
Abstract
With the development of e-commerce, e-commerce websites become very popular. People write reviews on products and rate the helpfulness of reviews in these websites. Reviews written by a user and reviews rated by a user actually reflect a user’s interests and disinterest. Thus, they are very useful for user profiling. In this paper, we explore users’ reviews and ratings on reviews for personalized search and propose a review-based user profiling method. And we also propose a priority-based result ranking strategy. For evaluation, we conduct experiments on a real-life data set. The experimental results show that our method can significantly improve the retrieval quality.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Currently, many academic works [1, 2] have been done on utilizing users’ data to construct user profiles for personalized search. Such data includes user’s manually selected interests [3], browsing history [4], social annotations [5] and microblog behaviours [6], etc. However, few works have been done on leveraging users’ reviews and ratings on reviews in e-commerce websites for personalized search.
In recent years, along with the flourish of e-commerce, e-commerce websites such as Amazon Footnote 1, Epinions Footnote 2 and Ciao UK Footnote 3 become widely popular. These websites allow users to write reviews on products and to rate the helpfulness of reviews. More specifically, a user may write a review on a product. We believe that users’ reviews and ratings on reviews in e-commerce websites can reflect a user’s concerns and unconcern. Therefore, they are very useful for user profiling and can improve the precision of user profiles. Previously, Moghaddam et al. [7] utilize them to achieve personalized review recommendation based on tensor factorization. However, existing research works do not make use of them for personalized search. To achieve personalized searching, a personalized search system ranks resources according to two guidelines: query relevance (relevance between a query and a resource profile) and user interest relevance (relevance between a user profile and a resource profile). In existing works on personalized search such as [5, 8, 9], a personalized search system aggregates the above relevance and return resources with highest aggregation values. To meet the basic requirement of a personalized search system, most researchers emphasize the effect of query relevance on aggregation values by assigning it with a larger weight. However, result ranking only based on aggregation values can not ensure that resources returned satisfy a user’s basic information needs.
In our work, to construct a user profile, we propose a novel review-based user profiling method which can capture a user’s concerns and unconcern. To ensure that resources returned satisfy a user’s basic information needs, we propose a priority-based result ranking strategy. Resources should have different priority based on how well they satisfy a user’s basic information needs, and they are ranked according to their aggregation values and priorities. The contributions of our work are listed as follows.
-
To construct precise user profiles, we utilize them and propose a novel review-based user profiling method which can capture a user’s both concerns and unconcern.
-
We reveal the limitation of existing result ranking strategy which can not guarantee resources returned satisfy a user’s basic information needs. To overcome the limitation, we introduce priority into result ranking strategy for personalized search.
-
For evaluation, we conduct experiments on a real-life data set crawled from Epinions. The experimental results show that our method outperforms the stated-of-the-art methods in personalized search.
2 Related Works
Currently, many works have been done on personalized search, such as [1]. Current strategies of these works fall into two categories [10]: Automatic query expansion and result re-ranking. Automatic query expansion (AQE), such as [2, 11], refers to modifying the original query by expanding it or assigning different weights to the terms in query. To re-rank the result list, Ma et al. [3] utilize users’ selected interests and propose a framework that maps users’ interests onto the categories of Open Directory Project(ODP). Xu et al. [5] take advantage of folksonomy and present a personalized search framework in which the rank of a web page is influenced by topic matching between user’s interests and web page’s topics.
3 Preliminary
In a personalized search system, there are a set of users denoted by U, a set of queries denoted by Q issued by users, and a set of resources available on web denoted by R. For each resource in R, they can be represented by some features. Thus, it is a common practice to adopt Vector Space Model (VSM) to represent a resource.
Definition 1
A resource profile for a resource j denoted by \(\overrightarrow{R_{j}}\), is a vector of feature:value pairs:
where n is the number of features in a resource profile, \(f^{r}_{j,k}\) is the \(k^{th}\) feature used for describing resource j and \(w_{j,k}\) indicates to what degree the resource j possesses feature k. A higher value of the \(w_{j,k}\) for the feature k indicates that to larger extent the resource j possesses feature k.
