
Abstract
This chapter covers the data mining techniques applied to the processing of clinical data to detect cardiovascular diseases. Technology evaluation and rapid development in medical diagnosis have always attracted the researchers to deliver novelty. Chronic diseases such as cancer and cardiac have been under discussion to ease their treatments using computer aided diagnosis (CAD) by optimizing their architectural complexities with better accuracy rate. To design a medical diagnostic system, raw ECG Signals, clinical and laboratory results are utilized to proceed further processing and classification. The significance of an optimized system is to give timely detection with lesser but essential clinical attributes for a patient to ensue surgical or medical follow-up. Such appropriate diagnostic systems which can detect abnormalities in clinical data and signals are truly vital and various soft computing techniques based on data mining have been applied. Hybrid approaches derived from data mining algorithms are immensely incorporated for extraction and classification of clinical records to eliminate possible redundancy and missing details which can cause worse overhead issues for the designed systems. It also extends its applications in selection, processing and ranking clinical attributes which are integral components of any medical diagnostic system. Such systems are evaluated by determining the performance measures such as system’s accuracy, sensitivity and specificity. Various supervised and unsupervised learning algorithms have been ensemble with feature processing methods to optimize in the best possible manner to detect cardiac abnormalities. This chapter analyzes all the earlier applied approaches for the cardiac disease and highlights the associated inadequacies. It also includes the architectural constraints of developing classification models. Hybrid methodologies combined with requisite clinical extraction and ranking tools to enhance system’s efficiency are also discussed. This systematic analysis of recent applied approaches for cardiac disease, aids in the domain of clinical data processing to discuss the present limitations and overcome the forthcoming complexity issues in terms of time and memory. Further, it explains that how efficient techniques for data processing and classification have not been used appropriately by considering their strengths in either phase, which leads to processing overhead and increased false alarms. Overall, the aim of this chapter is to resolve assorted concerns and challenges for designing optimized cardiac diagnostic systems with well tuned architecture.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
- Computer aided diagnosis (CAD)
- Electrocardiography (ECG)
- University of California
- Irvine (UCI)
- Pattern classification
- Supervised learning
9.1 Introduction
With the advancements in the computing technologies, various researchers are implementing problem specific applications in different fields. In the medical domain, digitization of clinical procedure is also rapidly taking over the manual practice. Disease identification by utilizing computer aided diagnosis has become a promising application for medical specialists because of their efficient handling and timely processing but faces several challenges which need to be determined. Several studies have been done to highlight the possible medical issue for consideration and mostly refer to the errors caused by information technology. Figure 9.1 shows the distribution of possible medical error and the maximum portion is for technical errors which is 44 %.

Distribution of medical errors [12]
Appropriate handling of medical records is very important to assist doctors and technologist to bring new technologies which provide rapid disease prediction and proceed towards its treatment. Efficient systems such as decision support systems, management systems, and computer aided diagnosis (CAD) systems are in demand to ease hospitals in managing and organizing data records.
9.1.1 Data Mining Applications in Health Care
Data mining is mainly used for optimized extraction and learning required for the large amount of disease record and its attributes with binary/multiple states to predict the presence of specific diseases in patients. Among many factors, only a few are relevant enough to identify the disease in patients and this could be done by training the detection systems with available disease attributes and search for an optimal subset of attributes which are more relevant to diagnosis. Systematic disease diagnosis is expensive and unavailable in rural areas where medical specialists are also less in numbers. These systems are also required to support doctors while making decisions for patients to overcome any error in examining crucial symptoms.
9.1.2 Significance of Data Mining in Designing Clinical Diagnostic System
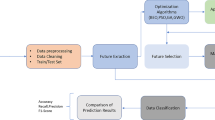
The integral components for designing any clinical diagnostic system are shown in Fig. 9.2. Data Mining Algorithms play a significant part for optimizing the system performance by appropriate selection of procedures for these components which overall increases the system accuracy.

