
Abstract
Different designs of receiver correlators and front ends will cause different biases in terms of the pseudorange. In this paper, we present an algorithm to derive GNSS receiver-dependent code biases by estimating an additional code bias for each satellite based on different orbit and clock products and apply the calibrated biases in user positioning. One-month data from 117 globally distributed multi-GNSS experiment stations are selected to analyze the characteristics of BeiDou Navigation Satellite System (BDS) code biases, including BDS-2 and BDS-3 satellites. It is shown that the BDS code biases on B1I and B3I signals differ by receiver type, receiver model, antenna type, or even unknown factors. The code biases on BDS-2 satellites can reach up to 4 ns from peak to peak, while they are within 2 ns for BDS-3 satellites. The receiver-dependent code biases are calibrated based on the broadcast ephemeris and the precise products. With a correlation coefficient of approximately 0.9, it is demonstrated that the calibrated code biases are in agreement not only among different products, but also with previous result of BDS-2. To validate the effect of the calibrated code biases, we apply them in single point positioning (SPP), precise point positioning (PPP), and real-time kinematic (RTK) positioning. It is proven that with corrected BDS code biases, SPP users will benefit from an overall improvement of 9.5%, 9.9%, and 27.4% at B1I, B3I, and B1I/B3I ionosphere-free frequencies. For the ionosphere-free based positioning using BDS-3 only, the impact of code biases cannot be ignored. The corrected code biases will accelerate the convergence performance in PPP. For RTK applications, especially for single-frequency users, the fixing rate and ratio values will also improve when the code biases are corrected.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
By the end of September 2019, the Chinese BeiDou Navigation Satellite System (BDS) consisted of 15 BDS-2 and 19 BDS-3 satellites in operation. With the continuous launch of new BDS satellites, the third phase of BDS is planned to be completed by the end of 2020, which will consist of 3 Geostationary Orbit (GEO), 3 Inclined Geosynchronous Orbit (IGSO), and 24 Medium Earth Orbit (MEO) satellites (CSNO 2018a). The BDS constellation will gradually make a transition from BDS-2 to BDS-3. Nevertheless, the coexistence of BDS-2 and BDS-3 will last for a few years. With the current satellites in orbit, BDS can provide a global positioning, navigation, and timing service, with a positioning accuracy within 10 m (95%) in the horizontal and vertical directions (CSNO 2018b; Zhang et al. 2019a).
As a rapidly developing system, BDS exhibits some special characteristics in terms of observations. Hauschild et al. (2012) first report the variation of elevation-dependent multipath error in the BDS MEO satellite. Wanninger and Beer (2015) calibrate this satellite-induced code variation for BDS-2 IGSO and MEO satellites and give an elevation-dependent and frequency-dependent correction model. Furthermore, Lou et al. (2017) found similar code bias variation for BDS-2 GEO satellites based on globally distributed stations and suggest a third-order polynomial correction model. With such satellite-induced code variation being corrected, the improvements in BDS-2 ambiguity resolution, precise point positioning, and precise orbit determination can be observed (Wanninger and Beer 2015; Guo et al. 2016; Lou et al. 2017; Geng et al. 2017). For the experimental BDS-3 (BDS-3e) and BDS-3 satellites, it is found that these kinds of code biases are significantly reduced (Zhang et al. 2017, 2019b; Yang et al. 2018; Xie et al. 2018).
In addition to the satellite-induced code variation, a receiver-related bias also exists for BDS-2 satellites. Gong et al. (2018) analyze the receiver-dependent code biases of BDS-2 and find that these biases are not only receiver manufacturer dependent, but also even receiver model dependent. For example, code biases for the Septentrio receiver can be divided into two groups, namely POLARX4/POLAR4TR and POLAR5/POLAR5TR. However, for the Trimble receiver, although two apparent groups of code biases are also observed for the same satellites, no classification rule can be concluded.
The receiver-dependent code biases may result from the different designs of receiver front ends, correlator spacing, and multipath mitigation techniques adopted in receivers, which may lead to inconsistencies in differential code bias (DCB) estimation (Hauschild and Montenbruck 2016a, b). Montenbruck et al. (2014) and Wang et al. (2016) prove that when different networks of receivers are employed, a bias between the estimated DCB will exist. Hauschild et al. (2019) further assess the difference of DCB and satellite clock solutions based on different receiver types. However, other effects such as different antenna types are not taken into account in the study and the results of the newest BDS-3 satellites are not discussed. For BDS, it is reported that the BDS monitoring receivers are made by Chinese manufacturers and multiple parallel narrow correlation techniques are adopted, while wide correlation techniques are widely adopted in commercial receivers (Tan 2018). Therefore, a bias between the BDS-2 broadcasted timing group delay (TGD) and the DCB provided by the multi-GNSS experiment (MGEX) is also found (Montenbruck et al. 2014; Zhang et al. 2016). Since July 2017, this bias is significantly decreased (Wang et al. 2019a), as the narrow correlated pseudorange is replaced by the wide correlated pseudorange in the BDS control segment (Zhang et al. 2020). Meanwhile, an apparent TGD difference between BDS-2 and BDS-3 is observed, which can be 3.8 ns in TGD1. Wang et al. (2019a) infer that different monitoring receivers are employed in the BDS-2 and BDS-3 control segment. Additionally, Li et al. (2019) find that when a network with mixed receivers is processed, the estimated receiver DCB differences between BDS-2 and BDS-3 are not close to zero. Li et al. (2019) attribute this to the different receiver manufacturers. Therefore, it is worthwhile to further investigate the characteristics of the receiver-dependent code bias of BDS-3.
