
Abstract
The literature on public choice has largely argued that when several actors are part of a decision-making process, the results will be biased towards overspending. However, the empirical studies of the effect of minorities and coalition governments on spending have yielded mixed support for this theoretical claim. This chapter argues that the inconclusiveness of the empirical evidence is related to problems of standard regression models to accurately capture unobserved heterogeneity. We use data from Spanish municipalities for the period 2004–2011 to compare the results of four typically used estimation methods: mean comparison, OLS, fixed-effects regression and matching. We argue that out of these models, matching deals better with unobserved heterogeneity and selection bias of the type of government, allowing us to reduce estimating error. The results show that, when we account for these problems in a matching model, minorities run lower surpluses than single party majorities. This result did not arise in simple mean comparisons or OLS models, or even in the fixed-effects specification. These results give support to the law of 1/n (Weingast, Journal of Political Economy 96: 132–163, 1981) and also underscore that in order to identify correctly the impact of government characteristics on policy-making, we need to understand that these are not randomly assigned across our units of observation. This advises the use of more quasi-experimental methods in our empirical research.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
Budget deficits are a common phenomenon in industrialized economies. However, we still know little about what determines whether countries or other political units run deficits. As public spending can be a countercyclical instrument, a recession or an increase in unemployment, like the ones currently experienced in Western economies, could justify temporary budget deficits (Alesina and Roubini 1992). The key question is therefore why certain governments have used them systematically, following a pattern that led many countries to reach unsustainable levels of debt (Grilli et al. 1991).
It is widely believed that this phenomenon cannot be fully explained by economic variables (Volkerink and de Haan 2001). Therefore, there has been research studying other political causes such as the electoral system (Grilli et al. 1991), the number of parties with parliamentary representation (Volkerink and de Haan 2001), or the partisanship of government (Carlsen 1997). Among these political determinants of deficits, the type of government has been a usual suspect. Since Weingast et al.’s (1981) seminal contribution, most theoretical models predict that when spending decisions have to be agreed by several actors, the result would be overspending. Therefore we should observe higher deficits under minority or coalition governments than under single party majority governments. However, empirical evidence on this issue has been quite mixed.
In this chapter we argue that the inconclusiveness of the empirical evidence is related to problems of standard regression models to accurately capture unobserved heterogeneity. We use data from Spanish municipalities for the period 2004–2011 to compare the results of four typically used estimation methods: mean comparison, OLS, FE and matching. We argue that out of these models, matching deals better with unobserved heterogeneity and selection bias of the type of government. In addition, matching allows us to reduce estimating error.
Our matching model finds that minorities run lower surpluses. This result did not arise in simple mean comparisons or OLS models, or even in the FE specification. We believe that the lack of effect found in those models is due to a problem that is common to proportional representation systems, which is that the group of municipalities that have minority governments is likely to be fundamentally different than those that have majority governments across a range of characteristics that are relevant for fiscal outcomes. While our matching model is not free from problems, it provides a simple way to soften some of the most common empirical concerns that arise when estimating the effects of the type of government and it does so in a more efficient way.
This chapter proceeds as follows. The next section provides an overview of the current state of the art with regard to the effect of the type of government on fiscal outcomes. We also point out which are the limitations of previous research. Section 3 presents the Spanish case. In Sects. 4 and 5 we discuss the methods used in this chapter and the data. Section 6 displays all the empirical analyses, and discusses the results. Finally, Sect. 6 concludes and gives some notes on directions for future research.
