
Abstract
In this paper, we describe mating patterns in the USA from 1964 to 2017 and measure the impact of changes in marital preferences on between-household income inequality. We rely on the recent literature on the econometrics of matching models to estimate complementarity parameters of the household production function. Our structural approach allows us to measure sorting along multiple dimensions and to effectively disentangle changes in marital preferences and in demographics, addressing concerns that affect results from existing literature. We answer the following questions: Has assortativeness increased over time? Along which dimensions? To what extent can the shifts in marital preferences explain inequality trends? We find that, after controlling for other observables, assortative mating in education has become stronger. Moreover, if mating patterns had not changed since 1971, the 2017 Gini coefficient between married households would be 6% lower. We conclude that about 25% of the increase in between-household inequality is due to changes in marital preferences. Increased assortativeness in education positively contributes to the rise in inequality, but only modestly.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
The study of mating patterns, especially assortativeness, traces back to the seminal work of Becker (1973, 1974, 1991). Becker’s earliest model of a competitive marriage market aims at rationalizing both household specialization and the homogamy observed in the data with respect to several non-labor market traits (e.g., education, ethnicity, religion). Becker points at the structure of the household production function to explain marriage patterns: complementarity between inputs leads to optimal positive assortative mating, whereas substitutability leads to negative assortative mating.
In light of such observations on Becker’s work, studying marriage patterns reveals much about intra-household dynamics. Differences in mating dynamics over time and space may be the result of transformations in the institution of the family, labor market conditions, available household-production technology, gender roles, etc. For instance, one could wonder whether Becker’s observation that we should expect a negative association between spouses’ wage rates due to household specialization still applies to modern families despite the improvements in home technology and narrower gender wage gap.Footnote 1 Changes in the cultural and legal framework also matter for the evolution of marital preferences, due to their influence on marriage flows and on the allocation of resources across and within couples.
In recent years, marital sorting has become the object of increasing attention because of its relationship with growing inequalities between households. Researchers have focused on the relationship between marriage patterns, between-household income inequality, and long-run economic outcomes (e.g., Burtless 1999; Fernández et al. 2005). The compelling research question is whether stronger assortativeness with respect to some crucial dimensions—notably, education—is associated with higher inequality.
The aim of this paper is to build a connection between changes in the structure of marital gains and the increasing income inequality observed in the USA. We address the following questions: has assortative mating increased over time? And, if yes, along which dimensions? What is the impact of shifts in marital preferences on household income inequality? The framework we adopt follows Choo and Siow (2006) and Galichon and Salanié (2015)’s observation that joint marital surplus can be identified with data on matches in a static, competitive matching framework. We employ the recent estimation technique proposed by Dupuy and Galichon (2014) and estimate the degree of complementarity and substitutability between the spouses’ traits. Such estimates stand as our measures of the strength of marital sorting.
This structural approach allows us to contribute to the literature on sorting and inequality by overcoming some limitations affecting studies based on standard measures of assortativeness, such as correlation coefficients, homogamy rates, and frequency tables. Disentangling changes in marital preferences and demographics is crucial because of important changes in the marginal distributions of people’s traits in the USA during the last decades (e.g., aging of the population, overall increase in schooling attainment, closing of the gender wage gap, and reversal of the gender gap in higher education). In addition, our analysis is not limited to educational assortativeness: the multidimensional matching model of Dupuy and Galichon (2014) provides tools to study complementarity on education, as well as interactions between other socioeconomic traits. Following this new approach, we rediscuss the findings of several key papers in the marriage literature, such as Fernández et al. (2005), Schwartz and Mare (2005), and more recently Greenwood et al. (2014), Eika et al. (forthcoming), and Greenwood et al. (2016).
The theoretical framework of Dupuy and Galichon (2014) is grounded on transferable utility models and logit formalism, and extends the seminal matching model of Choo and Siow (2006) to the multidimensional and continuous case. Agents are fully informed about potential partners’ characteristics, but the econometrician only observes traits x ∈ X and y ∈ Y, respectively, for men and women, where X and Y are continuous and multidimensional. The empirical strategy relies on a bilinear parametrization for the systematic marriage surplus function, i.e., Φ(x,y) = x′Ay. It follows that we can measure the degree of complementarity or substitutability by estimating the marital preference parameters, i.e., the elements of the affinity matrixA, since \(\partial ^{2}{\Phi }/\partial x_{j}\partial y_{k}=A_{jk}\). These will be our measures of assortativeness. In addition, after estimating A, we recover the optimal probability distribution of matches πA(x,y), which, in other words, is the simulated joint frequency table of partners’ types in equilibrium. The latter depends on both the structure of preferences given by A and the marginal distributions of observable types f(x) and g(y): operating on the parameters A, we can compute the predicted distribution of couples’ traits under counterfactual preferences. For instance, we can artificially increase the value of one parameter of A, say the strength of assortative mating on education, and check how the distribution of partners’ types \(\pi ^{A^{\prime }}(x,y)\) changes at the new (counterfactual) marriage market equilibrium.
In practice, we estimate marital preference parameters for the USA over the period 1964–2017 with Current Population Survey data to track sorting dynamics through the analysis of preferences. We consider the following observable variables: age, education, hourly wage, hours worked, and ethnic background. We subsequently use the marriage patterns predicted by the model—the optimal matching function πA(x,y)—to construct counterfactual household income distributions. To do so, we substitute the actual preferences measured for a given wave with counterfactual preferences measured for a different wave. This means that we provide a prediction of how people would have sorted into married couples in a given year if their marital preferences had been equal to those of another cohort (e.g., to their parents’ or grandparents’). In this way, we study the contribution of changes in marital preferences to the observed marriage patterns and to the evolution of inequality in several illustrative examples.
To the best of our knowledge, this is the first attempt to analyze the evolution of marital preferences in the USA by means of structural estimation techniques in a multidimensional matching framework.Footnote 2 We hereby provide a complete analysis of assortativeness along multiple observable socioeconomic traits, track changes in sorting patterns over time, and assess to what extent they can explain the rise in between-household income inequality in the last decades.
The paper is organized as follows. Section 2 provides a brief literature review, while Section 3 introduces the theoretical framework. In Section 4, we describe CPS data and our sample selection criteria. Then, we present and discuss our results: in Section 5, the trends in marital preferences, while in Section 6 the counterfactual analysis of inequality. Section 7 concludes.
2 Previous findings
2.1 Evolution of mating patterns
A crucial question that the literature has tried to answer in different ways is whether assortativeness has increased over time. The demographic and sociological literature often makes use of log-linear models to explain mating patterns and measure assortativeness. Log-linear models for contingency tables help “specify how the size of a cell count depends on the levels of the categorical variables for that cell” (Agresti 2007, Chapter 7, p. 204). Several papers relying on this methodology focus on assortativeness on education: the contingency table of size I × I tells the frequency of couples by partners’ education ij, with i,j ∈{1,...I} being the individual schooling level. If matching were random, the following regression would exhibit a good fit:
where μij is the frequency of a couple with education ij, \({\lambda _{i}^{M}}\) is the vector of men’s educational level effects, and \({\lambda _{j}^{W}}\) is the vector of women’s educational level effects. Under random matching, marginal distributions are sufficient to explain the entries of the contingency tables. Nonetheless, if matching is not random, then one needs to include other regressors to explain the couples’ joint distribution. “Homogamy models” contain an additional regressor measuring the impact of educational homogamy on the log-joint frequency log μij (e.g., Johnson 1980; Kalmijn 1991b; Schwartz and Mare 2005). “Crossing models” contain additional regressors measuring the impact of crossing an educational barrier (e.g., a college-graduate marrying a dropout, see Mare (1991), Smits et al. (1998), and Schwartz and Mare (2005). Log-linear models can be rewritten as multinomial choice models (see Agresti 2013; Schwartz and Graf 2009) surprisingly close in spirit to the matching model class of Choo and Siow (2006). In the equivalent multinomial logit model, the categorical response variable would be the wife’s (or the husband’s) education to represent the choice of the husband (or the wife’s) conditional on his (her) schooling level. However, a basic choice model of this kind does not take into account that men and women actually seek a partner in a competitive environment: the choice of one agent affects the pool of partners available for other agents. As a consequence, it is not possible to interpret the coefficients as the “true” preference parameters. In the structural framework proposed by Choo and Siow (2006) and Galichon and Salanié (2015), it is instead possible to estimate the parameters of the model so that the matching market is indeed at equilibrium. In these equilibrium models, every agent’s choice is constrained by the choices of other “competitors” and the market must clear, i.e., the sum of singles and married must be equal to the total number of individuals by type and sex.
Several studies apply log-linear models or closely related ones to study changes in educational assortativeness in marriage patterns in the USA. Most agree that educational assortative mating strengthened in the second part of the twentieth century (Mare 1991; Kalmijn 1991a, 1991b; Qian and Preston 1993) and the first decade of the twenty-first (Schwartz and Mare 2005). However some other studies argue that educational homogamy stayed constant or declined. For instance, Fu and Heaton (2008) observe a decline between 1980 and 2000. Liu and Lu (2006) maintain that the intensity of educational homogamy increased from 1960 to 1980 but then started decreasing. Interestingly, most papers also agree that one of the strongest trends is the increase in the frequency of marriages between highly educated individuals. Several papers use log-linear models to explore other matching dimensions, sometimes in multidimensional frameworks, although the number of variables stays low (2 or 3 typically) because of methodological limitations. Johnson (1980) and Kalmijn (1991a) analyze religion; Schoen and Wooldredge (1989) and Fu and Heaton (2008), ethnicity; Qian and Preston (1993), age; Kalmijn (1991b) and Blackwell (1998), parents’ education; Stevens and Schoen (1988), language spoken. Some empirical findings on assortativeness in the USA are particularly interesting since they can be compared with ours. Qian and Preston (1993) find that homogamy with respect to age increased (from 1972 to 1987), while Fu and Heaton (2008) find that racial homogamy decreased (from 1980 to 2000).
In the economic literature, some analyses of mating patterns rely on simple descriptive statistics. For instance, Fryer (2007) uses the probabilities of crossing racial barriers to describe the patterns of racial intermarriage in the USA and explore the possible driving forces behind the trends. Other researchers assess the strength of educational assortativeness through the comparison with counterfactual distributions. The simplest indicators of this kind are “homogamy rates” which are the ratios between the actual frequency of a couples’ joint education and the counterfactual frequency computed under random matching. Contingency tables to compare actual and counterfactual joint distributions are similar (if not identical) to homogamy rates (e.g., Greenwood et al. 2014). Another possibility is to compare the actual distribution to the counterfactual under perfect positive assortative mating (e.g., Liu and Lu 2006). While generally insightful, homogamy rates and similar measures are not suitable for comparisons across different populations and even across different categories within the same population. The size of the homogamy rate is hardly comparable when the marginals become smaller. Hence, it is hard to make a comparison between homogamy for PhD graduates, who represent a small share of the population, and high school diplomas, who represent a large share. In consequence, researchers opt for aggregate measures of assortativeness that take into account the different size that each category has in the population (e.g., Greenwood et al. 2014; Eika et al. forthcoming). Using such measures based on homogamy rates, Eika et al. (forthcoming) conclude that marital sorting in the USA on education slightly increased over the period 1980–2007. The findings of Greenwood et al. (2014) are similar: relying on several measures, some of which based on homogamy rates, they find that assortativeness on education has increased over the period 1960–2005.
2.2 Assortativeness and inequality
Another crucial question is whether changes in mating patterns can partly explain trends in income inequality between households. Many authors are concerned with the possibility that more assortativeness on socioeconomic characteristics—particularly on education—can lead to higher household income inequality. Since education is a primary dimension of assortativeness, and since highly educated individuals typically have higher income, more educational homogamy implies that high-income individuals will marry with each other more and more frequently. Nevertheless, it is not straightforward to disentangle the effect of changes in marital preferences from the shifts in the marginal distributions. This is particularly relevant because of the closing of the educational gap between men and women in the last decades and women’s increased participation in the labor force.
The landmark contributions by Fernández and Rogerson (2001) and Fernández et al. (2005) make an attempt to model the trends in household inequality in order to shed some light on the roles played by sorting, fertility, and children’s education. Fernández and Rogerson (2001) set a model in which individuals are either skilled or unskilled and marry more or less frequently with partners of the same educational level according to an exogenous parameter accounting for the degree of homogamy on the marriage market. Since the children of highly educated families will be more likely to go to college, mating patterns are crucial in order to explain the steady-state level of inequality. Fernández et al. (2005) introduce a simple two-round matching model in order to endogenize the strength of sorting on education. They find that, in the steady state, a higher degree of sorting—measured as the correlation between partners’ incomes—is associated with higher income inequality.Footnote 3 Both papers argue that educational assortativeness exacerbates inequality in the long run, in disagreement with Kremer (1997), who states that sorting has a negligible impact on steady-state inequality. Although the structural approach of these models is extremely insightful to understand through which channels mating patterns may influence inequality in the long run, we believe that their conclusions might—to some extent—depend on their specific measure of educational assortativeness. In particular, Fernández et al. (2005) show that the Pearson correlation coefficient between partners’ education correctly measures the degree of assortativeness. However, this conclusion can be reached only under the restrictive assumptions necessary for their two-round matching model. Indeed, in most alternative matching models, a change in the correlation rate may well be due to a change in marital preferences as well as to a shift in the marginals. Hence, since a higher correlation rate does not necessarily imply more assortativeness, we propose to relate alternative measures of assortativeness to income inequality in order to check whether their conclusions are robust.
As previously mentioned, Greenwood et al. (2016) set up a model of educational choice, marriage, and the household, and estimate its steady state. With respect to the papers mentioned above, the focus is now more on household technology and changes in the wage distribution rather than intergenerational transmission. The authors run a number of counterfactual experiments that help understand what forces contributed to the rise of inequality. In particular, they determine that changes in the wage structure alone explain 39% of the increase. They subsequently stress that changes in marriage patterns account for 18.6% of the increase, which grows to 35.6% when allowing households to adjust their labor supply. In the present paper, we also disentangle changes in the wage distribution from transformations to the structure of marital gains, while we also control for changes in the marginal distribution of other observables (e.g., race and ethnicity). On the other hand, Greenwood et al. (2016) make explicit assumptions about household behavior and their model insightfully predicts how households adjust their labor supply. In this way, they separately assess the effects of changes in home technology and in taste for educational homogamy on income inequality. We compare our empirical findings to theirs in Section 6.
Besides the abovementioned papers, most research focus on the empirics in the hope of assessing the impact of changes in marital preferences on income inequality in the USA correctly. Measuring the strength of educational assortativeness is not straightforward and several approaches have been tried. The work by Burtless (1999) is an early example of counterfactual analysis of inequality. In order to assess the degree of inequality that we would observe in 1996 if matching patterns did not change since 1979, Burtless shuffles the observed married couples in 1996 and reassigns spouses as follows: if the man whose income had rank r married a woman with rank s in 1979, the man with rank r in 1996 is assigned to the woman with rank s from the same year. Cancian and Reed (1998) and Western et al. (2008) suggest using decomposition methods on the changes in the variance of household income. The methodology consists of dividing the household population into groups according to certain characteristics (e.g., age, education, children) and then studying the trends in income variance within and between groups.
Schwartz (2010) focuses on marital preferences and is thus more closely related to our analysis. She uses the log-linear models explained in Section 2.1 to build counterfactual distributions of partners’ income.Footnote 4 The author concludes that inequality would have been lower without the shifts in income assortativeness.Footnote 5
The works of Greenwood et al. (2014) and Eika et al. (forthcoming) also aim to assess the impact of changes in educational assortativeness on inequality.Footnote 6 Using contingency tables, Greenwood et al. (2014) show that, under random matching, the counterfactual Gini coefficient in 2005 for USA would be lower than the actual (about 2.3% less). In addition, using standardized contingency tables with several controls (e.g., children, participation in the labor force), they assess that, had sorting patterns been constant since 1960, the 2005 Gini coefficient would be almost unaffected (only about 0.3% less). Eika et al. (forthcoming) conduct a similar analysis to study the trends in household income inequality in the USA between 1980 and 2007. They employ a methodology which consists of building counterfactuals by combining the partners’ joint distribution of schooling attainment from a given year with the conditional distribution of income given the educational level from another year. They conclude that, had returns to schooling not changed since 1980, 2007 household income inequality would have been much lower (about 23% less). In addition, the authors also remark that, without the overall increase in schooling attainment at the individual level, 2007 inequality would be even higher. Finally, they assess that, had 1980 marital preferences been the same as in 2007, we would have not observed any relevant difference in household income inequality. Their findings are thus consistent with those of Greenwood et al. (2014), although the time lapse considered is different.
3 Theoretical framework
Dupuy and Galichon (2014, hereafter DG) extend the setting of Choo and Siow (2006) and Galichon and Salanié (2015) to the multidimensional and continuous case. Here, we closely follow the methodology of DG. We first briefly recall the theoretical framework and the estimation technique.
3.1 Matching model
In this frictionless transferable utility framework, men and women are characterized by a vector of characteristics \(x\in \mathcal {X}\) for men, and \(y\in \mathcal {Y}\) for women. Note that, with a large set of continuous variables, every individual is virtually unique in his (her) observable type given by x (y). A matching is a probability distribution that tells the odds of a couple with observable types x and y to be matched. When a man x and a woman y match, they receive systematic utility sharesU and V respectively, both of which depend on the combination of observable types (x,y) only. In addition, a man of type x experiences a random sympathy shockεk that is individual specific to the potential partner k of type yk. Hence, the two components being additive, the man’s payoff from a match with a woman k of type y is given by \(U(x,y^{k})+\frac {\sigma }{2}\varepsilon ^{k}\), where the scalar σ measures the relevance of the unobservable component. A woman’s payoff can be written in an analogous way.
When the sympathy shock is of Gumbel type, the setting is completely analogous to Choo and Siow (2006). However, DG suggest assuming that each man chooses his partner within a set of infinite but countable “acquaintances,” each with characteristics (yk,εk) over the space \(\mathcal {Y}\times \mathbb {R}\): such set is the enumeration of a Poisson process with intensity dy × e−εdε, which leads us to a continuous logit framework. Under this assumption, the shock εk is independent from the observables. Every man solves the following problem:
and so do women with due changes in notation.
DG show that it is possible to recover the optimal matching π(x,y) and the equilibrium shares U(x,y) and V (x,y), so that the scarcity constraints hold and Φ(x,y) ≡ U(x,y) + V (x,y), as implied by the transferable utility assumption, where Φ(x,y) denotes the systematic surplus. Provided two functions a(x) and b(y) so that π(x,y) is feasible—the sum of married individuals of a given type does not exceed their initial number—the equilibrium is thus fully characterized by:
-
1.
The optimal matching function π(x,y), which tells the probability of matching (equivalently, the relative frequency at equilibrium) for a couple with observables (x,y):
$$ \pi(x,y)= \exp\left( \frac{{\Phi}(x,y)-a(x)-b(y)}{\sigma}\right). $$(2) -
2.
The shares of systematic surplus at equilibrium for each couple with observables (x,y):
$$ \begin{array}{@{}rcl@{}} U(x,y) & =& \frac{{\Phi}(x,y)+a(x)-b(y)}{2} \end{array} $$(3)$$ \begin{array}{@{}rcl@{}} V(x,y) & =& \frac{{\Phi}(x,y)+b(y)-a(x)}{2} \end{array} $$(4)so that U(x,y) + V (x,y) gives the total systematic surplus at equilibrium, i.e., Φ(x,y).
3.2 Specification
In this paper, we consider the following parametrization of the systematic surplus, introduced by Ciscato et al. (forthcoming):