Although Gong et al. (2018) have analyzed the receiver-dependent code biases of BDS-2 and find they are related to receiver types, there are some limitations in their research, as follows: (1) The estimated biases are based on B1I/B2I ionosphere-free combination and are not applicable to single-frequency users; (2) the calibrated biases are referred to the Trimble receiver, whereas neither the clock in the broadcast ephemeris nor that in the precise products is aligned to it, which makes the provided biases not applicable at a single station. Considering limitation (1), Zheng et al. (2019) proposed a new method to calibrate the BDS-2 receiver-dependent code biases of each frequency based on triple-frequency observations. However, limitations (2) remain. Besides, for BDS-3 satellites, triple-frequency data are not currently available on many types of receivers. Therefore, for users adopting broadcast ephemeris or MGEX precise products, it is necessary to provide a correction model on each frequency including BDS-2 and BDS-3.
The aim of this research is to investigate and calibrate the code biases among different receivers with the current BDS constellation. First, the algorithm of code biases estimation is presented. Then, the data and settings for BDS code biases estimation are introduced. Based on the data, we fully analyze the characteristics of BDS code biases and carefully calibrate them. With the calibrated values, we apply them in single point positioning (SPP), precise point positioning (PPP), and real-time kinematic (RTK) to validate the impact of BDS receiver-dependent code biases. Finally, some conclusions are presented.
2 Method
For GNSS pseudorange observations, the clock error from satellites differs by frequencies due to the code interchannel bias, which is called TGD or DCB (Odijk 2017). For the BDS satellite clock in the broadcast ephemeris, it refers to the B3I frequency (CSNO 2018a), and TGDs are the corrections from B3I to other frequencies. Taking the BDS raw observation at frequencies of B1I and B3I as an example, their positioning model can be written as:
where \(P_{i}\) is the raw measurement of the pseudorange at frequency i; \(t_{{{\text{rcv}}_{i} }}\) is the receiver clock offset including the receiver hardware delay at frequency i; \(t^{{{\text{sat}}}}\) is the satellite clock offset on B3I; \(\delta_{{{\text{rela}}}}\) is the satellite relativity correction; \(\delta_{{{\text{trop}}}}\) and \(\delta_{{{\text{iono}}}}\) are the troposphere and ionosphere delays, respectively; \(f_{{1}}\) and \(f_{3}\) are the frequencies of BDS at B1I and B3I, respectively; TGD1 is the TGD correction from B3I to B1I; and \(\delta_{{{\text{P}}_{i} }}\) is the pseudorange observation noise.
Note that it is usually assumed that the TGD correction on one satellite is the same for all receivers in Eq. (1). However, it is proved that the TGD is related to the designs of receiver front ends, correlator spacing, and multipath mitigation techniques (Hauschild and Montenbruck 2016a, b), therefore resulting in different values on different receivers. Assuming that an additional code bias exists after the common TGD correction, Eq. (1) can be rewritten as:
where \({\text{cb}}_{i}\) stands for the code bias after TGD correction at frequency i, which is considered as a constant value on each satellite.
For static stations, with known coordinates, we could derive the satellite-dependent code biases using Eq. (2). In Eq. (2), the satellite clock and coordinates can be derived from the broadcast ephemeris or the post-processed precise products. The troposphere and ionosphere delays can be corrected by models. Other errors such as satellite relativity, phase center offset/variation, and the station tidal effect can be precisely modeled. Therefore, the remaining unknown parameters in Eq. (2) are the receiver clock and the satellite-dependent code biases, which are linearly correlated. To separate them, one can constrain the sum of the code biases as zero (Gong et al. 2018; Zheng et al. 2019).
The signal-in-space range error (SISRE) of BDS-2 is worse than BDS-3 (Zhang et al. 2019a), and the GEO and IGSO satellites of BDS-2 are not visible by all stations, or at a low elevation, which may suffer from a severe multipath effect, whereas current BDS-3 are all MEO satellites and are visible by all stations. We decide to constrain the sum of code biases for BDS-3 as zero:
where s is the satellite PRN of BDS-3, with a minimum value of 19 and a maximum value of 37, since there are few stations that are capable to track satellites with PRN larger than 37 when this research is carried out.
Note that in Eq. (2), the code biases are based on the input orbit, clock, and TGD products. When different products are used, the corresponding code biases are also different. In the research of Gong et al. (2018) and Zheng et al. (2019), the code biases are differenced with respect to a reference station to eliminate the effect of satellite clock error. However, when using the calibrated code biases, the corresponding satellite clock referred to the reference station should also be adopted, which is not available as public product. Therefore, to get the code biases based on the available products, i.e., the broadcast ephemeris or the MGEX precise products, we decide not to adopt the differencing strategy.
For the stochastic model of the code observation in Eq. (2), it can be described as:
where \(\sigma\) is the variance of the code observation, while \(\sigma_{{{\text{SISRE}}}}^{{}}\), \(\sigma_{{{\text{Trop}}}}^{{}}\), \(\sigma_{{{\text{Iono}}}}^{{}}\), and \(\sigma_{{{\text{Meas}}}}^{{}}\) stand for the SISRE of the BDS satellites, the troposphere error after model correction, the ionosphere error after model correction, and the measurement noise of the pseudorange.
