
Abstract
In this paper, we propose a novel adaptive kernel for the radial basis function neural networks. The proposed kernel adaptively fuses the Euclidean and cosine distance measures to exploit the reciprocating properties of the two. The proposed framework dynamically adapts the weights of the participating kernels using the gradient descent method, thereby alleviating the need for predetermined weights. The proposed method is shown to outperform the manual fusion of the kernels on three major problems of estimation, namely nonlinear system identification, patter classification and function approximation.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The RBF neural networks have shown excellent performance in a number of problems of practical interest. In [24], the reservoirs of brine are analyzed for physicochemical properties using the RBF neural networks with the genetic algorithms. The proposed model is called the GA-RBF model and has shown good results compared to the previous approaches. In [12], the RBF kernel is used to predict the pressure gradient with high accuracy. In the context of nuclear physics, RBF has been effectively used to model the stopping power data of materials as in [15]. A comprehensive discussion of various applications can be found in [6].
In the recent years, considerable advancement has been made in the field. In [23], a couple of new RBF construction algorithms are proposed with the aim of increasing error convergence rates with fewer computational nodes. The first method expands popular Incremental Extreme Learning Machine algorithms by adding Nelder-Mead simplex optimization. The second algorithm uses Levenberg-Marquardt algorithm to optimize the positions and heights of RBF. The results have shown better error performance compared to the previous research. A new architecture of the optimized RBF neural network classifier is developed with the aid of fuzzy clustering and data preprocessing techniques in [19]. In [7], a bee-inspired algorithm, called cOptBees, has been used with heuristics to automatically select the number, location and dispersions of basis functions to be used in the RBF networks. The resultant BeeRBF is shown to be competitive and has the advantage of automatically determining the number of centers. To accelerate the learning for the large-scale data sequence, an incremental learning algorithm is proposed in [2]. The merits of fuzzy and crisp clustering are effectively combined in [18].
In [5], orthogonal least-square-based alternative learning procedure is proposed. In the algorithm, the centers of the RBF are selected one by one in a rational way until an adequate network has been constructed. In [10], a novel RBF network with the multikernel is proposed to obtain an optimized and flexible regression model. The unknown centers of the multikernels are determined by an improved k-means clustering algorithm. An orthogonal least squares (OLS) algorithm is used to determine the remaining parameters. Another learning algorithm proposed in [13] simplifies the neural network training through the use of an adaptive computation algorithm (ACA). The convergence of the ACA is analyzed by the Lyapunov criterion. In [3], a sequential framework Meta-Cognitive Radial Basis Function network (McRBFN) and its Projection-based Learning (PBL) referred to as PBL-McRBFN is proposed. The PBL-McRBFN is inspired by human meta-cognitive learning principles. The proposed algorithm is evaluated on two practical problems, namely the acoustic emission signal classification and the mammogram for cancer classification. In [4], a nonparametric supervised classifier based on neural networks is proposed and is referred to as Self-Adaptive Growing Neural Network (SAGNN). The SAGNN allows a neural network to adapt its size and structure according to the training data. The performance of the method is evaluated for fault diagnosis and compared with various nonparametric supervised neural networks. A hybrid optimization strategy is proposed in [26] by incorporating the adaptive optimization of particle swarm optimization (PSO) into a genetic algorithm (GA), named the HPSOGA. The proposed strategy is used for determining the parameters of radial basis function neural networks automatically (e.g., the number of neurons and their respective centers and radii).