Definition 2
A user profile for a user i, denoted by \(\overrightarrow{U}_{i}\), is a vector of feature:value pairs, i.e.,
where n is the number of features in a user profile, \(f_{i,k}^{u}\) is user i’s \(k^{th}\) feature extracted from i’s data and \(v_{i,k}\) denotes user i’s concern degree on feature k. The higher value of \(v_{i,k}\) is, the user i is more concerned about the feature k.
Definition 3
A query issued by user i denoted by \(\overrightarrow{q}_{i}\) is a vector of terms as follows:
where \(t_{u,k}\) is the \(k^{th}\) term of the query issued by user i, and m is the total number of terms in a query. A personalized search system should return resources which not only satisfy a user’s query, but also satisfy the user’s personal interests. To achieve this goal, a personalized search system usually undergoes three processes.
The first one is query relevance, which is to find out to what extent resources satisfy a user’s basic information needs. The query relevance of a resource can be measured by a query relevance function as follows:
A higher result of \(\gamma \) function means that a resource is more relevant to a query.
The second process is user interest relevance, which is to determine to what degree a user is interested in resources. The user interest relevance of a resource can be measured by a user interest relevance function as follows:
where U is a set of users. A higher result of \(\theta \) function suggests that the user is more interested in the resource. A positive result of \(\theta \) implies that a user is interested in a resource, while a negative one implies that a user is disinterested in a resource.
The last process is result ranking. A personalized search system aggregates query relevance and user interest relevance for each resource, ranks resources with an appropriate strategy, and return resources in a result list to the user.
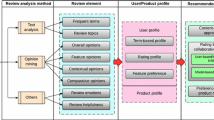
4 Review-Based User Profiling
4.1 Relationships Between Users’ Reviews and Ratings on Reviews in E-Commerce Websites, and Users’ Concerns and Unconcern
In an e-commerce website, a user can write a review on a product. Based on what a user mentions in an original review, we can identify what the user concerns about. Also, a user can give a helpfulness rating to a review in an e-commerce website. According to features appear in a user’s high-score review, we can find out the user’s concerns. By contrast, according to features appear in a user’s low-score review, we can get to know what the user is disinterested in. Although most of the time, users just skip reviews they consider to be useless, for users who rate useless reviews with low scores, we consider that their low-score reviews still show what they are disinterested in.
4.2 Review-Based User Profiling Method
Based on the above illustrations, we believe that users’ reviews and ratings on reviews can make a contribution to user profiling. We make the following assumptions.
Assumption 1
For a user u, all the features mentioned in a review written by u are assumed as u’s concerned features.
Assumption 2
For a user u, all the features mentioned in a review rated by u with a high score are assumed as u’s concerned features.
Assumption 3
For a user u, all the features mentioned in a review rated by u with a low score are assumed as u’s unconcerned features.
According to Assumptions 1, 2 and 3, we propose a novel review-based user profiling method which can capture a user’s concerns and unconcern. For each review-based user profile constructed by this method, it is composed of a user’s concerned features and unconcerned features. These features are extracted from reviews written by the user or rated by the user. Formally, a review-based user profile can be defined as follows.
Definition 4
A review-based user profile (RUP) for a user i, denoted by \(\overrightarrow{U}_{i}\), is a vector of feature:value pairs, i.e.,
where \(f_{i,k}\) is user i’s \(k^{th}\) feature that occurs in reviews written by i, rated by i or both, \(v_{i,k}\) represents user i’s concern degree on feature k and n is the total number of features that occur in i’s all kinds of reviews.
Since it is common for a feature to appear in several reviews and kinds of reviews, we make the following assumption on calculating users’ concern degree on features.
Assumption 4
For a user i and two given features x and y, if x appears in reviews written by i or reviews rated by i with a high score more frequently, we assume that i is more concerned about x than y.