System design for disease detection
Data collected from the clinical patients is processed and transformed into an acceptable form using feature processing algorithms such as PCA, KPCA, and LDA etc. Newly transformed features are further scored or extracted using optimized statistical or mathematical methods such as Fisher Score, Genetic Algorithms, and RFE etc. Classification of patient’s records as normal or abnormal requires supervised or unsupervised techniques which are tuned using their associated parameters to achieve maximum detection rate with less false alarms. Some commonly used classifiers are Support Vector Machines (SVM), Naïve Bayes, Clustering, Neural Network (NN), and Decision trees (DT).
9.1.3 Clinical Prerequisite for Diagnostic System of Cardiac Disease
Heart disease is one of the leading causes of deaths around the globe. In one of the American heart association (AHA) survey, Coronary Artery Disease (CAD) is considered main killer of US citizens [2]. Coronary Artery Disease (CAD) causes the coronary arteries to contract and slowly solidify which leads to chronic type of heart attacks. There are various symptoms and indications which determine the patient is suffering with CAD.
Among different CAD related factors like sex, age cannot be changed but other factors regarding lifestyle can be adjusted such as participating in physical activities or lowering blood pressure and cholesterol etc. can decrease the CAD possibility. Diabetic patients can also prevent from severity by taking proper diet and physical routines. Further brief analysis of possible types of these risk factors is as below in Fig. 9.3.

Uncontrollable and controllable risk factors for cardiac patients
To use the patient’s details from specific hospital or physician makes the proposed system limited to be compared or improvised by other researchers of the field. Various medical repositories are available which have standardized datasets from renowned clinics around the globe. University of California, Irvine (UCI) have a database library which stores a variety of data sets for cardiac disease, cancers, clinical syndromes, including different data types ranging from textual, categorical, image and signal to be utilized by researchers of specific field to further ensemble or revised the earlier approaches of the disease to improve performance of designed diagnostic systems.
The UCI datasets specified for heart disease are collected from hospitals such as Cleveland, Hungarian, Switzerland and Long Beach. All of these have different record size but same 13 attributes which are used for experimental purpose to further evaluate critical attributes relative to the data mining technique used for selection or extraction. The records are identified by class labels which are either normal or abnormal used to distinguish cardiac patients and normal ones. The abnormal records have further level of disease severity on the basis of angiography. The class distribution of these datasets is as shown in Table 9.1.
Among the above mentioned UCI heart datasets, Cleveland is one mostly used for experiments which helps to relate the results of earlier approaches before proposing a better diagnostic system. There is also an issue of redundancy and missing records in theses datasets and to avoid such complications the preferred Cleveland data set is further modified by eliminating duplicate records which decreases the record size from 303 to 270.
This modified dataset with only two label identifiers (0 or 1) is named as Statlog dataset which helps in benchmarking for the applied algorithms in relative to Cleveland dataset. Both are widely used datasets for designing cardiac diagnostic system with appropriate attribute processing to train the selected classifier for better precision rate. The clinical attributes of Cleveland and Statlog are provided in Table 9.2.
9.2 Review of Data Mining Techniques Applied for Cardiac Disease Detection
There are a variety of data mining algorithms utilized for detecting cardiac abnormalities either as a single approaches for classifier or in ensemble formation with suitable feature processing techniques. The main aim of these applied single or hybrid systems for classification of medical records is to achieve best possible precision and accuracy rate with selected methods either for feature extraction or classification.
These numerous researches related to the diagnosis of heart disease have been discussed and explained in detail depending upon their architectural configuration using specific data mining technique. These approaches are categorized in the following sections which highlight their designed mechanism and performance measures.
-
Decision support systems
-
Supervised SVM classification approaches
-
Neural network classification approaches
-
Probabilistic classification approaches.
