
Abstract
The amount of data has increased exponentially as a consequence of the availability of new data sources and the advances in data collection and storage. This data explosion was accompanied by the popularization of the Big Data term, addressing large volumes of data, with several degrees of complexity, often without structure and organization, which cannot be processed or analyzed using traditional processes or tools. Moving towards Big Data Warehouses (BDWs) brings new problems and implies the adoption of new logical data models and tools to query them. Hive is a DW system for Big Data contexts that organizes the data into tables, partitions and buckets. Several studies have been conducted to understand ways of optimizing its performance in data storage and processing, but few of them explore whether the way data is structured has any influence on how quickly Hive responds to queries. This paper investigates the role of data organization and modelling in the processing times of BDWs implemented in Hive, benchmarking multidimensional star schemas and fully denormalized tables with different Scale Factors (SFs), and analyzing the impact of adequate data partitioning in these two data modelling strategies.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
The advancements in Information and Communications Technology (ICT) contributed to the ever-increasing volume of data being currently generated in our daily activities [1]. Organizations are currently drowning in data, leading to severe data storage and processing difficulties when using traditional technologies [2]. This phenomenon is known as Big Data, mainly defined as data with high volume and variety (e.g., different data types, structures and sources), flowing at different velocities (e.g., batch, interactive and streaming) [3, 4], and aims to solve the problems of traditional data storage and processing technologies (e.g., centralized relational databases), since they provide high performance, scalability and fault-tolerance [5], generally at significant lower costs than traditional enterprise-grade technologies [6]. Hadoop is one of the main open source technologies in Big Data environments. It is divided into two main components: the Hadoop Distributed File System (HDFS), which is Hadoop’s scalable and schema-less storage layer [7], capable of processing huge amounts of unstructured data on a cluster of commodity hardware [8]; and YARN, frequently defined as a sort of operative system for Hadoop, assuring that batch (e.g., MapReduce, Hive), interactive (e.g., Hive, Tez, Spark) and streaming (e.g., Spark Streaming, Kafka) applications use the cluster’s resources as efficiently as possible, by adequately managing the resources in the cluster [9, 10].
Since DWs have long been a fundamental enterprise asset to support decision making [11], practitioners are looking into new ways of modernizing their current Data Warehousing installations [12, 13]. Hadoop is seen as one of the potential candidates for such endeavor. However, due to the fact that there is a lack of methodological approaches for DW design on Hadoop, practitioners often apply their current knowledge on traditional DWs, i.e., deploying star or snowflake schema DWs on Hive (the propeller of the SQL-on-Hadoop movement) [14]. Despite current efforts to accommodate this type of data processing on Hive (e.g., cost based optimizer, map joins) [15], Hadoop was originally conceived to store and process huge amounts of data in a sequential fashion. Therefore, there are questions that remain fairly unanswered by the scientific community and practitioners: Is a multidimensional DW a suitable design pattern for Data Warehousing in Hive? Are these schemas more efficient than fully denormalized tables? Do Hive’s partitions have a significant effect in the execution times of typical Online Analytical Processing (OLAP) queries?
In order to help the community planning their BDWs and contribute to certain methodological aspects of data modelling and organization, this paper attempts to provide answers to these three questions, by benchmarking a Hive DW based on the Star Schema Benchmark (SSB) [16], using different SFs and two query engines, in order to provide observations based on different SQL-on-Hadoop systems: Hive on Tez [15], which can be considered the more efficient and stable query execution engine currently available for Hive; and Engine-X (real name omitted due to licensing limitations), which is a SQL-on-Hadoop system that can execute queries on Hive tables to provide low latency query execution for Business Intelligence (BI) applications, since Hive on Tez’s latency still remains relatively high [17]. Furthermore, this paper also addresses relevant guidelines regarding Hive’s data organization capabilities, such as data partitioning, which can considerably increase the performance of Hive DWs. Practitioners can use the insights provided by this paper to build their modern Data Warehousing infrastructure on Hadoop, or to migrate from a DW based on a Relational Database Management System (RDBMS).
This document is structured as follows: Sect. 2 presents scientific contributions related to this work; Sect. 3 discusses the materials and methods used in this research process; Sect. 4 presents the results obtained in the benchmark; Sect. 5 contains a discussion regarding the results and their usefulness for an adequate DW design on Hadoop (Hive), concluding with some remarks about this work.