For the estimation of the code biases, the satellite coordinates, satellite clock, and TGD are derived from the broadcast ephemeris or the precise products. According to the current research (Li et al. 2019; Zhang et al. 2019a), the SISRE of BDS is set as:
The troposphere delay is corrected by the GPT2w and VMF model (Böhm et al. 2015). The ionosphere delay is corrected by the Global Ionosphere Maps (GIM) model for single-frequency data (Schaer et al. 1998), and the corresponding variance is defined by:
where \({\text{mf}}_{{{\text{Trop}}}}\) is the mapping function of the slant troposphere correction and 0.05 m is regarded as the precision of the GPT2w model (Böhm et al. 2015), \(\sigma_{{{\text{VTEC}}}}\) is the precision of the vertical ionosphere correction from GIM model, and \({\text{mf}}_{{{\text{Iono}}}}\) is the mapping function at the pierce point position.
To mitigate the multipath and noise error from low-elevation satellites, we set the cutoff elevation as 15°, and the measurement noise is determined by an elevation-dependent function (Zhang et al. 2019a):
where Ele is the satellite elevation and \(\sigma_{0}\) is the measurement noise of the pseudorange observation, which is set as 0.3 m.
By applying the least-squares method, the code biases on each satellite can be estimated together with the receiver clock, in which the code biases are estimated as constant parameters, while the receiver clock is different at each epoch and estimated with white noise. Note that, in this research, we focus on the analysis of B1I and B3I signals, as they are the common signals of BDS-2 and BDS-3 satellites.
3 Data collection and settings
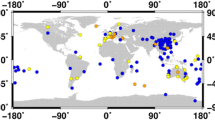
For the estimation of BDS code biases, 117 globally distributed MGEX stations with the ability to track BDS-2 and BDS-3 signals are selected (Johnston et al. 2017), as shown in Fig. 1. The stations in the Americas are excluded from our selection as the visible satellite number is still limited in these regions (Zhang et al. 2019a). These stations are equipped with different receiver types, including Javad, Septentrio, Trimble, and Leica. The detailed receiver information of these stations is summarized in Table 1. Note that among all the receivers, the Septentrio receiver with the POLARX4/4TR model and all Leica receivers cannot track the B3I signal. Therefore, for these receivers, only code biases of B1I will be analyzed in the following results. A similar problem occurs on some satellites for the Septentrio receivers with the POLARX5/5TR model, except for the latest firmware version 0.0.0–181002 and 5.3.0. As for the Trimble and Leica receivers, pseudo-random noise (PRN) numbers larger than 30 cannot be tracked by the time of this research, which may also be due to a firmware problem. Among the Trimble receivers, three of them are equipped with the latest model of ALLOY, whereas the others are equipped with the NETR9 model. It should also be pointed out that for each identical receiver type, various types of antennas are employed.

One hundred and seventeen selected MGEX stations for BDS code biases calibration. The red, green, blue, and black points stand for the Javad, Septentrio, Trimble, and Leica receivers, respectively. The smaller map shows the enlargement of stations located in European regions
For a reliable and statistical result, one month of data spanning from the day of year (DOY) 161 to 190 in 2019 are collected at these stations with a data sampling rate of 30 s. Note that during the experimental period, the receiver type, receiver model, firmware version, and antenna types are kept unchanged.
4 Analysis of calibrated BDS receiver-dependent code biases
Following the code biases estimation methodology, we derive the daily BDS code biases of each station at B1I and B3I frequencies using one month of data. Note that in the following analysis, the code biases are referred to the biases after TGD or DCB correction. Based on the statistical results, we discuss the characteristics of the receiver-related code biases and the relationship of code biases derived from different products and compare the code biases of BDS-2 with those obtained by other researches.
4.1 Calibrated BDS code biases from the broadcast ephemeris
Based on the BDS broadcast ephemeris, the one-month results of BDS code biases are estimated. The averaged values at B1I and B3I frequencies for three BDS-2 satellites with different orbit types, namely C03, C10, and C12, and three BDS-3 satellites, namely C21, C27, and C33, are depicted in Figs. 2 and 3. As concluded by Gong et al. (2018), the code biases are receiver-type dependent. Therefore, we separate the code biases into different groups by receiver type, as shown by the different point colors in Figs. 2 and 3. Note that C03 is a GEO satellite and is not visible by some stations.

Average code biases with one-month data at the B1I frequency. The point colors represent different receiver types. Note that C33 cannot be tracked by the Trimble and Leica receivers

Average code biases with one-month data at the B3I frequency. The point colors represent different receiver types. Please note that the B3I signal is not tracked by some Septentrio receivers and all Leica receivers, and C33 cannot be tracked by the Trimble receivers
Generally, it can be seen that among the six selected satellites, the maximum code biases can be larger than 4 ns on some BDS-2 satellites for some specific stations, whereas most of the code biases on BDS-3 satellites are within 2 ns, except for C27 at B3I frequency. Meanwhile, the dispersion of code biases on BDS-2 is also larger than that on BDS-3. Similarly, it can also be seen that the code biases are receiver-type dependent.