9.2.1 Decision Support Systems
Decision Support System has been the key interest for many researchers in heart disease detection by utilizing Genetic Algorithm and Fuzzy Logic to obtain optimized results with significant detection rate. Many authors have applied variations of earlier approaches by incorporating statistical techniques to select few numbers of features from the dataset to get better performance in heart disease detection.
In recent times, a decision support system was proposed to increase prediction accuracy for heart disease by using hypothesis based testing constraints for evaluating rules from training set in combination with the supervised classification method. GINI index was used to get features with minimal index needed for rules generation to solve detection uncertainty with higher probability. They used certain features such as hypertension, diabetes, Blood pressure systolic and diastolic along with age and gender for heart dataset collected from Andhra Pradesh hospital and achieved 98 % accuracy rate [9]. Such association of classification technique with unsupervised rules, achieves possible higher prediction rate with unseen data patterns.
A decision support system (DSS) for heart disease was proposed using rough set theory by using UCI heart dataset for system validation. They achieved 83 % accuracy, 81 % sensitivity and 85 % specificity using fuzzy DSS. This ensemble system performed better as reduced number of rules was used to develop an efficient FDSS [23]. The missing data from the training set was also imputed using ANN and RST.
Another fuzzy decision support system was designed by using extracted rules and Rough Set Theory. They used data from ipoh specialist hospital for classification. They compared their FDSS result with other methods like MLP, KNN, C4.5 and RIPPER. They proved that their system can perform better than cardiologists in detecting Coronary Artery Disease by doing a comparative experiment. For this purpose, they compared the result of 30 patients from a Cleveland dataset with cardiologist evaluation and get an accuracy of 87 %, while three different cardiologists could only achieve 67, 67 and 73 % accuracies respectively. This method worked with learning, the input data and their details from defined rules. They used reduced rules with the help of RST to get higher accuracy.
9.2.2 Supervised SVM Classification Approaches
A supervised learning algorithm such as Support Vector Machines has mostly been used in the detection of heart disease because of its generalization abilities for unseen clinical patterns which varies by integrating various selection and extraction tools. Review of some of single and hybrid approaches using SVM is provided in this section.
In an earlier approach for detection of heart disease [3], Support Vector Machine was used with an integer coded genetic algorithm. SVM worked by determining support vectors and further removed unnecessary features using GA to get higher performance rate. The UCI heart dataset was used in which Cleveland database has 13 features and 303 records. When only few sensitive features extracted from GA were used out of 13, the accuracy was 72.55 %, which was higher as compared to classification accuracy 61.93 % with all features. While doing binary classification SVM achieved 90.57 % accuracy. The author also highlighted that such systems are required to be verified on larger datasets.
Fung and Mangasarian applied different variations of SVM such as Newton method (NSVM), LSVM and CPLEX SVM with their Newton linear programming (NLPSVM) which works fast and easily on linear equation with the UCI Cleveland heart dataset. They used linear and nonlinear classification approaches. With linear classifier, NSVM and LSVM both obtained 87.2 % in training and 86.6 % in testing. In nonlinear classifier [8], reduced NSVM achieved maximum test accuracy 87.1 % in 0.53 seconds while CPLEX SVM achieved 87.8 % train accuracy.
Srivastava and Bhambhu applied SVM with different kernel functions on medical datasets including UCI heart dataset because of its better generalization ability and accuracy without being affected with data dimension and size. SVM depends on different parameters associated with its kernel functions like RBF is the default kernel function with cost parameter C and gamma \(\gamma \) as parameters. Proper tuning is required to get maximum accuracy. For this purpose, 5-fold cross validation was used to find the suitable parametric combination of C and \(\gamma \). RSES were also used for rule based classification [25]. The cross validation rate for heart dataset was 82.5 % with RBF kernel which was better than RSES performance.