2 Related Work
Today’s data volume and data structure appear to be a major problem challenging the processing power of traditional DWs, since the inherent rules/strategies for relational data models can be less effective and efficient for patterns extracted from text, images, videos or sensor data, for example [6]. Data is no longer centralized and limited to the Online Transaction Processing (OLTP) systems of the organizations, being now highly distributed, with different structures, and growing at an exponential rate. Therefore, the BDW differs substantially from the traditional DW, since its schema must be based on new logical models that are more flexible than relational ones [18]. The BDW implies new features and changes, such as highly distributed data processing capabilities; scalability at low cost; ability to analyze large volumes of data without creating samples; processing and visualization of data at the right time to improve the decision-making process; integration of diverse data structures from internal or external data sources; support of extreme processing workloads [19, 20].
In this new context, the data schema can change over time according to the storage or analytical requirements, being important to consider an adequate data model, as it ensures that the analytical needs are properly considered, allowing different analytical perspectives on data [21, 22].
Hive is a widely used DW, adopted by many organizations to manage and process large volumes of data, and was created by Facebook as a way to improve Hadoop query capabilities that were very limiting and not very productive [14]. This DW software for Big Data contexts organizes the data into tables (each table corresponding to a HDFS directory), partitions (sub-directories of the table directory) and buckets (segments of files in HDFS), and provides a SQL-based query language called HiveQL [14, 22]. Inside Facebook, it is heavily used for reporting, ad hoc querying and analysis [8], and according to [14], the main advantages include the simplicity in the implementation of ad hoc analysis and the ability to provide data processing services at a fraction of the cost of a more traditional storage infrastructure.
Total denormalization of data can be a way to improve query performance, as [23] demonstrates by comparing a relational DW with a fully denormalized DW using Greenplum, a Massively Parallel Processing (MPP) DW system. Other works such as [22] propose specific rules for structuring a data model on Hive by transforming a multidimensional data model (commonly used for traditional DWs) into a tabular data model, allowing data analysis in Big Data Warehousing environments. One of these rules includes a suggestion for the identification of Hive partitions and buckets, mentioning that is important to study the balance between the cardinality of the attributes and their distribution, also following Hive’s official documentation [24].
There are also some works discussing the implementation of BDWs using NoSQL databases, despite the fact that they are mainly designed to scale OLTP applications with random access patterns [25], instead of fast sequential access patterns. Examples of such works can be highlighted: [26] studies the implementation of a DW based on a document-oriented NoSQL database; and, [27] discusses a set of rules to transform a multidimensional DW in column-oriented and document-oriented NoSQL data models.
SQL-on-Hadoop systems have been pointed as the de facto solution for Big Data Warehousing. Although the list of SQL-on-Hadoop systems is fairly extensive, this work points systems such as Hive [14]; Presto [28]; Impala [29]; Spark SQL [30]; and Drill [31], which were already evaluated, in works that compare and discuss their performance [17, 30, 32,33,34].
There is, however, a significant absence in the literature about the way data should be modeled in Hive, and how the definition of partitions and buckets can be optimized, as these can significantly improve the performance of BDWs. This work seeks to fulfill this scientific gap by benchmarking multidimensional star schemas and fully denormalized tables implemented in several Hive DWs that use different SFs (sizes), providing a clear overview of the impact of the adopted data models in the system efficiency. Moreover, the impact of data partitions is also analyzed for both data modelling strategies. This is of major relevance to both researchers and practitioners related to the topic of Big Data Warehousing, since it can foster future research and support design patterns for DWs in Big Data environments, exposing reproducible and comparable results.
3 Materials and Methods
Since this paper discusses some best practices for Big Data modelling and organization in Hive DWs, the guidelines and considerations here provided must be adequately validated, in order to produce strongly-supported and replicable results. Consequently, a benchmark was conducted to evaluate the performance of a Hive DW in different scenarios. This section describes the materials and methods used in this research.
