
Abstract
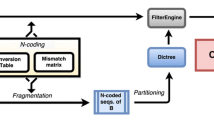
We propose a new algorithm called the MCCM (Match Chaining-based cDNA Mapping) algorithm that allows mapping cDNAs to the genomes efficiently and accurately, utilizing local matches called MUMs (maximal unique matches) or MRMs (maximal rare matches) obtained with suffix trees. From the MUMs (or MRMs), our algorithm selects appropriate matches which are related to the cDNA mapping. We call the selection the match chaining problem. Several O(klogk)-time algorithms are known where k is the number of the input matches, but they do not permit overlaps of the matches. We propose a new O(klogk)-time algorithm for the problem with provision for overlaps. Previously, only an O(k 2)-time algorithm existed. Furthermore, we also incorporate a restriction on the distances between matches for accurate cDNA mapping. We examine the performance of our algorithm through computational experiments using sequences of the FANTOM mouse cDNA database and the mouse genome. According to the experiments, the MCCM algorithm is not only very fast, but also very accurate: We achieved >95% specificity and >97% sensitivity at the same time against the mapping results of the FANTOM annotators.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others


References
Aho, A.V., Hopcroft, J.E., Ullman, J.D.: Data Structures and Algorithms. Addison-Wesley, Reading (1983)
Altschul, S.F., Gish, W., Miller, W., Myers, E.W., Lipman, D.J.: Basic local alignment search tool. J. Mol. Biol. 215, 403–410 (1990)
Adelson-Velskil, G.M., Landis, E.M.: Soviet Math (Dokl.) 3, 1259–1263 (1962)
Bender, M.A., Farach, M.: The LCA problem revisited. In: Gonnet, G.H., Viola, A. (eds.) LATIN 2000. LNCS, vol. 1776, pp. 88–94. Springer, Heidelberg (2000)
Bentley, J., Maurer, H.: Efficient worst-case data structures for range searching. Acta Informatica 13, 155–168 (1980)
Delcher, A.L., Kasif, S., Fleischmann, D., Paterson, J., White, O., Salzberg, S.L.: Alignment of whole genomes. Nucleic Acids Res. 27(11), 2369–2376 (1999)
Delcher, A.L., Phillippy, A., Carlton, J., Salzberg, L.: Fast algorithms for large-scale genome alignment and comparison. Nucleic Acids Res. 30(11), 2478–2483 (2002)
FANTOM Consortium and the RIKEN Genome Exploration Research Group Phase I & II Team, Analysis of the mouse transcriptome based on functional annotation of 60,770 full-length cDNAs. Nature, 420, 563-573 (2002)
Farach, M.: Optimal suffix tree construction with large alphabets. In: Proc. 38th IEEE Symp. Foundations of Computer Science, pp. 137–143 (1997)
Florea, L., Hartzell, G., Zhang, Z., Rubin, G.M., Miller, W.: A computer program for aligning a cDNA Sequence with a Genomic DNA Sequence. Genome Res. 8, 967–974 (1998)
Gelfand, M.S., Mironov, A.A., Pevzner, P.A.: Gene recognition via spliced sequence alignment. Proc. Natl. Acad. Sci. USA 93, 9061–9066 (1996)
Gusfield, D.: Algorithms on strings, trees, and sequences: computer science and computational biology. Cambridge University Press, Cambridge (1997)
Hoehl, M., Kurtz, S., Ohlebusch, E.: Efficient multiple genome alignment. Bioinformatics 18(Suppl. 1), S312–S320 (2002)
Kent, W.J.: The BLAST-like alignment tool. Genome Res. 12, 656–664 (2002)
Labrador, M., Mongelard, F., Plata-Rengifo, P., Bacter, E.M., Corces, V.G., Gerasimova, T.I.: Protein encoding by both DNA strands. Nature 409, 1000 (2001)
Manber, U., Myers, G.: Suffix arrays: a new method for on-line string searches. SIAM J. Comput. 22(5), 935–948 (1993)
McCreight, E.M.: A space-economical suffix tree construction algorithm. J. ACM 23, 262–272 (1976)
Mott, R.: EST GENOME: A program to align spliced DNA sequences to unspliced genomic DNA. Comput. Applic. Biosci. 13(4), 477–478 (1997)
Myers, E., Miller, W.: Chaining multiple-alignment fragments in subquadratic time. In: Proc. ACM-SIAM Symp. on Discrete Algorithms, pp. 38–47 (1995)
Ogasawara, J., Morishita, S.: Fast and sensitive algorithm for aligning ESTs to Human Genome. In: Proc. 1st IEEE Computer Society Bioinformatics Conference, Palo Alto, CA, pp. 43–53 (2002)
Sze, S.-H., Pevzner, P.A.: Las Vegas algorithms for gene recognition: suboptimal and error-tolerant spliced alignment. J. Comp. Biol. 4(3), 297–309 (1997)
Ukkonen, E.: On-line construction of suffix-trees. Algorithmica 14, 249–260 (1995)
Usuka, J., Zhu, W., Brendel, V.: Optimal spliced alignment of homologous cDNA to a genomic DNA template. Bioinformatics 16(3), 203–211 (2000)
Weiner, P.: Linear pattern matching algorithms. In: Proc. 14th Symposium on Switching and Automata Theory, pp. 1–11 (1973)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2003 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Shibuya, T., Kurochkin, I. (2003). Match Chaining Algorithms for cDNA Mapping. In: Benson, G., Page, R.D.M. (eds) Algorithms in Bioinformatics. WABI 2003. Lecture Notes in Computer Science(), vol 2812. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-39763-2_33
Download citation
DOI: https://doi.org/10.1007/978-3-540-39763-2_33
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-20076-5
Online ISBN: 978-3-540-39763-2
eBook Packages: Springer Book Archive