
Abstract
Literatures have indicated that well-balanced groups facilitate students’ learning performance in collaborative learning environments. For instructors, to construct well-balanced groups needs to take efforts and time to consider large number of students and characteristics. Hence, how to automatically construct well-balanced collaborative learning groups has been a popular issue for collaborative learning. This paper proposes a genetic algorithm (GA)-based grouping strategy to assist instructors in constructing inter-homogeneous and intra-heterogeneous collaborative learning groups considering multiple student characteristics. Several data sets with different problem sizes, such as number of students and characteristics, are employed as experimental materials. Experimental results have demonstrated that the proposed grouping method is effective, efficient and robust.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Collaborative learning is defined as learners learning together in order to solve problems and accomplish common goals [1], which has validated as one useful technique to enhance students’ learning performance in education context [2–4]. Further, adequate groups can assist learners to promote their learning performance through the interactions of group members [5–7]. Numerous researches have indicated the factors that influence collaborative learning success, including inter-group homogeneity, intra-group heterogeneity, grouping criteria and so on [8–10]. The grouping criterion contains different grouping characteristics of students, such as knowledge level, leadership, gender, and so on [10–13]. That is, how to construct adequate groups is one of the important issues in collaborative learning.
Since the number of students and characteristics become larger which results in that grouping problem is harder to solve by instructors, the consideration for all the student characteristics becomes a multi-objective problem. Hence, to cope the aforementioned problems, this paper proposes a grouping strategy which adopts Genetic algorithm (GA) [11, 14, 15] with Technique for Order Performance by Similarity to Ideal Solution (TOPSIS) [7, 16] to achieve inter-homogeneous and intra-heterogeneous collaborative learning groups. The reasons adopting GA with TOPSIS in this paper is that GA with TOPSIS is one suitable method to solve grouping problems for multiple objectives problems. Besides, the proposed grouping strategy can facilitate instructors to obtain a better grouping result within a reasonable computation time, even for large scale problems. To evaluate the performance and robustness of the proposed strategy, several experiments with different problem sizes have also been conducted to compare the proposed method with other competing strategies.
The rest of this paper is organized as follows. Section 2 introduces the basic concepts of GA and TOPSIS. Section 3 describes the mathematical and algorithmic formulation of the proposed grouping strategy. Section 4 analyzes the results with different problem sizes. Section 5 presents the conclusions of the proposed strategy.
2 Related Work
This section describes the basic concepts of Genetic algorithm (GA), and Technique for Order Performance by Similarity to Ideal Solution (TOPSIS).
GA is proposed by Holland in 1975 [17]. The spirit of GA is “natural selection and survival of the fittest”, and it has been widespread used in many complex optimization problems. GA comprises several components processing including chromosome encode, initial population, fitness evaluation and three genetic operator including selection operator, crossover operator and mutation operator. Each operation is detailed in the following section.
TOPSIS is proposed by Hwang and Yoon in 1981 [18]. TOPSIS has solved many decision making multi-objective problems. The procedure of TOPSIS can be described in the following four steps [19, 20]:
- Step 1.:
-
Constructs a \( I \times Q \) decision matrix with respect to \( I \) alternatives and \( Q \) criteria
- Step 2.:
-
Determines the positive-ideal solution and negative-ideal solution
- Step 3.:
-
Uses the m-dimensional Euclidean distance to compute two measures
- Step 4.:
-
Computes the relative closeness to the ideal solution
3 The Proposed Strategy
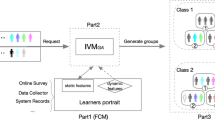
The details of different components and main features of the proposed method will be shown in this section. Of them one special component focuses on pre-categorizing all students in order to ensure the quality of intra-heterogeneous groups. The other components include the encoding of solutions, initial population, fitness function, the selection, crossover, and mutation. The final subsection describes the elitism. Figure 1 presents the flow of the proposed method.