3.1 Infrastructure
The infrastructure used in this work consists of a Hadoop cluster with 5 nodes, configured as 1 HDFS NameNode (YARN ResourceManager) and 4 HDFS DataNodes (YARN NodeManagers). The hardware used in each node includes: (i) 1 Intel core i5, quad core, with a clock speed ranging between 3.1 GHz and 3.3 GHz; (ii) 32 GB of 1333 MHz DDR3 Random Access Memory (RAM), with 24 GB available for query processing; (iii) 1 Samsung 850 EVO 500 GB Solid State Drive (SSD) with up to 540 MB/s read speed and up to 520 MB/s write speed; (iv) 1 gigabit Ethernet card connected through Cat5e Ethernet cables and a gigabit Ethernet switch. The operative system installed in every node is CentOS 7 with an XFS file system. The Hadoop distribution being used is the Hortonworks Data Platform (HDP) 2.6.0 with the default configurations, apart from the HDFS replication factor, which was set to 2. Besides Hadoop itself, an Engine-X master is also installed on the NameNode, as well as 4 Engine-X workers on the 4 remaining DataNodes. All Engine-X’s configurations are left to their defaults, except the memory configuration, which was set to use 24 GB of the 32 GB available in each worker (same as the memory available for YARN applications in each DataNode/NodeManager).
3.2 Datasets and Queries
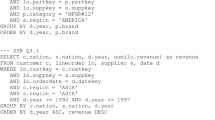
This work uses the SSB [16] and, therefore, it considers both the SSB dataset, which is a traditional sales DW modelled according to the multidimensional structures (stars) presented in [11], and the thirteen SSB queries to analyze its performance for typical OLAP workloads. As this paper is interested in evaluating the performance of different data modelling and organization strategies for Hive DWs, despite the significant advancements both in Hive (on Tez) and Engine-X to adequately process traditional star schemas (e.g., cost based optimizers, map joins) [15], denormalized models are also evaluated, since these structures have been typically preferred in the Hadoop ecosystem. In fact, as previously discussed in Sect. 2, recent approaches for Big Data Warehousing are already focusing on fully denormalized structures to support analytical tasks [22, 23, 35]. Therefore, both the original SSB relational tables and a fully denormalized table were implemented in the Hive DW, in order to evaluate their performance in Big Data environments. The data is stored as Hive tables using the ORC format and compressed using ZLIB. All the thirteen SSB queries were also adapted to the fully denormalized table, providing the same results as the original SSB dimension and fact tables.
3.3 Test Scenarios
As previously mentioned, this paper aims to analyze the impact of different data models and different ways to organize the data in the BDW, so the tests to be performed will consist of: (i) Scenario A: Measuring the variation in the processing time using the star model vs. the denormalized model; (ii) Scenario B: Measuring the variation in the processing time using data partitions, applied both to the star model and to the denormalized model. The insights provided by this paper also take into consideration two SQL-on-Hadoop systems, to verify if the results are comparable among different query engines. In this benchmark, Engine-X and Hive (on Tez) are used. Furthermore, since one of the objectives of this paper is to understand the impact of different data organization strategies, and being partitioning an inherent feature of Hive, it is important to understand how it behaves when partitions are created. Figure 1 presents the test scenarios implemented in this work, namely scenario A and B. In order to achieve more rigorous results, several scripts were coded for executing each query four times. These scripts were adapted according to the SQL-on-Hadoop system (Hive or Engine-X), the applied data model (star or denormalized) and the organization strategy (with or without partitions). All Hive scripts are available on GitHub (https://github.com/epilif1017a/bigdatabenchmarks).

Test scenarios.
Moreover, it is important to highlight that for Engine-X, the queries were executed using two different joins strategies: distributed joins and broadcast joins. The distributed joins strategy can handle larger join operations but is typically slower. Broadcast joins can be substantially faster, but require that the right side of the join fits in a fraction of the memory available in each node. Such distinction is not made for Hive, since cost based optimization, map joins and other related configurations work by default in HDP 2.6.0, which automatically assure the best join strategies according to the cluster’s configuration.
4 Results
This section presents the results achieved in the test scenarios discussed previously, not only comparing the performance of a Hive DW modeled using the star schema approach [11] with one modelled using a fully denormalized table, but also analyzing the performance impact of adequate data partitioning strategies in Hive. The results depicted in this section are relevant to highlight several factors that practitioners must take into consideration when designing BDWs.
