
Abstract
Optimum allocation of test resources is of crucial importance for the efficiency of breeding programs. Our objectives were to (1) determine the optimum allocation of the number of lines, test locations, as well as number and type of testers in hybrid maize breeding using doubled haploids with two breeding strategies for improvement of general combining ability (GCA), (2) compare the maximum selection gain (ΔG) achievable under both strategies, and (3) give recommendations for the optimum implementation of doubled haploids in commercial hybrid maize breeding. We calculated ΔG by numerical integration for two two-stage selection strategies with evaluation of (1) testcross performance in both stages (BS1) or (2) line per se performance in the first stage followed by testcross performance in the second stage (BS2). Different assumptions were made regarding the budget, variance components (VCs), and the correlation between line per se performance and GCA. Selection gain for GCA increased with a broader genetic base of the tester. Hence, testers combining a large number of divergent lines are advantageous. However, in applied breeding programs, the use of single- or double-cross testers in the first and inbred testers in the second selection stage may be a good compromise between theoretical and practical requirements. With a correlation between line per se performance and GCA of 0.50, ΔG for BS1 is about 5% higher than for BS2, if an economic weight of line per se performance is neglected. With increasing economic weight of line per se performance, relative efficiency of BS2 increased rapidly resulting in a superiority of BS2 over BS1 already for an economic weight for line per se performance larger than 0.1. Considering the importance of an economic seed production, an economic weight larger than 0.1 seems realistic indicating the necessity of separate breeding strategies for seed and pollen parent heterotic groups.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Inbred line development by doubled haploid technology is currently adopted as a routine method in commercial hybrid maize breeding programs in North America (Seitz 2005) and Europe (Schmidt 2004). The use of doubled haploids offers the possibility to evaluate potential hybrid cultivars from the very beginning of the selection process. With a large number of lines in each heterotic group, the number of factorial crosses among them becomes rapidly prohibitive. Hence, new lines are usually tested in combination with one or several testers to evaluate their general combining ability (GCA, Hallauer et al. 1988). Specific combining ability (SCA) acts as a masking effect in determining GCA. Its influence can be reduced by using genetically broad testers and/or an increased number of testers (Hallauer and Miranda 1981). However, choice of type and number of testers also affect the optimum allocation of test resources. As plant breeders have only a fixed budget available, they must find a compromise between (1) the number of initial lines to be tested and (2) the intensity of their testing as determined by the number of testers, test locations, years, and replications.
A selection strategy may involve one or several stages of selection. With multi-stage selection, the initial population of lines is evaluated in one year and based on the test results, a superior subset is selected for further evaluation and selection in subsequent year(s). Considering one-stage selection for GCA between inbred lines in maize, Federer and Sprague (1947) and Keller (1949) investigated the optimum allocation of the number of testers, lines, and replications. They concluded that for a fixed budget, the selection gain (ΔG) was increased by increasing the number of testers even at the expense of the number of lines and replications. Schnell (1996) extended these investigations to two-stage selection for early testing in maize considering also the number of test locations. For a fixed budget corresponding to 1,200 testcross plots, he suggested to use one tester in the first and seven testers in the second stage of selection. However, simplified genetic models and covariances were used for calculation of selection gain. In addition, a larger genetic variance is expected with doubled haploids in comparison with segregating lines.
Several experimental studies examined the impact of testers with narrow versus broad genetic base (for review see Hallauer and Miranda 1981). To our knowledge, investigations on the type of testers within the context of optimum allocated test resources have not been reported in the literature. An economic production of hybrid seed requires an acceptable line per se performance of the seed parent. For this and other reasons, evaluation of line per se performance may be an interesting alternative to testcross evaluations in the first selection stage. An assessment of this alternative selection strategy based on line per se performance and testcross performance is not available in maize.
We calculated the maximum ΔG by numerical integration to optimize the allocation of test resources in hybrid maize breeding using doubled haploids under two two-stage selection strategies with evaluation of (1) testcross performance in both stages, or (2) line per se performance in the first stage followed by testcross performance in the second stage. Different assumptions were made regarding the budget, variance components, correlation between line per se performance and GCA, and economic weight of line per se performance and GCA. Our objectives were to (1) determine the optimum allocation of the number of lines, test locations, as well as number and type of testers for each strategy, (2) compare the maximum ΔG achievable under both strategies, and (3) give recommendations for the optimum implementation of doubled haploids in commercial hybrid maize breeding.