Assumption 4 illustrates that how much a user concerns about a feature is related to the feature’s frequency in different kinds of reviews. A user’s concern degree on a particular feature is positively correlated with the feature’s frequency in the user’s original reviews and high-score reviews, while it is negatively correlated with the feature’s frequency in the user’s low-score reviews. To be notice, a feature’s concern degree is irrelevant to the sentiment words within reviews. Because sentiment words only show user’s preference or detestation on a feature of a particular product, but not the user’s concern degree on the feature. The following axioms in line with Assumption 4:
Axiom 1
For a user i and a feature \(k\in F_{i,w}\bigcup F_{i,h}, k\notin F_{i,l}\), if \(f_{i,k}^w=1, f_{i,k}^h=1\) and \(f_{i,k}^l=0\), then \(v_{i,k}=1\).
Axiom 2
For a user i and a feature \(k\notin F_{i,w}\bigcup F_{i,h}, k\in F_{i,l}\), if \(f_{i,k}^w=0, f_{i,k}^h=0\) and \(f_{i,k}^l=1\), then \(v_{i,k}=-1\).
Axiom 3
For a user i and two features \(k_{1}, k_{2}\in F_{i,w}\bigcup F_{i,h} \bigcup F_{i,l}\), if \(f_{i,k_{1}}^{w}=f_{i,k_{2}}^{w}\), \(f_{i,k_{1}}^{h}>f_{i,k_{2}}^{h}\) and \(f_{i,k_{1}}^{l}=f_{i,k_{2}}^{l}\), then \(v_{i,k_{1}}>v_{i,k_{2}}\).
Axiom 4
For a user i and two features \(k_{1}, k_{2}\in F_{i,w}\bigcup F_{i,h} \bigcup F_{i,l}\), if \(f_{i,k_{1}}^{w}>f_{i,k_{2}}^{w}\), \(f_{i,k_{1}}^{h}=f_{i,k_{2}}^{h}\) and \(f_{i,k_{1}}^{l}=f_{i,k_{2}}^{l}\), then \(v_{i,k_{1}}>v_{i,k_{2}}\).
Axiom 5
For a user i and two features \(k_{1}, k_{2}\in F_{i,w}\bigcup F_{i,h} \bigcup F_{i,l}\), if \(f_{i,k_{1}}^{w}=f_{i,k_{2}}^{w}\), \(f_{i,k_{1}}^{h}=f_{i,k_{2}}^{h}\) and \(f_{i,k_{1}}^{l}>f_{i,k_{2}}^{l}\), then \(v_{i,k_{1}}<v_{i,k_{2}}\).
where \(F_{i,w}\), \(F_{i,h}\) and \(F_{i,l}\) are sets of features appear in i’s original reviews, high-score reviews and low-score reviews, \(f_{i,k}^{w}\), \(f_{i,k}^{h}\) and \(f_{i,k}^{l}\) are frequencies of feature k appears in original reviews, high-score reviews and low-score reviews, respectively. Axioms 1 and 2 specify the boundary case of \(v_{i,k}\). If a feature never occurs in a user’s low-score reviews, but it appears in every high-score reviews and original reviews of the user, then this feature may be the user’s concerned feature, hence \(v_{i,k}\)=1. On the contrary, if a feature never occurs in a user’s original reviews or high-score reviews, but it occurs in every low-score reviews of the user, then this feature may be the user’s most unconcerned feature, hence \(v_{i,k}\)=−1. Axioms 3, 4 and 5 specify the essence of calculating user’s concerned degree for each features. The higher frequency of a feature occurs in a user’s original reviews or high-score reviews is, the user is more concerned about the feature. By contrast, the higher frequency of a feature occurs in a user’s low-score reviews is, the user is less concerned about the feature.
