
Abstract
This paper studies the problem of learning semantic segmentation from image-level supervision only. Current popular solutions leverage object localization maps from classifiers as supervision signals, and struggle to make the localization maps capture more complete object content. Rather than previous efforts that primarily focus on intra-image information, we address the value of cross-image semantic relations for comprehensive object pattern mining. To achieve this, two neural co-attentions are incorporated into the classifier to complimentarily capture cross-image semantic similarities and differences. In particular, given a pair of training images, one co-attention enforces the classifier to recognize the common semantics from co-attentive objects, while the other one, called contrastive co-attention, drives the classifier to identify the unshared semantics from the rest, uncommon objects. This helps the classifier discover more object patterns and better ground semantics in image regions. In addition to boosting object pattern learning, the co-attention can leverage context from other related images to improve localization map inference, hence eventually benefiting semantic segmentation learning. More essentially, our algorithm provides a unified framework that handles well different WSSS settings, i.e., learning WSSS with (1) precise image-level supervision only, (2) extra simple single-label data, and (3) extra noisy web data. It sets new state-of-the-arts on all these settings, demonstrating well its efficacy and generalizability.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Recently, modern deep learning based semantic segmentation models [6, 7], trained with massive manually labeled data, achieve far better performance than before. However, the fully supervised learning paradigm has the main limitation of requiring intensive manual labeling effort, which is particularly expensive for annotating pixel-wise ground-truth for semantic segmentation. Numerous efforts are motivated to develop semantic segmentation with weaker forms of supervision, such as bounding boxes [47], scribbles [38], points [3], image-level labels [48], etc. Among them, a prominent and appealing trend is using only image-level labels to achieve weakly supervised semantic segmentation (WSSS), which demands the least annotation efforts and is followed in this work.
To tackle the task of WSSS with only image-level labels, current popular methods are based on network visualization techniques [78, 84], which discover discriminative regions that are activated for classification. These methods use image-level labels to train a classifier network, from which class-activation maps are derived as pseudo ground-truths for further supervising pixel-level semantics learning. However, it is commonly evidenced that the trained classifier tends to over-address the most discriminative parts rather than entire objects, which becomes the focus of this area. Diverse solutions are explored, typically adopting: image-level operations, such as region hiding and erasing [32, 69], regions growing strategies that expand the initial activated regions [29, 64], and feature-level enhancements that collect multi-scale context from deep features [35, 71].

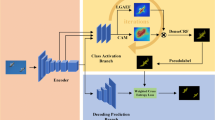
(a) Current WSSS methods only use single-image information for object pattern discovering. (b–c) Our co-attention classifier leverages cross-image semantics as class-level context to benefit object pattern learning and localization map inference.
These efforts generally achieve promising results, which demonstrates the importance of discriminative object pattern mining for WSSS. However, as shown in Fig. 1(a), they typically use only single-image information for object pattern discovering, ignoring the rich semantic context among the weakly annotated data. For example, with the image-level labels, not only the semantics of each individual image can be identified, the cross-image semantic relations, i.e., two images whether sharing certain semantics, are also given and should be used as cues for object pattern mining. Inspired by this, rather than relying on intra-image information only, we further address the value of cross-image semantic correlations for complete object pattern learning and effective class-activation map inference (see Fig. 1(b–c)). In particular, our classifier is equipped with a differentiable co-attention mechanism that addresses semantic homogeneity and difference understanding across training image pairs. More specifically, two kinds of co-attentions are learned in the classifier. The former one aims to capture cross-image common semantics, which enables the classifier to better ground the common semantic labels over the co-attentive regions. The latter one, called contrastive co-attention, focuses on the rest, unshared semantics, which helps the classifier better separate semantic patterns of different objects. These two co-attentions work in a cooperative and complimentary manner, together making the classifier understand object patterns more comprehensively.
In addition to benefiting object pattern learning, our co-attention provides an efficient tool for precise localization map inference (see Fig. 1(c)). Given a training image, a set of related images (i.e., sharing certain common semantics) are utilized by the co-attention for capturing richer context and generating more accurate localization maps. Another advantage is that our co-attention based classifier learning paradigm brings an efficient data augmentation strategy, due to the use of training image pairs. Overall, our co-attention boosts object discovering during both the classifier’s training phase as well as localization map inference stage. This provides the possibility of obtaining more accurate pseudo pixel-level annotations, which facilitate final semantic segmentation learning.
Our algorithm is a unified and elegant framework, which generalizes well different WSSS settings. Recently, to overcome the inherent limitation in WSSS without additional human supervision, some efforts resort to extra image-level supervision from simple single-class data readily available from other existing datasets [37, 50], or cheap web-crawled data [20, 54, 55, 70]. Although they improve the performance to some extent, complicated techniques, such as energy function optimization [20, 59], heuristic constraints [13, 55], and curriculum learning [70], are needed to handle the challenges of domain gap and data noise, restricting their utility. However, due to the use of paired image data for classifier training and object map inference, our method has good tolerance to noise. In addition, our method also handles domain gap naturally, as the co-attention effectively addresses domain-shared object pattern learning and achieves domain adaption as a part of co-attention parameter learning. We conduct extensive experiments on PASCAL VOC 2012 [11], under three WSSS settings, i.e., learning WSSS with (1) PASCAL VOC image-level supervision only, (2) extra simple single-label data, and (3) extra web data. Our algorithm sets state-of-the-art on each case, verifying its effectiveness and generalizability.
2 Related Work
Weakly Supervised Semantic Segmentation. Recently, lots of WSSS methods have been proposed to alleviate labeling cost. Various weak supervision forms have been explored, such as bounding boxes [10, 47], scribbles [38], point supervision [3], etc. Among them, image-level supervision, due to its less annotation demand, gains most attention and is also adopted in our approach.
Current popular solutions for WSSS with image-level supervision rely on network visualization techniques [78, 84], especially the Class Activation Map (CAM) [84], which discovers image pixels that are informative for classification. However, CAM typically only identifies small discriminative parts of objects. Therefore, numerous efforts are made towards expanding the CAM-highlighted regions to the whole objects. In particular, some representative approaches make use of image-level hiding and erasing operations to drive a classifier to focus on different parts of objects [32, 36, 69]. A few ones instead resort to a regions growing strategy, i.e., view the CAM-activated regions as initial “seeds” and gradually grow the seed regions until cover the complete objects [2, 24, 29, 64]. Meanwhile, some researchers investigate to directly enhance the activated regions on feature-level [33, 35, 71]. When constructing CAMs, they collect multi-scale context, which is achieved by dilated convolution [71], multi-layer feature fusion [35], saliency-guided iterative training [64], or stochastic feature selection [33]. Some others accumulate CAMs from multiple training phases [25], or self-train a difference detection network to complete the CAMs with trustable information [56]. In addition, a recent trend is to utilize class-agnostic saliency cues to filter out background responses [12, 24, 33, 36, 64, 69, 71] during pseudo ground-truth generation.