where the first O observable variables are ordered and the last U are unordered. Examples of ordered variables are age, education, and wage, whereas ethnicity and working sector are unordered. Note that transformations of raw variables, such as polynomials, logarithms, and ranks, could be added as additional controls.
Our main specification implies that the matrix of parameters A—called affinity matrix—looks as follows:
The O × O entries of the submatrix \(\tilde {A}\) determine whether the (ordered) variables are complementary or substitutes, as well as the intensity of the affinity (or repulsion) between the two inputs. The elements of the diagonal submatrix Λ tell us whether homogamy with respect to one of the unordered variables results in an increase rather than in a decrease of the systematic surplus. All the other elements of the matrix are constrained to zero.
3.3 Estimation
To compute equilibrium quantities, we solve for a(x) and b(y) enforcing the market scarcity constraints through an iterative projection fitting procedure for given parameters A and σ. Hence, note that, according to the crucial result of Shapley and Shubik (1971), the equilibrium matching of a decentralized matching market is also the one that maximizes social gain. We define the function \(\mathcal {W}(A,\sigma )\) as follows:
where \(\mathcal {M}\) is the set of feasible matchings and where expected values with subscript π are taken with respect to the optimal matching probabilities.
DG set the following convex optimization problem in order to estimate the matrix B = A/σ:
where the expected value with subscript \(\hat {\pi }\) is taken with respect to the relative frequencies observed in the data. The first-order conditions of the problem imply that we are matching the co-moments of men’s and women’s characteristics predicted by the model with the corresponding empirical co-moments observed in the data. In practice, we are computing B so that the following holds:
for each couple (i,j) of ordered characteristics. Similarly, B must be such that the following holds:

