
Abstract
Often the best performing deep neural models are ensembles of multiple base-level networks, nevertheless, ensemble learning with respect to domain adaptive person re-ID remains unexplored. In this paper, we propose a multiple expert brainstorming network (MEB-Net) for domain adaptive person re-ID, opening up a promising direction about model ensemble problem under unsupervised conditions. MEB-Net adopts a mutual learning strategy, where multiple networks with different architectures are pre-trained within a source domain as expert models equipped with specific features and knowledge, while the adaptation is then accomplished through brainstorming (mutual learning) among expert models. MEB-Net accommodates the heterogeneity of experts learned with different architectures and enhances discrimination capability of the adapted re-ID model, by introducing a regularization scheme about authority of experts. Extensive experiments on large-scale datasets (Market-1501 and DukeMTMC-reID) demonstrate the superior performance of MEB-Net over the state-of-the-arts. Code is available at https://github.com/YunpengZhai/MEB-Net.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Person re-identification (re-ID) aims to match persons in an image gallery collected from non-overlapping camera networks [14, 16, 40]. It has attracted increasing interest from the computer vision community thanks to its wide applications in security and surveillance. Though supervised re-ID methods have achieved very decent results, they often experience catastrophic performance drops while applied to new domains. Domain adaptive person re-ID that can well generalize across domains remains an open research challenge.
Unsupervised domain adaptation (UDA) in re-ID has been studied extensively in recent years. Most existing works can be broadly grouped into three categories. The first category attempts to align feature distributions between source and target domains [35, 39], aiming to minimize the inter-domain gap for optimal adaptation. The second category addresses the domain gap by employing generative adversarial networks (GAN) for converting sample images from a source domain to a target domain while preserving the person identity as much as possible [5, 22, 24, 36]. To leverage the target sample distribution, the third category adopts self-supervised learning and clustering to predict pseudo-labels of target-domain samples iteratively to fine-tune re-ID models [7, 8, 15, 30, 37, 43]. Nevertheless, the optimal performance is often achieved by ensemble that integrates multiple sub-networks and their discrimination capability. However, ensemble learning in domain adaptive re-ID remains unexplored. How to leverage specific features and knowledge of multiple networks and optimally adapt them to an unlabelled target domain remains to be elaborated.
In this paper, we present an multiple expert brainstorming network (MEB-Net), which learns and adapts multiple networks with different architectures for optimal re-ID in an unlabelled target domain. MEB-Net conducts iterative training where clustering for pseudo-labels and models feature learning are alternately executed. For feature learning, MEB-Net adopts a mutual learning strategy where networks with different architectures are pre-trained in a source domain as expert models equipped with specific features and knowledge. The adaptation is accomplished through brainstorming-based mutual learning among multiple expert models. To accommodate the heterogeneity of experts learned with different architectures, a regularization scheme is introduced to modulate the experts’ authority according to their feature distributions in the target domain, and further enhances the discrimination capability of the re-ID model.
The contributions of this paper are summarized as follows.
-
We propose a novel multiple expert brainstorming network (MEB-Net) based on mutual learning among expert models, each of which is equipped with knowledge of an architecture.
-
We design an authority regularization to accommodate the heterogeneity of experts learned with different architectures, modulating the authority of experts and enhance the discrimination capability of re-ID models.
-
Our MEB-Net approach achieves significant performance gain over the state-of-the-art on commonly used datasets: Market-1501 and DukeMTMC-reID.
2 Related Works
2.1 Unsupervised Domain Adaptive Re-ID
Unsupervised domain adaptation (UDA) for person re-ID defines a learning problem for target domains where source domains are fully labeled while sample labels in target domains are totally unknown. Methods have been extensively explored in recent years, which take three typical approaches as follows.
Feature Distribution Alignment. In [21], Lin et al. proposed minimizing the distribution variation of the source’s and the target’s mid-level features based on Maximum Mean Discrepancy (MMD) distance. Wang et al. [35] utilized additional attribute annotations to align feature distributions of source and target domains in a common space.
Image-Style Transformation. GAN-based methods have been extensively explored for domain adaptive person re-ID [5, 22, 24, 36, 49]. HHL [49] simultaneously enforced cameras invariance and domain connectedness to improve the generalization ability of models on the target set. PTGAN [36], SPGAN [5], ATNet [22] and PDA-Net [18] transferred images with identity labels from source into target domains to learn discriminative models.