Since the supervision provided in above problem setting is so weak, another category of approaches explores to leverage more image-level supervision from other sources. There are mainly two types: (1) exploring simple and single-label examples [37, 50] (e.g., images from existing datasets [17, 53]); or (2) utilizing near-infinite yet noisy web-sourced image [20, 54, 55, 70] or video [20, 34, 59] data (also referred as webly supervised semantic segmentation [26]). In addition to the common challenge of domain gap between the extra data and target semantic segmentation dataset, the second-type methods need to handle data noise.
Past efforts only consider each image individually, while only few exceptions [12, 54] address cross-image information. [54] simply applies off-the-shelf co-segmentation [27] over the web images to generate foreground priors, instead of ours encoding the semantic relations into network learning and inference. For [12], although also exploiting correlations within image pairs, the core idea is to use extra information from a support image to supplement current visual representations. Thus the two images are expected to better contain the same semantics, and unmatched semantics would bring negative influences. In contrast, we view both semantic homogeneity and difference as informative cues, driving our classifier to more explicitly identify the common as well as unshared objects, respectively. Moreover, [12] only utilizes single image to infer the activated objects, but our method comprehensively leverages the cross-image semantics in both classifier training and localization map inference stages. More essentially, our framework is neat and flexible, which is not only able to learn WSSS from clean image-level supervision, but general enough to naturally make use of extra noisy web-crawled or simple single-label data, contrarily to previous efforts which are limited to specific training settings and largely dependent on complicated optimization methods [20, 59] or heuristic constraints [55].
Deterministic Neural Attention. Differentiable attention mechanisms enable a neural network to focus more on relevant elements of the input than on irrelevant parts. With their popularity in the field of natural language processing [8, 39, 43, 49, 60], attention modeling is rapidly adopted in various computer vision tasks, such as image recognition [14, 23, 58, 65, 72], domain adaptation [66, 82], human pose estimation [9, 63, 76], object detection [4] and image generation [75, 80, 85]. Further, co-attention mechanisms become an essential tool in many vision-language applications and sequential modeling tasks, such as visual question answering [41, 44, 74, 77], visual dialog [73, 83], vision-language navigation [67], and video segmentation [42, 61], showing its effectiveness in capturing the underlying relations between different entities. Inspired by the general idea of attention mechanisms, this work leverages co-attention to mine semantic relations within training image pairs, which helps the classifier network learn complete object patterns and generate precise object localization maps.
3 Methodology
Problem Setup. Here we follow current popular WSSS pipelines: given a set of training images with image-level labels, a classification network is first trained to discover corresponding discriminative object regions. The resulting object localization maps over the training samples are refined as pseudo ground-truth masks to further supervise the learning of a semantic segmentation network.
Our Idea. Unlike most previous efforts that treat each training image individually, we explore cross-image semantic relations as class-level context for understanding object patterns more comprehensively. To achieve this, two neural co-attentions are designed. The first one drives the classifier to learn common semantics from the co-attentive object regions, while the other one enforces the classifier to focus on the rest objects for unshared semantics classification.
3.1 Co-attention Classification Network
Let us denote the training data as \(\mathcal {I}=\{(\textit{\textbf{I}}_n,\textit{\textbf{l}}_n)\}_n\), where \(\textit{\textbf{I}}_n\) is the \(n^{th}\) training image, and \(\textit{\textbf{l}}_{n}\in \{0,1\}^K\) is the associated ground-truth image label for K semantic categories. As shown in Fig. 2(a), image pairs, i.e., \((\textit{\textbf{I}}_m,\textit{\textbf{I}}_n)\), are sampled from \(\mathcal {I}\) for training the classifier. After feeding \(\textit{\textbf{I}}_m\) and \(\textit{\textbf{I}}_n\) into the convolutional embedding part of the classifier, corresponding feature maps, \(\textit{\textbf{F}}_{m\!}\!\in ~\!\!\mathbb {R}^{C\times H\times W\!}\) and \(\textit{\textbf{F}}_{n\!}\!\in ~\!\!\mathbb {R}^{C\times H\times W\!}\), are obtained, each with \(H\times W\) spatial dimension and C channels.
As in [25, 33, 34], we can first separately pass \(\textit{\textbf{F}}_{m}\) and \(\textit{\textbf{F}}_{n}\) to a class-aware fully convolutional layer \(\varphi (\cdot )\) to generate class-aware activation maps, i.e., \(\textit{\textbf{S}}_{m\!}=\varphi (\textit{\textbf{F}}_{m})\!\in \!\mathbb {R}^{K\times H\times W\!}\) and \(\textit{\textbf{S}}_{n\!}=\varphi (\textit{\textbf{F}}_{n})\!\in \!\mathbb {R}^{K\times H\times W\!}\), respectively. Then, we apply global average pooling (GAP) over \(\textit{\textbf{S}}_{m}\) and \(\textit{\textbf{S}}_{n}\) to obtain class score vectors \(\textit{\textbf{s}}_{m\!}\!\in \!\mathbb {R}^{K\!}\) and \(\textit{\textbf{s}}_{n\!}\!\in \!\mathbb {R}^{K\!}\) for \(\textit{\textbf{I}}_{m\!}\) and \(\textit{\textbf{I}}_n\), respectively. Finally, the sigmoid cross entropy (CE) loss is used for supervision:
So far the classifier is learned in a standard manner, i.e., only individual-image information is used for semantic learning. One can directly use the activation maps to supervise next-stage semantic segmentation learning, as done in [24, 34]. Differently, our classifier additionally utilizes a co-attention mechanism for further mining cross-image semantics and eventually better localizing objects.

(a) In addition to mining object semantics from single-image labels, semantic similarities and differences between paired training images are both leveraged for supervising object pattern learning. (b) Co-attentive and contrastive co-attentive features complimentarily capture the shared and unshared objects. (c) Our co-attention classifier is able to learn object patterns more comprehensively. Zoom-in for details.