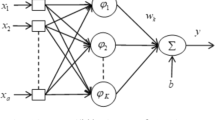
Architecture of an RBF neural network
Essentially the architecture of RBF networks consists of three layers: (1) an input layer, (2) a nonlinear hidden layer, and (3) a linear output layer, refer to Fig. 1. Let \(\mathbf {x} \in \mathbb {R}^{m_0}\) be the input vector, and then the overall mapping of the RBF network, \(s:\mathbb {R}^{m_0}\rightarrow \mathbb {R}^{1}\), is given as:
where \(m_1\) is the number of neurons in the hidden layer, \(\mathbf {x}_i \in \mathbb {R}^{m_0}\) are the centers of the RBF network, \(\mathbf {w}_i\) are the synaptic weights connecting the hidden layer to output neuron, b is the bias term of the output neuron, and \(\phi _i\) is the basis function of the ith hidden neuron. Without loss of generality and for simplicity, a single output neuron is considered. Conventional RBF networks employ a number of kernels such as multiquadrics, inverse multiquadrics and Gaussian [14]. The Gaussian kernel, due to its versatility, is considered to be the most commonly used kernel [25]:
where \(\sigma \) is the spread of the Gaussian kernel. In one form or the other, the kernels use the concept of distance measure with the centers of the network. Conventionally, the Euclidean distance has been used as an efficient distance metric. Recently, it has been argued that the cosine distance metric has some complimentary properties to offer compared to the Euclidean distance measure [1]:
where the term \(\gamma > 0\), a very small constant, is added to the denominator to avoid the indeterminant form of (3) in case \(\left\| \mathbf {x}\right\| \) or \(\left\| \mathbf {x}_i\right\| \) is zero. Accordingly, a novel kernel has been proposed to fuse the cosine and Euclidean distances [1]:
where \(\phi _{i1}(\mathbf {x}.\mathbf {x}_i)\) and \(\phi _{i2}(\left\| \mathbf {x}-\mathbf {x}_i\right\| )\) are the cosine and Euclidean kernels, respectively, with corresponding fusion weights \(\alpha _{1}\) and \(\alpha _{2}\).
Harnessing the distinctive properties of the cosine and Euclidean kernels, the formulation in (4) has shown some good results compared to the conventional Euclidean kernel [1]. We however argue that the fusion of the two kernels is manual and the weights \(\alpha _{1}\) and \(\alpha _{2}\) are adjusted in a hit-and-trial manner. Without any prior information, a common practice is to assign equal weights to the two kernels, i.e., \(\alpha _1=\alpha _2=0.5\) . As such, there is no dynamic method of optimizing these weights for a given data set. We therefore propose a novel framework to adaptively optimize the weight assignment using the steepest descent method [22].
The rest of the paper is organized as follows: In Sect. 2, the proposed novel adaptive kernel is thoroughly discussed. This is followed by extensive experiments in Sect. 3. The paper is finally concluded in Sect. 4.
2 Proposed Method
We consider \(\alpha _1\) and \(\alpha _2\) in (4) to be dynamically adaptive variables:
where the normalization of the mixing weights ensures that \(\alpha _1(n)+\alpha _2(n)=1\). The new kernel is therefore defined as:
The overall mapping, at the nth learning iteration linked to a specific epoch, can now be written as:
where the synaptic weights \(w_i(n)\) and bias b(n) are adapted at each iteration. We define a cost function \(\mathcal {E}(n)\) as:
where d(n) is the desired output at the \(n^{th}\) iteration and e(n) the instantaneous error between the desired output and the actual output of the neuron \(e(n)=d(n)-y(n)\). The update rule for the kernel’s weight is given by:
Using the chain rule of differentiation for the cost function in (9) yields:
which upon the simplification of the partial derivatives in (11) results in:
and using (10) and (12), the update rule for \(\alpha _1(n)\) is found to be:
Similarly, the update rule for \(\alpha _2(n)\) can be shown to be:
The update equations of the weight and bias are given as:
The proposed approach is dynamic and does not require prior assignment of the weights for the participating kernels.
3 Experimental Results
The proposed novel kernel for the RBF is evaluated for three important tasks: (1) nonlinear system identification, (2) pattern recognition and (3) function approximation. All the experiments were conducted using Matlab on an Intel(R) Core(TM) i7-3770 CPU @ 3.4GHz machine with 4GB memory.
3.1 Nonlinear System Identification

