
Abstract
The faster and regular usage of Web 2.0 technologies like Online Social Networks (OSNs) addicted to millions of users worldwide. This popularity made target for spammers and fake users to spread phishing attack, viruses, false news, pornography and unwanted advertisements like URLs, images and videos etc. The present paper proposes a behavioral analysis-based framework for classifying spam contents in real time by aggregating machine learning techniques and genetic algorithm. The main procedure of the work is, firstly based on social networks spam policy, novel profile based and content-based features are proposed to facilitate spam detection. Secondly, accumulate a dataset from various social networks like Facebook, Twitter, and Instagram including spam and non-spam profiles. For suitable feature selections, we have used a genetic algorithm and various classifiers for decision making. In order to attest the effectiveness of our proposed framework, we have compared with existing techniques.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Due to the busy schedule of a human being, people use OSNs such as Facebook, Twitter and Instagram for their communication, sharing of thoughts with their friends, post messages, share valuable views and discuss hot topics. These websites play an important role in people’s daily life [1,2,3]. Unfortunately, these activities of social platform become a new gateway for social spammers to achieve their goals such as spreading malware, posting spam content, and doing other illicit activities. Basically, social spammer spotting is a binary classification approach using feature analysis. In order to improvise the performance, suitable feature selections are required. The spreading of malicious content degrades user performance, experience, and various functions at server site such as analysis of user behavior, database server and resource recommendation. Therefore, it becomes desirable to develop a framework for detecting spammer and their activities. Currently, there have been few solutions developed by academicians and industry to detect spammer and their behavior in a social network platform. These solutions are either ineffective due to public feature analysis and manual selection of features [4, 5].
This paper investigates spammer in the social platform by analyzing public and private features by using suitable feature selection based on genetic algorithm and machine learning approach. Meanwhile, in order to improve the performance of the proposed framework, we utilize various social network information and label dataset by using API and crawler to guide the machine learning approach easily. We empirically evaluate the proposed framework on real-world dataset and depict the benefit of the proposed framework. The remaining parts of the paper are organized as follows. In Sect. 2, we reviewed related work for spammer detection. Section 3 describes our proposed framework and suitable feature selection approach. In Sect. 4, we describe an analysis of result and comparative work with others. Finally, in Sect. 5, we conclude our paper and some future research direction.
2 Related Work
Detection of social spammer becomes a hot subject in industry and academic field. Spam is an unwanted message spread through a social network platform. In recent years, many methods and frameworks have been proposed by academician to detect spammer on OSNs including feature analysis, social graph-based analysis and various optimization techniques. In [6], the author used support vector machine to classify the malicious content from a legitimate one. He analyzed app similarity and post name similarity content spread through various users as advertisements. In [7], the author analyzes the user characterization based on the user interaction with their followers. After collecting various features from different profiles, author used a machine learning method to separate spammer contents. The author in [8], identified the spammer content in twitter profile by analyzing the behavior of the user and generated trust score based on profile features. In [9], the author evaluated 4 different features using 16 online learning algorithms and chooses the best-suited algorithm to detect spammer in machine learning environment. The author uses nonnegative matrix factorization based integral framework for spammer detection in social media by implementing collaborative factorization principle [10]. In [11], the author uses extreme learning machine based supervised machine for spammer detection. A set of features are extracted by the crawler and process these datasets using extreme machine learning approach.
In [12], author proposed a trust rank based on URLs posted by various users using direct message principle. An invitation graph scheme proposed for detecting Sybil nodes in various social network platforms to analyze profile characteristics [13, 14]. In [15], the author proposed a model called COLOR + to detect spammer accounts in a social network in mobile devices by analyzing messages shared by the users. The approach proposed in [16, 17] analyze user behavior pattern according to the data interest and user behavior in a different group to detect spammer in a social network. The author identifies various kinds of anomalies using past behavior that deviates from the current one. In [18], the author observed the model that stores various processes related to information processing in a social platform for detecting spammer. If the observation lie-down below the threshold, it said to be anomalous. After exploring all the above articles, we conclude that spammer on OSNs can be very harmful for social users and their information. They need to be detected and removed at users end. After all, we came to the conclusion that we need some suitable feature extraction algorithm and optimization technique for better feature selections to helps spammer detection.
3 Spammer Detection Framework
Spammer detection framework is depicted in Fig. 1. We collected dataset from various social networks like Facebook, Twitter, and Instagram by using our crawler and API. The dataset divided into two different sets called training data and testing data. Each dataset contains various features associated with different profiles through feature extraction mechanism.