The main flow of the proposed method
3.1 Pre-categorizing
To evaluate all features, each characteristic of a student in a class must be a numerical value. However, each characteristic may have different values spreading in a range, which includes following steps:
- Step 1.:
-
Normalizing every considered characteristic should be taken. After normalization, every characteristic is fitted between 0 and 1. It is calculated as following:
$$ Z_{sq} = \frac{{X_{sq} - X_{q}^{min} }}{{X_{q}^{max} - X_{q}^{min} }} $$(1) - Step 2.:
-
The characteristics of each student are calculated to obtain their represented value \( P_{s} \) which represents their overall performance in the class with S students
- Step 3.:
-
The mean value \( \bar{P} \) and standard deviation \( P^{\sigma } \) of the class are derived from all students’ \( P_{s} \) value in the class
- Step 4.:
-
Three categories \( L_{i} , {\text{where }}\,\,\,1 \le i \le 3, \) which represent low, medium and high performance of the students were divided based on the mean \( \bar{P} \) and the standard deviation \( P^{\sigma } \). The concept is expressed as Eq. (2) and \( N_{s} \) is denoted as a student, where \( 1 \le s \le S \)
$$ \begin{aligned} L_{1} = & \left\{ {N_{s} | P_{s} < \bar{P} - P^{\sigma } } \right\} \\ L_{2} = & \left\{ {N_{s} | \bar{P} - P^{\sigma } \le P_{s} \le \bar{P} + P^{\sigma } } \right\} \\ L_{3} = & \left\{ {N_{s} | \bar{P} + P^{\sigma } < P_{s} } \right\} \\ \end{aligned} $$(2) - Step 5.:
-
The number of students in three categories are calculated to obtain their respective ratio \( R_{{L_{i} }} \), where \( 1 \le i \le 3 \), for the summation fitting the instructor’s assignment in which each group has \( M \) members. The operations for calculating ratio of three categories is expressed in the following Ratio-calculating Algorithm, where \( N_{{L_{i} }} \) denotes number of members in category \( L_{i} \). Let \( TE \) denotes total error value of the ratio, \( CP_{i} \) denotes the carrying probability of the corresponding ratio \( R_{{L_{i} }} \), and \( \varepsilon_{i} \) demotes the carry value of the corresponding ratio \( R_{{L_{i} }} \), where the \( \varepsilon_{i} \) must be 1 or 0

Furthermore, the students are sorted into three new categories \( L_{i}^{'} , {\text{where }}1 \le i \le 3, \) according to the ratio shown in Eq. (3), where \( N_{s}^{'} \) denotes sorted students in ascending order.
3.2 Encoding of the Solution and Initial Population
In GA, a chromosome, i.e. an individual, represents a feasible solution for problem. An individual with \( {\text{S}} \) students is represented by a matrix. The number of columns in the matrix corresponds to \( {\text{M}} \) members of each group and the number of rows corresponds to \( {\text{G}} \) groups. If there are \( {\text{S mod M}} \) remainder students, there will be \( {\text{S mod M}} \) groups having \( {\text{M}} + 1 \) members.
In initial population stage, the students are randomly assigned to their corresponding levels according to the ratios of three categories. Hence, each group has three categories members with the ratios. An example of an individual is shown in Fig. 2. The Levels 1, 2 and 3 collect the students belonging to categories \( L_{1} \), \( L_{2} \) and \( L_{3} \), respectively.