Nonlinear system identification using RBF neural network
Complex control systems and industrial processes can be effectively modeled using nonlinear systems [17]. Nonlinear system identification is a method for estimating the mathematical model of a nonlinear system using the inputs and outputs of the system. RBF neural networks have shown to achieve good performance in this context [8, 9, 16]. To evaluate the efficacy of the proposed novel kernel, we consider a highly nonlinear system, shown in Fig. 2:
where r(t) and y(t) are the input and output of the system, respectively, n(t) is the disturbance modeled assumed to be \(\mathcal {N}(0,\sigma _d^2)\), \(a_i\)s are the polynomial coefficients describing the zeros of the system, and \(b>0\) is a constant. For the purpose of this experiment, r(t) is taken to be a step function. In Fig. 2, the system is defined by its impulse response h(t), while \(\hat{y}(t), \hat{h}(t)\) and e(t) are the estimated output, estimated impulse response and the error of estimation, respectively. The simulation parameters chosen for the experiments are: \(a_1=2\), \(a_2=-0.5\), \(a_3=-0.1\), \(a_4=-0.7\), \(b=3\) and \(\sigma _d^2=0.0025\).

Comparison of the output of the nonlinear system

Nonlinear system: the MSE curves for various approaches

Nonlinear system: adaptation of the mixing parameters with respect to time
For the RBF structure, the number of neurons was selected to be 401 and the centers were uniformly spaced between −50 and 50 with a step size of 0.25. The initial weights and bias values were initialized to zero. For the Gaussian kernel, the spread \(\sigma \) was set to 0.1, and for the cosine kernel, a small value of \(\gamma = 1e-\)50 was used. For the proposed approach, the initial values of \(\alpha _1\) and \(\alpha _2\) are taken to be 0.5. Figure 3 shows the estimated output of the proposed approach compared to the actual output, the Euclidean kernel (\(\alpha _1=0, \alpha _2=1\)), cosine kernel (\(\alpha _1=1, \alpha _2=0\)) and the manual fusion of the two kernels (\(\alpha _1=\alpha _2=0.5\)). Note that due to the most precise estimation, the Euclidean kernel overlaps the actual output and therefore cannot be distinguished. The mean square error (MSE) curves are depicted in Fig. 4. The Euclidean kernel produces the best performance achieving a minimum MSE of −6.1943 dB in 1379 iteration epochs, while the cosine kernel performs poorly with an MSE of 2.7887 dB. Without any prior information, the proposed approach dynamically gives more weight to the Euclidean kernel, attaining a minimum MSE of −6.1547 dB in 1447 iterations which is quite comparable to the Euclidean kernel. The final values of the weights were found to be \(\alpha _1=0.002\) and \(\alpha _2=0.998\). The proposed approach is substantially better compared to the manual fusion of kernels which achieved a minimum MSE of −5.5176 dB in 1992 iterations. Variation of the mixing parameters with respect to the iteration epochs is depicted in Fig. 5. For the comparison of time complexity of the proposed method with manual fusion of the two kernels, we investigated the training time for 2000 epochs. The proposed method utilizes 550.78 s, whereas the manual fusion of the two kernel takes 537.74 s. The experiment clearly shows that in the absence of any prior knowledge, the proposed approach adaptively emphasizes the effective Euclidean kernel and achieves a comparable performance.
3.2 Pattern Classification
Machine learning methods have been used with great success in bioinformatics [21]. One of the important applications is the prediction of cancer using gene microarray data. In this experiment, we target the prediction of leukemia disease using the standard Leukemia ALL/AML data [11]. The data set consists of 38 training samples from bone marrow specimens (27 ALL and 11 AML) and 34 testing samples. There are 34 test samples (20 ALL and 14 AML) prepared under different experimental conditions including 24 bone marrow and 10 blood sample specimens. The data set consists of 7129 genes. The Minimum Redundancy and Maximum Relevance (mRMR) is an established technique to select the most significant genes [21]. The mRMR technique was used to select only the top five genes for our experiments. For the RBF structure, the number of neurons was selected to be 38 and the centers were chosen using the subtractive clustering method of [20] with an influence factor of 0.1. The initial weights and bias values were initialized to zero. For the Gaussian kernel, the spread \(\sigma \) was set to 0.2, and for the cosine kernel, a small value of \(\gamma = 1e-\)50 was used. For the proposed approach, the initial values of \(\alpha _1\) and \(\alpha _2\) are taken to be 0.5. For the training phase, the MSE curves of different approaches are shown in Fig. 6.