Spammer Detection Framework
3.1 Data Collection
We collected dataset from various social networks by using crawler and API. Crawler runs on chrome extension to extract profile content and user information related to user profiles. API boosts up the performance of crawler to extract private information about the user. We collected more than 2500 profile information on each social network depicted in Table 1. The dataset contains both spammers as well as legitimate profile information. In addition, we collect some profile activities based on privacy principle applied to social networks.
3.2 Training and Test Set Data
The collected dataset separated into two different sets called training set and test set. To obtain the model we have to conduct some experimental analysis of training data, whereas to determine the level of accuracy of the trained model testing data used. For an experimental approach, we used 10-cross-validation technique to separate the dataset into training and test sets.
3.3 Preprocessing
Transforming the raw information into a perceivable format, preprocessing is required in a machine learning approach. To detect the spammer in OSNs, our proposed model needs preprocess the generated content using various approaches like data streaming, folding approach, stopwatch removal, and tokenization.
3.4 Manual Feature Selections
Features are required as a reference to separate spammer from legitimate. Based on related work mentioned above, we select some profile and content-based features for our proposed model. We analyze the most popular features related to user profiles. For the feature extraction, we use web crawler run on chrome extension. Various features used in this research are depicted in Table 2.
3.5 Suitable Feature Selection Using GA
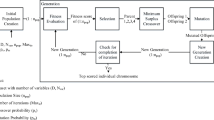
To detect suspicious profiles in OSNs is a challenging task. By analyzing suitable user profile and content-based features related to a user account is highly necessary for observation. The manual selection of features leads to lower accuracy and higher training time in a machine learning environment. To overcome the above issues, we used GA (Genetic algorithm) for a better selection of features. Genetic algorithms are based on evolution and natural selections to solve different diverse types of problem. The entire process of GA covered 5 different stages called initial population, selection, mating, crossover, and mutation. The algorithm starts with individuals’ selection of chromosomes called population. Each chromosome consists of a sequence of genes that could be various characteristics of individual users. In the next phase crossover is used to produce next level chromosomes. At later, mutation is used to find various suitable combinations. Similar processes are carried out to find final level of features that are suitable and gives better output describes in algorithm 1. The related experimental analysis for selecting various features shows in Fig. 2. Fitness of every individual is calculated using matching percentage of every population with the normal sample.

Feature selection based on Genetic algorithm
Where,
Ai = number of chromosomes matching individuals
A = Total size of the chromosomes
We tested Euclidian and Minkowski distance measure formula in genetic algorithm in different trial to calculate the distance between parent and new chromosomes. To detect the malicious content, Euclidian formula also used. The distance between two chromosomes can be calculated by using Eq. (2).
To calculate the power value between chromosomes, we use Minkowski distance measure formula using p-norm dimension depicted in Eq. (3).