For the Javad receivers, the code biases of most stations show a good consistency, except for four stations, which seem to concentrate on a different group, especially at the B3I frequency. We find out that these four stations are all connected to the LEIAR25 antenna, while other stations are connected to other antenna types. As pointed out by Hauschild and Montenbruck (2016b), different low-noise amplifiers in different antenna types may lead to a different distortion of the individual satellite signals, which yields different code biases, even though they are equipped with identical receivers. Therefore, we decide to separate the code biases of Javad receivers into two groups, i.e., Javad and Javad (AR25), which are equipped without or with an LEICAR25 antenna, as shown by the points in red and violet in Figs. 2 and 3, respectively.
For the Septentrio receivers, as shown in Table 1, there are two receiver models among the selected stations, namely POLARX4/POLARX4TR and POLARX5/ POLARX5TR. For the POLARX4/POLARX4TR receiver, the B3I signal is untrackable. For the code biases at the B1I frequency, we can see that they are divided into two groups, which correspond to the two receiver models. This conclusion is the same as the results of Gong et al. (2018) and Zheng et al. (2019). Therefore, in this research, we also separate the Septentrio receivers as Septentrio (X4) and Septentrio (X5), which correspond to POLARX4/POLARX4TR and POLARX5/ POLARX5TR, respectively.
For the Trimble receivers, as mentioned above, three stations are equipped with the ALLOY model. For the code biases at the B1I frequency, it can be observed that for most satellites, the code biases of the ALLOY model are significantly different from those of the NETR9 model. Furthermore, similar to the conclusions presented by Gong et al. (2018), we also find that the code biases among the NETR9 model can be divided into two groups, as shown by the different colors for Trimble-1 and Trimble-2 in Fig. 2. However, we also could not find a rule to separate these two groups. For example, unlike the Javad receiver, the same antenna type is found in both groups, and both groups contain various types of antenna. For the code biases at the B3I frequency, it appears that they are more concentrated and do not show a receiver model-dependent characteristic compared with that at the B1I frequency.
For the Leica receivers, although GR50, GR30, and GR25 models are equipped at different stations, it is seen that the code biases at the B1I frequency are very stable among different stations. Therefore, in this research, we classify all the Leica receivers as the same group.
Having classified the receiver groups of the code biases, we calculate the average value and the corresponding standard deviation (STD) of each satellite for each group at B1I and B3I frequencies, as shown in Fig. 4. It is shown that most of the calibrated code biases for BDS-3 are within 2 ns, whereas they are within 6 ns for BDS-2, and the corresponding STD values of BDS-3 are also smaller than those of BDS-2, which demonstrates that the signal distortion effect for BDS-3 is significantly decreased. Moreover, it is interesting that the code biases of BDS-3 satellites for different receiver types show a better consistency with similar biases on the same satellite compared with those of BDS-2, which also indicates that the receivers employed on BDS monitoring stations are different from those on MGEX stations (Wang et al. 2019a; Zhang et al. 2020).

Calibrated BDS code bias from broadcast ephemeris. The point colors represent different receiver types, and the error bar stands for the corresponding standard deviation
From Fig. 4, we can also see that a difference between BDS-2 and BDS-3 satellites seems to exist. Wang et al. (2019a) also find an average difference of 3.8 ns on TGD1 between BDS-2 and BDS-3 when comparing the BDS broadcasted TGD and MGEX DCB. Therefore, we compute the code biases difference between B1I and B3I, namely the biases of TGD1, for each classified receiver type:
where dTGD1 indicates the code bias between B1I and B3I after TGD correction.
The results are plotted in Fig. 5. It can be seen that the biases of TGD1 for BDS-3 are smaller than 2 ns, whereas a constant bias ranging from − 6 to 2 ns is found at BDS-2 for different receiver types. Therefore, we can conclude that the 3.8 ns difference between BDS-2 and BDS-3 is a result of the weighted average value of different receiver types adopted in the MGEX DCB estimation. Besides, it is worth mentioning that the biases of TGD1 for the Trimble ALLOY and Javad receivers obviously differ from those for the Trimble NETR9 and Septentrio receivers and are much smaller. It can be inferred that if more Trimble ALLOY and Javad receivers are used for BDS DCB determination, the difference of TGD1 between BDS-2 and BDS-3 would be smaller than 3.8 ns. This also explains the existence of systematic differences between BDS-2 and BDS-3, which reaches 3 to 4 ns, when different stations are selected in DCB estimation (Li et al. 2019).

BDS code bias between B1I and B3I after TGD correction. The point colors represent different receiver types
4.2 Comparison of BDS code biases from different products
As mentioned in Method section, when different products are used, the estimated code biases are also different. The above results are based on the BDS broadcast ephemeris and the errors from the orbit, clock, and TGD cannot be neglected. To reduce the orbit and clock error from satellites, we use the post-processed precise orbit and clocks provided by Wuhan University (WUM) (Wang et al. 2019b) and the DCB products from the Chinese Academy of Science (CAS) (Wang et al. 2019a). It should be pointed out that different from the traditional B1I/B2I ionosphere-free combination, the clocks of WUM refer to B1I/B3I ionosphere-free combination. Hence, Eq. (2) should be rewritten as:
where \({\text{DCB}}_{{\text{C2I,C6I}}}\) means the DCB correction from B3I to B1I.
