
Abstract
In this paper a driving mode estimation model based in machine learning architecture is presented. With the statistic method, Random Forest, the highest inference of driving variables is determined through the best attributes for a training model based in OBD II data. Engine sensors variables are obtained with the aim of explaining the behavior of the PID signals in relation to the driving mode of a person, according to specific consumption and engine performance, characterizing the signals behavior in relation to the different driving modes. The investigation consists of 4 power tests in the dynamometer bank at 25%, 50%, 75% and 100% throttle valve opening to determine the relationship between engine performance and normal vehicle circulation, through the engine most influential variables like MAP, TPS, VSS, Ax and each the transmission ratio infer in the fuel consumption study and engine performance. In this study Random Forest is used achieving an accuracy rate of 0.98905.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Facing the increase in environmental pollution caused by greenhouse gas emissions produced by combustion engines [1], electronic injection systems were implemented. Through the on-board diagnostic (OBD-II), available since 1994 [2], different variables of sensors are obtained, like longitudinal acceleration (Ax), Engine Speed (RPM), Vehicle Speed Sensor (VSS), Manifold Air Flow (MAF), Manifold Absolute Pressure (MAP) [3]. A methodology used to determine sensors behavior is carried out by driving modes study (Sport, Normal and ECO) where Lv et al. [4], highlight behaviors and interactions between the driver and the vehicle, these modes are identified according to driving styles by means of maneuvers [5], to estimate fuel consumption and polluting emissions [6]. Due to the average driver can increase efficiency by 10% simply by changing the driving mode [7], Hooker et al., in case of Eco drive mode, covers low consumption driving behaviors due to the accelerator pedal differential use [8], which influences in fuel economy and vehicle emissions to reduce its environmental impact [9]. In addition, an efficient driving mode is the main solution to reduce greenhouse gases emission produced by the vehicles [10]. According to Sivak et al., factors such as drivers decision respect to the vehicle maintenance or route selection influence in fuel economy [9], as well as making early gear changes avoid high speeds, reduce polluting emissions and fuel consumption [11, 12]. Lapuerta et al. [13], considers how it infers the altitude above sea level effect in internal combustion engines due to the air density that modifies its thermodynamic cycle and as consequence decreases the engine power, increases the polluting emissions and fuel consumption, considering Cuenca altitude, 2550 m.a.s.l. [14].
2 Materials and Methods
2.1 Experimental Overview
For the development of the present investigation, a review of previous researches was realized to propose an adequate data acquisition and analysis methodology. Zhou et al. [15], propose an optimization model of engine repair based on the classification of a Random Forest algorithm, which by adaptation and decision of more significant variables allows classifying engine real data, demonstrating that the more samples are trained the higher the classification accuracy. Considering the weight of applied variables can reach 79.1% of precision in the applied model. Damström et al. [16], propose a methodology that consists of finding the ideal number of groupings controlling similar characteristics between them by means of a cross correlation, but it has the disadvantage that it doesn’t guarantee to find a global minimum which the approximation of cluster centroid changes its results. Based in the Corcoba et al. methodology [17], a diffuse logic system was used to simulate human behavior to estimate an efficient driver behavior by input and output variables, its output is rated with a classification between 0 to 1 depending how efficient the driving is, the proposal characterized the driving style by the data acquisition through telemetry. Pereira et al. [18], present a mobile application based on diffuse logic, through OBD-II data acquisition to characterize the driving efficiency by estimating the specific consumption with an accuracy of 85% in this model.
Oñate et al. [19], propose an intelligent system of erratic driving diagnosis through OBD-II and GPS data acquisition, which proposes reduce accidents by extracting driving signals, mathematical signal analysis and driving fault detection through Neural Networks, evaluating the model they guaranteed its viability and reliability. Chen et al. [20], present a semi – supervised classification method through a Support Vector Machine (SVM) algorithm, by data acquisition of velocity and engine speed data by OBD II from gasoline and diesel passengers vehicles with the vehicle identification number (VIN), it can classify the vehicles through a specific classification rule, whose purpose is applying to vehicles with internet connection and to improve estimation of CO2 emissions. Corcoba et al. present an efficient driving model through OBD-II data acquisition by a smartphone which provides ecological driving suggestions to the driver for bad driving habits, with the aim of improve the driving style through the efficiency consumption by algorithms such as J48 [21], Naïve Bayes and Random Forest, where the last one allows a better control of random attributes for each node and was selected because its execution time is less than J48, especially when the attributes number or the training set is bigger with a classification certainty of 83.17 and 71.15% respectively.
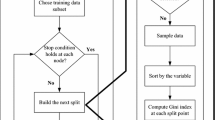
Given the background, the following methodology is proposed (Fig. 1):