3.6 Classification Based on Machine Learning Approach
The targeted classifier produced the outputs as spammer and legitimate using various features extracted by our crawler. We used various classifiers, namely Support vector machine (SVM), Random forest, bagging, J48, decision tree and Logistic Regression. To evaluate predictive models, we use 10-fold cross validation by partitioning original sample into training set and test set. The evaluation result in the form of precision, recall, true positive rate, false positive rate and ROC area observed for decision making.
4 Experiment and Result Analysis
We use different social networks dataset, which contains more than 2500 user information’s. Our crawler run on chrome extension extracts profile information along with date and time of every activities posted by the user. In the evaluation process, we consider confusion matrix for spammer detection. The proposed approach is evaluated various metrics, namely true positive rate, true negative rate, precision, recall and F-score related to classifiers. Accuracy is the ratio of total correctly classified instances of both classes over total instances in the dataset and expressed as,
4.1 Data Analysis
We observed that, by using various characteristics analysis, the follower of legitimate users is more as compared to the spammers in twitter account. But, the number of likes by the user for any event is more by spammers. As expected, spammers spread more advertisements and fraudulent information’s in different social network to attract users. After all, Random forest classifier gives higher accuracy as compared to other classifications. But, in Logistic regression, false positive rate is less in Twitter dataset depicted in Table 3, Table 4 and Table 5.
4.2 Performance Analysis
We evaluate our proposed framework by using various classifications and compared the analysis with some existing approaches. Particularly our experimental approach in the form of accuracy is higher as compared to other state of art techniques. It reaches higher accuracy above 99% in all social network platforms. Likewise, the precession of various analyses is higher as compared to other approaches. Especially, by using genetic algorithm, accuracy in every case increases by 12% to 15% as compared to normal feature selection. The selection of suitable features from group of all features by GA achieved higher detection rate. In all experimental approach, SVM produces lower accuracy due to structured dataset. Comparative analysis of various classifications in different social platforms with other existing approaches like Ameen et al., (2017) [19], Ala’m et al., (2017) [20] and Herzallah et al., (2017) [21] depicted in Fig. 3, Fig. 4, Fig. 5 and Fig. 6.