Similarly, we obtain the BDS receiver-dependent code biases based on the precise products, which are illustrated in Fig. 6. Compared with the results in Fig. 4, we can see that the code biases from the precise products are smaller than those from the broadcast ephemeris, especially at the B3I frequency, most of which are within 2 ns. This is because the stations used in precise orbit determination for WUM and DCB estimation at CAS are equipped with Javad, Septentrio, and Trimble receivers, which are eventually a weighted result of the code biases. However, it is worth mentioning that the code biases on BDS-2 satellites are more dispersed for different receiver types, especially at the B1I frequency. This indicates that different receivers do not maintain a good consistency in tracking the BDS-2 signal compared with BDS-3.

Calibrated BDS code biases from the WUM precise product. The point colors represent different receiver types, and the error bar stands for the corresponding standard deviation
As a comparison, Fig. 7 gives the STD of the calibrated code biases based on the broadcast ephemeris and the precise products. We can see that the STD based on the precise products is smaller than that based on the broadcast ephemeris. This is reasonable as the errors from satellite orbit, clock, and DCB are smaller when the precise products are applied. Meanwhile, it is also found that the STD for BDS-3 satellites is less than 0.5 ns when the precise products are applied, which is much smaller than that for BDS-2. Besides the poor ability of the receivers to track BDS-2 signals, it may also be attributed to the fact that the GEO and IGSO satellites for BDS-2 cannot be observed by all of the stations or may suffer from a severe multipath effect due to a low satellite elevation.

STD of the calibrated BDS code biases from the broadcast ephemeris (BRD) and the precise product (WUM). The STD is the averaged STD of different receiver types
Since the calibrated code biases refer to the satellite clock and TGD/DCB, or in other words, refer to the receivers used in the precise orbit determination and TGD/DCB estimation, they should show consistency when the basis difference is corrected. To eliminate the basis difference, we compared the broadcast ephemeris with the precise products at B1I and B3I frequencies. According to Montenbruck et al. (2018), the main contribution of the difference between the broadcast ephemeris and the precise products comes from the orbit difference in the radial and clock offset difference. Hence, the difference can be expressed as:
where R and Clk denote the orbit difference in the radial direction and the clock offset difference between the broadcast ephemeris and precise products.
To derive more reliable results, we compare the difference between the broadcast ephemeris and the precise products with the one-month data from DOY 161 to 190 in 2019. Note that the orbit in the broadcast ephemeris refers to the satellite antenna phase center, whereas the precise orbit refers to the satellite mass center. Therefore, this difference should be corrected when comparing the orbit difference (Zhang et al. 2019a). Meanwhile, as previously indicated, the difference of reference clock between the broadcast ephemeris and the precise products should be corrected by TGD or DCB (Montenbruck et al. 2018).
After correcting the average basis difference of the one-month result, the code biases from the broadcast ephemeris and the precise products are comparable. Figure 8 plots the relationship between these two sets of code biases for the Javad receiver. Considering that the orbit accuracy of BDS GEO satellites is much worse than that of IGSO and MEO satellites (Guo et al. 2017) and the GEO satellites are not observed by all stations in code biases estimation, they are excluded from Fig. 8. It is shown that the two sets of code biases have a linear correlation with the coefficients of 0.86 and 0.92 at B1I and B3I frequencies, respectively. The slope of the linear fitting function is also 0.90 and 0.99, which also implies that the scale of the code biases is at a similar level. Moreover, the code biases on BDS-3 satellites are more correlated, indicating that the accuracy of the calibrated code biases of BDS-3 satellites is better than that of BDS-2.

Relationship between calibrated BDS code biases of the Javad receiver using the broadcast ephemeris (BRD) and the precise product (WUM). GEO satellites are excluded. The red dashed line plots their relationship after linear fitting and R2 is the correlation coefficient
4.3 Comparing BDS-2 code biases with other results
Zheng et al. (2019) calibrate the code biases of BDS-2 based on triple-frequency data. As external validation, we compare our derived code biases from the WUM precise products with those from triple-frequency data, which adopt the precise orbit and clocks from GeoForschungsZentrum (GFZ) and DCB products from Deutschen Zentrums für Luft-und Raumfahrt (DLR). Since the code biases provided by Zheng et al. (2019) are sets of values relative to those of the Trimble-1 receiver, we also difference our results with the Trimble-1 receiver. Again, we exclude the GEO satellites and align the values of other BDS-2 satellites to a zero-mean value. Figure 9 compares the common receiver types of the two results at the B1I frequency for four other different receiver types, together with the linear fitting model and correlation coefficient. We find that the slope of the linear function and the correlation coefficient are close to 1.0 for all the four receiver types, which proves that the two results agree well.

Relationship between our calibrated code biases from precise products (WUM) and results from triple-frequency at the B1I frequency for BDS-2. GEO satellites are excluded. The biases are relative to the Trimble-1 receiver at each satellite and then aligned to a zero-mean value. The red dashed line plots their relationship after linear fitting and R2 is the correlation coefficient
5 Validation of BDS receiver-dependent code biases
In this section, to validate the impact of the calibrated code biases, we apply them in user positioning in terms of SPP, PPP, and RTK. The results obtained with the corrected code biases are compared with the raw results without correction. When correcting the code biases, they are added to the pseudorange measurements according to Eqs. (2) and (6).