Self-supervised Learning. Recently, the problem about how to leverage the large number of unlabeled samples in target domains have attracted increasing attention [7, 23, 37, 38, 41, 44, 50]. Clustering [7, 43, 46] and graph matching [41] methods have been explored to predict pseudo-labels in target domains for discriminative model learning. Reciprocal search [23] and exemplar-invariance approaches [38] were proposed to refine pseudo labels, taking camera-invariance into account concurrently. SSG [8] utilized both global and local feature of persons to build multiple clusters, which are then assigned pseudo-labels to supervise the model training.
However, existing works barely explored the domain adaptive person re-ID task using methods of model ensemble, which have achieved impressive performance on many other tasks.
2.2 Knowledge Transfer
Distilling knowledge from well trained neural networks and transferring it to another model/network has been widely studied in recent years [1,2,3, 11, 19, 42]. The typical approach of knowledge transfer is the teacher-student model learning, which uses the soft output distribution of a teacher network to supervise a student network, so as to make student models learn discrimination ability from teacher models.
The mean-teacher model [33] averaged model weights at different training iterations to create supervisions for unlabeled samples. Deep mutual learning [45] adopted a pool of student models by training them with supervision from each other. Mutual mean teaching [9] designed a symmetrical framework with hard pseudo-labels as well as refined soft labels for unsupervised domain adaptive re-ID. However, existing methods with teacher-student mechanisms mostly adopted a symmetrical framework which largely neglected the different confidence of teacher networks when they are heterogeneous.
2.3 Model Ensemble
There is a considerable number of previous works on ensembles with neural networks. A typical approach [13, 29, 31, 34] generally create a series of networks with shared weights during training and then implicitly ensemble them at test time. Another approach [28] focus on label refinery by well trained networks for training a new model with higher discrimination capability. However, these methods cannot be directly used on unsupervised domain adaptive re-ID tasks, where the training set and the testing set share non-overlapping label space.

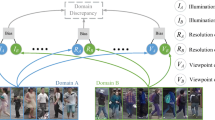
Overview of proposed multiple expert brainstorming network (MEB-Net). Multiple expert networks with different architectures are first pre-trained in the source domain and then adapted to the target domain through brainstorming.

Flowchart of proposed expert brainstorming in MEB-Net, which consists of two components, feature extraction and mutual learning. In mutual learning, multiple expert networks are organized to collaboratively learn from each other by their predictions and the pseudo-labels, and improve themselves for the target domain in an unsupervised mutual learning manner. More details are described in Sect. 3.4.
3 The Proposed Approach
We study the problem of unsupervised domain adaptive re-ID using model ensemble methods from a source-domain to a target-domain. The labelled source-domain dataset are denoted as \(\mathcal {S}=\{X_s, Y_s\}\), which has \(N_s\) sample images with \(M_s\) unique identities. \(X_s\) and \(Y_s\) denote the sample images and the person identities, where each sample \(x_s\) in \(X_s\) is associated with a person identity \(y_s\) in \(Y_s\). The \(N_t\) sample images in the target-domain \(\mathcal {T} = \{X_t\}\) have no identity available. We aim to leverage the labelled sample images in \(\mathcal {S}\) and the unlabelled sample images in \(\mathcal {T}\) to learn a transferred re-ID model for the target-domain \(\mathcal {T}\).
3.1 Overview
MEB-Net adopts a two-stage training scheme including supervised learning in source domains (Fig. 1a) and unsupervised adaptation to target domains (Fig. 1b). In the initialization phase, multiple expert models with different network architectures are pre-trained by the source dataset in a supervised manner. Afterwards the trained experts are adapted to the target domain by iteratively brainstorming with each other using the unlabelled target-domain samples. In each iterative epoch, pseudo-labels are predicted for target samples via clustering which are then utilized to fine-tune the expert networks by mutual learning. In addition, the authority regularization is employed to modulate the authority of expert networks according to their discrimination capability during training. In this way, the knowledge from multiple networks is fused, enhanced, and transferred to the target domain, as described in Algorithm 1.