Methodology
2.2 OBD-II Data Acquisition Though Data Logger Device
OBD-II data acquisition is realized by the data logger device, “Freematics ONE+”, which allows to extract all the Electronic Control Unit (ECU) sensors data and register the information in a “.CSV” archive, it’s saved in a micro SD for a later processing and research. Stored Variables are shown on Table 1.
For the experiment development, some test were realized on the dynamometer bank MAHA LP 3000 based in the ISO 17359 2018 “Condition monitoring and diagnostics of machines” [22] to obtain engine power and specific consumption data according to quality criterions.
To characterize method based in Meseguer et al. [1,2,3], Dörr et al. propose analyze driving incidence factors, such as, input, study, noise and controllable variables. These variables are shown in Table 2.
2.3 Signal Filtering
Motor signals when acquiring data present noise due to the existence of incidence factors in the vehicle, for this reason, these signals go through a filter stage; this consists in a comparison between real signals versus those obtained from sensors, for this purpose the S-Golay filter [24] was applied in order to obtain clean signals for a correct interpretation.
3 Results
3.1 Experimentation Results
With 4 power test, the vehicle performance was characterized as the volumetric fuel consumption that a low engine speed it is low, then when speed engine is increased by the increased throttle opening, the volumetric fuel consumption gets a gradually increase due to a bigger amount of air – fuel mixture causing more engine power, (see Fig. 2).

Volumetric consumption
Relating obtained results of volumetric fuel consumption with engine power at 25%, 50%, 75% and 100% throttle valve opening, engine specific consumption is determined by (1):
Where:
-
\( \dot{v} = Fuel\,Volumetric\,Flow\,(l/h) \)
-
\( \rho = Fuel\,Density\,(g/l) \)
-
\( {\text{P}} = Engine\,Power\,(kW). \)
The engine specific consumption depends directly of engine speed and the input air – fuel mixture regulated by the throttle valve opening angle, (see Fig. 3).

Engine specific consumption.
3.2 Machine Learning Architectures Application
For obtained data application from dynamometer bank in real driving cycles a model that explain the relationship between engine performance and normal circulation vehicle is proposed, for later determine by means of an artificial neural network application the fuel consumption and finally to apply fuzzy logic to obtain the driving mode.
Vehicle performance depends directly of transmissions ratios of each gear, so these values are obtained by the application of K-means method based in relation analysis between speed vehicle and speed engine (VSS/RPM) taken from a normal driving cycle, (see Fig. 4).

Driving estimation model
Where the following transmission ratios values are obtained (Table 3):
Fuel Volumetric Consumption depends directly of engine speed and the vehicle gear selected, as shown in (2) (see Fig. 5).

K-means classification.
Where:
-
\( C_{n} = Fuel\,Volumetric\,Consumption\,for\,each\,gear\,(l/h) \)
-
\( R_{n} = Transmission\,Ration\,for\,each\,gear \)
-
\( RPM = Engine\,Speed\,(rpm) \)
Relating fuel consumption with engine power delivered, the specific consumption for each gear is found, in which can be noted minimum values for each one of the selected gear, that are ideal values in which the vehicle should circulate (see Fig. 6).

Fuel volumetric consumption

Specific consumption for each gear.
Given the performance, maximum engine acceleration for each selected gear is determined, as shown in (3)
Where:
-
\( A_{x} = Longitudinal\,Acceleration \)
-
\( \eta_{i} = Gear\,efficiency \)
-
\( M_{nor} = Normal\,Momentum \)
-
\( \frac{{R_{c} \,R_{cn} }}{re} = R_{n} = Total\,Transmission\,Ratio \)
-
\( m_{veh} = Vehicle\,Mass \)
-
\( \gamma_{m} = Rotative\,Mass\,Coficient \)
-
\( n = Selected\,gear \)
-
\( \gamma_{m} = 1,05 + 0,0025R_{n}^{2} \)
Vehicle maximum acceleration for each gear depends on engine speed and due to transmission ratio of the vehicle velocity [25], as shown in Fig. 8.