Co-attention for Cross-Image Common Semantics Mining. Our co-attention attends to the two images, i.e., \(\textit{\textbf{I}}_m\) and \(\textit{\textbf{I}}_n\), simultaneously, and captures their correlations. We first compute the affinity matrix \(\textit{\textbf{P}}\) between \(\textit{\textbf{F}}_{m}\) and \(\textit{\textbf{F}}_{n}\):
where \(\textit{\textbf{F}}_{m\!}\!\in \!\mathbb {R}^{C\times HW\!\!}\) and \(\textit{\textbf{F}}_{n\!}\!\in \!\mathbb {R}^{C\times HW\!\!}\) are flattened into matrix formats, and \(\textit{\textbf{W}}_{\!\textit{\textbf{P}}}\!\in \!\mathbb {R}^{C\times C\!}\) is a learnable matrix. The affinity matrix \(\textit{\textbf{P}}\) stores similarity scores corresponding to all pairs of positions in \(\textit{\textbf{F}}_{m}\) and \(\textit{\textbf{F}}_{n}\), i.e., the \((i,j)^{th}\) element of \(\textit{\textbf{P}}\) gives the similarity between \(i^{th}\) location in \(\textit{\textbf{F}}_{m}\) and \(j^{th}\) location in \(\textit{\textbf{F}}_{n}\).
Then \(\textit{\textbf{P}}\) is normalized column-wise to derive attention maps across \(\textit{\textbf{F}}_{m\!}\) for each position in \(\textit{\textbf{F}}_{n}\), and row-wise to derive attention maps across \(\textit{\textbf{F}}_{n\!}\) for each position in \(\textit{\textbf{F}}_{m}\):
where softmax is performed column-wise. In this way, \(\textit{\textbf{A}}_n\) and \(\textit{\textbf{A}}_m\) store the co-attention maps in their columns. Next, we can compute attention summaries of \(\textit{\textbf{F}}_{m}\) (\(\textit{\textbf{F}}_{n}\)) in light of each position of \(\textit{\textbf{F}}_{n}\) (\(\textit{\textbf{F}}_{m}\)):
where \(\textit{\textbf{F}}^{m\cap n\!}_{m}\) and \(\textit{\textbf{F}}^{m\cap n}_{n}\) are reshaped into \(\mathbb {R}^{C\times W\times H}\). Co-attentive feature \(\textit{\textbf{F}}^{m\cap n}_m\), derived from \(\textit{\textbf{F}}_{n}\), preserves the common semantics between \(\textit{\textbf{F}}_{m\!}\) and \(\textit{\textbf{F}}_{n\!}\) and locate the common objects in \(\textit{\textbf{F}}_{m}\). Thus we can expect only the common semantics \(\textit{\textbf{l}}_{m\!}\cap \textit{\textbf{l}}_{n}\)Footnote 1 can be safely derived from \(\textit{\textbf{F}}^{m\cap n}_{m}\), and the same goes for \(\textit{\textbf{F}}^{m\cap n}_{n}\). Such co-attention based common semantic classification can let the classifier understand the object patterns more completely and precisely.
To make things intuitive, consider the example in Fig. 2, where \(\textit{\textbf{I}}_m\) contains Table and Person, and \(\textit{\textbf{I}}_n\) has Cow and Person. As the co-attention is essentially the affinity computation between all the position pairs between \(\textit{\textbf{I}}_m\) and \(\textit{\textbf{I}}_n\), only the semantics of the common objects, Person, will be preserved in the co-attentive features, i.e., \(\textit{\textbf{F}}^{m\cap n\!}_{m}\) and \(\textit{\textbf{F}}^{m\cap n\!}_{n}\) (see Fig. 2(b)). If we feed \(\textit{\textbf{F}}^{m\cap n}_{m}\) and \(\textit{\textbf{F}}^{m\cap n}_{n}\) into the class-aware fully convolutional layer \(\varphi \), the generated class-aware activation maps, i.e., \(\textit{\textbf{S}}^{m\cap n\!}_{m}=\varphi (\textit{\textbf{F}}^{m\cap n\!}_{m})_{\!}\!\in _{\!}\!\mathbb {R}^{K\times H\times W\!\!}\) and \(\textit{\textbf{S}}^{m\cap n\!}_{n}\!=_{\!}\!\varphi (\textit{\textbf{F}}^{m\cap n\!}_{n})_{\!}\!\in _{\!}\!\mathbb {R}^{K\times H\times W\!\!}\), are able to locate the common object Person in \(\textit{\textbf{I}}_{m\!}\) and \(\textit{\textbf{I}}_n\), respectively. After GAP, the predicted semantic classes (scores) \(\textit{\textbf{s}}^{m\cap n}_{m}\!\in \!\mathbb {R}^{K\!}\) and \(\textit{\textbf{s}}^{m\cap n}_{n}\!\in \!\mathbb {R}^{K\!}\) should be the common semantic labels \(\textit{\textbf{l}}_{m\!}\cap \textit{\textbf{l}}_{n}\) of \(\textit{\textbf{I}}_{m\!}\) and \(\textit{\textbf{I}}_n\), i.e., Person.
Through co-attention computation, not only the human face, the most discriminative part of Person, but also other parts, such as legs and arms, are highlighted in \(\textit{\textbf{F}}^{m\cap n}_{m}\) and \(\textit{\textbf{F}}^{m\cap n}_{n}\) (see Fig. 2(b)). When we set the common class labels, i.e., Person, as the supervision signal, the classifier would realize that the semantics preserved in \(\textit{\textbf{F}}^{m\cap n}_{m}\) and \(\textit{\textbf{F}}^{m\cap n}_{n}\) are related and can be used to recognize Person. Therefore, the co-attention, computed across two related images, explicitly helps the classifier associate semantic labels and corresponding object regions and better understand the relations between different object parts. It essentially makes full use of the context across training data.
Intuitively, for the co-attention based common semantic classification, the labels \(\textit{\textbf{l}}_{m\!}\cap \textit{\textbf{l}}_n\) shared between \(\textit{\textbf{I}}_m\) and \(\textit{\textbf{I}}_n\) are used to supervise learning:
Contrastive Co-attention for Cross-Image Exclusive Semantics Mining. Aside from the co-attention described above that explores cross-image common semantics, we propose a contrastive co-attention that mines semantic differences between paired images. The co-attention and contrastive co-attention complementarily help the classifier better understand the concept of the objects.