The following is a possible function to calculate concern degree of each feature, which satisfies Axioms 1–5.
where \(\alpha \) and \(\beta \) are free parameters to adjust the effects of different kinds of reviews on features’ concern degree, \(W_{i}\) is a set of reviews written by i, \(H_{i}\) and \(L_{i}\) are sets of high-score and low-score reviews rated by i respectively, \(W_{i,k}\), \(H_{i,k}\) and \(L_{i,k}\) are sets of i’s original reviews, high-score reviews an low-score reviews containing feature k respectively, and \(\omega \) helps to normalize the effects of reviews with different scores:
where \(r_{i,y}\) indicates user i’s rating on review y, \(r_{max}\) and \(r_{min}\) are the maximal and minimal helpfulness rating of a review respectively, and \(\theta \) is a threshold to distinguish high-score reviews from the low-score reviews. A higher value of \(\alpha \) implies a user’s original reviews play more important roles in calculation of \(v_{i,k}\). Besides, a higher value of \(\beta \) indicates that a user’s low-score reviews have a greater impact on the calculation of a feature’s concern degree. By utilizing users’ reviews and ratings on reviews in e-commerce websites, our review-based user profiling method can construct user profiles which is able to reflect a user’s concerns and unconcern.
5 Resource Profiling
To identify to what extent a feature in a resource profile can describe a resource, we adopt the normalized term frequency (NTF) [9] to measure the weight of feature as follows.
where \(c_{j,x}\) is times of feature x used for describing resource j, \(C_{j}\) is the set of features of resource j, and \(|C_{j}|\) indicates the total number of features of resource j.
6 Personalized Search
6.1 Query Relevance Measurement and User Interest Relevance Measurement
In our work, we adopt the Cosine Similarity measurement to realize the first two processes of personalized searching. The value of query relevance function \(\gamma \) in Eq. 1 and user interest relevance function \(\theta \) in Eq. 2 can be obtained by Eqs. 6 and 7 respectively.
where \(\overrightarrow{U}_{i}\) is user i’s user profile, \(\overrightarrow{R}_{j}\) is resource j’s resource profile and \(\overrightarrow{q}_{i}\) is a query issued by user i.
6.2 Limitations of Current Result Ranking Strategy
In current works on personalized search [8, 9], to rank resources, most researchers first adopt one of the multiplication aggregation functions or the addition aggregation functions to aggregate resources’ query relevance and user interest relevance. For example, Xu et al. [5] adopt Weighted Borda-Fuse as the aggregation function shown as follows:
where \(\delta \) is a free parameter to adjust the effects of query relevance and user interest relevance on aggregation values, \(\gamma (\overrightarrow{q}_{i}, \overrightarrow{R}_{j})\) is query relevance and \(\theta (\overrightarrow{U}_{i}, \overrightarrow{R}_{j})\) is user interest relevance. Then they rank resources according to their aggregation values. A resource with a higher aggregation value gets a higher position in a result list.
To meet the basic requirement of a search system, they usually assume that query relevance is more important than user interest relevance in an aggregation function. Thus, they assign a larger weight to query relevance in an aggregation function. For example, \(\delta \) in Eq. 8 may be assigned with a value in the range [0.5, 1). However, no matter how large the weight of query relevance is, there is always a chance that resources which well match a user’s interest but fails to satisfy a user’s basic information needs are returned. Thus, assigning query relevance with a larger weight still can not ensure that resources returned by a personalized search system satisfy a user’s basic information needs.
6.3 Priority-Based Result Ranking Strategy
To overcome the limitation and meet the basic requirement of a search system, we introduce priority into result ranking strategy. Instead of assuming that query relevance is more important than user’s interest relevance, we assume that query relevance is prior to user interest relevance. Resources returned by a personalized search system should satisfy a user’s basic information needs and had better satisfy a user’s interests. More specifically, resources in a result list are assigned with different priorities according to how many keywords of a query they satisfy. Resources whose profiles contain all of the keywords of the query gain the highest priority, while resources whose profiles contain none of the keywords of the query gain the lowest priority. For resources with different priorities, resources with higher priority always get higher positions than resources with lower priority. For resources with the same priority, they are ranked according to their aggregation values of query relevance and user interest relevance. Even if a resource with lower priority gains a high aggregation value due to its matching with the user profile, the position of this resource in a result list will be lower than any of the resources with higher priority (satisfying more keywords of a query). By introducing priority into personalized search, our method ensure that resources returned satisfy a user’s basic information needs.