Materials and methods
Breeding strategies
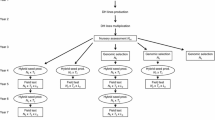
Doubled haploid lines generated from several F1 crosses via in vivo haploid induction are evaluated for line per se performance and/or testcross performance. The target variable is GCA or a selection index of line per se performance and GCA. We investigated two strategies to evaluate the doubled haploid lines. In both strategies, the lines are evaluated in two consecutive years. In the first year, N 1 lines are evaluated and a subset N 2 of the most superior lines are selected for evaluation in the second year. The five best doubled haploid lines are selected after these two selection stages to give opportunity to further selection also on SCA. Breeding strategy one (BS1) represents two-stage selection based on testcross evaluation of N j lines with T j testers at L j locations in stage j (j = 1, 2). Tester number and tester type can vary in both stages. The investigated tester types were inbred lines, single-crosses, double-crosses, or double-double crosses. In breeding strategy two (BS2), the lines are evaluated for line per se performance in the first stage and for testcross performance with T 2 testers in the second stage at L j locations, respectively. Without restrictions on L j , ΔG is maximum for one replication per location (Sprague and Federer 1951; Utz 1969; Melchinger et al. 2005). For this reason, we set the number of replications to one for all calculations. An overview of the notation used throughout this treatise is given in Table 1.
Calculation of selection gain
Our target variable was the selection index H = a GCA g GCA + a LP g LP (Cochran 1951), where a refers to the economic weight and g to the genotypic effect of GCA and line per se performance (LP), respectively. We used mostly a LP = 0 restricting the target variable to GCA. For comparison, we also calculated a LP = 0.1 and 0.2 with a GCA = 1 − a LP. The selection criterion in the second stage is an optimum index of the phenotypic means of the lines evaluated in the first and second stage with I = b 1 x 1 + b 2 x 2, where x refers to the phenotypic mean and b to its weight in stage one or two.
Calculation of ΔG is based on the well-known formula of Cochran (1951) with uni- and bivariate normal integrals for selected fractions and the square root of heritabilities of x 1 and x 2. For a detailed description of the calculation of ΔG, the reader is referred to Wricke and Weber (1986). For BS1, heritability is calculated by \({h^2_{x_j} = \sigma^2_{\rm GCA}/\sigma^2_{x_j}}\) with
where σ 2GCA and σ 2SCA refer to the variance of GCA and SCA effects, σ 2GCA × y to the variance of GCA × year interactions, σ 2GCA × l to the variance of GCA × location interactions, σ 2GCA × l × y to the variance of GCA × location × year interactions, σ 2SCA × y , σ 2SCA × l , and σ 2SCA × l × y to the respective interactions with SCA, as well as σ 2 e to the variance of the plot error. Tester type is defined by M j , the number of inbred lines combined in a tester. We assumed an equal contribution of the gametes of the inbred lines combined in the tester to the testcross progenies, with M j = 1, 2, 4, 8 referring to an inbred line, a single-cross, a double-cross, or a double-double cross tester, respectively. The covariance between testcross means of doubled haploid lines evaluated in two years was calculated as
where L c and T c refer to the number of locations and tester lines (T j × M j ) common to both selection stages. For BS2, \({h_{x_1}^2 = \sigma_{\rm Line}^2 /\sigma_{x_1}^2}\) with
where σ 2Line refers to the genetic variance among lines, σ 2Line × y to the variance of line × year interactions, σ 2Line × l to the variance of line × location interactions, σ 2Line × l × y to the variance of line × location × year interactions, as well as σ 2 e to the variance of the plot error. In the second stage, heritability was calculated as for BS1. The covariance between line and testcross means of doubled haploid lines in the two years was calculated as
where ρ(LP, GCA) refers to the genetic correlation between line per se performance and GCA. We assumed Cov(Line × l, GCA × l) = 0, because experimental values are lacking and a small value is expected from theory. The extension of the formulas for ΔG expected for an optimum index in the second stage and a LP > 0 is straightforward in multivariate selection (Baker 1986).