3.2 Learning in Source Domains
The proposed MEB-Net aims to transfer the knowledge of multiple networks from a labelled source domain to an unlabelled target domain. For each architecture, a deep neural network (DNN) model \(\mathcal {M}^k\) parameterized with \(\theta ^k\) (a pre-trained expert) is first trained in a supervised manner. \(\mathcal {M}^k\) transforms each sample image \(x_{s,i}\) into a feature representation \(f(x_{s,i}|\theta ^k)\), and outputs a predicted probability \(p_j(x_{s,i}|\theta ^k)\) of image \(x_{s,i}\) belonging to the identity j. The cross entropy loss with label smoothing is defined as
where \(q_j = 1-\varepsilon + \frac{\varepsilon }{M_s}\) if \(j=y_{s,i}\), otherwise \(q_j=\frac{\varepsilon }{M_s}\). \(\varepsilon \) is a small constant, which is set as 0.1. The softmax triplet loss is also defined as
where \(x_{s,i+}\) denotes the hardest positive sample of the anchor \(x_{s,i}\), and \(x_{s,i-}\) denotes the hardest negative sample. \(\Vert \cdot \Vert \) denotes the L\(_2\) distance. The overall loss is therefore calculated as
With K network architectures, the supervised learning thus produces K pre-trained re-ID models each of which acts as an expert for brainstorming.

3.3 Clustering in the Target Domain
In the target domain, MEB-Net consists of a clustering-based pseudo-label generation procedure and a feature learning procedure, which are mutually enforced. Each epoch consists of three steps: (1) For sample images in the target domain, each expert model extracts convolutional features \(f(X_t|\theta ^k)\) and determines the ensemble features by averaging features extracted by multiple expert models \(f(X_t) = \frac{1}{K} \sum _{k=1}^K f(X_t|\theta ^k)\); (2) A mini-batch k-means clustering is performed on \(f(X_t)\) to classify all target-domain samples into \(M_t\) different clusters; (3) The produced cluster IDs are used as pseudo-labels \(\widetilde{Y_t}\) for the training samples \(X_t\). The steps 3 and 4 in Algorithm 1 summarize this clustering process.
3.4 Expert Brainstorming
With multiple expert models \(\{\mathcal {M}^k\}\) with different architectures which absorb rich knowledge from the source domain, MEB-Net aims to organize them to collaboratively learn from each other and improve themselves for the target domain in an unsupervised mutual learning manner, Fig. 2.
In each training iteration, the same batch of images in the target domain are first fed to all the expert models \(\{\mathcal {M}^k\}\) parameterized by \(\{\theta ^k\}\), to predict the classification confidence predictions \(\{p(x_{t,i}|\theta ^k)\}\) and feature representations \(\{f(x_{t,i}|\theta ^k)\}\). To transfer knowledge from one expert to others, the class predictions of each expert can serve as soft class labels for training other experts. However, directly using the current predictions as soft labels to train each model decreases the independence of expert models’ outputs, which might result in an error amplification. To avoid this error, MEB-Net leverages the temporally average model of each expert model, which preserves more original knowledge, to generate reliable soft pseudo labels for supervising other experts. The parameters of the temporally average model of expert \(\mathcal {M}^k\) at current iteration T are denoted as \(\varTheta _T^k\), which is updated as
where \(\alpha \in [0,1]\) is the scale factor, and the initial temporal average parameters are \({\varTheta }_{0}^k = \theta ^k\). Utilizing this temporal average model of expert \(\mathcal {M}^e\), the probability for each identity j is predicted as \(p_j(x_{t,i}|\varTheta _{T}^e)\), and the feature representation is calculated as \(f(x_{t,i}|\varTheta _{T}^e)\).