for each unordered characteristic i.
3.4 Identification with multiple markets
One drawback of the original model of DG is that only B = A/σ is identified, i.e., A is identified up to a scalar. This is mainly irrelevant when studying assortativeness on a single market, since comparing different entries of the matrix B is equivalent to comparing the elements of A. Nonetheless, Ciscato et al. (forthcoming) stress that it is not possible to compare the affinity matrices of different markets without a further restriction on A.Footnote 7
Denote At the affinity matrix in year t. In order to compare marriage markets over time, we assume that the Frobenius norm of the submatrix \(\tilde {A}^{t}\) is equal to 1 for every t, i.e., \(||\tilde {A}^{t}||=1\) ∀t. This implies that \(\frac {\tilde {B}^{t}}{||\tilde {B}^{t}||}=\tilde {A}^{t}\), which in turn implies that \(\sigma ^{t}=\frac {1}{||\tilde {B}^{t}||}\). This means that we interpret large global changes in the submatrix \(\tilde {A}\) as due to a shift in the relative relevance of unobservables in mating.
Although we need to introduce this further restriction to proceed with cross-market analysis, note that the optimal matching function π(x,y) only depends on B = A/σ. Hence, it stays unchanged under different identification assumptions. This makes the results of our counterfactual analysis of inequality in Section 6 robust with respect to different restrictions on the parameters A and σ. We provide a formal proof for this statement in Appendix A.
3.5 Counterfactual methodology
An interesting, but still unused, feature of DG’s model is the possibility to compute counterfactual equilibrium matching by operating on the matrix of preference parameters A. The idea is to infer the marital preferences (At,σt) from cross-sectional data on couples (Xt,Yt) for a given year t and then compute the equilibrium matching P(s,s;t) ≡ π(xs,ys;At,σt) for population data (Xs,Ys) under the same marital preferences. In this way, by comparing the counterfactual P(s,s;t) with the actual P(s,s;s), we can tell how people would match if preferences stayed unchanged between period s and t.
Using P(s,s;t) together with data (Xs,Ys), we can compute the counterfactual distribution of couples’ characteristics. For instance, we can compute the distribution of household income, as well as various measures of inequality, such as the Gini coefficient. In this way, we can tell to what extent the distribution of household characteristics has changed because of shifts in marital preferences.
Moreover, it is also possible to create a counterfactual match between subpopulations from different cross-sections. In fact, we can predict the matching P(s,t;s) originating from a fictional situation in which men from year s met women from year t, with the preference parameter s. In this way, it is possible to assess how changes in the marginals influenced the match in order to address specific questions. Although we do not employ this last type of experiment, we recommend it for future research.
While this counterfactual analysis unveils the hidden potential of the model of DG, it also shows an important limitation concerning its empirical application to the marriage market. In the absence of a more explicit household model that explains how agents determine their labor supply and advance in their working career, we are forced to consider wage rates and working hours as exogenous characteristics. The counterfactual analysis does not take into account that spouses adjust their labor supply and take on different working careers according to the partners’ characteristics and household decision-making process.
4 Data
The paper uses CPS data from 1964 to 2017 (March Supplement) from the Integrated Public Use Microdata Series (IPUMS). CPS data provides a detailed representation of the married male and female populations in the USA over time. Hence, they provide us with reliable “photographs” of the marriage market equilibrium we aim to study. In reality, people are likely to meet and marry in small, local marriage markets. Because of the limited sample size of CPS yearly database,Footnote 8 we do not account for heterogeneity in sorting patterns across smaller geographical units (such as states or counties) and we present aggregate trends at the USA level.
In this section, we describe the construction of the main variables of interest and the selection of the samples. We also present summary statistics on our population of couples before turning to estimation.
4.1 Construction of variables
Our empirical analysis makes use of five key variables: age, education, wage, hours of work, and race. In a few cases, such as age, the construction of the variable is straightforward as we take the raw data without further adjustments. In the following, we explain how we deal with other variables.
-
Educational attainment is available for all years, but with various levels of detail. IPUMS provides a 12-level education variable, which we convert into years of schooling, and to which we refer as the “continuous education variable.” However, this variable is not entirely consistent across years (the coding changed after 1992). To overcome this difficulty (and provide summary statistics on broader education groups), we constructed two other education variables, one with 5 levels and one with 4 levels.Footnote 9 Robustness of the results is checked for each of these specifications.
-
As concerns hours of work per week, the most consistent variable across waves is “hours worked last week,” as the usual hours of work are not available prior to 1976. However, we check the robustness of our main results obtained with the first definition by implementing checks with the latter, as well as with a combination of the two.
-
We define annual labor income as the sum of salary, self-employment income, and farming income. These components are top-coded. However, as top-coded observations account for only a (very) small fraction of the sample, the results are not affected by the way we deal with them, and we eventually choose to drop them.
-
We compute hourly wages using labor income, hours of work per week, and weeks of work per year.Footnote 10 We constructed it as follows:
$$ \text{wage}=\frac{\text{labor income}}{\text{hours}\times\text{weeks}} $$(6)However, the wage variable may feature abnormally low or abnormally high values. We follow Schmitt (2003)’s advice to trim the data, dropping values below 1$ or above 100$ (in 2002 dollars), while keeping observations with a zero wage. All income and wage variables are converted to 1999 dollars.
-
There is no consistent race/ethnicity variable across years. In the early waves of the CPS data, individuals are only classified as White, Black, or Other. After 1971, it becomes possible to separately identify Hispanics and, after 1988, Asians.Footnote 11 Across the years, the race variable became more detailed, allowing individuals to declare a mixed ethnic background. However, when comparing preferences across waves, we need to use a consistent specification of the variable. We mainly use three different specifications: (1) Black or White, available since 1962 and considering Hispanics as White after 1971; (2) Black, White, Hispanic, and Other, available since 1971 and reallocating Asians into the residual category Others; (3) Black, White, Hispanic, and Asian, available since 1988.
In most of our specifications, we use five variables, namely age, education, hourly wage, hours of work, and race. We test the robustness of our results to the inclusion of other variables (such as occupation) or to alternative coding of the variables.
4.2 Sample selection
For every cross-section (i.e., every wave of the survey), we consider the current matches as those resulting from the stable equilibrium of the marriage market. In our empirical analysis of the marriage market equilibrium, we need to decide what matches to include in the sample, which results in several practical issues. First of all, we recall that our analysis of the marriage market equilibrium does not include singles; we exclude never married, separated, divorced, and widowed individuals from the sample. In addition, we do not include unmarried couples in our main sample; cohabitation out of wedlock can be a “trial period” before marriage but also an alternative to it, which makes it hard to distinguish the two cases in the data. Couples where spouses live in different households and same-sex couples are also excluded. On the other hand, we do not make any distinction between individuals that married once and those who married more than once.
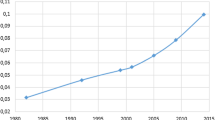
Most importantly, we select couples where at least one of the partners is between ages 23 and 35.Footnote 12 The bracket roughly corresponds to the core of prime adulthood and aims to exclude individuals still at school.Footnote 13 Although in reality the matches we observe took place at different points in time, we assume that, for each cross-section, individuals aged between 23 and 35 compete on the same marriage market. In this case, marriage markets are not rigidly defined by age brackets. In particular, the age difference between the partners and the age of first marriage may vary greatly. However, our empirical analysis relies on the assumption that sorting dynamics are relatively homogeneous for the age bracket 23–35 for each wave. We also select an alternative subsample of couples where we apply different age cutoffs based on the median age of first marriage in that year (see Fig. 1). We use this sample to run robustness checks. Details are provided in Section 5.1 and Table 1.