Optimum allocation of resources
The allocation of test resources refers to triples (T j , L j , N j ) for each tester type in all stages j. An element (T * j , L * j , N * j ) is denoted as an optimum allocation if it maximizes ΔG in the set of admissible allocations, which are valid for the budget, variance components, and tester type considered. The value of ΔG at its corresponding optimum allocation (T * j , L * j , N * j ) was denoted as ΔG *. The optimum allocation of test resources for each scenario was obtained by a grid search in the space of admissible resource allocations by increasing N 1 by one between its minimum and maximum possible value under the allocation considered.
Economic frame and quantitative-genetic parameters
A fixed total budget for (1) producing the doubled haploid lines and (2) evaluating their testcross progenies in two selection stages was defined in terms of testcross plot equivalents as N 1 C + N 1 T 1 L 1 + N 2 T 2 L 2, assuming equal plot sizes in all selection stages. Therein, the production cost C of one doubled haploid line was assumed to equal half the cost of one testcross plot equivalent (C = 0.5), corresponding to the actual costs of doubled haploid production in breeding companies most advanced in the doubled haploid technique (G. Seitz, personal communication). We compared three budgets with 500, 1,000, and 5,000 testcross plot equivalents. We assumed that each tester is evaluated at each location. Alternatively, we considered that each tester × line combination is evaluated only in a single location. With that assumption, T j L j is reduced to T j in Eqs. 1, 2 and the calculation of the budget.
We determined the optimum allocation for different scenarios of variance component for line per se performance and testcross performance (Table 2). These variance components were chosen based on combined analyses of variance in testcrosses of doubled haploid populations in commercial breeding programs and in elite germplasm of the maize breeding program of the University of Hohenheim (Longin et al. 2006a; Schrag et al. 2006). In addition, variance components were varied to cover a wide range of scenarios. The reference scenarios VC2.2 for testcross performance and VC5 for line per se performance resulted in heritabilities on a plot basis of 0.11 and 0.28, respectively. The larger h 2 for line per se performance in comparison with testcross performance is in accordance with results of experimental studies (Seitz 1989; Gallais 1997; Mihaljevic et al. 2005). This is due to similar non-genetic variances but larger genetic variances for line per se performance than for testcross performance. We investigated three assumptions concerning the genetic correlation between line per se performance and GCA with ρ(LP, GCA) = 0.25, 0.50, and 0.75, which were based on results published by Mihaljevic et al. (2005) and Weiss (1981).
Results
For all parameters being only marginally affected by varying budget and variance components, representative results were presented for intermediate values of the budget (1,000) and variance components (VC2.2). Deviations from these assumptions are explicitly stated. A fourfold increase in the ratio σ2 SCA/σ 2GCA from VC1 to VC3 resulted in an approximately doubled optimum number T *2 , a 50% reduction in L *2 , slightly decreased N *1 , and a reduction in ΔG * of more than 7% (Table 3). For a given ratio σ2 SCA/σ2 GCA, the use of double-double cross instead of inbred testers resulted in a substantial reduction in T *2 and a parallel increase in L *2 , a minor increase in N *1 , and an increase in ΔG * of at least 6%. Restricting the tester type in the second stage to inbreds resulted in fairly stable values of T * j and L * j for all tester types. However, N *1 decreased with the use of genetically broad testers in the first stage. In addition, the possibility of using genetically broad testers only in the first stage reduced their superiority over inbred testers in comparison with non-restricted tester types in both stages.
Further results were presented for single-cross testers in the first stage and inbred testers in the second stage, because these tester types are most commonly used in applied maize breeding programs. With increasing L 2 or T 2, ΔG increased strongly up to a maximum and decreased thereafter (Fig. 1). In the vicinity of the maximum, all response curves of ΔG were flat for varying values of L 2, T 1, and T 2. The optimum number L *2 depended strongly on T 2 with smaller values of L *2 being obtained with larger values of T 2 (Fig. 1a). The optimum number T *1 was always one (Fig. 1b). For T 1 > 1, the reduction in ΔG depended on the ratio σ 2SCA / σ 2GCA with a bigger loss for smaller values of σ 2SCA .