4.1 Scenario A: Star Schema vs. Fully Denormalized Table
Relational DWs have long been the backbone of many decision support systems in organizations. In contrast, with the wide acceptance of Hadoop and Hive, denormalized structures became more common, allowing the reading and writing of data to large and contiguous sections of disk drives, optimizing I/O performance [36]. During a significant period of time, Hadoop and the processing of huge amounts of denormalized data (often unstructured) became synonymous. However, with the constant improvements made in Hadoop and related projects, and with organizations increasingly demanding adequate support for relational structures in Big Data environments, there was a wave of efforts to improve the performance of SQL-on-Hadoop systems, in order to efficiently support traditional BI applications based on multidimensional DWs. Nevertheless, there is one question that still remains fairly unanswered by the scientific community: “What are the performance advantages/disadvantages of structuring Hadoop-based DWs according to traditional and relational rules?”.
Table 1 illustrates the results for different scaling factors, SF = 10, SF = 30, SF = 100 and SF = 300 workloads, both for Hive and Engine-X query engines. As previously discussed in Subsect. 3.3, two different join strategies were tested for Engine-X: distributed and broadcast. Processing times for broadcast joins are presented between parentheses in Table 1, and since they always outperformed distributed joins, overall performance considerations between the star schema and the denormalized table only take broadcast joins into account. As demonstrated by the results from the experiments conducted in this work, which are presented in Table 1 (lower values are highlighted in bold), despite being feasible to implement multidimensional DWs in Hadoop, it may not be the most efficient approach.
According to the experimentations with different SFs, the star schema only outperformed the denormalized table in 14 out of the 104 query executions, namely in Hive’s SF = 10 workload (Q1.1, Q1.2, Q1.3 and Q2.2); in Hive’s SF = 30 workload (Q1.3 and Q2.2); in Hive’s SF = 100 workload (Q2.2); in Hive’s SF = 300 workload (Q1.1, Q1.2, Q1.3 and Q4.3); and, in Engine-X’s SF = 300 workload (Q1.1, Q1.2 and Q1.3). If one takes a closer look at the pattern of Q1 in the SSB, it can be concluded that it should favor the star schema. Considering that the star schema fact table is roughly 3 times smaller than the denormalized table, and since Q1 only joins the fact table with the date dimension, the smaller size should compensate for the overhead of performing a single join operation. However, this does not happen in Hive’s SF = 100 workload, where the denormalized table outperformed the star schema for all Q1 queries.
Moreover, in Hive’s SF = 10, SF = 30 and SF = 100 workloads, Q2.2 also performs better for the star schema. After analyzing the particularities of Q2.2, one can conclude that Hive’s query execution engine (Tez) may have demonstrated some performance degradation when performing string range comparisons in larger amounts of data. In this case, Q2.2 contained the following predicate: “p_brand1 between ‘MFGR#2221’ and ‘MFGR#2228’”. However, this trend is not transposed to the SF = 300 workload, in which Q2.2 is significantly slower for the star schema when compared to the denormalized table.
Regarding the remaining 90 query executions, the denormalized table outperformed the star schema 84 times, and both achieved the same result 6 times. In Hive’s workloads, the minimum overall performance advantage for the denormalized table was 4% (SF = 10) and the maximum overall advantage was 73% (SF = 300), which means that, in the best scenario, the denormalized table was able to complete the workload 73% faster than the star schema. With the increase of the dataset size, also increases the gain in performance, clearly benefiting Big Data scenarios. This performance difference is more noteworthy than in Engine-X’s workloads, wherein the denormalized table tends to perform between 30% and 48% faster than the star schema. These results demonstrate that while it is feasible to implement multidimensional DWs in Hive, this approach is not always optimal when analyzing query execution times, since it is often outperformed by a purely denormalized structure.
If one takes a closer look at Engine-X’s SF = 300 workload, at a first glance, it might seem that the performance advantage of the denormalized table faded out when compared to previous workloads. However, the SF = 300 is the first workload in which the total size of the denormalized table does not fit in the total amount of memory available for querying in the cluster (96 GB), containing around 139 GB of data stored in ORC files, while the entire star schema DW for the same SF contains approximately 51 GB of data in the same format. Given the fact that one is comparing a DW that is 45% larger than the total amount of memory with a DW that totally fits in memory, and it is still 30% faster on average, this highlights the fact that denormalized structures bring more benefits in terms of pure performance when processing queries over large datasets.