Median age at first marriage. The trends for the median age at first marriage were estimated with CPS data by the Fertility and Family Statistics Branch of the US Census Bureau and are available online: https://www.census.gov/data/tables/time-series/demo/families/marital.html
On this delicate point, we differ substantially from most of the matching literature. For instance, Chiappori et al. (2017) use 2010 Census data to construct the population vectors cohort by cohort. Their method relies on the assumption that each cohort is a separated marriage market.Footnote 14 Nonetheless, we aim to estimate the intensity of assortativeness on age and document its trend over time. The selection criterion proposed by Chiappori et al. (2017), instead, assumes an extremely rigid sorting pattern with respect to age. This is a well-known limitation in the matching literature. Including age among the matching variables is a first attempt to deal with this problem.
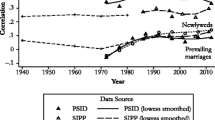
One of the main concerns affecting age restrictions is self-selection due to divorce. Separation and divorce allow observing only the prevailing unions at a given point in time, and this may lead to some problems in the interpretation of the results. For example, cohorts born in 1950 have been largely affected by changes in divorce laws in the 1970s, and their divorce rate is particularly high. Divorce may primarily destroy non-assortative matches. Hence, the marriage patterns observed in 2010 for this cohort might result from a selection process through divorce, instead of being the result of specific tastes at the moment of the match. In order to overcome this potential bias, it could be advised to work with a subsample of newlyweds (as also suggested by Schwartz and Mare (2005)). Unfortunately, in most cases, data on marital history are not available.
Finally, note that the estimation algorithm works best with samples with order of magnitude equal to 3. For some waves, the sample of observations respecting our selection criteria is greater than 10,000. In Appendix B, we propose a methodology to ensure that the sample is highly representative of the sorting patterns when we must reduce its size.
4.3 Baseline sample
The changes in the availability of data and potential problems arising from the construction of the variables motivate the use of alternative samples. In spite of this, we choose three baseline specifications described in Table 1 in Appendix C that we use to present our main findings. Sample A covers all waves from 1964 to 2017, but employs a limited specification of the race variable: only Blacks and Whites are distinguished. Sample B covers waves from 1971 to 2017, but contains a more detailed race/ethnicity variable: the available categories are Blacks, Hispanics, Whites, and Others. Sample C only covers waves from 1988 to 2017, but, with respect to Sample B, includes an additional racial category for Asians. We introduce three different baseline samples since data about race and ethnicity are not consistent across years. We are primarily concerned with potential biases due to the misspecification of ethnic traits and the exclusion of minorities from the sample. While discussing our main findings, we run several robustness checks that employ different subsamples. These are also described in Table 1 in Appendix C.
4.4 Summary statistics
The population that we consider in the empirical analysis has gone through major changes in the past 50 years. The median age at first marriage has increased over this period, from 22.8 years old (resp. 20.3 years old) for men (resp. women) in 1960 to 29.5 years old (resp. 27.4) in 2017. Trends for the median age of first marriage are displayed in Fig. 1.Footnote 15 At the same time, the share of unmarried individuals has greatly increased (see Fig. 2).

Share of married individuals by age and cohort. Share of married couples by age and cohort using CPS data 1964–2017. To be in the data, individuals must be ages 18 to 65. Couples where one partner is still at school are excluded. The vertical lines represent the age interval (23–35) used for selecting our main samples
The rise in educational achievement is depicted in panels (a) and (b) of Fig. 3. Only a relatively smaller fraction of individuals now belongs to low education categories (below high school or high school degree), while an increasing share of the population falls into higher education categories (some college, college degree, or above). Note that this trend is especially striking for women, who now appear to be more educated than men, while the reverse was true in the 1960s.Footnote 16

Summary statistics. Married couples from CPS data 1964–2017. To be in the sample, couples must have at least one partner between ages 23 and 35. Couples where one partner is still at school are also excluded. Discontinuity around 1992 for schooling trends is due to a change in the variable specification made by the US Census Bureau. Discontinuities in the race trends are also due to the addition of new categories in the set of possible answers. We use 5 levels of education: (BHS) below high school degree, (HS) high school degree, (SC) some college, (CG) college degree, and (CG+) 5+ years of college
In panels (c) and (d), we describe the racial composition of our sample. We can separately identify the four major racial groups (White, Black, Hispanic, and Asian) after 1988. From the graph, it seems that Hispanics used to declare themselves as White prior to 1971, while Asians composed the majority of the “Others” category. The share of Black in the samples is relatively constant, while Hispanics and Asians account for an increasing share of the population at the expense of the White category.
One major change in families in the past 50 years is the increased participation of women in the labor market. This is represented in panel (e) of Fig. 3. Our measure of employment for our sample is the share of people with a strictly positive wage.Footnote 17 The graph shows a dramatic increase for women, although the rate stabilized after 1990. Finally, panel (f) depicts the wage ratio for women relative to men (conditionally on having a strictly positive wage). This increase has been identified as one of the main factors of change for families (see Becker 1973, 1991, on specialization within households and human capital investment of women).
When we look at the joint characteristics of the spouses (Fig. 4), we notice a strong positive correlation between the partners’ age and education, which is a first hint that these traits are complements. While correlation by age decreases over time, the trend of correlation by education is instead unclear. On the other hand, we observe an increasing trend for the correlations by hours worked and hourly wage. Interestingly, these co-moments are first weakly negative and then weakly positive. Finally, the share of interracial marriages has increased over time.

Partners’ traits. Samples used: baseline A. Baseline sample B is used for the trend of interracial marriage (right panel)
5 Trends in matching patterns
In this section, we describe trends for the diagonal elements of the affinity matrix estimated using the baseline sample A described in Section 4.3 over the period 1964–2017. Estimation follows the steps explained in Section 3. Estimates of the Aij entries are obtained for every year and shown in the graphs below. We display the point estimates, as well as the confidence intervals. Data are standardized so that the covariance matrices \(E_{\hat {\pi }}[x^{\prime }x]\) and \(\hat {E_{\hat {\pi }}}[y^{\prime }y]\) have diagonal entries equal to 1 for a reference year.Footnote 18 This allows us to compare different estimates of A within and across years. We also use local constant regression smoothing (LOWESS) to ease the interpretation of the results. Finally, we present several robustness checks in order to understand whether our baseline findings suffer from variable misspecification, sample selection, or endogeneity problems. We provide an exhaustive list of the checks in Appendix C.
5.1 Age
Our results show that spouses’ ages are strongly complementary. However, Fig. 5 also shows an unambiguous decrease in age assortativeness. This may appear in contrast with previous results by Atkinson and Glass (1985) and Qian and Preston (1993), who claim that in the USA homogamy by age increased up to 1987. Nonetheless, this trend could be explained by a progressive passage from a traditional form of marriage—where the woman is slightly younger than the man—to a variety of different unions. For instance, Atkinson and Glass (1985) notice that spouses with a similar socioeconomic background tend to be of the same age more and more frequently. Moreover, couples where the husband is younger or where the difference in partners’ ages is high are more and more socially acceptable. What we find is, in fact, that the strength of sorting decreased, which means that several age combinations now coexist at equilibrium.

Assortativeness in age. Sample used: baseline A. The figure displays the estimated trend of the diagonal element of the marital preference parameter matrix A capturing the interaction between husband’s and wife’s ages. We observe a decrease in age complementarity
The age bracket we consider is large enough to include most couples married in the years preceding the survey year we look at.Footnote 19 However, since our age cutoffs are fixed (the youngest spouse must be at most 35), and since people tend to marry later and later over the time period considered, the composition of our sample in terms of marriage duration is likely to change over time. To address this issue, we consider an alternative sample made of couples where at least one partner’s age is in the interval \([\bar {a}_{t}-4,\bar {a}_{t}+2]\), where \(\bar {a}_{t}\) is the median age of first marriage for men in year t.Footnote 20 Sorting trends obtained with this sample present some differences with respect to those obtained with our baseline sample (see Fig. 16). These differences are most likely due to the different compositions in terms of year of birth and marriage duration. However, note that all qualitative results hold (the slope of the trends is the same as in our main findings). In particular, the strength of sorting with respect to age is lower, since the sample’s age range is reduced, but the trend is still decreasing.
5.2 Education
Figure 6 represents the trend of assortativeness in education between 1962 and 2017. We find a general increase in assortativeness in education. This is in line with the results of Greenwood et al. (2014), and with most of the findings in the literature (see Section 2). Nonetheless, as explained throughout the paper, we argue that our estimates only capture marital preferences and are cleansed from any demographic effect. These findings also provide further support to those of Chiappori et al. (2017), who document a rise in educational assortativeness for cohorts born between 1943 and 1972. While they also take a structural approach, they need to assume a fixed sorting structure for age and are limited to a unidimensional matching. Since we work in a multivariate setting, we can “control” for other observables and also conclude that assortativeness in education is comparable in strength to age, whereas it is much higher than wage or hours of work (see Figs. 7 and 8). As concerning possible misspecification of the schooling level variable, we find that our results are robust to different measures of educational attainment (detailed findings available on request).