Selection gain (ΔG) in two-stage selection for GCA as a function of a the number of test locations and inbred testers in the second stage, assuming T *1 and L *1 , and b the number of inbred testers in the second stage for different numbers of single-cross testers in the first stage and ratios of σ 2SCA /σ 2GCA = 1/4 (dotted lines), 1/2 (dashed lines), and 1 (solid lines), assuming L *1 and L *2 for each scenario. In both figures, a budget of 1,000 testcross plot equivalents and variance components VC2.2 were assumed. For explanation of abbreviations, see Table 1
The impact of varying budget and variance components on the optimum allocation and ΔG was hardly affected by the ratio σ 2SCA /σ 2GCA . Thus, results were presented only for σ 2SCA /σ 2GCA = 1/2. In both breeding strategies, increasing the budget from 500 to 5,000 testcross plot equivalents resulted in a more than sixfold increase in N *1 , approximately doubled values of T *2 , L *2 , and N *2 , as well as a 50% higher ΔG * (Table 4). For BS1, a fourfold increase in the non-genetic variance from VC2.1 to VC2.3 resulted in (1) an increase in L * j of at least 50%, (2) a decrease in N *1 of 30%, (3) a slight reduction in T *2 , and (4) a reduction in ΔG * of more than 30%. For BS2, a fourfold increase in the non-genetic variance of the first selection stage from VC4 to VC6 had only a minor effect on T *2 , L *1 , and L *2 , but resulted in decreased N *1 , increased N *2 , and a 6% reduction in ΔG *. In BS1, evaluating each tester × line combination only at a single location resulted in (1) doubled T *1 , (2) tripled T *2 and L *2 , and (3) an increase of 6% in ΔG *. Similar results were obtained for BS2 (data not shown). With increasing ρ(LP, GCA) in BS2, the optimum number of N *2 was approximately halved, T *2 , L *1 , and N *1 were affected only slightly, and ΔG * increased more than 19%.
Discussion
Selection gain is the most widely used criterion to optimize selection strategies. Selection theory was developed by assuming an infinite sample size, although populations of medium size are used commonly in plant breeding (Cochran 1951; Hanson and Brim 1963; Utz 1969; Tomerius 2001; Grüneberg et al. 2004). This assumption simplifies the calculations considerably and results only in marginally inflated ΔG and similar optimum allocation of test resources compared to finite sample sizes (Cochran 1951; Finney 1966; Utz 1969; Longin et al. 2006b).
Optimum use of resources is primarily a matter of heritability
We used one replication per location, which maximizes ΔG if the number of locations is unrestricted (Sprague and Federer 1951; Utz 1969; Melchinger et al. 2005). For instance, superiority in ΔG for one replication compared with two replications increased from 1.5% for L j = 1 towards more than 5% for optimum L * j (data not shown). This can be explained by the fact that heritability is more increased by increasing L j and/or T j than by an increasing number of replications.
The use of different locations (L c = 0) and tester lines (T c = 0) either as inbred tester or in combination as single-crosses, double-crosses, or double-double crosses in both stages increased ΔG (data not shown). This is due to the reduction of the error part of the covariance between phenotypic means of the stages (Eqs. 2, 4). However, differences in ΔG * between the extremes of using no common location (L c = 0) or tester line (T c = 0) or all locations (L c = L 1) and tester lines of the first stage also in the second stage (T c = min(T 1 × M 1, T 2 × M 2)) were small, ranging from 0.5 – 1% for L c and 0.7–1.3% for T c . In addition, the optimum allocation was affected only marginally. These small differences can be explained by the flat response curves of ΔG in the vicinity of the maximum (Fig. 1). Consequently, we limited our further discussion to the common practice in maize breeding of using the locations (L c = L 1) and tester lines (T c = min(T 1 × M 1, T 2 × M 2)) of the first stage also in the second stage.
Evaluating progenies of each tester × line combination at a single location instead of evaluating progenies of tester × line combination at all locations led to an increased ΔG * of up to 7.6% for large non-genetic variances (VC2.3, Table 4). This is due to a considerably increased h 2, which can be explained by a substantially larger optimum number of T * j and L * j and the fact that the reduced product T j L j = T j affects only three of the eight non-genetic variances (Eq. 1). Thus, this simple change in breeding policy represents a very promising method in first testcross evaluations of new lines.