7 Experiments
7.1 Data Set
The data set we use to evaluate our method is crawled from Epinions. We create a subset of 1345 users, who writes or rates 10–50 reviews about electronics or computer hardware from our data set, and the subset also contains 4430 reviews and 29395 user-review-rate tuples. On average, each user writes 3 reviews and rates 22 reviews. Among 29395 user-review-rate tuples in the subset, the ratings of almost 95 % of them is 5. We randomly split the data set into two parts, 80 percent of them are used as the training set and 20 percent of them are used as the test set. To test our method, we randomly extract two keywords from each review in the test set and take these keywords as input queries. In our experiments, we assume that relevant reviews for a query issued by user i are referred to reviews which not only satisfies all of the keywords of the query, but also written by i or rated by i with a high score.
7.2 Evaluation Metrics
We employ two metrics here to evaluate the effectiveness of our method.
The first metric we use is Mean Reciprocal Rank (MRR) which is a statistic for evaluating a ranking to a query. The reciprocal rank of a query result is the multiplicative inverse of the rank of the first correct answer. The mean reciprocal rank is the average of the reciprocal ranks of results for all the queries in the test set. It’s defined as follows:
where m is the number of queries in the test set, \(rank_{i}\) is the position of the relevant resource in a result list for the query i. The larger the MRR is, the faster and easier for the user to find out the reviews he or she wants.
The second metric we use is Precision@n, which is used for measuring how often relevant resources are in the top-N result list. It’s defined as follows:
where Q is the number of all queries in the test set and M denotes the times of relevant resources returned in the top-N result list for each query in the test set. The larger the Precision@n is, the more effectiveness our method is.
7.3 Baseline Methods
Considering this is the first effort to apply users’ reviews and ratings on reviews to personalized search, we compare our method with three most similar works [5, 8, 9] in collaborative tagging system. A review can be considered as a resource in an e-commerce website and features mentioned in a review can be considered as tags annotated on a resource (review). Xu et al. [5] (denoted by SIGIR’08) measure the weight of each tag in the user profile based on TF-IDF and BM25, and adopts the cosine similarity to measure the relevance. Vallet et al. [8] (denoted by ECIR’10) refine the measurement of tags in the user profile by using an aggregation of BM25 values. Cai et al. [9] (denoted by CIKM’ 10) reveal the limitations of measuring tags’ weights based on TF-IDF and BM25, and propose a novel personalized search framework.
7.4 Experimental Results
We compare our methods with the baseline methods. The experimental results of our methods and baseline methods are shown in Figs. 1 and 2. Figure 1 describes the comparison of our method and the baseline methods on MRR metric. According to it, the MRR value of RUP, CIKM’10, SIGIR’08 and ECIR’10 are 0.220, 0.199, 0.137 and 0.089 respectively. RUP significantly outperforms CIKM’10 by 10 %.

Comparison between our method and baseline methods on MRR

Comparison between our method and baseline methods on Precision@n
Figure 2 depicts the trend of RUP, CIKM’10, SIGIR’08 and ECIR’10 on Precision metric with different n. The number of n denotes the size of a result list. From Fig. 2, with the increase of n, the Precision of all four methods increase. For all values of n (i.e., from 1 to 20), our method outperforms the baseline methods. When n=1 and n=5, the advantage of our method is obvious. When n=1, the Precision@1 value of RUP, CIKM’10, SIGIR’08 and ECIR’10 are 11 %, 9.5 %, 5.5 % and 3.5 %. When n=5, the Precison@5 of RUP, CIKM’10, SIGIR’08 and ECIR’10 are 31.8 %, 28.1 %, 19.3 % and 10.7 %. Based on the comparison between our method and the baseline methods, we can conclude that our method which utilize both users’ reviews and ratings on reviews to construct user profiles and introduce priority into the result ranking can significantly improve the personalized performance.
8 Conclusions
In this paper, we explore users’ reviews and ratings on reviews for user profiling in personalized search. In order to improve the precision of user profiles, we propose a review-based user profiling method RUP, which can capture both a user’s concerns and unconcern. Besides, to ensure a personalized system return resources that can satisfy a user’s basic information needs, we introduce priority into personalized search. The experimental results show that our method can outperform the baseline methods.