The MSE curves for the training phase of the pattern classification problem

Pattern classification: adaptation of the mixing parameters with respect to time
The Euclidean kernel outperforms the cosine kernel achieving a minimum MSE of −279.9331 dB. The proposed method dynamically gives more weight to the Euclidean kernel achieving an MSE of −122.4990 dB with \(\alpha _1=0.3121\) and \(\alpha _2=0.6879\). Note that although the Euclidean kernel achieves the minimum MSE for the training data, it is merely the case of overfitting where a classifier achieves the best performance on the training set but fails on the test data. Variation of the mixing parameters with respect to epochs is depicted in Fig. 7. In Fig. 6, after the 65th epoch, the MSE of Euclidean kernel becomes lower than the cosine kernel; noteworthy is the corresponding flip in the weights adaptively assigned by the proposed approach in Fig. 7. Note that the weights become stable after 400 epochs. The manual fusion of the two kernels (\(\alpha _1=\alpha _2=0.5\)) results in an MSE of −73.6652 dB which is inferior to the proposed method. The training accuracies of all the approaches are presented in Table 1, and note that all approaches result in 100 % accuracy for the training samples. The total training time for the proposed method is found to be 12.98 s, whereas the manual fusion of the two kernel takes 12.65 s.
True evaluation of any predictive system is for the case of unseen samples, i.e the “testing phase”. Although the Euclidean kernel achieves the minimum MSE during the training phase, the proposed approach demonstrated that the best performance for the testing stage is achieved with an accuracy of 97.06 %. The Euclidean kernel was trained “too well” on the training samples and therefore incurred the problem of “overfitting” attaining a test accuracy of only 58.82 %. The proposed dynamic fusion of the two kernels outperformed the manual fusion (\(\alpha _1=\alpha _2=0.5\)) by a margin of 2.94 %.
We provide an intuitive understanding of the proposed approach using this pattern classification problem. The data which are not linearly separable in the original space pose a challenging task in the classification theory. Cover’s theorem states that such data can be mapped into a high-dimensional space using a nonlinear mapping function (kernel function), thereby resulting in a linearly separable data in the transformed space.
Selection of an appropriate kernel is an important issue to be considered. A good kernel will result in optimal separation of classes in the transformed space, thereby improving the performance on unseen test samples. Using fusion of multiple kernels is often a good idea to harness the complementary properties of various kernels. The weights of the combining kernels play an important role in such cases. Selecting weights on random bases may result in an inefficient fusion. The proposed adaptive fusion framework automatically selects the best weights for the combining kernels, resulting in maximum separation of classes. We demonstrate this through clustering of the Leukemia data set consisting of 38 samples (27 Class A and 11 Class B) and 5 attributes. For demonstration purposes, we choose two centers \(c_1\) and \(c_2\) which are the means of classes A and B, respectively. The mapping of the samples in the 2D—space using various kernels is shown in Fig. 8.

Clustering of the Leukemia data using various kernels. Note the class separation for the proposed kernel
It can be seen that cosine kernel efficiently separates the two classes in the 2D-space, while the Euclidean kernel maps all the samples to origin (overlapping samples seen as one green circle). The manual fusion of the kernels (with equal weights) results in a decreased class separation compared to the cosine kernel. The proposed adaptive fusion of the two kernels automatically assigns more weight to the cosine kernel thereby resulting in better clustering compared to the manual fusion.
3.3 Function Approximation
We consider the problem of approximation of a nonlinear function defined by:
The function in Eq. (18) is approximated using various kernels. For all experiments, 121 centers were considered and the learning rate was taken to be \(\eta =1\times 10^{-3}\). The centers were chosen through the subtractive clustering method of [20] with an influence factor of 0.1. The initial weights and bias values were initialized to zero. For the Gaussian kernel, the spread \(\sigma \) was set to 0.2, and for the cosine kernel, a small value of \(\gamma = 1e-\)50 was used. For the proposed approach, the initial values of \(\alpha _1\) and \(\alpha _2\) are taken to be 0.5. A total of 121 values of x and y are used for training ranging from −1 to 1 with a step size of 0.2. Testing has been conducted on 100 data points ranging from −0.9 to 0.9 with a step size of 0.2. For the test data, Fig. 9 shows the estimated output of the proposed approach compared to the actual output, the Euclidean kernel (\(\alpha _1=0, \alpha _2=1\)), the cosine kernel (\(\alpha _1=1, \alpha _2=0\)) and the manual fusion of the two kernels (\(\alpha _1=\alpha _2=0.5\)) in reduced dimension.