There are certain queries in which the star schema’s execution times although slower, are fairly comparable with the denormalized table’s execution times, but there is also a significant number of queries in which the star schema is more than 50% slower (sometimes more than 100% slower). Even with Engine-X’s broadcast joins strategy, results do not favor the multidimensional approach for DWs in Big Data environments. Such phenomenon is also typically aggravated with an increased SF (specially for Hive), highlighting the data volume bottleneck in multidimensional BDWs. Consequently, whether one uses HiveQL or a more interactive SQL-on-Hadoop system like Engine-X’s to query a Hadoop-based DW, it can be stated that a denormalized structure is able to typically outperform a multidimensional approach, with less potential bottlenecks when the volume of data increases.
Another troubling factor for multidimensional DWs on Hadoop is the fact that their performance, according to this benchmark, is only comparable to the performance of a denormalized table when efficient techniques such as broadcast joins are applied. With the distributed joins strategy in Engine-X or with Hive (on Tez), the star schema performance is often alarming and query execution times are significantly high. However, there is one relatively important caveat when employing broadcast joins: the broadcasted table (right side of the join) must be small enough to fit in the memory of each node (technically, in a small fraction of the memory available for queries), because if the broadcasted input is too large, “out of memory” errors can occur, due to the lack of memory to process all inputs. This suits to several dimension tables, as they are typically small, but for DWs implementing type 2 slowly changing dimensions [11], for example, this join strategy may not be feasible [23]. Not only does the star schema present certain memory requirements, but also, in this benchmark, the star schema tends to show a significant CPU overhead when compared to the denormalized modelling approach. On average, in Engine-X’s SF = 300 workload, the star schema uses 143% more CPU time, despite being on average 43% slower than the denormalized table. Consequently, as Fig. 2 demonstrates, higher CPU usage can be considered as another disadvantage of the star schema approach for DWs in Big Data environments.

Star schema and denormalized table CPU time and execution time comparison.
4.2 Scenario B: Data Organization (Hive Partitions)
One of the biggest problems of a DW, either traditional or in Big Data environments, is how to partition the data. Data partitioning refers to splitting data into separate physical units that can be treated independently. Thus, proper partitioning can bring benefits to a DW in terms of loading, accessing, storing and monitoring data [37]. According to [24], the attribute(s) on which partitioning will be applied should have low cardinality, in order to avoid the creation of a high number of subdirectories on HDFS.
Usually, Hive analyzes the entire table to answer a query and that may compromise its performance. For huge volumes of data, partitioning can dramatically improve queries performance. However, according to [36], this only happens if the partition schemes reflect common filters to the data, being usually defined with the attribute that appears more often in the “where” conditions of the queries. However, there is a question that remains: “What is the true impact of partitioning on processing time?”. Table 2 presents the results for SF = 10, SF = 30, SF = 100 and SF = 300 workloads for a star schema and for a denormalized table, respectively, both for Hive and Engine-X. Considering the results obtained in Sect. 4.1, the tests for Engine-X using the star schema will only contemplate the broadcast join strategy.
Analyzing the results, one can conclude that there is a significant improvement when using data partitioning, being few the cases where tables with no partitions behave better. Considering the percentages of decrease/increase in times obtained when using partitions, in all scenarios there is a decrease in queries execution time. In Hive’s workloads, the minimum overall performance advantage was 2% and the maximum advantage was 63%, which means that, in the best scenario (star schema SF = 300), the partitioned table was able to complete the workload 63% faster than the table without partitions. Engine-X is generally faster than Hive and in its workloads the maximum advantage was 46%, in the denormalized table SF = 300 workload.
As mentioned before, usually, a table should be partitioned by the attribute that appears more often in the “where” condition of the queries. Considering the queries used in this work, most of them were filtered by year, namely Q1.1, Q1,3, Q3.1, Q3.2, Q3.3, Q4.2 and Q4.3. Therefore, the attribute “year” was used to create the partitions and, as can be seen in Table 2, generally these were the queries that were more influenced by data partitioning. For almost all scenarios, these queries obtained better results after partitioning the data. In the cases where additional time was needed due to partitioning, it was not very significant, only surpassing the 10 s’ mark in one of the cases (on Hive).