2 Literature Review
What’s the relation between fiscal outcomes and the type of government? This question has attracted the attention of a large theoretical and empirical literature. In the theoretical public choice literature, it is normally expected that coalition governments will lead to higher expenditure and deficits. This claim owes much to Weingast et al. (1981) and Shepsle and Weingast (1981) seminal formalization of the common-pool problem. According to their theoretical model, Weingast et al. (1981) suggest that when public policy decisions are made with the agreement of several decision-makers (as in coalition governments and minority governments that need parliamentary supports), all actors have incentives to pursue their policy agenda and overspend. Each actor internalizes the (electoral) benefits of expenditure in those policies that favour their constituency. However, the costs of financing them are shared among all actors, so they only internalize the fraction of the cost that their constituents will have to pay (Scartascini and Crain 2001). This leads to the ‘law of 1/n’. Assuming that public programs are financed by general taxes, each party will support a level of expenditure for her constituency, such that the marginal benefit equals 1/n of its marginal costs, where n equals the number of actors (Weingast et al. 1981).
This theoretical argument suggests that minority governments, in which the incumbent party either forms a coalition or looks for supports in the legislature, would cause greater deficits and public debt. These straightforward theoretical predictions, however, have not found strong empirical support.
The usual approach is based on Roubini and Sachs’ (1989a) seminal contribution. These authors created a political dispersion index for 15 OECD countries with four categories—one party majority government, coalition government with two or three coalition partners, coalition government with four or more coalition partners and minority governments. Based on an OLS analysis, they concluded that more fragmented governments lead to higher deficits. Since these first empirical studies, other research on deficits has yielded results in a similar direction, concluding that fragmented governments, in a variety of forms, solve the common-pool problem causing more spending and higher deficits (Roubini and Sachs 1989b; Borrelli and Royed 1995; Franzese 2000; Balassone and Giordano 2001; Woo 2003; Bawn and Rosenbluth 2006; or Falcó- Gimeno and Jurado 2011, among others).
Other research has been critical with the outcomes of this literature, describing it as inconsistent and not robust to slight changes of the model (de Haan and Sturm 1997). This line of research refutes the view that more unified governments are less prone to deficits (Alt and Lowry 1994) or that divided governments systematically run budget deficits (de Haan and Sturm 1994, 1997; de Haan et al. 1999).
Most of this research tends to rely on country-level data. Given that elections do not take place every year, analyses tend to draw on few country-level observations. Only recently, the literature has turned to analyse the political determinants of budget deficits by using data at the sub-national level. Ashworth and Heyndels (2005)—for the case of Flemish municipalities—Le Maux et al. (2011)—for the case of French Departments—and Baskaran (2013)—for the German Länder—find that coalition governments are associated with more spending.
In this chapter, we contribute to the growing body of research that studies the effects of the type of government at sub-national levels by studying its effects on fiscal outcomes of Spanish municipalities. We show that standard regression models may not be enough to control for significant differences in the characteristics of municipalities that have majority governments compared to those that have minority or coalition governments. Having several periods of study allows controlling for unobserved heterogeneity through fixed effects. However, when the number of periods is small and there are few municipalities that change their type of government from one election to the next, fixed effects models may yield either unreliable or inefficient results. We discuss the results of matching model as a simple alternative that may reduce estimation error.
3 The Spanish Case
Spain has three levels of government: National, Regional and Local. Elections at the local level, which are the focus of this study, follow a proportional representation system that assigns votes to representatives according to the D’Hondt rule. In order to obtain representation a party has to obtain more than 5 % of the valid votes. The number of representatives that each municipality elects depends on the population of the municipality and ranges between seven for municipalities of less than 1,000 inhabitants to more than 50 for larger municipalities such as Madrid and Barcelona.
There are two main parties in Spain. The main left-wing party is the Partido Socialista (PSOE), while the main conservative party is the Partido Popular (PP). Combined, the two main parties usually obtain approximately 70–80 % of the national vote on local elections. In many municipalities, however, neither PP nor PSOE obtain enough support to form a majority so they have to negotiate the formation of a government with one or several of the many smaller parties that obtain representation in the municipality. In addition, in some regions like Catalonia and Basque country there are nationalist parties such as PNV and CiU that are strong in their geographical areas of influence. Spain has a proportional representation system and a multiparty system. As a result, in many municipalities the strongest parties do not have enough electoral support to form an absolute majority government. This provides us with useful variation.