Comparison of the output of the nonlinear function for various kernels

The MSE curves for the training phase of the function approximation problem

Function approximation: adaptation of the mixing parameters with respect to time
The MSE curves are depicted in Fig. 10. The Euclidean kernel produces the best performance achieving a minimum MSE of −18.6619 dB, while the cosine kernel performs poorly with an MSE of −4.9277 dB. Without any prior information, the proposed approach dynamically gives more weight to the Euclidean kernel. The proposed approach attains a minimum MSE of −18.4076 dB which is comparable to the Euclidean method. The proposed approach is substantially better compared to the manual fusion of kernels which achieved a minimum MSE of −15.6181 dB. Variation of the mixing parameters with respect to the iteration epochs is depicted in Fig. 11. The final values of the weights were found to be \(\alpha _1=0.0060\) and \(\alpha _2=0.9940\). The experiment clearly shows that in the absence of any prior knowledge, the proposed approach adaptively emphasizes the effective Euclidean kernel and achieves better performance. For the comparison of the time complexity of the proposed method with manual fusion of the two kernels, we investigated the training time for 10,000 epochs. The total training time for the proposed method is found to be 586.3 s, whereas the manual fusion of the two kernel takes 578.2 s.
4 Conclusion
In this research, a novel kernel for the RBF neural network is proposed. The proposed framework adaptively fuses the Euclidean and cosine distance measures, thereby harnessing the complementary properties of the two. The proposed algorithm is dynamic and adaptively learns the optimum weights of the participating kernels for a given problem. The efficacy of the proposed kernel is demonstrated on three important problems, namely nonlinear system identification, pattern classification and function approximation. The proposed algorithm has shown to comprehensively outperform the manual fusion of the two kernels. For the problem of nonlinear system identification, the proposed framework adaptively assigns a higher fusion weight to the Euclidean kernel achieving a comparable performance. The proposed algorithm performs better than the manual fusion of the two kernels. Therefore, in the absence of any prior knowledge, the proposed method is shown to emphasize the most effective kernel. For the pattern classification problem, the proposed method dynamically assigns more weight to the Euclidean kernel and achieves a comparable training accuracy of 100 %. For the more challenging testing phase, the proposed optimized fusion attains the best accuracy of 97.06 %. Note that the proposed approach outperformed the best conventional kernel, i.e., the Euclidean kernel by meaningfully utilizing the complementary properties of the cosine kernel. For the function approximation problem, the Euclidean kernel produces the best performance achieving a minimum MSE of −18.6619 dB, while the cosine kernel performs poorly with an MSE of −4.9277 dB. Without any prior information, the proposed approach dynamically gives more weight to the Euclidean kernel and achieved a minimum MSE of −18.4076 dB. The experiments clearly demonstrate that the proposed optimum fusion of kernels will always perform equal to or better than the best participating kernel.
References
W. Aftab, M. Moinuddin, M.S. Shaikh, A novel kernel for RBF based neural networks, in Abstract and Applied Analysis 2014 (2014). doi:10.1155/2014/176253
S.H.A. Ali, K. Fukase, S. Ozawa, A fast online learning algorithm of radial basis function network with locality sensitive hashing. Evol. Syst. 2016, 1–14 (2016)
G.S. Babu, S. Suresh, Meta-cognitive RBF network and its projection based learning algorithm for classification problems. Appl. Soft Comput. 13(1), 654–666 (2013)