However, it is important to highlight that the creation of partitions, although it optimized certain queries, can be a disadvantage for other queries that do not consider the filters by the attribute used for partitioning. Q2.2 and Q4.1 are two of the most affected queries, both for Hive and Engine-X, since the increase can reach the 138 and 29 s, respectively. Q3.1, Q3.2 and Q3.3 are the queries that not always suffer a decrease by the application of partitions, despite having the filter. After analyzing the “where” conditions of these queries, it is important to highlight that although they are filtered by year, this filter only excludes the partition year of 1998, so to answer these queries, both Hive and Engine-X must search the other 6 partitions (6 folders), thus justifying that in some cases it may take more time or not be affected by the defined data organization. This outperformance in a context with no partitions, is also mainly verified in lower SFs, since when the volume of data is smaller the advantages of not having to search the entire dataset is pointless, because it does not contain a significant amount of data. In contrast, for higher SFs, not having to scan the entire dataset means not having to process a considerable amount of data.
Other queries showing a decrease in execution time, even without considering the filter in their “where” conditions, may be related to a rearrangement of the queries optimizer used in each tool, or to particularities of the queries that execute faster when data is organized by folders. This should be further evaluated in future work. The results here obtained also consolidate the results presented in the previous section, since it is clear the performance advantage of the denormalized table when it is also partitioned. Thus, the best scenario (the one with the lowest processing time), is the scenario considering a partitioned and denormalized table, using Engine-X for query execution.
5 Discussion and Conclusions
This work presented an evaluation and discussion of adequate data modelling and organization strategies for Hadoop (Hive) DWs in Big Data environments. The SSB benchmark was used to evaluate the performance of a star schema DW and a fully denormalized DW, with and without data partitioning. Four SFs were used, namely: SF = 10; SF = 30; SF = 100; and SF = 300. Two SQL-on-Hadoop systems (Hive on Tez and Engine-X) were used to query the DW and to observe if the insights provided in this paper are reproducible in more than one Big Data querying engine.
Regarding the comparison between DWs built using star schemas and DWs built using fully denormalized tables, this paper concludes that Hadoop-based DWs benefit from using a fully denormalized data modelling strategy, since the results achieved in the benchmark showed a significant performance advantage over the multidimensional DW design strategy throughout all scaling factors. Despite being feasible to implement DWs on Hive using the star schema, this may not be the most efficient design pattern, despite saving a significant amount of storage, since the SSB fully denormalized dataset was 3 times bigger than the original dataset in a multidimensional format. Storage space, which is becoming increasingly cheaper, is the price to pay in BDWs that use fully denormalized tables, but the advantages can be sufficient to overcome this disadvantage, including the following, according to this benchmark: faster query execution (very often more than 50% faster); less memory requirements regarding specific join strategies (broadcast joins); and less intensive CPU usage.
Consequently, despite the innumerous efforts in several SQL-on-Hadoop systems to adequately support queries over multidimensional structures (e.g., adequate cost based optimizers, map joins), it can be stated that Hadoop-based DWs still favor fully denormalized structures that do not rely on join operations to answer OLAP queries. Such approach avoids the cost of performing join operations in Big Data environments. These results corroborate previous studies (please see Sect. 2 for more details) arguing that denormalized tables showed better performance than star schemas when using specific MPP Data Warehousing systems.
Regarding the different data organization strategies, this paper also concludes that there is a clear advantage in partitioning data, since the results obtained in the benchmark showed a significant decrease in query execution time when Hive tables are adequately partitioned. Thus, the results presented in this paper reinforce the potential benefit of creating data partitions easier to process, since, depending on the query being executed, these techniques can drastically reduce processing time. It also proves that, once the queries are known in advance, using the attribute that appears more often as a filter for partitioning is effectively one of the best partitioning strategies, consolidating previous studies.
For future work, one aims to continue studying the impact of other data partitioning strategies, as well as the impact of adequate bucketing strategies in Hive DWs, in order to complement the insights depicted in this paper. Moreover, one also aims to propose structured guidelines for the automatic creation of materialized views in Big Data Warehousing environments.