As shown in Fig. 2(a), for \(\textit{\textbf{I}}_m\) and \(\textit{\textbf{I}}_n\), we first derive class-agnostic co-attentions from their co-attentive features, i.e., \(\textit{\textbf{F}}^{m\cap n\!}_{m}\) and \(\textit{\textbf{F}}^{m\cap n\!}_{n}\), respectively:
where \(\sigma (\cdot )\) is the sigmoid activation function, and the parameter matrix \(\textit{\textbf{W}}_{\textit{\textbf{B}}}\!\in \!\mathbb {R}^{1\times C}\) learns for common semantics collection and is implemented by a convolutional layer with \(1\times 1\) kernel. \(\textit{\textbf{B}}^{m\cap n}_{m\!}\) and \(\textit{\textbf{B}}^{m\cap n}_{n\!}\) are class-agnostic and highlight all the common object regions in \(\textit{\textbf{I}}_{m\!}\) and \(\textit{\textbf{I}}_{n}\), respectively, based on which we derive contrastive co-attentions:
The contrastive co-attention \(\textit{\textbf{A}}^{m\!\setminus \!n}_{m}\) of \(\textit{\textbf{I}}_m\), as its superscript suggests, addresses those unshared object regions that are only of \(\textit{\textbf{I}}_m\), but not of \(\textit{\textbf{I}}_n\), and the same goes for \(\textit{\textbf{A}}^{n\!\setminus \!m}_{n}\). Then we get contrastive co-attentive features, i.e., unshared semantics in each images:
‘\(\otimes \)’ denotes element-wise multiplication, where the attention values are copied along the channel dimension. Next, we can sequentially get class-aware activation maps, i.e., \(\textit{\textbf{S}}^{m\!\setminus \! n\!}_{m}\!=_{\!}\!\varphi (\textit{\textbf{F}}^{m\!\setminus \! n}_{m})\!\in \!\mathbb {R}^{K\times H\times W}\) and \(\textit{\textbf{S}}^{n\!\setminus \! m\!}_{n}\!=_{\!}\!\varphi (\textit{\textbf{F}}^{n\!\setminus \! m}_{n})\!\in \!\mathbb {R}^{K\times H\times W}\), and semantic scores, i.e., \(\textit{\textbf{s}}^{m\!\setminus \! n\!}_{m}=\text {GAP}(\textit{\textbf{S}}^{m\!\setminus \! n}_{m})\!\in \!\mathbb {R}^{K\!}\) and \(\textit{\textbf{s}}^{n\!\setminus \! m\!}_{n}=\text {GAP}(\textit{\textbf{S}}^{n\!\setminus \! m}_{n})\!\in \!\mathbb {R}^{K}\). For \(\textit{\textbf{s}}^{m\!\setminus \! n}_{m}\) and \(\textit{\textbf{s}}^{n\!\setminus \! m}_{n}\), they are expected to identify the categories of the unshared objects, i.e., \(\textit{\textbf{l}}_{m\!}\!\setminus \!\textit{\textbf{l}}_n\) and \(\textit{\textbf{l}}_{n\!}\!\setminus \!\textit{\textbf{l}}_m\)Footnote 2.
Compared with the co-attention that investigates common semantics as informative cues for boosting object patterns mining, the contrastive co-attention addresses complementary knowledge from the semantic differences between paired images. Figure 2(b) gives an intuitive example. After computing the contrastive co-attentions between \(\textit{\textbf{I}}_m\) and \(\textit{\textbf{I}}_n\) (Eq. 7), Table and Cow, which are unique in their original images, are highlighted. Based on the contrastive co-attentive features, i.e., \(\textit{\textbf{F}}^{m\!\setminus \! n}_{m}\) and \(\textit{\textbf{F}}^{n\!\setminus \! m}_{n}\), the classifier is required to accurately recognize Table and Cow classes, respectively. When the common objects are filtered out by the contrastive co-attentions, the classifier has a chance to focus more on the rest image regions and mine the unshared semantics more consciously. This also helps the classifier better discriminate the semantics of different objects, as the semantics of common objects and unshared ones are disentangled by the contrastive co-attention. For example, if some parts of Cow are wrongly recognized as Person-related, the contrastive co-attention will discard these parts in \(\textit{\textbf{F}}^{n\!\setminus \! m}_{n}\). However, the rest semantics in \(\textit{\textbf{F}}^{n\!\setminus \! m}_{n}\) may be not sufficient enough for recognizing Cow. This will enforce the classifier to better discriminate different objects.
For the contrastive co-attention based unshared semantic classification, the supervision loss is designed as:
More In-depth Discussion. One can interpret our co-attention classifier from a view of auxiliary-task learning [16, 45], which is investigated in self-supervised learning field to improve data efficiency and robustness, by exploring auxiliary tasks from inherent data structures. In our case, rather than the task of single-image semantic recognition which has been extensively studied in conventional WSSS methods, we explore two auxiliary tasks, i.e., predicting the common and uncommon semantics from image pairs, for fully mining supervision signals from weak supervision. The classifier is driven to better understand the cross-image semantics by attending to (contrastive) co-attentive features, instead of only relying on intra-image information (see Fig. 2(c)). In addition, such strategy shares a spirit of image co-segmentation [42, 62]. Since the image-level semantics of training set are given, the knowledge about some images share or unshare certain semantics should be used as a cue, or supervision signal, to better locate corresponding objects. Our co-attention based learning pipeline also provides an efficient data augmentation strategy, due to the use of paired samples, whose amount is near the square of the number of single training images.
3.2 Co-attention Classifier Guided WSSS Learning
Training Co-attention Classifier. The overall training loss for our co-attention classifier ensembles the three terms defined in Eqs. 1, 5, and 9:
The coefficients of different loss terms are set as 1 in our all experiments. During training, to fully leverage the co-attention to mine the common semantics, we sample two images \((\textit{\textbf{I}}_m, \textit{\textbf{I}}_n)\) with at least one common class, i.e., \(\textit{\textbf{l}}_m\cap \textit{\textbf{l}}_n\!\ne \!\mathbf {0}\).
Generating Object Localization Maps. Once our image classifier is trained, we apply it over the training data \(\mathcal {I}=\{(\textit{\textbf{I}}_n,\textit{\textbf{l}}_n)\}_n\) to produce corresponding object localization maps, which are essential for semantic segmentation network training. We explore two different strategies to generate localization maps.
-
Single-round feed-forward prediction, made over each training image individually. For each training image \(\textit{\textbf{I}}_n\), running the classifier and directly using its class-aware activation map (i.e., \(\textit{\textbf{S}}_{n\!}\!\in \!\mathbb {R}^{K\times H\times W}\)) as the object localization map \(\textit{\textbf{L}}_{n}\), as most previous network visualization based methods [25, 34, 55] done.