Mutual Identity Loss. For each expert model \(\mathcal {M}^k\), the mutual identity loss of models learned by a certain expert \(\mathcal {M}^e\) is defined as the cross entropy between the class prediction of the expert \(\mathcal {M}^k\) and the temporal average model of the expert \(\mathcal {M}^e\), as
The mutual identity loss for expert \(\mathcal {M}^k\) is set as the average of above losses of models learned by all other experts, as
Mutual Triplet Loss. For each expert model \(\mathcal {M}^k\), the mutual triplet loss of models learned by a certain expert \(\mathcal {M}^e\) is also defined as binary cross entropy, as
where \(\mathcal {P}_i({\theta }^k)\) denotes the softmax of the feature distance between negative sample pairs:
where \(x_{t,i+}\) denotes the hardest positive sample of the anchor \(x_{t,i}\) according to the pseudo-labels \(\widetilde{Y_t}\), and \(x_{t,i-}\) denotes the hardest negative sample. \(\Vert \cdot \Vert \) denotes \(L_2\) distance. The mutual triplet loss for expert \(\mathcal {M}^k\) is calculated as the average of above triplet losses of models learned by all other experts, as
Voting Loss. In order to learn stable and discriminative knowledge from the pseudo-labels obtained by clustering as described in Sect. 3.3, we introduce voting loss which consists of the identity loss and the triplet loss. For each expert model \(\mathcal {M}^k\), the identity loss is defined as cross entropy with label smoothing, as
where \(q_j = 1-\varepsilon + \frac{\varepsilon }{M_t}\) if \(j=\widetilde{y}_{t,i}\), otherwise \(q_j=\frac{\varepsilon }{M_t}\). \(\varepsilon \) is small constant. The softmax triplet loss is defined as:
where \(x_{t,i+}\) denotes the hardest positive sample of the anchor \(x_{t,i}\), and \(x_{t,i-}\) denotes the hardest negative sample. \(\Vert \cdot \Vert \) denotes L\(_2\) distance. The voting loss is defined by summarizing the identity loss and the triplet loss:
Overall Loss. For each expert model \(\mathcal {M}^k\), the individual brainstorming loss is defined by
The overall loss is defined by the sum loss of the individual brainstorming for each expert model.

Illustration of our proposed authority regularization. It modulates the authority of different experts according to the inter-/intra-cluster scatter of each single expert. A larger scatter means better discrimination capability.
3.5 Authority Regularization
Expert networks with different architectures are equipped with various knowledge, and thus have different degrees of discrimination capability in the target domain. To accommodate the heterogeneity of experts, we propose an authority regularization (AR) scheme, which modulates the authority of different experts according to the inter-/intra-cluster scatter of each single expert, Fig. 3. Specifically, for each expert \(\mathcal {M}\) we extract sample features \(f(x|\varTheta _T)\) and cluster all the training samples in the target domain into \(M_t\) groups as \(\mathbb {C}\). The intra-cluster scatter of the cluster \(\mathbb {C}_i\) is defined as
where \(\mu _i=\sum _{x \in \mathbb {C}_i} f(x|\varTheta _T)/n_t^i\) is the average feature of the cluster \(\mathbb {C}_i\) (with \(n_t^i\) samples). The inter-cluster scatter is defined as
where \(\mu =\sum _{i=1}^{N_t} f(x_{t,i}|\varTheta _T)/N_t\) is the average feature of all training samples in the target domain. To evaluate the discrimination of each expert model in the unlabeled target domain, the inter-/intra-cluster scatter J is defined as
J gets larger when the inter-cluster scatter is larger or the intra-cluster scatter is smaller. And a larger J means better discrimination capability. Before feature learning in each epoch, we calculate J scatter for each expert \(\mathcal {M}^e\) as \(J^e\), and defined expert authority \(w^e\) as the mean normalization of \(J^e\), as
We re-define the mutual identity loss in Eq. 6 and the mutual triplet loss in Eq. 9 as the weighted sum of \(\mathcal {L}_{mid}^{k\leftarrow e}\) and \(\mathcal {L}_{mtri}^{k\leftarrow e}\) for other experts, as
and
With the regularization scheme, MEB-Net modulates the authority of experts to facilitate discrimination in the target domain.
4 Experiments
4.1 Datasets and Evaluation Metrics
We evaluate the proposed method on Market-1501 [47] and DukeMTMC-reID [27, 48].
Market-1501: This dataset contains 32,668 images of 1,501 identities from 6 disjoint cameras, among which 12,936 images from 751 identities form a training set, 19,732 images from 750 identities (plus a number of distractors) form a gallery set, and 3,368 images from 750 identities form a query set.
DukeMTMC-reID: This dataset is a subset of the DukeMTMC. It consists of 16,522 training images, 2,228 query images, and 17,661 gallery images of 1,812 identities captured using 8 cameras. Of the 1812 identities, 1,404 appear in at least two cameras and the rest (distractors) appear in a single camera.
Evaluation Metrics: In evaluations, we use one dataset as the target domain and the other as the source domain. The used metrics are Cumulative Matching Characteristic (CMC) curve and mean average precision (mAP).