Vehicle maximum acceleration for each gear
For an efficient driving gear changes should be done when specific consumption is relatively low according with Fig. 7. Table 4 shows values where fuel consumption is minimized.
Random Forest algorithm is presented, which its main purpose is to find relationship between input and output study variables, to determine more important variables in fuel consumption according with driving characteristics. Through study attributes, Random Forest allows to classify real engines data, demonstrating that while more samples being trained the greater would be the classification accuracy [15], also it allows a better control of the random attributes number for each node with an execution time really efficient [21], proving that fuel consumption depends directly of MAP, TPS, VSS, Ax and the selected gear, but not from engine speed, because this factor is in close relationship with VSS and Ax, with a determination index of 0.98905, (see Fig. 9).

Random forrest.
From this, an artificial neural network is trained to estimate the volumetric fuel consumption based on determined variables with 16661 samples to estimate the driving mode. The prediction is efficient due to the high reliability of RNA with a global index of 0.98905 (Table 5).
The found settings (see Fig. 10):

Relationship between expected values and estimated values by ANN
With this model an efficient vehicle speed is estimated by VSS and acceleration is determined to evaluate change gear according to engine speed. As the engine speed increases, a gear change is required, with the aim of increase vehicle speed and avoid excessive fuel consumption so that when the gear change is made the engine revolutions fall until get the new gear, considering that if the change gear is not realized, fuel consumption gets increased.
By Predictor importance the strength of the relationship of the predictors and the PID data result is quantified by the import of the samples, the viability of the established model is determined according to its importance and the training given.
In this work a diffuse classifier such as Manami is proposed with a total of 43 rules, which has many input variables: speed, acceleration, volumetric fuel consumption of the vehicle and determines the driving mode between Sport, Normal and Eco. The classifier is applied to obtained data in real driving (see Fig. 11) during start-up the Sport driving mode is used meanwhile eco mode is used in decelerations and small displacements and for the rest of scenarios normal mode is frequently used.