-
Multi-round co-attentive prediction with extra reference information, which is achieved by considering extra information from other related training images (see Fig. 1(c)). Specifically, given a training image \(\textit{\textbf{I}}_n\) and its associated label vector \(\textit{\textbf{l}}_n\), we generate its localization map \(\textit{\textbf{L}}_{n\!}\) in a class-wise manner. For each semantic class \(k\!\in \!\{1,\cdots ,K\}\) labeled for \(\textit{\textbf{I}}_n\), i.e., \(l_{n,k}=1\) and \(l_{n,k}\) is the \(k^{th}\) element of \(\textit{\textbf{l}}_n\), we sample a set of related images \(\mathcal {R}=\{\textit{\textbf{I}}_r\}_r\) from \(\mathcal {I}\), which are also annotated with label k, i.e., \(l_{r,k}=1\). Then we compute the co-attentive feature \(\textit{\textbf{F}}^{m\cap r}_{n\!}\) from each related image \(\textit{\textbf{I}}_r\!\in \!\mathcal {R}\) to \(\textit{\textbf{I}}_n\), and get the co-attention based class-aware activation map \(\textit{\textbf{S}}^{m\cap r}_{n\!}\). Given all the class-aware activation maps \(\{\textit{\textbf{S}}^{m\cap r}_{n\!}\}_r\) from \(\mathcal {R}\), they are integrated to infer the localization map only for class k, i.e., \(L_{n,k\!}=\frac{1}{|\mathcal {R}|}\!\sum _{r\in \mathcal {R}\!}S^{m\cap r}_{n,k\!}\!\). Here \(L_{n,k\!}\!\in \!\mathbb {R}^{H\times W\!}\) and \(S^{(\cdot )}_{n,k\!}\!\in \!\mathbb {R}^{H\times W\!}\) indicate the feature map at \(k^{th\!}\) channel of \(\textit{\textbf{L}}_{n\!}\!\in \!\mathbb {R}^{K\times H\times W\!}\) and \(\textit{\textbf{S}}^{(\cdot )}_{n\!}\!\in \!\mathbb {R}^{K\times H\times W\!}\), respectively. ‘\(|\cdot |\)’ numerates the elements. After inferring the localization maps for all the annotated semantic classes of \(\textit{\textbf{I}}_n\), we can get \(\textit{\textbf{L}}_{n}\).
These two localization map generation strategies are studied in our experiments (Sect. 4.4), and the last one is more favored, as it uses both intra- and inter-image semantics for object inference, and shares a similar data distribution of the training phase. One may notice that the contrastive co-attention is not used here. This is because contrastive co-attentive feature (Eq. 8) is from its original image, which is effective for boosting feature representation learning during classifier training, while contributes little for localization maps inference (with limited cross-image information). Related experiments can be found at Sect. 4.4.
Learning Semantic Segmentation Network. After obtaining high-quality localization maps, we generate pseudo pixel-wise labels for all the training samples \(\mathcal {I}\), which can be used to train arbitrary semantic segmentation network. For pseudo groundtruth generation, we follow current popular pipeline [22, 24, 25, 33, 34, 79], that uses localization maps to extract class-specific object cues and adopts saliency maps [21, 40] to get background cues. For the semantic segmentation network, as in [22, 25, 33, 34], we choose DeepLab-LargeFOV [6].
Learning with Extra Simple Single-Label Images. Some recent efforts [37, 50] are made towards exploring extra simple single-label images from other existing datasets [17, 53] for further boosting WSSS. Though impressive, specific network designs are desired, due to the issue of domain gap between additionally used data and the target complex multi-label dataset, i.e., PASCAL VOC 2012 [11]. Interestingly, our co-attention based WSSS algorithm provides an alternate that addresses the challenge of domain gap naturally. Here we revisit the computation of co-attention in Eq. 2. When \(\textit{\textbf{I}}_m\) and \(\textit{\textbf{I}}_n\) are from different domains, the parameter matrix \(\textit{\textbf{W}}_{\!\textit{\textbf{P}}}\), in essence, learns to map them into a unified common semantic space [46] and the co-attentive features can capture domain-shared semantics. Therefore, for such setting, we learn three different parameter matrixes for \(\textit{\textbf{W}}_{\!\textit{\textbf{P}}}\), for the cases where \(\textit{\textbf{I}}_m\) and \(\textit{\textbf{I}}_n\) are from (1) the target semantic segmentation domain, (2) the one-label image domain, and (3) two different domains, respectively. Thus the domain adaption is efficiently achieved as a part of co-attention learning. We conduct related experiments in Sect. 4.2.
Learning with Extra Web Images. Another trend of methods [20, 26, 55, 70] address webly supervised semantic segmentation, i.e., leveraging web images as extra training samples. Though cheaper, web data are typically noisy. To handle this, previous arts propose diverse effective yet sophisticated solutions, such as multi-stage training [26] and self-paced learning [70]. Our co-attention based WSSS algorithm can be easily extended to this setting and solve data noise elegantly. As our co-attention classifier is trained with paired images, instead of previous methods only relying on each image individually, our model provides a more robust training paradigm. In addition, during localization map inference, a set of extra related images are considered, which provides more comprehensive and accurate cues, and further improves the robustness. We experimentally demonstrate the effectiveness of our method in such a setting in Sect. 4.3.
3.3 Detailed Network Architecture
Network Configuration. In line with conventions [25, 71, 81], our image classifier is based on ImageNet [31] pre-trained VGG-16 [57]. For VGG-16 network, the last three fully-connected layers are replaced with three convolutional layers with 512 channels and kernel size \(3\times 3\), as done in [25, 81]. For the semantic segmentation network, for fair comparison with current top-leading methods [2, 25, 33, 56], we adopt the ResNet-101 [19] version Deeplab-LargeFOV architecture.
Training Phases of the Co-attention Classifier and Semantic Segmentation Network. Our co-attention classifier is fully end-to-end trained by minimizing the loss defined in Eq. 10. The training parameters are set as: initial learning rate (0.001) which is reduced by 0.1 after every 5 epochs, batch size (5), weight decay (0.0002), and momentum (0.9). Once the classifier is trained, we generate localization maps and pseudo segmentation masks over all the training samples (see Sect. 3.2). Then, with the masks, the semantic segmentation network is trained in a standard way [25] using the hyper-parameter setting in [6].
Inference Phase of the Semantic Segmentation Network. Given an unseen test image, our segmentation network works in the standard semantic segmentation pipeline [6], i.e., directly generating segments without using any other images. Then CRF [30] post-processing is performed to refine predicted masks.
4 Experiment
Overview. Experiments are first conducted over three different WSSS settings: (1) The most standard paradigm [24, 25, 56, 69] that only allows image-level supervision from PASCAL VOC 2012 [11] (see Sect. 4.1). (2) Following [37, 50], additional single-label images can be used, yet bringing the challenge of domain gap (see Sect. 4.2). (3) Webly supervised semantic segmentation paradigm [26, 34, 55], where extra web data can be accessed (see Sect. 4.3). Then, in Sect. 4.4, ablation studies are made to assess the effectiveness of essential parts of our algorithm.