Another work was done by Qu et al. [20], in which they described SVM as an efficient classifier based on its performance on different datasets and to further enhance its accuracy on large datasets they combined SVM with cluster based approach Affinity Propagation (AP). It gives output in less time with no early initialization of cluster centers extensively in experiments. The UCI heart dataset was used with APSVM and SVM. Both classifier algorithms SVM and APSVM were used for 5 times to predict the classes and as result APSVM performed better than SVM by increasing accuracy around 1.92 %. The average accuracy of APSVM was 83.33 %, while SVM average accuracy was 81.40 %.
In recent years, [22] proposed SVM based recursive feature elimination (RFE) method using local search operators for feature selection. Basically, it was a wrapper technique used by assigning certain scores to all the features and arranging them in descending order. Features with lesser score were ignored. They applied this technique on various UCI datasets and achieved better results. The classifier accuracy was tested with different sets of features to find the suitable feature set which provides maximum performance. They also re-used the features which were eliminated in earlier stages of selection to give them another chance which eventually enhanced the classifier performance.
9.2.3 Neural Network Classification Approaches
In another work done by Das et al. [7], they applied an ensemble approach of neural network using SAS enterprise miner 5.2 for heart disease detection using UCI Cleveland dataset. They allocated 70 % for training and remaining 30 % for validation. Their work also shows that increasing neural network nodes have no effect on boosting the performance. They achieved 89.01 % accuracy with sensitivity and specificity of 80.95 and 95.91 % respectively.
Later in 2012, Shouman et al. [24] compared KNN with ensemble neural network and obtained higher accuracy (97.4 %) and specificity (99 %) with value of K equal to 7. They also integrated voting with KNN but there was decrease in accuracy from 97.4 to 92.7 %. Even though voting increased the accuracy when used with decision trees.
In 2013, Mehmet Can proposed a system with parallel distributed NN having a single hidden layer and boosted it with filtering and majority voting system. They believed that this system can get more than 90 % of accuracy for each class among the used UCI heart dataset [4]. Polat et al. achieved 84.5 % by applying a method that uses an artificial immune system (AIS) [19] , while in another hybrid technique [16], accuracy was 87 %.
Artificial Immune Recognition System (AIRS) was used with fuzzy weighted preprocessing to assign weights to 9 reduced features of a heart dataset after normalization on the scale of [0 1]. AIRS scored 92.59 % accuracy, using splited training and testing sets [18]. In similar way Artifical Neural Network [11] achieved 86.8 % accuracy with fuzzy neural network
9.2.4 Probabilistic Classification Approaches
Subbalakshmi [26] suggested Naïve Bayes for prediction system in combination with other data mining techniques to extract hidden information from the heart dataset and determine patients having heart disease along with conditional probability.
1n 2011, Cardiac system using UCI heart dataset achieved 85.4 % using naïve Bayes. Apart from classification techniques, researchers proposed a kernel Fisher score based feature selection for heart and SPECT datasets from UCI [17]. The dataset was initially transformed to feature space using RBF or Linear kernel and then F-score was applied to get score value for each feature.
Another Naive Bayes approach was used for classification of the UCI heart disease dataset which applies both supervised learning and statistical approach [15]. Three experiments were performed by changing the training instances and they achieved accuracies as 88.76, 89.58 and 88.96 % respectively.
9.3 Performance Analysis of Applied Classification Approaches for Cardiac Disease Detection
In this section, the results of these data mining approaches are further compared with their classification performance, which will provide a comparative overview for the existing limitations and significant contribution expected from a cardiac diagnostic system for the possible performance enhancement and complications eradication.
The performance measures used for the comparison of the classifiers are mostly accuracy, sensitivity and specificity. Accuracy determines the percentage of correctly identified normal and abnormal patterns from total record size. Below mentioned data mining techniques are estimated using system accuracy.
9.3.1 Extensive Comparison for Various Applied Data Mining Approaches
They are various classifiers applied for cardiac diagnostic systems to increase system accuracies. In following categories, different types of classification algorithms are analyzed to evaluate the potential classification approach which can increase the classification performance with minimum architectural complexities. The selected classification methods are as below:
-
Support vector machines classification
-
Neural network classification
-
Decision trees classification
-
Naïve bayes classification.