Assortativeness in education. Sample used: baseline A. The figure displays the estimated trend of the diagonal element of the marital preference parameter matrix A capturing the interaction between husband’s and wife’s schooling levels. We observe an increase in education complementarity

Assortativeness in wage. Sample used: baseline A. The figure displays the estimated trend of the diagonal element of the marital preference parameter matrix A capturing the interaction between husband’s and wife’s wages. We observe a possible rising of a relatively weak wage complementarity which was not observed in the early waves

Assortativeness in hours of work. Sample used: baseline A. The estimated trend of the diagonal element of the marital preference parameter matrix A capturing the interaction between husband’s and wife’s hours worked. We observe a possible rising of a relatively weak complementarity in hours worked which was not observed in the early waves
5.3 Wage
The estimates for wage assortativeness are presented in Fig. 7. In the earliest waves, the estimates of the affinity matrix parameter for wages are not significantly different from 0. However, assortativeness in hourly wage rates has steadily increased up to the 2000s and is significantly positive in every wave since the mid-1980s. In the last 15 years, it seems that the estimate stabilized around a value of 0.05. The trend for the wage estimate is parallel to the closing of the wage gap and may suggest that men developed a stronger incentive to look for a spouse among high earners. Since our estimation includes both hours of work and hourly wages among the matching variables, and since we construct hourly wages using hours of work, we test the robustness of our results using annual earnings instead of wages.Footnote 21 The results are displayed in Fig. 17 in the appendix and are very similar to those obtained with our baseline sample.
In spite of this (weak) positive assortativeness, Becker (1973) suggested that the spouses’ wages should be substitutes because of household specialization, while main non-labor-market traits are expected to be complements. Unfortunately, our result is not a good test for Becker’s predictions: since many women (as shown in panel (e), Fig. 3) are not part of the labor force—especially in the earlier waves—we are not able to observe their wage potential. In other words, we are not able to determine the shadow price of time spent away from the labor market to which Becker refers to in his analysis of the household. As a result, the estimates we present do not capture marital preferences because of this endogeneity issue affecting the observed hourly wage rates (see also Ciscato et al. forthcoming).
To understand to what extent our main findings are affected by endogenous workforce participation choices, we run two parallel estimations with different subsamples (see Appendix C, checks 3 and 4). First, we only estimate the affinity matrix for a subsample of couples where both spouses have a positive wage. With respect to our baseline results (Fig. 7), we find evidence of positive assortative mating on wages since the earliest waves, and the strength of assortativeness is now constantly larger (Fig. 18). Second, when we only consider the subsample of childless couples, the estimates for wages’ complementarity are even higher (Fig. 19). These checks seem to suggest that, for households where household specialization is expected to be less pronounced, sorting on spouses’ wages is indeed stronger. Nonetheless, as both fertility and labor force participation are the outcomes of endogenous choices, none of the two subsamples can be considered as representative of the population preferences. Further research is needed in this direction.
Finally, we construct a measure of potential income that allows us to deal with non-participation (see Appendix C, check 5). We predict wages using a standard selection model (Heckman 1979). We estimate the trends of marital preferences and report the result in Fig. 20. The main important finding is that we observe positive assortative mating on wages since the earliest waves. The trend is increasing with a slope comparable to the one obtained with baseline sample A. We discuss the potential implications on inequality trends in Section 6.5 in light of the results of our decomposition exercise.
5.4 Hours worked
Trends in mating preferences for hours of work are represented in Fig. 8. Similarly to the case of wages, the estimates for the earliest waves are not significantly different from 0 and are even negative for some waves, whereas we observe an irregular increase starting from the 1980s. The increasing trend seems consistent with the shift from production complementarities as the main source of marriage gains to consumption-based complementarities (Stevenson and Wolfers 2007). While in traditional families one spouse—typically the wife—focused on housework and the other on the labor market, now partners may benefit from similar time schedules.
Once again, what the estimate for hours worked captures cannot be interpreted in terms of preferences at the moment of the match, since spouses most likely adjust their labor supply after the marriage. Checks 3 and 4, described in Section 5.3, lead to the following results: for couples where both partners are employed, we observe positive assortative mating on time schedules for any wave (Fig. 18), while for childless couples the positive sorting is even stronger (Fig. 19). In both cases, the strength of complementarity increases over time, similar to the baseline trend. Although these estimates are biased because of selection, it seems that couples where household specialization is weaker indeed display more homogeneous working time schedules and leisure time spent together.
5.5 Race
Figure 9 reports our estimates of the racial homogamy parameter for baseline samples A, B, and C, described in Section 4.3. We observe a sharp decline in the taste for homogamy when considering the race specification Black-White: the most significant decrease took place during the 1960s, when the last anti-miscegenation laws were ruled unconstitutional, whereas we observe a steady but only a slight decrease from the 1970s. Interestingly, when switching to the specification Black-White-Hispanic-Others (sample B), the trend is instead slightly increasing over the period 1971–2017. Finally, when the specification Black-White-Hispanic-Asian-Others is considered (sample C), the trend is increasing up to the mid-2000s, and then is slightly decreasing. In general, however, the results depend on how many groups are considered, that is, on the level of detail of the classification scheme. Studies on racial homogamy face the same issue, as the number of racial groups may vary depending on the availability of the data, or on how individuals are allowed to report their race. We can conclude that, although the data show a growing number of interracial marriages, the latter became less desirable since the 1970s when considering a detailed level of ethnic fragmentation, and that only recently the trend might have been reversed.

Assortativeness in race, by number of race included. Samples used: baselines A, B, and C (see Appendix C). The figure displays the estimated trend of the homogamy preference parameter for race contained in matrix A. We observe an increase in the preference for racial homogamy
We can further read into our results by switching from our main parametric specification (5) to an alternative one, where, instead of treating race as a categorical variable denoted xR,yR ∈{White,Black,Hispanic,Other}, we include one dummy for each of the four racial groups. In other words, given our 4 racial categories, we restrict to 0 the diagonal elements representing the interaction terms of type, say,  , and are left with 4 × 4 − 4 off-diagonal parameters to estimate. In this way, in our robustness check 6, we are able to identify the surplus change resulting from marrying a partner with a different racial background relatively to matching within one’s own racial group. Trends are indeed heterogeneous by racial group (see Fig. 21). Blacks appear as the most segregated racial group, suffering the highest penalties for interracial marriage on the market. However, most trends associated with interracial couples where one partner is Black suggest that these interracial marriages have grown more attractive (or at least not less attractive). On the other hand, Hispanics and Whites seem to have grown apart on the marriage market, with the trend only being reversed from late 2000s. Hence, this should explain our original conclusion: interracial marriage is found to be less and less attractive over time when including Hispanics as a separate ethnic group.
, and are left with 4 × 4 − 4 off-diagonal parameters to estimate. In this way, in our robustness check 6, we are able to identify the surplus change resulting from marrying a partner with a different racial background relatively to matching within one’s own racial group. Trends are indeed heterogeneous by racial group (see Fig. 21). Blacks appear as the most segregated racial group, suffering the highest penalties for interracial marriage on the market. However, most trends associated with interracial couples where one partner is Black suggest that these interracial marriages have grown more attractive (or at least not less attractive). On the other hand, Hispanics and Whites seem to have grown apart on the marriage market, with the trend only being reversed from late 2000s. Hence, this should explain our original conclusion: interracial marriage is found to be less and less attractive over time when including Hispanics as a separate ethnic group.
Our findings are particularly counterintuitive because the share of interracial couples has been growing as the American population becomes more and more multi-ethnic. In this case, disentangling preferences from demographics leads us to a result in contrast with conclusions from previous works. Fryer (2007) uses a specification White-Black-Asian for his race variable and concludes that preference for homogamy decreased throughout the last century. This seems to be in line with our estimates obtained with baseline sample A, where Hispanics are mainly considered as Whites. However, Fu and Heaton (2008) use a White-Black-Hispanic-Asian specification to describe ethnic groups. Our results are opposed to theirs, as they conclude that taste for racial homogamy decreased over the period 1980–2000.
5.6 Unobservables
We recall that the scalar σ measures the relevance of the unobservable random preference shock. The higher σ, the more matching appears as random to the observers. Figure 10 displays the values of σ obtained under our identification assumption given in Section 3.4 and with baseline sample A. The clear increasing trend suggests that socioeconomic observables matter less today than they did 50 years ago. The role played by the parameter σ in our theoretical framework suggests that there are two forces offsetting each other. On the one hand, we report that taste for racial homogamy and positive assortativeness in education have increased in strength. On the other hand, the relevance of the socioeconomic observables that we take into account has decreased.

