators computed on the data from different simulation runs.
We consider 10 runs generated with the same initial setting and using different series of random values. We assume that a model outcome (final firms’ sales levels) depends partly on their structural properties (initial values and dynamic equations) and partly on randomness. We consider each firm’s series as an instance of a (partly) stochastic process, the overall variance of which (structural and stochastic) can be approximated by the variance shown by the whole population of firms in a single run. Indicating with \(x^{k}_{i}\) the final level of sales of firm i produced during the k th simulation run, and x k the average of all firms sales produced during simulation run k, we can then define the total variance of our series for simulation k as:
Since we have 10 simulation runs, we can take the average of this variance over different runs to get a more reliable estimate of the total variance of the process generating the firms’ results.
We can consider this index the intra-simulation variance of our results; it is an estimation of the total variety that firms are subject to during a simulation run as the cumulative effect of structural and random effects.
To estimate the contribution of randomness, we use the values from each specific firm across different simulation runs. The variance computed over these 10 values (data for one firm over all simulation runs) will indicate the variety due to differing random events only, since the structural properties of the firm are the same across all simulations.
where x i is the average value for firm i across all the 10 simulation runs. Having 100 firms, we can take the average of 100 cross-simulation variances as an estimation of the variety induced by randomness only.
We call this index inter-simulation variance, because it indicates the variety generated by comparing structurally identical processes across simulations using different random events.
Table 4 reports the values for these indicators for the two simulation settings discussed in the paper. As a rough indicator of the distribution, we also report the maximum and minimum variance values obtained by the two samples of 10 simulations and 100 firms for the intra- and inter-simulation variance respectively. As an indication of the contribution of randomness to the model results, we report the ratio between inter-simulation variance and intra-simulation variance. This ratio will be 0 in case there were no variance due to randomness, that is, each firm provides perfectly identical results for each run. Conversely, the index would be 1 in case the variance across firms registered during a simulation run is identical to the variance registered by any given firm in different simulation runs.
The data clearly indicate that the variance generated in any given run across all firms account for more than 99 % of the variance computed also across different runs. This can only be obtained if the values of sales for a firm differ from the values for other firms but is practically constant in different simulation runs.
Rights and permissions
About this article
Cite this article
Valente, M. Evolutionary demand: a model for boundedly rational consumers. J Evol Econ 22, 1029–1080 (2012). https://doi.org/10.1007/s00191-012-0290-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00191-012-0290-4
Keywords
- Evolutionary economics
- Consumer theory
- Bounded rationality
- Marketing and preferences
- Simulation models
- Market structure