9.3.1.1 Support Vector Machines Classification
In [13], researchers compared SVM with RIPPER, Decision Tree, ANN and achieved accuracy as 84.12, 81.08, 79.05 and 80.06 % respectively. They proved that SVM performs better in detection cardiovascular disease from UCI dataset.
Different feature sets generated by Genetic Algorithm [10] were used for classification using a repeated wrapper method with SVM which achieved an accuracy of 84.07 % for multi-class and 76.20 % average accuracy for binary classification.
9.3.1.2 Neural Network
Authors [6] used Neural Network, Naïve Bayes and Decision trees on UCI Heart and Statlog datasets by using one of them for training and another for testing. They selected 13 regular features along with 2 more features representing obesity and smoking to increase the accuracy of the detection system. They achieved 100 and 99.25 % accuracy for neural networks with 15 and 13 features correspondingly. Naïve Bayes and Decision trees scored 90.74 and 99.62 % with 15 features respectively. They also worked on determining missing values from the dataset by using mean mode method for preprocessing phase.
9.3.1.3 Naïve Bayes Classification
Cheung [5] applied C4.5, Naïve Bayes, BNND and BNNF for classification and got accuracies of 81.11, 81.48, 81.11 and 80.96 %, respectively.
9.3.1.4 Decision Trees Classification
In one of the earlier approaches, [1] compared two different techniques which are Decision Trees and Naïve Bayes for risk prediction using UCI heart dataset. They stated that naïve bayes which efficiently works using conditional probability scored 96.5 % accuracy, needs little enhancement in terms of feature selection, whereas decision tree achieved 99.2 % accuracy with a model generation time of 0.02 and 0.09 s respectively.
9.3.2 Limitations of Applied Data Mining Approaches
Mostly applied classification methods suffer training overhead or local minima issues. Commonly used classifiers like Support Vector Machines and Neural Network algorithms face optimization problems in tuning their associated architectural parameters which increases the system overhead and reduces possible performance measures.
Neural network classifier includes number of hidden layers which delays the training process for learning patterns and related labels. SVM works well for linear as well non-linear data dimension, but demands its kernel functions to be set at the appropriate values depending upon the input data to speed up the training and testing process.
Naive Bayes utilizes assumptions which sometimes cause a decrease in accuracy rate while decision trees have the tendency of handling high dimensional data along with unnecessary iterations which needs to be overcome during classification. Decision trees have better performance than naïve Bayes, but take more time in the building model, whereas naïve Bayes takes same time duration with reduced feature set and raw data. For this purpose, UCI heart dataset [21] have mostly been processed by feature extraction tools to select few features from 13 attributes for training and testing on the basis of their fitness level using genetic algorithm. Apart from GA, statistical methods like t-score or fisher score are also used to rank potential features for the classifier procedure.
From literature survey [7] we have came across that mostly accuracies have been between 50 and 90 %.
9.4 Recommendations for Optimized Data Mining Mechanism in Health Care
Some significant suggestions for proposing an optimized diagnostic system for cardiac centers are as follows:
9.4.1 Hybrid System Formation
Hybrid techniques are more efficient as they have above 80 % precision in comparison to single technique used for heart disease detection. An author conducted a survey of different applied data mining approaches such as naïve Bayes, Artificial Neural Network (ANN), SVM and decision tree with their performance on heart dataset. These single classification methods can be further enhanced using boosting and bagging to improve system performance.
9.4.2 Suitable Feature Processing Technique
Earlier researchers have suggested to used both wrapper and filter methods for processing symptoms of UCI heart dataset [14]. They mentioned that filter eliminates the unnecessary symptoms along with decreasing the data dimension which increases the accuracy rate, whereas wrapper uses threshold level to get extract data attributes which are above the set level and removing other irrelevant features. Different classes such as absence, mild, moderate, staring and serious can also used for comparison of the selected features based on a wrapper and filter methods.