4.2 Implementation Details
MEB-Net is trained by two stages: pre-training in source domains and the adaptation in target domains.
Stage 1: Pre-training in Source Domains: We first pre-train three supervised expert models on the source dataset as described in Sect. 3.2. We adopt three architectures: DenseNet-121 [12], ResNet-50 [10] and Inception-v3 [32] as backbone networks for the three experts, and initialize them by using parameters pre-trained on the ImageNet [4]. Zero padding is employed on the final features to obtain representations of the same 2048 dimensions for all networks. During training, the input image is resized to \(256\times 128\) and traditional image augmentation was performed via random flipping and random erasing. For each identity from the training set, a mini-batch of 64 is sampled with P = 16 randomly selected identities and K = 4 randomly sampled images for computing the hard batch triplet loss. We use the Adam [17] with weight decay 0.0005 to optimize parameters. The initial learning rate is set to 0.00035 and is decreased to 1/10 of its previous value on the 40th and 70th epoch in the total 80 epochs.
Stage 2: Adaptation in Target Domains. For unsupervised adaptation on target datasets, we follow the same data augmentation strategy and triplet loss setting. The temporal ensemble momentum \(\alpha \) in Eq. 4 is set to 0.999. The learning rate is fixed to 0.00035 for overall 40 epochs. In each epoch, we conduct mini-batch k-means clustering and the number of groups \(M_t\) is set as 500 for all target datasets. Each epoch consists of 800 training iterations. During testing, we only use one expert network for feature representations.
4.3 Comparison with State-of-the-Arts
We compare MEB-Net with state-of-the-art methods including: hand-crafted feature approaches (LOMO [20], BOW [47], UMDL [25]), feature alignment based methods (MMFA [21], TJ-AIDL [35], UCDA-CCE [26]), GAN-based methods (SPGAN [5], ATNet [22], CamStyle [51], HHL [49], ECN [50] and PDA-Net [18]), pseudo-label prediction based methods (PUL [6], UDAP [30], PCB-PAST [44], SSG [8] MMT [9]). Table 1 shows the person Re-ID performance while adapting from Market1501 to DukeMTMC-reID and vice versa.
Hand-Crafted Feature Approaches. As Table 1 shows, MEB-Net outperforms hand-crafted feature approaches including LOMO, BOW and UMDL by large margins, as deep network can learn more discriminative representations than hand-crafted features.
Feature Alignment Approaches. MEB-Net significantly exceeds the feature alignment unsupervised Re-ID models. The reason lies in that it explores and utilizes the similarity between unlabelled sample in target domains in an more effective manner of brainstorming.
GAN-Based Approaches. The performance of these approaches is diverse. In particular, ECN performs better than most methods using GANs because it enforces cameras in-variance as well as latent sample relations. However, MEB-Net can achieve higher performance than GAN-based methods without generating new images, which indicates its more efficient use of the unlabelled samples.
Pseudo-labels Based Approaches. The line of approaches perform clearly better than other approaches in most cases, as they fully make use of the unlabelled target samples by assigning pseudo-labels to them according to sample feature similarities. For a fair comparison, we report MMT-500 with the cluster number of 500, which is the same as the proposed MEB-Net. As Table 1 shows, MEB-Net achieves an mAP of \(76.0\%\) and a rank-1 accuracy of \(89.9\%\) for the DukeMTMC-reID\(\rightarrow \)Market1501 transfer, which outperforms the state-of-the-art (by MMT-500) by \(4.8\%\) and \(2.2\%\), respectively. And for Market1501\(\rightarrow \)DukeMTMC-reID transfer, MEB-Net obtains an mAP of \(66.1\%\) and a rank-1 accuracy of \(79.6\%\) which outperforms the state-of-the-art by \(3.0\%\) and \(2.8\%\), respectively.
4.4 Ablation Studies
Detailed ablation studies are performed to evaluate the components of MEB-Net as shown in Table 2.
Supervised Models vs. Direct Transfer. We first derive the upper and lower performance bounds by the supervised models (trained using labelled target-domain images) and the direct transfer models (trained using labelled source-domain images) for the ablation studies as shown in Table 2. We evaluate all three architectures and report the best results in Table 2. It can be observed that the huge performance gaps between the Direct Transfer models and the Supervised Models due to the domain shift.