Evaluation Metric. In our experiments, the standard intersection over union (IoU) criterion is reported on the val and test sets of PASCAL VOC 2012 [11]. The scores on test set are obtained from official PASCAL VOC evaluation server.
4.1 Experiment 1: Learn WSSS only from PASCAL VOC [11] Data
Experimental Setup: We first conduct experiment following the most standard setting that learns WSSS with only image-level labels [24, 25, 56, 69], i.e., only image-level supervision from PASCAL VOC 2012 [11] is accessible. PASCAL VOC 2012 contains a total of 20 object categories. As in [6, 69], augmented training data from [18] are also used. Finally, our model is trained on totally 10,582 samples with only image-level annotations. Evaluations are conducted on the val and test sets, which have 1,449 and 1,456 images, respectively.
Experimental Results: Table 1a compares our approach and current top-leading WSSS methods with image-level supervision, on both PASCAL VOC12 val and test sets. We can observe that our method achieves mIoU scores of 66.2 and 66.9 on val and test sets respectively, outperforming all the competitors. The performance of our method is 87% of the DeepLab-LargeFOV [6] trained with fully annotated data, which achieved an mIoU of 76.3 on val set. When compared to OAA+ [25], current best-performing method, our approach obtains the improvement of 1.0% on val set. This verifies that the localization maps produced by our co-attention classifier effectively detect more complete semantic regions towards the whole target objects. Note that our network is elegantly trained end-to-end in a single phase. In contrast, many other recent approaches use extra networks [2, 25, 56] to learn auxiliary information (e.g., integral attention [25], pixel-wise semantic affinity [56], etc.), or adopt multi-step training [1, 69, 71].
4.2 Experiment 2: Learn WSSS With Extra Simple Single-Label Data
Experimental Setup: Following [37, 50], we train our co-attention classifier and segmentation network with PASCAL images and extra single-label images. The extra single-label images are borrowed from the subsets of Caltech-256 [17] and ImageNet CLS-LOC [53], and whose annotations are within 20 VOC object categories. There are a total of 20,057 extra single-label images.
Experimental Results: The comparisons are shown in Table 1b. Our method significantly improves the most recent method (i.e., AttnBN [37]) in this setting by 5.0% and 4.2% in val and test sets, respectively. With the fact that objects of the same category but from different domains share similar visual patterns [37], our co-attention provides an end-to-end strategy that efficiently captures the common, cross-domain semantics, and learns domain adaption naturally. Even AttnBN is specifically designed for addressing such setting by knowledge transfer, our method still suppresses it by a large margin. Compared with the setting in Sect. 4.1 where only PASCAL images are used for training, our method obtains improvements on both val and test sets, verifying that it successfully mines knowledge from extra simple single-label data and copes with domain gap well.
4.3 Experiment 3: Learn WSSS with Extra Web-Sourced Data
Experimental Setup: We also conduct experiments using both PASCAL VOC images and webly craweled images as training data. We use the web data provided by [55], which are retrieved from Bing based on class names. The final dataset contains 76,683 images across 20 PASCAL VOC classes.
Experimental Results: Table 1c gives performance comparisons with previous webly supervised segmentation methods. As seen our method outperforms all other approaches and sets new state-of-the-arts with mIoU score of 67.7 and 67.5 on PASCAL VOC 2012 val and test sets, respectively. Among the compared methods, Hong et al. [20] utilize richer information of the temporal dynamics provided by additional large-scale videos. In contrast, although only using static data, our method still outperforms it on the val and test sets by 9.6% and 8.8%, respectively. Compared with Shen et al. [55] using the same web data as ours, our method substantially improves it by a clear margin of 3.6% on the test set.
4.4 Ablation Studies
Inference Strategies. Table 2 shows mIoU scores on PASCAL VOC 2012 val set w.r.t. different inference modes (see Sect. 3.2). When using the traditional inference mode “single-round feed-forward”, our method substantially suppresses basic classifier, by improving mIoU score from 61.7 to 64.7. This evidences that co-attention mechanism (trained in an end-to-end manner) in our classifier improves the underlying feature representations and more object regions are identified by the network. We can observe that by using more images to generate localization maps, our method obtains consistent improvement from “Test image only” (64.7), to “Test images and other related images” (66.2). This is because more semantic context are exploited during localization map inference. In addition, using contrastive co-attention for localization map inference doesn’t boost performance (66.2). This is because the contrastive co-attentive features for one image are derived from the image itself. In contrast, co-attentive features are from the other related image, thus can be effective in the inference stage.
(Contrastive) Co-attention. As seen in Table 3, by only using co-attention (Eq. 5), we already largely suppress the basic classifier (Eq. 1) by 3.8%. When adding additional contrastive co-attention (Eq. 9), we obtain mIoU improvement of 0.7%. Above analysis verify our two co-attentions indeed boost performance.
Number of Related Images for Localization Map Inference. For localization map generation, we use 3 extra related images (Sect. 3.2). Here, we study how the number of reference images affect the performance. From Table 4, it is easily observed that when increasing the number of related images from 0 to 3, the performance gets boosted consistently. However, when further using more images, the performance degrades. This can be attributed to the trade-off between useful semantic information and noise brought by related images. From 0 to 3 reference images, more semantic information is used and more integral regions for objects are mined. When further using more related images, useful information reaches its bottleneck and noise, caused by imperfect localization of the classifier, takes over, decreasing performance.
5 Conclusion
This work proposes a co-attention classification network to discover integral object regions by addressing cross-image semantics. With this regard, a co-attention is exploited to mine the common semantics within paired samples, while a contrastive co-attention is utilized to focus on the exclusive and unshared ones for capturing complimentary supervision cues. Additionally, by leveraging extra context from other related images, the co-attention boosts localization map inference. Further, by exploiting additional single-label images and web images, our approach is proven to generalize well under domain gap and data noise. Experiments over three WSSS settings consistently show promising results.
Notes
- 1.
The set operation ‘\(\cap \)’ is slightly extended here to represent bitwise-and.
- 2.
The set operation ‘\(\setminus \)’ is slightly extend here, i.e., \(\textit{\textbf{l}}_{n\!}\!\setminus \!\textit{\textbf{l}}_m=\textit{\textbf{l}}_{n\!}-\textit{\textbf{l}}_{n\!}\cap \textit{\textbf{l}}_m\).