5.1 Single point positioning
For the validation of the code biases on SPP, one-week data from DOY 196 to 202 in 2019 at the 117 MGEX stations are used. During the processing of SPP, the broadcast ephemeris is adopted. The troposphere delay is corrected by the GPT2w and VMF model (Böhm et al. 2015). The ionosphere delay is corrected by the BDS Klobuchar model (CSNO 2018a) for single-frequency data or eliminated by ionosphere-free combination for dual-frequency data. The position dilution of precision (PDOP) threshold is set as 6 and the cutoff elevation is set as 10°. Hence, the parameters to be estimated are the station coordinates and the receiver clock at each epoch. For the assessment of the SPP performance, the estimated coordinates are compared with the reference position in terms of the root mean square (RMS).
When correcting the code biases, the stations are corrected by the corresponding code biases according to their receiver types. Figure 10 compares the three-dimensional (3D) RMS of SPP for each station at B1I, B3I, and B1I/B3I frequencies. The results are divided by different groups according to their receiver type. For a numerical observation, Table 2 summarizes the average RMS of each receiver type and the overall performance, along with the corresponding improvement when the code biases are corrected. It can be seen that the positioning accuracy is significantly improved for most stations and the improvement differs by receiver type and frequency, from 3.4% at the B3I frequency for the Javad receiver to 38.0% at the B1I/B3I frequency for the Septentrio (X5) receiver. The overall improvement of the 117 stations is 9.5%, 9.9%, and 27.4% at B1I, B3I, and B1I/B3I frequencies, respectively.

SPP performance for different types of receivers at B1I, B3I, and B1I/B3I frequencies. The y-axis represents the one-week 3D RMS of the positioning error at each station. The x-axis represents the stations, which are divided by different groups according to their receiver type
As previously analyzed, the code biases on BDS-2 satellites are much larger than those on BDS-3. With the development and completion of BDS-3, the BDS-2 satellite will retire gradually after 2020. With a value within 2 ns for most BDS-3 satellites, it is necessary to investigate the effect of the code biases in BDS-3-only positioning. Table 2 presents the overall SPP performance at different frequencies using BDS-3 satellites. Through the comparison, we can see that the code biases do not exhibit much difference at B1I and B3I frequencies, with improvements of 2.3% and 1.4%, respectively. However, the improvement is 11.6% at the B1I/B3I frequency, which is not negligible. Such a big improvement may be because the code biases are amplified after ionosphere-free combination. Therefore, it is suggested that code biases correction should be applied, even if only BDS-3 satellites are used.
As mentioned above, we cannot find a rule to separate the Trimble-1 and Trimble-2 receivers. For a random Trimble NETR9 receiver, it is difficult to classify its receiver type of code biases correction. Therefore, we can adopt the average value of Trimble-1 and Trimble-2. To verify the impact of this solution, we compare the SPP performance of all Trimble NETR9 receivers with code biases correction using the two types or their average values. Table 3 presents the comparison results at different frequencies. It is shown that the improvement using the separated types of correction is slightly better than using the average values, which is reasonable. However, on the other hand, the improvement using the average values is still 10.8% at single frequencies and 18.7% at the B1I/B3I frequency. Therefore, for a Trimble NETR9 receiver with an unknown code biases type, we suggest using average code biases correction.
5.2 Precise point positioning
For PPP application, it has been proven that the code biases will affect the convergence performance (Zheng et al. 2019). In this section, we also assess the BDS-2 + BDS-3 PPP convergence performance with the calibrated code biases. The WUM precise products are adopted, and the corresponding code biases refer to the WUM precise products are adopted. The troposphere wet delay and carrier phase ambiguities are estimated as parameter with random walk noise and constant parameters, respectively. By excluding some stations with insufficient satellite numbers, the one-week data with about 43 stations from DOY 196 to 202 are processed using the B1I/B3I ionosphere-free combination in static and kinematic mode.
For an overall evaluation of the PPP performance, we calculate the average horizontal and vertical absolute positioning errors every 5 min. Figure 11 shows a comparison of the PPP convergence performance in the first 90 min with and without code biases correction. Compared with the raw measurements, the improvements of PPP with the code biases corrected are significant, especially in the horizontal direction. The code biases correction benefits static PPP in the first hour, whereas the improvement can still be seen after 90 min in the kinematic mode.

Static and kinematic PPP convergence performance in the horizontal and vertical directions. The results are the average value of all stations spanning 1 week. “S” and “K” represent static and kinematic PPP mode, while “raw” and “corrected” indicate pseudorange measurements without and with the code biases correction
5.3 RTK
As the code biases differ among different receiver types, it is expected that the code biases will also affect the ambiguity resolution in RTK when different receiver types are used at the base station and the rover station. To validate this, we select two short baselines. One is a 70 m baseline from str2 to str1 with the receiver types of Trimble-2 and Septentrio (X5), while the other is an 8 m baseline from kerg to krgg with the receiver types of Trimble-1 and Trimble ALLOY. The data on DOY 197 in 2019 are used for comparison regarding the B1I single-frequency and B1I/B3I dual-frequency mode. For the RTK strategy, the single epoch ambiguity resolution (AR) method without considering the troposphere and ionosphere difference is applied, and the ambiguity is considered as fixed when the ratio value is larger than 3 after the LAMBDA method (Teunissen 1995) and the 3D positioning error is less than 5 cm.