Voting Loss: We create baseline ensemble models that only use voting loss. Specifically, pseudo-labels are predicted by averaging the features outputted from all expert networks, and then used to supervise the training of each expert network individually by optimizing the voting loss. As Table 1 shows, the Baseline model outperforms the Direct Transfer model by a large margin. This shows that the voting loss effectively make use of the ensemble models to predict more accurate pseudo-labels and fine-tune each network.
Temporally Average Networks: The model removing the temporally average models is denoted as “MEB-Net w/o \(\varTheta _T\)”. For this experiment, we directly use the prediction of the current networks parameterized by \(\theta _T\) instead of the temporally average networks with parameters \(\varTheta _T\) as soft labels. As Table 2 shows, distinct drops of 5.3% mAP and 2.8% rank-1 accuracy are observed for Market1501\(\rightarrow \)DukeMTMC-reID transfer. Without using temporally average models, networks tend to degenerate to be homogeneous, which substantially decreases the learning capability.
Effectiveness of Mutual Learning: We evaluate the mutual learning component in Sect. 3.4 from two aspects: the mutual identity loss and the mutual triplet loss. The former is denoted as “MEB-Net w/o \(\mathcal {L}_{mid}\)”. Results show that mAP drops from 76.0% to 70.2% on Market-1501 dataset and from 66.1% to 60.4% on DukeMTMC-reID dataset. Similar drops can also be observed when studying the mutual triplet loss, which are denoted as “MEB-Net w/o \(\mathcal {L}_{mtri}\)”. For example, the mAP drops to 74.9% and 63.0% for DukeMTMC-reID\(\rightarrow \)Market-1501 and vice versa, respectively. The effectiveness of the mutual learning, including both two mutual loss, can be largely attributed to that it enhances the discrimination capability of all expert networks.
Authority Regularization: We verify the effectiveness of the proposed authority regularization (Sect. 3.5) of MEB-Net. Specifically, we remove the authority regularization, and set authority \(w=1\) (in Eq. 19 and Eq. 20) equally for all expert models. The model is denoted as “MEB-Net w/o AR”, of which the results are shown in Table 1. Experiments without authority regularization shows distinct drops on both Market-1501 and DukeMTMC-reID datasets, which indicates that equivalent brainstorming among experts hinders feature discrimination because an unprofessional expert may provide erroneous supervision.
4.5 Discussion
Comparison with Baseline Ensemble
Considering that ensemble models usually achieve more superior performance than a single model, we compare mAPs of our approach with other baseline methods, including single model transfer and baseline model ensemble. Results are shown in Table. 3. The baseline model ensemble uses all networks to extract average features of unlabelled samples for pseudo-label prediction, but without mutual learning among them while adaptation in the target domain. The improvement of baseline ensemble than single model transfer is because of more accurate pseudo-labels. However, MEB-Net performs significantly better than all compared methods. It validates that MEB-Net provides a more effective ensemble method with respect to domain adaptive person re-ID.

Evaluation with different epoch. The performance of all networks ascend to a stable value after 20 epochs.
Number of Epochs. We evaluate the mAP of MEB-Net after each epoch, respectively. As shown in Fig. 4, the models become stronger when the iterative clustering proceeds. The performance is improved in early epochs, and finally converges after 20 epochs for both datasets.
5 Conclusion
The paper proposed a multiple expert brainstorming network (MEB-Net) for domain adaptive person re-ID. MEB-Net adopts a mutual learning strategy, where networks of each architecture are pre-trained to initialize several expert models while the adaptation is accomplished through brainstorming (mutual learning) among expert models. Furthermore, an authority regularization scheme was introduced to tackle the heterogeneity of experts. Experiments demonstrated the effectiveness of MEB-Net for improving the discrimination ability of re-ID models. Our approach efficiently assembled discrimination capability of multiple networks while requiring solely a single model during inference time throughout.