Fiscal autonomy of local governments in Spain comes from two sources. First, they have taxing powers on certain areas. Second, they also have spending powers, particularly in social care, security, environment protection, and local events. Thus, despite the fact that a share of the municipality’s revenues is obtained through transfers from either the national or the regional governments, municipalities have room to increase/decrease their expenditure or raise/lower their taxes. In addition, during our period of study (2003–2011), Spain had no balanced budget rule to limit their fiscal autonomy.
4 Methods
Our empirical strategy consists of comparing and discussing the results from four different methods of estimation of the effects of the type of government on fiscal outcomes. We first use a simple mean comparison and a t-test. Secondly we estimate an OLS regression. We proceed then to run fixed effects models, to exploit within-municipality variation. Finally we propose a matching estimation as a way to overcome some of the empirical problems that arise when using the previous methods, in particular when the goal is to address effects related to elections.
In order to explain the advantages and disadvantages of each method of estimation we follow the impact evaluation literature and distinguish between treatment and control observations. Control observations are municipalities where the incumbent party won a majority of the seats in the local assembly and therefore can form a single party majority government. Our treatment observations are those where the winning party could not form a majority by itself (it did not reach 50 % of the councilors of the municipality council). These are municipalities where the winning party had to find support of other parties to pass the budget, either by forming a government coalition or by seeking for support in the assembly. Ideally, if we want to isolate the effect of the treatment (having a minority government) on the outcome variable of interest (fiscal deficit), we would want the treatment (being a minority) to be randomly distributed across municipalities. If this was the case, a simple mean comparison of fiscal deficits in municipalities with a majority government and those without, would give us an unbiased estimate of the causal effect of the treatment. This is because, in that case, due to the random assignment (and if the sample is large enough), the characteristics of the population can be assumed to be equally distributed across treatment and control municipalities.
Obviously, the problem is that minority governments are not randomly assigned across municipalities. Municipalities with minority governments are likely to be fundamentally different than those in which the mayor forms a majority government. When analysing fiscal outcomes in proportional representation systems like the Spanish one, there are several characteristics that are likely non-random across majorities and minority governments. Let us discuss some of them and their implications for our analysis.
First, it is reasonable to think that mayors that were perceived as good managers in the previous election have a higher probability of forming a majority government in this election. Therefore, if we compare the mean deficit across majorities and minorities, we may find statistically significant differences that could not be attributed to the type of government but could rather be explained by the different ability levels of the mayors across treatment and control groups.
Similarly, if smaller municipalities are more likely to enjoy a majority government—which is the case when seats are allocated using the D’Hondt rule—and also have different taxing and spending powers compared to larger municipalities, we may find that a simple mean comparison yields a difference in fiscal deficits between majorities and non-majorities. This difference, however, could be due to either the type of government or the different fiscal powers of municipalities in the control group compared to those in the treatment group.
Finally, another example relevant for our case would be that of ideological differences among majority and minority governments. Conservative parties could be more likely to form majority governments than left-wing parties (or vice versa) if it were harder for them to find partners to elect a mayor when they do not obtain more than 50 % of the seats in the municipality council, or if they have support that is more concentrated geographically. Then differences in mean fiscal deficits between majorities and minorities could be due to either the treatment or more conservative governments running higher or lower deficits. This example is particularly relevant for the Spanish case because in many municipalities the Popular Party is the only conservative party that obtains representation on the municipality council while there are several parties on the left side of the political scale.