Table 4 lists the BDS-2 + BDS-3 AR fixing rate comparison of the two baselines using the single-frequency and dual-frequency data. For the dual-frequency RTK, the fixing rate is at a similar level as the model strength is strong enough to fix ambiguities at most epochs. For the single-frequency RTK, when the code biases are corrected, a noticeable improvement in the fixing rate is observed, i.e., from 63.5 to 86.9% for the baseline str2–str1 and from 57.8 to 92.9% for the baseline kerg–krgg.
To further investigate the contribution of the code biases correction on AR, we compare the ratio value distribution, in which the percentage of the ratio value higher than a specific value is computed. The statistical results are shown in Fig. 12. It can be seen that the ratio value becomes higher for both single-frequency and dual-frequency RTK when the code biases are corrected. Therefore, when different types of receivers are used in RTK, the receiver-dependent code biases should be corrected.

Percentage of ratio value after ambiguity resolution. “SF” and “DF” represent single-frequency and dual-frequency
6 Conclusions
In this contribution, we analyzed the receiver-dependent code biases with the current BDS constellation. One-month results from 117 MGEX stations show that the BDS code biases after TGD correction on BDS-2 satellites can be larger than 4 ns, whereas they are within 2 ns on most BDS-3 satellites. It is demonstrated that the signal distortion effect on BDS-3 is significantly decreased compared with BDS-2, and receivers keep better consistency in tracking the BDS-3 signal. Generally, the code biases differ by receiver type, receiver model, antenna type, or even unknown factors, which require further investigation.
We derived the BDS receiver-dependent code biases based on the broadcast ephemeris and the precise products. Our results show that these two sets of code biases agree well with a correlation coefficient of 0.86 and 0.92 at B1I and B3I frequencies, respectively, while the code biases based on the precise products show smaller STD. Meanwhile, we also demonstrate that our calibrated code biases of BDS-2 correspond to the results presented by other researches.
With our provided BDS receiver-dependent code biases, users can correct them in terms of absolute positioning, including SPP, PPP, and relative positioning such as RTK. Our validation results show that with the code biases corrected, SPP users can benefit from a 3D RMS improvement of 9.5%, 9.9%, and 27.4% at B1I, B3I, and B1I/B3I frequencies, respectively. Code biases correction can also accelerate the PPP convergence performance. For RTK users, the ratio value and the fixing rate will become higher when the code biases are corrected. We also prove that the code biases of BDS-3 will be enlarged after ionosphere-free combination and cannot be ignored. As for a normal Trimble NETR9 receiver with an unknown code biases type, the average values are recommended.
It should be pointed out that the code biases refer to the clock and TGD/DCB corrections. When different products are used, our calibrated code biases are no longer applicable. Meanwhile, the change of receivers in precise orbit determination and TGD/DCB determination will also affect the values of code biases. The monitoring and in-time calibration of code biases based on different products will be continuous work in the future. Furthermore, for the new satellites and new signals of BDS-3, it is also worth investigating their characteristics of code biases.
Data availability statement
The GNSS data are provided by the Multi-GNSS Experiment (MGEX), which are available from ftp://cddis.gsfc.nasa.gov/. The precise clock and orbits are provided by IGS analysis center Wuhan University at ftp://igs.gnsswhu.cn/. The DCB products are provided by the Chinese Academy of Science at ftp://ftp.gipp.org.cn/.
References
Böhm J, Möller G, Schindelegger M, Pain G, Weber R (2015) Development of an improved empirical model for slant delays in the troposphere (GPT2w). GPS Solut 19:433–441
CSNO (2018a) BeiDou navigation satellite system signal in space interface control document open service signal B3I (Version 1.0). China Satellite Navigation Office, February 2018
CSNO (2018b) Development of the BeiDou navigation satellite system (Version 3.0). China Satellite Navigation Office, December 2018
Geng T, Xie X, Zhao Q, Liu X, Liu J (2017) Improving BDS integer ambiguity resolution using satellite-induced code bias correction for precise orbit determination. GPS Solut 21(3):1191–1201
Gong X, Lou Y, Zheng F, Gu S, Shi C, Liu J, Jing G (2018) Evaluation and calibration of BeiDou receiver-related pseudorange biases. GPS Solut 22(4):98
Guo F, Li X, Liu W (2016) Mitigating BeiDou satellite-induced code bias: taking into account the stochastic model of corrections. Sensors 16(6):909
Guo F, Li X, Zhang X, Wang J (2017) Assessment of precise orbit and clock products for Galileo, BeiDou, and QZSS from IGS multi-GNSS Experiment (MGEX). GPS Solut 21(1):279–290
Hauschild A, Montenbruck O (2016) A study on the dependency of GNSS pseudorange biases on correlator spacing. GPS Solut 20(2):159–171