The main aim of the feature or variable selection is to select desired features which fulfill certain criteria set for the selection process and overall decreases the dimension of the raw data set by ignoring other features which does not count much for system’s accuracy. An optimal feature subset not only decreases the dimension and the cost factor, but also improves classification accuracy. For medical dataset, it is really important to ignore irrelevant features which affect the training process because of their noisy data or redundancy.
9.5 Conclusion
This chapter highlights various data mining techniques designed for the optimized detection of possible cardiac abnormalities. Proposing such systems help the physicians to provide immediate surgical or medical follow-up for the concerning patients depending upon the disease severity identified by the diagnostic system. These systems need training with the historical clinical record to enhance the classifier’s learning ability for detecting any unseen patient record with given critical attributes. The main focus of this chapter is on the different data mining approaches proposed and optimized for the detection of heart disease using standardized data attributes available for the researchers like UCI heart data sets having patients’ records with required attributes which can help in predicting the designed system for comparison with related applied methodologies. These clinical dataset samples defined by the column wise attributes needs proper processing. To perform such data analysis, various methods and algorithms have been utilized, but lacked with appropriate dimension reduction as well the time complexity in handling wrong or missing values. For this purpose, feature transformation and subset selection are two main integral components to save maximum time of model construction by eliminating the irrelevant portion of the dataset. Feature selection chooses a subset of minimum features with maximum probability distribution as of the original set of features whereas data filtering overcomes possible outliers issues in dimensionality also known as called feature preprocessing. This integral component assists the medical doctors to take only the relevant tests and examination, which are relevant to the heart disease diagnosis. Finally, this chapter encourages biomedical researchers to design modified hybrid mechanisms by understanding various beneficial data mining algorithms to enhance performance measures of medical diagnostic systems for timely detection of cardiac patients in nominal time.
References
Anbarasi, M., Anupriya, E., Iyengar, N.C.H.S.N.: Enhanced prediction of heart disease with feature subset selection using genetic algorithm. Int. J. Eng. Sci. Technol. 2(10), (2010)
Association, A.H.: http://www.americanheart.org (2013). Accessed 22 Feb 2014
Bhatia, S., Prakash, P., Pillai, G.N.: SVM based decision support system for heart disease classification with integer-coded genetic algorithm to select critical features. Paper presented at the proceedings of the world congress on engineering and computer science (WCECS), San Francisco, 22–24 Oct 2008
Can, M.: Diagnosis of cardiovascular diseases by boosted neural networks. SE Europe J. Soft Comput. 2(1), (2013)
Cheung, N.: Machine Learning Techniques for Medical Analysis. University of Queenland, Australia (2001)
Dangare, C.S., Apte, S.S.: Improved study of heart disease prediction system using data mining classification techniques. Int. J. Comput. Appl. 47(10), 44–48 (2012)
Das, R., Turkoglu, I., Sengur, A.: Effective diagnosis of heart disease through neural networks ensembles. Expert Syst. Appl. 36, 7675–7680 (2009)
Fung, G.M., Mangasarian, O.L.: A feature selection newton method for support vector machine classication. Comput. Optim. Appl. 28, 185–202 (2004)
Jabbar, M.A., Chandra, D.P., Deekshatulu, D.B.L.: Heart disease prediction system using associative classification and genetic algorithm. Paper presented at the international conference on emerging trends in electrical, electronics and communication technologies-ICECIT, India (2012)