References
Ahn, J., Cho, S., Kwak, S.: Weakly supervised learning of instance segmentation with inter-pixel relations. In: CVPR (2019)
Ahn, J., Kwak, S.: Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation. In: CVPR (2018)
Bearman, A., Russakovsky, O., Ferrari, V., Fei-Fei, L.: What’s the point: semantic segmentation with point supervision. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9911, pp. 549–565. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46478-7_34
Cao, J., Pang, Y., Li, X.: Triply supervised decoder networks for joint detection and segmentation. In: CVPR (2019)
Chaudhry, A., Dokania, P.K., Torr, P.H.: Discovering class-specific pixels for weakly-supervised semantic segmentation. In: BMVC (2017)
Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. TPAMI 40(4), 834–848 (2017)
Chen, L.-C., Zhu, Y., Papandreou, G., Schroff, F., Adam, H.: Encoder-decoder with atrous separable convolution for semantic image segmentation. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11211, pp. 833–851. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01234-2_49
Cheng, J., Dong, L., Lapata, M.: Long short-term memory-networks for machine reading. In: EMNLP (2016)
Chu, X., Yang, W., Ouyang, W., Ma, C., Yuille, A.L., Wang, X.: Multi-context attention for human pose estimation. In: CVPR (2017)
Dai, J., He, K., Sun, J.: BoxSup: exploiting bounding boxes to supervise convolutional networks for semantic segmentation. In: ICCV (2015)
Everingham, M., Eslami, S.A., Van Gool, L., Williams, C.K., Winn, J., Zisserman, A.: The pascal visual object classes challenge: a retrospective. IJCV 111(1), 98–136 (2015)
Fan, J., Zhang, Z., Tan, T.: CIAN: cross-image affinity net for weakly supervised semantic segmentation. In: AAAI (2020)
Fang, H., Lu, G., Fang, X., Xie, J., Tai, Y., Lu, C.: Weakly and semi supervised human body part parsing via pose-guided knowledge transfer. In: CVPR (2018)
Fu, J., et al.: Dual attention network for scene segmentation. In: CVPR (2019)
Ge, W., Yang, S., Yu, Y.: Multi-evidence filtering and fusion for multi-label classification, object detection and semantic segmentation based on weakly supervised learning. In: CVPR (2018)
Gidaris, S., Singh, P., Komodakis, N.: Unsupervised representation learning by predicting image rotations. In: ICLR (2018)
Griffin, G., Holub, A., Perona, P.: Caltech-256 object category dataset (2007)
Hariharan, B., Arbeláez, P., Bourdev, L., Maji, S., Malik, J.: Semantic contours from inverse detectors. In: ICCV (2011)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
Hong, S., Yeo, D., Kwak, S., Lee, H., Han, B.: Weakly supervised semantic segmentation using web-crawled videos. In: CVPR (2017)
Hou, Q., Cheng, M.M., Hu, X., Borji, A., Tu, Z., Torr, P.: Deeply supervised salient object detection with short connections. TPAMI 41(4), 815–828 (2019)
Hou, Q., Jiang, P., Wei, Y., Cheng, M.M.: Self-erasing network for integral object attention. In: NeurIPS (2018)
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: CVPR (2018)
Huang, Z., Wang, X., Wang, J., Liu, W., Wang, J.: Weakly-supervised semantic segmentation network with deep seeded region growing. In: CVPR (2018)
Jiang, P.T., Hou, Q., Cao, Y., Cheng, M.M., Wei, Y., Xiong, H.K.: Integral object mining via online attention accumulation. In: ICCV (2019)
Jin, B., Ortiz Segovia, M.V., Susstrunk, S.: Webly supervised semantic segmentation. In: ICCV (2017)
Joulin, A., Bach, F., Ponce, J.: Discriminative clustering for image co-segmentation. In: CVPR (2010)
Kim, D., Cho, D., Yoo, D., So Kweon, I.: Two-phase learning for weakly supervised object localization. In: ICCV (2017)
Kolesnikov, A., Lampert, C.H.: Seed, expand and constrain: three principles for weakly-supervised image segmentation. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9908, pp. 695–711. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46493-0_42
Krähenbühl, P., Koltun, V.: Efficient inference in fully connected CRFs with Gaussian edge potentials. In: NeurIPS (2011)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural networks. In: NeurIPS (2012)
Kumar Singh, K., Jae Lee, Y.: Hide-and-seek: forcing a network to be meticulous for weakly-supervised object and action localization. In: ICCV (2017)
Lee, J., Kim, E., Lee, S., Lee, J., Yoon, S.: FickleNet: weakly and semi-supervised semantic image segmentation using stochastic inference. In: CVPR (2019)
Lee, J., Kim, E., Lee, S., Lee, J., Yoon, S.: Frame-to-frame aggregation of active regions in web videos for weakly supervised semantic segmentation. In: ICCV (2019)
Lee, S., Lee, J., Lee, J., Park, C.K., Yoon, S.: Robust tumor localization with pyramid grad-cam. arXiv preprint (2018)
Li, K., Wu, Z., Peng, K.C., Ernst, J., Fu, Y.: Tell me where to look: guided attention inference network. In: CVPR (2018)
Li, K., Zhang, Y., Li, K., Li, Y., Fu, Y.: Attention bridging network for knowledge transfer. In: ICCV (2019)
Lin, D., Dai, J., Jia, J., He, K., Sun, J.: ScribbleSup: scribble-supervised convolutional networks for semantic segmentation. In: CVPR (2016)
Lin, Z., et al.: A structured self-attentive sentence embedding. In: ICLR (2017)
Liu, J.J., Hou, Q., Cheng, M.M., Feng, J., Jiang, J.: A simple pooling-based design for real-time salient object detection. In: CVPR (2019)
Lu, J., Yang, J., Batra, D., Parikh, D.: Hierarchical question-image co-attention for visual question answering. In: NeurIPS (2016)
Lu, X., Wang, W., Ma, C., Shen, J., Shao, L., Porikli, F.: See more, know more: unsupervised video object segmentation with co-attention Siamese networks. In: CVPR (2019)
Luong, M.T., Pham, H., Manning, C.D.: Effective approaches to attention-based neural machine translation. In: EMNLP (2015)
Nguyen, D.K., Okatani, T.: Improved fusion of visual and language representations by dense symmetric co-attention for visual question answering. In: CVPR (2018)
Odena, A., Olah, C., Shlens, J.: Conditional image synthesis with auxiliary classifier GANs. In: ICML (2017)
Pan, B., Cao, Z., Adeli, E., Niebles, J.C.: Adversarial cross-domain action recognition with co-attention. In: AAAI (2020)
Papandreou, G., Chen, L.C., Murphy, K.P., Yuille, A.L.: Weakly-and semi-supervised learning of a deep convolutional network for semantic image segmentation. In: ICCV (2015)
Pathak, D., Shelhamer, E., Long, J., Darrell, T.: Fully convolutional multi-class multiple instance learning. arXiv preprint (2014)