Notes
- 1.
- 2.
- 3.
References
Ghorab, M.R., Zhou, D., OConnor, A., Wade, V.: Personalised information retrieval: survey and classification. User Model. User-Adapt. Interact. 23(4), 381–443 (2013)
Haiduc, S., De Rosa, G., Bavota, G., Oliveto, R., De Lucia, A., Marcus, A.: Query quality prediction and reformulation for source code search: the refoqus tool. In: Proceedings of the 2013 International Conference on Software Engineering, Series ICSE 2013, pp. 1307–1310. IEEE Press, Piscataway (2013). http://dl.acm.org/citation.cfm?id=2486788.2486991
Ma, Z., Pant, G., Sheng, O.R.L.: Interest-based personalized search. ACM Trans. Inf. Syst. (TOIS) 25(1), 5 (2007)
Matthijs, N., Radlinski, F.: Personalizing web search using long term browsing history. In: Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Series WSDM 2011, pp. 25–34. ACM, New York (2011). http://doi.acm.org/10.1145/1935826.1935840
Xu, S., Bao, S., Fei, B., Su, Z., Yu, Y.: Exploring folksonomy for personalized search. In: Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Series SIGIR 2008, pp. 155–162. ACM, New York (2008). http://doi.acm.org/10.1145/1390334.1390363
Younus, A., O’Riordan, C., Pasi, G.: A language modeling approach to personalized search based on users’ microblog behavior. In: Rijke, M., Kenter, T., Vries, A.P., Zhai, C.X., Jong, F., Radinsky, K., Hofmann, K. (eds.) ECIR 2014. LNCS, vol. 8416, pp. 727–732. Springer, Heidelberg (2014)
Moghaddam, S., Jamali, M., Ester, M.: Etf: extended tensor factorization model for personalizing prediction of review helpfulness. In: Proceedings of the Fifth ACM International Conference on Web Search and Data Mining, Series WSDM 2012, pp. 163–172. ACM, New York (2012). http://doi.acm.org/10.1145/2124295.2124316
Vallet, D., Cantador, I., Jose, J.M.: Personalizing web search with folksonomy-based user and document profiles. In: Gurrin, C., et al. (eds.) ECIR 2010. LNCS, vol. 5993, pp. 420–431. Springer, Heidelberg (2010). doi:10.1007/978-3-642-12275-0-37
Cai, Y., Li, Q.: Personalized search by tag-based user profile and resource profile in collaborative tagging systems. In: Proceedings of the 19th ACM International Conference on Information and Knowledge Management, pp. 969–978. ACM (2010)
Pitkow, J., Schütze, H., Cass, T., Cooley, R., Turnbull, D., Edmonds, A., Adar, E., Breuel, T.: Personalized search. Commun. ACM 45(9), 50–55 (2002). doi:10.1145/567498.567526
Carpineto, C., Romano, G.: A survey of automatic query expansion in information retrieval. ACM Comput. Surv. (CSUR) 44(1), 1 (2012)
Acknowledgement
This work is supported by National Natural Science Foundation of China (Grant NO. 61300137), the Guangdong Natural Science Foundation, China (NO. S2013010013836), Science and Technology Planning Project of Guangdong Province China NO. 2013B010406004, the Fundamental Research Funds for the Central Universities, SCUT.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Yang, Y., Hu, S., Cai, Y., Du, Q., Leung, Hf., Lau, R.Y.K. (2016). Exploring Reviews and Ratings on Reviews for Personalized Search. In: Gong, Z., Chiu, D., Zou, D. (eds) Current Developments in Web Based Learning. ICWL 2015. Lecture Notes in Computer Science(), vol 9584. Springer, Cham. https://doi.org/10.1007/978-3-319-32865-2_16
Download citation
DOI: https://doi.org/10.1007/978-3-319-32865-2_16
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-32864-5
Online ISBN: 978-3-319-32865-2
eBook Packages: Computer ScienceComputer Science (R0)