Sigma. Samples used: baselines A, B, and C (see Appendix C). The estimated trend of the parameter σ capturing the relevance of idiosyncratic preference shocks in our matching model. We observe an increase of the relevance of unobservables in matching
In robustness check 7, we purposely omit education in order to understand how this would bias our findings, and particularly how this would change the relative importance of the entropy observed by the econometrician as measured by σ. This exercise shows that omitting a key variable such as education results in upward-biased estimates of complementarities of traits that are positively correlated with the omitted variable. In this case, omitting education results in higher estimates for complementarity on age and wage, as well as for preference for ethnic homogamy (see Fig. 22). In addition, σ is found to be higher, and its trend increases more steeply. In this omitted-variable specification, unobservables play a more relevant role, and their importance grows faster than in our baseline specification.
6 Counterfactual analysis
One key motivation behind the analysis of marital preferences is to understand their contribution to the changes in mating patterns and between-household inequality. To conduct our counterfactual analysis, we used CPS data for the years 1971 and 2017. We use the baseline sample B, which includes four racial groups (White, Black, Hispanic, Others). We try to answer two questions: (a) what would be the marriage patterns, for example the joint distribution of education, if individuals married as in 1971? And (b) how would inequality change if individuals had the same marital preferences as in 1971?
As explained in Section 3.5, once estimated A1971 and with (X2017,Y2017) at hand, we can compute the counterfactual optimal matching P(2017,2017;1971) in order to compare it with the marriage market equilibrium predicted by the model with the actual 2017 preferences.Footnote 22 In this section, we report the results of our counterfactual analysis for two variables: age and education. We subsequently proceed with the analysis of inequality trends and a decomposition exercise to understand which parameters are associated with the inequality rise.
6.1 Education
To ease the representation of the results, we gather individuals in three educational types: high school and below (HS), some college (C), and college degree and above (C+). We first compute the counterfactual market equilibrium P(2017,2017;1971). The upper distribution in Fig. 11 displays the relative frequencies of each of the six possible types of match that would result from matching if the preferences of the 2017 population were the same as in 1971. The relative frequencies reported in the second line are the result of a different counterfactual experiment. We now fix all the parameters to their 2017 values except for the one capturing the interaction between partners’ education, which is allowed to take its 1971 value. In this way, we isolate the effect of the change in this single parameter on the marriage market outcome. In the last line, we report the joint aggregate equilibrium distribution of educational types predicted by the model for year 2017. Comparing lines 2 and 3, we note that the increase in complementarity shrinks the shares of couples crossing educational barriers. On the other hand, endogamous marriages are more frequent. With the help of line 1, we conclude that these changes observed above turn out to be mostly offset by shifts in other parameters, which leads us to conclude that the evolution of marital preferences had little impact on the joint distribution of partners’ schooling levels. One main reason is likely to be the increase in the parameter σ, which decreases the relevance of socioeconomic observables on the marriage market.

Assortativeness in education, counterfactual distribution. Sample used: baseline B. The marginal distributions of characteristics (X2017,Y2017) are taken from 2017 data for the three figures. In the first line, we show the counterfactual joint distribution of partners’ educational levels (high school and below (HS), some college (C), and college degree and above (C+)) obtained using 1971 marital preferences. In the second line, we show the counterfactual distribution obtained using 2017 marital preferences but allowing the schooling complementarity parameter to be equal to its 1971 value as in Fig. 6. In the third line, we show the actual distribution obtained with 2017 marital preferences
6.2 Age
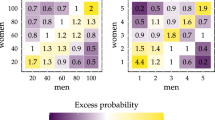
We repeat a similar experiment with age, as illustrated in Fig. 12, where we computed the joint distribution of spouses’ age with both actual and counterfactual marital preferences, then we looked at the difference between the two. Remember that, as discussed in Section 5.1, in 1971 there used to be a relatively stronger sorting on age than in 2017. From Fig. 12, we note that, under counterfactual 1971 preferences, we would observe far more couples where the husband is around 2 or 3 years older than the wife (the darkest cells are mostly right above the diagonal) and slightly more couples with partners of the same age (the cells on the diagonal are dark). These two types of couples, and especially those with a slightly older husband, can be considered as the most “traditional.” However, the change in preferences made them less frequent in favor of other types of marriages. Indeed, under actual 2017 preferences, we observe far more couples where the distance between spouses’ ages is greater (the white cells are far from the diagonal). In particular, there are many more couples where the wife is more than 5 years older than the husband.

Assortativeness in age, counterfactual distribution. Sample used: baseline B. The figures depict the differences in joint frequencies of partners’ ages between the actual distribution obtained with 2017 preferences and the counterfactual one obtained with 1971 preferences (P(2017,2017;2017) − P(2017,2017;1971)). We show such frequencies in a three-dimensional space and in the corresponding “elevation” map. The darker the block, the more couples of the corresponding age in the counterfactual outcome outnumber their peers in the actual. The lighter the block, the more couples of the corresponding age in the actual outcome outnumber their peers in the counterfactual. Remember that the sample may include individuals of any age, although we require that at least one of the partners is between ages 23 and 35 for the couple to be in the sample
6.3 Inequality
The purpose of the previous sections was to show how the change of the affinity matrix directly translates into a different marriage market outcome. We can now compute household income distributions and then Gini coefficients. For each potential couple, we compute the total labor income of the household, while the optimal matching matrix P(s,s;t) tells us the corresponding frequency of this type of couple at equilibrium. For any two years s and t, we use individual traits distribution from year s and marital preference parameters from year t and compute the Gini coefficient using the optimal matching matrix P(s,s;t)—i.e., the counterfactual frequency table of the couples’ type—and the vectors of spouses’ incomes xs and ys. We denote the predicted Gini coefficient computed with male and female population vectors from year s and with marital preferences (At,σt) from year t as \(\mathcal {G}(s,s;t)\).
We aim to study the evolution of inequality from 1971 to 2017. In particular, we ask the following question: what inequality patterns would we observe in year s if the year s population had the same marital preferences as in 1971? To answer, we first compute the Gini coefficient predicted by the model for every year s using preferences in year s, \(\mathcal {G}(s,s)\). Then, we fix marital preferences to their 1971 levels but predict marriage patterns for the population in year s. Hence, we can compute \(\mathcal {G}(s,{1971})\) using the counterfactual labor income distribution. We replicate this exercise every 4 years starting from our reference year 1971 and always fixing marital preference parameters to their 1971 levels. In Fig. 13, we plot the predicted Gini coefficients with actual preferences (solid line) and with counterfactual preferences (dashed line), while the dotted line depicts how the Gini coefficient would change (in percentage) if individuals had the same tastes as in 1971. While inequality is steadily increasing since 1971, the solid and dashed lines slowly diverge from each other, which means that the rise of household income inequality has been exacerbated by the shifts in marital preferences.

Counterfactual analysis, Gini coefficients since 1971. Sample used: baseline B. The figure shows the estimated actual trend of the between-household Gini coefficient and a counterfactual trend obtained by fixing marital preferences to their 1971 values
Similarly to Eika et al. (forthcoming), we observe a clear increase in income inequality among married households over the last 45 years, from 26.76 points in 1971 to 36.56 in 2017. However, were marital preferences constant since 1971, the current Gini would be lower by 2.43 points (equal to 34.13, that is about 6% less). Our experiment indicates that 24.80% of the rise in inequality in total household labor income between 1971 and 2017 can be attributed to changes in preferences on the marriage market.
6.4 Decomposition
Finally, we decompose the share of the increase of the Gini coefficient that we attribute to shifts in marital preference parameters (Fig. 14). On the right of the vertical axis, we find the main forces that contributed to the rise of household inequality. Not surprisingly, increased complementarity in partners’ education is one of them, albeit not the strongest. In fact, despite the modest size of their increases (see Figs. 7 and 8), the changes that have concerned sorting on wage rates and working hours seem to be the main driving forces behind the inequality rise. However, even small variations in the parameters may result in large fluctuations of macroeconomic outcomes if the marginal distributions change. Since the wage structures, the wage gender gap, and women’s participation in the workforce have radically changed (see panels (e) and (f) in Fig. 3), the interaction of such transformations with marital preference evolution has amplified inequality growth. In addition, an important share of the change in the Gini coefficient is due to shifts in cross-interactions, i.e., of those parameters that do not lie on the diagonal of the affinity matrix. In particular, the interaction between one’s education and his/her partner’s wage and the interaction between husband’s wage and wife’s hours worked play a prominent role. Some of these trends can be found in Appendix C, Fig. 15, and once again our estimates suggest that such interactions are relatively weak and have not changed much over time.Footnote 23 Finally, looking at the left of the vertical axis, we find that the increase of the parameter σ has hampered inequality by reducing the relevance of socioeconomic observables in matching. Another counterforce to the rise of inequality is the decrease in assortative mating on age.Footnote 24