Hauschild A, Montenbruck O (2016) The effect of correlator and front-end design on GNSS pseudorange biases for geodetic receivers. Navigation 63(4):443–453
Hauschild A, Montenbruck O, Sleewaegen JM, Huisman L, Teunissen PJ (2012) Characterization of compass M-1 signals. GPS Solut 16(1):117–126
Hauschild A, Steigenberger P, Montenbruck O (2019) Inter-receiver GNSS pseudorange biases and their effect on clock and DCB estimation. In: Proceedings of the 32nd international technical meeting of the satellite division of The Institute of Navigation (ION GNSS+ 2019), Miami, Florida, September 2019. pp 3675–3685
Johnston G, Riddell A, Hausler G (2017) The international GNSS service. In: Teunissen PJG, Montenbruck O (eds) Springer handbook of global navigation satellite systems, 1st edn. Springer, Cham, pp 967–982
Li X, Xie W, Huang J, Ma T, Zhang X, Yuan Y (2019) Estimation and analysis of differential code biases for BDS3/BDS2 using iGMAS and MGEX observations. J Geod 93(3):419–435
Lou Y, Gong X, Gu S, Zheng F, Feng Y (2017) Assessment of code bias variations of BDS triple-frequency signals and their impacts on ambiguity resolution for long baselines. GPS Solut 21(1):177–186
Montenbruck O, Hauschild A, Steigenberger P (2014) Differential code bias estimation using multi-GNSS observations and global ionosphere maps. Navig J Inst Navig 61(3):191–201
Montenbruck O, Steigenberger P, Hauschild A (2018) Multi-GNSS signal-in-space range error assessment—methodology and results. Adv Space Res 61(12):3020–3038
Odijk D (2017) Positioning model. In: Teunissen P, Montenbruck O (eds) Springer handbook of global navigation satellite systems, 1st edn. Springer International Publishing, Dordrecht, pp 606–607
Schaer S, Gurtner W, Feltens J (1998) IONEX: the ionosphere map exchange format version 1. Accessed 06 Aug 2019. ftp://igs.org/pub/data/format/ionex1.pdf
Tan S (2018) GNSS systems and engineering: the Chinese Beidou navigation and position location satellite. Wiley, Hoboken, pp 207–208
Teunissen PJ (1995) The least-squares ambiguity decorrelation adjustment: A method for fast GPS integer ambiguity estimation. J Geod 70:65–82
Wang N, Yuan Y, Li Z, Montenbruck O, Tan B (2016) Determination of differential code biases with multi-GNSS observations. J Geod 90(3):209–228
Wang C, Zhao Q, Guo J, Liu J, Chen G (2019) The contribution of intersatellite links to BDS-3 orbit determination: model refinement and comparisons. Navigation 66(1):71–82
Wang N, Li Z, Montenbruck O, Tang C (2019) Quality assessment of GPS, Galileo and BeiDou-2/3 satellite broadcast group delays. Adv Space Res 64(9):1764–1779
Wanninger L, Beer S (2015) BeiDou satellite-induced code pseudorange variations: diagnosis and therapy. GPS Solut 19(4):639–648
Xie X, Fang R, Geng T, Wang G, Zhao Q, Liu J (2018) Characterization of GNSS signals tracked by the iGMAS network considering recent BDS-3 satellites. Remote Sens 10(11):1736
Yang Y, Xu Y, Li J, Yang C (2018) Progress and performance evaluation of BeiDou global navigation satellite system: data analysis based on BDS-3 demonstration system. Sci China Earth Sci 61(5):614–624
Zhang Y, Chen J, Zhou J, Yang S, Wang B, Chen Q, Gong X (2016) Analysis and application of BDS broadcast ephemeris bias. Acta Geodaeticaet Cartograph Sin 45(S2):64–71
Zhang X, Wu M, Liu W, Li X, Yu S, Lu C, Wickert J (2017) Initial assessment of the COMPASS/BeiDou-3: new-generation navigation signals. J Geod 91(10):1225–1240
Zhang X, Li X, Lu C, Wu M, Pan L (2019a) A comprehensive analysis of satellite-induced code bias for BDS-3 satellites and signals. Adv Space Res 63(9):2822–2835
Zhang Y, Kubo N, Chen J, Wang J, Wang H (2019b) Initial positioning assessment of BDS new satellites and new signals. Remote Sens 11(11):1320
Zhang Y, Chen J, Gong X, Chen Q (2020) The update of BDS-2 TGD and its impact on positioning. Adv Space Res 65(11):2645–2661
Zheng F, Gong X, Lou Y, Gu S, Jing G, Shi C (2019) Calibration of BeiDou triple-frequency receiver-related pseudorange biases and their application in BDS precise positioning and ambiguity resolution. Sensors 19(16):3500
Acknowledgments
This work is mainly funded by the Key R&D Program of Guangdong Province (No. 2018B030325001); the National Natural Science Foundation of China (No. 11673050); the Key Program of Special Development Funds of Zhangjiang National Innovation Demonstration Zone (No. ZJ2018-ZD-009), and the National Key R&D Program of China (No. 2018YFB0504300). The GNSS observation data and products provided by MGEX are acknowledged.
Author information
Authors and Affiliations
Contributions
YZ performed the research and wrote the paper. JC designed the research. NK and JC reviewed and revised the paper. AW helped analyzing the results.
Corresponding author
Rights and permissions
About this article

Cite this article
Zhang, Y., Kubo, N., Chen, J. et al. Calibration and analysis of BDS receiver-dependent code biases. J Geod 95, 43 (2021). https://doi.org/10.1007/s00190-021-01497-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00190-021-01497-6