The broader the genetic base of a tester, the higher is ΔG for GCA (Table 3). For instance, the use of double-double cross testers instead of inbred testers resulted in a 9.5% higher ΔG for reference variance components VC2.2. This is in harmony with results of experimental studies (cf. Hallauer and Miranda 1981) and can be explained by an increase in h 2 without requiring more testcross plots (Eq. 1). However, in applied breeding programs, use of genetically broad testers is uncommon due to additional efforts required for their production, and the possibility of early identification of promising single-cross hybrids when using inbred testers. Thus, the use of inbred testers in the second stage of selection is very appealing in hybrid maize breeding with doubled haploids. However, the use of single-cross or double-cross instead of inbred testers in the first stage increased ΔG * between 2.6 and 4.4% for larger ratios σ 2SCA /σ 2GCA . In applied breeding programs, intra-pool single-cross hybrids are frequently applied as testers in the first stage and inbred lines in the second selection stage (Schipprack, personal communication). Thus, we restricted our further discussion to single-cross and inbred testers in the first and second stage, respectively.
Use of previous information for selection
Results of previous selection stages are often neglected for further selection in applied plant breeding programs. For two-stage selection on GCA, superiority in ΔG by using results of the first stage in the second selection stage in comparison with neglecting this information was mostly around 1% (data not shown). This increase in ΔG was more than 2% with an increasing h 2 or decreasing selected fraction for first years’ results. In addition, the optimum allocation of test resources was only marginally affected by using or neglecting previous information for selection. As databases are commonly used in modern plant breeding, the above discussed increase in ΔG of 1–2% can be accomplished without any experimental expenditures.
Relative efficiency of breeding strategies
Selection gain in BS1 was clearly larger than for BS2 except for ρ(LP, GCA) = 0.75, without any economic weight for line per se performance (Table 4). This is due to the differences in the correlation between selection and target criterion in first stage (ρ1). For BS1, \({\rho_1 = \sqrt{h_{x_1}^2},}\) whereas for BS2, \({\rho_1 =\sqrt{h_{x_1}^2} \times \rho({\rm LP}, {\rm GCA}).}\) Results of experimental studies suggest that ρ(LP, GCA) = 0.50 is realistic for grain yield (Seitz et al. 1992; Mihaljevic et al. 2005). Consequently, ΔG for BS1 is about 5% higher than for BS2.
Production costs of hybrid seed for single-crosses depends strongly on an acceptable yield level of the seed parent line. Thus, the assumption of no economic weight for line per se performance is not appropriate for the seed parent heterotic group. Therefore, we additionally calculated ΔG assuming an economic weight for line per se performance larger than zero (Table 5). For ρ(LP, GCA) = 0.50, the relative efficiency of BS2 increased rapidly with increasing economic weight for line per se performance, and resulted in a superiority of BS2 over BS1 already for an economic weight for line per se performance larger than 0.1. This is due to the change from direct to indirect selection in the first stage in BS1 and vice versa in BS2. Consequently, for the seed parent heterotic group, choice of BS2 improves the selection gain.
Optimum allocation of test resources
Optimum allocation of test resources for BS1 and BS2 was similar assuming no economic weight for line per se performance and ρ(LP, GCA) = 0.75 or an economic weight for line per se performance of 0.1 and ρ(LP, GCA) = 0.5 (Tables 4, 5). With decreasing economic weight for line per se performance or ρ(LP, GCA), the optimum allocation of BS2 changed towards a more intensive evaluation of testcross progenies in the second selection stage. This result indicates the importance of specific optimizations of test resources. For no economic weight for line per se performance and ρ(LP, GCA) < 0.75, optimum allocation for BS2 was L *1 = 1 (Table 4). With the assumption of one replication per location, however, this includes a high risk in applied breeding because of possibility of failure at one location due to biotic or abiotic stresses and other hazards and, thus, complete loss of the first stage. Therefore, L 1 = 2 is advantageous for reducing this risk with only a small sacrifice in ΔG.