Decomposition of Gini coefficient shift 1971–2017 due to marital preferences. Sample used: baseline B. In the labels, the first trait is the husband’s and the second is the wife’s, e.g., Wage-Educ refers to the interaction between the husband’s wage rate and the wife’s education. On the right of the vertical axis, there can be found the parameters that contributed to raise inequality; on the left of the vertical axis, those that pushed in the opposite direction, leading to a decrease
6.5 Discussion
In our counterfactual analysis, we consider changes in sorting along several dimensions, not only education, and show that changes in marital preferences must be regarded as an important driving force behind the recent rise in inequality. We conclude that changes in sorting account for almost 25% of the total increase in household income inequality among married couples, as measured by the Gini coefficient. In line with theoretical predictions of Fernández et al. (2005) and previous empirical findings, educational assortativeness is shown to have a positive impact on income inequality. Greenwood et al. (2014) and Eika et al. (forthcoming) find that changes in educational assortativeness had almost no direct impact on inequality, and point to changes in labor market participation and returns to education as the main forces explaining household income inequality trends. While we do find a positive effect of increasing educational sorting on inequality, we also conclude that this effect is of second order when other controls are included among the matching variables.
Greenwood et al. (2016) suggest that, all else constant, changes in the marginal distribution of hourly wages are key in understanding the increase in household income inequality. Our findings suggest that changes in the marginal distribution of wages paired with a small, but significant, increase in the strength of sorting along hourly wages and hours worked account for a sizable share of the inequality rise. While, unlike Greenwood et al. (2016), we are unable to discuss the role of endogenous labor-supply adjustments, we run several robustness checks to understand how the endogeneity of labor supply choices can bias our findings. Results obtained with a sample of two-earner households (Fig. 18), childless couples (Fig. 19), and with potential income as a matching variable (Fig. 20) lead us to the following considerations: first, our main estimates on complementarities on hourly wages and hours worked are likely to be downward biased; and second, the same robustness checks confirm that the direction and the size of the changes are mainly unaffected by the bias.
Finally, Greenwood et al. (2014) and Greenwood et al. (2016) suggest that the uneven decline of marriage has further contributed to the rise of inequality across households, as individuals with low education have become comparatively less likely to be married in the cross-section. In this paper, we exclude the extensive margin from the analysis—i.e., the choice of marriage vs singlehood—and thus we do not relate changes in assortative mating to the decline of marriage, consistently with the logit framework of DG.Footnote 25 In a related project, Dupuy and Weber (2018) discuss the importance of the extensive margin as opposed to the intensive margin in a model of educational assortative mating: while changes along the extensive margin play a greater role, changes along both margins positively contribute to the rise of inequality.
7 Conclusions and perspectives
Our analysis calls into question and updates previous results on the evolution of mating patterns and their implications for inequality. It aims to provide the most recent and complete picture of mating patterns in the USA relying on a structural approach that is new to this literature. The framework introduced by Dupuy and Galichon (2014) not only allows us to disentangle preferences and demographics effectively, but also to work in a multidimensional and continuous setting. This flexible specification presents an advantage with respect to previous works in that it allows us to analyze different dimensions of sorting at once, in order to understand to what extent marital preferences explain the rise in inequality, and which dimensions actually have contributed the most to the increase. On the other hand, we limit ourselves to documenting the changes in sorting patterns and household dynamics without attempting to explain the driving forces behind such transformations. Our work is thus complementary to the richer theoretical frameworks proposed by Fernández et al. (2005) and Greenwood et al. (2016).
Throughout our paper, we provide a detailed picture of the evolution of marital preferences in the USA over the period 1964–2017. In line with the majority of previous works, we find that, even after including several other personal traits, positive assortative mating on education has become stronger and stronger over time. At the same time, positive assortative mating on age has decreased and household specialization seems to be weaker. We also find that, overall, the relevance of socio-economic observable traits has decreased on the marriage market. Finally, preference for racial homogamy seems to have increased since the 1970s. These results seem to be driven by Whites and Hispanics—the fastest growing ethnic minority—growing less and less attracted to each other on the marriage market.
In the second part, we run counterfactual experiments to assess the impact of the shifts in marital preferences on between-household income inequality. We find that, had preferences not changed since 1971, the Gini coefficient would have been 6% lower: this implies that about 25% of the rise of income inequality over the period 1971--2017 is due to changes in sorting patterns. Our results complement those of Greenwood et al. (2014), Eika et al. (forthcoming), and Greenwood et al. (2016) on educational assortativeness. While we find that shifts in marital preferences do matter, we show that they only account for a significant but limited share of the inequality rise. Finally, when decomposing the contribution of marital preferences to the increase in the Gini coefficient, we find that changes in interactions among labor market traits can explain a large share of it. Since the 1980s, couples exhibit a weak but significant complementarity in wage rates and hours worked. This, jointly with important changes in the wage distribution, has crucially contributed to the rise of income inequality. The increased complementarity of spouses’ education is also a factor, although the decreased relevance of socioeconomic observables in matching and the decreased complementarity of spouses’ age are sufficient to offset its effect.
Notes
The survey of Stevenson and Wolfers (2007) tracks the changes that the institution of the family has gone through in recent decades, and presents several significant research questions that need to be answered.
The methodology consists of finding a log-linear model with good fit to explain a contingency table with the distribution of income by percentile (plus one category containing zero-income observations). Then, one can compute predicted frequencies after removing certain regressors to reproduce counterfactual situations.
Schwartz (2010) uses the ratios between the median income of the top 20% households (high class) over the median income of the middle 60% (medium class) or the median income of the top 20% (low class) as measures of inequality.
As for Greenwood et al. (2014), we hereby refer to the revised findings published in the corrigendum.
Alternatively, one could put an additional restriction on the parameters σ, for instance σ = 1 on each market. Ciscato et al. (forthcoming) propose to normalize the social gain \(\mathcal {W}(A,\sigma )\).
In addition, in CPS waves before 1976, there is no state variable at the household level. Only broad geographical areas are reported.
The 5-level variable is constructed as follows: (1) below high school degree, (2) high school degree, (3) some college, (4) college degree, and (5) 5+ years of college. With 4 levels only, we distinguish: (1) below high school degree, (2) high school degree, (3) college degree, and (4) 5+ years of college.
The number of weeks working in the past year is usually available as a continuous variable. However, it is sometimes only available as a grouped variable, which we use to proxy the number of weeks worked in the past year.
Comparing summary statistics before and after 1971 suggests that most Hispanics declared themselves as White, whereas the category Others mostly contains Asians before 1988.
We also exclude students aged more than 23 by combining data on school attendance and reasons for not participating to the labor market.
More precisely, each cohort t of young men matches with the cohort t + 1 of young women.
The trends for the median age at first marriage have been estimated with CPS data by the Fertility and Family Statistics Branch of the US Census Bureau and are available online: https://www.census.gov/data/tables/time-series/demo/families/marital.html. Details about the estimation method can be found in ?[ ()Chapter 9]siegel2004methods. The 1970 and the 1980 Census and the American Community Survey (ACS) contain survey data about the year of marriage: a comparison of the estimated CPS trends with these data sources reveals that the estimates are indeed accurate.
The graph also shows the discrepancy in the education variable in 1992, as a large share of the population previously categorized as having a high school degree now appears in the “Some College” category.
The share of employed people may appear extremely high in some cases (for men at the beginning of the period for example), but this may be due to our sample selection criteria based on age and marital status. In addition, we consider a person as employed as long as we are able to compute a wage, that is, as long as she worked in the past year.
In practice, we first compute \((diag(E_{\hat {\pi }}[x_{1991}^{\prime }x_{1991}]))^{-1/2}\) for men’s population in 1991, and then use it as a scaling factor for every cross-section. We do the same for women.
In fact, in spite of the increasing median age of first marriage, most people still get married before they turn 35. The share of married people in a cohort is indeed approximately constant after 35 (see Chapter 1, Browning et al. 2014.
The difference between the median age for men and for women is approximately constant over the time period considered, and is around 2 years (see Fig. 1).
Precisely, we replace wages by the variable log(1 + wa) where wa are (possibly 0) annual earnings.
Alternatively, we could compare the counterfactual matching P(2017, 2017; 1971) with the actual frequencies observed in the data, rather than those predicted by the model. However, since the model does an excellent job in reproducing the actual frequencies, the two exercises yield similar results.
The only trend that we find is a slight—and barely significant—decrease of the negative interaction between men’s wage and women’s working hours. This parameter may partly capture the wife’s wealth effect on labor supply.
However, the effect is small and is not displayed in Fig. 14.
As discussed by DG (see Appendix C in particular) and Ciscato et al. (forthcoming), the distributional assumption on the stochastic terms of the marital payoff functions is such that the choice model (1) is logit and benefits from the property of the independence of irrelevant alternatives. Under this assumption, treating the composition of the married population as exogenously given does not affect the empirical findings.
References
Agresti A (2007) An Introduction to Categorical Data Analysis, 2nd edn. Wiley, Hoboken
Agresti A (2013) Categorical Data Analysis, 3rd edn. Wiley, Hoboken
Atkinson MP, Glass BL (1985) Marital age heterogamy and homogamy, 1900 to 1980. J Marriage Fam 47(3):685–691
Becker GS (1973) A theory of marriage: Part i. J Polit Econ 81(4):813–846
Becker GS (1974) A theory of marriage: Part ii. J Polit Econ 82(2):S11–S26
Becker GS (1991) A Treatise on the Family. Harvard University Press, Cambridge
Blackwell DL (1998) Marital homogamy in the United States: the influence of individual and paternal education. Soc Sci Res 27(2):159–188
Browning M, Chiappori PA, Weiss Y (2014) Economics of the Family. Cambridge University Press, Cambridge
Burtless G (1999) Effects of growing wage disparities and changing family composition on the us income distribution. Eur Econ Rev 43(4):853–865
Cancian M, Reed D (1998) Assessing the effects of wives’ earnings on family income inequality. Rev Econ Stat 80(1):73–79
Chiappori PA, Salanié B, Weiss Y (2017) Partner choice, investment in children, and the marital college premium. Am Econ Rev 107(8):2109–67
Choo E, Siow A (2006) Who marries whom and why. J Polit Econ 114 (1):175–201
Ciscato E, Galichon A, Goussé M (forthcoming) Like attract like? a structural comparison of homogamy across same-sex and different-sex households. Journal of Political Economy
Dupuy A, Galichon A (2014) Personality traits and the marriage market. J Polit Econ 122(6):1271–1319
Dupuy A, Weber S (2018) Marital patterns and income inequality. Tech. rep
Eika L, Mogstad M, Zafar B (forthcoming) Educational assortative mating and household income inequality. Journal of Political Economy
Fernández R, Rogerson R (2001) Sorting and long-run inequality. Q J Econ 116(4):1305–1341
Fernández R, Guner N, Knowles J (2005) Love and money: a theoretical and empirical analysis of household sorting and inequality. Q J Econ 120(1):273–344
Fryer RG (2007) Guess who’s been coming to dinner? trends in interracial marriage over the 20th century. J Econ Perspect 21(2):71–90
Fu X, Heaton TB (2008) Racial and educational homogamy: 1980 to 2000. Sociol Perspect 51(4):735–758
Galichon A, Salanié B (2015) Cupid’s invisible hand: social surplus and identification in matching models. Tech. rep., SSRN Working Paper Series
Greenwood J, Guner N, Kocharkov G, Santos C (2014) Marry your like: assortative mating and income inequality. Am Econ Rev Pap Proc 104(5):348–353
Greenwood J, Guner N, Kocharkov G, Santos C (2016) Technology and the changing family: a unified model of marriage, divorce, educational attainment, and married female labor-force participation. Am Econ J Macroecon 8(1):1–41
Heckman JJ (1979) Sample selection bias as a specification error. Econometrica 47(1):153–161
Johnson RA (1980) Religious Assortative Mating in the United States. Academic Press, Cambridge
Kalmijn M (1991a) Shifting boundaries: trends in religious and educational homogamy. Am Sociol Rev 56(6):786–800
Kalmijn M (1991b) Status homogamy in the United States. Am J Sociol 97 (2):496–523
Kremer M (1997) How much does sorting increase inequality?*. Q J Econ 112 (1):115–139
Liu H, Lu J (2006) Measuring the degree of assortative mating. Econ Lett 92(3):317–322
Mare RD (1991) Five decades of educational assortative mating. Am Sociol Rev 56(1):15–32
Qian Z, Preston SH (1993) Changes in American marriage, 1972 to 1987: availability and forces of attraction by age and education. Am Sociol Rev 58(4):482–495
Schmitt J (2003) Creating a consistent hourly wage series from the current population survey’s outgoing rotation group 1979-2002. Tech. rep., CEPR Working Paper
Schoen R, Wooldredge J (1989) Marriage choices in North Carolina and Virginia, 1969-71 and 1979-81. J Marriage Fam 51(2):465–481
Schwartz CR (2010) Earnings inequality and the changing association between spouses’ earnings. Am J Sociol 115(5):1524
Schwartz CR, Graf NL (2009) Assortative matching among same-sex and different-sex couples in the united states, 1990–2000. Demogr Res 21(28):843
Schwartz CR, Mare RD (2005) Trends in educational assortative marriage from 1940 to 2003. Demography 42(4):621–646
Shapley LS, Shubik M (1971) The assignment game i: the core. Int J Game Theory 1(1):111–130
Siegel JS, Swanson DA (2004) The Methods and Materials of Demography. Elsevier Academic Press, California
Smits J, Ultee W, Lammers J (1998) Educational homogamy in 65 countries: an explanation of differences in openness using country-level explanatory variables. Am Sociol Rev 63(2):264–285
Stevens G, Schoen R (1988) Linguistic intermarriage in the United States. J Marriage Fam 50(1):267–279
Stevenson B, Wolfers J (2007) Marriage and divorce: changes and their driving forces. J Econ Perspect 21(2):27–52
Western B, Bloome D, Percheski C (2008) Inequality among American families with children, 1975 to 2005. Am Sociol Rev 73(6):903–920
Acknowledgments
The authors thank the editor and two anonymous reviewers for very helpful comments. Additionally, the authors acknowledge the insightful comments of Arnaud Dupuy, Alfred Galichon, Sonia Jaffe, Andreas Steinhauer, Frederic Vermeulen, Paul Vertier, and seminar participants at University of Chicago, Sciences Po Paris, and the RES Symposium of Junior Researchers. The data used in this paper are available from IPUMS-CPS, University of Minnesota, www.ipums.org.
Funding
Weber is grateful for financial support from the France Chicago Center Exchange Fellowship and for the hospitality of the CEHD at the University of Chicago where part of this paper was written.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Responsible editor: Junsen Zhang
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Neutrality of optimal matching
According to DG, the equilibrium matching is described by the function 2. Take the log of π(x,y) so that:
The first component is x′By: without the identification assumption with multiple markets described in Section (3.4), we are still able to identify B = A/σ unequivocally. In fact, under any assumption to disentangle A from σ, a sample (X,Y ) yields a unique estimate \(\hat {B}\).
As concerns the second and third components a(x)/σ and b(x)/σ, define \(\tilde {a}(x)=\exp (a(x)/\sigma )\) and \(\tilde {b}(x)=\exp (b(x)/\sigma )\). We can rewrite (2) as:
and plug it into the accounting constraints:
DG suggest solving this system by means of an IPFP algorithm. Notice that we can conclude that, for a given set of parameters B, there is a unique solution given by vectors \(\tilde {a}^{*}\) and \(\tilde {b}^{*}\), and thus a unique solution π∗.
Appendix B: Improvements to the estimation procedure
Depending on the year, our samples may contain many individuals. However, for computational reasons, estimation can only be performed on a subset of the population. Doing so, we do not make full use of the data to compute the empirical variance-covariance matrix. If the subsample’s size is too small, this may even introduce some bias in the estimates. Since the estimation strategy relies on matching the theoretical co-moments to the empirical counterparts, we pick a random subsample whose co-moments of interest are close to those of the full sample. Hence, we use the following procedure to select the subsamples:
Procedure 1
Let N be the number of couples in the population:
-
Step 0.
Compute the empirical variance-covariance \(\hat {V}\equiv E[XY]\) with the full sample
-
Step 1.
Draw a subsample of size n < N and compute the empirical variance covariance matrix \(\hat {V}_{n}\)
-
Step 2.
Check if \(|\hat {V}-V_{n}|<\epsilon \times \hat {V}\) for a given level of precision 𝜖.
-
Step 3.
If step 2 is satisfied, use Vn and the corresponding subsample to estimate the affinity matrix, otherwise repeat steps 1–3.
Appendix C: Samples
Appendix D: Additional figures