All three examples discussed above are relevant for the Spanish case and in all three (as well as in other examples), a t-test of the differences in means in the outcome variable of interest would not be useful as a tool to identify the causal effect of the treatment. Due to the problem originating from non-randomly distributed characteristics of the population of interest across majorities and minorities, one possibility could be to simply run an OLS regression to control for observable characteristics such as size, or ideology of the mayor. We could then estimate a model of the form:
Where Y would be the fiscal outcome of interest (either deficit, expenditures or revenues) in municipality i and year t; Treatment would take value 1 for municipalities that have minority governments; and X would be a vector of observable characteristics that we believe are non-random across treatment and control observations such as municipality size, the ideology of the major, local economic conditions, election year and several others). Note that in this specification we would be using mostly between variation,Footnote 1 which implies that our counterfactual—our estimate of the fiscal outcome that treatment observations would have had if they had not received the treatment—is given by the fiscal outcomes of municipalities with similar observable characteristics. If the simple model of Eq. (2) is saturated so that we include all relevant differences between treatment and control municipalities, b 1 would give us an unbiased estimate of the effect of the type of government on fiscal outcomes.
One problem of an OLS model like the one presented in Eq. (1), however, is that the ability of the model to correctly estimate the effect of the treatment relies on all relevant characteristics that differ across the treatment and control groups to be included in the model. If there are unobservable characteristics that differ between groups, then the estimates of b 1 could be far from the true treatment effect. A potential improvement upon the OLS estimation is to add a vector of individual fixed effects, which is possible in our case given that we have two electoral terms in our database. We can therefore estimate the following equation:
where λ i is the set of municipality fixed effects and all the other variables are the same as in (1). The fixed effects vector controls for unobserved time-invariant characteristics. This specification uses within variation, which implies that in this case identification arises from comparing the same municipality both when it has a minority government and when it has a majority one. The counterfactual of each treatment observation would be given by the fiscal outcomes of the same municipality but in periods where the mayor did not form a majority government. Because of the ability of this model to control for both time-varying observable characteristics and unobservable time-invariant characteristics, this model is more likely to approximate better the average treatment effect. It has several problems, however, that prevent us from considering it ideal for our purposes. First, as with the OLS estimation of Eq. (1) it relies on all relevant observable time-varying characteristics being included and correctly parameterized. Second, if the number of municipalities that change their treatment status from one period to another is small, the effect would be identified from a small number of observations, which increases estimation error. Therefore, if it is relatively rare that municipalities change between minority and majority, it may be not just that we are identifying effects off of few observations, but that we are identifying effects off of rarities or unusual cases that behave differently than most. Third, there might be time-varying unobserved characteristics that could differentially affect treatment and control observations (e.g. ability level of the candidates, voter’s information) that could still be related with fiscal outcomes and that could, therefore, confound the effect of the type of government on fiscal outcomes.
A fourth possibility that we explore in this chapter is to estimate a matching model. Matching methods (see, for example, Stuart and Rubin 2007, or Stuart 2010) aim to approximate the randomization ideal by selecting among non-treated observations, those that are more similar to treated observations across all observable characteristics. In particular, matching methods choose for each treated observation, a control observation that closely resembles or is even equal to the treated one in terms of observable characteristics. This is a key advantage for our purposes because we can use a matching algorithm to select control municipalities that have the same size, that have similar starting economic situation or electoral support for the mayor, and in which mayors belong to the same party. Therefore, the matching algorithm would allow us to avoid having treatment and control groups that are not balanced, which in turn avoids confounding the effect due to the type of government with the effects due to size, ideology or pre-existing economic conditions. In addition, matching requires much less modeling assumptions than standard regression methods. An additional advantage is that matching may also reduce estimation error (see Stuart and Rubin 2007; Smith 1997) because, even though matching uses less observations—e.g. it only uses a subsample of non-treated observations that are good controls—the fact that there is a better balance among treatment and control allows improving efficiency.
Matching, however, only assures balance on observable characteristics. The identifying assumption is that unobserved characteristics of control and treatment observations are similar. This is a plausible assumption in many cases because it is reasonable to think that if two municipalities are very similar across a wide range of observable characteristics, unobserved characteristics may also behave similarly in both places. While this argument is frequently used also to justify OLS estimation, the goal of matching is precisely to assure balanced observations while in a regular regression framework covariates control for general differences across all observations.