M. Barakat, D. Lefebvre, M. Khalil, F. Druaux, O. Mustapha, Parameter selection algorithm with self adaptive growing neural network classifier for diagnosis issues. Int. J. Mach. Learn. Cybern. 4(3), 217–233 (2013)
S. Chen, C.F. Cowan, P.M. Grant, Orthogonal least squares learning algorithm for radial basis function networks. IEEE Trans. Neural Netw. 2(2), 302–309 (1991)
W. Chen, Z.J. Fu, C.S. Chen, Recent Advances in Radial Basis Function Collocation Methods (Springer, Heidelberg, 2014)
D.P.F. Cruz, R.D. Maia, L.A. da Silva, L.N. de Castro, BeeRBF: a bee-inspired data clustering approach to design RBF neural network classifiers. Neurocomputing 172, 427–437 (2016)
V. Elanayar, Y.C. Shin et al., Radial basis function neural network for approximation and estimation of nonlinear stochastic dynamic systems. IEEE Trans. Neural Netw. 5(4), 594–603 (1994)
M.J. Er, S. Wu, J. Lu, H.L. Toh, Face recognition with radial basis function (RBF) neural networks. IEEE Trans. Neural Netw. 13(3), 697–710 (2002)
L. Fu, M. Zhang, H. Li, Sparse RBF networks with multi-kernels. Neural Process. Lett. 32(3), 235–247 (2010)
T.R. Golub, D.K. Slonim, P. Tamayo, C. Huard, M. Gaasenbeek, J.P. Mesirov, H. Coller, M.L. Loh, J.R. Downing, M.A. Caligiuri et al., Molecular classification of cancer: class discovery and class prediction by gene expression monitoring. Science 286(5439), 531–537 (1999)
M.A. Halali, V. Azari, M. Arabloo, A.H. Mohammadi, A. Bahadori, Application of a radial basis function neural network to estimate pressure gradient in water–oil pipelines. J. Taiwan Inst. Chem. Eng. 58, 189–202 (2016)
H.G. Han, J.F. Qiao, Adaptive computation algorithm for RBF neural network. IEEE Trans. Neural Netw. Learn. Syst. 23(2), 342–347 (2012)
S.O. Haykin, Neural Networks: A Comprehensive Foundation (Prentice Hall PTR, Upper Saddle River, NJ, 1994)
M.M. Li, B. Verma, Nonlinear curve fitting to stopping power data using RBF neural networks. Expert Syst. Appl. 45, 161–171 (2016)
R.P. Lippmann, Pattern classification using neural networks. IEEE Commun. Mag. 27(11), 47–50 (1989)
K.S. Narendra, K. Parthasarathy, Identification and control of dynamical systems using neural networks. IEEE Trans Neural Netw. 1(1), 4–27 (1990)
A.D. Niros, G.E. Tsekouras, A novel training algorithm for RBF neural network using a hybrid fuzzy clustering approach. Fuzzy Sets Syst. 193, 62–84 (2012)
S.K. Oh, W.D. Kim, W. Pedrycz, Design of radial basis function neural network classifier realized with the aid of data preprocessing techniques: design and analysis. Int. J. Gen. Syst. 45(4), 434–454 (2016)
N.R. Pal, D. Chakraborty, Mountain and subtractive clustering method: improvements and generalizations. Int. J. Intell. Syst. 15(4), 329–341 (2000)
H. Peng, F. Long, C. Ding, Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 27(8), 1226–1238 (2005)
D. Psaltis, A. Sideris, A. Yamamura et al., A multilayered neural network controller. IEEE Control Syst. Mag. 8(2), 17–21 (1988)
P.D. Reiner, Algorithms for Optimal Construction and Training of Radial Basis Function Neural Networks, PhD thesis (Auburn University, 2015)
A. Tatar, S. Naseri, N. Sirach, M. Lee, A. Bahadori, Prediction of reservoir brine properties using radial basis function (RBF) neural network. Petroleum 1(4), 349–357 (2015)
D. Wettschereck, T. Dietterich, Improving the performance of radial basis function networks by learning center locations, in Advances in Neural Information Processing Systems, vol. 4 ed. by J. E. Moody, S. J. Hanson and R. P. Lippmann (Morgan Kaufmann, San Mateo, CA, 1992), pp. 1133–1140
J. Wu, J. Long, M. Liu, Evolving RBF neural networks for rainfall prediction using hybrid particle swarm optimization and genetic algorithm. Neurocomputing 148, 136–142 (2015)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Khan, S., Naseem, I., Togneri, R. et al. A Novel Adaptive Kernel for the RBF Neural Networks. Circuits Syst Signal Process 36, 1639–1653 (2017). https://doi.org/10.1007/s00034-016-0375-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-016-0375-7