Characterization of the driving mode [23]
Through the characterization of the driving modes it is determined that the Ecodriving mode is the most efficient due to the differentiated use of the acceleration pedal which establishes the specific consumption is low compared to the other modes by optimizing fuel consumption in a random route of conduction.
4 Conclusions
In this paper it was obtained a model that explains PID´s signals behavior according to a person driving mode through thresholds values based on Machine Learning architecture by statistic method Random Forest that identifies the major importance variables on the estimation of fuel consumption in order to classify the driving modes in a random route, representing by sections the driving modes Eco drive, Normal and Sport according to driving behavior. Random Forest allows estimating sensors variables values that are unknown, with great precision through data set adjustments using characteristics of engine sensors variables, with the advantage that the model presents a minimum error for driving mode data classification of each vehicle with a determination index of 0.98905. PID’s signals like MAP, TPS, VSS, Ax and the selected gear, directly influence in the person driving mode due to the big input mixture air – fuel, where highlights specific consumption, polluting emissions and vehicle performance considering that engine speed doesn’t have a relationship with VSS and Ax, it doesn’t infer in the model behavior. The application of K-means method based on the analysis of the relationship between vehicle speed and engine speed (VSS/RPM) though obtained data from the dynamometer bank establishes a model based on the specific consumption and engine performance for driving modes characterization under normal driving conditions.
This paper aims to facilitate the study of future projects for the determination of the estimation of the driving mode through Machine Learning architectures applied to the study of the analysis of polluting emissions.
References
Meseguer, J., Toh, C.K., Calafate, C.T., Cano, J., Manzoni, P.: Assessing the impact of driving behavior on instantaneous fuel consumption. In: 12th Annual IEEE Consumer Communications and Networking Conference (CCNC) (2015)
International Organization for Standardization, Road vehicles, Diagnostic systems, Keyword Protocol 2000 (1999)
Meseguer, J., Toh, C.K., Calafate, C., Cano, J.Y., Manzoni, P.: DrivingStyles: a mobile platform for driving styles and fuel consumption characterization. J. Commun. Netw. 19(2), 162–168 (2017)
Lv, C., et al.: Cyber-physical system based optimization framework for intelligent powertrain control. SAE Int. J. Commer. Veh. 10(1), 254–264 (2017)
Mohd, T.A.T., Hassan, M., Aris, I., Azura, C., Ibrahim, B.S.K.K.: Application of fuzzy logic in multi-mode driving for a battery electric vehicle energy management. Int. J. Adv. Sci. Eng. Inf. Technol. 7, 284–290 (2017)
Dia, H., Panwai, S.: Impact of driving behavior on emissions and road network performance. In: IEEE International Conference on Data Science and Data Intensive Systems (2015)
Barkenbus, J.N.: Eco-driving: an overlooked climate change initiative. Energy Policy 38(2), 762–769 (2010)
Hooker, J.N.: Optimal driving for single-vehicle fuel economy. Transp. Res. A Gen. 22(3), 183–201 (1988)
Sivak, M., Schoettle, B.: Eco-driving: strategic, tactical, and operational decisions of the driver that influence vehicle fuel economy. Transp. Policy 22, 96–99 (2012)
Andrieu, C., Saint Pierre, G.: Comparing effects of eco-driving training and simple advices on driving behavior. Procedia – Soc. Behav. Sci. 54, 211–220 (2012)
Beckx, C., Panis, L.I., De Vlieger, I., Wets, G.: Influence of gear changing behavior on fuel-use and vehicular exhaust emissions. Highw. Urban Environ. 12, 45–51 (2007)
McIlroy, R., Stanton, N., Godwin, L., Wood, A.: Encouraging eco-driving with visual, auditory, and vibrotactile stimuli. IEEE Trans. Hum.-Mach. Syst. 47(5), 661–672 (2017)
Lapuerta, M., Armas, O., Agudelo, J., Sánchez, C.: Study of the altitude effect on internal combustion engine operation. Part 1: performance. Technol. Inf. 17(5), 21–30 (2006)
Rivera, N., Chica, J., Zambrano, I., García, C.: Estudio del comportamiento de un motor ciclo otto de inyección electrónica respecto de la estequiometría de la mezcla y del adelanto al encendido para la ciudad de cuenca. Revista Politécnica 40(1), 59–67 (2017)
Zhou, Y., Guo, J., Fu, L., Liang, T.: Research on aero-engine maintenance level decision based on improved artificial fish-swarm optimization random forest algorithm. In: 2018 International Conference on Sensing, Diagnostics, Prognostics, and Control (2018)
Damström, J., Gerlitz, C.: Classification of Power Consumption Patterns for Swedish Households Using K-means. K4. Power Consumption Analysis (2016)
Corcoba, V., Muñoz, M.: Eco-driving: energy saving based on driver behavior. In: XVI Jornadas de ARCA sobre Sistemas Cualitativos y sus Aplicaciones en Diagnosis, Robótica e Inteligencia Ambiental (JARCA) (2015)
Pereira, A., Alves, M., Macedo, H.: Vehicle driving analysis in regard to fuel consumption using fuzzy logic and OBD-II devices. In: 2016 8th Euro American Conference on Telematics and Information Systems (EATIS) (2016)
Oñate, J.A., Christian M. Quintero, G., Pérez, J.M.: Intelligent erratic driving diagnosis based on artificial neural networks. In: IEEE ANDESCON (2010)
Chen, S., Lin, R., Liu, W., Tsai, J.: The semi-supervised classification of petrol and diesel passenger cars based on OBD and support vector machine algorithm. In: 2017 International Conference on Orange Technologies (ICOT) (2017)
Corcoba, V., Muñoz, M.: Artemisa: using an android device as an eco-driving assistant. Cyber J.: Multidiscip. J. Sci. Technol. J. Sel. Areas Mechatron. (JMTC), June Edition, 3–7 (2011)
ISO 17359: Condition monitoring and diagnostics of machines (2018)
Google Maps. https://www.google.com/maps. Accessed 01 July 2019
Pang, C.K., et al.: Intelligent energy audit and machine management for energy-efficient manufacturing. In: IEEE 5th International Conference on Cybernetics and Intelligent Systems (CIS) (2011)
Aparicio, F., Vera, C., Díaz, V.: Teoría de los vehículos automóviles. Universidad Politécnica de Madrid, Madrid, pp. 279–285 (1995)
Acknowledgment
To Mr. Nestor Diego Rivera Campoverde, for his direction and unconditional collaboration in the realization of the paper with his contributions and his knowledge throughout the entire process, in addition to the GIIT Transportation Engineering Research Group for his support for the completion of the paper.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Molina Campoverde, J.J. (2020). Driving Mode Estimation Model Based in Machine Learning Through PID’s Signals Analysis Obtained From OBD II. In: Botto-Tobar, M., Zambrano Vizuete, M., Torres-Carrión, P., Montes León, S., Pizarro Vásquez, G., Durakovic, B. (eds) Applied Technologies. ICAT 2019. Communications in Computer and Information Science, vol 1194. Springer, Cham. https://doi.org/10.1007/978-3-030-42520-3_7
Download citation
DOI: https://doi.org/10.1007/978-3-030-42520-3_7
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-42519-7
Online ISBN: 978-3-030-42520-3
eBook Packages: Computer ScienceComputer Science (R0)