References
Anil, R., Pereyra, G., Passos, A., Ormandi, R., Dahl, G.E., Hinton, G.E.: Large scale distributed neural network training through online distillation. arXiv preprint arXiv:1804.03235 (2018)
Bagherinezhad, H., Horton, M., Rastegari, M., Farhadi, A.: Label refinery: improving ImageNet classification through label progression. arXiv preprint arXiv:1805.02641 (2018)
Chen, T., Goodfellow, I., Shlens, J.: Net2Net: accelerating learning via knowledge transfer. arXiv preprint arXiv:1511.05641 (2015)
Deng, J., Dong, W., Socher, R., Li, L., Li, K., Li, F.: ImageNet: a large-scale hierarchical image database. In: IEEE CVPR (2009)
Deng, W., Zheng, L., Ye, Q., Kang, G., Yang, Y., Jiao, J.: Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person re-identification. In: IEEE CVPR (2018)
Fan, H., Zheng, L., Yan, C., Yang, Y.: Unsupervised person re-identification: clustering and fine-tuning. TOMCCAP 14(4), 83:1–83:18 (2018)
Fan, H., Zheng, L., Yang, Y.: Unsupervised person re-identification: clustering and fine-tuning. CoRR abs/1705.10444 (2017)
Fu, Y., Wei, Y., Wang, G., Zhou, Y., Shi, H., Huang, T.S.: Self-similarity grouping: a simple unsupervised cross domain adaptation approach for person re-identification. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 6112–6121 (2019)
Ge, Y., Chen, D., Li, H.: Mutual mean-teaching: pseudo label refinery for unsupervised domain adaptation on person re-identification. arXiv preprint arXiv:2001.01526 (2020)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015)
Huang, G., Liu, Z., Van Der Maaten, L., Weinberger, K.Q.: Densely connected convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4700–4708 (2017)
Huang, G., Sun, Yu., Liu, Z., Sedra, D., Weinberger, K.Q.: Deep networks with stochastic depth. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9908, pp. 646–661. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46493-0_39
Jia, M., Zhai, Y., Lu, S., Ma, S., Zhang, J.: A similarity inference metric for RGB-infrared cross-modality person re-identification. In: IJCAI 2020, June 2020
Jin, X., Lan, C., Zeng, W., Chen, Z.: Global distance-distributions separation for unsupervised person re-identification. arXiv preprint arXiv:2006.00752 (2020)
Jin, X., Lan, C., Zeng, W., Chen, Z., Zhang, L.: Style normalization and restitution for generalizable person re-identification. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3143–3152 (2020)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Li, Y.J., Lin, C.S., Lin, Y.B., Wang, Y.C.F.: Cross-dataset person re-identification via unsupervised pose disentanglement and adaptation. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 7919–7929 (2019)
Li, Y., Yang, J., Song, Y., Cao, L., Luo, J., Li, L.J.: Learning from noisy labels with distillation. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 1910–1918 (2017)
Liao, S., Hu, Y., Zhu, X., Li, S.Z.: Person re-identification by local maximal occurrence representation and metric learning. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015
Lin, S., Li, H., Li, C., Kot, A.C.: Multi-task mid-level feature alignment network for unsupervised cross-dataset person re-identification. In: BMVC (2018)
Liu, J., Zha, Z.J., Chen, D., Hong, R., Wang, M.: Adaptive transfer network for cross-domain person re-identification. In: IEEE CVPR (2019)
Liu, Z., Wang, D., Lu, H.: Stepwise metric promotion for unsupervised video person re-identification. In: IEEE ICCV, pp. 2448–2457 (2017)
Lv, J., Wang, X.: Cross-dataset person re-identification using similarity preserved generative adversarial networks. In: Liu, W., Giunchiglia, F., Yang, B. (eds.) KSEM, pp. 171–183 (2018)
Peng, P., et al.: Unsupervised cross-dataset transfer learning for person re-identification. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
Qi, L., Wang, L., Huo, J., Zhou, L., Shi, Y., Gao, Y.: A novel unsupervised camera-aware domain adaptation framework for person re-identification. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 8080–8089 (2019)
Ristani, E., Solera, F., Zou, R.S., Cucchiara, R., Tomasi, C.: Performance measures and a data set for multi-target, multi-camera tracking. In: IEEE ECCV Workshops (2016)
Shen, Z., He, Z., Xue, X.: Meal: Multi-model ensemble via adversarial learning. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 4886–4893 (2019)
Singh, S., Hoiem, D., Forsyth, D.: Swapout: Learning an ensemble of deep architectures. In: Advances in Neural Information Processing Systems, pp. 28–36 (2016)