Comparative analysis of Accuracy

Comparative analysis of Precision

Comparative analysis of Recall

Comparative analysis of F-Measure
5 Conclusion and Future Work
The paper presents a Genetic algorithm-based feature selection approach with machine learning classifier to detect spammers in social network platform. A set of content and behavioral features are collected from Twitter, Facebook and Instagram using our crawler. By investigating various user behaviors, we provided a detection mechanism to detect spammer content in OSNs. Through a set of experiment and rating with a real-world dataset, proposed framework produces better accuracy and detection rate as compared to other frameworks. Next, we plan to extend our proposed framework in the following aspects. Firstly, we consider other private features related to the users account to detect spammer. Secondly, we wish to improve the detection rate by using other optimization approaches. Finally, design an online detection mechanism, which automatically detect the spammer behavior in social network platform.
References
Zhang, Z., Gupta, B.B.: Social media security and trustworthiness: overview and new direction. Fut. Generation Comput. Syst. 86, 914–925 (2018)
Gupta, B.B., Gupta, S., Gangwar, S., Kumar, M., Meena, P.K.: Cross-site scripting (XSS) abuse and defense: exploitation on several testing bed environments and its defense. J. Inf. Priv. Secur. 11(2), 118–136 (2015)
Zhang, Z., Sun, R., Zhao, C., Wang, J., Chang, C.K., et al.: CyVOD: a novel trinity multimedia social network scheme. Multimedia Tools Appl. 76(18), 18513–18529 (2017)
Brezinski, K., Guevarra, M., Ferens, K.: Population Based Equilibrium in Hybrid SA/PSO for Combinatorial Optimization: Hybrid SA/PSO for Combinatorial Optimization. Int. J. Softw. Sci. Comput. Intell. (IJSSCI) 12(2), 74–86 (2020)
Harrath, Y., Bahlool, R.: Multi-objective genetic algorithm for tasks allocation in cloud computing. Int. J. Cloud Appl. Comput. (IJCAC) 9(3), 37–57 (2019)
Sahoo, S.R., Gupta, B.B.: Classification of various attacks and their defence mechanism in online social networks : a survey. Enterp. Inf. Syst. pp. 1–33 (2019). http://doi.org/10.1080/17517575.2019.1605542
Sahoo, S.R., Gupta, B.B.: Classification of spammer and non-spammer content in online social network using genetic algorithm-based feature selection. Enterprise Inf. Syst. 710–736 (2020). http://doi.org/10.1080/17517575.2020.1712742
Singh, M., Bansal, D., Sofat, S.: Who is who on twitter–spammer, fake or compromised account? a tool to reveal true identity in real-time. Cybern. Syst. 49(1), 1–25 (2018)
Sahoo, S.R., Gupta, B.B.: Fake profile detection in multimedia big data on online social networks. Int. J. Inf. Comput. Secur. 303–331 (2020). http://doi.org/10.1504/IJICS.2020.105181
Yu, D., Chen, N., Jiang, F., Fu, B., Qin, A.: Constrained NMF-based semi-supervised learning for social media spammer detection. Knowl.-Based Syst. 125, 64–73 (2017)
Sahoo, S.R., Gupta, B.B.: Popularity-based detection of malicious content in facebook using machine learning approach. In: First International Conference on Sustainable Technologies for Computational Intelligence, pp. 163–176. Springer, Singapore (2020)
Gyongyi, Z., Garcia-Molina, H., Pedersen, J.: Combating Web spam with trust rank. In: Proceedings of the Thirteeth International Conference on Very Large Data Bases, vol. 30, VLDB 2004, pp. 576–587 (2004)
Xue, J., Yang, Z., Yang, X., Wang, X., Chen, L., Dai, Y.: Votetrust: leveraging friend invitation graph to defend against social network sybils. In: Proceeding of the 32nd IEEE International Conference on Computer Communications, INFOCOM 2013 (2013)
Alweshah, M., Al Khalaileh, S., Gupta, B.B., Almomani, A., Hammouri, A.I., Al-Betar, M.A.: The monarch butterfly optimization algorithm for solving feature selection problems. Neural Comput. Appl. 1–15 (2020)
Sahoo, S.R., Gupta, B.B.: Hybrid approach for detection of malicious profiles in twitter. Comput. Electric. Eng. 65–81, 2019 (2019). https://doi.org/10.1016/j.compeleceng.2019.03.003
Ahmed, M., Mahmood, A.N., Hu, J.: A survey of network anomaly detection techniques. J. Network Comput. Appl. 60, 19–31 (2016)
Jain, A.K., Gupta, B.B.: Towards detection of phishing websites on client-side using machine learning based approach. Telecommun. Syst. 68(4), 687–700 (2018)
Kaur, R., Kaur, M., Singh, S.: A novel graph centrality based approach to analyze anomalous nodes with negative behavior. Procedia Comput. Sci. 78, 556–562 (2016)
Ameen, A.K., Kaya, B.: Detecting spammers in twitter network. Int. J. Appl. Math. Electron. Comput. 5(4), 71–75 (2017)
Ala’M, A.-Z., Faris, H. et al.: Spam profile detection in social networks based on public features. In: 2017 8th International Conference on Information and Communication Systems (ICICS), pp. 130–135. IEEE (2017)
Herzallah, W., Faris, H., Adwan, O.: Feature engineering for detecting spammers on twitter: Modelling and analysis. J. Inf. Sci. 0165551516684296 (2017)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Sahoo, S.R., Gupta, B.B., Choi, C., Hsu, CH., Chui, K.T. (2020). Behavioral Analysis to Detect Social Spammer in Online Social Networks (OSNs). In: Chellappan, S., Choo, KK.R., Phan, N. (eds) Computational Data and Social Networks. CSoNet 2020. Lecture Notes in Computer Science(), vol 12575. Springer, Cham. https://doi.org/10.1007/978-3-030-66046-8_26
Download citation
DOI: https://doi.org/10.1007/978-3-030-66046-8_26
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-66045-1
Online ISBN: 978-3-030-66046-8
eBook Packages: Computer ScienceComputer Science (R0)