An example of an individual
3.3 Fitness Evaluation
The main goal of the proposed method is to obtain inter-homogeneous and intra-heterogeneous groups. Therefore, it is important to define an adequate evaluation to fit the main goal. In this paper, the fitness evaluation is for evaluating the fitness value of individuals with \( {\text{Q}} \) characteristics. The grouping problem is to optimally assign \( {\text{S}} \) students, each with \( {\text{Q }} \) characteristics, to \( {\text{G}} \) groups. To address the problem, a fitness value \( {\text{F}}_{\text{i}} \) was shown in Eq. (4), where \( \overline{\text{GP}} \), \( {\text{GP}}^{\upsigma} \) and \( \upomega \) respectively denote the mean value of all groups of an individual, the standard deviation of all groups of an individual, and the weight of \( \overline{\text{GP}} \) and \( {\text{GP}}^{\upsigma} \). In Eq. (4), \( {\text{GP}}_{\text{g}} \) denotes the relative closeness to the ideal solution for the gth group of an individual, where \( 1 \le {\text{g}} \le {\text{G}} \). Equation (5) expresses the mathematical formulation of \( {\text{GP}}_{\text{g}} \), where \( {\text{W}}_{\text{q}} \), \( {\text{E}}_{\text{g}} \) and \( {\text{Z}}_{{{\text{s}},{\text{q}}}}^{\text{g}} \) respectively denote the weight of criteria \( {\text{q}} \), the number of members in the gth group, and the value of the qth criterion of the sth learner of the gth group of an individual. The ideal value of \( {\text{V}}_{\text{q}}^{ + } \) and \( {\text{V}}_{\text{q}}^{ - } \) must be 1 or 0 according to the criteria \( {\text{q}}, 1 \le {\text{q}} \le {\text{Q}} \).
3.4 Selection Operator
The objective of selection operator is selecting the better individuals from current population to ensure the more suitable individuals can be preserved in next generation. Roulette wheel selection mechanism [21] is employed in this paper. Figure 3 presents an example of Roulette wheel. An individual \( {\text{i}} \) of current population has a portion \( {\text{A}}_{\text{i}} \) of all areas in the roulette according to their fitness value \( {\text{F}}_{\text{i}} \) and has a random probability to select the corresponding individual in next generation. The larger proportion an individual has in the area, the more probability it can be preserved in next generation.

Roulette wheel example

Evolution of optimal fitness of 50 students with GA and the proposed strategy

Variations of standard deviation of the optimal fitness values derived by random, GA and the proposed strategy as the number of students increase
3.5 Crossover Operator
The goal of crossover operator is interchanging genes of individuals to recombine features. C1 operator is one of the famous crossover operator [22]. One version of C1 operator [10] is modified to fit the chromosome data structure in this proposed strategy. There are two steps in the proposed version. Firstly, chooses two parents with crossover probability \( {\text{P}}_{\text{c}} \) to do crossover and randomly generates crossover points for each group. Next, offspring preserves the corresponding parent’s left part of genes according to the crossover point of each row while the right part of genes are derived from the order of genes in different levels of the other parent.
3.6 Mutation Operator
The goal of mutation operator is altering genes to reproduce new individuals [23]. The mutation operator includes two steps in the proposed strategy. In the first step, each level has a probability \( {\text{P}}_{\text{l}} \) to do mutation. In the second steps, if a level is selected then two genes are randomly chosen to swap in the selected level.
3.7 Elitism
In this stage, the proposed strategy uses the elitist schema to select the best individual to replace the worst one from the population in generation \( {\text{k}} \). Therefore, it can be sure that the population is better in generation \( {\text{k}} + 1 \) than in generation \( {\text{k}} \) and the best individual will be kept in \( {\text{k}} + 1 \) generation.
4 Experiments and Discussions
This paper employs several data sets, such as number of students and characteristics, with different problem sizes as experimental materials to analyze the solution quality, executing time, search speed and stability. Subsect. 4.1 describes the experimental setting. Subsect. 4.2 compares the performance including execution time and search speed of the proposed strategy with other competing methods. Subsect. 4.3 analyzes the solution quality of the proposed strategy. Subsect. 4.4 presents the analyses of robustness.
4.1 Experimental Setting
All experiments run on a laptop computer with an Intel Core i7, 2.10 GHz processor, 4 GB RAM using C programming language in CodeBlocks environments. There are five students in each group. The probability of crossover is set to 0.85, the probability \( {\text{P}}_{\text{l}} \) is set to 0.15, the population size is set to 20 and the number of generation is set to 100. Each scenario is run 100 times for calculating the average fitness value of the 100 runs in order to get the objective representation of fitness value and execution time of each data set. There are different problem sizes of simulated (uniformly distribution) data sets with four characteristics to compare among random, GA [10] and the proposed method. The first and the second characteristics are set to positive features while the third and the fourth are set to negative features. Each weight of characteristic is set to 0.5.