Paulus, R., Xiong, C., Socher, R.: A deep reinforced model for abstractive summarization. In: ICLR (2018)
Pinheiro, P.O., Collobert, R.: From image-level to pixel-level labeling with convolutional networks. In: CVPR (2015)
Qi, X., Liu, Z., Shi, J., Zhao, H., Jia, J.: Augmented feedback in semantic segmentation under image level supervision. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9912, pp. 90–105. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46484-8_6
Roy, A., Todorovic, S.: Combining bottom-up, top-down, and smoothness cues for weakly supervised image segmentation. In: CVPR (2017)
Russakovsky, O., et al.: ImageNet large scale visual recognition challenge. IJCV 115(3), 211–252 (2015)
Shen, T., Lin, G., Liu, L., Shen, C., Reid, I.: Weakly supervised semantic segmentation based on web image co-segmentation. In: BMVC (2017)
Shen, T., Lin, G., Shen, C., Reid, I.: Bootstrapping the performance of webly supervised semantic segmentation. In: CVPR (2018)
Shimoda, W., Yanai, K.: Self-supervised difference detection for weakly-supervised semantic segmentation. In: ICCV (2019)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint (2014)
Sun, M., Yuan, Y., Zhou, F., Ding, E.: Multi-attention multi-class constraint for fine-grained image recognition. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11220, pp. 834–850. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01270-0_49
Tokmakov, P., Alahari, K., Schmid, C.: Weakly-supervised semantic segmentation using motion cues. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9908, pp. 388–404. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46493-0_24
Vaswani, A., et al.: Attention is all you need. In: NeurIPS (2017)
Wang, W., Lu, X., Shen, J., Crandall, D.J., Shao, L.: Zero-shot video object segmentation via attentive graph neural networks. In: ICCV (2019)
Wang, W., Shen, J.: Higher-order image co-segmentation. IEEE TMM 18(6), 1011–1021 (2016)
Wang, W., Zhu, H., Dai, J., Pang, Y., Shen, J., Shao, L.: Hierarchical human parsing with typed part-relation reasoning. In: CVPR (2020)
Wang, X., You, S., Li, X., Ma, H.: Weakly-supervised semantic segmentation by iteratively mining common object features. In: CVPR (2018)
Wang, X., Girshick, R., Gupta, A., He, K.: Non-local neural networks. In: CVPR (2018)
Wang, X., Li, L., Ye, W., Long, M., Wang, J.: Transferable attention for domain adaptation. In: AAAI (2019)
Wang, X., et al.: Reinforced cross-modal matching and self-supervised imitation learning for vision-language navigation. In: CVPR (2019)
Shimoda, W., Yanai, K.: Distinct class-specific saliency maps for weakly supervised semantic segmentation. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9908, pp. 218–234. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46493-0_14
Wei, Y., Feng, J., Liang, X., Cheng, M.M., Zhao, Y., Yan, S.: Object region mining with adversarial erasing: a simple classification to semantic segmentation approach. In: CVPR (2017)
Wei, Y.: STC: a simple to complex framework for weakly-supervised semantic segmentation. TPAMI 39(11), 2314–2320 (2016)
Wei, Y., Xiao, H., Shi, H., Jie, Z., Feng, J., Huang, T.S.: Revisiting dilated convolution: a simple approach for weakly-and semi-supervised semantic segmentation. In: CVPR (2018)
Woo, S., Park, J., Lee, J.-Y., Kweon, I.S.: CBAM: convolutional block attention module. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11211, pp. 3–19. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01234-2_1
Wu, Q., Wang, P., Shen, C., Reid, I., Van Den Hengel, A.: Are you talking to me? Reasoned visual dialog generation through adversarial learning. In: CVPR (2018)
Xiong, C., Zhong, V., Socher, R.: Dynamic coattention networks for question answering. In: ICLR (2017)
Xu, T., et al.: AttnGAN: fine-grained text to image generation with attentional generative adversarial networks. In: CVPR (2018)
Ye, Q., Yuan, S., Kim, T.-K.: Spatial attention deep net with partial PSO for hierarchical hybrid hand pose estimation. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9912, pp. 346–361. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46484-8_21
Yu, Z., Yu, J., Cui, Y., Tao, D., Tian, Q.: Deep modular co-attention networks for visual question answering. In: CVPR (2019)
Zeiler, M.D., Fergus, R.: Visualizing and understanding convolutional networks. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8689, pp. 818–833. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10590-1_53
Zeng, Y., Zhuge, Y., Lu, H., Zhang, L.: Joint learning of saliency detection and weakly supervised semantic segmentation. In: ICCV (2019)
Zhang, H., Goodfellow, I., Metaxas, D., Odena, A.: Self-attention generative adversarial networks. In: ICML (2019)
Zhang, X., Wei, Y., Feng, J., Yang, Y., Huang, T.S.: Adversarial complementary learning for weakly supervised object localization. In: CVPR (2018)
Zhang, Y., Nie, S., Liu, W., Xu, X., Zhang, D., Shen, H.T.: Sequence-to-sequence domain adaptation network for robust text image recognition. In: CVPR (2019)
Zheng, Z., Wang, W., Qi, S., Zhu, S.C.: Reasoning visual dialogs with structural and partial observations. In: CVPR (2019)
Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., Torralba, A.: Learning deep features for discriminative localization. In: CVPR (2016)
Zhu, Z., Huang, T., Shi, B., Yu, M., Wang, B., Bai, X.: Progressive pose attention transfer for person image generation. In: CVPR (2019)
Acknowledgements
This work was partially supported by Zhejiang Lab’s Open Fund (No. 2019KD0AB04), Zhejiang Lab’s International Talent Fund for Young Professionals, CCF-Tencent Open Fund, and grants from Beijing Academy of Artificial Intelligence (BAAI) (No. BAAI2020ZJ0205).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Sun, G., Wang, W., Dai, J., Van Gool, L. (2020). Mining Cross-Image Semantics for Weakly Supervised Semantic Segmentation. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, JM. (eds) Computer Vision – ECCV 2020. ECCV 2020. Lecture Notes in Computer Science(), vol 12347. Springer, Cham. https://doi.org/10.1007/978-3-030-58536-5_21
Download citation
DOI: https://doi.org/10.1007/978-3-030-58536-5_21
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-58535-8
Online ISBN: 978-3-030-58536-5
eBook Packages: Computer ScienceComputer Science (R0)