In our particular case, we present the results of two different matching models: a propensity score matching and matching based on Mahalanobis distance. In practice both methods lead to similar results but, given that both rely on different assumptions, they both together demonstrate the robustness of results. Our propensity score matching uses a logit regression model to estimate the probability of each observation belonging to the treatment. The covariates in this model are the same as those included in vector X in the OLS and FE models (Eqs. (1) and (2) described above). We then match each observation in the treatment group to the observation or observations in the control group that have the closest propensity score (nearest neighbour matching). Matching based on Mahalanobis distance is similar except that it uses a different measure—Mahalanobis distance instead of a propensity score—to select which observations are close to each other in terms of observables. In the results section we show that our matching method achieves a reasonable balance across groups.
5 Data
We estimate the four models described in the previous section using data from two Spanish local elections. The two periods of study are the electoral term from 2003 to 2007 and the one from 2007 to 2011. The two periods under study include a period of economic expansion (2003–2007) and a period of economic downturn. In both elections the two main parties obtained similar aggregate results overall, with PSOE obtaining 34.83 % of the vote share in 2003 and 34.92 % in 2007 and PP obtaining 34.29 % in 2003 and 35.62 % in 2007.
We use three sources of data. Our dependent variables (fiscal outcomes) were obtained from the Ministry of Public Finance. More specifically, they come from the Base de Datos Presupuestarios de los Entes Locales database, which provides very detailed information both on total expenditures and revenues of municipalities and on different types of expenditures and revenues. In this chapter we focus mainly on deficit or surplus, but we also use total expenditures and revenues to show how deficits or surpluses are produced.
Data on electoral results in each municipality were obtained from the Electoral Results Database collected by the Ministerio del Interior (Ministry of Internal Affairs). This database has information on the number of registered voters in each municipality, the number of valid votes and the number of votes obtained by each party in each election. We also obtained data on the party of the mayor that was finally elected.
Data on other characteristics of the municipality such as overall population and local economic conditions were obtained from La Caixa Database. This database offers information on unemployment, and several other indicators of economic activity in the municipality. This database only has information on municipalities that have more than 1,000 inhabitants, so we had to drop municipalities below that threshold. Although this reduces the sample size, municipalities that have more than 1,000 inhabitants represent more than 70 % of the total population of Spanish voters.
6 Results
Our first results are a set of t-test analyses on differences in fiscal outcomes between municipalities with a minority government and a single party majority. Results are shown in Table 1. It can be observed that mean differences between types of government are small. At a first glance, minority and majority governments generate very similar levels of fiscal deficits. While minority governments fall into an average per-municipality surplus of 1.11 %, majority governments produce an average per-municipality surplus of 1.106 %. This means that, although the level of surplus/deficit is lower/higher in minority governments, the mean differences are negligible and not significant.
This first analysis points to minority governments not showing a different fiscal behaviour compared to majority governments. However, as indicated in the methods section, a t-test analysis does not allow us to take into account the existence of characteristics that can alternatively explain deficit levels. In Table 2, we run OLS regressions on our dependent variable including a set of covariates that allow us to control for potential alternative explanations of higher deficits that might correlate with the type of government. As discussed in an earlier section, a straightforward control is the partisan colour of the government. To account for these effects, we include two variables that capture if the municipality’s major belongs to any of the main right- and left-wing parties in Spain: PP government and PSOE government. Right wing governments are presumed to be fiscally conservative and therefore we should expect them to run lower deficits. On the other hand, it is expected that the effect of left-wing governments will go in the opposite direction.