References
Dumbill, E.: Making sense of big data. Big Data 1, 1–2 (2013). doi:10.1089/big.2012.1503
Chen, M., Mao, S., Liu, Y.: Big data: a survey. Mob. Netw. Appl. 19, 171–209 (2014). doi:10.1007/s11036-013-0489-0
Ward, J.S., Barker, A.: Undefined by data: a survey of big data definitions. arXiv:1309.5821 [cs. DB] (2013)
NBD-PWG: NIST Big Data Interoperability Framework: Volume 6, Reference Architecture. National Institute of Standards and Technology (2015)
Philip Chen, C.L., Zhang, C.-Y.: Data-intensive applications, challenges, techniques and technologies: a survey on Big Data. Inf. Sci. 275, 314–347 (2014). doi:10.1016/j.ins.2014.01.015
Krishnan, K.: Data Warehousing in the Age of Big Data. Morgan Kaufmann Publishers Inc., San Francisco (2013)
Shvachko, K., Kuang, H., Radia, S., Chansler, R.: The hadoop distributed file system. In: 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), pp. 1–10 (2010)
Thusoo, A., Shao, Z., Anthony, S., Borthakur, D., Jain, N., Sen Sarma, J., Murthy, R., Liu, H.: Data warehousing and analytics infrastructure at Facebook. In: Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, pp. 1013–1020. ACM, New York (2010)
Apache Hadoop: Welcome to Apache Hadoop. https://hadoop.apache.org/
Vavilapalli, V.K., Murthy, A.C., Douglas, C., Agarwal, S., Konar, M., Evans, R., Graves, T., Lowe, J., Shah, H., Seth, S., Saha, B., Curino, C., O’Malley, O., Radia, S., Reed, B., Baldeschwieler, E.: Apache hadoop YARN: yet another resource negotiator. In: Proceedings of the 4th Annual Symposium on Cloud Computing, pp. 5:1–5:16. ACM, New York (2013)
Kimball, R., Ross, M.: The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling. Wiley, Hoboken (2013)
Russom, P.: Evolving data warehouse architectures in the age of big data. The Data Warehouse Institute (2014)
Russom, P.: Data warehouse modernization in the age of big data analytics. The Data Warehouse Institute (2016)
Thusoo, A., Sarma, J.S., Jain, N., Shao, Z., Chakka, P., Zhang, N., Antony, S., Liu, H., Murthy, R.: Hive-a petabyte scale data warehouse using hadoop. In: IEEE 26th International Conference on Data Engineering (ICDE), pp. 996–1005. IEEE (2010)
Huai, Y., Chauhan, A., Gates, A., Hagleitner, G., Hanson, E.N., O’Malley, O., Pandey, J., Yuan, Y., Lee, R., Zhang, X.: Major technical advancements in apache Hive. In: Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, pp. 1235–1246. ACM, New York (2014)
O’Neil, P.E., O’Neil, E.J., Chen, X.: The star schema benchmark (SSB) (2009)
Floratou, A., Minhas, U.F., Özcan, F.: SQL-on-hadoop: full circle back to shared-nothing database architectures. Proc. VLDB Endow. 7, 1295–1306 (2014). doi:10.14778/2732977.2733002
Tria, F.D., Lefons, E., Tangorra, F.: Design process for big data warehouses. In: 2014 International Conference on Data Science and Advanced Analytics (DSAA), pp. 512–518 (2014)
Goss, R.G., Veeramuthu, K.: Heading towards big data building a better data warehouse for more data, more speed, and more users. In: 2013 24th Annual SEMI Advanced Semiconductor Manufacturing Conference (ASMC), pp. 220–225. IEEE (2013)
Mohanty, S., Jagadeesh, M., Srivatsa, H.: Big Data Imperatives: Enterprise: Big Data Warehouse, BI Implementations and Analytics. Apress, New York City (2013)
Santos, M.Y., Costa, C.: Data models in NoSQL databases for big data contexts. In: Tan, Y., Shi, Y. (eds.) DMBD 2016. LNCS, vol. 9714, pp. 1–11. Springer, Cham (2016). doi:10.1007/978-3-319-40973-3_48
Santos, M.Y., Costa, C.: Data warehousing in big data: from multidimensional to tabular data models. In: Ninth International C* Conference on Computer Science & Software Engineering (C3S2E), pp. 51–60. ICPS (ACM) (2016)
Jukic, N., Jukic, B., Sharma, A., Nestorov, S., Korallus Arnold, B.: Expediting analytical databases with columnar approach. Decis. Support Syst. 95, 61–81 (2017). doi:10.1016/j.dss.2016.12.002