Relevant cross-interactions. Sample used: baseline A. The figures display the estimated trends of the off-diagonal elements of the marital preference parameter matrix A that have some relevance in our decomposition exercise in Section 6.4. In the labels, the first trait is the husband’s and the second is the wife’s, e.g., Wage-Educ refers to the interaction between the husband’s wage rate and the wife’s education

Sample selection by median age. Sample used: check 1 (see Appendix C). The figures compare our baseline results on estimated trends of the diagonal elements of the marital preference parameter matrix A with those obtained using a subsample of couples where at least one partner is aged between the contemporaneous female median age at first marriage (minus 2) and the contemporaneous male median age at first marriage (plus 2)

Sorting on annual earnings. Sample used: check 2 (see Appendix C). The figures show estimated trends of the diagonal elements of the marital preference parameter matrix A when annual earnings are used instead of wages

All couples and working couples (where both partners work). Sample used: check 3 (see Appendix C). The figures compare our baseline results on estimated trends of the diagonal elements of the marital preference parameter matrix A with those obtained using a subsample of couples where both spouses work

All couples and childless couples. Sample used: check 4 (see Appendix C). The figures compare our baseline results on estimated trends of the diagonal elements of the marital preference parameter matrix A with those obtained using a subsample of childless couples

Sorting on potential income. Sample used: check 5 (see Appendix C). The figures compare our baseline results on estimated trends of the diagonal elements of the marital preference parameter matrix A with those obtained using a measure of potential wages


Education omitted. Sample used: check 7 (see Appendix C). The figures compare our baseline results on estimated trends of the diagonal elements of the marital preference parameter matrix A with those obtained when purposefully omitting education

Cohabitating and married couples. Sample used: check 8 (see Appendix C). The figures compare our baseline results on estimated trends of the diagonal elements of the marital preference parameter matrix A with those obtained using a subsample of cohabitating couples. Data on cohabitating couples are only available since 1995 and the size of the sample is considerably smaller
Rights and permissions
About this article

Cite this article
Ciscato, E., Weber, S. The role of evolving marital preferences in growing income inequality. J Popul Econ 33, 307–347 (2020). https://doi.org/10.1007/s00148-019-00739-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00148-019-00739-4