4.2 Performance Comparisons
For random, GA and the proposed strategy, Tables 1 and 2 present the performance results with different number of students and characteristics, where the performance contains fitness value and execution time. Table 1 shows that random method can save more execution time than GA and the proposed method, but it has poorer fitness value than the others with different number of students. In addition, the proposed strategy can use less execution time to obtain the nearer optimal solution than GA method. Table 2 shows that no matter what the number of characteristics is, the proposed strategy is more effective than the other two. To sum, the proposed strategy has the most effective than the other two methods.
Furthermore, in order to compare the search speed of the proposed strategy with GA method, Fig. 4 presents the variations of optimal fitness value within 1000 generations. It shows the proposed strategy is more efficient than GA because that when the optimal fitness value is set to 0.787, the proposed strategy needs 54 generations and GA needs 340 generations to evolution. In other words, GA will spend more time and efforts to get the same fitness value than the proposed strategy.

Variations of standard deviation of the optimal fitness values derived by random, GA and the proposed strategy as the number of students’ characteristics increases
4.3 Comparison of Grouping Results
In this subsection, to compare the grouping results of three methods, Tables 3 and 4 present the standard deviation of the inter-groups and intra-groups against different number of students and characteristics. Table 3 shows that despite different number of students, the proposed method always has smaller standard deviation of inter-groups and larger standard deviation of intra-groups than the random and GA methods. Table 4 shows that no matter what number of characteristics is the standard deviation of inter-groups and intra-groups of the proposed method is better than random and GA methods. In other words, the proposed method has better grouping results than random and GA methods against different number of characteristics.
4.4 Comparisons of Robustness
To analyze the robustness of optimal fitness values obtained from the random, GA and the proposed strategy, two different data sets, such as different number of students and characteristics, will be conducted to compare the proposed strategy with random and GA methods. Each method would run 100 times with each data set then the standard deviation of these 100 optimal fitness values is computed. Figure 5 shows the variations of standard deviation of the optimal fitness values derived from the proposed strategy is significantly better than the other competing methods. The proposed strategy is more stable than the other two with different number of students. Figure 6 shows that the variations of standard deviation of optimal fitness values derived from the proposed strategy is more stable than the other two methods.
5 Conclusion
This paper has proposed the grouping strategy based on GA to address multiple characteristics grouping problems for cooperative learning environments, which constructs better inter-homogeneous and intra-heterogeneous groups. In this paper, the pre-categorization stage and a well-designed chromosome-like data structure has designed to enhance the performance of the proposed strategy. Furthermore, a novel mutation operator is designed for fitting the chromosome, which improves the performance but doesn’t lead to non-convergence of the solution.
To evaluate the proposed strategy, several data sets with different problem sizes, such as number of students and characteristics, were conducted to compare the solution quality, executing time, search speed and stability of the proposed strategy with the other methods. The experimental results have demonstrated the proposed grouping strategy (1) possesses better performance, grouping result and robustness than the random and GA methods, and (2) achieves the goal of obtaining better inter-homogeneous and intra-heterogeneous groups.