Response curves of ΔG revealed that a careful allocation of the test resources is important, if only a small number of L 2 and T 2 is available (Fig. 1). With larger values of L 2 and T 2, however, response curves become flatter and therefore strongly reduce the risk of choosing an unfavorable allocation of test resources. For instance, choice of T 2 = 5 instead of the optimum T 2 = 3 reduced ΔG only to a small extent, if the number of L 2 was reduced in parallel. These findings are in harmony with results of previous studies (Utz 1969; Melchinger et al. 2005; Longin et al. 2006a). Decreasing augmentation of ΔG with increasing L 2 and T 2 can be explained by decreasing slopes of (1) h 2 for increasing values of L j and T j and (2) selection intensity for increasing values of N 1 (Becker 1993).
For selection among genetically fixed lines, ΔG in both breeding strategies depends on the selected fraction and h 2. Variation in the budget or number of finally selected lines (data not shown) mainly affected the selected fraction and to a smaller degree h 2 (Table 4). The budget was the major factor affecting ΔG by its strong impact on the selected fraction. Variance components affect h 2 directly, and with larger non-genetic variance, h 2 was strongly reduced. Heritability can be increased most efficiently by larger numbers of L j (Eq. 1). However, this requires a parallel reduction in N j and T j for BS1 and BS2, and reduces ΔG considerably (Table 4).
Implications for hybrid development
In second cycle breeding, where new lines were developed by crossing elite inbreds within heterotic groups, the number of initial lines is normally too large to be tested in factorial crosses with several testers. Therefore, a breeder must find a compromise between (1) selection for GCA to reduce the number of initial lines and (2) parallel selection for GCA and SCA to identify superior hybrids. Optimization of breeding strategies for GCA and SCA must be based on different definitions of the gain criterion, exploiting either σ 2GCA or 2 σ 2GCA + σ 2SCA . This requires additional research.
Nevertheless, the findings of our study allow some conclusions to link GCA and SCA selection. For the seed parent heterotic group, the use of BS2 is most suitable with an allocation of resources adapted to the economic weight of line per se performance. For the pollen parent heterotic group, BS1 is most suitable with (1) use of several genetically broad testers, such as two-way or four-way intra-pool hybrids, and (2) evaluation of the progenies of each tester only at a single location in the first stage. The selection in the first stage strongly reduces the number of lines in the second stage, enabling an evaluation of factorial crosses with more than six testers in the second selection stage. Consequently, this strategy represents a good compromise between the large number of initial lines and early exploitation of GCA and SCA for rapid identification and economical seed production of superior hybrids.
References
Baker RJ (1986) Selection indices in plant breeding. CRC Press, Boca Raton, pp 97–108
Becker H (1993) Pflanzenzüchtung. (In German) Verlag Eugen Ulmer, Stuttgart, pp 129–132
Cochran WG (1951) Improvement by means of selection. In: Proc 2nd Berkeley Symp Math Stat Prob, pp 449–470
Federer WT, Sprague GF (1947) A comparison of variance components in corn yield trials: I. Error, tester × line, and line components in top-cross experiments. J Am Soc Agron 39:453–463
Finney DJ (1966) An experimental study of certain screening processes. J R Stat Soc B 28:88–109
Gallais A (1997) Combined testcross and S1 selection for the improvement of testcross and inbred performances. Crop Sci 37:1126–1133
Grüneberg WJ, Abidin E, Ndolo P, Pereira CA, Hermann M (2004) Variance component estimations and allocation of resources for breeding sweetpotato under East African conditions. Plant Breed 123:311–315
Hallauer AR, Miranda JB (1981) Quantitative genetics in maize breeding. Iowa State University Press, Ames, pp 267–298
Hallauer AR, Russell WA, Lamkey KR (1988) Corn breeding. In: Sprague GF, Dudley JW (eds) Corn and corn improvement, 3rd edn. Am Soc Agronomy, Madison, pp 463–564