We also include several economic variables that control for the propensity to spend more at the local level. First, we include the effects of the unemployment rate on fiscal outcomes with two variables: the average unemployment rate in the municipality during the electoral term and the increase in unemployment over the electoral cycle. The former controls for the structural need of social spending in the municipality. The latter accounts for the impact of increases in social need that might have occurred in the specific electoral term and which might have put the local budget under pressure. Secondly, we also include the local market share, also as a level and increment. Unfortunately, we do not have GDP data at the local level. However, the local market share, taken from La Caixa Database, measures the normalized purchase capacity of the municipality relative to the total national market, and it is a good proxy of the level of economic activity.
Finally, at the institutional level, we also include the size of the local assembly. The rationale is twofold. First, as we explained above, majority governments might be more likely to be formed in small municipalities. When the assembly magnitude is low, the D’Hondt rule over-represents bigger parties that will be able to form a majority with lower vote shares. In addition, small municipalities have fewer competencies allocated and they have fewer areas of responsibility. Therefore, they might be less in need of spending and perhaps could be able to run more consolidated budgets.
Taking these variables into account, we run OLS models with clustered and robust standard errors and including a dummy for the second electoral term to consider different structural levels in the period 2008–2011 compared to 2004–2007. Column 1 of Table 2 shows the results. We find that our variable of interest—minority governments—is non-significant. This specification, therefore, points to conclusions that are similar to those obtained when looking at mean comparisons and seems to indicate that minority governments do not spend more than majority governments. Drawing upon our standard regression results, we cannot say that minority governments are more (or less) fiscally irresponsible.
These results, however, cannot rule the existence of unobserved heterogeneity. These models assumed that the characteristics of the population are equally distributed across treatment and control municipalities. As we explained in the methods section, there might be alternative variables not included in the model that might correlate with minority governments and that alternatively can also correlate with fiscal deficits. In order to control for that unobserved heterogeneity, the standard solution in the literature has been to exploit within unit variation with the inclusion of fixed effects. The results using this procedure are included in column 2 of Table 2. In this specification some of the control variables drop their significance levels, as they basically explain between municipality differences, instead of within-municipality variation. As regards our main variable of interest, now we do obtain a positive coefficient that points to minority governments running 0.3 percentage point higher surpluses than majority governments, which contradicts the theoretical predictions of a large part of the literature. However, this coefficient is non-significant. Both the unexpected sign and the non-significance in this case, given that we are using within variation, could be due to the pool of municipalities that change their type of government status from one regression to another being relatively small and very heterogeneous.
So far, we have performed the standard analyses found in the literature. Drawing upon them, we cannot conclude that minority governments produce larger deficits. This finding is in line with the mixed evidence in the literature. As we explained above, in all these analyses we have tried to control for local level conditions that may bias the likelihood of receiving benefits. However, we cannot completely rule out that unobserved heterogeneity or endogeneity of the main independent variable distorts our results. Minority governments are still likely to be fundamentally different than those that have majority governments across a range of characteristics that are relevant for fiscal outcomes.
As a potential solution, our last set of analyses use matching methods to account—in a different way than regression methods—for those conditions that make minority governments more likely. More importantly, matching methods restrict the analyses to a subset of observations that are more comparable, reducing the estimation error. In addition, this method does not require establishing a further multivariate analysis between fiscal outcomes and the type of government. Matching equivalent observations already controls for contextual conditions, so a bivariate relation can be established (Ho et al. 2007).
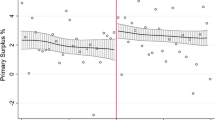
We use a propensity score matching as our benchmark model. In the first stage we match observations according to the same set of observables that were included as covariates in the OLS and FE specifications of Table 2. In addition, we use a bootstrapping algorithm with 100 replications to nuance the effect of outliers. This first stage yields a very balanced set of observations. Figure 1 shows that there are a large number of treated and untreated observations with similar propensity scores. This can be seen as our sample having leverage for the analysis.