Song, L., et al.: Unsupervised domain adaptive re-identification: Theory and practice. CoRR abs/1807.11334 (2018)
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.: Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15(1), 1929–1958 (2014)
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z.: Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2818–2826 (2016)
Tarvainen, A., Valpola, H.: Mean teachers are better role models: weight-averaged consistency targets improve semi-supervised deep learning results. In: Advances in Neural Information Processing Systems, pp. 1195–1204 (2017)
Wan, L., Zeiler, M., Zhang, S., Le Cun, Y., Fergus, R.: Regularization of neural networks using dropconnect. In: International Conference on Machine Learning, pp. 1058–1066 (2013)
Wang, J., Zhu, X., Gong, S., Li, W.: Transferable joint attribute-identity deep learning for unsupervised person re-identification. In: IEEE CVPR (2018)
Wei, L., Zhang, S., Gao, W., Tian, Q.: Person transfer GAN to bridge domain gap for person re-identification. In: IEEE CVPR (2018)
Wu, J., Liao, S., Lei, Z., Wang, X., Yang, Y., Li, S.Z.: Clustering and dynamic sampling based unsupervised domain adaptation for person re-identification. In: IEEE ICME, pp. 886–891 (2019)
Wu, Y., Lin, Y., Dong, X., Yan, Y., Ouyang, W., Yang, Y.: Exploit the unknown gradually: one-shot video-based person re-identification by stepwise learning. In: IEEE CVPR (2018)
Yang, F., et al.: Part-aware progressive unsupervised domain adaptation for person re-identification. IEEE Trans. Multimed. (2020)
Yang, F., Yan, K., Lu, S., Jia, H., Xie, X., Gao, W.: Attention driven person re-identification. Pattern Recogn. 86, 143–155 (2019)
Ye, M., Ma, A.J., Zheng, L., Li, J., Yuen, P.C.: Dynamic label graph matching for unsupervised video re-identification. In: IEEE ICCV, pp. 5152–5160 (2017)
Yim, J., Joo, D., Bae, J., Kim, J.: A gift from knowledge distillation: fast optimization, network minimization and transfer learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4133–4141 (2017)
Zhai, Y., Lu, S., Ye, Q., Shan, X., Chen, J., Ji, R., Tian, Y.: Ad-cluster: augmented discriminative clustering for domain adaptive person re-identification. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
Zhang, X., Cao, J., Shen, C., You, M.: Self-training with progressive augmentation for unsupervised cross-domain person re-identification. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 8222–8231 (2019)
Zhang, Y., Xiang, T., Hospedales, T.M., Lu, H.: Deep mutual learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4320–4328 (2018)
Zheng, L., et al.: MARS: a video benchmark for large-scale person re-identification. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9910, pp. 868–884. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46466-4_52
Zheng, L., Shen, L., Tian, L., Wang, S., Wang, J., Tian, Q.: Scalable person re-identification: a benchmark. In: The IEEE International Conference on Computer Vision (ICCV), December 2015
Zheng, Z., Zheng, L., Yang, Y.: Unlabeled samples generated by GAN improve the person re-identification baseline in vitro. In: IEEE ICCV (2017)
Zhong, Z., Zheng, L., Li, S., Yang, Y.: Generalizing a person retrieval model hetero- and homogeneously. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11217, pp. 176–192. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01261-8_11
Zhong, Z., Zheng, L., Luo, Z., Li, S., Yang, Y.: Invariance matters: exemplar memory for domain adaptive person re-identification. In: IEEE CVPR (2019)
Zhong, Z., Zheng, L., Zheng, Z., Li, S., Yang, Y.: CamStyle: a novel data augmentation method for person re-identification. IEEE TIP 28(3), 1176–1190 (2019)
Acknowledgement
This work is partially supported by grants from the National Key R&D Program of China under grant 2017YFB1002400, the National Natural Science Foundation of China (NSFC) under contract No. 61825101, U1611461 and 61836012.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Zhai, Y., Ye, Q., Lu, S., Jia, M., Ji, R., Tian, Y. (2020). Multiple Expert Brainstorming for Domain Adaptive Person Re-Identification. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, JM. (eds) Computer Vision – ECCV 2020. ECCV 2020. Lecture Notes in Computer Science(), vol 12352. Springer, Cham. https://doi.org/10.1007/978-3-030-58571-6_35
Download citation
DOI: https://doi.org/10.1007/978-3-030-58571-6_35
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-58570-9
Online ISBN: 978-3-030-58571-6
eBook Packages: Computer ScienceComputer Science (R0)