References
Dillenbourg, P.: What do you mean by collaborative learning? In: Dillenbourg, P. (ed.) Cognitive and Computational Approaches Collaborative-Learning, pp. 1–19. Elsevier, Oxford (1999)
Dillenbourg, P.: Collaborative Learning: Cognitive and Computational Approaches. Advances in Learning and Instruction Series. ERIC, New York (1999)
Dewiyanti, S., et al.: Students’ experiences with collaborative learning in asynchronous computer-supported collaborative learning environments. Comput. Hum. Behav. 23(1), 496–514 (2007)
Kreijns, K., Kirschner, P.A., Jochems, W.: The sociability of computer-supported collaborative learning environments. Educ. Technol. Soc. 5(1), 8–22 (2002)
Webb, N.M.: Student interaction and learning in small groups. Rev. Educ. Res. 52(3), 421–445 (1982)
Barkley, E.F., Cross, K.P., Major, C.H.: Collaborative Learning Techniques: A handbook for College Faculty. Jossey-Bass, San Francisco (2004)
Wang, Y.-M., Elhag, T.: Fuzzy TOPSIS method based on alpha level sets with an application to bridge risk assessment. Expert Syst. Appl. 31(2), 309–319 (2006)
Dalton, D.W., Hannafin, M.J., Hooper, S.: Effects of individual and cooperative computer-assisted instruction on student performance and attitudes. Educ. Tech. Res. Dev. 37(2), 15–24 (1989)
Hooper, S., Hannafin, M.J.: Cooperative CBI: The effects of heterogeneous versus homogeneous grouping on the learning of progressively complex concepts. J. Educ. Comput. Res. 4(4), 413–424 (1988)
Moreno, J., Ovalle, D.A., Vicari, R.M.: A genetic algorithm approach for group formation in collaborative learning considering multiple student characteristics. Comput. Educ. 58(1), 560–569 (2012)
Yin, P.-Y., et al.: A particle swarm optimization approach to composing serial test sheets for multiple assessment criteria. Educ. Technol. Soc. 9(3), 3–15 (2006)
Hwang, G.-J., et al.: An enhanced genetic approach to composing cooperative learning groups for multiple grouping criteria. Educ. Technol. Soc. 11(1), 148–167 (2008)
Yannibelli, V., Amandi, A.: A deterministic crowding evolutionary algorithm to form learning teams in a collaborative learning context. Expert Syst. Appl. 39(10), 8584–8592 (2012)
Falkenauer, E.: Genetic algorithms and grouping problems. Wiley, New York (1998)
Wang, D.-Y., Lin, S.S., Sun, C.-T.: DIANA: A computer-supported heterogeneous grouping system for teachers to conduct successful small learning groups. Comput. Hum. Behav. 23(4), 1997–2010 (2007)
Chen, C.-T.: Extensions of the TOPSIS for group decision-making under fuzzy environment. Fuzzy Sets Syst. 114(1), 1–9 (2000)
Holland, J.H.: Adaptation in Natural and Artificial Systems. The University of Michigan Press, Ann Arbor (1975)
Hwang, C.-L., Yoon, K.: Multiple attribute decision making. Springer, New York (1981)
Shyur, H.-J., Shih, H.-S.: A hybrid MCDM model for strategic vendor selection. Math. Comput. Model. 44(7), 749–761 (2006)
Yu, X., et al.: Rank B2C e-commerce websites in e-alliance based on AHP and fuzzy TOPSIS. Expert Syst. Appl. 38(4), 3550–3557 (2011)
Weise, T., Global optimization algorithms–theory and application. Self-Published (2009)
Reeves, C.R.: A genetic algorithm for flowshop sequencing. Comput. Oper. Res. 22(1), 5–13 (1995)
Goldberg, D.E.: Genetic algorithms in search, optimization, and machine learning. Addison-Wesley Longman Publishing, Boston (1989)
Acknowledgment
The authors would like to thank Shun-Hsi Chung for his suggestions in this paper. The research is partially supported by the National Science Council of the Republic of China under the grant number NSC 102-2221-E-241-015.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Tien, HW., Lin, YS., Chang, YC., Chu, CP. (2015). A Genetic Algorithm-Based Multiple Characteristics Grouping Strategy for Collaborative Learning. In: Chiu, D., et al. Advances in Web-Based Learning – ICWL 2013 Workshops. ICWL 2013. Lecture Notes in Computer Science(), vol 8390. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-662-46315-4_2
Download citation
DOI: https://doi.org/10.1007/978-3-662-46315-4_2
Published:
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-662-46314-7
Online ISBN: 978-3-662-46315-4
eBook Packages: Computer ScienceComputer Science (R0)