Apache Hive: Apache Hive Documentation - Apache Software Foundation. https://cwiki.apache.org/confluence/display/Hive/Home
Cattell, R.: Scalable SQL and NoSQL data stores. ACM SIGMOD Rec. 39, 12–27 (2011). doi:10.1145/1978915.1978919
Chevalier, M., Malki, M.E., Kopliku, A., Teste, O., Tournier, R.: Document-oriented models for data warehouses - NoSQL document-oriented for data warehouses. Presented at the 18th International Conference on Enterprise Information Systems 2 March (2017)
Yangui, R., Nabli, A., Gargouri, F.: Automatic transformation of data warehouse schema to NoSQL data base. Procedia Comput Sci. 96, 255–264 (2016). doi:10.1016/j.procs.2016.08.138
Presto: Presto | Distributed SQL Query Engine for Big Data. https://prestodb.io/
Kornacker, M., Behm, A., Bittorf, V., Bobrovytsky, T., Choi, A., Erickson, J., Grund, M., Hecht, D., Jacobs, M., Joshi, I., Kuff, L., Kumar, D., Leblang, A., Li, N., Robinson, H., Rorke, D., Rus, S., Russell, J., Tsirogiannis, D., Wanderman-milne, S., Yoder, M.: Impala: a modern, open-source SQL engine for hadoop. In: Proceedings of the CIDR 2015, California, USA (2015)
Armbrust, M., Xin, R.S., Lian, C., Huai, Y., Liu, D., Bradley, J.K., Meng, X., Kaftan, T., Franklin, M.J., Ghodsi, A., et al.: Spark SQL: relational data processing in spark. In: Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, pp. 1383–1394. ACM (2015)
Hausenblas, M., Nadeau, J.: Apache Drill: interactive ad-hoc analysis at scale. Big Data 1, 100–104 (2013)
Chen, Y., Qin, X., Bian, H., Chen, J., Dong, Z., Du, X., Gao, Y., Liu, D., Lu, J., Zhang, H.: A study of SQL-on-hadoop systems. In: Zhan, J., Han, R., Weng, C. (eds.) BPOE 2014. LNCS, vol. 8807, pp. 154–166. Springer, Cham (2014). doi:10.1007/978-3-319-13021-7_12
Kornacker, M., Behm, A., Bittorf, V., Bobrovytsky, T., Choi, A., Erickson, J., Grund, M., Hecht, D., Jacobs, M., Joshi, I., Kuff, L., Kumar, D., Leblang, A., Li, N., Robinson, H., Rorke, D., Rus, S., Russell, J., Tsirogiannis, D., Wanderman-milne, S., Yoder, M.: Impala: a modern, open-source SQL engine for hadoop. In: Proceedings of the CIDR 2015, California, USA (2015)
Santos, M.Y., Costa, C., Galvão, J., Andrade, C., Martinho, B., Lima, F.V., Costa, E.: Evaluating SQL-on-hadoop for big data warehousing on not-so-good hardware. In: Proceedings of International Database Engineering & Applications Symposium (IDEAS 2017), Bristol, United Kingdom (2017)
Santos, M.Y., Martinho, B., Costa, C.: Modelling and implementing big data warehouses for decision support. J. Manag. Anal. 4, 111–129 (2017)
Capriolo, E., Wampler, D., Rutherglen, J.: Programming Hive. O’Reilly Media Inc., Sebastopol (2012)
Inmon, W.H.: Building the Data Warehouse. Wiley, Hoboken (2005)
Acknowledgements
This work is supported by COMPETE: POCI-01-0145- FEDER-007043 and FCT – Fundação para a Ciência e Tecnologia within the Project Scope: UID/CEC/00319/2013, and funded by the SusCity project, MITP-TB/CS/0026/2013, and by the Portugal Incentive System for Research and Technological Development, Project in co-promotion nº. 002814/2015 (iFACTORY 2015–2018).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Costa, E., Costa, C., Santos, M.Y. (2017). Efficient Big Data Modelling and Organization for Hadoop Hive-Based Data Warehouses. In: Themistocleous, M., Morabito, V. (eds) Information Systems. EMCIS 2017. Lecture Notes in Business Information Processing, vol 299. Springer, Cham. https://doi.org/10.1007/978-3-319-65930-5_1
Download citation
DOI: https://doi.org/10.1007/978-3-319-65930-5_1
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-65929-9
Online ISBN: 978-3-319-65930-5
eBook Packages: Computer ScienceComputer Science (R0)