Jayanthi, S., Mariammal, D.: Survey on single and hybrid mining approaches in heart disease diagnosis. Int. J. Emerg. Technol. Res. 1(1), 219–224 (2013)
Kahramanli, H., Allahverdi, N.: Design of a hybrid system for the diabetes and heart diseases. Expert Syst. Appl. 35(1–2), 82–89 (2008). doi:10.1016/j.eswa.2007.06.004
Kohn, L.T.C.J., Donaldson, M.S. (eds.): To err is human: building a safer health system. National Academy Press, Washington, Committee on Quality of Health Care in America (2000)
Kumari, M., Godara, S.: Comparative study of data mining classification methods in cardiovascular disease prediction. Int. J. Comput. Sci. Technol. 2(2), (2011)
Kuttikrishnan, M., Dhanabalachandran, M.: A novel approach for cardiac disease prediction and classification using intelligent agents. Int. J. Comput. Sci. Inf. Secur. 8(5), (2010)
Medhekar, D.S., Bote, M.P., Deshmukh, S.D.: Heart disease prediction system using naive bayes. Int. J. Enhanced Res. Sci. Technol. Eng. 2(3), (2013)
Ozen, S., Gunes, S.: Attribute weighting via genetic algorithms for attribute weighted artificial immune system (AWAIS) and its application to heart disease and liver disorders problems. Expert Syst. Appl. 36(1), 386–392 (2009). doi:10.1016/j.eswa.2007.09.063
Polat, K., Gunes, S.: A new feature selection method on classification of medical datasets: kernel f-score feature selection. J. Expert Syst. Appl. 36, 10367–10373 (2009)
Polat, K., Şahan, S., Güneş, S.: Automatic detection of heart disease using an artificial immune recognition system (AIRS) with fuzzy resource allocation mechanism and k-nn (nearest neighbour) based weighting preprocessing. Expert Syst. Appl. 32(2), 625–631 (2007) doi:10.1016/j.eswa.2006.01.027
Polat, K., Şahan, S., Kodaz, H., Güneş, S.: A new classification method to diagnosis heart disease: supervised artificial immune system (AIRS). Paper presented at the proceedings of the turkish symposium on artificial intelligence and neural networks (TAINN) (2005)
Qu, W., Wang, W., Liu, F.: A novel classifier with support vector machine based on ap clustering. J. Comput. Inf. Syst. 9(10), 4041–4048 (2013)
Ratnakar, S., Rajeswari, K., Jacob, R.: Prediction of heart disease using genetic algorithm for selection of optimal reduced set of attributes. Int. J. Adv. Comput. Eng. Netw. 1(2), (2013)
Samb, M.L., Camara, F., Ndiaye, S., et al.: A novel RFE-SVM-based feature selection approach for classification. Int. J. Adv. Sci. Technol. 43 (2012)
Setiawan, N.A., Venkatachalam, P.A., Hani, A.F.M.: Diagnosis of coronary artery disease using artificial intelligence based decision support system. Paper presented at the proceedings of the international conference on man-machine systems (ICoMMS), Batu Ferringhi, Penang, 11–13 Oct 2009
Shouman, M., Turner, T., Stocker, R.: Applying k-nearest neighbour in diagnosing heart disease patients. Int. J. Inf. Educ. Technol. 2(3), (2012)
Srivastava, D.K., Bhambhu, L.: Data classification using support vector machine. J. Theor. Appl. Inf. Technol. 12(1), (2010)
Subbalakshmi, G.: Decision support in heart disease prediction system using Naïve bayes. IJCSE 2(2), (2011)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this chapter
Cite this chapter
Kausar, N., Palaniappan, S., Samir, B.B., Abdullah, A., Dey, N. (2016). Systematic Analysis of Applied Data Mining Based Optimization Algorithms in Clinical Attribute Extraction and Classification for Diagnosis of Cardiac Patients. In: Hassanien, AE., Grosan, C., Fahmy Tolba, M. (eds) Applications of Intelligent Optimization in Biology and Medicine. Intelligent Systems Reference Library, vol 96. Springer, Cham. https://doi.org/10.1007/978-3-319-21212-8_9
Download citation
DOI: https://doi.org/10.1007/978-3-319-21212-8_9
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-21211-1
Online ISBN: 978-3-319-21212-8
eBook Packages: EngineeringEngineering (R0)