Hanson WD, Brim CA (1963) Optimum allocation of test material for two-stage testing with an application to evaluation of soybean lines. Crop Sci 3:43–49
Keller KR (1949) A comparison involving the number of, and relationship between, testers in evaluating inbred lines of maize. Agron J 41:323–331
Longin CFH, Utz HF, Reif JC, Schipprack W, Melchinger AE (2006a) Hybrid maize breeding with doubled haploids: I. One-stage versus two-stage selection for testcross performance. Theor Appl Genet 112:903–912
Longin CFH, Utz HF, Melchinger AE, Reif JC (2006b) Hybrid maize breeding with doubled haploids: Comparison between selection criteria. Acta Agron Hung. DOI 10.1556/AAgr.54.2006.3
Melchinger AE, Longin CF, Utz HF, Reif JC (2005) Hybrid maize breeding with doubled haploid lines: quantitative genetic and selection theory for optimum allocation of resources. In: Proceedings of the 41st annual Illinois Corn Breeders’ School 2005, Urbana-Champaign, pp 8–21
Mihaljevic R, Schön CC, Utz HF, Melchinger AE (2005) Correlations and QTL correspondence between line per se and testcross performance for agronomic traits in four populations of European maize. Crop Sci 45:114–122
Schmidt W (2004) Hybridmaiszüchtung bei der KWS SAAT AG. (In German) In: Bericht über die 54. Tagung der Vereinigung der Pflanzenzüchter und Saatgutkaufleute Österreichs 2003, Gumpenstein, pp 1–6
Schnell FW (1996) Über Zuchtplanung und die Entscheidungsspielräume des Pflanzenzüchters (in German). Vorträge Pflanzenzüchtung 33:227–244
Schrag TA, Melchinger AE, Sørensen AP, Frisch M (2006) Prediction of single-cross hybrid performance for grain yield and grain dry matter content in maize using AFLP markers associated with QTL. Theor Appl Genet, in press
Seitz G (1989) Experimentelle und theoretische Untersuchungen zur Beziehung zwischen Linieneigenleistung und allgemeiner Kombinationsfähigkeit bei Silomais. (in German) PhD Thesis, University of Hohenheim, Stuttgart
Seitz G (2005) The use of doubled haploids in corn breeding. In: Proceedings of the 41st annual illinois corn Breeders’ School 2005, Urbana-Champaign, pp 1–7
Seitz G, Geiger HH, Schmidt GA, Melchinger AE (1992) Genotypic correlations in forage maize. II: relationship between inbred line and testcross performance. Maydica 37:101–105
Sprague GF, Federer WT (1951) A comparison of variance components in corn yield trials: II. Error, year × variety, location × variety and variety components. Agron J 42:535–541
Tomerius AM (2001) Optimizing the development of seed-parent lines in hybrid rye breeding. PhD Thesis, University of Hohenheim (http://opus-ho.uni-stuttgart.de/hop/volltexte/2001/10/pdf/tomerius.pdf)
Utz HF (1969) Mehrstufenselektion in der Pflanzenzüchtung. (In German) Arbeiten der Universität Hohenheim, vol 49, Verlag Eugen Ulmer, Stuttgart
Weiss KMR (1981) Beziehungen zwischen Linienleistung, Heterosis und Hybridleistung bei Mais. PhD Thesis, University of Hohenheim
Acknowledgments
This research was supported by funds from DFG, grant no. 1070/1, International Research Training Group “Sustainable Resource Use in North China” to C. F. H. Longin. The authors appreciate the editorial work of Dr. J. Muminović, whose suggestions considerably improved the style of the manuscript. In addition, the authors thank Dr. G. Seitz, AgReliant Genetics, Westfield, IN, USA and Dr. W. Schipprack, Institute of Plant Breeding, Seed Science, and Population Genetics, University of Hohenheim, Stuttgart, Germany for their valuable suggestions We greatly appreciate the helpful comments and suggestions of two anonymous reviewers.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by H. C. Becker.
C. Friedrich H. Longin and H. Friedrich Utz have contributed equally to this work.
Rights and permissions
About this article
Cite this article
Longin, C.F.H., Utz, H.F., Melchinger, A.E. et al. Hybrid maize breeding with doubled haploids: II. Optimum type and number of testers in two-stage selection for general combining ability. Theor Appl Genet 114, 393–402 (2007). https://doi.org/10.1007/s00122-006-0422-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00122-006-0422-z