Propensity scores and treatment distribution
Once we estimate the propensity of each municipality to be a minority, we use both the nearest and the two nearest neighbour methods to compare fiscal outcomes of municipalities with different treatments, but similar propensity scores. Results are displayed in columns 1 and 2 of Table 3.
The most relevant finding of Table 3 is that once we tackle the non-random assignment concern through matching we do find significant differences on the generation of balanced budgets, which did not arise in more standard regression techniques. Minority governments produce fiscal deficits/surpluses between 0.57 and 0.64 perceptual points higher/lower than majority governments. These are differences of a relevant magnitude. The mean surplus in the sample is 1.1 %. This means that minority governments can run budgets with just around half of the total surplus of majority governments.
To account for the robustness of these results, we have replicated the analysis using the Mahalanobis Distance as the criterion to match treated and untreated observations. The results are displayed in columns 3–4 of Table 3 and are basically similar to the propensity score matching analyses. In fact, the significance and magnitude of the results actually increase, confirming the previous conclusions. Minority governments run larger fiscal deficits than majority governments.
Altogether, the matching estimations have shown that the standard methods used in the literature on the political economy of fiscal deficits might not be enough to disentangle the relation between type of government and fiscal outcomes. OLS regressions and fixed effects models did not yield significant effects of the type of government on budget deficits. Tackling the problem of non-random assignment through matching, we have found evidence that minority governments run more unbalanced budgets than majority governments.
7 Conclusions
This chapter provides two main results that we think are a contribution to the literature on the political economy of fiscal deficits. First, we have shown the importance of going beyond standard regression techniques to analyse the effect of the type of government on fiscal outcomes. In order to identify correctly the impact of minority governments on policy-making, we need to understand that minority governments are not randomly assigned across municipalities. Municipalities with minority governments are likely to be fundamentally different than those in which the mayor forms a majority government. This violates the assumptions of standard regression techniques yielding biased estimators. In this paper we have shown that when we do not account of the non-random assignment, the type of government has no effect on fiscal deficits. However, we have shown that by using matching techniques, we can estimate the effect more precisely and show that minority governments are likely to produce more unbalanced budgets than majority governments.
We think this chapter also contributes to set up an agenda for future research. We believe that this chapter shows that some of the assumptions necessary for the regression models to hold are actually implausible when using electoral or government data. This would require applying other research designs and techniques that allows us to track down causality better and rule out the risk of unobserved heterogeneity, confounding explanations and endogeneity (see, for instance Artés and Jurado 2014). Here we have proposed a matching estimator as a step in that direction. However we are aware that the matching model used in this chapter also has drawbacks because the identifying assumption is that unobserved characteristics of control and treatment observations are similar. Future research should investigate other methods that can potentially eliminate that concern.
Notes
- 1.
Unless there were few municipalities and many years, in which the variation would be mostly over time. However, this is less likely to occur in voting data.
References
Alesina, A., & Roubini, N. (1992). Political cycles in OECD economies. The Review of Economic Studies, 59(4), 663–688.
Alt, J. E., & Lowry, R. C. (1994). Divided government, fiscal institutions, and budget deficits: Evidence from the states. American Political Science Review, 88(4), 811–828.
Artés, J., & Jurado, I. (2014). Do majority governments lead to lower fiscal deficits? A regression discontinuity approach. Manuscript.
Ashworth, J., & Heyndels, B. (2005). Government fragmentation and budgetary policy in “good” and “bad” times in Flemish municipalities. Economics and Politics, 17, 245–263.
Balassone, F., & Giordano, R. (2001). Budget deficits and coalition governments. Public Choice, 106(3–4), 327–349.
Baskaran, T. (2013). Coalition governments, cabinet size, and the common pool problem: Evidence from the German states. European Journal of Political Economy 32, 356–376.
Bawn, K., & Rosenbluth, F. (2006). Short versus long coalitions: Electoral accountability and the size of the public sector. American Journal of Political Science, 50(2), 251–265.
Borrelli, S. A., & Royed, T. J. (1995). Government ‘strength’ and budget deficits in advanced democracies. European Journal of Political Research, 28(2), 225–260.
Carlsen, F. (1997). Counterfiscal policies and partisan politics: Evidence from industrialized countries. Applied Economics, 29(2), 145–151.
de Haan, J., & Sturm, J.-E. (1994). Political and institutional determinants of fiscal policy in the European community. Public Choice, 80, 157–172.
de Haan, J., & Sturm, J.-E. (1997). Political and economic determinants of OECD budget deficits and governments expenditures: A reinvestigation. European Journal of Political Economy, 13, 739–750.
de Haan, J., Sturm, J. E., & Beekhuis, G. (1999). The weak government thesis: Some new evidence. Public Choice, 101(3–4), 163–176.
Falcó-Gimeno, A., & Jurado, I. (2011). Minority governments and budget deficits: The role of the opposition. European Journal of Political Economy, 27, 554–565.
Franzese, R. J. (2000). Electoral and partisan manipulation of public debt in developed democracies, 1956–90. In R. A. Strauch & J. Von Hagen (Eds.), Institutions, politics and fiscal policy (pp. 61–83). Boston: Kluwer Academic Press.
Grilli, V., Masciandaro, D., & Tabellini, G. (1991). Political and monetary institutions and public financial policies in the industrial countries. Economic Policy, 13, 342–392.
Ho, D., Imai, K., King, G., & Stuart, E. A. (2007). Matching as nonparametric preprocessing for reducing model dependence in parametric causal inference. Political Analysis, 15, 199–236.
Le Maux, B., Rocaboy, Y., & Goodspeed, T. (2011). Political fragmentation, party ideology and public expenditures. Public Choice, 147, 43–67.
Roubini, N., & Sachs, J. (1989a). Government spending and budget deficits in the industrial countries. Economic Policy, 8.
Roubini, N., & Sachs, J. (1989b). Political economic determinants of budget deficits in the industrial economies. NBER Working Paper 2682.
Scartascini, C., & Crain, M. (2001). The size and composition of government spending in multi-party systems. Public Choice Society Meetings, Mimeo.
Shepsle, K. A., & Weingast, B. R. (1981). Structure-induced equilibrium and legislative choice. Public Choice, 37(3), 503–519.
Smith, H. L. (1997). Matching with multiple controls to estimate treatment effects in observational studies. Sociological Methodology, 27(1), 325–353.
Stuart, E. A. (2010). Matching methods for causal inference: A review and a look forward. Statistical Science, 25, 1–21.
Stuart, E. A., & Rubin, D. B. (2007). Best practices in quasi-experimental designs: Matching methods for causal inference. In J. Osborne (Ed.), Best practices in quantitative social science (pp. 155–176). Thousand Oaks, CA: Sage Publications. Chapter 11.
Volkerink, B., & de Haan, J. (2001). Fragmented government effects on fiscal policy: New~evidence. Public Choice, 109(2001), 221–242.
Weingast, B. R., Shepsle, K., & John, C. (1981). The political economy of benefits and costs: A neoclassical approach to distributive politics. Journal of Political Economy, 96, 132–163.
Woo, J. (2003). Economic, political, and institutional determinants of public deficits. Journal of Public Economics, 87(3), 387–426.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this chapter
Cite this chapter
Artés, J., Jurado, I. (2015). Fiscal Deficits and Type of Government: A Study of Spanish Local Elections. In: Schofield, N., Caballero, G. (eds) The Political Economy of Governance. Studies in Political Economy. Springer, Cham. https://doi.org/10.1007/978-3-319-15551-7_19
Download citation
DOI: https://doi.org/10.1007/978-3-319-15551-7_19
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-15550-0
Online ISBN: 978-3-319-15551-7
eBook Packages: Business and EconomicsEconomics and Finance (R0)